2.1. Physics-Informed Synthetic Data Generation
The foundation of this study rests on the generation of synthetic data that respects the established physical relationships between composition, microstructure, mechanical properties, and hole expansion behavior. Rather than creating arbitrary data points, the generation algorithm implemented validated empirical models extracted from peer-reviewed literature, ensuring that each synthetic steel condition represented a physically plausible combination of features. This physics-informed approach distinguishes the present work from naive data augmentation strategies, which may inadvertently generate impossible material states. The data generation framework incorporates three primary empirical models that have been independently validated by multiple research groups. First, Chen et al. [
33] documented through extensive experimental testing that the hole expansion ratio exhibits distinct behavioral regimes depending on the ultimate tensile strength level. For steels with ultimate tensile strength (UTS) below 700 MPa, the HER decreases approximately linearly with increasing strength, reflecting the fundamental strength-ductility trade-off and the progressive reduction in work hardening capacity as strength increases. The linear relationship arises because moderate-strength steels retain sufficient ductility to accommodate the stress concentrations at the sheared edges through plastic deformation, rather than crack propagation. For steels with UTS exceeding 700 MPa, the HER plateaus at approximately 30–40% regardless of further strength increases. This saturation behavior indicates that once the strength reaches this threshold, local strain localization and crack initiation are controlled by the microstructural toughness and defect tolerance rather than the bulk mechanical properties. The plateau value of 30–40% represents the intrinsic edge formability limit for high-strength martensitic or bainitic microstructures under typical sheared-edge conditions.
Second, Kim et al. [
20] performed a comprehensive machine learning analysis of experimental dual-phase and complex-phase steel conditions, systematically investigating the influence of chemical composition, phase fractions, and mechanical properties on hole expansion ratio. Their feature importance analysis using multiple algorithms consistently identified the bainite volume fraction as the strongest positive HER predictor. The beneficial effect of bainite stems from its unique microstructural characteristics: fine laths of low-carbon ferrite decorated with cementite particles provide a favorable combination of strength (from grain refinement and precipitation) with retained ductility and toughness (from the soft ferrite matrix and fine-scale structure). In contrast, the martensite volume fraction was a critical, negative predictor. The body-centered tetragonal crystal structure of martensite with a high interstitial carbon content creates extreme hardness but minimal ductility, making martensitic regions unable to accommodate the intense local strains around expanding holes. The carbon equivalent content also showed a negative correlation with the HER because of its role in promoting hard phases and increasing the overall hardenability. These findings provide quantitative guidance for weighting the microstructural effects in synthetic data generation algorithms. Third, Paul [
34] established nonlinear correlations between the uniaxial tensile properties and shear-edge hole expansion ratio through systematic testing of several steel grades. His work documented that the yield-to-tensile strength ratios for dual-phase steels typically ranged from 0.55 to 0.75, which is considerably lower than the ratios of 0.85 to 0.95 observed in conventional high-strength low-alloy steels. This low yield ratio stems from the composite microstructure, where soft ferrite yields at low stress, while hard martensite continues elastic loading, depressing the apparent yield strength, and the martensite volume fraction dominates the ultimate strength. Paul also quantified the relationship between strain hardening exponent (
n-value) and formability, showing that materials with higher n-values distribute strain more uniformly and resist premature necking or localization. The total elongation serves as an additional indicator of bulk ductility, with a higher elongation generally correlating with an improved hole expansion capability. However, this relationship is weaker than that of the n-value because elongation measures global deformation behavior rather than local deformation behavior. Building on these three foundational models, the synthetic data generation proceeded through a multi-step algorithm executed in Python 3.1.1. The chemical compositions were sampled from the range characteristics of commercial DP590 through DP1180 steels based on the published specifications from ArcelorMittal (East Chicago, IN, USA) [
35] and WorldAutoSteel (Brussels, Belgium) [
36]. The carbon content was uniformly sampled between 0.05 and 0.20 wt.%, encompassing the range from low-carbon DP590 to higher-carbon DP1180 grades. Manganese, the primary austenite stabilizer in DP steels, was sampled between 0.8 and 2.7 wt.%. Silicon, which was used for solid solution strengthening and to suppress cementite formation during austempering, ranged from 0.1 to 0.7 wt.%. Optional alloying elements, chromium (0–0.5%) and molybdenum (0–0.2%), were included to represent higher performance grades with enhanced hardenability. For each sampled composition, the carbon equivalent was calculated using the standard formula CE = C + Mn/6 + (Cr + Mo + Si)/5 + (Ni + Cu)/6, providing a single metric that correlates with hardenability and weldability. Microstructure generation requires ensuring that the phase fractions sum to 100% while maintaining physically realistic distributions of the microstructure. The martensite volume fraction was sampled uniformly between 15 and 80%, spanning low-martensite DP590 to high-martensite DP980. The typical Properties of Commercial DP Steel Grades are presented. The synthetic data generation framework was informed by the typical property ranges of commercial dual-phase steel grades, as summarized in
Table 1. These grades span the strength range of interest for automotive applications, from moderate-strength DP590 (UTS ~ 635 MPa) used in structural reinforcements to ultra-high-strength DP1180 (UTS ~ 1180 MPa) used in critical-safety components. The microstructural evolution across this strength spectrum, characterized by an increasing martensite volume fraction from 20 to 30% in DP590 to 55–70% in DP1180, directly influences the formability behavior, with higher-strength grades exhibiting progressively lower hole expansion ratios. The bainite volume fraction was then sampled from zero to the remaining fraction after martensite allocation, representing steels in which bainite forms during continuous cooling after the martensite transformation is completed. The ferrite volume fraction was calculated as the balance to ensure that the three phases summed to 100. This sampling strategy naturally generates higher ferrite fractions in low-martensite steels and lower ferrite fractions in high-martensite steels, mimicking the inverse relationship observed in the actual intercritical annealing of DP steels, where an increase in the annealing temperature produces more austenite that subsequently transforms to martensite. In our data generation framework, V
M (martensite volume fraction) and V
B (bainite volume fraction) were treated as independent predictive variables, following the nomenclature used in the literature [
20,
33,
34]. The distinction between these phases requires multiple characterization techniques beyond SEM imaging, including microhardness mapping, EBSD crystallographic analysis, or TEM. Industrial practice often reports “hard phase” content without a strict phase differentiation. However, when characterized using appropriate techniques, martensite and bainite exhibit distinct mechanical properties: martensite shows higher hardness (>500 HV) but lower toughness owing to its body-centered tetragonal structure and high carbon supersaturation, whereas bainite exhibits intermediate hardness (300–450 HV) with superior toughness owing to its fine ferritic lath structure. This distinction justifies their separate treatment as predictive features in machine learning models, as validated by Kim et al. [
20], who found that V
B and V
M contributed independently to HER prediction using experimental datasets with multi-technique phase characterization.
The mechanical properties were calculated from the microstructure and composition using empirically derived relationships that captured the strengthening contributions of each constituent phase. The ultimate tensile strength was computed using the following Equation:
where V
M and V
B represent the martensite and bainite volume percentages, respectively, and C represents the carbon content in wt.%; and ε represents realistic measurement scatter drawn from a Gaussian distribution with zero mean and standard deviation of 40 MPa. The base strength of 400 MPa represents a soft ferrite matrix, whereas the coefficients (7 MPa per % martensite, 2.5 MPa per % bainite, and 1000 MPa per wt.% carbon) capture the empirical strengthening effectiveness of each contributor. These coefficients were calibrated against published tensile data for commercial DP steels to reproduce realistic strength ranges. The yield strength was calculated to maintain the characteristic yield-to-tensile strength ratios for dual-phase steels, following Paul’s documentation [
34]:
where δ is uniformly sampled between 0 and 0.20, producing YS/UTS ratios between 0.55 and 0.75. This low yield ratio distinguishes dual-phase steels from conventional ferritic-pearlitic steels and provides excellent formability, making DP grades valuable for complex stamping operations. The total elongation was inversely correlated with the strength, which encoded the universal strength-ductility trade-off observed in metallic materials. For UTS values below 650 MPa, TE was sampled from 22 to 30%; for UTS between 650 and 850 MPa, TE ranged from 16 to 22%; for UTS between 850 and 1050 MPa, TE ranged from 12 to 16%; and for UTS exceeding 1050 MPa, TE was limited to 8–12%. These ranges match the documented performance envelopes for commercial AHSS grades and prevent the generation of unrealistic high-strength–high-ductility combinations, which would violate fundamental dislocation mechanics. The total elongation was assigned based on the well-established inverse relationship between the strength and ductility of dual-phase steels (
Table 2). This relationship reflects the fundamental trade-off in AHSS design: a higher martensite content increases the strength but reduces the work-hardening capacity and uniform elongation. The ranges in
Table 2 were derived from extensive automotive industry datasets [
35,
36,
37] and incorporated the typical batch-to-batch variability observed in production materials.
The hole expansion ratio calculation incorporates both the strength-dependent baseline behavior and microstructural modifications. For steels with a UTS below 700 MPa, the baseline HER
base was calculated as follows:
by implementing the linear decrease reported by Chen et al. [
33]. For steels with a UTS at or above 700 MPa, the baseline HER
base was uniformly sampled between 32 and 44% to represent the plateau region. Microstructural corrections were applied as follows:
where the coefficients were α
VB = 20 (bainite promotion), α
VM = 18 (martensite depression), α
C = 40 (carbon penalty), and β = 0.15 (elongation effect). These coefficients were calibrated to match the relative feature importance reported by Kim et al. [
20], while maintaining HER values within realistic bounds. Realistic experimental noise was added by sampling from a Gaussian distribution with a zero mean and standard deviation equal to 5% of the calculated HER value. This noise level simulates the coefficient of variation typically observed in industrial hole expansion testing, which ranges from 5 to 10% owing to edge condition variations, local microstructural heterogeneity, punch alignment imperfections, and operator-dependent crack detection [
37]. Including appropriate noise prevents machine-learning models from overfitting to deterministic relationships and ensures that the learned patterns are robust against experimental scatter. Additional features were added to the datasets. The strain hardening exponent was calculated as
This reflects the established correlations between work hardening, ductility, and strength. The plastic strain ratio (r-value) was uniformly sampled between 0.7 and 1.4, representing the typical anisotropy of cold-rolled AHSS sheets. The final synthetic dataset comprised 300 samples (
Supplementary Data File S1) with 14 input features and one target variable, with an ultimate tensile strength ranging from 596 to 1152 MPa (mean 881 MPa, standard deviation 141 MPa), and a hole expansion ratio ranging from 15.0 to 76.4% (mean 31.6%, standard deviation 11.4%).
Figure 1 shows the representative microstructure of DP1180 steel, which is the highest-strength grade in the DP family, modeled in this study. The SEM image clearly reveals a dual-phase architecture consisting of a ferrite matrix (F, light regions) and hard secondary phase regions (M, dark regions with a characteristic lath morphology). As SEM observations alone cannot definitively distinguish martensite from bainite, such phase identification requires complementary techniques, including microhardness measurements, EBSD, or TEM. This dual-phase microstructure forms through cooling from the intercritical (ferrite-α + austenite-γ) temperature during thermomechanical processing (TMP). In DP1180, the hard phase volume fraction typically reaches 55–70%, representing the upper bound of the microstructural range encoded in our synthetic data generation framework (combined hard phase content: 15–80%). Lower-strength grades exhibit progressively lower hard phase fractions: DP590 (~25–30%), DP780 (~35–40%), and DP980 (~50–55%), establishing an inverse relationship between the hard phase content and HER, which is a central component of Equation (4). This metallurgical gradient across the DP steel families, where an increasing hard phase fraction provides a higher ultimate tensile strength but reduces edge formability, provides the physical foundation for the machine learning models developed in this study [
38].
2.2. Machine Learning Methodology
Machine learning analysis followed the best practices for model development and evaluation to provide reliable performance estimates and to identify the optimal algorithm. Data preprocessing began by splitting the 300-sample dataset into training (180 samples, 60%), validation (60 samples, 20%), and test (60 samples, 20%) subsets using stratified sampling to ensure similar HER distribution across all splits. Feature standardization was performed using StandardScaler Scikit-learn 1.3 to transform all features to zero mean and unit variance according to xscaled = (x − μ)/σ, where μ and σ represent the mean and standard deviation calculated exclusively from the training data and applied without refitting to the validation and test datasets.
Twelve machine learning algorithms were evaluated as baseline models: Linear Regression, Ridge Regression (L2 regularization), Lasso Regression (L1 regularization), ElasticNet (combined L1/L2), Decision Tree, Random Forest, Extra Trees, Gradient Boosting, AdaBoost, K-Nearest Neighbors, Support Vector Regression with RBF kernel, and Support Vector Regression with linear kernel.
Each baseline model was trained on the training set using default or conservative hyperparameters and evaluated using the validation set. The top four algorithms underwent comprehensive hyperparameter optimization using GridSearchCV scikit-learn 1.3.0 with 3-fold cross-validation on the combined training and validation datasets. The 3-fold cross-validation was selected to balance the computational efficiency with a reliable performance estimation.
With 240 samples available for hyperparameter tuning (combined training and validation sets), 3-fold CV allocated 160 samples for training and 80 for validation in each fold, providing adequate sample sizes for both learning and evaluation purposes. Higher fold counts (5-fold or 10-fold) would substantially increase the computational requirements for the extensive hyperparameter grids evaluated (totaling 73 configurations across four algorithms) while offering diminishing returns for the primary objective of relative algorithm comparison. The independent test set (60 samples, 20% of the total data) provided unbiased final performance estimates, making the CV fold count less critical for the ultimate model validation. For Random Forest and Extra Trees, the parameter grid explored n
estimators (100, 200), max
depth (20, None), min
samples_split (2, 5), min
samples_leaf (1, 2), and max
features (sqrt). For Gradient Boosting, the grid explored n
estimators (100, 200), max
depth (3, 5), learning_rate (0.05, 0.1), subsample (0.8, 1.0), and min
samples split (2, 5). For Support Vector Regression, the grid explored C (1, 10, 100), gamma (scale, 0.01, 0.1), and ϵ (0.1). The model performance was quantified using three metrics: R
2 = 1 − Σ(y
i − ŷ
i)
2/Σ(y
i − ȳ)
2, RMSE = √[Σ(y
i − ŷ
i)
2/n], and MAE = Σ|y
i − ŷ
i|/n. The feature importance for the tree-based models was calculated using the mean decrease in impurity (Gini importance). All analyses were performed using Python 3.11, NumPy 1.24, Pandas 2.0, Scikit-learn 1.3, Matplotlib 3.7, and Seaborn 0.12.
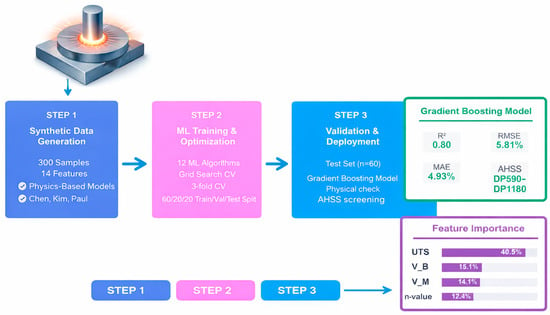
Figure 2 shows a schematic representation of the workflow adopted in this study, illustrating synthetic data generation based on physics-based algorithms and UTS-HER relationships, dataset construction and preprocessing, algorithm evaluation and optimization, model training and testing, and feature importance analysis for physical consistency and for model development.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}