1. Introduction
As a predominant material in civil engineering, concrete is extensively used in structures like bridges, roads, tunnels, and dams. However, the long-term performance of concrete in service, particularly its creep behavior, is a critical factor affecting structural durability and safety. For example, prestressed continuous rigid-frame bridges often show excessive long-term deflection and web cracking during prolonged use [
1]. Concrete containment structures in nuclear power plants may undergo gradual performance deterioration during prolonged use [
2]. In addition, the cracking of industrial concrete floors can lead to reduced load-bearing capacity and impaired structural durability [
3]. These challenges highlight the need for systematic research on the creep characteristics of low-carbon concrete materials.
The selection of low-carbon concrete materials, such as fly ash admixtures and silica fume, as a common low-carbon concrete material is driven by the need to promote sustainable development. As in
Figure 1, these materials have the following characteristics: fine particle size, high specific surface area, and high chemical reactivity. Concrete mixed with an appropriate amount of silica fume has the property of significantly improving the compressive strength, durability and corrosion resistance of concrete [
4,
5,
6,
7]. For example, Hangzhou Hanglong Plaza (
Figure 2a), Wuhan Center Building (
Figure 2b) and other buildings use such materials, effectively reducing carbon emissions and practicing the concept of green low-carbon. However, compared to ordinary concrete, the creep behavior of low-carbon concrete materials remains unclear, especially under varying conditions, and the specific mechanisms influencing this creep behavior have not yet been fully elucidated [
8,
9,
10]. Therefore, accurately predicting the creep behavior of low-carbon concrete materials has become an urgent challenge that needs to be addressed.
Traditional creep studies are based on extensive experimental data. These experiments typically require lengthy observation periods and are limited by the complexity of the experimental conditions [
11]. To date, most international creep studies can be categorized as using nonlinear theoretical models. For example, Bu P, Li Y, Li Y, et al. employed fracture mechanics theory to analyze the actual energy release rate at crack tips in materials undergoing creep deformation [
12]. This approach revealed the strain energy accumulation patterns in concrete microcracks under sustained loading, effectively demonstrating the coupling mechanism between concrete damage and creep. Internationally recognized prediction models include four versions proposed by the European Concrete Committee and the International Federation for Prestressing (CEB-FIP): the CEB-FIP (MC1970) model [
13], the CEB-FIP (MC1978) model [
13], the CEB-FIP (MC1990) model [
14], and the FIB MC2010 model [
15]. The American Concrete Institute (ACI) Committee 209 introduced the ACI-209R (1982) model [
13] and the ACI-209R (1992) model [
16] in 1982 and 1992, respectively. Subsequently, Professor Bažant and colleagues developed the B4 model [
17] based on micro-prestressing solidification theory, incorporating comprehensive considerations of concrete strength, composition, and long-term creep behavior. Although these models progressively account for various factors influencing concrete creep, they exhibit certain limitations in predicting long-term deformation characteristics.
Recent advancements in data acquisition technologies and computational methodologies have propelled machine learning-based modeling approaches into increasing prominence within creep research. Machine learning techniques have emerged as effective tools for addressing the nonlinear behavior of concrete [
18,
19,
20,
21,
22]. Notably, Taha et al. developed an artificial neural network (ANN) with a single hidden layer containing six neurons for masonry creep prediction. However, this study considered only four parameters and validated the model with a limited dataset of 14 samples, resulting in constrained generalizability [
18]. Given that concrete creep represents typical time-series data, the integration of temporal modeling frameworks appears particularly promising. Thanh Bui-Tien et al. demonstrated the superiority of temporal models over conventional approaches through adaptive cells and deep learning methods in bridge damage assessment using time-series data [
23]. Jian Liu et al. developed a multivariate time-series model for asphalt pavement rutting prediction, which outperformed comparative frameworks including ARIMAX, Gaussian process, and mechanistic–empirical (M-E) models [
24]. Wang et al. established an LSTM network-based concrete creep model using experimental data, achieving satisfactory prediction accuracy. Nevertheless, this model neglected the influence of material properties and environmental factors on creep behavior [
25]. These studies collectively indicate that temporal modeling architectures exhibit distinct advantages in processing time-dependent, nonlinear data with inherent noise through neural networks and deep learning paradigms. Their demonstrated effectiveness stems from their inherent ability to capture temporal dependencies and complex interaction patterns within sequential data structures.
In machine learning models, parameter configuration directly determines predictive performance, making parameter optimization particularly critical [
26]. Optimization algorithms exhibit unique advantages and are extensively used for tuning machine learning parameters. The Crested Porcupine Optimizer (CPO), proposed in 2024 [
27], represents a novel metaheuristic algorithm. It features a robust global search ability, rapid convergence, minimal parameter requirements, easy implementation, and synergistic compatibility with other algorithms. These characteristics have enabled its application across diverse fields such as water resources management [
28] and geological exploration [
29]. While standard CPO demonstrates notable merits, challenges persist, including local optima entrapment, parameter sensitivity, computational efficiency limitations, and restricted adaptability in dynamic environments. Addressing these issues remains a significant research frontier. Algorithmic enhancement strategies have proven effective in improving optimization performance. For example, an in-depth analysis of various methods for improving the Sine Cosine Algorithm (SCA) not only comprehensively summarizes its advantages and disadvantages, but also provides a broader study of meta-heuristic optimization algorithms [
30]. Huang et al. introduced a simulated degradation mechanism to counteract the insufficient global search capacity in particle swarm optimization, achieving marked improvement in solution accuracy [
31].
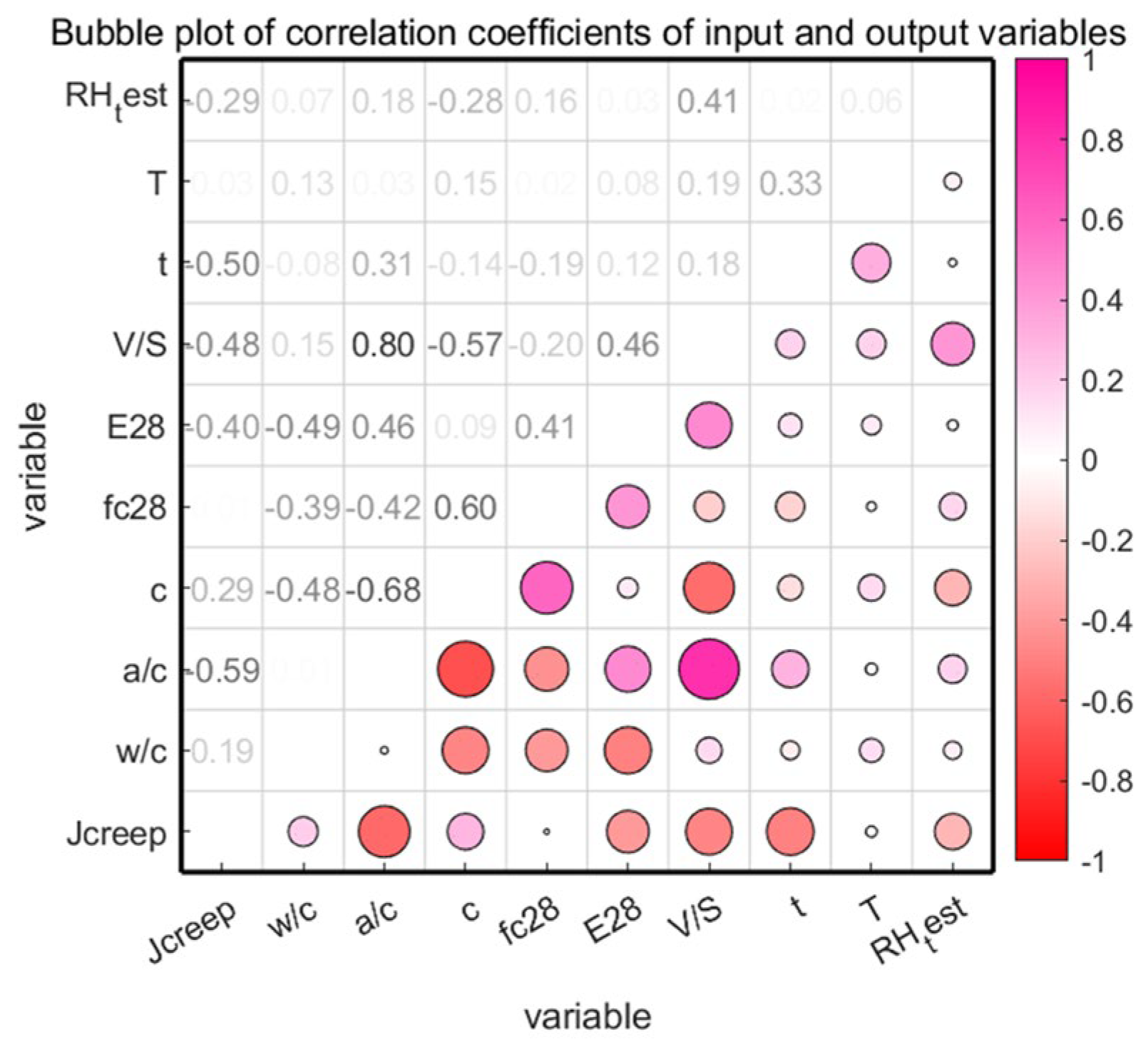
In summary, this study utilizes the characteristics of time series of low-carbon concrete material data, together with the consideration of multivariate variables such as material properties, environmental parameters and historical values, and establishes a time series deep learning prediction model based on the improvement of three machine learning models, namely, artificial neural networks (ANN), random forests (RF), and long- and short-term memory networks (LSTM), to predict creep. In order to improve the prediction ability of the model, four strategies are used to optimize and improve the CPO, and a new adaptive crown porcupine optimization algorithm (ACCPO) is established; the combination of the ACCPO and the time-series model greatly improves the prediction effect.
3. Machine Learning Models
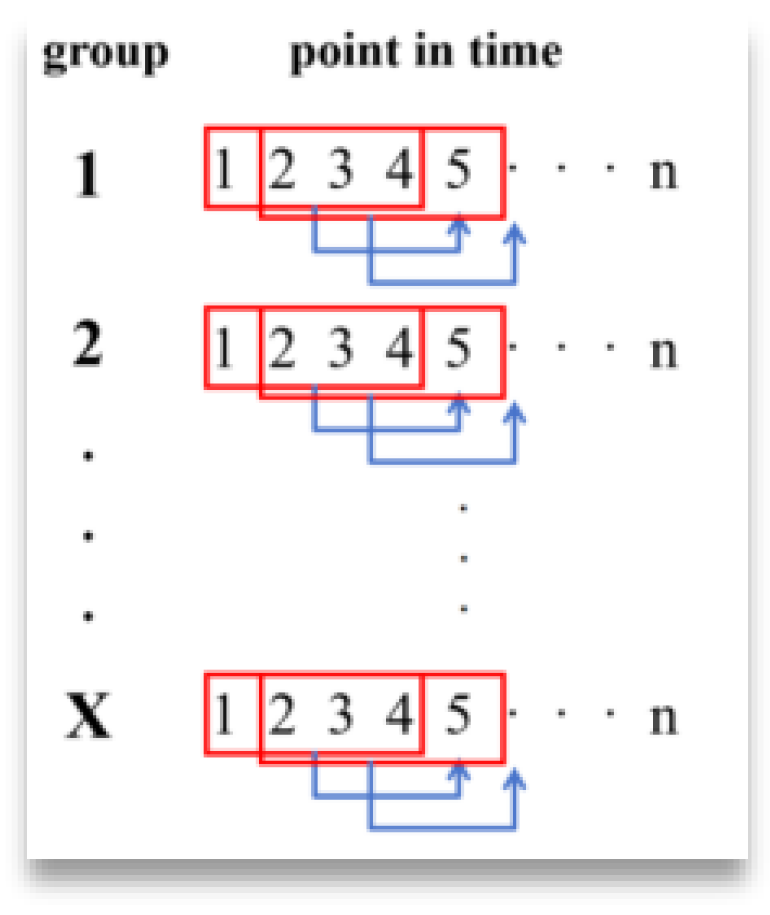
Figure 8 represents a group with n time points, and the first four points are read each time to predict the next point, and so on to the nth point; i.e., the sliding window slides in a node-by-node sliding pattern within the same trial group.
The second case regards sliding within the different experimental groups in the way shown in
Figure 9.
The sliding window in this figure will jump directly to the beginning of the next sample after the training of the previous set of data is completed, starting the traversal of the second set of samples, and so on, until all the data have been trained.
3.1. ANN Model
The Artificial Neural Network (ANN) is not designed to take into account the properties of time series per se [
43]. The inputs and outputs of an ANN are independent, and it is not able to capture temporal dependencies as automatically as a specialized LSTM. Therefore, a sliding window is almost essential when seeking to process time series with ANN. Through sliding windows, we can transform the time series data into a format that the ANN can understand, and train time series models in this way. An ANN usually consists of input, hidden and output layers. ANN neural networks are widely used in model prediction due to their powerful nonlinear mapping capabilities [
44].
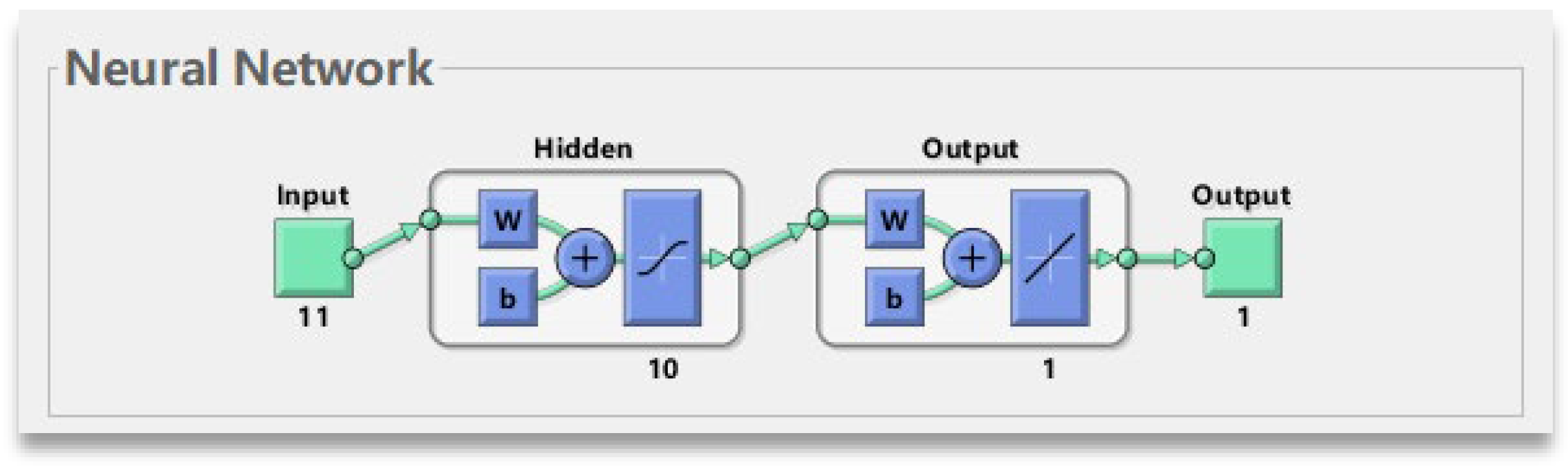
Finding the optimal neuron in an ANN model is very important. Therefore, in this manuscript, we first use an empirical formula to determine a range of values, and then use an algorithm to optimize and fix the optimal value. The expression is
where m represents the number of nodes in the input layer, and n represents the number of nodes in the output layer, a ∈ (1, 10).
Secondly, AS weights and biases are optimized using the established ACCPO.
Figure 10 shows the input, hidden and output layers that the ANN neural network has.
3.2. RF Model
Random Forest is an integrated learning method that works by voting or averaging results to obtain a final prediction [
45]. It is not specifically designed to be used for time series data per se, but when dealing with time series problems, the model can also be adapted to achieve the desired results [
46].
The key parameters of Random Forest mainly include the number of trees (the more decision trees, the better the performance of the model usually is, but the computational cost will increase accordingly) and the number of randomly selected features (the number of randomly selected features when each node is split; usually, the number of randomly selected features is equal to the square root or logarithmic value of the total number of features). In general, the selection of the number of features affects the bias and variance of the model.
Figure 11 shows the RF model.
The performance of RF depends largely on the setting of its hyperparameters, such as the number of decision trees (n_estimators), the maximum depth of decision trees (max_depth), etc., in order to improve the accuracy and efficiency of the time series prediction. So by adjusting the hyperparameters such as the number of trees, the maximum depth of the tree, etc., to make the model optimal, the hyperparameters in the established ACCPO optimized Random Forest model can help the RF to achieve better performance in the time series prediction task.
3.3. LSTM Model
For the Long Short-Term Memory recurrent neural network (LSTM), the model itself is usable for time series prediction, as compared to the machine learning models mentioned above [
47]. For the study of LSTM, the weights and biases in the model, the setting of important hyperparameters, and the selection of the sliding window have a greater impact on the model. In this study, a brand new LSTM is constructed for training by processing the dataset.
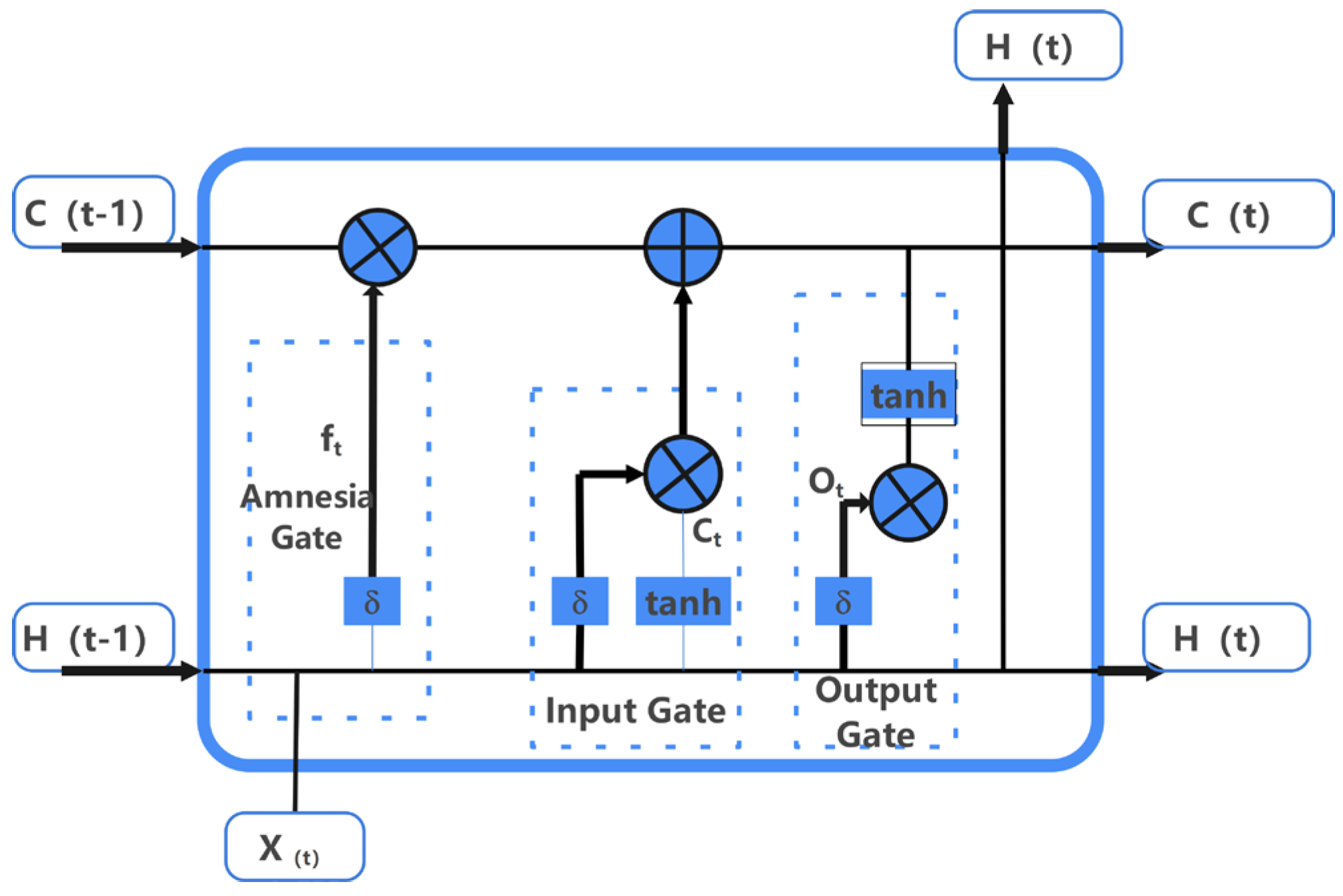
Regarding weights and biases in LSTM, LSTM recurrent neural networks introduce memory units (memory states) to control data transmission between hidden layers. A memory unit in an LSTM network consists of three gate structures: input gates, forget gates, and output gates. The input gates determine how much of the current input is retained in the current unit state; the forget gates determine how much of the previous unit state is retained in the current unit state; and the output gates determine how much of the current unit state is output. The structure is shown in
Figure 12.
The structural functions of each gate of the LSTM network are shown below in Equations (25)–(27),
where I
t, f
t and O
t are the vector values of the input, forgetting and output gates of a node of the LSTM neural network at time t, respectively; x
t is the input at time t; b
i, b
f and b
o are the corresponding bias values of the gate structures, respectively; w
1 is the connection weight between the input node and the hidden node; w
2 is the connection weight between the hidden node and the output node; h
t−1 is the output at time t−1, which represents the hidden state (hidden state) of the LSTM. h
t−1 is the output at time t−1, representing the hidden state of the LSTM.
For the optimization of weights and bias, we use Adam’s algorithm. Adam combines the advantages of two optimization algorithms, the AdaGrad algorithm [
48] and RMSProp algorithm [
49]. The first-order moment estimation and second-order moment estimation of the gradient are considered comprehensively by these, and different values of the learning rate are determined based on the results of the moment estimation, with the following expressions:
here, m
t and v
t are the first-order moment estimates and second-order moment estimates of the current gradient; g
t is the current gradient value; β
1 and β
2 are the coefficients.
Usually the values of m
t and v
t are corrected for bias, and the corrected Adam’s method expression is shown in the following:
Finally, when using LSTM models for time series prediction, selecting and optimizing hyperparameters is crucial for model performance. The hyperparameters that need to be optimized include the number of hidden layer nodes, the learning rate, and the batch size.
3.4. Model Evaluation Indicators
3.4.1. Single Indicator
In this study, root mean square error (RMSE), mean absolute error (MAE) and coefficient of determination (R
2) are used to evaluate the performance of the model. R
2 is mainly used to measure the correlation between the actual values and the predicted values. The closer the R
2 is to 1, the smaller the MAE is, and the higher the model accuracy is. The following are the mathematical expressions for the three evaluation metrics:
N in this equation denotes the number of samples; q0 denotes the actual value; denotes the actual average value; qt denotes the output value; denotes the output mean, .
3.4.2. Composite Indicators
In order to compare the prediction performances of different types of machine learning prediction models, this paper unifies the above three single statistical indexes (Equations (33)–(35)) into one comprehensive index for analysis, i.e., the Synthesis Performance Index (SPI) [
50], as shown in Equation (36).
where N is the number of selected statistical indicators used to measure the prediction performance. In this paper, N = 3 because R
2, RMSE and MAE are selected. In addition, P
j is the jth statistical parameter, and at the same time, P
max,j and P
min,j are the maximum and minimum indicators of the selected jth statistical parameter in the set of values of the machine learning model used, respectively. As can be seen from Equation (36), the size of the SPI value is distributed between [0, 1], and in terms of the overall prediction performance, when the value of SPI is closer to 0, it indicates that the performance of the machine learning prediction model represented by it is better, and vice versa, when the value of SPI is closer to 1, it indicates that the effectiveness of the machine learning prediction model represented by it is worse. In this paper, in terms of prediction performance, the SPI obtained from different types of machine learning training will be given the distribution of the advantages and disadvantages of the prediction effect of the model according to the size of its value.
5. Results
We divide the nine different models into training sets and test sets to obtain two evaluation metric summary tables, as shown in
Table 12 and
Table 13.
Firstly, looking at
Section 2.5 Test Function, combined with
Figure 4,
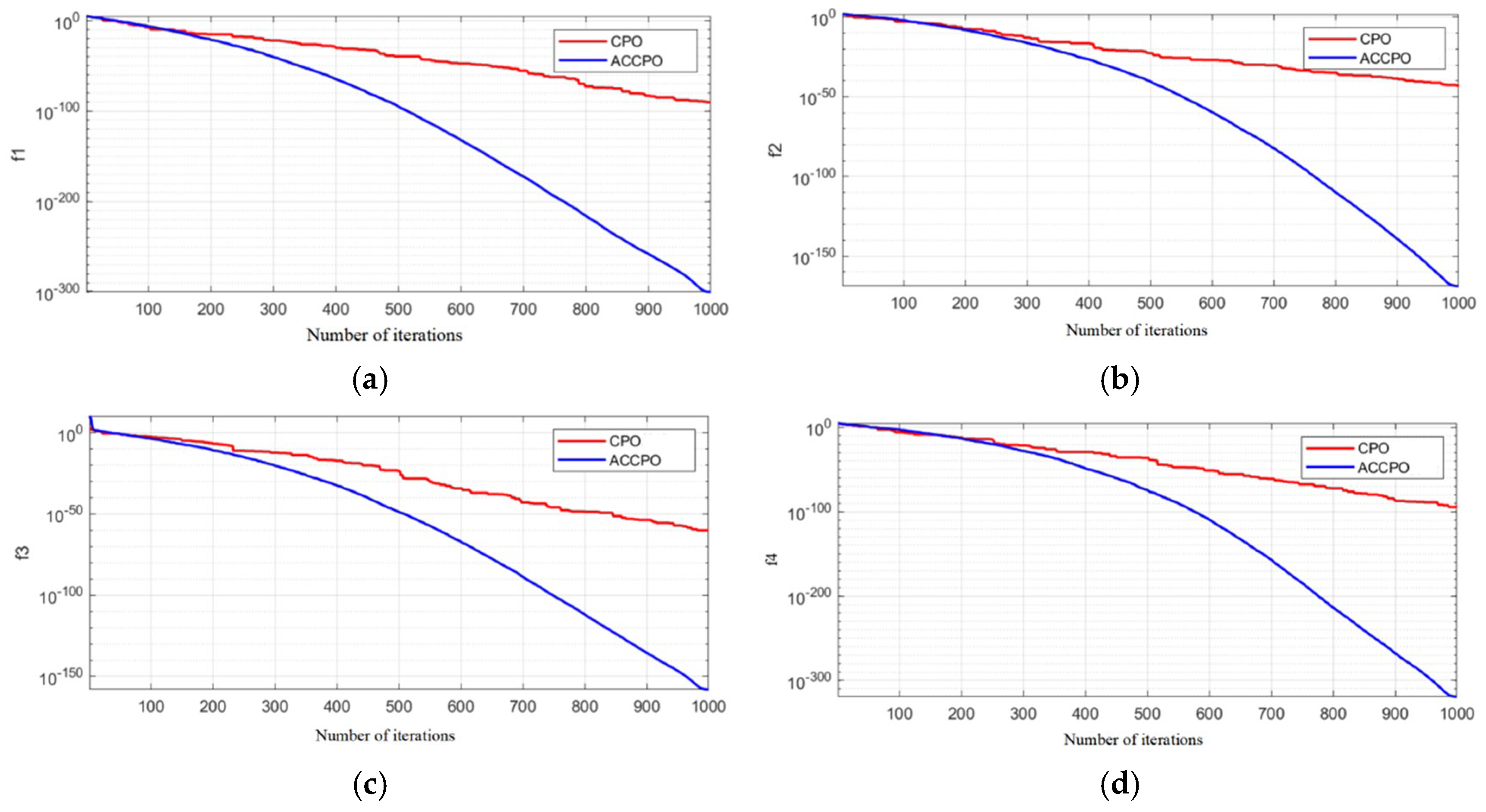
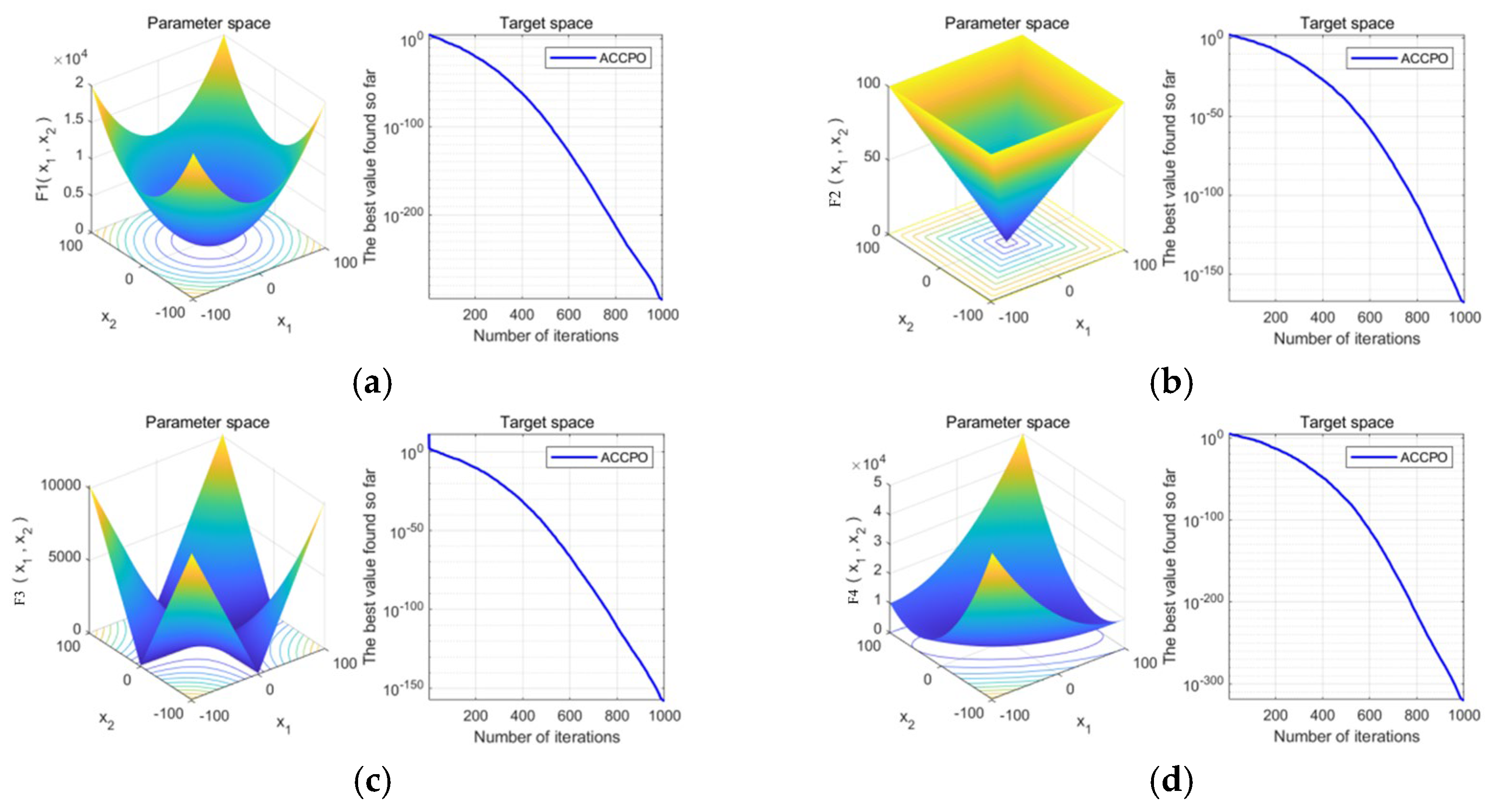
Table 5 shows that after the initial verification of the test function, the effect of the CPO algorithm following gradual optimization to ACCPO is further improved, implying that the improvement of the algorithm is successful.
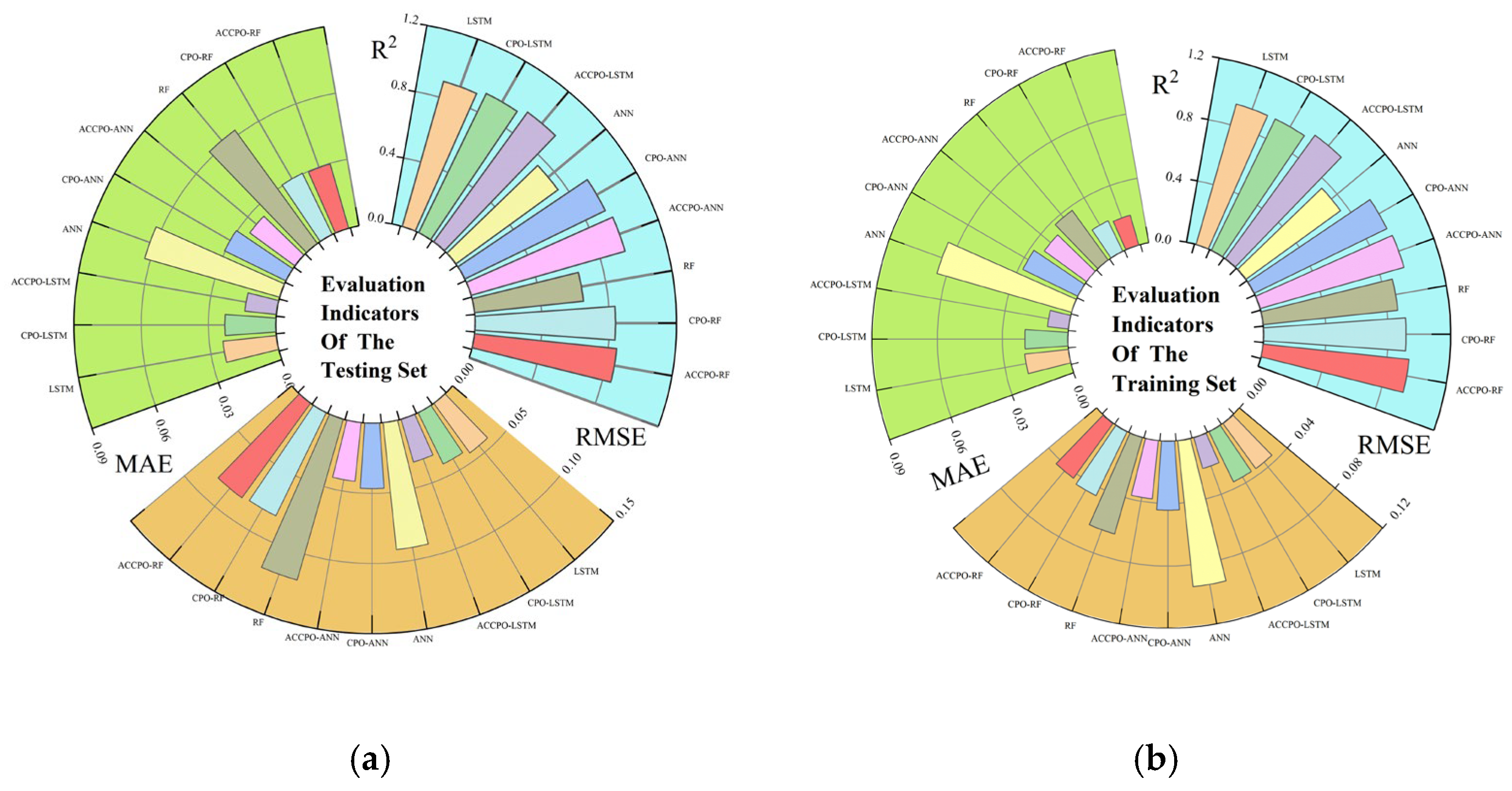
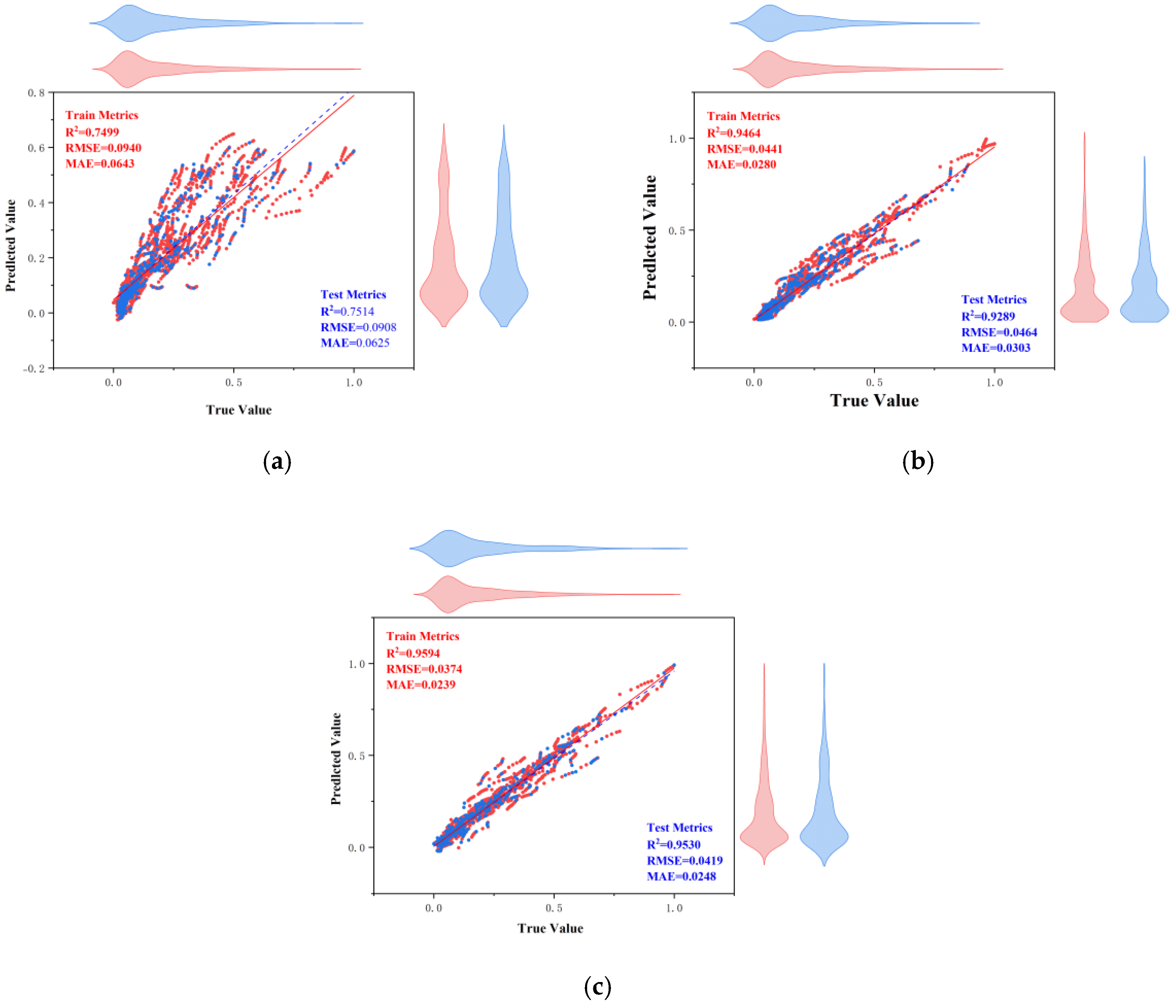
Secondly, the performances of the nine models on the training and test sets were compared using three evaluation metrics, as shown in
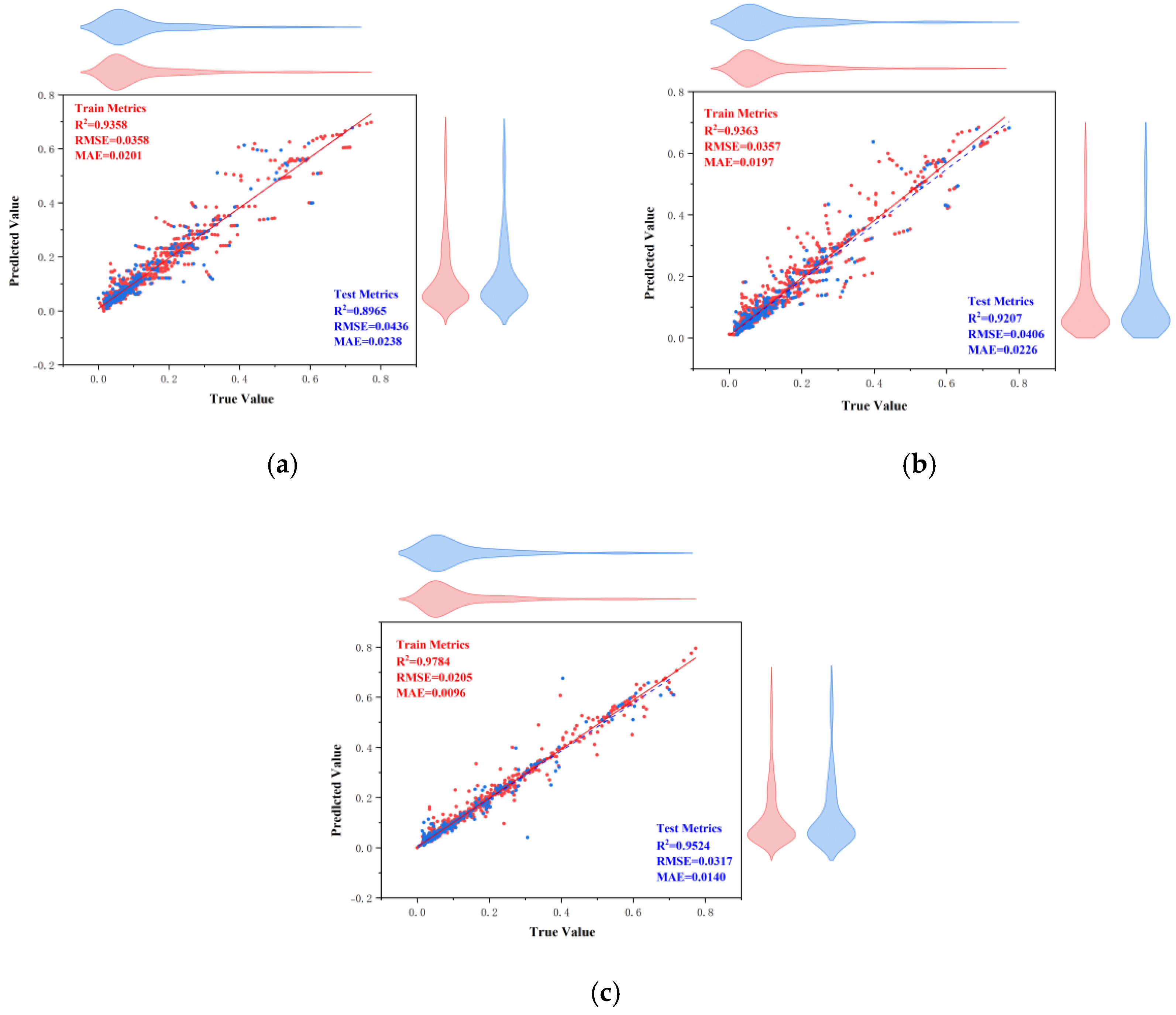
Figure 19. From this, it can be seen that it is feasible to use the CPO algorithm for model performance enhancement. From this, it can also be concluded that the effects of the optimized algorithm ACCPO are further enhanced compared to CPO, thus verifying that the optimization of the algorithm is successful. Further, the ACCPO-LSTM model performed the best overall—on the training set, it achieved an R
2 of 0.9784, an RMSE of 0.0205, and an MAE of 0.0096, surpassing all other models. On the test set, it maintained high accuracy, with an R
2 of 0.9524, an RMSE of 0.0317, and an MAE of 0.014.
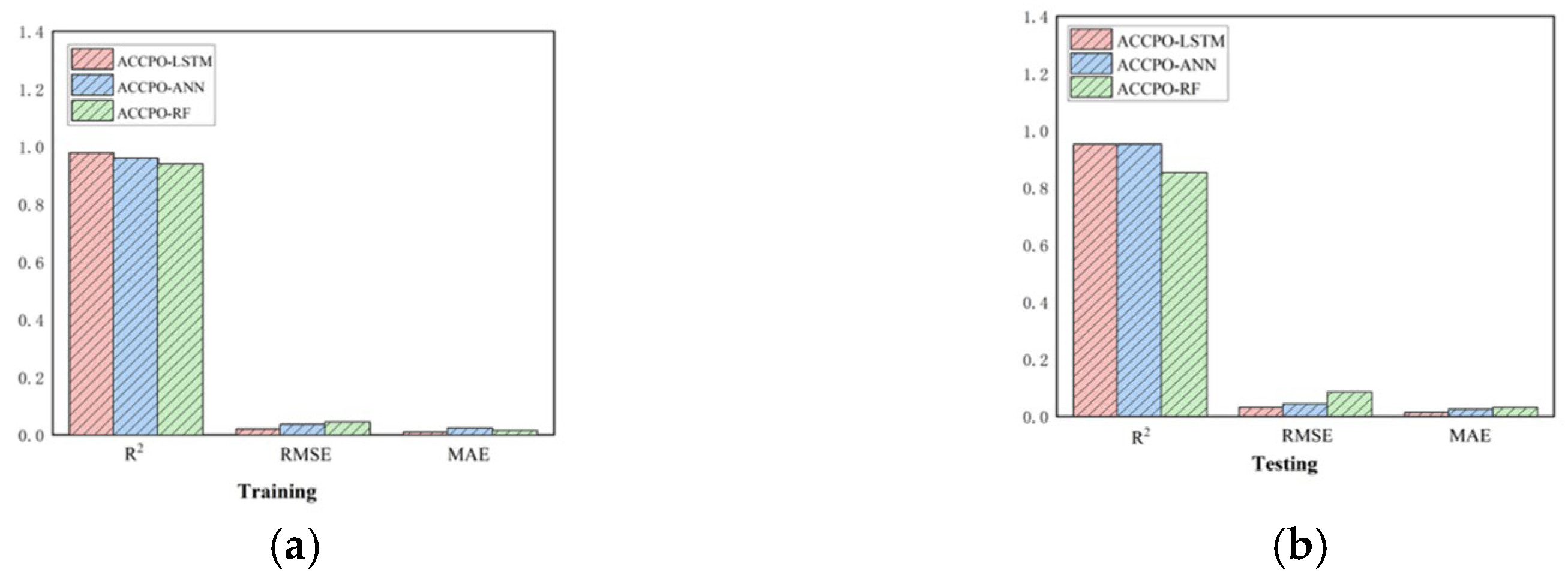
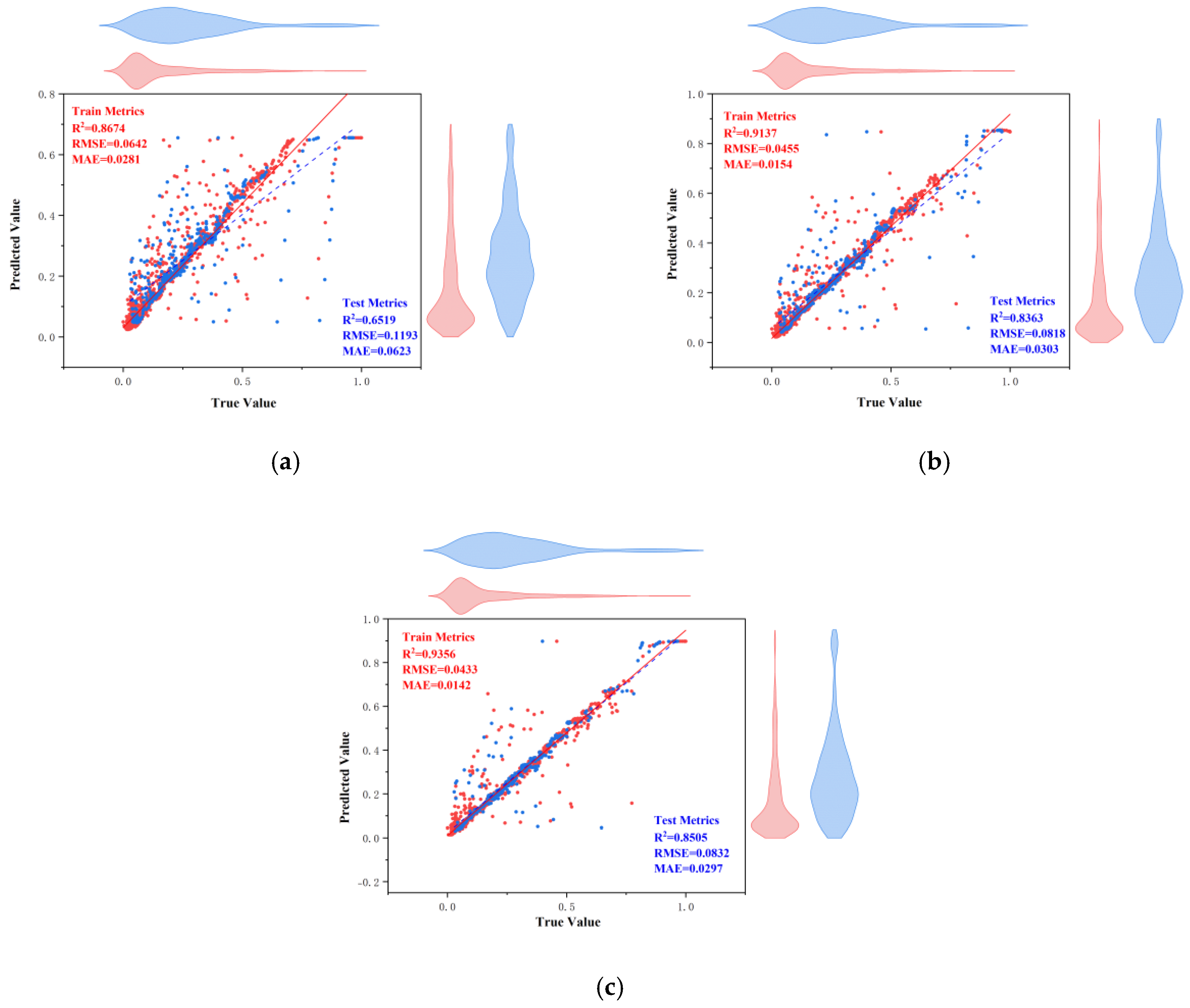
Thirdly, based on three evaluation metrics, we can see the effect of training the ACCPO algorithm in order to enhance the ANN, RF and LSTM models on the training and test sets, as shown in
Figure 20. The ACCPO-LSTM model exhibits the best performance on both the training and test sets, achieving the highest R
2 and the lowest RMSE and MAE. Thus, it is evident that this model surpasses the other two models.
Figure 19.
Three evaluation metrics corresponding to the 9 models: (a) representing the training sets, and (b) representing the testing sets.
Figure 19.
Three evaluation metrics corresponding to the 9 models: (a) representing the training sets, and (b) representing the testing sets.
Figure 20.
Three evaluation metrics for the ACCPO optimization model: (a) represents the training sets, and (b) represents the testing sets.
Figure 20.
Three evaluation metrics for the ACCPO optimization model: (a) represents the training sets, and (b) represents the testing sets.
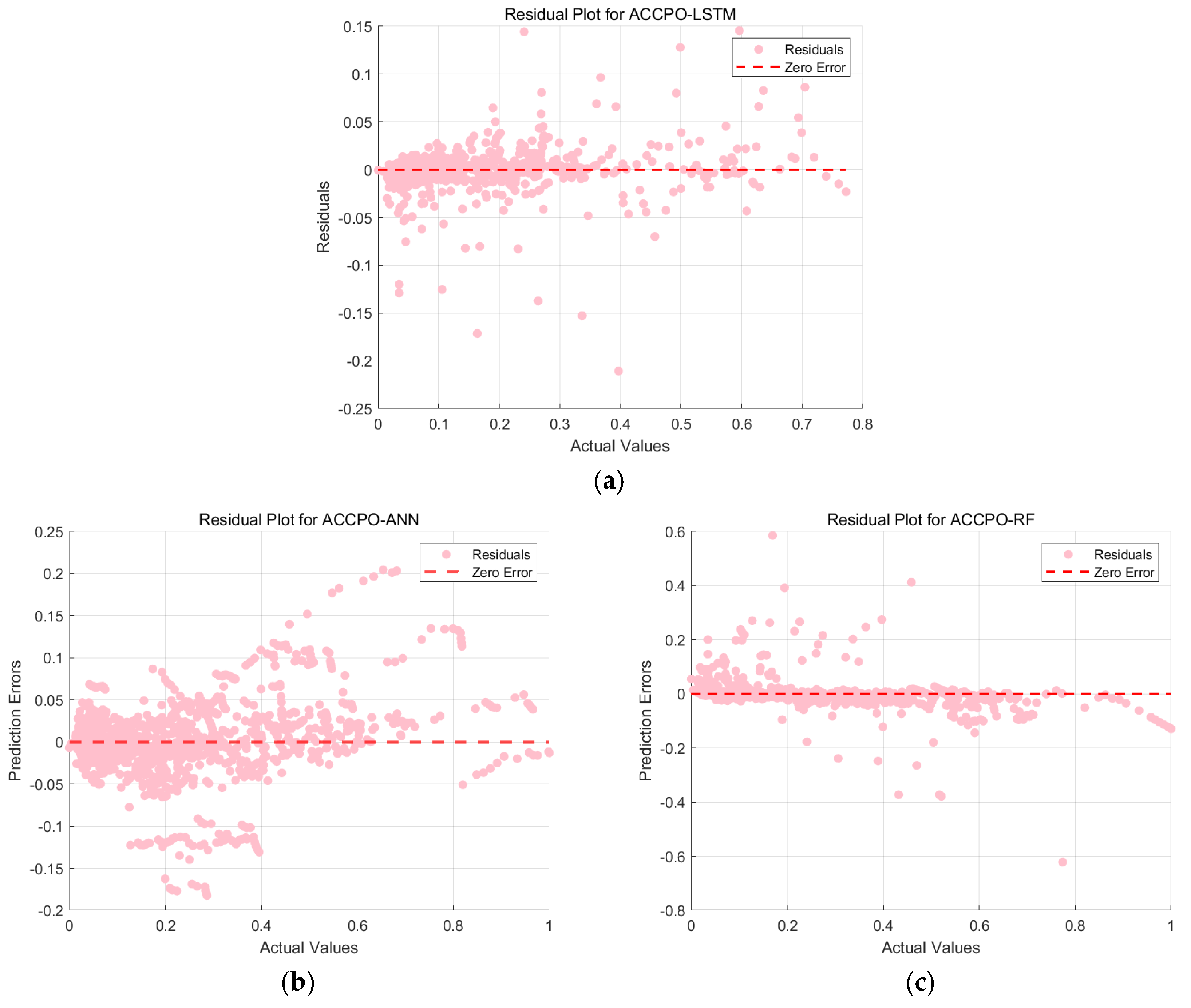
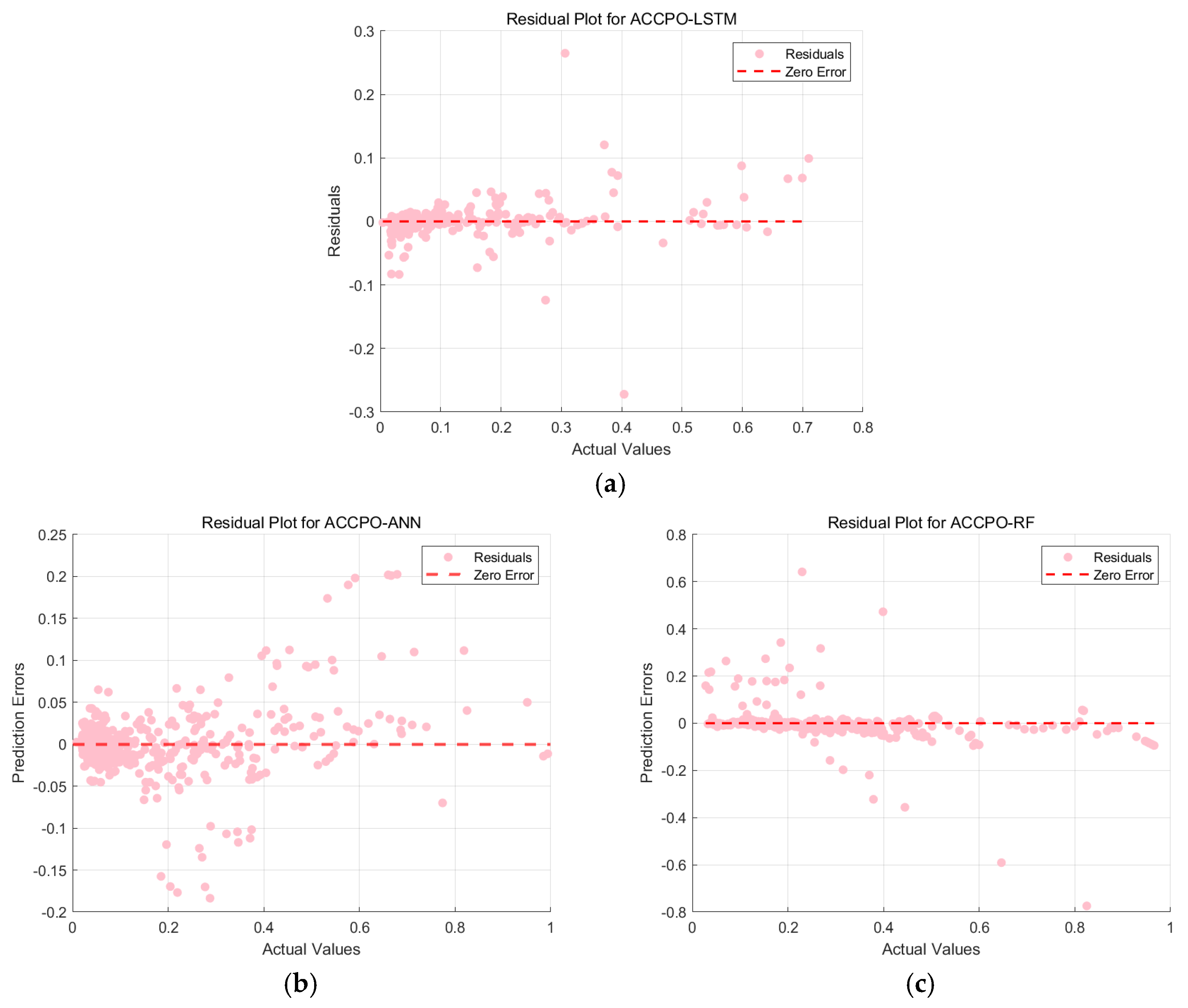
This is then combined with the residual plots of the training and test sets, as shown in
Figure 21 and
Figure 22. The residuals of the ACCPO-LSTM model are more tightly clustered around the horizontal axis, indicating a closer alignment between predicted and actual values. Thus, residual analysis confirms that the ACCPO-LSTM model possesses the strongest predictive capability.
Thus, by analyzing the three evaluation indicators, as well as performing the residual analysis, it is possible to draw the following conclusion: the LSTM model enhanced by the ACCPO algorithm performs the best.
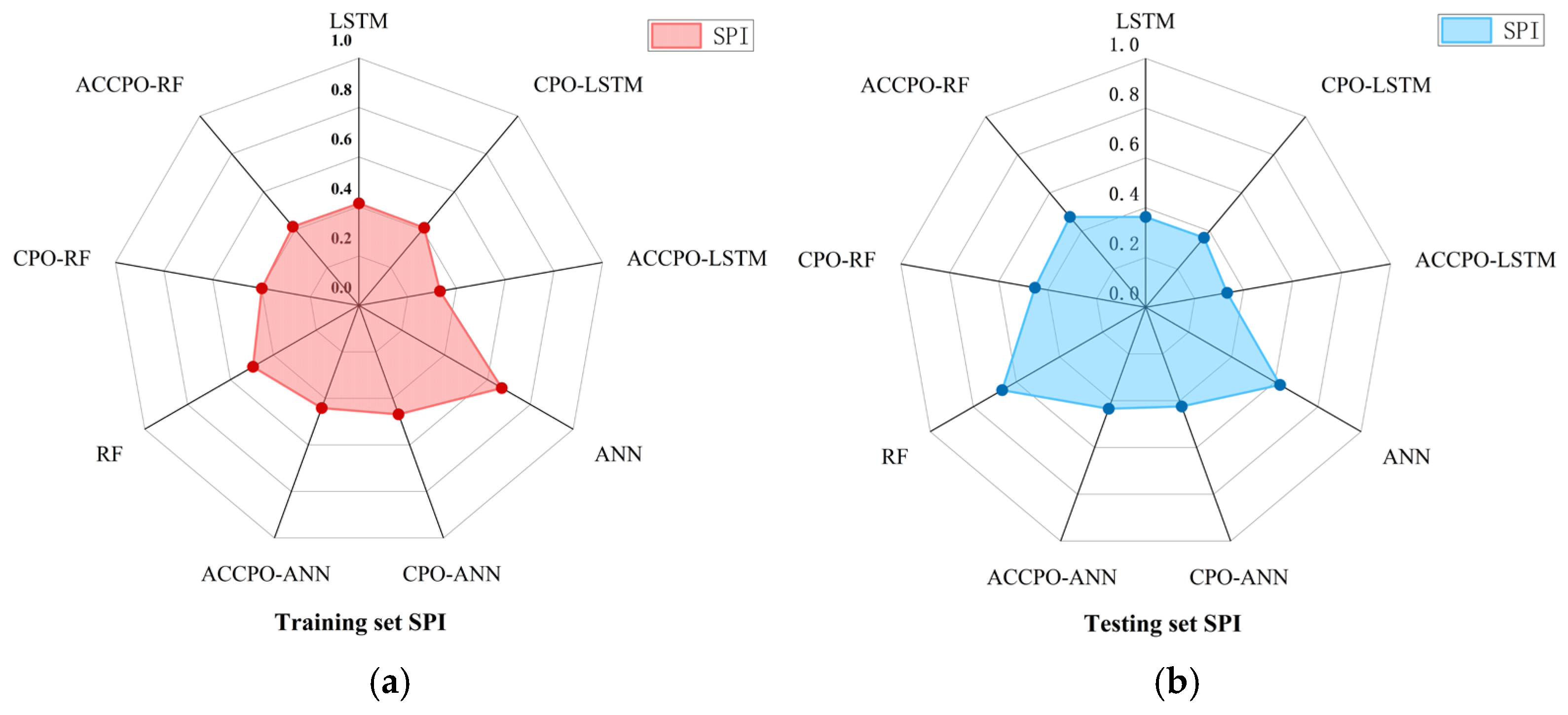
Finally, a comparative analysis of the model’s composite indicators allows for a clearer and more intuitive comparison, as shown in
Figure 23. Since the SPI value ranges from 0 to 1, a smaller value indicates better overall model predictability. The radar chart clearly shows that the ACCPO-LSTM model achieves the smallest SPI value across the entire machine learning model range, indicating its superior overall predictive performance.
Overall, with the above four results, it can be concluded that the optimization of the algorithm is successful. The ACCPO optimization method performed well across multiple models, significantly enhancing their predictive capabilities, particularly for LSTM and ANN. Further, while RF exhibited poor training set performance, its test set performance improved following ACCPO optimization.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}