
Data-Driven Parameter Selection and Modeling for Concrete Carbonation



Abstract
:1. Introduction
2. Data-Driven Parameter Selection
2.1. Data Collection and Description
2.2. Parameter Evaluation and Selection
- Parameter performance in controlling and predicting the durability of concrete under the impact of uncertainties of carbonation depth needs to be evaluated.
- Parameters should reduce the dispersion of carbonation depth.
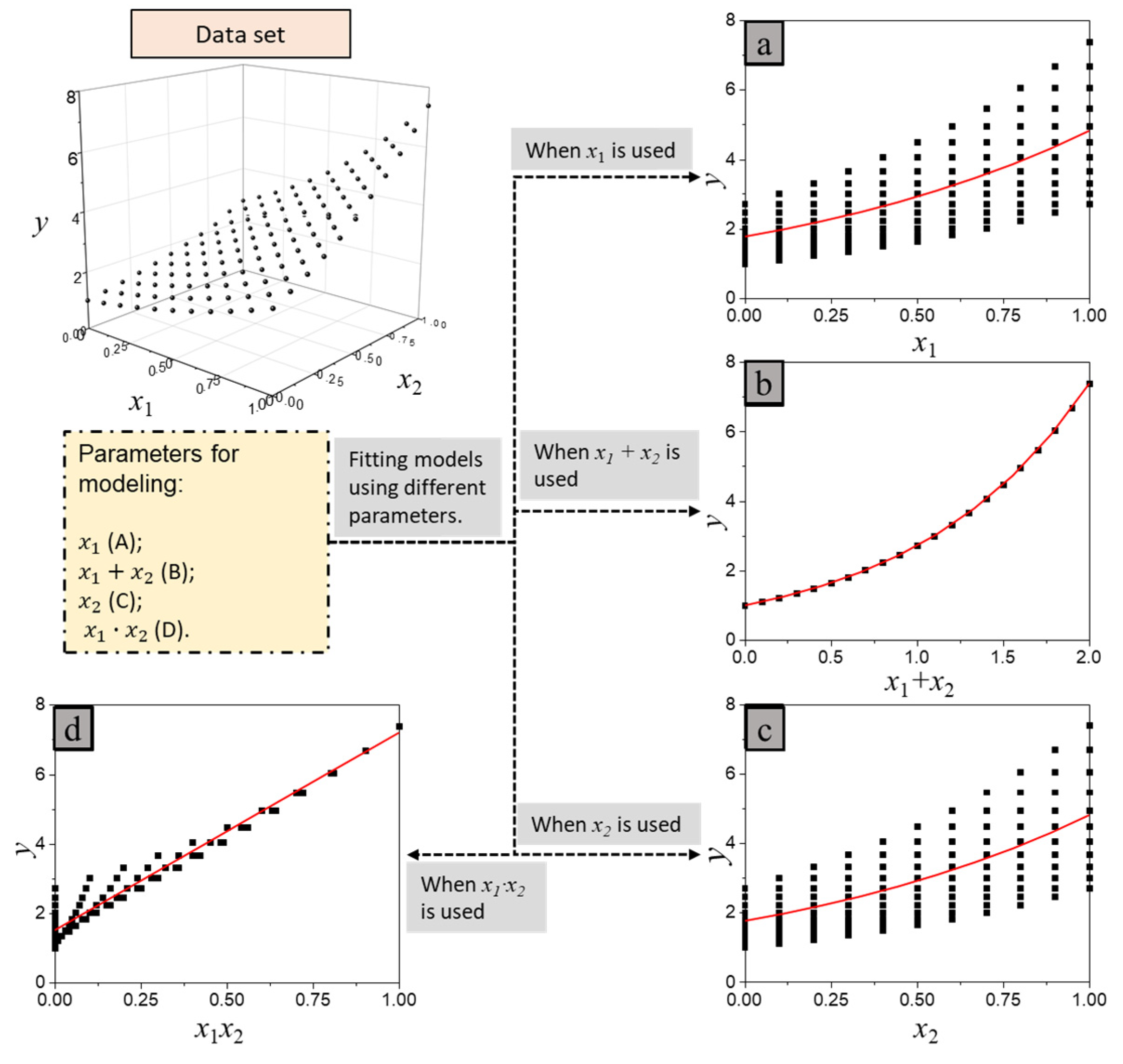
2.2.1. Method
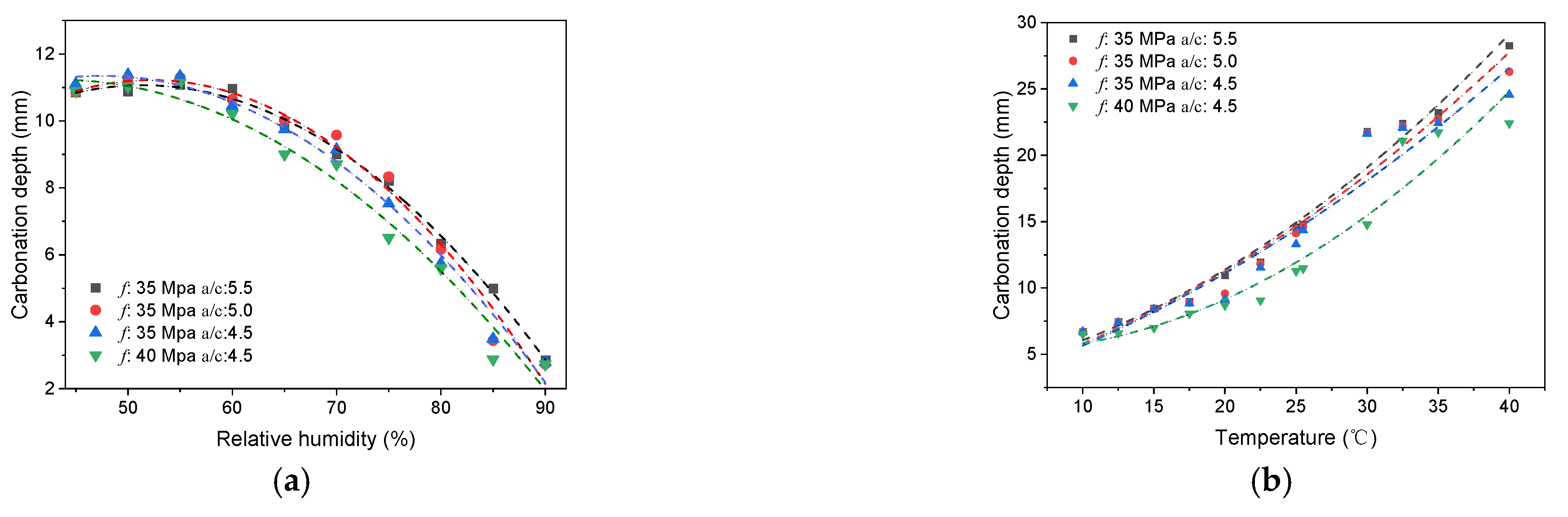
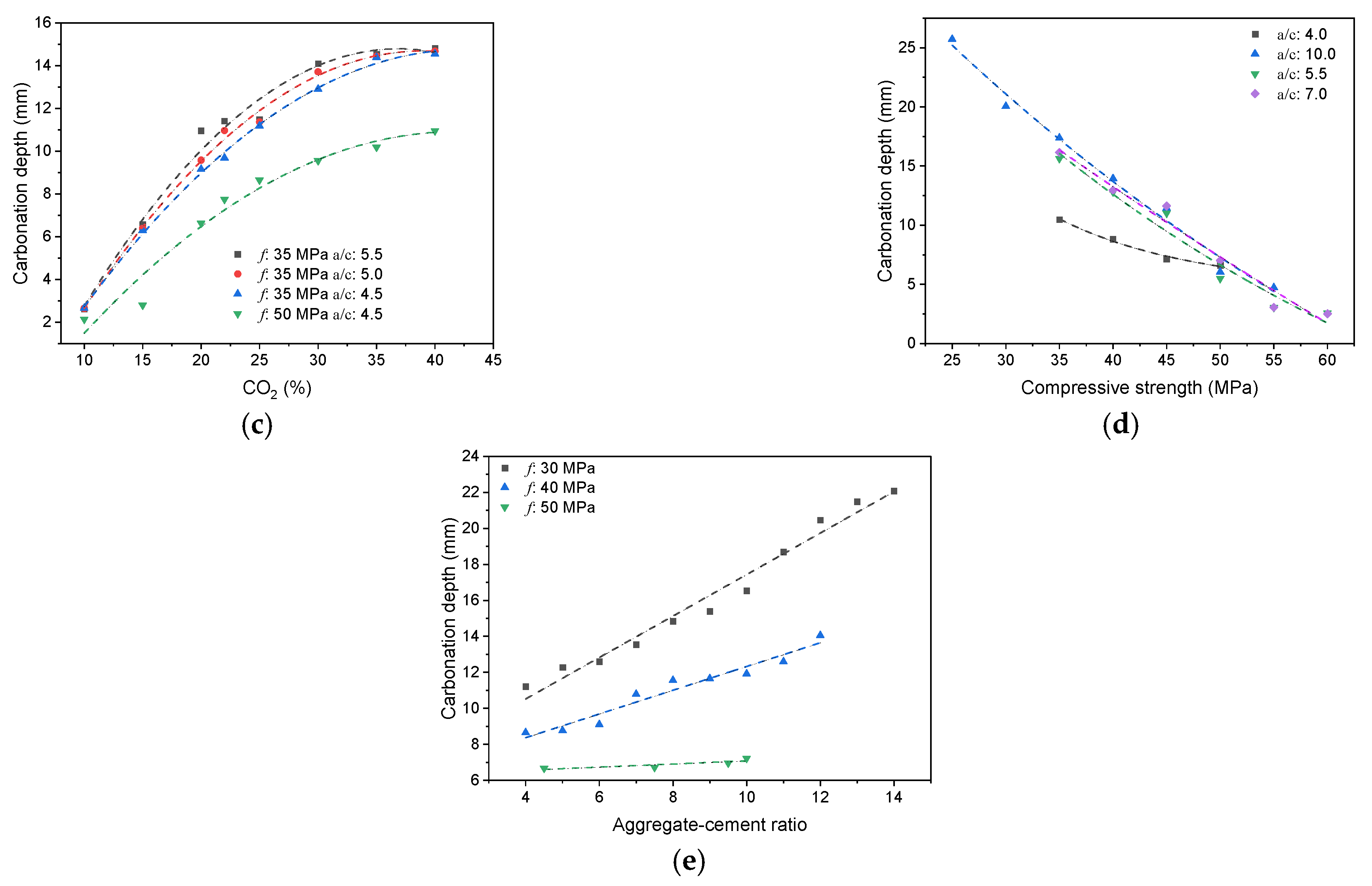
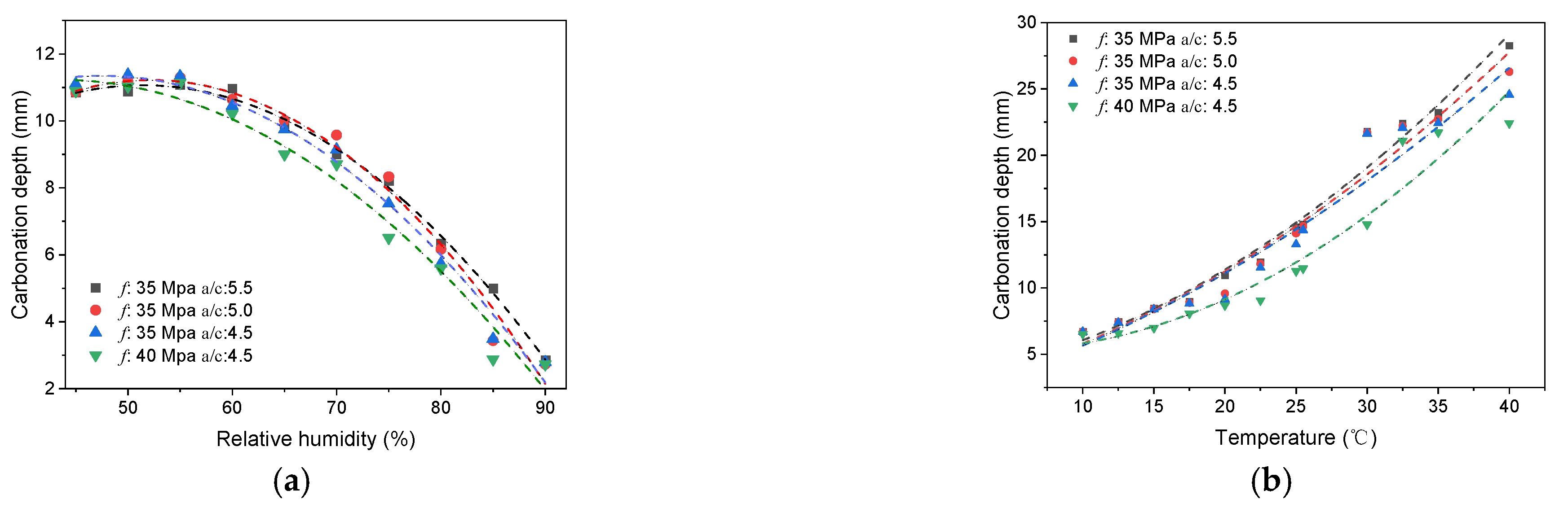
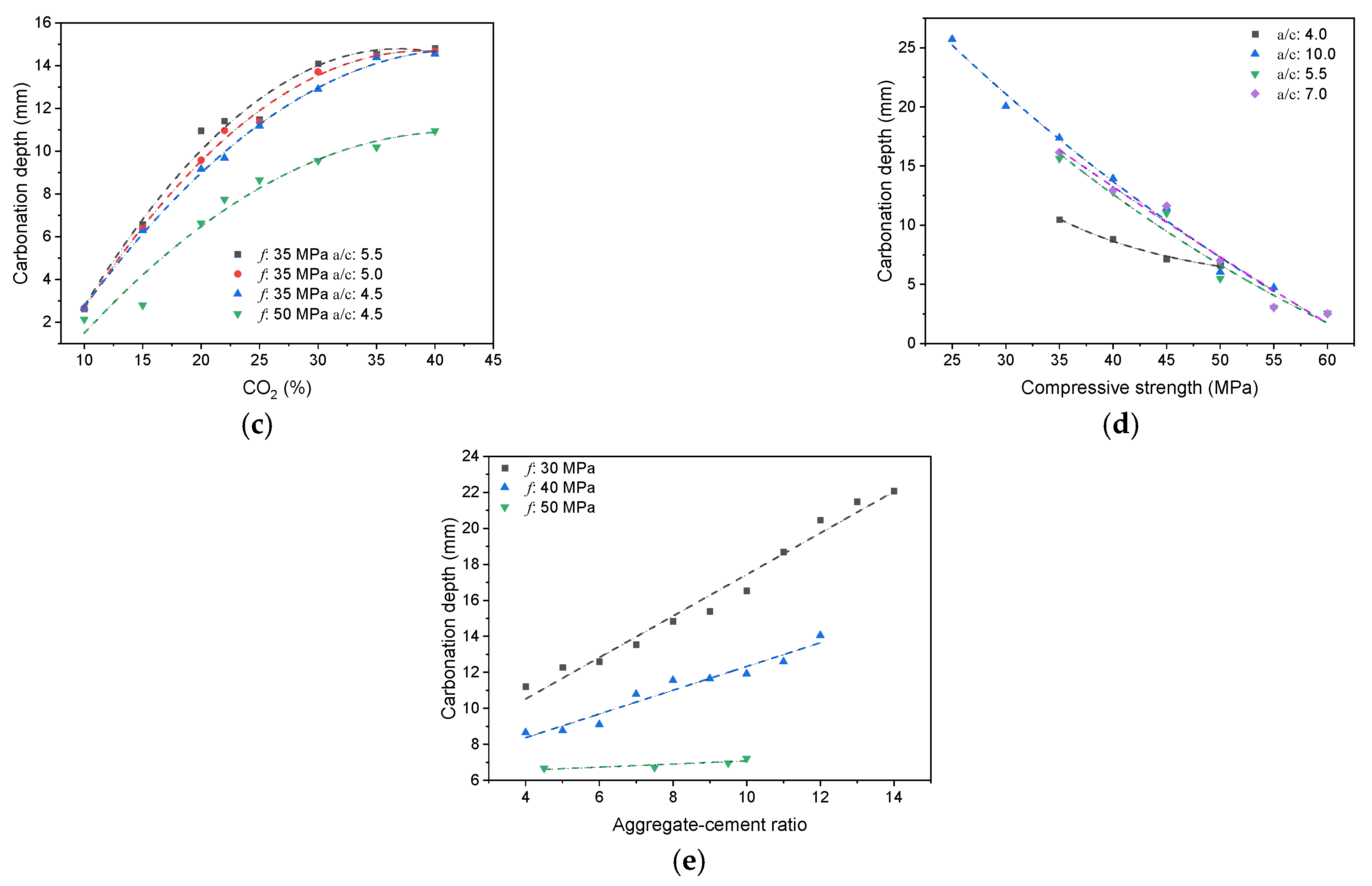
2.2.2. Results and Discussions
3. Parameter Combinations and Verification
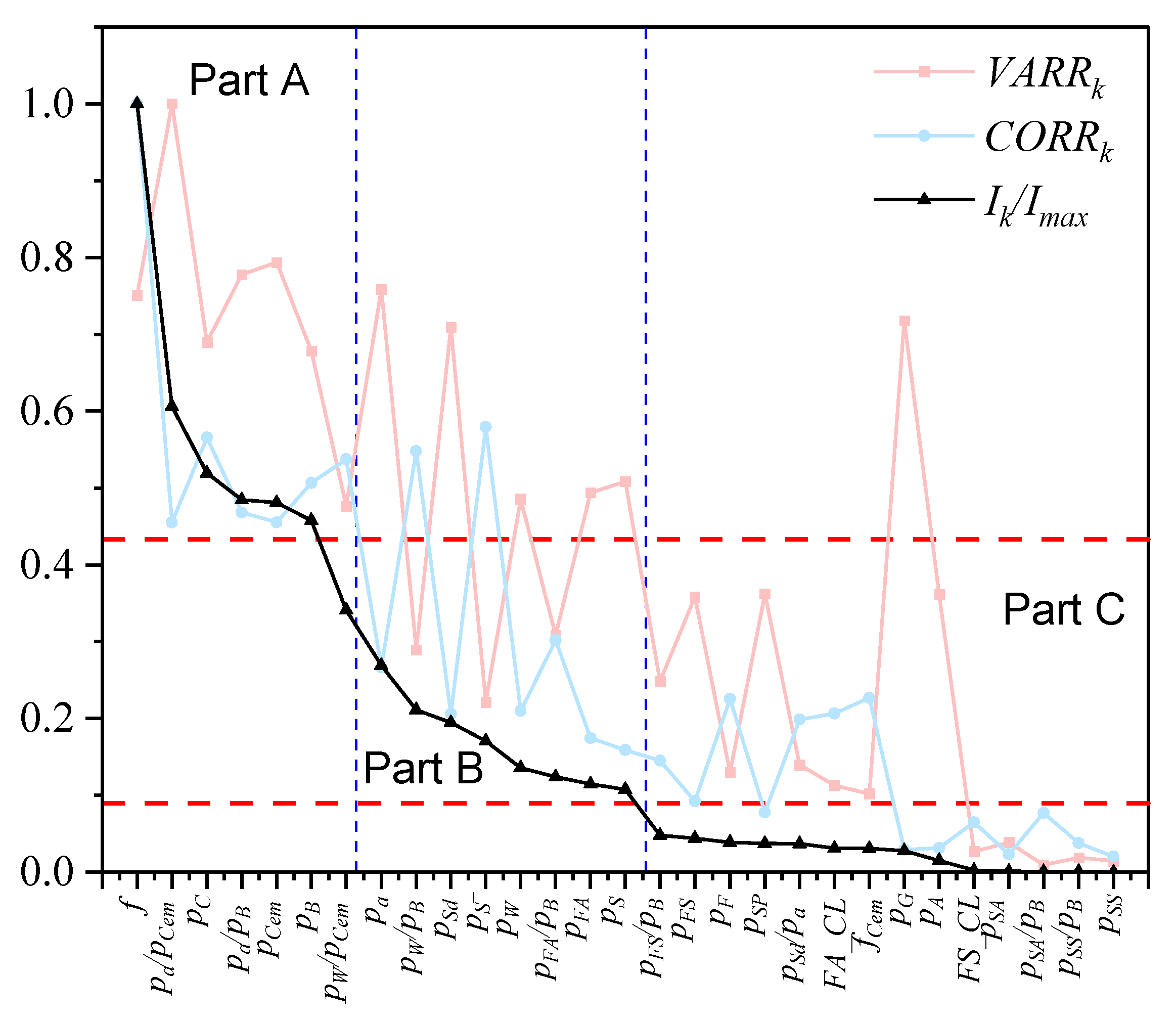
3.1. Evaluation of Factor Groups
- Determine the number of parameters included in the group;
- Assume that one group consists of m factors, sort all factors from largest to smallest according to their , and calculate ;where implies the possibility that factor cannot be replaced by previous factors and denotes the of factor . can be calculated by:where denotes Spearman’s correlation coefficient between and , and is used to make sure that ; i.e., if , ; otherwise, . It is noted that should be equal to one.
- Sort all groups from largest to smallest according to their .
3.2. Validation of Suggested Parameters
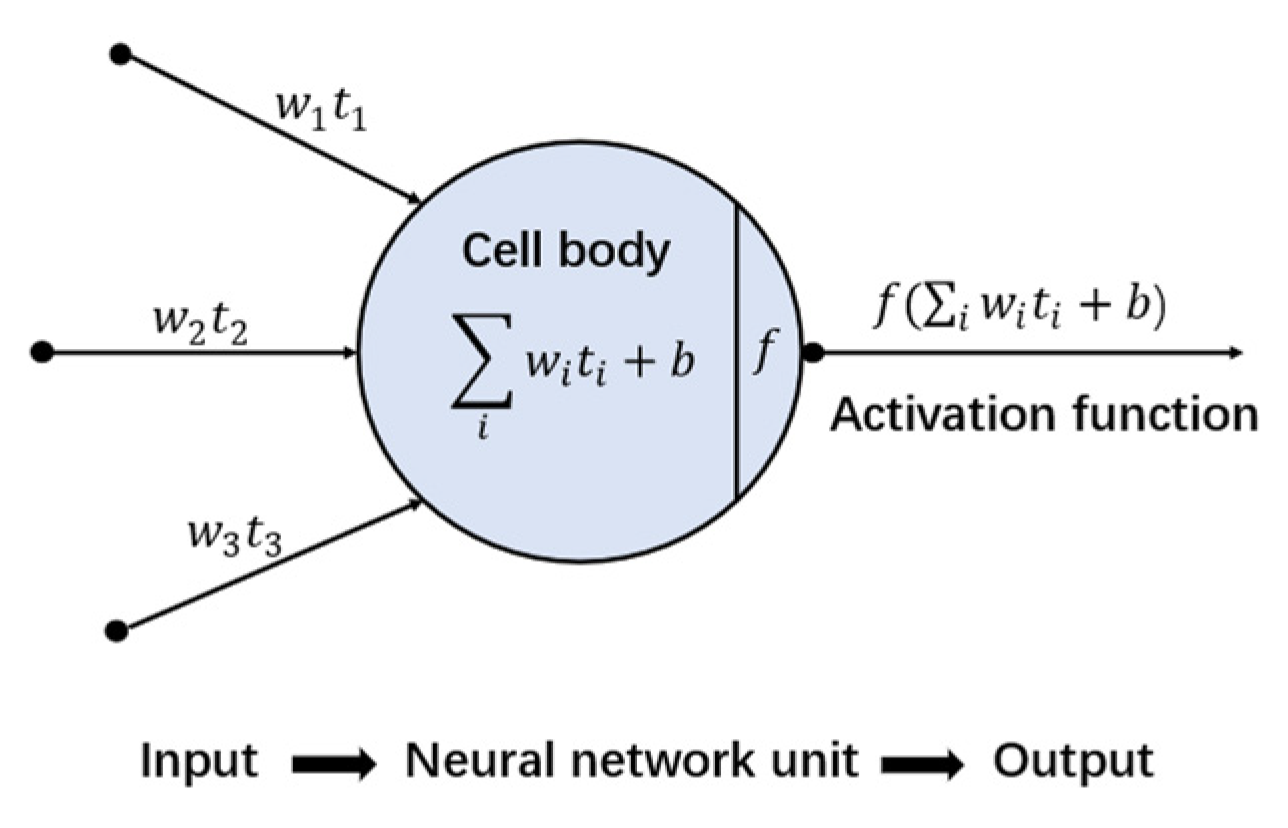
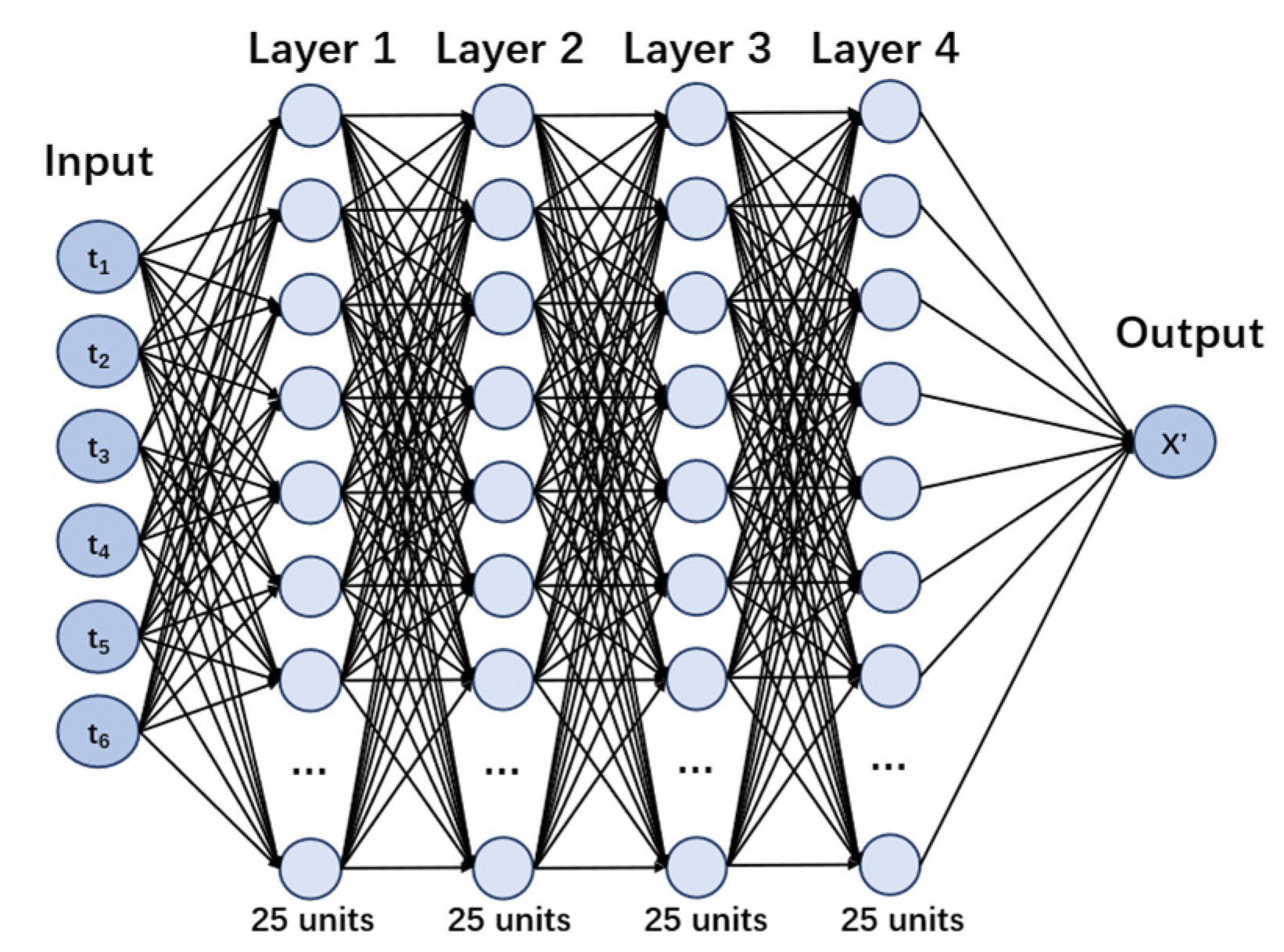
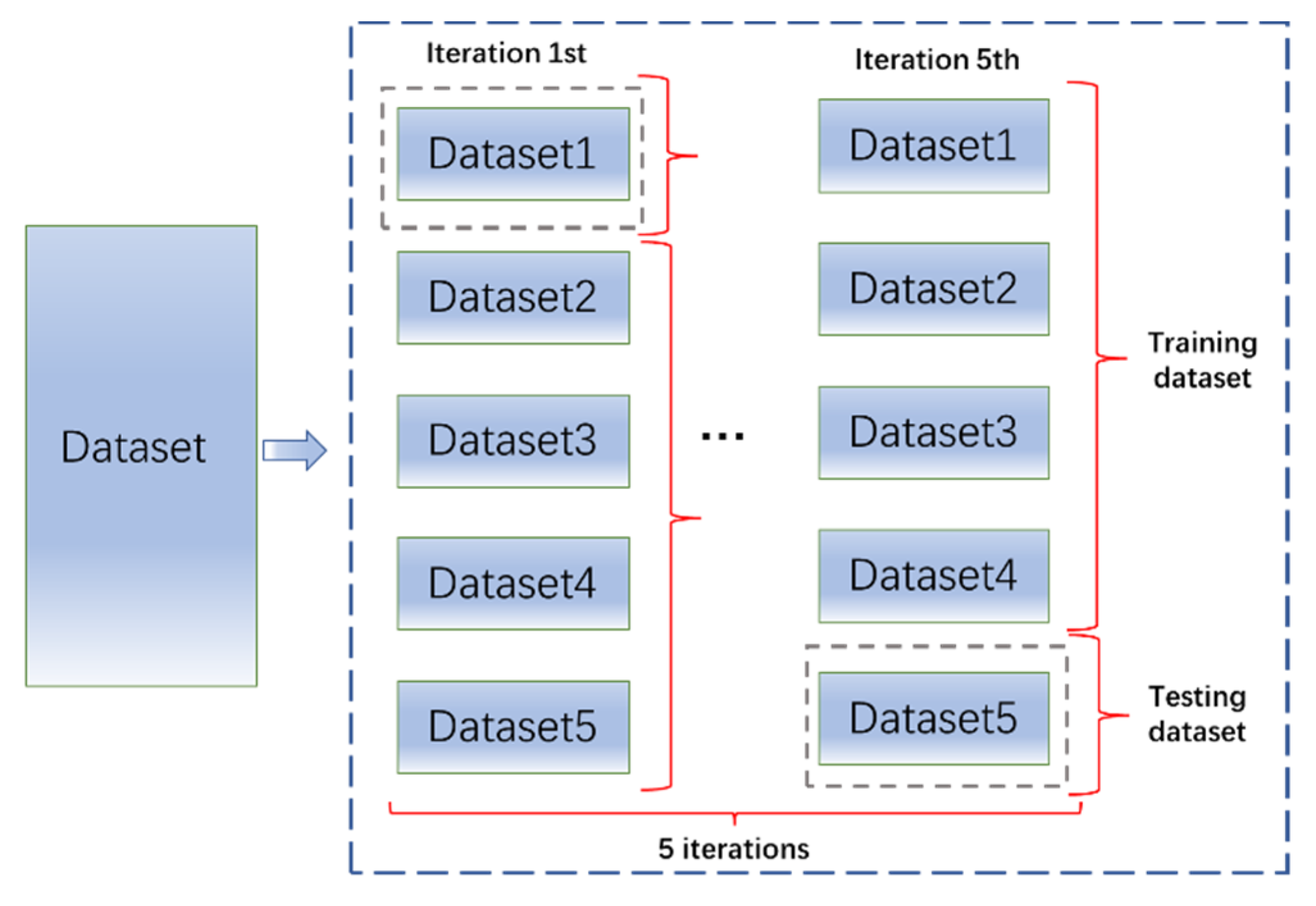
3.2.1. ML Methods
3.2.2. Verification and Discussions
4. Practical Carbonation Models for Existing Concrete Structures
4.1. Establishment of the Practical Model
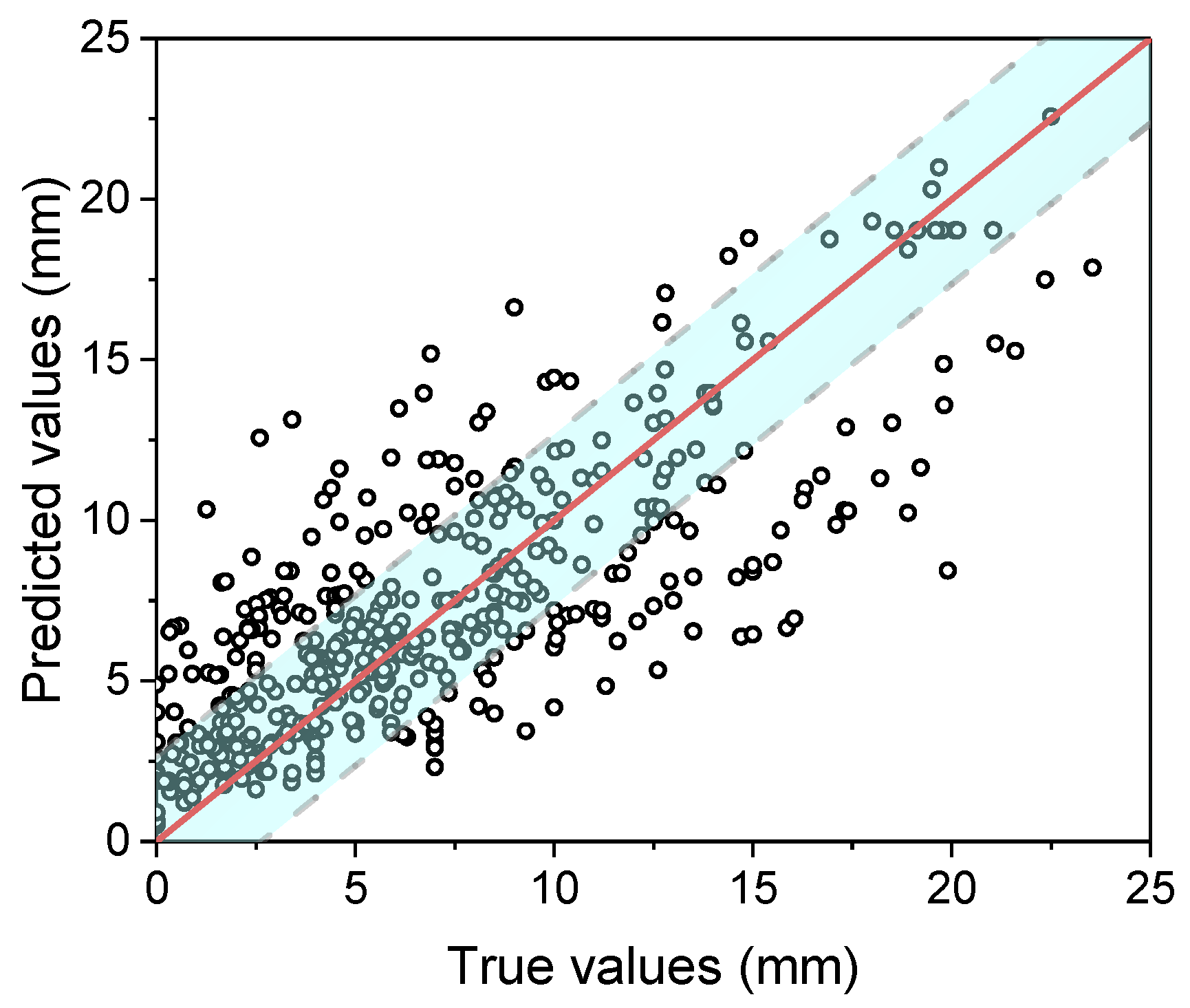
4.2. Verification of Models
5. Conclusions
- Single-parameter analysis showed that compressive strength had the highest correlation with carbonation depth and that the aggregate–cement ratio can minimize the uncertainties of carbonation depth. The method proposed in this study to evaluate single factors and the effects of parameter groups was effective. The results showed that the mean square error of ML models using the three selected parameters can reach 14.04 mm2, which was lower than the values obtained with ML models using six concrete mix design parameters (17.67 mm2) and close to the results from ML models using all parameters (11.61 mm2). Because appropriate groups improved the models’ performance and reduced their complexity, the mean square error of ML models using five selected parameters was able to reach 11.01 mm2, which was even lower than the values obtained with ML models using all parameters.
- Several machine learning models were developed to predict concrete carbonation depth. Through appropriate parameter selection, the models realized a high accuracy with a few parameters. For existing concrete structures, two concrete-related parameters (concrete strength and aggregate–cement ratio) and environmental factors were used to build a model via neural network methods. The results showed that the mean error of this model was about 2.5 mm. Based on this model, an empirical model was developed. The model was very simple and calculation-friendly. The results showed that this practical model had a high accuracy on both accelerated and natural carbonation datasets (mean absolute error = 1.56 mm).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Šavija, B.; Lukovic, M. Carbonation of cement paste: Understanding, challenges, and opportunities. Constr. Build. Mater. 2016, 117, 285–301. [Google Scholar] [CrossRef] [Green Version]
- Peter, M.A.; Muntean, A.; Meier, S.A.; Böhm, M. Competition of several carbonation reactions in concrete. A parametric study. Cement Concr. Res. 2008, 38, 1385–1393. [Google Scholar] [CrossRef] [Green Version]
- Ekolu, S.O. Model for practical prediction of natural carbonation in reinforced concrete: Part 1-formulation. Cement Concr. Compos. 2018, 86, 40–56. [Google Scholar] [CrossRef]
- Ahmad, S. Reinforcement corrosion in concrete structures, its monitoring and service life prediction––A review. Cement Concr. Compos. 2003, 25, 459–471. [Google Scholar] [CrossRef]
- Jiang, L.; Lin, B.; Cai, Y. A model for predicting carbonation of high-volume fly ash concrete. Cement Concr. Res. 2000, 30, 699–702. [Google Scholar] [CrossRef]
- Papadakis, V.G.; Fardis, M.N.; Vayenas, C.G. Effect of composition, environmental factors and cement-lime mortar coating on concrete carbonation. Mater. Struct. 1992, 25, 293–304. [Google Scholar] [CrossRef]
- Saetta, A.V.; Schrefler, B.A.; Vitaliani, R.V. 2-D model for carbonation and moisture/heat flow in porous materials. Cement Concr. Res. 1995, 25, 1703–1712. [Google Scholar] [CrossRef]
- Mi, R.; Pan, G.; Liew, K.M. Predicting carbonation service life of reinforced concrete beams reflecting distribution of carbonation zones. Constr. Build. Mater. 2020, 255, 119367. [Google Scholar] [CrossRef]
- Hwang, J.; Kwak, H.; Shim, M. Numerical approach for concrete carbonation considering moisture diffusion. Mater. Struct. 2020, 53, 1550. [Google Scholar] [CrossRef]
- Kwon, S.; Song, H. Analysis of carbonation behavior in concrete using neural network algorithm and carbonation modeling. Cement Concr. Res. 2010, 40, 119–127. [Google Scholar] [CrossRef]
- Lee, H.; Lee, H.; Suraneni, P. Evaluation of carbonation progress using AIJ model, FEM analysis, and machine learning algorithms. Constr. Build. Mater. 2020, 259, 119703. [Google Scholar] [CrossRef]
- Khunthongkeaw, J.; Tangtermsirikul, S.; Leelawat, T. A study on carbonation depth prediction for fly ash concrete. Constr. Build. Mater. 2006, 20, 744–753. [Google Scholar] [CrossRef]
- Sisomphon, K.; Franke, L. Carbonation rates of concretes containing high volume of pozzolanic materials. Cement Concr. Res. 2007, 37, 1647–1653. [Google Scholar] [CrossRef]
- Mo, L.; Zhang, F.; Deng, M.; Jin, F.; Al-Tabbaa, A.; Wang, A. Accelerated carbonation and performance of concrete made with steel slag as binding materials and aggregates. Cement Concr. Compos. 2017, 83, 138–145. [Google Scholar] [CrossRef]
- Hussain, S.; Bhunia, D.; Singh, S.B. Comparative study of accelerated carbonation of plain cement and fly-ash concrete. J. Build. Eng. 2017, 10, 26–31. [Google Scholar] [CrossRef]
- Papadakis, V.G. Effect of fly ash on portland cement systems: Part I. Low-calcium fly ash. Cement Concr. Res. 1999, 29, 1727–1736. [Google Scholar] [CrossRef]
- Lv, X.; Dong, Y.; Wang, R.; Lu, C.; Wang, X. Resistance improvement of cement mortar containing silica fume to external sulfate attacks at normal temperature. Constr. Build. Mater. 2020, 258, 119630. [Google Scholar] [CrossRef]
- Poon, C.; Kou, S.; Lam, L. Compressive strength, chloride diffusivity and pore structure of high performance metakaolin and silica fume concrete. Constr. Build. Mater. 2006, 10, 858–865. [Google Scholar] [CrossRef]
- Rossignolo, J.A. Interfacial interactions in concretes with silica fume and SBR latex. Constr. Build. Mater. 2009, 23, 817–821. [Google Scholar] [CrossRef]
- Wang, Q.; Yan, P.; Yang, J.; Zhang, B. Influence of steel slag on mechanical properties and durability of concrete. Constr. Build. Mater. 2013, 47, 1414–1420. [Google Scholar] [CrossRef]
- Han, F.; Jin, H.; Wang, D. Influence of steel slag and limestone powder on the anti-carbonation properties of concrete. Bull. Chin. Ceram. Soc. 2014, 33, 1573–1577. (In Chinese) [Google Scholar]
- Li, Z.; He, Z.; Chen, X. The performance of carbonation-cured concrete. Materials 2019, 12, 3729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, Z.; Li, S.; Fu, C.; Dong, Z.; Zhang, X.; Jin, N.; Xia, T. Macrocell corrosion of steel in concrete under carbonation, internal chloride admixing and accelerated chloride penetration conditions. Materials 2021, 14, 7691. [Google Scholar] [CrossRef]
- Yue, Y.; Wang, J.J.; Basheer, P.A.M.; Bai, Y. Establishing the carbonation profile with raman spectroscopy: Effects of fly ash and ground granulated blast furnace slag. Materials 2021, 14, 1798. [Google Scholar] [CrossRef]
- Ye, H.; Jin, N. Degradation mechanisms of concrete subjected to combined environmental and mechanical actions: A review and perspective. Comput. Concr. 2019, 23, 107–119. [Google Scholar]
- Rozière, E.; Loukili, A.; Cussigh, F. A performance based approach for durability of concrete exposed to carbonation. Constr. Build. Mater. 2009, 23, 190–199. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Zhang, C.; Cao, L.; Romagnoli, A. On the feature engineering of building energy data mining. Sustain. Cities Soc. 2018, 39, 508–518. [Google Scholar] [CrossRef]
- Yuan, P.; Duanmu, L.; Wang, Z. Coal consumption prediction model of space heating with feature selection for rural residences in severe cold area in China. Sustain. Cities Soc. 2019, 50, 101643. [Google Scholar] [CrossRef]
- Li, Y.; Li, T.; Liu, H. Recent advances in feature selection and its applications. Knowl. Inf. Syst. 2017, 53, 551–577. [Google Scholar] [CrossRef]
- Reshef, D.; Reshef, Y.; Finucane, H.; Grossman, S.; McVean, G.; Turnbaugh, P.; Lander, E.; Mitzenmacher, M.; Sabeti, P. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lazar, C.; Taminau, J.; Meganck, S. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE ACM Trans. Comput. Biol. 2012, 9, 1106–1119. [Google Scholar] [CrossRef] [PubMed]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Mundra, P.A.; Rajapakse, J.C. Svm-Rfe with Mrmr filter for gene selection. IEEE Trans. Nanobiosci. 2010, 9, 31–37. [Google Scholar] [CrossRef]
- Kim, S.; Ouyang, M.; Zhang, X. Compute Spearman Correlation Coefficient with Matlab/CUDA; University of Louisville: Louisville, KY, USA, 2012. [Google Scholar]
- Papadakis, V.G.; Antiohos, S.; Tsimas, S. Supplementary cementing materials in concrete: Part II: A Fundamental estimation of the efficiency factor. Cement Concr. Res. 2002, 32, 1533–1538. [Google Scholar] [CrossRef]
- Duan, K.; Cao, S.; Li, J.; Xu, C. Prediction of neutralization depth of R.C. bridges using machine learning methods. Crystals 2021, 11, 210. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Shen, Z.; Yang, H.; Zhang, S. Neural network approximation: Three hidden layers are enough. Neural Netw. 2021, 141, 160–173. [Google Scholar] [CrossRef]
- Nitish, S.; Geoffrey, H.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shishegaran, A.; Varaee, H.; Rabczuk, T.; Shishegaran, G. High correlated variables creator machine: Prediction of the compressive strength of concrete. Comput. Struct. 2021, 247, 106479. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Sistonen, E. Machine learning for durability and service-life assessment of reinforced concrete structures: Recent advances and future directions. Autom. Constr. 2017, 77, 1–14. [Google Scholar] [CrossRef]
- Monteiro, I.; Branco, F.A.; Brito, J.D.; Neves, R. Statistical analysis of the carbonation coefficient in open air concrete structures. Constr. Build. Mater. 2012, 29, 263–269. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.J. A Practical mathematical model of concrete carbonation depth based on the mechanism. Ind. Build. 1998, 1, 16–19. (In Chinese) [Google Scholar]
- Niu, D.; Chen, Y.; Yu, S. Model and reliability analysis for carbonation of concrete structures. J. Xi’an Univ. Archit. Technol. 1995, 27, 365–369. (In Chinese) [Google Scholar]
- Gong, L.; Su, M.; Wang, H. Concrete multi-coefficient carbonation equation and its application. Concrete 1985, 6, 10–16. (In Chinese) [Google Scholar]
- A, R.; Yan, P. Carbonation characteristics of concrete with different fly-ash contents. J. Chin. Ceram. Soc. 2011, 1, 7–12. (In Chinese) [Google Scholar]
- Qiu, Y. Prediction of natural carbonation of fly ash concrete. Dev. Guide Build. Mater. 1989, 2, 15–17. (In Chinese) [Google Scholar]
- Zhao, Y. Prediction of Concrete Carbonation Depth Based On Model Similarity Theory; Northwest A & F University: Xianyang, China, 2017. [Google Scholar]
- Sun, B.; Mao, S.; Wang, J.; Di, X.; Ren, R. Experimental study on correlation between natural carbonation and accelerated carbonation of long-term observation concrete specimens. Build. Struct. 2019, 49, 92–98. (In Chinese) [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Unit | Histogram | Min | Max | Mean | Valid | Explanation |
|---|---|---|---|---|---|---|---|
| kg/m3 | 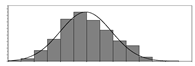 | 30 | 693 | 297 | 7351 | Weight of cement used per unit volume of concrete | |
| kg/m3 | 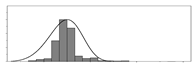 | 80 | 456 | 176 | 7351 | Weight of water used per unit volume of concrete | |
| kg/m3 |  | 0 | 506 | 72 | 7351 | Weight of fly ash used per unit volume of concrete | |
| kg/m3 | 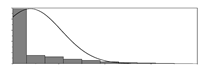 | 0 | 372 | 39 | 7351 | Weight of furnace slag used per unit volume of concrete | |
| kg/m3 |  | 0 | 228 | 1 | 7351 | Weight of steel slag used per unit volume of concrete | |
| kg/m3 |  | 0 | 59 | 1 | 7351 | Weight of silica ash used per unit volume of concrete | |
| kg/m3 | 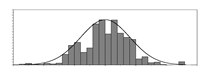 | 367 | 1071 | 700 | 6573 | Weight of sand used per unit volume of concrete | |
| kg/m3 | 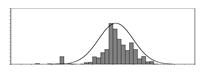 | 601 | 1319 | 1114 | 6573 | Weight of gravel used per unit volume of concrete | |
| - | 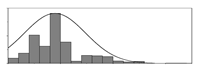 | 0 | 3.5 | 0.9 | 6695 | Weight of water reducer used per unit weight of the binder | |
| Mpa | 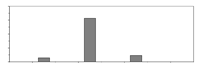 | 32.5/42.5/52.5 | 7787 | Cement strength level | |||
| FA_CL | - |  | Ⅰ/Ⅱ/Ⅲ | 6491 | Class of fly ash | ||
| FS_CL | - |  | S75/S95/S105 | 3924 | Class of furnace slag | ||
| kg/m3 | 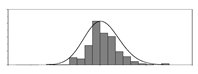 | 970 | 2237 | 1815 | 6573 | Weight of aggregate used per unit volume of concrete | |
| kg/m3 | 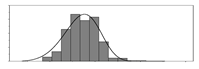 | 200 | 842 | 409 | 7351 | Weight of binder used per unit volume of concrete | |
| - | 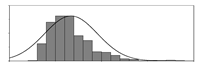 | 0.25 | 4 | 0.67 | 8100 | Water–cement ratio | |
| - |  | 0.23 | 0.95 | 0.44 | 8100 | Water–binder ratio | |
| - | 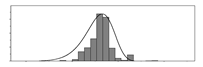 | 0.23 | 0.56 | 0.39 | 7308 | Sand ratio | |
| - | 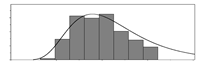 | 2.23 | 70 | 7.14 | 6573 | Aggregate–cement ratio | |
| - | 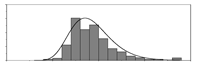 | 1.86 | 10.5 | 4.66 | 6573 | Aggregate–binder ratio | |
| % | 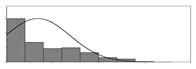 | 0 | 80 | 17 | 8133 | Percentage of fly ash | |
| % |  | 0 | 80 | 16 | 8133 | Percentage of furnace slag | |
| % |  | 0 | 60 | 0.3 | 8133 | Percentage of steel slag | |
| % |  | 0 | 15 | 0.2 | 8133 | Percentage of silica ash | |
| kg/m3 | 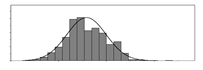 | 56 | 436 | 206 | 7289 | Weight of CaO used per unit volume of concrete | |
| kg/m3 | 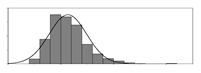 | 42 | 305 | 113 | 7289 | Weight of SiO2 used per unit volume of concrete | |
| kg/m3 | 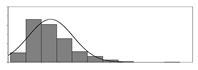 | 10 | 159 | 42 | 7289 | Weight of Al2O3 used per unit volume of concrete | |
| kg/m3 | 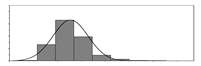 | 7 | 55 | 17 | 7289 | Weight of Fe2O3 used per unit volume of concrete | |
| kg/m3 |  | 3 | 15 | 8 | 7289 | Weight of SO3 used per unit volume of concrete | |
| Mpa |  | 8 | 95 | 43 | 5781 | Compressive strength of concrete at 28 days | |
| 1 | −0.69 | 0.47 | −0.22 | 0.4 | −0.16 | −0.54 | −0.35 | −0.47 | −0.47 | −0.1 | 0.29 | 0.29 | 0.51 | 0.66 | 0.28 | |
| −0.69 | 1 | 0.22 | 0.43 | −0.26 | 0.19 | 0.75 | 0.61 | 0.76 | 0.49 | 0.09 | −0.5 | −0.3 | −0.7 | −0.98 | −0.52 | |
| 0.47 | 0.22 | 1 | 0.19 | 0.22 | 0.03 | 0.15 | 0.21 | 0.23 | −0.15 | −0.01 | −0.18 | −0.05 | −0.19 | −0.21 | −0.21 | |
| −0.22 | 0.43 | 0.19 | 1 | −0.87 | −0.44 | −0.15 | 0.89 | 0.84 | 0.25 | −0.5 | −0.33 | 0.01 | −0.27 | −0.44 | −0.99 | |
| 0.4 | −0.26 | 0.22 | −0.87 | 1 | 0.46 | 0.28 | −0.73 | −0.66 | −0.3 | 0.49 | 0.23 | 0 | 0.2 | 0.28 | 0.86 | |
| −0.16 | 0.19 | 0.03 | −0.44 | 0.46 | 1 | 0.69 | −0.53 | −0.32 | −0.05 | 0.99 | −0.03 | −0.24 | −0.25 | −0.18 | 0.37 | |
| −0.54 | 0.75 | 0.15 | −0.15 | 0.28 | 0.69 | 1 | 0 | 0.22 | 0.32 | 0.61 | −0.33 | −0.34 | −0.58 | −0.74 | 0.07 | |
| −0.35 | 0.61 | 0.21 | 0.89 | −0.73 | −0.53 | 0 | 1 | 0.95 | 0.39 | −0.61 | −0.36 | −0.05 | −0.33 | −0.59 | −0.89 | |
| −0.47 | 0.76 | 0.23 | 0.84 | −0.66 | −0.32 | 0.22 | 0.95 | 1 | 0.42 | −0.42 | −0.42 | −0.14 | −0.46 | −0.74 | −0.86 | |
| −0.47 | 0.49 | −0.15 | 0.25 | −0.3 | −0.05 | 0.32 | 0.39 | 0.42 | 1 | −0.11 | −0.2 | 0 | −0.2 | −0.42 | −0.27 | |
| −0.1 | 0.09 | −0.01 | −0.5 | 0.49 | 0.99 | 0.61 | −0.61 | −0.42 | −0.11 | 1 | 0.01 | −0.2 | −0.18 | −0.08 | 0.44 | |
| 0.29 | −0.5 | −0.18 | −0.33 | 0.23 | −0.03 | −0.33 | −0.36 | −0.42 | −0.2 | 0.01 | 1 | −0.22 | 0.65 | 0.56 | 0.4 | |
| 0.29 | −0.3 | −0.05 | 0.01 | 0 | −0.24 | −0.34 | −0.05 | −0.14 | 0 | −0.2 | −0.22 | 1 | 0.51 | 0.36 | 0.06 | |
| 0.51 | −0.7 | −0.19 | −0.27 | 0.2 | −0.25 | −0.58 | −0.33 | −0.46 | −0.2 | −0.18 | 0.65 | 0.51 | 1 | 0.8 | 0.39 | |
| 0.66 | −0.98 | −0.21 | −0.44 | 0.28 | −0.18 | −0.74 | −0.59 | −0.74 | −0.42 | −0.08 | 0.56 | 0.36 | 0.8 | 1 | 0.52 | |
| 0.28 | −0.52 | −0.21 | −0.99 | 0.86 | 0.37 | 0.07 | −0.89 | −0.86 | −0.27 | 0.44 | 0.4 | 0.06 | 0.39 | 0.52 | 1 |
| Number of Factors | No. | Groups |
|---|---|---|
| 3 factors | 3-1 | |
| 3-2 | ||
| 3-3 | ||
| 4 factors | 4-1 | |
| 4-2 | ||
| 4-3 | ||
| 5 factors | 5-1 | |
| 5-2 |
| No. | Groups | SVR-MSE | XGB-MSE | DNN-MSE |
|---|---|---|---|---|
| 3-1 | 21.62 | 14.04 | 18.68 | |
| 3-2 | 22.64 | 15.46 | 17.85 | |
| 3-3 | 20.96 | 14.20 | 16.62 | |
| 4-1 | 19.41 | 12.01 | 15.16 | |
| 4-2 | 20.11 | 13.09 | 17.01 | |
| 4-3 | 20.89 | 13.33 | 16.21 | |
| 5-1 | 19.36 | 12.16 | 12.77 | |
| 5-2 | 18.70 | 11.01 | 14.39 | |
| 5-3 | 42.37 | 17.67 | 42.27 | |
| 17-1 | [CO2], RH, T, t, all parameters in Table 2 | 17.48 | 11.61 | 14.05 |
| Models | Papadakis [6] | Morinaga [6] | Monteiro [45] | Zhang [46] | Niu [47] | Gong [48] | This Paper | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error (mm) | AVG 1 | M 1 | AVG | M | AVG | M | AVG | M | AVG | M | AVG | M | AVG | M |
| 3 days | 15.8 | 11.3 | 36.6 | 30.4 | 2.7 | 2.1 | 3.3 | 2.7 | 2.2 | 1.7 | 8.2 | 4.5 | 2.0 | 1.4 |
| 7 days | 22.4 | 17 | 55.3 | 45 | 4.2 | 3.3 | 4.9 | 4.1 | 2.6 | 1.8 | 12.1 | 6.7 | 2.2 | 1.5 |
| 14 days | 31.4 | 22.3 | 72.5 | 59.3 | 6.7 | 5.3 | 7.4 | 6.1 | 3.4 | 2.5 | 16.8 | 10.1 | 3.2 | 2.3 |
| 28 days | 49.2 | 35.4 | 109.5 | 88.9 | 9.7 | 7.7 | 11.8 | 10.1 | 4.4 | 3.1 | 27.9 | 15.6 | 4.0 | 2.9 |
| All | 37.0 | 22.8 | 85.1 | 58.2 | 7.7 | 5.1 | 8.8 | 6.0 | 3.7 | 2.5 | 20.6 | 10.9 | 3.3 | 2.3 |
| RH (%) | T (°C) | [CO2] (%) | f (MPa) | a/c | t (days) | True Values (mm) | Predicted Values (mm) | Errors (mm) |
|---|---|---|---|---|---|---|---|---|
| 57 | 13 | 0.03 | 38.95 | 5.85 | 28 | 0 | 0.9 | 0.9 |
| 57 | 13 | 0.03 | 38.95 | 5.85 | 56 | 0 | 1.3 | 1.3 |
| 57 | 13 | 0.03 | 38.95 | 5.85 | 90 | 1.3 | 1.6 | 0.3 |
| 57 | 13 | 0.03 | 38.95 | 5.85 | 180 | 7.1 | 2.3 | 4.8 |
| 57 | 13 | 0.03 | 38.95 | 5.85 | 270 | 9.4 | 2.8 | 6.6 |
| 57 | 13 | 0.03 | 38.95 | 5.85 | 360 | 9.3 | 3.3 | 6.0 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 28 | 1.5 | 1.7 | 0.2 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 60 | 2.1 | 2.5 | 0.4 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 90 | 2.5 | 3.0 | 0.5 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 122 | 2.8 | 3.5 | 0.7 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 158 | 3.3 | 4.0 | 0.7 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 195 | 3.4 | 4.5 | 1.1 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 227 | 3.6 | 4.8 | 1.2 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 250 | 3.8 | 5.1 | 1.3 |
| 63 | 19 | 0.03 | 30.20 | 6.22 | 280 | 4.2 | 5.4 | 1.2 |
| 63 | 19 | 0.03 | 25.6 | 6.70 | 28 | 1.7 | 2.1 | 0.4 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 60 | 2.4 | 3.1 | 0.7 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 90 | 2.8 | 3.8 | 1.0 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 122 | 3.2 | 4.4 | 1.2 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 158 | 3.7 | 5.0 | 1.3 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 195 | 3.9 | 5.5 | 1.6 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 227 | 4.2 | 6.0 | 1.8 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 250 | 4.7 | 6.3 | 1.6 |
| 63 | 19 | 0.03 | 25.60 | 6.70 | 280 | 5.3 | 6.6 | 1.3 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 28 | 2.1 | 1.5 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 60 | 2.8 | 2.2 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 90 | 3.3 | 2.7 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 122 | 3.7 | 3.1 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 158 | 4.3 | 3.5 | 0.8 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 195 | 4.5 | 3.9 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 227 | 4.8 | 4.2 | 0.6 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 250 | 5.6 | 4.5 | 1.1 |
| 63 | 19 | 0.03 | 33.30 | 6.39 | 280 | 6.3 | 4.7 | 1.6 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 28 | 2.4 | 1.6 | 0.8 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 60 | 3.4 | 2.4 | 1.0 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 90 | 4.0 | 2.9 | 1.1 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 122 | 4.7 | 3.4 | 1.3 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 158 | 5.3 | 3.9 | 1.4 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 195 | 5.8 | 4.3 | 1.5 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 227 | 5.7 | 4.7 | 1.0 |
| 63 | 19 | 0.03 | 31.60 | 7.11 | 250 | 7.2 | 4.9 | 2.3 |
| 63 | 19 | 0.03 | 31.60 | 8.40 | 280 | 7.6 | 5.3 | 2.3 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 28 | 2.6 | 1.5 | 1.1 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 60 | 3.7 | 2.1 | 1.6 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 90 | 4.3 | 2.6 | 1.7 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 122 | 4.9 | 3.1 | 1.8 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 158 | 5.7 | 3.5 | 2.2 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 195 | 6.4 | 3.9 | 2.5 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 227 | 6.1 | 4.2 | 1.9 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 250 | 7.4 | 4.4 | 3.0 |
| 63 | 19 | 0.03 | 35.00 | 8.40 | 280 | 8.2 | 4.6 | 3.6 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 28 | 3.2 | 1.5 | 1.7 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 60 | 4.2 | 2.2 | 2.0 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 90 | 4.8 | 2.7 | 2.1 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 122 | 5.5 | 3.2 | 2.3 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 158 | 6.6 | 3.6 | 3.0 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 195 | 7.0 | 4.0 | 3.0 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 227 | 7.4 | 4.3 | 3.1 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 250 | 8.5 | 4.5 | 4.0 |
| 63 | 19 | 0.03 | 35.00 | 9.81 | 280 | 9.1 | 4.8 | 4.3 |
| 57 | 12.4 | 0.03 | 29.80 | 3.32 | 2190 | 5.0 | 5.7 | 0.7 |
| 57 | 12.4 | 0.03 | 29.80 | 3.32 | 9125 | 15.1 | 11.6 | 3.5 |
| 75 | 20 | 0.03 | 32.05 | 4.32 | 41 | 1.1 | 1.3 | 0.2 |
| 75 | 20 | 0.03 | 32.05 | 4.32 | 224 | 2.67 | 3.0 | 0.0 |
| 73 | 15 | 0.03 | 16.10 | 6.00 | 183 | 6.8 | 4.9 | 1.9 |
| 73 | 15 | 0.03 | 20.20 | 6.61 | 183 | 5.3 | 4.0 | 1.3 |
| 73 | 15 | 0.03 | 25.50 | 6.72 | 183 | 4.7 | 3.1 | 1.6 |
| 73 | 15 | 0.03 | 16.10 | 6.00 | 365 | 7.0 | 6.9 | 0.1 |
| 73 | 15 | 0.03 | 20.20 | 6.61 | 365 | 6.5 | 5.7 | 0.8 |
| 73 | 15 | 0.03 | 25.50 | 6.72 | 365 | 4.8 | 4.4 | 0.4 |
| 73 | 15 | 0.03 | 16.10 | 6.00 | 1095 | 12.1 | 12.0 | 0.1 |
| 73 | 15 | 0.03 | 20.20 | 6.61 | 1095 | 10.1 | 9.8 | 0.3 |
| 73 | 15 | 0.03 | 25.50 | 6.72 | 1095 | 9.7 | 7.6 | 2.1 |
| 73 | 15 | 0.03 | 16.10 | 6.00 | 1825 | 16.1 | 15.4 | 0.7 |
| 73 | 15 | 0.03 | 20.20 | 6.61 | 1825 | 14.4 | 12.6 | 1.8 |
| 73 | 15 | 0.03 | 25.50 | 6.72 | 1825 | 9.9 | 9.9 | 0.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, K.; Cao, S. Data-Driven Parameter Selection and Modeling for Concrete Carbonation. Materials 2022, 15, 3351. https://doi.org/10.3390/ma15093351
Duan K, Cao S. Data-Driven Parameter Selection and Modeling for Concrete Carbonation. Materials. 2022; 15(9):3351. https://doi.org/10.3390/ma15093351
Chicago/Turabian StyleDuan, Kangkang, and Shuangyin Cao. 2022. "Data-Driven Parameter Selection and Modeling for Concrete Carbonation" Materials 15, no. 9: 3351. https://doi.org/10.3390/ma15093351
APA StyleDuan, K., & Cao, S. (2022). Data-Driven Parameter Selection and Modeling for Concrete Carbonation. Materials, 15(9), 3351. https://doi.org/10.3390/ma15093351