1. Introduction
Determining the engineering properties of soil layers is critical in geotechnical projects. Thus, field and laboratory tests are required in the evaluation of soil properties in geotechnical engineering. Field and laboratory experiments are the best ways to understand the complex behavior of soil layers, but those experiments involve several shortcomings. Among them, time and budget constraints are specially considered major disadvantages of the experiments. Geotechnical engineers need to determine critical soil properties without time and budget restrictions. However, many conventional field tests do not allow measuring required soil-design parameters directly; empirical correlations are commonly used to determine these design parameters [
1].
The undrained shear strength (
cu) is generally used as a geotechnical design parameter for clay soil, and it is one of these design parameters that is challenging to directly measure in the field. The
cu value can be determined using unconfined or triaxial compression tests in a laboratory or using a hand penetrometer in the field. Estimating
cu and unconfined compressive strength (
qu =
cu/2) is possible using the findings of the standard penetration test (SPT) performed in the field. The
qu value is determined through unconfined compression or unconsolidated undrained (UU) tests. Many researchers have proposed various correlations between
NSPT and
qu. The correlation recommended by Terzaghi and Peck [
2], between
qu and
NSPT in fine-grained soils is given in
Table 1.
In geotechnical engineering, the SPT stands out as one of the most widely used methods in the field to evaluate the resistance of soil layers. The standard penetration resistance of soil layers is expressed by the number of blows, SPT N-value (
NSPT), recorded for the last two 150-mm layers [
3]. Here, the
NSPT value does not directly provide the
cu value that is used as a geotechnical design parameter. This situation has led many researchers to develop other correlations to predict the
cu value using
NSPT [
4,
5,
6].
Table 2 shows the correlation between
NSPT and
cu according to soil classification from the literature [
7,
8,
9].
Machine learning techniques have newly acquired great consideration among researchers in multiple disciplines [
10]. Researchers have tried to develop the precise prediction and interpretability of models by using various decision-trees machine learning algorithms such as decision trees [
11], random forests [
12], classification and regression trees [
13], and support vector regression [
14]. Also, numerous research groups around the world have recognized the extraordinary potential these algorithms can bring to geotechnical engineering. Some researchers used a number of machine learning approaches (i.e., artificial neural network (ANN), support vector regression (SVR), and random forest (RF)) to predict cone penetration test (CPT) data according to soil classification. The results clearly indicated that both ANN and RF techniques showed precise predictions [
15]. Some other researchers utilized machine learning techniques to estimate the stability of organic soils and they demonstrated that the ANN models showed the best precision accuracy [
16,
17]. Choi et al. [
18] showed a few learning algorithms (deep neural networks, RF, and SVR) to estimate the leakage stress that is employed during drilling in the petroleum industry. Genetic algorithms were utilized to optimize site surveys for the design of pile foundations [
19]. In addition, the group method of data handling (GMDH-type NN) approach was used for several geotechnical engineering applications. Mola-Abasi and Eslami [
20], derived the GMDH models to predict shear strength parameters (
c and
φ) from CPTu data. Choobbasti and Valizadeh [
21], used the GMDH-type NN to determine the optimal amount of clay and Nano-CuO to obtain the maximum undrained cohesion. In particular, Kalantary et al. [
6] developed a mathematical model using an optimized GMDH-NN with a genetic algorithm and designed a correlation between
cu and
N60. Also, Mbarak et al. [
1] examined the relationship between parameters obtained by the undrained shear strength (
cu) and SPT test in fine-grained soils with their statistical model based on soil physical properties.
This study presents mathematical models that predict cu values using artificial intelligence technology. Additionally, the objective of this study is to obtain the most effective model for the prediction of undrained shear strength. The GMDH-type NN was compared with other models (i.e., SVR and RF) and classical regression (i.e., linear regression); the performance of the models was determined by using the correlation coefficient (R2), root-mean-square error (RMSE), and mean absolute error (MAE). In the prediction of the cu value, various soil parameters were used as input parameters and the models were made by various soil types. Moreover, the effect of the input variables on the prediction model was evaluated with the SHAP (SHApley Additive ExPlanations) approach according to the extreme gradient boosting (XGBoost) ensemble learning algorithm in this study. The novelty and main contributions of the study are as follows:
Prediction of undrained shear strength was provided with high accuracy by the polynomial neural network based on the GMDH-type NN approach;
SPT-value and soil physical properties input variables were analyzed with the XGBoost ensemble learning-based SHAP approach;
It was ensured that the prediction model was obtained only with high-impact inputs;
As an alternative to traditional methods, it is provided to obtain a self-organized predictive model for undrained shear strength;
A predictive model with high performance on a small dataset was designed and implemented.
2. Methods and Procedures
2.1. Dataset
According to the findings of the literature [
22,
23,
24], a total of 211 samples from soils classified as CH, CL, MH, and ML were used to assemble the dataset. This study was conducted using the results of
NSPT, effective stress (
σv’),
cu,
PL, LL, and
PI of the 211 samples.
Figure 1 presents the data with frequency histograms to reflect the distribution of the dataset. In addition, it shows that the statistical assumptions were met with the provision of multivariate normal distribution of the data, nonuniform distribution of independent (predictor) variables, non-linearity among independent (predictor) variables, and covariance. In addition,
Table 3 presents the data as the descriptive statistics of the variables.
2.2. Pre-Processing
In order to build up a decent and widely applicable prediction model, the independent variables must be normalized and identified within a certain range. A min–max method is frequently used in the normalization of variables. The min–max method normalizes the independent variables of the data to the [0,1] range. The normalization of the min–max method is expressed as follows:
where
x and
xnorm represent data value and normalized data, respectively.
2.3. Machine Learning Approaches
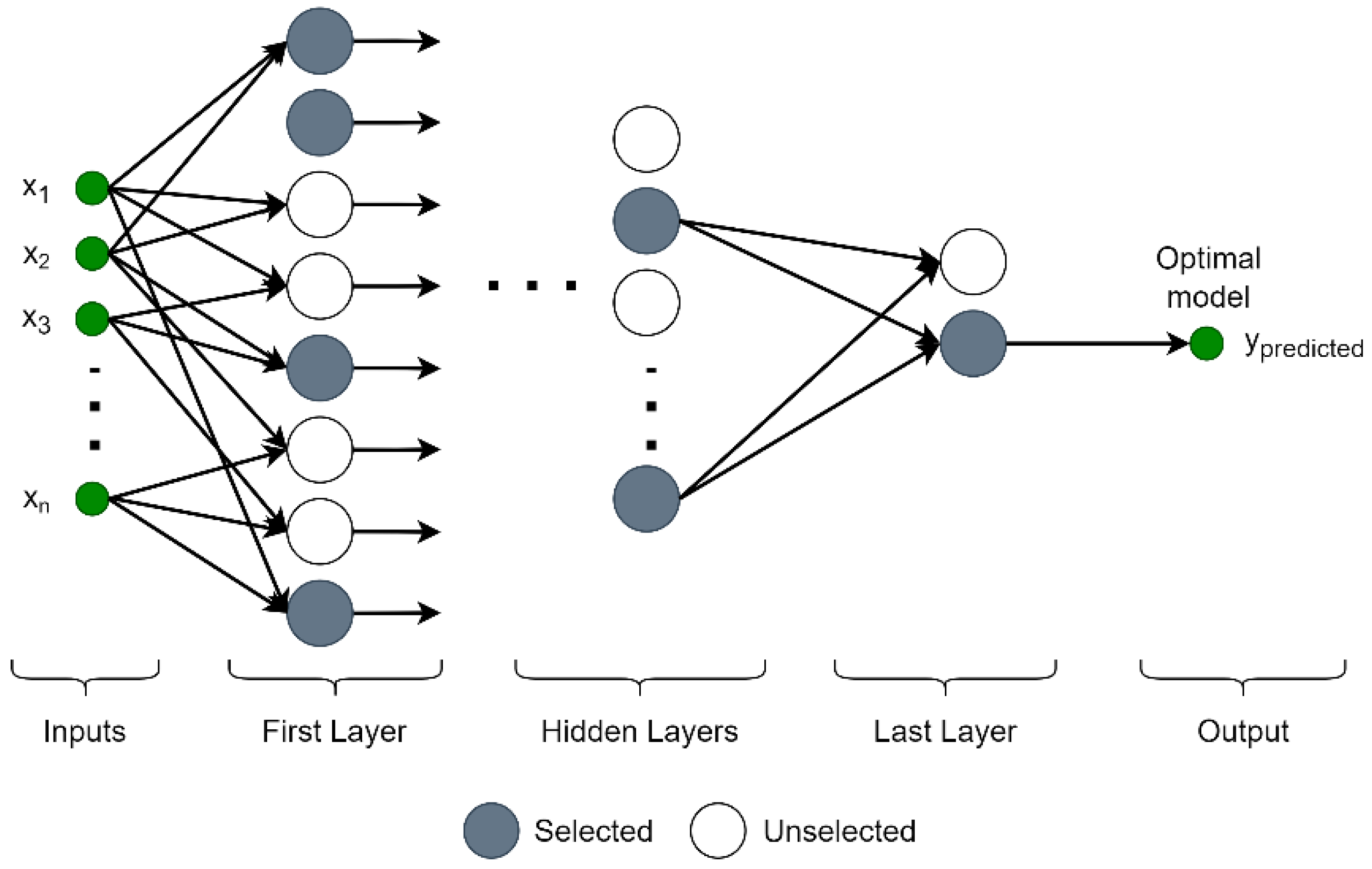
ANN models, such as multilayer perception, are extensively used in regression and classification. A multilayered neural network comprises one input, multiple hidden, and one output layer. In this network model, each cell in the hidden layer uses all inputs in the input layer. The use of all inputs in all cells in the network structure may cause overfitting problems and reduce performance. Difficulties and deficiencies are encountered in setting bias and weight coefficients, especially when handling small-sized data sets.
Therefore, instead of this network model in which all inputs and cells in all layers are used, the GMDH-type NN, a self-organizing network model that acts based on the input data, is preferred [
25,
26]. The schematic structure of the GMDH-type NN is shown in
Figure 2.
The GMDH-type NN is one of the best model prediction methods for problems involving complex structures. The GMDH-type NN model is a multilayered structure using only the cells that can yield the most efficient and accurate results. Each layer comprises independent cells used in pairs and is integrated with a quadratic polynomial as the activation function. The cells in all layers run independently from each other, and only the outputs from the previous layer that minimize the error rate are preferred. Thus, instead of using cells in all layers, the best network model comprising optimal cells is created [
27]. The GMDH-type NN is used as a model that maps a given input vector
to the predicted
output. It is expected that the predicted
output is as close as possible to the actual
output. Thus,
M results obtained for data pairs in a multi-input single-output network model are observed as follows [
28]
The output predicted to obtain
output from input vector
is shown as follows:
The least-squares method is applied between the actual outputs
and predicted outputs
to determine the GMDH model. The cells in which the errors calculated using the least-squares method are minimized are selected:
The GMDH-type NN is identified based on input and output parameters emphasized in the form of the gradually complicated Kolmogorov–Gabor polynomial function [
29]. Expressed as a nonlinear function form, the Kolmogorov–Gabor function is defined as:
Here,
α shows the polynomial coefficients and
. Typically, the Kolmogorov–Gabor polynomial, which gives a nonlinear polynomial form, is written in the form of a quadratic polynomial containing only two variables [
27]:
The GMDH-type NN predicts the output for each set of input parameters
and
and is used to predict
αi (1, 2, …, 5) coefficients that reduce RMSE between the estimated and real outputs. With
M representing the total number of data, minimizing the RMSE between the predicted and actual outputs is as follows:
In the basic form of the GMDH algorithm, all binary probabilities of independent variables from
n inputs in total provide the establishment of the regression structure using the polynomial form given in Equation (6) to obtain the actual output data
. The cell count in the hidden layer in the GMDH network model structure is determined by
. In the next step, creating
M data triples as
from the actual output data is possible. The resulting matrix form can be expressed as:
The essential form of the GMDH algorithm is expressed in matrix form and Equation (5) can be rewritten as:
Here
represents the actual output vector, and
presents the unknown coefficient vector of the quadratic polynomial vector. The predicted
A matrix is expressed for different
p,
q as follows:
The least-squares method for multi-regression analysis solves the normal equation as follows:
The resultant
α coefficients give the best coefficient vector of the quadratic polynomial given in Equation (6) for all
M data triangulation. After calculating the descriptive coefficient vector of the quadratic polynomial, the objective function is used as a selection criterion to eliminate the cells with high error rates.
Here, ypre and ymea are the predicted and actual outputs, respectively; n indicates the total number of data.
The SVR method separates the dataset with the help of a hyperplane and minimizes the errors within the boundary line. A kernel function is used to perform linear separation in the dataset. The SVR method, which creates an optimal hyperplane between data points, provides curve fitting with the maximum number of data [
30,
31]. In the prediction model obtained by training the data, linear, radial basis, and polynomial kernel functions can be used. The main benefit of SVR is that computational complexity is independent of input space size [
32]. Additionally, it has a strong capacity for generalization and good prediction accuracy. The SVR, a method of supervised learning trains with a loss function that penalizes both high and low erroneous predictions equally.
The RF regression method is a machine learning method that can predict accurately in predictive analysis when the target output parameter and input variables have a non-linear relationship [
33,
34]. The RF technique is a supervised learning algorithm that does regression using the ensemble learning approach. The ensemble learning method combines predictions from different machine learning algorithms to produce a more accurate forecast from a single model. The predictions of all decision trees are combined to provide more accurate outputs in the RF algorithm, which reduces overfitting in model training. The variety of trees used increases the robustness of the model obtained as a result of regression [
35]. RF regression models generally show strong and accurate performance on parameters with nonlinear relationships. The disadvantages can be listed as the lack of interpretability, the occurrence of over-fitting, and the need to select the number of trees included in the model.
The linear regression method, which is one of the simplest regression methods that provide the prediction of a parameter, is frequently preferred due to its straightforward and useful mathematical structure [
36]. In the linear regression method, the mathematical equation of the target parameter to be predicted is obtained using a slope and intercept value. The target parameter and the input variables are shown by linear regression as:
where
denotes output,
and
represent input variables and the coefficients of the regression model, respectively.
2.4. Performance Evaluation Metrics
Various metrics can be used to measure and evaluate the performance of prediction models. In this study, the R
2, RMSE, and MAE values of the predicted and actual target parameters are calculated in the performance evaluation of regression models. The R
2, RMSE, and MAE are expressed mathematically as:
where
ymea,
ypre, and
ym denote the average of actual output, estimated output, and actual output, respectively.
N represents the total number of data. The degree of fitting increases with R
2 proximity to 1. RMSE and MAE are used to evaluate the model’s prediction ability. For the RMSE and MAE, the prediction model will be more accurate and its accuracy will be higher with a smaller value.
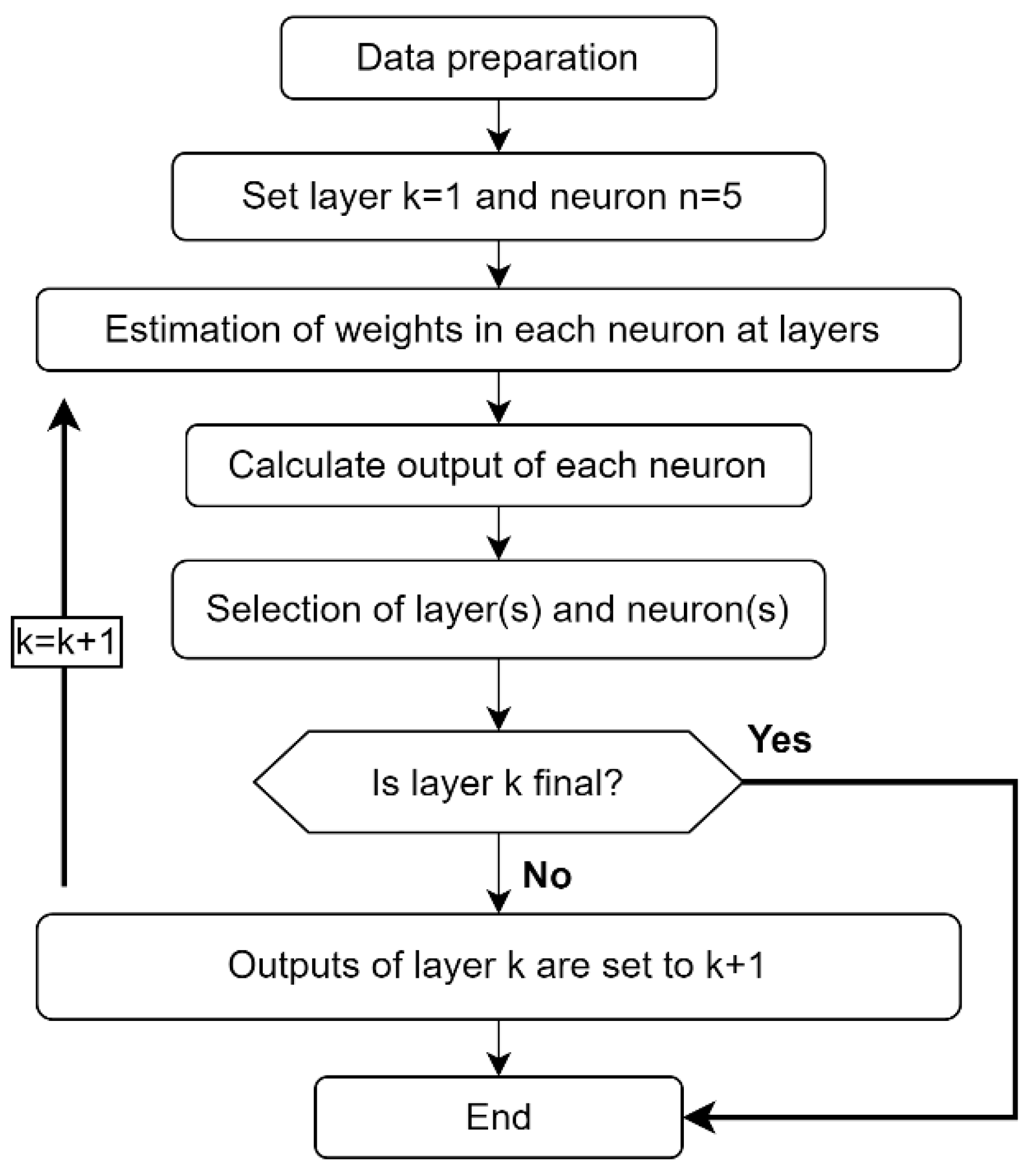
2.5. Procedures
The proposed approach for the prediction of
cu is given in
Figure 3. In order to predict
cu, the dataset is first put into the pre-processing phase. In this phase, the data should be initially normalized and independent variables should be selected. Then, a prediction model design phase is started. In this phase, different regression methods are applied and performance evaluation is calculated for different regression methods.
The GMDH-type NN approach is used to obtain the models and the results are compared with the most commonly used linear, RF, and SVR methods. Tree numbers [50,100,200,500] were selected for the RF model and the optimal number of trees was set to 50 by parameter grid search. The radial basis, which provides the best performance, was used as the core function for the SVR model. In addition, the degree and penalty parameter C were set to 3 and 1, respectively.
In the GMDH-type NN algorithm, the maximum number of layers and neurons in each layer is set to 5 as initial values. Then, the optimal number of layers and neurons was determined to minimize the error between the target and the predicted output using a grid search algorithm. Also, the selection pressure value on the layers is set to 0.8. In the design of the prediction models, 80% of the dataset is used for training and 20% for testing.
In this study, train and test data were randomly selected and the performance evaluation of the produced prediction models was obtained as a result of 10 trials.
Figure 4 shows the flowchart of the proposed GMDH-type NN approach.
The GMDH-type NN, which is a machine learning-based method, is preferred to obtain a new and effective mathematical model that can be used to predict undrained shear strength. The GMDH-type NN structure, wherein input parameters are used as a binary polynomial, selects the most suitable neurons that minimize errors, and predicts output shear strength values accurately and effectively. Four different GMDH-type NN models are designed for various input parameters to obtain mathematical models for the cu prediction. The R2, MAE, and RMSE values are obtained for all prediction models designed and compared with the regression models (i.e., linear, RF, and SVR).
3. Results and Discussion
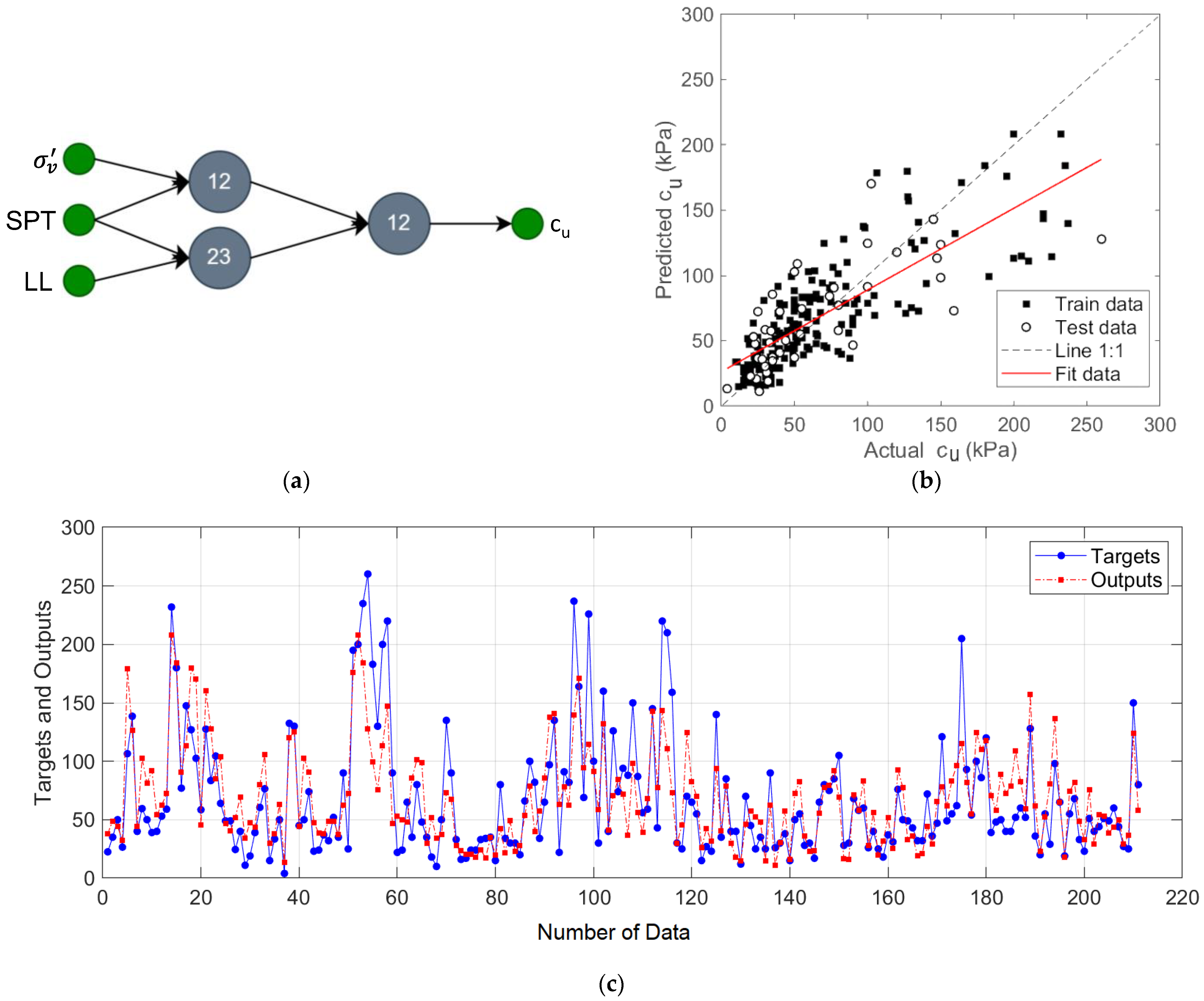
In the first designed GMDH-type NN model, the prediction of
cu was performed for the input variables
σv’,
NSPT, and
LL. The network structure, regression plot, and output prediction values for this model are shown in
Figure 5.
In this network structure shown in
Figure 5a, the pairs of input variables {
σv’ and
NSPT} and {
NSPT and
LL} were processed in two neurons, and the outputs of these neurons were formed into a pair and the predicted output was obtained. The results showed that this two-layer model has R
2 of 0.79, MAE of 6.02, and RMSE of 24.94 values.
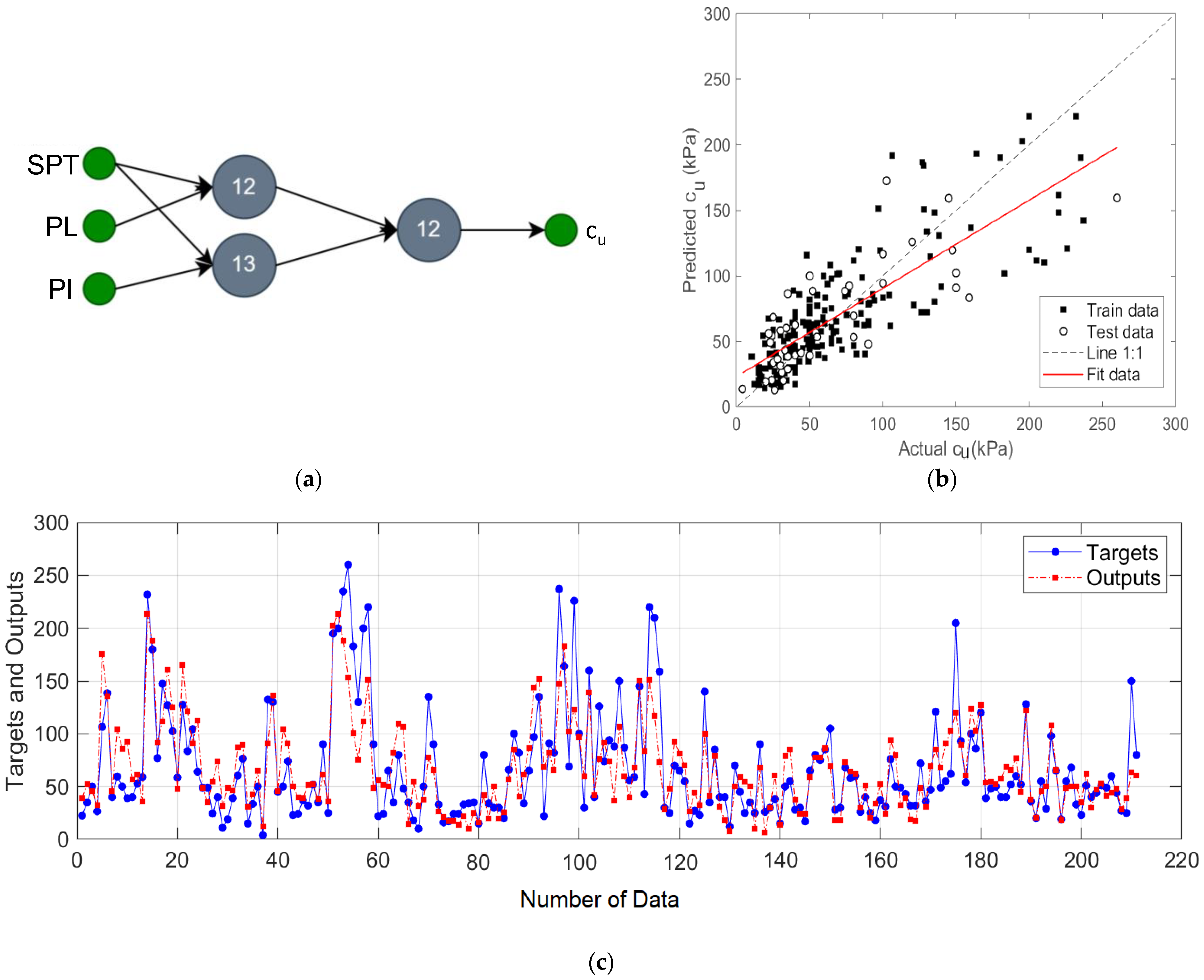
The GMDH-type NN model designed with
NSPT,
PL, and
PI input variables is shown in
Figure 6a and the results of this model are given in
Figure 6b,c. In this designed model, input variable pairs {
NSPT and
PL} and {
NSPT and
PI} were processed in two neurons, and prediction of output was performed by creating a pair of these neuron outputs. In this model, where the best results were obtained with two layers; NN, R
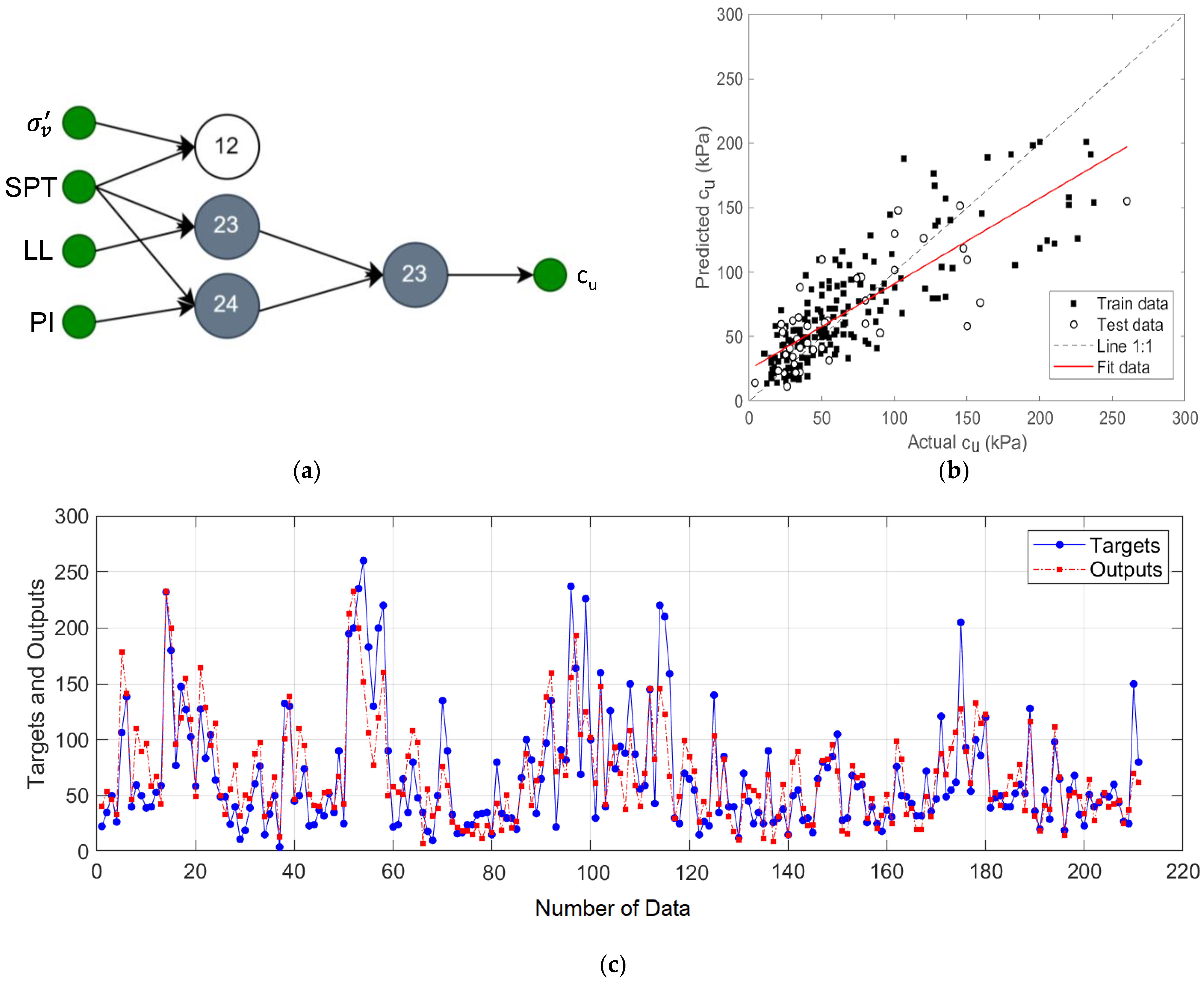
2 of 0.82, MAE of 14.65, and RMSE of 23.05 values were achieved.
Figure 6c shows the target and predicted output values for this model.
The GMDH-type NN structure for the model was designed using
σv’,
NSPT,
LL, and
PI input variables, and the results for this model are given in
Figure 7. In the first layer of this network, neuron outputs for {
σv’,
NSPT}, {
NSPT,
LL} and {
NSPT,
PI} input pairs were calculated and {
σv’,
NSPT} output from these neurons was disabled because it increased the error rate. Then, the remaining neuron outputs are paired to generate the predicted output. The R
2, MAE, and RMSE of this designed model are 0.82, 14.91, and 22.88, respectively.
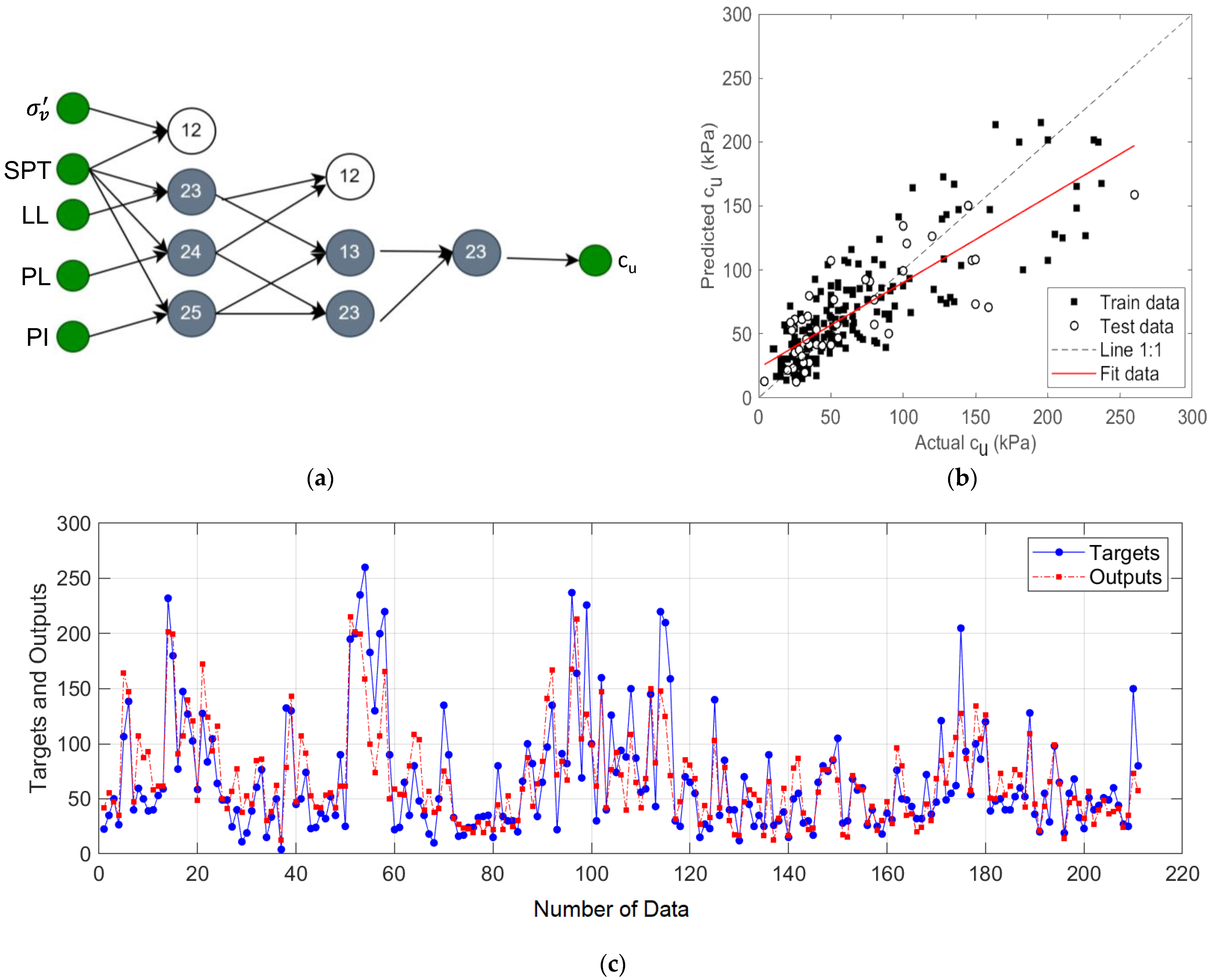
The GMDH-type NN structure using all input variables and the performance results of this model are given in
Figure 8. In this model, the variable pair {
σv’,
NSPT} was disabled because it increased the error rate, and the remaining neuron outputs formed pairs and were used in the next layer. The results given in
Figure 8b,c show that the GMDH-type NN model achieved R
2 of 0.83, MAE of 14.64, and RMSE of 22.74 values.
In order to evaluate the performance of prediction models, the GMDH-type NN method was compared with linear regression, RF, and SVR methods.
Table 4 summarizes the performance evaluation of linear, RF, SVR, and GMDH-type NN regression models with different input parameters in the prediction of
cu.
As mentioned above, the four regression methods were used to design the prediction models of cu. The results of R2 on average for the linear, RF, SVR, and GMDH, which imply a higher degree of fitting, are 0.5 ± 0.04, 0.55 ± 0.02, 0.61 ± 0.02, and 0.82 ± 0.02, respectively. In addition, the results of MAE on average for the four prediction models are 23.68 ± 0.75, 20.95 ± 0.33, 18.38 ± 0.87, and 15.06 ± 0.57, respectively. Also, the RMSE values are 33 ± 1.28, 31.06 ± 0.83, 28.98 ± 0.58, and 23.4 ± 0.9 corresponding to the linear, RF, SVR, and GMDH methods. The linear, RF, and SVR have R2 values of about 0.5, while the GMDH-type NN method had the highest R2 values of 0.8.
The linear, RF, and SVR methods show that the R2 value is independent of the number of input parameters. In the linear regression and SVR methods, the highest R2 value and lowest error rates have been achieved when the input parameters were σv’, NSPT and LL. In addition, when the input parameters were NSPT, PL, and PI, the highest R2 value and lowest error rates have been obtained in the RF method. However, when increased the number of input parameters (i.e., σv’, NSPT, LL, PL, and PI), a higher R2 value is achieved in the GMDH-type NN. The highest prediction performance was obtained with the GMDH-type NN by using σv’, NSPT, LL, PL, and PI input variables. This proposed model had the highest R2 value and the lowest MAE and RMSE values. As a result of the evaluation, the GMDH-type NN approach shows more reliability in estimating cu than other regression methods.
The effect of the input variables on the model output was additionally observed with the SHAP (SHApley Additive ExPlanations) approach. The SHAP is a game-theoretic method for expressing any machine learning model’s output. The SHAP determines the ideal parameters by using the conventional Shapley values from game theory and their related extensions. Extreme gradient boosting (XGBoost) decision tree, which is a high-speed exact algorithm, was used to obtain SHAP values.
Figure 9 shows the average SHAP values of the input variables on the model output.
Figure 9a shows the average SHAP value of each input variable. Average SHAP results clearly indicate that the input variable of
NSPT has the most effect on the
cu prediction compared to other input variables. The summation of the SHAP value magnitudes of the input variables on all samples and the sorting and distribution of the effects of each variable on the model output is shown in
Figure 9b. The results reveal that the
NSPT value significantly affects the prediction of
cu compared to other input parameters.
4. Conclusions
This study investigated the performance of machine learning models for the prediction of cu. The GMDH-type NN approach was used with varying input parameters in order to design the prediction models. In the cu prediction models, NSPT, σv’, LL, PL, and PI were used as input variables. Then, the results of GMDH-type NN were compared with the most commonly used linear regression, RF, and SVR methods. The performance of those methods was evaluated with the R2, MAE, and RMSE. Also, the effect of the number of input parameters for prediction models was studied. In addition, since the four prediction models for each method have been derived with different input variables, the most effective input parameter was determined by using a game-theoretic approach.
The results showed that the proposed a three-layer GMDH-type NN model had a higher regression coefficient (R2) and lower error rates (MAE and RMSE) in all combinations of input parameters compared to other methods used in the prediction of cu. Moreover, the results revealed that when we increased the number of input parameters (i.e., σv’, NSPT, LL, PL, and PI) in the GMDH-type NN model, the model achieved high reliability compared to the lower number of input parameters.
The effects of the input variables on the prediction model were evaluated with the SHAP (SHApley Additive ExPlanations) approach based on the extreme gradient boosting (XGBoost) ensemble learning algorithm. The SHAP results revealed that the NSPT value was the most influential parameter in the estimation of the cu value compared to other parameters for all prediction models.
In summary, the results of the GMDH-type NN model showed that it is feasible to use artificial intelligence technology for the prediction of the undrained shear strength (cu). By using the GMDH-type NN approach, the problems of experimental restrictions can be solved, and more accurate values can be achieved in the prediction of cu. Moreover, this method is expected to be well used to predict other geotechnical design parameters and further understand the complex behavior of clay soil.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}