
Swin–UNet++: A Nested Swin Transformer Architecture for Location Identification and Morphology Segmentation of Dimples on 2.25Cr1Mo0.25V Fractured Surface

Abstract
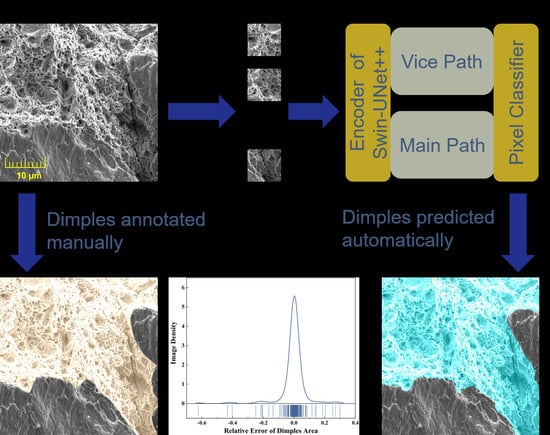
:
1. Introduction
2. Methods
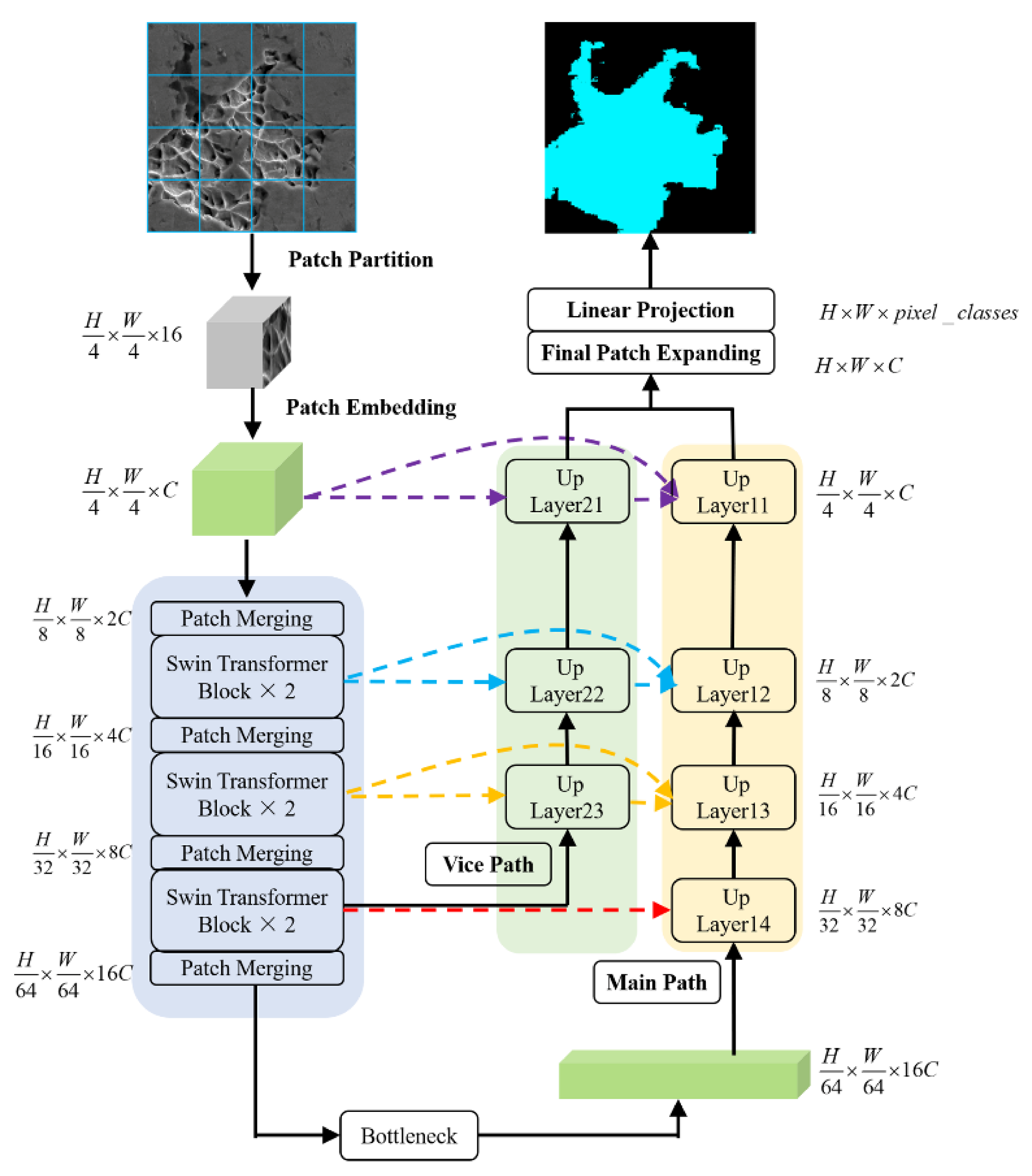
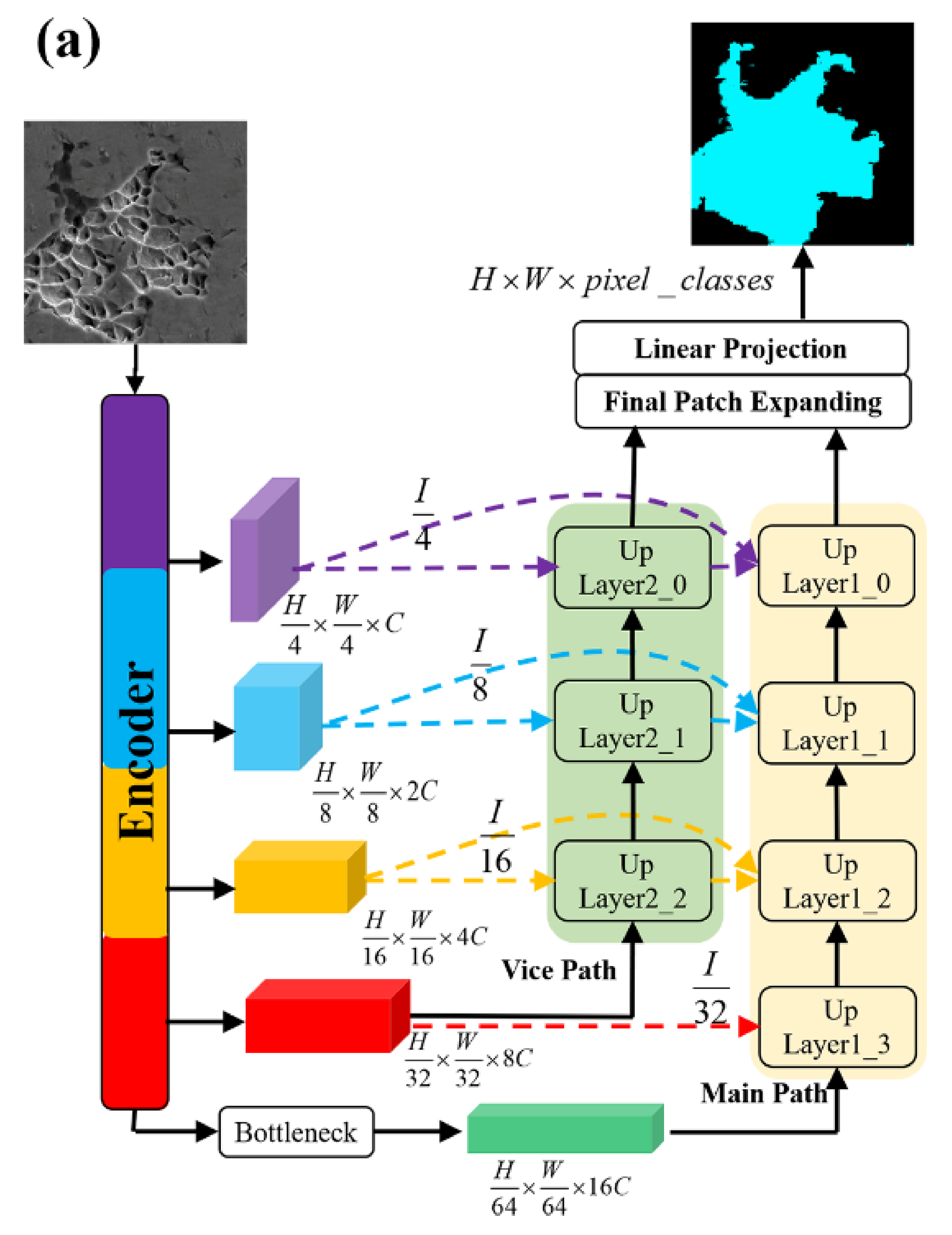
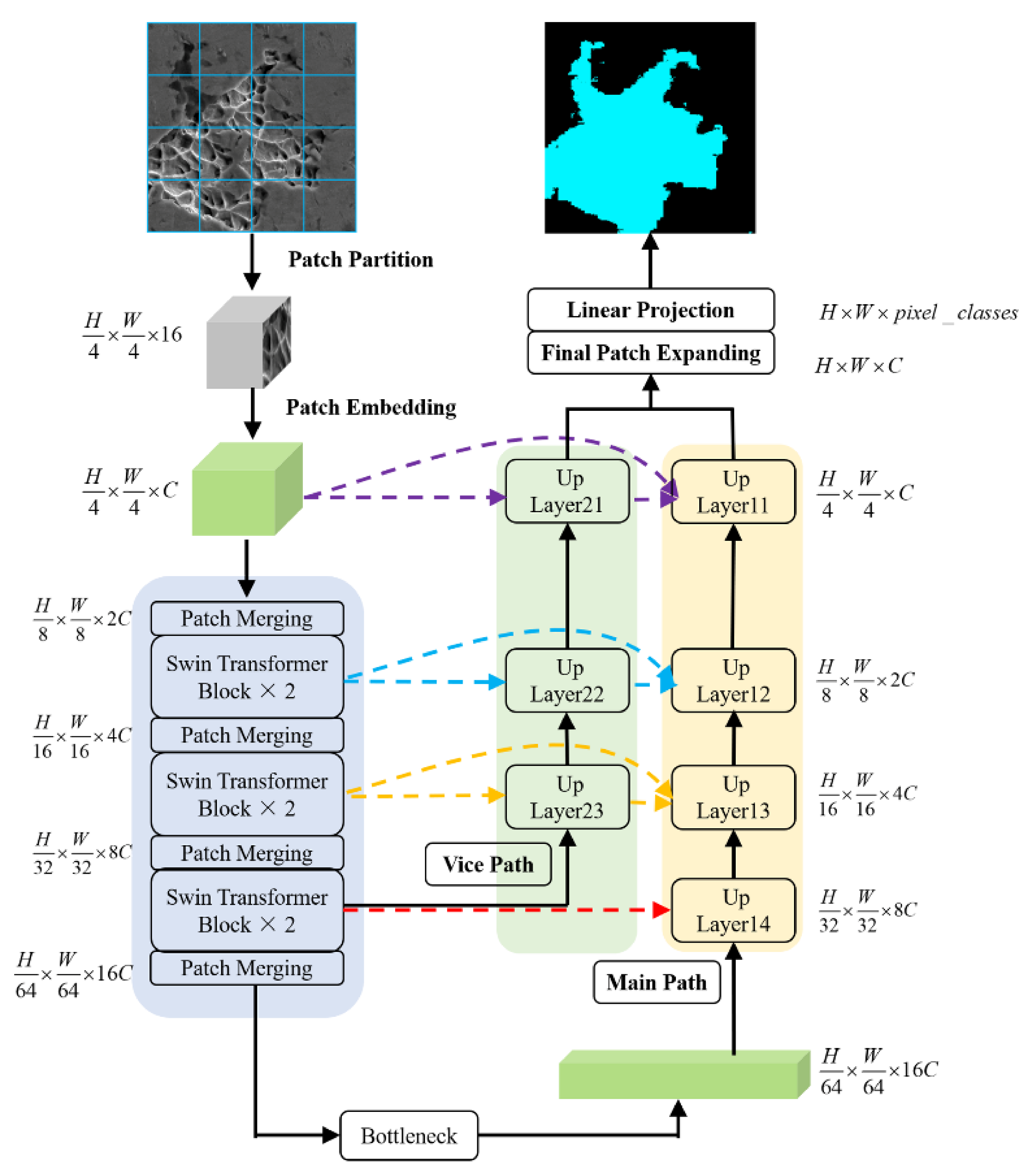
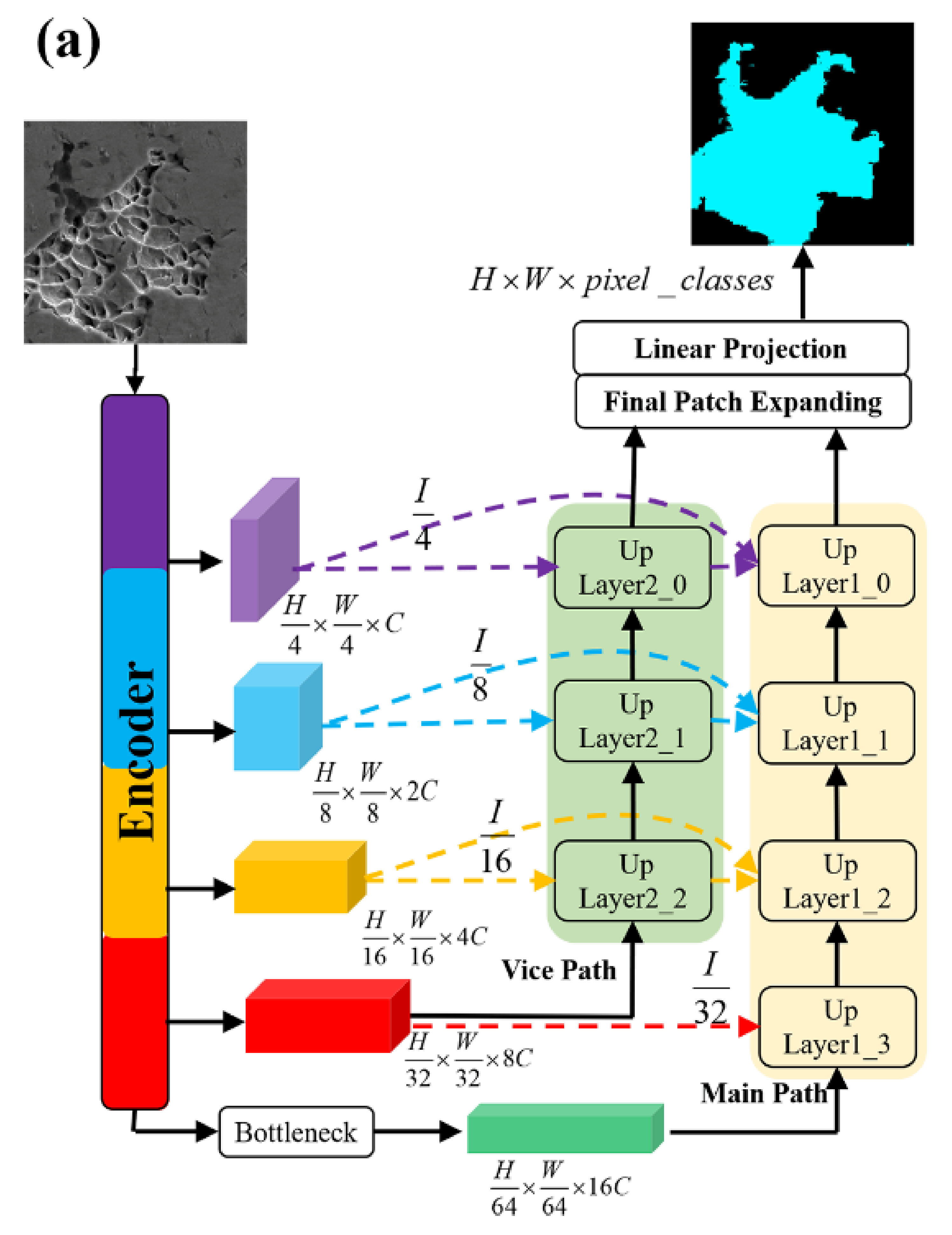
2.1. Network Architecture
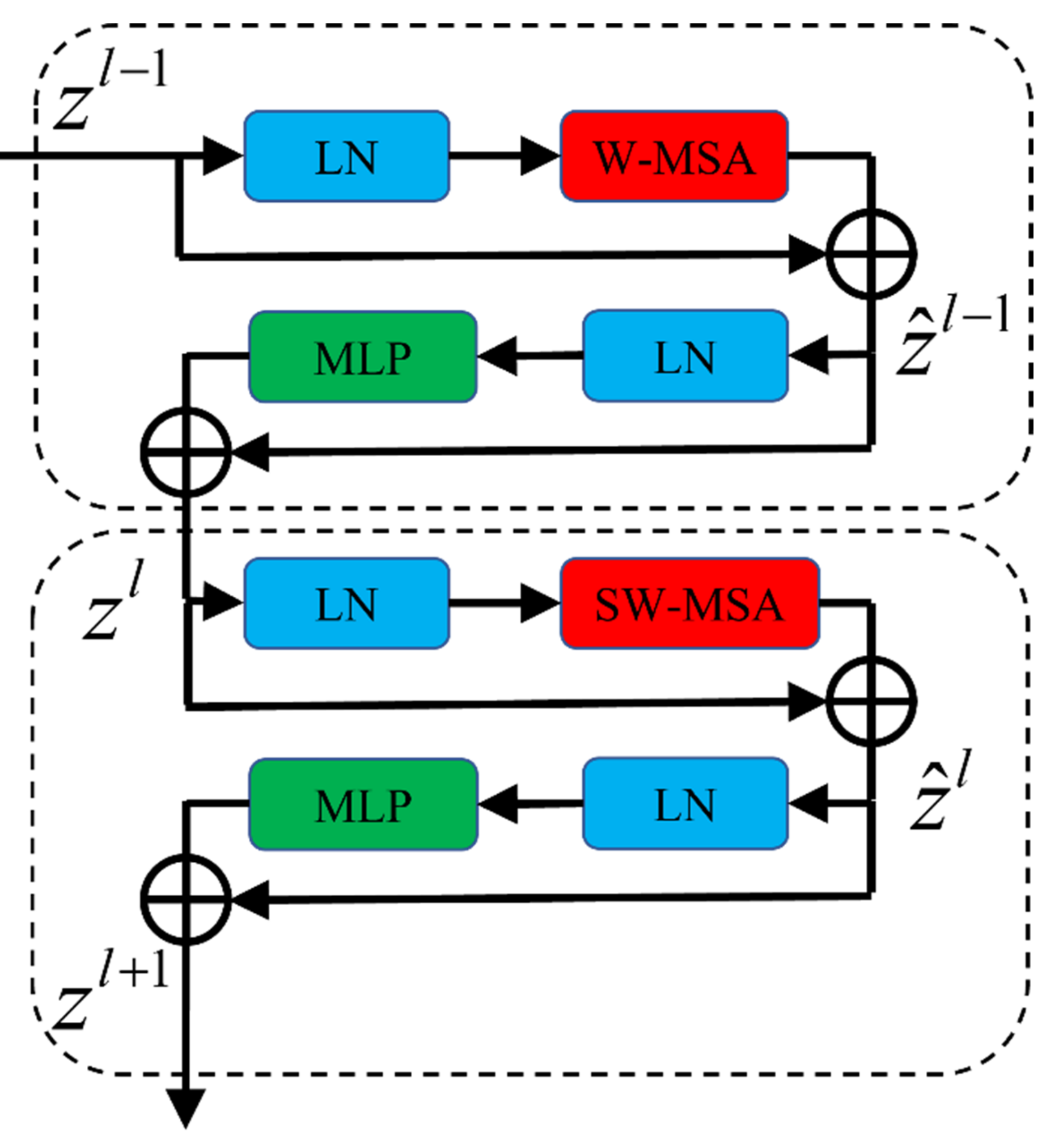
2.2. Swin Transformer Block
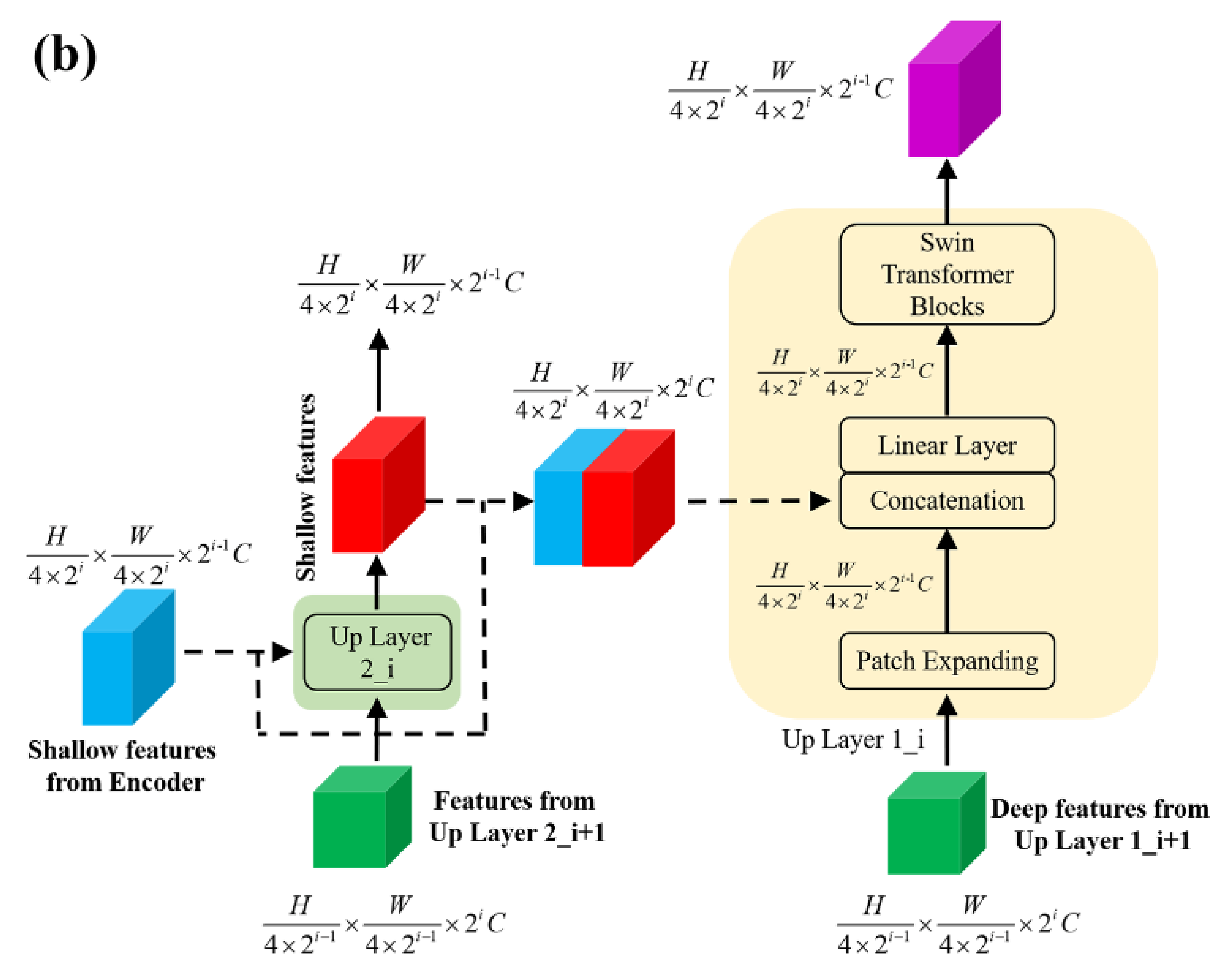
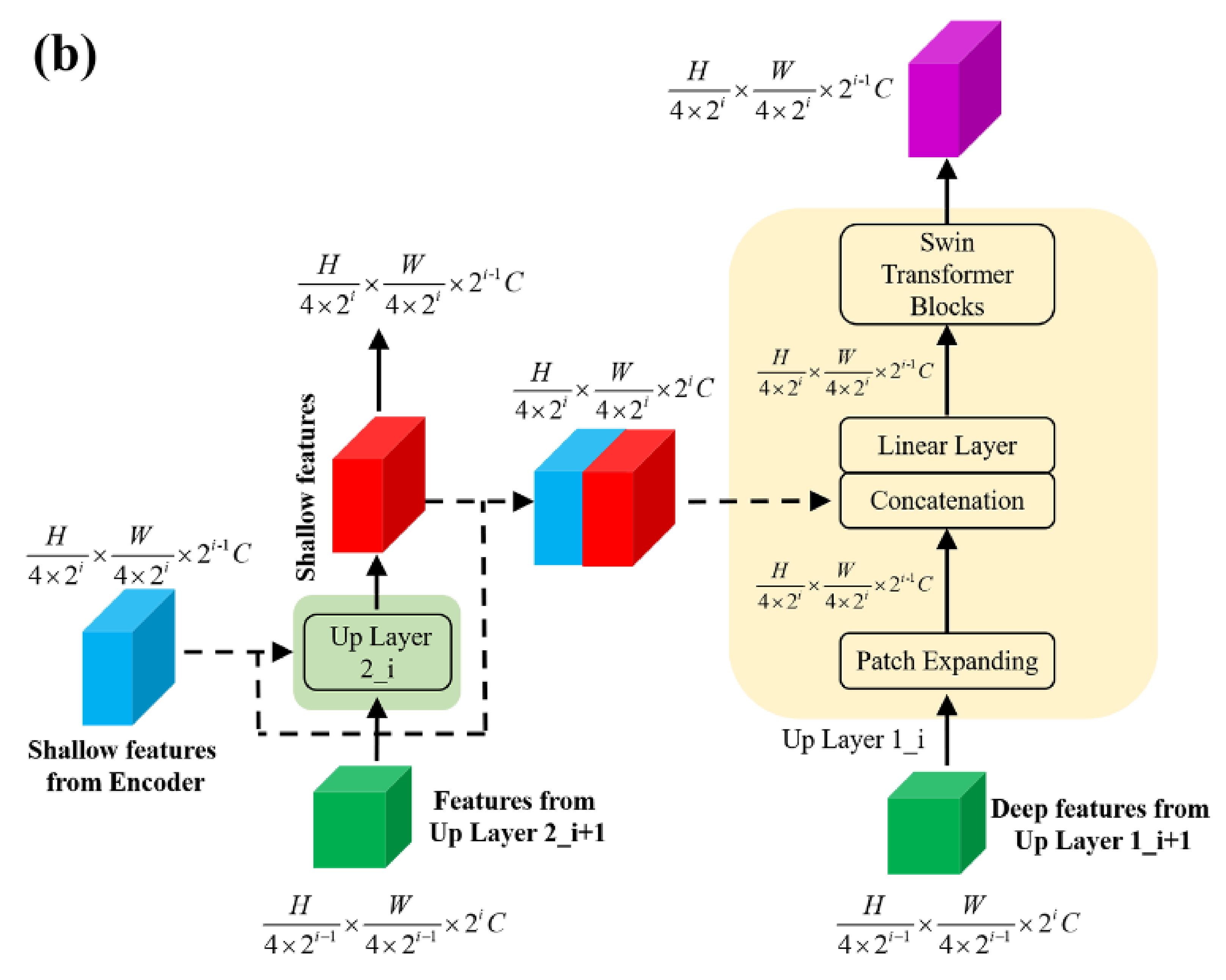
2.3. Decoder
3. Results and Discussion
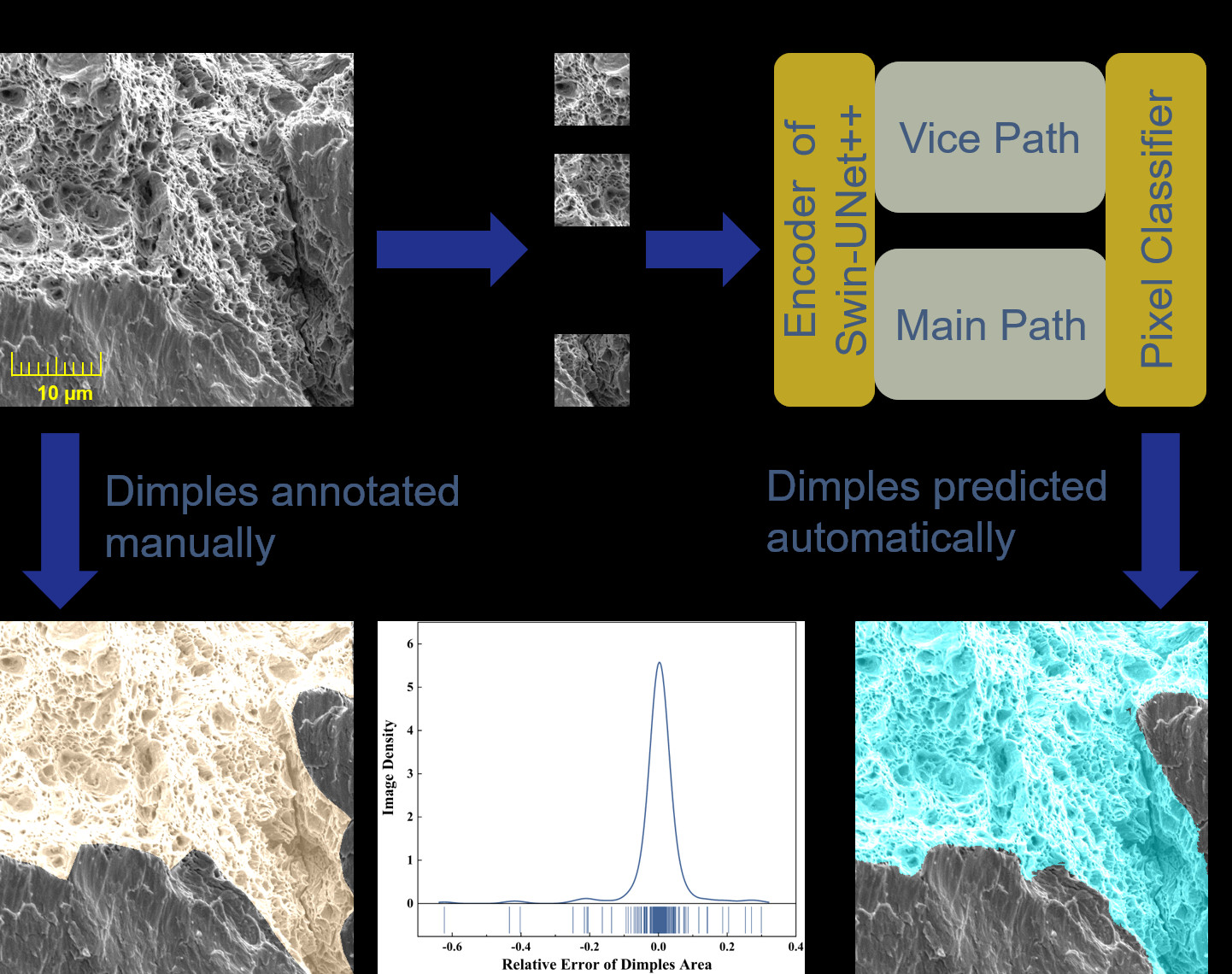
3.1. Datasets
3.2. Training Details
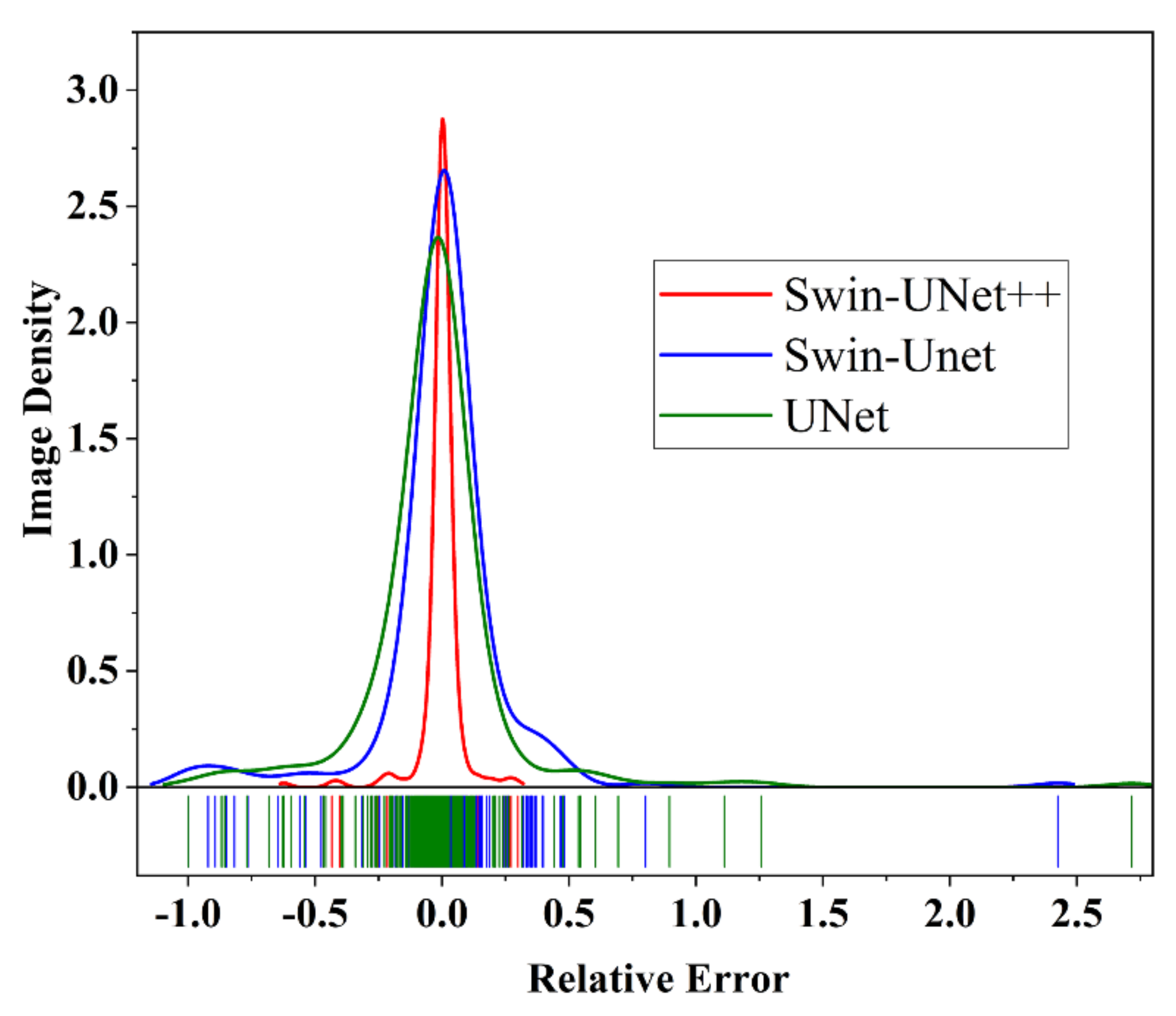
3.3. Training and Segmentation Results
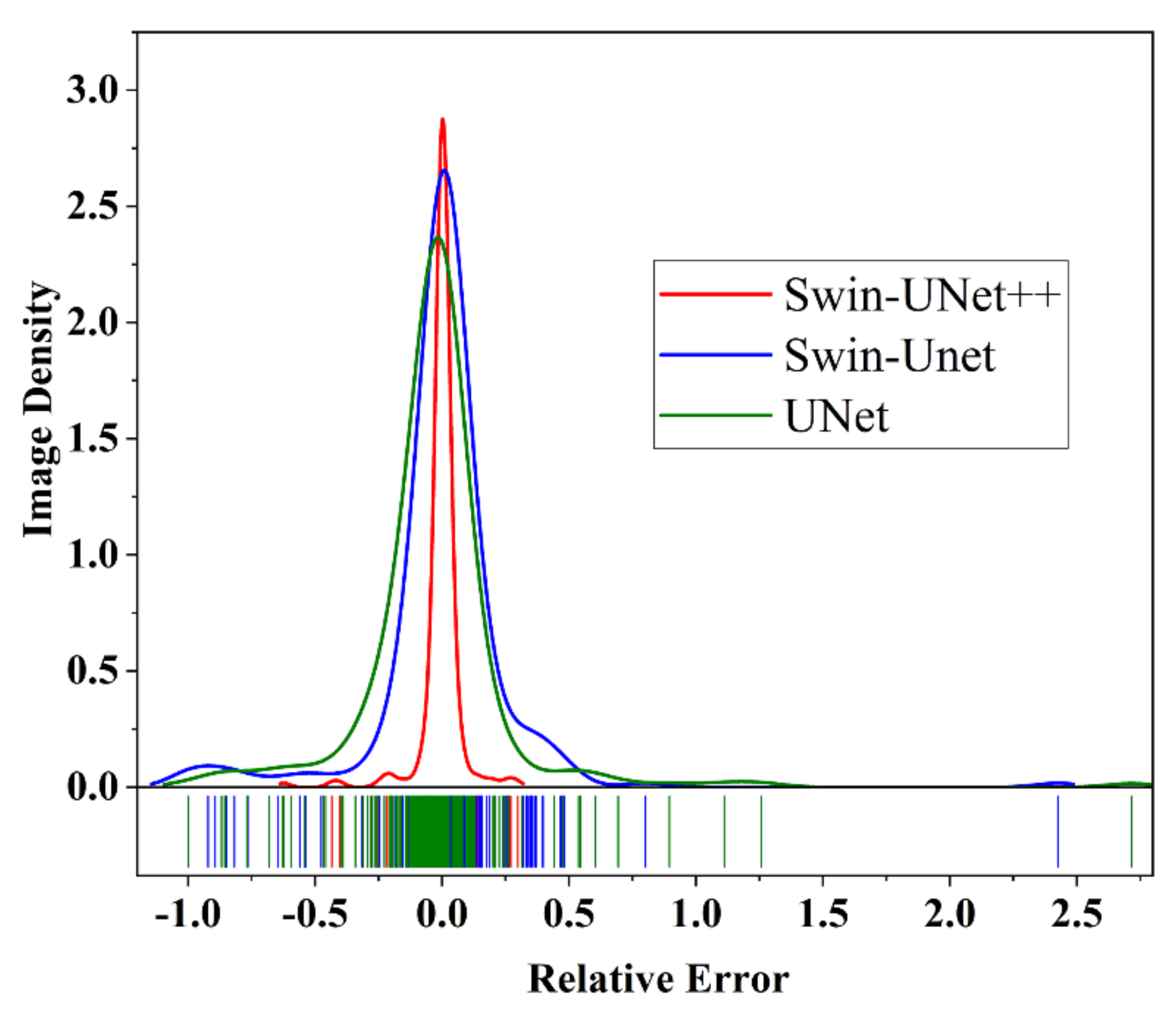
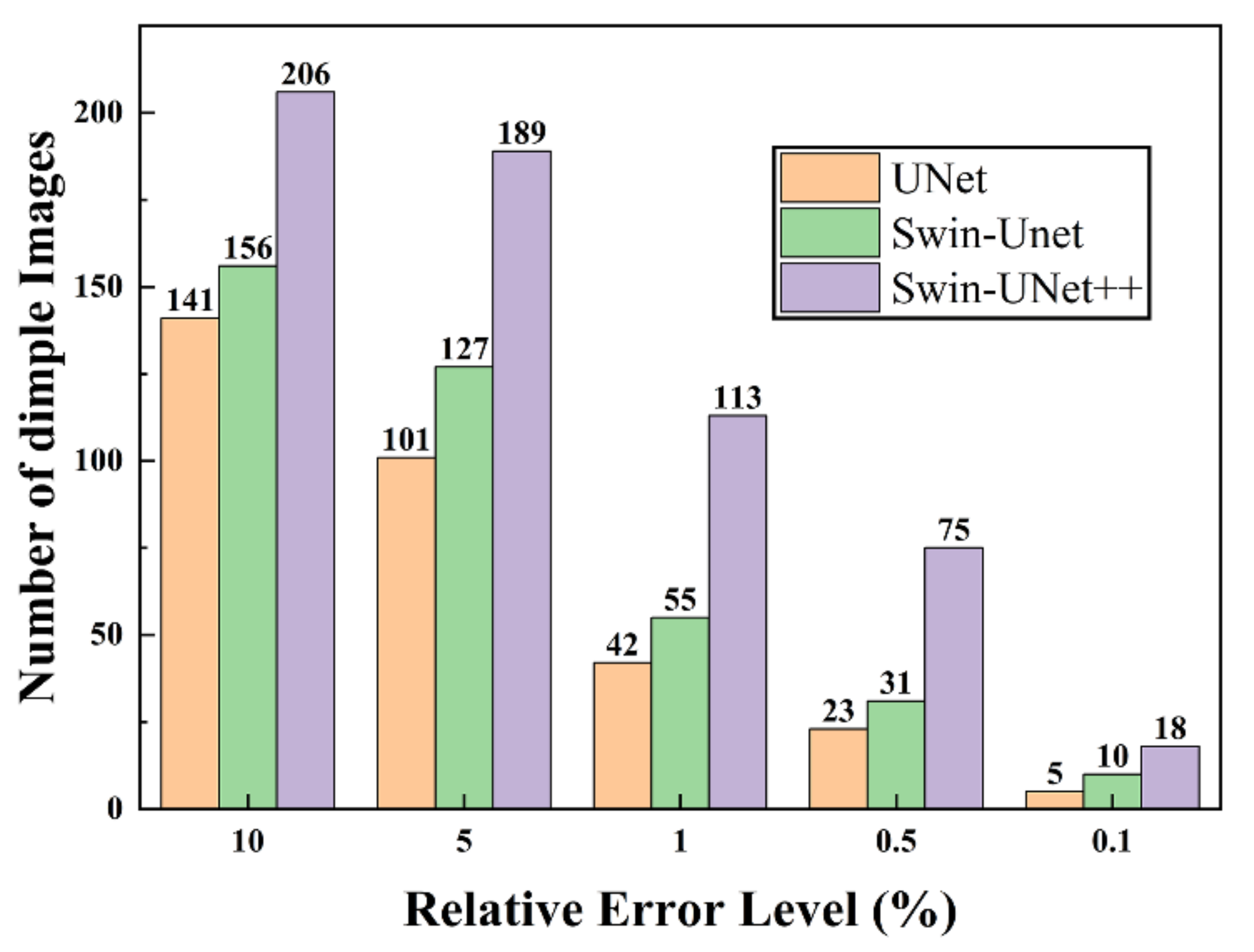
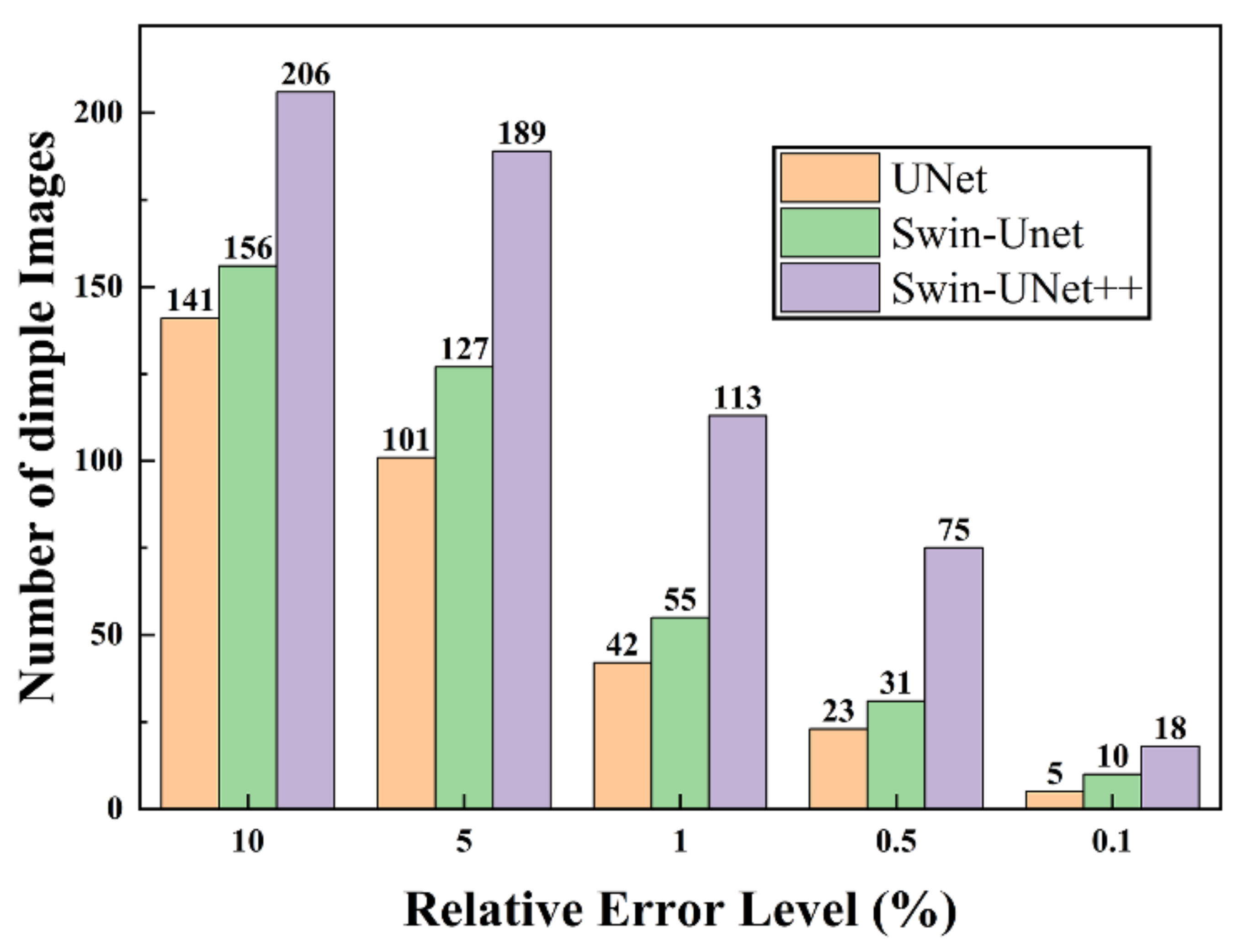
3.4. Dimples Area Calculation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| CNN | Convolution neural network |
| HE | Hydrogen embrittlement |
| SOTA | State-of-the-art |
| NLP | Natural language processing |
| MLP | Multi-layer perception |
| LN | Layer normalization |
| DSC | Dice similarity coefficient |
| HD95 | 95% Hausdorff distance |
| H | Height of input picture |
| W | Width of input picture |
| C | The output dimensions of embedding layer |
References
- Peral, L.B.; Zafra, A.; Blasón, S.; Rodríguez, C.; Belzunce, J. Effect of hydrogen on the fatigue crack growth rate of quenched and tempered CrMo and CrMoV steels. Int. J. Fatigue 2019, 120, 201–214. [Google Scholar] [CrossRef]
- Song, Y.; Chai, M.; Yang, B.; Han, Z.; Ai, S.; Liu, Y.; Cheng, G.; Li, Y. Investigation of the Influence of Pre-Charged Hydrogen on Fracture Toughness of As-Received 2.25Cr1Mo0.25V Steel and Weld. Materials 2018, 11, 1068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peral, L.B.; Zafra, A.; Belzunce, J.; Rodríguez, C. Effects of hydrogen on the fracture toughness of CrMo and CrMoV steels quenched and tempered at different temperatures. Int. J. Hydrog. Energy 2019, 44, 3953–3965. [Google Scholar] [CrossRef]
- Zafra, A.; Peral, L.B.; Belzunce, J.; Rodríguez, C. Effects of hydrogen on the fracture toughness of 42CrMo4 steel quenched and tempered at different temperatures. Int. J. Pres. Ves. Pip. 2019, 171, 34–50. [Google Scholar] [CrossRef]
- Álvarez, G.; Peral, L.B.; Rodríguez, C.; García, T.E.; Belzunce, F.J. Hydrogen embrittlement of structural steels: Effect of the displacement rate on the fracture toughness of high-pressure hydrogen pre-charged samples. Int. J. Hydrog. Energy 2019, 44, 15634–15643. [Google Scholar] [CrossRef]
- Martelo, D.; Sampath, D.; Monici, A.; Morana, R.; Akid, R. Correlative analysis of digital imaging, acoustic emission, and fracture surface topography on hydrogen assisted cracking in Ni-alloy 625+. Eng. Fract. Mech. 2019, 221, 106678. [Google Scholar] [CrossRef]
- Macek, W.; Branco, R.; Szala, M.; Marciniak, Z.; Ulewicz, R.; Sczygiol, N.; Kardasz, P. Profile and Areal Surface Parameters for Fatigue Fracture Characterisation. Materials 2020, 13, 3691. [Google Scholar] [CrossRef]
- Macek, W.; Branco, R.; Korpyś, M.; Łagoda, T. Fractal dimension for bending–torsion fatigue fracture characterisation. Measurement 2021, 184, 109910. [Google Scholar] [CrossRef]
- Ma, Y.; Yang, T.; Feng, W.; Li, G.; Zhang, X. Improved fracture resistance of the Ag/SnO2 contact materials using Cu nanoparticles as additive. J. Alloy. Compd. 2020, 843, 156055. [Google Scholar] [CrossRef]
- Li, X.W.; Tian, J.F.; Kang, Y.; Wang, Z.G. Quantitative analysis of fracture surface by roughness and fractal method. Scripta. Mater. 1995, 33, 803–809. [Google Scholar] [CrossRef]
- Konovalenko, I.; Maruschak, P.; Prentkovskis, O. Automated Method for Fractographic Analysis of Shape and Size of Dimples on Fracture Surface of High-Strength Titanium Alloys. Metals 2018, 8, 161. [Google Scholar] [CrossRef] [Green Version]
- Kosarevych, R.Y.; Student, O.Z.; Svirs’ka, L.M.; Rusyn, B.P.; Nykyforchyn, H.M. Computer analysis of characteristic elements of fractographic images. Mater. Sci 2013, 48, 474–481. [Google Scholar] [CrossRef]
- Jin, L.; Gao, S.; Li, Z.; Tang, J. Hand-Crafted Features or Machine Learnt Features? Together They Improve RGB-D Object Recognition. In Proceedings of the 2014 IEEE International Symposium on Multimedia, Chengdu, China, 10–12 December 2014; pp. 311–319. [Google Scholar]
- Yuan, Y.X.; Li, B.P.; Meng, M.Q.H. Improved Bag of Feature for Automatic Polyp Detection in Wireless Capsule Endoscopy Images. IEEE Trans. Autom. Sci. Eng. 2016, 13, 529–535. [Google Scholar] [CrossRef]
- Silva, J.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer. Int. J. Comput. Ass. Rad. 2014, 9, 283–293. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Smirnov, E.A.; Timoshenko, D.M.; Andrianov, S.N. Comparison of Regularization Methods for ImageNet Classification with Deep Convolutional Neural Networks. Aasri. Proc. 2014, 6, 89–94. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yadav, S.; Patra, S.; Arora, C.; Banerjee, S. Deep CNN with color lines model for unmarked road segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 18–20 September 2017; pp. 585–589. [Google Scholar]
- Dewangan, S.K.; Samal, S.; Kumar, V. Microstructure exploration and an artificial neural network approach for hardness prediction in AlCrFeMnNiWx High-Entropy Alloys. J. Alloy. Compd. 2020, 823, 153766. [Google Scholar] [CrossRef]
- Oh, J.M.; Narayana, P.L.; Hong, J.-K.; Yeom, J.-T.; Reddy, N.S.; Kang, N.; Park, C.H. Property optimization of TRIP Ti alloys based on artificial neural network. J. Alloy. Compd. 2021, 884, 161029. [Google Scholar] [CrossRef]
- Wan, P.; Zou, H.; Wang, K.; Zhao, Z. Research on hot deformation behavior of Zr-4 alloy based on PSO-BP artificial neural network. J. Alloy. Compd. 2020, 826, 154047. [Google Scholar] [CrossRef]
- Wang, Y.S.; Linghu, R.K.; Zhang, W.; Shao, Y.C.; Lan, A.D.; Xu, J. Study on deformation behavior in supercooled liquid region of a Ti-based metallic glassy matrix composite by artificial neural network. J. Alloy. Compd. 2020, 844, 155761. [Google Scholar] [CrossRef]
- Chowdhury, A.; Kautz, E.; Yener, B.; Lewis, D. Image driven machine learning methods for microstructure recognition. Comput. Mater. Sci. 2016, 123, 176–187. [Google Scholar] [CrossRef] [Green Version]
- Kautz, E.; Ma, W.; Jana, S.; Devaraj, A.; Joshi, V.; Yener, B.; Lewis, D. An image-driven machine learning approach to kinetic modeling of a discontinuous precipitation reaction. Mater. Charact. 2020, 166, 110379. [Google Scholar] [CrossRef]
- Ma, W.; Kautz, E.J.; Baskaran, A.; Chowdhury, A.; Joshi, V.; Yener, B.; Lewis, D.J. Image-driven discriminative and generative machine learning algorithms for establishing microstructure-processing relationships. J. Appl. Phys. 2020, 128, 134901. [Google Scholar] [CrossRef]
- Wang, Z.-L.; Ogawa, T.; Adachi, Y. A Machine Learning Tool for Materials Informatics. Adv. Theor. Simul. 2020, 3, 1900177. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Ngan, A.H.W. Extracting dislocation microstructures by deep learning. Int. J. Plast. 2019, 115, 18–28. [Google Scholar] [CrossRef]
- Li, W.; Field, K.G.; Morgan, D. Automated defect analysis in electron microscopic images. NPJ Comput. Mater. 2018, 4, 36. [Google Scholar] [CrossRef] [Green Version]
- Gola, J.; Britz, D.; Staudt, T.; Winter, M.; Schneider, A.S.; Ludovici, M.; Mucklich, F. Advanced microstructure classification by data mining methods. Comput. Mater. Sci. 2018, 148, 324–335. [Google Scholar] [CrossRef]
- Konovalenko, I.; Maruschak, P.; Brezinova, J.; Brezina, J. Morphological Characteristics of Dimples of Ductile Fracture of VT23M Titanium Alloy and Identification of Dimples on Fractograms of Different Scale. Materials 2019, 12, 2051. [Google Scholar] [CrossRef] [Green Version]
- Sinha, A.; Suresh, K.S. Deep Learning based Dimple Segmentation for Quantitative Fractography. In Pattern Recognition, Proceedings of the ICPR International Workshops and Challenges, Proceedings of the Lecture Notes in Computer Science, Milan, Italy, 10–15 January 2021; Springer International Publishing: Cham, Switzerland; pp. 463–474.
- Chen, J.N.; Lu, Y.Y.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. Available online: https://arxiv.org/abs/2102.04306v1 (accessed on 27 September 2021).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. Available online: https://arxiv.org/abs/2010.11929v2 (accessed on 27 September 2021).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. Available online: https://arxiv.org/abs/2103.14030v2 (accessed on 27 September 2021).
- Hu, C.; Wang, Y.Y.; Chen, J.; Jian, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. Available online: https://arxiv.org/abs/2105.05537 (accessed on 27 September 2021).
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. UNet plus plus: A Nested U-Net Architecture for Medical Image Segmentation. Lect. Notes Comput. Sci. 2018, 11045, 3–11. [Google Scholar]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain Tumor Segmentation Using Convolutional Neural Networks in MRI Images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef]
- Guo, Z.; Guo, N.; Gong, K.; Zhong, S.A.; Li, Q. Gross tumor volume segmentation for head and neck cancer radiotherapy using deep dense multi-modality network. Phys. Med. Biol. 2019, 64, 205015. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DSC/% | HD95 |
|---|---|---|
| UNet | 85.47 | 85.76 |
| Swin–Unet | 86.95 | 59.33 |
| Swin–UNet++ | 94.65 | 22.99 |
| Models | Number of Images | Mean | Standard Deviation | Maximum |
|---|---|---|---|---|
| UNet | 226 | 0.1472 | 0.2736 | 2.716 |
| Swin–Unet | 226 | 0.1295 | 0.2524 | 2.426 |
| Swin–UNet++ | 226 | 0.03386 | 0.07348 | 0.6230 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Song, Y.; Chai, M.; Han, Z.; Zhang, Y. Swin–UNet++: A Nested Swin Transformer Architecture for Location Identification and Morphology Segmentation of Dimples on 2.25Cr1Mo0.25V Fractured Surface. Materials 2021, 14, 7504. https://doi.org/10.3390/ma14247504
Liu P, Song Y, Chai M, Han Z, Zhang Y. Swin–UNet++: A Nested Swin Transformer Architecture for Location Identification and Morphology Segmentation of Dimples on 2.25Cr1Mo0.25V Fractured Surface. Materials. 2021; 14(24):7504. https://doi.org/10.3390/ma14247504
Chicago/Turabian StyleLiu, Pan, Yan Song, Mengyu Chai, Zelin Han, and Yu Zhang. 2021. "Swin–UNet++: A Nested Swin Transformer Architecture for Location Identification and Morphology Segmentation of Dimples on 2.25Cr1Mo0.25V Fractured Surface" Materials 14, no. 24: 7504. https://doi.org/10.3390/ma14247504
APA StyleLiu, P., Song, Y., Chai, M., Han, Z., & Zhang, Y. (2021). Swin–UNet++: A Nested Swin Transformer Architecture for Location Identification and Morphology Segmentation of Dimples on 2.25Cr1Mo0.25V Fractured Surface. Materials, 14(24), 7504. https://doi.org/10.3390/ma14247504