
Pop-In Identification in Nanoindentation Curves with Deep Learning Algorithms



Abstract
:1. Introduction
2. Methods
2.1. Nanoindentation Testing
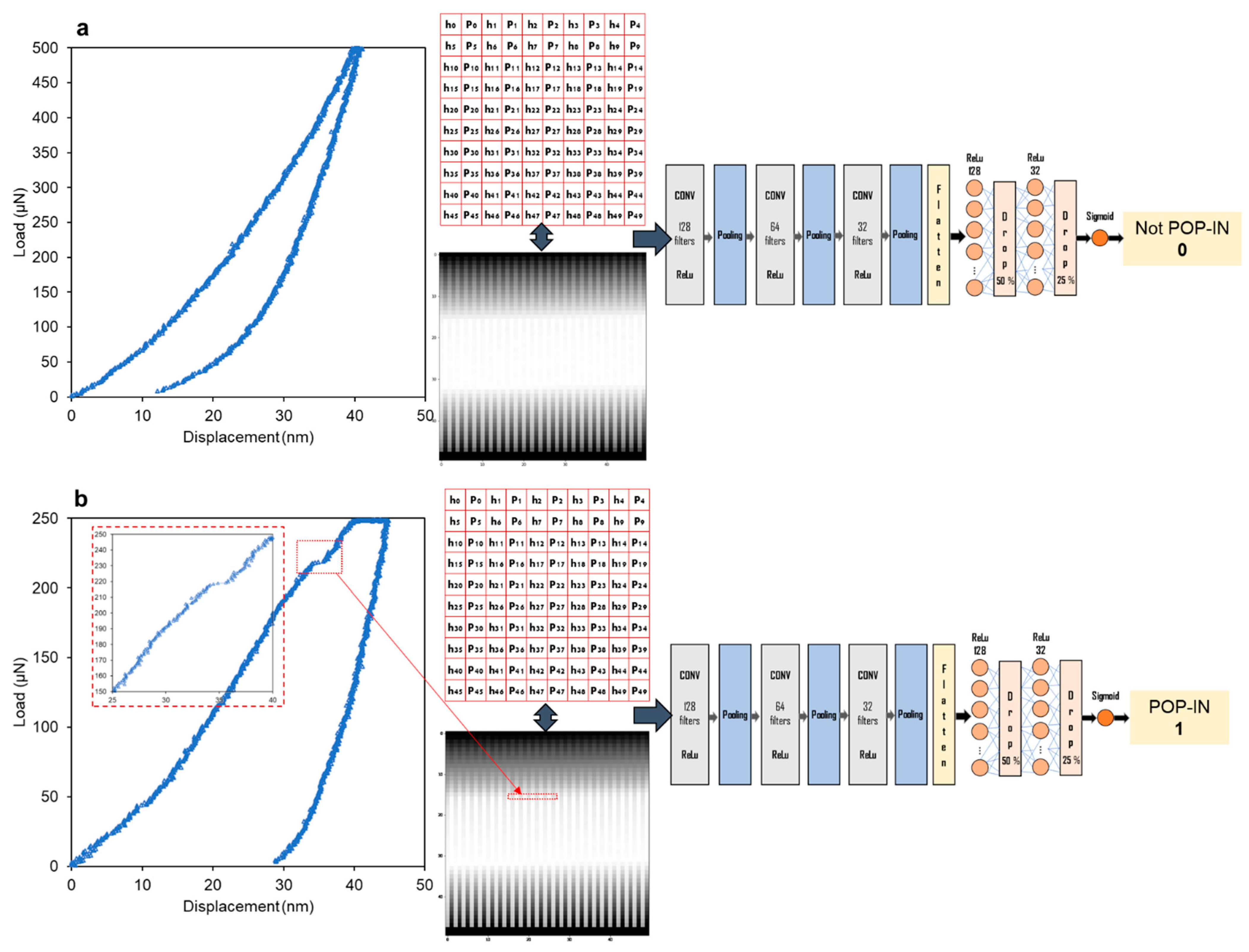
2.2. Data Preparation
Cross-Validation of the Data
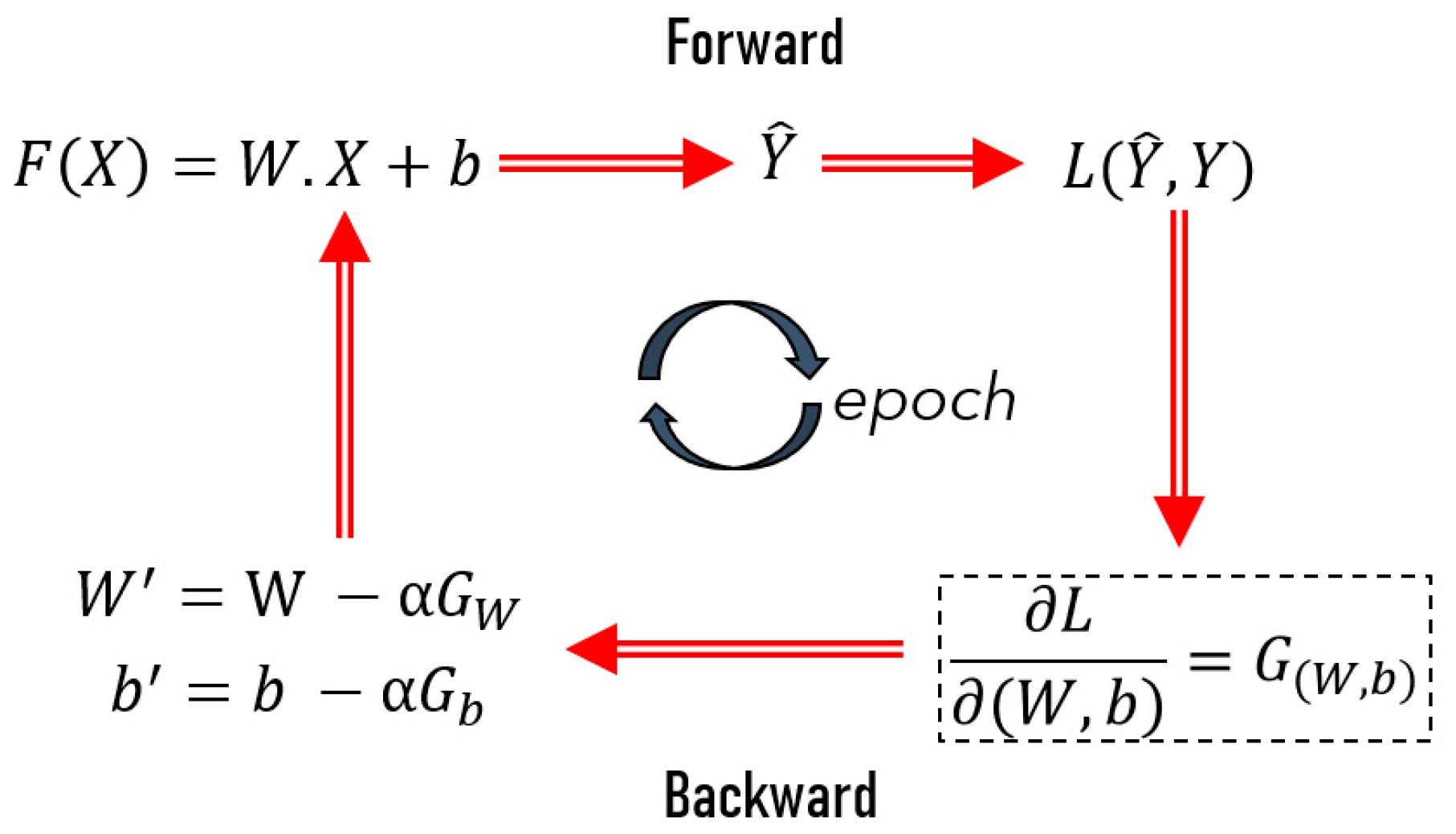
2.3. Convolutional Neural Networks (CNN) Model
- 1.
- In the forward propagation: a function, F, is dependent on the input variable X (e.g., images), a given number of linear operators W (filters or image kernels), and multiple bias terms (b) are applied to estimate a prediction output .
- 2.
- In backpropagation:
- a.
- The loss function, L, is used to calculate the difference between the generated output and the expected output (given by the data);
- b.
- Then, the gradient, , (partial derivatives of L with respect to W and b) of the loss function is calculated to update the values of the filters and bias terms (.
- 3.
- The updated values of the filters and bias terms are introduced in step i, repeating the forward and backward propagation of a defined number of iterations (epochs) until approaching the minimum of the loss function.
3. Results and Discussion
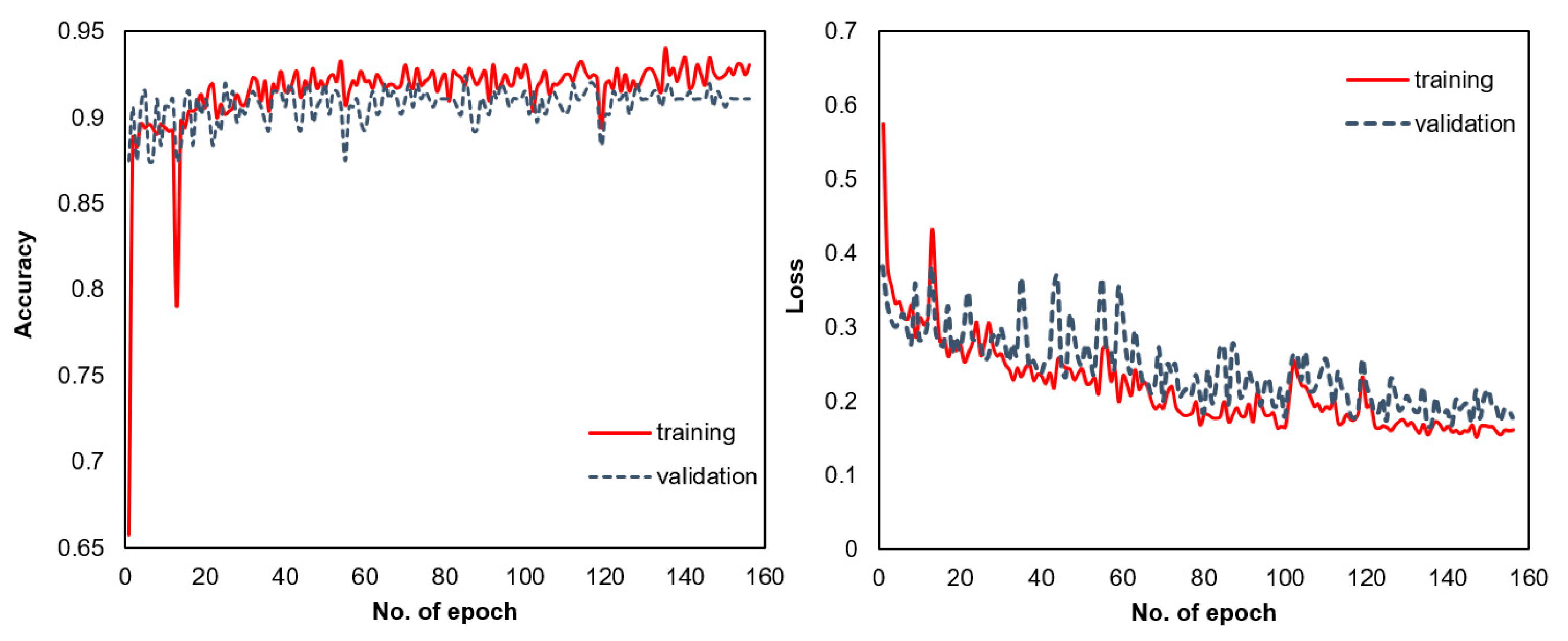
3.1. Convolutional Neural Network (CNN) Model
3.2. Robustness Evaluation of the CNN Architecture and Model
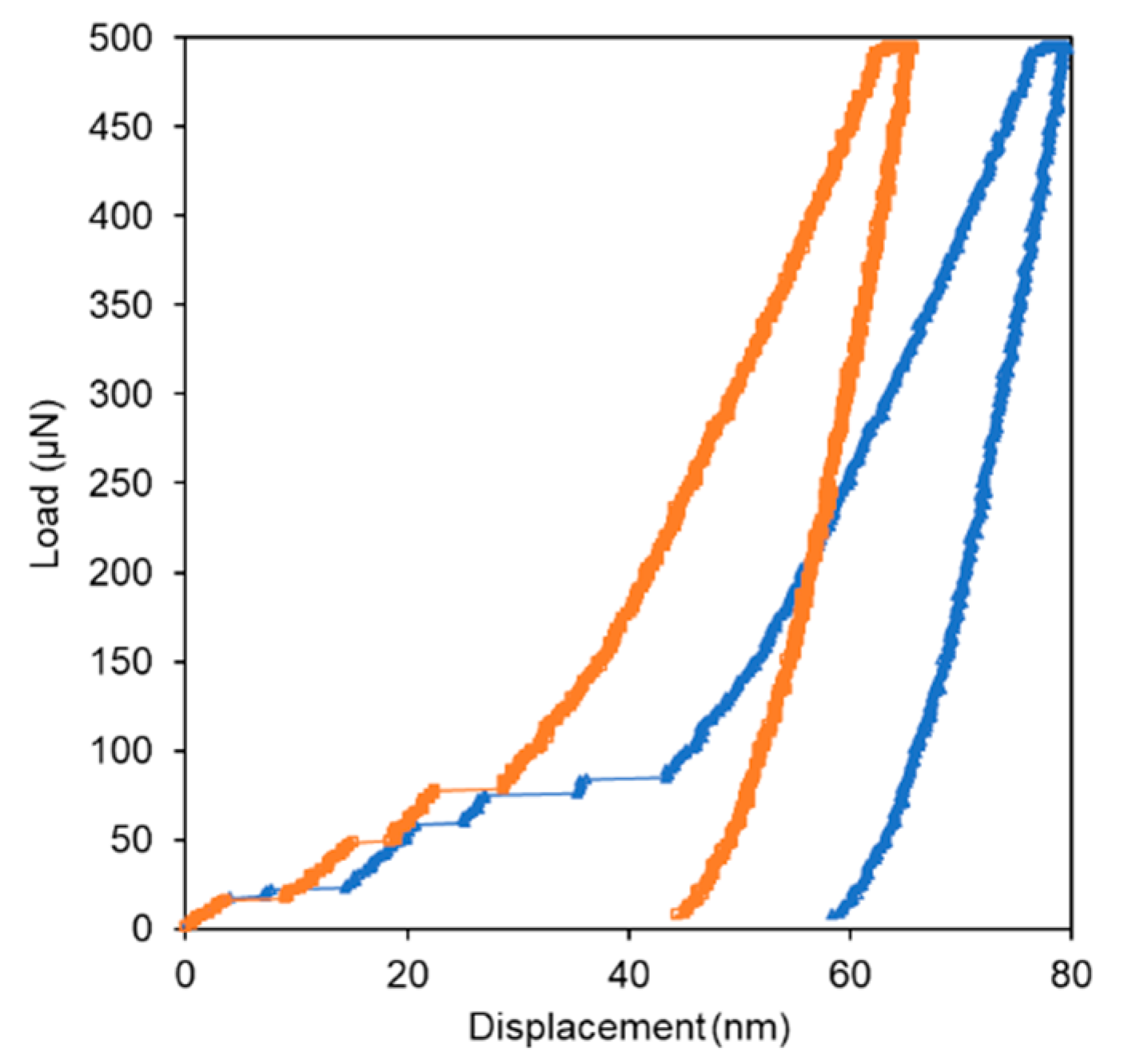
3.2.1. Influence of the Unloading Curve on the Accuracy of the CNN Model
3.2.2. Artificial Pop-ins
4. Conclusions
5. Suggestions for Future Development
- The quantification of pop-in events (location, length, and probability), which requires an algorithm designed for object detection, a more complex architecture of the neural network, and a different dataset structure. Similarly, the detailed identification of the spatial location of tests where pop-in events occur, pop-in quantification, and their correlation with the mechanical properties by indentation could help better understand the mechanisms which create the pop-ins;
- Studying the effect of aspects related to data configuration (sampling, noise, size, and padding) in the implementation and output of the CNN model;
- Applications of similar models to nanoindentation datasets, including load, displacement, and time variables; additionally, datasets obtained by CSM (continuous stiffness measurement) methods could certainly provide relevant information;
- Applications of similar algorithms to study property prediction, which is an exciting possibility, to establish relationships between nanoindentation data and mechanical properties, e.g., abrasion resistance.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hintsala, E.D.; Hangen, U.; Stauffer, D.D. High-Throughput Nanoindentation for Statistical and Spatial Property Determination. JOM 2018, 70, 494–503. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Hintsala, E.; Li, N.; Becker, B.R.; Cheng, J.Y.; Nowakowski, B.; Weaver, J.; Stauffer, D.; Mara, N.A. High-Throughput Nanomechanical Screening of Phase-Specific and Temperature-Dependent Hardness in AlxFeCrNiMn High-Entropy Alloys. JOM 2019, 71, 3368–3377. [Google Scholar] [CrossRef]
- Vranjes-Wessely, S.; Misch, D.; Kiener, D.; Cordill, M.J.; Frese, N.; Beyer, A.; Horsfield, B.; Wang, C.; Sachsenhofer, R.F. High-speed nanoindentation mapping of organic matter-rich rocks: A critical evaluation by correlative imaging and machine learning data analysis. Int. J. Coal Geol. 2021, 247, 103847. [Google Scholar] [CrossRef]
- Roa, J.J.; Phani, P.S.; Oliver, W.C.; Llanes, L. Mapping of mechanical properties at microstructural length scale in WC-Co cemented carbides: Assessment of hardness and elastic modulus by means of high speed massive nanoindentation and statistical analysis. Int. J. Refract. Hard Met. 2018, 75, 211–217. [Google Scholar] [CrossRef]
- Vignesh, B.; Oliver, W.C.; Kumar, G.S.; Phani, P.S. Critical assessment of high speed nanoindentation mapping technique and data deconvolution on thermal barrier coatings. Mater. Des. 2019, 181, 108084. [Google Scholar] [CrossRef]
- Koumoulos, E.P.; Tofail, S.A.M.; Silien, C.; de Felicis, D.; Moscatelli, R.; Dragatogiannis, D.A.; Bemporad, E.; Sebastiani, M.; Charitidis, C.A. Metrology and nano-mechanical tests for nano-manufacturing and nano-bio interface: Challenges & future perspectives. Mater. Des. 2018, 137, 446–462. [Google Scholar] [CrossRef] [Green Version]
- Němeček, J.; Lukeš, J.; Němeček, J. High-speed mechanical mapping of blended cement pastes and its comparison with standard modes of nanoindentation. Mater. Today Commun. 2020, 23, 100806. [Google Scholar] [CrossRef]
- Fu, K.; Tang, Y.; Chang, L. Toughness Assessment and Fracture Mechanism of Brittle Thin Films Under Nano-Indentation. In Fracture Mechanics—Properties, Patterns and Behaviours; Alves, L.M., Ed.; InTech: London, UK, 2016. [Google Scholar] [CrossRef] [Green Version]
- Fischer-Cripps, A.C. Nanoindentation, 3rd ed.; Springer: New York, NY, USA, 2011. [Google Scholar]
- Field, J.S.; Swain, M.V.; Dukino, R.D. Determination of fracture toughness from the extra penetration produced by indentation-induced pop-in. J. Mater. Res. 2003, 18, 1412–1419. [Google Scholar] [CrossRef]
- Wu, D.; Nieh, T.G. Incipient plasticity and dislocation nucleation in body-centered cubic chromium. Mater. Sci. Eng. A 2014, 609, 110–115. [Google Scholar] [CrossRef]
- Pöhl, F. Pop-in behavior and elastic-to-plastic transition of polycrystalline pure iron during sharp nanoindentation. Sci. Rep. 2019, 9, 15350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papanikolaou, S.; Cui, Y.; Ghoniem, N. Avalanches and plastic flow in crystal plasticity: An overview. Model. Simul. Mater. Sci. Eng. 2017, 26, 013001. [Google Scholar] [CrossRef] [Green Version]
- Britton, T.B.; Randman, D.; Wilkinso, A.J. Nanoindentation study of slip transfer phenomenon at grain boundaries. J. Mater. Res. 2009, 24, 607–615. [Google Scholar] [CrossRef]
- Schuh, C.A.; Nieh, T.G.; Kawamura, Y. Rate Dependence of Serrated Flow During Nanoindentation of a Bulk Metallic Glass. J. Mater. Res. 2002, 17, 1651–1654. [Google Scholar] [CrossRef]
- Beake, B.D.; Goel, S. Incipient plasticity in tungsten during nanoindentation: Dependence on surface roughness, probe radius and crystal orientation. Int. J. Refract. Hard Met. 2018, 75, 63–69. [Google Scholar] [CrossRef] [Green Version]
- Jiapeng, S.; Cheng, L.; Han, J.; Ma, A.; Fang, L. Nanoindentation Induced Deformation and Pop-in Events in a Silicon Crystal: Molecular Dynamics Simulation and Experiment. Sci. Rep. 2017, 7, 10282. [Google Scholar] [CrossRef] [PubMed]
- Malzbender, J.; de With, G. The use of the indentation loading curve to detect fracture of coatings. Surf. Coat. Technol. 2001, 137, 72–76. [Google Scholar] [CrossRef]
- Juliano, T.; Domnich, V.; Buchheit, T.; Gogotsi, Y. Numerical Derivative Analysis of Load-Displacement Curves in Depth-Sensing Indentation. MRS Online Proc. Libr. 2003, 791, 75. [Google Scholar] [CrossRef]
- Sato, Y.; Shinzato, S.; Ohmura, T.; Hatano, T.; Ogata, S. Unique universal scaling in nanoindentation pop-ins. Nat. Commun. 2020, 11, 4177. [Google Scholar] [CrossRef]
- Bolin, R.; Yavas, H.; Song, H.; Hemker, K.J.; Papanikolaou, S. Bending Nanoindentation and Plasticity Noise in FCC Single and Polycrystals. Crystals 2019, 9, 652. [Google Scholar] [CrossRef] [Green Version]
- Malzbender, J.; de With, G. The use of the loading curve to assess soft coatings. Surf. Coat. Technol. 2000, 127, 265–272. [Google Scholar] [CrossRef]
- Mercier, D. PopIn, 2021. Available online: https://github.com/DavidMercier/PopIn (accessed on 20 September 2021).
- Phani, P.S.; Oliver, W.C. Critical examination of experimental data on strain bursts (pop-in) during spherical indentation. J. Mater. Res. 2020, 35, 1028–1036. [Google Scholar] [CrossRef] [Green Version]
- Koumoulos, E.; Konstantopoulos, G.; Charitidis, C. Applying Machine Learning to Nanoindentation Data of (Nano-) Enhanced Composites. Fibers 2020, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Koumoulos, E.P.; Paraskevoudis, K.; Charitidis, C.A. Constituents Phase Reconstruction through Applied Machine Learning in Nanoindentation Mapping Data of Mortar Surface. J. Compos. Sci. 2019, 3, 63. [Google Scholar] [CrossRef] [Green Version]
- Konstantopoulos, G.; Koumoulos, E.P.; Charitidis, C.A. Classification of mechanism of reinforcement in the fiber-matrix interface: Application of Machine Learning on nanoindentation data. Mater. Des. 2020, 192, 108705. [Google Scholar] [CrossRef]
- Lu, L.; Dao, M.; Kumar, P.; Ramamurty, U.; Karniadakis, G.E.; Suresh, S. Extraction of mechanical properties of materials through deep learning from instrumented indentation. Proc. Natl. Acad. Sci. USA 2020, 117, 7052–7062. [Google Scholar] [CrossRef] [Green Version]
- Weng, J.; Lindvall, R.; Zhuang, K.; Ståhl, J.-E.; Ding, H.; Zhou, J. A machine learning based approach for determining the stress-strain relation of grey cast iron from nanoindentation. Mech. Mater. 2020, 148, 103522. [Google Scholar] [CrossRef]
- Daugela, A.; Chang, C.H.; Peterson, D.W. Deep-learning based characterization of nanoindentation induced acoustic events. Mater. Sci. Eng. A 2021, 800, 140273. [Google Scholar] [CrossRef]
- Tyulyukovskiy, E.; Huber, N. Identification of viscoplastic material parameters from spherical indentation data: Part I. Neural networks. J. Mater. Res. 2006, 21, 664–676. [Google Scholar] [CrossRef]
- Huber, N.; Konstantinidis, A.; Tsakmakis, C. Determination of Poisson’s Ratio by Spherical Indentation Using Neural Networks—Part I: Theory. J. Appl. Mech. 2000, 68, 218–223. [Google Scholar] [CrossRef]
- Huber, N.; Tsakmakis, C. Determination of Poisson’s Ratio by Spherical Indentation Using Neural Networks—Part II: Identification Method. J. Appl. Mech. 2000, 68, 224–229. [Google Scholar] [CrossRef]
- Hysitron TI 980 Nanoindenter, (n.d.). Available online: https://www.bruker.com/en/products-and-solutions/test-and-measurement/nanomechanical-test-systems/hysitron-ti-980-nanoindenter.html (accessed on 3 October 2021).
- Kim, P. Convolutional Neural Network. In MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Kim, P., Ed.; Apress: Berkeley, CA, USA, 2017; pp. 121–147. [Google Scholar] [CrossRef]
- Bernico, M. Deep Learning Quick Reference: Useful Hacks for Training and Optimizing Deep Neural Networks with TensorFlow and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Brownlee, J. Imbalanced Classification with Python: Better Metrics, Balance Skewed Classes, Cost-Sensitive Learning; Machine Learning Mastery, 2020. [Google Scholar]
- Capehart, T.W.; Cheng, Y.-T. Determining constitutive models from conical indentation: Sensitivity analysis. J. Mater. Res. 2003, 18, 827–832. [Google Scholar] [CrossRef]
- Papanikolaou, S. Learning local, quenched disorder in plasticity and other crackling noise phenomena. Npj Comput. Mater. 2018, 4, 1–7. [Google Scholar] [CrossRef]
- Marteau, J.; Bigerelle, M. Relation between surface hardening and roughness induced by ultrasonic shot peening. Tribol. Int. 2015, 83, 105–113. [Google Scholar] [CrossRef]
- Rio, A.L.; Martin, M.; Perera-Lluna, A.; Saidi, R. Effect of sequence padding on the performance of deep learning models in archaeal protein functional prediction. Sci. Rep. 2020, 10, 14634. [Google Scholar] [CrossRef]
- Merayo, D.; Rodríguez-Prieto, A.; Camacho, A.M. Prediction of Mechanical Properties by Artificial Neural Networks to Characterize the Plastic Behavior of Aluminum Alloys. Materials 2020, 13, 5227. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Precision | Recall | F1-Score | No. of Matrices |
|---|---|---|---|---|
| 0 (no pop-in) | 0.92 | 0.92 | 0.92 | 119 |
| 1 (pop-in) | 0.90 | 0.90 | 0.90 | 105 |
| Classes | Precision | Recall | F1-Score | No. of Matrices |
|---|---|---|---|---|
| 0 (no pop-in) | 0.94 | 0.90 | 0.92 | 119 |
| 1 (pop-in) | 0.89 | 0.93 | 0.91 | 105 |
| Classes | Precision | Recall | F1-Score | No. of Matrices |
|---|---|---|---|---|
| 0 (no pop-in) | 0.93 | 0.87 | 0.90 | 116 |
| 1 (pop-in) | 0.94 | 0.96 | 0.95 | 228 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kossman, S.; Bigerelle, M. Pop-In Identification in Nanoindentation Curves with Deep Learning Algorithms. Materials 2021, 14, 7027. https://doi.org/10.3390/ma14227027
Kossman S, Bigerelle M. Pop-In Identification in Nanoindentation Curves with Deep Learning Algorithms. Materials. 2021; 14(22):7027. https://doi.org/10.3390/ma14227027
Chicago/Turabian StyleKossman, Stephania, and Maxence Bigerelle. 2021. "Pop-In Identification in Nanoindentation Curves with Deep Learning Algorithms" Materials 14, no. 22: 7027. https://doi.org/10.3390/ma14227027
APA StyleKossman, S., & Bigerelle, M. (2021). Pop-In Identification in Nanoindentation Curves with Deep Learning Algorithms. Materials, 14(22), 7027. https://doi.org/10.3390/ma14227027