
Deep-Learning-Based Segmentation of Fresh or Young Concrete Sections from Images of Construction Sites


 ,
,  , and
, and
Abstract
:1. Introduction
2. Investigational Methodology
2.1. Data Acquisition
2.2. Data Training
2.3. Evaluation Process and Metrics
- True positives (TP): an outcome where the model correctly predicts the positive class.
- True negative (TN): an outcome where the model correctly predicts the negative class.
- False positive (FP): an outcome where the model incorrectly indicates the positive class, but it is actually negative.
- False negatives (FN): an outcome where the model incorrectly indicates the negative class, but it is actually positive.
3. Results and Discussion
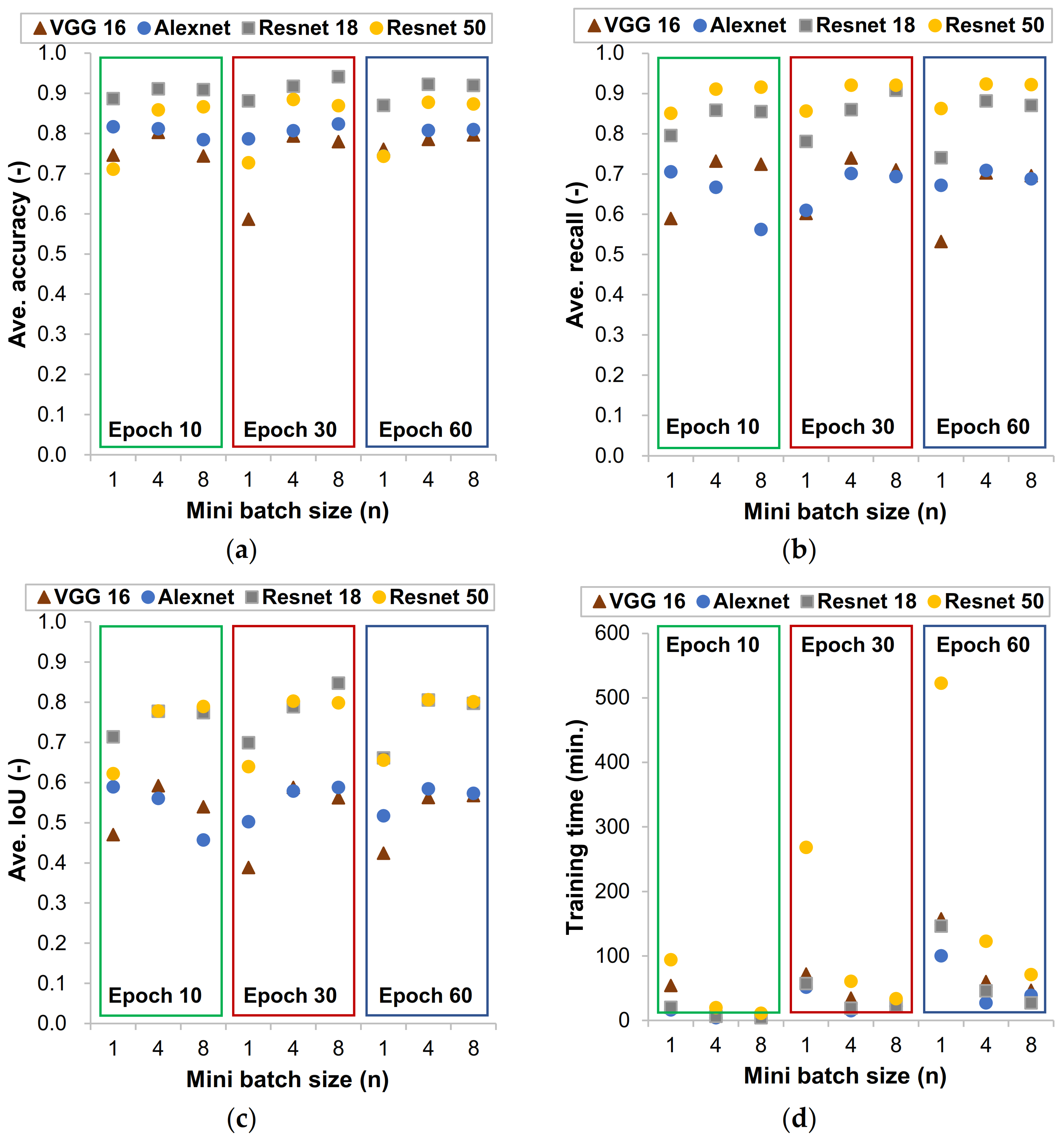
3.1. Effects of Epoch and Batch Size
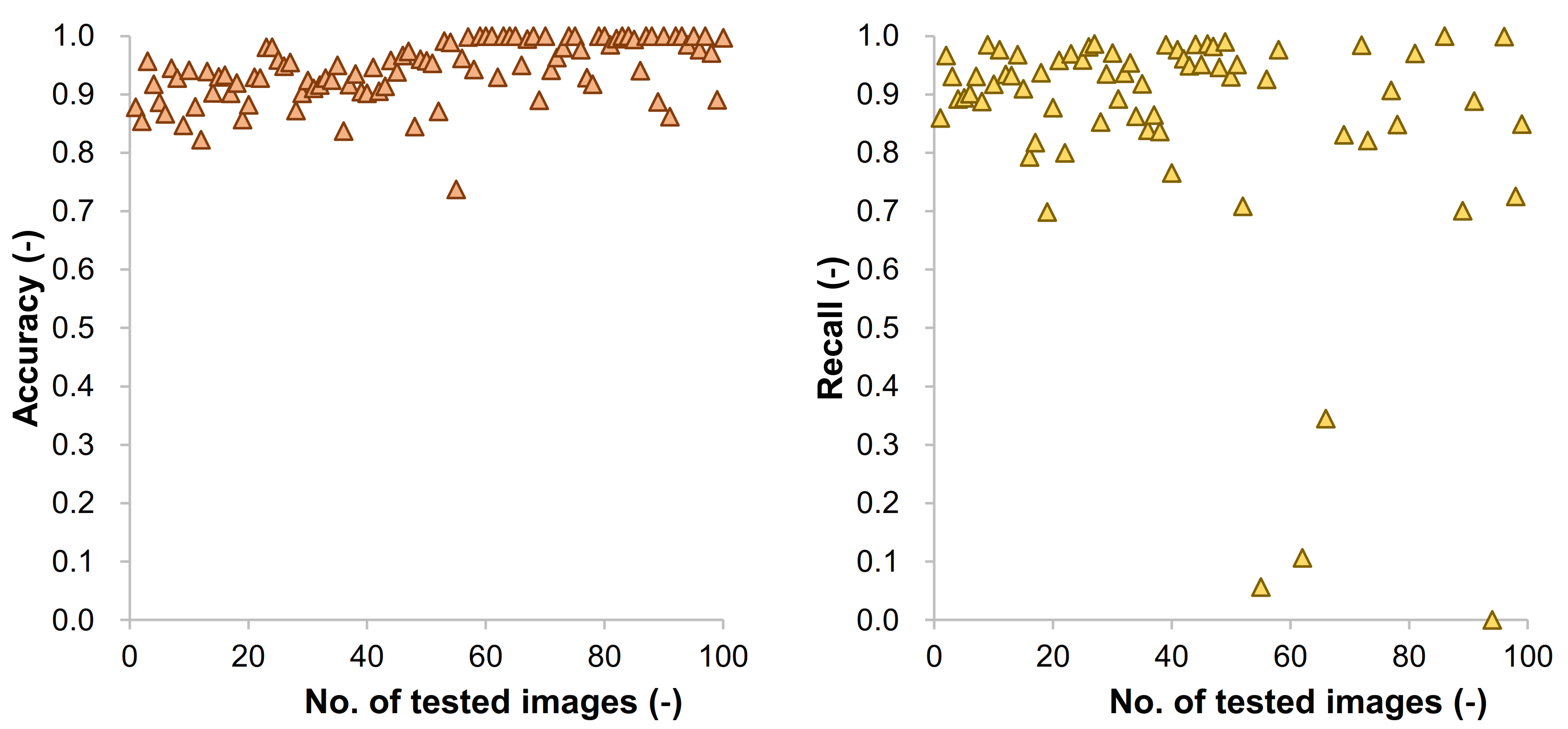
3.2. Case Study: Thresholding Approaches
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Joshi, S.K. On Application of Image Processing: Study of Digital Image Processing Techniques for Concrete Mixture Images and Its Composition. IJERT 2014, 3, 1137–1146. [Google Scholar]
- Hoang, N.-D. Detection of Surface Crack in Building Structures Using Image Processing Technique with an Improved Otsu Method for Image Thresholding. Adv. Civ. Eng. 2018, 2018, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kabir, S.; Rivard, P.; He, D.-C.; Thivierge, P. Damage assessment for concrete structure using image processing techniques on acoustic borehole imagery. Constr. Build. Mater. 2009, 23, 3166–3174. [Google Scholar] [CrossRef]
- Lee, B.Y.; Kim, Y.Y.; Yi, S.-T.; Kim, J.-K. Automated image processing technique for detecting and analysing concrete surface cracks. Struct. Infrastruct. Eng. 2013, 9, 567–577. [Google Scholar] [CrossRef]
- Rivera, J.P.; Josipovic, G.; Lejeune, E.; Luna, B.N.; Whittaker, A.S. Automated Detection and Measurement of Cracks in Reinforced Concrete Components. ACI Struct. J. 2015, 112, 397–406. [Google Scholar] [CrossRef]
- Choi, J.-I.; Lee, Y.; Kim, Y.Y.; Lee, B.Y. Image-processing technique to detect carbonation regions of concrete sprayed with a phenolphthalein solution. Constr. Build. Mater. 2017, 154, 451–461. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Akinosho, T.D.; Oyedele, L.O.; Bilal, M.; Ajayi, A.O.; Delgado, M.D.; Akinade, O.O.; Ahmed, A.A. Deep learning in the construction industry: A review of present status and future innovations. J. Build. Eng. 2020, 32, 101827. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Kaseko, M.S.; Ritchie, S.G. A neural network-based methodology for pavement crack detection and classification. Transp. Res. Part C Emerg. Technol. 1993, 1, 275–291. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, B.; Cho, S. Image-based concrete crack assessment using mask and region-based convolutional neural network. Struct. Control Health Monit. 2019, e2381. [Google Scholar] [CrossRef]
- Song, Y.; Huang, Z.; Shen, C.; Shi, H.; Lange, D.A. Deep learning-based automated image segmentation for concrete petrographic analysis. Cem. Concr. Res. 2020, 135, 106118. [Google Scholar] [CrossRef]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer vision techniques for construction safety and health monitoring. Adv. Eng. Inform. 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Achanta, R.; Susstrunk, S. Superpixels and polygons using simple non-iterative clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 4651–4660. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1713–1721. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2018, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Alom, Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Zhu, Q.; He, Z.; Zhang, T.; Cui, W. Improving Classification Performance of Softmax Loss Function Based on Scalable Batch-Normalization. Appl. Sci. 2020, 10, 2950. [Google Scholar] [CrossRef]
- Schwenke, C.; Schering, A. True Positives, True Negatives, False Positives, False Negatives; Wiley Encyclopedia of Clinical Trials; Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Maeda-Gutiérrez, V.; Galván-Tejada, C.E.; Zanella-Calzada, L.A.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Luna-García, H.; Magallanes-Quintanar, R.; Méndez, C.A.G.; Olvera-Olvera, C.A. Comparison of Convolutional Neural Network Architectures for Classification of Tomato Plant Diseases. Appl. Sci. 2020, 10, 1245. [Google Scholar] [CrossRef] [Green Version]
- Hoffer, E.; Hubara, I.; Soudry, D. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. Adv. Neural Inf. Process. Syst. 2017, 30, 1731–1741. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Model | FCN | SegNet | DeepLab V3+ | DeepLab V3+ |
|---|---|---|---|---|
| Backbone encoder | AlexNet [9] | VGG 16 [28] | ResNet 18 [16] | ResNet 50 [16] |
| Parameters | ~60 million | ~138 million | ~11 million | ~23 million |
| Neurons | 650,000 | 5504 | 4096 | |
| Input image size | 227 × 227 | 224 × 224 | 224 × 224 | 224 × 224 |
| Convolutional layer | 5 | 3 | 5 | 5 |
| Fully connected layer | 3 | 3 | 1 | 1 |
| Max pooling layer | 5 | 5 | 2 (1 average) | 2 (1 average) |
| Total connections | 24 | 40 | 78 | 192 |
| Total layers | 25 | 41 | 71 | 177 |
| Output type | Classification | Classification | Classification | Classification |
| Training Parameters | Options Used |
|---|---|
| Optimization algorithm | SGDM |
| Momentum | 0.9 |
| Execution environment | Single GPU |
| L2 regularization | 0.0005 |
| Shuffle | Every epoch |
| Initial learn rate | 0.003 |
| Learn rate schedule | Piece-wise |
| Mini batch size | Varied |
| Max epochs | Varied |
| Machine and Software Environment | Selections Used |
|---|---|
| System type | Microsoft Windows 10, 64-bit |
| RAM | 24 GB |
| Processor | Intel(R) Core™ i7-7700 CPU @ 3.6 GHz |
| Graphics driver | NVIDIA GeForce RTX 2080 Ti 11 GB |
| Execution environment | MATLAB, R2020a |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mesfin, W.M.; Cho, S.; Lee, J.; Kim, H.-K.; Kim, T. Deep-Learning-Based Segmentation of Fresh or Young Concrete Sections from Images of Construction Sites. Materials 2021, 14, 6311. https://doi.org/10.3390/ma14216311
Mesfin WM, Cho S, Lee J, Kim H-K, Kim T. Deep-Learning-Based Segmentation of Fresh or Young Concrete Sections from Images of Construction Sites. Materials. 2021; 14(21):6311. https://doi.org/10.3390/ma14216311
Chicago/Turabian StyleMesfin, Woldeamanuel Minwuye, Soojin Cho, Jeongmin Lee, Hyeong-Ki Kim, and Taehoon Kim. 2021. "Deep-Learning-Based Segmentation of Fresh or Young Concrete Sections from Images of Construction Sites" Materials 14, no. 21: 6311. https://doi.org/10.3390/ma14216311
APA StyleMesfin, W. M., Cho, S., Lee, J., Kim, H.-K., & Kim, T. (2021). Deep-Learning-Based Segmentation of Fresh or Young Concrete Sections from Images of Construction Sites. Materials, 14(21), 6311. https://doi.org/10.3390/ma14216311