1. Introduction
Additive manufacturing or 3D printing techniques allow small batches of parts to be produced directly, economically, and flexibly [
1]. There are different additive manufacturing techniques; however, fused deposition modeling (FDM) printers are the most extended due to their low cost and the wide variety of materials that can be used [
2,
3,
4].
FDM printers offer a large number of print parameters: print temperature, layer height, print speed, print acceleration, and flow rate, among others. When a part is printed, it is difficult to predict a priori if it will receive an adequate surface finish [
5,
6].
Data mining techniques are used to improve the quality of processes and products based on data gathered from previous experiences [
7,
8,
9]: they are used to find out which parameters are most influential in surface finishing in electrical discharge machining (EDM) processes [
10]. They are also used to predict the wear of a tool in milling processes [
11] or to increase the accuracy of high-speed machining of titanium alloys [
12].
Data mining techniques can be classified into supervised (classification, regression) and unsupervised (clustering, association rules, correlations). Classification techniques are widely utilized [
9]. To use these techniques, different classes must be established in which each instance in the database must belong to a class; the rest of the attributes of the instance are used to predict that class. The objective of these algorithms is to maximize the accuracy ratio of the classification of new instances [
13].
Decision trees are one of the most widely used classification techniques in data mining [
13]. Tree nodes represent a condition relative to a given attribute. The leaves indicate the number of instances that belong to a class and that satisfy the conditions imposed in the previous nodes. By means of this type of algorithms, it is possible to create models that allow for predictions such as whether a register with certain attributes will belong to one class or another. There are several classification algorithms: C4.5 [
14], random forest [
15], random tree [
16].
Previous work has focused on the use of classification techniques in additive manufacturing processes. Wu et al. [
17,
18] applied random forest, k-nearest neighbor, and anomaly detection techniques to detect defects caused by a cyberattack on an FDM printer during part fabrication. Amini and Chang [
19] used classification techniques to reduce defects in metal parts manufacturing processes using selective laser melting (SLM) printers. Recently, Li et al. [
20] have generated and checked models using different machine learning algorithms to predict the surface roughness of 3D printed parts using FDM; in this case, the authors used a design of experiments with three variables (layer height, print temperature, and print speed/flow rate) and measured the roughness in a unique direction.
The objective of this work is to analyze which decision tree algorithm (C4.5, random forest, or random tree) is the best to predict the surface finish (Ra,0 and Ra,90) of a FDM printed part. Data mining models have been developed from a training dataset consisting of 27 instances with attributes of layer height, print temperature, flow rate, print speed, print acceleration, Ra,0 class, and Ra,90 class. These models have been tested using a dataset with 15 additional instances.
2. Materials and Methods
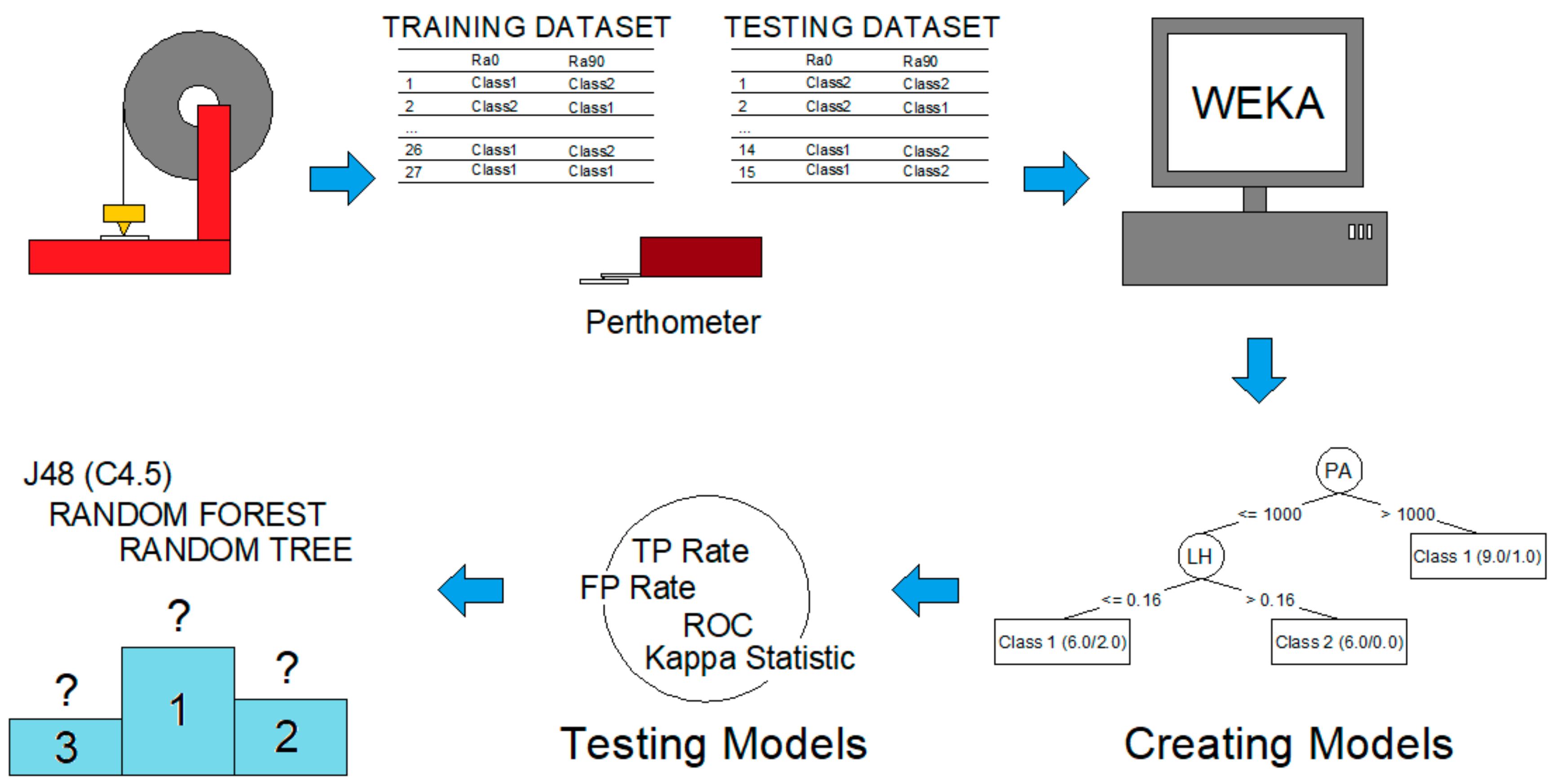
Figure 1 shows the different stages that constitute the methodology followed in this work: 3D printing, surface roughness measurements, data mining, models generation, models testing, and comparison between algorithms.
2.1. 3D Printing and Surface Roughness Measurements
To carry out the present study, 27 specimens of dimensions 25.0 mm × 25.0 mm × 2.4 mm were printed, following a design of fractionated orthogonal experiments, with five factors and three levels. The parameters used and the values assigned to each level are shown in
Table 1.
The specimens were designed using SolidWorks software. The selection of values for print parameters and numerical code (NC) generation was done using CURA software. The specimens were manufactured using an Ender 3 printer, with a diameter nozzle equal to 0.4 mm.
The polyethylene terephthalate glycol (PETG) filament was supplied by Smart Materials 3D (Smart Materials 3D, Alcalá la Real, Spain). Although there are not many published works on PETG, it is a filament increasingly used in the industry, having mechanical characteristics similar to ABS but printed with the ease of a PLA [
21].
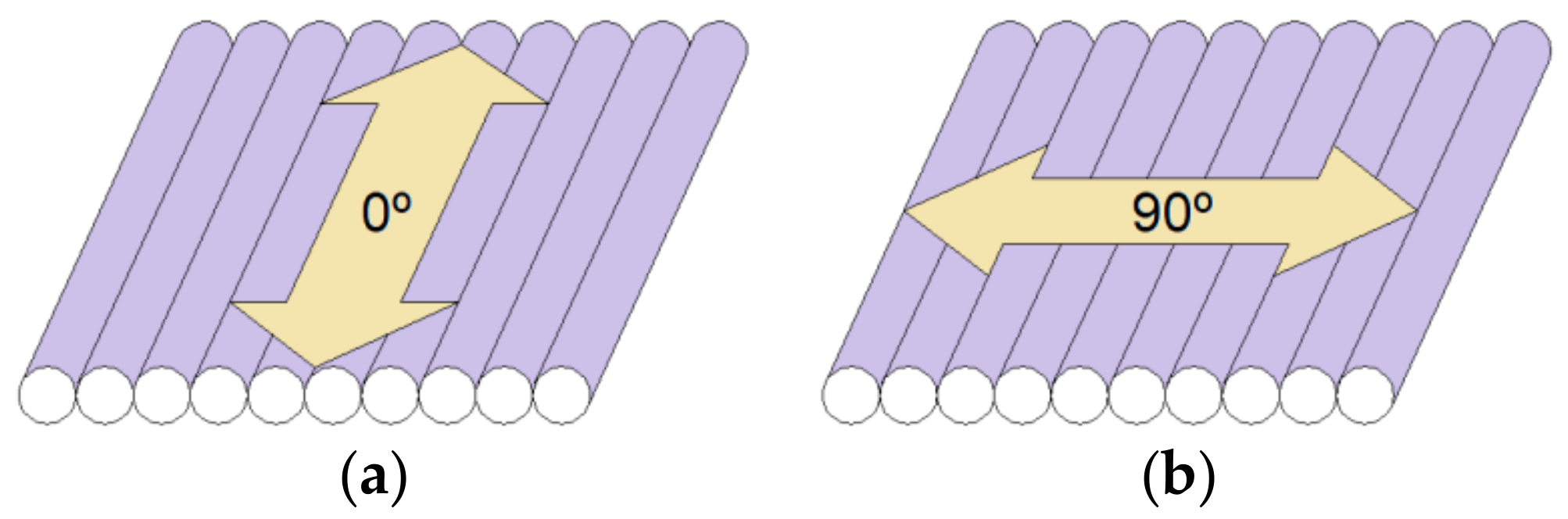
Once printed, the roughness of the specimens was measured using a Mitutoyo perthometer model SJ-201 (Mitutoyo, Kawasaki, Japan). Five measurements were made in each specimen and direction, 0° and 90°, as seen in
Figure 2. The representative value was calculated as the arithmetic mean of the five measurements. The resulting values are shown in
Table 2.
The models were generated using the free software WEKA (Waikato Environment for Knowledge Analysis). The roughness values were divided into two classes (class 1 and class 2) from the mean of the values of
Ra,0 and
Ra,90. For
Ra,0, class 1 includes 0–4.43 μm and class 2 is from 4.43 to 10.64 μm. For
Ra,90, class 1 includes 0–11.63 μm and class 2 includes 11.63–32.99 μm. To validate the model obtained, 15 additional specimens were printed using random values for the parameters under study, as seen in
Table 3. Likewise, five roughness measurements were performed on each specimen and direction, obtaining the representative values by means of the arithmetic mean.
2.2. Data Mining and Decision Trees
The data mining process consists of several steps: (1) integration and data collection, which coincides with the previous paragraph; (2) selection, cleaning and transformation, in which the data were prepared in .arff format, which are files used by WEKA; (3) data mining, consisting of applying the algorithms to the data and generating patterns and models; (4) evaluation and interpretation of the information generated; (5) generation of knowledge and decision making.
In this work, three algorithms based on decision trees are compared: J48 (a variation of WEKA for C4.5), random forest, and random tree. The algorithms are briefly presented below.
2.2.1. J48 (C4.5)
The J48 is WEKA’s version of the C4.5 algorithm. Algorithm C4.5, created by Quinlan [
14], allows the generation of decision trees. It is an iterative algorithm that consists of dividing the data in each stage into two groups using the concept of information entropy. This partitioning process is recursive and stops when all records of a sheet belong to the same class or category.
2.2.2. Random Forest
The random forest method was developed by Breiman [
15]. It consists of constructing multiple decision trees using random combinations and orders of variables before constructing a random tree using bootstrap aggregating (also known as bagging). This highly accurate algorithm is capable of handling hundreds of variables without excluding any [
16].
2.2.3. Random Tree
The random tree is an algorithm halfway between a simple decision tree and a random forest. Random trees are a set of predictor trees called forest. The classification mechanisms are as follows: the random tree classifier obtains the input characteristic vector, classifies it with each tree in the forest, and produces the class label that received the most “votes” [
13].
3. Results
This work proposes the use of decision trees and data mining techniques to predict which values should be selected for the print parameters of PETG flat specimens, manufactured by FDM. The dataset used as a training dataset to develop the models is shown in
Table 4.
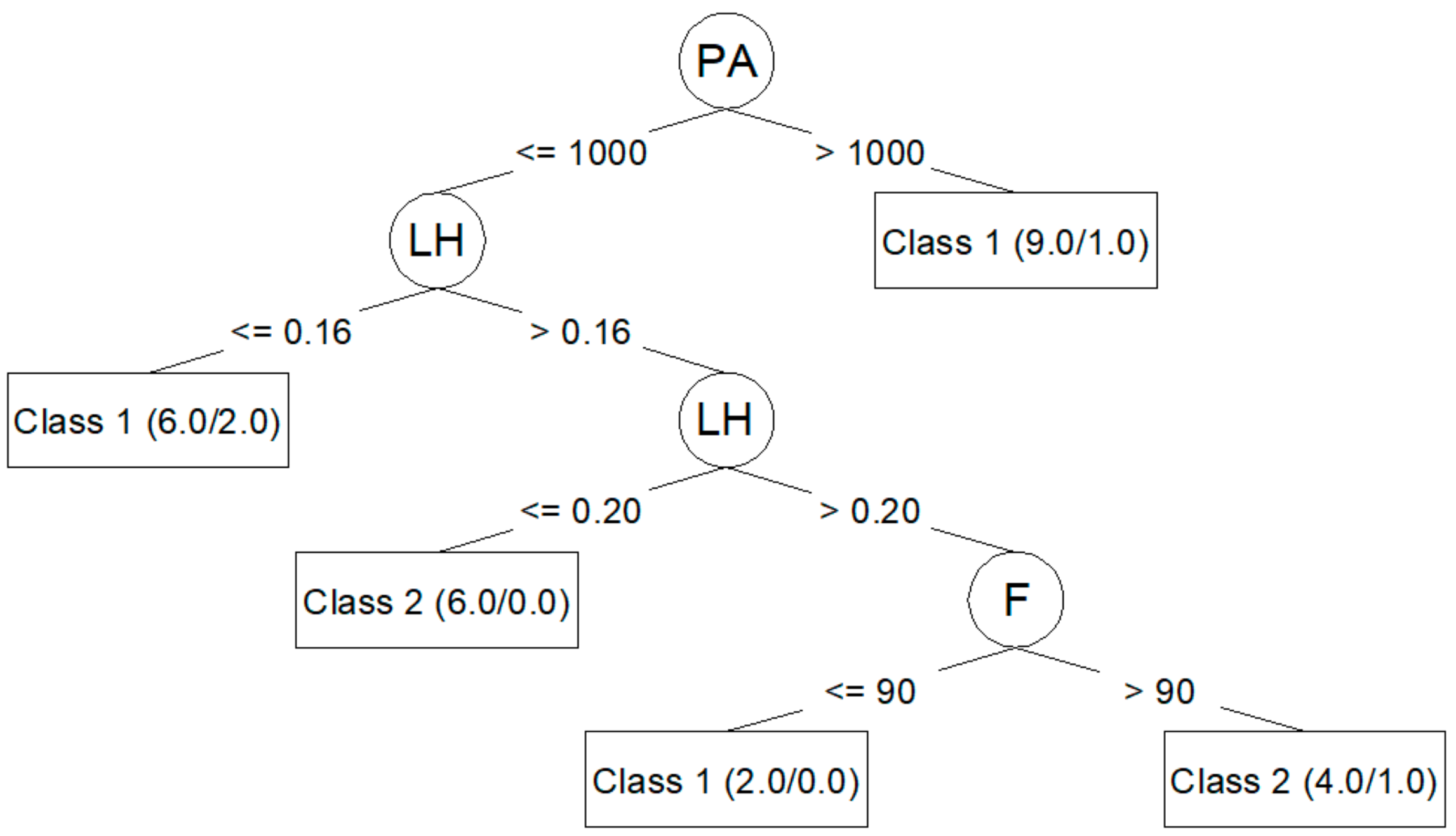
Algorithm J48 (C4.5) generates decision trees that can be represented graphically.
Figure 3 shows the decision tree generated for
Ra,0 from the corresponding training dataset.
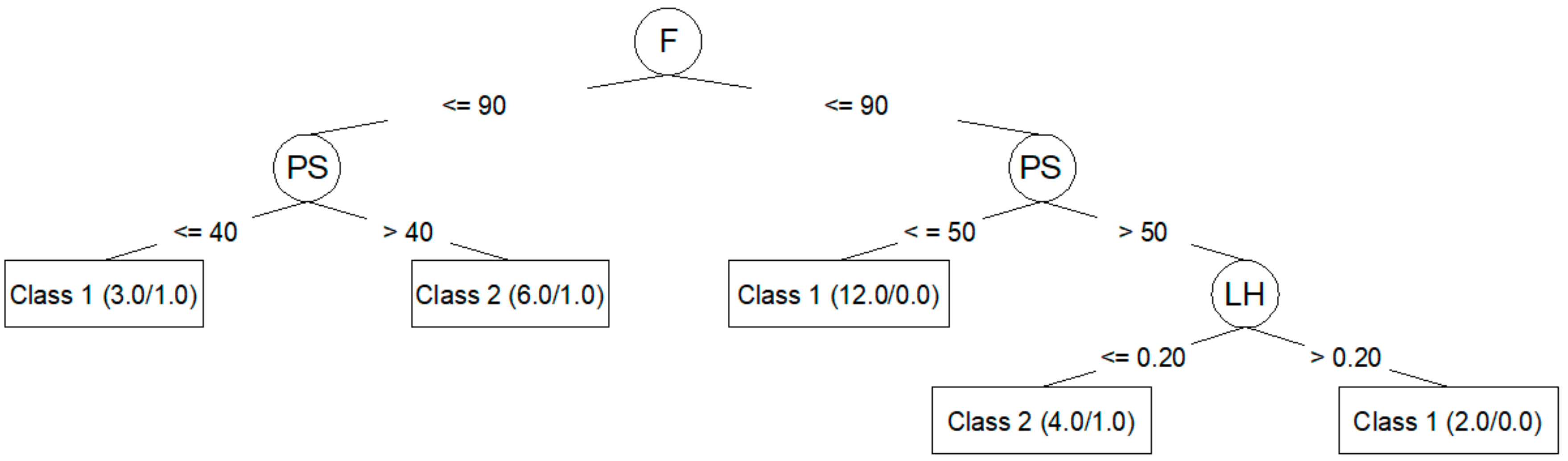
Figure 4 shows the decision tree generated for
Ra,90.
Once the models have been generated using the algorithms studied, they have been checked using the dataset shown in
Table 5. The results of each algorithm for the prediction of
Ra,0 are shown in
Table 6 and
Table 7. Likewise, the results for the prediction of
Ra,90 are presented in
Table 8 and
Table 9.
Table 10 shows the time used by each algorithm to construct and validate the models.
The J48 algorithm allows for the generation of simple trees that can be easily understood and interpreted, as seen in
Figure 3 and
Figure 4. In these trees, it is clear which parameters are most important to reduce
Ra,0 (PA, LH, F) and
Ra,90 (F, PS, LH). However, the models created by means of the J48 algorithm are those that adjust the worst to the test data, as seen in
Table 6 and
Table 8: a 60.00% success rate for
Ra,0; a 73.33% success rate for
Ra,90; and a negative kappa statistic in both cases.
Table 7 and
Table 9 show that the precision for the models created using the J48 algorithm is lower than that achieved by the rest of the models, and that the value of the area under the ROC is very low.
The random forest algorithm slightly improves the results of J48, as seen in
Table 6 and
Table 8; the model created using this algorithm provides 66.67% success for
Ra,0 and 80.00% success for
Ra,90. In this case, the kappa statistic is close to zero for
Ra,0 and negative for
Ra,90.
Table 7 and
Table 9 show that the precision of both models increases, as does the area under ROC. This algorithm does not generate trees that can be plotted.
The models generated by the random tree algorithm are the ones that obtain the best results in this case, as seen in
Table 6 and
Table 8, with an 80% success rate for
Ra,0 and 86.67% success rate for
Ra,90. It obtains a positive kappa statistic in both cases: 0.2857 for
Ra,0 and 0.5946 for
Ra,90. These values can be classified as fair and moderate according to
Table 11.
Table 7 and
Table 9 show that the precision of both models is higher than in the cases analyzed above; the area under ROC is 0.673 for the
Ra,0 model and 0.923 for the
Ra,90 model. In addition, as can be seen in
Table 10, this algorithm took the least time to build the models.
4. Discussion
In the present work, three classification tree algorithms were used to predict the surface finish of FDM-printed PETG flat specimens. The algorithms used were J48, random forest, and random tree. The software used to generate the models was WEKA [
13].
The J48 algorithm has been widely used to study problems in the manufacturing area related to quality improvement in production processes [
10,
22]. In this work, the J48 generated models that classified training dataset data very well. Additionally, this algorithm made it possible to create trees that can be plotted and that are easily understood [
10,
16,
23,
24]. This algorithm also allowed for the identification of the most influential parameters in roughness: PA, LH, and F for
Ra,0; F, PS, and LH for
Ra,90. These results coincide with those obtained by the authors in previous works [
25]: PA is the parameter with the greatest influence on
Ra,0; F, PS, and LH are the parameters with the greatest influence on
Ra,90. However, in this case, the models created with J48 algorithm were not able to predict the data used in the test. This may be related to overfitting problems [
13,
26].
In the problem addressed, the random forest algorithm obtained better results than J48, as could be expected from the literature [
27,
28,
29]. Although it does not generate a graphical model, this algorithm is widely used by other authors in problems similar to the one studied [
30].
In this work, the random tree algorithm generated the best models for
Ra,0 and
Ra,90. Previously, other authors have also chosen this algorithm for its properties [
31]. An additional advantage of this algorithm is its calculation time, which is the fastest of those studied [
32].
5. Conclusions
In the present work, three models were created and compared to predict the surface roughness of flat pieces printed on PETG by FDM. For this purpose, data mining classification were used, such as J48 (C4.5), random forest, and random tree. The software used to generate the models was the open source software WEKA.
The model generated by random tree obtains better results. It correctly classifies a priori 80% of the instances in the case of Ra,0 and 86.67% of the instances in the case of Ra,90. It is the only algorithm of the three evaluated that achieves a positive kappa statistic, qualified as fair for Ra,0 and moderate for Ra,90. It obtains the highest accuracy and area under ROC and is also the fastest algorithm of the three analyzed.
In future works, we intend to study whether the decision trees can be used to generate models that allow for the prediction of a better dimensional accuracy of the parts manufactured by FDM. The impact of other print factors on the surface properties of printed parts, such as nozzle diameter, will also be studied.








{kind=link}
{kind=link}
{kind=link}
{kind=link}