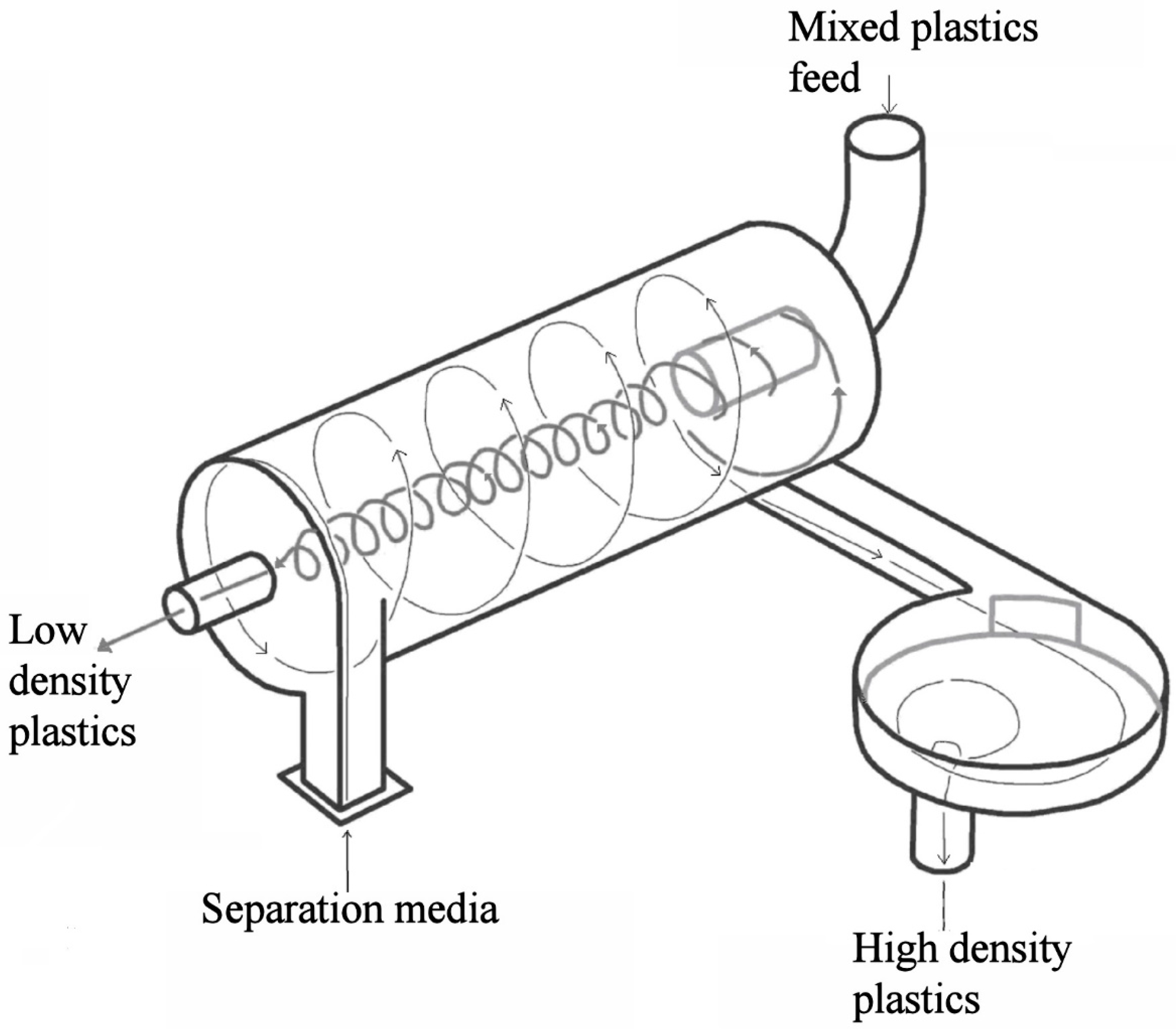
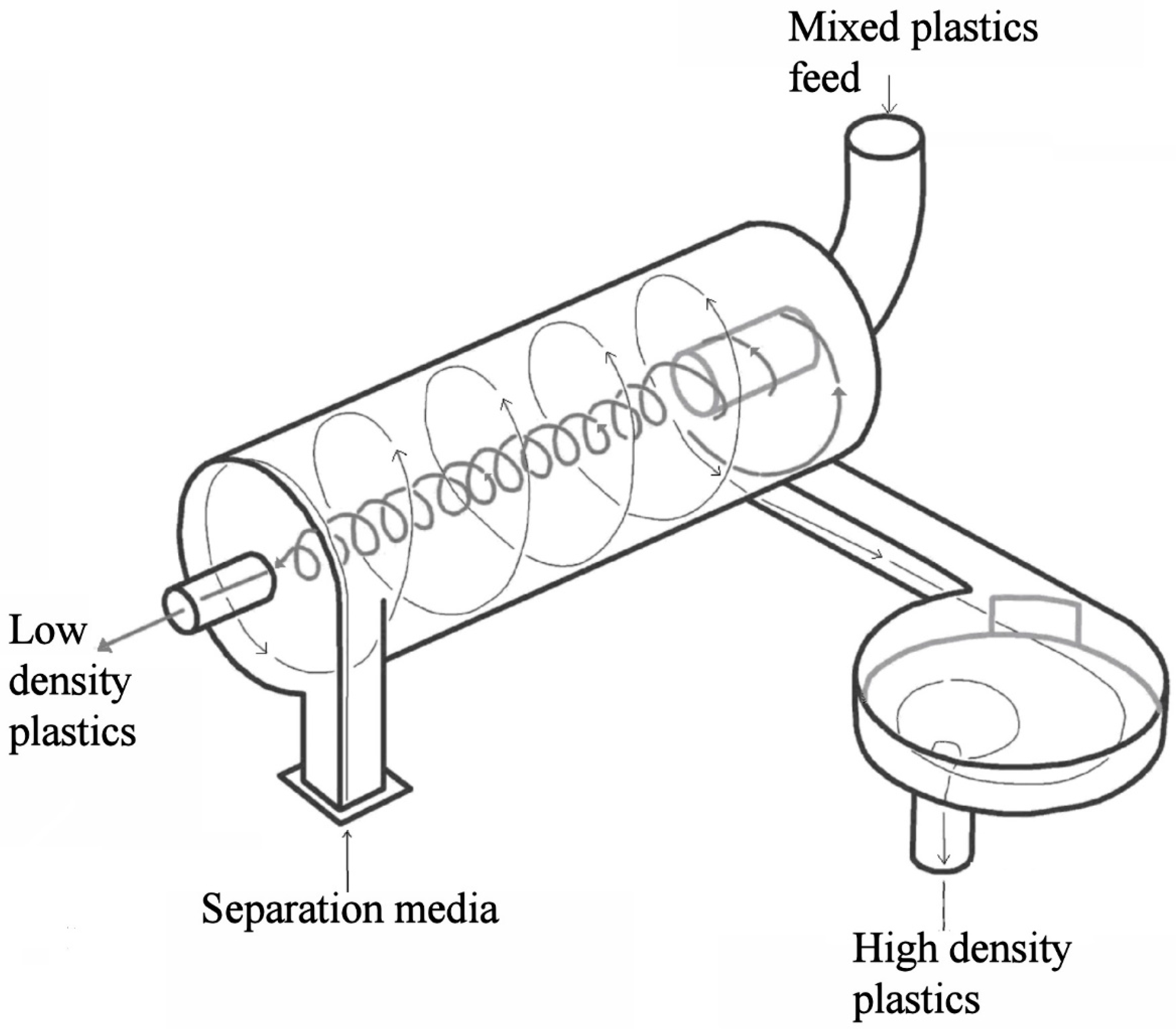
2.1. Description of LARCODEMS Test Procedure
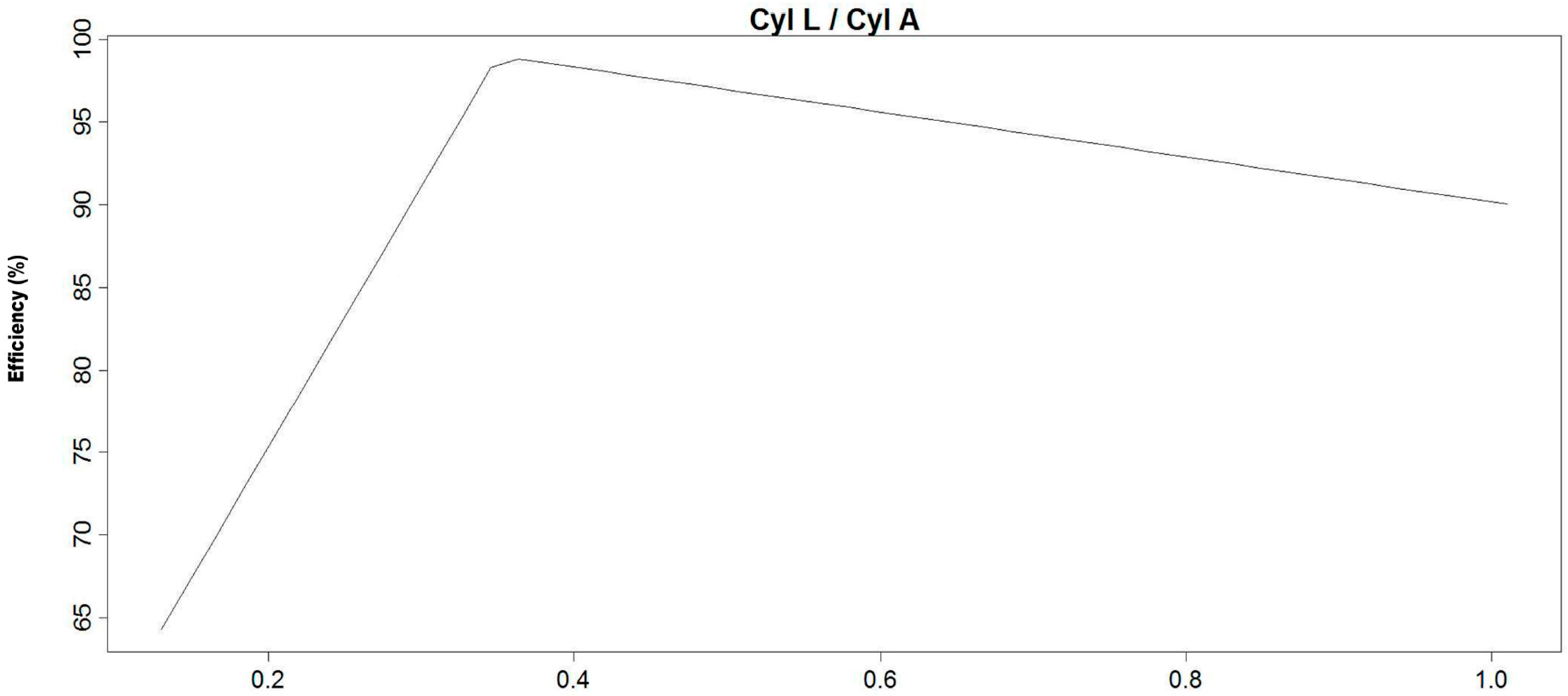
The 110 mm diameter laboratory version of LARCODEMS was designed to be operated with a 12, 21.4, 32.9, and 45 cm long separation cylinder lengths (CL). Three scaled versions (52, 72, and 172 mm diameter) of the 45 cm long 110 mm LARCODEMS were built for inclusion in these tests. Since these versions were scaled to the same relative dimensions of the 110 mm model, the relative cylinder, SP, FP, and diaphragm areas (DA) are constant.
Fragments and pellets of 1.5 to 2.8 mm of different types of plastics with a wide range of densities were selected based on their differences in densities and differences in visual appearances for the separation tests. Densities of these were controlled to 0.002 g/cc by weight to volume ratios determined in methyl alcohol (to avoid air bubbles adhering to the plastic particles). The types were selected such that their densities (e.g., 0.940, 0.955, 0.962, 1.002, 1.034, 1.043, 1.143, and 1.160) were both greater and less than that of the separation media (water). Approximately 2000 particles for each density were combined and fed into the vortex of the LARCODEMS. The processing within the device was accomplished within some 20 seconds. The SP and FP products obtained for a given test were dried, sorted manually by plastic type, and each fraction weighed. This setup of the test procedure required some 15 hours per sample to complete. The efficiency of the separation obtained was determined as the difference in the percentage of recovery of particles denser than 1.0 g/cc in the sink product and the percentage of recovery of particles with a density <1.0 g/cc in the sink product.
The following are the variables that were employed as input data for the models of the LARCODEMS efficiency feeding either into the vortex or with media are:
(A) Separation tests with the plastic particles being fed into the vortex were conducted with:
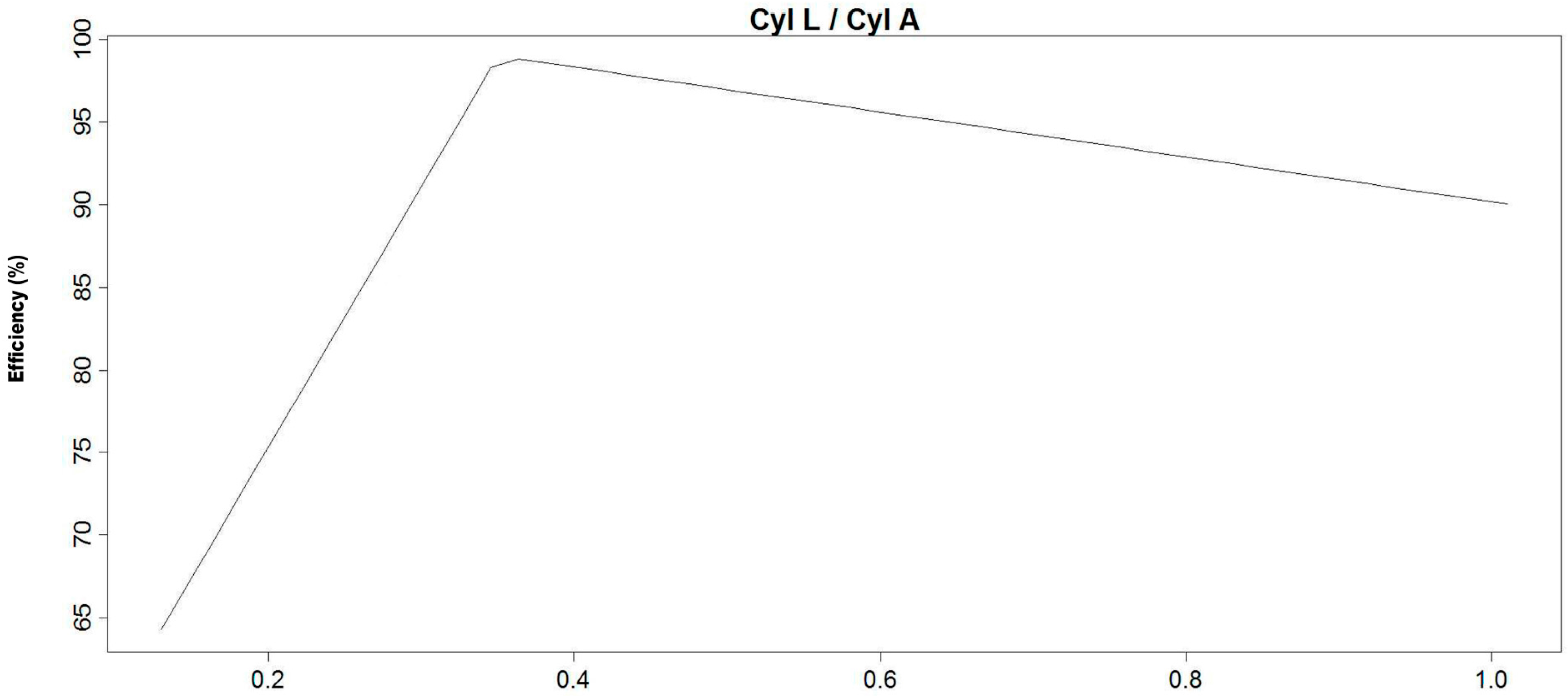
Twelve, 21.4, 32.9 and 45 cm long separation cylinder versions with and without a vortex extractor of the 110 mm LARCODEMS.
Fifty-two, 72, and 172 mm diameter versions of the scaled 45 cm long, 110 mm LARCODEMS.
Variations in diameter of the feed DA of the 110 mm LARCODEMS.
Variations in FPA of the 110 mm LARCODEMS.
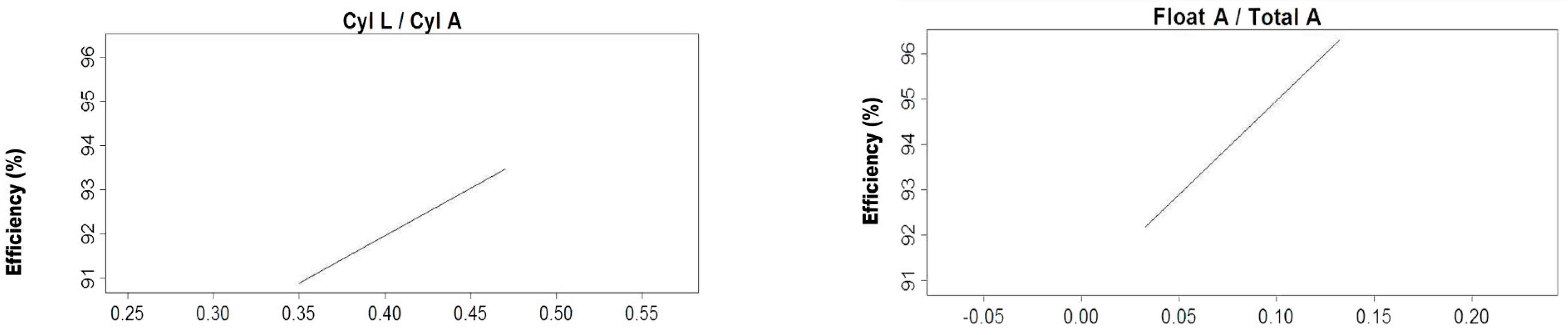
Variations in SPA of the 52, 72, 110, and 172 mm LARCODEMS.
Three variations in total media feed flow rate for all of the above variables when separations of plastic particles that had received a treatment (TM) to reduce hydrophobic effects were conducted without a VE.
Five variations in total media feed flow rate for all of the above variables when separations were conducted without a VE.
(B) Separation tests with the plastic particles being fed with the separation media (FPM) were conducted with:
The 32.9 cm-long and the 45 cm-long separation cylinder versions with and without a vortex extractor of the 110 mm LARCODEMS.
Variations in diameter of the float port of the 110 mm LARCODEMS.
Three variations in total media feed flow rate for all of the above variables when separations of plastic particles that had received a treatment (TM) to reduce hydrophobic effects were conducted without a vortex extractor.
Five variations in total media feed flow rate for all of the above variables when separations were conducted without a vortex extractor.
Since the four different versions of the LARCODEMS used in this investigation were scaled to almost identical proportions, the volumes of media flow are a function of the area of the exit ports and the feed diaphragm relative to the area of the separation cylinder.
2.2. The Multivariate Adaptive Regression Splines
Multivariate adaptive regression splines (MARS) are techniques in the family of multivariate nonparametric regression, based in the adjustment of its parameters to the data to be modelled. These types of models were introduced by Friedman in 1991 [
10]. In other words, MARS is a multivariate method able to generate models based on several input variables. The use of MARS in the present research is due to its ability to model nonlinearities and interaction between parameters. At the beginning of the research, the use of linear regression models was checked without satisfactory results. The main advantage of MARS is that it is able to effectively model relationships and patterns that are not able for other regression methods. MARS are based on measures of explanatory variables
on sizes
for predicting values of the continuous dependent variable
, of size
. The MARS model can be represented as:
where
is the error vector of dimension
. With classification and regression trees (CART) models as the base [
11], MARS can be considered a generalization with the capacity of overcoming some of the limitations of CART, as it does not require any information a priori relating the relationships between dependent and independent variables. CART is a statistical method for multivariate analysis that creates a decision tree which strives to correctly classify the members of a population. The MARS regression model is constructed by piecewise polynomials, also called splines, which have smooth connections. This is performed through fitting basis functions to distinct intervals of the independent variables. The polynomials joining points are named as
, and are known as knots, nodes, or breakdown points. The splines for MARS are polynomials, concretely two-sided truncated power functions, which can be expressed as follows [
12,
13]:
Considering
basis functions, a MARS model can be expressed with the next expression of the estimation of the dependent variable [
14]:
where
is a constant,
the coefficients of the
, and its correspondent
basis function is
.
Then, MARS models use, as required inputs, the model and the knot positions for each individual variable to be optimized. For a dataset containing objects and explanatory variables, then, the number of basis functions would be pairs of spline basis functions, given by the above equations Equation (2), with knot locations , with and .
To reach the expression of the model that MARS provides, a selection of basis functions in consecutive pairs is necessary. The selection of the basis functions can be done with a two-at-a-time forward stepwise procedure [
15]. This forward stepwise selection of basis function leads to an over-fitted model; this means that although it fits the training data well, it becomes a very complex model that is not able to make predictions accurately with new objects. To avoid this issue, basis functions which are redundant are removed one at a time using a backward stepwise procedure. The selection of which basis functions must be included in the model, MARS utilizes generalized cross-validation (GCV). GCV consist of the calculus of the mean squared residual error divided by a penalty dependent on the model complexity. The GCV criterion is defined in the following way:
The model complexity has a penalty, denoted as
, that increases with the number of basis functions required by the model, following the next expression:
which depends on the number of basis function M, and
is the smoothing parameter that characterizes the penalty for each basis function included into the model. When
takes large values, fewer basis functions are to be included in the model and consequently, smoother function estimates. The selection of the parameter
is discussed in [
10].
In order to analyse a MARS model, surface plots can be used to visualise the interactions and relations between the basis functions. Let
be the set of all single variable basis functions that contain only
. In the same way,
is the set of basis functions of two variables,
and
, and
the set of all basis functions of three variables. The MARS model can be rewritten as a series of sums in the following form:
where the first sum is with all the basis functions of one variable, the second is with the basis functions with only two variables. The third sum is over the basis functions of three variables. The expression above is known as ANOVA decomposition since it is similar to the ANOVA decomposition of experimental design [
10]. The interaction of a MARS model, based on two variables, is determined by:
For higher level interactions, they are defined in the same way.
The estimated importance [
16,
17] of the explanatory variables in the model can be used to construct the basis functions. Determinate predictor importance is, in general, a complex problem that requires several criteria. To obtain reliable results, GCV is usually used to count the number of models subsets (nsubsets) in which each variable is included, and the residual sum of squares (RSS). The definition of the RSS is:
Then, the expression of GCV can be rewritten as:
2.4. Model Training and Validation
The steps followed during the training and validation of all the models are detailed below:
Firstly, data were split in training and validation datasets. As the calculus of efficiency is a regression problem, the function determines the quantiles of the dataset and samples within those groups. The split of the data in training and validation sets was performed using the k-fold cross-validation methodology for
. The data was randomly split into five distinct blocks of equal size. Afterwards, the first block of data is left out and the model is fit. This model is used to predict the held-out block. This process was continued until all five held-out blocks had been predicted. A total of 1000 versions of the five-fold cross-validation for both models was created. The k-fold cross-validation is a well-known methodology that was already used in previous studies by the authors with successful results [
23,
24,
25].
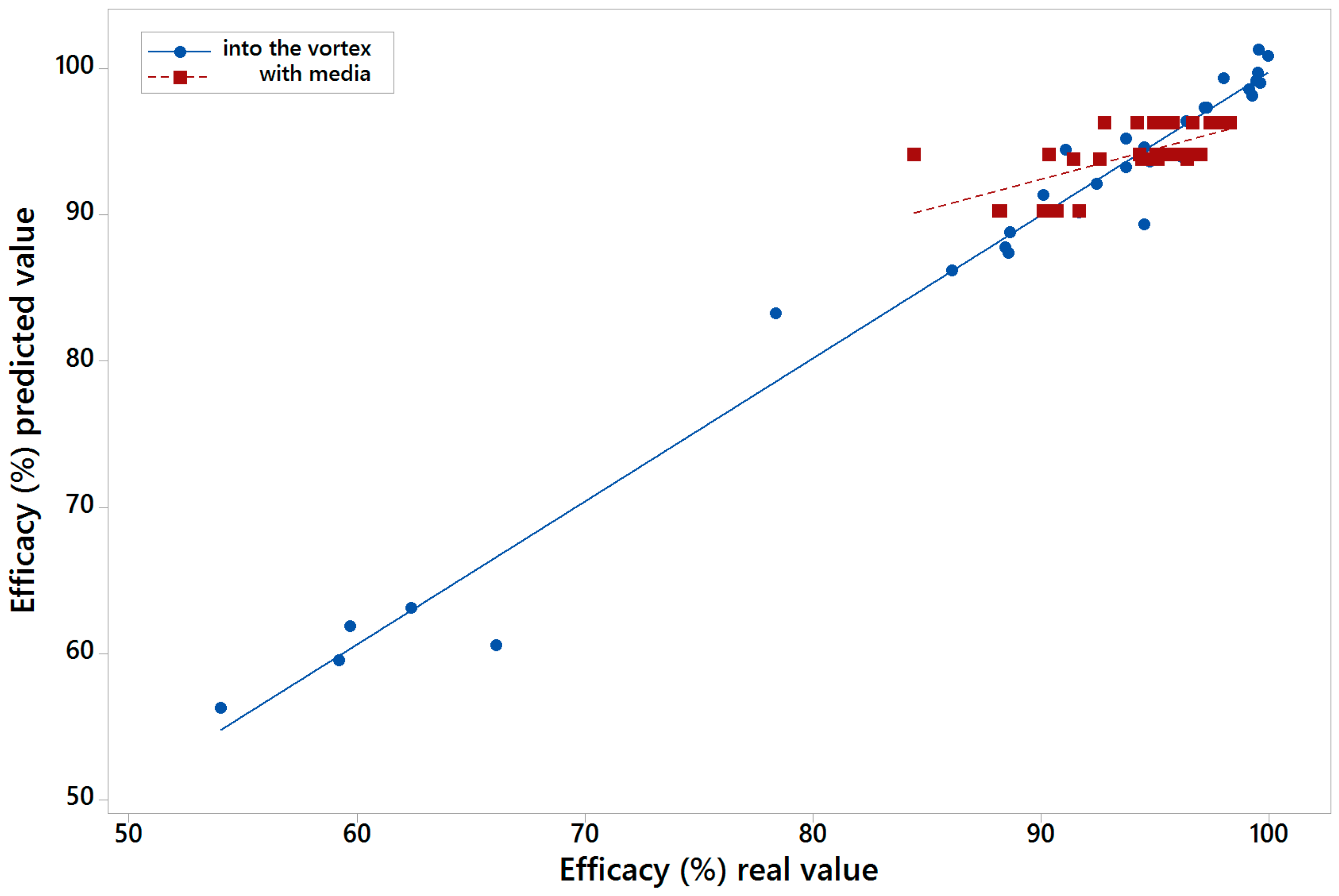
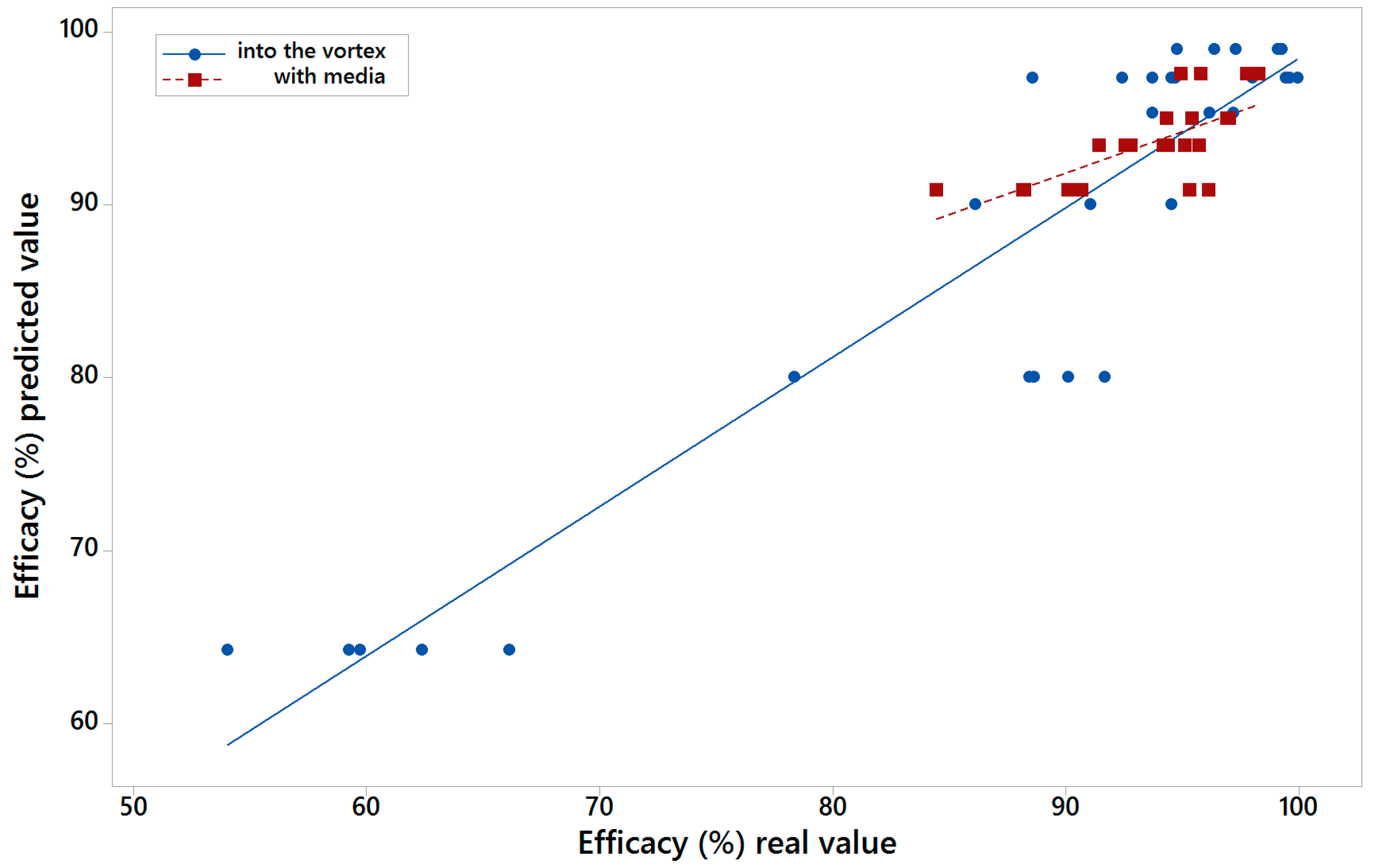
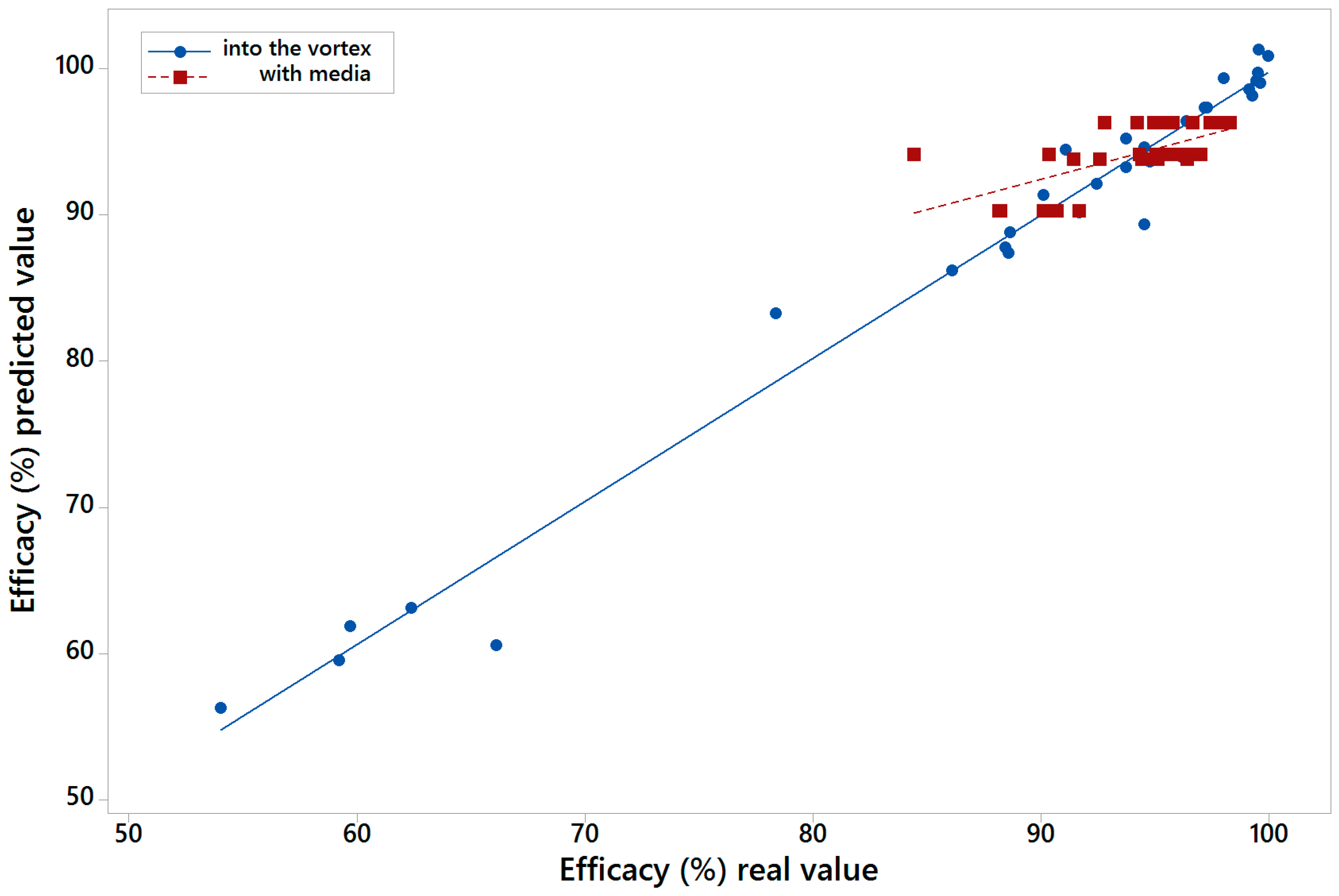
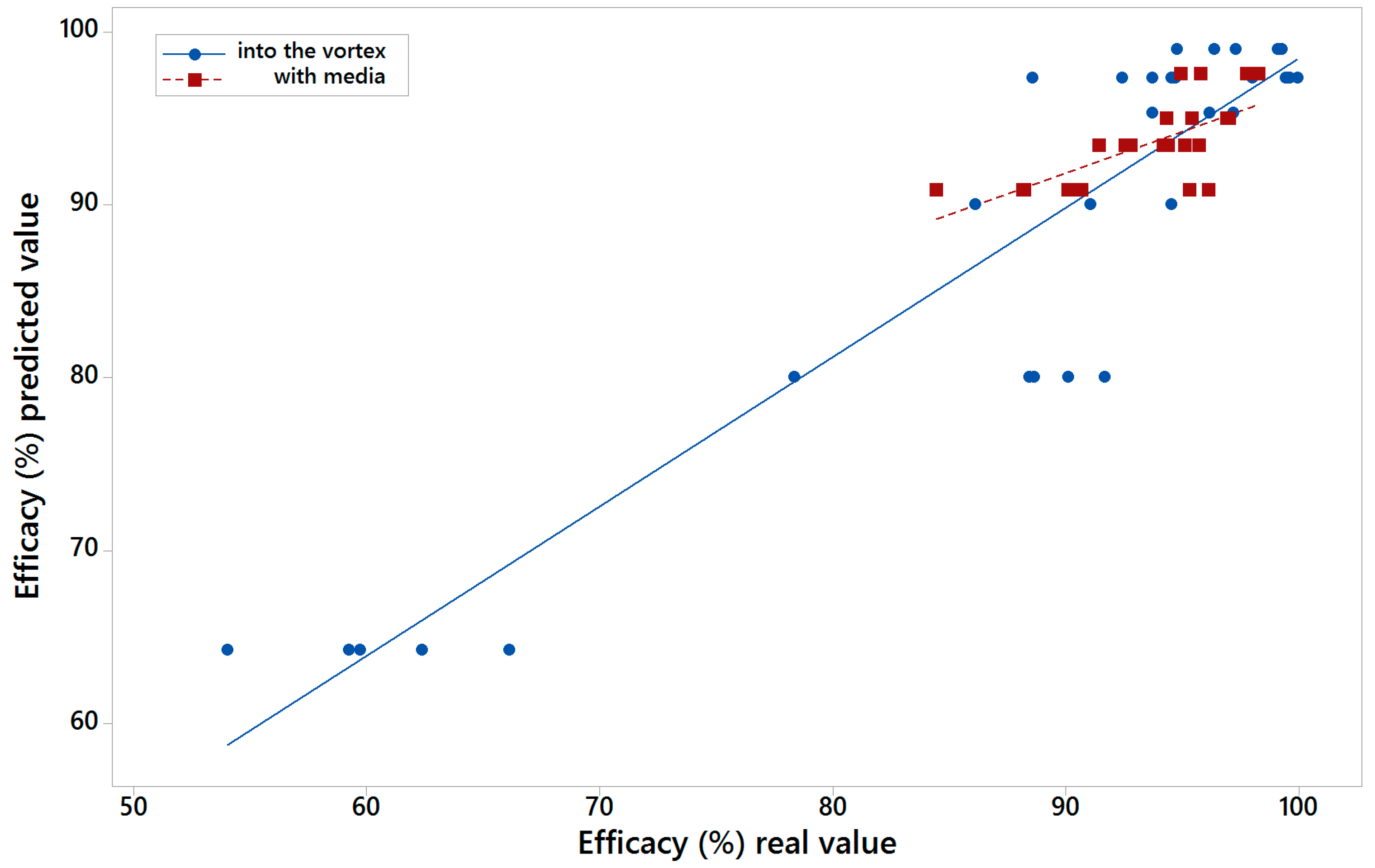
For each one of the five models of the five-fold cross-validation, the performance parameters MAE, RMSE, and R2 were calculated. This permitted the determination of the minimum, average, and maximum values of those parameters in each one of the 1000 models replications.
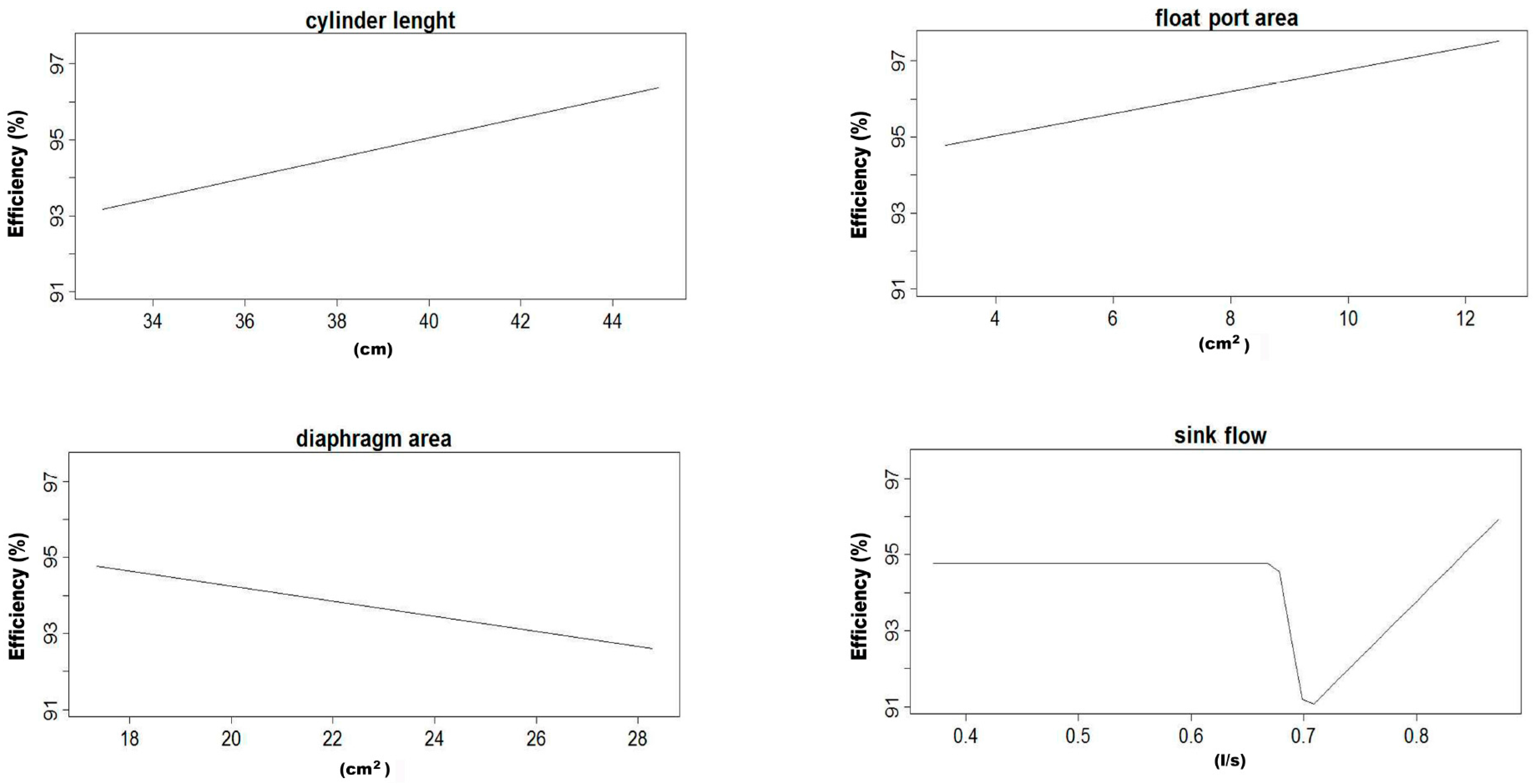
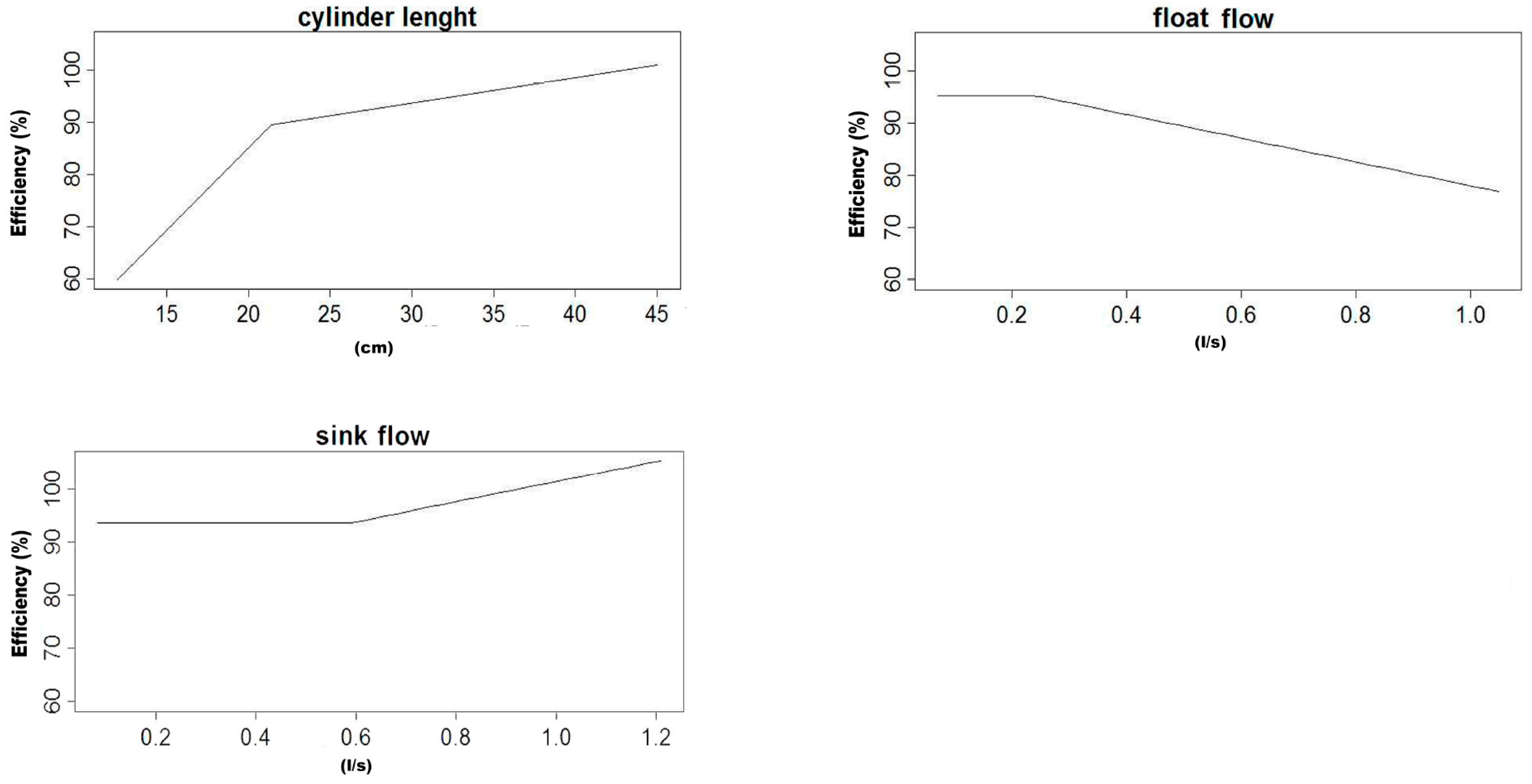
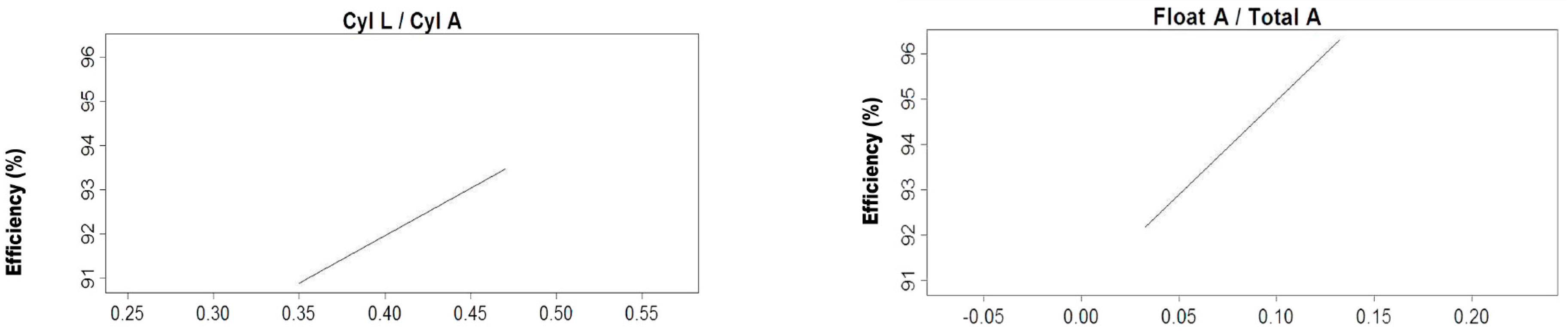
After the calculus of all the models referred above, an average model was calculated for the vortex feed scenario and another for the with-media scenario with the two sets of variables, indicating both its performance and the importance of the variables that take part in them.
The 1000 replicas of the five-fold cross-validation methodology are made in order to assure that with independence of the data subset selected, the trained MARS model is able to perform a good prediction of the efficacy. In the case of the average model, it is calculated in order to know the importance of the different variables for the prediction of the efficiency, and also having a parametric model of the LARCODEMS efficiency for both feeds. This model could help in order to know the behaviour of the efficiency variables when changes are performed in both the machine and the volume of flow.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}