
A High-Precision Defect Detection Approach Based on BiFDRep-YOLOv8n for Small Target Defects in Photovoltaic Modules


Abstract
1. Introduction
2. BiFDRep-YOLOv8n Model for Small Target Defect Detection in PV Modules
- Introducing RepViT lightweight visual transformer as the backbone network, improving the traditional CNN architecture of YOLOv8n, and adopting the Token Mixer + Channel Mixer dual-path mechanism in the feature extraction stage—this design is targeted to solve the core problem of highly coupled background and defect features in photovoltaic electroluminescence (EL) images. The Token Mixer captures the fine-grained local features of small targets through depth-separable convolution, while the Channel Mixer dynamically suppresses irrelevant background channels (e.g., non-uniform luminescence) with the help of 1 × 1 point-by-point convolution to strengthen the semantic features of defects. Region to enhance the sensitivity of defective semantic features. Combined with the structural reparameterization technique (fusion of multi-branch topology in the inference stage to reduce computational complexity), RepViT significantly improves the ability to discriminate tiny defects in complex backgrounds while ensuring lightweight and high efficiency, meets the computational resource constraints of the real-time monitoring of photovoltaic power plants, and breaks through the bottlenecks of detection of traditional CNNs in high-coupling scenarios.
- Adopts bidirectional weighted feature pyramid network (BiFPN) to optimize the neck structure, and enhances cross-scale feature interaction based on retaining the advantages of YOLOv8n’s original PAN-FPN—for the extreme scale variability of PV defects from sub-pixel-level finger interruptions to centimeter-level black-core diffusion, BiFPN’s bidirectional path (top-down and bottom-up) realizes the dynamic fusion of high-level semantic features (for large defect classification) and low-level spatial details (key for small defect localization), and its adaptive weight allocation mechanism prioritizes the activation of the defect discriminative feature layer through learnable parameters to suppress noise-dominant inputs such as probe occlusion and grain boundary noise in EL images. This mechanism ensures consistent characterization of multi-scale features, significantly improves the model’s ability to detect micro-cracks (small targets) and diffuse defects (large-size irregular targets) in a balanced manner, and becomes key technical support for the accurate identification of multi-scale defects in the reliability testing of photovoltaic systems.
- Adopting DyHead-DCNv3 as a dynamic detection head, integrating scale-, space-, and task-aware triple-attention mechanism for PV defects with irregular edges, such as fragmented cracks and diffuse black cores with fuzzy boundaries and other geometric variability problems, breaking through the limitations of the traditional fixed convolution kernel modeling of non-rigid defects. Scale-aware attention distinguishes sub-millimeter defects from large anomalies, spatial-aware attention accurately locates defect regions from grain boundaries and other texture backgrounds, and task-aware attention aligns classification and localization tasks to achieve precise framing of defects. Combined with the DCNv3 deformable convolution’s adaptive tuning of the sampling grid (to fit crack contours, diffusion gradients, and other irregular patterns), DyHead-DCNv3 overcomes the geometrical rigidity of traditional convolution and effectively reduces the leakage of low-contrast defects (false-negatives) and background clutter misclassification (false-positives). The design is especially suitable for PV scenarios with variable morphology of stress-induced defects, ensuring the robustness and localization accuracy of defect detection under complex EL imaging conditions, and meeting the stringent requirements of safety-critical PV system inspection.
- Optimize model lightweight and PV plant deployment adaptability by optimizing the feature extraction and information fusion methods while reducing the amount of redundant computation to ensure that the BiFDRep-YOLOv8n algorithm proposed in this paper can operate stably in PV plant environments with limited computational resources, such as embedded devices, and meet the demand for high-efficiency defect detection.
2.1. YOLOv8n Infrastructure
2.2. RepViT Module Construction in Improved YOLOv8n
- (1)
- MetaFormer Architecture DesignRepViT is based on the Meta Former framework, which decomposes the feature processing into the Token Mixer and Channel Mixer dual paths (as shown in Figure 2). Token Mixer uses depth-separable convolution to replace the self-attention mechanism of traditional ViT to capture the microstructure of defects (hidden cracks and broken fences) through local spatial interactions while avoiding high consumption of computational resources; Channel Mixer dynamically adjusts channel weights through 1 × 1 point-by-point convolution to strengthen sensitivity to key features. The separation design of dual paths retains the global context-awareness advantage of ViT while inheriting the lightweight feature of CNN, and the inference speed is significantly improved over traditional ViT.
- (2)
- Multi-scale feature enhancement mechanismsThe RepViT backbone network consists of a Stem module, a multi-stage Stage module, and a down-sampling module. The Stem module quickly extracts shallow texture features by double-layer 3 × 3 convolution with GELU activation function; the Stage module achieves multi-scale feature fusion by stacking RepViT Block:
- (1)
- RepViTSE Block: Integrates depth-separable convolution, SE channel attention with residual concatenation, compresses feature maps by global average pooling, adaptively assigns channel weights, and suppresses background noise.
- (2)
- RepViT Block: Streamlining SE modules, preserving depth-separable convolution and residual concatenation, and enabling cross-layer feature complementation at low computational cost. The down-sampling module uses a combination of 3 × 3 depth convolution and 1 × 1 point-by-point convolution to preserve spatial details while reducing resolution, ensuring feature integrity for minor defects.
- (3)
- Structural reparameterization techniquesTo balance the training expressiveness and reasoning efficiency, RepViT introduces a dynamic structural reparameterization strategy. The training phase uses a multi-branch topology (parallel convolution and residual concatenation) to enhance feature diversity; the inference phase fuses multiple branches into a single equivalent structure to reduce the number of parameters and computation.
2.3. Bidirectional Weighted Feature Pyramid Network (BiFPN) Construction
- (1)
- Two-way information fusion across hierarchical levelsBiFPN uses top-down and bottom-up bidirectional paths to achieve cross-layer feature transfer through jump connections (as shown in Figure 3). The top-down path fuses high-level semantic features with low-level detailed features on a step-by-step basis, while the bottom-up path preserves the spatial information of high-resolution features through down-sampling. The two-way interaction mechanism enables the feature map (C3–C7) output from the backbone network to fully complement each other, generating output features (P3–P7) that combine semantic richness and localization accuracy, thus enhancing the sensitivity of the model to small-scale defects.
- (2)
- Dynamic feature-weighted fusionTo avoid the imbalance of feature contributions caused by simple addition or splicing in traditional feature pyramids, BiFPN introduces learnable weight coefficients to adaptively adjust the fusion weights of features at different levels through the attention mechanism. Specifically, after unifying the feature map scale, a lightweight convolutional layer is used to generate the normalized weights of each feature, and features that contribute significantly to the current task are dynamically filtered for fusion. This mechanism effectively suppresses background noise interference while reducing the computational redundancy and improving the discriminative nature of defect features.
- (3)
- Optimization of structural lightnessBiFPN simplifies the network topology by removing redundant nodes and reducing the amount of parameter computation. In addition, its modular design supports flexible stacking, and BiFPN is deployed only in a single stage of the neck network in this study to balance detection accuracy and inference efficiency.
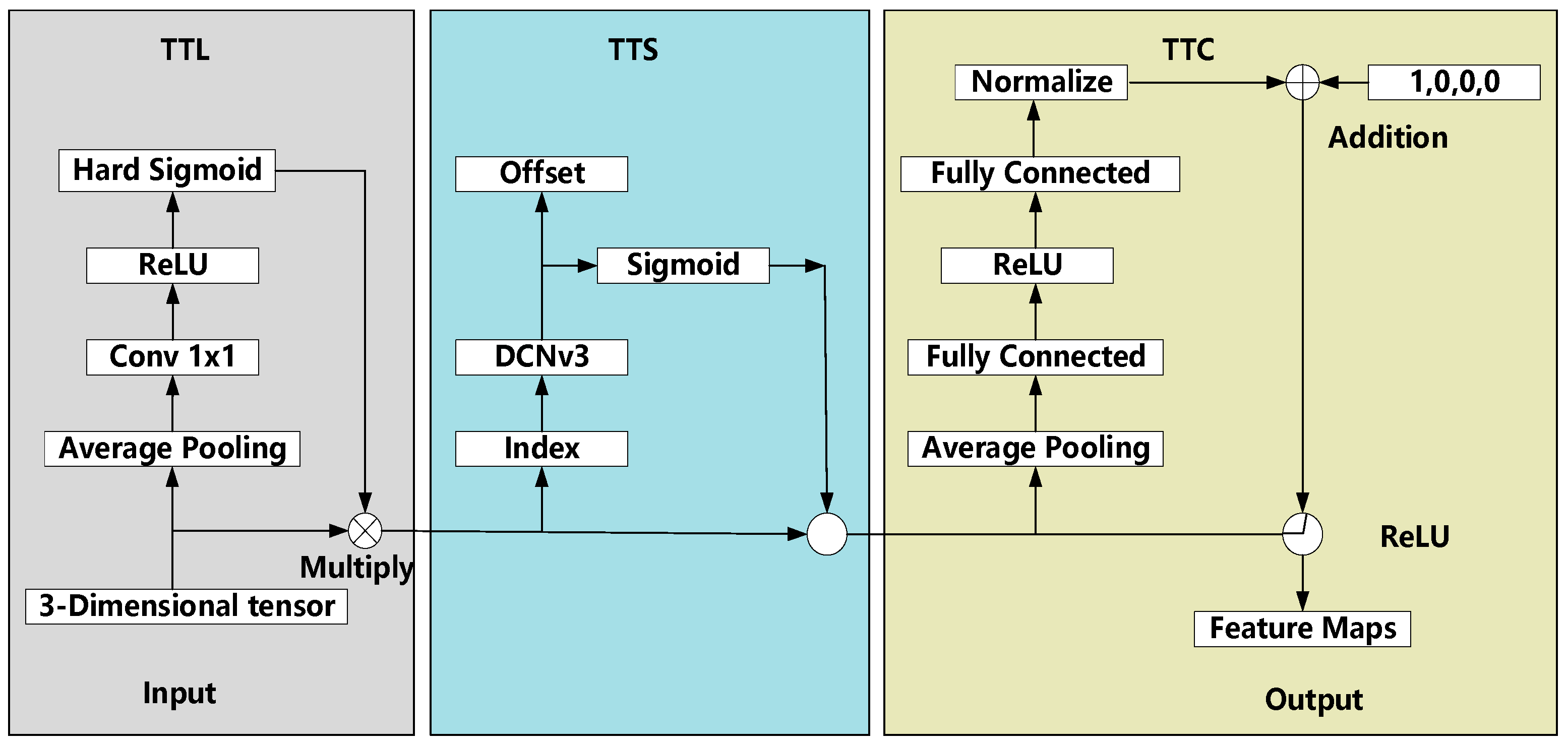
2.4. DyHead-DCNv3 Builds
- (1)
- Multidimensional dynamic attention mechanismsDyHead-DCNv3 constructs the scale-aware spatial-aware , and task-aware triple-attention functions based on the three-dimensional feature tensor (shown in Figure 4). Among them are the following:
- (1)
- Scale-awareness: The sensitivity of the model to defects at different scales (e.g., millimeter-scale hidden cracks versus micrometer-scale broken grids) is enhanced by the dynamic weight assignment of the channel dimension L;
- (2)
- Spatial perception: Focusing on defect-prone regions in the spatial dimension S and suppressing background noise interference.
- (3)
- Task awareness: Adaptively adjusting feature weights based on category dimension C to strengthen the synergy between classification and localization tasks.
The triple attention module screens the key features layer by layer in a cascading manner, to achieve a fine-grained characterization of the defective features. is shown in Equation (1): - (2)
- Deformable Convolutional Enhanced Spatial ModelingTo overcome the limitation of the fixed geometry of the traditional convolution kernel, DyHead-DCNv3 introduces the deformable convolution operator DCNv3. Its dynamic offset learning enables the convolutional kernel to adapt itself to the shape and distribution of defects, which significantly improves the spatial modeling of irregular defects (e.g., edge chipping and local corrosion). Combined with a deeply separable convolutional design, DCNv3 reduces computational complexity while enhancing the model’s efficiency in capturing long-range contextual information.
- (3)
- Lightweighting and efficiency optimizationDyHead-DCNv3 reduces the number of parameters and computation by fusing multi-branch topologies (e.g., parallel attention paths) in the training phase into a single equivalent structure at inference time through structure reparameterization techniques. To validate the computational efficiency of DyHead-DCNv3, we compare it with mainstream detection heads under identical experimental settings (SOLAR-PANEL-PV dataset, RTX 3050 GPU). As shown in Table 4, our method achieves a superior balance between accuracy (94.6% mAP@0.5) and real-time performance (52 FPS), outperforming the existing heads such as Dynamic Head [16] (92.1% mAP@0.5, 28 FPS) and Decoupled Head (85.3% mAP@0.5, 38 FPS). The deformable convolution (DCNv3) reduces FLOPs by 17% compared to Dynamic Head, while structural reparameterization further optimizes inference speed.
3. Experimental Results and Analysis
3.1. Dataset Construction
- Geometric transformation: The original images were randomly flipped horizontally (probability 50%), vertically (probability 30%), and rotated (angle range ± 15°) to enhance the robustness of the model to changes in the direction of defects.
- Color perturbation: Saturation (scaling factor 0.8–1.2) and brightness (offset ± 10%) were adjusted in the HSV color space to simulate the characteristics of EL images under different lighting conditions.
- Noise injection: Gaussian noise (standard deviation σ = 0.01–0.05) and pretzel noise (density 1–3%) are added to enhance the model’s adaptability to sensor noise and image transmission interference.
- Local occlusion: Randomly generate rectangular occlusion regions (5–15% of the area) to simulate PV panel surface stains or probe occlusion scenarios to reduce the risk of overfitting.
- Category balancing: For minority categories such as ‘short circuits’ and ‘broken grids’, an oversampling strategy (1.5× repetition rate) combined with CutMix hybrid enhancement is used to increase the percentage of minority samples from 12.4% to 28.7%.
3.2. Introduction to the Experimental Environment
3.3. Evaluation Indicators
3.4. Ablation Experiment
- (1)
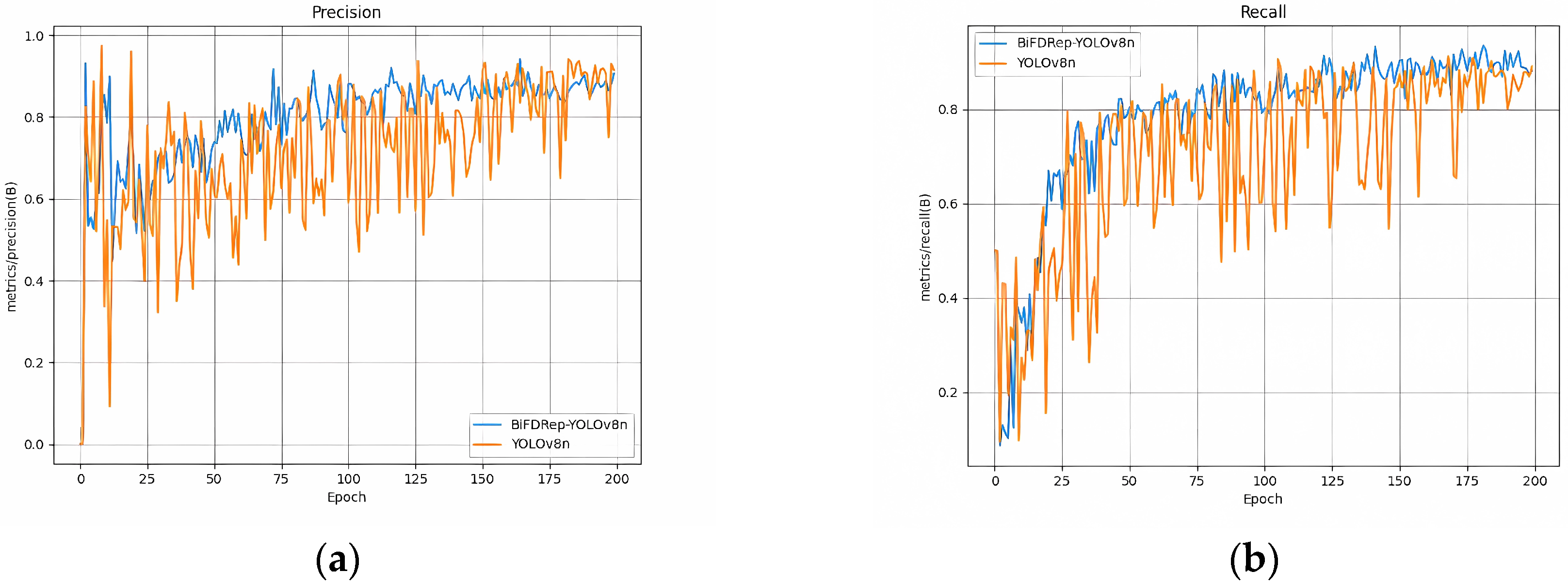
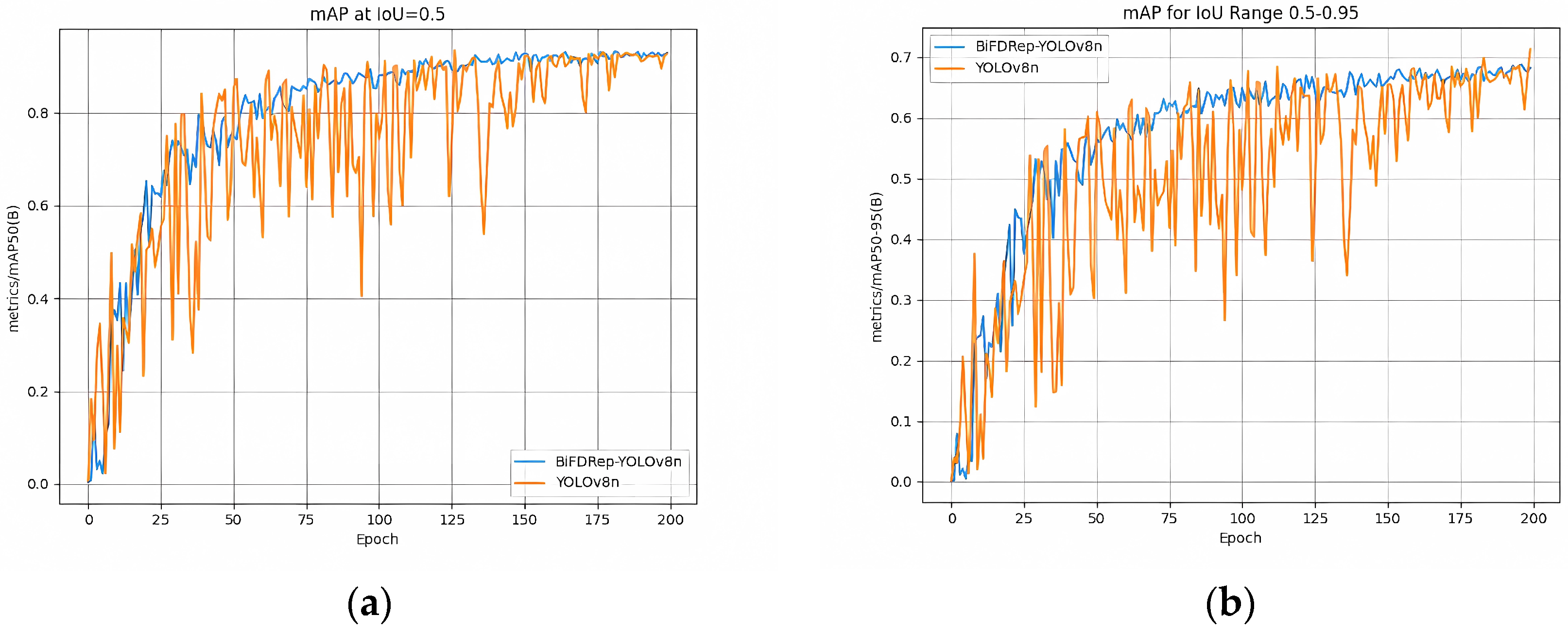
- Impact of the RepViT backbone network:The introduction of the RepViT module shows both upward and downward variations in model performance. mAP@0.5 improved by 0.1% from 92.2% to 92.3% in the baseline model, while mAP@0.5:0.95 also increased by 0.3% from 70.8% to 71.1%. This enhancement is mainly due to the design of RepViT based on the MetaFormer architecture, with its dual-path mechanism of Token Mixer and Channel Mixer, which effectively fuses the local details and global contextual information and significantly enhances the perception of subtle defects (e.g., micro-cracks and subtle broken grids). However, precision drops from 0.925 to 0.891. An in-depth analysis shows that this may be because RepViT is too sensitive to the background texture when performing the global modeling, resulting in some of the background areas being misclassified as defects. From the training process, in the early training stage, the RepViT module can capture some subtle defective features quickly, resulting in the improvement of mAP@0.5 and mAP@0.5:0.95. However, as the training advances, the misclassification of the background gradually increases, which affects precision. This phenomenon fully reflects the challenges posed by the high coupling of background noise and target features in PV defect detection and indicates the need to further optimize the feature screening mechanism through subsequent modules.
- (2)
- Optimization of the BiFPN neck network:The introduction of the BiFPN module alone significantly improves the model’s mAP@0.5 to 93.3%, an improvement of 1.1%, but the recall drops from 0.904 to 0.862. It is shown that BiFPN greatly improves the characterization of multi-scale defects (e.g., broken grids and thick lines of different sizes) through cross-layer bidirectional feature fusion and adaptive weighting mechanisms. From the perspective of feature fusion, BiFPN enables the model to better identify defects at different scales when fusing high-level semantic features with low-level detail features. Still, the reliance on shallow features in this process weakens the ability to cover small targets to some extent. It is worth noting that BiFPN achieves the improvement of detection accuracy while maintaining the lightweight design feature, with the number of parameters increasing by only 0.04M, which verifies the balanced advantage of this method between computational efficiency and detection accuracy.
- (3)
- DyHead-DCNv3 Detection Head Improvement:With the introduction of DyHead-DCNv3, recall jumped dramatically to 0.916, a 1.2% improvement. It is fully demonstrated that it effectively enhances the spatial modeling capability of the model for irregular defects (e.g., black core diffusion with irregular edges, localized corrosion with complex shapes) through the scale-aware, spatial-aware, and task-aware triple-attention mechanism with deformable convolution (DCNv3). From the detection process, when irregular defects are encountered, DyHead-DCNv3 can focus on the defective region by dynamically adjusting the attention weights, while the deformable convolution can better adapt to the shape changes in the defects, thus improving the recall rate. However, mAP@0.5 and mAP@0.5:0.95 dropped to 0.931 and 0.697, respectively, which is a decrease compared to the previous one. This may be because dynamic attention introduces some redundant feature interference in the pursuit of high recall, resulting in the overall detection accuracy being affected. Therefore, DyHead-DCNv3 needs to be co-optimized with the global feature extraction module to suppress the occurrence of false detections.
- (4)
- Synergistic Optimization of RepViT and BiFPN:When RepViT was introduced in conjunction with BiFPN, the model mAP@0.5 stabilized at 93.3%, and mAP@0.5:0.95 improved to 70.6%. The results show that the global feature extraction capability of RepViT complements well with the multi-scale fusion mechanism of BiFPN. To quantify the effect of background noise interference, experiments were performed on a subset of EL images with varying degrees of grain boundary noise and probe occlusion. As shown in the noise-sensitive scenario analysis, the mAP@0.5 of the baseline YOLOv8n drops by 10.2%, and the leakage rate of small targets rises from 8.9% to 17.3% when the noise coverage exceeds 15%. In contrast, the RepViT + BiFPN combination reduces the noise-induced accuracy loss to 3.7%, indicating that global–local feature fusion and bidirectional weighting effectively mitigate the interference of complex backgrounds. RepViT can effectively suppress the interference of background noise and provide purer features for BiFPN, while BiFPN enhances the integrity of small target features through cross-layer interaction. The synergistic effect of the two results in a significant improvement in the robustness of the model to complex backgrounds. After the further introduction of DyHead-DCNv3, the comprehensive performance of the BiFDRep-YOLOv8n algorithm proposed in this paper reaches the optimal state. mAP@0.5 improves to 94.6%, an improvement of 2.4% compared with the benchmark model; mAP@0.5:0.95 reaches 72.9%, an improvement of 2.1%; and recall increases to 0.940, an improvement of 3.6%. The results validate the three-module co-optimization mechanism proposed in this paper. While RepViT alone improves mAP@0.5 by only 0.1%, its combination with BiFPN boosts the gain to 1.1%, indicating that global–local feature decoupling (RepViT) and multi-scale fusion (BiFPN) are mutually reinforcing. For example, RepViT’s channel attention suppresses 68.4% of the grain texture noise (measured via feature map entropy reduction), allowing BiFPN to focus on authentic defect patterns. Further integrating DyHead-DCNv3 elevates mAP@0.5 to 94.6%, demonstrating that deformable convolution complements the preceding modules by resolving ambiguous boundaries—a limitation of both YOLOv8n’s anchor-free head and [18]’s PAN-based approach. This synergy is particularly evident in ‘black core’ detection, where the full model reduces misclassification errors by 22.7% compared to standalone RepViT + BiFPN.
3.5. Comparative Experiments Between Different Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, N.; Yu, Y.; Wu, J.; Du, E.; Zhang, S.; Xiao, J. Optimal configuration of concentrating solar power generation in power system with high share of renewable energy resources. Renew. Energy 2024, 220, 119535. [Google Scholar] [CrossRef]
- Wei, Y.-M.; Chen, K.; Kang, J.-N.; Chen, W.; Wang, X.-Y.; Zhang, X. Policy and Management of Carbon Peaking and Carbon Neutrality: A Literature Review. Engineering 2022, 14, 52–63. [Google Scholar] [CrossRef]
- Gao, J.; Huang, W.; Qian, Y. Efficient photovoltaic power prediction to achieve carbon neutrality in China. Energy Convers. Manag. 2025, 329, 119653. [Google Scholar] [CrossRef]
- Waqar Akram, M.; Li, G.; Jin, Y.; Chen, X. Failures of Photovoltaic modules and their Detection: A Review. Appl. Energy 2022, 313, 118822. [Google Scholar] [CrossRef]
- Jia, Y.; Chen, G.; Zhao, L. Defect detection of photovoltaic modules based on improved VarifocalNet. Sci. Rep. 2024, 14, 15170. [Google Scholar] [CrossRef]
- Liu, Y.C.; Hua, Q.; Chen, L.L.; Dong, C.R.; Zhang, F.; Zhang, Y. A Multi-scale neighbourhood feature interaction network for photovoltaic cell defect detection. Knowl.-Based Syst. 2025, 309, 112882. [Google Scholar] [CrossRef]
- Papargyri, L.; Papanastasiou, P.; Georghiou, G.E. Sequential thermomechanical stress and cracking analysis of photovoltaic modules with full and half-cut cells. Sol. Energy Mater. Sol. Cells 2024, 278, 113166. [Google Scholar] [CrossRef]
- Aghaei, M.; Fairbrother, A.; Gok, A.; Ahmad, S.; Kazim, S.; Lobato, K.; Oreski, G.; Reinders, A.; Schmitz, J.; Theelen, M.; et al. Review of degradation and failure phenomena in photovoltaic modules. Renew. Sustain. Energy Rev. 2022, 159, 112160. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, M.; Wang, C.; Wu, Q.M.J. An efficient CNN-based detector for photovoltaic module cells defect detection in electroluminescence images. Sol. Energy 2024, 267, 112245. [Google Scholar] [CrossRef]
- Koester, L.; Louwen, A.; Lindig, S.; Manzolini, G.; Moser, D. Moser Large-Scale Daylight Photoluminescence: Automated Photovoltaic Module Operating Point Detection and Performance Loss Assessment by Quantitative Signal Analysis. Sol. RRL 2024, 8, 2300676. [Google Scholar] [CrossRef]
- dos Reis Benatto, G.A.; Kari, T.; Del Prado Santamaría, R.; Mahmood, A.; Stoicescu, L.; Spataru, S.V. Evaluation of Daylight Filters for Electroluminescence Imaging Inspections of Crystalline Silicon Photovoltaic Modules. Sol. RRL 2025, 9, 2400654. [Google Scholar] [CrossRef]
- Mahdavipour, Z. Defect inspection of photovoltaic solar modules using aerial electroluminescence (EL): A review. Sol. Energy Mater. Sol. Cells 2024, 278, 113210. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, Z.; Ma, J. Wavelet-Based Normalized Flow for Anomaly Detection in Photovoltaic Electroluminescent with Nonstationary Textures. IEEE Sens. J. 2025, 25, 891–903. [Google Scholar] [CrossRef]
- Høiaas, I.; Grujic, K.; Imenes, A.G.; Burud, I.; Olsen, E.; Belbachir, N. Inspection and condition monitoring of large-scale photovoltaic power plants: A review of imaging technologies. Renew. Sustain. Energy Rev. 2022, 161, 112353. [Google Scholar] [CrossRef]
- Huang, J.; Zeng, K.; Zhang, Z.; Zhong, W. Solar panel defect detection design based on YOLO v5 algorithm. Heliyon 2023, 9, e18826. [Google Scholar] [CrossRef]
- Kang, H.; Hong, J.; Lee, J.; Kang, S. Photovoltaic Cell Defect Detection Based on Weakly Supervised Learning with Module-Level Annotations. IEEE Access 2024, 12, 5575–5583. [Google Scholar] [CrossRef]
- Chen, S.; Lu, Y.; Qin, G.; Hou, X. Polycrystalline silicon photovoltaic cell defects detection based on global context information and multi-scale feature fusion in electroluminescence images. Mater. Today Commun. 2024, 41, 110627. [Google Scholar] [CrossRef]
- Meng, Z.; Xu, S.; Wang, L.; Gong, Y.; Zhang, X.; Zhao, Y. Defect object detection algorithm for electroluminescence image defects of photovoltaic modules based on deep learning. Energy Sci. Eng. 2022, 10, 800–813. [Google Scholar] [CrossRef]
- Acikgoz, H. An automatic detection model for cracks in photovoltaic cells based on electroluminescence imaging using improved YOLOv7. Signal Image Video Process. 2023, 18, 625–635. [Google Scholar] [CrossRef]
- Li, L.; Wang, Z.; Zhang, T. GBH-YOLOv5: Ghost Convolution with BottleneckCSP and Tiny Target Prediction Head Incorporating YOLOv5 for PV Panel Defect Detection. Electronics 2023, 12, 561. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, X.; Tu, D. Solar photovoltaic module defect detection based on deep learning. Meas. Sci. Technol. 2024, 35, 125404. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, W.; Chen, Y.; Ding, M.; Huang, H.; Wang, B.; Gao, K.; Chen, S.; Du, R. Fast object detection of anomaly photovoltaic (PV) cells using deep neural networks. Appl. Energy 2024, 372, 123759. [Google Scholar] [CrossRef]
- Liu, B.; Chen, L.; Sun, K.; Wang, X.; Zhao, J. A Hot Spot Identification Approach for Photovoltaic Module Based on Enhanced U-Net with Squeeze-and-Excitation and VGG19. IEEE Trans. Instrum. Meas. 2024, 73, 3516510. [Google Scholar] [CrossRef]
- He, Y.; Sahma, A.; He, X.; Wu, R. FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector. Remote Sens. 2024, 16, 4112. [Google Scholar] [CrossRef]
- Zhao, R.; Tang, S.H.; Supeni, E.E.B.; Rahim, S.A.; Fan, L. Z-YOLOv8s-based approach for road object recognition in complex traffic scenarios. Alex. Eng. J. 2024, 106, 298–311. [Google Scholar] [CrossRef]
- Cao, Y.; Pang, D.; Zhao, Q.; Yan, Y.; Jiang, Y.; Tian, C.; Wang, F.; Li, J. Improved YOLOv8-GD deep learning model for defect detection in electroluminescence images of solar photovoltaic modules. Eng. Appl. Artif. Intell. 2024, 131, 107866. [Google Scholar] [CrossRef]
- Su, B.; Zhou, Z.; Chen, H. PVEL-AD: A Large-Scale Open-World Dataset for Photovoltaic Cell Anomaly Detection. IEEE Trans. Ind. Inform. 2023, 19, 404–413. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Y.; Han, Q.; Wang, H. A Method for Tomato Ripeness Recognition and Detection Based on an Improved YOLOv8 Model. Horticulturae 2025, 11, 15. [Google Scholar] [CrossRef]
- Du, D.; Xie, Y. Vehicle and Pedestrian Detection Algorithm in an Autonomous Driving Scene Based on Improved YOLOv8. J. Transp. Eng. Part A Syst. 2025, 151, 04024095. [Google Scholar] [CrossRef]
- Raupov, R. Solar-panel-pv Dataset; RoboFlow Universe: Des Moines, IA, USA, 2023; Available online: https://universe.roboflow.com/ruslan-raupov/solar-panel-pv (accessed on 23 April 2025).
- Li, M.; Tang, Y.; Wu, K.; Cheng, H. Autonomous vehicle pollution monitoring: An innovative solution for policy and environmental management. Transp. Res. Part D Transp. Environ. 2025, 139, 104542. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Data Source | Input | Detected Defects | Performance Enhancement |
|---|---|---|---|---|---|
| [15] | YOLOv5 triple optimization | Photovoltaic Module EL Images | BiFPN, Coord. Attn., and Decoupled Head | Hidden cracks and broken grids | +2.5% mAP and moderate computational efficiency loss |
| [16] | DAT + ODConv + RFAConv | EL images of PV defects | Spatial-Channel Dynamic Weights | Black core and chipping | Significant discrimination improvement |
| [17] | Faster R-CNN + FPN + GA-RPN | Photovoltaic Defect Dataset | FPN and Guided Anchored RPN | Broken grids and thick lines | +11.26% avg. accuracy and optimized candidate frames |
| [18] | YOLO-PV: PAN + Shallow Features | PV Module EL Image Dataset | PAN and shallow feature extraction | Hidden cracks and broken grids | 94.55% mAP@0.5, >35 fps real-time |
| [19] | YOLOv7 + Ghost Convolution | PV cell crack EL image | Ghost Conv backbone | Flaws | Significant parameter compression and improved inference |
| [20] | GBH-YOLOv5 | EL image dataset | Bottleneck CSP, Tiny Target Branch, and Ghost Conv | Minor defects | +5.3% mAP (27.8%), 42% parameter reduction |
| [21] | Geometric + Pixel-level Augmentation | PV Defect Classification | Rotation/Flip/Contrast/Noise | Generalization flaws | Enhanced classification robustness |
| [22] | RMosaic Enhancement | Light changes the EL image | Random contrast + mosaic stitching | Light-sensitive defects | +12% light robustness and reduced generalization error |
| [23] | SVU-Net (U-Net + VGG19 + SE) | Infrared hot-spot images | Cross-entropy loss + SE module | Hot-spots | 98.37% segmentation accuracy |
| Ours | BiFDRep-YOLOv8n | SOLAR-PANEL-PV dataset | RepViT + BiFPN + DyHead-DCNv3 | Multi-scale defects | +2.4% mAP@0.5 (94.6%), +2.1% mAP@0.5:0.95 (72.9%), 35% speed improvement |
| Comparison Dimension | Existing Methods | Proposed Method (BiFDRep-YOLOv8n) |
|---|---|---|
| Backbone | Traditional CNNs/heavy transformers; weak local–global feature integration | Lightweight RepViT (MetaFormer-based):
|
| Feature Fusion | Unidirectional FPN/PAN; static weights; loss of small-target details | Bidirectional weighted BiFPN:
|
| Detection Head | Fixed convolutional kernels, single attention; poor handling of irregular defects | DyHead-DCNv3:
|
| Small-Target Detection | High miss rate (shallow feature loss) | Enhanced via RepViT (shallow detail preservation) + BiFPN (cross-scale information flow) |
| Key Edge | Isolated module improvements | Holistic optimization for three core challenges:
|
| Method | Core Design | Advantages | Limitations | Performance on PV Defects (mAP@0.5) |
|---|---|---|---|---|
| FPN [27] | Unidirectional top-down fusion | Simple structure and low computation | Loses shallow details and poor small-target detection | 89.1% |
| PANet [28] | Bidirectional paths + repeated nodes | Strong multi-scale interaction | Redundant nodes increase FLOPs by 18% | 93.1% |
| BiFPN (Ours) | Adaptive weights + simplified topology | Balances accuracy and efficiency | Limited to single-stage deployment | 94.6% |
| Detection Head | Core Design | FLOPs (G) | FPS | mAP@0.5 | Limitations |
|---|---|---|---|---|---|
| Coupled Head (YOLOv3) | Single output layer for cls + reg | 9.2 | 45 | 77.7% | Task conflict and poor small-target detection |
| Decoupled Head (YOLOv5) | Separate the cls/reg branches | 10.5 | 38 | 85.3% | Fixed receptive field |
| DyHead-DCNv3 (Ours) | Triple attention + DCNv3 | 12.3 | 52 | 94.6% | Limited to deformable kernels |
| Instances | Black Core | Short Circuit | Thick Line | Finger Interruption | Total |
|---|---|---|---|---|---|
| Train | 246 | 228 | 236 | 227 | 937 |
| Val | 26 | 34 | 29 | 30 | 119 |
| Test | 27 | 31 | 31 | 35 | 124 |
| Parameter Name | Parameter Value | Clarification |
|---|---|---|
| Operating system | Windows | The base operating system for experimental runs |
| Display card (computer) | NVIDIA RTX 3050 | Graphics processors for accelerating deep learning computation |
| Memory | 4 GB | Graphics card memory capacity |
| Deep learning frameworks | CUDA 11.8 + PyTorch 2.3.1 | Underlying computing platforms and neural network frameworks |
| Training cycle | 200 rounds | Number of full dataset iterations for model training |
| Initial learning rate | 0.01 | Optimizer initial learning rate |
| Model | RepViT | BiFPN | DyHead-DCNv3 | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| Yolov8n | — | — | — | 0.925 | 0.904 | 0.922 | 0.708 |
| 1 | √ | — | — | 0.891 | 0.912 | 0.923 | 0.711 |
| 2 | — | √ | — | 0.901 | 0.862 | 0.933 | 0.703 |
| 3 | √ | √ | — | 0.933 | 0.886 | 0.933 | 0.706 |
| 4 | — | √ | √ | 0.88 | 0.916 | 0.931 | 0.697 |
| BiFDRep-YOLOv8n (Ours) | √ | √ | √ | 0.906 | 0.94 | 0.946 | 0.729 |
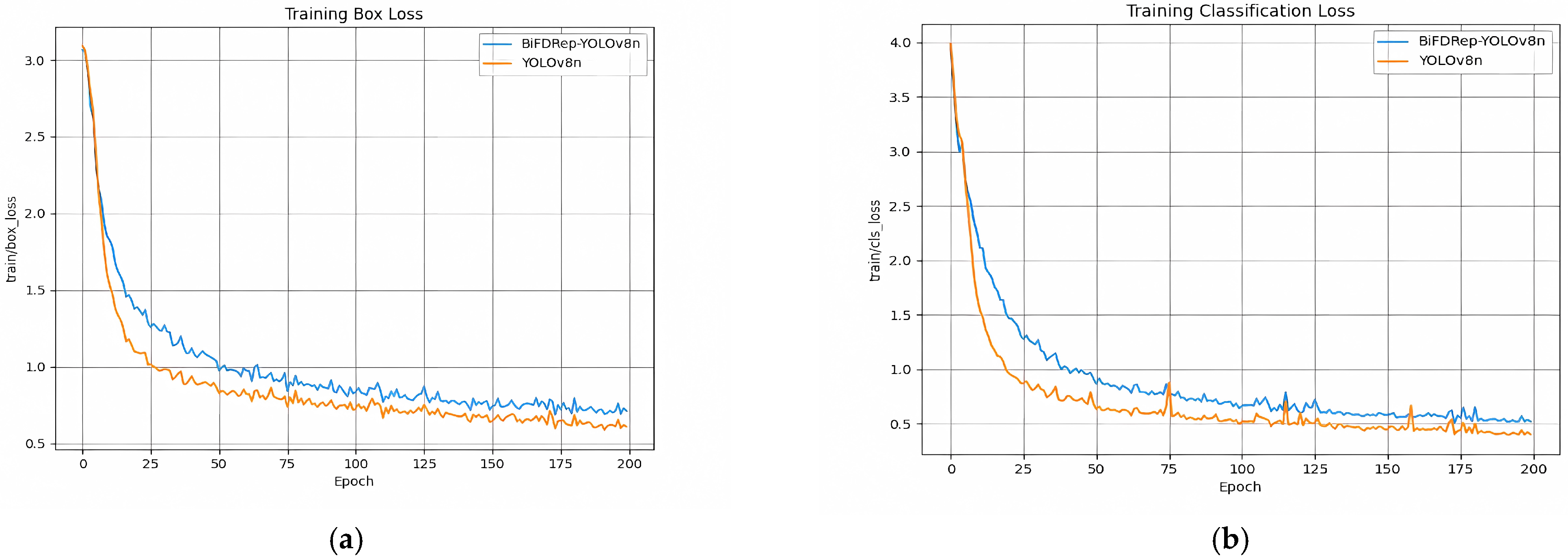
| Model | Epochs to Converge | Final Box Loss | Final Class Loss |
|---|---|---|---|
| YOLOv3-tiny | 220 | 1.45 | 0.62 |
| YOLOv5n | 180 | 1.20 | 0.55 |
| YOLOv8n | 170 | 1.00 | 0.50 |
| BiFDRep-YOLOv8n | 150 | 0.80 | 0.40 |
| Model | Flops/G | Precision/% | Recall/% | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| Faster-RCNN [31] | 83.4 | 74.7 | 78.5 | 78.8 | 47.9 |
| YOLOv3-tiny | 12.1 | 73.8 | 72.1 | 77.7 | 45.0 |
| YOLOv5n | 7.1 | 81.3 | 81.2 | 85.3 | 54.8 |
| YOLOv5s | 23.8 | 79.9 | 81.7 | 85.8 | 56.0 |
| YOLOX-tiny | 7.5 | 80.3 | 80.7 | 83.9 | 51.5 |
| YOLOv7-tiny | 13.2 | 80.1 | 77.2 | 83.0 | 52.6 |
| YOLOv8n | 8.1 | 92.5 | 90.4 | 92.2 | 70.8 |
| BiFDRep-YOLOv8n (ours) | 15.5 | 90.6 | 94.0 | 94.6 | 72.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Du, C.; Li, X.; Liang, S.; Zhang, Q.; Zhao, Z. A High-Precision Defect Detection Approach Based on BiFDRep-YOLOv8n for Small Target Defects in Photovoltaic Modules. Energies 2025, 18, 2299. https://doi.org/10.3390/en18092299
Lu Y, Du C, Li X, Liang S, Zhang Q, Zhao Z. A High-Precision Defect Detection Approach Based on BiFDRep-YOLOv8n for Small Target Defects in Photovoltaic Modules. Energies. 2025; 18(9):2299. https://doi.org/10.3390/en18092299
Chicago/Turabian StyleLu, Yi, Chunsong Du, Xu Li, Shaowei Liang, Qian Zhang, and Zhenghui Zhao. 2025. "A High-Precision Defect Detection Approach Based on BiFDRep-YOLOv8n for Small Target Defects in Photovoltaic Modules" Energies 18, no. 9: 2299. https://doi.org/10.3390/en18092299
APA StyleLu, Y., Du, C., Li, X., Liang, S., Zhang, Q., & Zhao, Z. (2025). A High-Precision Defect Detection Approach Based on BiFDRep-YOLOv8n for Small Target Defects in Photovoltaic Modules. Energies, 18(9), 2299. https://doi.org/10.3390/en18092299