1. Introduction
The growing demand for electricity and the need to minimize environmental impacts have driven the integration of Distributed Generation (DG) and Electric Power Distribution Systems (EPDS). The continued decline in the Levelized Cost of Energy (LCOE) has significantly enhanced the competitiveness of photovoltaic (PV) systems. According to the International Renewable Energy Agency (IRENA), the global weighted average LCOE for utility-scale solar PV dropped by 12% in 2023, reaching BRL 0.044/kWh—a 90% reduction since 2010 [
1]. This cost advantage positions solar PV as a cornerstone of future energy systems. As economic factors become increasingly favorable, it is essential for PV integration models to also consider social aspects to ensure alignment between optimal technical solutions and real-world feasibility. On the other hand, beyond the technical performance of distributed generation systems, there is a crucial role for social and economic factors to play in encouraging the acceptance of a successful deployment of renewable energy technologies. As discussed in [
2], social acceptance is strongly influenced by perceptions of fairness in cost and benefit distribution, access to trustworthy information, and opportunities for meaningful participation in planning processes. These elements are especially relevant in distributed generation projects, where visibility and proximity to communities amplify public scrutiny and expectations.
DG, which refers to electricity generation near consumption centers [
3], offers several advantages, including loss reduction, voltage profile enhancement, and improved system reliability. However, improper placement and sizing of DG units can lead to increased losses, voltage violations, and line overloading. Numerous studies have explored the optimal allocation and sizing of DG in EPDS. Given the nonlinear and nonconvex nature of this problem, most research efforts have focused on metaheuristic approaches, which consist of computational algorithms inspired by natural processes or heuristic strategies to efficiently explore large and complex search spaces. These methodologies provide approximate solutions to optimization problems where traditional mathematical approaches may be impractical [
4].
Particle Swarm Optimization (PSO) is a population-based metaheuristic inspired by the collective behavior of birds flocking or fish schooling. It optimizes a problem by iteratively improving candidate solutions, called particles, which move through the search space influenced by their own best-known position and the best-known position of the swarm. A PSO-based algorithm for optimal placement of DGs in radial EPDS is developed in [
5]. This method aims to minimize the voltage difference between specific buses. To carry out the load-flow analysis, the authors employ the backward/forward load flow method. A hybrid PSO combined with an analytical method is proposed in [
6] for the optimal placement and sizing of DGs. The algorithm is designed to handle various load distributions, including uniform, increasing, central, and random patterns in conventional distribution networks. In a similar line of research, [
7] presents a PSO integrated with the Crow Search Algorithm—a nature-inspired metaheuristic that mimics the intelligent foraging behavior of crows to explore and exploit the search space efficiently—to determine the optimal allocation, sizing, and number of DG units in distribution systems, aiming at total cost and power loss minimization. Other hybrid versions of PSO are reported in [
8,
9]. In both cases, the optimization process is divided into two sub-problems: the first addresses the allocation of DG units in critical buses, while the second determines their optimal sizing.
Ant Colony Optimization (ACO) is a metaheuristic inspired by the foraging behavior of ants, which use pheromone trails to find the shortest paths to food sources. This technique leverages collective intelligence to explore and exploit search spaces efficiently. The application of Ant Colony Optimization (ACO) for determining the optimal placement of DG units in medium-voltage distribution networks is presented in [
10]. The optimization aims to minimize real power losses while accounting for generator installation costs. The effectiveness of the proposed approach is evaluated using a 33-bus radial distribution system. A hybrid ACO approach is also proposed in [
11], which incorporates various DG penetration levels and the generation of active power, reactive power, or both.
Genetic Algorithms (GAs) are metaheuristic techniques inspired by the principles of natural selection and evolution, where candidate solutions undergo selection, crossover, and mutation to iteratively improve optimization performance. A GA-based approach for optimizing DG placement in radial distribution networks, which consider uncertainties in load and generation, is proposed in [
12]. An adaptive GA is employed, which incorporates a fuzzy-based method to model these uncertainties. The proposed strategy determines the optimal DG locations and generation capacities by minimizing network power losses and the maximum node voltage deviation. The implementation of GA and PSO approaches to determine the optimal allocation, sizing, and power factors of DG units in distribution systems is described in [
13]. In this case, seasonal uncertainties of generation and demand were considered to minimize annual energy losses and voltage deviations.
A hybrid GA integrated with a local search technique for the optimal placement of DG units and shunt capacitors in radial distribution systems is proposed in [
14]. The inclusion of the local search mechanism improves the algorithm’s ability to explore the solution space more effectively, enhancing the search process and increasing the likelihood of finding the global optimum. The proposed approach aims to minimize both total real power losses and overall voltage deviation. An implementation of a GA for optimizing the placement and sizing of DG units in direct current grids is presented in [
15], with the objective of reducing power losses and enhancing energy distribution efficiency. Other applications of GAs applied to the optimal allocation of DG are also reported in [
16,
17,
18].
The optimal location and sizing of DG in distribution networks are typically performed with a single objective, which is often to minimize active power losses. However, DG can also impact voltage levels and network stability. Consequently, numerous studies have explored the optimal placement and sizing of DG using multi-objective approaches. In such cases, the goal is usually to determine an optimal Pareto front, which represents a set of non-dominated solutions that balance conflicting objectives. Each solution on the Pareto front offers a trade-off between key performance criteria such as minimizing power losses, improving voltage profiles, and enhancing system stability.
A multi-objective approach for the optimal allocation of DG in radial distribution networks, which considers both technical and economic aspects, is proposed in [
19]. They employ the Improved Raven Roosting Optimization (IRRO) algorithm and game theory to obtain Pareto-optimal solutions that maximize the techno-economic benefits of DG integration. In this context, a weighted multi-objective index is designed to account for active and reactive power losses, voltage profile, line loading, and voltage stability as key technical improvement factors. Subsequently, Pareto optimality is applied to derive a set of optimal solutions, which balance conflicting objectives. The integration of DG allocation and network reconfiguration using Geometric Mean Optimization (GMO) to address both single- and multi-objective functions is presented in [
20]. Their objective is to maximize a voltage stability index while minimizing active power losses and voltage deviation.
A multi-objective approach that accounts for the spatiotemporal coupling between DG output and load demand in neighboring areas is presented in [
21] within a multi-objective optimization framework. Affine arithmetic (AA) is employed to characterize uncertainty, and a multi-objective optimization model for DG allocation is proposed in [
22]. This model aims to minimize investment costs, maximize revenue, reduce environmental impact, and minimize network losses. A multi-objective Bee Colony Algorithm (BCA) is implemented in [
23] to solve the optimal allocation of micro gas turbines, photovoltaic, wind power generation, and fuel cells in distribution networks. In this case, the authors consider the life cycle cost of DG units, voltage quality, voltage fluctuation, and power losses.
Given the critical role of DG in modern power networks, a significant amount of research has been conducted on this topic; other optimization techniques such as oppositional artificial rabbits optimization [
24] and thief and police algorithm [
25] have also been implemented to solve the optimal allocation and sizing of DG in EPDS. A comprehensive review of nature-inspired swarm intelligence algorithms for optimal DG allocation, with an emphasis on minimizing power losses in distribution networks, is provided in [
26]. Various algorithms are analyzed in terms of their effectiveness, convergence properties, and applicability to real-world power systems. A comprehensive review of the optimal allocation of DG is presented in [
27], covering key aspects such as objectives, constraints, methodologies, and algorithms. Other reviews regarding this subject are also presented in [
28,
29]. A current extensive overview presented in [
30] emphasizes the critical role of metaheuristic algorithms—particularly those inspired by physical and biological phenomena—in addressing the challenges of optimal reactive power dispatch (ORPD) in renewable energy-integrated systems. The results obtained highlight the effectiveness of these algorithms in reducing voltage deviation, minimizing power losses, and improving voltage stability by precisely controlling generator voltages and reactive power injection devices. Complementarily, two innovative metaheuristic algorithms, the White Shark Optimizer (WSO) and the Exponential Distribution Optimizer (EDO), for optimizing the placement and sizing of photovoltaic and wind turbine generators in radial distribution systems are proposed in [
31]. Simulations on the IEEE 33-bus system demonstrated that WSO could reduce power losses by up to 90.7% and improve the Voltage Deviation Index by nearly 99% while maintaining minimum voltage levels within acceptable operational limits. These results underscore the effectiveness of bio-inspired algorithms in addressing the nonlinear, multi-objective challenges of distributed generation planning in renewable energy-integrated systems.
This paper proposes a novel methodology for the optimal placement and sizing of photovoltaic distributed generation in electrical distribution networks, explicitly incorporating spatial and economic constraints through georeferenced data. The optimization process is implemented using a combination of Hybrid Evolutionary Strategies and Hybrid Genetic Algorithms, and its effectiveness is validated through simulations in OpenDSS and QGIS. The methodology is tested on both a benchmark IEEE 34-bus system and a real distribution feeder, demonstrating substantial improvements in system losses and voltage profiles. The remainder of the paper is structured as follows:
Section 2 presents the mathematical formulation of the problem,
Section 3 describes the optimization strategies,
Section 4 discusses the case studies and results, and
Section 5 concludes the paper with final remarks and future research directions.
3. Optimization Algorithms
Evolutionary Strategies (ES) and Genetic Algorithms (GAs) are bio-inspired optimization approaches designed to solve complex problems. Both belong to the broader family of Evolutionary Algorithms (EAs), which maintain a population of candidate solutions and iteratively modify them to improve performance over time.
ES and GAs share the fundamental principle of evolving a population through selection and recombination, driving solutions toward local or global optima [
34]. However, they differ in selection mechanisms, reproduction strategies, and population update rules, leading to distinct behaviors and effectiveness across different optimization scenarios. ES, such as Evolution Strategies (ES), follow a steady-state approach, where only a subset of solutions is modified per iteration. In contrast, GAs employ a generational approach, replacing the entire population in each evolutionary cycle. In this case, we implemented the
and
Evolutionary Strategies, which are optimization approaches based on evolution and are commonly used in evolutionary algorithms to solve complex problems. They differ in how they select individuals for the next generation.
Table 1 corresponds to the comparison of
and
strategies.
3.1. Evolutionary Strategy
The algorithm is one of the simplest and most effective evolutionary methods. It begins with an initial population of individuals, typically generated randomly. The core of this algorithm lies in its structured selection, reproduction, and replacement processes. Each individual is evaluated based on a fitness function that measures the quality of its characteristics. This evaluation determines which individuals are best suited for survival and reproduction.
After evaluation, truncation selection is applied, where the fittest individuals are chosen for the next generation. This ensures that only the best individuals are retained, promoting continuous improvement in population quality. The selected individuals, now parents, generate new offspring. Each of these parents produces offspring through mutation, introducing variations and increasing genetic diversity.
Reproduction results in a new population of
offspring, which completely replaces the parent population. This cycle of evaluation, selection, reproduction, and replacement continues until a stopping condition is met, such as a maximum number of generations or a satisfactory solution. It is essential that
is a multiple of
to ensure algorithm stability and avoid undesirable population fluctuations. Specific details about the implementation of this algorithm can be found in Algorithm 1.
| Algorithm 1 Evolutionary Strategy |
Require: (number of selected parents), (number of offspring)
- 1:
▹ Initialize population - 2:
for to do - 3:
- 4:
- 5:
end for - 6:
▹ Initialize Best with an appropriate value ▹ e.g., for minimization, initialize Best with a large value - 7:
while stopping condition not satisfied do - 8:
for each do - 9:
- 10:
if then ▹ For maximization; use < for minimization - 11:
- 12:
end if - 13:
end for - 14:
▹ Select top individuals - 15:
- 16:
for each do - 17:
for to do - 18:
- 19:
- 20:
- 21:
end for - 22:
end for - 23:
end while - 24:
return Best
|
3.2. Evolutionary Strategy
The algorithm differs from the approach through the operation of *Join*. While in , the parents are entirely replaced by their offspring in the next generation, in , the next generation consists of the parents along with the newly generated offspring. This means that parents compete directly with offspring in the selection process of the next iteration, maintaining a fixed population size of .
One of the key characteristics of the strategy is its ability to balance exploration and exploitation. Since high-quality parents remain in the population for multiple generations, the algorithm can retain beneficial traits over time, leading to a more stable evolutionary process. This retention of strong individuals often improves convergence speed compared to , where good solutions can be lost due to full population replacement.
However, this mechanism also introduces potential drawbacks. If a highly fit parent dominates the population, there is a risk of premature convergence, as the offspring may inherit traits that do not significantly diversify the search space. This can lead to stagnation, where the algorithm fails to explore new regions effectively. To mitigate this issue, strategies such as increased mutation rates or diversity-preserving selection mechanisms can be incorporated. Specific details about the implementation of this strategy can be found in Algorithm 2.
| Algorithm 2 Evolutionary Strategy |
- 1:
number of selected parents - 2:
number of offspring generated by the parents - 3:
- 4:
for times do - 5:
- 6:
end for - 7:
- 8:
while stopping condition not satisfied do - 9:
for each individual do - 10:
Evaluate() - 11:
if then - 12:
- 13:
end if - 14:
end for - 15:
the individuals in P with the best fitness - 16:
- 17:
for each individual do - 18:
for times do - 19:
- 20:
end for - 21:
end for - 22:
end while - 23:
return Best
|
The algorithm offers advantages over the approach. In , the population is entirely replaced in each generation, enabling rapid exploration of the solution space but potentially leading to the loss of high-quality individuals. In contrast, retains the fittest individuals from the previous generation, preserving genetic diversity and preventing the elimination of promising solutions. This retention mechanism enhances convergence toward a global optimal solution. However, it also introduces the risk of stagnation if a single dominant individual takes over the population, limiting further exploration.
3.3. Genetic Algorithm with Elitism
The GA with Elitism is an extension of the Evolution Strategy , sharing many of its fundamental principles while introducing significant improvements in selection and reproduction to ensure the retention of high-quality individuals. Initially, a population of size is randomly generated. Each individual is evaluated based on a fitness function that determines its quality. The best individual is continuously monitored for reference.
After the fitness evaluation, the top fittest individuals are selected as the elite. This elite subset is preserved in the next generation, ensuring that the best solutions are not lost. The elite selection process is crucial for preventing the premature loss of promising solutions and accelerating convergence toward optimal solutions.
The remaining individuals for the new generation are created through selection, crossover, and mutation. Two parents are chosen from the current population using a selection method (such as tournament selection or roulette wheel selection). These parents undergo crossover to produce two offspring, who then experience mutation to introduce genetic variability.
This cycle of selection, crossover, and mutation continues until the new generation is fully formed. The new population consists of both the generated offspring and the preserved elite individuals. The population is then updated with this new generation, and the iterative process continues until a stopping criterion is met, such as reaching a maximum number of generations or obtaining a sufficiently good solution. Further details on the implementation of this approach can be consulted in Algorithm 3.
| Algorithm 3 The Genetic Algorithm with Elitism |
- 1:
- 2:
- 3:
- 4:
for times do - 5:
- 6:
end for - 7:
- 8:
while stopping condition not satisfied do - 9:
for each individual do - 10:
Evaluate() - 11:
if then - 12:
- 13:
end if - 14:
end for - 15:
the fittest individuals in P - 16:
for times do - 17:
- 18:
- 19:
- 20:
- 21:
end for - 22:
- 23:
end while - 24:
return Best
|
3.4. Genetic Algorithm with Elitism
The Genetic Algorithm with Elitism shares many principles with the strategy but stands out due to the Union operation. In the approach, parents are entirely replaced by offspring in the next generation. In contrast, in , the next generation consists of both the parents and their offspring. This means that parents compete directly with their offspring in the subsequent iteration, introducing a new dynamic to the evolutionary process. Retaining high-fitness parents in the population can foster greater genetic diversity and facilitate the exploration of new regions within the search space.
However, this strategy also has drawbacks. A highly fit parent may dominate the population early on, leading to convergence toward its direct descendants and causing stagnation at a local optimum.
Although the approach is more exploratory than due to the continuous competition between parents and offspring, the presence of elitism ensures that the fittest individuals have a higher probability of persisting in future generations. This mechanism provides a balance between exploration and exploitation of solutions.
A hybrid approach can integrate the best aspects of both algorithms. Incorporating selection and reproduction mechanisms from both Evolution Strategies and Genetic Algorithms can enhance overall algorithm performance. This hybrid configuration allows for flexible adaptation to the specific characteristics of a given problem, increasing the chances of finding optimal solutions in a complex search space. This balanced combination of exploration and exploitation is particularly valuable in optimization problems where genetic diversity and the retention of high-quality individuals are crucial to preventing stagnation and achieving globally optimal solutions.
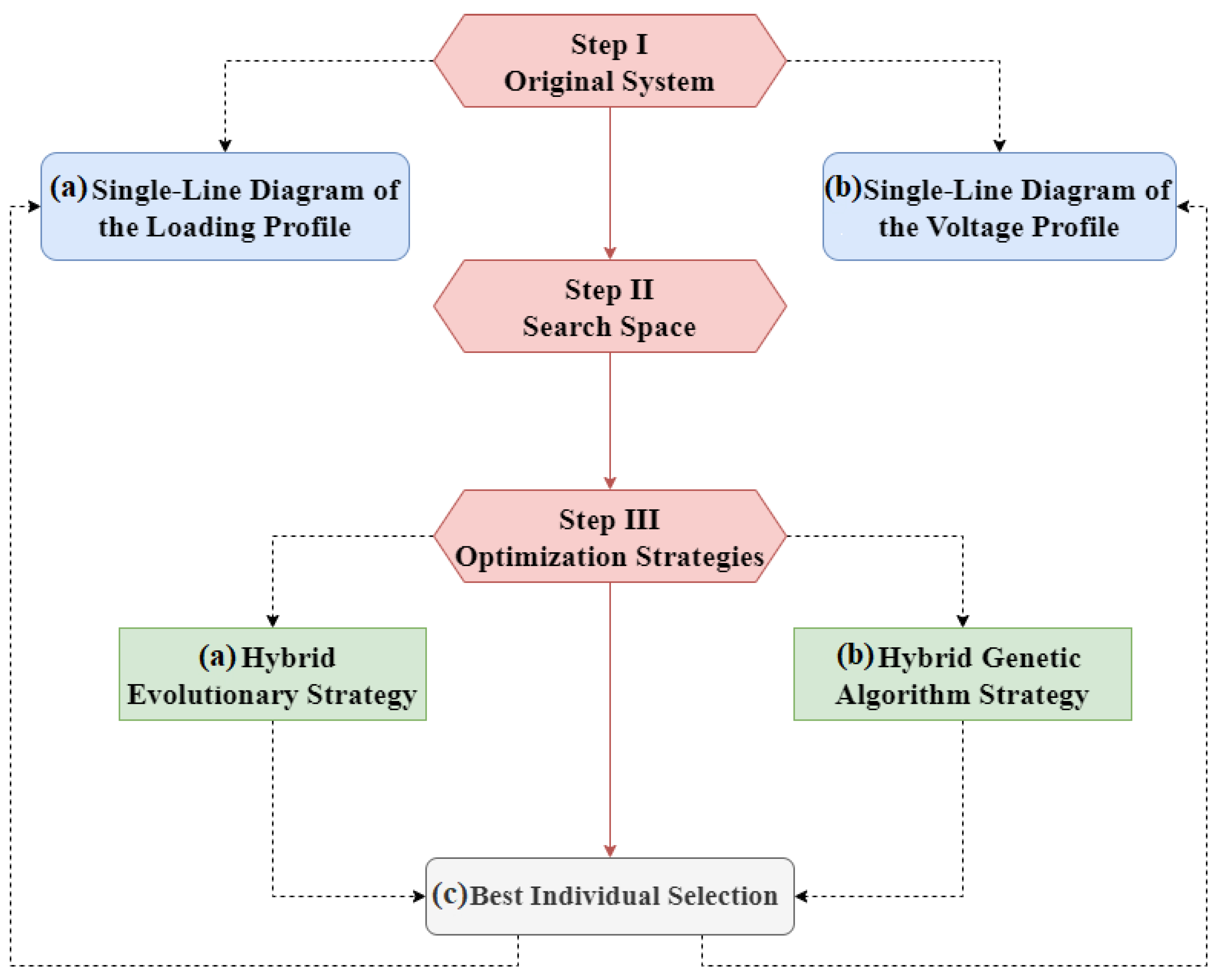
The computational tools used for system modeling and simulation were OpenDSS and QGIS. OpenDSS is an open-source software widely used for simulating EPDS, while QGIS is an open-source platform for Geographic Information Systems (GIS). This study employs a methodology divided into three main stages, illustrated in
Figure 1. Each stage is designed to address different aspects of optimizing electric distribution systems, utilizing evolutionary and genetic strategies.
3.5. Stage I: Original System
In Stage I, the target Electric Distribution System and its main limitations are defined. A comprehensive survey of the characteristics and parameters of the original system is conducted, including topology, loads, and existing generation capacity. The system’s performance is evaluated without the allocation of Distributed Generation (DG) through simulations in the OpenDSS software. The input parameters for this evaluation include the following:
Loads: Detailed information on the energy demands of the loads present in the system.
Lines: Specific data on the distribution lines that make up the system.
Available buses: Locations where DG resources can be allocated, which are characterized by the following:
- -
Available area: Available space in the bus, considering environmental and spatial constraints, as discussed in
Section 3.7.
- -
Available Budget: Available budget for the construction of the power plant at the specified bus, also detailed in
Section 3.7.
Geographic Coordinates: Precise locations of load and line elements for an accurate geographical representation of the system.
The simulations in OpenDSS allow obtaining essential performance parameters, such as Bus Voltage Profile (), Active Power Losses in the Line (), and Line Loading Profile (). Based on these parameters, important indicators for the Original System are defined:
Total Losses (
): Sum of the losses in each line, as given by Equation (
9), where
i corresponds to the specific line and
n to the number of the total lines in the system.
Violation of the upper voltage limit (): Counts the occurrences where the voltage profile at a bus exceeds the upper limit (in this case, set to 105%).
Violation of the lower voltage limit (): Sums the occurrences where the voltage at a bus falls below the lower limit (in this case set to 95%)
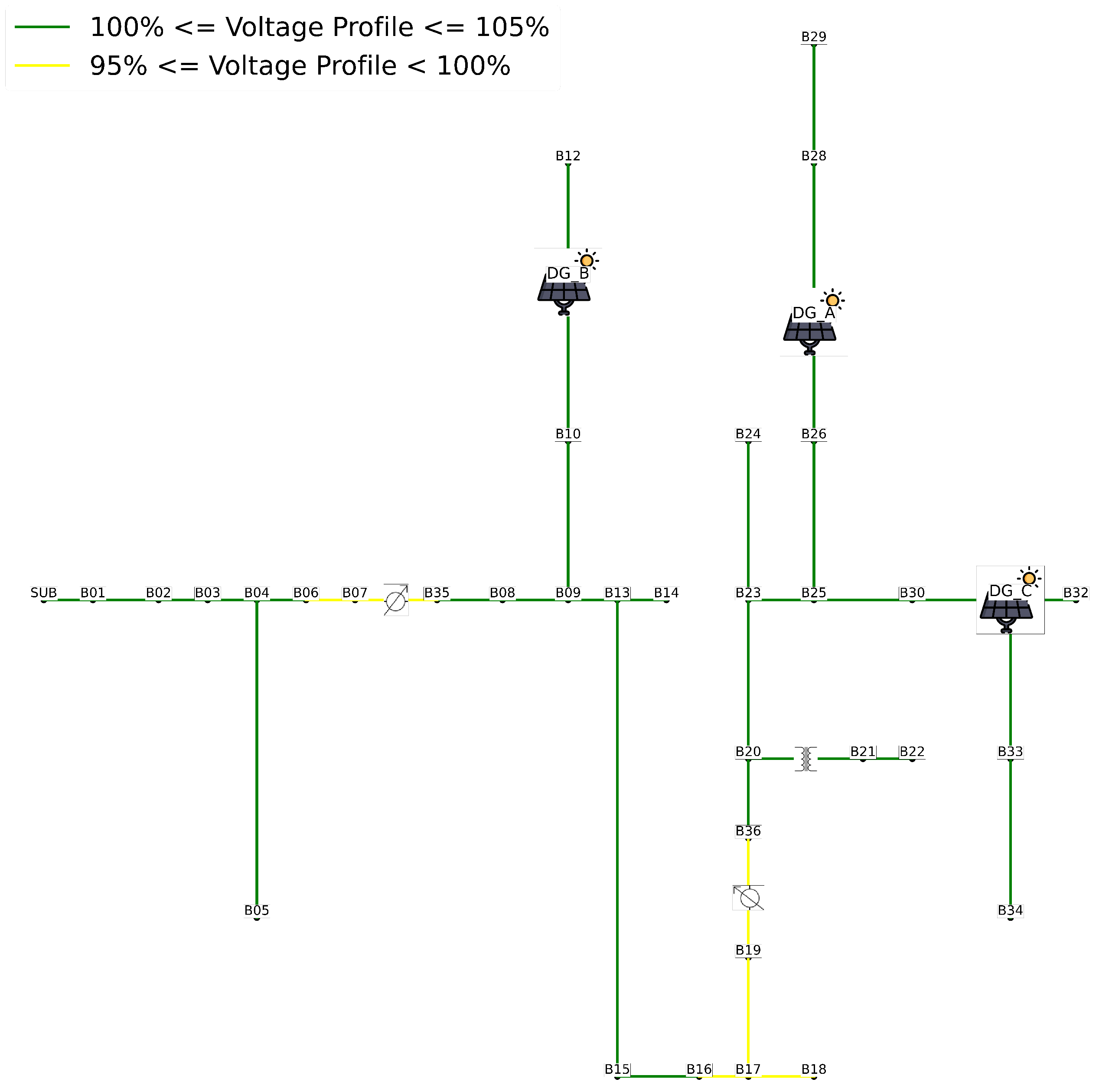
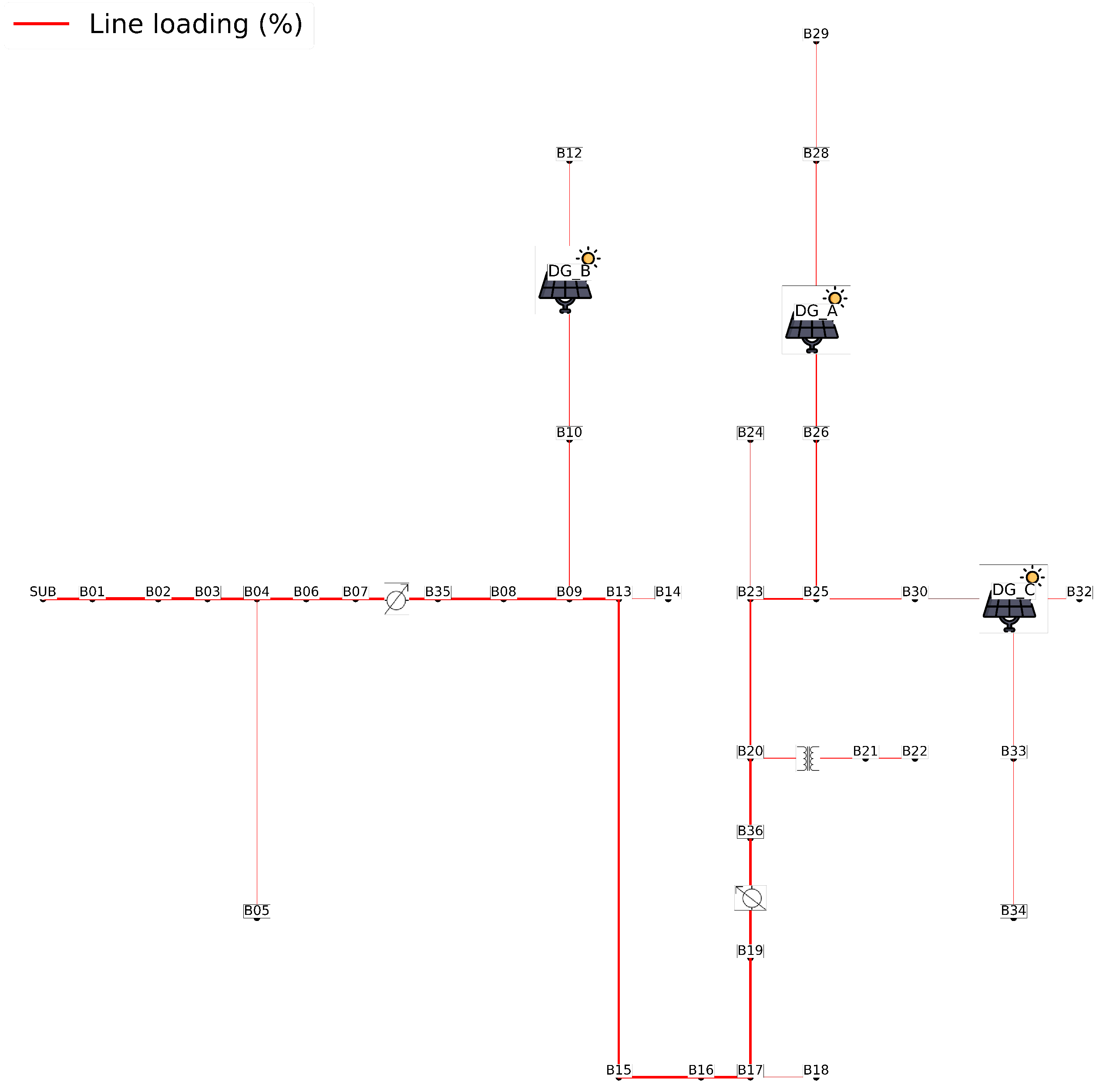
Both indicators, and , are calculated for all buses in the system. Each violation is added to the corresponding total. After obtaining the performance indicators, the information from and is used to plot the single-line diagrams of the loading profile and voltage profile behavior.
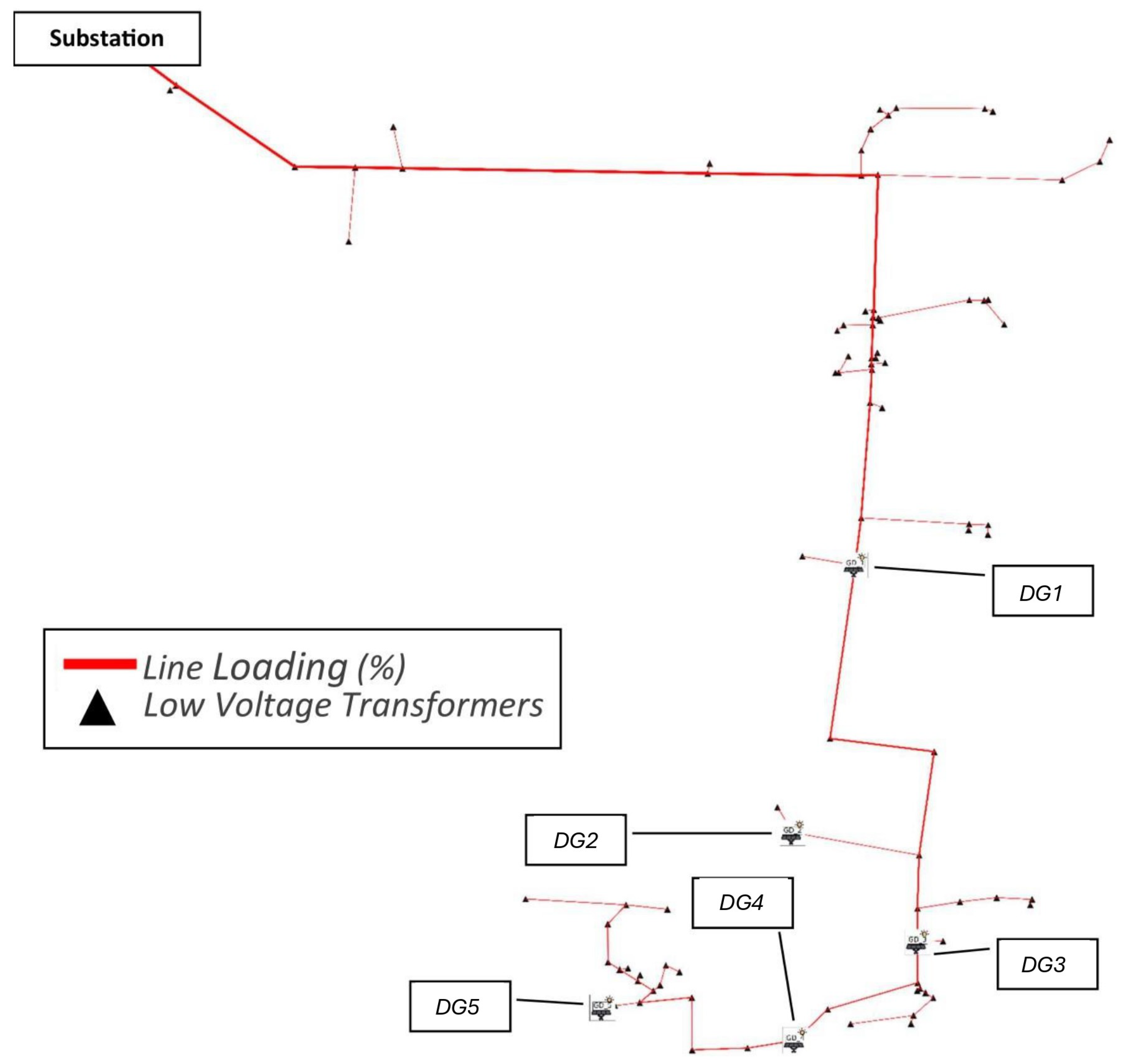
Single-Line Diagram of the Loading Profile: The line thickness corresponds to the percentage of bus loading relative to the total system loading, obtained by summing the individual loadings.
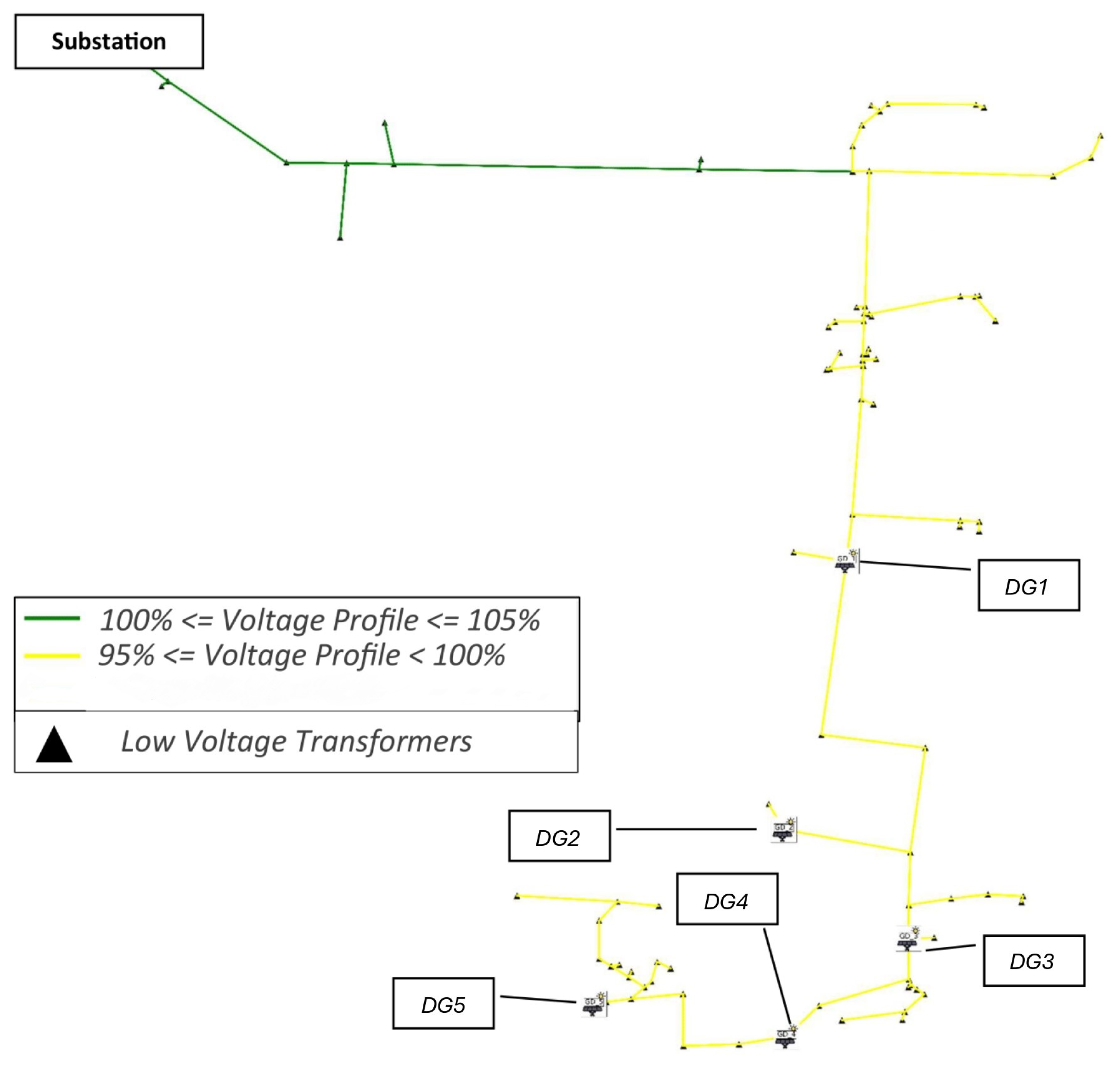
Single-Line Diagram of the Voltage Profile: The voltage values per bus () are interpreted in pu and plotted with colors according to the following criteria:
- -
: Red.
- -
: Green.
- -
: Yellow.
- -
: Blue.
These diagrams provide a clear visualization of the system’s behavior, both for the scenario without DG allocation and for scenarios with allocation throughout the EPDS.
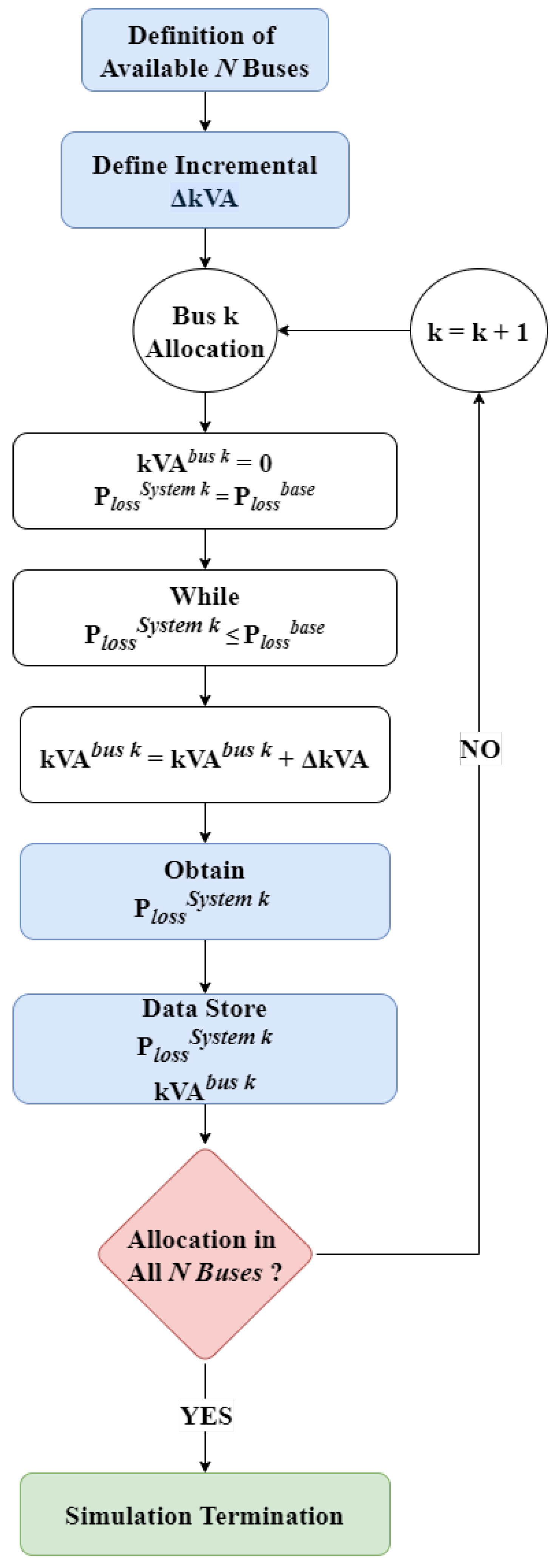
3.6. Stage II: Definition of the Search Space
This stage is initiated after defining the Distribution System and obtaining the performance indicators (
,
, and
) discussed in
Section 3.5. Its objective is to determine the reference generation values for each bus, aiming to achieve the greatest reduction in total system losses by allocating a solar power plant to a specific bus. The procedure followed in this step is illustrated in the flowchart presented in
Figure 2.
Using the available buses for DG allocation and defining the incremental power value , the procedure is as follows:
For each bus, the ideal power value that minimizes system losses is identified. This value corresponds to the minimum point of a parabolic curve associated with each bus. The resulting ideal power serves as a reference for the subsequent steps.
3.7. Stage III: Optimization Strategies
In this stage, a Hybrid Evolutionary Strategy and a Hybrid Genetic Algorithm are applied. Before discussing these algorithms, it is necessary to define the structure of the individuals, the selection, mutation, and crossover processes, and the evaluation of individual fitness.
3.7.1. Definition of Individuals
Each individual is represented by a vector of length l, where l is the total number of buses in the system. Each position in the vector takes a Boolean value (0 or 1) according to the following rule:
3.7.2. Initial Generation
Generation zero is created by defining a fixed number of individuals (
) and the total number of generations (
). Additionally, the minimum (
) and maximum (
) limits are established for the number of DG units allocated per individual. Each individual is generated randomly, while respecting the condition given by Equation (
12). Individuals that do not meet these criteria or allocate DG units to unavailable buses are discarded.
3.7.3. Generation Capacity
For each allocated plant, the power, cost, and occupied area are calculated based on spatial and budgetary limitations. The following reference parameters are used.
The power plant capacity at bus
k (
), its cost (
), and occupied area (
) are defined as follows:
where
is a random value between 0 and 1. The value of
is adjusted until the following conditions are satisfied:
3.7.4. Evaluation of Individual Fitness
After defining the individuals of generation zero and establishing their generation capacity, each individual is evaluated in terms of its fitness. During this evaluation, the following parameters are obtained:
: Total system losses with allocated DG units, calculated similarly to the original system ().
: Number of buses with voltage above 105% (in pu) for the individual.
: Number of buses with voltage above 95% (in pu) for the individual.
The parameters and are evaluated between 6:00 a.m. and 6:00 p.m., the hours during which DG has the greatest influence on the system.
Although the intermittency of PV generation is not modeled through stochastic or probabilistic approaches, the temporal variability of solar irradiation is inherently considered through the use of a realistic solar radiation curve based on data generated by PVsyst. This curve is used in the OpenDSS simulations to model the time-varying behavior of PV generation throughout the day.
In this study, the DG units are therefore modeled as time-dependent energy sources, following the irradiance curve rather than assuming constant power injection. However, dispatching actions, curtailments, or disconnections of PV plants are not considered in the simulations. The objective is to evaluate the impact of distributed solar generation under normal operation scenarios, assuming full availability in accordance with the reference irradiance profile.
3.7.5. Selection Criteria
All individuals are subjected to the following selection criteria:
Criterion 1: The voltage violations of the individual must not exceed those of the original system:
Criterion 2: The losses of the individual must be less than or equal to the average losses of the previous generation:
Individuals that do not meet these criteria are discarded, ensuring that only feasible and efficient solutions are passed on to the next generations.
3.7.6. Mutation of Individuals
After selecting the fittest individual, the mutation process begins. It is considered a system with 10 buses, where a given individual has 2 DG units allocated and has the following constraints:
The mutation process consists of selecting segments to be preserved and applying a perturbation to the segments that will undergo mutation. The new mutated individual corresponds to the combination of the preserved segment with the perturbed segment. The key assumptions are as follows:
To illustrate the process, suppose that
is a random real parameter that defines up to which part of the individual will be preserved. For
, positions B1 to B4 are kept unchanged, while positions B5 to B10, highlighted by the red frame in
Figure 3, are subject to mutation. In the preserved segment, there is one DG unit allocated; therefore, in the mutated segment, it is allowed to allocate between one and two DG units. After applying random Boolean values, a new mutated individual is obtained, as illustrated in
Figure 3.
If the new individual does not satisfy Assumptions 1 and 2, it is discarded, and a new value of is drawn to perform a new mutation.
3.7.7. Crossover of Individuals
The crossover process consists of combining two parent individuals, which are randomly selected after the mutation stage. Each parent represents a distinct DG allocation configuration across 10 buses, as shown in
Table 2. This procedure enables the generation of new individuals by inheriting characteristics from both parents, thereby enhancing population diversity and improving the exploration of the search space.
The crossover process is defined by the parameters
and
, which select specific segments from each “parent”. For
and
, the selected segments are shown in
Figure 4. The value of
is calculated as follows:
where
l is the total number of buses in the system.
The arrows in
Figure 4 illustrate the segments selected for the crossover: the horizontal arrow labeled
marks the portion taken from the first parent, while the arrow labeled
indicates the segment taken from the second parent.
Once the segments have been defined, a third individual—referred to as the “Child”—is generated by combining selected portions from both “Parents”. This recombination process allows the child to inherit characteristics from each parent, promoting genetic diversity in the population. The resulting “Child”, along with the original “Parents”, is presented in
Table 3.
The same assumptions previously defined for the mutation process also apply to the crossover operation. In addition, the two selected “Parents” must be distinct to ensure sufficient genetic diversity in the resulting “Child”. This diversity is essential for promoting variation within the population and enhancing the search for optimal solutions. The newly generated child will be included in the next generation of individuals.
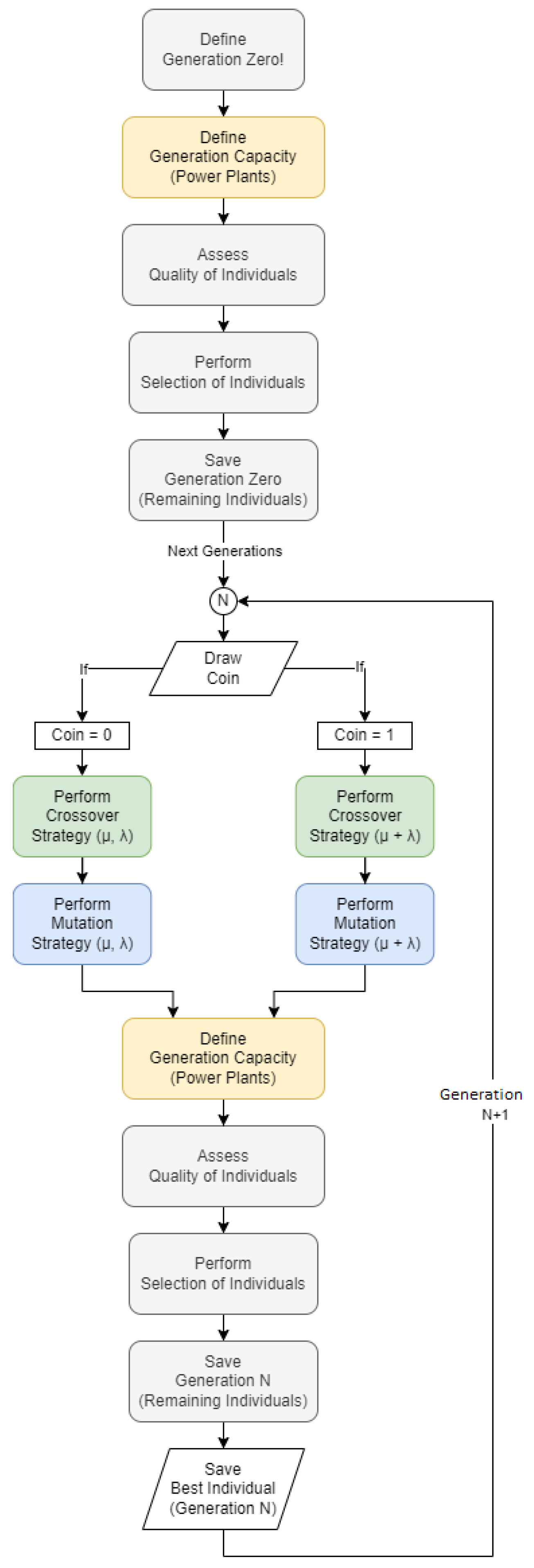
3.7.8. Hybrid Evolutionary Strategy
In this study, two variants of Evolutionary Strategies are employed: the
and the
. The Hybrid Evolutionary Strategy combines the benefits of both strategies throughout the generations, as illustrated in the flowchart in
Figure 5.
The process begins with the definition of Generation Zero and the determination of each plant’s generation capacity. Next, the Selection of Individuals is performed, where the fittest individuals are chosen, and the remaining ones are stored for later reference. The decision between the and strategies is made through a random draw (“Flip Coin”), where Coin = 0 applies the Evolutionary Strategy, and Coin = 1 applies the Evolutionary Strategy.
Each new individual is created from an individual randomly selected among the . Of the individuals in the current generation, are retained in the strategy, and the remaining are generated by applying mutation to the selected individuals, thus maintaining a population of individuals.
After selecting the fittest individuals in the strategy, all individuals of the next generation are generated by applying mutation to the remaining individuals. Each new individual is created from a randomly selected individual among the .
Out of the individuals in the current generation, are retained in the strategy, and the remaining individuals are generated by applying mutation to the selected individuals, keeping the population size at individuals.
After mutation, the individuals are evaluated based on their quality, and a new selection is performed. The best individual of each generation is the one with the lowest value, provided that and do not violate the limits of the Original System. At the end of all generations, the Overall Best Individual is selected from the best individuals of each generation.
3.7.9. Hybrid Genetic Algorithm Strategy
The main difference between the Hybrid GA Strategy and the Hybrid Evolutionary Strategy is the inclusion of crossover between two distinct individuals before the mutation process. The detailed flowchart is presented in
Figure 6.
According to the flowchart, crossover occurs between individuals before the mutation process. The decision-maker “Flip Coin” is used to choose between Elitism (Coin = 0) and Elitism (Coin = 1).
In the GA Strategy with Elitism , crossover is performed between two distinct individuals among the fittest selected ones, generating a new individual. The number of new individuals is equal to the population size (), resulting in offspring from crossover. These individuals then undergo the mutation process, generating mutated individuals, which form the next generation.
In the GA Strategy with Elitism , the fittest individuals from the previous generation are retained. Additionally, two distinct individuals among the are selected to generate new individuals through crossover. These new individuals then undergo mutation, resulting in mutated individuals, which are combined with the retained individuals, forming a total of individuals in the next generation.
After defining the individuals of the new generation, the process continues with the determination of the generation capacity of the allocated plants, the evaluation of individual quality, and the selection of the best individuals. The remaining individuals are stored, and the process advances to the next generation.
3.7.10. Definition of the Best Individual
After applying the optimization strategies, the next step is to define the best individual for each strategy to identify the solution with the best performance in the Distribution System. This process is essential to validate the effectiveness of the methods used. The best individual is selected based on the following criteria:
Performance Evaluation: Each individual is evaluated based on Total Losses (), Upper Voltage Violations (), and Lower Voltage Violations (). These parameters are analyzed for all system buses.
Metric Comparison: Individuals are primarily compared based on the reduction of total losses. Additionally, it is verified whether the bus voltages remain within acceptable limits (95% to 105% in p.u).
Final Selection: The best individual is the one that achieves the greatest reduction in total losses without voltage violations, ensuring system stability and efficiency.
This process ensures a rigorous and objective evaluation, allowing the identification of the most effective solution for the Distribution System. The analysis of the best individuals from each strategy provides valuable insights for future implementations.
5. Conclusions
This study proposed an innovative methodology for optimizing the allocation and sizing of photovoltaic distributed generation (DG) in electrical distribution systems. The main contribution lies in the integration of georeferenced spatial constraints into the optimization process, in addition to conventional technical and budgetary limitations. This multi-criteria approach enhances the realism of DG planning and ensures compatibility with physical and economic feasibility.
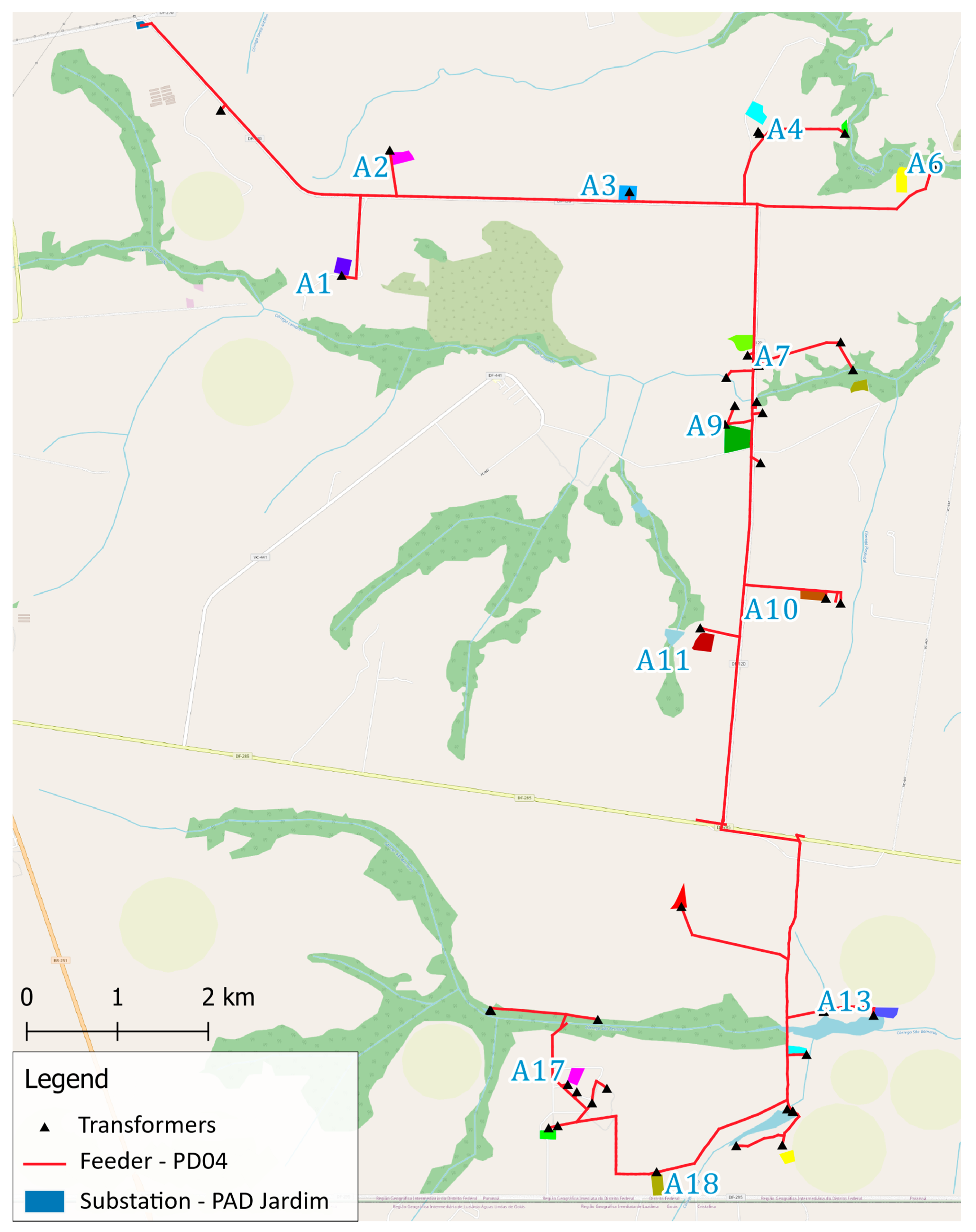
The methodology combines simulations in OpenDSS and QGIS with metaheuristic techniques, specifically the Hybrid Evolutionary Strategy and Hybrid Genetic Algorithm. Two case studies were conducted to validate the approach: the standard IEEE 34-bus distribution system and a real medium-voltage feeder. In both cases, the optimization model successfully identified the DG configurations that improved the performance of the system.
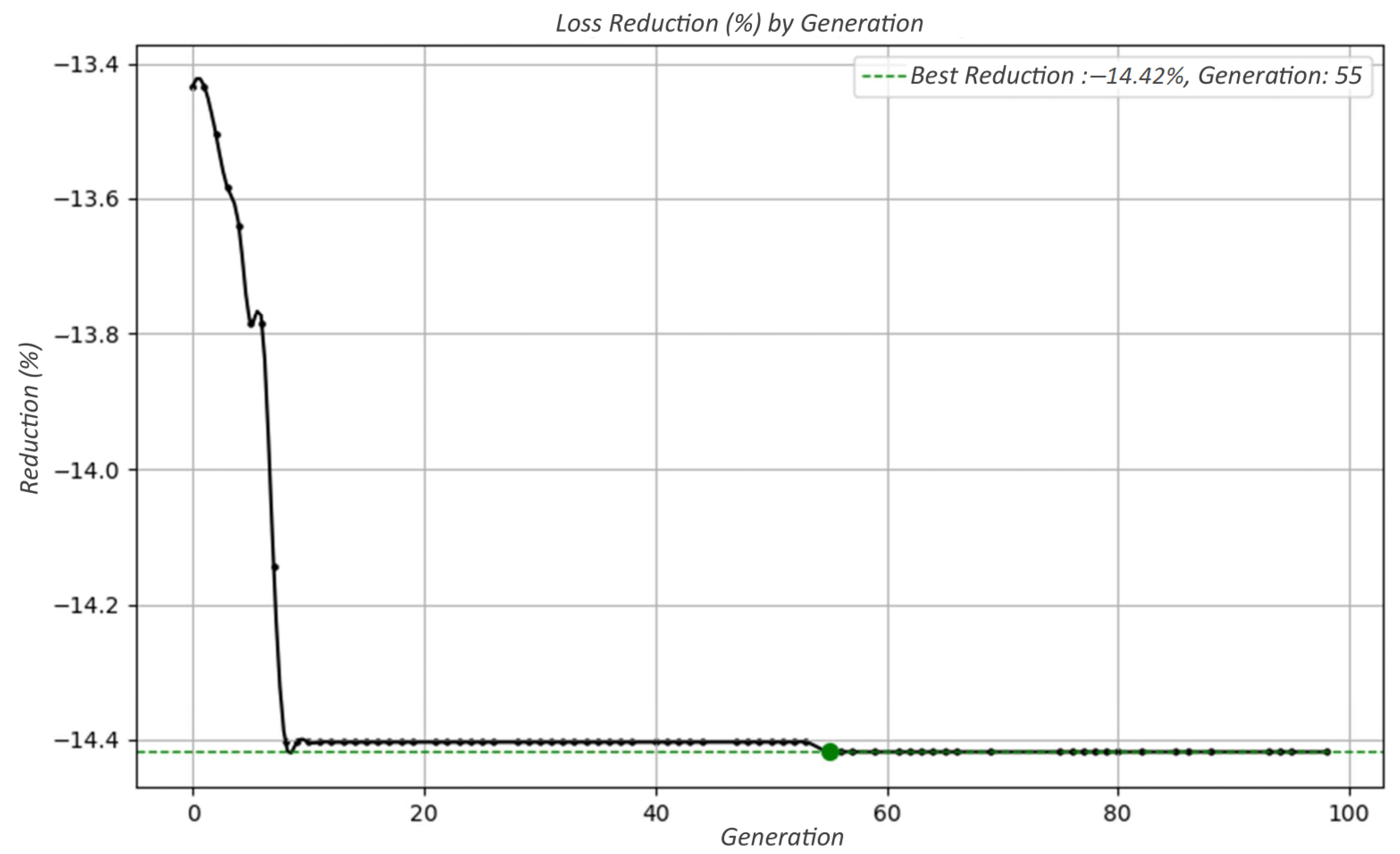
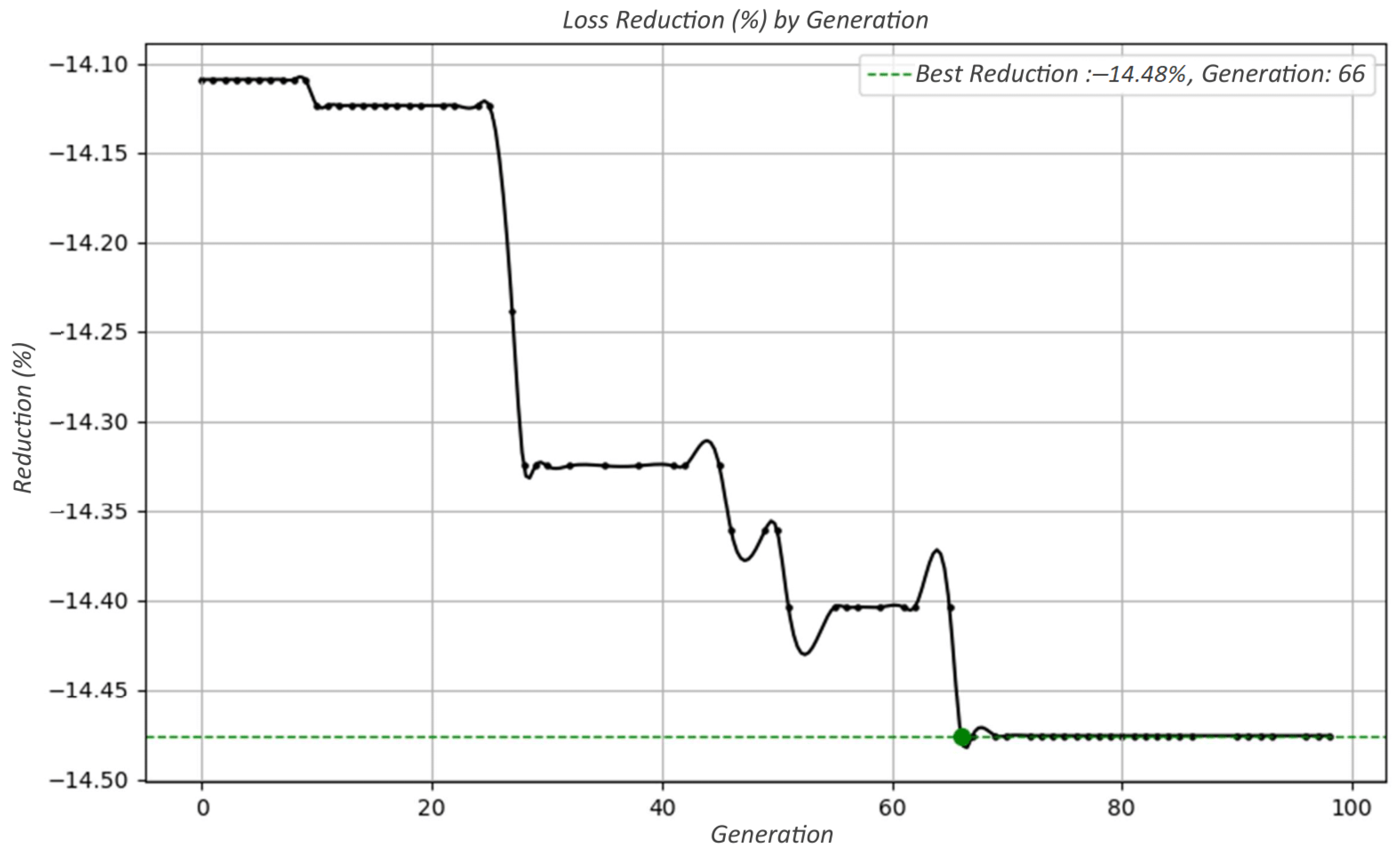
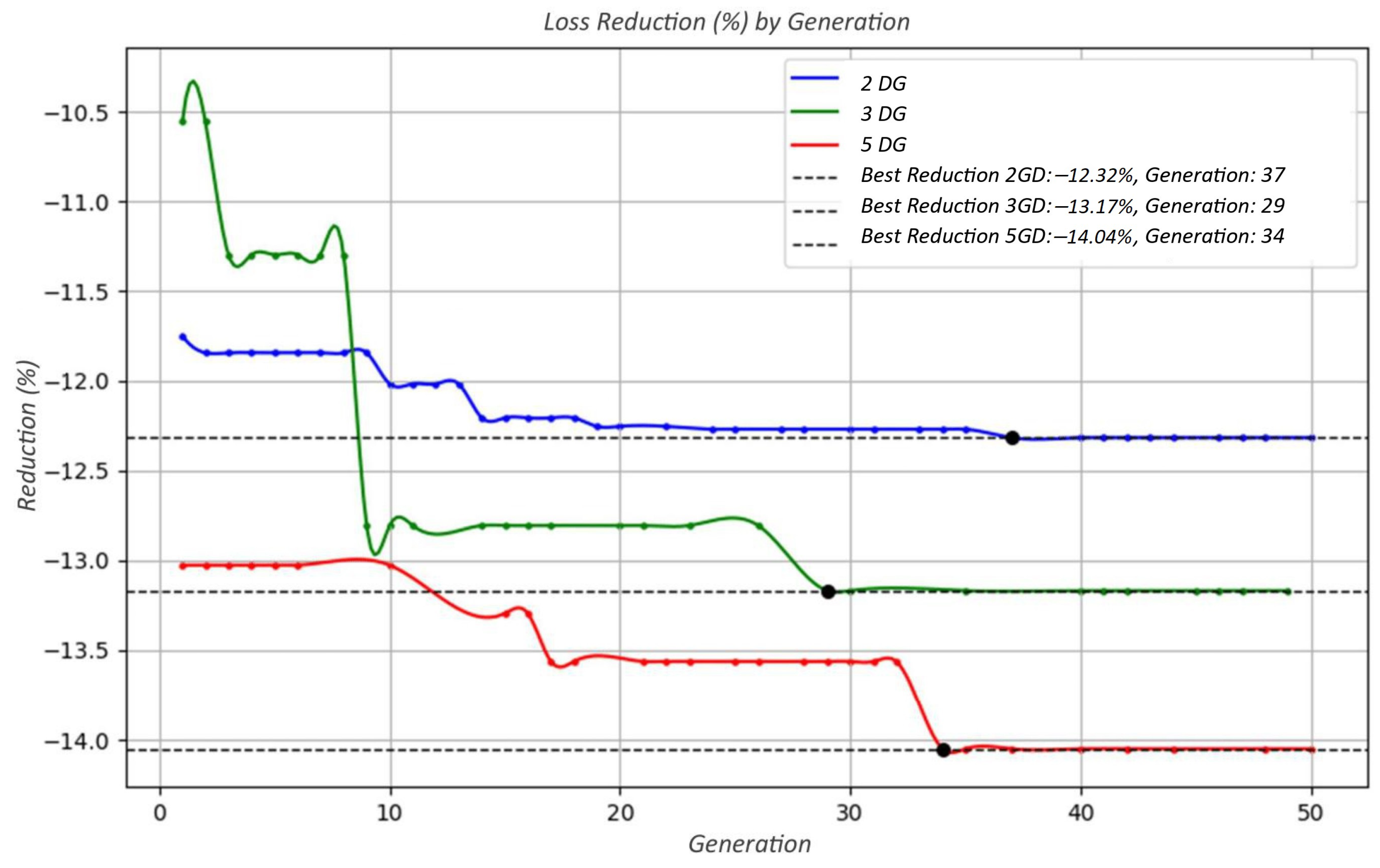
Quantitative results confirm the effectiveness of the methodology. In the IEEE 34-bus system, the allocation of photovoltaic units led to a 14.48% reduction in total energy losses and a 7.39% improvement in the voltage profile. For the real feeder, a similar strategy resulted in a loss reduction of 14.08% and an enhancement of 1.75% in voltage levels. These improvements demonstrate the technical value of properly allocated DG units, particularly when spatial feasibility is considered.
Furthermore, the use of hybrid metaheuristics provided robust convergence and high-quality solutions in a non-convex, multi-constrained optimization environment. The combination of spatial, technical, and economic constraints proved essential for producing feasible and efficient DG planning strategies.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}