1. Introduction
The cost of drilling wells for the exploration of hydrocarbon resources can vary between 30% and 60% of the average well costs [
1], while for deep geothermal wells, it can constitute as much as 50% to 75% of the average cost per well [
2]. In order to achieve significant cost reduction, it is necessary to reduce the effective drilling time and also the non-productive time associated with the mitigation of drilling incidents such as stuck pipe, loss of drilling fluid to the formation, drill-string twist-off, or equipment failure. The proper selection of drilling parameters, such as the drill-string revolutions per minute (RPM), weight on bit (WOB), and mud pump circulation rate can improve the rate of penetration (ROP) and also prevent the occurrence of drilling incidents, thus reducing both the effective drilling time and the non-productive time. To address this problem, advanced technical solutions for drilling parameter optimization [
3] and autonomous decision-making while drilling [
4] have been developed in recent years, and a successful demonstration of these technologies has been conducted on a full-scale test rig [
5].
A key prerequisite to facilitate optimal drilling parameter selection is the availability of predictive models that can evaluate the ROP in response to different drilling parameter combinations. Earlier ROP models were based on empirical correlations among drilling parameters, with the most notable ones being the Maurer model [
6], the Bingham model [
7] and the Bourgoyne and Young model [
8]. More recent efforts in this direction have been focused on including detailed descriptions of the physics of the cutting process [
9] and drill bit wear mechanisms [
10]. Physics-based ROP models, such as the ones mentioned earlier, require frequent re-calibration as the downhole conditions (e.g., rock strength, bit wear, or drill-string vibrations) change during drilling [
11].
In the past decade, data-driven modeling and machine learning (ML), in particular, have become an attractive alternative to the physics-based modeling of drilling processes, with ROP prediction among its top applications in this area. Artificial intelligence techniques, including ML, have joined model-based approaches across various subsurface-energy-extraction applications [
12,
13]. A comprehensive literature review by Barbosa et al. [
14] indicated that ML-based models can outperform traditional physics-based models in terms of ROP prediction accuracy and flexibility. Sabah et al. [
15] compared data mining methods with several machine learning algorithms to evaluate their accuracy and effectiveness in predicting ROP. Khosravanian and Aadnøy [
16] provide a recent comprehensive overview of different ML methods for ROP prediction, including artificial neural networks (ANNs), support vector machines, fuzzy inference systems, neurofuzzy models, and ensemble techniques. They emphasize the importance of data-driven modeling in optimizing drilling operations and achieving high ROP. Other commonly used ML algorithms for ROP modeling include random forests [
17,
18,
19,
20,
21], support vector regression [
22,
23,
24], gradient boosting [
20,
21,
25], the K-Nearest-Neighbors algorithm [
26] and recurrent neural networks [
18,
27,
28]. Hybrid methods combining physics with ML are also starting to emerge [
29,
30], and physics-informed ANNs are starting to emerge in a wider context [
31,
32], but they are beyond the scope of the current study.
The most frequently used input features for ML-based ROP models are WOB, RPM, hole depth, mud pump rate, mud weight, bit diameter, rock strength and bit wear [
14], while some models include more complex features such as bit hydraulics and cuttings transport [
33]. Some ML-based ROP models have been deployed into ROP optimization workflows and advisory systems, with reported ROP improvements of up to 33% in field tests [
25,
34,
35].
Despite these positive results, ML-based ROP-prediction models face several practical challenges that might hinder their robustness and acceptance in drilling automation and optimization workflows.
Firstly, when choosing training and test data sets for ROP models, one needs to take into account that drilling data are sequential, and therefore using a random train/test split may lead to models that perform well on the training and test sets but quite poorly when applied to other data sets [
36].
Secondly, ROP modeling is affected by the data distribution shift, where the same values of the input variables may produce different ROP values in two different rock formations. To avoid this pitfall, [
33] proposed training separate ANN models for individual formations, while [
19] applied the same concept for random forest and ensemble ROP models. The results of both studies indicated lower prediction errors for the formation-specific models than models relying on training data from multiple formations, although it can be argued that models trained on a specific formation are more prone to overfitting to that formation. When formation data are hard to estimate, the use of transfer learning that uses part of the data from the well being drilled [
37] or a continual learning framework [
38] can improve the results.
Finally, DNN models are complex function approximators that are hard for the end user to interpret. One way to improve the interpretability of an ML model is by including a measure of confidence, or rather uncertainty, in its predictions. This information can be critical when the model is used in an advisory system or a fully automated system, such that the user can build trust in the recommendations or actions taken by the system. Only a few studies have addressed uncertainty in ROP prediction, whether for physics-based or ML-based models [
14]. Uncertainty can be divided into aleatoric and epistemic [
39]. Aleatoric uncertainty arises from the inherent variability in the data, and the output variable (in this case, ROP) is treated as a probability distribution when training the ML model. The epistemic uncertainty results from the choice of model and input features. Ambrus et al. [
40] developed an ROP prediction model using a DNN with quantile regression to estimate the aleatoric uncertainty in the prediction. Bizhani and Kuru [
39] accounted for both types of uncertainty using a Bayesian neural network for ROP prediction. Both approaches showed promising results on several publicly available drilling data sets.
Verification with practical data is needed to understand how training data selection, input features (including formation data), and uncertainty estimation techniques impact the robustness of ROP prediction. Additionally, it is essential to determine whether the estimated uncertainty can indicate when a trained model is not valid for a test section, even if the mean prediction error remains within acceptable limits.
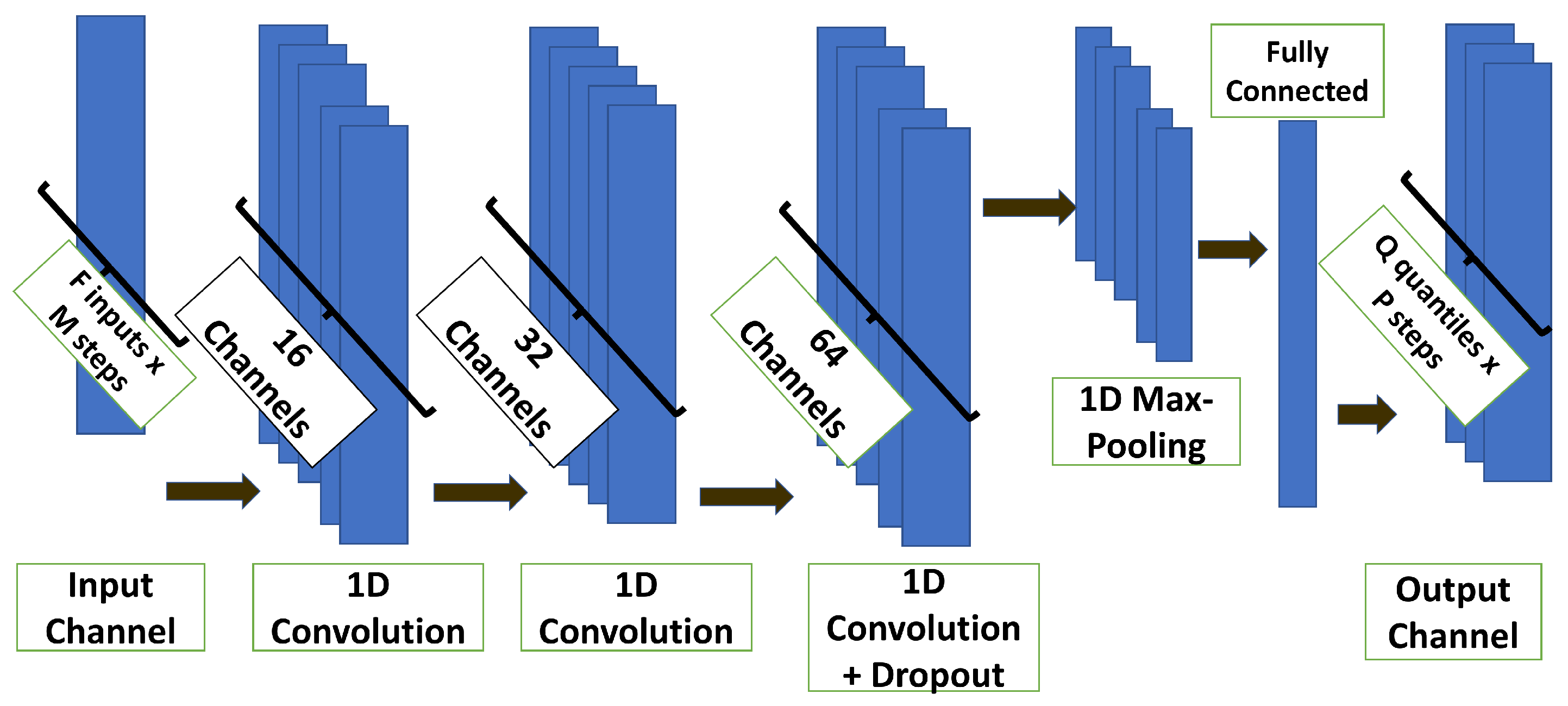
In this work, we build on the quantile regression DNN (QRDNN) framework to address the aforementioned questions with an application in a multi-lateral well drilled in the Alvheim field in the North Sea and nearby offset wells. The main contribution of this work is the investigation of how the choice of data for training this QRDNN model can affect the prediction quality in terms of both accuracy and uncertainty.
The paper is organized as follows:
Section 2 details the setup of experiments and data used in the study.
Section 3 describes the methodology, including the model architecture, feature selection and training strategies, and the metrics used for evaluating the models.
Section 4 shows the study results, followed by a discussion in
Section 5 and the conclusions in
Section 6.
4. Results
The results from the different training strategies are detailed in this section. The model outputs are computed by moving a window of 100 time steps over the input time series from the test sets and predicting the ROP for the next 100 steps. For the initial window, we keep all points in the prediction horizon, while for subsequent windows we store only the prediction at the 100th step, we average the predictions for selected quantiles (P10, P50, P90) and the true ROP over a 0.1 m measured depth interval and use these averaged values both for plotting and computing the evaluation metrics described in
Section 3.5. The P50 curve is used for MAE and MAPE, while the P10 and P90 curves are used for sharpness and AACE. This gives a confidence interval
= 0.8.
4.1. Models Trained on Hole-Size-Specific Data
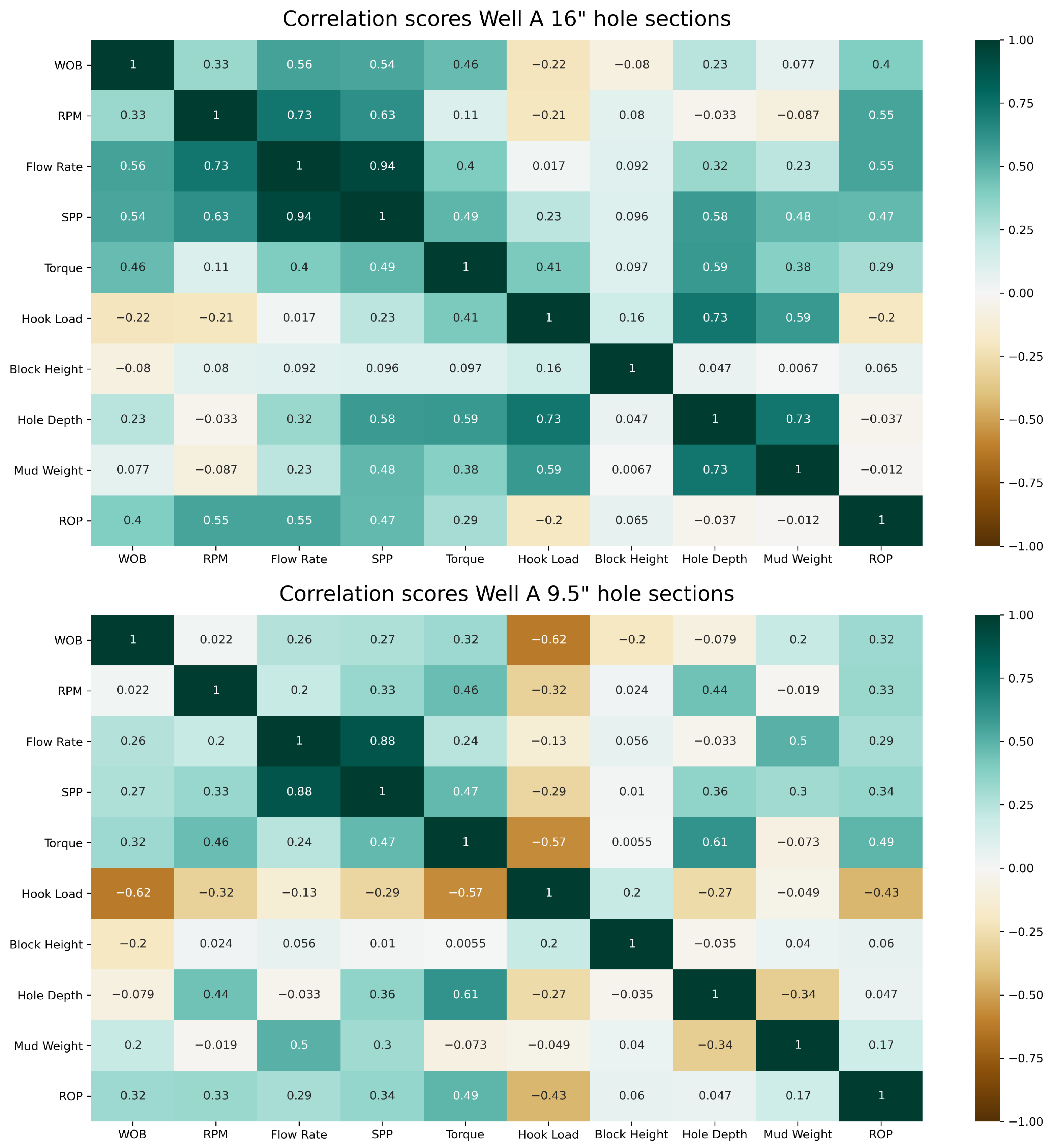
We start with the ROP predicted by models trained on Well A data sets with the hole-size-specific training strategies. In all these cases, the input feature set consists of WOB, surface RPM, surface torque and SPP, which were found to give the best results on the Well A test data sets.
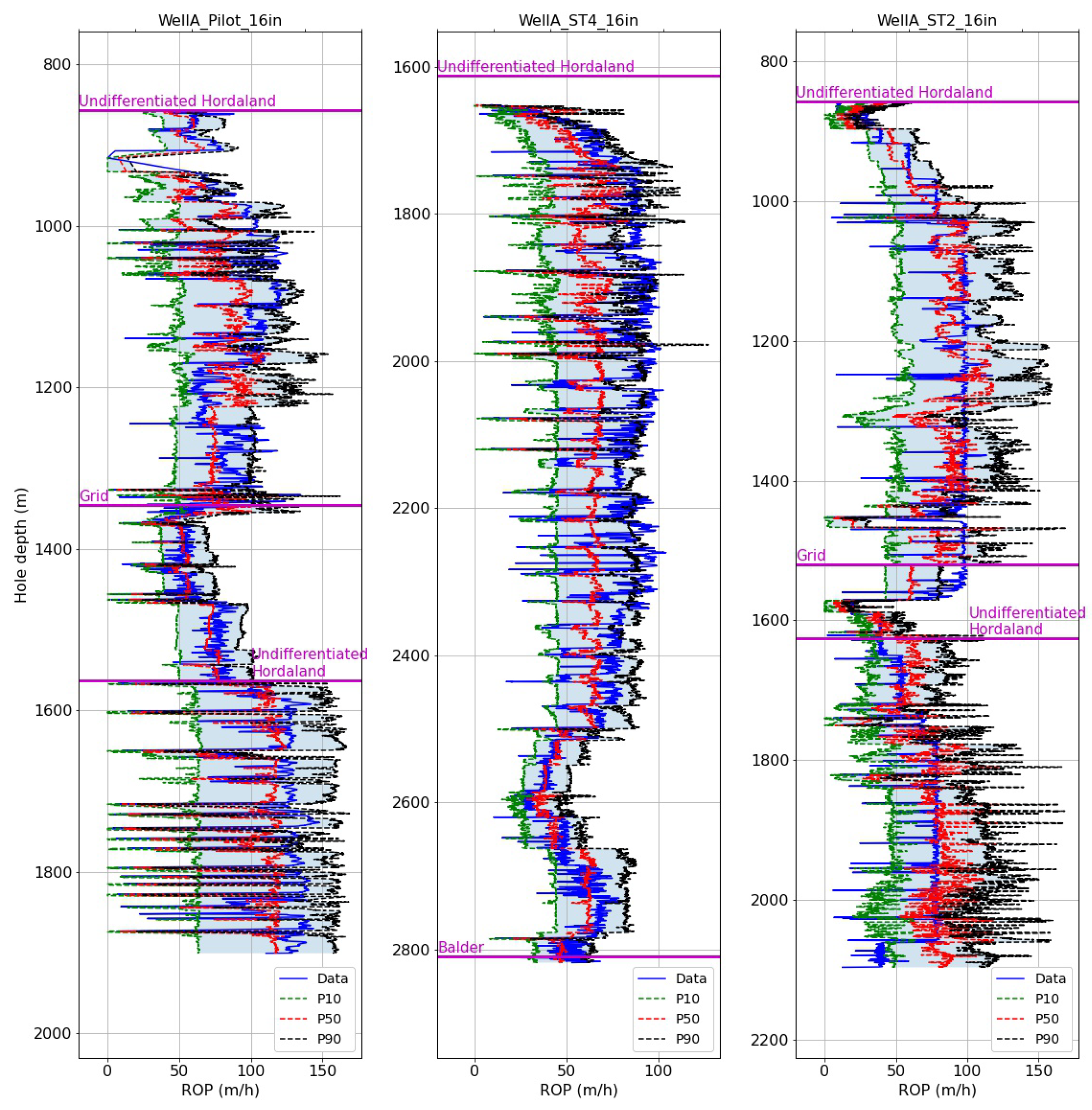
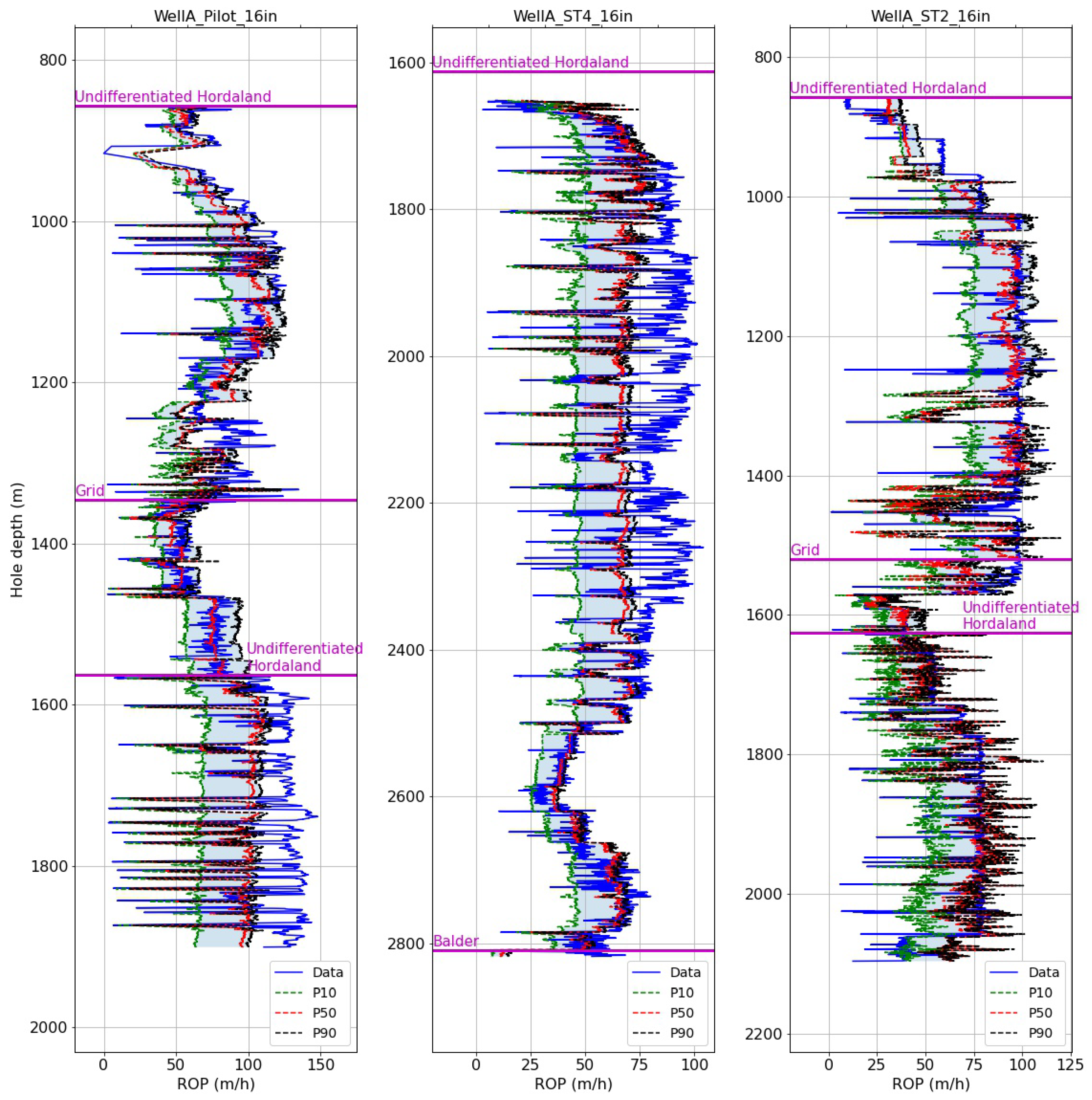
Figure 7 shows the depth-averaged true ROP (solid blue curve) and the predicted P10/P50/P90 (dashed curves) for the 16″ hole sections. The formation tops are annotated on the plots at the measured depths where they were encountered in each section. For the test data set (WellA_ST2_16in), the P50 curve follows the true curve quite well, and captures abrupt changes like the drop in ROP in the grid formation and around 1450 m. This results in MAE and MAPE values of of 15.7 m/h and 31.3%, respectively. The shaded light blue area between the P10 and P90 curves indicates the sharpness of the prediction, which appears wide for most of the section, spanning 100 m/h at certain depths.
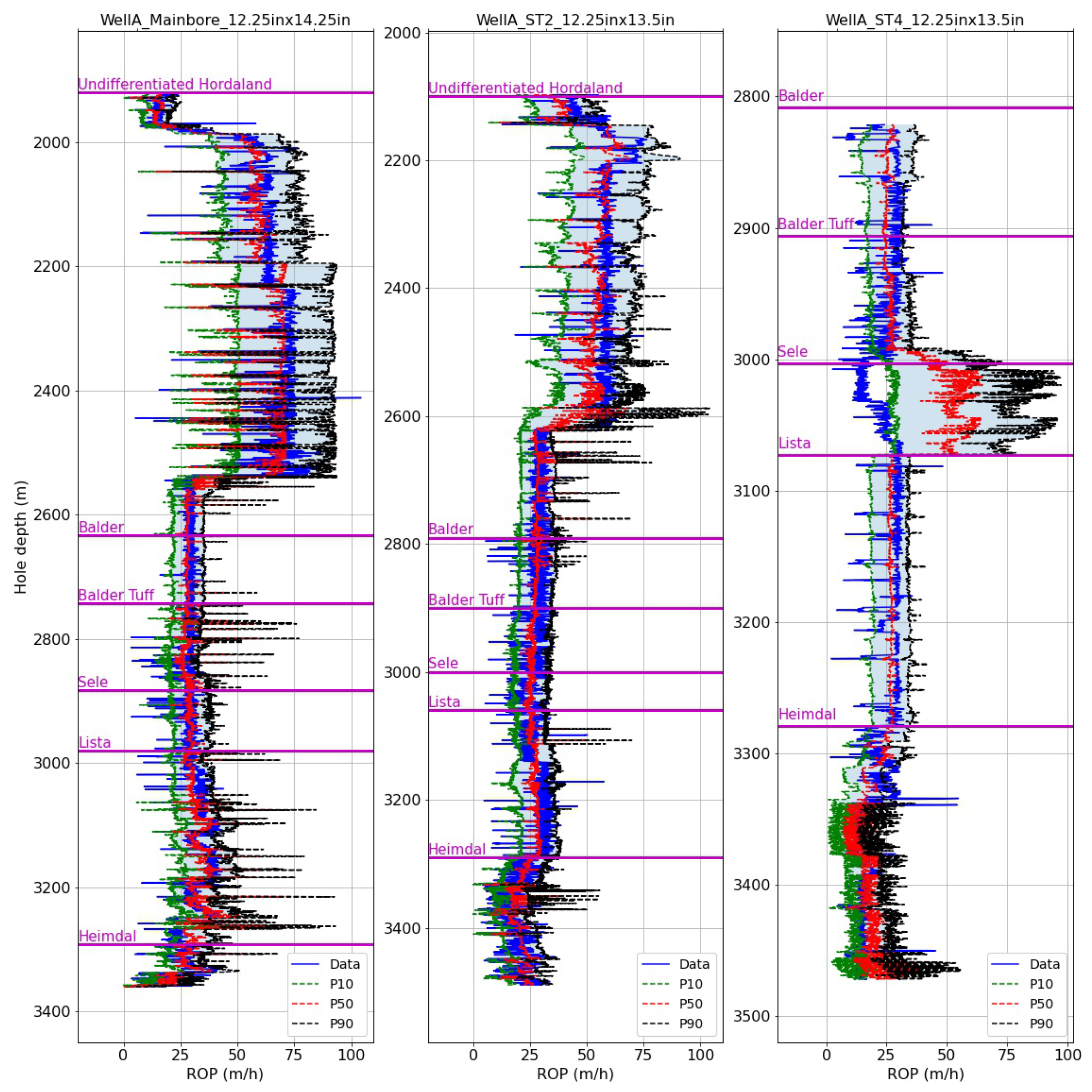
Figure 8 show the depth-averaged ROP and the predicted values for the 12.25″ sections with the hole-size-specific models. In all sections, below a depth of 2600 m, the ROP was limited to 15–30 m/h to achieve the required dogleg severity and also to deal with mud losses. The P50 curve tracks the true ROP curve very well for the training sections (WellA_Mainbore_12.25in × 14.25in, WellA_ST2_12.25in × 13.5in) and also for the test section (WellA_ST4_12.25in × 13.5in) with the exception of the Sele formation. The predictions in the Heimdal formation are close to the true ROP but quite noisy. Overall, this resulted in an MAE of 7.98 m/h and a MAPE of 43.8% for the test section.
Finally,
Figure 9 displays the prediction results for the 9.5″ hole sections. The first two plots correspond to the training sections, while the last two are the test sections. The model performance is evaluated in
Figure 10. The MAE and MAPE are higher on the test sections, with 10 m/h and 32.4%, respectively, for WellA_ST4_9.5in and 11.3 m/h and 56.7% for WellA_ST5_9.5in. The higher percent error for WellA_ST5_9.5in can be explained by the overall lower ROP values and reduced prediction accuracy around hard stringers compared to WellA_ST4_9.5in. The AACE for both test sections is around 10%, which is comparable to the first training section, and the sharpness is in the same range as well (24–30 m/h).
4.2. Models Trained on Formation-Specific Data
In this section, we show results for the models trained with the formation-specific strategy. As in
Section 4.1, the models use WOB, surface RPM, surface torque and SPP as inputs.
Figure 11 shows the results for the 16″ sections. For the test set (WellA_ST2_16in), the P50 curve follows the true curve closely for most of the section, while the span between the P10 and P90 curves is around 25 m/h. The MAE and MAPE on the test section are 13.5 m/h and 27.3%, respectively. The test set errors are notably lower than for the first training set (WellA_Pilot_16in), which achieved 19.6 m/h MAE and 29.2% MAPE with the formation-specific training strategy.
The results for the 12.25″ sections with formation-specific models are shown in
Figure 12. In this case, the P50 prediction for the test section has an MAE of 6.21 m/h and a MAPE of 30.3%. This is an improvement compared to the results with the hole-size-specific strategy (
Figure 8), coming mainly from the better prediction in the Sele formation. Also, the predictions with the formation-specific models are less noisy in the Heimdal formation compared to the hole-size-specific strategy. This highlights the advantage of the formation-specific training strategy, which can account for changes in the relationship between ROP and surface parameters due to differences in rock properties, whereas a model trained on an entire hole section would be less likely to capture these changes.
4.3. Comparison of Models Trained on Hole-Size-Specific and Formation-Specific Data
In this section, we compare the performance of the hole-size-specific and formation-specific models based on the four evaluation metrics.
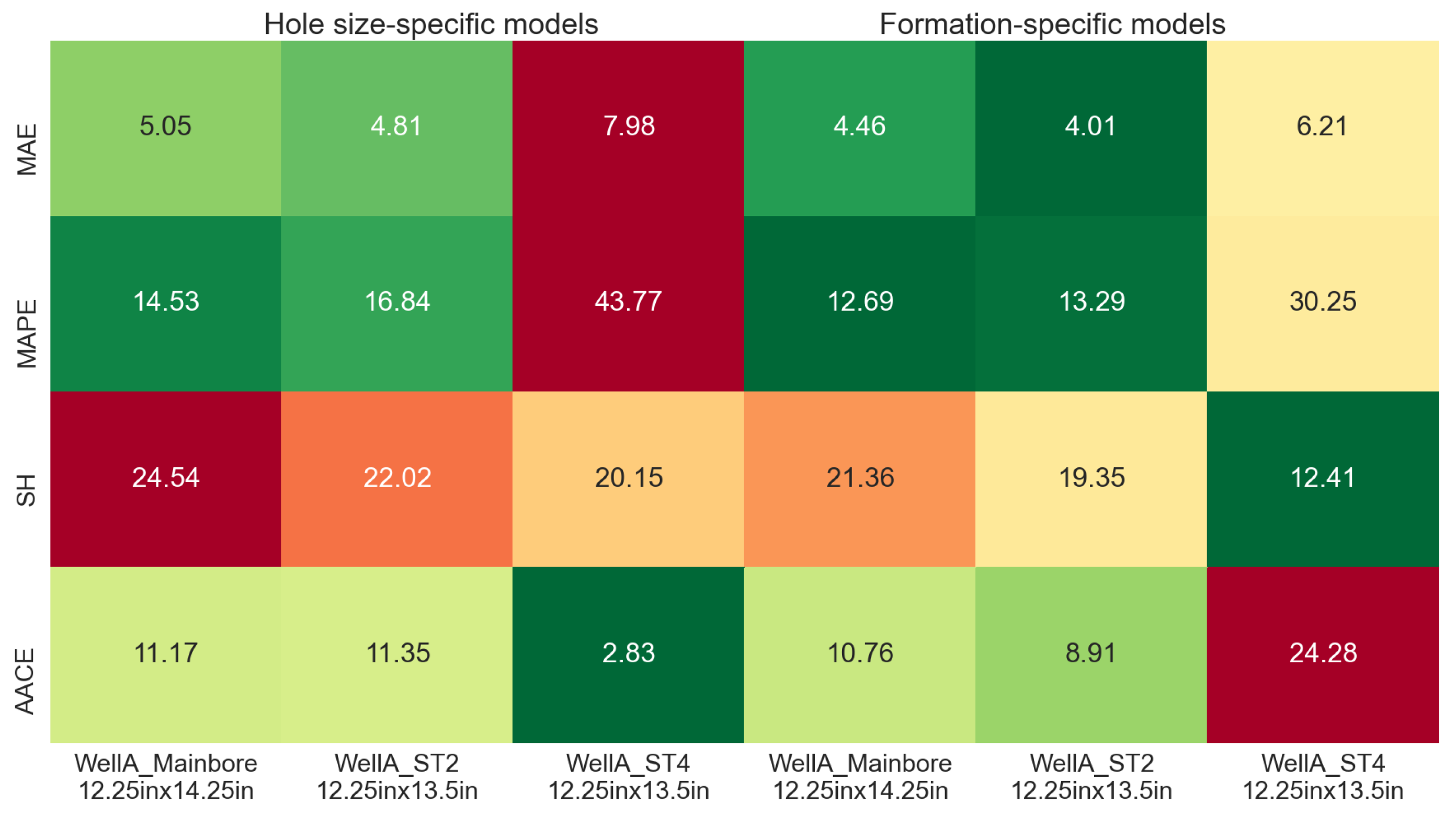
Figure 13 shows the overall performance comparison between the above training strategies on the 16″ sections. The cells are color-coded, with dark green indicating the lowest values for each metric and dark red the highest. For the test set (WellA_Pilot_16in), the MAE is lower with the formation-specific models (13.5 m/h compared to 15.7 m/h for hole-size-specific models), while the MAPE is also improved from 31.3% to 27.3%. While low AACE and high sharpness are considered better from an individual metric point of view, for the overall model performance, a balance between sharpness and AACE should be considered. With the hole-size-specific models, the test set AACE is 0.39%, while for the formation-specific models, it is 28.1%. This corresponds to a sharpness of about 24 m/h, compared to 59 m/h obtained with the hole-size-specific model. The AACE is significantly lower on the test set than on the training sets in the formation-specific case, which can be explained by the large number of ROP observations outside the P10–P90 range (see
Figure 11).
The performance of the different models for the 12.25″ sections is summarized in
Figure 14. For the test set (WellA_ST4_12.25in × 13.5in), the MAE is reduced from 7.98 m/h with the hole-size-specific models to 6.21 m/h with the formation-specific models, and the MAPE is significantly improved from 43.8% to 30.3% The formation-specific strategy resulted in higher sharpness and higher AACE on the test section compared to the hole-size-specific strategy, while for the training sections, both sharpness and AACE were slightly improved, which may indicate the possible overfitting of the models.
4.4. Models Trained on Offset–Well Data
In this section, we present some results from the offset–well training strategy applied on the Well A data sets. Each model is tested on the corresponding hole sections from Well A, including 26" and 17.5", which both use the 26" hole models, since offset–well data for the 17.5" section were very limited. In addition to different offset–well groups, we also evaluate the three different input sets, as explained in
Section 3.4. To provide some representative examples of how the predictions compare with different training and input sets, we choose WellA_Mainbore_12.25in × 14.25in and WellA_ST4_9.5in as the test sets.
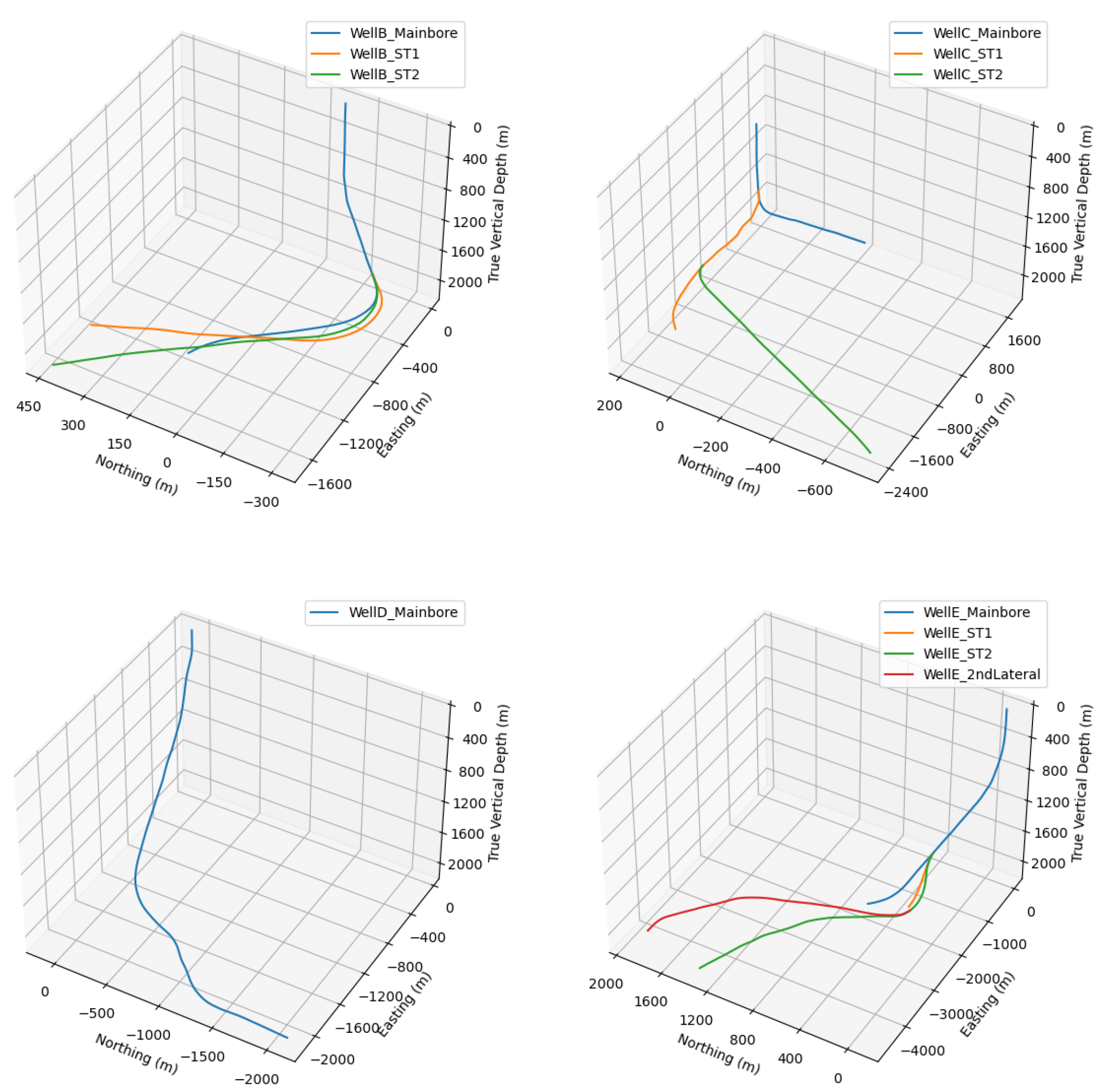
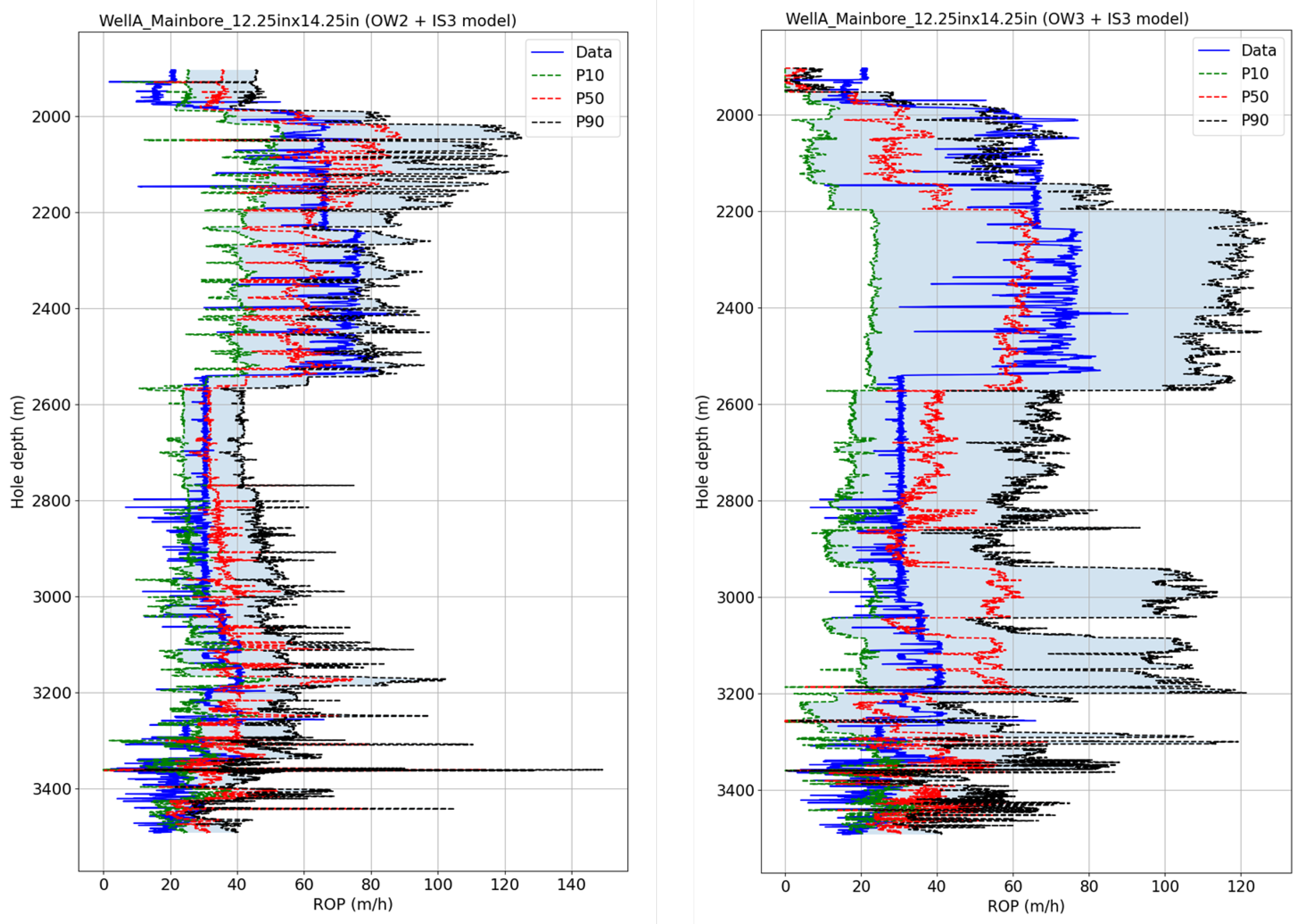
Figure 15 shows the ROP predictions for WellA_Mainbore_12.25in × 14.25in with two different offset–well training sets (OW2 and OW3) for input set 3. The first combination gives the MAE of 10.1 m/h and 34.5% MAPE, while the second one gives the MAE of 14.4 m/h and 42.9% MAPE. The first model has a tighter prediction interval, corresponding to a sharpness of 31 m/h, while the second one has a sharpness of 58.6 m/h, which correspond to AACE values of 4.13% and 2.4%, respectively. These differences can be explained by having more diverse training data in OW3 compared to OW2, which introduces some uncertainty in the prediction and widens the gap between the P10 and P90 curves. The offset–well training set OW3 contains data from WellD_Mainbore_13.5in, WellE_ST1_13.5in and WellE_ST2_13.5in, while OW2 contains only data from WellE_Mainbore_13.5in, which has about three times fewer data points than the OW3 data set. Also, WellE_Mainbore_13.5in recorded less variation in the ROP than the three data sets comprising OW3 (see
Table 2), and the ROP range observed in WellE_Mainbore_13.5in was closer to the one in WellA_Mainbore_12.25in × 14.25in. This can explain both the lower MAPE and narrower prediction interval obtained with the OW2 model compared to the OW3 model.
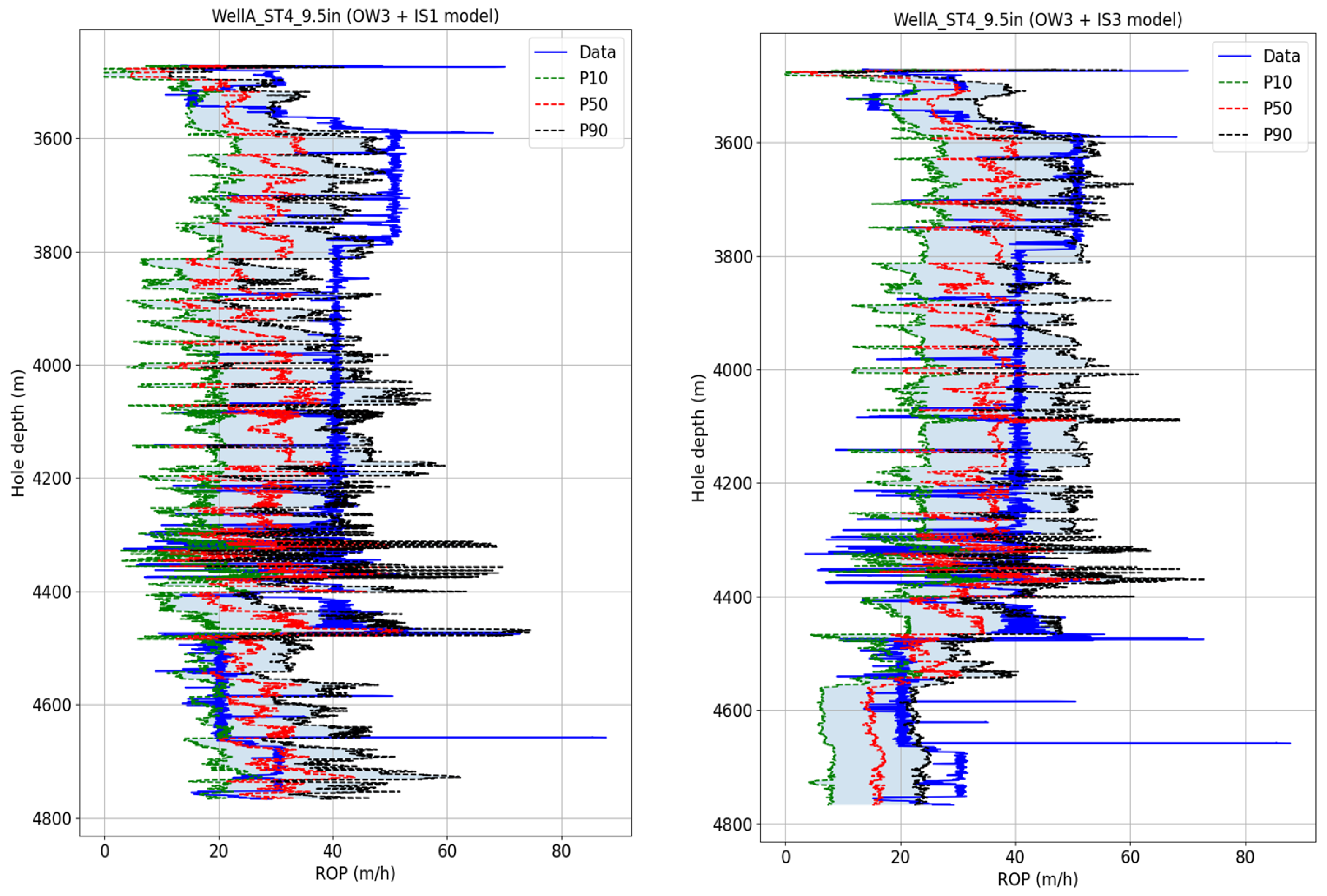
Figure 16 illustrates the ROP predictions for WellA_ST4_9.5in with the OW3 training set for input set 1 and input set 3. The first setup results in the MAE of 12.7 m/h and 36.8% MAPE, while the second one has 8.99 m/h MAE and 28.7% MAPE. The two offset–well models are comparable in terms of sharpness (21.5 m/h for the first one and 21.7 m/h), but the second one has a lower AACE at 15.1% compared to 31.5% for the first one. This can be confirmed by inspecting the plots in
Figure 16, where the true ROP curve on the right plot falls within the prediction interval for most of the section, while the one on the left plot falls out of it at several depths. The improvement in coverage of the true data, as well as the reduction in MAE and MAPE, can be explained by the additional input feature used in the model training, in this case, the flow rate.
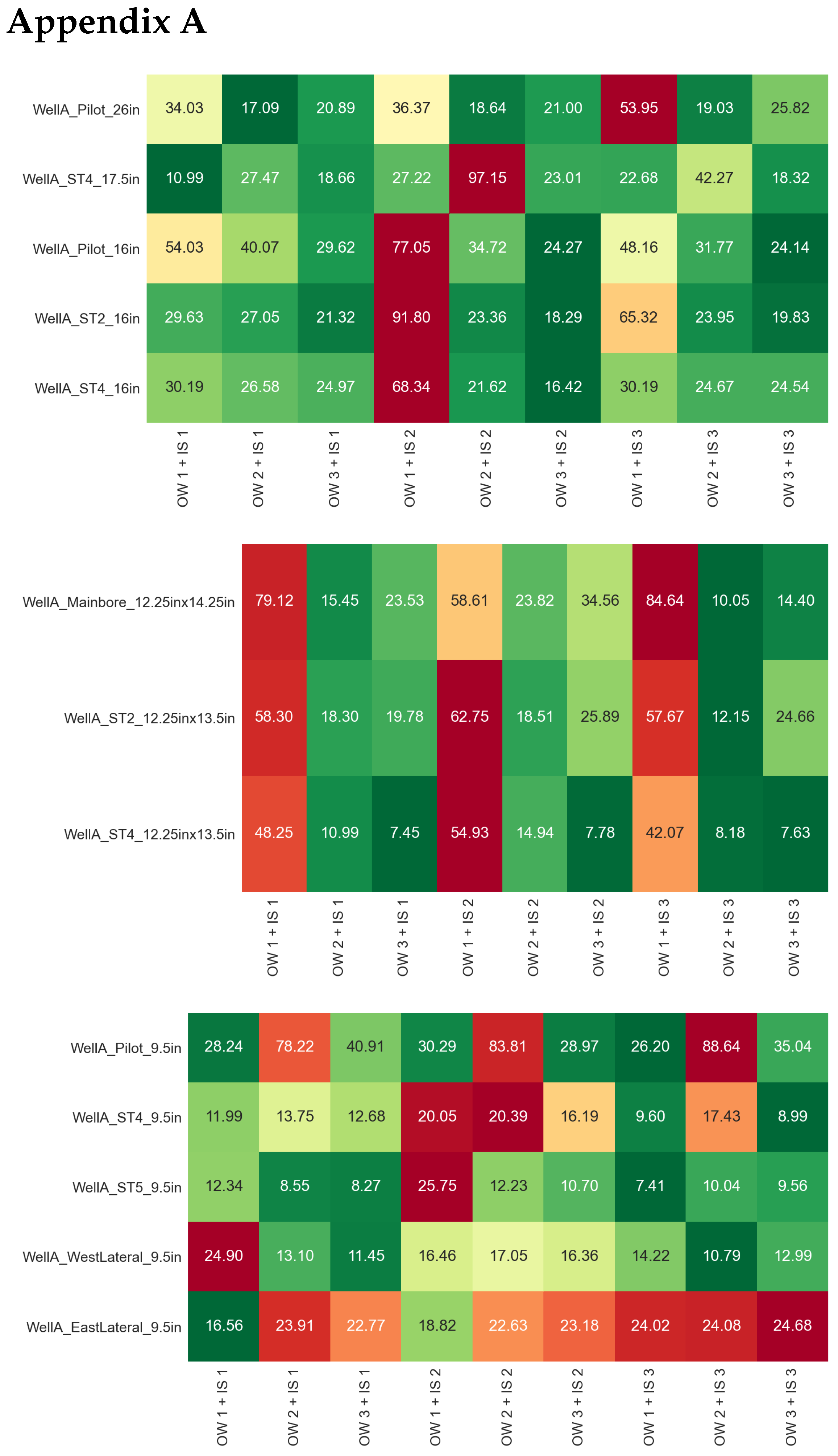
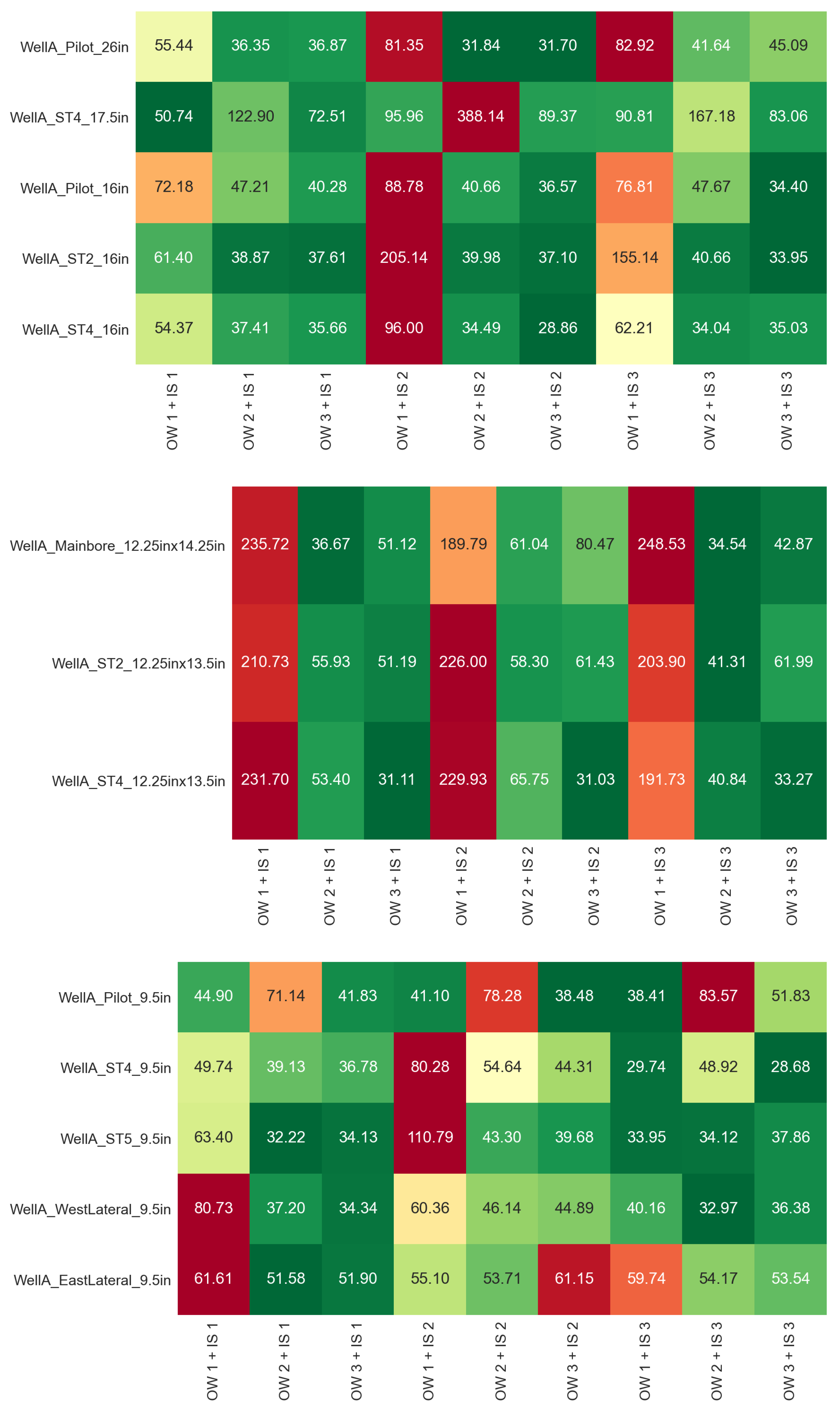
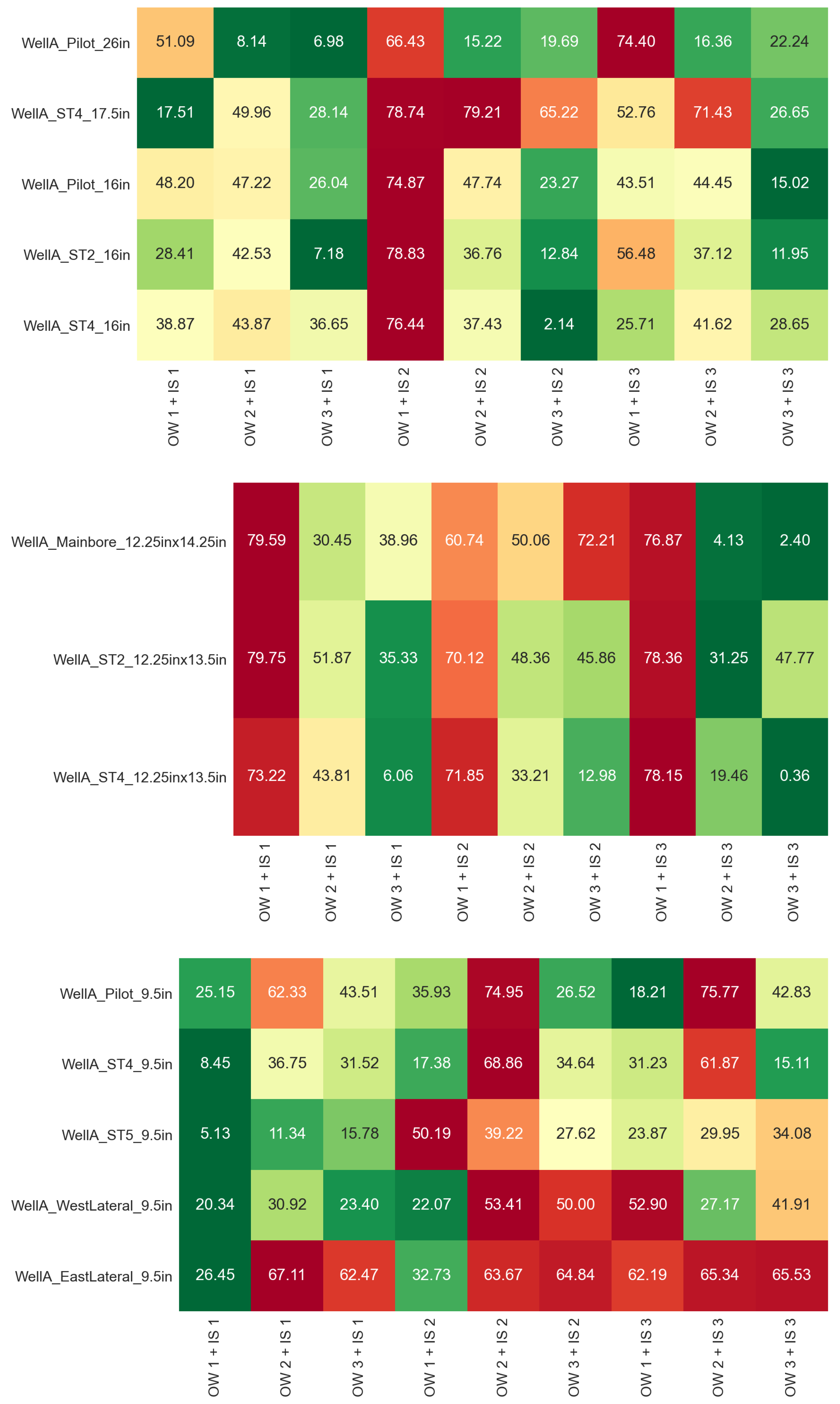
The complete evaluation for the different combinations of offset–well training sets and input feature sets is summarized in
Figure A1,
Figure A2,
Figure A3 and
Figure A4 in
Appendix A, but in this section, we only provide the key findings of this study. We analyze the results separately for the upper (26″, 17.5″, and 16″), intermediate (12.25″), and lower (9.5″) hole sections. A summary of this analysis is provided in
Table 7, which indicates the best model in terms of combined accuracy and robustness for each test set and the corresponding evaluation metrics.
For the upper hole sections, the lowest prediction errors overall are obtained with training set OW3 and input set 2, which gives a MAPE of 31.7% for WellA_Pilot_26in, 89.3% for WellA_ST4_17.5in, 36.6% for WellA_Pilot_16in, 37.1% for WellA_ST2_16in, and 28.9% for WellA_ST4_16in. The results for WellA_ST4_17.5in are quite inaccurate in terms of MAPE (the lowest error is 50.7% with training set OW2 and input set 1), but we recall that it uses the model trained for 26″ hole data and also that part of it was drilled with a roller cone bit, which can explain the reduced accuracy. The AACE generally follows the MAPE, with values as low as 6.98% for WellA_Pilot_26in and 2.14% for WellA_ST4_16in. Regarding the sharpness of the predictions, some models produce a very narrow range of predictions, for example, training set OW1 and input set 2, having a sharpness value as low as 0.72 m/h, whereas the AACE is above 75%.
For the intermediate hole sections, the prediction errors are generally lower, with the combination of training set OW2 and input set 3 and also with training set OW3 and input set 1. The best results in terms of MAPE are 34.5% for WellA_Mainbore_12.25in × 14.25in, 41.3% for WellA_ST2_12.25in × 13.5in, and 31.1% for WellA_ST4_12.25in × 13.5in. The lowest AACE values are reported for training set OW3 and input set 3, going as low as 0.36% for WellA_ST4_12.25in × 13.5in, which is lower than the AACE obtained with the models trained on the 12.25″ hole sections from Well A. On the other hand, training set OW1 with any input combination resulted in very poor accuracy, with a MAPE in excess of 190% and also large values of AACE, despite having low sharpness. These large errors can be explained by the fact that all the intermediate sections in Well A, training set OW2 and training set OW3 were drilled with an under-reamer, whereas the ones in training set OW1 did not use an under-reamer, which likely resulted in different drilling performance. The sharpness for the best-performing models is in the range of 13–25 m/h, which is similar to the range observed for the 12.25″ sections trained on Well A data.
For the lower hole sections (9.5″), there is no single model that outperforms the other ones in terms of combined accuracy and robustness. The best models result in a MAPE of 38.4% for WellA_Pilot_9.5in, 28.7% for WellA_ST4_9.5in, 32.2% for WellA_ST5_9.5in, 33.0% for WellA_WestLateral_9.5in and 55.1% for WellA_EastLateral_9.5in. For WellA_ST4_9.5in and WellA_ST5_9.5in, these results show an improvement compared to the model trained on the Well A 9.5″ sections themselves. Even for the other training set and input combinations, the MAPE stays below 50% for most cases, which can be considered within reasonable accuracy according to [
55]. Regarding the AACE, the combination of the training set OW1 and input set 1 achieved the lowest values overall (8.45% for WellA_ST4_9.5in and 5.13% for WellA_ST5_9.5in), but this comes with a higher MAPE and reduced sharpness. The majority of 9.5″ section models trained on offset wells have a sharpness around 15–20 m/h, compared to 24 m/h and above, which was reported for the model trained on Well A. Comparing this against AACE, it can be concluded that a sharpness around 20–30 m/h is preferable as it generally results in lower AACE for the 9.5″ hole sections. Some of the worst results, in terms of both MAPE and AACE, are recorded for WellA_PilotA_9.5in, which stands out among all the 9.5″ hole sections due to its larger overall ROP and different well inclination (see
Table 1 and
Figure 2). Also, the MAPE and AACE reported on WellA_EastLateral_9.5in are on average very high, which could be due to the presence of hard stringers and vibrations that may cause very different downhole conditions from the ones in the training sections, which affects the relationship between ROP and the surface drilling parameters. Therefore, it may be preferable to use this entire section or at least part of it for training the ROP model, as in
Section 4.1.
5. Discussion
Data-driven models for ROP prediction rely on large amounts of training data, either from different sections of the same well or from the nearby offset wells. Our model, based on the offset–well data, achieves predictions with good accuracy and robustness. As mentioned above, the presence of downhole vibrations may impact the relationship between ROP and the surface drilling parameters, leading to prediction errors. To improve model performance, inputs from downhole mechanical measurements (e.g., RPM, WOB, and torque measured in the BHA) could be added to the ROP model for wells where such downhole measurements are available. Another source of prediction error can be related to the geological and mechanical parameters of the rock formations drilled, which were not available from the drilling operation reports analyzed as part of our study. With the formation-specific training strategy, this error was reduced, but possible uncertainty related to the depth where a formation is encountered across different wells can also contribute to the prediction errors. In addition, short, hard stringer intervals interbedded in a softer formation are difficult to capture in the training data. If rock mechanical parameters are available, it would be possible to identify the hard stringers and use a separate ROP model training strategy for the intervals containing hard stringers.
In our study, we observed that not all offset–well data are relevant or useful for training the model. To ensure that the model is accurate and reliable, it is important to carefully select the offset–well data that are used for training the ROP models. ML and similarity analysis can help in the selection of representative training data sets.
One criterion that can be considered in this selection process is the distance to the target well, such that the model is trained on data that are geographically relevant, and similar lithologies are encountered during the drilling process. Lithology information can further improve the training, but if it is available, the uncertainty in the formation tops should be taken into account. Another criterion is to select offset wells that were drilled during a similar time period, as the target well can ensure that the model is trained on data that are more relevant to the current drilling conditions and operational practices. Selecting offset–well sections that have a similar well trajectory and orientation (vertical/inclined/horizontal) to the target well can also help improve the model quality.
The type of drill bit used (polycrystalline diamond compact, roller cone, or hybrid bit) and other downhole equipment (e.g., under-reamer, rotary steerable system, or downhole motor) should be the same as in the target well. The drilling platform type should also be similar, particularly for offshore drilling, where rig heave can have a significant impact on the drilling process and sensor readings. Here, the information on whether an active or passive heave compensation system is present could also be relevant. Finally, the selection process should prioritize offset wells that did not experience any drilling incidents, such as high levels of vibration, drill bit damage, stuck pipes or lost circulation, such that the model is trained only on data that are representative of normal drilling conditions. On the other hand, those wells or sections can be used to train dedicated models accounting for degradation in drilling conditions, for example, ROP models corresponding to different degrees of bit wear, which could be used to detect bit wear from real-time data in the target well.
Further work on this topic should explore the application of the QRDNN model in the context of data-driven drilling optimization by using the model predictions with the provided measure of confidence to aid in the selection of drilling parameters that maximize ROP while staying within operational constraints.
6. Conclusions
We presented an application of quantile regression deep neural network (QRDNN) models for the prediction of the rate of penetration (ROP) in a multi-lateral well drilled in the North Sea. Given the highly uncertain conditions of offshore drilling over several kilometers, QRDNNs provide not only a best-guess prediction (the median) but also an uncertainty range (from P10 to P90), offering valuable insight into potential variations in drilling performance without any additional calibration.
We analyzed the sensitivity of the results to inputs: a feature set comprising WOB, surface RPM, surface torque, and flow rate yielded the best performance in most cases. However, the primary focus was training data selection for the QRDNN model to balance accuracy and robustness. Three training strategies were evaluated based on hole size, formation tops, and offset–well data. The key quantitative findings are as follows:
The hole-size-specific training strategy produced accurate predictions on the training sets, but the mean absolute percentage error (MAPE) on test sets from the same well was relatively high, with a MAPE of 31.3% on the 16″ hole section, 43.8% on the 12.25″ section, and 32.4% and 56.7%, respectively, on two 9.5″ hole sections. On the other hand, the absolute average coverage error (AACE) was below 10% for all the test sections evaluated.
The formation-specific training strategy reduced the MAPE, producing a result of 27.3% for the 16" test section and 30.3% for the 12.2" test section. At the same time, the AACE increased above 24% for both test sections due to narrower prediction intervals (outer-quantile overfitting) compared to the first strategy.
The offset–well training strategy achieved a MAPE as low as 31.7% for the test well 26″ hole section, 28.9% for the 16″ hole sections, 31.1% for the 12.25″ hole sections, and 28.7% for the 9.5″ hole sections. The observed AACE was also low: 6.98% for 26″, 2.14% for 16″, 0.36% for 12.25″, and 5.13% for 9.5″ hole sections respectively. We observed that the inclusion of more offset wells in the training set reduced the MAPE and AACE and estimated more uncertainty in the predictions.
Thus, we recommend the offset–well training strategy for QRDNN-based ROP prediction. Within this approach, including more offset wells in the training set ensures lower prediction errors and better uncertainty estimation. This combination provides both accurate predictions and a quantifiable measure of confidence, making QRDNNs a valuable data-driven tool for drilling performance optimization.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}