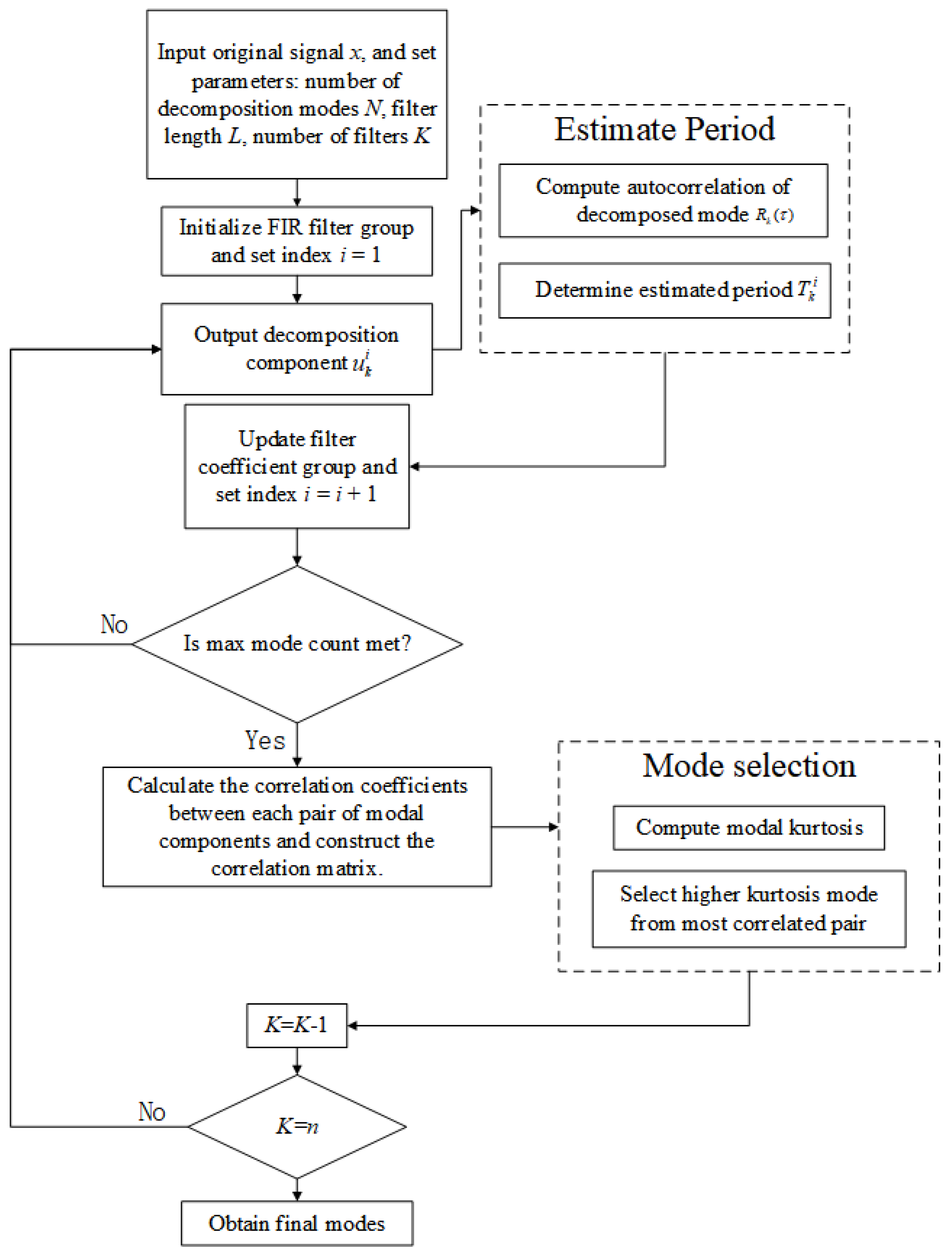
2.1. Principles and Characteristics of FMD
When the OLTC operates under mechanical fault scenarios, its vibration responses embed rich diagnostic characteristics that reflect distinct fault behaviors. FMD, initially designed for diagnosing faults in rotating equipment, is adapted in this study to suit OLTC diagnostic requirements and aims to iteratively extract modal components that carry diagnostic features by applying a sequence of limited-bandwidth impulse response filters. This approach suppresses irrelevant components while improving the separability and interpretability of fault-relevant features [
13]. FMD has exhibited strong adaptability and reliability in the context of OLTC fault diagnosis. The fundamental procedure of FMD signal decomposition is summarized as follows:
Provide the input signal x, define the filter length T, and initialize the iteration index i = 1. Specify the total number of filters K, then perform the initial modal decomposition based on the current parameters.
Output the decomposition components , where , ‘’ indicates convolution, and fk represents the k-th finite impulse response (FIR) filter.
Utilize the original signal x, the decomposed component
, and the calculated period
to update filter coefficients.
is identified as the time lag at which the autocorrelation function
reaches its peak after the zero crossing event. The autocorrelation is calculated as follows:
where
τ denotes the time delay and
t is the time index of the signal. Finally, the iteration index is updated as
i =
i + 1.
Continue to Step 2 if the predefined iteration limit has not been met; otherwise, move forward to Step 5.
Compute the correlation coefficient
for every pairwise combination of modal components
and
, using the formula below.
where
denotes the mean value of the corresponding modal component. Form a
matrix
containing the pairwise correlation coefficients, and identify the modal component with the lowest correlation—i.e., the one associated with the smallest maximum value in its corresponding row (or column) of
.
Compute the periodic correlation degree
CK of each modal component
uk using the following formula:
where
M is the correlation order, representing the number of periodic points used in the computation of
CK. The mode exhibiting the highest degree of periodic correlation is designated as the final extracted component. Then, increment the mode index:
K =
K + 1.
Assess whether the total number of extracted components K has attained the set value N. If this requirement is met, continue to Step 8; otherwise, revert to Step 2 and repeat the decomposition.
A schematic representation of the FMD algorithm is provided in
Figure 1.
The performance of FMD in analyzing OLTC vibration signals is highly sensitive to the parameter settings, which significantly affect the decomposition results [
24,
25,
26]. A short filter length
L may result in under-decomposition, whereas an excessively long filter may introduce significant noise into the decomposed components. Similarly, setting too few number of modes
N may cause the loss of critical features, while too many modes may result in redundant information [
15,
27]. The number of filters
K also plays a crucial role—if improperly chosen, it can either reduce the decomposition resolution or increase computational complexity unnecessarily [
28]. Since FMD lacks an inherent mechanism for adaptive parameter selection, optimization algorithms are required to perform parameter tuning and ensure the accurate extraction of critical fault features from OLTC vibration signals.
2.2. FMD Parameter Optimization via GOA
GOA draws inspiration from natural predator–prey dynamics and operates within the framework of swarm intelligence techniques [
14,
29]. The optimization process begins with the random initialization of a gazelle population, which serves as candidate solutions in the search process. The population is represented by an
position matrix
X, where
n denotes the number of agents and
d is the dimensionality of the problem. Each row in
X denotes the position vector of a candidate gazelle in the search domain. Gazelle population positions are defined by the position matrix
X as shown in Equation (4) as follows:
where
xi,j indicates the location of the
i-th gazelle in the
j-th dimension. The number of gazelles is
n, and the dimensionality of the problem space is
d. Each element
xi,j is initialized using the following:
where a random variable is
, and
UBj and
LBj represent the minimum and maximum permissible values along the
j-th search dimension. After each iteration, all individuals are evaluated using the fitness function. The top-performing gazelles are selected as elites, and their positions are stored in the elite matrix
E for guidance in subsequent generations. The elite matrix
E stores the positions of the top-performing individuals (elite gazelles), and is defined as follows:
where
denotes the coordinate of the
i-th elite individual along the
j-th axis.
During the development phase, each gazelle updates its position through a stochastic movement governed by the following rule:
where
gi represents the present location of the
i-th gazelle;
v refers to the movement scaling coefficient; and
are random values drawn from a uniform distribution.
Ei corresponds to the position vector of the associated elite agent from matrix
E.
When a predator is detected, the gazelle initiates an escape response modeled by either Lévy flight or Brownian motion. This process involves two stages: a global exploration phase characterized by large step movements and a local exploitation phase involving fine-tuned adjustments. The corresponding position update equations are defined as follows:
where
S represents the upper bound of the gazelle’s movement speed;
λ is the directional control factor;
RL and
RB are Lévy-distributed and Brownian-distributed random vectors, respectively;
is a uniformly distributed random number;
Ei is the position of the
i-th elite gazelle;
gi is the current position of the
i-th gazelle;
m and
T denote the current and the maximum allowed iterations; and
CF decreases in a nonlinear manner as iterations proceed, aiming to achieve a trade-off between exploration and exploitation.
To improve the algorithm’s potential for escaping from local optima, a predator–prey strategy is employed. This strategy simulates the natural behavioral shift between escape and social movement observed in prey animals. A decision is made based on a comparison between a random variable uniformly sampled from the interval
and the predation success rates (
PSRs). If
, the gazelle performs a random relocation within the search space boundary using a controlled scaling factor. Otherwise, a differential movement is executed based on randomly selected individuals from the population. The position update rule, which mathematically models this predator–prey strategy, is defined in Equation (11) below.
where
CF is the control factor from Equation (10), and
is a uniformly distributed random number. The binary control variable
U is defined as follows:
where,
gr1,
gr2 are two randomly selected position vectors from the current population. The variable
U is used to probabilistically suppress position updates in certain dimensions, thereby introducing adaptive stochastic behavior during the escape process.
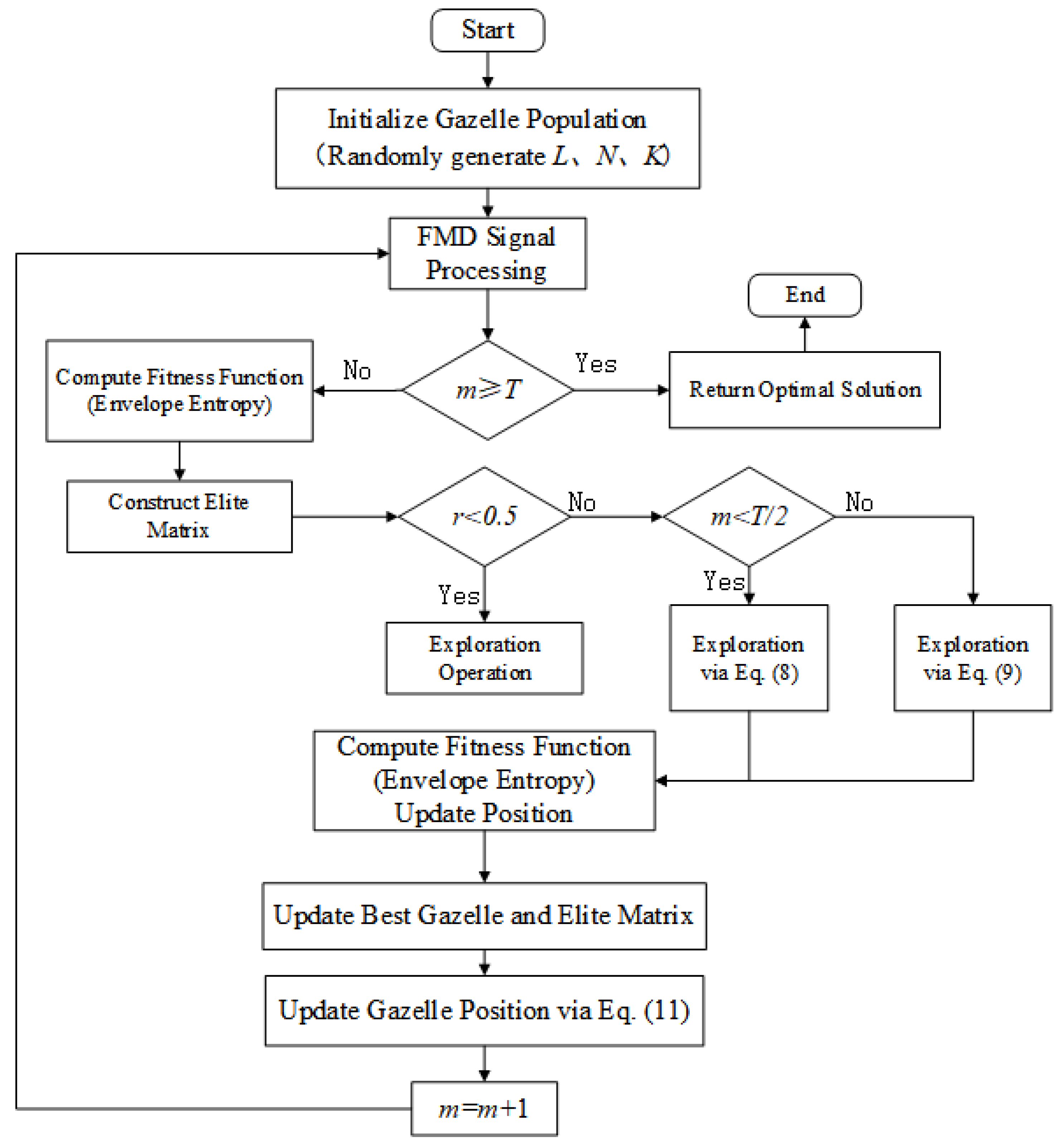
This work utilizes the GOA to optimize three parameters of the FMD process: the number of filters
K, the filter length
L, and the mode number
N. The algorithmic flow for GOA-based parameter optimization is depicted in
Figure 2. In the diagram,
denotes a uniformly distributed random number, and
T represents the predefined maximum number of iterations, while
m indicates the index of the current iteration.
Each gazelle represents a parameter combination {
L,
K,
N} corresponding to the filter length, the number of filters, and the mode number, respectively. FMD is applied to the original signal using these parameters, and the envelope entropy of the decomposed signal is used as the fitness function, which is defined as follows:
In these equations,
ak corresponds to the amplitude value of the
k-th component in IMF set after envelope extraction, and
pk is the normalized amplitude. A lower envelope entropy implies that the extracted features are more concentrated and that the noise is reduced, which is advantageous for accurate fault identification [
30,
31].
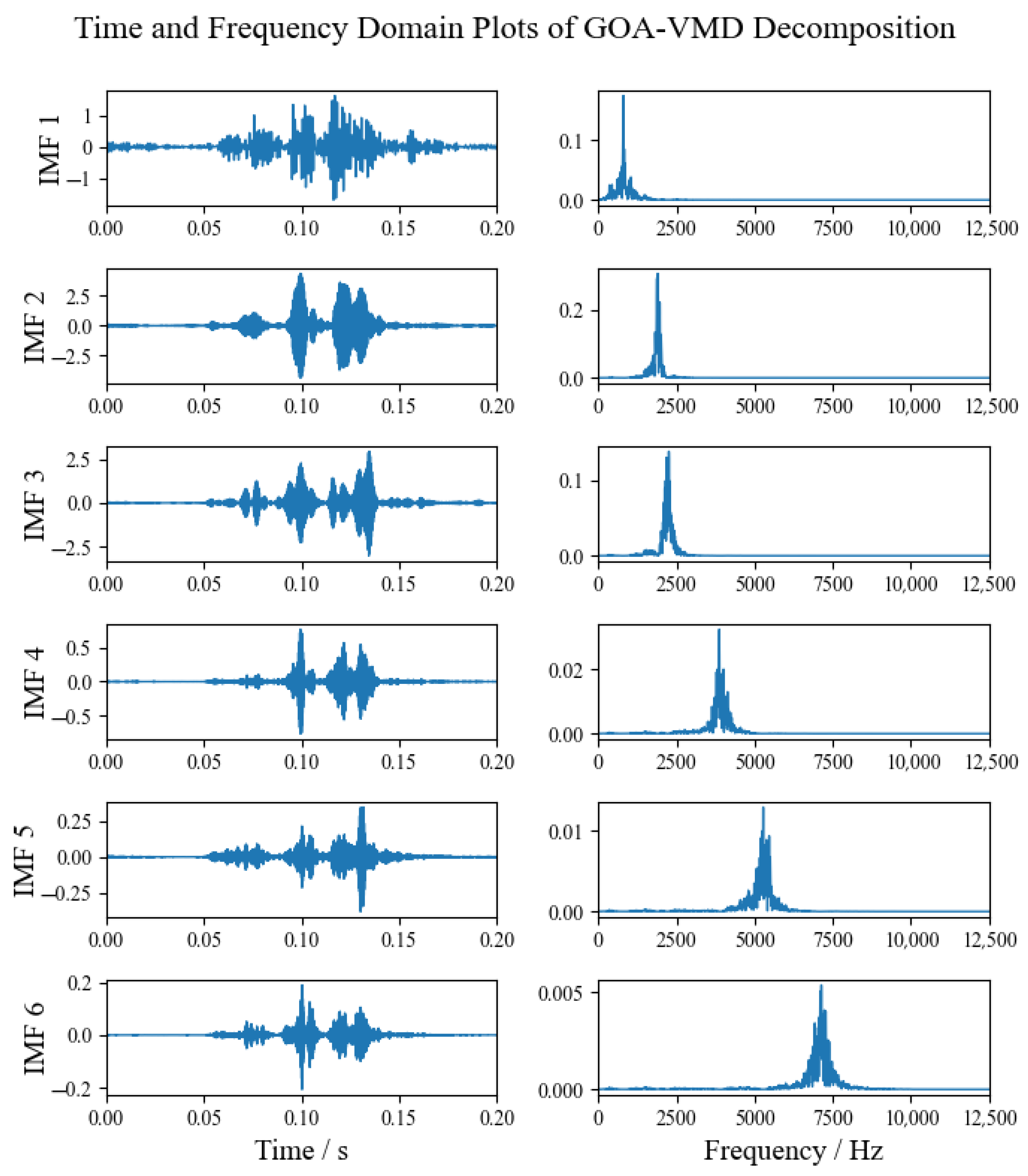
2.3. Time Domain Feature Extraction from Vibration Signals
The FMD process generates IMFs, each corresponding to specific frequency bands of the OLTC vibration signals, thereby capturing critical information reflective of the system’s operational state. In order to characterize the impulsive and oscillatory behavior of the signal, four typical statistical indices in the time domain—namely peak factor, impulse factor, waveform factor, and margin factor—are computed from the IMFs [
32,
33,
34,
35].
The peak factor (
PF), which quantifies the signal’s sharpness or impulsiveness, is mathematically described as follows:
A high peak factor typically reveals sudden transient phenomena within OLTC vibration signals, often caused by mechanical shocks or abrupt contacts. The impulse factor (
IF) reflects the impulsiveness of the signal and is expressed as follows:
For impact-type faults in OLTC systems, the impulse factor tends to exhibit significantly elevated values. The waveform factor (
WF) describes the waveform characteristics and distortion level of the signal. It is computed by the following:
This metric is frequently employed to assess the extent of waveform deformation and to distinguish periodic shock patterns from stochastic noise elements in the signal. The margin factor (
MF) reflects whether the signal contains isolated high peaks, and is defined as follows:
This indicator evaluates whether the signal is approaching an extreme operating condition. A relatively large margin factor implies the presence of a prominent, isolated peak in the signal, which often corresponds to a transient event or an abnormal operating state.
2.4. Transformer-Based Classification Model Architecture and Implementation
The multiple intrinsic mode functions (IMFs) derived from the decomposition of the OLTC vibration signals exhibit varying levels of significance and distinct time domain characteristics. In addition, potential correlations may exist among the IMFs, which necessitate that classification models account for inter-feature dependencies. The Transformer, recognized as a cutting-edge deep learning framework, excels in modeling sequences and capturing global feature relationships, rendering it highly effective for handling intricate temporal data [
21,
22,
36].
The proposed Transformer-based classification model comprises an encoder module and a classification head. The model receives a 24-dimensional input vector, derived by calculating four time domain statistical indicators from each of the six extracted IMFs. Positional encoding is initially added to preserve the sequential information. The encoded input is then processed by a multi-head self-attention mechanism, consisting of two encoder layers with four attention heads each and a model dimensionality of 128. The processed output is passed through a dense layer containing 64 neurons, followed by a Dropout operation set at a rate of 0.1 to reduce the risk of overfitting. Finally, a Softmax activation layer is employed to produce the classification probabilities. The schematic diagram of the designed model architecture is shown in
Figure 3.
To ensure both robust feature representation and architectural simplicity, the model is tailored for fault diagnosis, particularly in cases with scarce annotated data [
37]. The configuration parameters employed in the Transformer model are summarized in
Table 3.
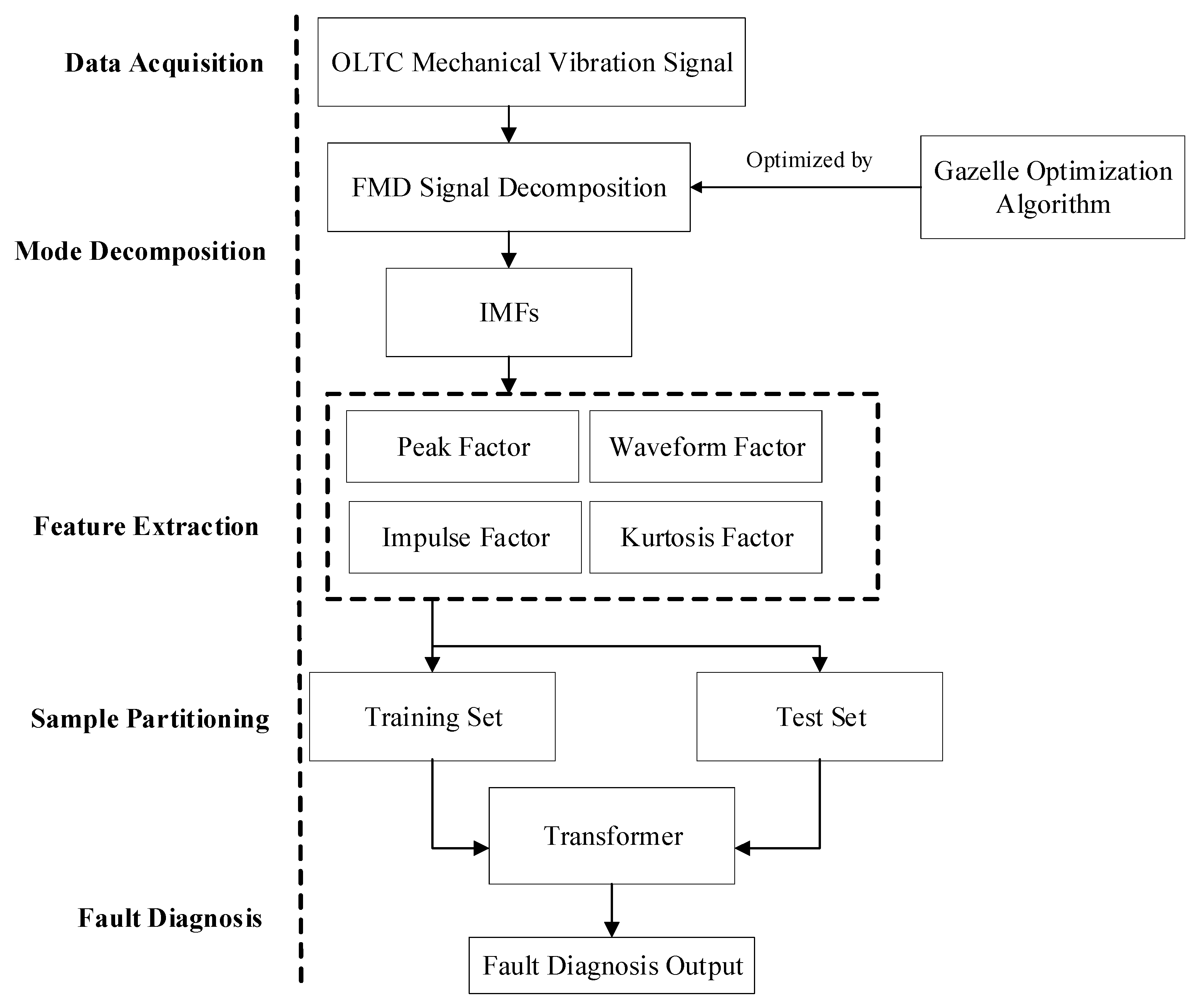
Based on the aforementioned model architecture and training configuration, the proposed OLTC mechanical fault diagnosis framework consists of five key stages: data acquisition, modal decomposition, feature extraction, sample construction, and fault classification. The overall process is illustrated in
Figure 4.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}