1. Introduction
Under the carbon neutrality target, the rapid growth of integrated wind power intensifies grid stability challenges caused by wind energy’s inherent intermittency. Wind power prediction, as a key link in new energy dispatch and stable operation of the power grid, has received widespread attention in recent years. Accurate wind power prediction not only helps improve the operational efficiency of the power system, but also enhances the grid’s ability to accept fluctuating power sources, thereby promoting the effective utilization and integration of wind energy. In this context, it is particularly important to study efficient wind power prediction methods.
The forecasting tasks for wind power can be divided into three categories based on time scale: ultra short term (minute level), short term (hour level), and regional day ahead forecasting. Among them, ultra-short-term forecasting focuses on real-time processing of high-frequency data, while short-term forecasting requires a balance between accuracy and computational efficiency. Current research on ultra-short-term and short-term wind power forecasting has continued to deepen in aspects such as model improvement and combination, feature extraction, and interpretability. Regarding predictive model applications, early research relied heavily on statistical models (such as autoRegressive integrated moving average (ARIMA), support vector machine (SVM)), or traditional machine learning (such as artificial neural network (ANN)), but was limited by its ability to model volatility, randomness, and complex nonlinear relationships, making it difficult to meet high-precision requirements [
1]. With the rise of deep learning technology, models based on long short-term memory model (LSTM), gated recurrent unit (GRU), temporal convolutional network (TCN), Transformer, etc., have become mainstream due to their strong ability to capture temporal features. However, single models still have insufficient generalization ability in complex meteorological scenarios, prompting researchers to turn to hybrid models. For example, reference [
2] combines wave division (WD), improved gray wolf optimizer based on fuzzy C-means clusters (IGFCM), and Seq2Seq model with attention mechanism based on LSTM to propose a new short-term wind power prediction method. However, RNNs like LSTM and GRU cannot parallelize computations due to sequential time-step processing, leading to slower computational speed. Their hidden state transmission mechanisms also suffer from gradient vanishing/exploding when modeling long-term dependencies. Reference [
3] designed a multitask learning framework called multi-task temporal feature attention—LSTM (MTTFA-LSTM) that integrates attention mechanisms to enhance multivariate prediction capabilities. However, standalone attention layers only perform single global interaction on input sequences, lacking the hierarchical information refinement of Transformer encoders (shallow layers capture local patterns; deep layers integrate complex semantics), resulting in insufficient feature representation depth. A convolutional neural network—bidirectional LSTM (CNN-BiLSTM) model was constructed by combining multi-head attention mechanism in reference [
4], which captures long-term dependencies in wind power time series through global feature extraction. While multi-head attention improves representation ability by parallelizing multiple attention heads to capture diverse interaction patterns, it remains purely linear operations without stabilization mechanisms for deep stacking. Additionally, Reference [
5] combines CNN and LSTM to extract spatiotemporal features, and reference [
6] proposes a novel hybrid structure for wind power interval prediction based on predicted density estimation. Reference [
7] proposed an adaptive weighted combination prediction method based on deep deterministic policy gradient (DDPG) to consider local behavior accompanied by external environmental changes. Reference [
8] used ensemble learning methods to combine preprocessing methods, empirical mode decomposition (EMD), information-based methods, permutation entropy (PE), and machine learning techniques (artificial neural networks, ANNs) to achieve stronger wind power prediction performance than a single ANN. Reference [
9] proposed a new neural network-based ensemble system for predicting wind speed.
In addition, the quality of feature extraction directly impacts predictive performance. Current research optimizes input features through strategies such as multi-source data fusion, feature selection and denoising, and decomposition techniques. In terms of multi-source data fusion, reference [
10] integrates meteorological data (wind speed, wind direction, temperature, pressure), geographic information (wind field layout), and historical power data. Reference [
11] proposed a cross regional data transfer learning framework (WG Refine), but its adaptability to complex terrain areas still needs to be validated. In terms of feature selection and denoising, reference [
1] adopts a hybrid adaptive decomposition denoising algorithm to solve the problems of unreasonable decomposition and residual noise. In terms of decomposition techniques, methods such as variational mode decomposition (VMD) and empirical mode decomposition (EMD) are widely used in multi-scale analysis. Reference [
12] combines VMD and GRU to achieve accurate wind power prediction, while reference [
7] decomposes subsequences into VMD and inputs them into ANN. Meanwhile, references [
4,
13] used the multivariate variational mode decomposition (MVMD) method to simultaneously analyze wind power and meteorological sequences. Reference [
14] uses the Energy Entropy Theory (EVMD) to determine the number of VMD and solve the problem of excessive VMD. Reference [
15] proposes a VMD-CEMDAN dual decomposition strategy to improve model prediction accuracy. The quadratic decomposition ensemble BiLSTM model in reference [
4] reduces noise interference through multi-level decomposition. The aforementioned studies have not adequately considered the incomplete feature extraction at individual time steps from a local-global perspective, nor have they sufficiently explored how to improve accuracy through this approach.
In addition, in terms of model interpretability, existing research has gradually introduced feature analysis and visualization methods. Reference [
16] combines the SHAP (Shapley Additive exPlans) algorithm to quantify the importance of features and clarify the impact of key variables such as wind speed and temperature on prediction results; reference [
17] proposed the IFTT model, which utilizes Variable Attention Network (VAN) and Decoupled Feature Temporal Self Attention Network (DFTA) modules to enhance interpretability and provide a basis for decision support. However, most deep learning models still face the “black box” problem and urgently need to develop interpretable frameworks (such as attention visualization) to provide transparent explanations for the decision-making process. Although the inertia seal optimization algorithm (ISOA) in reference [
1] improves model robustness by dynamically adjusting parameters, the physical meaning analysis of providing weight allocation is not yet complete. In addition, although the Graph Attention Network (GAT) in reference [
18] can model the spatial correlation of wind fields, its graph structure construction process relies heavily on manual experience and urgently needs to be combined with automated graph learning methods (such as GraphSAGE) to improve interpretability. Current interpretability methods predominantly rely on post hoc interpretation tools, neglecting intuitive visualization of latent regularities within the features actually extracted by models.
In summary, three critical research gaps persist:
- (1)
Feature Decoupling Deficiency: While extensive exploration has been conducted on hybrid models in wind power forecasting, few architectures systematically integrate the global dependency modeling advantages of Transformers with the local feature extraction capabilities of Temporal Convolutional Networks (TCNs). This separation prevents synergistic interaction between two critical features: on one hand, Transformers can model long-term dependencies across time steps but may lose local fluctuation details and native sequential characteristics due to positional encoding mechanisms; on the other hand, TCNs excel at capturing sequential order and local features but exhibit weaker global feature extraction due to limited receptive fields. This fragmentation creates a “global-local imbalance” dilemma in complex wind power scenarios—prediction accuracy remains improvable when handling highly volatile sequences.
- (2)
Dynamic Adaptation Gap: Mainstream hybrid models depend on static fusion strategies (e.g., simple concatenation or fixed-weight summation), failing to adapt to dynamically evolving wind power fluctuation patterns. Meanwhile, adaptive activation function properties are often overlooked. Breaking through these rigid mechanisms can enhance deep learning models’ adaptive feature fusion capabilities, further improving training quality and predictive accuracy.
- (3)
Interpretability Barrier: Existing studies face “interpretability fragmentation” issues. Traditional methods either ignore self-interpretability exploration or depend on post hoc tools, seldom focusing on the latent regularity expressions of extracted features themselves. This hinders deeper understanding of how deep learning models comprehend features.
To bridge the aforementioned research gaps, this study makes the following contributions:
- (1)
Feature Decoupling-Fusion Paradigm: Addressing the “global-local imbalance”, we propose a dual-channel temporal learning architecture that innovatively integrates Transformer’s global dependency modeling with TCN’s local feature extraction. This hybrid framework combines series-parallel configurations to preserve original sequence characteristics lost during Transformer encoding. The global channel employs Transformer encoder to capture long-term temporal evolution patterns, while the local channel utilizes dilated convolution TCN residual blocks to precisely extract localized abrupt features after linear transformation. Prior to model training, we apply the Isolation Forest algorithm [
19] for unsupervised outlier detection in wind power data, exploring internal two-dimensional patterns and eliminating anomalies.
- (2)
Dual-Level Adaptive Learning Mechanism: We introduce dynamic optimization at both feature fusion and activation function levels. For feature fusion, we replace static weights with learnable parameters through differentiable channel weighting optimization. The architecture integrates ACON adaptive activation functions to enhance dynamic regulation capabilities during training, breaking through conventional deep learning models’ adaptability limitations.
- (3)
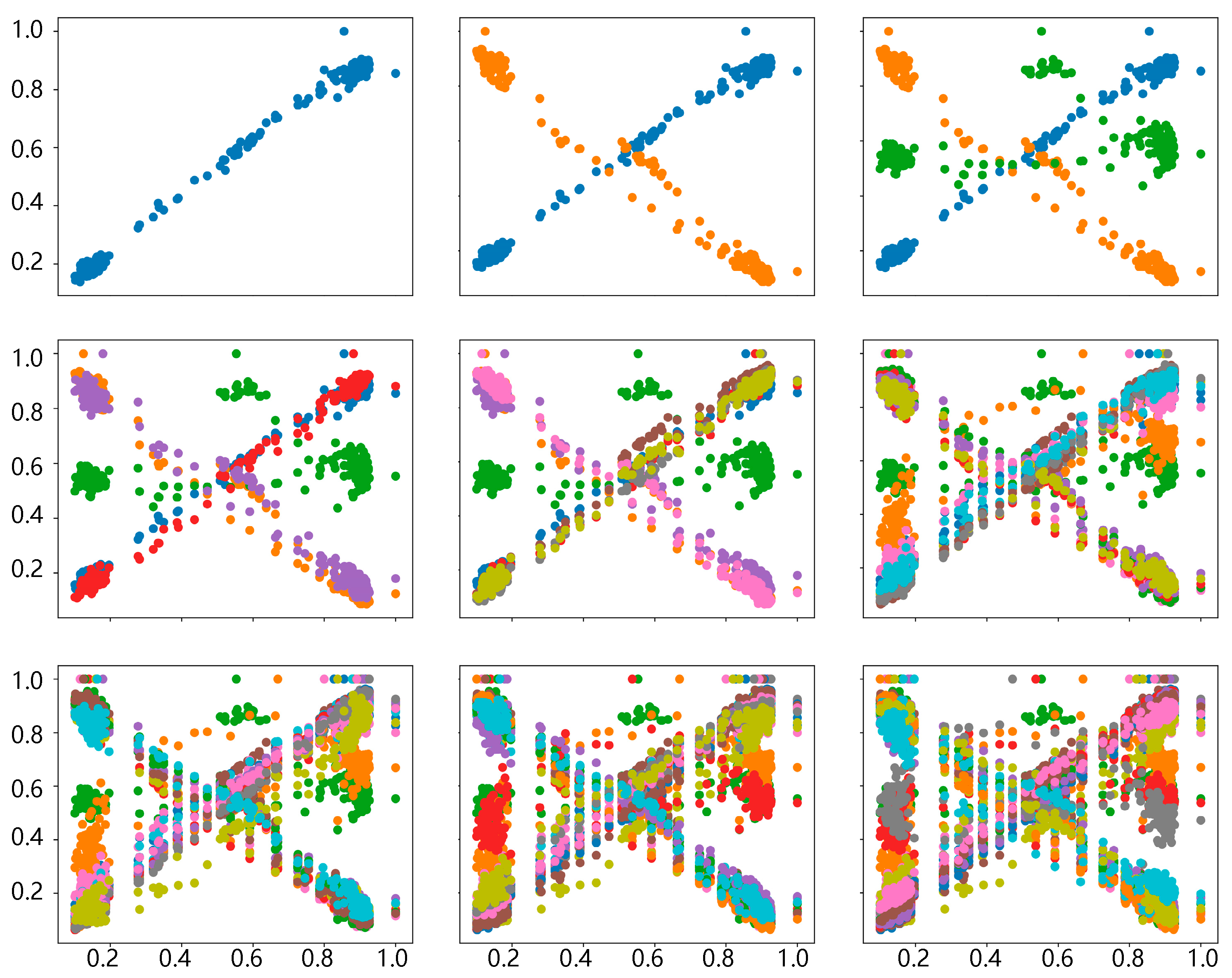
Interpretable Feature Visualization: We visualize adaptively fused features through scatter/kde plots, demonstrating the model’s intrinsic understanding of wind power characteristics. This visualization facilitates interpretation of how deep learning models comprehend temporal features through our dual-channel extraction and adaptive fusion processes.
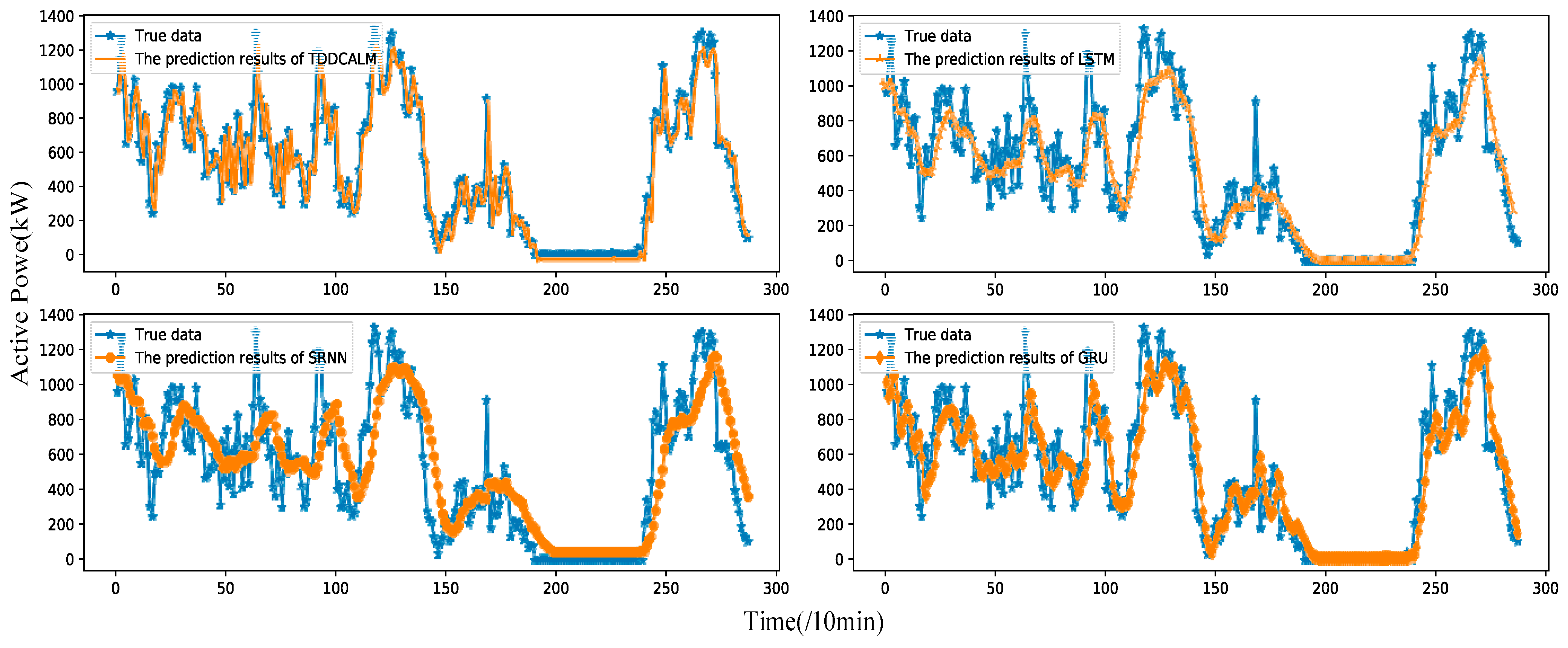
To verify the reliability of the proposed method using actual wind power datasets, comparisons with traditional models showed that this method can effectively extract the characteristics of severe fluctuations in time-domain signals, and the prediction results are sufficient to meet the accuracy requirements of short-term wind power prediction. Without any artificial noise reduction, it can still achieve good results.
The rest of this paper is organized as follows:
Section 2 introduces the data processing workflow.
Section 3 describes the basic architecture of the TDDCALM.
Section 4 presents the short-term wind power prediction method based on the TDDCALM.
Section 5 details the case study section.
Section 6 concludes this paper.
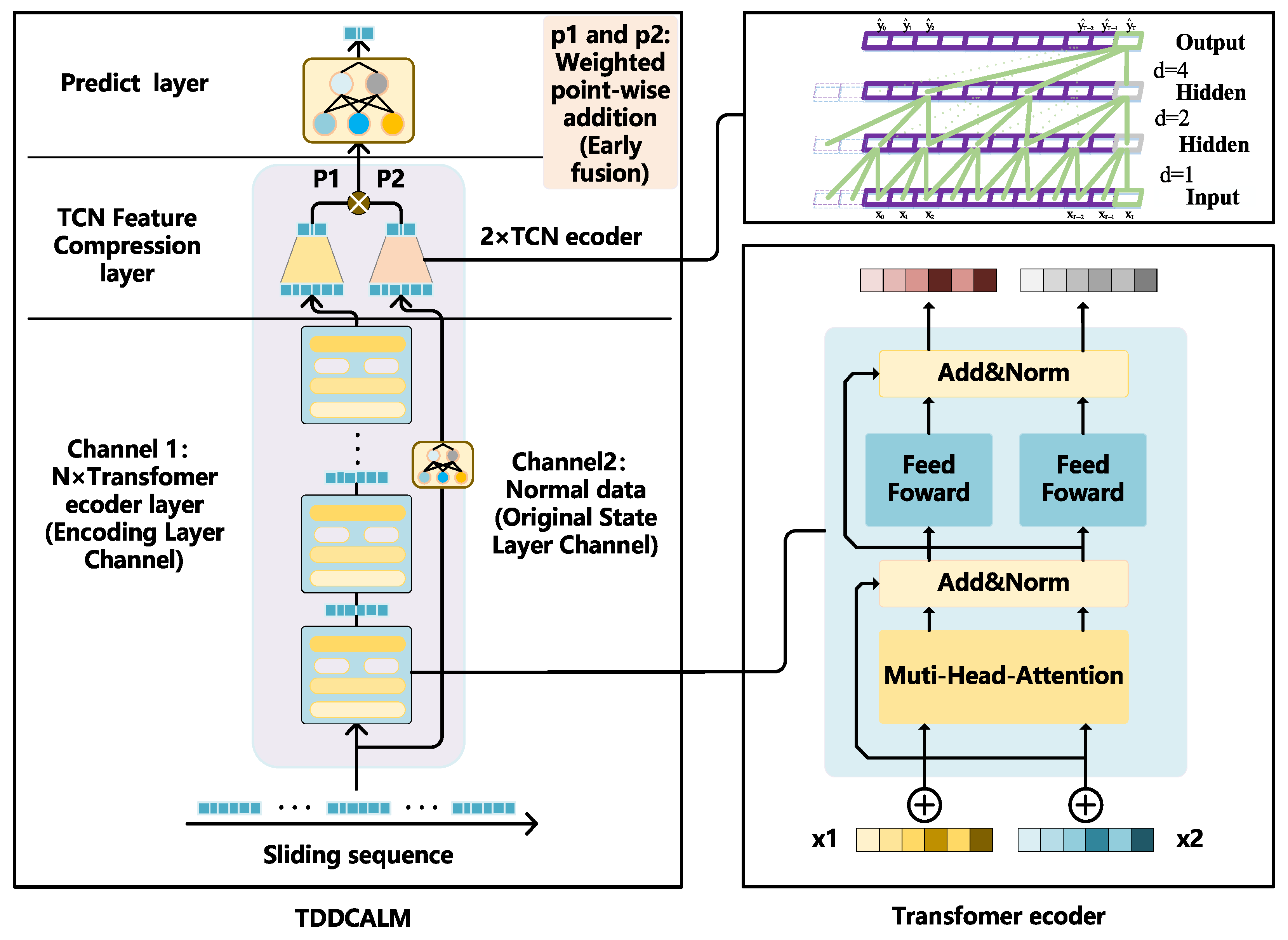
3. Architecture of TDDCALM
Transformer performs excellently in sequence modeling tasks due to its parallelizability, non-strict data requirements, and many superiorities, making it widely used in sequence generation tasks. When processing time series data, Transformer relies entirely on attention mechanisms, which can avoid long-range dependency problems and effectively mine global features of the sequence. However, for time series with high volatility, Transformer often performs slightly worse. In addition, this article believes that the position encoding method may result in the loss of some sequence features.
Besides Transformer, TCN, as one of the commonly used models for time series modeling, has more stable gradients and smaller memory than RNNs. Structurally, residual connection blocks [
26] are advantageous for training deep TCN architectures, dilated convolutions provide flexible receptive fields, and causal convolutions [
27] can rely solely on past data for data extraction, without the problem of leakage of future data to be predicted. The above structural characteristics enable it to exhibit performance close to or even surpassing RNNs in most time series modeling and regression prediction tasks. TCN has obvious advantages, but due to its limited receptive field, it is not suitable for problems that require long-term memory, and it is difficult to achieve the effect of extracting global features in a single turn with Transformer. This article combines the advantages of both and proposes a modeling method that integrates two different data features.
Firstly, decouple the data into different channels and divide them into the following two forms:
- (1)
Feature vectors encoded by Transformer;
- (2)
Linear transformation layer of raw data.
Perform feature extraction on the above two channels separately. Channel 1 integrates attention mechanism and contains global dependency information of input sequence elements. The output data has discreteness, and although there is positional encoding to represent element positions, some sequential features may still be missing. Channel 2 possesses the sequential features missing from channel 1, but cannot represent the global dependencies of individual elements. The emphasis of the two is different, and this article believes that the above two features should be involved in training simultaneously. Based on the above ideas, this article proposes the TDDCALM. TDDCALM feeds channel 1 and channel 2 into two TCN encoders for feature compression, and performs adaptive weighted early fusion on the compressed features. In Channel 2, the primary purpose of applying a linear transformation layer to raw data is to extract and enhance useful features. Although these features originate from the original data, linear transformation enables more effective identification of underlying patterns or relationships within the data structure. This operation improves learning efficiency and representation quality in subsequent TCN layers. Furthermore, linear transformation facilitates partial normalization of data distribution discrepancies, thereby enhancing model generalization capabilities. Simultaneously add ACON adaptive activation function layer instead of ReLU. The depth of the model helps to obtain more complex temporal fluctuation characteristics, while the width of the model (i.e., two channels) enables the TDDCALM to use an adaptive weighted early fusion mechanism to allocate channel weights reasonably, thereby adapting to sequence prediction tasks with different fluctuation characteristics. The basic structure of the TDDCALM is shown in
Figure 1, which may be more concise compared to Transformer:
3.1. Original State and Encoding Layer Channel
Reference [
28] proposed a temporal representation learning framework based on a Transformer encoder, which does not use a decoder and only utilizes the encoder for unsupervised representation learning of the temporal sequence. The obtained feature vectors can be applied to downstream tasks such as regression and classification with good results. Only using an encoder structure can reduce the training parameters by half while ensuring the effectiveness of feature extraction. This article draws on this idea and uses a Transformer encoder to perform the first feature encoding on the temporal sequence, in order to explore the global features within the temporal sliding window of the temporal sequence. The joint training of encoding channels and predictors does not require greedy pre-training. As shown in
Figure 1, channel 2 retains the serialization features of the original data, while channel 1 is encoded to contain the global dependencies of elements.
The encoding channel is composed of a serial Transformer encoder, which is mainly composed of multi-head self-attention and feedforward network. Each encoder is independent of the others and has no parameter sharing.
For input sequences
H = [
w1, …,
wn] at different time steps, self-attention is applied for encoding. The attention mechanism emulates the biological process of observation, which aligns internal experiences with external sensory inputs to enhance the precision of observations in specific regions [
29]. This mechanism can rapidly extract important features from sparse data through a top-down information selection process that filters out irrelevant information [
30].
The self-attention mechanism improves upon the standard attention by reducing external information dependency, and is better suited for uncovering internal correlations within data and features [
28], as shown in Equation (4).
where
dk denotes the dimension of column vectors in input matrices
Q and
K. The projection matrices
WQ ∈ R
dk×dh,
WK ∈ R
dk×dh, and
WV ∈ R
dk×dh represent weights.
Compared to single-head attention, multi-head attention enables parameter matrices to form multiple subspaces, allowing the model to simultaneously extract information from different projection spaces. This enhances learning effectiveness and facilitates parallel training. To maximize the extraction of interaction information, the model employs multi-head self-attention, as defined in Equation (6):
In Equation (6) the output projection matrix WO ∈ Rdh × Mdv, and projection matrices WQm ∈ Rdk×dh, WKm ∈ Rdk×dh, and WVm ∈ Rdk×dh, where m ∈ {1, …, M}.
Traditional Transformers employ multi-head self-attention to encode sequences
H = [
w1, …,
wn], but neglect positional information of sequence elements. This issue is addressed through positional encoding, with the encoded results shown in Equation (9):
The embedded vector representation of a sequence element is denoted as Swn, the vector representation at position n corresponds to its positional encoding PEn, and the 2i dimension of the positional encoding vector at position n is denoted as PEn,2i, where the encoding vector dimension is represented as d.
Since the sequential features lost in Transformer encoder can be compensated by another channel, this study does not implement a positional encoding mechanism here.
3.2. Tcn Feature Compression Layer
After the TDDCALM extracts information through channel division, the extracted features need to be encoded separately via two TCN structures to reduce data dimensions and condense them into more distinct features.
TCN is a fully convolutional network architecture specifically designed for sequential data, characterized by three key components:
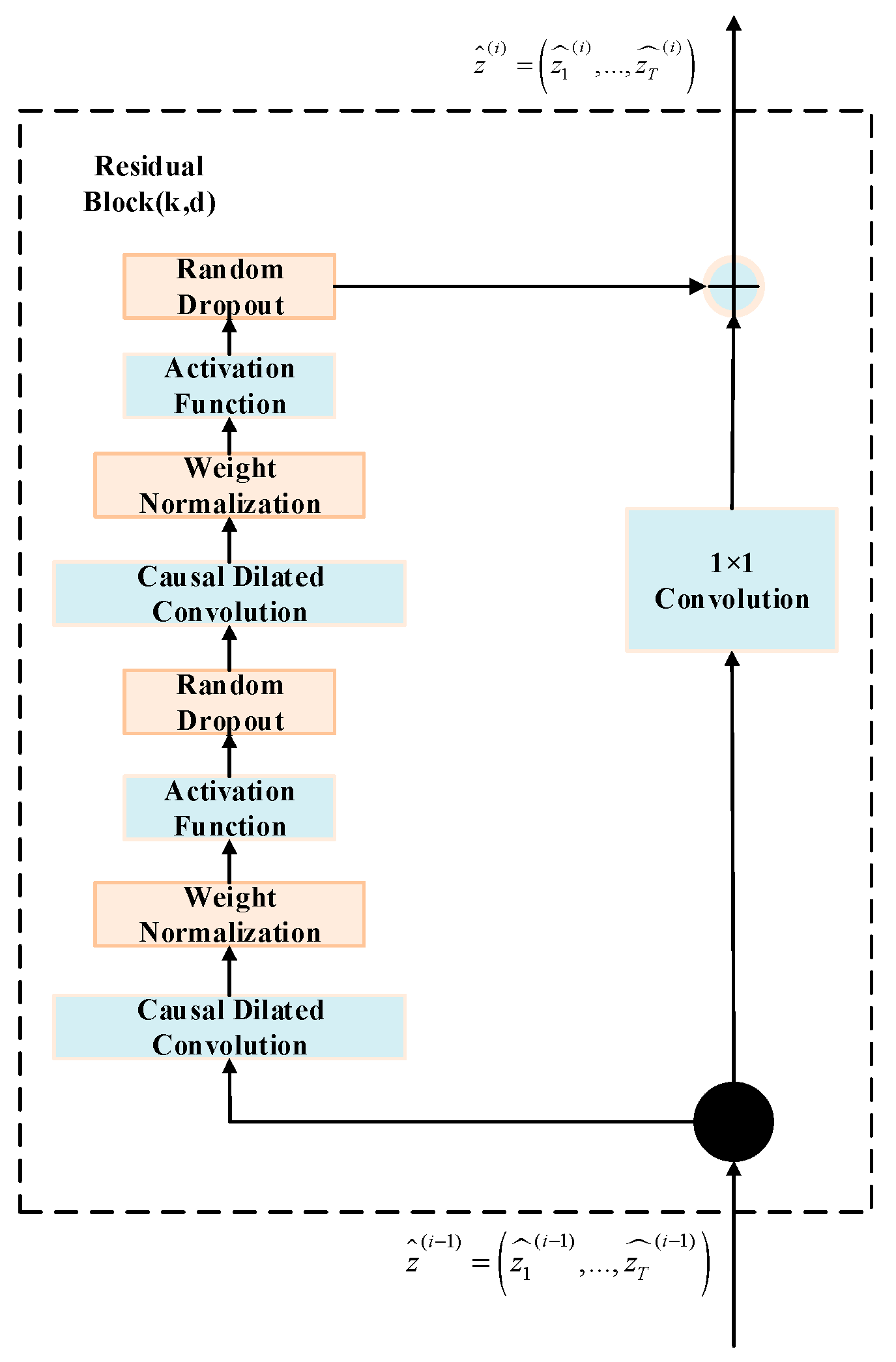
3.2.1. Residual Connections
To enable cross-layer information transmission in the network, TCN adopts residual connection patterns. As shown in
Figure 2, replacing single-layer convolutions with residual block structures enhances trainability.
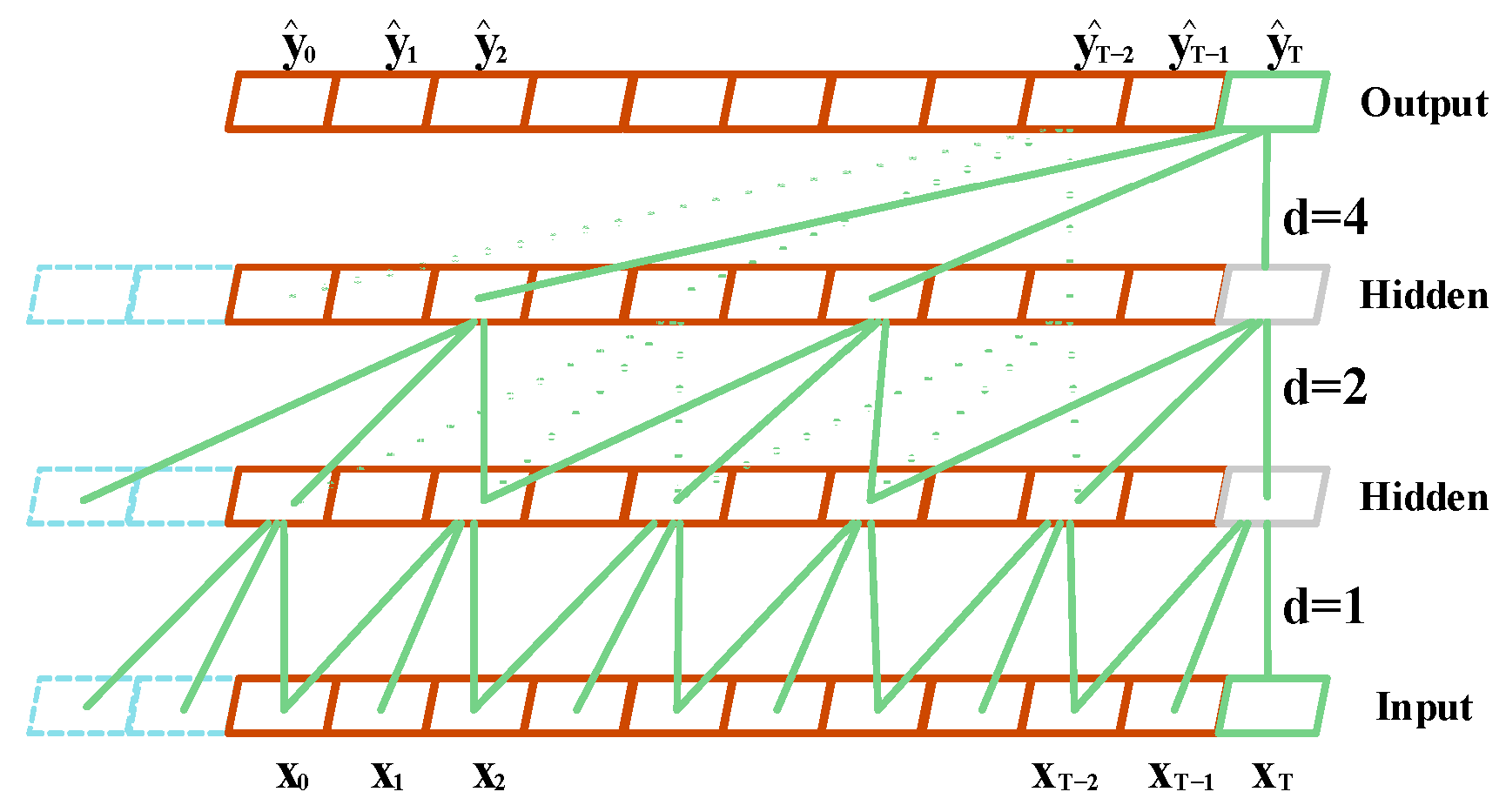
3.2.2. Dilated Convolutions
To address the problem of network depth limitations caused by fixed kernel sizes, TCN introduces dilated convolutions (also known as atrous convolutions). Unlike traditional convolutions, dilated convolutions perform sampling with interval d (as illustrated in
Figure 3), which expands receptive fields across network layers, enabling flexible receptive field adaptation.
3.2.3. Causal Convolutions
To apply traditional convolutional architectures to sequential data, temporal constraints must be added through causal convolutions. This unidirectional structure only accesses past information, preventing future data leakage.
Deep neural networks benefit from residual blocks through convolutional operations and network regularization. This structure mitigates challenges associated with increasing network depth, including computational resource consumption, overfitting, gradient explosion, and vanishing gradients.
The operations of dilated convolutions and residual blocks are mathematically defined in Equations (12) and (13), respectively.
Here, the input is x ∈ Rn, the convolution kernel is f: {0, …, k − 1}→R, and Activation(·) denotes the activation function.
3.3. Feature Adaptive Weighted Early Fusion
After the dual-channel features are encoded by TCN, further measures are required for feature fusion before the predictor [
31], termed early fusion. Common early fusion strategies in deep learning theory include the following:
- (1)
Sequential feature fusion, which directly concatenates the two features.
- (2)
Parallel strategy fusion, which combines the two features into a composite vector.
The literature [
32] introduces canonical correlation analysis (CCA) for feature fusion. This method transforms features by exploiting correlations between input features, producing transformed features with higher correlation than the original sets. However, it neglects the relationships between class structures within the dataset. To address this limitation, the literature [
33] proposes a feature fusion method called DCA (Discriminant Correlation Analysis). This approach maximizes correlations between corresponding features in the two sets while simultaneously maximizing inter-class differences, effectively overcoming the shortcomings of CCA.
Considering architectural constraints and practical engineering requirements, this study proposes an adaptive weighted early fusion method to achieve reasonable weight allocation between the dual channels. Specifically, learnable channel weight coefficients are defined, and features are weighted and fused before prediction. During training, the channel coefficients are updated iteratively to optimize weight proportions. The two channels may have unequal importance, and their assigned weight coefficients may not be equal. Manual parameter tuning would incur unnecessary workload, so an adaptive mechanism is adopted to let the model automatically adjust dual-channel weights. The model outputs the trained weight results after completion, quantifying the relative importance of the two features.
In this study, the weight of the encoded channel is defined as
P1, and the weight of the raw data channel is defined as
P2. These weights must satisfy the relationship specified in Equation (14):
An increase in parameters could cause model redundancy and slow training speed. Therefore, Equation (14) is used to reduce parameters, with the objective of training being to converge P1 and P2 to an appropriate proportion. The weights are initialized through the creation of new parameters and updated during training alongside other learnable parameters in the neural network according to gradient variations from the loss function. Specifically, for each training batch, the model first performs forward propagation to obtain predicted outputs, then calculates the loss between predictions and ground truth labels. Subsequently, the system automatically computes gradients of the loss with respect to P1 and P2, and adjusts their values using optimization algorithms to minimize the overall loss function.
Define
P = [
P1,
P2]
T Update using gradient descent
where
L(·) denotes the loss function, and
L satisfies L-smooth. According to gradient descent convergence theory, when the learning rate
η <
L/2 (where
L is the Lipschitz constant of the loss function), the weight sequence
P(k) converges to the global optimal solution
P*.
Meanwhile, during training, the constraint function (14) compresses the search space into a one-dimensional subspace, effectively mitigating divergence risks inherent in high-dimensional optimization while enhancing training stability.
3.4. ACON Layer Adaptive Activation Function
Activation functions can enhance model nonlinearity, and their types influence network characteristics, thereby affecting training performance. This study adopts the adaptive activation function framework ACON (Activate or Not) [
34], which autonomously learns activation states and automatically searches for optimal activation functions per layer. It includes three variants—ACON-A, ACON-B, and ACON-C—defined in Equations (17), (18), and (19), respectively. The general form is presented in Equation (20):
The parameters q1, q2, and β are all learnable. During training, ACON approximates the optimal activation functions for each layer, thereby improving the model’s training performance ceiling.
Replacing traditional ReLU layers with ACON layers indirectly enhances model generalization. Meanwhile, ACON possesses higher gradient stability, enabling it to avoid gradient oscillation issues caused by the bimodal distribution of gradients in Swish/GELU functions.
In summary, the TDDCALM can be expressed as Equation (21)
where F(·,·) denotes adaptive weighted early fusion, TCN(·) represents feature compression, Tra(·) indicates the encoding channel, and L (·) corresponds to linear transformation.
4. Short-Term Wind Power Forecasting Model Based on TDDCALM
Wind farm data are typically influenced by numerous internal and external factors, often exhibiting complex variations. Time series of wind power and wind speed, in particular, frequently display significant fluctuations within short periods.
As a major branch of machine learning, deep learning can enhance feature extraction capabilities of wind power data by increasing network depth and architectural complexity. Most existing wind power forecasting studies based on deep neural networks employ RNNs or TCNs for modeling. Traditional approaches, however, suffer limitations in predicting future peaks and troughs of wind power due to multiple influencing factors.
Accurate extraction of short-term wind power fluctuations hinges on precisely capturing the invariant periodic characteristics of wind power time series. Beyond stacking network layers, it is crucial to improve the model’s ability to fully utilize power time series data.
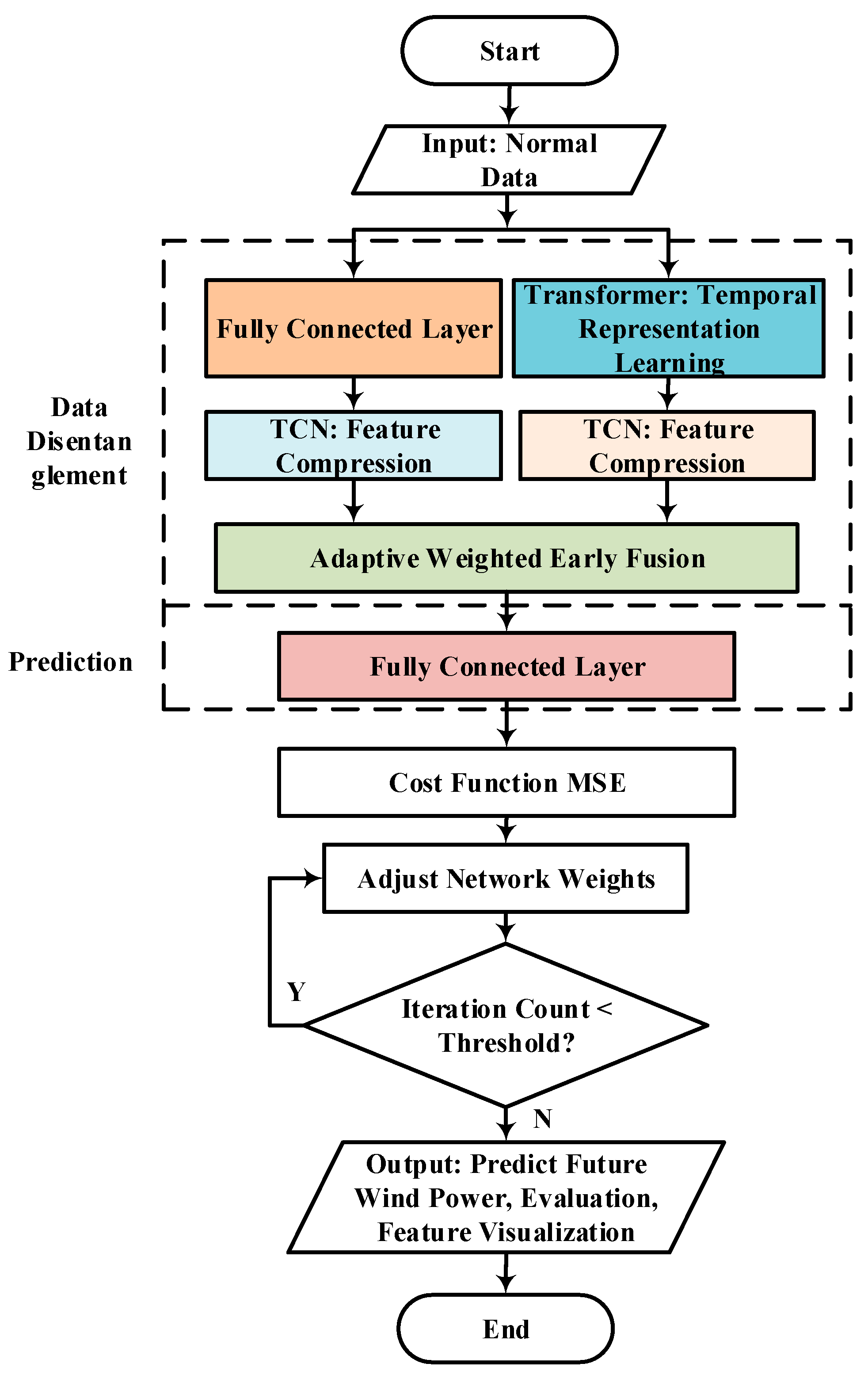
To maximize the utilization of short-term wind power data, the key lies in directing the model to extract diverse forms and perspectives of features from the same dataset. This study proposes three improvements to traditional models:
- (1)
After screening outliers, wind power data are decoupled into distinct forms and perspectives of features within the model. These features are processed through two parallel channels, compensating for the disadvantage of limited data volume in short-term wind power forecasting while accounting for multiple potential influencing factors.
- (2)
Constructing diverse forms and perspectives of features ensures adequate exposure of characteristics even with limited data volume. Each feature form carries an implicit importance weight. This study enables the model to adaptively adjust the contribution ratios of different features during training, thereby better accommodating the multi-layered nature of wind power time series.
- (3)
Activation functions (e.g., Sigmoid, ReLU) interact with network weights, occasionally causing issues like gradient explosion—a fundamental challenge in deep learning. While self-adaptive weight adjustment already provides flexibility, this study further introduces adaptive activation functions. The model can automatically search and adjust the optimal activation function for each layer, mitigating the aforementioned problems to some extent.
The modeling process of the aforementioned study is shown in
Figure 4.
4.1. Data Preprocessing and Parameter Settings
Wind turbine data collected in inland wind farms are often affected by uncontrollable factors and contain numerous outliers. These outliers are first screened using unsupervised methods and then normalized. The processed data serve as training input for subsequent model development.
The TDDCALM essentially solves an optimization problem using the mean squared error (MSE) loss function during training. Common optimization algorithms include Adam and SGD. Among these, Adam dynamically adjusts learning rates and updates parameters. This study selects Adam as the optimization algorithm and employs grid search to identify the optimal parameter combination. Key parameter settings include the following: one stacked Transformer encoder (N = 1), a TCN convolution kernel size of 3, a dropout rate of 0.2, and a compression layer with input dimensions [8324, 9, 1] and output dimensions [8324, 16]. The initial learning rate is set to 0.01.
4.2. Wind Power Time Series Feature Extraction
The Transformer encoder’s encoding operation combines multi-head self-attention, normalization, and residual units. The self-attention computation is defined in Equation (7), while the multi-head self-attention mechanism is detailed in Equation (6). Compared to basic self-attention, multi-head variants enable more comprehensive feature extraction. TCN is described as a hybrid network combining one-dimensional full convolution and causal convolution. Its convolutional operations reduce large samples to smaller ones, achieving dimensionality reduction and feature aggregation. Dilated convolutions and residual block computations are defined in Equations (12) and (13), respectively. The fused features incorporate global and sequential information from individual time windows, each carrying distinct weight contributions.
Define the wind power time series signal
xt as the sum of a global dependency component
gt and a local fluctuation component
lt
where
ϵt is the noise term.
The Hilbert space signal decomposition theorem states that non-stationary time series can be decoupled into slowly varying components
gt′ with long-range properties and transient components
lt′ with local properties [
35]. The dual-channel structure inherently resembles a parallel approximation of these two components through orthogonal feature subspaces.
4.3. Training Process
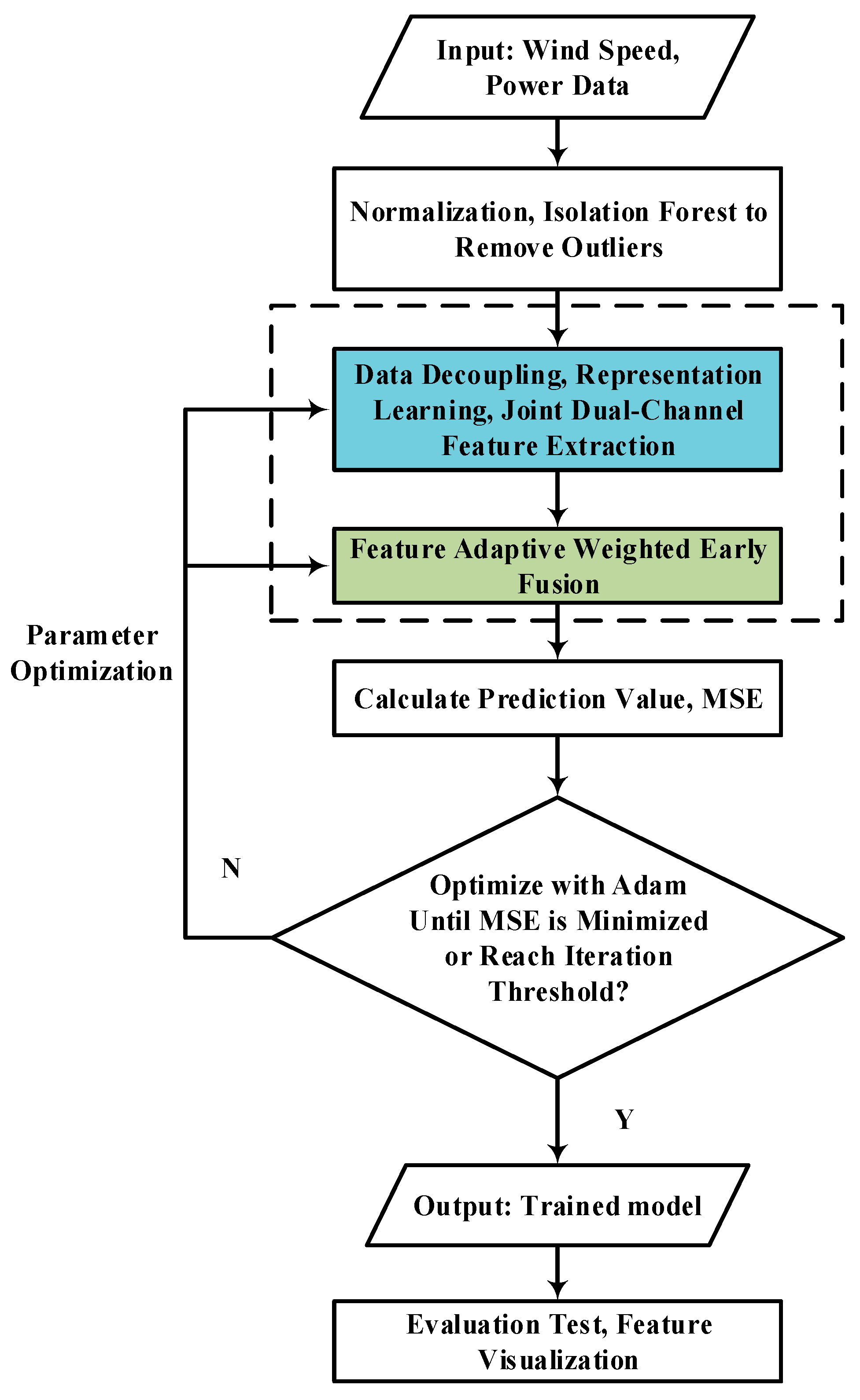
The detailed algorithm solution procedure of this study is shown in
Figure 5.
As shown in
Figure 5, power and wind speed are taken as inputs, normalized after outlier screening. The data is decoupled into two states, with features extracted separately from each state and then fused for training the predictor. The Adam algorithm optimizes the mean squared error (MSE), updating network weights through backpropagation according to the MSE. This process repeats until the MSE reaches its minimum value or the iteration count meets the threshold. After completion, the model outputs predicted results, fused feature latent vectors, and channel weight coefficients. The proposed model distills wind power time series into 32 key features. Subsequent sections evaluate model performance using test sets and visualize the fused features.
4.4. Feature Interpretation via Multiple Visualization Methods
Wind farms involve numerous internal and external influencing factors, causing complex variations in wind speed and power, particularly evident in short-term fluctuations. These characteristics are difficult to extract due to limited data volumes and multiple influencing factors.
For wind power data with multiple influencing factors, traditional methods focus on data transformation approaches, including time series signal decomposition, segmented modeling, and state processing. Post-processed modeling methods typically use shallow architectures. However, these shallow structures struggle to extract deep features from high-dimensional wind power data, which are heavily influenced by data states and types.
The proposed model employs a deep architecture capable of accurately extracting hierarchical features from wind power fluctuations. To demonstrate this explicitly, deep features are described intuitively.
Traditional feature visualization methods include heatmaps and scatter plots to show high/low-dimensional feature distributions and correlations. This paper globally samples feature vectors from the model’s base layer, presenting mapped scatter plots and inter-feature kernel density plots at the end of the document.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}