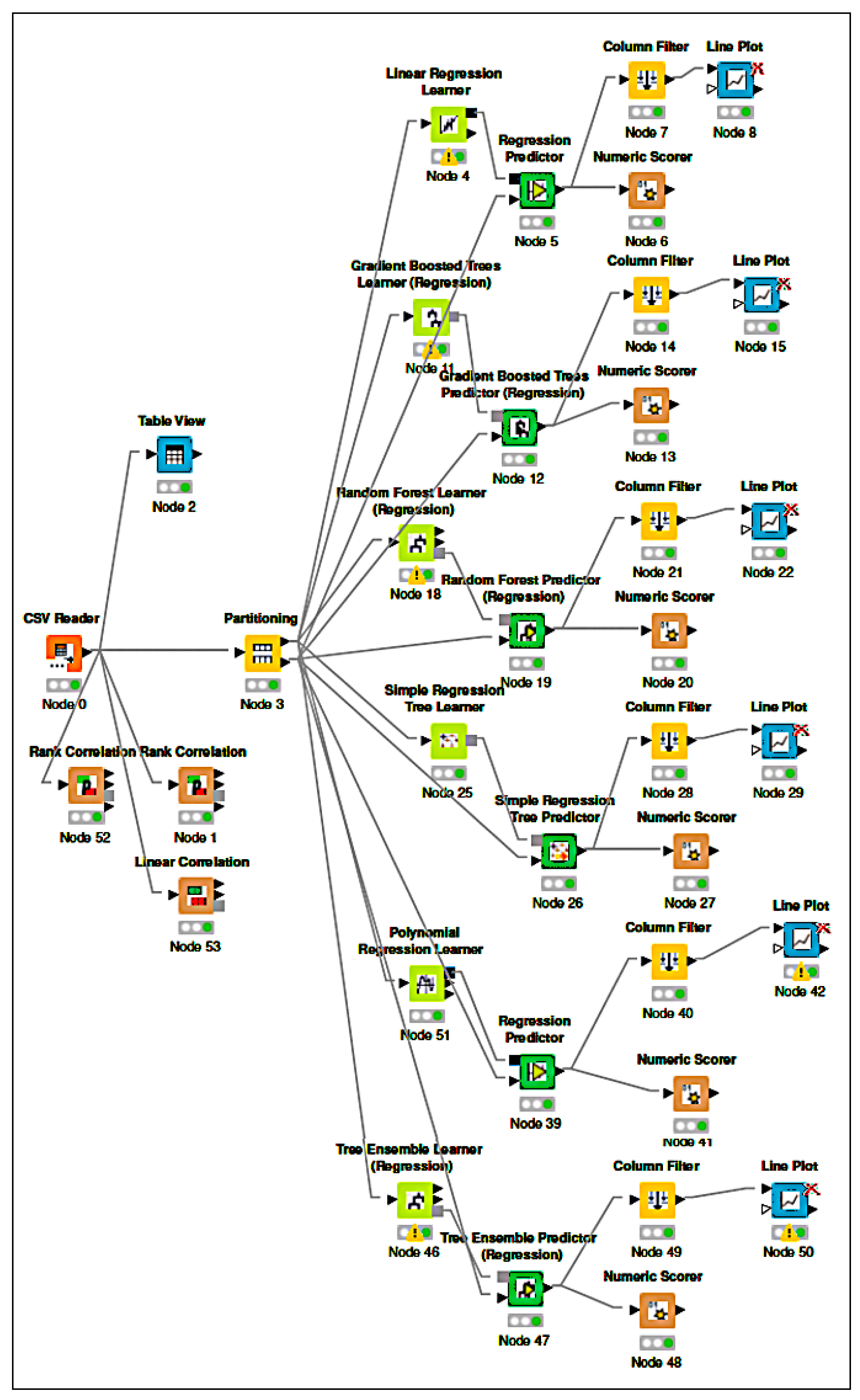
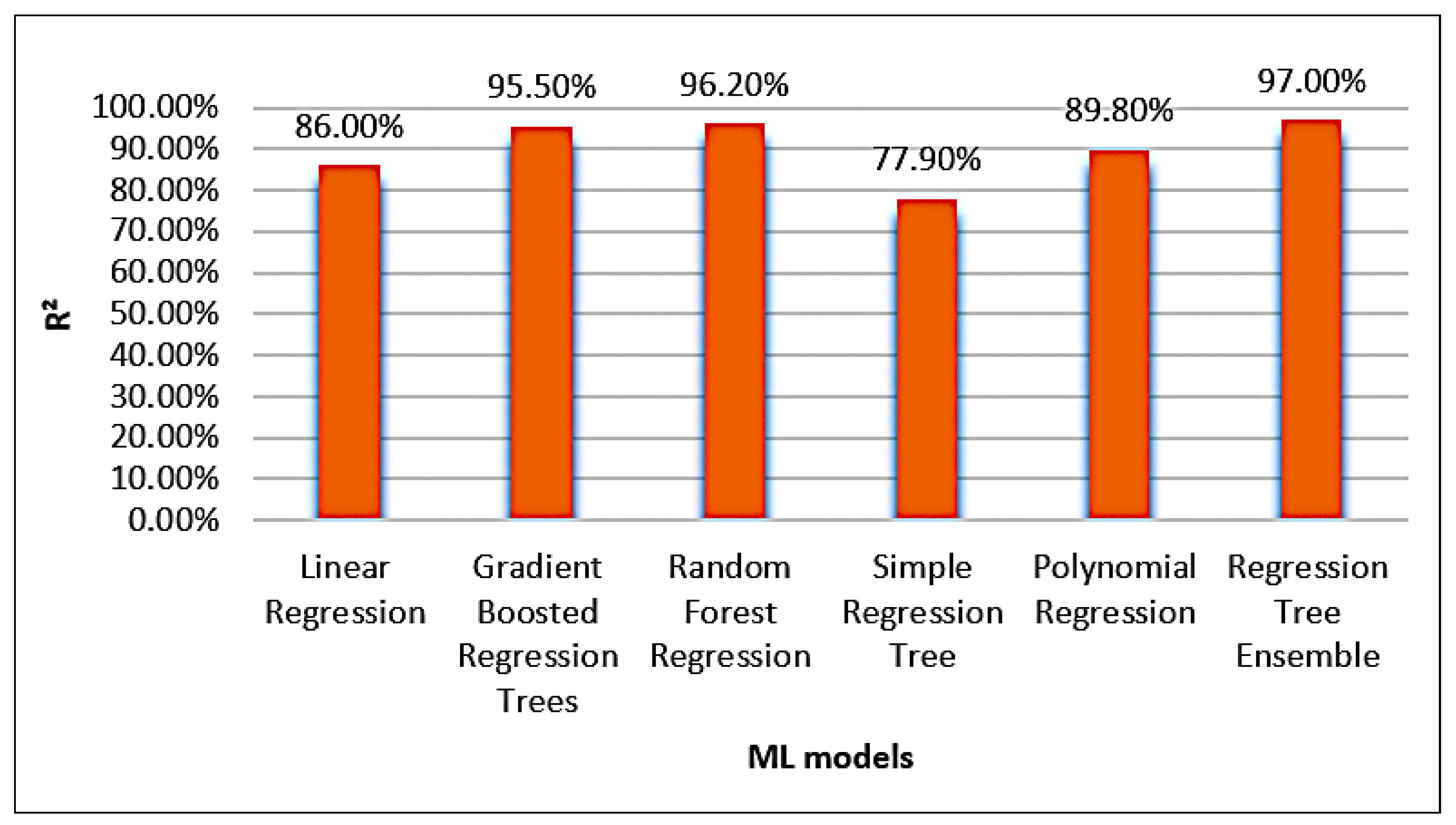
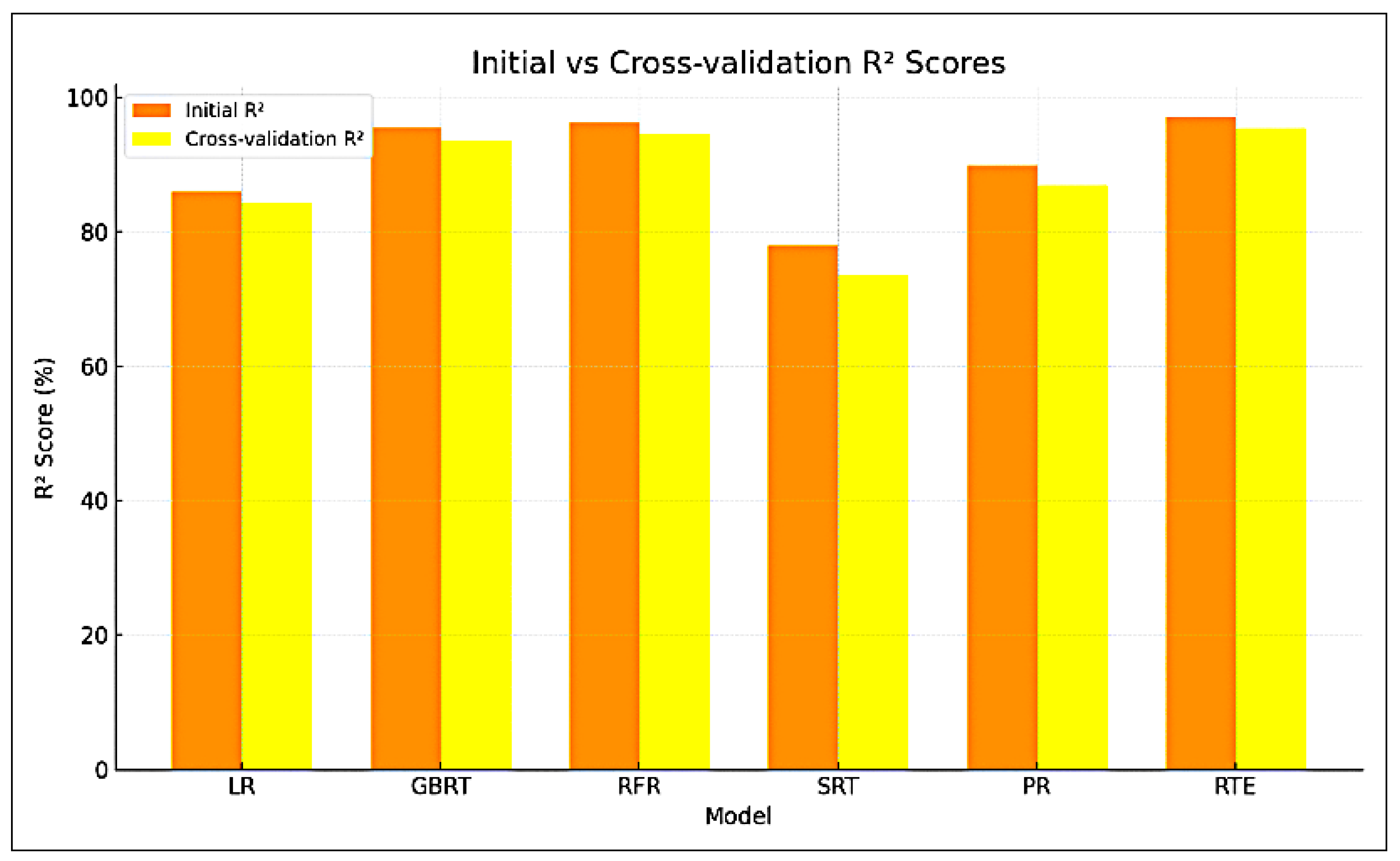
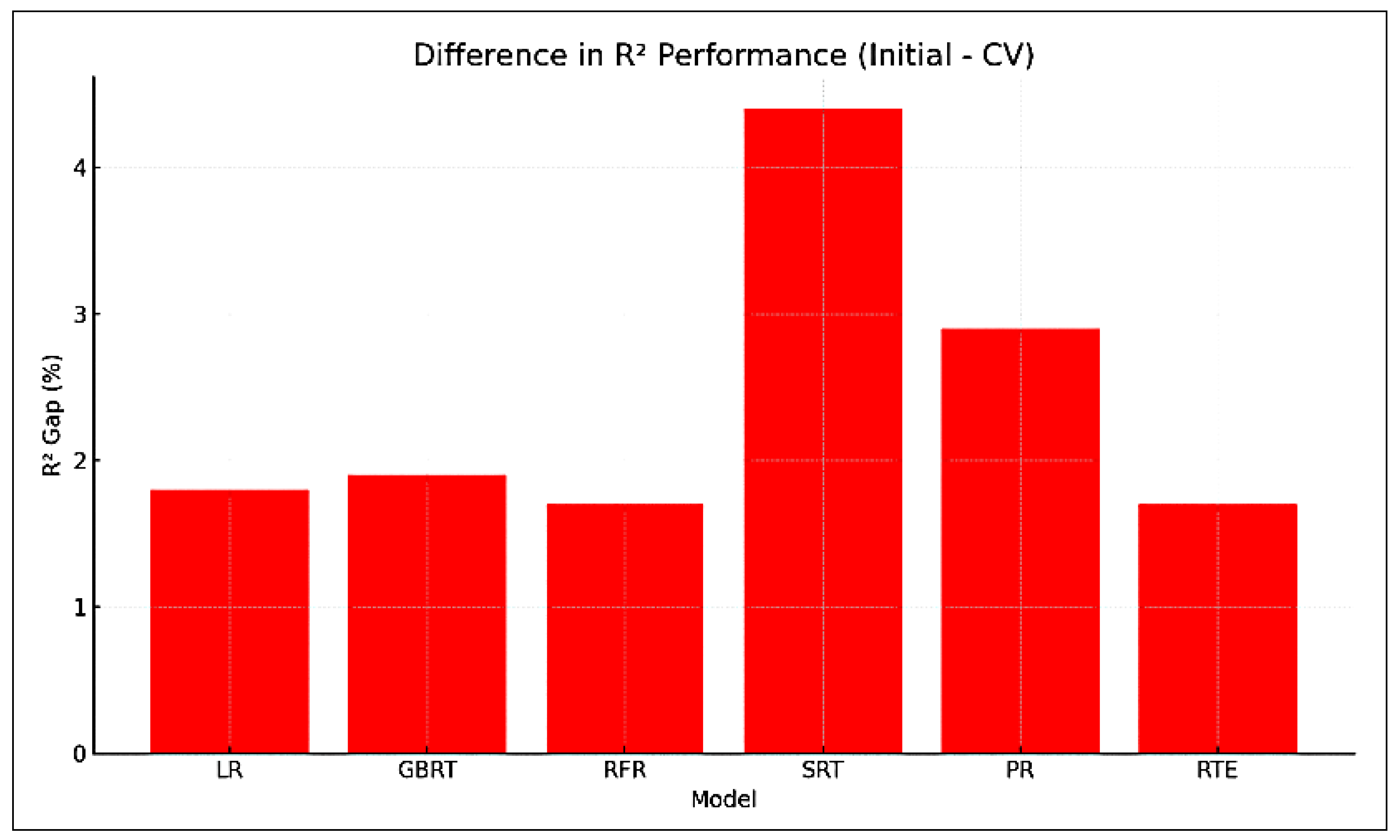
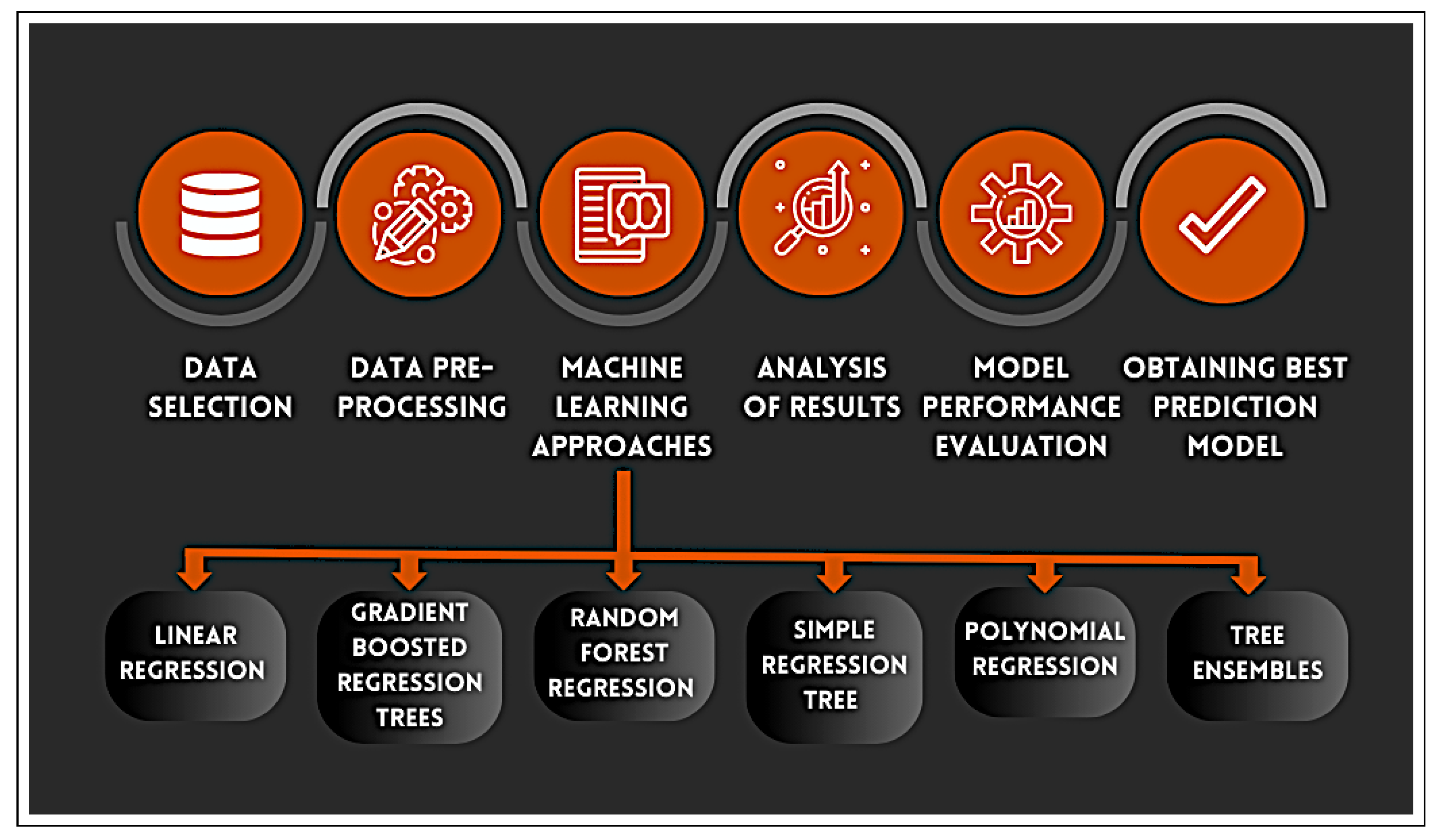
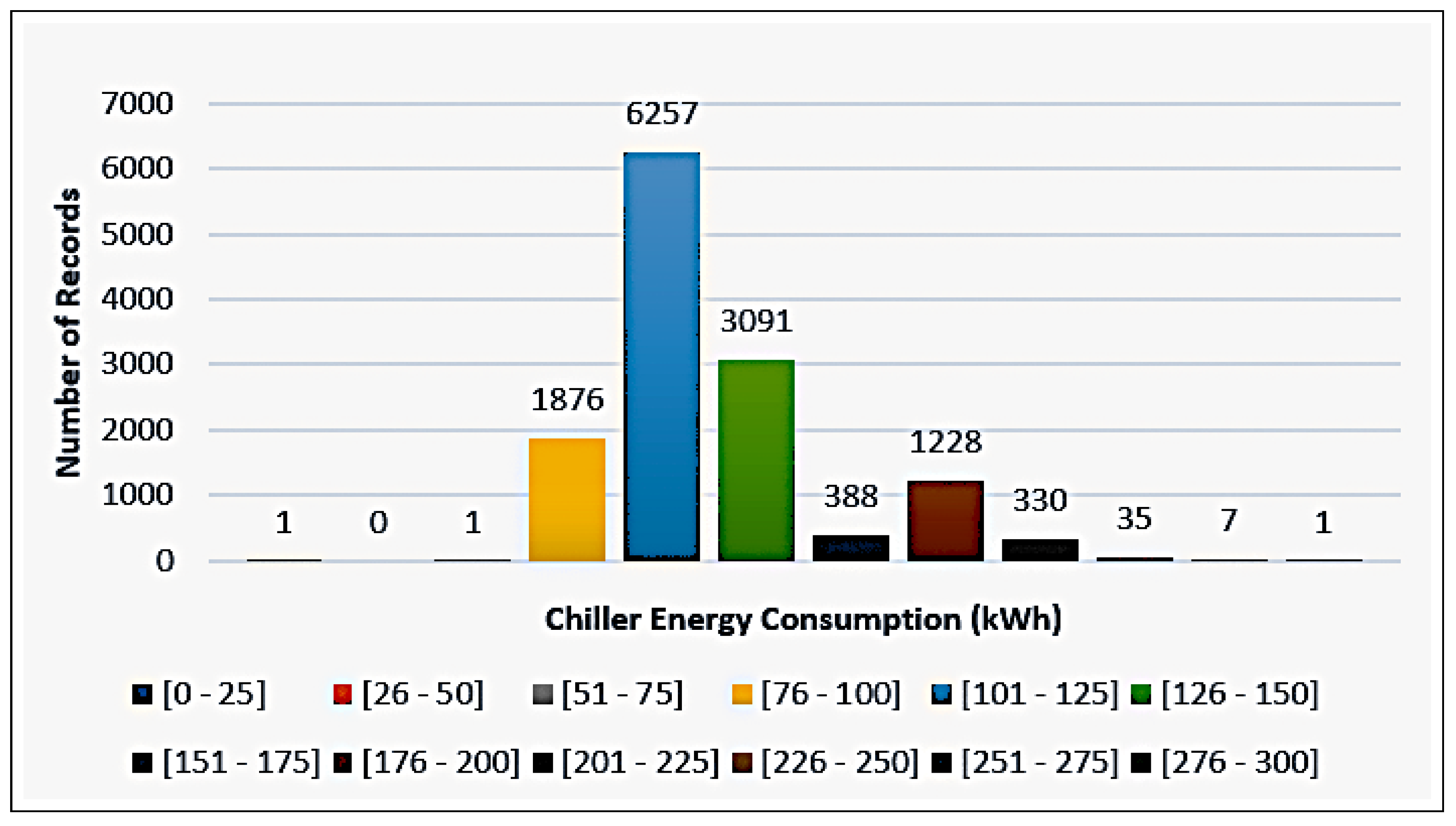
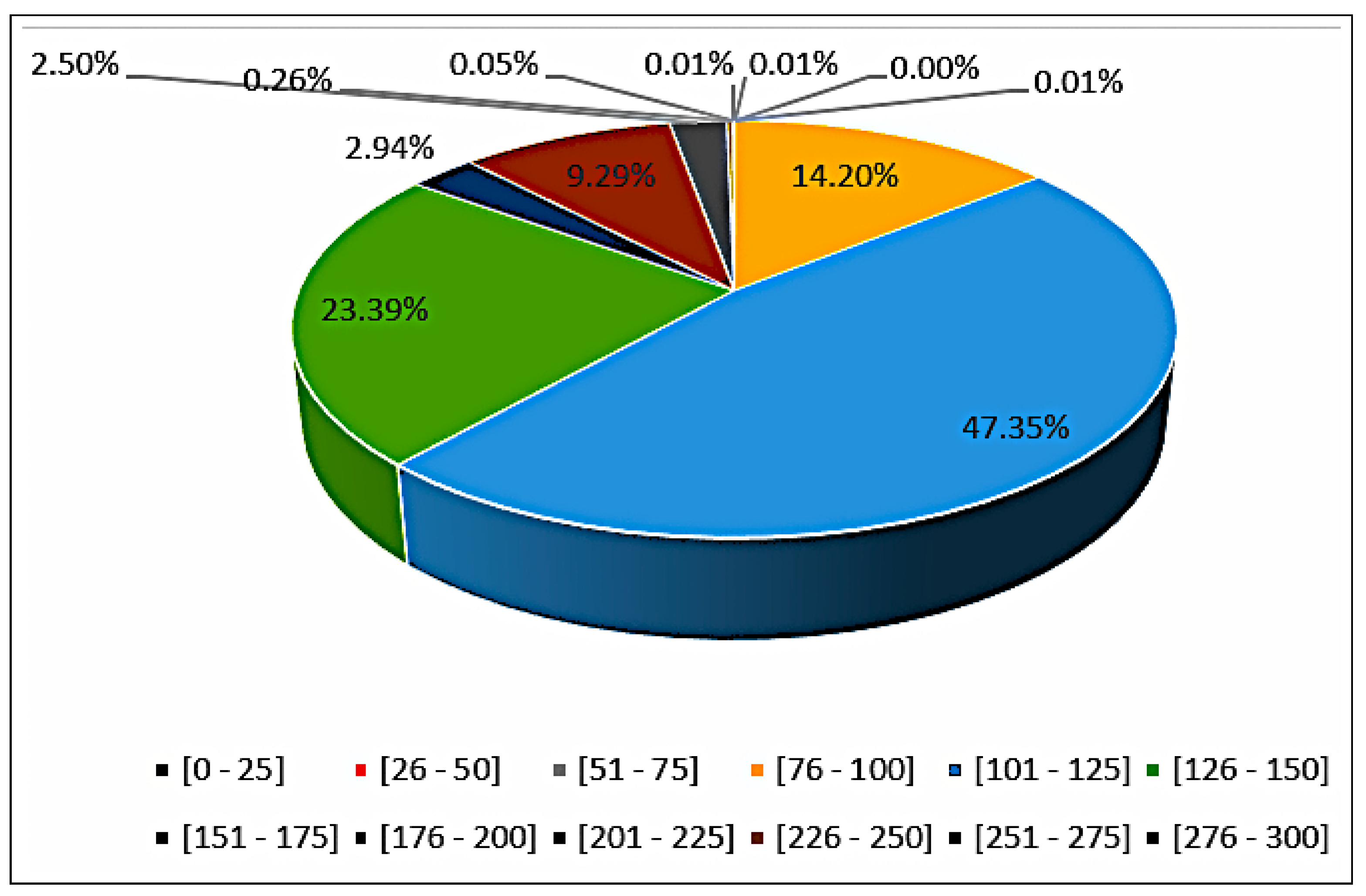
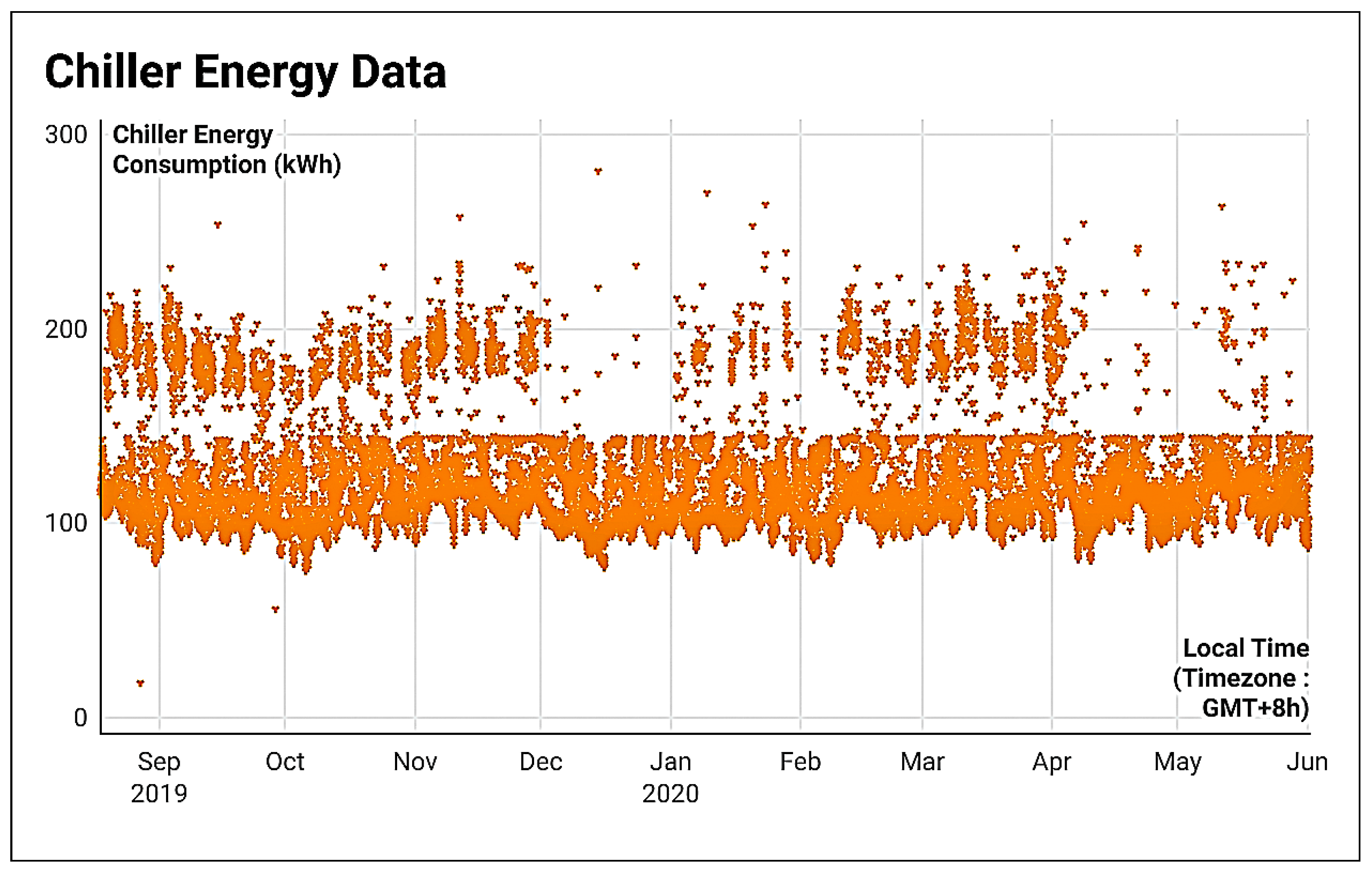
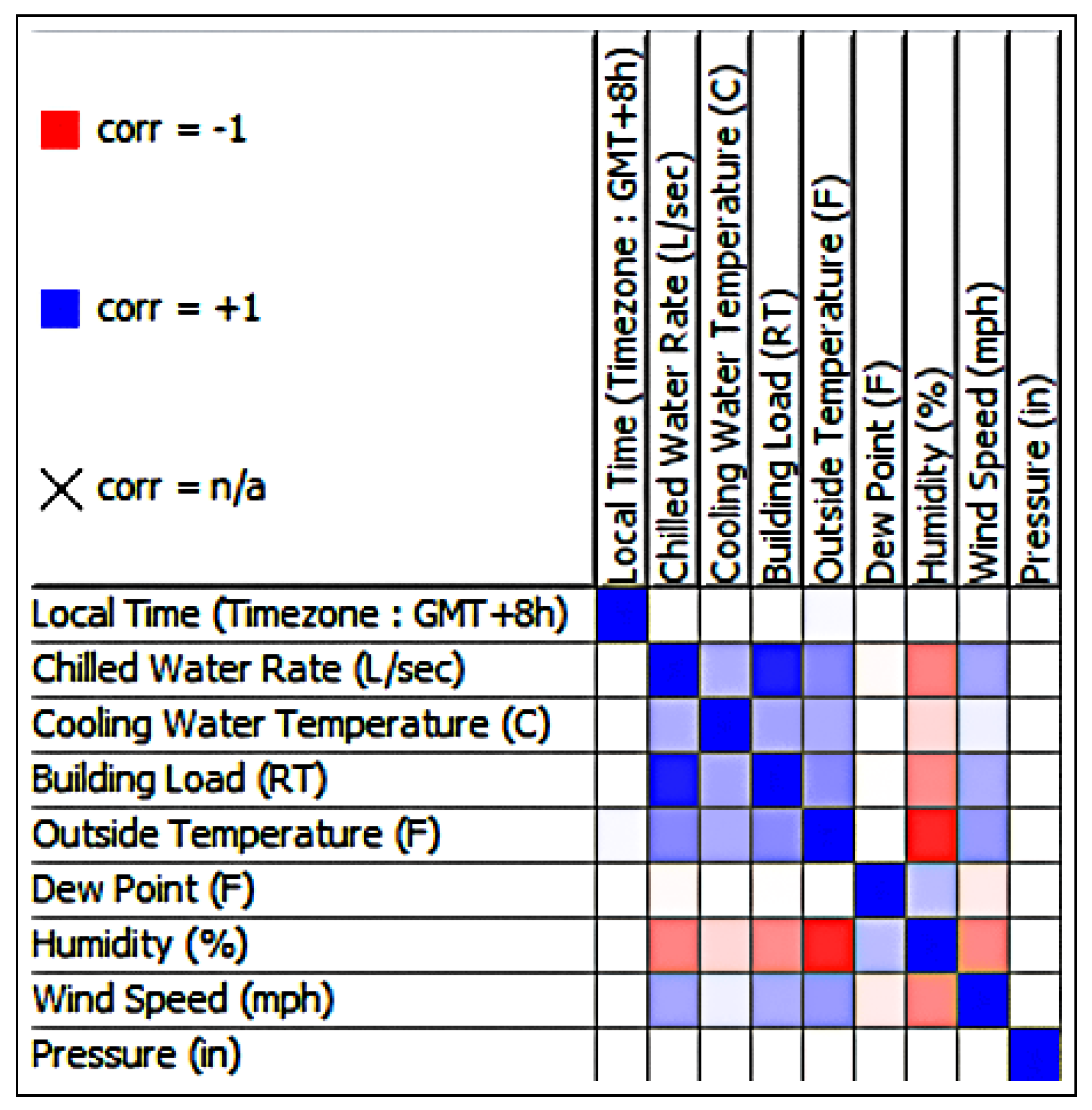
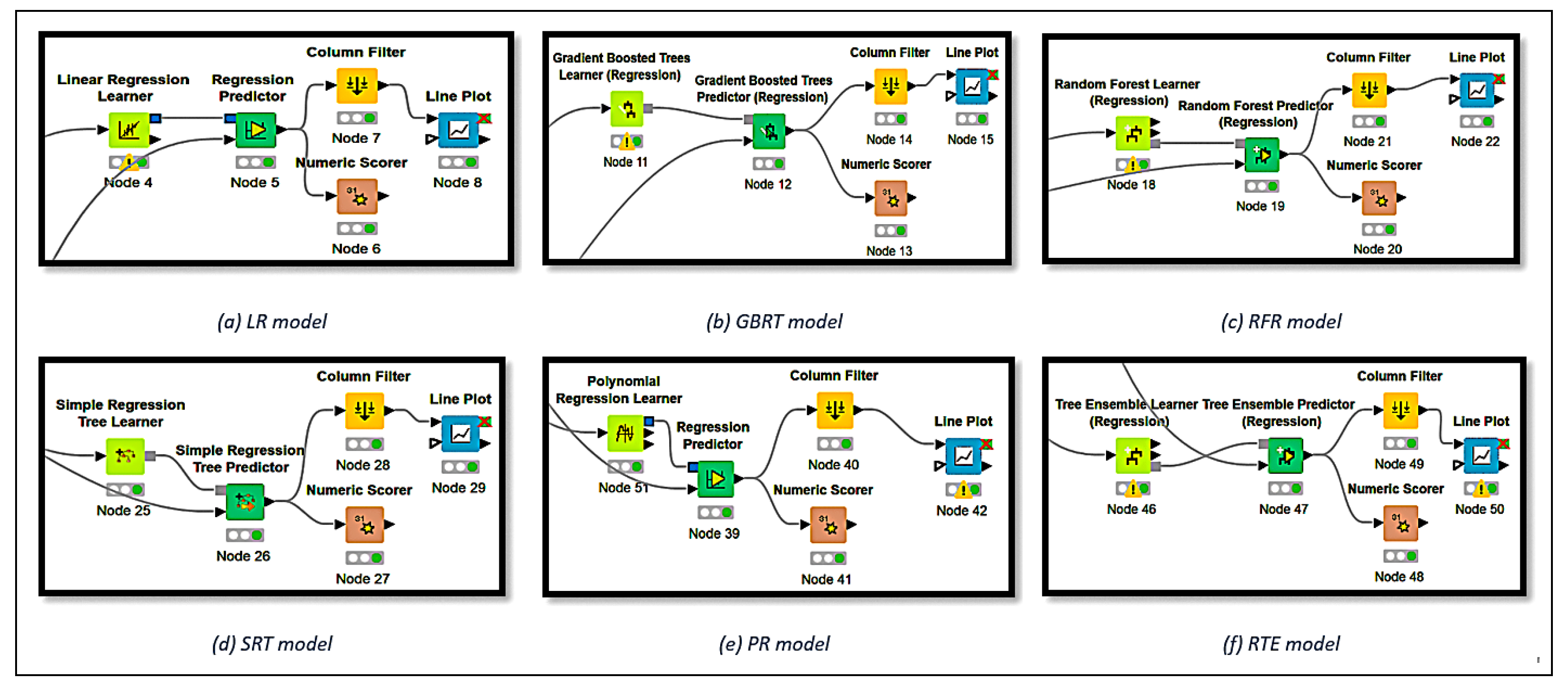
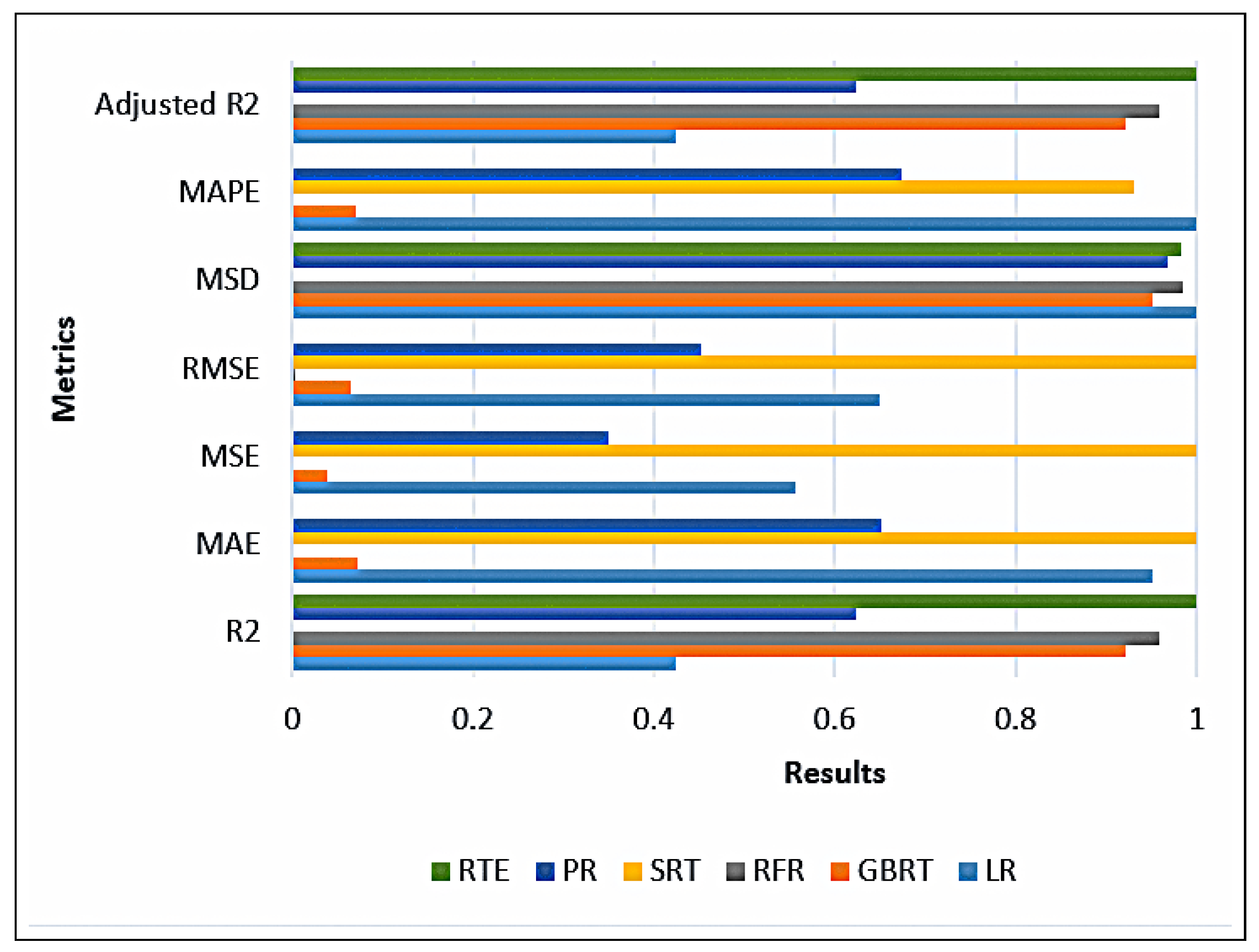
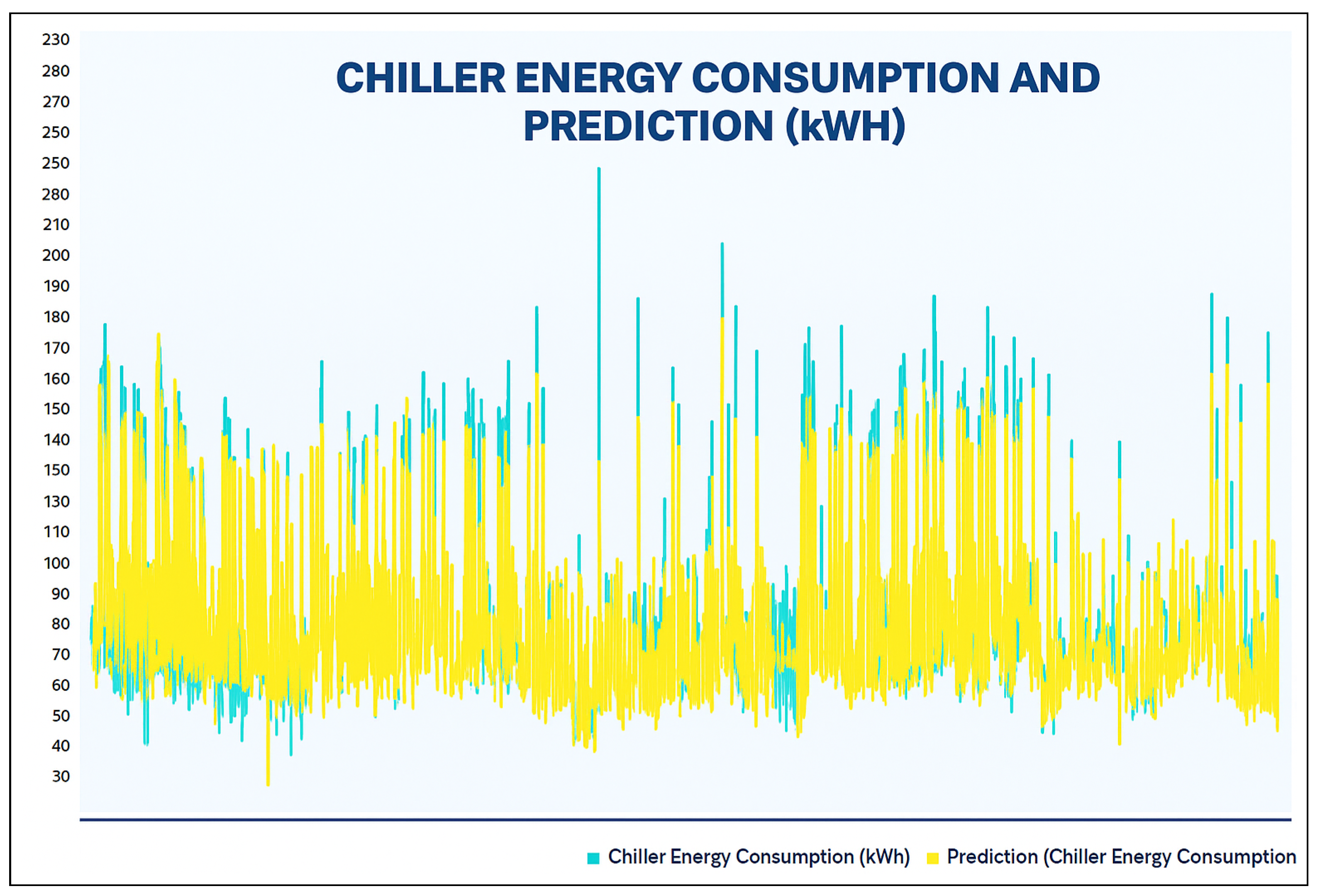
A profusion of scholarly research endeavors have been dedicated to investigating the domain of cooling energy, addressing a wide spectrum of challenges, resolutions, and prospects within the field of intelligent energy management. This section presents a comprehensive overview of the existing literature on forecasting the energy consumption for intelligent and optimized energy management. To identify the most impactful and relevant contributions, a systematic bibliographic search was conducted, covering peer-reviewed publications from July 2018 to February 2025. The search encompassed leading scientific databases, including IEEE Xplore, ScienceDirect, SpringerLink, and Google Scholar, and employed targeted keywords such as energy consumption, energy management, ML, supervised learning, regression, predictive models, and data mining. Studies were selected based on strict inclusion criteria: the application of ML algorithms to real-world energy datasets, the implementation of rigorous validation protocols, and the comparison of proposed approaches with conventional methods. The exclusion criteria eliminated purely theoretical studies without empirical validation, those lacking the proper documentation, and those relying exclusively on synthetic data. This rigorous selection process ensured the compilation of a representative and high-quality corpus of literature that captured the recent advancements in data-driven energy forecasting, with direct implications for the design and implementation of intelligent energy management systems.
The research [
14] investigated the intricate evolution of the energy consumption trends in the United States, propelled by multifaceted drivers such as demographic shifts, technological advancements, and evolving consumer behaviors. This study advances the proposition that ML algorithms substantially enhance the forecasting precision across residential, commercial, and industrial energy sectors. Drawing on comprehensive datasets, this study evaluates diverse ML models, demonstrating the superior predictive reliability of logistic regression within the given context. This research further critiques the limitations of the conventional statistical methods in modeling nonlinearities and behavioral complexities, advocating for a transition toward data-driven, adaptive forecasting frameworks. By positioning accurate energy demand predictions as a foundational element for sustainable development and climate resilience, this study underscores the strategic value of ML in optimizing energy resource management and informing policy interventions. The study [
15] investigates the application of advanced ML algorithms to optimizing the energy consumption forecasting for office building HVAC and lighting systems, components that collectively represent a significant share of total energy use, with HVAC alone accounting for up to 40%. Four regression-based models were evaluated: Extra Trees Regressor (ETR), Voting Hybrid Regression (VHR), Multi-Layer Perceptron Regression (MLPR), and K-Nearest Neighbors Regression (K-NN). Leveraging two years of real-world operational data, the ETR model achieved the highest predictive performance, with an R
2 of 0.9943 and an RMSE of 0.4352, indicating exceptional accuracy. These findings underscore the effectiveness of ensemble-based methods, particularly boosted regression trees, in modeling complex, nonlinear patterns and managing data variability, thereby offering robust, interpretable, and scalable solutions for sustainable energy management in commercial office environments. The authors of [
16] proposed a hybrid forecasting framework that synergistically integrated advanced ML algorithms with metaheuristic optimization techniques to enhance the predictive accuracy of electricity consumption models. Specifically, the framework combines gradient boosting methods with three optimization algorithms. The proposed models were empirically validated using real-world electricity consumption datasets from Turkey. Among the various configurations, the XGBoost-SSA hybrid demonstrates a superior performance, attaining the highest coefficient of determination (R²) and the lowest forecasting error metrics. This study distinguishes itself through its methodological robustness, high predictive fidelity, and tangible applicability to real-world energy management scenarios. Nonetheless, limitations persist regarding the model’s cross-regional generalizability and the absence of benchmarking against deep-learning-based time series models. The study [
17] explores the application of ML algorithms to predicting the energy consumption in U.S. residential buildings. It uses the Residential Energy Consumption Survey (RECS) dataset to develop predictive models for the Energy Use Intensity (EUI) in apartments and single-family houses, employing tree-based algorithms such as LightGBM, CatBoost, and XGBoost. This study also incorporates SHAP (SHapley Additive exPlanations) to analyze the importance and interactions of household features in determining energy consumption, providing valuable insights for energy-efficient building design and retrofitting strategies. The results highlight key factors, including building size, heating methods, climate conditions, and building age, as significant contributors to energy use. By offering personalized energy saving strategies for different building types, this study contributes to the growing body of knowledge on energy efficiency and the integration of ML into building energy management. U. Ali et al. [
18] proposed a scalable and robust framework for forecasting the energy consumption across urban residential building stocks, leveraging ensemble-based ML techniques. This approach integrates data acquisition, archetype development, parametric simulation, and predictive modeling to address the key limitations of conventional urban energy modeling, most notably the limited availability and heterogeneity of large-scale building data. Applied to Ireland’s residential building stock, this framework synthesizes a dataset representing one million dwellings characterized by 19 critical parameters. By disaggregating the end-use energy demands, such as heating, lighting, domestic hot water, photovoltaic generation, and appliance loads, this model enhances the resolution and interpretability. Ensemble learning methods achieve a predictive accuracy of 91%, markedly surpassing the traditional modeling techniques (76%). This study offers a data-driven, policy-relevant tool to support urban planners and decision-makers in evaluating retrofitting strategies and advancing sustainable energy transitions at scale. Sijun Xu et al. [
19] studied the effects of individual factors on power savings and thermal management. They summarized the main factors in various cooling systems for reducing the power consumption, realized data management, and described the corresponding research, as well as the optimization methods. They also investigated data center cooling systems and described their principles, which take three main forms: air cooling systems, liquid cooling systems, and free cooling systems. Moreover, the power usage effectiveness (PUE) values and simultaneous cooling loads for different systems are provided. The study [
20] presents a robust and interpretable machine learning framework for accurately forecasting the energy consumption for residential heating. The proposed model employs a stacking ensemble architecture comprising LightGBM, Random Forest, and XGBoost, with the hyperparameters optimized via Particle Swarm Optimization (PSO) and preceded by dimensionality reduction through Self-Organizing Maps (SOMs). Achieving a predictive accuracy of 95.4%, the model demonstrates strong generalizability and performance. Beyond prediction, the integration of SHapley Additive exPlanations (SHAP) and causal inference techniques enables both interpretability and the identification of underlying cause–effect relationships. Notably, variations in air and water pipe temperatures were found to significantly impact the energy usage. This methodological framework not only enhances the precision and transparency of energy demand modeling but also offers actionable insights for building managers to implement efficient, cost-effective heating strategies, particularly during high-demand winter periods. S. Kapp [
21] proposes a hybrid modeling framework for forecasting the energy consumption in industrial buildings by integrating domain-specific physical system knowledge with ML techniques. Utilizing data from 45 manufacturing facilities, the model incorporates a comprehensive set of features, including environmental variables (e.g., air enthalpy, solar radiation), support system metrics (e.g., motors, steam usage, compressed air), and operational parameters (e.g., production throughput, workforce levels, and facility size). A linear regression model applied to a transformed feature space outperformed a conventional support vector machine, achieving a superior predictive accuracy while maintaining model interpretability. This physically informed, data-driven approach offers a scalable and practical solution for uncovering energy saving opportunities within complex industrial systems. Mohd Herwan Sulaiman and Zuriani Mustaffa [
22] proposed the Barnacles Mating Optimizer (BMO) to solve the optimal chiller loading (OCL) problem by reducing the total energy consumption while considering certain limitations in the multi-cooling system. To show the effectiveness of the BMO, it was tested on three different cooling systems (6-unit, 4-unit, and 3-unit chiller systems) and its results compared with those of other modern optimization algorithms, where it was recognized that it could provide competitive results and was effective in achieving the lowest energy consumption to solve the OCL problem. The authors of [
23] demonstrated that existing Thermal Energy Storage cooling facilities could be one of the most cost-effective resources for achieving state and government carbon neutrality goals, applied model predictive control (MPC), and evaluated the site performance of a campus-wide TES cooling facility. It aims to self-consume electricity generated on site, reduce carbon emissions into the grid, and reduce utility bills. The performance of MPC was evaluated against a carefully selected baseline period. The results of the MPC showed a reduction in the excess PV capacity by approximately 25%, greenhouse gas emissions by 10%, and the peak electricity demand by 10%. In [
24], the authors proposed an analysis of the statistical relationship between the energy performance and life cycle costs (LCCs) of a cooling plant operating in medium- and large-scale application scenarios, with an evaluation of its impact under the same heat demand conditions. A case study of a Cuban hotel with 138 sets of differently arranged cooling stations was selected. The results indicated that the design of the overall chiller and the distribution of the cooling capacity between chillers have a significant impact on the energy consumption of the cooling plant, with Spearman’s Rho and Kendall’s Tau correlation indices of 0.625 and 0.559. Considering the LCCs, only the distribution of the cooling capacity between the chillers had an effect, with a Kendall Tau correlation index of 0.289. For the total cooling capacity studied, the statistical test applied indicated that this design variable did not affect the performance of the cooling plant. The study [
25] assessed the efficacy of data-driven methodologies for predicting and forecasting the chiller power consumption within HVAC systems using real-time operational data from an academic building in Taiwan. A comparative analysis was conducted between a conventional thermodynamic linear regression model and a Multi-Layer Perceptron (MLP) neural network for consumption predictions, as well as among three deep learning architectures, MLP, a one-dimensional Convolutional Neural Network (1D-CNN), and Long Short-Term Memory (LSTM), for minute-ahead forecasting. The MLP model demonstrated a superior performance over that of the traditional thermodynamic approaches, yielding an R² of 0.971. For short-term forecasting, the LSTM model outperformed its counterparts with an R² of 0.994, underscoring its capability to capture the temporal dependencies in high-resolution energy data. Beyond the predictive accuracy, this study highlights real-world applications of these models, including proactive maintenance scheduling and intelligent switching of the energy sources based on the anticipated load, thereby advancing the energy efficiency and cost optimization in smart building operations. Jee-Heon Kim et al. [
26] conducted a study on developing an energy consumption model for the refrigerant in an HVAC system using an ML algorithm based on artificial neural networks to find the optimal conditions. The developed model was also evaluated for its accuracy. It was improved in terms of various input parameters, as the model was able to predict the power consumption with 99.07% accuracy based on eight input variables. In addition, a standard reference building was designed to generate operating data for the refrigeration system during extended cooling periods (warm-weather months).
Table 1 provides a synthesized comparison of the reviewed studies, emphasizing their key findings and contributions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}