1. Introduction
With increasing worries regarding energy shortages and global climate issues, the research and development of renewable energy have garnered significant global interest [
1]. As a clean, safe, and sustainable energy source, solar energy is essential to meeting worldwide renewable energy demands, delivering substantial economic and environmental benefits. Currently, solar energy utilization technologies are primarily categorized into photovoltaics and solar thermal systems [
2]. Among these, photovoltaics has quickly emerged as a leading technology. However, the inherent variability and intermittency of solar resources lead to fluctuating output from photovoltaic (PV) generation, which presents notable challenges to power grid security and stability [
3]. These challenges include issues with voltage management, frequency stability, reverse power flow, and harmonic distortion. To address these grid-related challenges associated with PV integration, PV power forecasting models have increasingly emerged as a key research focus in solar energy [
4]. Accurate and reliable PV power forecasting is essential to maximizing solar energy utilization, enhancing the economic performance of PV plants, and supporting efficient power market trading and grid operation scheduling [
5].
The random fluctuations and intermittency of PV power arise from changing meteorological conditions [
6]. PV power is influenced by multiple meteorological parameters, including irradiance, temperature, wind speed, and aerosol concentration [
7,
8]. Major fluctuations in PV power are primarily driven by cloud formation, movement, and dissipation [
9]. This information can be obtained from both satellite imagery and ground-based sky images [
10]. Compared with the broad coverage provided by satellite images, ground-based sky images can quickly reveal cloud dynamics directly above the PV plant, offering crucial information for PV forecasting. Ground-based sky images provide detailed information about cloud spatial distribution, brightness, and shape [
11]. Incorporating ground-based sky images into PV power forecasts can significantly improve predictive accuracy.
Currently, PV forecasting utilizing ground-based sky images is mainly divided into cloud motion vector (CMV) methods and deep learning approaches. CMV methods use sky images to predict the future distribution of clouds by accurately calculating key parameters, such as cloud matching [
12], cloud cover index [
13], and cloud motion displacement vectors [
14,
15]. These methods typically conduct PV forecasting through linear extrapolation [
16]. Reference [
17] utilized the Shi–Tomasi approach for detecting feature points and implemented Lucas–Kanade optical flow to monitor feature points throughout consecutive images. Subsequently, average cloud velocity and direction were determined through linear regression, and solar radiation was predicted using long short-term memory networks. Reference [
18] proposed a two-stage cloud velocity estimation and classification framework that integrates algorithms for extracting and matching cloud image features, thereby enhancing the accuracy of PV power forecasts.
Deep learning methods are widely adopted for powerful nonlinear approximation capabilities and robust generalization abilities. Common deep learning architectures encompass convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM) networks, and gated recurrent units (GRUs) [
19,
20,
21,
22]. CNNs can effectively extract spatial features through local receptive fields and weight sharing, while RNNs and their variants are more adept at extracting temporal features [
23]. Reference [
24] employed residual networks (ResNets) and stacked sky images incorporating cloud motion spatiotemporal information to predict PV generation for the next 5 to 10 min without using additional time-series models. Reference [
25] applied mathematical and physical methods to extract spatial features, which were then input into an LSTM model to estimate solar irradiance and predict PV power. However, the limited analysis of spatial or temporal features constrains the accuracy of these models. Three-dimensional convolutional neural networks (3D-CNNs) and convolutional LSTM (ConvLSTM) have been introduced to directly capture spatiotemporal features. Reference [
26] developed two CNN-based architectures to process sky image sequences and suggested that traditional CNNs may not adequately capture temporal features. ConvLSTM incorporates convolutional operations within LSTM units for modeling. Reference [
27] developed a ConvLSTM-based prediction model incorporating an attention mechanism within the decoder. This design fully utilizes the spatiotemporal correlations in regional photovoltaic generation to achieve rolling forecasts for regional PV power.
Owing to the pronounced volatility of PV power under changing meteorological conditions, using only a single model is insufficient to comprehensively capture the spatiotemporal feature information. To comprehensively extract the spatiotemporal feature information of sky images for PV power forecasting, CNN-LSTM architecture integrates a series of convolutional and LSTM layers, where the convolutional layers extract spatial features and input them to the LSTM network, which extracts complex features and captures irregular trends in the dataset [
28]. Reference [
29] introduced a dual-stream network combining CNNs and GRUs, which extract spatial and temporal features in parallel, followed by a self-attention mechanism to enhance forecasting performance. However, in deep learning methods, the exploration of spatial and temporal features within spatiotemporal feature information remains insufficient, indicating that further research is needed to enhance prediction performance.
The aforementioned studies primarily focus on extracting overall features from sky images and historical PV power. Insufficient spatiotemporal feature extraction impacts PV prediction performance. Spatial feature extraction is typically performed by CNNs through sliding window convolutions with small kernels. Under rapidly changing meteorological conditions, CNNs may only detect small-scale cloud movements and fail to capture large-scale cloud motion. Therefore, extracting both global and local features from spatial data is crucial to improving performance.
Transformers, known for their parallel computing capability and strong proficiency in modeling long-range dependencies, have demonstrated remarkable success in natural language processing [
30]. Although Transformers have been applied to temporal feature extraction in PV forecasting, the potential of Vision Transformers for capturing global spatial features from sky images remains underexplored, especially in the extraction of deep detailed features at the edges of cloud masses. Therefore, introducing visual Transformers for the extraction of spatiotemporal feature would enhance the learning ability and generalizability of the framework.
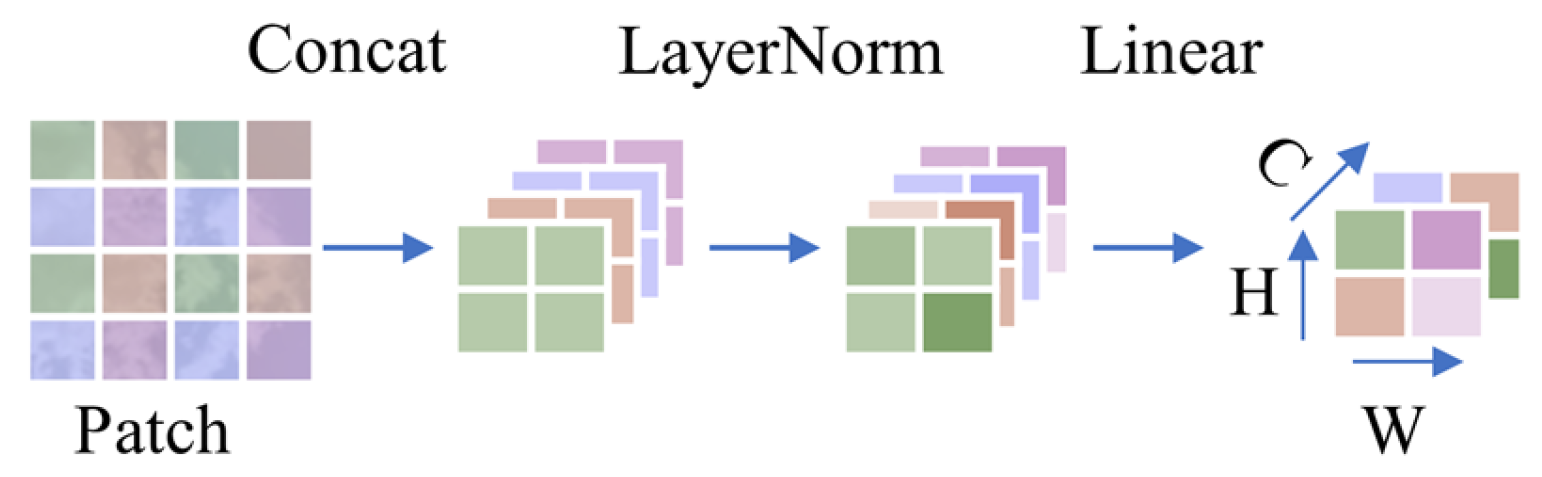
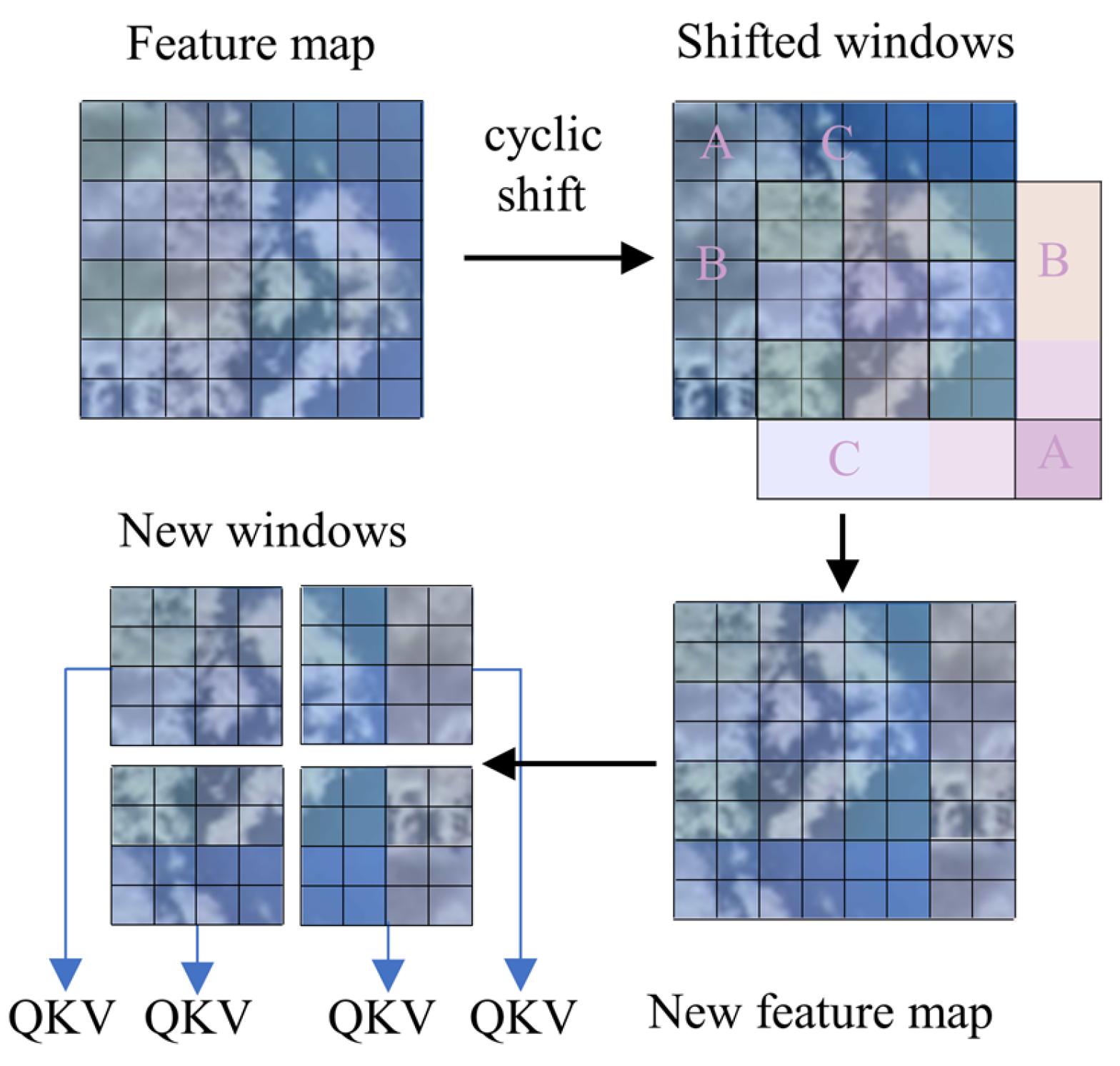
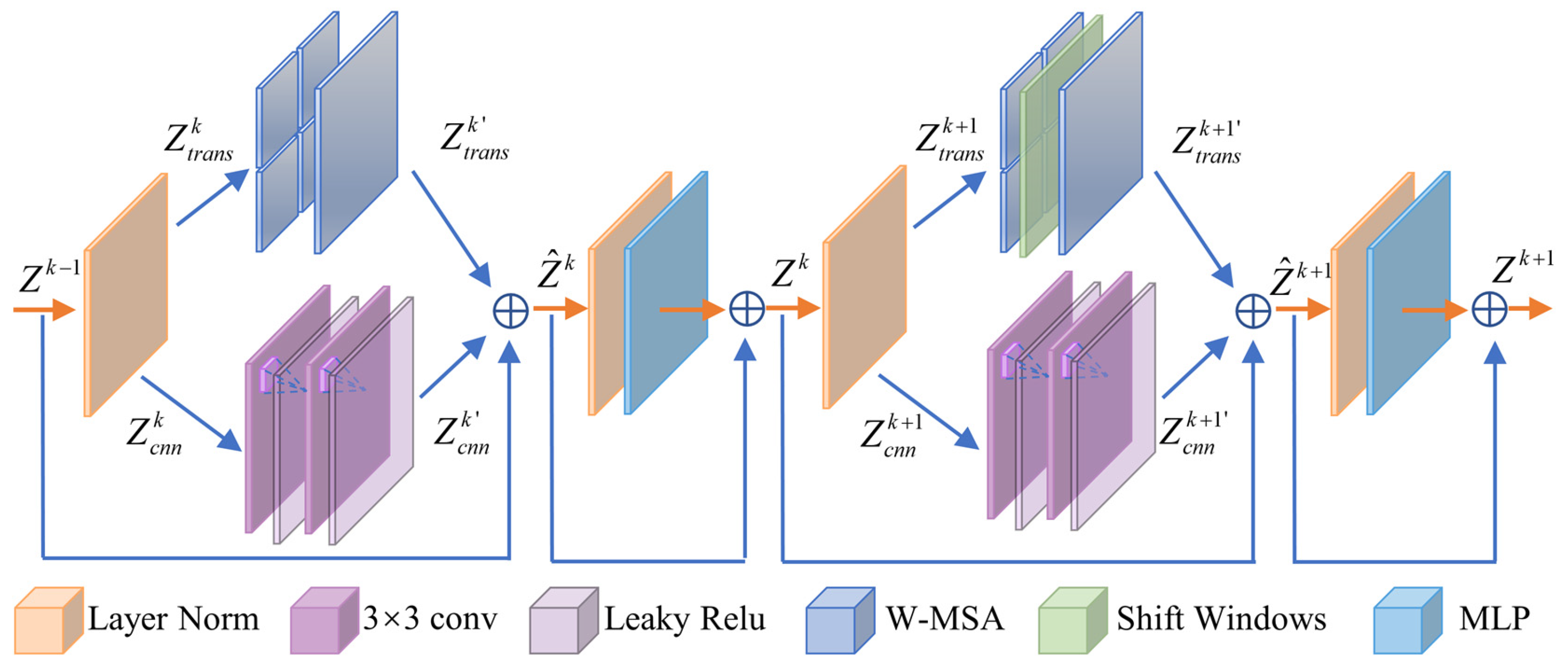
To address the limitations in existing approaches, this paper proposes a hybrid framework for spatiotemporal feature information extraction to improve forecasting accuracy. The proposed framework adopts a dual-stream backbone network with shifted windows Transformer (Swin Transformer) and a convolutional neural network (CNN) operating in parallel. First, the Swin Transformer–CNN backbone network extracts spatial features from ground-based sky image sequences, where Swin Transformer and the CNN capture global and local features in parallel and adaptively fuse them to form spatial features. Second, a long short-term memory network extracts temporal features from spatial feature sequences and historical PV power data, which are subsequently fused to construct comprehensive spatiotemporal feature information. Finally, this fused representation is mapped to PV power output for multi-step forecasting. The main contributions of this paper are summarized as follows:
A Swin Transformer–CNN–LSTM-based learning framework is proposed for image-driven PV power forecasting. The experimental results demonstrate that the proposed framework demonstrates strong performance across various prediction time horizons and weather conditions on benchmark datasets and exhibits good generalizability on lab datasets.
A spatial feature extraction module based on Swin Transformer and a CNN is designed to separately capture global and local spatial features from sky image sequences. These features are adaptively fused to form crucial spatial representations for accurate PV forecasting.
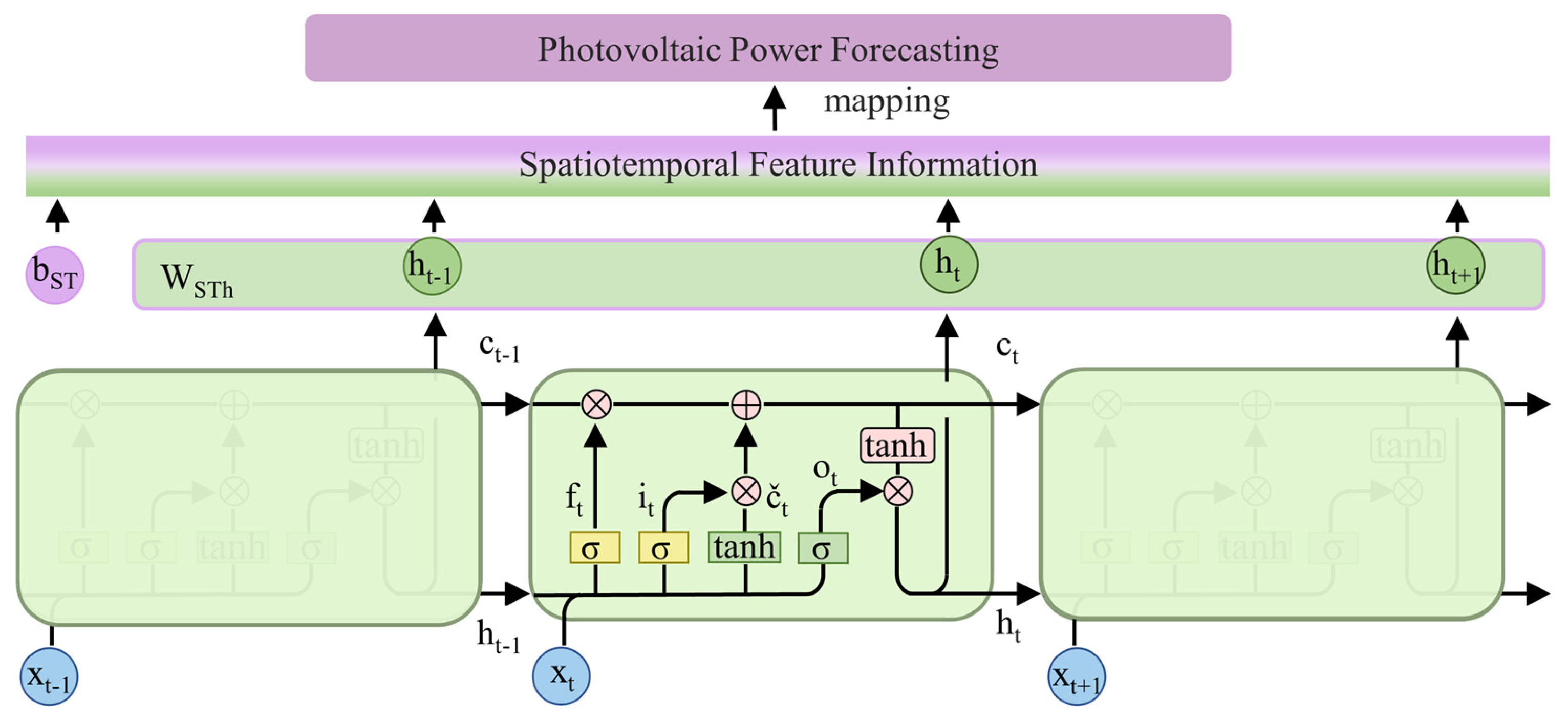
A spatiotemporal feature extraction module based on LSTM is developed to jointly learn temporal dynamics from both spatial feature sequences and PV power data, enabling the construction of rich spatiotemporal representations for forecasting.
The remainder of the paper is structured as follows:
Section 2 details the methodology of the proposed framework.
Section 3 presents the experiment and results.
Section 4 presents the discussion.
Section 5 concludes the paper.












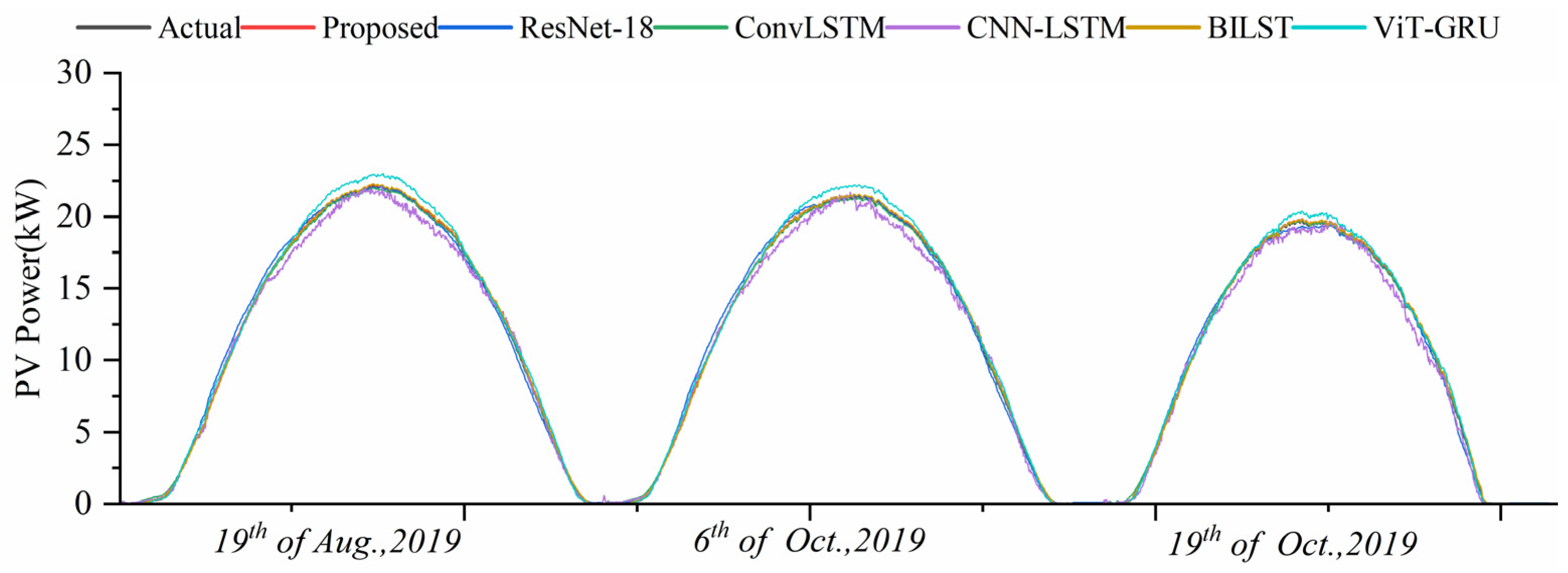
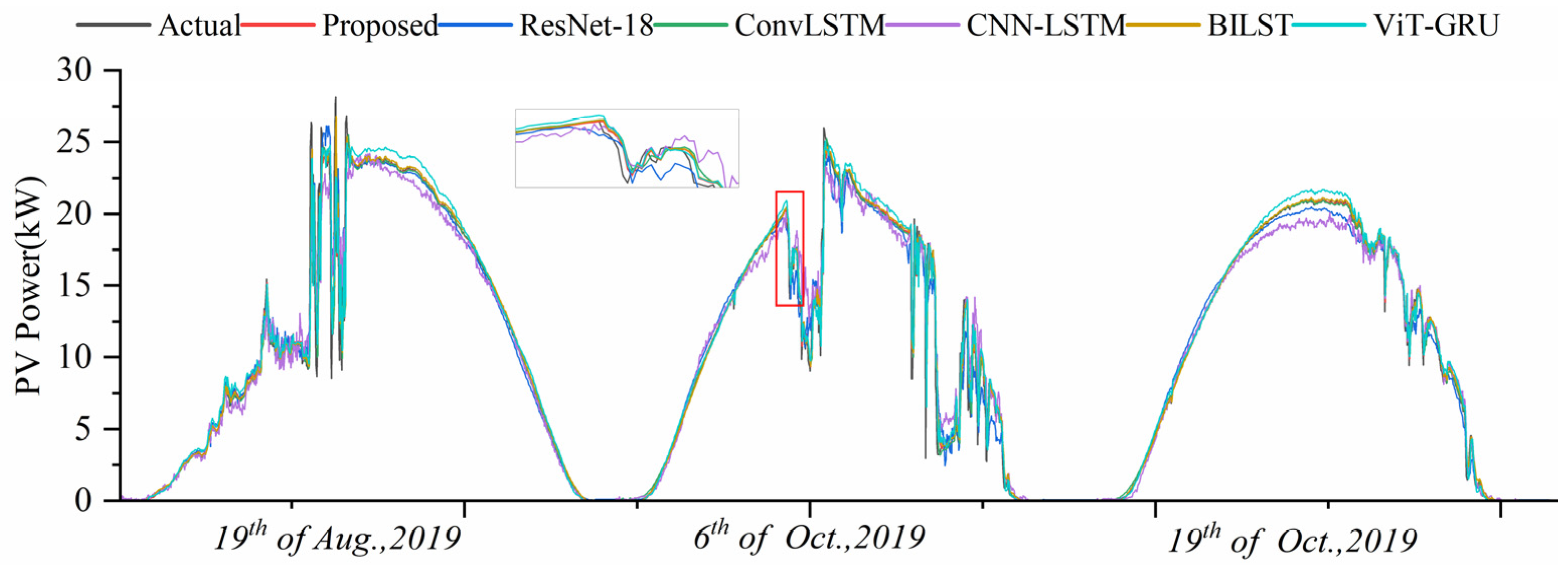
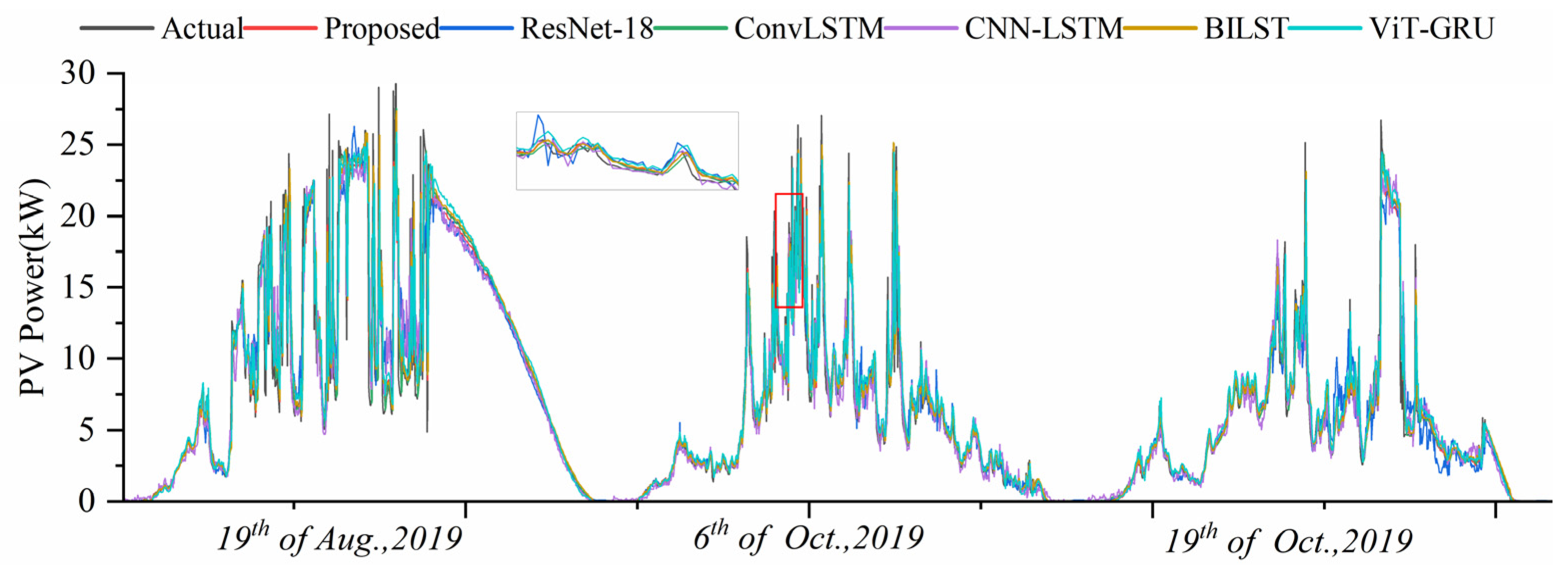
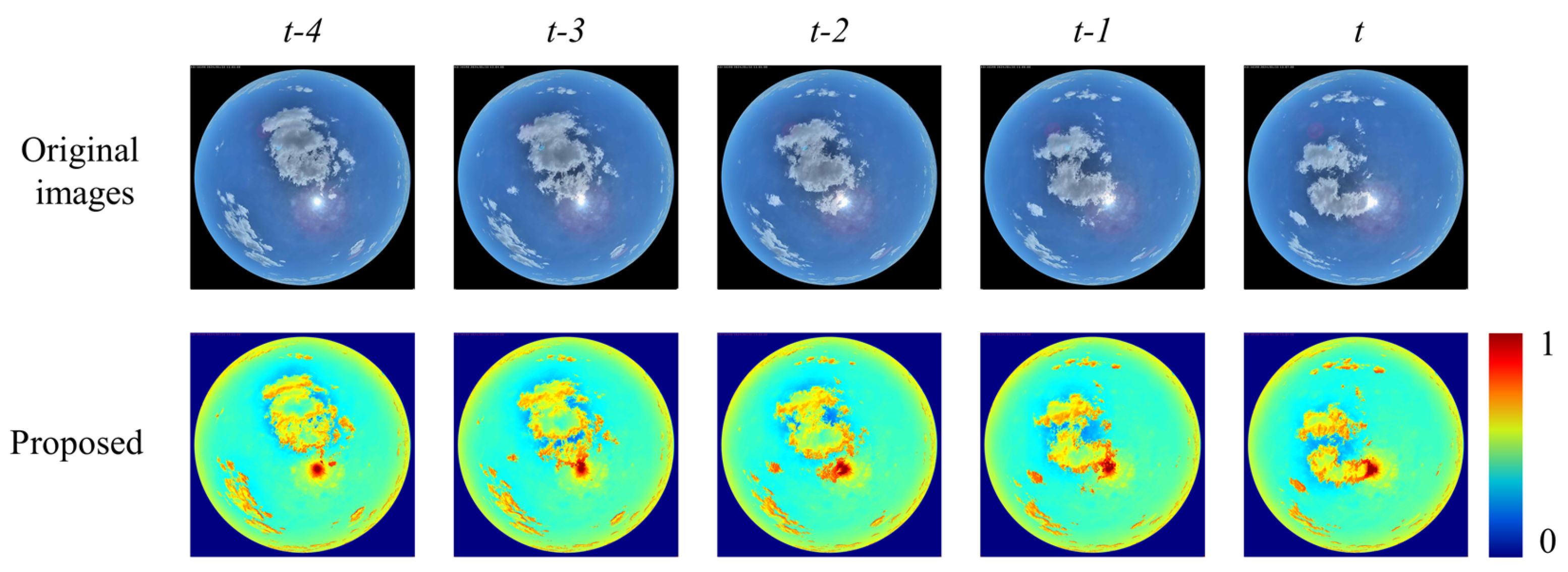

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}