
Machine Learning with Administrative Data for Energy Poverty Identification in the UK



Abstract
1. Introduction
1.1. The Scope of Energy Poverty in England
1.2. The Need for Alternative Approaches
1.3. Machine Learning vs. Traditional Methods
1.4. Existing Research on Machine Learning for Energy Poverty
1.5. Research Gaps in Current Studies
- Balanced Accuracy: Measures both a model’s sensitivity (True Positive Rate) and specificity (True Negative Rate).
- Recall (True Positive Rate, Sensitivity): Measures the proportion of actual energy-poor households correctly identified by the model. This is particularly important when the goal is to capture as many vulnerable households as possible.
- Precision: Measures the proportion of households classified as energy-poor that are actually energy-poor. A high precision ensures that resources are directed to those truly in need, minimising the misclassification of non-energy-poor households.
- F1-score: The harmonic means of precision and recall which provide a balanced metric when dealing with imbalanced datasets.
1.6. The UK Government’s Machine Learning Pilot Study
1.7. Objectives of This Paper
- (1)
- Improve model accuracy, precision, and F1-score while maintaining recall at levels comparable to the UK government’s benchmark pilot model.
- (2)
- Evaluate different administrative datasets and feature combinations to enhance predictive power, such as census data.
- (3)
- Compare the performance of different resampling techniques to mitigate class imbalance and improve the detection of energy-poor households.
- (4)
- Use SHAP values to enhance model interpretability and assess feature importance.
- Census data alone has predictive power for energy poverty classification, even without direct energy consumption data.
- Adding more socioeconomic and housing-related proxies (e.g., income, floor area, dwelling type) will improve model accuracy.
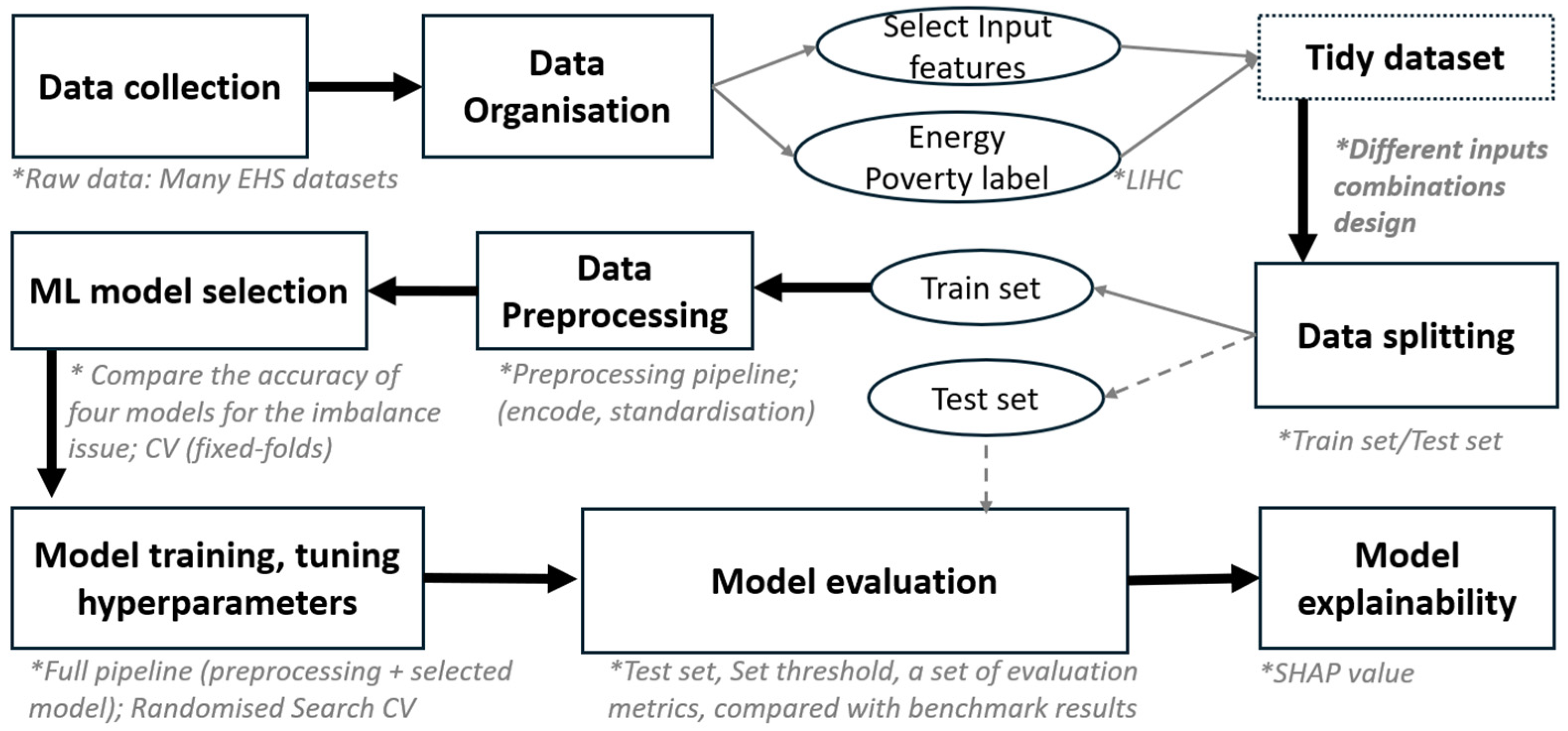
2. Materials and Methods
2.1. Data Collection and Organisation
2.1.1. Input Feature Selection
- Census Data Proxies [38,39]: A total of 17 variables representing household composition, socioeconomic classification, and living conditions, including household size, number of dependent children, tenure, long-term illness or disability status, heating fuel type, and detailed dwelling type (eight categories).
- Other Input Proxies: Three variables, including household annual income, total floor area, and dwelling type (two categories: whether household is a house or flat).
2.1.2. Input Combinations
- Combination 1 (census-only): This combination assesses the standalone predictive capability of census data in identifying energy poverty. This model is named “COM-1” in the analysis.
- Combination 2 (census + other inputs): Expands Combination 1 by incorporating additional proxies. Notably, floor area and dwelling type (two categories) can be obtained from Building 3D Modelling Lab [40], highlighting the potential for using these accessible data sources as predictive inputs, while (estimated) household income can be obtained from companies such as Experian. This model is named “COM-2” in the analysis.
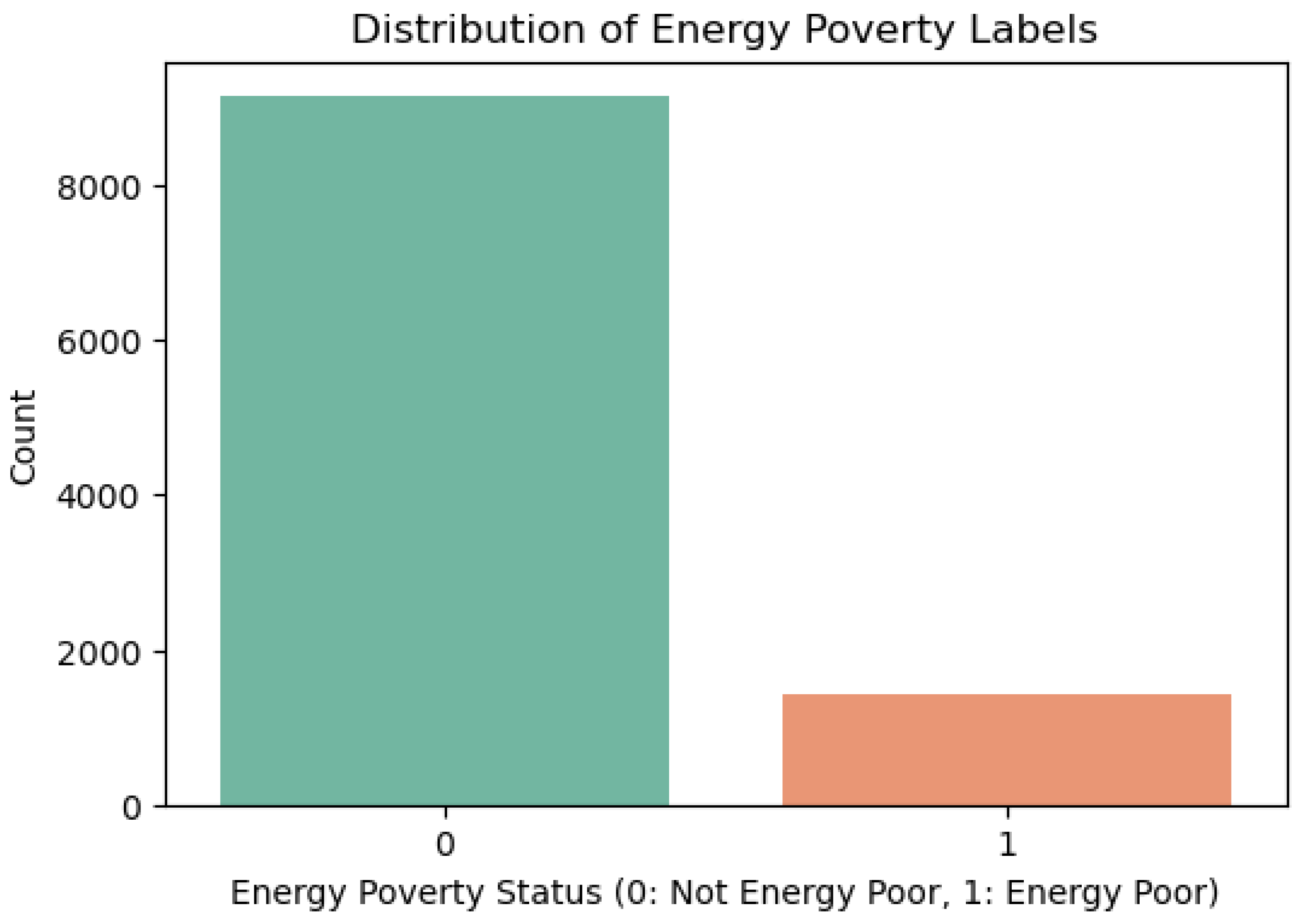
2.1.3. Energy Poverty Label
- High Cost: The household’s equivalised fuel costs exceed the national median.
- Low Income: The household’s equivalised after-housing-cost (AHC) income falls below an adjusted threshold.
2.2. Data Splitting and Preprocessing Pipeline
- Numerical variables: We apply data standardisation using StandardScaler [46], which transforms features to have a mean of zero and a standard deviation of one. Standardisation ensures that numerical variables with different scales do not disproportionately influence the model.
- Categorical variables: We use One-Hot Encoding [47], which converts categorical features into a binary format, allowing machine learning models to process them effectively. This method prevents the model from misinterpreting categorical values as ordinal relationships, preserving the integrity of categorical data.
2.3. Machine Learning Model Selection
- Resampling techniques: We apply Random Undersampling before training to reduce the bias towards the majority class. Undersampling techniques are used for reducing the imbalance ratio by removing samples from the majority class [54]. This approach helps balance class representation, ensuring that the model does not disproportionately prioritise the majority class, thereby improving its ability to identify energy-poor houses.
- Class weight adjustment: Another effective approach is adjusting class weights in the model’s cost function, assigning higher weights to the minority class to make misclassification more costly and to improve recall for fuel-poor households [55]. For RF, we set class weight as “balanced”, which automatically assigns weights to be inversely proportional to class frequencies, reducing bias toward the majority class. For XGBoost, we adjust the algorithms with the scale pos weight parameter, which is typically calculated as the ratio of the number of negative samples to the number of positive samples in the training data. This adjustment ensures that the model gives sufficient importance to the minority class, enhancing its ability to correctly identify fuel-poor households.
2.4. Model Training and Hyperparameter Tuning
2.5. Model Evaluation and Explainability
- Accuracy: Measures the proportion of correctly classified households.
- Precision: Indicates how many of the predicted fuel-poor households are actually fuel-poor.
- Recall (Sensitivity, True Positive Rate): Measures the proportion of actual fuel-poor households correctly identified by the model. A higher recall ensures fewer False Negatives.
- F1-Score: Represents the harmonic mean of precision and recall, providing a balanced measure of model performance.
- Balanced Accuracy: Measures both the model’s sensitivity (True Positive Rate) and specificity (True Negative Rate).
- ROC and AUC (Area Under Curve): The ROC (Receiver Operating Characteristic) curve plots the trade-off between a model’s recall (True Positive Rate) and False Positive Rate (FPR) at different classification thresholds:
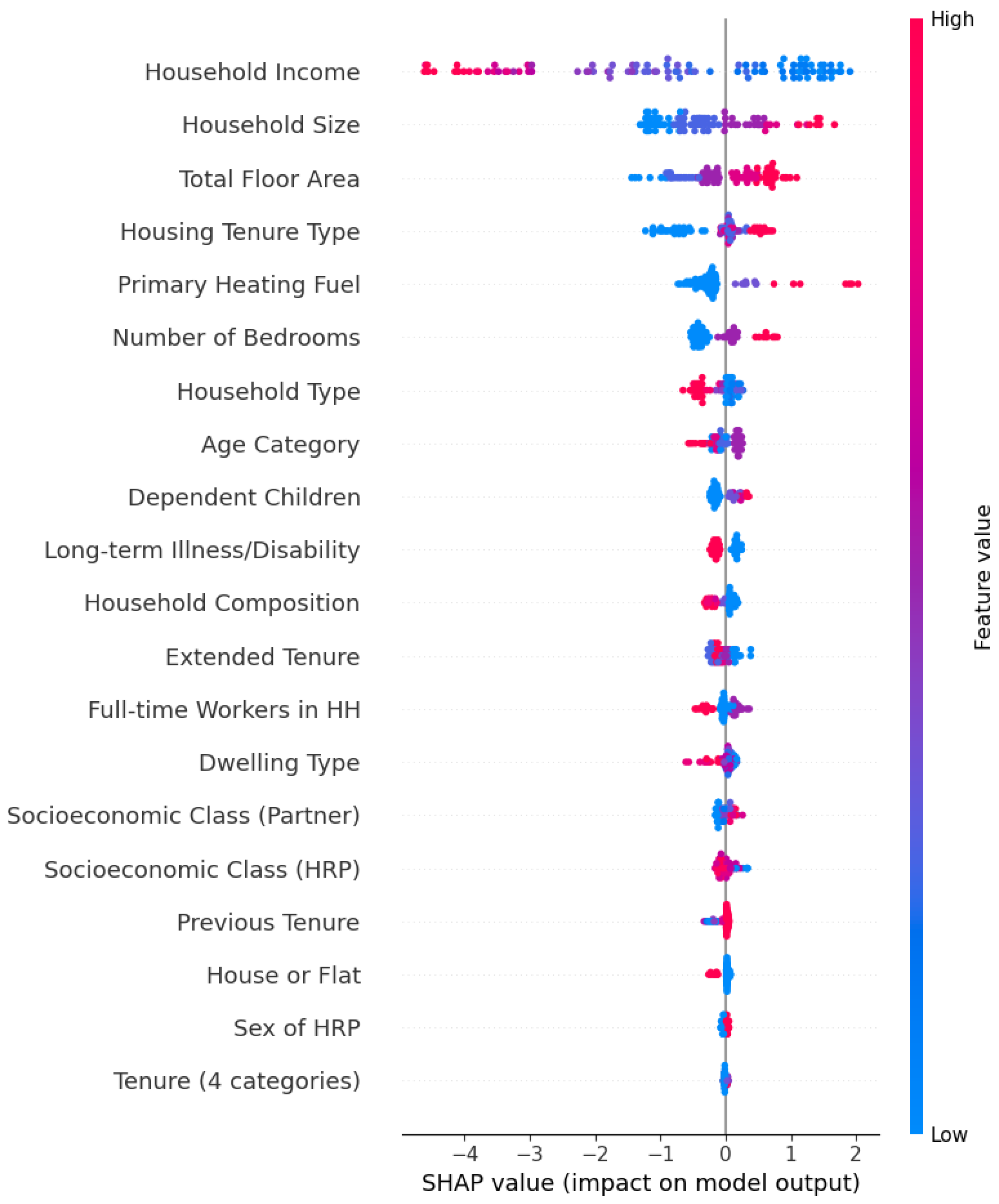
- Feature Importance: Identifying which input features contribute the most to predicting energy poverty.
- Local Interpretability: Explaining individual household predictions, allowing insights into why certain households are classified as energy-poor.
- Fairness Assessment: Ensuring that predictions align with logical socioeconomic and housing-related indicators rather than arbitrary biases.
3. Results
3.1. Machine Learning Approach Selection
3.2. Models Performance Metrics
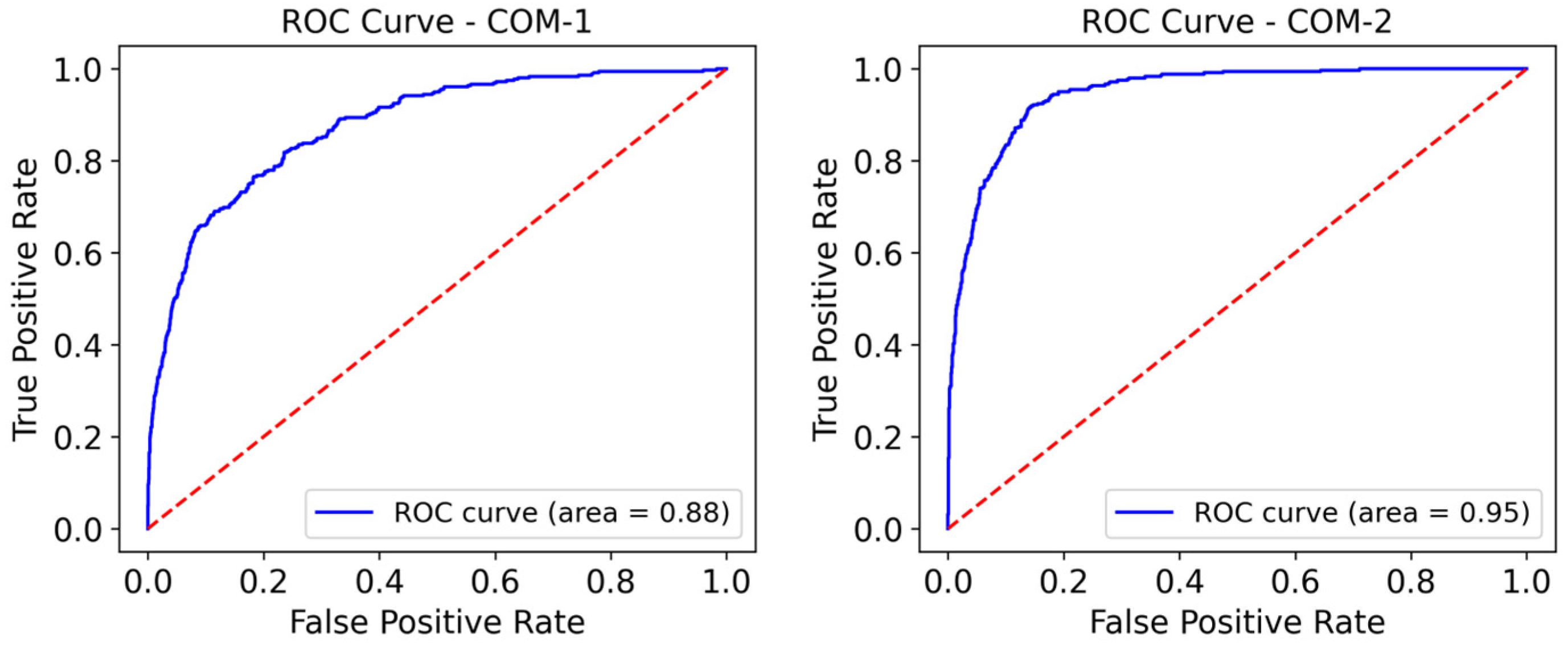
3.3. Models’ ROC Curve and AUC Value
3.4. SHAP Value of the Best Performance Model
4. Discussion and Limitations
4.1. Discussion
- Enhance rapid assessments of energy poverty using readily available datasets without the need for direct household surveys or complex financial data collection.
- Support local authorities and policymakers in designing targeted interventions by identifying households most at risk, enabling data-driven decision-making for financial aid distribution and energy efficiency programmes.
- Facilitate real-time monitoring of energy vulnerability trends by integrating additional real-world data sources, such as smart meter consumption, energy tariffs, and weather data, to track changes in household energy usage patterns over time, allowing the early detection of households struggling with energy costs or dynamically updating its predictions to reflect changing economic and environmental conditions.
- By identifying at-risk households before they fall into severe fuel poverty, social programmes can be more preventative rather than reactive, leading to better long-term outcomes.
4.2. Limitations
- (1)
- Trade-offs between model simplicity and predictive accuracy
- (2)
- Limitations of census and administrative data
- (3)
- Integration of energy consumption and smart meter data
- (4)
- Ethical considerations and model transparency
- (5)
- Proxy variables rather than actual administrative datasets
- (6)
- Algorithmic bias
5. Conclusions
- (1)
- Machine learning offers a data-driven approach to the identification of energy poverty in specific households.
- (2)
- Census data has predictive power for energy poverty identification. Using a set of administrative features as the input, our best performing machine learning model can identify 91% of energy-poor households, with 51% of predicted energy-poor households actually being energy-poor, a superior performance compared to the benchmark model.
- (3)
- Policymakers can benefit from integrating machine-learning-based models into energy poverty identification frameworks.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EHS | English Housing Survey |
| SHAP | SHapley Additive exPlanations |
| CV | Cross-Validation |
| LIHC | Low Income High Cost |
| LILEE | Low Income Low Energy Efficiency |
| MEPI | Multidimensional Energy Poverty Index |
| RF | Random Forest |
| XGBoosting | Extreme Gradient Boosting |
| DT | Decision Tree |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| MLP | Multilayer Perceptron |
| ANN | Artificial Neural Network |
| PDC | Passive Design Characteristics |
Appendix A. Proxy Data Selection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proxy | Variable Name | Description | Value Labels Example |
|---|---|---|---|
| Proxy census data based on criteria through the 2021 Census from the ONS website [72]. | hhsizex | Number of persons in the household | 1, 2, 3, 4 |
| sft | Number of full-time workers in household | 1, 2, 3, 4 | |
| nssech9 | NS-SEC Socioeconomic Classification—HRP | 1 “higher managerial and professional occupations”. 2 “lower managerial and professional occupations”. | |
| nssecp9 | NS-SEC Socioeconomic Classification—HRP’s partner | 1 “higher managerial and professional occupations”. 2 “lower managerial and professional occupations”. | |
| hhtype11 | Household type—All 11 categories | 1 “couple with no child(ren)”. 2 “couple with dependent child(ren) only”. | |
| ager | Report age categories | 1 “16 to 24” 2 “25 to 34” 3 “35 to 44” | |
| sexhrp | Sex of household reference person | 1 “male” 2 “female” | |
| hhcomp1 | Household composition, focussing on HRP (seven categories) | 1 “married/cohabiting couple” 2 “lone parent, male HRP” 3 “lone parent, female HRP” | |
| ndepchild | Number of dependent children in household | 1, 2, 3 | |
| hhltsick | Anyone in household with long-term illness or disability | 1 “yes” 2 “no” | |
| tenure2 | Tenure group 2 | 1 “own outright” 2 “buying with mortgage (including shared ownership)” 3 “local authority tenant” | |
| prevten | Tenure of previous home of HRP | 1 “new household” 2 “owned outright” 3 “buying with a mortgage” | |
| tenex | Extended tenure of household | 1 “own with mortgage” 2 “own outright” 3 “privately rent” | |
| tenure4x | Tenure—Four categories. | 1 “owner occupied” 2 “private rented” 3 “local authority” 4 “housing association” | |
| Bedrqx | Number of bedrooms | 1, 2, 3 | |
| fuelx | Type of fuel used for the main or primary space heating system | 1 “gas fired system” 2 “oil fired system” 3 “solid fuel fired system” 4 “electrical system” | |
| DWtype | Dwelling type (eight categories) | 1 “small terraced house” 2 “medium/large terraced house” 3 “semi-detached house” | |
| Proxy for other inputs | housex | Whether the dwelling is a house or flat (two categories) | 1 “house or bungalow” 2 “flat” |
| HYEARGRx | Household gross annual income (inc. income from all adult household members) | 100,000.00: “£100,000 or more” | |
| FloorArea | Total floor area | Numeric |
Appendix B. Hyperparameter Tuning for XGBoosting Model
- colsample_bytree: Controls the fraction of features (columns) used in each tree, reducing overfitting while maintaining predictive power.
- gamma: Determines the minimum loss reduction required to split a node, helping prevent unnecessary splits and improving model regularisation.
- learning_rate: Controls the step size in updating weights, with a lower value improving model stability but requiring more boosting rounds.
- max_depth: Specifies the maximum depth of each tree, balancing model complexity and overfitting.
- n_estimators: Sets the number of boosting rounds, with more estimators potentially improving performance but increasing computational cost.
- reg_alpha & reg_lambda: Represent L1 and L2 regularisation terms, which help prevent overfitting by penalising large coefficients.
- subsample: Defines the fraction of training data used per boosting iteration, reducing variance and improving generalisation.
| Hyperparameter | COM-1 | COM-2 | Extended Model |
|---|---|---|---|
| colsample_bytree | 0.70 | 0.69 | 0.96 |
| gamma | 4.68 | 4.68 | 4.04 |
| learning_rate | 0.05 | 0.05 | 0.2 |
| max_depth | 11 | 11 | 8 |
| n_estimators | 250 | 250 | 383 |
| reg_alpha | 5.4 | 8.04 | 8.04 |
| reg_lambda | 6.96 | 6.96 | 1.87 |
| subsample | 0.61 | 0.61 | 0.95 |
Appendix C. Confusion Matrix Results
| COM-1 | ||||
|---|---|---|---|---|
| Set Threshold = 0.23 | ||||
| Classification | Precision | Recall | F1-Score | Support |
| Not Energy-Poor | 0.98 | 0.61 | 0.70 | 2285 |
| Energy-Poor | 0.27 | 0.90 | 0.41 | 358 |
| Accuracy | 0.65 | 2643 | ||
| Macro Avg | 0.62 | 0.76 | 0.58 | 2643 |
| Weighted Avg | 0.88 | 0.65 | 0.70 | 2643 |
| balanced accuracy = 0.76, ROC curve (area = 0.88) | ||||
| COM-2 | ||||
| Set Threshold = 0.45 | ||||
| Classification | Precision | Recall | F1-Score | Support |
| Not Energy-Poor | 0.98 | 0.86 | 0.92 | 2285 |
| Energy-Poor | 0.51 | 0.91 | 0.65 | 358 |
| Accuracy | 0.87 | 2643 | ||
| Macro Avg | 0.75 | 0.88 | 0.79 | 2643 |
| Weighted Avg | 0.92 | 0.87 | 0.88 | 2643 |
| balanced accuracy = 0.88, ROC curve (area = 0.95) | ||||
| Extended Model (Add SAP Value) | ||||
| Set Threshold = 0.43 | ||||
| Classification | Precision | Recall | F1-Score | Support |
| Not Energy-Poor | 0.98 | 0.88 | 0.93 | 2285 |
| Energy-Poor | 0.56 | 0.90 | 0.69 | 358 |
| Accuracy | 0.89 | 2643 | ||
| Macro Avg | 0.77 | 0.89 | 0.81 | 2643 |
| Weighted Avg | 0.92 | 0.89 | 0.90 | 2643 |
| balanced accuracy = 0.90, ROC curve (area = 0.96) | ||||
| Benchmark Model | ||||
| Classification | Precision | Recall | F1-Score | Support |
| Not Energy-Poor | 0.98 | 0.64 | 0.77 | 2396 |
| Energy-Poor | 0.24 | 0.90 | 0.37 | 296 |
| Accuracy | 0.67 | 2692 | ||
| Macro Averaged | 0.61 | 0.77 | 0.57 | 2692 |
| Weighted Averaged | 0.90 | 0.67 | 0.74 | 2692 |
| balanced accuracy = 0.77, ROC curve (area = 0.89) | ||||
References
- Moore, R. Definitions of fuel poverty: Implications for policy. Energy Policy 2012, 49, 19–26. [Google Scholar] [CrossRef]
- Waddams Price, C.; Brazier, K.; Wang, W. Objective and subjective measures of fuel poverty. Energy Policy 2012, 49, 33–39. [Google Scholar] [CrossRef]
- Steve, P.; Audrey, D. Energy Poverty and Vulnerable Consumers in the Energy Sector Across the EU: Analysis of Policies and Measures; Policy Report: European Commission for Energy, Climate Change, Environment; European Commission: Brussels, Belgium, 2015.
- Bentley, R.; Daniel, L.; Li, Y.; Baker, E.; Li, A. The effect of energy poverty on mental health, cardiovascular disease and respiratory health: A longitudinal analysis. Lancet Reg. Health—West. Pac. 2023, 35, 100734. [Google Scholar] [CrossRef] [PubMed]
- Huebner, G.M.; Hanmer, C.; Zapata-Webborn, E.; Pullinger, M.; McKenna, E.J.; Few, J.; Elam, S.; Oreszczyn, T. Self-reported energy use behaviour changed significantly during the cost-of-living crisis in winter 2022/23: Insights from cross-sectional and longitudinal surveys in Great Britain. Sci. Rep. 2023, 13, 21683. [Google Scholar] [CrossRef]
- Al Kez, D.; Foley, A.; Abdul, Z.K.; Del Rio, D.F. Energy poverty prediction in the United Kingdom: A machine learning approach. Energy Policy 2024, 184, 113909. [Google Scholar] [CrossRef]
- Annual Fuel Poverty Statistics Report: 2024. GOVUK. Available online: https://www.gov.uk/government/statistics/annual-fuel-poverty-statistics-report-2024 (accessed on 12 March 2025).
- A Critical Analysis of the New Politics of Fuel Poverty in England—Lucie Middlemiss. 2017. Available online: https://journals.sagepub.com/doi/full/10.1177/0261018316674851 (accessed on 29 August 2024).
- Sovacool, B.K. Fuel poverty, affordability, and energy justice in England: Policy insights from the Warm Front Program. Energy 2015, 93, 361–371. [Google Scholar] [CrossRef]
- Fuel Poverty Statistics Methodology Handbooks. GOVUK. 2024. Available online: https://www.gov.uk/government/publications/fuel-poverty-statistics-methodology-handbook (accessed on 13 February 2025).
- Committee on Fuel Poverty Annual Report: 2024. GOVUK. Available online: https://www.gov.uk/government/publications/committee-on-fuel-poverty-annual-report-2024 (accessed on 3 October 2024).
- Better Use of Data and AI in Delivering Benefits to the Fuel Poor: Research Report and CFP’s Recommendations. GOVUK. Available online: https://www.gov.uk/government/publications/better-use-of-data-and-ai-in-delivering-benefits-to-the-fuel-poor-research-report-and-cfps-recommendations (accessed on 13 February 2025).
- Homepage|SocialWatt. Available online: https://www.socialwatt.eu/en (accessed on 12 March 2025).
- ENPOR. IEECP. Available online: https://ieecp.org/projects/enpor/ (accessed on 12 March 2025).
- Department for Business, Energy & Industrial Strategy (BEIS). Machine Learning and Fuel Poverty Targeting: Annex A. 2017. Available online: https://assets.publishing.service.gov.uk/media/5a823bc5e5274a2e87dc1d8c/need-framework-annex-a-fuel-poverty-targeting.pdf (accessed on 2 December 2024).
- Ghorbany, S.; Hu, M.; Yao, S.; Wang, C.; Nguyen, Q.C.; Yue, X.; Alirezaei, M.; Tasdizen, T.; Sisk, M. Examining the role of passive design indicators in energy burden reduction: Insights from a machine learning and deep learning approach. Build. Environ. 2024, 250, 111126. [Google Scholar] [CrossRef] [PubMed]
- Spandagos, C.; Tovar Reaños, M.A.; Lynch, M.Á. Energy poverty prediction and effective targeting for just transitions with machine learning. Energy Econ. 2023, 128, 107131. [Google Scholar] [CrossRef]
- Mukelabai, M.D.; Wijayantha, K.G.U.; Blanchard, R.E. Using machine learning to expound energy poverty in the global south: Understanding and predicting access to cooking with clean energy. Energy AI 2023, 14, 100290. [Google Scholar] [CrossRef]
- van Hove, W.; Dalla Longa, F.; van der Zwaan, B. Identifying predictors for energy poverty in Europe using machine learning. Energy Build. 2022, 264, 112064. [Google Scholar] [CrossRef]
- Abbas, K.; Butt, K.M.; Xu, D.; Ali, M.; Baz, K.; Kharl, S.H.; Ahmed, M. Measurements and determinants of extreme multidimensional energy poverty using machine learning. Energy 2022, 251, 123977. [Google Scholar] [CrossRef]
- Dalla Longa, F.; Sweerts, B.; van der Zwaan, B. Exploring the complex origins of energy poverty in The Netherlands with machine learning. Energy Policy 2021, 156, 112373. [Google Scholar] [CrossRef]
- Wang, H.; Maruejols, L.; Yu, X. Predicting energy poverty with combinations of remote-sensing and socioeconomic survey data in India: Evidence from machine learning. Energy Econ. 2021, 102, 105510. [Google Scholar] [CrossRef]
- Hong, Z.; Park, I.K. Comparative Analysis of Energy Poverty Prediction Models Using Machine Learning Algorithms. J. Korea Plan. Assoc. 2021, 56, 239–255. [Google Scholar] [CrossRef]
- Thölke, P.; Mantilla-Ramos, Y.-J.; Abdelhedi, H.; Maschke, C.; Dehgan, A.; Harel, Y.; Kemtur, A.; Mekki Berrada, L.; Sahraoui, M.; Young, T.; et al. Class imbalance should not throw you off balance: Choosing the right classifiers and performance metrics for brain decoding with imbalanced data. NeuroImage 2023, 277, 120253. [Google Scholar] [CrossRef] [PubMed]
- Owusu-Adjei, M.; Ben Hayfron-Acquah, J.; Frimpong, T.; Abdul-Salaam, G. Imbalanced class distribution and performance evaluation metrics: A systematic review of prediction accuracy for determining model performance in healthcare systems. PLoS Digit. Health 2023, 2, e0000290. [Google Scholar] [CrossRef]
- Machine Learning and Synthetic Minority Oversampling Techniques for Imbalanced Data: Improving Machine Failure Prediction. Comput. Mater. Contin. 2023, 75, 4821–4841. [CrossRef]
- Lee, W.; Seo, K. Downsampling for Binary Classification with a Highly Imbalanced Dataset Using Active Learning. Big Data Res. 2022, 28, 100314. [Google Scholar] [CrossRef]
- What Is Administrative Data?—ADR UK. Available online: https://www.adruk.org/our-mission/administrative-data/ (accessed on 13 February 2025).
- National Energy Efficiency Data-Framework (NEED). GOVUK. 2024. Available online: https://www.gov.uk/government/collections/national-energy-efficiency-data-need-framework (accessed on 10 March 2025).
- Data Sets|Experian Business. Experian Product Database 2024. Available online: https://www.experian.co.uk/business-products/data-sets/ (accessed on 10 March 2025).
- Department for Work and Pensions. GOVUK 2025. Available online: https://www.gov.uk/government/organisations/department-for-work-pensions (accessed on 10 March 2025).
- Ordnance Survey|Great Britain’s National Mapping Service. Ordnance Survey. Available online: https://www.ordnancesurvey.co.uk/ordnance-survey-see-a-better-place (accessed on 10 March 2025).
- Camboni, R.; Corsini, A.; Miniaci, R.; Valbonesi, P. Mapping fuel poverty risk at the municipal level. A small-scale analysis of Italian Energy Performance Certificate, census and survey data. Energy Policy 2021, 155, 112324. [Google Scholar] [CrossRef]
- English Housing Survey. GOVUK 2025. Available online: https://www.gov.uk/government/collections/english-housing-survey (accessed on 10 March 2025).
- Service, U.D. UK Data Service. Available online: https://ukdataservice.ac.uk/ (accessed on 10 March 2025).
- Ministry of Housing, Communities and Local Government. English Housing Survey, 2021: Housing Stock Data. [data collection]. UK Data Service. SN: 9229. 2024. Available online: https://beta.ukdataservice.ac.uk/datacatalogue/doi/?id=9229#!#1 (accessed on 13 February 2025).
- Ministry of Housing, Communities and Local Government. English Housing Survey, 2021–2022: Household Data. [data collection]. UK Data Service. SN: 9230. 2024. Available online: https://beta.ukdataservice.ac.uk/datacatalogue/studies/study?id=9230 (accessed on 13 February 2025). [CrossRef]
- Demography Variables Census 2021—Office for National Statistics. Available online: https://www.ons.gov.uk/census/census2021dictionary/variablesbytopic/demographyvariablescensus2021 (accessed on 2 December 2024).
- Housing, England and Wales—Office for National Statistics. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/housing/bulletins/housingenglandandwales/census2021 (accessed on 14 March 2025).
- UCL Building Stock Lab. UCL Energy Institute 2022. Available online: https://www.ucl.ac.uk/bartlett/energy/research/building-stock-lab (accessed on 10 March 2025).
- Kelly, S.; Crawford-Brown, D.; Pollitt, M.G. Building performance evaluation and certification in the UK: Is SAP fit for purpose? Renew. Sustain. Energy Rev. 2012, 16, 6861–6878. [Google Scholar] [CrossRef]
- Department for Business, Energy & Industrial Strategy. English Housing Survey: Fuel Poverty Dataset, 2021. [Data Collection]. UK Data Service. SN: 9243. 2024. Available online: https://beta.ukdataservice.ac.uk/datacatalogue/studies/study?id=9243 (accessed on 13 February 2025).
- Fuel_Poverty_Methodology_Handbook_2020_LIHC. Available online: https://assets.publishing.service.gov.uk/media/603fcdaee90e077dd08f15e6/Fuel_Poverty_Methodology_Handbook_2020_LIHC.pdf (accessed on 13 February 2025).
- What is Standardization in Machine Learning. GeeksforGeeks 00:13:59+00:00. Available online: https://www.geeksforgeeks.org/what-is-standardization-in-machine-learning/ (accessed on 10 March 2025).
- Jo, T. Data Encoding. In Machine Learning Foundations: Supervised, Unsupervised, and Advanced Learning; Jo, T., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 47–68. ISBN 978-3-030-65900-4. [Google Scholar]
- StandardScaler. Scikit-Learn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html (accessed on 10 March 2025).
- One-Hot Encoding—An Overview|ScienceDirect Topics. Available online: https://www.sciencedirect.com/topics/computer-science/one-hot-encoding (accessed on 10 March 2025).
- Fitting Model on Imbalanced Datasets and How to Fight Bias—Version 0.13.0. Available online: https://imbalanced-learn.org/stable/auto_examples/applications/plot_impact_imbalanced_classes.html#sphx-glr-auto-examples-applications-plot-impact-imbalanced-classes-py (accessed on 13 February 2025).
- Belyadi, H.; Haghighat, A. Chapter 5—Supervised learning. In Machine Learning Guide for Oil and Gas Using Python; Belyadi, H., Haghighat, A., Eds.; Gulf Professional Publishing: Houston, TX, USA, 2021; pp. 169–295. ISBN 978-0-12-821929-4. [Google Scholar]
- Niaz, N.U.; Shahariar, K.M.N.; Patwary, M.J.A. Class Imbalance Problems in Machine Learning: A Review of Methods And Future Challenges. In Proceedings of the 2nd International Conference on Computing Advancements; Association for Computing Machinery: New York, NY, USA, 2022; pp. 485–490. [Google Scholar]
- Nakatsu, R.T. An Evaluation of Four Resampling Methods Used in Machine Learning Classification. IEEE Intell. Syst. 2021, 36, 51–57. [Google Scholar] [CrossRef]
- Zhu, M.; Xia, J.; Jin, X.; Yan, M.; Cai, G.; Yan, J.; Ning, G. Class Weights Random Forest Algorithm for Processing Class Imbalanced Medical Data. IEEE Access 2018, 6, 4641–4652. [Google Scholar] [CrossRef]
- XGBoost for Imbalanced Classification|XGBoosting. Available online: https://xgboosting.com/xgboost-for-imbalanced-classification/ (accessed on 10 March 2025).
- Resampling Strategies—Reproducible Machine Learning for Credit Card Fraud Detection—Practical Handbook. Available online: https://fraud-detection-handbook.github.io/fraud-detection-handbook/Chapter_6_ImbalancedLearning/Resampling.html (accessed on 18 February 2025).
- Kamaldeep. How to Improve Class Imbalance Using Class Weights in Machine Learning? Analytics Vidhya 2020. Available online: https://www.analyticsvidhya.com/blog/2020/10/improve-class-imbalance-class-weights/ (accessed on 18 February 2025).
- King, R.D.; Orhobor, O.I.; Taylor, C.C. Cross-validation is safe to use. Nat. Mach. Intell. 2021, 3, 276. [Google Scholar] [CrossRef]
- García, V.; Mollineda, R.A.; Sánchez, J.S. Index of Balanced Accuracy: A Performance Measure for Skewed Class Distributions. In Pattern Recognition and Image Analysis; Araujo, H., Mendonça, A.M., Pinho, A.J., Torres, M.I., Eds.; Springer: Berlin, Heidelberg, 2009; pp. 441–448. [Google Scholar]
- Takkala, H.R.; Khanduri, V.; Singh, A.; Somepalli, S.N.; Maddineni, R.; Patra, S. Kyphosis Disease Prediction with help of RandomizedSearchCV and AdaBoosting. In Proceedings of the 2022 13th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 3–5 October 2022; pp. 1–5. [Google Scholar]
- Sharma, N.; Malviya, L.; Jadhav, A.; Lalwani, P. A hybrid deep neural net learning model for predicting Coronary Heart Disease using Randomized Search Cross-Validation Optimization. Decis. Anal. J. 2023, 9, 100331. [Google Scholar] [CrossRef]
- Kumar, S. Evaluation Metrics For Classification Model. Analytics Vidhya 2021. Available online: https://www.analyticsvidhya.com/blog/2021/07/metrics-to-evaluate-your-classification-model-to-take-the-right-decisions/ (accessed on 10 March 2025).
- Nohara, Y.; Matsumoto, K.; Soejima, H.; Nakashima, N. Explanation of machine learning models using shapley additive explanation and application for real data in hospital. Comput. Methods Programs Biomed. 2022, 214, 106584. [Google Scholar] [CrossRef]
- Service, U.D.; Smith, L. The Smart Energy Research Lab: Fair on Fuel. UK Data Service 2022. Available online: https://ukdataservice.ac.uk/2022/04/27/serlfaironfuel/ (accessed on 17 March 2025).
- Admin Welcome to the Smart Energy Research Lab. Smart Energy Research Lab. Available online: https://serl.ac.uk/ (accessed on 17 March 2025).
- Webborn, E.; Elam, S.; McKenna, E.; Oreszczyn, T. Utilising smart meter data for research and innovation in the UK. ECEEE Summer Study 2019, 2019, 1387–1396. Available online: https://www.eceee.org/library/conference_proceedings/eceee_Summer_Studies/2019/8-buildings-technologies-and-systems-beyond-energy-efficiency/utilising-smart-meter-data-for-research-and-innovation-in-the-uk/ (accessed on 17 March 2025).
- Mischos, S.; Dalagdi, E.; Vrakas, D. Intelligent energy management systems: A review. Artif. Intell. Rev. 2023, 56, 11635–11674. [Google Scholar] [CrossRef]
- Hajkowicz, S.A.; Heyenga, S.; Moffat, K. The relationship between mining and socio-economic well being in Australia’s regions. Resour. Policy 2011, 36, 30–38. [Google Scholar] [CrossRef]
- Due Kadenic, M. Socioeconomic value creation and the role of local participation in large-scale mining projects in the Arctic. Extr. Ind. Soc. 2015, 2, 562–571. [Google Scholar] [CrossRef]
- Yıldız, T.D. How can shares be increased for indigenous peoples in state rights paid by mining companies? An education incentive through direct contribution to the people. Resour. Policy 2023, 85, 103948. [Google Scholar] [CrossRef]
- Ge, J.; Lei, Y. Mining development, income growth and poverty alleviation: A multiplier decomposition technique applied to China. Resour. Policy 2013, 38, 278–287. [Google Scholar] [CrossRef]
- Admin. Accessing SERL Data. Smart Energy Research Lab. Available online: https://serl.ac.uk/researchers/ (accessed on 19 March 2025).
- Chen, Z. Ethics and discrimination in artificial intelligence-enabled recruitment practices. Humanit. Soc. Sci. Commun. 2023, 10, 567. [Google Scholar] [CrossRef]
- Variables by Topic—Office for National Statistics. Available online: https://www.ons.gov.uk/census/census2021dictionary/variablesbytopic (accessed on 2 December 2024).


| Authors and Year | Case and Scope | EP Indicator | ML Model | Input Features | Model Performance | Imbalance Issue |
|---|---|---|---|---|---|---|
| Al Kez et al., 2024 [6] | UK, 12,000 residents | LILEE | RF | Income, energy efficiency, satellite remote sensing data, eight socioeconomic factors | Accuracy, Precision, Recall, F1-score | Oversampling; Downsampling |
| Ghorbany et al., 2024 [16] | US, Chicago, 227,000 GSV images | Energy burden | CNN, DT, RF, SVR | PDC indicators, demographic characteristics | Accuracy (74.2%) | No |
| Spandagos et al., 2023 [17] | EU, 500,000 data points | MEPI | DT, RF, KNN, XGBoost | Household income, type, dwelling type, social benefits, etc. | Accuracy (72%), F1-score Precision, Recall. The AUC value is 0.78. | No |
| Mukelabai et al., 2023 [18] | Global South, 11,480 data points | Access to clean cooking | XGBoost, CatBoost | Primary energy use, household expenditure, female literacy | Accuracy (97%), F1-score (97%) | No |
| Willem Van Hove et al., 2022 [19] | Europe, 11 countries | LIHC | CatBoost | Income, floor area, household size, dwelling age | True Positive Rate (60–74%) | No |
| Abbas et al., 2022 [20] | Asia and Africa, 59 countries | MEPI | MLP | Rooms, wealth, education, family size, marital status | Accuracy | No |
| Francesco Dalla Longa et al., 2021 [21] | Netherlands, neighbourhood and household levels | LIHC | XGBoosting | Income, house value, ownership, population density | Accuracy (77%), F1-score (74%) | Downsampling |
| Wang et al., 2021 [22] | India, 51 districts | MEPI | RF | Household size, age, rural/urban, education, remote sensing data | Accuracy (78.95%), Recall (90.01%) | No |
| Hong Z and Park I, 2021 [23] | South Korea, 8814 observations | Income and expenditure | DT, ANN, RF, XGBoosting, SVM | Income, food expense, floor area, household size, education | Accuracy (95%), F1-score (98%) | Oversampling |
| Machine Learning Models | COM-1 | COM-2 | ||
|---|---|---|---|---|
| Accuracy | Balanced Accuracy | Accuracy | Balanced Accuracy | |
| RF + undersampling | 0.78 | 0.78 | 0.86 | 0.87 |
| RF + class weight | 0.78 | 0.78 | 0.86 | 0.87 |
| XGBoost + undersampling | 0.78 | 0.78 | 0.87 | 0.87 |
| XGBoost + (scale_pos_weight) | 0.82 | 0.78 | 0.90 | 0.87 |
| Aspect | Traditional Method | Machine Learning Approach |
|---|---|---|
| Data Requirement | Extensive data collection (AHC income, fuel costs, energy needs, housing expenses, etc.) | Minimal and accessible (household income, SAP score, census data, floor area) |
| Computational Efficiency | Time-consuming manual collection and calculations | Automated predictions with efficient computation |
| Scalability | Limited scalability due to complex data requirements | Highly scalable due to reduced data dependency |
| Accuracy | Reliable but constrained by data availability | Comparable or better-than-benchmark performance |
| Interpretability | Fixed rule-based approach, difficult to break down individual household-level factors | SHAP values show the contribution of each feature to an individual household’s classification |
| Handling of Non-Linearity | Assumes a fixed income–energy cost threshold, ignoring non-linear relationships | Capture complex interactions between income, housing, and energy efficiency |
| Household-Level Insights | Provides only a binary classification (energy-poor or not) based on predefined thresholds | Analysis at the individual household level, revealing why specific households are energy-poor |
| Policy Implications | Requires detailed household-level data, limiting rapid assessments | Enables faster, data-driven decisions, even in data-limited contexts |
| Future Application | Static methodology with limited adaptability | Can integrate smart meter data to measure and identify energy poverty more dynamically and comprehensively |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; McKenna, E. Machine Learning with Administrative Data for Energy Poverty Identification in the UK. Energies 2025, 18, 3054. https://doi.org/10.3390/en18123054
Zheng L, McKenna E. Machine Learning with Administrative Data for Energy Poverty Identification in the UK. Energies. 2025; 18(12):3054. https://doi.org/10.3390/en18123054
Chicago/Turabian StyleZheng, Lin, and Eoghan McKenna. 2025. "Machine Learning with Administrative Data for Energy Poverty Identification in the UK" Energies 18, no. 12: 3054. https://doi.org/10.3390/en18123054
APA StyleZheng, L., & McKenna, E. (2025). Machine Learning with Administrative Data for Energy Poverty Identification in the UK. Energies, 18(12), 3054. https://doi.org/10.3390/en18123054