
Physics-Informed Multi-Agent DRL-Based Active Distribution Network Zonal Balancing Control Strategy for Security and Supply Preservation

 ,
,  and
and 
Abstract
1. Introduction
- Compared with previous security reinforcement learning algorithms, this paper proposes a multi-agent security reinforcement learning algorithm based on a local physical model, which ensures the security of the policy through strict physical model constraints. The proposed method does not rely on any a priori knowledge and is fully guaranteed to satisfy the security constraints of the system during operation.
- For large-scale and clustered distributed photovoltaic grid connections, we design a training structure based on a centralized training–decentralized execution (CTDE) framework, while incorporating a sequential updating methodology to enhance the effectiveness of the training and to achieve zonal balancing control and efficient power preservation.
2. Materials and Methods
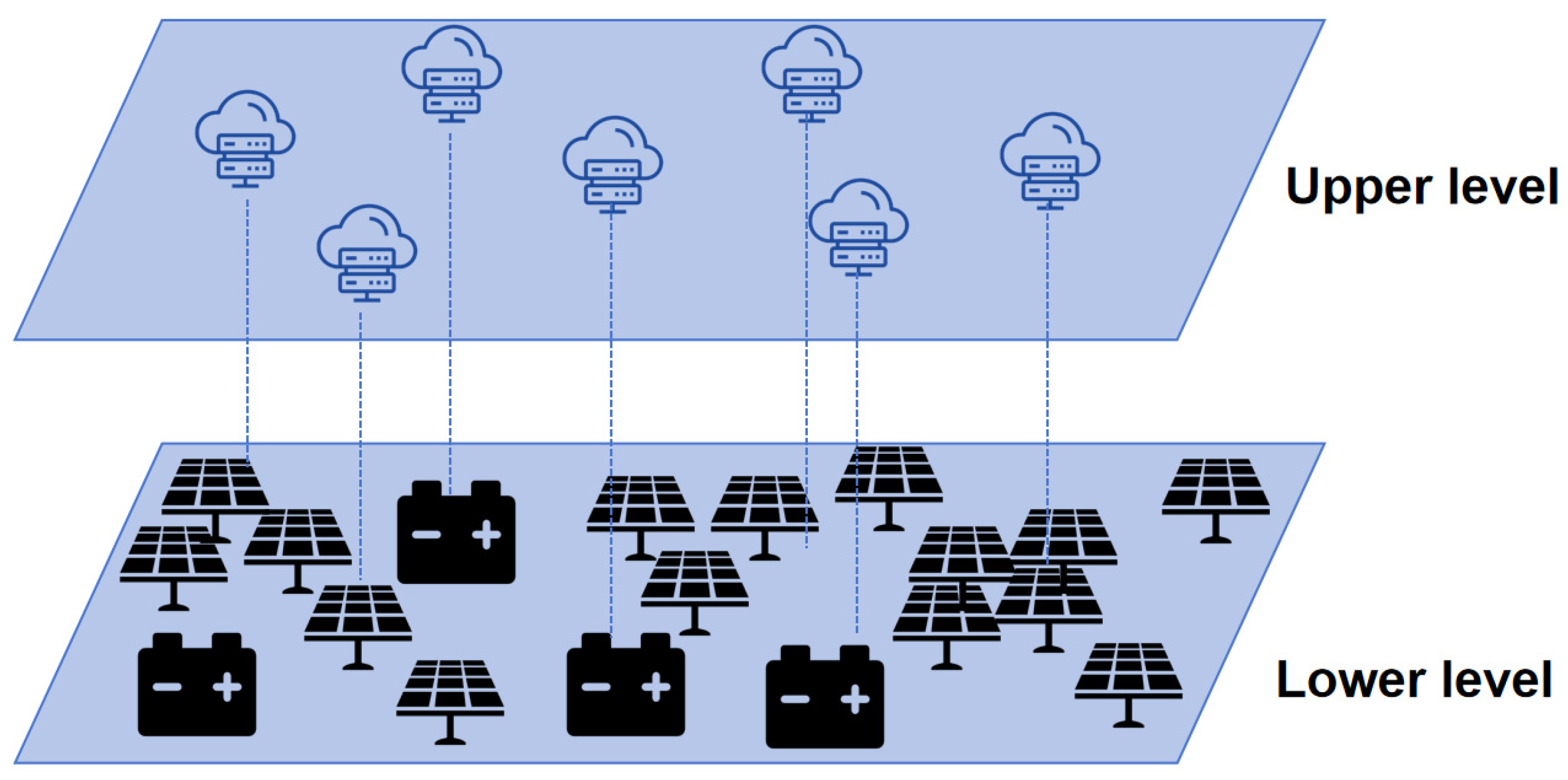
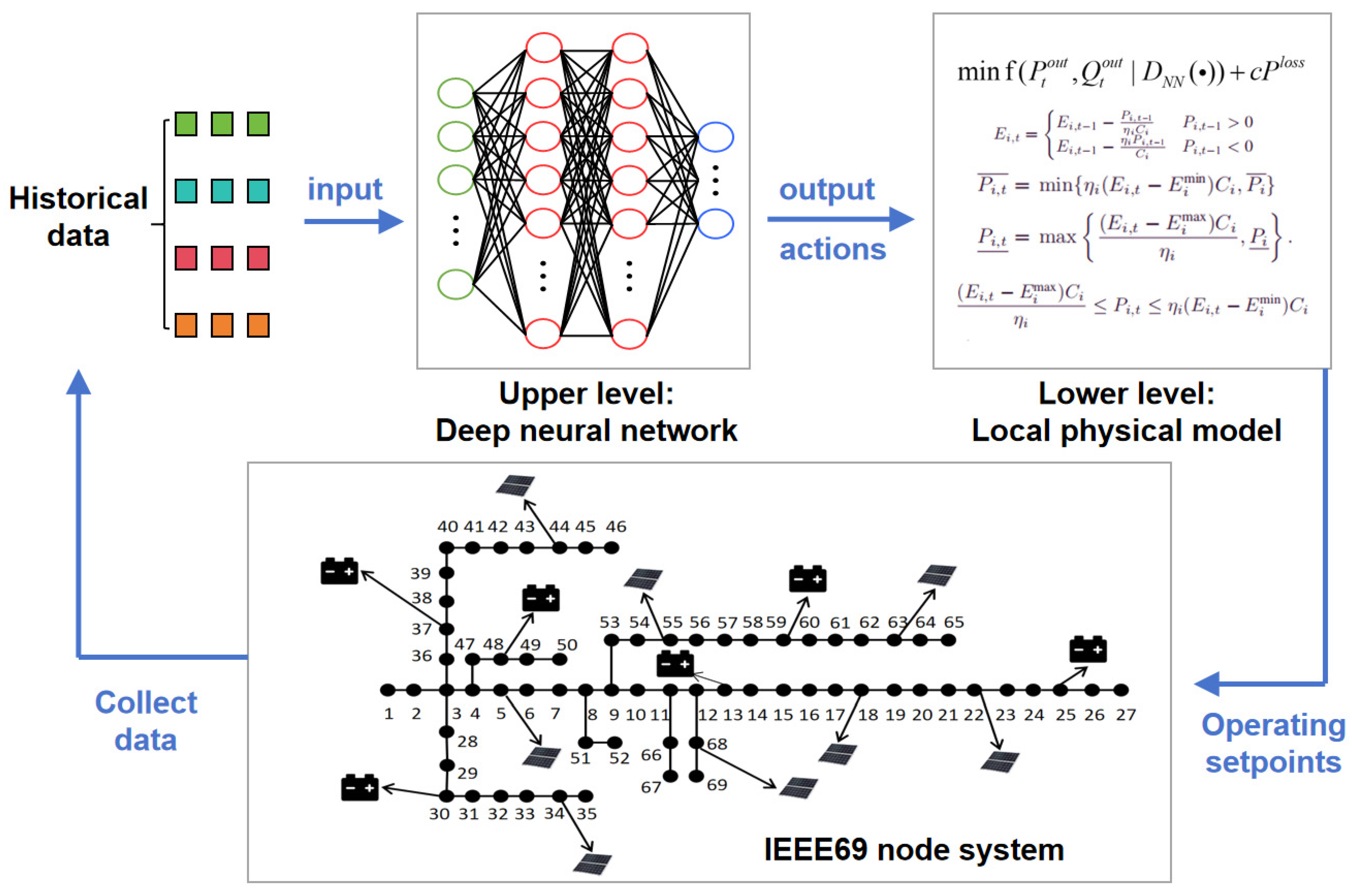
2.1. A Secure Scheduling Framework Based on Local Physical Models
2.1.1. Overall Framework and Core Principles
2.1.2. Local Optimization Models Based on Physical Models
2.1.3. Global ADN Model
2.2. A Partition Balancing Control Strategy Based on Sequential Updates
2.2.1. Dec-POMDP Formulation
2.2.2. Sequential Update Strategy
| Algorithm 1 The Proposed Hybrid Model–Data-Driven Approach with MAPPO |
| 1: Initialize replay buffer , Number of episode , Episode length . 2: do 3:’ do 4: do 5: . 6: end for 7: . 8: Solve the local model and obtain operation set-points. 9: and record them in buffer . 10: end for 11: Sample a mini-batch from . 12: do 13: based on Equations (25) and (26). 14: end for 15: by using MSE: 16: 17: end for |
3. Results
3.1. Simulation Setup
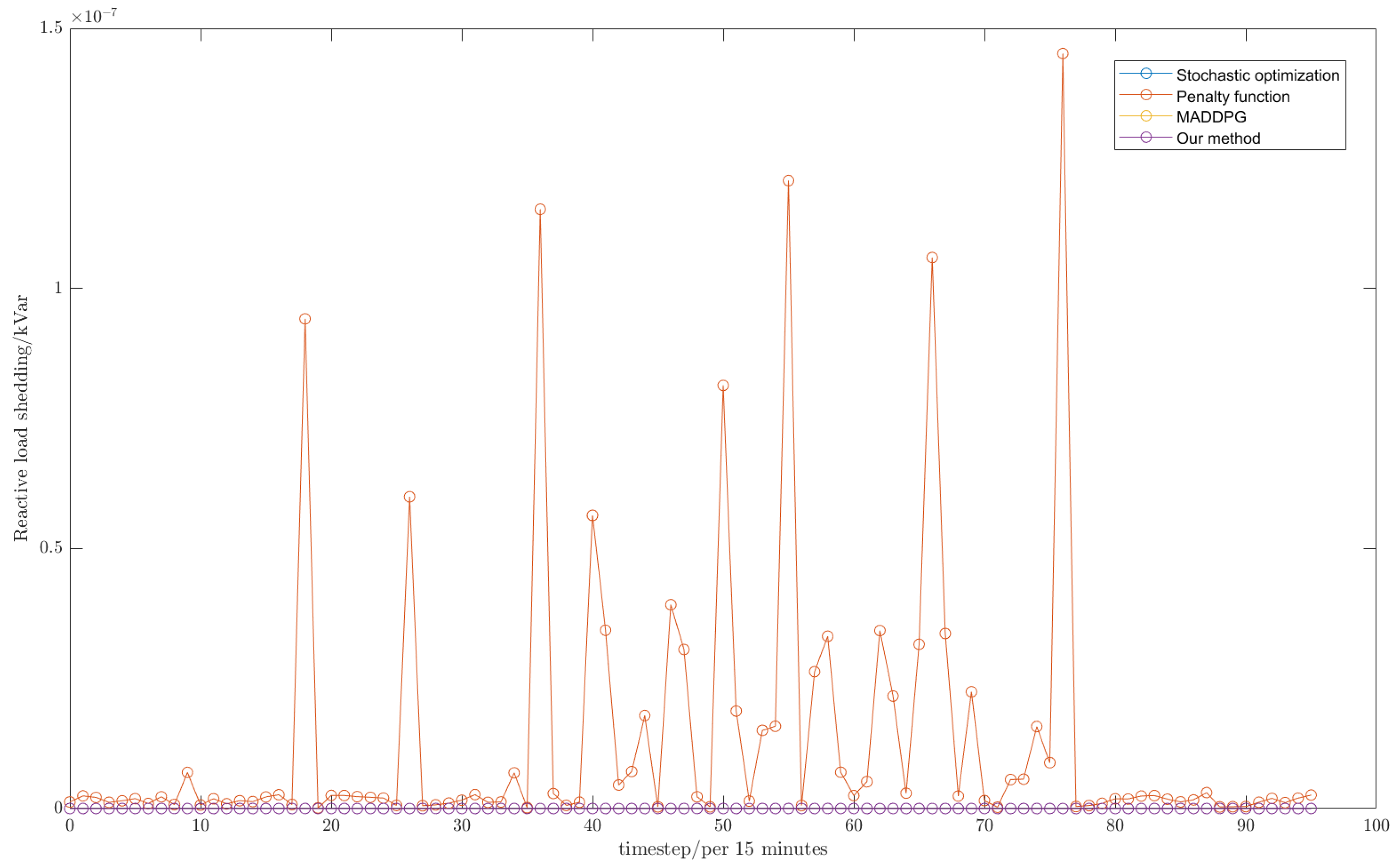
3.2. Performance Evaluation of the Proposed Algorithm
3.3. Comparison with Existing Algorithms
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DG | Distributed generation |
| DPV | Distributed photovoltaics |
| ADN | Active distribution network |
| MINLP | Mixed-integer nonlinear programming |
| MILP | Mixed-integer linear programming |
| DRL | Deep reinforcement learning |
| MARL | Multi-agent reinforcement learning |
| CTDE | Centralized training decentralized execution |
| DNN | Deep neural network |
| SOC | State of charge |
| MADDPG | Multi-agent deep deterministic policy gradient |
| PPO | Proximal policy optimization |
| ReLU | Rectified linear unit |
References
- Ma, Z. Form and Development Trend of Future Distribution System; China Electric Power Research Institute: Beijing, China, 2015. [Google Scholar]
- Lopes, J.A.P.; Hatziargyriou, N.; Mutale, J.; Djapic, P.; Jenkins, N. Integrating distributed generation into electric power systems: A review of drivers, challenges and opportunities. Electr. Power Syst. Res. 2007, 77, 1189–1203. [Google Scholar] [CrossRef]
- Qian, T.; Fang, M.; Hu, Q.; Shao, C.; Zheng, J. V2Sim: An Open-Source Microscopic V2G Simulation Platform in Urban Power and Transportation Network. IEEE Trans. Smart Grid 2025, 1. [Google Scholar] [CrossRef]
- Qian, T.; Liang, Z.; Shao, C.; Guo, Z.; Hu, Q.; Wu, Z. Unsupervised learning for efficiently distributing EVs charging loads and traffic flows in coupled power and transportation systems. Appl. Energy 2025, 377, 124476. [Google Scholar] [CrossRef]
- Liang, Z.; Qian, T.; Korkali, M.; Glatt, R.; Hu, Q. A Vehicle-to-Grid planning framework incorporating electric vehicle user equilibrium and distribution network flexibility enhancement. Appl. Energy 2024, 376, 124231. [Google Scholar] [CrossRef]
- Shang, Y.; Li, D.; Li, Y.; Li, S. Explainable spatiotemporal multi-task learning for electric vehicle charging demand prediction. Appl. Energy 2025, 384, 125460. [Google Scholar] [CrossRef]
- Xie, S.; Wu, Q.; Zhang, M.; Guo, Y. Coordinated Energy Pricing for Multi-Energy Networks Considering Hybrid Hydrogen-Electric Vehicle Mobility. IEEE Trans. Power Syst. 2024, 39, 7304–7317. [Google Scholar] [CrossRef]
- Xin-gang, Z.; Zhen, W. Technology, cost, economic performance of distributed photovoltaic industry in China. Renew. Sustain. Energy Rev. 2019, 110, 53–64. [Google Scholar] [CrossRef]
- Carrasco, J.M.; Franquelo, L.G.; Bialasiewicz, J.T.; Galvan, E.; PortilloGuisado, R.C.; Prats, M.A.M.; Leon, J.I.; Moreno-Alfonso, N. Power-Electronic Systems for the Grid Integration of Renewable Energy Sources: A Survey. IEEE Trans. Ind. Electron. 2006, 53, 1002–1016. [Google Scholar] [CrossRef]
- Hu, Z.; Su, R.; Veerasamy, V.; Huang, L.; Ma, R. Resilient Frequency Regulation for Microgrids Under Phasor Measurement Unit Faults and Communication Intermittency. IEEE Trans. Ind. Inform. 2025, 21, 1941–1949. [Google Scholar] [CrossRef]
- Braun, M.; Stetz, T.; Bründlinger, R.; Mayr, C.; Ogimoto, K.; Hatta, H.; Kobayashi, H.; Kroposki, B.; Mather, B.; Coddington, M.; et al. Is the distribution grid ready to accept large-scale photovoltaic deployment? State of the art, progress, and future prospects. Prog. Photovolt. Res. Appl. 2012, 20, 681–697. [Google Scholar] [CrossRef]
- Yan, G.; Wang, Q.; Zhang, H.; Wang, L.; Wang, L.; Liao, C. Review on the Evaluation and Improvement Measures of the Carrying Capacity of Distributed Power Supply and Electric Vehicles Connected to the Grid. Energies 2024, 17, 4407. [Google Scholar] [CrossRef]
- Huang, Y.; Lin, Z.; Liu, X.; Yang, L.; Dan, Y.; Zhu, Y.; Ding, Y.; Wang, Q. Bi-level Coordinated Planning of Active Distribution Network Considering Demand Response Resources and Severely Restricted Scenarios. J. Mod. Power Syst. Clean Energy 2021, 9, 1088–1100. [Google Scholar] [CrossRef]
- Huang, S.; Han, D.; Pang, J.Z.F.; Chen, Y. Optimal Real-Time Bidding Strategy for EV Aggregators in Wholesale Electricity Markets. IEEE Trans. Intell. Transp. Syst. 2025, 26, 5538–5551. [Google Scholar] [CrossRef]
- Xie, S.; Wu, Q.; Hatziargyriou, N.D.; Zhang, M.; Zhang, Y.; Xu, Y. Collaborative Pricing in a Power-Transportation Coupled Network: A Variational Inequality Approach. IEEE Trans. Power Syst. 2023, 38, 783–795. [Google Scholar] [CrossRef]
- Wang, C.; Yan, M.; Pang, K.; Wen, F.; Teng, F. Cyber-Physical Interdependent Restoration Scheduling for Active Distribution Network via Ad Hoc Wireless Communication. IEEE Trans. Smart Grid 2023, 14, 3413–3426. [Google Scholar] [CrossRef]
- Wang, C.; Lin, W.; Wang, G.; Shahidehpour, M.; Liang, Z.; Zhang, W.; Chung, C.Y. Frequency-Constrained Optimal Restoration Scheduling in Active Distribution Networks With Dynamic Boundaries for Networked Microgrids. IEEE Trans. Power Syst. 2025, 40, 2061–2077. [Google Scholar] [CrossRef]
- Ji, H.; Wang, C.; Li, P.; Ding, F.; Wu, J. Robust Operation of Soft Open Points in Active Distribution Networks With High Penetration of Photovoltaic Integration. IEEE Trans. Sustain. Energy 2019, 10, 280–289. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Y.; Li, P.; Wang, C.; Ji, H.; Ge, L.; Song, Y. Local voltage control strategy of active distribution network with PV reactive power optimization. In Proceedings of the 2017 IEEE Power & Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar]
- Li, X.; Hu, C.; Luo, S.; Lu, H.; Piao, Z.; Jing, L. Distributed Hybrid-Triggered Observer-Based Secondary Control of Multi-Bus DC Microgrids Over Directed Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2025, 72, 2467–2480. [Google Scholar] [CrossRef]
- Qi, J.; Ying, A.; Zhang, B.; Zhou, D.; Weng, G. Distributed Frequency Regulation Method for Power Grids Considering the Delayed Response of Virtual Power Plants. Energies 2025, 18, 1361. [Google Scholar] [CrossRef]
- Wang, C.; Xu, Y.; Pang, K.; Shahidehpour, M.; Wang, Q.; Wang, G.; Wen, F. Imposing Fine-Grained Synthetic Frequency Response Rate Constraints for IBR-Rich Distribution System Restoration. IEEE Trans. Power Syst. 2025, 40, 2799–2802. [Google Scholar] [CrossRef]
- Yang, Q.; Wang, G.; Sadeghi, A.; Giannakis, G.B.; Sun, J. Two-Timescale Voltage Control in Distribution Grids Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 2313–2323. [Google Scholar] [CrossRef]
- Chen, X.; Qu, G.; Tang, Y.; Low, S.; Li, N. Reinforcement Learning for Selective Key Applications in Power Systems: Recent Advances and Future Challenges. IEEE Trans. Smart Grid 2022, 13, 2935–2958. [Google Scholar] [CrossRef]
- Qian, T.; Liang, Z.; Shao, C.; Zhang, H.; Hu, Q.; Wu, Z. Offline DRL for Price-Based Demand Response: Learning From Suboptimal Data and Beyond. IEEE Trans. Smart Grid 2024, 15, 4618–4635. [Google Scholar] [CrossRef]
- Qian, T.; Ming, W.; Shao, C.; Hu, Q.; Wang, X.; Wu, J.; Wu, Z. An Edge Intelligence-Based Framework for Online Scheduling of Soft Open Points With Energy Storage. IEEE Trans. Smart Grid 2024, 15, 2934–2945. [Google Scholar] [CrossRef]
- Qian, T.; Liang, Z.; Chen, S.; Hu, Q.; Wu, Z. A Tri-Level Demand Response Framework for EVCS Flexibility Enhancement in Coupled Power and Transportation Networks. IEEE Trans. Smart Grid 2025, 16, 598–611. [Google Scholar] [CrossRef]
- Cao, D.; Zhao, J.; Hu, J.; Pei, Y.; Huang, Q.; Chen, Z.; Hu, W. Physics-Informed Graphical Representation-Enabled Deep Reinforcement Learning for Robust Distribution System Voltage Control. IEEE Trans. Smart Grid 2024, 15, 233–246. [Google Scholar] [CrossRef]
- Jiang, C.; Lin, Z.; Liu, C.; Chen, F.; Shao, Z. MADDPG-Based Active Distribution Network Dynamic Reconfiguration with Renewable Energy. Prot. Control. Mod. Power Syst. 2024, 9, 143–155. [Google Scholar] [CrossRef]
- Sun, X.; Qiu, J. Two-Stage Volt/Var Control in Active Distribution Networks With Multi-Agent Deep Reinforcement Learning Method. IEEE Trans. Smart Grid 2021, 12, 2903–2912. [Google Scholar] [CrossRef]
- Wang, T.; Ma, S.; Tang, Z.; Xiang, T.; Mu, C.; Jin, Y. A Multi-Agent Reinforcement Learning Method for Cooperative Secondary Voltage Control of Microgrids. Energies 2023, 16, 5653. [Google Scholar] [CrossRef]
- Yang, X.; Liu, H.; Wu, W. Attention-Enhanced Multi-Agent Reinforcement Learning Against Observation Perturbations for Distributed Volt-VAR Control. IEEE Trans. Smart Grid 2024, 15, 5761–5772. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Yan, D.; Qian, G.; Li, J.; Shi, X.; Xu, J.; Wei, M.; Ji, H.; Yu, H. Multi-Agent Deep Reinforcement Learning-Based Distributed Voltage Control of Flexible Distribution Networks with Soft Open Points. Energies 2024, 17, 5244. [Google Scholar] [CrossRef]
- Zhan, H.; Jiang, C.; Lin, Z. A Novel Graph Reinforcement Learning-Based Approach for Dynamic Reconfiguration of Active Distribution Networks with Integrated Renewable Energy. Energies 2024, 17, 6311. [Google Scholar] [CrossRef]
- Zhang, Q.; Dehghanpour, K.; Wang, Z.; Qiu, F.; Zhao, D. Multi-Agent Safe Policy Learning for Power Management of Networked Microgrids. IEEE Trans. Smart Grid 2021, 12, 1048–1062. [Google Scholar] [CrossRef]
- Zhang, J.; Sang, L.; Xu, Y.; Sun, H. Networked Multiagent-Based Safe Reinforcement Learning for Low-Carbon Demand Management in Distribution Networks. IEEE Trans. Sustain. Energy 2024, 15, 1528–1545. [Google Scholar] [CrossRef]
- Li, H.; He, H. Learning to Operate Distribution Networks With Safe Deep Reinforcement Learning. IEEE Trans. Smart Grid 2022, 13, 1860–1872. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Lakshmanan, K. An Online Actor–Critic Algorithm with Function Approximation for Constrained Markov Decision Processes. J. Optim. Theory Appl. 2012, 153, 688–708. [Google Scholar] [CrossRef]
- Hua, D.; Peng, F.; Liu, S.; Lin, Q.; Fan, J.; Li, Q. Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning. Energies 2025, 18, 333. [Google Scholar] [CrossRef]
- Kim, D.; Oh, S. TRC: Trust Region Conditional Value at Risk for Safe Reinforcement Learning. IEEE Robot. Autom. Lett. 2022, 7, 2621–2628. [Google Scholar] [CrossRef]
- Zhang, Q.; Leng, S.; Ma, X.; Liu, Q.; Wang, X.; Liang, B.; Liu, Y.; Yang, J. CVaR-Constrained Policy Optimization for Safe Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 830–841. [Google Scholar] [CrossRef]
- Chen, P.; Liu, S.; Wang, X.; Kamwa, I. Physics-Shielded Multi-Agent Deep Reinforcement Learning for Safe Active Voltage Control With Photovoltaic/Battery Energy Storage Systems. IEEE Trans. Smart Grid 2023, 14, 2656–2667. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, S.; Wang, L.; Lu, Z.; Wu, C.; Wen, X.; Shou, G. Autonomous Driving via Knowledge-Enhanced Safe Reinforcement Learning. IEEE Trans. Intell. Veh. 2024, 1–14. [Google Scholar] [CrossRef]
- Zhao, H.; Zhao, J.; Qiu, J.; Liang, G.; Dong, Z.Y. Cooperative Wind Farm Control With Deep Reinforcement Learning and Knowledge-Assisted Learning. IEEE Trans. Ind. Inform. 2020, 16, 6912–6921. [Google Scholar] [CrossRef]
- Lin, H.; Shen, X.; Guo, Y.; Ding, T.; Sun, H. A linear Distflow model considering line shunts for fast calculation and voltage control of power distribution systems. Appl. Energy 2024, 357, 122467. [Google Scholar] [CrossRef]
- Neumann, F.; Hagenmeyer, V.; Brown, T. Assessments of linear power flow and transmission loss approximations in coordinated capacity expansion problems. Appl. Energy 2022, 314, 118859. [Google Scholar] [CrossRef]
- Song, T.; Han, X.; Zhang, B. Multi-Time-Scale Optimal Scheduling in Active Distribution Network with Voltage Stability Constraints. Energies 2021, 14, 7107. [Google Scholar] [CrossRef]
- Kuba, J.; Feng, X.; Ding, S.; Dong, H.; Wang, J.; Yang, Y. Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL. arXiv 2022, arXiv:2208.01682. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.M.; Wu, Y. The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games. arXiv 2021, arXiv:2103.01955. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Features | References |
|---|---|---|
| Penalty function method | most direct; cannot completely guarantee safety and is the least effective | [38,39] |
| Trust domain method | can ensure safety; too conservative to be optimal | [40,41] |
| Security exploration method | improves the security of the training process; it is challenging to obtain correct and sufficient a priori knowledge | [42,43,44] |
| Parameters | Specific Values |
|---|---|
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| clip coefficient | 0.2 |
| entropy coefficient | 0.01 |
| discount factor | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, B.; Li, Y.; Qiu, W.; Zhang, R.; Jiang, Z.; Wang, W.; Qian, T.; Hu, Q. Physics-Informed Multi-Agent DRL-Based Active Distribution Network Zonal Balancing Control Strategy for Security and Supply Preservation. Energies 2025, 18, 2959. https://doi.org/10.3390/en18112959
Zhai B, Li Y, Qiu W, Zhang R, Jiang Z, Wang W, Qian T, Hu Q. Physics-Informed Multi-Agent DRL-Based Active Distribution Network Zonal Balancing Control Strategy for Security and Supply Preservation. Energies. 2025; 18(11):2959. https://doi.org/10.3390/en18112959
Chicago/Turabian StyleZhai, Bingxu, Yuanzhuo Li, Wei Qiu, Rui Zhang, Zhilin Jiang, Wei Wang, Tao Qian, and Qinran Hu. 2025. "Physics-Informed Multi-Agent DRL-Based Active Distribution Network Zonal Balancing Control Strategy for Security and Supply Preservation" Energies 18, no. 11: 2959. https://doi.org/10.3390/en18112959
APA StyleZhai, B., Li, Y., Qiu, W., Zhang, R., Jiang, Z., Wang, W., Qian, T., & Hu, Q. (2025). Physics-Informed Multi-Agent DRL-Based Active Distribution Network Zonal Balancing Control Strategy for Security and Supply Preservation. Energies, 18(11), 2959. https://doi.org/10.3390/en18112959