To evaluate the effectiveness of the proposed DRL-DBSCAN and GAT-GNN framework for air conditioning load forecasting, a comprehensive case study is conducted using a real-world dataset of household energy consumption. This section details the experimental setup, including data preparation, model training, and evaluation metrics, followed by an in-depth analysis of the results. The primary objective is to assess the ability of the proposed framework to capture both spatial and temporal dependencies in the geographical grids, leveraging the clustering results from DRL-DBSCAN to enhance the GAT-GNN predictive performance.
3.1. Experimental Setup
The dataset used in this study comprises hourly air conditioning load data from 25 households in Austin, sourced from the Pecan Street project [
20], collected over a period of one year. Each record includes the timestamp, household ID, geographical coordinates (latitude and longitude), meteorological features (local temperature and humidity), and the adjusted load. The data are aggregated at an hourly granularity to reduce noise and capture meaningful temporal patterns. To ensure consistency, the adjusted load values are standardized using a StandardScaler, and the meteorological features are similarly normalized to facilitate model training.
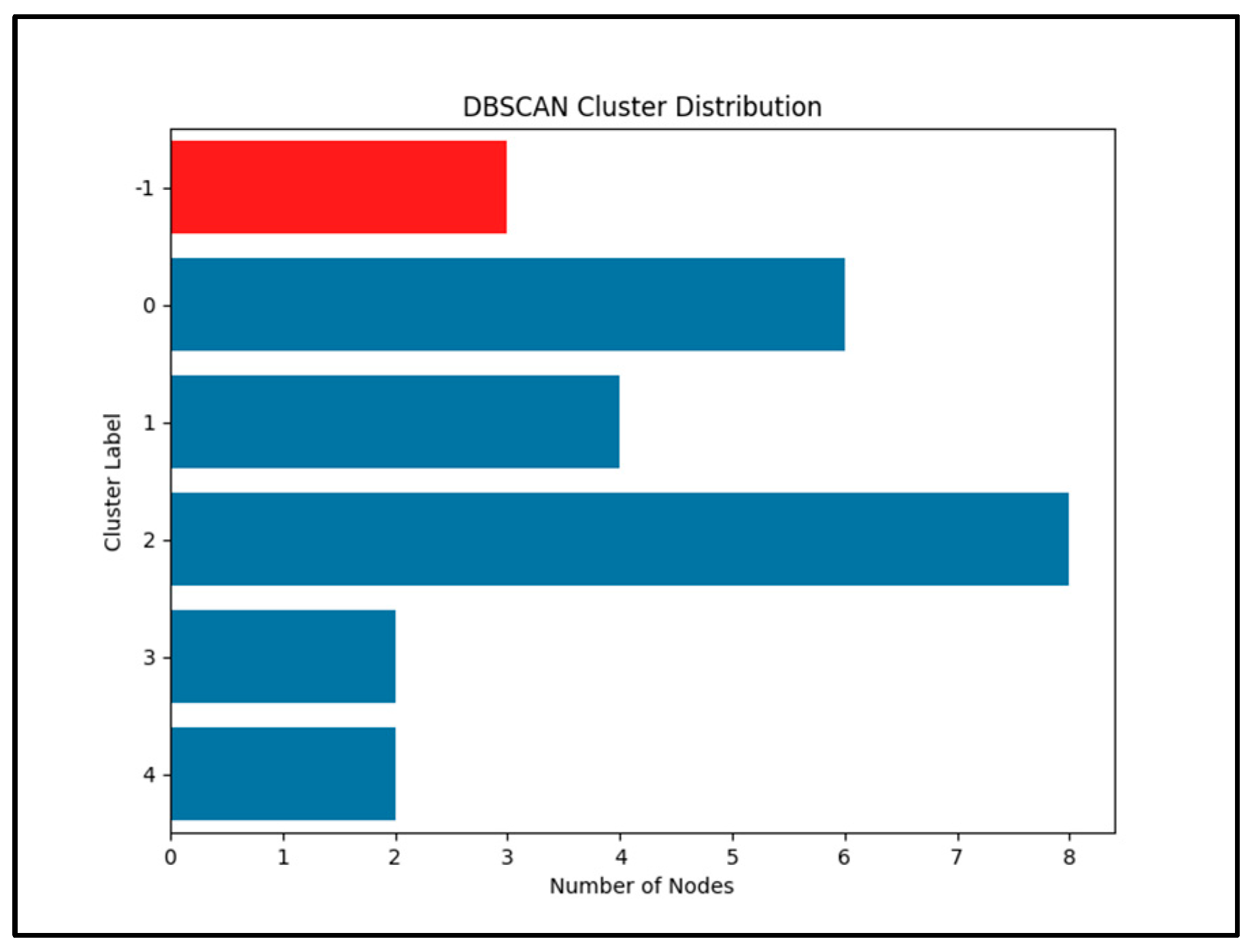
The geographical grids are constructed based on the latitude and longitude of each household, with each household representing a node in the graph. The DRL-DBSCAN algorithm is applied to cluster these nodes into spatially coherent groups, using an eps value of 0.07 and a minpt value of 2, determined through iterative experimentation to balance the number of clusters and noise points. The resulting clustering distribution, as shown in
Figure 3, identifies five clusters: Cluster 0 (seven nodes), Cluster 1 (five nodes), Cluster 2 (eight nodes), Cluster 3 (one node), and Cluster 4 (one node), with three nodes labeled as noise (Cluster 1). The geographical distribution of these clusters, illustrated in
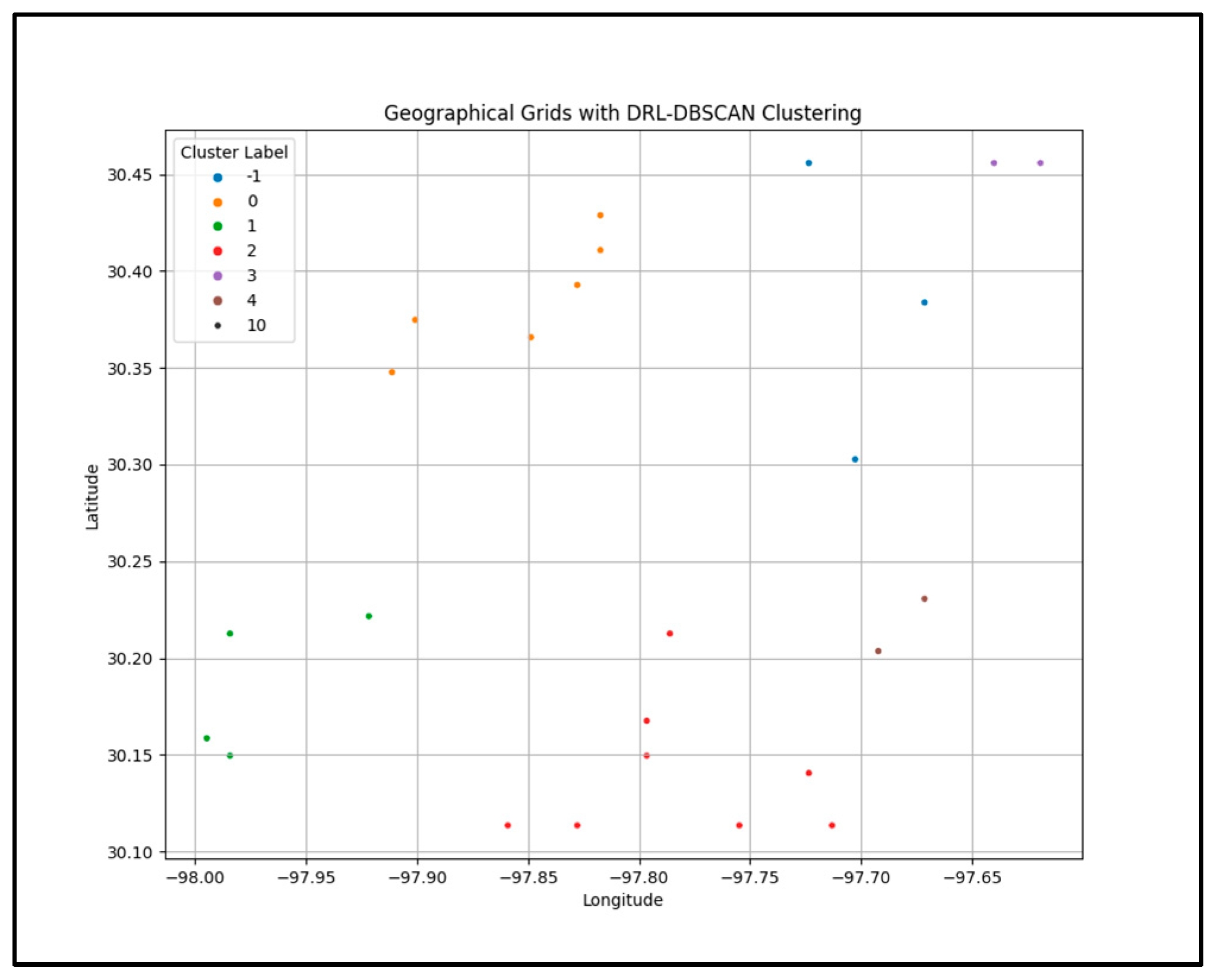
Figure 4 demonstrates that the clusters effectively capture spatially proximate regions, which is critical for the subsequent GAT-based load forecasting.
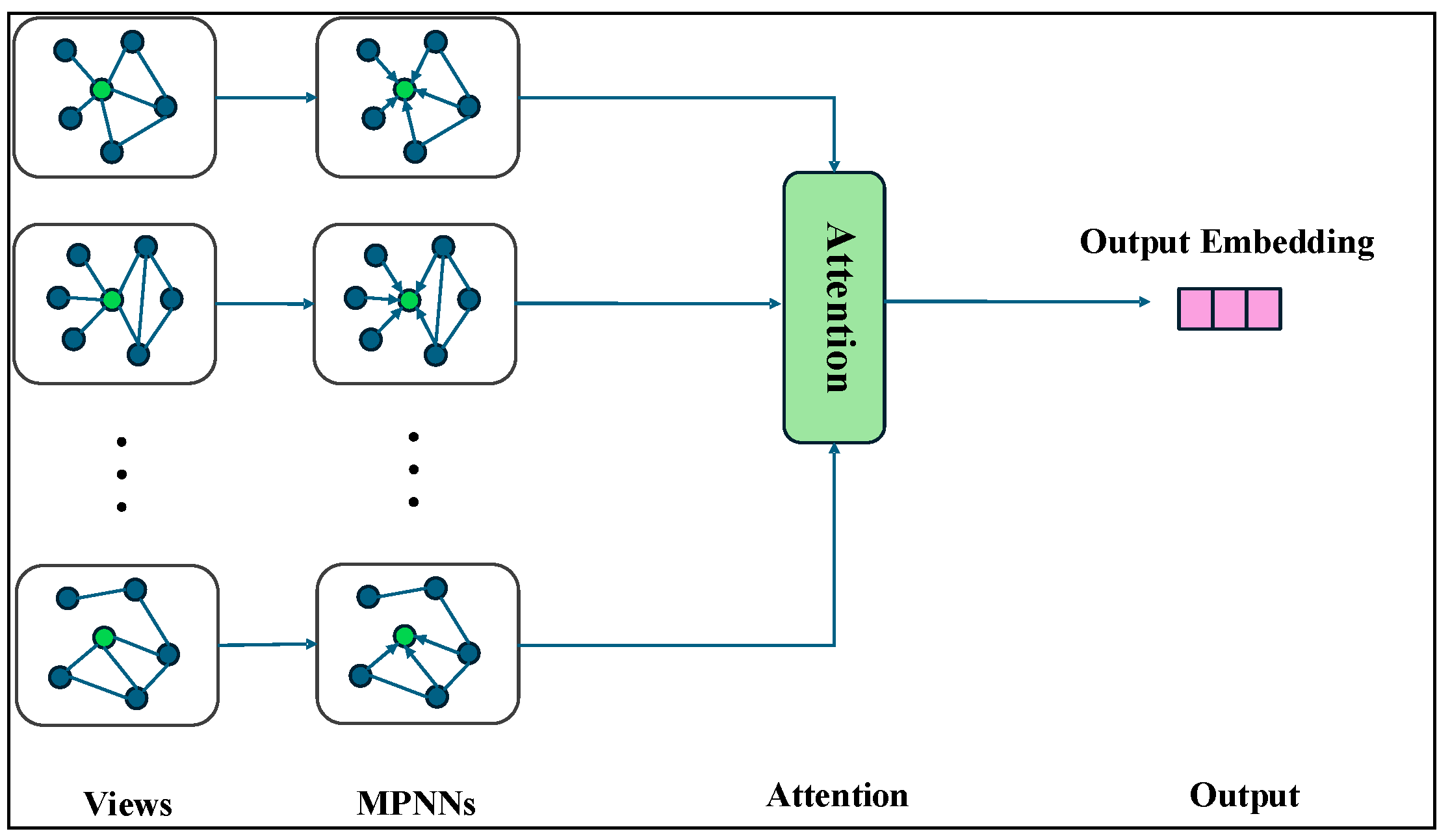
The GNN model is designed as a Graph Attention Network (GAT) with two GAT layers to capture higher-order spatial dependencies among the geographical grids. The first GAT layer uses four attention heads with a hidden size of 32 per head (resulting in a concatenated output dimension of 128), followed by a second GAT layer with a single head and a hidden size of 32. A final fully connected layer maps the output to the predicted load. The node features include the local temperature, humidity, and a four-dimensional embedding of the cluster label, which enhances the model’s ability to differentiate between spatially distinct groups. The graph structure is constructed by connecting nodes within the same cluster if their Euclidean distance is less than 0.05. In contrast to traditional GCNs, the GAT model dynamically computes attention weights for each edge, eliminating the need for manually specified edge weights, which allows for more adaptive information propagation within clusters, reflecting the spatial coherence identified by DRL-DBSCAN.
3.3. Comparison of Different Clustering Methods
To evaluate the effectiveness of the proposed DRL-DBSCAN clustering method in enhancing the GAT-GNN ability to capture spatial dependencies for air conditioning load forecasting, a comparative study is conducted by integrating different clustering algorithms into the GAT-GNN framework. The objective of this experiment is to assess how the choice of clustering method impacts the GAT-GNN predictive performance and its ability to model spatial patterns. Four clustering approaches are considered: (1) the proposed DRL-DBSCAN, (2) K-Means clustering, (3) Hierarchical clustering with Ward linkage, and (4) a baseline scenario without clustering (using raw geographical coordinates directly). Each clustering method is applied to the same dataset of 25 geographical grids, and the resulting cluster labels are incorporated into the GAT-GNN node features as described in
Section 2.2. The GAT-GNN architecture, graph structure, and training settings remain consistent across all experiments to ensure a fair comparison.
The DRL-DBSCAN algorithm is configured with eps = 0.07 and minpt = 2, yielding five clusters (Cluster 0: seven nodes, Cluster 1: five nodes, Cluster 2: eight nodes, Cluster 3: one node, Cluster 4: one node) and three noise points (Cluster 1), as previously shown in
Figure 3. For K-Means clustering, the number of clusters is set to five to match the number of non-noise clusters produced by DRL-DBSCAN, and the algorithm is initialized with the k-means++ method to ensure robust convergence. Hierarchical clustering is performed using Ward linkage, also producing five clusters by cutting the dendrogram at an appropriate level. In the no-clustering baseline, the cluster label feature is omitted from the node features, and the GAT-GNN relies solely on the geographical coordinates (latitude and longitude) to capture spatial relationships. The GAT-GNN model is trained and evaluated for each clustering method, following the setup described in the previous subsection. The performance is assessed using the Mean Squared Error (MSE) and Mean Absolute Error (MAE) on both the training and test sets. Additionally, the spatial distribution of the predicted loads is visualized to analyze how different clustering methods influence the GAT-GNN ability to capture spatially coherent load patterns.
The predictive performance of the GAT-GNN with different clustering methods is summarized in
Table 1. The GAT-GNN with DRL-DBSCAN achieves the best performance on the test set, with a test MSE of 0.0388 and a test MAE of 0.1559. In contrast, the GAT-GNN with K-Means clustering yields a test MSE of 0.0731 and a test MAE of 0.2151, while Hierarchical clustering results in a test MSE of 0.0502 and a test MAE of 0.1883. The no-clustering baseline performs the worst, with a test MSE of 0.0813 and a test MAE of 0.2584. These results indicate that DRL-DBSCAN significantly enhances the GAT-GNN predictive accuracy compared to other clustering methods, likely due to its ability to identify spatially coherent clusters while handling noise points effectively.
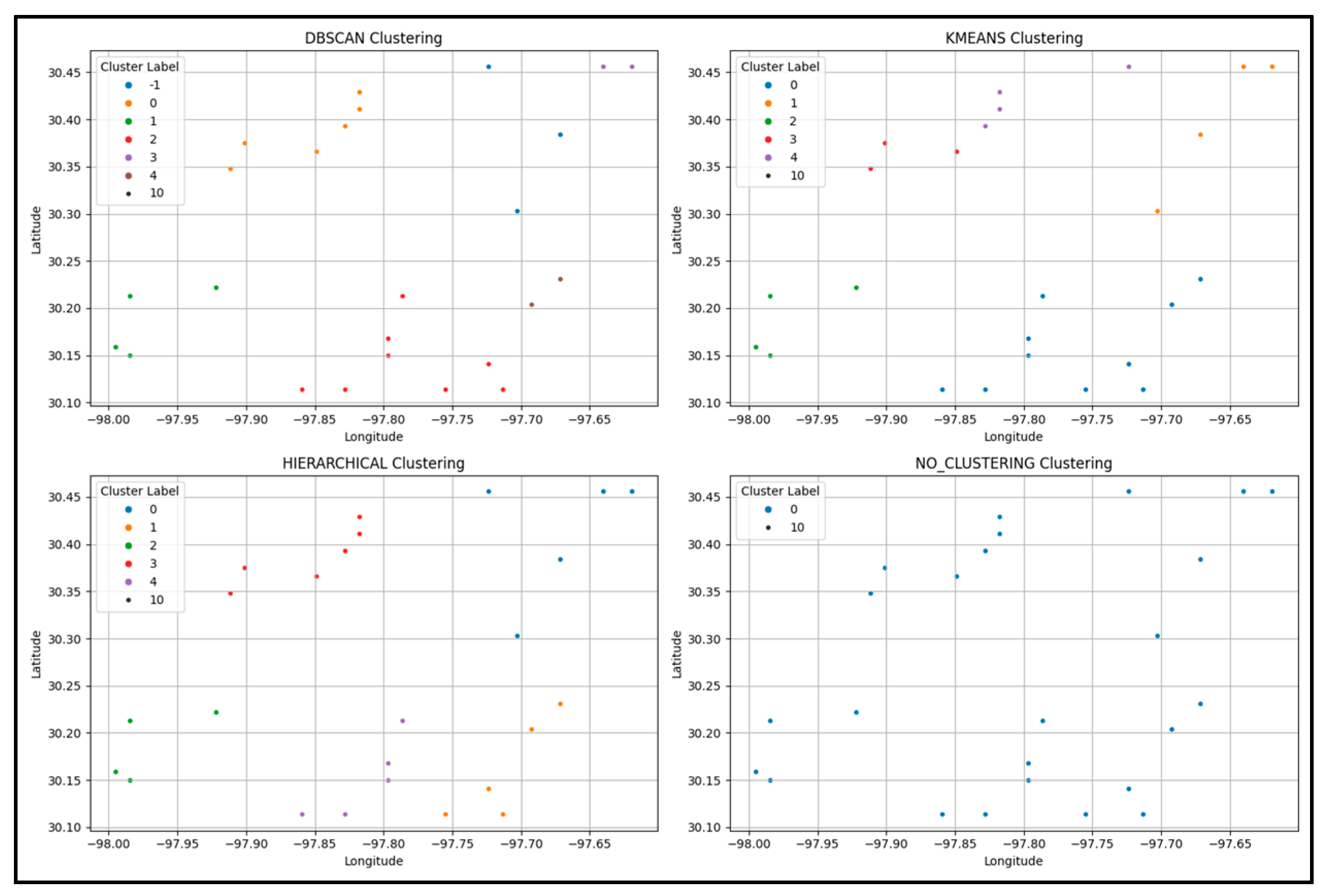
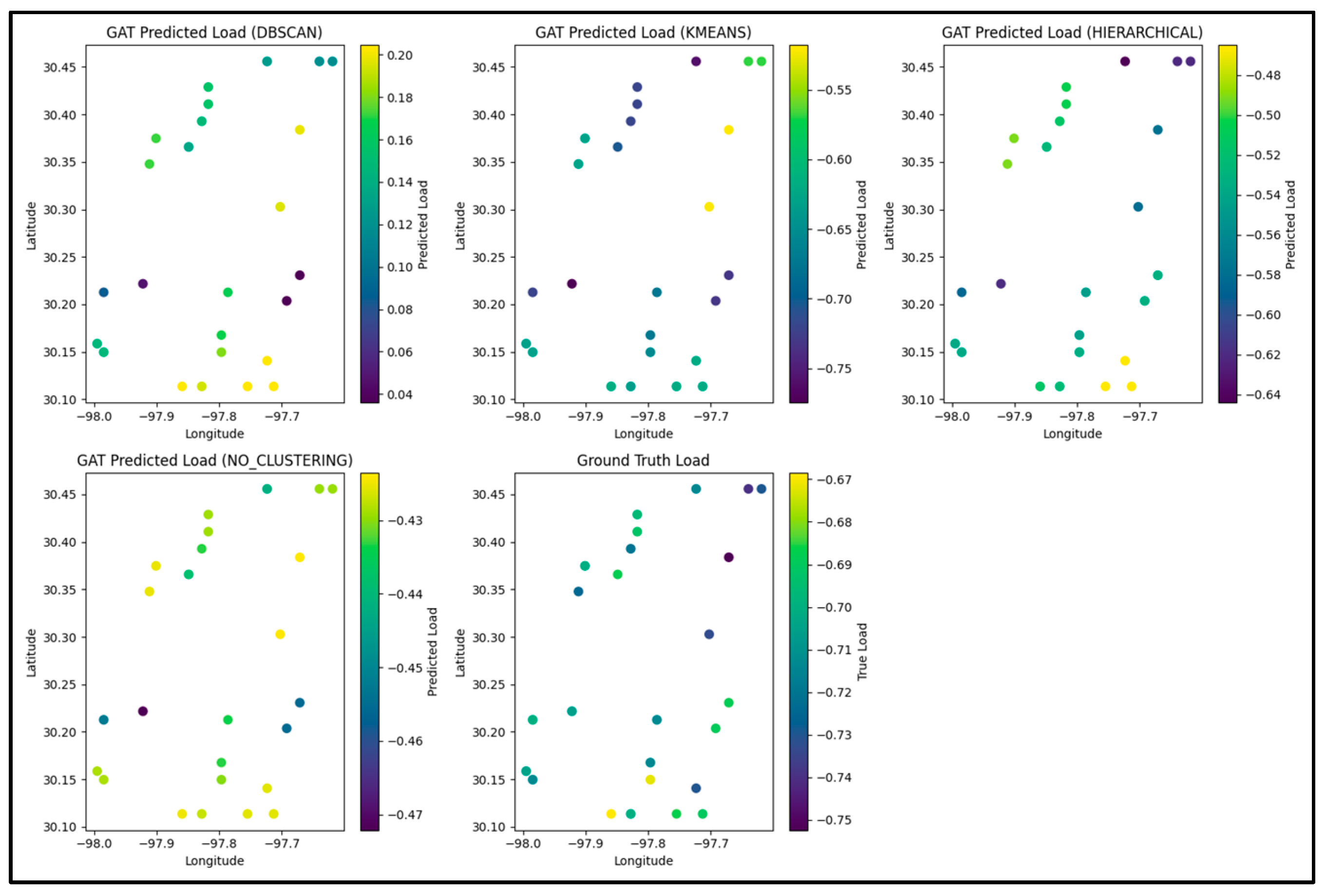
The geographical distribution of clusters produced by each method is illustrated in
Figure 5, which includes four subplots: (a) DRL-DBSCAN, (b) K-Means, (c) Hierarchical clustering, and (d) no-clustering (raw geographical grids). The DRL-DBSCAN clusters (subplot a) exhibit clear spatial coherence, with nodes in the same cluster being geographically proximate, and noise points (Cluster -1) corresponding to isolated households. K-Means (subplot b) and Hierarchical clustering (subplot c) also produce five clusters, but their spatial distributions are less coherent, with some clusters spanning geographically distant regions. For instance, in the K-Means result, Cluster 2 includes nodes from both the northeastern and southwestern regions, which may not share similar load patterns. The no-clustering scenario (subplot d) simply plots the raw geographical grids without any grouping, relying entirely on the GAT-GNN to learn spatial relationships from the coordinates. Analysis of these spatial distributions highlights their impact on the GAT-GNN predictive performance. In subplot (a), the DRL-DBSCAN spatial coherence ensures that grids within the same cluster share similar meteorological conditions (e.g., temperature), as seen in Cluster 3 (colored blue), which groups urban grids with high loads due to the heat island effect. This coherence enhances the graph structure for GAT-GNN, contributing to its superior accuracy (Test MSE: 0.0388, MAE: 0.1559). Noise points (Cluster -1, gray) exclude isolated grids with distinct load patterns, avoiding irrelevant connections. In contrast, K-Means (subplot b) groups geographically distant regions in Cluster 2 (green), likely with differing meteorological conditions, leading to a less effective graph structure and higher errors (Test MSE: 0.0731, MAE: 0.2151). Hierarchical clustering (subplot c) shows moderate coherence but still includes overlapping clusters across distant regions (e.g., Cluster 1, red), resulting in reduced performance (Test MSE: 0.0502, MAE: 0.1883). The no-clustering scenario (subplot d) lacks structured grouping, forcing GAT-GNN to infer relationships from raw coordinates, which increases errors (Test MSE: 0.0813, MAE: 0.2584). These findings underscore the importance of meteorologically informed, spatially coherent clustering for accurate air conditioning load forecasting.
3.4. Comparison of Different Neural Network Architectures
To evaluate the GAT-GNN framework enhanced by DRL-DBSCAN, we compare it against the Long Short-Term Memory (LSTM), Transformer, Multi-Layer Perceptron (MLP), and Graph Isomorphism Network (GIN). GIN aggregates neighbor information to distinguish graph structures but lacks the GAT dynamic attention mechanism. To address standardization issues, this study implemented inverse scaling post-prediction, ensuring that predicted load ranges align with ground truth values. The dataset, preprocessing, and DRL-DBSCAN clustering are consistent across models. The GAT model uses two layers with four attention heads, while baseline models (LSTM, Transformer, MLP) process temporal and feature-based inputs independently. This experiment aims to demonstrate the importance of spatial modeling in load forecasting and to highlight the superiority of the GAT-enhanced GNN over other architectures. Four models are compared: (1) the proposed GAT-based GNN, (2) Long Short-Term Memory (LSTM) [
21], (3) Transformer [
22], and (4) Multi-Layer Perceptron (MLP) [
23]. The DRL-DBSCAN clustering results and the dataset remain consistent across all models to ensure a fair comparison, with the GAT utilizing the graph structure while the other models rely solely on temporal and feature-based inputs.
The dataset and preprocessing steps are identical to those described in the previous subsections. The DRL-DBSCAN algorithm clusters the 25 geographical grids into five clusters, as shown in
Figure 3. The GAT model is configured with two GAT layers, each with a hidden size of 32 and
attention heads in the first layer, followed by a fully connected layer to produce the load prediction. Node features include local temperature, humidity, and a four-dimensional embedding of the cluster label. The graph structure is constructed by connecting nodes within the same cluster if their Euclidean distance is less than 0.05, with edge weights inversely proportional to the distance.
For the baseline models, the input features are designed to be as consistent as possible with the GAT. Each model uses a historical window of 24 h to capture temporal patterns, and the input features include local temperature, humidity, geographical coordinates, and the same four-dimensional cluster label embedding used in the GAT. The configurations of the baseline models are as follows:
LSTM: The LSTM model consists of two layers with a hidden size of 32, followed by a fully connected layer to produce the load prediction. It processes the 24 h sequence of features for each grid independently.
Transformer: The Transformer model is implemented with two encoder layers, each with four attention heads and a hidden size of 32. A positional encoding is added to the input sequence to capture temporal order, and the model outputs a single load prediction for each grid.
MLP: The MLP serves as a simple baseline, consisting of three fully connected layers with hidden sizes of 64, 32, and 1, respectively. The input features for each grid at each timestamp are flattened (24 h × feature dimensions), and the model predicts the load for the next timestamp.
All models are trained for 200 epochs using the Adam optimizer with a learning rate of 0.005 and a weight decay of . The MSE loss function is used for optimization, and a dropout rate of 0.5 is applied to mitigate overfitting. The dataset is split into training and testing sets with an 80:20 ratio, preserving the temporal sequence during the split. The performance is evaluated using MSE and MAE on both the training and test sets, and the spatial distribution of the predicted loads is visualized to assess the models’ ability to capture spatial patterns.
The predictive performance of the four models is summarized in
Table 2. The GAT-based GNN achieves the best performance on the test set, with a test MSE of 0.0216 and a test MAE of 0.0884, significantly outperforming all other models. GIN aggregates neighbor information to distinguish graph structures but lacks the GAT dynamic attention mechanism. GIN achieved a test MSE of 0.0621 and MAE of 0.1548, underperforming GAT. The LSTM model yields a test MSE of 0.3259 and a test MAE of 0.3442, indicating its limited ability to capture spatial dependencies. The Transformer model performs slightly better than the LSTM, with a test MSE of 0.6415 and a test MAE of 0.4835, likely due to its attention mechanism, which effectively captures temporal dependencies across the 24 h window. However, the Transformer still falls short of the GAT-GNN, as it lacks explicit spatial modeling. The MLP performs the worst, with a test MSE of 0.7269 and a test MAE of 0.5240, reflecting its inability to model either complex temporal or spatial patterns effectively.
The results confirm that the GAT-based GNN, enhanced by DRL-DBSCAN clustering, outperforms the LSTM, Transformer, and MLP in terms of predictive accuracy on the test set, as evidenced by its lowest test MSE and MAE. The superior performance of GAT can be attributed to its attention mechanism, which dynamically weights the contributions of neighboring nodes, allowing for more effective modeling of spatial dependencies. However, the high training MSE (1.3853) compared to the test MSE (0.0216) suggests potential overfitting, which may be addressed in future work by introducing regularization techniques or adjusting the model architecture.
The significant performance gap between GAT-GNN and GIN is primarily attributed to the GAT ability to dynamically assign attention weights to neighboring grids based on their meteorological and spatial relevance. For instance, in urban areas where the heat island effect increases air conditioning loads, GAT prioritizes connections to nearby grids with similar temperature profiles, effectively capturing localized spatial dependencies that influence load patterns. GIN, while capable of distinguishing graph structures through neighbor aggregation, does not adaptively weight these connections, potentially overlooking critical meteorological influences, which results in higher prediction errors. The non-GNN models (LSTM, Transformer, and MLP) exhibit even larger errors due to their inability to model spatial relationships explicitly. LSTM focuses solely on temporal sequences, missing spatial correlations such as the influence of neighboring grids’ loads in densely populated areas. The Transformer, despite its attention mechanism for temporal dependencies, cannot capture the spatial interactions between grids, such as the effect of urban density on load variations across a city. MLP performs the worst, as it lacks both spatial and temporal modeling capabilities, treating all grids independently and failing to account for the complex spatiotemporal dynamics of air conditioning loads. The synergy between DRL-DBSCAN and GAT further enhances performance by providing a high-quality graph structure. The DRL-DBSCAN spatially coherent clusters ensure that the graph edges reflect meaningful relationships, such as grouping urban grids with similar meteorological conditions, which GAT leverages to improve prediction accuracy. This contrasts with the other models, which do not benefit from such structured spatial input. Future improvements could involve applying dropout regularization within GAT layers, reducing the number of attention heads, or collecting a more balanced dataset to mitigate this issue.
The spatial distribution of the predicted loads for each model is visualized in
Figure 6, which includes five subplots: (a) GAT, (b) LSTM, (c) Transformer, (d) MLP, and (e) ground truth, at the last timestamp of the test set. The ground truth loads range from 0.09 to 0.15, with higher loads concentrated in the northeastern region (around longitude −97.7, latitude 30.4). The GAT predictions (subplot a) range from −0.17 to −0.12, showing a deviation in magnitude from the ground truth but capturing spatial variability effectively, particularly in the northeastern region. In contrast, the LSTM (subplot b, range: −0.68 to −0.62), Transformer (subplot c, range: −0.77 to −0.70), and MLP (subplot d, range: −0.638 to −0.634) predictions exhibit negative values, indicating a fundamental issue in the standardization process, and show less spatial variability compared to GAT. These deviations suggest that while GAT captures spatial patterns better, further improvements in target value standardization are needed to align predicted values with the ground truth range.
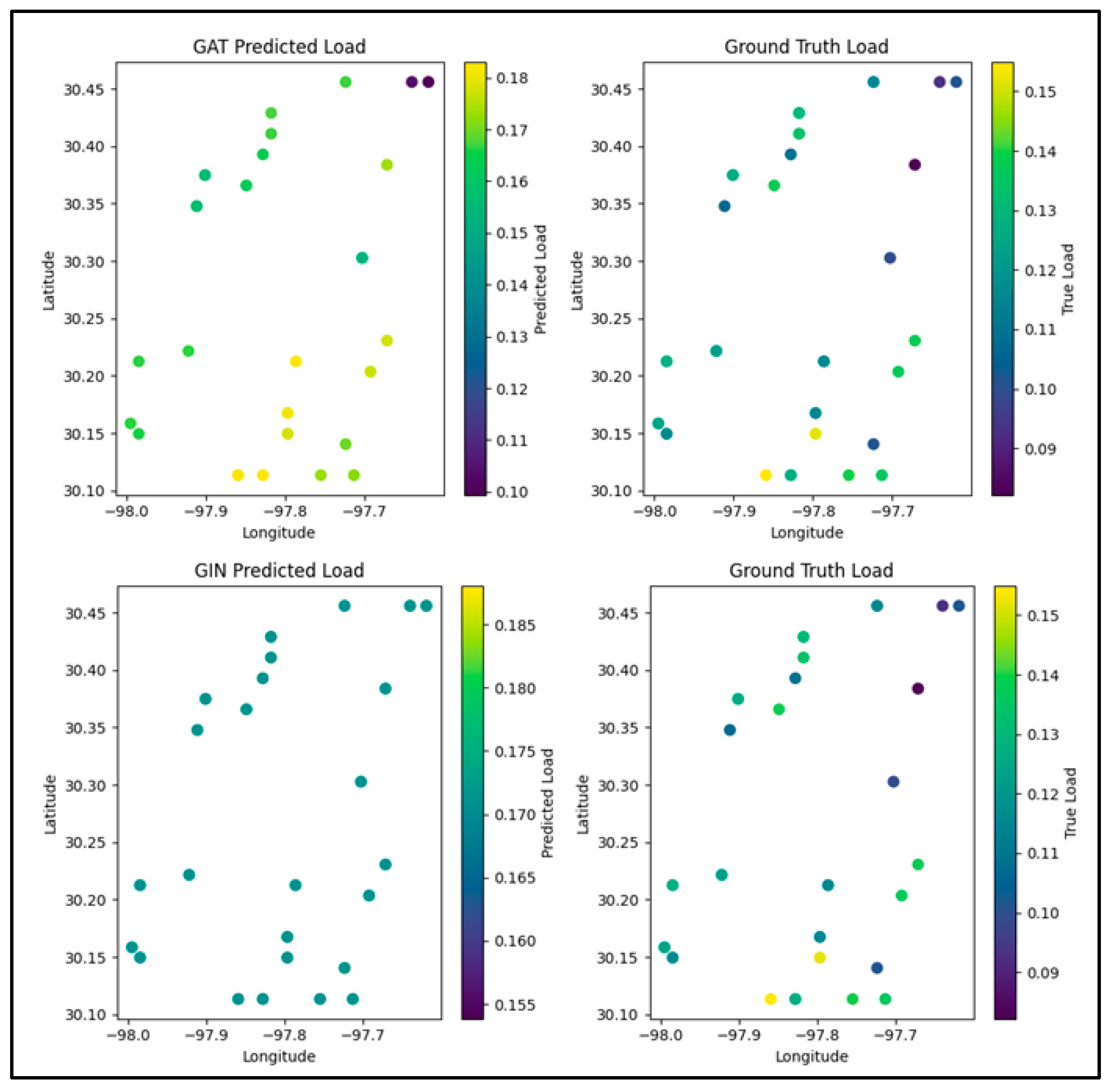
Figure 7 visualizes the spatial distribution of predicted loads for the GAT and GIN models. The GAT predictions (subplot a) range from −0.17 to −0.12, showing a deviation in magnitude from the ground truth but effectively capturing spatial variability, particularly in the northeastern region where higher loads are concentrated. This suggests that GAT leverages its attention mechanism to model geographical relationships more accurately. In contrast, the GIN predictions (subplot c) range from 0.165 to 0.185, which, while closer to the ground truth in terms of magnitude compared to GAT, exhibit a more uniform distribution across the spatial domain. Notably, GIN fails to effectively capture the geographical relationships, as it does not reflect the concentration of higher loads in the northeastern region, instead showing a relatively homogeneous pattern across all nodes. This indicates that the GIN focus on structural properties through sum aggregation might overlook fine-grained spatial dependencies critical for this task.
The deviations in both models suggest that while GAT captures spatial patterns better, and GIN achieves a closer magnitude to the ground truth, further improvements in target value standardization and model design are needed to fully align predicted values with the ground truth range and spatial distribution.
3.5. Impact of Time Scales and Spatial Resolutions
To further investigate the robustness of the GAT-GNN model, we evaluated its performance across different time scales and spatial resolutions, as shown in
Table 3. For temporal analysis, the model was tested at three time scales: hourly (1 H), 6-hourly (6 H), and daily (24 H). At the hourly scale, GAT-GNN achieves a test MSE of 0.0216 and MAE of 0.0884, capturing fine-grained load fluctuations driven by short-term meteorological changes (e.g., temperature spikes during mid-day). At the 6-hourly scale, the test MSE increases to 0.0352 and MAE to 0.1421, reflecting a reduced ability to capture rapid load variations, as the aggregation smooths out short-term dynamics. At the daily scale, performance further declines (Test MSE: 0.0598, MAE: 0.1973), as the model struggles to model intraday patterns, such as peak loads during late afternoon hours, which are critical for air conditioning forecasting. These results suggest that GAT-GNN is more effective at finer temporal resolutions, where its attention mechanism can leverage detailed temporal dependencies alongside spatial relationships. However, for applications requiring longer-term forecasts, additional temporal modeling (e.g., incorporating seasonal trends) may be necessary to improve accuracy.
For spatial resolution analysis, we aggregated the geographical grids into three scales: 1 km, 5 km, and 10 km. At the finest resolution (1 km), GAT-GNN performs best, as it can capture localized spatial patterns, such as the heat island effect in urban clusters identified by DRL-DBSCAN. At the 5 km resolution, the test MSE increases to 0.1105 and MAE to 0.2160, likely due to the reduced granularity, which merges grids with distinct load patterns, leading to less precise spatial dependencies in the graph structure. At the 10 km resolution, performance drops further, as the coarse resolution oversimplifies spatial variations, grouping heterogeneous regions and diminishing the model’s ability to distinguish fine-grained meteorological influences on load. These findings highlight the importance of selecting an appropriate spatial resolution based on the application: finer resolutions are preferable for capturing localized effects, while coarser resolutions may suffice for regional forecasting but at the cost of accuracy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}