

Variational Autoencoder Based Anomaly Detection in Large-Scale Energy Storage Power Stations



Abstract
1. Introduction
1.1. Architecture of Battery Energy Storage Power Stations
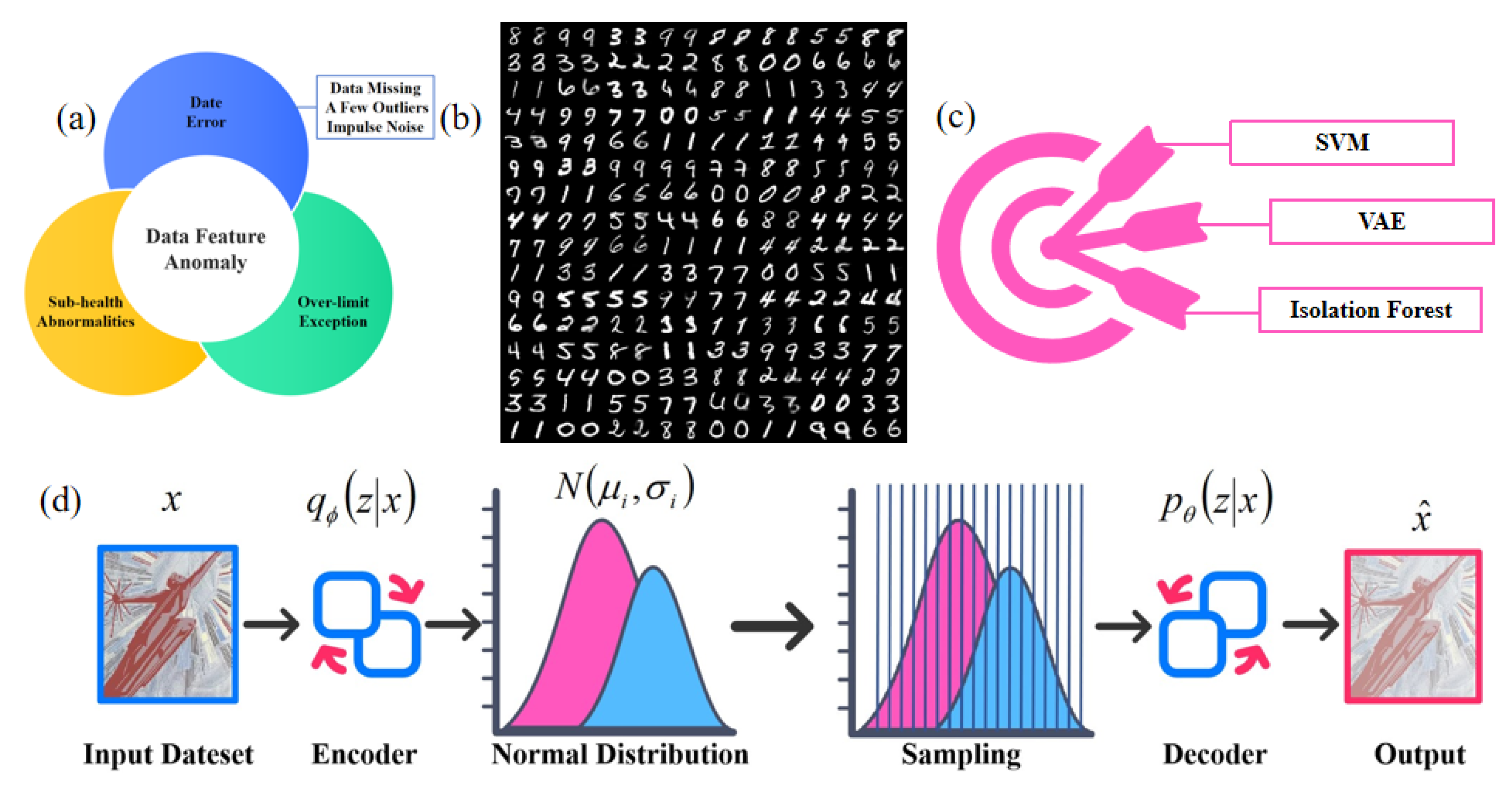
1.2. Anomaly Detection in Energy Storage Power Stations
1.3. Anomaly Detection Algorithms
2. VAE-Based Anomaly Detection Model
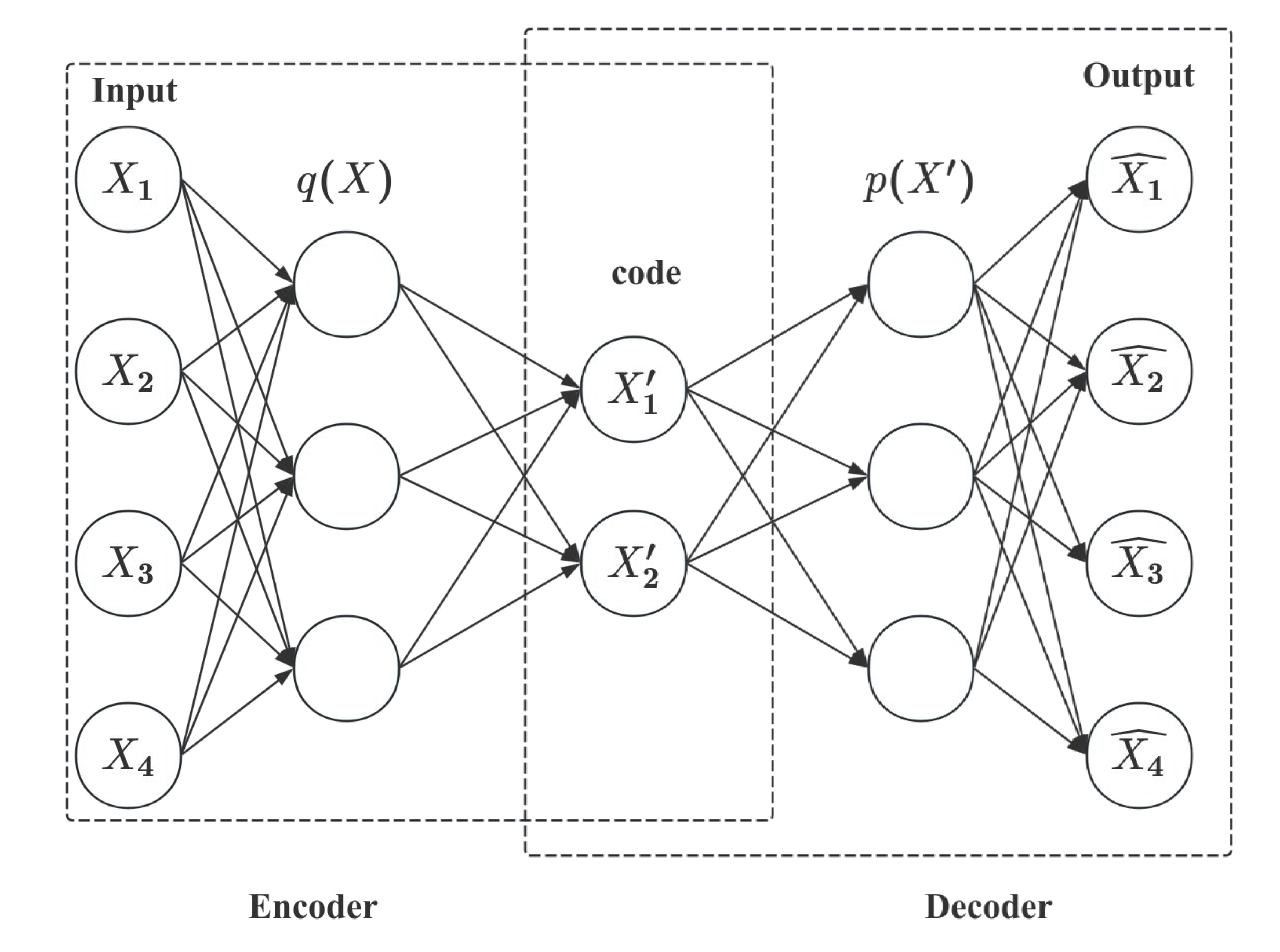
2.1. Variational Autoencoder Working Principle
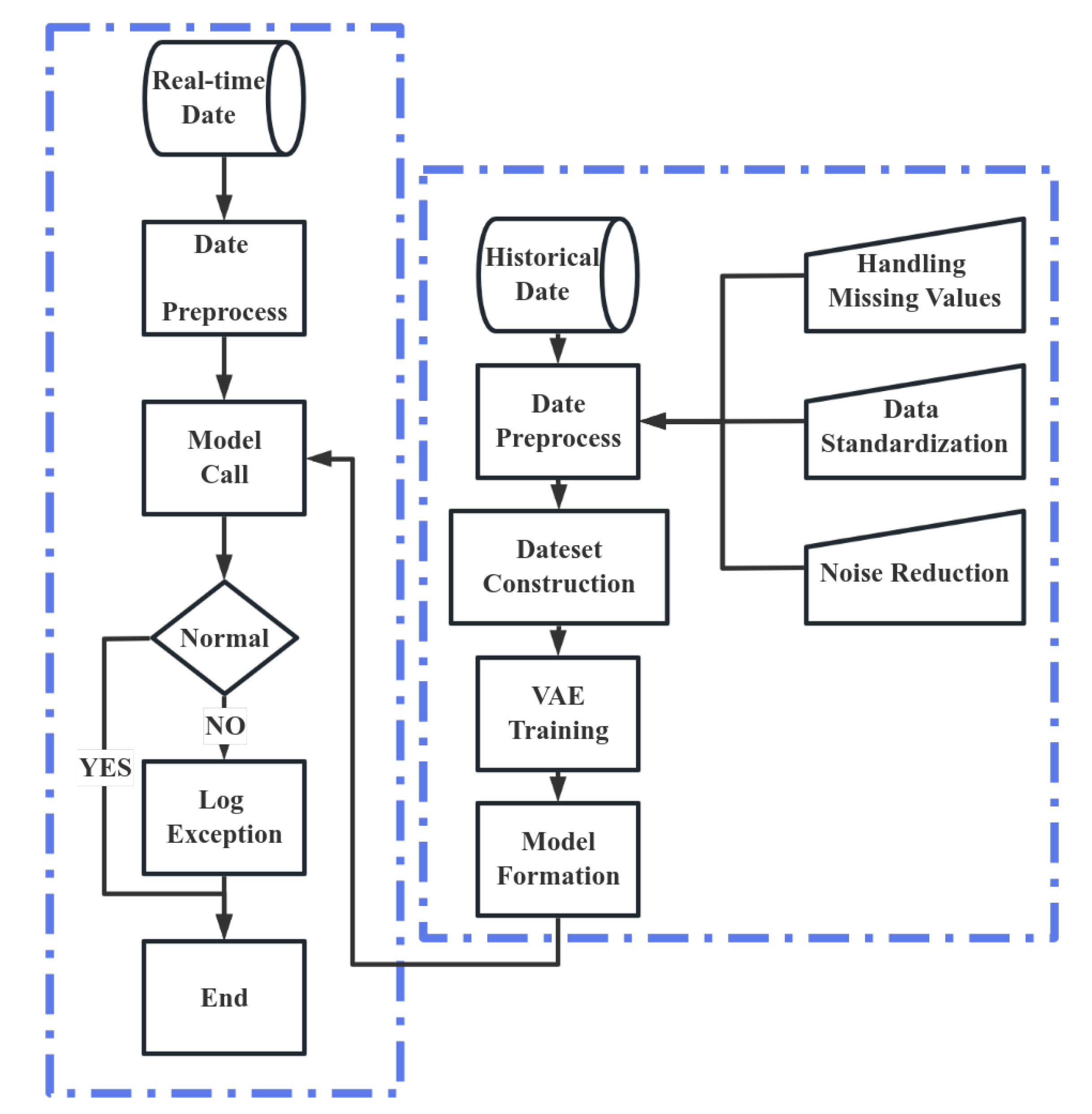
2.2. Anomaly Detection Process
3. Experiment
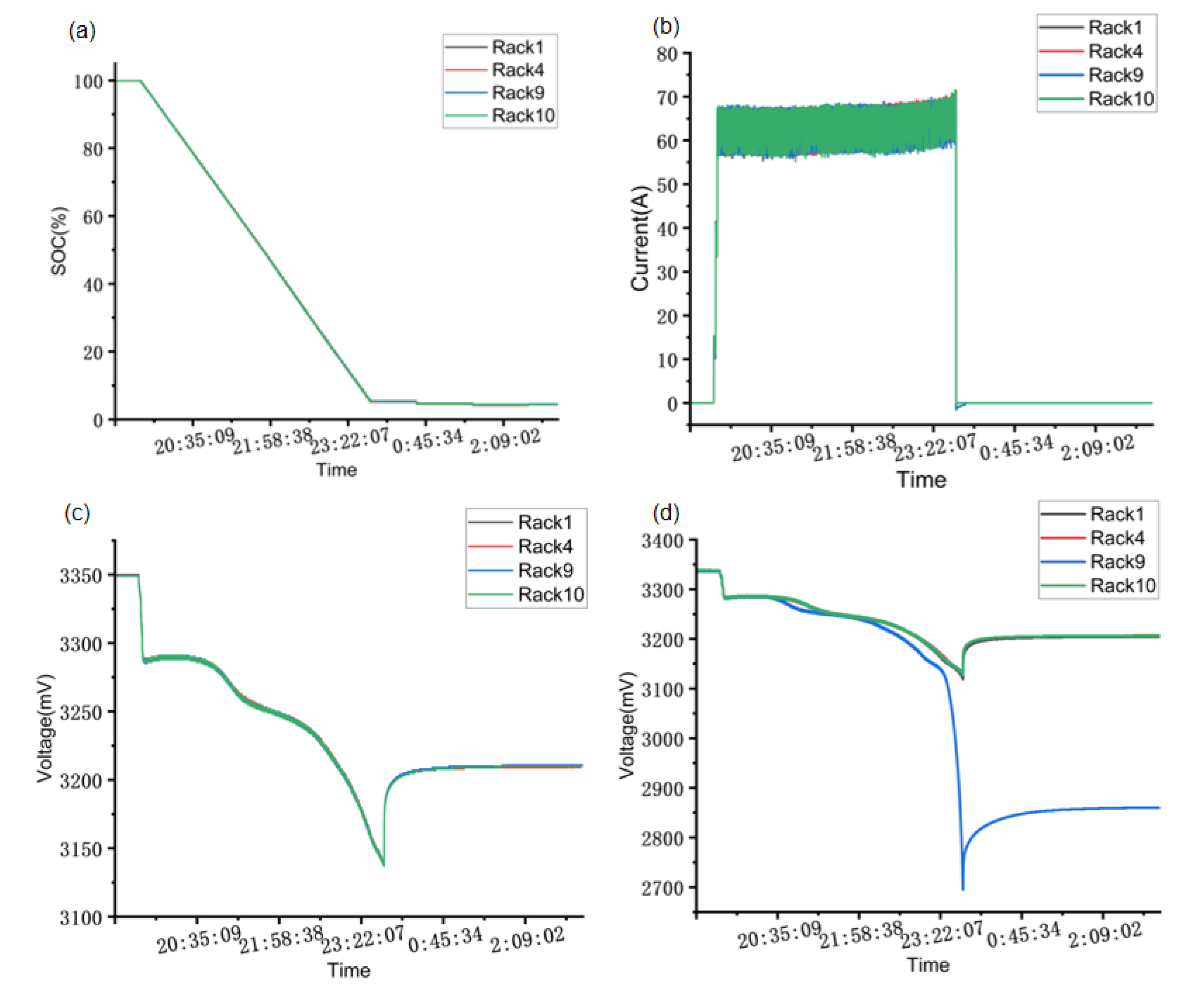
3.1. Experimental Data
3.2. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jin, Y.; Zhao, Z.; Miao, S.; Wang, Q.; Sun, L.; Lu, H. Explosion hazards study of grid-scale lithium-ion battery energy storage station. J. Energy Storage 2021, 42, 102987. [Google Scholar] [CrossRef]
- Olatomiwa, L.; Mekhilef, S.; Ismail, M.S.; Moghavvemi, M. Energy management strategies in hybrid renewable energy systems: A review. Renew. Sustain. Energy Rev. 2016, 62, 821–835. [Google Scholar] [CrossRef]
- Faraji, F.; Majazi, A.; Al-Haddad, K. A comprehensive review of flywheel energy storage system technology. Renew. Sustain. Energy Rev. 2017, 67, 477–490. [Google Scholar]
- Jamil, M.; Sharma, S.K.; Singh, R. Fault detection and classification in electrical power transmission system using artificial neural network. SpringerPlus 2015, 4, 1–13. [Google Scholar] [CrossRef]
- Michalski, K.; Kośka-Wolny, M.; Chmielowski, K.; Bedla, D.; Petryk, A.; Guzdek, P.; Dąbek, K.A.; Gąsiorek, M.; Grübel, K.; Halecki, W. Examining the Potential of Biogas: A Pathway from Post-Fermented Waste into Energy in a Wastewater Treatment Plant. Energies 2024, 17, 5618. [Google Scholar] [CrossRef]
- Cha, J. Partial least squares. Adv. Methods Mark. Res. 1994, 407, 52–78. [Google Scholar]
- MacGregor, J.F.; Kourti, T. Statistical process control of multivariate processes. Control. Eng. Pract. 1995, 3, 403–414. [Google Scholar] [CrossRef]
- Xu, X.; Jia, W.; Xu, S.; Ning, F.; Lei, J. Relationship between high-level color features and temperature mapping of magnesium alloy surface images based on the K-nearest neighbor algorithm. Appl. Therm. Eng. 2025, 259, 124940. [Google Scholar] [CrossRef]
- Wan, H.P.; Zhu, Y.K.; Luo, Y.; Todd, M.D. Unsupervised deep learning approach for structural anomaly detection using probabilistic features. Struct. Health Monit. 2025, 24, 3–33. [Google Scholar] [CrossRef]
- Ma, Q.; Sun, C.; Cui, B.; Jin, X. A novel model for anomaly detection in network traffic based on kernel support vector machine. Comput. Secur. 2021, 104, 102215. [Google Scholar] [CrossRef]
- Bounsiar, A.; Madden, M.G. One-Class Support Vector Machines Revisited. In Proceedings of the 2014 International Conference on Information Science & Applications (ICISA), Seoul, Republic of Korea, 6–9 May 2014; pp. 1–4. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Vigna, G.; Kemmerer, R.A. NetSTAT: A network-based intrusion detection system. J. Comput. Secur. 1999, 7, 37–71. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Mũnoz-Marí, J.; Bovolo, F.; Gómez-Chova, L.; Bruzzone, L.; Camp-Valls, G. Semisupervised one-class support vector machines for classification of remote sensing data. IEEE Trans. Geosci. Remote Sens. 2020, 48, 3188–3197. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended isolation forest. IEEE Trans. Knowl. Data Eng. 2019, 33, 1479–1489. [Google Scholar] [CrossRef]
- Xu, H.; Pang, G.; Wang, Y.; Wang, Y. Deep isolation forest for anomaly detection. IEEE Trans. Knowl. Data Eng. 2023, 35, 12591–12604. [Google Scholar] [CrossRef]
- Lesouple, J.; Baudoin, C.; Spigai, M.; Tourneret, J.Y. Generalized isolation forest for anomaly detection. Pattern Recognit. Lett. 2021, 149, 109–119. [Google Scholar]
- Chabchoub, Y.; Togbe, M.U.; Boly, A.; Chiky, R. An in-depth study and improvement of isolation forest. IEEE Access 2022, 10, 10219–10237. [Google Scholar] [CrossRef]
- Ahmed, S.; Lee, Y.; Hyun, S.H.; Koo, I. Unsupervised machine learning-based detection of covert data integrity assault in smart grid networks utilizing isolation forest. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2765–2777. [Google Scholar] [CrossRef]
- Duan, X.; Yan, H.; Tian, D.; Zhou, J.; Su, J.; Hao, W. In-vehicle CAN bus tampering attacks detection for connected and autonomous vehicles using an improved isolation forest method. IEEE Trans. Intell. Transp. Syst. 2021, 24, 2122–2134. [Google Scholar] [CrossRef]
- Li, T.; Liu, X.; Lin, Z.; Morrison, R. Ensemble offshore wind turbine power curve modelling–an integration of isolation forest, fast radial basis function neural network, and metaheuristic algorithm. Energy 2022, 239, 122340. [Google Scholar] [CrossRef]
- Lew, A.J.; Buehler, M.J. Encoding and exploring latent design space of optimal material structures via a VAE-LSTM model. Forces Mech. 2021, 5, 100054. [Google Scholar] [CrossRef]
- Jing, T.; Zheng, P.; Xia, L.; Liu, T. Transformer-based hierarchical latent space VAE for interpretable remaining useful life prediction. Adv. Eng. Inform. 2022, 54, 101781. [Google Scholar] [CrossRef]
- Ding, J.; Zhang, Q.; Wang, J.; Huo, W. ADS-B anomaly detection method based on Transformer-VAE. Syst. Eng. Electron. 2023, 45, 3680–3689. [Google Scholar]
- Dairi, A.; Harrou, F.; Sun, Y.; Khadraoui, S. Short-term forecasting of photovoltaic solar power production using variational auto-encoder driven deep learning approach. Appl. Sci. 2020, 10, 8400. [Google Scholar] [CrossRef]
- Staffini, A.; Svensson, T.; Chung, U.I.; Svensson, A.K. A disentangled VAE-BiLSTM model for heart rate anomaly detection. Bioengineering 2023, 10, 683. [Google Scholar] [CrossRef]
- Memarzadeh, M.; Matthews, B.; Avrekh, I. Unsupervised anomaly detection in flight data using convolutional variational auto-encoder. Aerospace 2020, 7, 115. [Google Scholar] [CrossRef]
- Zhou, Y.; Liang, X.; Zhang, W.; Zhang, L.; Song, X. VAE-based deep SVDD for anomaly detection. Neurocomputing 2021, 453, 131–140. [Google Scholar] [CrossRef]
- Ai, Q.; He, L.; Liu, S.; Xu, Z. Bype-vae: Bayesian pseudocoresets exemplar vae. Adv. Neural Inf. Process. Syst. 2021, 34, 5910–5920. [Google Scholar]
- Razghandi, M.; Zhou, H.; Erol-Kantarci, M.; Turgut, D. Smart home energy management: VAE-GAN synthetic dataset generator and Q-learning. IEEE Trans. Smart Grid 2023, 15, 1562–1573. [Google Scholar] [CrossRef]
- Li, J.; Ye, M.; Ma, X.; Wang, Q.; Wang, Y. SOC estimation and fault diagnosis framework of battery based on multi-model fusion modeling. J. Energy Storage 2023, 65, 107296. [Google Scholar] [CrossRef]
- Niu, G.; Dong, X.; Chen, Y. Motor fault diagnostics based on current signatures: A review. IEEE Trans. Instrum. Meas. 2023, 72, 1–19. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, Z.; Shu, X.; Xiao, R.; Shen, J.; Liu, Y.; Liu, Y. Online surface temperature prediction and abnormal diagnosis of lithium-ion batteries based on hybrid neural network and fault threshold optimization. Reliab. Eng. Syst. Saf. 2024, 243, 109798. [Google Scholar] [CrossRef]
- Sun, J.; Chen, S.; Xing, S.; Guo, Y.; Wang, S.; Wang, R.; Wang, R.; Wu, Y.; Wu, X. A battery internal short circuit fault diagnosis method based on incremental capacity curves. J. Power Sources 2024, 602, 234381. [Google Scholar] [CrossRef]
- Zheng, Y.; Luo, Q.; Cui, Y.; Dai, H.; Han, X.; Feng, X. Fault identification and quantitative diagnosis method for series-connected lithium-ion battery packs based on capacity estimation. IEEE Trans. Ind. Electron. 2021, 69, 3059–3067. [Google Scholar] [CrossRef]
- Kim, S.B.; Lee, S.H. Development of Aging Diagnosis Device Through Real-time Battery Internal Resistance Measurement. Int. J. Internet Broadcast. Commun. 2022, 14, 129–135. [Google Scholar]
- Albertus, P.; Girishkumar, G.; McCloskey, B.; Sánchez-Carrera, R.S.; Kozinsky, B.; Christensen, J.; Luntz, A.C. Identifying capacity limitations in the Li/oxygen battery using experiments and modeling. J. Electrochem. Soc. 2011, 158, A343. [Google Scholar] [CrossRef]
- Wang, J.; Liu, S.; Lin, C.; Wang, F.; Liu, C.; Su, Y.; Chen, S.; Wu, F. Experimental study on the internal resistance and heat generation characteristics of lithium ion power battery with NCM/C material system. SAE Int. J. Passeng. Cars-Electron. Electr. Syst. 2018, 11, 131–138. [Google Scholar] [CrossRef]
- Zhao, B.; Hu, J.; Xu, S.; Wang, J.; Zhu, Y.; Zhang, L.; Gao, C. Estimation of the SOC of energy-storage lithium batteries based on the voltage increment. IEEE Access 2020, 8, 198706–198713. [Google Scholar] [CrossRef]
- Ouyang, D.; Chen, M.; Liu, J.; Wei, R.; Weng, J.; Wang, J. Investigation of a commercial lithium-ion battery under overcharge/over-discharge failure conditions. RSC Adv. 2018, 8, 33414–33424. [Google Scholar] [CrossRef] [PubMed]
- Alavi, M.; Wang, D.; Luo, M. Short-circuit fault diagnosis for three-phase inverters based on voltage-space patterns. IEEE Trans. Ind. Electron. 2014, 61, 5558–5569. [Google Scholar] [CrossRef]
- Farmann, A.; Sauer, D.U. A study on the dependency of the open-circuit voltage on temperature and actual aging state of lithium-ion batteries. J. Power Sources 2017, 347, 1–13. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Kobak, D.; Berens, P. The art of using t-SNE for single-cell transcriptomics. Nat. Commun. 2019, 10, 5416. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rack1 | Rack4 | |||||||
| A | P | R | F1 | A | P | R | F1 | |
| Isolation Forest | 78 ± 11% | 83 ± 13% | 92 ± 19% | 85 ± 14% | 73 ± 15% | 7 ± 8% | 1 ± 19% | 77.5 ± 13% |
| SVM | 68 ± 3% | 76 ± 24% | 1 ± 16% | 81 ± 4% | 69 ± 17% | 62 ± 5% | 1 ± 16% | 76 ± 15% |
| VAE | 98 ± 15% | 96 ± 3% | 1 ± 17% | 98 ± 13% | 1 ± 3% | 1 ± 7% | 1 ± 11% | 1 ± 2% |
| Rack9 | Rack10 | |||||||
| A | P | R | F1 | A | P | R | F1 | |
| Isolation Forest | 66 ± 19% | 74 ± 7% | 1 ± 22% | 79 ± 5% | 67 ± 23% | 75 ± 3% | 1 ± 3% | 8 ± 21% |
| SVM | 73 ± 3% | 65 ± 8% | 1 ± 13% | 79 ± 6% | 74 ± 25% | 82 ± 1% | 1 ± 7% | 85 ± 24% |
| VAE | 99 ± 2% | 99 ± 1% | 1 ± 2% | 99 ± 9% | 95 ± 7% | 93 ± 1% | 97 ± 9% | 91 ± 17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, T.; Xu, P.; Guo, D.; Sun, L.; Ma, K.; Wang, Y.; Han, X. Variational Autoencoder Based Anomaly Detection in Large-Scale Energy Storage Power Stations. Energies 2025, 18, 2770. https://doi.org/10.3390/en18112770
Ji T, Xu P, Guo D, Sun L, Ma K, Wang Y, Han X. Variational Autoencoder Based Anomaly Detection in Large-Scale Energy Storage Power Stations. Energies. 2025; 18(11):2770. https://doi.org/10.3390/en18112770
Chicago/Turabian StyleJi, Tuo, Pinghu Xu, Dongliang Guo, Lei Sun, Kangji Ma, Yanan Wang, and Xuebing Han. 2025. "Variational Autoencoder Based Anomaly Detection in Large-Scale Energy Storage Power Stations" Energies 18, no. 11: 2770. https://doi.org/10.3390/en18112770
APA StyleJi, T., Xu, P., Guo, D., Sun, L., Ma, K., Wang, Y., & Han, X. (2025). Variational Autoencoder Based Anomaly Detection in Large-Scale Energy Storage Power Stations. Energies, 18(11), 2770. https://doi.org/10.3390/en18112770