

Trustworthiness of Deep Learning Under Adversarial Attacks in Power Systems



Abstract
1. Introduction
- Investigated vulnerabilities of deep learning models in cyber-physical power systems under adversarial attacks.
- Analyzed and implemented three important adversarial methods: the Fast Gradient Sign Method, DeepFool, and Jacobian-Based Saliency Map Attacks.
- Demonstrated the consequences of adversarial attacks on power system trustworthiness and functionality.
- Proposed a new framework to assess and model adversarial risks in power systems.
2. Related Work
3. Background: Adversarial Attacks
3.1. DeepFool
- -
- : The pertubations that will fool the classifier
- -
- : Our original input
- -
- arg min : The smallest possible perturbation that causes misclassification
3.2. JSMA
- -
- : This represents our modified input that fools the classifier
- -
- : This is our original input sample
- -
- : This operator finds the argument that maximizes the saliency map
3.3. FGSM
- -
- : the perturbed input that will fool the classifier;
- -
- : this is our original input sample;
- -
- : this is a small constant that controls the magnitude of the perturbation;
- -
- : the gradient of the loss function with respect to the input.
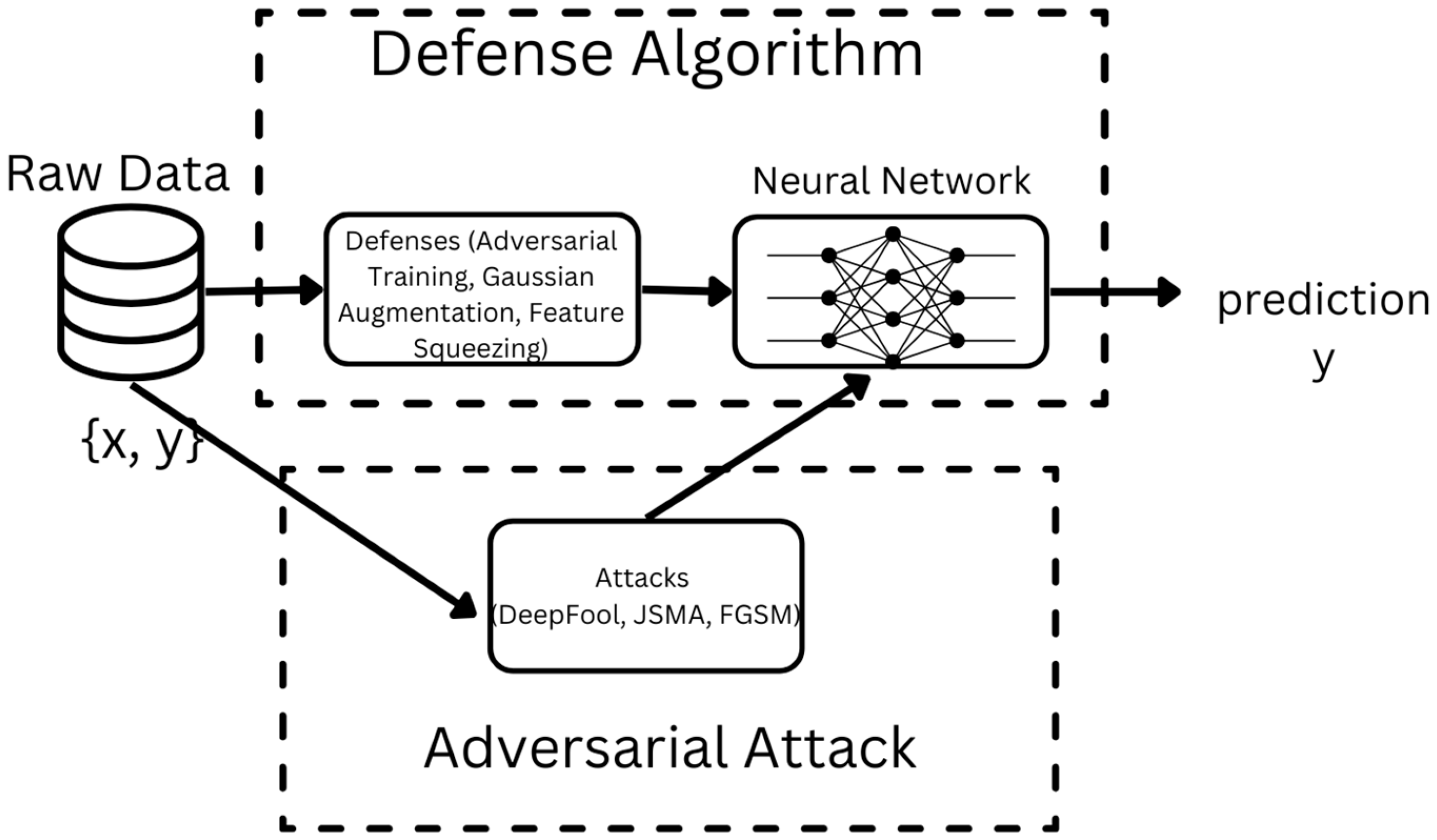
4. Materials and Methods
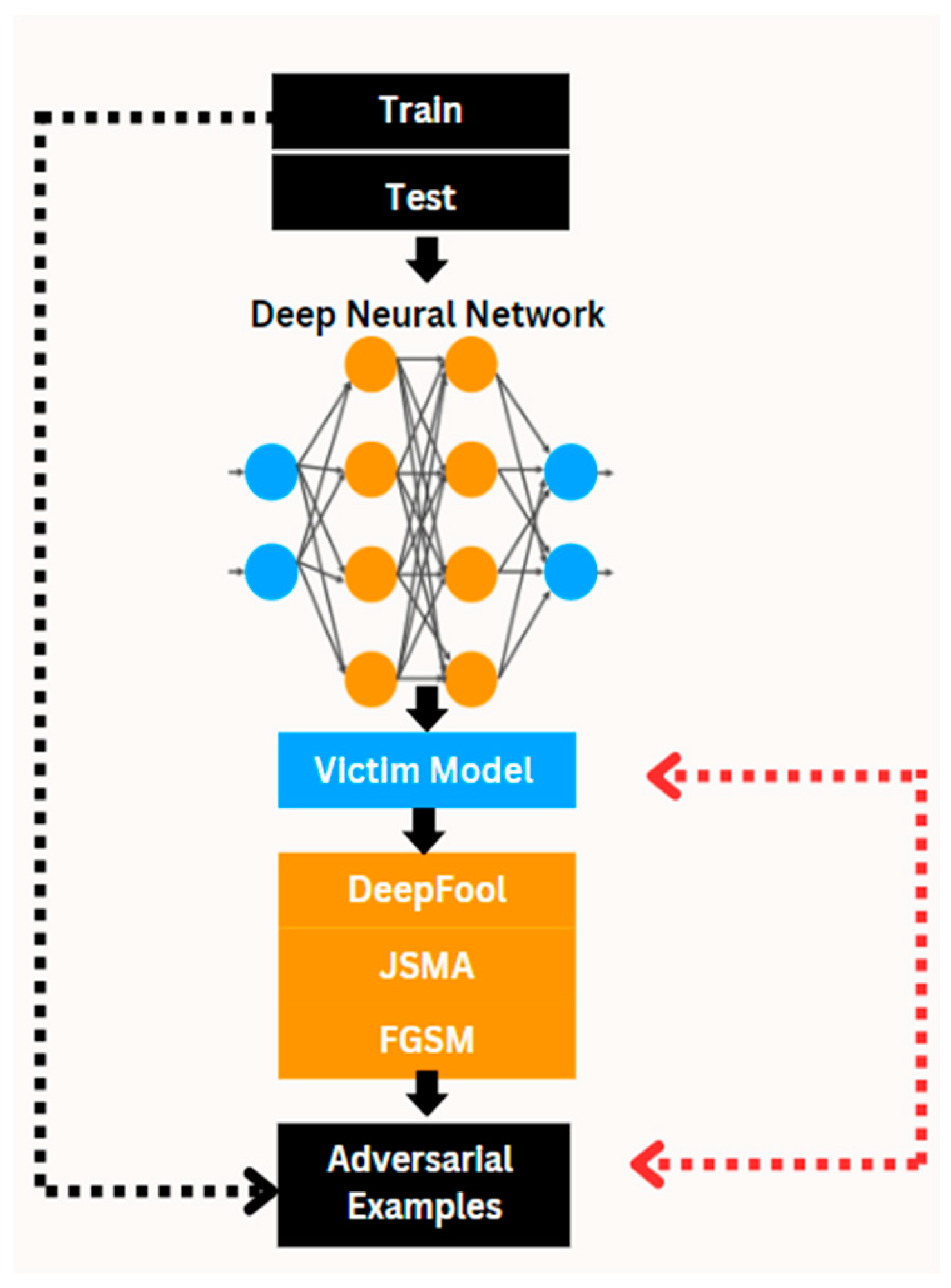
4.1. Proposed DL Framework Under Adversarial Attacks
4.2. Algorithm
| Algorithm 1: Effects of Adversarial Attacks on Deep Learning Algorithm |
|
5. Experiments and Results
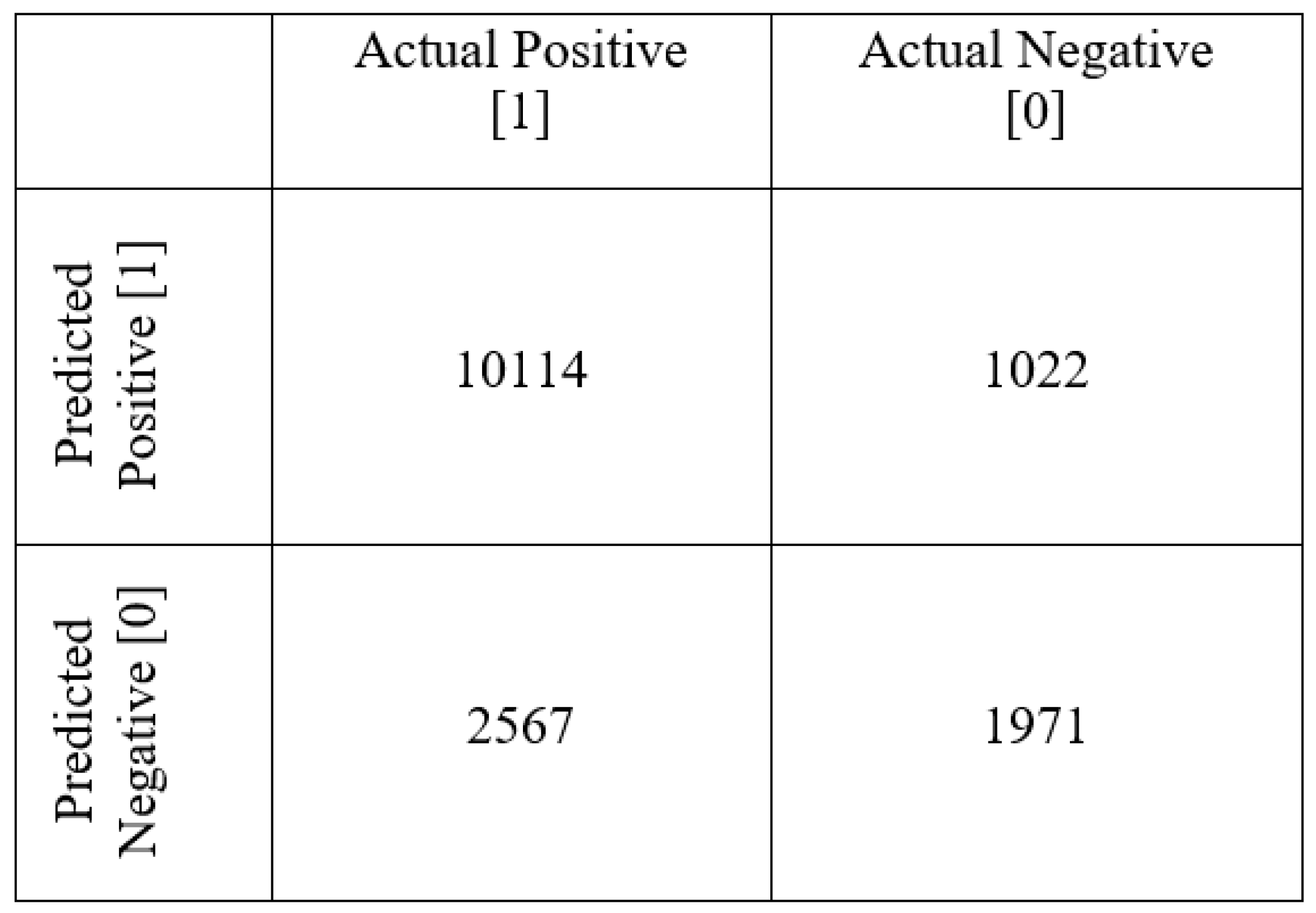
5.1. Experimental Setup
Datasets
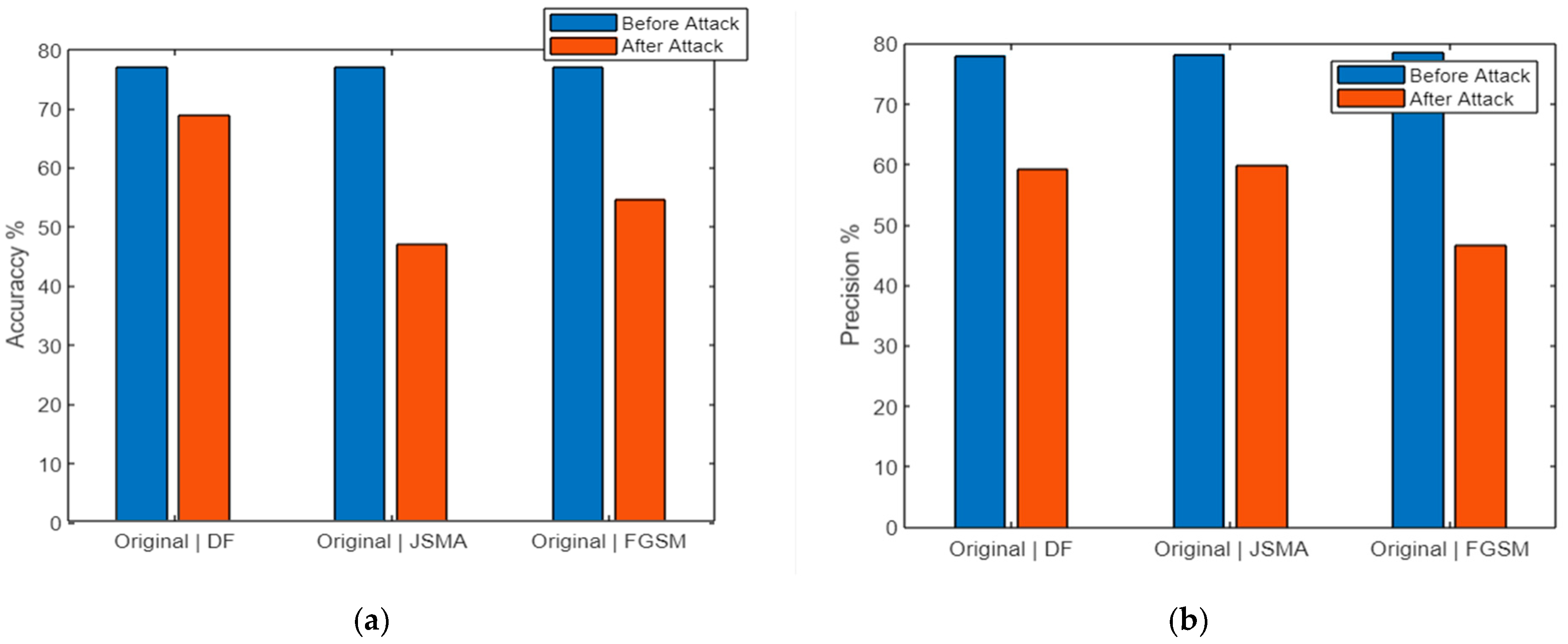
5.2. Results and Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. HotFlip: White-Box Adversarial Examples for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 31–36. [Google Scholar]
- Jiang, X.; Zhang, J.; Hug, G.; Harding, B.J.; Makela, J.J.; Domı, A.D. Spoofing GPS receiver clock offset of phasor measurement units. IEEE Trans. Power Syst. 2013, 28, 3253–3262. [Google Scholar]
- Tiscareno, K.K. The Growing Cyber-Risk to Our Electricity Grids-and What to Do About It. Available online: https://www.weforum.org/stories/2019/04/the-growing-risk-to-our-electricity-grids-and-what-to-do-about-it/ (accessed on 1 December 2024).
- IEA. World Energy Outlook 2020. Available online: https://www.iea.org/reports/world-energy-outlook-2020 (accessed on 10 December 2024).
- Nicolas, D.; Figueroa, H.; Wang, Y.; Elmannai, W.; Giakos, G.C. Adversarial machine learning architecture in AI-driven power systems. In Proceedings of the 2023 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Abu Dhabi, United Arab Emirates, 14–17 November 2023; pp. 0317–0322. [Google Scholar]
- Hug, G.; Giampapa, J.A. Vulnerability assessment of AC state estimation with respect to false data injection cyber-attacks. IEEE Trans. Smart Grid 2012, 3, 1362–1370. [Google Scholar] [CrossRef]
- Cheng, Y.; Yamashita, K.; Follum, J.; Yu, N. Adversarial purification for data-driven power system event classifiers with diffusion models. IEEE Trans. Power Syst. 2025. [Google Scholar] [CrossRef]
- Ding, J.; Qammar, A.; Zhang, Z.; Karim, A.; Ning, H. Cyber threats to smart grids: Review, taxonomy, potential solutions, and future directions. Energies 2022, 15, 6799. [Google Scholar] [CrossRef]
- Liberati, F.; Garone, E.; Di Giorgio, A. Review of cyber-physical attacks in smart grids: A system-theoretic perspective. Electronics 2021, 10, 1153. [Google Scholar] [CrossRef]
- Ghiasi, M.; Niknam, T.; Wang, Z.; Mehrandezh, M.; Dehghani, M.; Ghadimi, N. A comprehensive review of cyber-attacks and defense mechanisms for improving security in smart grid energy systems: Past, present and future. Electr. Power Syst. Res. 2023, 215, 108975. [Google Scholar] [CrossRef]
- Ribas Monteiro, L.F.; Rodrigues, Y.R.; Zambroni de Souza, A. Cybersecurity in cyber–physical power systems. Energies 2023, 16, 4556. [Google Scholar] [CrossRef]
- Ciapessoni, E.; Cirio, D.; Kjølle, G.; Massucco, S.; Pitto, A.; Sforna, M. Probabilistic risk-based security assessment of power systems considering incumbent threats and uncertainties. IEEE Trans. Smart Grid 2016, 7, 2890–2903. [Google Scholar] [CrossRef]
- Sayghe, A.; Zhao, J.; Konstantinou, C. Evasion attacks with adversarial deep learning against power system state estimation. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting (PESGM), 7–8 December 2020; pp. 1–5. [Google Scholar]
- Manandhar, K.; Cao, X.; Hu, F.; Liu, Y. Detection of faults and attacks including false data injection attack in smart grid using Kalman filter. IEEE Trans. Control Netw. Syst. 2014, 1, 370–379. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, R.; Zhao, W.; Yin, P.; Li, Y. A survey on coordinated attacks against cyber–physical power systems: Attack, detection, and defense methods. Electr. Power Syst. Res. 2025, 241, 111286. [Google Scholar] [CrossRef]
- Pandey, R.K.; Misra, M. Cyber security threats—Smart grid infrastructure. In Proceedings of the 2016 National Power Systems Conference (NPSC), Bhubaneswar, India, 19–21 December 2016; pp. 1–6. [Google Scholar]
- Li, Y.; Zhang, S.; Li, Y. AI-enhanced resilience in power systems: Adversarial deep learning for robust short-term voltage stability assessment under cyber-attacks. Chaos Solitons Fractals 2025, 196, 116406. [Google Scholar] [CrossRef]
- Mirzaee, P.H.; Shojafar, M.; Cruickshank, H.; Tafazolli, R. Smart grid security and privacy: From conventional to machine learning issues (threats and countermeasures). IEEE Access 2022, 10, 52922–52954. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Sahay, R.; Zhang, M.; Love, D.J.; Brinton, C.G. Defending adversarial attacks on deep learning-based power allocation in massive MIMO using denoising autoencoders. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 913–926. [Google Scholar] [CrossRef]
- Heinrich, R.; Scholz, C.; Vogt, S.; Lehna, M. Targeted adversarial attacks on wind power forecasts. Mach. Learn. 2024, 113, 863–889. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, T.; Li, S.; Yuan, X.; Ni, W.; Hossain, E.; Poor, H. Adversarial Attacks and Defenses in Machine Learning-Powered Networks: A Contemporary Survey. arXiv 2023, arXiv:2303.06302. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast is better than free: Revisiting adversarial training. arXiv 2020. [Google Scholar] [CrossRef]
- Uttam Adhikari, S.P.; Morris, T. Industrial Control System (ICS) Cyber Attack Datasets. 2014. Available online: https://sites.google.com/a/uah.edu/tommy-morris-uah/ics-data-sets (accessed on 10 December 2024).
- Pan, S.; Morris, T.; Adhikari, U. Developing a hybrid intrusion detection system using data mining for power systems. IEEE Trans. Smart Grid 2015, 6, 3104–3113. [Google Scholar] [CrossRef]
- Arzamasov, V. Electrical Grid Stability Simulated Data [Dataset]. 2018. Available online: https://archive.ics.uci.edu/dataset/471/electrical+grid+stability+simulated+data (accessed on 10 December 2024).
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Manoj, B.; Sadeghi, M.; Larsson, E.G. Adversarial attacks on deep learning based power allocation in a massive MIMO network. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Initiatives | Methods | Techniques | Objectives | Advantages | Limitations |
|---|---|---|---|---|---|
| Hug. et al. [7] | Demonstrated JSMA attacks on state estimation process | Jacobian-based Saliency Map Attack (JSMA) | Expose vulnerabilities in state estimation to adversarial attacks | Significantly degrades classification accuracy disrupting state estimation | Need for strong defenses against adversarial attacks |
| Manandhar et al. [15] | FGSM attacks on demand response models can alter demand projections | Fast Gradient Sign Method (FGSM) | Highlight risks of FGSM attacks on demand response models | Reduces accuracy, skewing demand forecasts and risking grid instability | Significance of protecting AI-models from FGSM-based attacks |
| Mirzaee et al. [19] | Overemphasis on single attack methods | Single attack method analysis | Identify gaps in focusing on single attack methods | Reveals how single attacks like DeepFool can drop multiclass accuracy exposing broader vulnerabilities | Focus on multifaceted attack strategies |
| Pandey and Misra [17] | Adversarial attacks can disrupt power supply, cause financial losses, and compromise safety | Adversarial attack simulation | Assess impact of adversarial attacks on power system operations | Causes significant performance drops, leading to operational disruptions | Inclusion of adversarial resilience in AI-model design |
| Kurakin et al. [20] | Emphasized the importance of adversarial resilience from the design phase | Adversarial resilience design principles | Advocate for resilience in AI design for critical infrastructure | Highlights need for resilience against attacks like DeepFool, which reduces accuracy, preventing major disruptions | Comprehensive defense strategies and holistic approach needed in critical infrastructure security |
| Sahay et al. [21] | Defended adversarial attacks on deep learning-based power allocation using denoising autoencoders | Denoising autoencoders | Mitigate adversarial attacks on power allocation systems | Mitigates specific attacks, maintaining power allocation stability despite attacks like FGSM | Limited to specific types of attacks |
| Heinrich et al. [22] | Targeted adversarial attacks on wind power forecasts | Targeted adversarial attack simulation | Evaluate impact of adversarial attacks on wind power forecasting | Disrupts wind power forecasting, dropping accuracy with the FGSM, affecting renewable energy integration | Lack of generalizability across different deep learning architectures |
| Wang et al. [23] | Surveyed adversarial attacks and defenses in machine learning models | Literature survey | Provide an overview of adversarial attacks and defenses in ML models | Identifies attacks like JSMA that lower accuracy aiding in understanding network performance degradation | High computational cost and complexity |
| Ding et al. [9] | Highlighted vulnerabilities in power grids due to communication reliance | AI-based detection methods | Identify cybersecurity challenges in power grids and propose AI-based solutions | Detects vulnerabilities exploited by attacks like DeepFool, improving grid security awareness | Limited focus on smaller grid operators’ vulnerabilities |
| Ghiasi et al. [11] | Reviewed cyberattacks and proposed intelligent methods for detection | Unsupervised learning for FDIA detection | Enhance smart grid security through intelligent detection and mitigation | Enhances detection of stealthy attacks like JSMA reducing false negatives in smart grids | Assumes static attack models, may not address adaptive threats |
| Binary Class | Original | Poisoned | |||||||
| Precision (%) | F1 (%) | Recall (%) | Accuracy (%) | Precision (%) | F1 (%) | Recall (%) | Accuracy (%) | ||
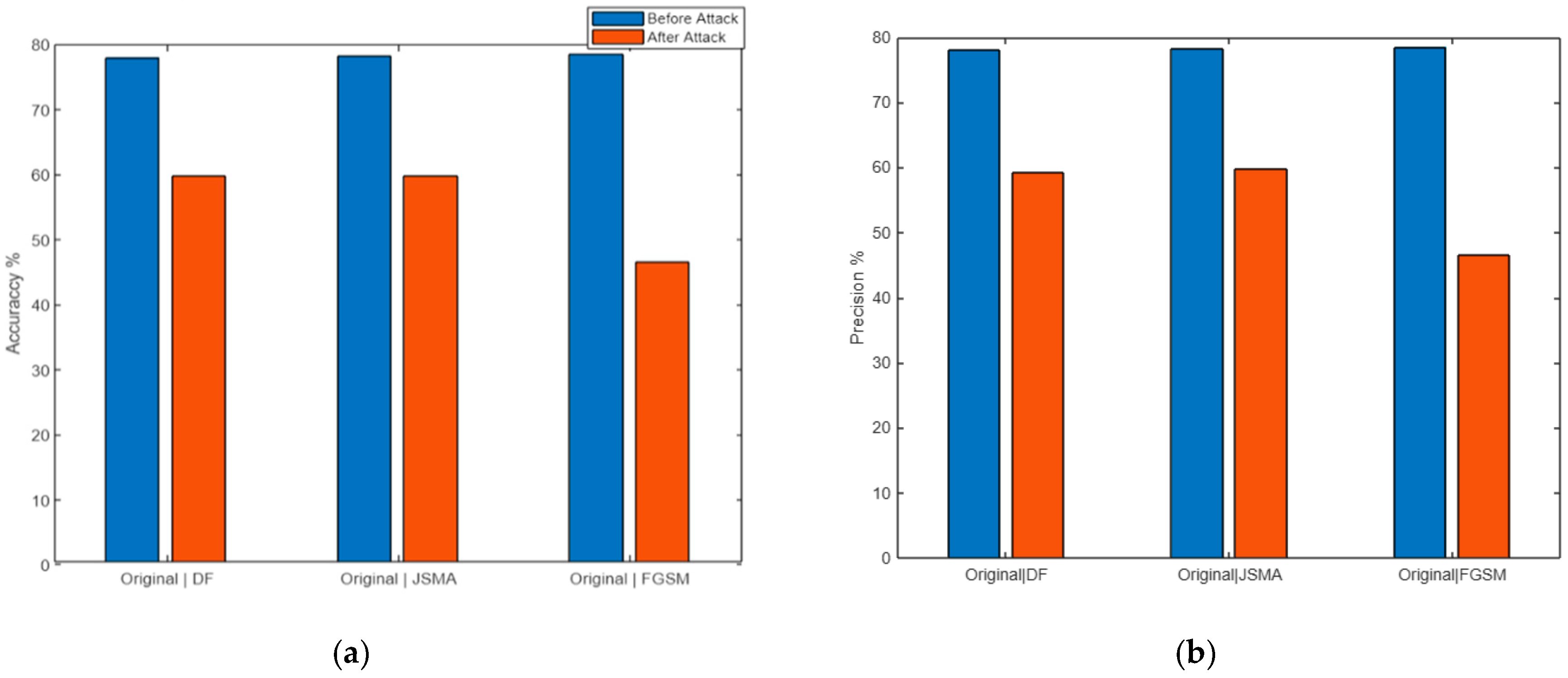
| DeepFool | 77.028 | 75.602 | 74.859 | 77.022 | 68.966 | 58.343 | 60.055 | 68.856 | |
| JSMA | 76.994 | 75.635 | 74.966 | 76.999 | 47.181 | 58.242 | 49.298 | 47.186 | |
| FGSM | 77.043 | 75.699 | 75.177 | 77.049 | 54.732 | 61.534 | 56.276 | 54.742 | |
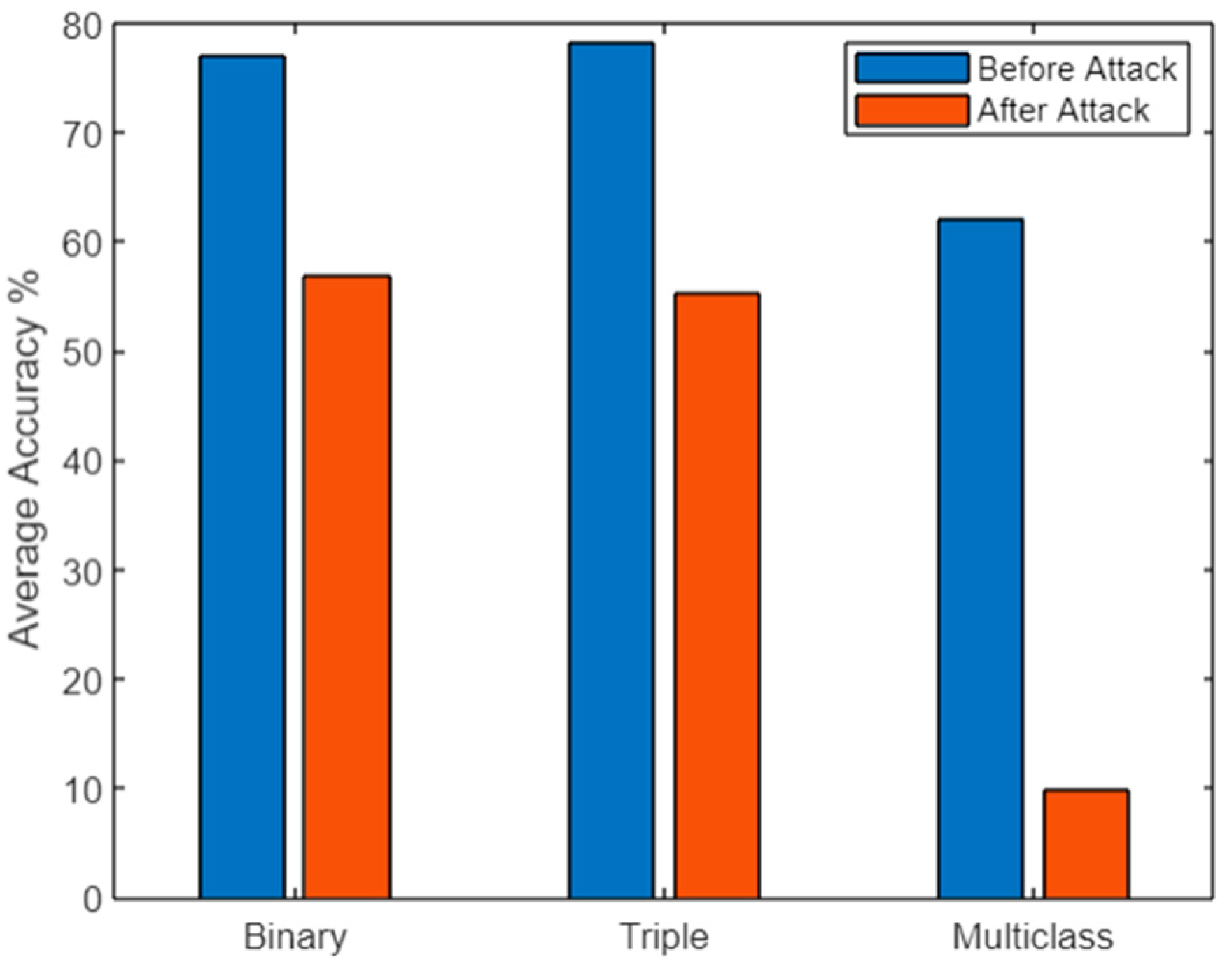
| Triple Class | DeepFool | 78.015 | 76.244 | 75.596 | 78.01 | 59.31 | 56.571 | 53.898 | 59.778 |
| JSMA | 78.215 | 76.487 | 79.064 | 78.222 | 59.768 | 64.333 | 59.583 | 59.778 | |
| FGSM | 78.539 | 76.576 | 76.482 | 78.551 | 46.551 | 59.811 | 50.451 | 46.561 | |
| Multi- Class | DeepFool | 62.974 | 63.534 | 62.805 | 60.983 | 4.638 | 6.944 | 3.551 | 4.6 |
| JSMA | 61.482 | 62.179 | 61.372 | 61.493 | 15.889 | 18.317 | 15.306 | 15.91 | |
| FGSM | 60.974 | 61.579 | 60.771 | 63.983 | 8.914 | 12.097 | 8.883 | 8.926 | |
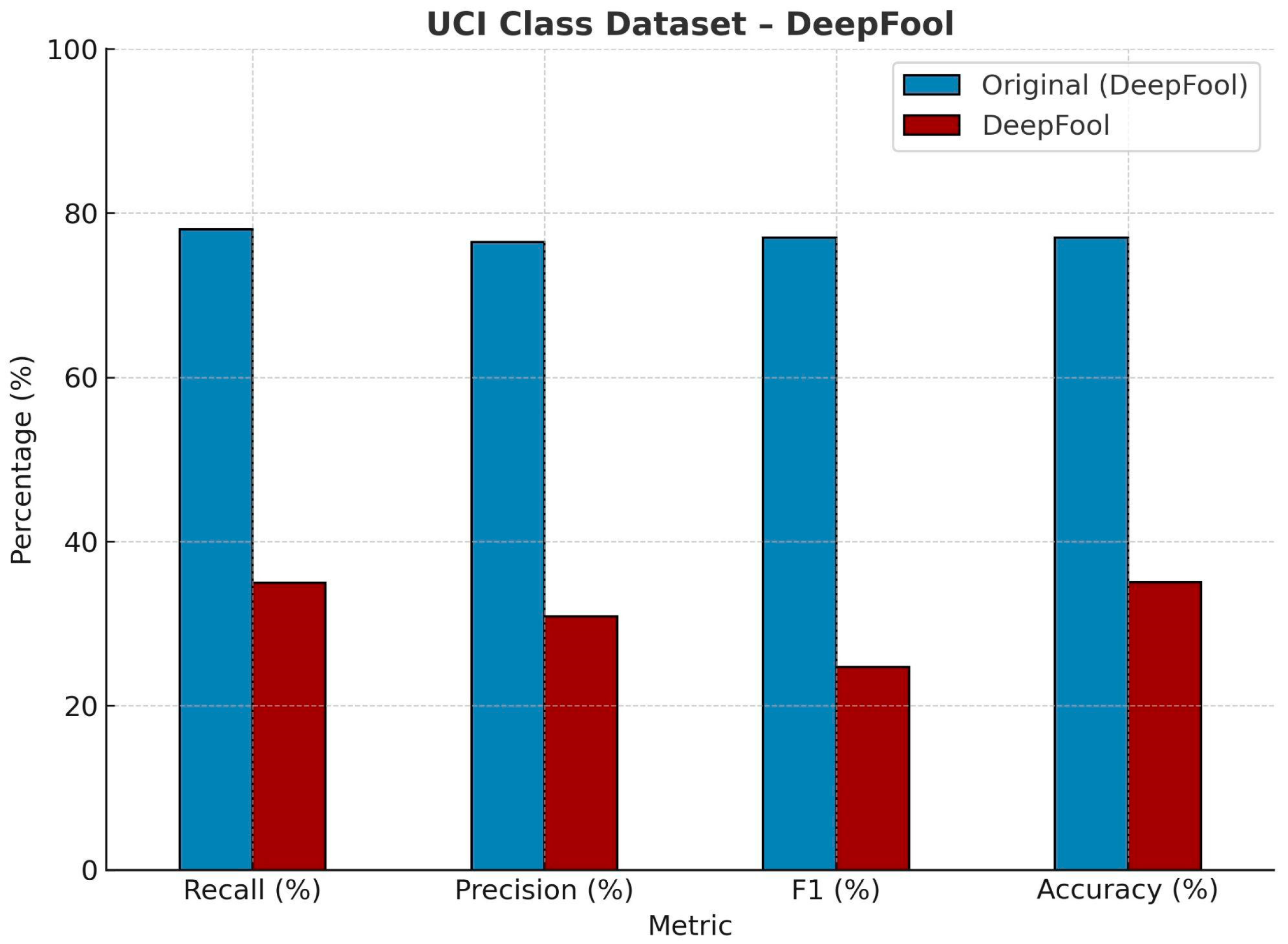
| UCI Class Dataset—DeepFool. | ||||
| Recall (%) | Precision (%) | F1 (%) | Accuracy (%) | |
| Original | 78.58 | 76.59 | 77.57 | 77.85 |
| DeepFool | 34.99 | 30.87 | 24.71 | 35.04 |
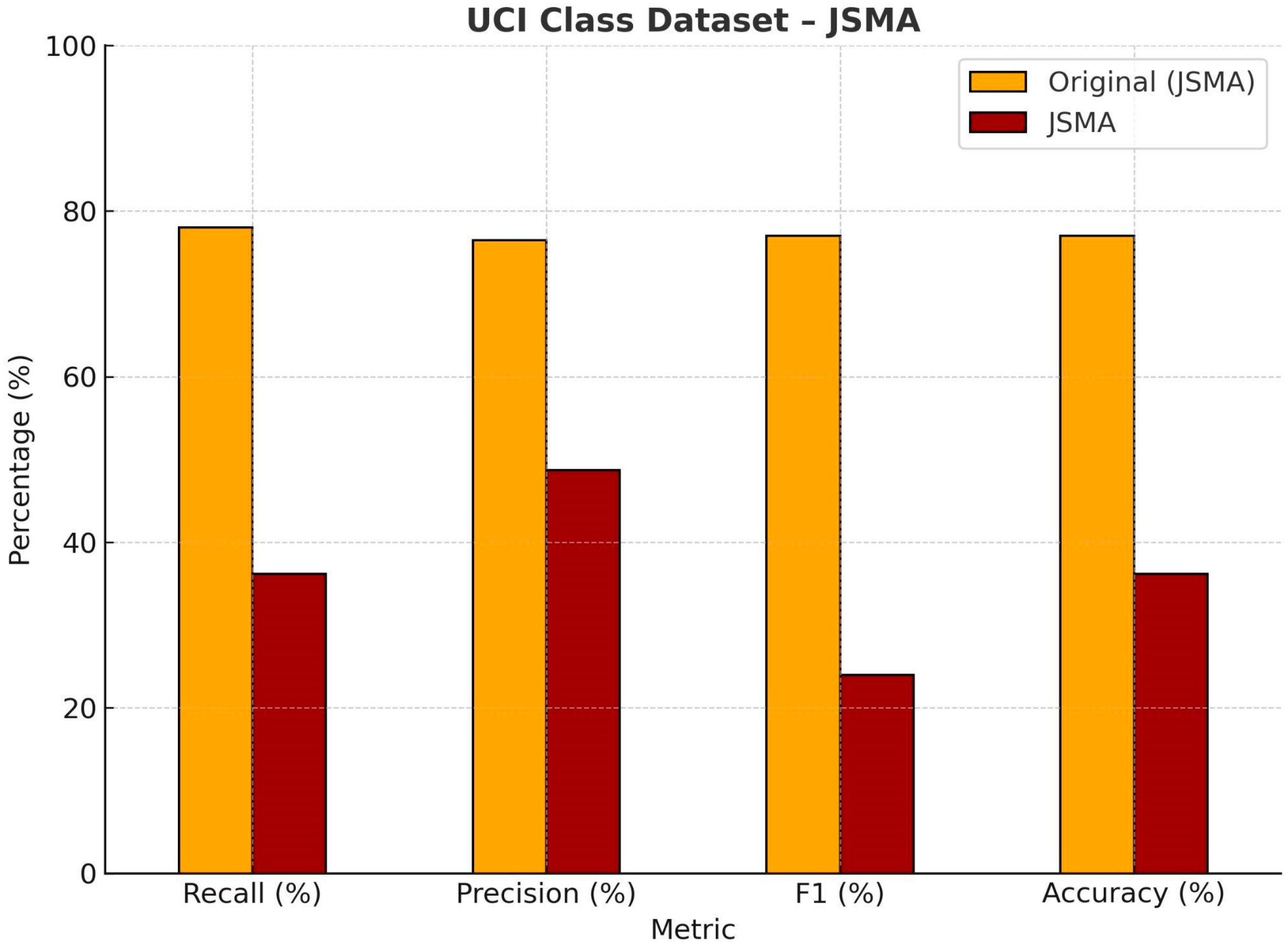
| UCI Class Dataset—JSMA | ||||
| Recall (%) | Precision (%) | F1 (%) | Accuracy (%) | |
| Original | 78.76 | 76.62 | 77.76 | 77.46 |
| JSMA | 36.17 | 48.75 | 24.00 | 36.17 |
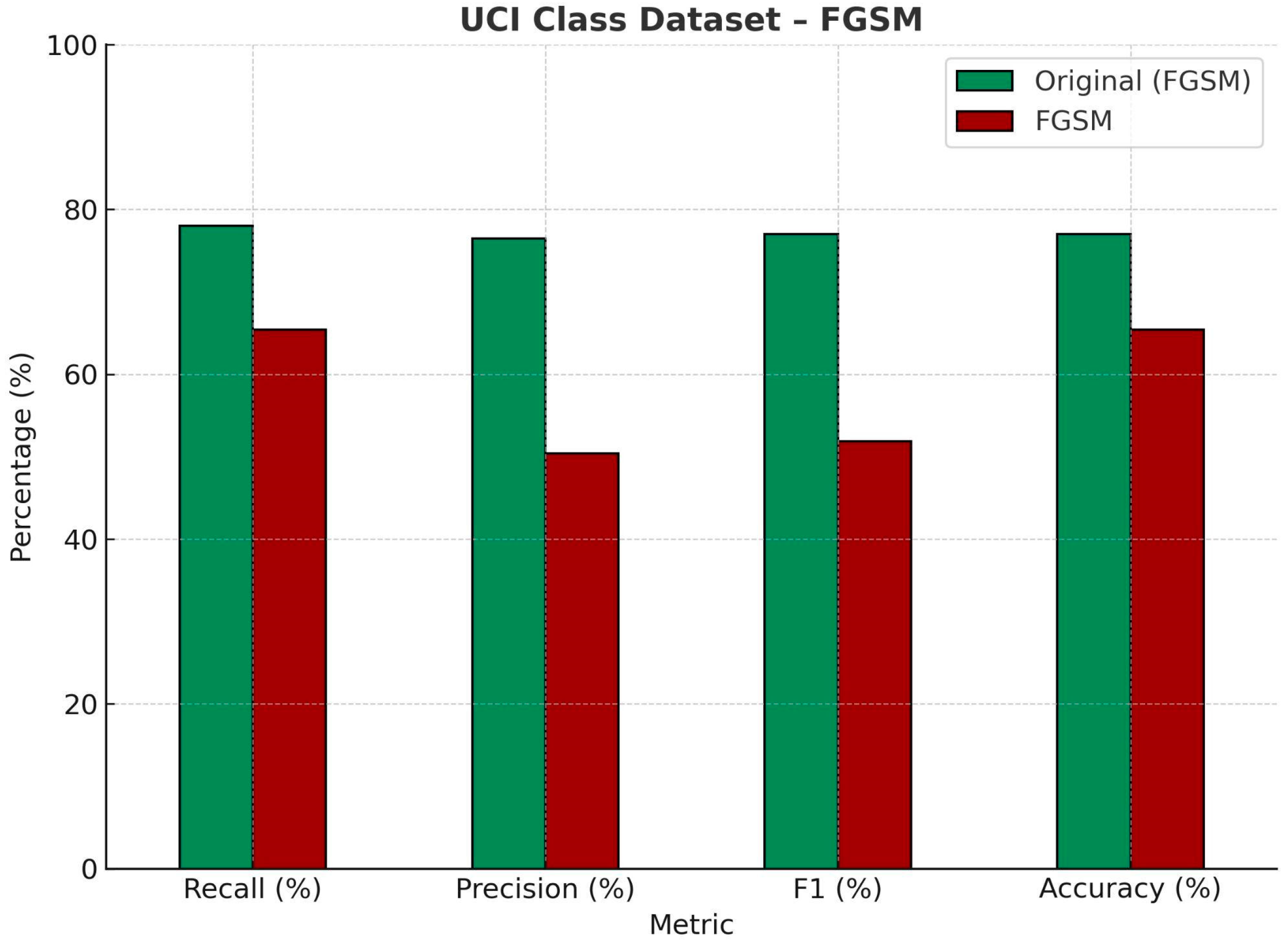
| UCI Class Dataset—FGSM | ||||
| Recall (%) | Precision (%) | F1 (%) | Accuracy (%) | |
| Original | 78.16 | 76.52 | 77.16 | 77.16 |
| FGSM | 65.38 | 50.41 | 51.85 | 65.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicolas, D.; Orozco, K.; Mathew, S.; Wang, Y.; Elmannai, W.; Giakos, G.C. Trustworthiness of Deep Learning Under Adversarial Attacks in Power Systems. Energies 2025, 18, 2611. https://doi.org/10.3390/en18102611
Nicolas D, Orozco K, Mathew S, Wang Y, Elmannai W, Giakos GC. Trustworthiness of Deep Learning Under Adversarial Attacks in Power Systems. Energies. 2025; 18(10):2611. https://doi.org/10.3390/en18102611
Chicago/Turabian StyleNicolas, Dowens, Kevin Orozco, Steve Mathew, Yi Wang, Wafa Elmannai, and George C. Giakos. 2025. "Trustworthiness of Deep Learning Under Adversarial Attacks in Power Systems" Energies 18, no. 10: 2611. https://doi.org/10.3390/en18102611
APA StyleNicolas, D., Orozco, K., Mathew, S., Wang, Y., Elmannai, W., & Giakos, G. C. (2025). Trustworthiness of Deep Learning Under Adversarial Attacks in Power Systems. Energies, 18(10), 2611. https://doi.org/10.3390/en18102611