1. Introduction
In nuclear engineering field, computational modeling software is used to assess the behavior of systems, structures, and components (SCCs) governed by partial differential equations (PDEs) [
1]. Usually, such tools solve the PDE directly with the use of finite element analysis (FEA). FEA breaks SSCs into a finite number of discrete elements and nodes, allowing FEA software to solve the equations efficiently. FEA-based simulations rely on iteratively solving PDEs that correspond to specific physics models. Typically, the analysis of the problem to be investigated needs to be discretized into several timesteps. Increasing the number of timesteps results in a solution with higher resolution in the time domain, but it typically leads to a higher computational cost. FEA uses predictions of the previous step to solve the current status at each iteration. The order of PDEs and the density of the mesh increase can lead to computationally expensive simulations. Reduced-order modeling (ROM) and surrogate models are considered useful methods for this purpose. In order to reduce the dimensionality of high-order models, the ROM approach is the most commonly deployed, while surrogate models are used to substitute FEA.
Traditional ROM, including principal component analysis and proper orthogonal decomposition, are limited by their intrinsic linearity. Consequently, solutions involving artificial intelligence, such as Artificial Neural Networks (ANNs), Convolutional Neural Networks (CNNs) [
2], and Multilayer Perceptrons (MLPs), have proven to be alternative solutions for reducing the dimensionality of non-linear systems in physics [
3,
4,
5]. The rapid development of surrogate models in the AI field can be detected by their capacity to evaluate both linear and non-linear functions that are inherent in their weights.
In the nuclear reactor fuel engineering domain, surrogate models can represent an opportunity to enhance the computational efficiency of simulations, especially when dealing with phenomena like pellet-cladding interaction (PCI) and pellet-cladding mechanical interaction (PCMI). These interactions are mechanistically complex, coupling fuel’s neutronic and thermal behaviors, which are challenging to model with high fidelity, due to the computationally expensive nature of detailed simulations characterized by multiphysics and multiscale domains. There are few studies in the open literature related to surrogate modeling in the nuclear field, especially for fuel performance assessment.
This study [
6] proposes a Long Short-Term Memory Stacked Ensemble (LSTM-SE) surrogate model for predicting the microstructural evolution and mechanical properties of AISI 316L stainless steel fuel cladding under different temperature and radiation dose rates. Precipitation kinetics were modeled with a kinetic Monte Carlo (KMC) approach, and finite element method (FEM) analysis was performed for evaluating the mechanical properties. The surrogate model proved very accurate (error range of ≤6%) and was 1000× faster compared with conventional physics-based simulations.
A surrogate model with ANNs with the purpose of improving the safety of nuclear plants via a systematic study of the response of containment structures under internal pressure was developed in [
7]. A finite element model, validated with experimental data, was used for performing a Sobol sensitivity study with regard to material uncertainty. The study demonstrated the significant role of concrete compressive capacity and the force of prestress, with varying importance for different levels of pressure. The surrogate model, replacing expensive FE simulations, enabled a wider and more effective investigation of uncertainties. An alternative technique in the nuclear domain employed the Improved Lump Mass Stick (I-LMS) model for the AP1000 nuclear power plant (NPP), thus providing improved accuracy when compared against classical Lump Mass Stick (LMS) models [
8]. Through applying the Kriging surrogate model, mass condensation optimization for shear walls was achieved successfully. The I-LMS model reduced the error by frequency from 23.04% to 6.57%, increased the modal assurance criterion (MAC) value, and showed greater accuracy for structural dynamic response when compared against the finite element model (FEM) analysis.
The present study [
9] introduces a hybrid surrogate model-based multi-objective optimization method for designing spherical fuel element (SFE) canisters in high-temperature gas-cooled reactors (HTGRs). A FE method–discrete element method (FEM–DEM) coupled model was developed for drop analysis, identifying key design variables and constraints. A hybrid radial basis function–response surface method (RBF–RSM) surrogate model was employed to approximate the numerical model, and NSGA-II was used for optimization, demonstrating high accuracy and lower computational expense. Surrogate models to update the Bayesian finite element (FE) model in structural health monitoring (SHM) and damage prognosis (DP) are developed in [
10]. A miter gate structural system is analyzed, considering three predominant damage modes. Polynomial chaos expansion (PCE) and Gaussian process regression (GPR) surrogate models are developed and compared with direct FE evaluations. The results show that surrogate-based Bayesian updating achieves sufficient accuracy, while reducing the computational time by approximately 4-fold, demonstrating the feasibility of surrogate models for efficient large-scale structural assessments.
The authors of manuscript [
11] successfully applied surrogate-based approaches to core depletion problems, integrating physics-based models like VERA-CS for improved predictive capability. The algorithm provides ROM, which is then utilized for Bayesian estimation for calibrating the neutronic and thermohydraulic parameters. Based on experimental and operational data, the results demonstrated that ROM could help to decrease uncertainty in key reactor attributes.
Therefore, surrogate models offer a time-efficient alternative for simulating complex physical phenomena such as PCMI [
12], providing quicker results compared to detailed 2D and 3D fuel code software. Both PCI and PCMI still remain key challenges in the nuclear domain. These phenomena, first observed in water-cooled reactors in the 1960s, have been studied extensively to understand and evaluate their effects on Zircaloy cladding [
13]. Fission gas release, involving low-solubility gases, such as Xenon and Krypton, produced during fission, also plays a key role in fuel design. If these gases remain in the fuel pellet, they promote swelling that intensifies mechanical interaction with the cladding. On the other hand, if released into the gas gap, their relatively low thermal conductivity can increase the fuel temperature and possibly lead to cladding cracking. These phenomena are inherently complex and difficult to model, due to their coupling with both neutronic and thermal behavior. Consequently, fuel performance codes depend significantly on the accuracy of their PCMI modeling [
14].
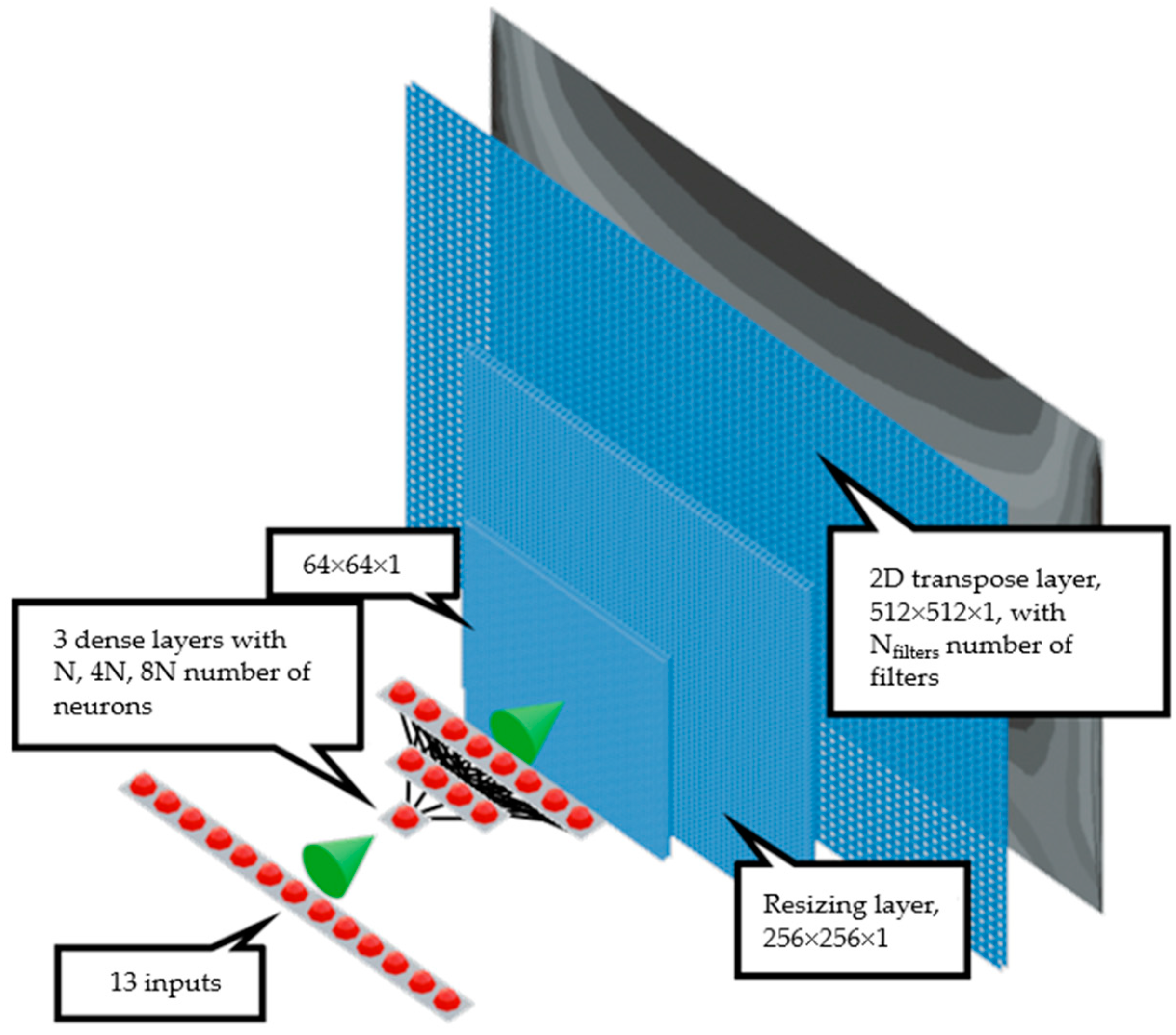
Therefore, surrogate models approximate the outcomes of computationally expensive simulations, significantly reducing the required computational time and resources. By employing surrogate models, it is possible to achieve a balance between accuracy and efficiency; they are particularly useful in scenarios where full-scale simulations are excessively expensive. To this end, a surrogate model based on CNNs is proposed to investigate the thermomechanical behavior of a PWR fuel pellet. The results show impressive cost-saving in terms of computational time compared to FE analysis. The surrogate model, once trained, predicts the stress field in less than 1 s, which is much faster compared to full FE analysis, which needs about 17 s (wall time).
3. Results
3.1. Quantitative Evaluation: Mean Squared Error (MSE)
To quantify the model’s performance, the Mean Squared Error (MSE) [
28] between the real and predicted output matrices was calculated. The MSE was computed for each prediction type (displacement, von Mises stress, creep strain), providing an overall measure of the model’s accuracy.
The average MSE for each prediction type is shown in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7. These tables show the results obtained via 5-fold validation for a selection of neurons and filters. In the tables, N is the number of neurons and N
filters is the number of filters. The green shading highlights the best-performing configurations, while the red shading indicates the worst-performing one.
The best setups were used as the final models.
As shown in
Table 2,
Table 4 and
Table 6, models with fewer neurons outperformed those with a higher number of neurons in the present study. While it is possible that more complex models could eventually surpass the simpler ones with extended training time, this approach is not currently feasible, due to computational constraints and time limitations.
Moreover, the ability of lighter models to predict quickly and accurately is highly advantageous, especially in real-time applications, where speed and efficiency are critical. These models provide a practical balance between performance and resource utilization, making them suitable for deployment in various scenarios.
On the other hand,
Table 3,
Table 5 and
Table 7 highlight the importance of finding the right balance between the number of neurons and filters. This balance is crucial for optimizing model performance, as it ensures that the model is neither too simple to capture the necessary patterns, nor too complex to train efficiently within reasonable timeframes.
A larger dataset can improve CNN performance. However, it must be pointed out that additional data could significantly alter the best-performing setups. Depending on whether the new data are simpler or more complex, the optimal configurations of neurons and filters might change accordingly.
3.2. Comparison of Real and Predicted Outputs
The model’s performance was first evaluated by comparing the predicted output matrices (creep strain, displacement, and von Mises stress) with the actual ground truth data. Visual comparisons of the real and predicted images were made for several test samples, highlighting the model’s ability to accurately predict spatial variations in mechanical properties.
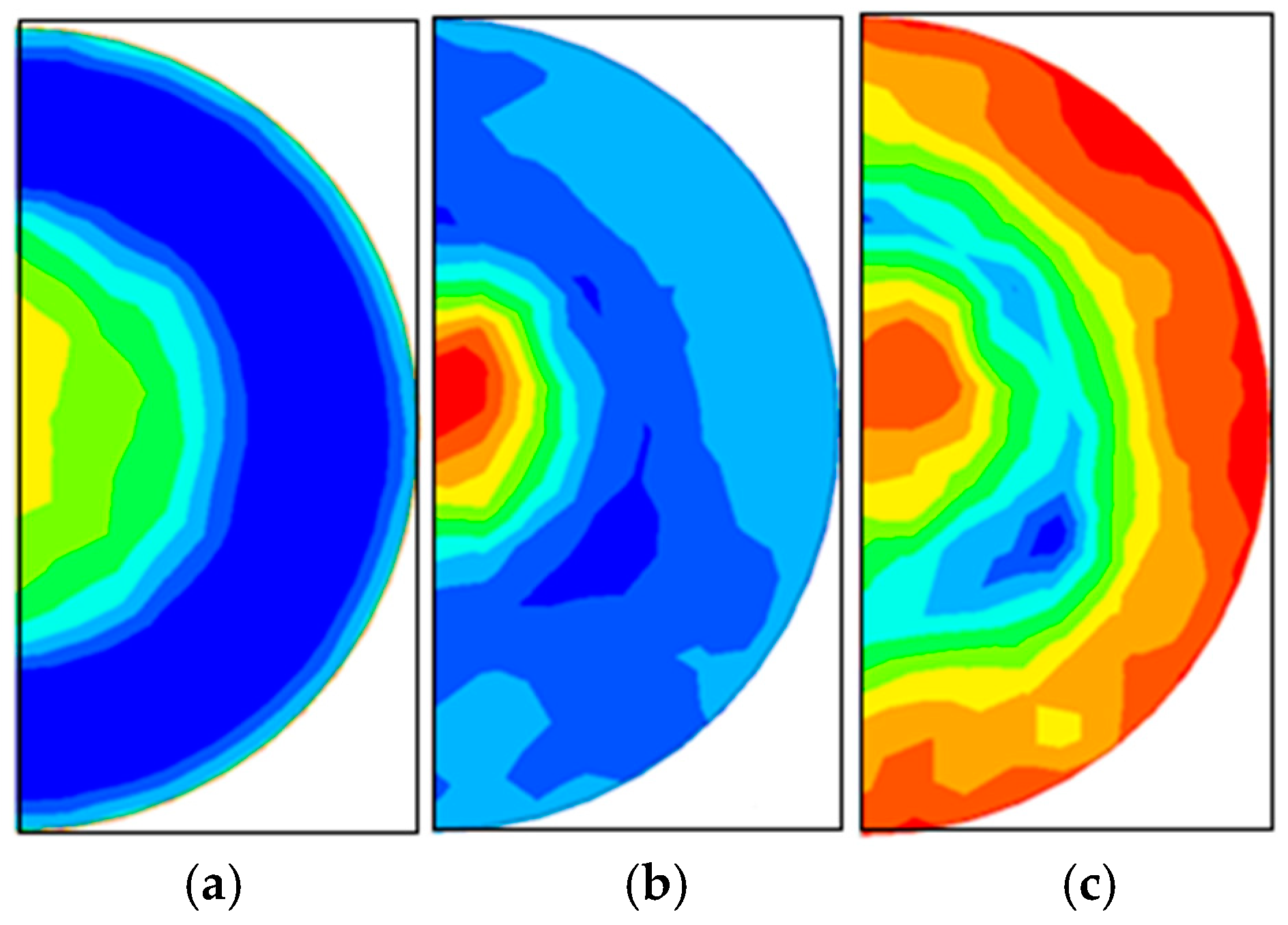
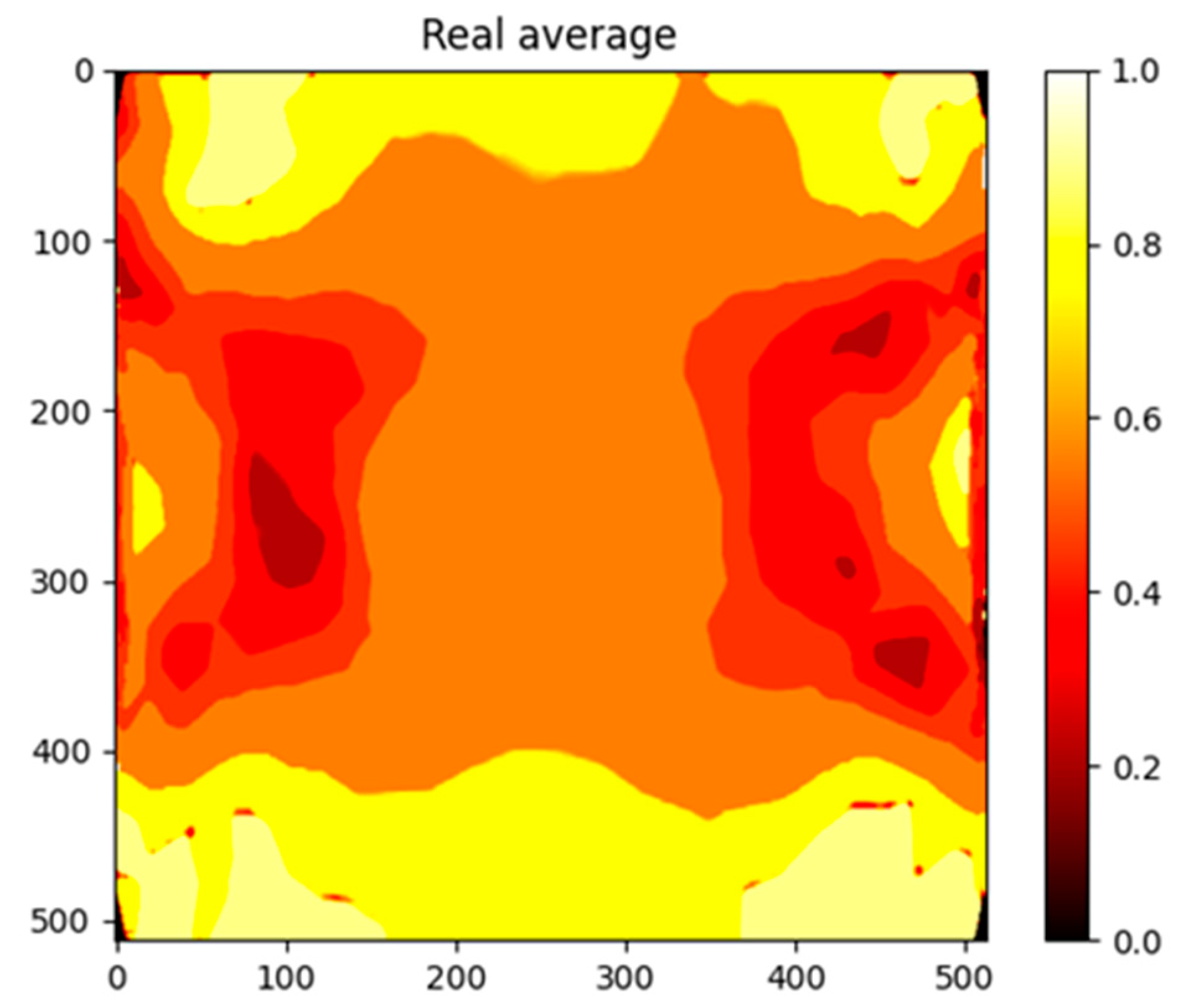
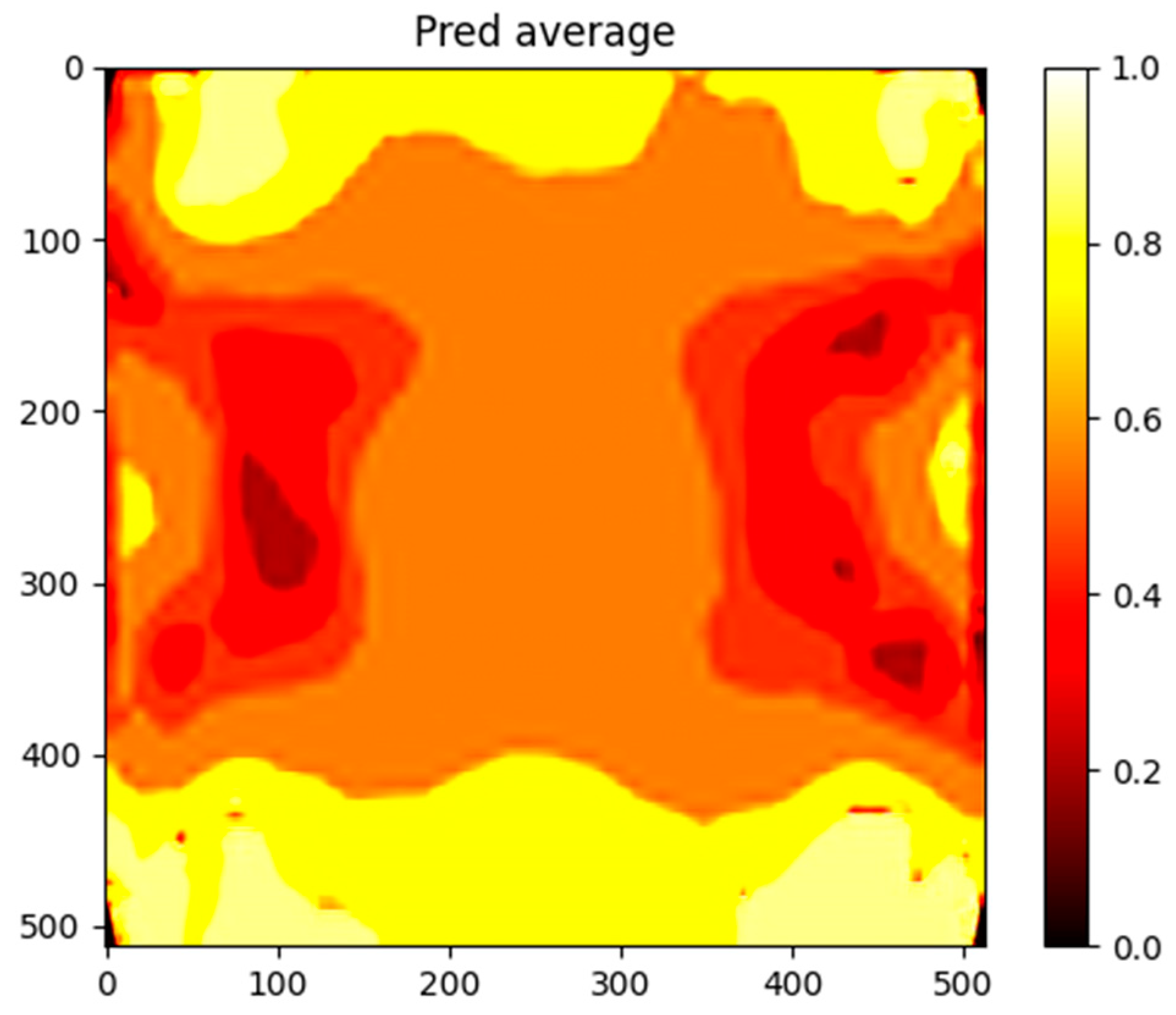
Figure 5 and
Figure 6 show the real and predicted images for a sample from the test set. The predicted images closely resemble the actual patterns, demonstrating the model’s ability to capture the complex spatial relationships between input features and the target outputs.
3.3. Visualizing Error Distributions
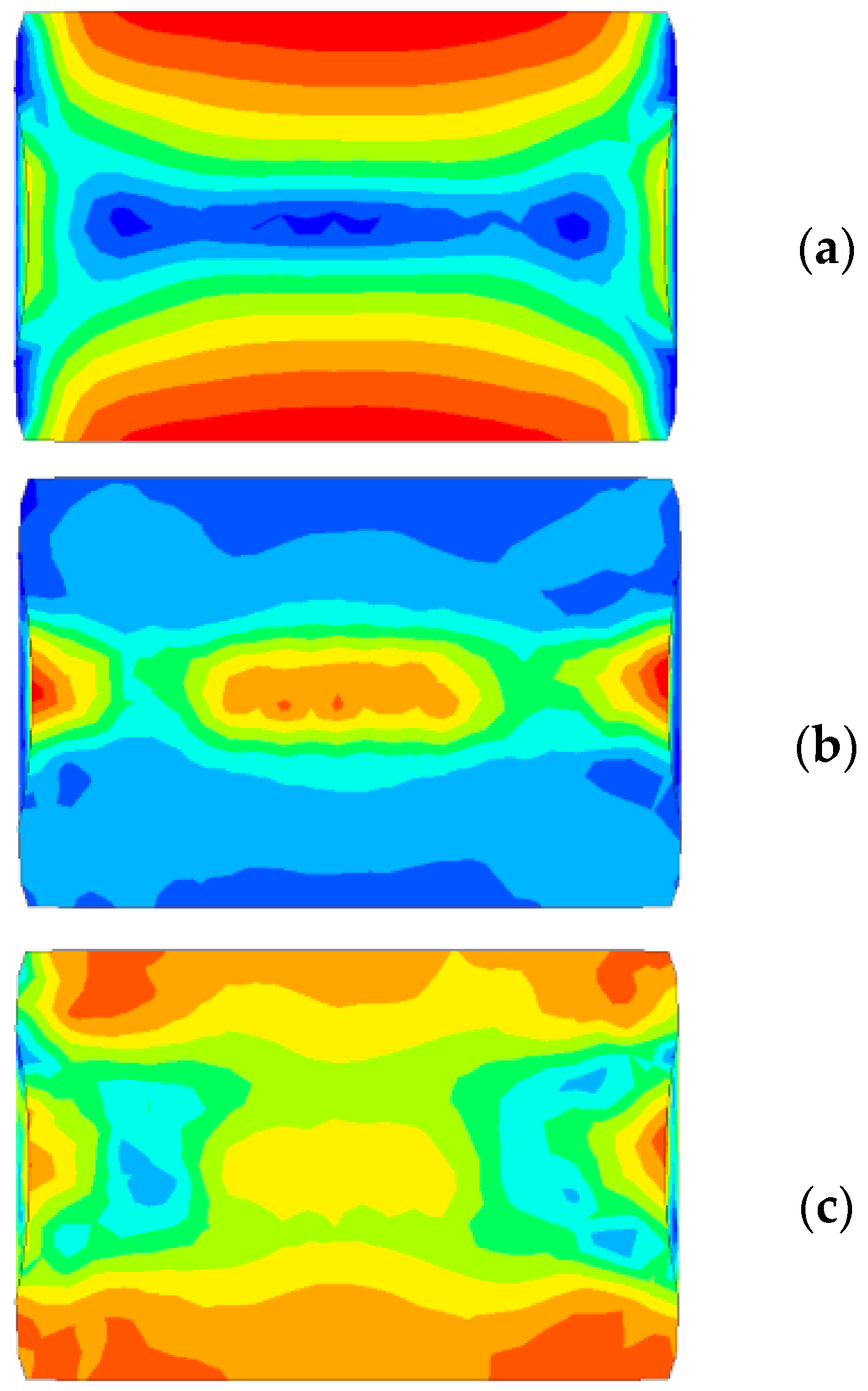
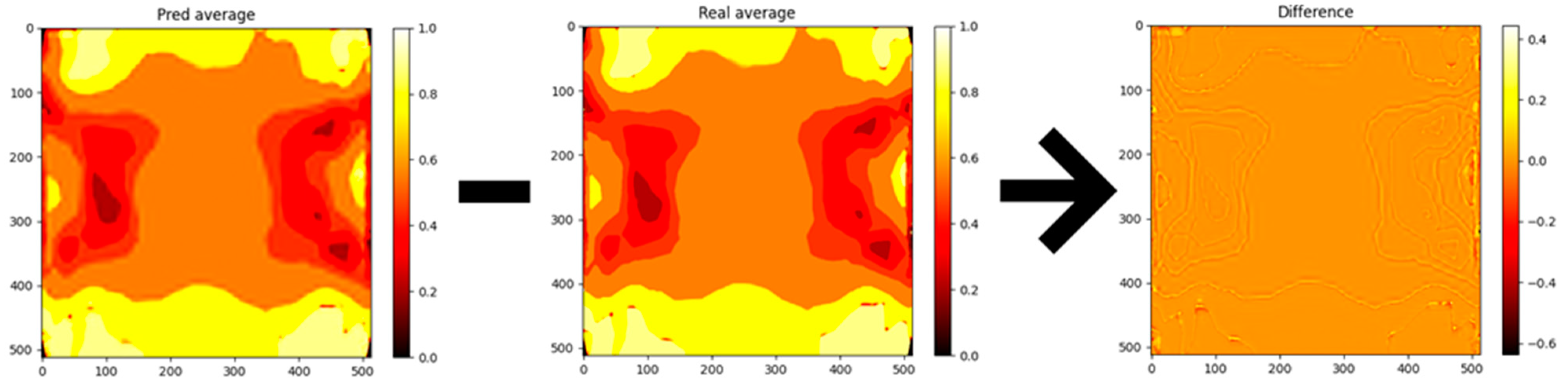
To further analyze the model’s performance, error distribution heatmaps were generated for the predicted outputs. These heatmaps, shown in
Figure 7, visualize the absolute error between the predicted and real values for each pixel in the 512 × 512 output matrices. The heatmaps provide insights into which regions of the material exhibit higher prediction errors. However, as can be seen from the figure, errors only appear when the proposed CNN model gives smoothed predictions. The reason for this is that Mentat images can average regions; therefore, networks learn to slightly smooth these regions, turning discrete values into a continuous scale. Nevertheless, we believe that a continuous values approach has benefits, as it allows for the identification of areas with maximum and minimum values.
3.4. Speed Evaluation
High-fidelity nuclear fuel codes are essential for modeling complex phenomena such as PCI and PCMI, but they are often computationally intensive, due to their reliance on finite element methods and multiphysics coupling. Surrogate models, including Convolutional Neural Network (CNN)-based approaches, provide a fast and accurate alternative by approximating detailed simulations, enabling efficient analysis for tasks such as optimization, uncertainty quantification, and design evaluation. The proposed CNN approach is much faster than FE code, and is on par with some of the fastest available methods. It must be mentioned that speed depends on the selected prediction strategy, as loading models sometimes takes much longer than the prediction process itself. Therefore, the more images generated in a single session, the more significant the advantage in generation speed between our proposed model and Mentat. Once trained, the surrogate model can predict the stress field in less than 1 s, whereas the finite element (FE) analysis takes approximately 17 s.
Table 8 and
Table 9 summarize the configuration and timing information for FE analysis and surrogate analysis.
3.5. Limitations
Currently, the implemented program is still in early development and has limitations. For now, the edges of the mesh (white fields on Mentat images) are converted to global minimum values; for this reason, the user must manually identify which areas are not part of the mesh. While Convolutional Neural Networks are inherently capable of training on a wide range of image-based data, the current model’s performance is constrained by the size and diversity of the available training dataset. The CNN demonstrated strong predictive accuracy for the specific simulation cases it was trained on. However, its generalization capability remains limited when applied to unseen scenarios with different geometries or boundary conditions. As more complex, varied, and representative simulation data become available, the model’s ability to generalize and accurately predict across a broader range of conditions is expected to improve. Notably, the inclusion of such diverse data in the training process would enable the CNN to effectively learn and replicate behavior under a wider spectrum of operational conditions.
3.6. HPC Training Acceleration
High-Performance Computing (HPC) refers to the use of powerful computing resources to solve complex problems that require significant processing power [
28,
29,
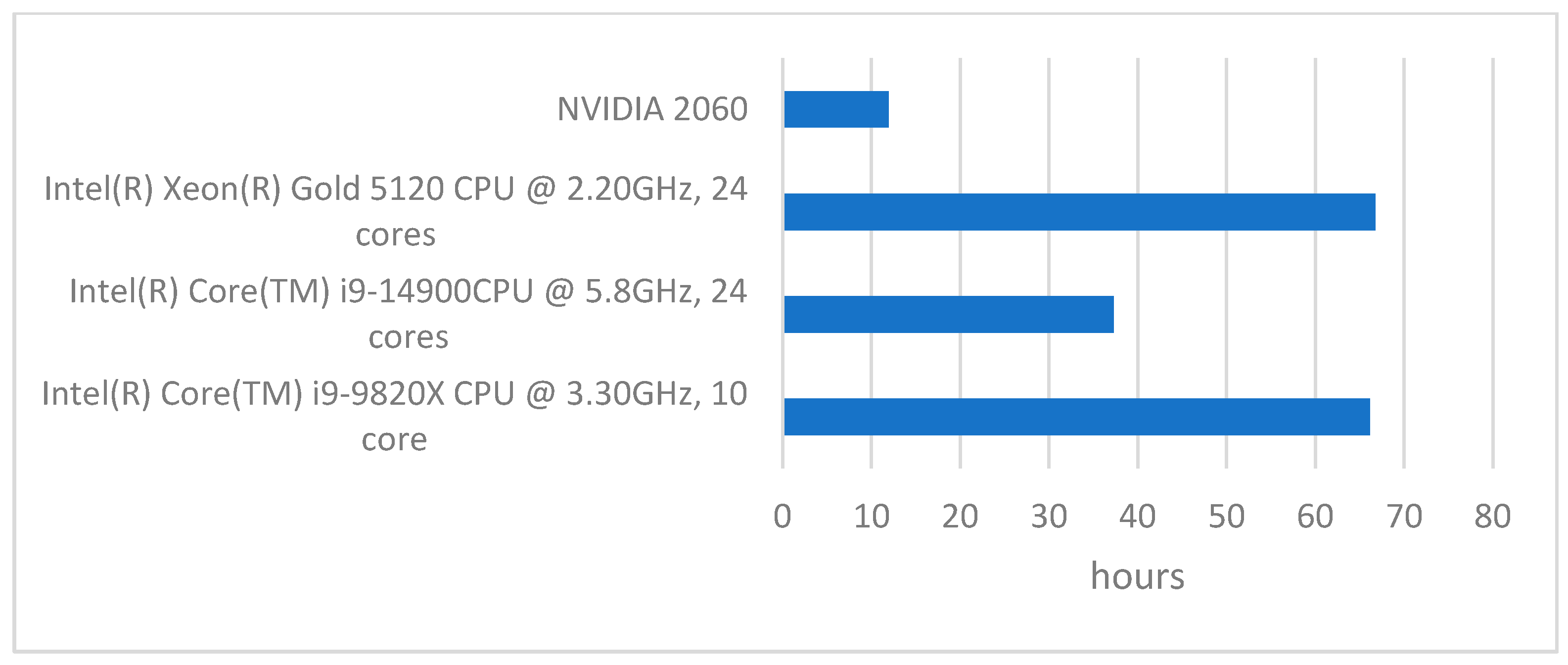
30]. HPC systems leverage parallel computing, high-speed networks, and optimized hardware architectures to perform large-scale simulations, deep learning tasks, and scientific computations efficiently. To this end, a benchmarking study was conducted to highlight the importance of HPC for future AI-training processes. The CNN model was developed on an i9 with 24 cores, an i9 with 10 cores, a Xeon Gold with 24 cores, and an NVIDIA 2060 GPU (TSMC, Taiwan).
The benchmarking results show a clear advantage of using a GPU for CNN-based FEM surrogate modeling. The NVIDIA 2060 completed the task in just 11.95 h, significantly outperforming all tested CPUs. This was expected, as GPUs are designed for parallel computation, making them highly efficient for deep learning workloads. Among the CPUs, the Intel Core i9-14900 delivered the best performance, finishing the task in 37.32 h. Its combination of 24 cores and a high clock speed of 5.8 GHz allows it to process data much faster than the other processors. In contrast, the Intel Xeon Gold 5120 (Intel Corporate, USA), despite having the same number of cores (24), performed almost twice as slowly, taking 66.79 h.
This is due to its lower clock speed of 2.20 GHz, which limits its ability to process tasks quickly, despite the high core count. The Intel Core i9-9820X, with 10 cores and a clock speed of 3.30 GHz, performed similarly to the Xeon Gold 5120, taking 66.15 h to complete the task. This suggests that while more cores can improve calculations, clock speed plays a crucial role in overall performance, especially for deep learning workloads that require fast data processing. Overall, these results highlight the importance of using GPUs for CNN-based simulations, as even a mid-range GPU like the NVIDIA 2060 far surpasses high-end CPUs in efficiency. If a GPU is not available, a CPU with a higher clock speed, like the i9-14900, is the best alternative. However, for large-scale computation, relying on CPU processing alone would result in significantly longer execution times. The results are summarized in
Figure 8.
4. Conclusions
This study has successfully demonstrated the potential of Convolutional Neural Network (CNN) surrogate models to significantly enhance the computational efficiency of finite element analyses in the nuclear fuel domain. By integrating advanced AI techniques, this study effectively reduced the computational time required for high-fidelity simulations by several orders of magnitude. The main results are as follows:
The CNN model achieves a simulation speed that is approximately 17 times faster than traditional finite element analysis (FEA), reducing the computation time from 17 s per simulation to about 1 s.
The CNN model maintains low Mean Squared Error (MSE) rates: the MSE for von Mises stress predictions in the best-performing setups was as low as 0.000678, indicating a high level of accuracy
The integration of High-Performance Computing (HPC) was crucial for managing the extensive computation required for training and deploying the CNN models: the NVIDIA 2060 GPU completed the training tasks in just 11.95 h, a substantial improvement over the Intel Core i9-9820X CPU, which took approximately 66.15 h for the same tasks.
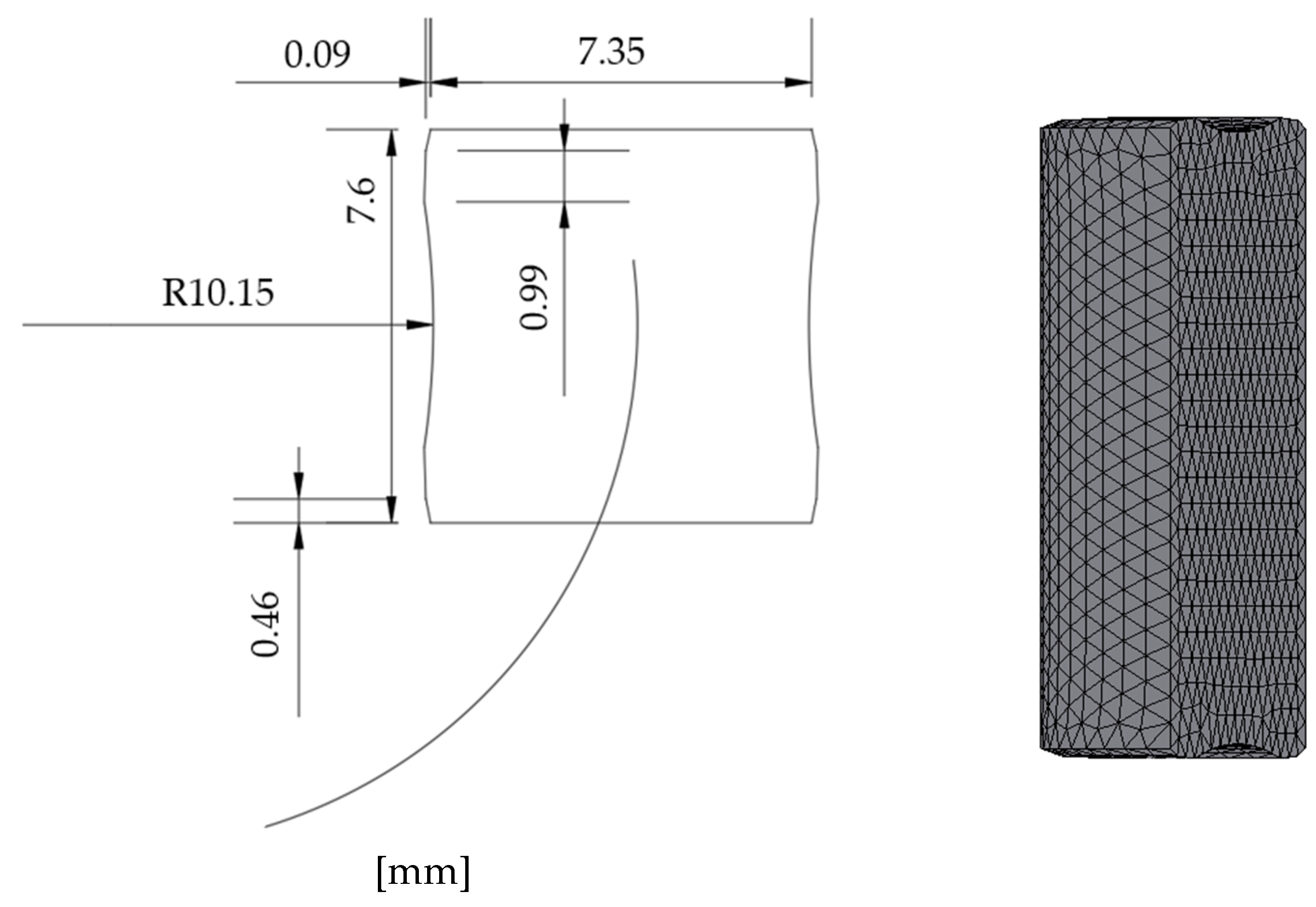
Even though the code developed shows good performance, improvements still need to be made. Currently, it is still in early development and has limitations. At this development stage, it only takes pressure as changing input. Also, the edges of the mesh (white fields in
Figure 2) are converted to global minimum values, and for this reason, the user must manually identify which areas are not part of the mesh.
In the future, continuous development efforts are required to refine this model. This includes enhancing the model’s capability to automatically recognize and interpret complex geometries and conditions within the simulation environment. By overcoming these challenges, the model can be fully integrated into the operational frameworks of NPPs, ensuring effective deployment in real-world scenarios.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}