3.1. Data Description
This section uses data from one company for the case study. This dataset has ‘Minimum Horizontal Stress’, ‘Maximum Horizontal Stress’, ‘Max Horizontal—Min Horizontal’, ‘Vertical Stress’, ‘Vertical—Min Horizontal’, ‘Elasticity Modulus’, ‘Poisson’s Ratio’, ‘Fracturing Fluid Viscosity’, ‘Flow Rate’, and 9 fracability influencing factors. At the same time, there are ‘Total Fracture Area’, ‘Natural Fracture Area’, ‘Main Fracture Area’, ‘Ratio Of Natural Fracture To Main Fracture Area’, ‘Main Fracture Width’, ‘Main Fracture Length’, and ‘Main Fracture Height’.
The dataset has a total of 800 sets of data samples, and the division ratio of training set, validation set, and test set is 6:2:2. In order to reduce the overfitting problem, we introduced an early stopping mechanism based on the validation set data.
3.3. Analysis of Impact Factors
- (1)
Scenario 1: The Total Crack Area
For example, in
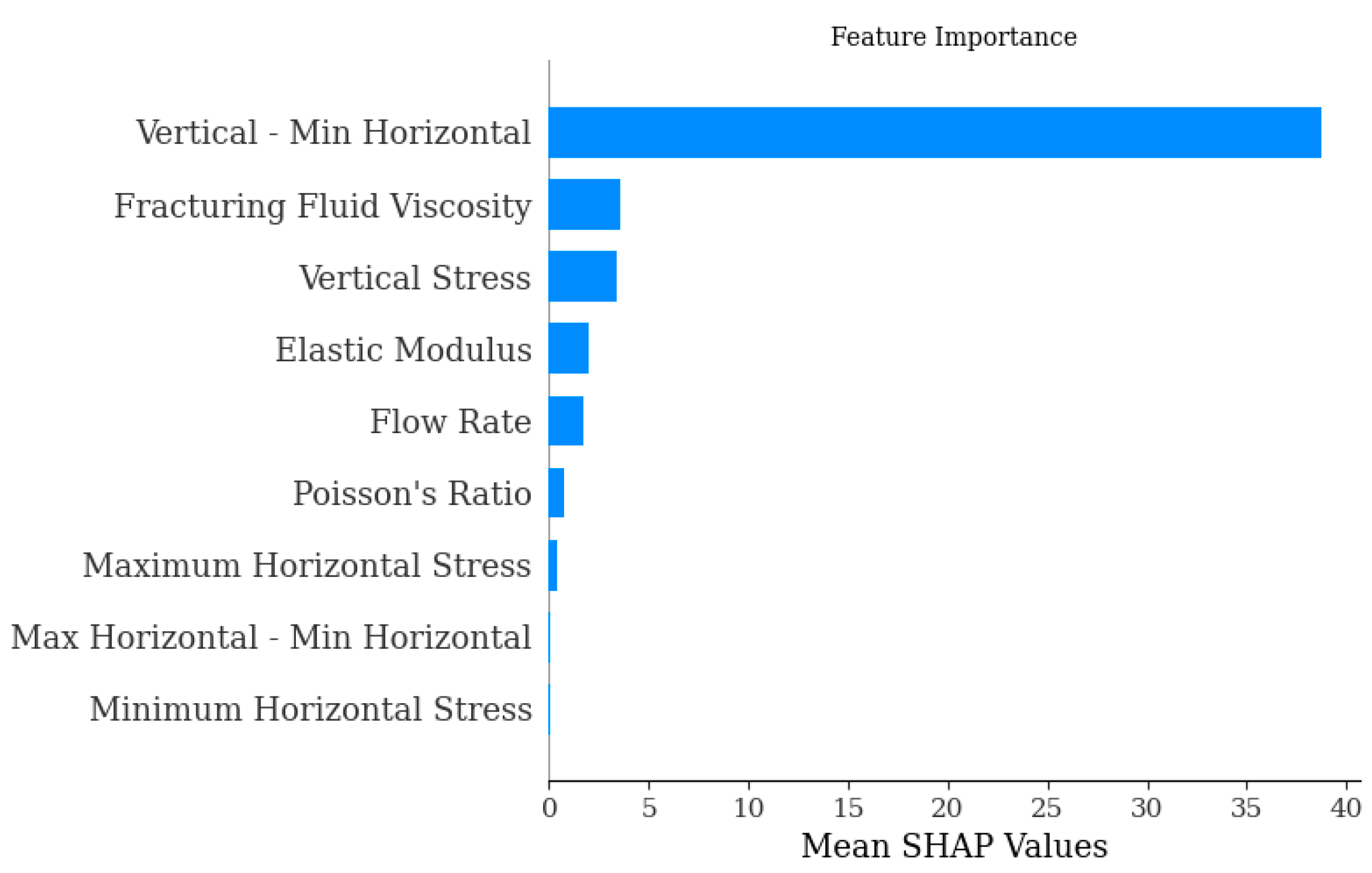
Figure 1, the importance of each feature decreases downward along the vertical axis. In
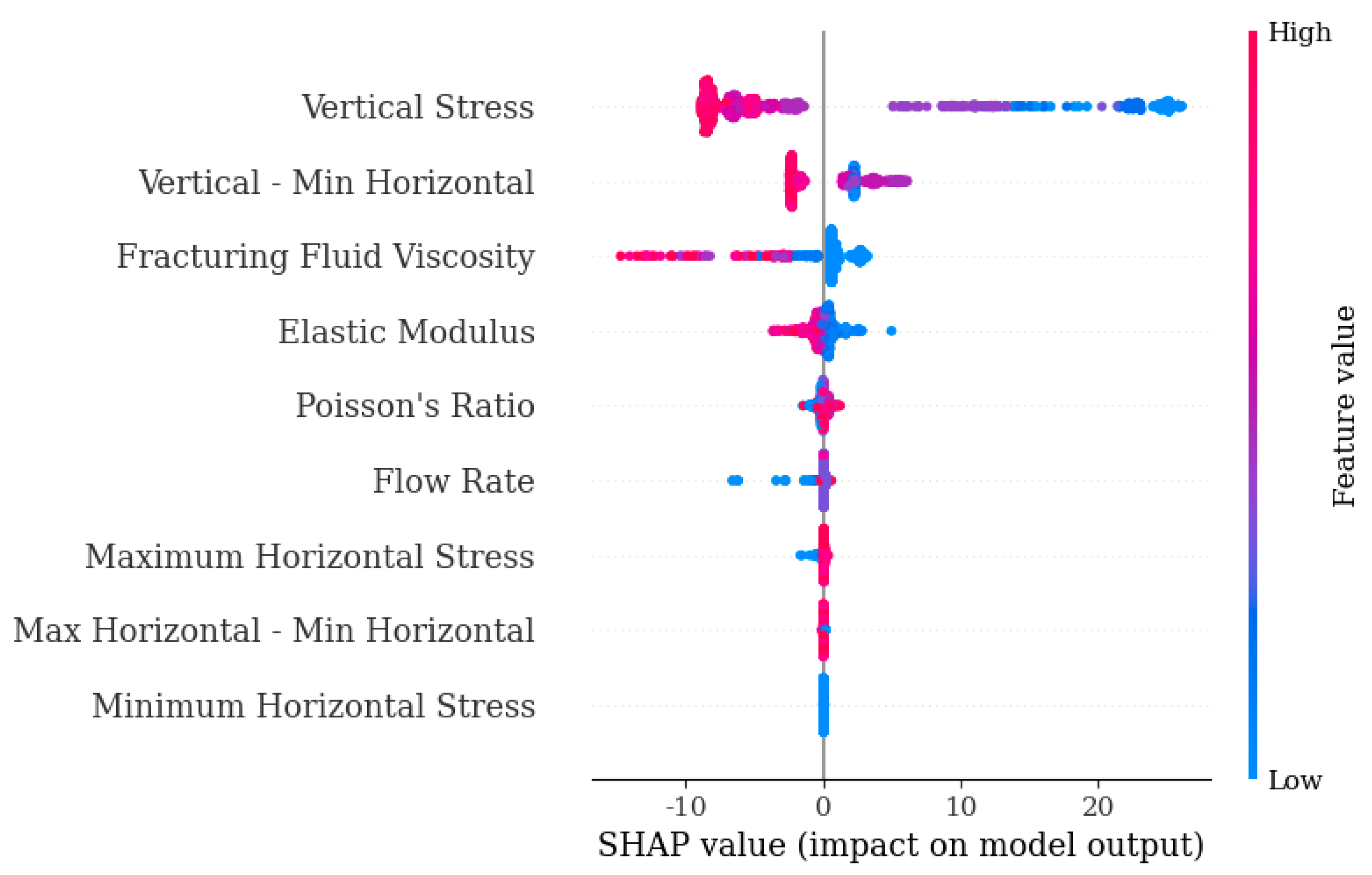
Figure 2, the importance of features on the left side of the Summary diagram decreases from top to bottom, and the order of importance in
Figure 2 is consistent with that in the
Figure 1. The larger the value of a feature on the right side of the figure, the redder the colour. The Dependence diagram in
Figure 3 mainly reflects the relationship between a certain feature and its SHAP value, showing the trend of change in the SHAP value as the feature value changes.
The analysis of
Figure 1 and
Figure 2 shows that the “Vertical—Min Horizontal”, i.e., the difference between the Vertical Stress and the horizontal minimum stress, has the greatest influence on the total crack area and far exceeds the influence of the other features on the prediction results. Therefore, the “Vertical—Min Horizontal” feature is analysed separately.
Next, we analyse ‘Vertical—Min Horizontal’. Looking at
Figure 2, we can see that the larger SHAP values of this influence factor are mostly distributed in the negative direction. This phenomenon indicates that the influence factor is more likely to be negative in this scenario. However, there are cases where the factor has a smaller value when the SHAP value is negative, and similarly when the SHAP value is positive. This result shows that there is a threshold value that shifts the positive and negative influence of the factor.
As shown in
Figure 3, the SHAP value changes significantly when ‘Vertical—Min Horizontal’ is 5. When the value is greater than 5, the SHAP value is negative, which means that when the eigenvalue is greater than 5, the factor has a negative effect on the total crack area. When the eigenvalue is less than 5, it is a positive influence.
- (2)
Scenario 2: The Area of Natural Cracks
The analysis of
Figure 4 and
Figure 5 shows that the “Vertical—Min Horizontal”, i.e., the difference between the Vertical Stress and the horizontal minimum stress, has the greatest influence on the natural crack area and far exceeds the influence of the other features on the prediction results. Therefore, the “Vertical—Min Horizontal” feature is analysed separately.
Next, we analyse ‘Vertical—Min Horizontal’. Looking at
Figure 5, we can see that the larger SHAP values of this influence factor are mostly distributed in the negative direction. This phenomenon suggests that the influence factor is more likely to be negative in this scenario. However, there are also cases where the factor has a small value when the SHAP is negative, and a similar phenomenon exists when the SHAP is positive. This result shows that there is a threshold value that shifts the positive and negative influence of the factor.
As shown in
Figure 6, the SHAP value changes significantly to positive and negative values at a value of 5 for this factor. When the value of this factor is greater than 5, the SHAP value becomes negative. This phenomenon illustrates that the factor has a positive effect when the eigenvalue is less than 5 and a negative effect when the eigenvalue is greater than 5.
- (3)
Scenario 3: The Main Crack Area
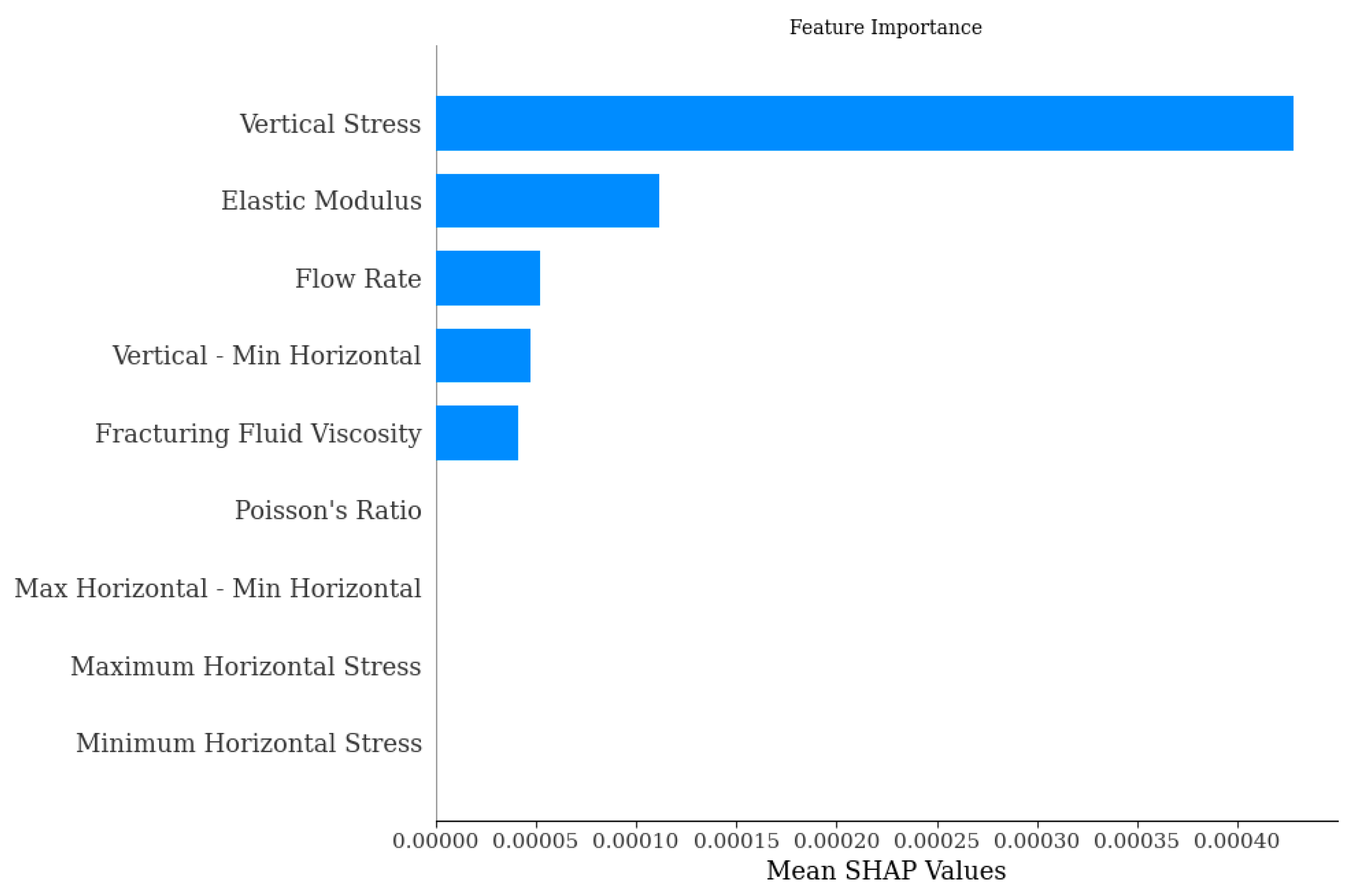
The analysis of
Figure 7 shows that the “Vertical—Min Horizontal”, i.e., the difference between the Vertical Stress and the horizontal minimum stress, has the greatest impact on the predicted results. Second, the Vertical Stress also has a large impact on the predicted results, so these two features are analysed separately.
Next we analyse ‘Vertical—Min Horizontal’. Looking at
Figure 8, we can see that the larger SHAP values of this influence factor are mostly distributed in the positive direction. This phenomenon suggests that the influence factor is more likely to be positive in this scenario. However, there are also cases where the factor has a small value when SHAP is positive, and a similar phenomenon exists when SHAP is positive. This result suggests that there is a threshold where the positive and negative impacts of the factor shift. Observe the similarity between ‘Vertical Stress’ and ‘Vertical—Min Horizontal’.
We further analyse the critical phenomenon of the factor ‘Vertical—Min Horizontal’. As shown in
Figure 9, the SHAP value changes significantly at a value of 5 for this factor. This result shows that there is a negative effect when the factor is less than 5 and a positive effect when the value is more than 5.
As shown in
Figure 10, ‘Vertical—Min Horizontal’, there is a clear distinction between positive and negative SHAP values at 75, with 75 being the critical value for this factor.
- (4)
Scenario 4: The Ratio of Natural Crack To Main Crack Area
As can be seen in
Figure 11, the Vertical Stresses have the greatest impact on the predicted results. Therefore, the effect of Vertical Stress on the prediction of “natural crack/main crack area ratio” is analysed separately.
Next, we analyse ‘Vertical Stress’. Looking at
Figure 12, we can see that the larger SHAP values of this factor are mostly distributed in the negative direction. This result indicates that the influence factor is more likely to be negative in this scenario.
The critical value of ‘Vertical Stress’ is analysed in
Figure 13. It can be seen from the figure that the value of this influence factor changes significantly at 70. That is, when the value is greater than 70, it has a negative impact in this scenario, and when it is less than 70, it has a positive impact.
- (5)
Scenario 5: The Main Crack Widths
The analysis of
Figure 14 shows that Vertical Stress and modulus of elasticity have a greater influence on the width of the main crack, and these two characteristics are analysed separately.
Looking at
Figure 15, we can conclude that the SHAP values with larger values of this influence factor are mostly distributed in the positive direction. This phenomenon indicates that the influence of this factor is more likely to be positive in the predicting of main crack widths. For ‘Elastic Modulus’, the pattern is opposite to that of ‘Vertical Stress’.
As shown in
Figure 16 and
Figure 17, the SHAP value changes significantly at a value of 70 for ‘Vertical Stress’ and 25 for ‘Elastic Modulus’. This phenomenon indicates that the critical points of ‘Vertical Stress’ and ‘Elastic Modulus’ are 70 and 25, respectively.
- (6)
Scenario 6: The Length of Main Cracks
The analysis of
Figure 18 shows that the Vertical Stresses have the greatest influence on the predicted results and far outweigh the other features. Therefore, the Vertical Stresses are analysed separately.
Next, we analyse ‘Vertical Stress’. Looking at
Figure 19, we can see that the SHAP values of this factor are mostly distributed in the positive direction. This phenomenon suggests that the influence factor is more likely to be positive in this scenario. However, there are also cases where the factor has a small value when the SHAP is positive, and similarly when the SHAP is negative. This result suggests that there is a threshold value that shifts the positive and negative influence of the factor.
As shown in
Figure 20, the SHAP value changes significantly at ‘Vertical Stress’ 70. When the value is greater than 70, the influence factor has a negative influence, and when the characteristic value is less than 70, it has a positive influence.
- (7)
Scenario 7: The Height of Main Crack
The analysis of
Figure 21 shows that the “Vertical—Min Horizontal” has the greatest impact on the prediction results and far outweighs the other features. Therefore, “Vertical—Min Horizontal” is analysed separately.
Next, we analyse ‘Vertical—Min Horizontal’. Looking at
Figure 22, we can see that the larger SHAP values of this influence factor are mostly distributed in the positive direction. This phenomenon indicates that the influence factor is more likely to be positive in this scenario.
The influence of ‘Vertical—Min Horizontal’ on this scenario is further analysed. As shown in
Figure 23, the positive and negative influences shift when the value of this influence is 5.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}