1. Introduction
Wind power is a crucial component of renewable energy sources, representing one of the most viable alternatives to traditional fossil fuels thanks to its eco-friendly properties. This can contribute to decreasing reliance on fossil fuels and mitigating environmental pollution [
1]. The Global Wind Energy Council has documented a significant rise in worldwide wind energy capacity, reaching 906 Gigawatt (GW), which represents an annual increase of 9%. The year 2023 was expected to be a milestone, with projections indicating that it would be the inaugural year to witness the addition of more than 100 GW of new capacity across the globe. Their estimates also predict a remarkable expansion of 1221 GW in new capacity from 2023 to 2030 [
2]. Accurate predictions of wind speed are essential for the effective management of wind energy generation [
3]. Generally, precise forecasts of wind speed can enhance the efficiency of wind resource utilization and reduce the effects of wind energy variability on the stability of the electrical grid, facilitating cost-effective and efficient wind farm operations [
4]. Therefore, the importance of accurate wind-speed forecasting is growing in terms of reducing the costs and risks linked to power supply systems [
5].
Numerous scholars have endeavored to craft models that yield precise deterministic forecasts of wind speeds. These endeavors have categorized models into four distinct groups: physical, statistical, artificial intelligence (AI)-based, and hybrid models [
6,
7]. Among these, numerical weather prediction models, such as the weather research and forecasting model [
8], are recognized as the most prominent physical models. They predict wind speeds using intricate mathematical equations that factor in meteorological variables like humidity and temperature [
9], proving particularly effective for medium-to-long-range forecasts of wind speed [
10]. On the other hand, statistical models, such as auto-regressive moving average [
11], auto-regressive integrated moving average [
12], and vector auto-regression [
13], differ from physical models by relying solely on historical data of wind speeds for predictions. These models are adept at capturing the linear variability of wind speeds and excel in forecasting over short-term periods [
14]. AI-based models primarily tackle the nonlinear dynamics of wind speed, incorporating simple neural networks (for instance, the back-propagation neural network [
15], Elman neural network [
16], and multilayer perceptron [
17]), along with support vector machines [
18] and extreme learning machines [
19]. Studies indicate that while deep learning offers suboptimal interpretability, it yields commendable predictive outcomes [
20]. Presently, a plethora of deep learning methods have been employed for wind-speed forecasting, such as deep belief networks [
21], convolutional neural networks (CNNs) [
22], long short-term memory networks (LSTM) [
23], gated recurrent units (GRUs) [
24], and temporal convolutional networks (TCNs) [
25]. TCN-based approaches [
26] utilize convolutional kernels to detect temporal changes by moving across the time dimension. Zhang et al. [
27] proposed a novel integrated model, blending VMD, the Sparrow Search Algorithm, and bidirectional GRU, that leverages TCNs. It has been observed in various studies that deep learning models often outshine both classical machine learning and statistical models in terms of nonlinear predictive capabilities and feature extraction prowess [
28]. The consensus among many scholars is that no single model can fully encapsulate the intricate variations in wind speed, leading to the creation of diverse hybrid models [
8]. Zhang et al. [
29] developed a hybrid model that merges noise-reduction techniques, optimization strategies, statistical approaches, and deep learning. Neshat et al. [
30] introduced a novel hybrid model with a deep learning-based evolutionary approach, featuring a bidirectional LSTM, an efficient hierarchical evolutionary decomposition technique, and an enhanced generalized normal distribution optimization method.
The transformer model has achieved remarkable success in fields such as computer vision and natural language processing, and it is pivotal in bridging the gaps between diverse research domains. In the realm of time series forecasting, transformer-based models have gained prominence due to their multi-head self-attention (MHSA) mechanism. Both the transformer and its adaptations have been proposed for time sequence forecasting tasks [
31]. The transformer model, renowned for its effectiveness in the realm of wind-speed prediction, has become a prominent tool in this area. For instance, Wu et al. [
32] introduced a novel EEMD-Transformer-based hybrid model for predicting wind speeds. Zhou et al. [
33] presented the informer, a model designed for long sequence time forecasts, characterized by a ProbSparse self-attention mechanism for optimal time complexity and memory efficiency. Yang et al. [
34] developed a causal inference-enhanced informer methodology employing an advanced variant of the informer model, specifically adapted for long-term time series analysis. Bommidi et al. [
35] developed a composite approach that harnesses the predictive strength of the transformer model alongside the analytical prowess of ICEEMDAN to improve wind-speed prediction accuracy. Huang et al. [
36] present a new hybrid forecasting model for short-term power load that effectively decomposes power load data into subsequences of varying complexities; employs BPNN for less complex subsequences and transformers for more intricate ones; and amalgamates the forecasts to form a unified prediction. Wang et al. [
37] utilized the transformer as a core component to devise an innovative convolutional transformer-based truncated Gaussian density framework, offering both precise wind-speed predictions and reliable probabilistic forecasts. Zeng et al. [
38] introduced the DLinear model, which explores the impacts of various design elements of long-sequence time forecast models on their capability to extract temporal relationships. Nie et al. [
39] present a novel transformer-based framework for multivariate time series forecasts and self-supervised representation learning. This framework, termed the channel-independent Patch Time Series Transformer (PatchTST), markedly improves long-term forecasting precision.
Within the hybrid modeling framework, original wind-speed data are segmented into subseries with distinct frequencies and analyzed individually using specialized models, and their forecasts are amalgamated to produce the final prediction outcome [
40]. For instance, Li et al. [
41] employed the VMD technique to segregate wind-speed data into intrinsic mode functions (IMFs) of varying frequencies, with each IMF being analyzed through a bidirectional LSTM model. Similarly, Wu et al. [
42] utilized VMD to segment wind speed and integrated these segments with multiple meteorological variables to construct a deep-learning model with interpretability. Geng et al. [
43] propose a novel prediction framework to enhance short-term power load forecasting accuracy, utilizing a particle swarm optimization (PSO)-enhanced VMD in conjunction with a TCN incorporating an attention mechanism. Zhang et al. [
44] proposed a hybrid deep learning model for wind-speed forecasting that combines CNN, bidirectional LSTM, an enhanced sine cosine algorithm, and EDM based on time-varying filtering to improve prediction accuracy. Moreover, Altan et al. [
45] presented a predictive model that combines ICEEMDAN decomposition and LSTM, employing grey wolf optimization to fine-tune the weighted coefficients of each IMF for enhanced forecasting precision.
The literature review highlights several existing gaps in the field of wind-speed prediction. Wind-speed prediction studies based on transformers are relatively scarce compared to those based on other deep learning models. This highlights the necessity for a further in-depth exploration of the potential of transformer-based models within the wind-speed prediction domain. In the realm of wind-speed prediction models based on transformers, the majority are designed for long-term forecasting. There is a notable scarcity of models for medium-term, short-term, and ultra-short-term predictions. This indicates a pressing need for the development of transformer-based models that can effectively address medium-term, short-term, and ultra-short-term wind-speed forecasting. Additionally, there is a scarcity of transformer-based wind-speed prediction models that integrate data decomposition algorithms and other models, indicating a need for further exploration of the potential of hybrid forecasting models based on transformers. In response to the aforementioned challenges and needs, this paper introduces a hybrid wind-speed prediction model named DBO-VMD-TCN-Transformer, which integrates Dung Beetle Optimizer (DBO) algorithm-enhanced VMD, TCN, and transformer technologies. The contributions of the study are as follows:
The model utilizes the DBO algorithm to autonomously determine the most effective decomposition parameters for VMD. This approach significantly reduces signal loss during the decomposition phase and enhances the overall performance of VMD.
A hybrid forecasting model that combines TCN with transformers is introduced. TCN is employed to extract original wind-speed features, which are then fed into the transformer for multi-step short-term wind-speed prediction.
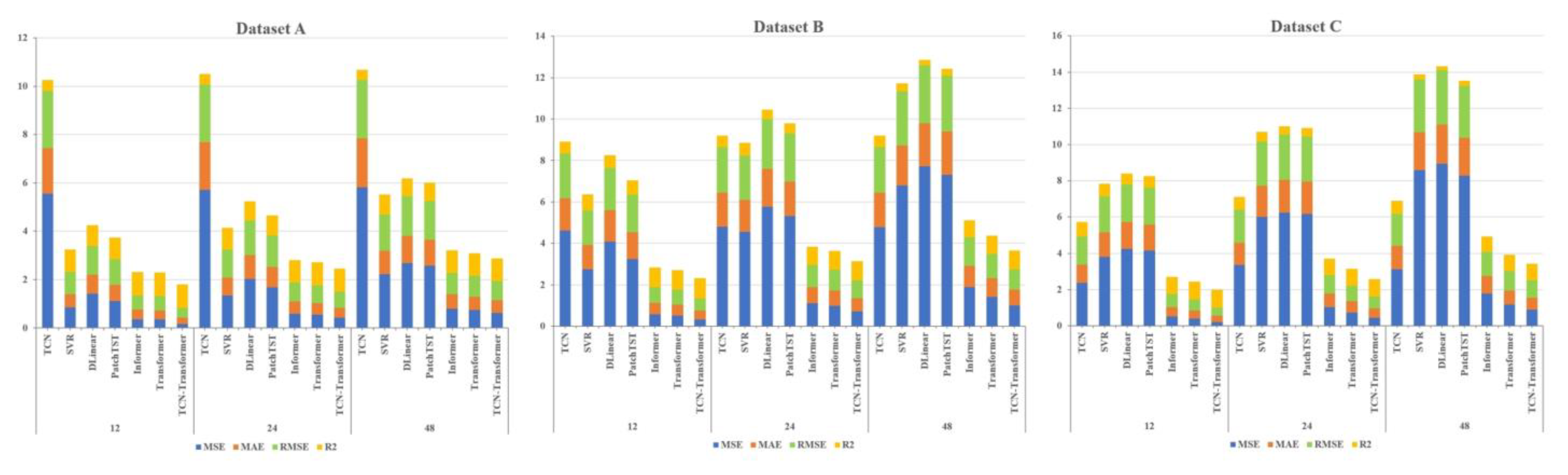
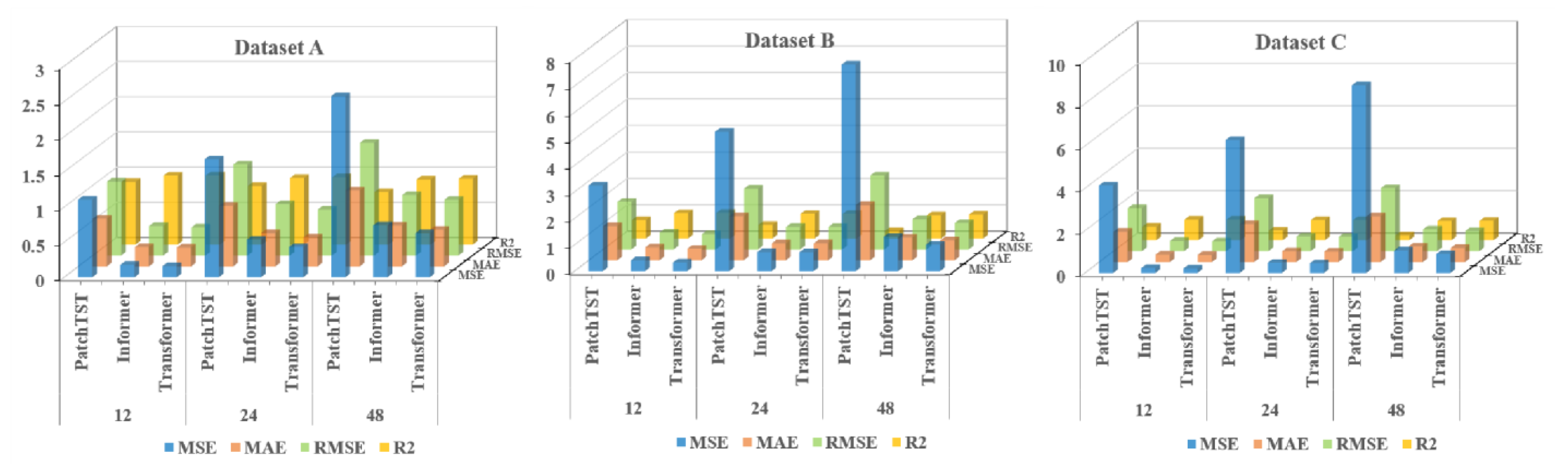
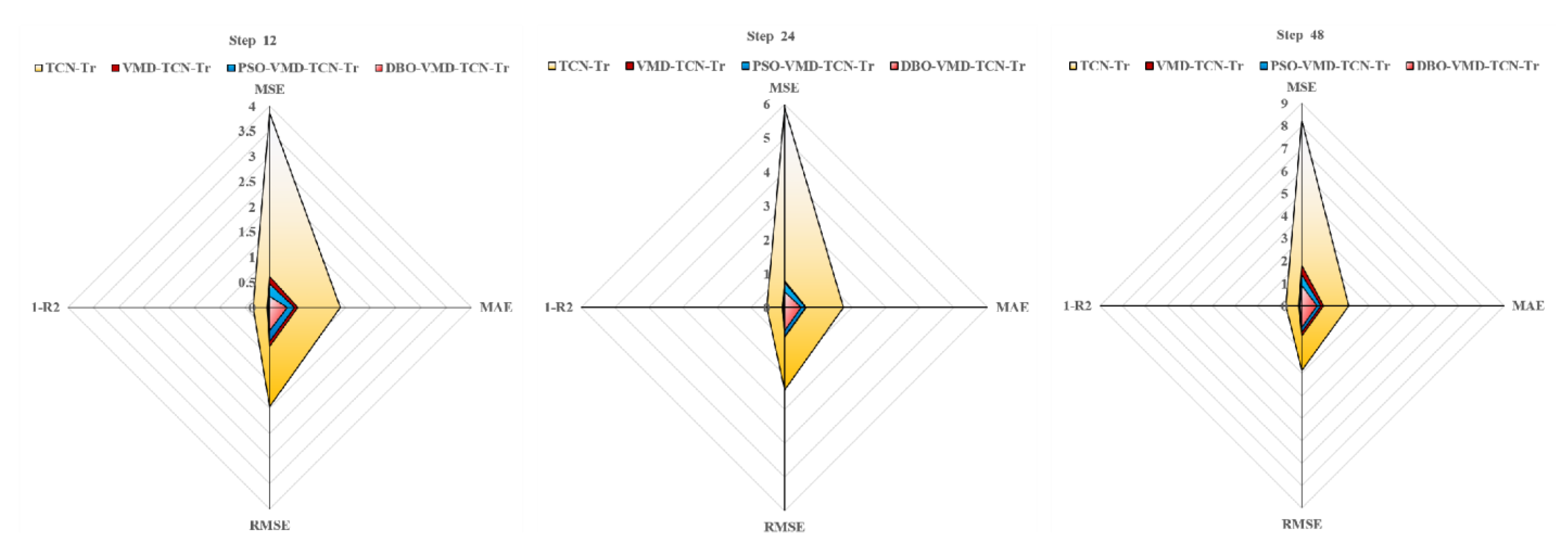
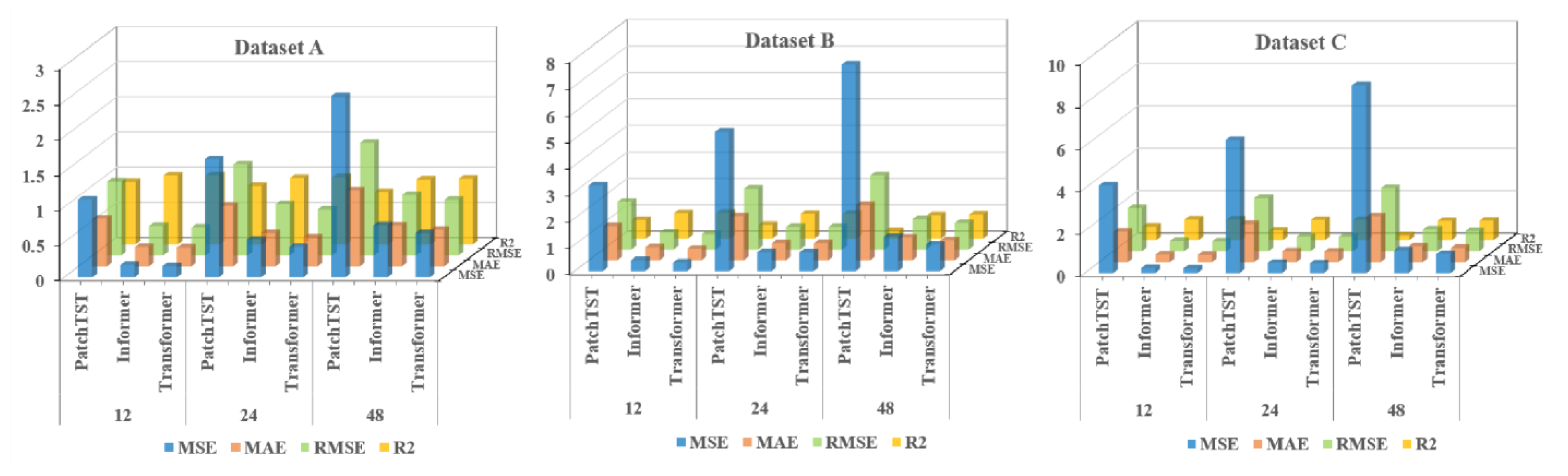
The DBO-VMD-TCN-Transformer model is compared with TCN, support vector regression (SVR), transformer, informer, PatchTST, Dlinear, VMD-TCN-Informer, and VMD-TCN-PatchTST models. Experimental results on three distinct datasets demonstrate that the developed model outperforms others in all four key metrics of evaluation (MAE, MSE, RMSE, and R2).
2. Methods and Materials
2.1. Flow Chart of the Proposed Model
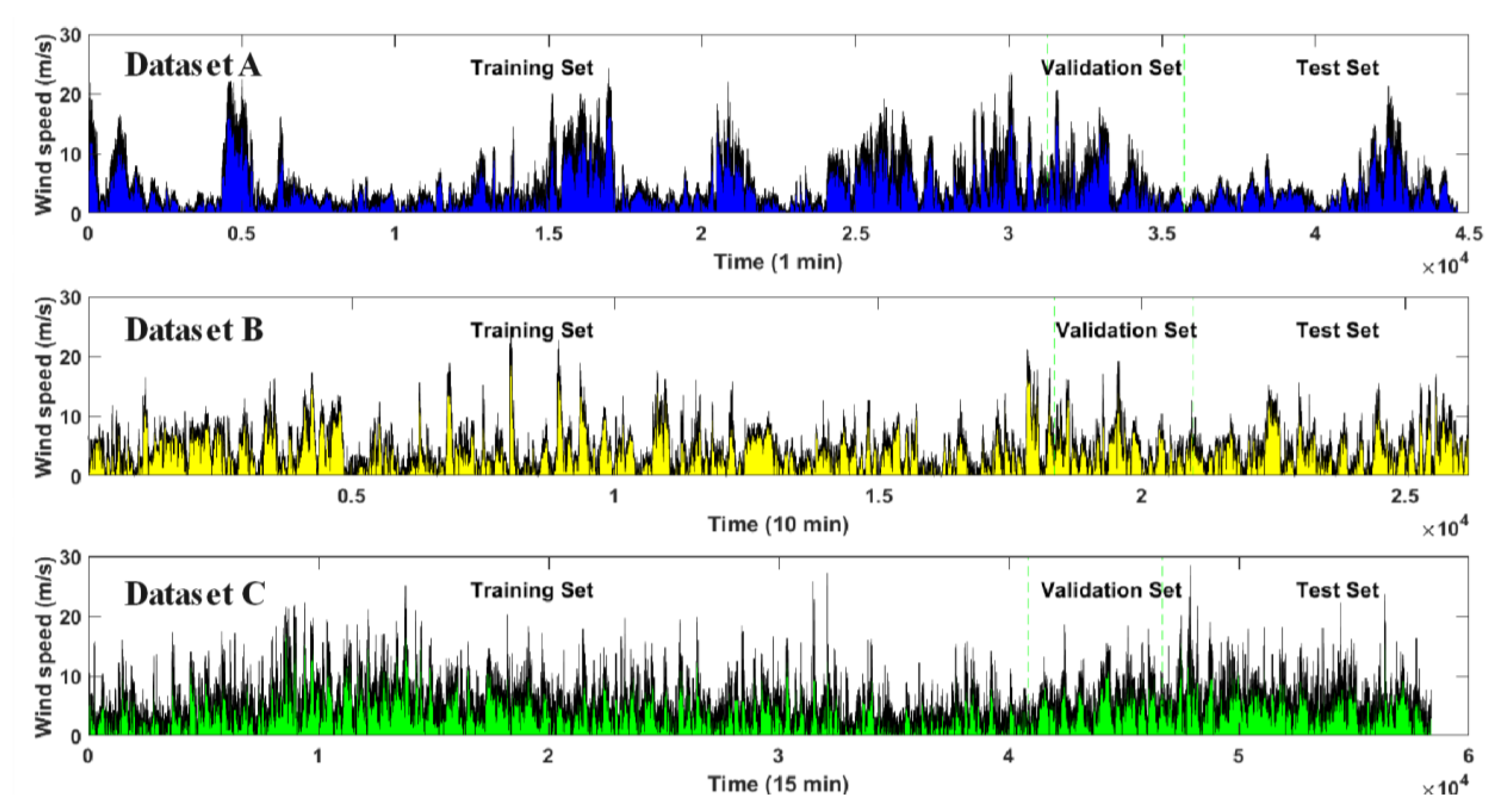
A novel composite forecasting approach is presented, illustrated in
Figure 1, which integrates the advantages of DBO-enhanced VMD, TCN, and transformer technologies, concisely referred to as the DBO-VMD-TCN-Transformer. The approach is delineated across three phases: The initial phase involves partitioning the gathered wind-speed data into training, validation, and test groups. Utilizing the DBO algorithm, the optimal parameters for VMD are determined automatically, leading to the segmentation of wind-speed data into various IMFs. In the second phase, the decomposed data are fed into the TCN model to extract features from the high-resolution wind-speed data. These features are subsequently used for multi-step, short-term prediction through a transformer model. The TCN-Transformer architecture is devised to elucidate the complex relationships between historical inputs and forecasted outcomes. The final phase is dedicated to the exposition and analysis of empirical results obtained from three distinct datasets, assessing the framework’s effectiveness and stability via four principal performance metrics (MSE, MAE, RMSE, and R
2) in conjunction with the Diebold Mariano (DM) test.
2.2. Variational Mode Decomposition
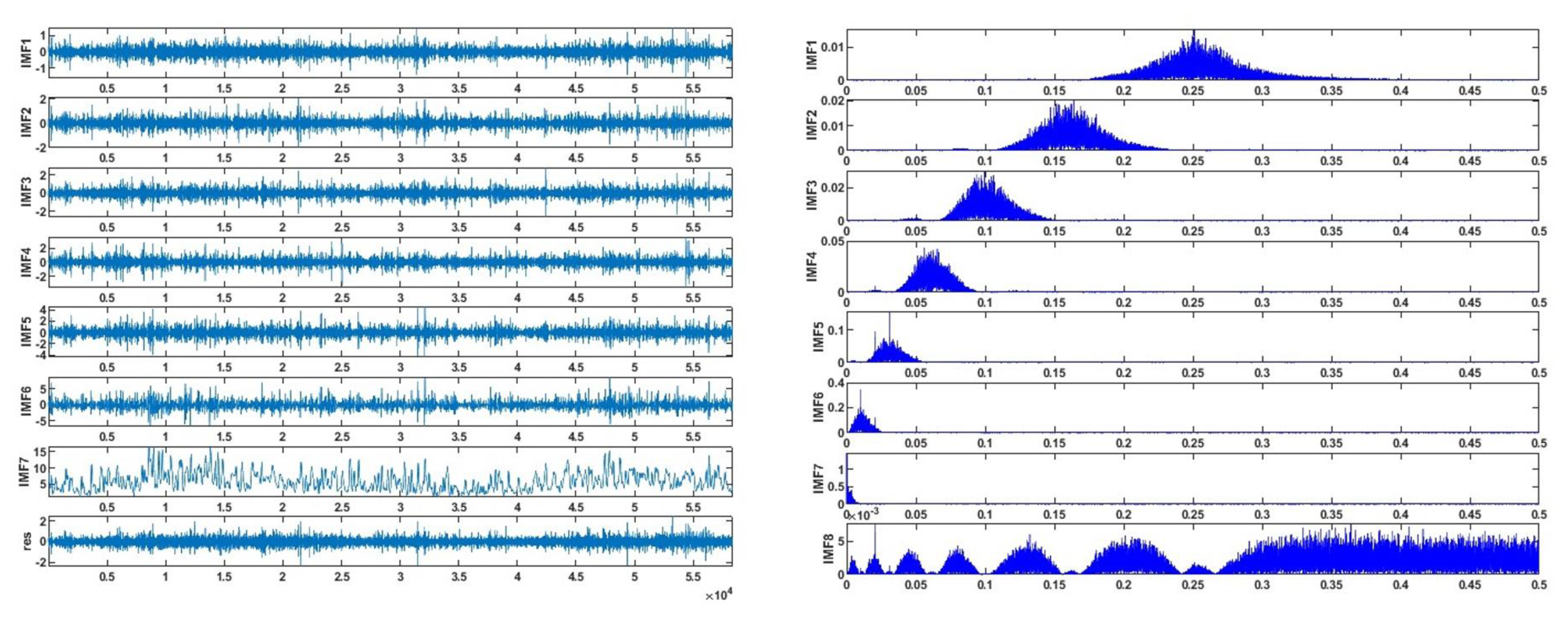
VMD is a contemporary technique in signal processing that has been increasingly adopted for its effectiveness. It excels in pinpointing the optimal central frequencies and minimizing bandwidth for each mode during analysis, thereby effectively isolating intrinsic mode functions and segmenting the frequency domain [
46]. Unlike empirical mode decomposition and wavelet analysis, VMD offers enhanced signal reconstruction capabilities and superior noise immunity. The algorithm decomposes a signal into K distinct frequency bands and stable sub-signals, each characterized by unique oscillatory components with varying frequencies and amplitudes. This approach, optimized through a variational method, seeks to balance the total estimated bandwidths against the minimization of bandwidth sums for each mode, thus achieving an optimal decomposition. The formal definition of VMD in signal decomposing is given by Equation (1).
In the formulation, the component of mode kth is indicated as , and the central frequency for this component is denoted by . The representation for the Dirac distribution is given as .
To tackle the original constrained variational formula, the approach integrates a penalty coefficient
α along with a Lagrange multiplier
λ. This integration effectively shifts the problem from a constrained framework to an unconstrained setting. As a result of this process, a revised Lagrange formula, referred to as expression (2), is derived.
For attaining the ideal outcome, the initial values for the parameters
,
,
, and
are set, with
n being initially fixed at 0. Following this setup, a repetitive process begins in which
n is progressively increased with each pass. Throughout every step of this process, the parameters
,
and
undergo adjustments based on the latest computations.
2.3. Dung Beetle Optimization
The algorithm was introduced by Xue and Shen in 2023 [
47]. The foundational Dung Beetle algorithm updates the positions of the population by mimicking four natural behaviors observed in dung beetles: rolling, spawning, foraging, and stealing.
During the rolling process, dung beetles engage in the behavior of shaping dung into spherical forms and propelling them forward swiftly to minimize competition from fellow beetles. The beetles determine their movement direction by using environmental light, aiming to propel the dung ball in the straightest line achievable. Equation (6) delineates the method for recalibrating the position of the dung beetle engaged in rolling:
where
t symbolizes the iteration count currently in progress, and
represents the dung beetle’s location after
t iterations. The text initially sets
to indicate the beetle’s adherence to or deviation from its set path, where
a value of
is randomly assigned as 1 for no change in direction and −1 for a shift in direction.
is defined as the imperfection factor with
a value of 0.1, and
b is a constant within
, with
a value of 0.3 specified in the implementation.
is identified as the least favorable global value.
mimics the effect of sunlight, where a higher
suggests a greater distance from the light source.
Naturally, in the absence of light or on uneven terrain, dung beetles lack the ability to determine their movement direction. Under such conditions, they ascend the dung ball and perform a dance—a behavior that aids in deciding the direction for subsequent movement. The mathematical expression for updating the dung beetle’s position based on this dance is outlined in Equation (7).
. The position is not updated when or .
In the spawning process, dung beetles choose secure locations for egg-laying. Mirroring this behavior, a strategy for selecting boundaries to represent these areas was introduced, as outlined below:
where
and
signify the lower and upper limits, respectively, of the area designated for spawning.
is recognized as the current local optimal site,
, and
symbolizes the maximum iteration count. When a spawning dung beetle identifies the most favorable area for spawning, it proceeds to spawn within that zone. The spawning area is subject to continuous variation, ensuring the ongoing search for the region containing the current optimal solution while avoiding entrapment in local optima. The modification in the position of a spawning dung beetle is formalized in Equation (9):
Here, and are random values with a magnitude of and Dim, which refers to the dimensionality of the optimization challenge, represents the problem’s dimension.
Within the foraging process, dung beetles engaging in foraging behavior similarly prioritize the selection of a secure location, akin to their approach in egg-laying. The precise definition of this area is provided through Equation (10).
In this context,
signifies the globally optimal position, whereas
and
are indicative of the lower and upper thresholds of the prime foraging zone.
and
, on the other hand, delineate the lower and upper limits relevant to problem resolution. Each act of foraging by a dung beetle translates into a revision of its position, with the update process for a foraging dung beetle’s location detailed in Equation (11):
Here, represents a normally distributed random numeral, and is a vector within of size Dim.
During the stealing process, certain dung beetles are known to pilfer dung balls from their counterparts. The globally optimal position
is designated as the site of these competed-for dung balls. The process of theft is characterized by the positional update of the steal dung beetle, with the specific update mechanism detailed in Equation (12):
Here, is a fixed value set at 0.5 in the study, quantifies the randomness factor, and Dim elucidates the dimensionality of the problem at hand.
2.4. Temporal Convolutional Network
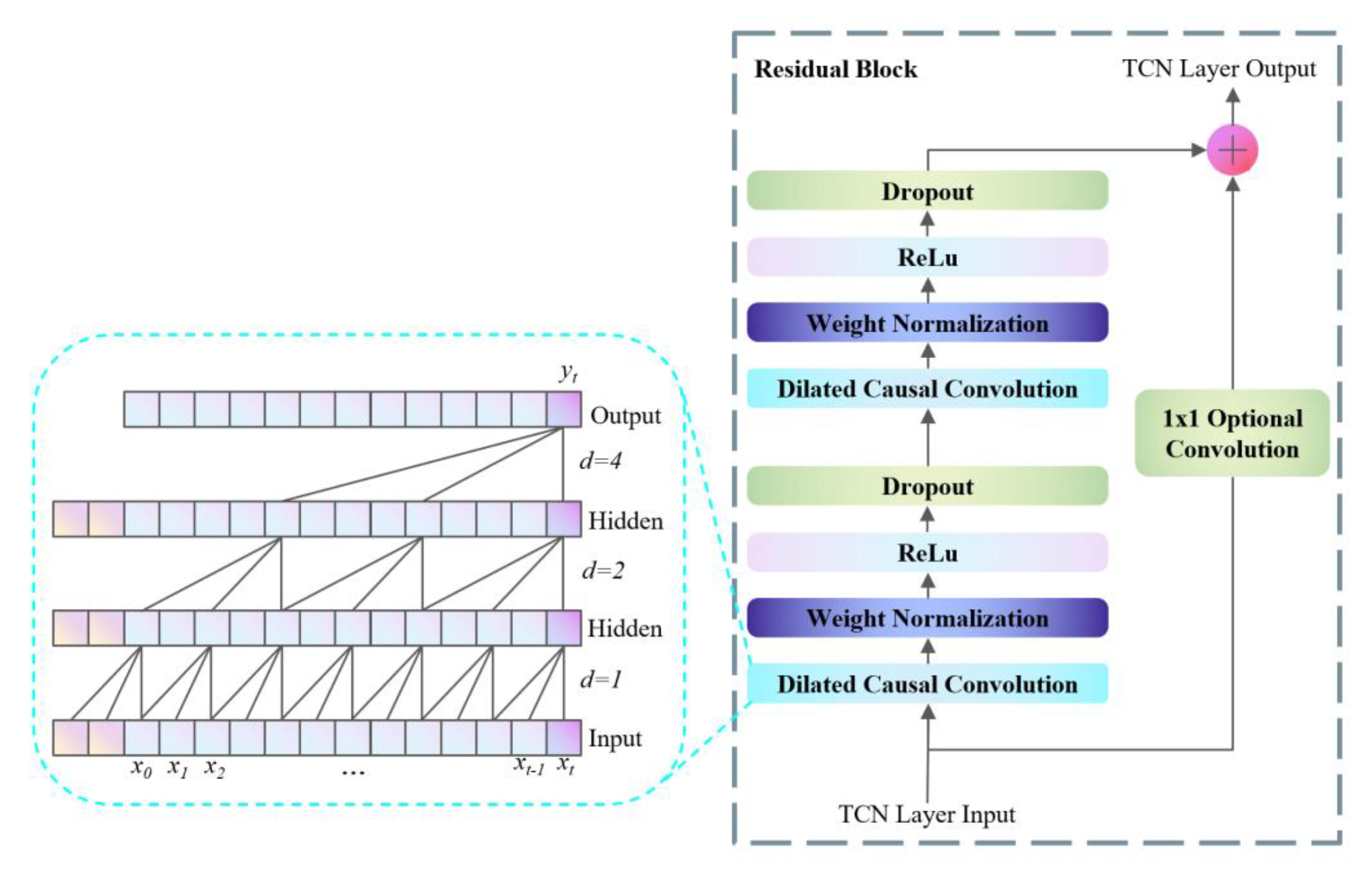
Derived from the foundational architecture of CNN, TCNs represent an evolutionary development that incorporates one-dimensional convolutional layers structured causally with extended lengths for both inputs and outputs. This design allows for the simultaneous processing of historical and spatial information. Moreover, the inherent capability of CNNs to execute parallel operations contributes to a significant reduction in processing time. When juxtaposed with long short-term memory networks (LSTM), TCNs display a more straightforward and coherent structure, enhanced training and convergence efficiency, and the capacity to learn historical data akin to recurrent neural networks (RNNs) without inadvertently revealing future information. Additionally, TCNs offer superior stability in overcoming challenges associated with gradients exploding or vanishing and demand lower memory usage, positioning them as a more practical option for specific analytical tasks.
The architecture of the network is elaborately depicted in
Figure 2, which illustrates that the TCN [
48] primarily consists of three key components: causal convolution, dilated convolution, and residual connections. The design principle behind causal convolution is to ensure that the model’s predictions are based solely on past and present inputs, rather than future inputs, aligning with the temporal sequence’s natural causality. As demonstrated in the left portion of
Figure 2, causal convolutions are structured such that the information for a given time point t incorporates data from preceding time points, thereby embedding a temporal hierarchy within the model layers. The effectiveness of causal convolution in feature extraction is constrained by the dimensions of its kernel, leading to the need for multiple linearly stacked layers to apprehend extensive dependencies. To address this limitation, TCNs employ an expanded convolution strategy, known as dilated convolution. Dilated convolutions, by design, require padding on either side of the input layer (left or right, depending on the convolution direction) commonly achieved through zero-padding. This approach allows for a broader receptive field without increasing the number of layers, thereby efficiently capturing wider temporal relationships without raising computational complexity or the number of parameters. The formal definition of dilated convolution is given by Equation (13):
where * denotes the convolution operation,
represents the convolution kernel,
represents the dilation factor,
signifies the filter size, and
indicates the sequence element for the dilated convolution. Typically, the dilation factor
experiences an exponential increase in correlation with the network’s increasing depth. Augmenting both the dilation factor
and the convolution kernel’s dimension
results in an expanded receptive field for the TCN. Unlike standard convolutions, dilated convolutions sample the input at intervals, effectively expanding the receptive field with a controlled sampling rate determined by the dilation factor
.
As the number of layers in the network increases, it becomes essential to tackle challenges such as the vanishing gradient issue, necessitating the adoption of residual connections. Residual connections, particularly those utilizing
convolution blocks, facilitate the cross-layer transmission of information, ensuring consistency between the inputs and outputs. The mathematical representation of these connections is presented below:
In this equation, denotes the input, is the convolutional layer’s output, and signifies the ReLU activation function.
Displayed in the right section of
Figure 2, the residual module encompasses a sequence starting with dilation causal convolution followed by weight normalization, application of ReLU for activation, and incorporation of a Dropout layer to prevent overfitting. This configuration is iterated across four stages, resulting in an eight-layer structure. Throughout this process, residual connections utilizing
convolution blocks are employed to maintain consistent output dimensions.
2.5. Transformer
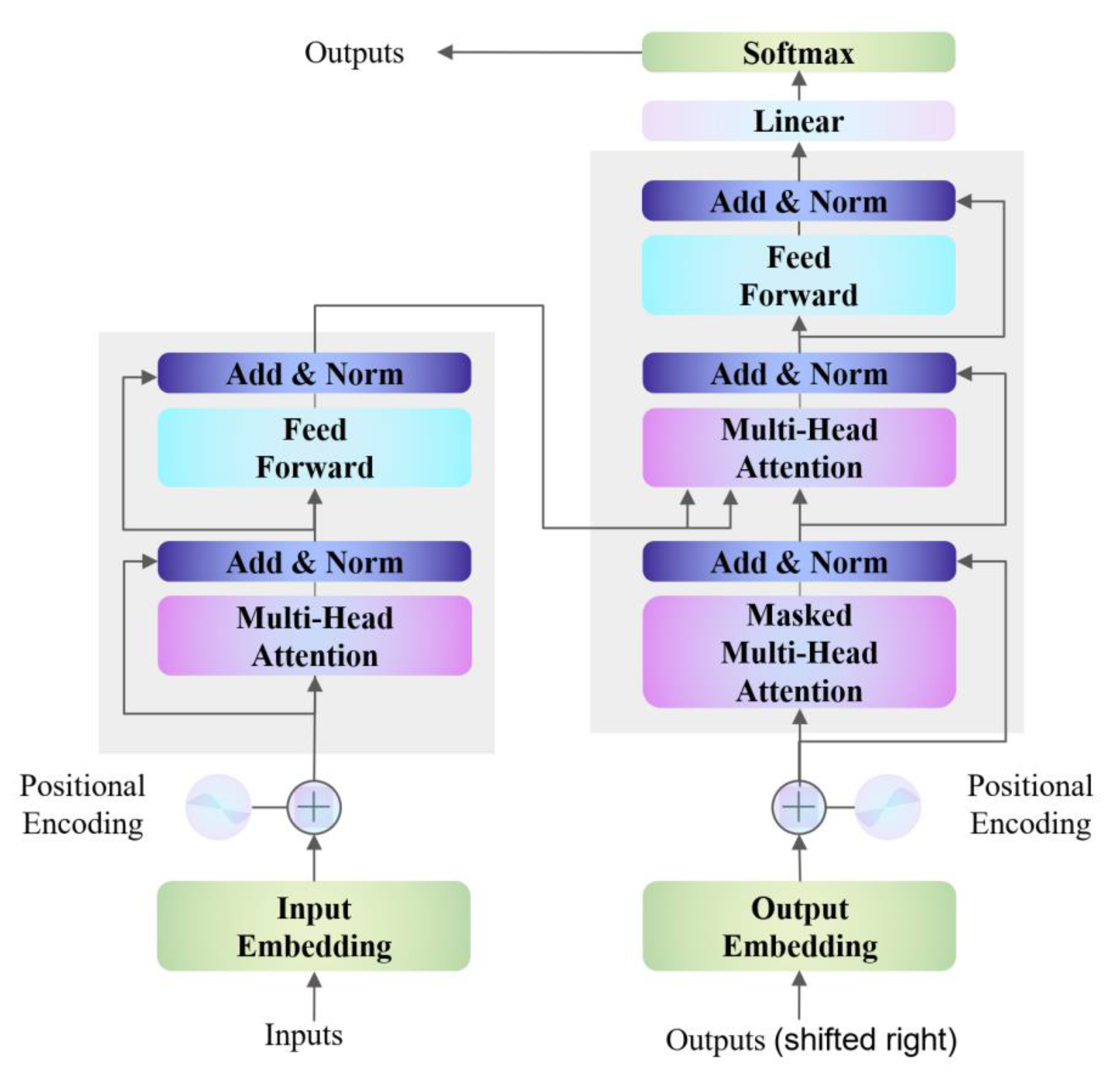
Transformers have achieved remarkable success in realms such as Natural Language Processing and image recognition, overcoming the limitations inherent in RNN and CNN-based forecasting models. CNNs often require many layers to achieve a significant receptive field, while RNNs rely on long time sequences for predictions. The self-attention mechanism of transformers addresses these issues by enabling direct access to sequence elements, thus facilitating a deeper exploration of the complex correlations within individual feature data. Moreover, their capacity for parallel processing significantly reduces training durations, allowing models to be trained on larger datasets compared to LSTM networks, enhancing their efficiency and applicability.
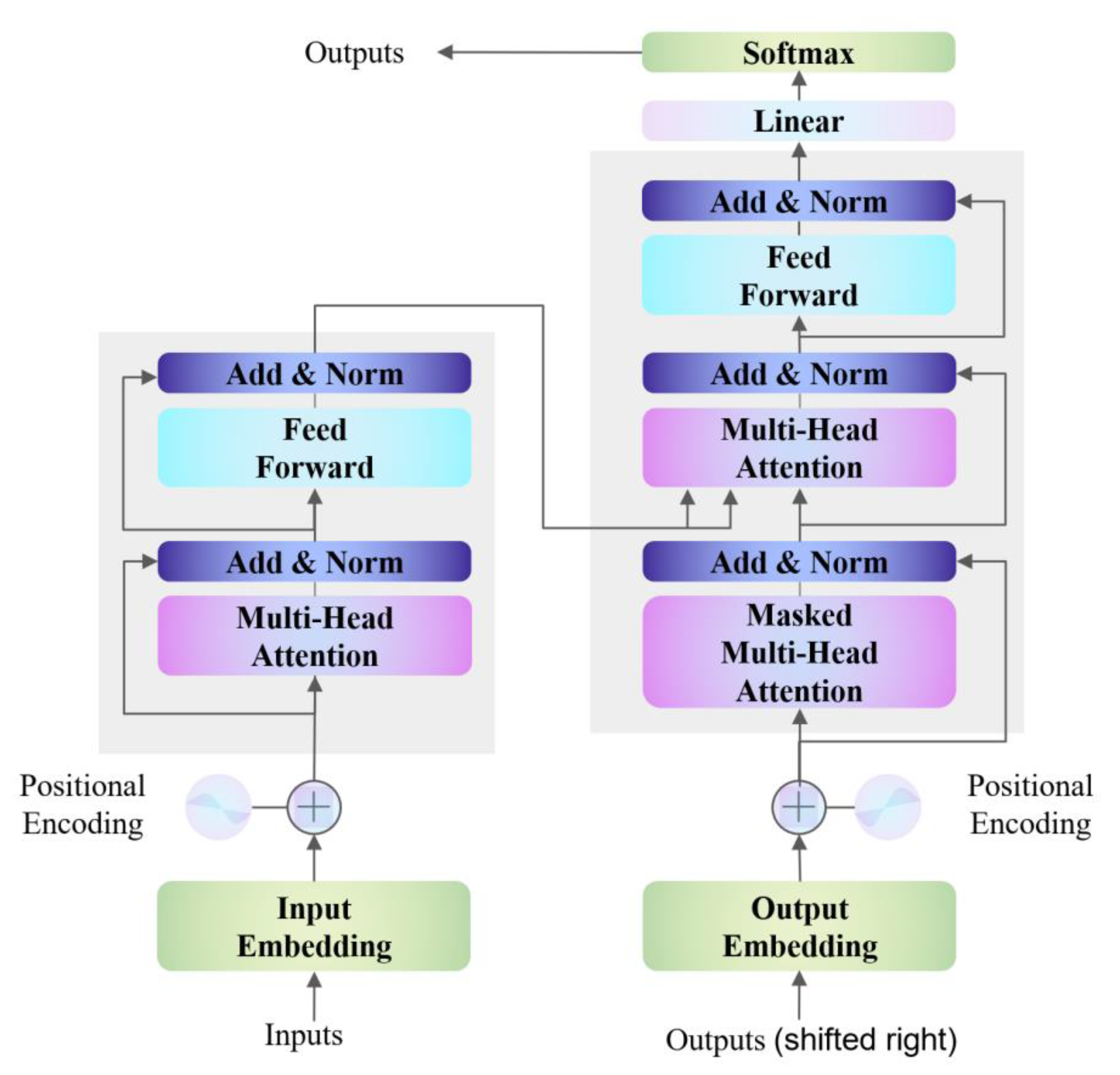
Figure 3 illustrates the intricate structure of the transformer network. The transformer architecture comprises two key elements: an encoder and a decoder [
49]. The encoder is tasked with transforming the input into a rich, high-dimensional representation that encapsulates contextual nuances, whereas the decoder is dedicated to feature reconstruction [
50].
Figure 3 delineates the comprehensive blueprint of the transformer model. Initial steps involve input embedding and position encoding before the data proceed to the encoder and decoder layers. Input embedding amalgamates various features into a unified representation, and position encoding ensures the retention of temporal attributes associated with each data point. The relevant mathematical formulation is provided as follows:
where
;
denotes the position index. The MHSA mechanism permits the model to concurrently compute linear transformations through various attention mechanisms, subsequently amalgamating diverse attentions to acquire a relatively more comprehensive feature information, thereby enhancing the efficacy of the self-attention layer. The MHSA mechanism emerges as a pivotal feature of the transformer, facilitating parallel processing of input data, a capability that sets it apart from sequential time sequence models like LSTM and TCN.
Figure 3 provides a visual representation of the transformer’s architecture. Within the MHSA framework, the input vector
is converted into
distinct sets of query, key, and value matrices. The three distinct matrices known as Q (Query), K (Key), and V (Value) can be generated. The corresponding equations are depicted as follows:
where
denotes the query matrix,
symbolizes the key matrix, and
represents the value matrix, with
and
being the adjustable parameters for the linear transformations. The MHSA divides the input into several independent feature spaces, facilitating the model’s ability to learn a broader spectrum of feature information [
51]. The process continues with the application of scaled dot-product attention to generate a series of output vectors:
Here,
is the result of the scaled dot-product attention mechanism, with
acting as the scaling factor for the attention weights. The outputs,
, are subsequently concatenated and subjected to a linear projection to yield the final output.
where
represents the learnable parameter of the MHSA mechanism, which is critical for encoding and aggregation info at each point for sequence.
4. Conclusions
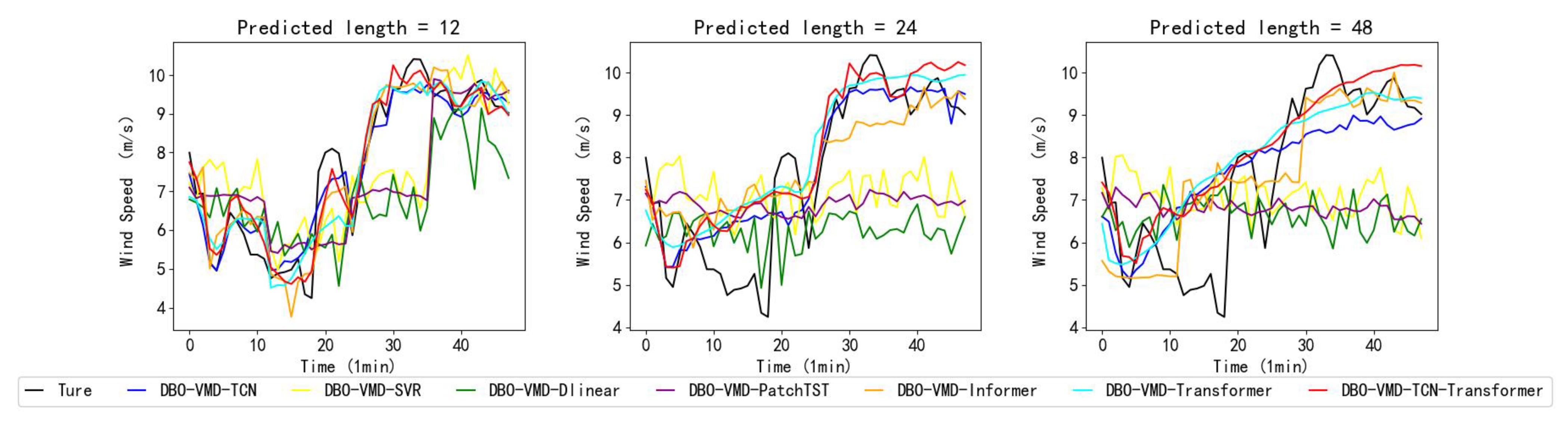
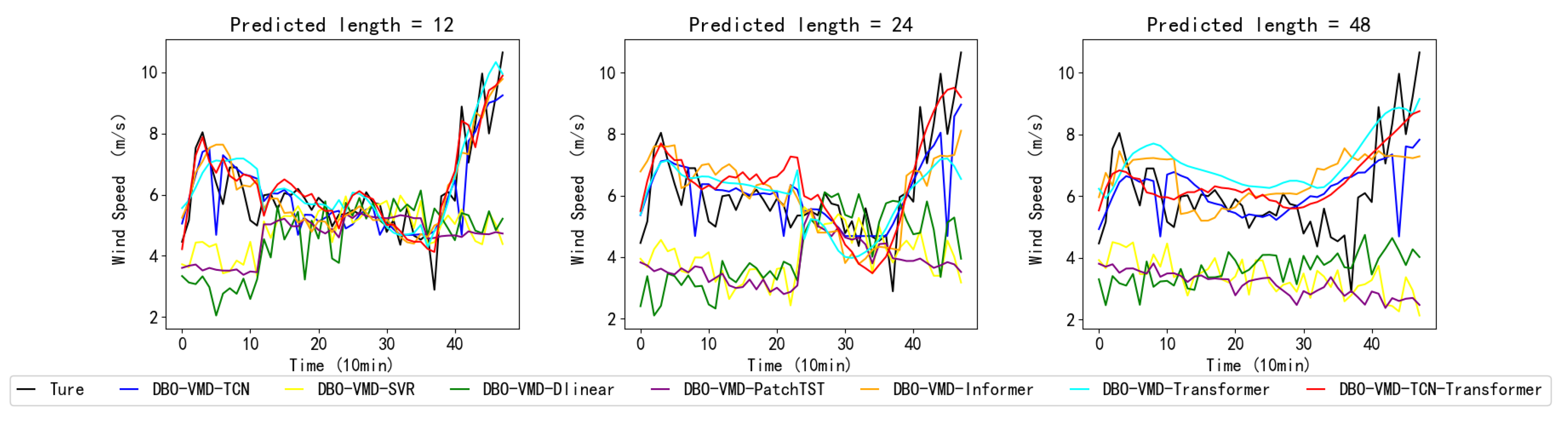
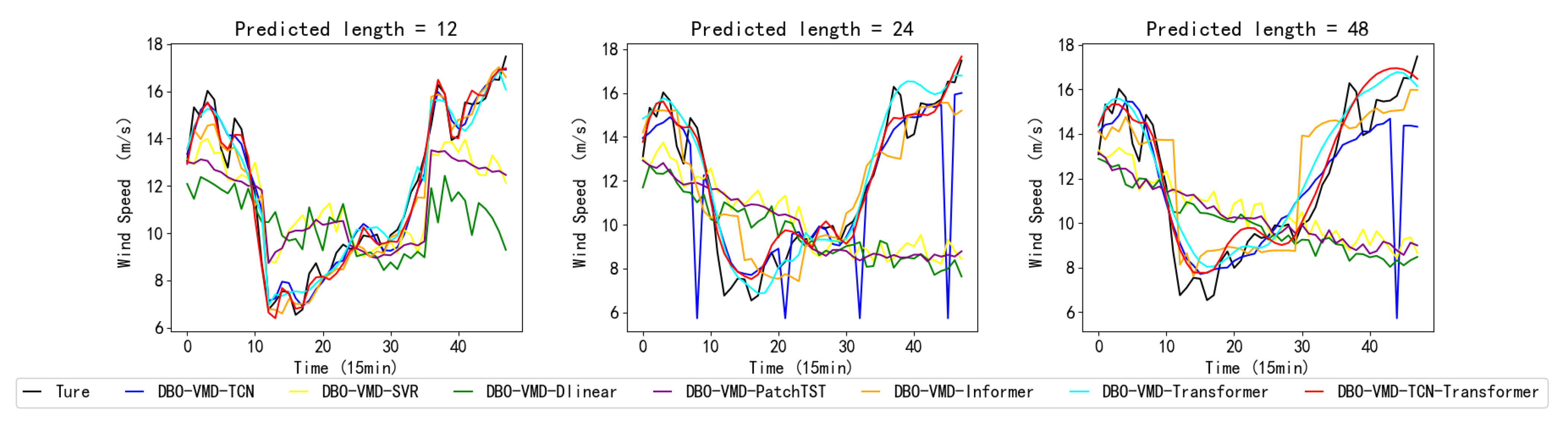
Addressing the need for enhanced accuracy in wind-speed forecasting and the scarcity of research on wind-speed short-term prediction utilizing the transformer architecture, this study introduces a hybrid wind-speed prediction model that integrates the transformer model, VMD, and TCNs. This innovative model aims to leverage the strengths of each component to enhance accuracy and efficiency in predicting wind speeds across various time horizons. By integrating the transformer’s ability to handle complex dependencies with the accuracy of VMD for wind-speed decomposing and the efficiency of TCNs for temporal analysis, this proposed model seeks to fill the gaps in current short-term wind-speed forecasting methodologies and extend the application of transformer-based models to a wider range of forecasting scenarios. The efficacy of the introduced model was validated and assessed using three real-world datasets. Experiments conducted with these datasets revealed that (1) compared to six benchmark models, the proposed model exhibits superior performance, showing an average improvement of 54.2% in MSE, MAE, and RMSE performance, and a 52.1% increase in R2 performance. (2) The transformer model demonstrates enhanced capabilities in short-term forecasting compared to the PatchTST and informer models. On average, its performance in the MSE, MAE, and RMSE metrics improved by 40.2%, while the R2 score increased by 20.8%. (3) The DBO-VMD strategy has proven effective in enhancing the accuracy and consistency of wind-speed forecasting results. Compared to models without VMD, the DBO-VMD-TCN-Transformer hybrid model shows an average performance improvement of 78.5% in MSE, MAE, and RMSE metrics, and a 50.0% increase in the R2 score. (4) The DM test indicates that the model exhibits statistically significant improvements over other baseline models at the 5% significance level.
Challenges include the incomplete optimization of hyperparameters and a deficit in error evaluation. Future research will delve into comprehensive studies on transformer-based hybrid models, the automation of hyperparameter optimization, and detailed error correction, with the aim of enhancing the precision of wind-speed predictions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}