
Overview of Wind and Photovoltaic Data Stream Classification and Data Drift Issues

 ,
,
Abstract
1. Introductions
2. Research on Data Stream Classification Methods and Their Applications
2.1. Data Stream Classification Methods
2.2. Application of Data Stream Classification to Wind and Photovoltaic Power Data
2.2.1. Data Streaming in Wind Power
- Fault Diagnosis Based on Electrical Indicators
- 2.
- Fault Diagnosis Based on Vibration Signals
2.2.2. Data Streaming in Photovoltaics
3. Functions for Various Drifts in the Data Stream and Their Forms
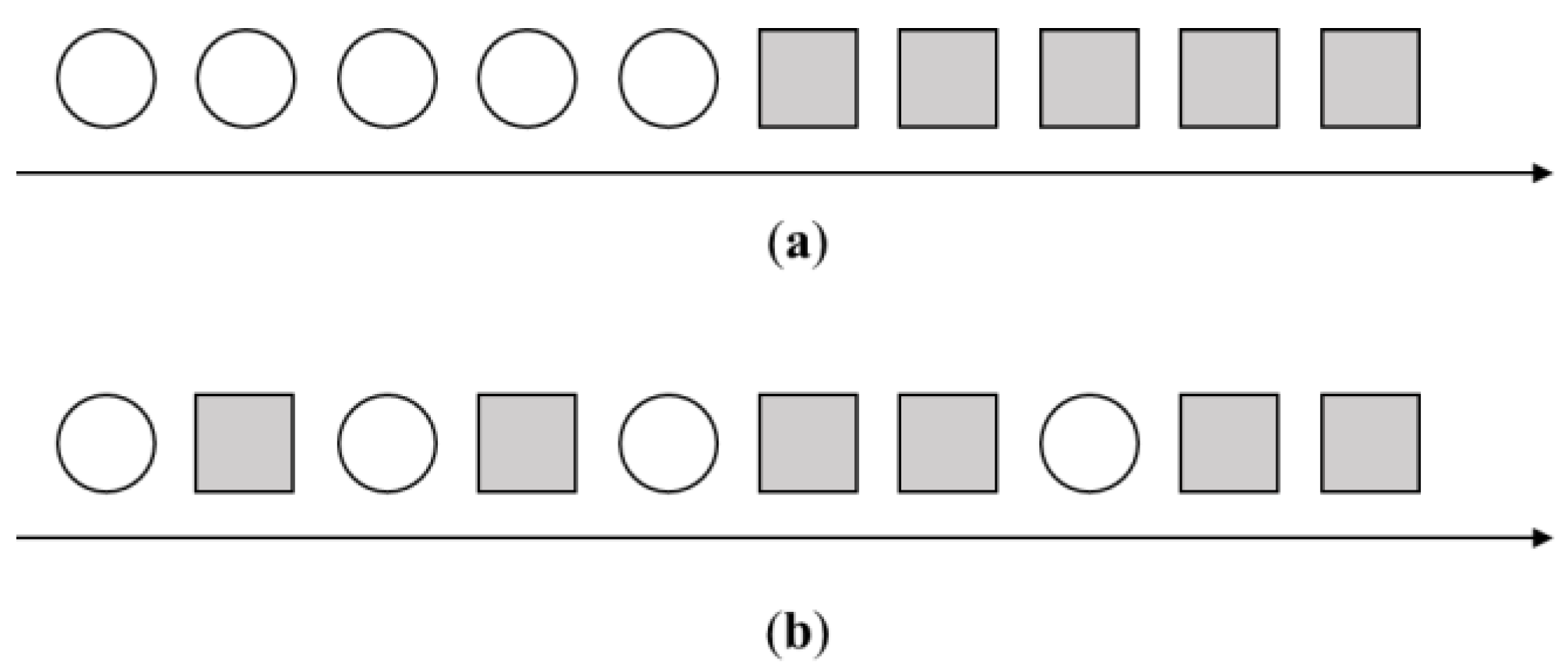
3.1. Covariate Drift
3.2. Prior Probability Drift
3.3. Concept Drift
3.3.1. Different Forms of Concept Drift
- Label drift
- 2.
- Feature Drift
- 3.
- Instance Drift
3.3.2. Concept Drift over Different Time Intervals
3.3.3. Concept Drift Detection Methods
- Error Rate-based Concept Drift Detection Method
- 2.
- Window-based Concept Drift Detection Methods
- 3.
- Concept Drift Detection Method based on Data Distribution
- 4.
- Multiple Hypothesis Testing Drift Detection Methods
3.3.4. Model Updating Strategies for Addressing Conceptual Drift
3.4. The Issue of Concept Drift in Data Stream Classification Research within Energy Systems
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADWIN | Adaptive Sliding Window Algorithm |
| BP | Back Propagation |
| CM | Competence Model-Based Drift Detection |
| CEVDT | Concept-Adapting Evolutionary Algorithm for Decision Tree |
| CVFDT | Concept-Adapting Very Fast Decision Tree |
| CFS | Correlation-Based Approach to Attribute Selection |
| CUSUM | Cumulative Sum |
| DMM | Drift Detection Method |
| DELM | Dynamic Extreme Learning Machine |
| DWM | Dynamic Weighted Majority |
| EDDM | Early Concept Drift Detection Method |
| e-Detector | Ensemble of Detectors |
| EDE | Equal Density Estimation |
| ECDD | EWMA for Concept Drift Detection |
| EWMA | Exponentially Weighted Moving Average Charts |
| FHDDM | Fast Hoeffding Drift Detection Method |
| FW-DDM | Fuzzy Windowing Drift Detection Method |
| GAN | Generative Adversarial Networks |
| HDDM | Heoffding’s Inequality Based Drift Detection Method |
| HCDTs | Hierarchical Change-Detection Tests |
| HHT-CU | Hierarchical Hypothesis Testing with Classification Uncertainty |
| HLFR | Hierarchical Linear Four Rate |
| HGA | Hybrid Genetic Algorithms |
| IV-Jac | Information Value and Jaccard Similarity |
| ITA | Information-Theoretic Approach |
| ID | Instance Drift |
| KS | Kolmogorov–Smirnov |
| KL | Kullback–Leibler |
| LLDD | Learning with Local Drift Detection |
| LFR | Linear Four Rate Drift Detection |
| LDD-DSDA | Local Drift Degree-Based Density Synchronized Drift Adaptation |
| LSTM | Long Short-Term Memory |
| NLA | Normalized Likelihood Allocation |
| OCDD | One-Class Drift Detector |
| OGMMF-VRD | Online Gaussian Mixture Model with Noise Filter for Handling Virtual and Real Concept Drifts |
| OS-PCA | Oversampling Principal Component Analysis |
| PL | Paired Learners |
| PV | Photovoltaic |
| RDDM | Reactive Drift Detection Method |
| SCD | Statistical Change Detection |
| STEPD | Statistical Test of Equal Proportion Detection |
| SVMs | Support Vector Machines |
| UCVFDT | Uncertainty-Handling and Concept-Adapting Very Fast Decision Tree |
| VFDT | Very Fast Decision Tree |
| WTGs | Wind Turbine Generators |
References
- IRENA. Renewable Electricity Capacity and Generation Statistics. 2023. Available online: https://www.irena.org/-/media/Files/IRENA/Agency/Publication/2023/Mar/IRENA_RE_Capacity_Statistics_2023.pdf (accessed on 1 August 2024).
- Fu-jiang, A.O.; Zong-feng, Q.I.; Bin, C.; Ke-di, H. Data Streams Mining Techniques and its Application in Simulation System. Comput. Sci. 2009, 36, 116. [Google Scholar]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Wozniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Hossain, M.L.; Abu-Siada, A.; Muyeen, S.M. Methods for Advanced Wind Turbine Condition Monitoring and Early Diagnosis: A Literature Review. Energies 2018, 11, 1309. [Google Scholar] [CrossRef]
- Ozturk, S. Forecasting Wind Turbine Failures and Associated Costs: Investigating Failure Causes, Effects and Criticalities, Modeling Reliability and Predicting Time-to-Failure, Time-to-Repair and Cost of Failures for Wind Turbines Using Reliability Methods and Machine Learning Techniques; ProQuest LLC: Ann Arbor, MI, USA, 2019. [Google Scholar]
- Jankowski, D.; Jackowski, K.; Cyganek, B. Learning Decision Trees from Data Streams with Concept Drift. In Proceedings of the 16th Annual International Conference on Computational Science (ICCS), San Diego, CA, USA, 6–8 June 2016; pp. 1682–1691. [Google Scholar]
- Rutkowski, L.; Jaworski, M.; Pietruczuk, L.; Duda, P. The CART decision tree for mining data streams. Inf. Sci. 2014, 266, 1–15. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.; Vynokurova, O.; Pliss, I.; Setlak, G.; Mulesa, P. Fast Learning Algorithm for Deep Evolving GMDH-SVM Neural Network in Data Stream Mining Tasks. In Proceedings of the 1st IEEE International Conference on Data Stream Mining and Processing (DSMP), Lviv, Ukraine, 23–27 August 2016; pp. 257–262. [Google Scholar]
- Borchani, H.; Larrañaga, P.; Gama, J.; Bielza, C. Mining multi-dimensional concept-drifting data streams using Bayesian network classifiers. Intell. Data Anal. 2016, 20, 257–280. [Google Scholar] [CrossRef]
- Kruschke, J.K.; Liddell, T.M. Bayesian data analysis for newcomers. Psychon. Bull. Rev. 2018, 25, 155–177. [Google Scholar] [CrossRef]
- Geiger, D. An entropy-based learning algorithm of Bayesian conditional trees. In Proceedings of the Eighth Conference on Uncertainty in Artificial Intelligence, Stanford, CA, USA, 17–19 July 1992; pp. 92–97. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Webb, G.I.; Boughton, J.R.; Wang, Z.H. Not so naive Bayes: Aggregating one-dependence estimators. Mach. Learn. 2005, 58, 5–24. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, H.S.; Wu, J.; Zhang, Y.; Jiang, J.; Long, G.D. Evolutionary Lazy Learning for Naive Bayes Classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3124–3129. [Google Scholar]
- Jiang, L.X.; Wang, D.H.; Cai, Z.H. Discriminatively Weighted Naive Bayes and Its Application in Text Classification. Int. J. Artif. Intell. Tools 2012, 21, 1250007. [Google Scholar] [CrossRef]
- Jiang, L.; Cai, Z.; Wang, D. Improving naive Bayes for classification. Int. J. Comput. Appl. 2010, 32, 328–332. [Google Scholar] [CrossRef]
- Jiang, L.X.; Zhang, H.R.; Su, J. Instance cloning local naive Bayes. In Advances in Artificial Intelligence, Proceedings of the 18th Conference of the Canadian Society for Computational Studies of Intelligence, Canadian AI 2005, Victoria, BC, Canada, 9–11 May 2005; Lecture Notes in Computer Science; Kegl, B., Lapalme, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3501, pp. 280–291. [Google Scholar]
- Zhang, Y.S.; Wu, J.; Zhou, C.; Cai, Z.H. Instance cloned extreme learning machine. Pattern Recognit. 2017, 68, 52–65. [Google Scholar] [CrossRef]
- Langley, P.; Sage, S. Induction of selective Bayesian classifiers. In Uncertainty Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 399–406. [Google Scholar]
- Domingos, P.; Pazzani, M. On the optimality of the simple Bayesian classifier under zero-one loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Bidi, N.; Elberrichi, Z. Feature Selection for Text Classification Using Genetic Algorithms. In Proceedings of the 8th International Conference on Modelling, Identification and Control (ICMIC), Algiers, Algeria, 15–17 November 2016; pp. 806–810. [Google Scholar]
- Dubey, V.K.; Saxena, A.K.; Shrivas, M.M. A Cluster-Filter Feature Selection Approach. In Proceedings of the International Conference on ICT in Business Industry and Government (ICTBIG), Indore, India, 18–19 November 2016. [Google Scholar]
- Chuang, L.Y.; Tsai, S.W.; Yang, C.H. Improved binary particle swarm optimization using catfish effect for feature selection. Expert Syst. Appl. 2011, 38, 12699–12707. [Google Scholar] [CrossRef]
- Oh, I.S.; Lee, J.S.; Moon, B.R. Hybrid genetic algorithms for feature selection. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1424–1437. [Google Scholar] [CrossRef] [PubMed]
- Unler, A.; Murat, A.; Chinnam, R.B. mr2PSO: A maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification. Inf. Sci. 2011, 181, 4625–4641. [Google Scholar] [CrossRef]
- Yan, X.S.; Wu, Q.H.; Sheng, V.S. A Double Weighted Naive Bayes with Niching Cultural Algorithm for Multi-Label Classification. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1650013. [Google Scholar] [CrossRef]
- Jia, W.; Zhihua, C. Attribute weighting via differential evolution algorithm for attribute weighted naive bayes (wnb). J. Comput. Inf. Syst. 2011, 7, 1672–1679. [Google Scholar]
- Jiang, Q.W.; Wang, W.; Han, X.; Zhang, S.S.; Wang, X.Y.; Wang, C. Deep Feature Weighting in Naive Bayes for Chinese Text Classification. In Proceedings of the 4th IEEE International Conference on Cloud Computing and Intelligence Systems (IEEE CCIS), Beijing, China, 17–19 August 2016; pp. 160–164. [Google Scholar]
- Taheri, S.; Yearwood, J.; Mammadov, M.; Seifollahi, S. Attribute weighted Naive Bayes classifier using a local optimization. Neural Comput. Appl. 2014, 24, 995–1002. [Google Scholar] [CrossRef]
- Kia, S.H.; Henao, H.; Capolino, G.A. Mechanical Transmission and Torsional Vibration Effects on Induction Machine Stator Current and Torque in Railway Traction Systems. In Proceedings of the IEEE Energy Conversion Congress and Exposition, San Jose, CA, USA, 20–24 September 2009; pp. 2643–2648. [Google Scholar]
- Stack, J.R.; Habetler, T.G.; Harley, R.G. Fault classification and fault signature production for rolling element bearings in electric machines. IEEE Trans. Ind. Appl. 2004, 40, 735–739. [Google Scholar] [CrossRef]
- Gong, X. Online Nonintrusive Condition Monitoring and Fault Detection for Wind Turbines; ProQuest LLC: Ann Arbor, MI, USA, 2012. [Google Scholar]
- Lin, T.; Yang, X.; Cai, R.Q.; Zhang, L.; Liu, G.; Liao, W.Z. Fault diagnosis of wind turbine based on Elman neural network trained by artificial bee colony algorithm. Renew. Energy Resour. 2019, 37, 612–617. [Google Scholar] [CrossRef]
- Liang, T.; Zhang, Y.J. Monitoring of wind turbine faults based on wind turbine power curve. Renew. Energy Resour. 2018, 36, 302–308. [Google Scholar] [CrossRef]
- Li, Z.Y.; Yu, J.F.; Chen, Y.G.; Wen, D.Z. Research on the Fault Diagnosis Technology for Direct-drive Wind Turbines Based on Characteristic Current. Control Inf. Technol. 2018, 76–80. [Google Scholar] [CrossRef]
- Caesarendra, W.; Kosasih, B.; Lieu, A.K.; Moodie, C.A.S. Application of the largest Lyapunov exponent algorithm for feature extraction in low speed slew bearing condition monitoring. Mech. Syst. Signal Process. 2015, 50–51, 116–138. [Google Scholar] [CrossRef]
- Tang, B.P.; Song, T.; Li, F.; Deng, L. Fault diagnosis for a wind turbine transmission system based on manifold learning and Shannon wavelet support vector machine. Renew. Energy 2014, 62, 1–9. [Google Scholar] [CrossRef]
- Barszcz, T.; Randall, R.B. Application of spectral kurtosis for detection of a tooth crack in the planetary gear of a wind turbine. Mech. Syst. Signal Process. 2009, 23, 1352–1365. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, J.; Yin, Z. Fault diagnosis of wind turbine gearbox using dual-tree complex wavelet decomposition. J. Beijing Jiaotong Univ. 2018, 42, 121–125. [Google Scholar]
- Zhang, X.; Zheng, L.; Liu, Z. The Fault Diagnosis of Wind Turbine Gearbox Based on Genetic Algorithm to Optimize BP Neural Network. J. Hunan Inst. Eng. (Nat. Sci. Ed.) 2018, 28, 1–6. [Google Scholar] [CrossRef]
- Guo, D.; Wang, L.; Guo, H.; Wu, W.; Han, X. Fault Diagnosis of Wind Power Generator Based on Improved Wavelet and BP NN. Proc. Electr. Power Syst. Autom. 2012, 24, 53–58. [Google Scholar]
- Shi, X. Anomaly Detection and Early Warning of Photovoltaic Array based on Data Mining; Shandong University: Jinan, China, 2019. [Google Scholar]
- Awudu, I.; Wilson, W.; Dahl, B. Hedging strategy for ethanol processing with copula distributions. Energy Econ. 2016, 57, 59–65. [Google Scholar] [CrossRef]
- Ahmadi Livani, M.; Abadi, M.; Alikhany, M.; Yadollahzadeh Tabari, M. Outlier detection in wireless sensor networks using distributed principal component analysis. J. AI Data Min. 2013, 1, 1–11. [Google Scholar]
- Park, H.J.; Kim, S.; Han, S.Y.; Ham, S.; Park, K.J.; Choi, J.H. Machine Health Assessment Based on an Anomaly Indicator Using a Generative Adversarial Network. Int. J. Precis. Eng. Manuf. 2021, 22, 1113–1124. [Google Scholar] [CrossRef]
- Shang, Y. Study on Photovoltaic Power Short-Term Forecast Based on Improved GRNN; Nanjing University of Posts and Telecommunications: Nanjing, China, 2018. [Google Scholar]
- Zhang, X. Research on Large-Scale PV Array Power Simulation System and Fault Diagnosis Technology; Qinghai University: Xining, China, 2016. [Google Scholar]
- Spataru, S.; Sera, D.; Kerekes, T.; Teodorescu, R. Diagnostic method for photovoltaic systems based on light I–V measurements. Sol. Energy 2015, 119, 29–44. [Google Scholar] [CrossRef]
- Yan, T. Development of Fault Monitoring System for Photovoltaic Module in Solar Power Station; Jiangsu University: Zhenjiang, China, 2019. [Google Scholar]
- Et-taleby, A.; Chaibi, Y.; Boussetta, M.; Allouhi, A.; Benslimane, M. A novel fault detection technique for PV systems based on the K-means algorithm, coded wireless Orthogonal Frequency Division Multiplexing and thermal image processing techniques. Sol. Energy 2022, 237, 365–376. [Google Scholar] [CrossRef]
- Akram, M.W.; Li, G.Q.; Jin, Y.; Chen, X. Failures of Photovoltaic modules and their Detection: A Review. Appl. Energy 2022, 313, 118822. [Google Scholar] [CrossRef]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Infer. 2000, 90, 227–244. [Google Scholar] [CrossRef]
- Moreno-Torres, J.G.; Raeder, T.; Alaiz-Rodríguez, R.; Chawla, N.V.; Herrera, F. A unifying view on dataset shift in classification. Pattern Recognit. 2012, 45, 521–530. [Google Scholar] [CrossRef]
- Joaquin, Q.-C.; Masashi, S.; Anton, S.; Neil, D.L. When Training and Test Sets Are Different: Characterizing Learning Transfer. In Dataset Shift in Machine Learning; MIT Press: Cambridge, MA, USA, 2009; pp. 3–28. [Google Scholar]
- Schlimmer, J.C.; Granger, R.H. Incremental learning from noisy data. Mach. Learn. 1986, 1, 317–354. [Google Scholar] [CrossRef]
- Liu, A.J.; Song, Y.L.; Zhang, G.Q.; Lu, J. Regional Concept Drift Detection and Density Synchronized Drift Adaptation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 2280–2286. [Google Scholar]
- Tantithamthavorn, C.; Hassan, A.E.; Matsumoto, K. The Impact of Class Rebalancing Techniques on the Performance and Interpretation of Defect Prediction Models. IEEE Trans. Softw. Eng. 2020, 46, 1200–1219. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Boston, MA, USA, 2011; pp. 587–605. [Google Scholar]
- Zhang, Y.H.; Chu, G.; Li, P.P.; Hu, X.G.; Wu, X.D. Three-layer concept drifting detection in text data streams. Neurocomputing 2017, 260, 393–403. [Google Scholar] [CrossRef]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Tsymbal, A.; Pechenizkiy, M.; Cunningham, P.; Puuronen, S. Dynamic integration of classifiers for handling concept drift. Inf. Fusion 2008, 9, 56–68. [Google Scholar] [CrossRef]
- Yu, S.J.; Wang, X.Y.; Príncipe, J.C. Request-and-Reverify: Hierarchical Hypothesis Testing for Concept Drift Detection with Expensive Labels. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 3033–3039. [Google Scholar]
- Dasu, T.; Krishnan, S.; Venkatasubramanian, S. An Information-Theoretic Approach to Detecting Changes in Multi-Dimensional Data Streams; In Interfaces; AT&T Labs: Atlanta, CA, USA, 2006. [Google Scholar]
- Lu, N.; Zhang, G.Q.; Lu, J. Concept drift detection via competence models. Artif. Intell. 2014, 209, 11–28. [Google Scholar] [CrossRef]
- Kifer, D.; Ben-David, S.; Gehrke, J. Detecting Change in Data Streams. VLDB Endow. 2004, 230, 108–133. [Google Scholar]
- Lu, N.; Lu, J.; Zhang, G.Q.; de Mantaras, R.L. A concept drift-tolerant case-base editing technique. Artif. Intell. 2016, 230, 108–133. [Google Scholar] [CrossRef]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Advances in Artificial Intelligence—Sbia 2004, Proceedings of the 17th Brazilian Symposium on Artificial Intelligence, Sao Luis, Maranhao, Brazil, 29 September–1 Ocotber 2004; Lecture Notes in Artificial Intelligence; Bazzan, A.L.C., Labidi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3171, pp. 286–295. [Google Scholar]
- Herbold, S.; Trautsch, A.; Grabowski, J. Global vs. local models for cross-project defect prediction A replication study. Empir. Softw. Eng. 2017, 22, 1866–1902. [Google Scholar] [CrossRef]
- Baena-Garcıa, M.; Campo-Avila, J.d.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams, Philadelphia, PA, USA, 20 August 2006; pp. 77–86. [Google Scholar]
- Ross, G.J.; Adams, N.M.; Tasoulis, D.K.; Hand, D.J. Exponentially weighted moving average charts for detecting concept drift. Pattern Recognit. Lett. 2012, 33, 191–198. [Google Scholar] [CrossRef]
- Barros, R.S.M.; Cabral, D.R.L.; Gonçalves, P.M.; Santos, S. RDDM: Reactive drift detection method. Expert Syst. Appl. 2017, 90, 344–355. [Google Scholar] [CrossRef]
- Liu, A.J.; Zhang, G.Q.; Lu, J. Fuzzy Time Windowing for Gradual Concept Drift Adaptation. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Naples, Italy, 9–12 July 2017. [Google Scholar]
- Frías-Blanco, I.; del Campo-Avila, J.; Ramos-Jiménez, G.; Morales-Bueno, R.; Ortiz-Díaz, A.; Caballero-Mota, Y. Online and Non-Parametric Drift Detection Methods Based on Hoeffding’s Bounds. IEEE Trans. Knowl. Data Eng. 2015, 27, 810–823. [Google Scholar] [CrossRef]
- Gama, J.; Castillo, G. Learning with local drift detection. In Advanced Data Mining and Applications, Proceedings of the International Conference on Advanced Data Mining and Applications, Berlin, Heidelberg, 14 August 2006; Lecture Notes in Artificial Intelligence; Li, X., Zaiane, O.R., Li, Z.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4093, pp. 42–55. [Google Scholar]
- Xu, S.L.; Wang, J.H. Dynamic extreme learning machine for data stream classification. Neurocomputing 2017, 238, 433–449. [Google Scholar] [CrossRef]
- Bifet, A.; Gavaldà, R. Learning from Time-Changing Data with Adaptive Windowing. In Proceedings of the 7th SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; Volume 7. [Google Scholar]
- Gözuaçik, Ö.; Can, F. Concept learning using one-class classifiers for implicit drift detection in evolving data streams. Artif. Intell. Rev. 2021, 54, 3725–3747. [Google Scholar] [CrossRef]
- Bach, S.H.; Maloof, M.A. Paired Learners for Concept Drift. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 23–32. [Google Scholar]
- Nishida, K.; Yamauchi, K. Detecting concept drift using statistical testing. In Proceedings of the 10th International Conference on Discovery Science, Sendai, Japan, 1–4 October 2007; pp. 264–269. [Google Scholar]
- Pesaranghader, A.; Viktor, H.; Paquet, E. Reservoir of diverse adaptive learners and stacking fast hoeffding drift detection methods for evolving data streams. Mach. Learn. 2018, 107, 1711–1743. [Google Scholar] [CrossRef]
- Yu, H.; Liu, W.; Lu, J.; Wen, Y.; Luo, X.; Zhang, G. Detecting group concept drift from multiple data streams. Pattern Recognit. 2023, 134, 109113. [Google Scholar] [CrossRef]
- Rad, R.H.; Haeri, M.A. Hybrid forest: A concept drift aware data stream mining algorithm. arXiv 2019, arXiv:1902.03609. [Google Scholar]
- Song, X.Y.; Wu, M.X.; Jermaine, C.; Ranka, S. Statistical Change Detection for Multi-Dimensional Data. In Proceedings of the 13th International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 667–676. [Google Scholar]
- Alippi, C.; Roveri, M. Just-in-time adaptive classifiers—Part I: Detecting nonstationary changes. IEEE Trans. Neural Netw. 2008, 19, 1145–1153. [Google Scholar] [CrossRef]
- Wang, H.; Abraham, Z. Concept Drift Detection for Streaming Data. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Du, L.; Song, Q.B.; Zhu, L.; Zhu, X.Y. A Selective Detector Ensemble for Concept Drift Detection. Comput. J. 2015, 58, 457–471. [Google Scholar] [CrossRef]
- Maciel, B.I.F.; Santos, S.; Barros, R.S.M. A Lightweight Concept Drift Detection Ensemble. In Proceedings of the 27th IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 1061–1068. [Google Scholar]
- Alippi, C.; Boracchi, G.; Roveri, M. Hierarchical Change-Detection Tests. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 246–258. [Google Scholar] [CrossRef]
- Yu, S.J.; Abraham, Z.; Wang, H.; Shah, M.; Wei, Y.T.; Príncipe, J.C. Concept drift detection and adaptation with hierarchical hypothesis testing. J. Frankl. Inst.-Eng. Appl. Math. 2019, 356, 3187–3215. [Google Scholar] [CrossRef]
- Raza, H.; Prasad, G.; Li, Y.H. EWMA model based shift-detection methods for detecting covariate shifts in non-stationary environments. Pattern Recognit. 2015, 48, 659–669. [Google Scholar] [CrossRef]
- Feng, G.; Zhang, G.; Jie, L.; Chin-Teng, L. Concept drift detection based on equal density estimation. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 24–30. [Google Scholar]
- Hulten, G.; Spencer, L.; Domingos, P. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Domingos, P.; Hulten, G. Mining high-speed data streams. In Proceedings of the Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 71–80.
- Manapragada, C.; Webb, G.; Salehi, M. Extremely Fast Decision Tree. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1953–1962. [Google Scholar]
- Jankowski, D.; Jackowski, K.; Cyganek, B. Learning Decision Trees from Data Streams with Concept Drift. Procedia Comput. Sci. 2016, 80, 1682–1691. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Y.; Shi, P.; Hu, Z. Learning very fast decision tree from uncertain data streams with positive and unlabeled samples. Inf. Sci. 2012, 213, 50–67. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Maloof, M.A. Dynamic weighted majority: A new ensemble method for tracking concept drift. In Proceedings of the 3rd IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; pp. 123–130. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental Learning of Concept Drift in Nonstationary Environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef]
- Oliveira, G.; Minku, L.L.; Oliveira, A.L.I. Tackling Virtual and Real Concept Drifts: An Adaptive Gaussian Mixture Model Approach. IEEE Trans. Knowl. Data Eng. 2023, 35, 2048–2060. [Google Scholar] [CrossRef]
- Severiano, C.A.; Silva, P.C.d.L.e.; Weiss Cohen, M.; Guimarães, F.G. Evolving fuzzy time series for spatio-temporal forecasting in renewable energy systems. Renew. Energy 2021, 171, 764–783. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, J.; Zhang, D.; Liu, Y. An incremental photovoltaic power prediction method considering concept drift and privacy protection. Appl. Energy 2023, 351, 121919. [Google Scholar] [CrossRef]
- Li, J.; Yu, H.; Zhang, Z.; Luo, X.; Xie, S. Concept Drift Adaptation by Exploiting Drift Type. ACM J. 2024, 18, 1–12. [Google Scholar] [CrossRef]
- Cabello-López, T.; Cañizares-Juan, M.; Carranza-García, M.; Garcia-Gutiérrez, J.; Riquelme, J.C. Concept Drift Detection to Improve Time Series Forecasting of Wind Energy Generation. In Hybrid Artificial Intelligent Systems, Proceedings of the 17th International Conference, HAIS 2022, Salamanca, Spain, 5–7 September 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 133–140. [Google Scholar]
- Wu, H.; Elizaveta, D.; Zhadan, A.; Petrosian, O. Forecasting online adaptation methods for energy domain. Eng. Appl. Artif. Intell. 2023, 123, 106499. [Google Scholar] [CrossRef]
- Lee, H.; Lee, J.-G.; Kim, N.-W.; Lee, B.-T. Model-agnostic online forecasting for PV power output. IET Renew. Power Gener. 2021, 15, 3539–3551. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Algorithms |
|---|---|
| Error rate-based | DDM [67] |
| EDDM [69] | |
| ECDD [70] | |
| RDDM [71] | |
| FW-DDM [72] | |
| HDDM [73] | |
| LLDD [74] | |
| DELM [75] | |
| Window-based | ADWIN [76] |
| OCDD [77] | |
| PL [78] | |
| STEPD [79] | |
| FHDDM [80] | |
| GDDM [81] | |
| Data distribution-based | ITA [63] |
| SCD [84] | |
| CM [56] | |
| EDE [91] | |
| LDD-DSDA [66] | |
| Multiple hypothesis testing | JIT [84] |
| LFR [85] | |
| IV-Jac [59] | |
| e-Detector [86] | |
| DDE [87] | |
| HCDTs [87] | |
| HLFR [89] | |
| HHT-CU [62] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Wu, Y.; Zhao, X.; Yang, Y.; Liu, S.; Shi, L.; Wu, Y. Overview of Wind and Photovoltaic Data Stream Classification and Data Drift Issues. Energies 2024, 17, 4371. https://doi.org/10.3390/en17174371
Zhu X, Wu Y, Zhao X, Yang Y, Liu S, Shi L, Wu Y. Overview of Wind and Photovoltaic Data Stream Classification and Data Drift Issues. Energies. 2024; 17(17):4371. https://doi.org/10.3390/en17174371
Chicago/Turabian StyleZhu, Xinchun, Yang Wu, Xu Zhao, Yunchen Yang, Shuangquan Liu, Luyi Shi, and Yelong Wu. 2024. "Overview of Wind and Photovoltaic Data Stream Classification and Data Drift Issues" Energies 17, no. 17: 4371. https://doi.org/10.3390/en17174371
APA StyleZhu, X., Wu, Y., Zhao, X., Yang, Y., Liu, S., Shi, L., & Wu, Y. (2024). Overview of Wind and Photovoltaic Data Stream Classification and Data Drift Issues. Energies, 17(17), 4371. https://doi.org/10.3390/en17174371