1. Introduction
In recent years, there has been a global consensus on the imperative to curtail carbon emissions to mitigate the impacts of global warming stemming from excessive greenhouse gas releases [
1]. Institutionalized carbon trading schemes and carbon pricing policies are considered pivotal drivers in advancing emission reduction goals and facilitating the transition toward a low-carbon economy [
2,
3]. The carbon price, as the fundamental metric within the carbon market, not only mirrors the dynamics of carbon allowance supply and demand but also exerts a significant influence on the decisions of investors and regulators [
4]. Precise forecasting of carbon prices is pivotal for steering investments toward carbon emission mitigation, bolstering the efficacy of emission reduction endeavors and providing a foundation for crafting policies directed at curbing carbon emissions [
5,
6]. However, in contrast to traditional financial markets, the carbon market is relatively young and characterized by an immature market system that is susceptible to external factors such as regulation and policies [
7]. These external factors contribute to significant fluctuations in the carbon price, meaning that the market is characterized by nonlinearity, non-stationarity, and uncertainty [
8], posing a great challenge for carbon price forecasting [
9,
10].
The significance of carbon prices has garnered extensive attention from scholars both domestically and internationally, leading to the development of numerous methods and models for carbon price forecasting. Traditional carbon price forecasting models, such as autoregressive integrated moving average (ARIMA) [
11], support vector regression (SVR) [
12], and random forest (RF) models [
13], have demonstrated certain abilities in carbon price forecasting. However, these models rely heavily on high-quality data and consequently exhibit limited accuracy when confronted with highly volatile carbon price data [
14], constraining their practical applicability. In recent years, deep learning models, such as long short-term memory (LSTM) [
15], gated recurrent unit (GRU) [
16], and other neural networks, have garnered attention for their ability to capture both long-term and short-term dependencies in time-series data. This capability has bestowed upon them an advantage over traditional models in regard to forecasting carbon prices. For example, Li et al. [
17] applied LSTM to forecast carbon prices in Hubei and Guangdong and compared them with traditional models. The results indicate that, from the perspective of the root mean square error (RMSE), the LSTM achieves a performance improvement of 68.07% to 82.09% compared to SVR. Deep learning models are adept at capturing the intricate nonlinear dynamics of carbon prices, substantially improving the precision of predictive models. Nonetheless, challenges such as overfitting and entrapment in local optima can impede their consistent ability to yield accurate forecasts [
18,
19].
Given the inherent volatility and complexity of the carbon market, skepticism regarding the accuracy and reliability of single predictive models has been prevalent, whether employing traditional or deep learning approaches [
20]. To enhance model performance, data decomposition techniques have been introduced into the field of carbon price forecasting, leading to the emergence of hybrid models [
18,
21]. For instance, Wu et al. [
1] combined variational mode decomposition (VMD) with CNN and BiLSTM networks to form a hybrid model, achieving precise prediction of short-term carbon prices in China. Their model outperforms 11 other models in comparative studies, demonstrating superior effectiveness. Liu and Shen [
22] employed a hybrid model combining empirical wavelet transform (EWT) with GRU to forecast the carbon price in the European Union Emissions Trading System (EU-ETS). Empirical research results demonstrate that the hybrid model significantly outperforms models that do not utilize data decomposition techniques in terms of prediction effectiveness and accuracy. Through data decomposition techniques, hybrid models initially decompose highly complex carbon price data into relatively simple subsequences and then combine these subsequences for modeling and forecasting [
23]. In this process, the data decomposition techniques effectively reduce the noise interference in the original data, allowing the model to focus more on extracting regular patterns. This approach can reduce the learning difficulty of the model, which, in turn, improves the prediction accuracy [
24].
In contemporary research pertaining to carbon price forecasting, a significant number of hybrid models that incorporate data decomposition techniques have been found to attain commendable levels of accuracy [
6,
12,
25]. The decomposition methods used by most high-accuracy hybrid models are generally based on the assumption that the waveforms of the training data decomposition and the complete data decomposition are consistent. However, such an assumption ignores the effects of data feature drift [
26]. Li et al. [
27] pointed out that the decomposition process should be updated incrementally with the arrival of new data and that existing one-time decomposition techniques can cause data leakage. One-time decomposition extracts complete data information during the decomposition process, resulting in the decomposition results at a particular time point being affected by future data, thereby exposing future trends during model training [
28]. Data leakage allows models to perform well on test sets but makes them less accurate and reliable when encountering truly unseen data [
23]. Many researchers have realized the data leakage problem caused by one-time decomposition and proposed many solutions to avoid it [
28,
29]. For example, Yan et al. [
23] developed a hybrid model integrating VMD and GUR, which prevents data leakage by sequentially incorporating data points into the decomposition process. However, due to the varying sequence lengths of each input, it is challenging to select an appropriate decomposition level using such a method. Consequently, this approach often encounters issues of over-decomposition and under-decomposition at the beginning and end of the data, leading to suboptimal results [
30]. To resolve the issue of inconsistent decomposition levels while avoiding data leakage, Gao et al. [
31] introduced a technique that employs EWT in conjunction with a sliding window approach for data decomposition. This method entails sliding a window along the original time series and decomposing the data within the window based on a specified decomposition level. Since the decomposition process only involves historical data, with both the sequence length and decomposition level already determined, it effectively prevents data leakage and inconsistencies in decomposition levels. When this data decomposition method is integrated with the Random Vector Functional Link (RVFL) network, the resulting hybrid model demonstrates superior performance compared to eleven other models across twenty publicly available datasets. Regrettably, to our knowledge, no study has yet delved into the issue of data leakage at each stage of model construction within the domain of carbon price forecasting. Further investigation is warranted to understand how data leakage impacts model training, optimization, and practical application processes.
In summary, the nonlinear, non-stationary, and uncertain nature of carbon prices has led to the predominant use of hybrid models that incorporate data decomposition techniques in carbon price forecasting. Data decomposition techniques effectively mitigate noise interference in carbon price data and enhance model performance. However, the incorrect implementation of data decomposition techniques may lead to data leakage, rendering the model highly precise but impractical for real-world applications.
To improve prediction accuracy while avoiding data leakage, this study proposes a leakage-free hybrid carbon price forecasting model named the SWEWT-GRU. First, we propose the sliding window empirical wavelet transform (SWEWT) algorithm to decompose the time-series data into multiple subcomponents within each sliding window, thereby constructing the input data. Next, the data are fed into a multi-layer GRU model, which serves to learn the underlying patterns and features inherent within the data. Finally, the tree-structured Parzen estimator (TPE) algorithm is employed to optimize the hyperparameters of the model, ensuring the stability of the model’s performance and obtaining the final predictions.
The main contributions can be summarized as follows. First, this study addresses the often-neglected issue of data leakage in the carbon price forecasting process, emphasizing the correct application of data decomposition techniques. It serves as a complement to data leakage management within the field of carbon price forecasting [
32]. Furthermore, through comparative experiments on varying levels of data leakage, this study, expanding on the research conducted by Gao et al. [
31], validated the unreliability of the models based on data leakage and provides a deeper understanding of the mechanisms and detrimental impacts of data leakage. Second, the SWEWT algorithm tailored for time-series decomposition is introduced. This method provides an effective solution to data leakage issues by relying exclusively on historical observations during the decomposition process. It scientifically minimizes the fluctuations and instabilities inherent in the original carbon price time-series data, thereby offering an efficient approach for feature decomposition and extraction. Third, based on the SWEWT algorithm, GRU model, and TPE optimization algorithm, the optimized SWEWT-GRU hybrid model proposed in this study can be used as an effective method for carbon price forecasting. By forecasting the closing price of the Guangdong Carbon Emission Allowance (GDEA), this model achieves predictive performance comparable to that of prior studies [
25,
33]. Supported by various comparative experiments, the simulation results confirm the stability and robustness of this model.
The remainder of this paper is organized as follows.
Section 2 explains the mathematical theory of the methodology and introduces the proposed model framework.
Section 3 describes empirical design, including the empirical process and results.
Section 4 provides the conclusions and discusses avenues for future improvements.
4. Conclusions and Implications
To achieve the goal of carbon neutrality, the carbon market is considered an effective instrument. The carbon price, as a key indicator of the carbon market, influences the formulation of carbon trading policies and the decisions of market participants. Accurate carbon price forecasting is beneficial for the healthy development of the carbon market. This study introduces the optimized SWEWT-GRU hybrid model, which significantly enhances the accuracy of carbon price forecasting and demonstrates practical utility in real-world applications. First, the carbon price data are decomposed and denoised using the EWT algorithm while employing the sliding window decomposition method to avoid data leakage. Subsequently, a multilayer GRU model is constructed using both original and decomposed data for prediction. To ensure the stability of the model, the TPE algorithm is utilized for hypertuning. By predicting the closing price of Guangdong Carbon Emission Allowance (GDEA) and conducting comparative experiments from various perspectives, the effectiveness and robustness of the model are evaluated, leading to the following conclusions.
First, by employing rigorous data handling techniques, we not only debunk the myth of “unreal high precision” but also substantially augment the practical applicability of our model. This suggests that data leakage management is necessary in the carbon price forecasting process and that data leakage management practices must be integrated into the forecasting framework to ensure that models are robust and reflect actual market dynamics.
Second, the proposed SWEWT algorithm stands out among other leakage-free decomposition techniques. It offers a dual advantage of mitigating data noise and circumventing the pitfalls of data leakage. This validates the feasibility of implementing specific strategies to mitigate data leakage within the prevalent hybrid models, thereby proposing a trajectory for future enhancements.
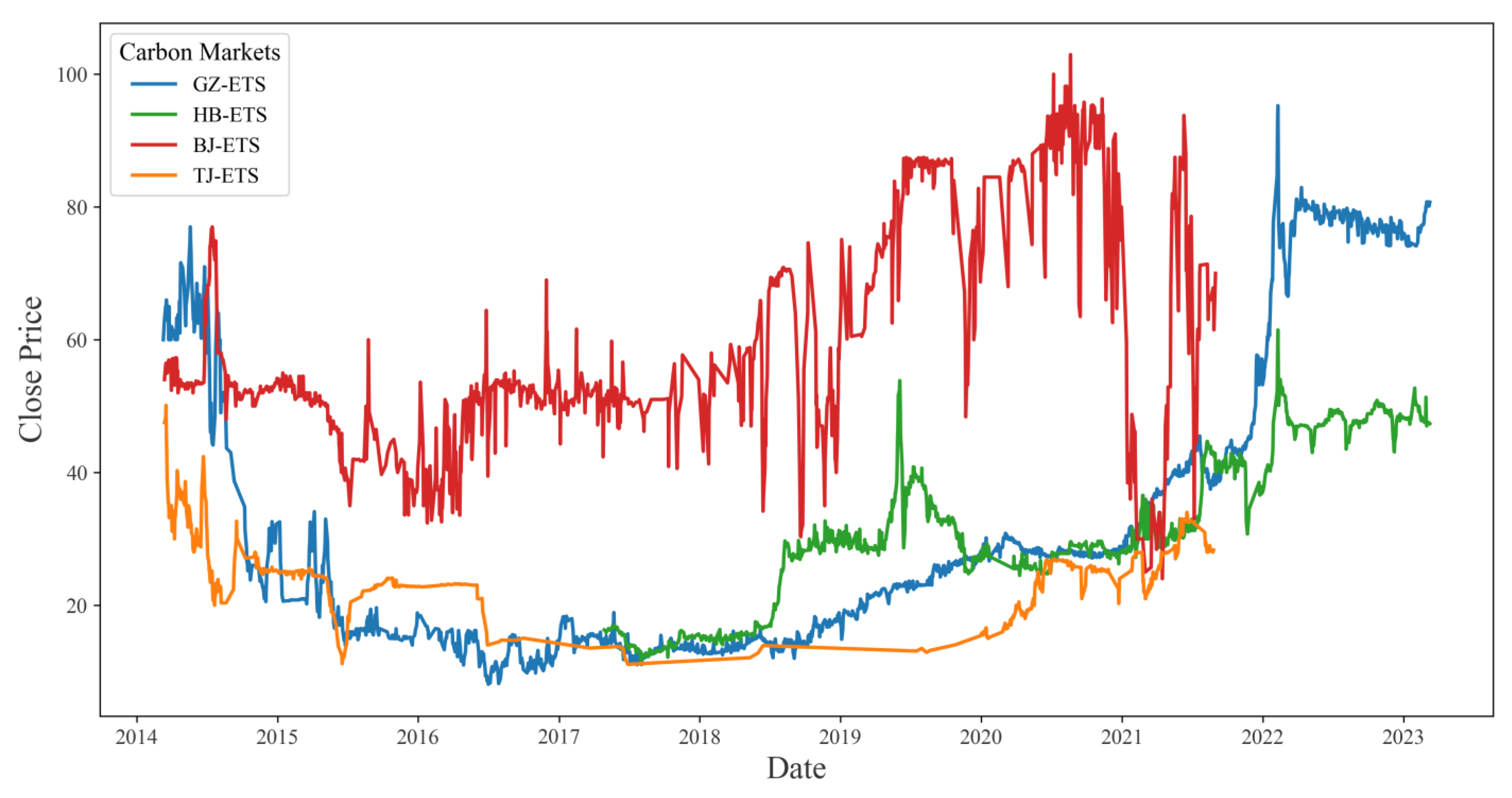
Third, the optimized SWEWT-GRU model represents a successful leakage-free time-series forecasting approach, offering reliable and accurate carbon price predictions. The model not only successfully predicts the trend of carbon trading data in the Guangzhou carbon market but also shows excellent performance in other regional carbon markets, indicating strong generalization capabilities. It offers a trajectory for developing an online carbon price forecasting model, which can facilitate precise market trend analysis for carbon market regulators and participants, thereby contributing to the sustainable growth of the carbon market.
In summary, the proposed SWEWT-GRU model demonstrates high accuracy and stability in carbon price forecasting. Its structural rationality and generalization capability have been validated, highlighting its promising application potential and reference value. However, the hybrid model proposed still has limitations. First, previous studies have shown that carbon price fluctuations are influenced by various factors, such as international markets, energy prices, and weather [
5,
19,
24]; however, this study considers only the situation of the carbon emissions trading market itself. Second, due to hardware constraints, this study adopts the GRU model, which has a relatively simple architecture, as the basic forecasting model. It would be worthwhile to compare it with emerging models such as TimesNet [
49] or Transformer [
50]. Finally, the EWT decomposition scale used in this study is limited to 4. In practical situations, this may result in the discarding of high-frequency signaling components, leading to the loss of some features in the original data [
31]. Further research is needed to investigate how the loss of these features may affect the model’s performance.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}