

Ultra-Short-Term Wind Power Prediction Based on the ZS-DT-PatchTST Combined Model


Abstract
1. Introduction
2. Analysis of Wind Power Data Characteristics
2.1. Analysis of Distribution Shift in Wind Power Data
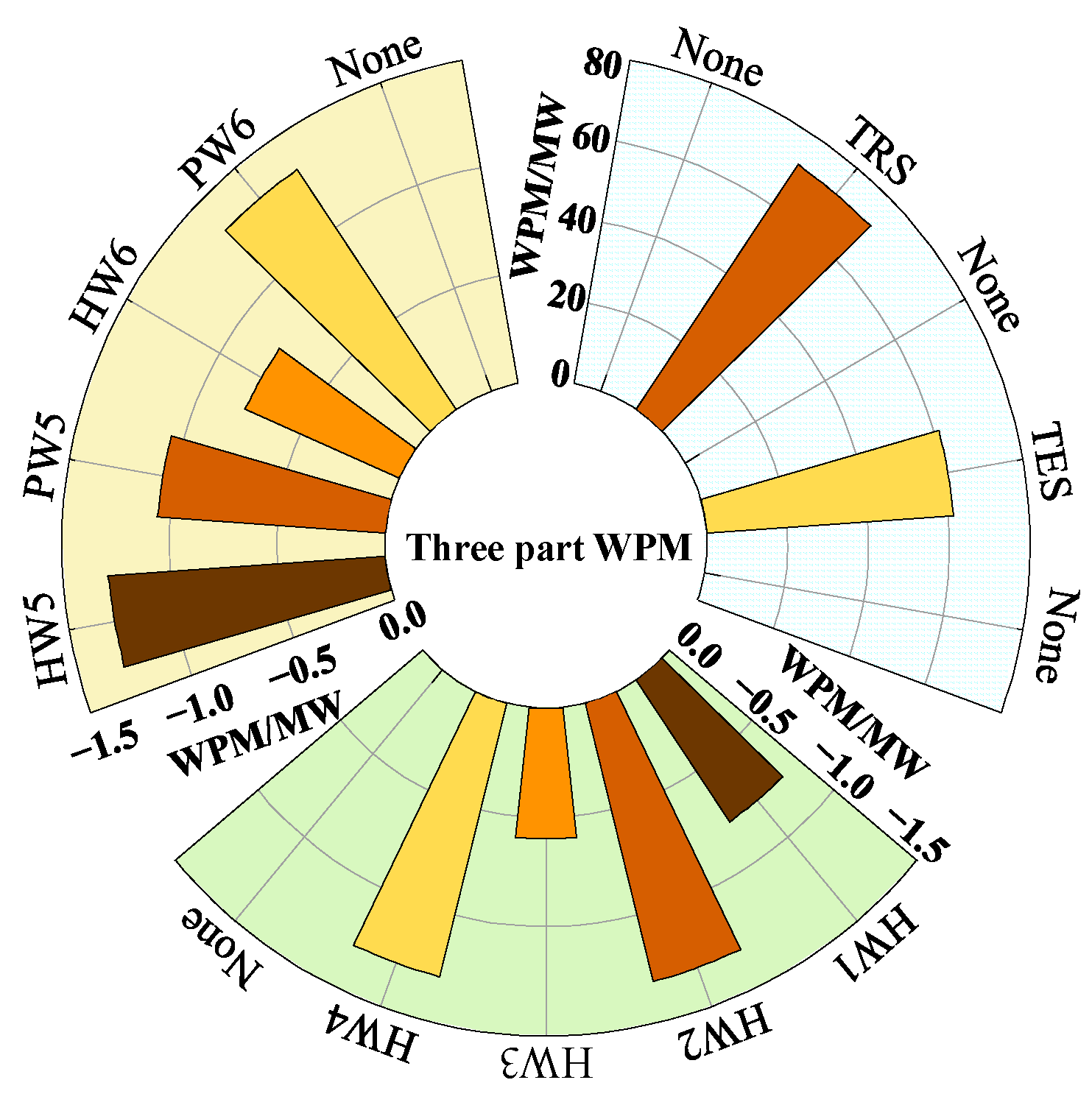
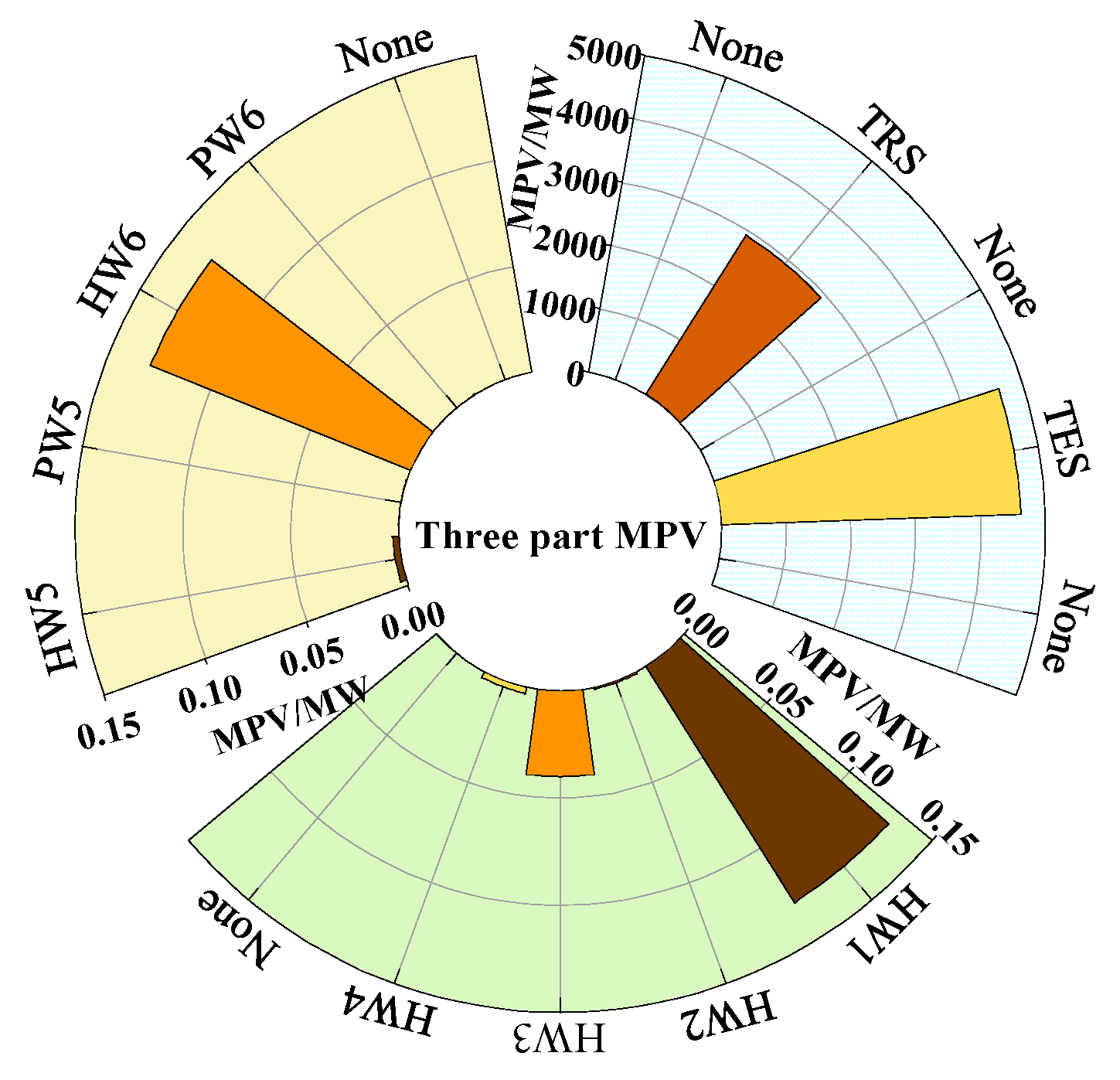
2.1.1. Mean Analysis
2.1.2. Variance Analysis
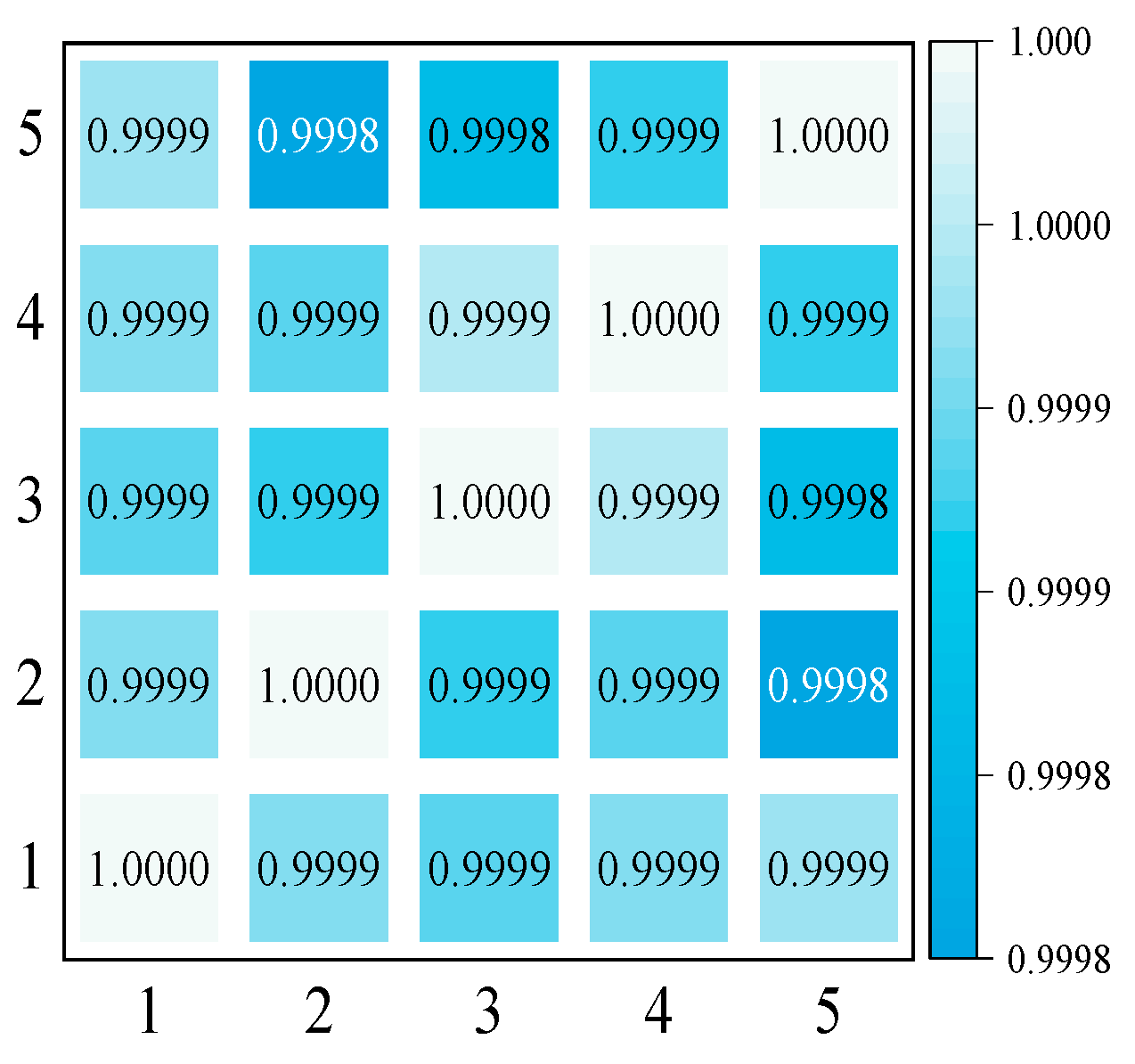
2.2. Analysis of Data Point Correlation in Wind Power Data
3. Prediction Model Based on ZS-DT-PatchTST
3.1. ZS Module
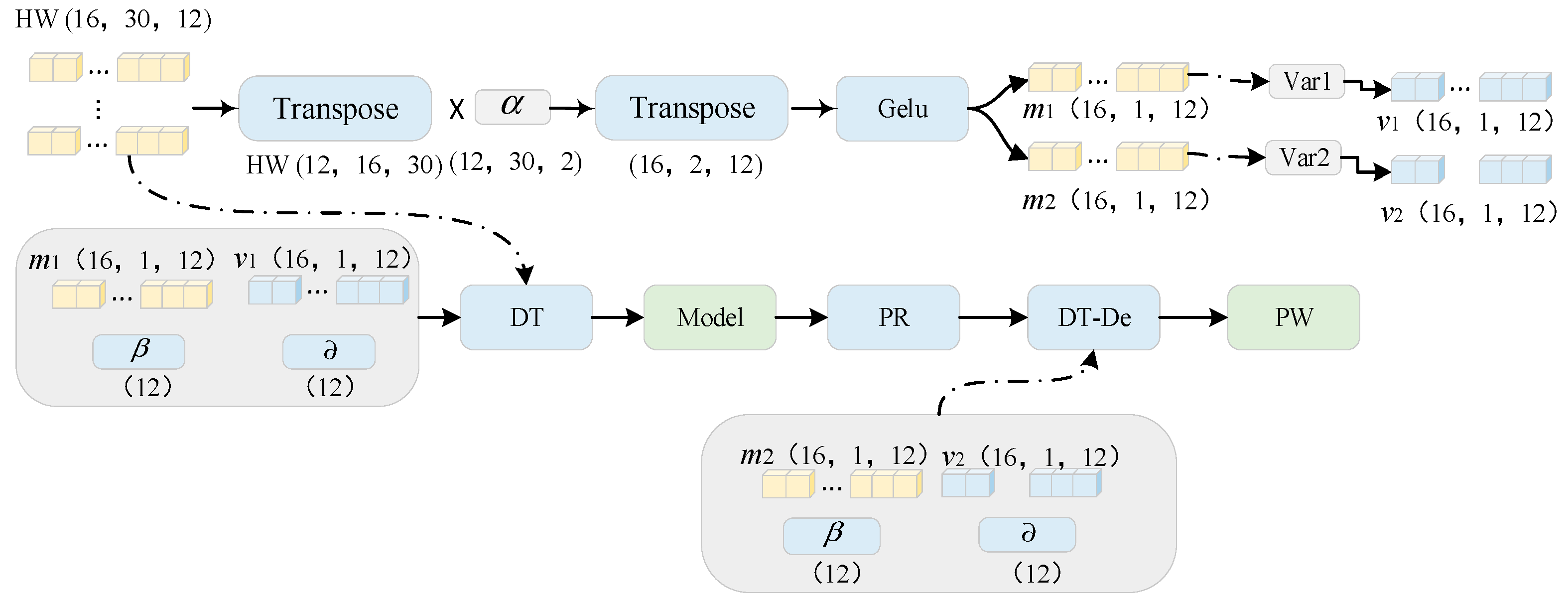
3.2. DT Module
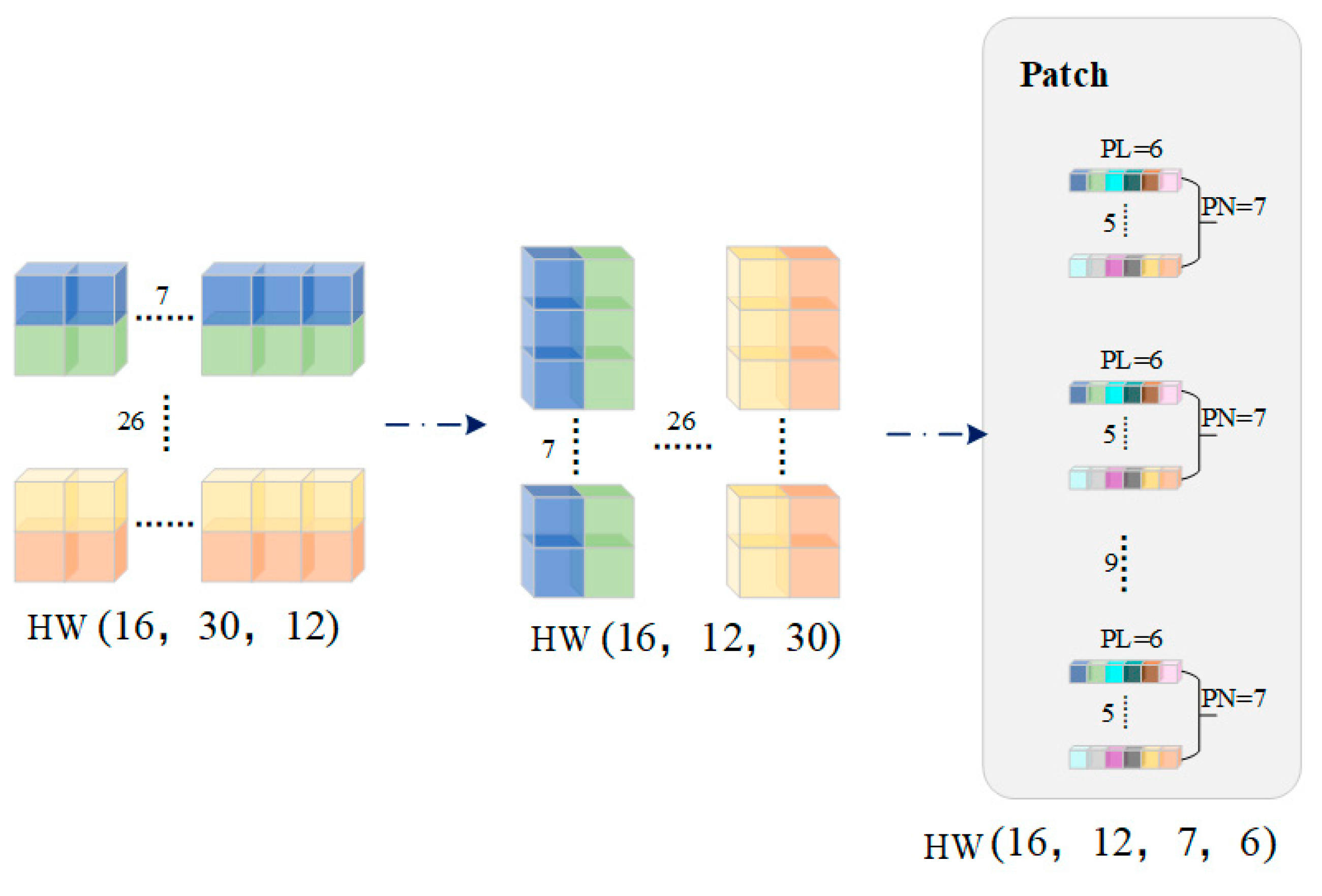
3.3. Patch Module
3.4. Embedding and Encoder
3.5. DT-Std Layer and ZS-De-Std Layer
4. Experimental Analysis
4.1. Evaluation Metrics
4.2. Hyperparametric Analysis
4.2.1. Batch_Size Hyperparameter Analysis
4.2.2. Encoder_Layers Hyperparameter Analysis
4.2.3. Patch_Len Hyperparameter Analysis
4.3. Experimental Results and Analysis
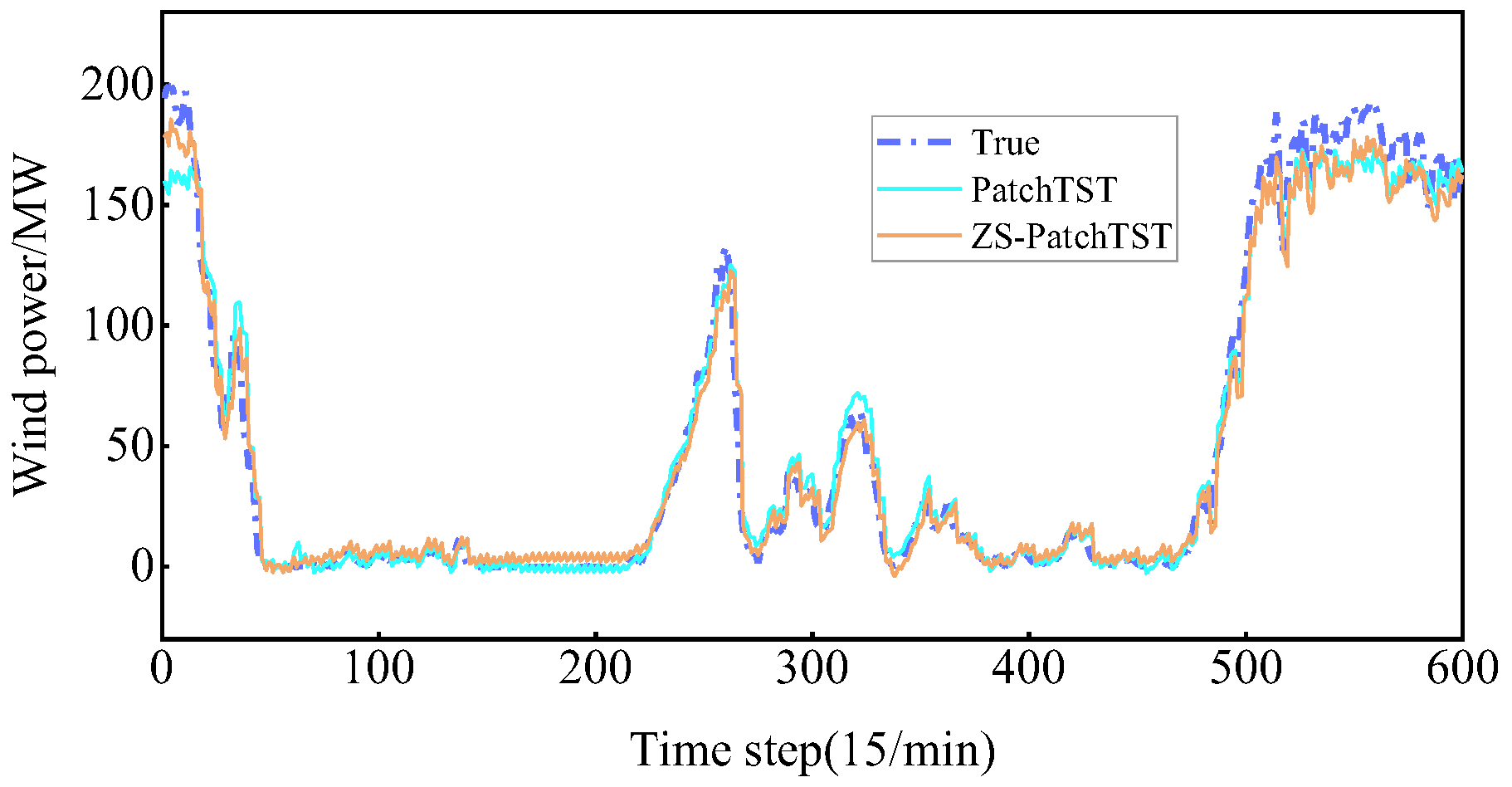
4.3.1. Impact of ZS Standardization on Prediction Results
4.3.2. Impact of DT Standardization on Prediction Results
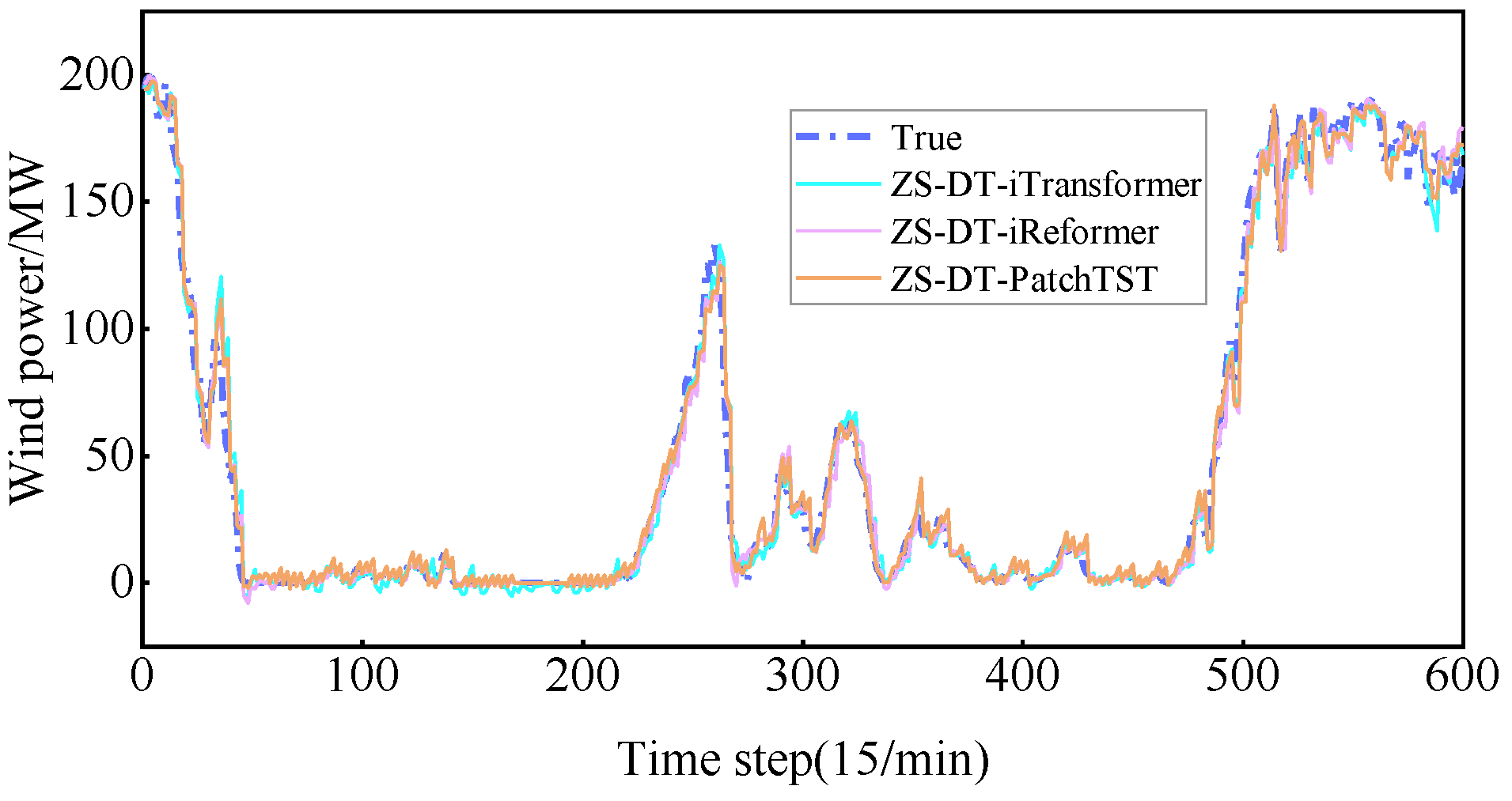
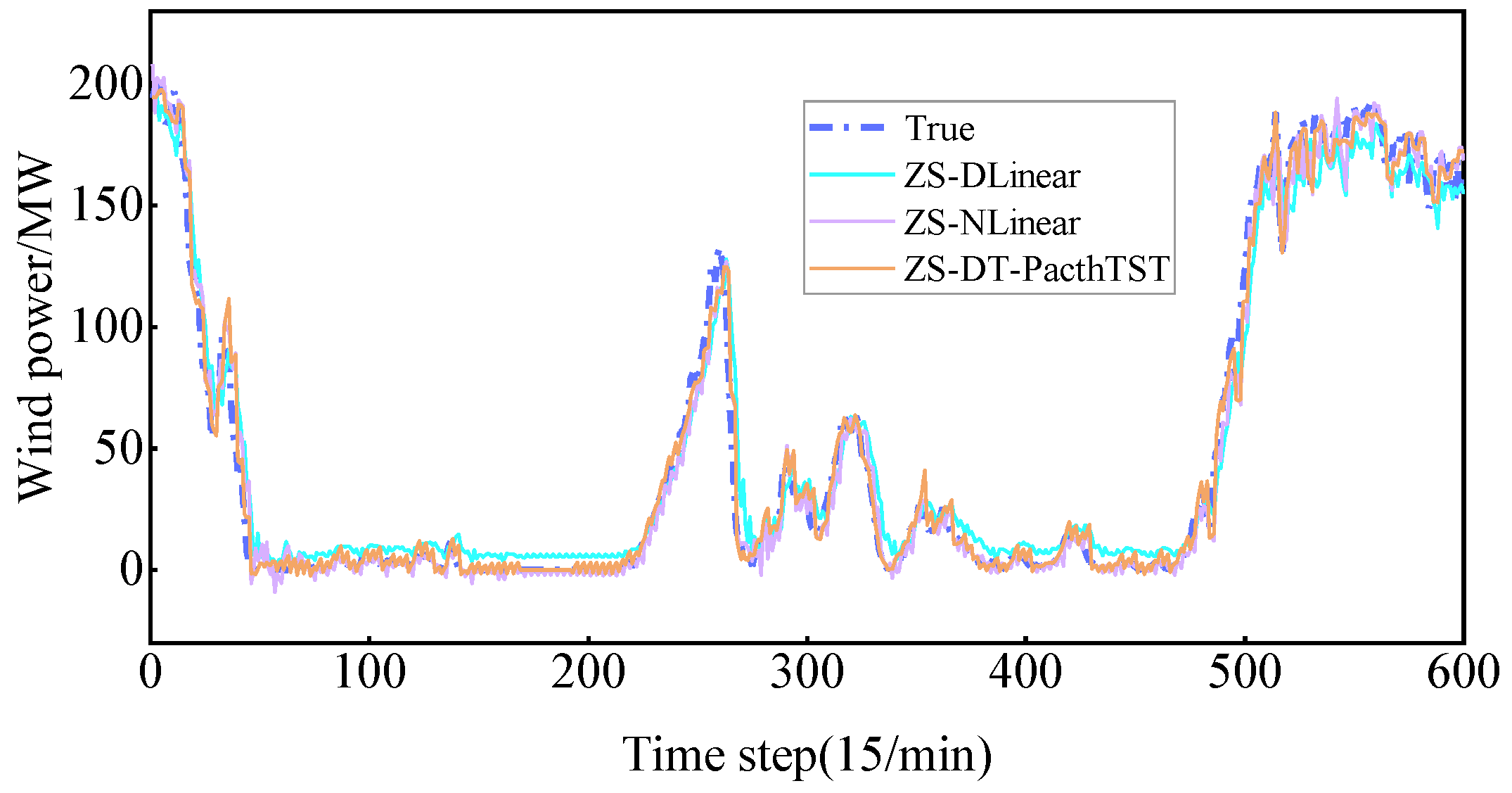
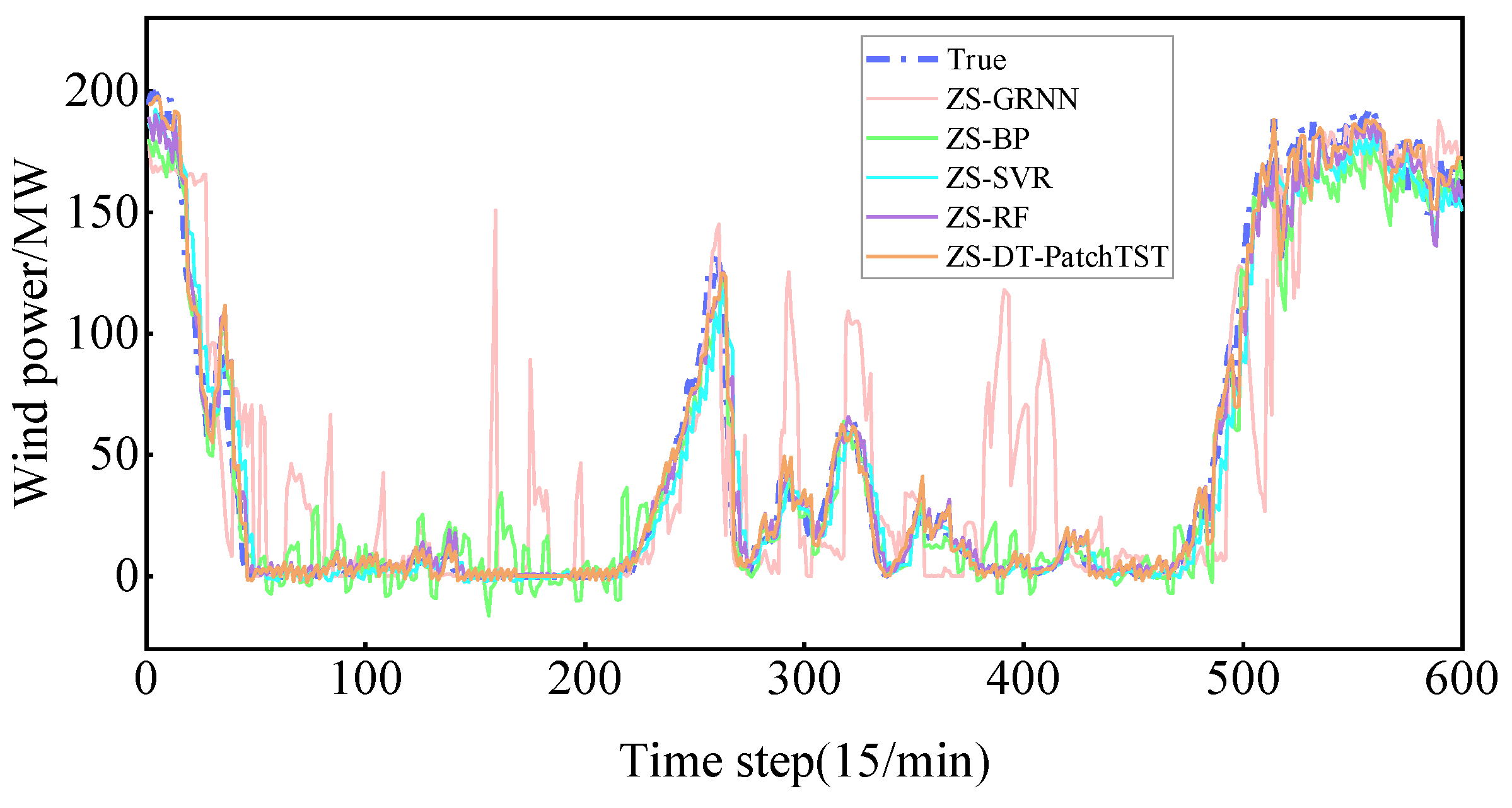
4.3.3. Comparative Analysis of ZS-DT-PatchTST and Common Time Series Prediction Models
- (1)
- Comparative analysis of ZS-DT-PatchTST model and former series models.
- (2)
- Comparison between ZS-DT-PatchTST model and linear models.
- (3)
- Comparison between the ZS-DT-PatchTST model and traditional machine learning models.
- (4)
- Comparison of ZS-DT-PatchTST with LSTM and GRU models.
4.3.4. Prediction Accuracy Analysis of Different Datasets
5. Conclusions
- By incorporating ZS normalization into the PatchTST model to address the distribution shift between training and testing datasets, the MAE and RMSE of the ZS-PatchTST model decreased by 1.03 MW and 2.12 MW, respectively, while the R2 increased by 1.31%. This validates that Z-score normalization can effectively mitigate the impact of distribution shift on model prediction accuracy.
- Building on the solution to the training and testing dataset distribution shift, ZS, RV, and DT were introduced to handle the distribution shift between data windows. The MAE and RMSE of the ZS-DT-PatchTST model decreased by 2.28 MW and 2.11 MW, respectively, compared to the ZS-PatchTST model, and R2 increased by 1.10%. The MAE and RMSE of the ZS-DT-PatchTST model compared to the ZS-RV-PatchTST model decreased by 0.35 MW and 1.10 MW, respectively, with an R2 increase of 0.54%. Similarly, compared to the ZS-ZS-PatchTST model, the MAE and RMSE decreased by 0.31 MW and 1.09 MW, with an R2 increase of 0.54%. This indicates that the problem of window distribution offset in wind power data can lead to a decrease in model prediction accuracy, and the DT model is more effective than ZS and RV in solving the problem of window distribution offset.
- Taking two wind power dataset 1 and wind power dataset 2 with different collection frequencies as benchmarks, the prediction error analysis of this paper’s model and the common time-series prediction model show that the prediction accuracy of this paper’s model is at the highest level in the test set. The MAE and RMSE of the proposed model in wind power dataset 1 are 5.95 MW and 10.89 MW, respectively, with an R2 of 97.38%, and the MAE and RMSE of the proposed model in wind power dataset 2 are 2.27 MW and 3.84 MW, respectively, with an R2 of 97.03%. Thus, using ZS-DT to deal with the problem of wind power data distribution bias and then combined with the PatchTST model to extract local features of wind power data for wind power prediction has certain advantages.
- Although the Z-score algorithm can be standardized by obtaining the mean and variance, thus reducing the impact of the distributional bias between the training set and the test set on the accuracy of model prediction, when the wind power data with a large proportion of anomalies are used, it will obviously affect the value of the mean and variance, which will, to a certain extent, affect the standardization of the dataset and the prediction of the model. Therefore, the selection of different standardization methods for different datasets needs to be followed up with more in-depth research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chang, Y.; Yang, H.; Chen, Y.X.; Zhou, M.R.; Yang, H.B.; Wang, Y.; Zhang, Y.R. A Hybrid Model for Long-Term Wind Power Forecasting Utilizing NWP Subsequence Correction and Multi-Scale Deep Learning Regression Methods. IEEE Trans. Sustain. Energy 2024, 15, 263–275. [Google Scholar] [CrossRef]
- Ahmadi, A.; Nabipour, M.; Mohammadi-Ivatloo, B.; Amani, A.M.; Rho, S.; Piran, M.J. Long-Term Wind Power Forecasting Using Tree-Based Learning Algorithms. IEEE Access 2020, 8, 151511–151522. [Google Scholar] [CrossRef]
- Papadopoulos, P.; Fallahi, F.; Yildirim, M.; Ezzat, A.A. Joint Optimization of Production and Maintenance in Offshore Wind Farms: Balancing the Short- and Long-Term Needs of Wind Energy Operation. IEEE Trans. Sustain. Energy 2024, 15, 835–846. [Google Scholar] [CrossRef]
- Xu, H.S.; Fan, G.L.; Kuang, G.F.; Song, Y.P. Construction and Application of Short-Term and Mid-Term Power System Load Forecasting Model Based on Hybrid Deep Learning. IEEE Access 2023, 11, 37494–37507. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, S.K. A Novel Two-Stage Framework for Mid-Term Electric Load Forecasting. IEEE Trans. Ind. Inform. 2024, 20, 247–255. [Google Scholar] [CrossRef]
- Sun, Z.X.; Zhao, S.S.; Zhang, J.X. Short-Term Wind Power Forecasting on Multiple Scales Using VMD Decomposition, K-Means Clustering and LSTM Principal Computing. IEEE Access 2019, 7, 166917–166929. [Google Scholar] [CrossRef]
- Zhao, M.L.; Zhou, X. Multi-Step Short-Term Wind Power Prediction Model Based on CEEMD and Improved Snake Optimization Algorithm. IEEE Access 2024, 12, 50755–50778. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.J.; Zhang, X.T.; Hou, K.Y.; Hu, J.Y.; Yao, G.Z. An Ultra-Short-Term Wind Power Forecasting Model Based on EMD-EncoderForest-TCN. IEEE Access 2024, 12, 60058–60069. [Google Scholar] [CrossRef]
- Xu, H.L.; Zhang, Y.R.; Zhen, Z.; Xu, F.; Wang, F. Adaptive Feature Selection and GCN With Optimal Graph Structure-Based Ultra-Short-Term Wind Farm Cluster Power Forecasting Method. IEEE Trans. Ind. Appl. 2024, 60, 1804–1813. [Google Scholar] [CrossRef]
- Li, Z.; Ye, L.; Zhao, Y.N.; Pei, M.; Lu, P.; Li, Y.L.; Dai, B.H. A Spatiotemporal Directed Graph Convolution Network for Ultra-Short-Term Wind Power Prediction. IEEE Trans. Sustain. Energy 2023, 14, 39–54. [Google Scholar] [CrossRef]
- An, G.Q.; Jiang, Z.Y.; Cao, X.; Liang, Y.F.; Zhao, Y.Y.; Li, Z.; Dong, W.C.; Sun, H.X. Short-Term Wind Power Prediction Based on Particle Swarm Optimization-Extreme Learning Machine Model Combined With Adaboost Algorithm. IEEE Access 2021, 9, 94040–94052. [Google Scholar] [CrossRef]
- Zhou, W.B.; Xin, M.; Wang, Y.L.; Yang, C.; Liu, S.S.; Zhang, R.Z.; Liu, X.D.; Zhou, L.N. An Ultra-Short-Term Wind Power Prediction Method Based On CNN-LSTM. In Proceedings of the 2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 15–17 March 2024; pp. 1007–1011. [Google Scholar]
- Pan, C.Y.; Wen, S.L.; Zhu, M.; Ye, H.L.; Ma, J.J.; Jiang, S. Hedge Backpropagation Based Online LSTM Architecture for Ultra-Short-Term Wind Power Forecasting. IEEE Trans. Power Syst. 2024, 39, 4179–4192. [Google Scholar] [CrossRef]
- Abedinia, O.; Ghasemi-Marzbali, A.; Shafiei, M.; Sobhani, B.; Gharehpetian, G.B.; Bagheri, M. Wind Power Forecasting Enhancement Utilizing Adaptive Quantile Function and CNN-LSTM: A Probabilistic Approach. IEEE Trans. Ind. Appl. 2024, 60, 4446–4457. [Google Scholar] [CrossRef]
- Saeed, A.; Li, C.S.; Danish, M.; Rubaiee, S.; Tang, G.; Gan, Z.H.; Ahmed, A. Hybrid Bidirectional LSTM Model for Short-Term Wind Speed Interval Prediction. IEEE Access 2020, 8, 182283–182294. [Google Scholar] [CrossRef]
- Sheng, A.D.; Xie, L.W.; Zhou, Y.X.; Wang, Z.; Liu, Y.C. A Hybrid Model Based on Complete Ensemble Empirical Mode Decomposition with Adaptive Noise, GRU Network and Whale Optimization Algorithm for Wind Power Prediction. IEEE Access 2023, 11, 62840–62854. [Google Scholar] [CrossRef]
- Yin, K.; Yang, Y.; Yao, C.P.; Yang, J.W. Long-Term Prediction of Network Security Situation Through the Use of the Transformer-Based Model. IEEE Access 2022, 10, 56145–56157. [Google Scholar] [CrossRef]
- Han, C.J.; Ma, T.; Gu, L.H.; Cao, J.D.; Shi, X.L.; Huang, W.; Tong, Z. Asphalt Pavement Health Prediction Based on Improved Transformer Network. IEEE Trans. Int. Transp. Syst. 2023, 24, 4482–4493. [Google Scholar] [CrossRef]
- Fauzi, N.A.; Ali, N.H.N.; Ker, P.J.; Thiviyanathan, V.A.; Leong, Y.S.; Sabry, A.H.; Jamaludin, M.Z.B.; Lo, C.K.; Mun, L.H. Fault Prediction for Power Transformer Using Optical Spectrum of Transformer Oil and Data Mining Analysis. IEEE Access 2020, 8, 136374–136381. [Google Scholar] [CrossRef]
- Wang, X.H.; Xia, M.C.; Deng, W.W. MSRN-Informer: Time Series Prediction Model Based on Multi-Scale Residual Network. IEEE Access 2023, 11, 65059–65065. [Google Scholar] [CrossRef]
- Bi, C.; Ren, P.; Yin, T.; Zhang, Y.; Li, B.; Xiang, Z. An Informer Architecture-Based Ionospheric foF2 Model in the Middle Latitude Region. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1005305. [Google Scholar] [CrossRef]
- Pan, G.L.; Wu, Q.H.; Ding, G.R.; Wang, W.; Li, J.; Zhou, B. An Autoformer-CSA Approach for Long-Term Spectrum Prediction. IEEE Wireless Commun. Lett. 2023, 12, 1647–1651. [Google Scholar] [CrossRef]
- Yang, C.; Yang, C.J.; Zhang, X.M.; Zhang, J.F. Multisource Information Fusion for Autoformer: Soft Sensor Modeling of FeO Content in Iron Ore Sintering Process. IEEE Trans. Ind. Inform. 2023, 19, 11584–11595. [Google Scholar] [CrossRef]
- Nie, Y.Q.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series is Worth 64 Words: Long-Term Forecasting with TransformErs. arXiv 2022, arXiv:2211.14730. [Google Scholar]
- Liu, Y.; Wang, W.; Chang, L.Q.; Tang, J. MSWI Multi-Temperature Prediction Based on Patch Time Series Transformer. In Proceedings of the 2024 36th Chinese Control and Decision Conference (CCDC), Xi’an, China, 25–27 May 2024; pp. 2369–2373. [Google Scholar]
- Zhang, L.L.; Shi, Y.; Jin, X.; Xu, S.J.; Wang, C.Y.; Liu, F.X. Water Quality Index Forecasting via Transformers: A Comparative Experimental Study. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 8114–8119. [Google Scholar]
- Yaro, A.S.; Maly, F.; Prazak, P.; Malý, K. Outlier Detection Performance of a Modified Z-Score Method in Time-Series RSS Observation with Hybrid Scale Estimators. IEEE Access 2024, 12, 12785–12796. [Google Scholar] [CrossRef]
- Liu, L.; Li, C.X.; Li, X.; Ge, Q.B. State of Energy Estimation of Electric Vehicle Based on GRU-RNN. In Proceedings of the 2022 37th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Beijing, China, 19–20 November 2022; pp. 115–120. [Google Scholar]
- Kim, T.; Kim, J.; Tae, Y.; Park, C.; Choi, J.; Choo, J. Reversible Instance Normalization for Accurate Time-Series Forecasting Against Distribution Shift. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 25–29 April 2022; pp. 1–25. [Google Scholar]
- Liu, Y.; Wu, H.X.; Wang, J.M.; Long, M.S. Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 9881–9893. [Google Scholar]
- Jha, A.; Dorkar, O.; Biswas, A.; Emadi, A. iTransformer Network Based Approach for Accurate Remaining Useful Life Prediction in Lithium-Ion Batteries. In Proceedings of the 2024 IEEE Transportation Electrification Conference and Expo (ITEC), Chicago, IL, USA, 19–21 June 2024; pp. 1–8. [Google Scholar]
- Fan, W.; Wang, P.Y.; Wang, D.K.; Wang, D.J.; Zhou, Y.C.; Fu, Y.J. Dish-Ts: A General Paradigm for Alleviating Distribution Shift in Time Series Forecasting. In Proceedings of the 2023 37th AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; pp. 7522–7529. [Google Scholar]
- Wu, J.J.; Guo, Y. Degradation Prediction of Proton Exchange Membrane Fuel Cell Considering Distribution Shift. In Proceedings of the 2023 7th International Conference on Electrical, Mechanical and Computer Engineering (ICEMCE), Xian, China, 20–22 October 2023; pp. 443–447. [Google Scholar]
- Kwok, W.M.; Streftaris, G.; Dass, S.C. A Novel Target Value Standardization Method Based on Cumulative Distribution Functions for Training Artificial Neural Networks. In Proceedings of the 2023 IEEE 13th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 20–21 May 2023; pp. 250–255. [Google Scholar]
- LI, G.; Ning, X.; Gong, W.L.; Zhou, L.H.; Guo, W.W. Evaluation Method of Distribution Network State Based on IT-II-Fuzzy K-means Clustering Algorithm for Imbalanced Data under PIOT. In Proceedings of the 2022 Asian Conference on Frontiers of Power and Energy (ACFPE), Chengdu, China, 21–23 October 2022; pp. 211–215. [Google Scholar]
- Shi, Z.H.; Xiao, J.; Jiang, J.H.; Zhang, Y.; Zhou, Y.H. Identifying Reliability High-Correlated Gates of Logic Circuits with Pearson Correlation Coefficient. IEEE Trans. Circuits Syst. 2024, 71, 2319–2323. [Google Scholar] [CrossRef]
- Zhao, Q.C.; Zhang, Y.Y.; Zhao, Z.Q.; Nie, Z.P. A Joint Inversion Approach of Electromagnetic and Acoustic Data Based on Pearson Correlation Coefficient. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704911. [Google Scholar] [CrossRef]
- Calik, N.; Güneş, F.; Koziel, S.; Pietrenko-Dabrowska, A.; Belen, M.A.; Mahouti, P. Deep-Learning-Based Precise Characterization of Microwave Transistors Using Fully-Automated Regression Surrogates. Sci. Rep. 2023, 13, 1445. [Google Scholar] [CrossRef]
- Hanifi, S.; Cammarono, A.; Zare-Behtash, H. Advanced Hyperparameter Optimization of Deep Learning Models for Wind Power Prediction. Renew. Energy 2024, 221, 119700. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Feature Name |
|---|---|
| 1 | Wind speed at height of 10 m (m/s) |
| 2 | Wind direction at height of 10 m (°) |
| 3 | Wind speed at height of 30 m (m/s) |
| 4 | Wind direction at height of 30 m (°) |
| 5 | Wind speed at height of 50 m (m/s) |
| 6 | Wind direction at height of 50 m (°) |
| 7 | Wind speed at the height of wheel hub (m/s) |
| 8 | Wind direction at the height of wheel hub (°) |
| 9 | Air temperature (°C) |
| 10 | Atmosphere pressure (hpa) |
| 11 | Relative humidity (%) |
| 12 | Wind Power (MW) |
| Hyperparameter Name | Parameter Setting |
|---|---|
| Batch_size | 16 |
| Train_epochs | 30 |
| D_model | 512 |
| H_heads | 8 |
| Encoder_layers | 3 |
| Patch_len | 6 |
| Stride | 4 |
| Dropout | 0.05 |
| Learning_rate | Adaptive Optimization |
| Parameter Values | MAE/MW | RMSE/MW | Time/s |
|---|---|---|---|
| 8 | 6.69 | 11.74 | 506.75 |
| 12 | 6.60 | 11.86 | 483.75 |
| 16 | 5.95 | 10.89 | 465.03 |
| 20 | 6.67 | 11.79 | 457.85 |
| 24 | 6.49 | 11.69 | 717.24 |
| Parameter Values | MAE/MW | RMSE/MW | Time/s |
|---|---|---|---|
| 1 | 6.59 | 11.66 | 162.14 |
| 2 | 7.02 | 11.89 | 317.34 |
| 3 | 5.95 | 10.89 | 465.03 |
| 4 | 6.23 | 11.35 | 1547.77 |
| Parameter Values | MAE/MW | RMSE/MW | Time/s |
|---|---|---|---|
| 4 | 6.92 | 11.74 | 465.32 |
| 5 | 6.65 | 11.67 | 416.81 |
| 6 | 5.95 | 10.89 | 465.03 |
| 7 | 6.66 | 11.65 | 308.79 |
| 8 | 6.28 | 11.58 | 257.45 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| PatchTST | 9.26 | 15.12 | 94.97 |
| ZS-PatchTST | 8.23 | 13.00 | 96.28 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS-PatchTST | 8.23 | 13.00 | 96.28 |
| ZS-RV-PatchTST | 6.30 | 11.99 | 96.84 |
| ZS-ZS-PatchTST | 6.26 | 11.98 | 96.84 |
| ZS-DT-PatchTST | 5.95 | 10.89 | 97.38 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS-DT-Transformer | 8.27 | 12.95 | 96.33 |
| ZS-DT-Informer | 7.98 | 12.45 | 96.61 |
| ZS-DT-Reformer | 7.11 | 12.18 | 96.74 |
| ZS-DT-NsTransformer | 6.60 | 11.64 | 97.02 |
| ZS-DT-iTransformer | 6.20 | 11.61 | 97.07 |
| ZS-DT-iReformer | 6.25 | 11.81 | 96.93 |
| ZS-DT-PatchTST | 5.95 | 10.89 | 97.38 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS-DLinear | 10.66 | 15.75 | 94.55 |
| ZS-NLinear | 7.19 | 12.92 | 96.33 |
| ZS-DT-PatchTST | 5.95 | 10.89 | 97.38 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS-GRNN | 25.51 | 38.73 | 70.10 |
| ZS-BP | 11.12 | 18.08 | 92.82 |
| ZS-SVR | 9.56 | 16.13 | 94.29 |
| ZS-RF | 7.42 | 12.72 | 96.45 |
| ZS-DT-PatchTST | 5.95 | 10.89 | 97.38 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS-TCN-BiGRU | 10.00 | 15.09 | 94.99 |
| ZS-LSTM | 9.21 | 13.10 | 96.22 |
| ZS-GRU | 8.86 | 12.76 | 96.41 |
| ZS-BiLSTM | 6.99 | 11.94 | 96.86 |
| ZS-DT-PatchTST | 5.95 | 10.89 | 97.38 |
| Model | MAE/MW | RMSE/MW | R2/% |
|---|---|---|---|
| ZS–Autoformer | 3.11 | 4.82 | 95.33 |
| ZS–Informer | 2.99 | 4.50 | 95.99 |
| ZS-TCN-BiGRU | 3.31 | 4.57 | 95.79 |
| ZS-LSTM | 2.74 | 4.33 | 96.22 |
| ZS-DLinear | 5.13 | 7.28 | 90.10 |
| ZS-NLinear | 2.76 | 4.29 | 96.31 |
| ZS-GRNN | 3.83 | 5.87 | 93.17 |
| ZS-SVR | 3.36 | 5.29 | 94.44 |
| ZS-DT-PatchTST | 2.27 | 3.84 | 97.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Xing, F.; Kang, L.; Zhang, M.; Qin, C. Ultra-Short-Term Wind Power Prediction Based on the ZS-DT-PatchTST Combined Model. Energies 2024, 17, 4332. https://doi.org/10.3390/en17174332
Gao Y, Xing F, Kang L, Zhang M, Qin C. Ultra-Short-Term Wind Power Prediction Based on the ZS-DT-PatchTST Combined Model. Energies. 2024; 17(17):4332. https://doi.org/10.3390/en17174332
Chicago/Turabian StyleGao, Yanlong, Feng Xing, Lipeng Kang, Mingming Zhang, and Caiyan Qin. 2024. "Ultra-Short-Term Wind Power Prediction Based on the ZS-DT-PatchTST Combined Model" Energies 17, no. 17: 4332. https://doi.org/10.3390/en17174332
APA StyleGao, Y., Xing, F., Kang, L., Zhang, M., & Qin, C. (2024). Ultra-Short-Term Wind Power Prediction Based on the ZS-DT-PatchTST Combined Model. Energies, 17(17), 4332. https://doi.org/10.3390/en17174332