Abstract
Amidst the global pursuit of environmental sustainability, the concurrent trends of decarbonization and intelligentization have emerged as critical strategic priorities. However, the interplay between these phenomena, particularly within the logistics sector, remains an underexplored area. This study investigates the complex dynamics between logistics intelligentization and decarbonization across 29 provinces in China from 2006 to 2019, providing a fresh perspective on a globally relevant issue. By employing Differential GMM, Systematic GMM, and instrumental variable-based GMM models, we evaluate the impact of logistics intelligence on carbon emissions while effectively addressing endogeneity issues inherent in the empirical analysis. Our findings reveal that the advancement of intelligent logistics correlates positively with increased carbon emissions, highlighting a significant incompatibility between decarbonization objectives and intelligentization efforts within the logistics sector. Additionally, we identify mediating pathways—specifically scale, structure, and technology effects—and moderating mechanisms that influence this relationship. These insights underscore the need for policymakers to establish environmental standards for intelligent technology adoption and to promote initiatives that reconcile intelligentization with sustainability goals. Ultimately, our study provides critical guidance for promoting sustainable and smart industrial growth in the logistics sector.
1. Introduction
Since 2006, China has been the world’s leading emitter of CO2, prompting the nation to set ambitious “dual-carbon” targets: achieving a carbon peak by 2030 and carbon neutrality by 2060. The logistics sector, a significant driver of China’s economy, stands out as a notable contributor to the nation’s carbon emissions. According to data from the Carbon Emission Accounts & Database (CEAD), the logistics industry has experienced a significant increase in carbon emissions, surging from 130.2 million tons in 1997 to 732.5 million tons in 2019. In addition, the industry’s total energy consumption has steadily increased from 261 million tons in 2010 to 439 million tons of standard coal equivalent in 2019. Notably, with the rapid growth of cross-border e-commerce, China’s logistics sector is actively expanding its reach overseas, underscoring the sector’s critical role in energy conservation and emission reduction efforts not only within China, but also globally.
Another global trend in the logistics industry is the rapid intelligentization propelled by advancements in artificial intelligence, automation and other technologies. This wave of digital transformation has been considered to not only redefine operational efficiencies, but is also increasingly guiding the path towards sustainable and decarbonized growth. For example, paperless shipping with emerging techniques such as Blockchain can decrease materials and energy consumption, enhance operational efficiency, and facilitate industrial restructuring, resulting in reductions in both carbon dioxide emissions and operation expenses [1,2,3]).
However, there is a growing body of research showing that intelligent technologies have considerably expanded demand in transportation and warehousing, thus leading to the growth of carbon emissions related to logistics [4,5,6]. This highlights the complexity of the nexus between intelligentization and decarbonization: intelligentization within the logistics industry holds the potential to significantly contribute to carbon dioxide emission reduction, but this potential can only be realized when it is congruent with the industry’s structure. This structure is inherently shaped by factor endowments and their configuration at specific stages of development [7]. Therefore, a lack of any proper understanding of the intelligentization–decarbonization nexus, coupled with the neglect of policy objectives that balance intelligentization and decarbonization, could lead to suboptimal outcomes in environmental sustainability. Particularly considering the extensive spatial distribution of the logistics industry, improper government guidance or industry planning could exacerbate uneven carbon emissions across regions, potentially undermining global efforts towards achieving the Paris Agreement goals.
The existing literature presents conflicting conclusions regarding their relationship, especially in the context of the logistics industry, pointing to a crucial gap in understanding how intelligence interacts with carbon emissions from the logistics sector in a holistic manner. To address the gap, this study employs panel data from the logistics industry from 29 provinces in China spanning from 2006 to 2019. First, we developed a method to evaluate compatibility between intelligentization and decarbonization development in the logistics industry. Then, we established a dynamic panel difference GMM model and a system GMM model to estimate the impacts of intelligence level change on decarbonization. We also introduced several innovative instrumental variables to solve the endogeneity issues in the model at multiple levels. Besides this, we explored the three mediation mechanisms of scale effect, technology effect, and structure effect, further deconstructing the internal connection between intelligentization and decarbonization in the logistics industry. The conclusions reveal that, within the period of 2006 to 2019, the intelligence level of logistics led to an increase in the growth of carbon emissions in the industry, demonstrating a lack of compatibility between intelligentization and decarbonization. The development of regional economic strength, market openness, and transportation efficiency mitigated the impact of intelligentization.
Our research makes several significant contributions to the existing literature. First, we have proposed a comprehensive metric for evaluating the level of intelligentization, offering a more nuanced understanding of digital transformation in logistics. In previous studies, we can see an absence of a universally recognized metric for quantifying the level of intelligence, particularly within the logistics industry. Previous researchers have often employed proxies such as the number of patents, online sales or the adoption of specific digital technologies [8,9]. Yet, these indicators display a lack of comprehensiveness, which may lead to an inaccurate assessment of the true state of digitalization. Second, we employed sophisticated econometric models that account for the inherent endogeneity between intelligentization and carbon emissions. In previous studies, an endogenous relationship between the two variables is evident, for instance, the deployment of intelligent technologies may initially increase energy consumption and carbon emissions due to the increasing demand [10,11]. The hidden shifts in market demand due to digitalization can alter the dynamics of the logistics industry, further complicating the assessment of its impact on carbon emissions. In our research, we established a dynamic panel difference GMM model and a system GMM model for estimation, overcoming the potential shortcomings of the static models that existing literature has commonly used. Finally, we thoroughly investigated the mediating effects of scale, technology, and structural factors, deepening the understanding of how intelligentization can be aligned with decarbonization efforts. Our findings underscore the complex trade-offs faced by policymakers in balancing intelligentization and carbon reduction objectives, providing them with empirical recommendations for fostering technological innovation while considering the potential market expansion effects of such technologies. As highlighted by the recent literature, achieving this balance is critical for realizing long-term environmental and economic sustainability [12,13]. This study makes a substantial contribution to this ongoing discourse. In this paper, the following sections include a literature review, a measurement of the intelligence level in logistics, the modeling strategy, a results analysis, and research conclusions and recommendations.
2. Literature Review
The logistics sector has displayed an acceleration in intelligent development in order to enhance industry operations. The concept of intelligent logistics was first introduced by the International Business Machines Corporation (IBM) in 2009. Although the academic community has yet to arrive at a consensus on its precise definition, essentially, it refers to the integration of intelligent technologies and mechanisms to enhance the level of automation and intelligence throughout the entire logistics system [14,15]. Zhao [13] asserts that intelligent transportation and logistics means that people use sensing, analysis, control, and communication technologies to improve traffic management, increase the efficiency of road traffic networks, and reduce environmental costs. According to Yigitcanlar [16], intelligent transportation improves environmental sustainability, and is more flexible in terms of service frequency, site location, coverage, and route. Currently, research in the field of intelligent logistics mainly focuses on advancements in intelligent logistics applications and innovative intelligent logistics operational models [17,18].
Some studies have analyzed the beneficial effects of intelligence on growth in the logistics industry. The early research of Kanninen [19] discussed how intelligent transport systems would solve the congestion problem and achieve economic efficiency in the industry. Banister [20] claimed that the advancement of information and communication technology can enhance transportation accessibility effectively. A recent study of Liu et al. [8] investigated the effects of intelligent logistics on the shareholder value of 149 listed Chinese logistic companies. They found that developing intelligent logistics policy can significantly improve those companies’ performance in the stock market. Moreover, the development of intelligence expands the market demand for logistics services [10] (Kos-Labedowicz et al. 2017). Samir et al. [9] examined how transport and logistics affected economic growth in developing countries in 2000–2016 using a GMM estimator. They found that transport and logistics contributed to FDI attractiveness and led to sustainable economic growth.
The research on decarbonization in transport and logistics mainly covers the measurement of carbon emissions [21], influencing factors affecting carbon emissions [22,23], and carbon emissions policies [24]. In particular, scholars employed panel data in the logistics sector relating to its extensive spatial distribution. For example, Bai et al. [25] developed a spatial econometric model to investigate the factors influencing carbon emissions in the logistics industry and their spatiotemporal heterogeneity. They found that the level of economic development, energy intensity, and electricity consumption had significant impacts on emissions.
Among all the influencing factors affecting carbon emissions, the advances in science and technology are among the most-discussed factors. Hu et al. [26] emphasized the need to consider the impact of intelligent transportation on the environment, particularly with regard to carbon dioxide emissions. Xu et al. [27] found that the development of the digital economy effectively inhibits urban carbon emissions, and this influence has obvious spatial heterogeneity. Chen et al. [28] examined the level of carbon emissions in the Yangtze River Delta region by categorizing technology into production technology, energy-saving technology, and energy-substitution technology. Their results demonstrate that technological advancements promote a reduction in carbon emissions.
The compatibility of new technology applications refers to the degree to which the use of new technologies aligns with current economic and social development needs [29]. As a determinant of technological innovation diffusion, compatibility has always been an important influencing factor encouraging people to innovate, accept, and promote the use of new technology [30,31].
Focusing on the compatibility between intelligence and decarbonization, the concept mainly pertains to whether economic intelligence’s advancement coincides with the process of decarbonization development. Existing research on this issue remains controversial. As shown in Table 1, on one hand, some scholars believe that intelligence can help mitigate the impact of carbon emissions. Goldfarb et al. [1] argued that intelligence technology shows natural advantages in reducing data-processing costs and transaction costs, and optimizing resource allocation across various industries. This improvement can enhance green total factor productivity and decrease the economy’s carbon emissions intensity. In the context of the logistics industry, studies like Yang et al. [12] and Zhao et al. [13] have also indicated that the growth of intelligent transportation can decrease logistic carbon emissions. On the other hand, some scholars argue that the adoption of novel technologies leads to a rise in carbon emissions. For instance, the research results of Nikhil [4] show that artificial intelligence may increase path dependence and lock-in in the steel industry, potentially impeding its decarbonization efforts. Meanwhile, Magazzino et al. [5] demonstrated a strong correlation between the rise in ICT penetration and an increase in electricity consumption, and that electricity consumption will further be converted into pollution emissions. Charfeddine and Kahia [32] also studied the positive relationship between ICT, renewable energy usage and carbon emission. Ren et al. [11] posited that the growth of digital and intelligent economic development has a rebound effect on energy consumption and carbon emissions, fueling the rapid expansion of the industrial scale, which, in turn, causes a surge in energy usage and carbon emissions within an economy. In general, whether intelligence is compatible with low-carbonization for a specific economic entity or industry is still a controversial issue.

Table 1.
Summary of recent publications on the intelligence–carbon emission relationship.
In summary, extensive research on technology progress and carbon emissions has been carried out by these scholars. But the conclusions on the intelligentization–decarbonization nexus are inconsistent in the context of the logistics industry. This might be attributed to the alignment or misalignment between the level of intelligence and the energy utilization structure in the industry [7]. Therefore, more effort should be made to examine the intelligentization–decarbonization nexus in logistics, particularly in the context of how intelligentization induces changes in the logistics market, an endogenous factor influencing carbon emissions. In this study, we provide advanced econometric analyses using panel data in China from 2006–2019, aiming to offer clear and robust findings that can inform strategies for sustainable development in this critical industry.
3. Assessing the Intelligence Level of Logistics Industry
3.1. Indicator System
The multifaceted nature of intelligent logistics development makes it challenging to assess with a sole indicator. Due to the lack of a unified and clear definition and the limitations of data availability, the index system and measurement method employed in logistics intelligence are widely used. Up to now, some primary measurement methods have emerged. The first one is the KPWW method. It measures the input of information in the logistics production process, and assesses the intelligence level of the logistics industry by its proportion with the total output of the logistics industry [33]. The second method is dynamic factor analysis. For example, Kostrzewski et al. [38] used this method to construct a dynamic evaluation index system and measured the level of logistics intelligence from three perspectives: logistics, economy and intelligent application. The third, and also the most commonly used, method is the multi-dimensional evaluation index system [39]. This method screens multiple indicators and uses entropy weighting to comprehensively measure the intelligence level of the logistics industry.
This paper mainly adopted a multi-dimensional evaluation index system method. An evaluation indicator system that encompasses three dimensions is created: input, interoperability, and output level. Considering the limitations of data availability in the logistics industry, some indicators are measured using the total industry data multiplied by the proportion of the logistics industry as proxy variables. The specific indicator system is shown in Table 2.
Table 2.
Intelligence evaluation indicator system.
3.2. Evaluation Method
Based on the evaluation indicator system, we have constructed a global entropy model and evaluated the logistics intelligence levels of 29 Chinese provinces from 2006 to 2019. The detailed steps are as follows: First, build a global evaluation matrix, using to present the indicator of region in year , and form data tables . is the cross-sectional data table of the year . Arrange the annual cross-sectional data tables and establish the subsequent global evaluation matrix as follows:
Second, standardize the data. To avoid a strange matrix, we transfer negative values and zeros through , where a is 0.0001. Then, the standardized formula is
Third, calculate the information entropy of the j-th index through
Fourth, calculate the difference coefficient and weight of the index
Finally, we can derive the comprehensive index of logistics intelligentization level as
3.3. Analysis of China’s Logistics Intelligentization Level
After calculating the level of intelligence in China’s logistics industry, a time trend chart of China’s national logistics intelligence level from 2006 to 2019 is presented in this part (see Figure 1). The figure shows a significant upward trend in the average level of intelligence, demonstrating the continuous improvement of intelligent logistics in China over the years. From 2006 to 2019, the level of intelligent logistics in China increased from 0.0579 to 0.1720. After further analyzing China’s logistics intelligentization at the regional level, nine provinces, including Tianjin, Shanghai, Hebei, Jiangsu, Fujian, Zhejiang, Jiangxi, Anhui, and Hunan, consistently exceeded the annual average level during the sample period. As time went by, more provinces showed higher logistics intelligence levels than the overall average. In 2018 and 2019, 28 provinces—excluding Xinjiang—had logistics intelligentization levels exceeding the overall average.
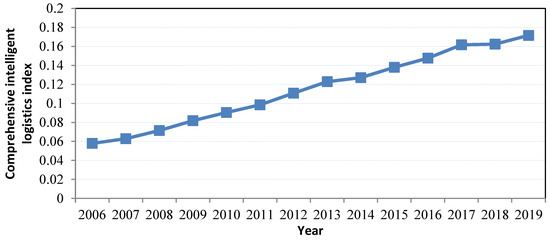
Figure 1.
Average comprehensive intelligent logistics index in China (2006–2019).
Furthermore, China’s logistics intelligence level exhibits significant regional heterogeneity. Figure 2 depicts a considerable growth trend over time in logistics intelligence in both northern and southern regions. Prior to 2014, the northern region had a higher logistics intelligence level; after 2014, the southern region surpassed the north, with the gap between the two gradually widening. Figure 3 displays the growth of logistics intelligence levels in East, Central, and West China. The figure indicates that the logistics intelligence level of the eastern region is noticeably higher than that in the central and western regions. Furthermore, the disparity between the eastern region and the central and western regions is continually increasing.
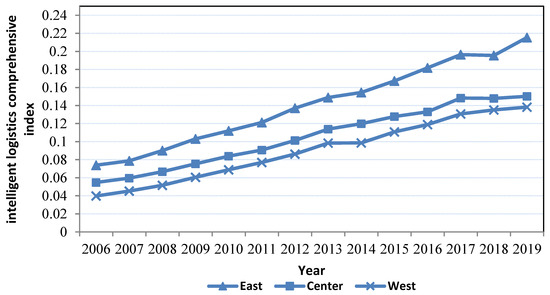
Figure 2.
Average comprehensive intelligent logistics index in East, Central and West China (2006–2019).
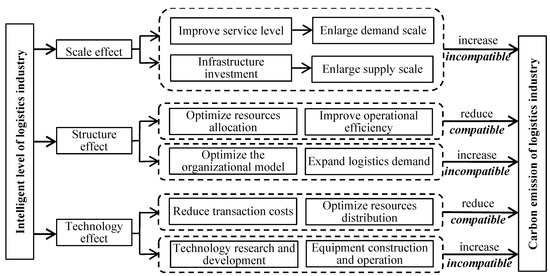
Figure 3.
Effect pathways of logistics intelligent level on industry carbon emissions.
4. Model Specification
4.1. Theoretical Model
The IPAT model, proposed by Ehrlich and Holdren (1971), describes the impact of population on environment. Its specific form is as follows:
This model demonstrates that P (population), A (affluence) and T (technology) all have equal elasticity to I (environment). Then, Dietz and Rosa [41] developed an expandable stochastic environmental impact assessment model, the STIRPAT model, as an extension of the IPAT model. The model is presented as follows:
In this model, the environmental impact could be carbon emissions, air quality or PM2.5 index. Population can be taken as the population size [42], urbanization rate [43] or labor force [44]. The affluence variable is usually GDP per capital [41,45,46]. is defined as a technological factor, measured by energy intensity, energy consumption structure, industry structure or other technological progress indicators [13,26,40]. The model includes the constant term α and the error term ε.
In this study, we employ the expandable STIRPAT model to investigate the impact of intelligentization level on carbon emissions in the logistics industry. The baseline model is formulated as follows:
4.2. Variable Selection and Data Processing
In our model (8), the dependent variable denotes carbon emissions in the logistics industry of region r in year t, representing environmental impact. There are several databases that publish the carbon emissions of the logistics industry (LCO2), such as WRI (World Resources Institute), Global Carbon Project (GCP), British Petroleum (BP), and China Carbon Emission Accounts & Datasets (CEADs), etc. In this paper, we adopt the carbon emission data on transportation, warehousing, and postal industries from the CEADs, because the CEADs employs the calculation method of the IPCC [47], which involves multiple factors related with the carbon emissions of 47 industry sectors.
is the intelligentization level of logistics, and represents technical factors. The population factor is . The influencing factors are and . is a random disturbance term. The data were sourced from a range of Chinese statistical publications, including the CEADs database, EPS database, China Energy Statistical Yearbook, China Statistical Yearbook on High Technology Industry, China Science and Technology Statistical Yearbook, China Statistical Yearbook of the Tertiary Industry, National Bureau of Statistics, Statistical Yearbook of the Chinese Investment in Fixed Assets, China Electronic and Information Industry Statistical Yearbook, and Yearbook of China Information Industry. The detailed information on those variables can be seen in Table 3.
Table 3.
Variable declaration.
To minimize the impact of the COVID-19 epidemic, this study focuses on the year 2006–2019. Tibet, Qinghai, Hong Kong, Macao and Taiwan are excluded due to significant data gaps. Ultimately, the final dataset covers panel data from 29 provinces between 2006 and 2019, with missing data points filled through linear interpolation. Additionally, to eliminate the impacts of price levels, this study has employed various measures such as the consumer price index (CPI), GDP deflator, fixed asset investment price index, and value-added index of secondary and tertiary industries to deflate the data. The data are log-transformed to reduce heteroskedasticity and enhance data stability. Table 4 exhibits the descriptive statistics of the related variables.
Table 4.
Descriptive statistics.
4.3. Endogenous Issues Discussion
Our model might have endogenous problems. First, we might have omitted variable bias since the omitted factor might affect carbon emission . Second, mutual causation between variables could be seen in our model, because it is possible that the government favorably promoted logistics intelligentization in regions with the most serious carbon emission. The bidirectional causation between and could lead to biased estimations. Third, the level of intellectualization in the logistics industry may include measurement errors since regional intellectualization development levels are not directly observable.
To address these possible endogeneity issues, we can apply the method of Lewbel [48], who constructed heteroscedasticity-based instrumental variables to address endogeneity issues when suitable exogenous instruments were not readily available. We can also construct instrumental variables for the core explanation variable to ensure unbiased estimation. The selection of instrumental variables for use in the panel data model must fulfill the requirements of correlation, exogeneity, and time variation [49]. The correlation requirement means that instrumental variables are highly correlated with . The exogeneity requirement refers to the instrumental variable being uncorrelated with any other factors and solely affecting the carbon emission . The time-varying requirement applies mostly to panel data and dictates that the instrumental variable possesses time-varying qualities. To fulfil the above three requirements, the following instrumental variables are specifically included:
- Quantity of intelligent logistics policy documents
Building on the works of Chen [50], Jefferson [51], and Hering [52], we have employed the number of policy documents () concerning intelligent logistics set out by local governments in various years as an instrumental variable to gauge the level of local intelligent logistics development. We gathered the policy data from the China Municipal Gazette Bulletin Periodical Literature Database. First of all, according to the relevant definitions of intelligent logistics, we screened out nine key words: “intelligence, wisdom, technology, Internet, Internet of Things, system, platform, informationization and digitalization”. Secondly, we used the search function of CNKI to search for government documents with the word “logistics” in their titles. On this basis, policies with at least one keyword in the full text were retrieved and the number was counted. Finally, because there were zero individual values in the policy quantity, it could not be logarithmized, so we added 1 to every policy quantity and then created logarithms while the relative size relationship of the data did not change. The “China Municipal Gazette Bulletin Periodical Literature Database” was built by CNKI, and contains 223 kinds of political newspaper bulletins, with a literature volume of 552,592. Users can search government documents by region, publishing authority and literature types, and navigate the literature according to their needs. Containing a variety of policies, it is an authoritative and standardized one-stop search platform for “red-top documents”. Here, the more policies that were related to intelligent logistics enacted by the government, the greater the focus and support given to the development of intelligent logistics. Consequently, the level of local intelligent logistics development is likely to be higher, satisfying the correlation requirement for the instrumental variable. Usually, these policies are not directly connected to carbon emissions of the logistics industry;
- 2.
- The intelligentization level of adjacent provinces
We used the average level of logistics intelligence in the neighboring provinces as the instrumental variable, denoted as . Research indicates that the intelligence level of the logistics industry features a spatial correlation [39]. Therefore, the level of intelligentization of logistics industries in surrounding regions would affect through ;
- 3.
- The number of post mails in 1979–1992
We employ the number of post mails () between 1979 and 1992 as an instrumental variable for analysis. According to the path dependence theory, the current level of intelligentization in the logistics industry is influenced by the historical scale of communication and information exchange, which in turn affects the adoption of subsequent technologies and equipment. Meanwhile, has no direct influence on the current carbon emissions . Therefore, can only affect the through . Additionally, the number of post mails is not affected by current carbon emissions, thus making suitable as an instrumental variable;
- 4.
- The interaction item of the topography feature and internet use scale
We also employed an interaction variable as the instrumental variable for is constructed by multiplying the inverse of the topographic relief degree with the lagged local internet users number in region . The topographic relief degree is exogenous and the number of internet users is closely related with logistics carbon emissions . Specifically, we have found that regions with lower topographic relief degrees exhibit higher internet penetration rates, which facilitates the implementation of intelligent logistics and leads to higher ;
4.4. Estimation Methods
Following the work of Lewbel [48], we used the dynamic panel Generalized Method of Moments (GMM) as the main estimation technique, because the carbon emissions from earlier periods can have an impact on subsequent periods. This interdependence over time can be effectively captured by employing a dynamic panel model, which allows for the identification of time effects in the analysis. We included the second-order lag term of the in Equation (9) as follows,
where represents an unobservable regional effect.
A Difference-GMM (DIF-GMM) estimation approach can be applied in this regression [53]. However, it has the problem of weak instrumental variables. Blundell and Bond [54] proposed the System GMM method (SYS-GMM), which added the horizontal equations to the DIF-GMM. This estimation approach has been proven to be more efficient, and yields lower heterogeneity in result [55]. To ensure validity and efficiency, we use the two-step SYS-GMM method with error correction in this paper [56].
5. Empirical Results Analysis
5.1. Regression Results of Basic Model
The results of the regression analysis are displayed in Table 5. Columns (1) through (3) in Table 4 display regression results without lagged explanatory variables. All coefficients of are significantly positive at the 1% level, indicating that the intelligence level of the logistics industry has a significant positive impact on carbon emissions. This conclusion aligns with the findings of Wang et al. [3] and Nikhil et al. [4]. This suggests that during the sample period, the development of intelligence within China’s logistics industry was not yet in line with efforts toward decarbonization. Columns (4) and (5) present the GMM estimation results. Under both GMM estimation methods, the p-value of AR(1) was less than 0.05, and the p-value of AR(2) was greater than 0.1. This indicates that the residual term had first-order serial correlation, but no second-order or higher-order serial correlation, thus passing the autocorrelation test. Furthermore, the p-values for the Sargan test with both GMM models exceeded 0.2, indicating that the null hypothesis of overall exogeneity in the instruments could not be rejected. As a result, the estimation results are consistent estimators.
Table 5.
Basic regression results.
GMM regression revealed a significantly positive coefficient of and at the 1% level, whether estimated by DIF-GMM or SYS-GMM. This means that the carbon emissions produced by the logistics industry in the first two years had a significant positive effect on the current period’s carbon emissions. The estimation results remain consistent, suggesting a lack of compatibility between decarbonization and intelligence development during 2006–2019. Moreover, the time-varying impact of intelligence on carbon emissions that we have identified is similar to the conclusions drawn by Sun et al. [21]. However, after employing a more rigorous and comprehensive set of indicators to measure intelligence, our overall results indicate that intelligence consistently promotes carbon emissions. This outcome diverges from the findings presented in Sun et al. [21], which suggest that subsequent increases in intelligence could lead to reductions in carbon emissions.
5.2. Regression Results with Instrumental Variables
The results of GMM regression with instrumental variables are displayed in Table 6. Column (1) shows the result estimated using the Lewbel method, while columns (2) to (5) present the results derived using different instrumental variables: policy quantity (Policy); adjacent provinces of LIL (nei_LIL); historical mail letters (letter); interaction term between the inverse of topographic relief and the number of internet users with a one-period lag (land_LIP), respectively. Columns (6) and (7) present the regression results obtained using three instrumental variables (nei_LIL, Policy, and land_LIP) and two instrumental variables (nei_LIL and land_LIP), respectively. The results indicate that all models satisfactorily passed the underidentification test and weak identification test (Cragg–Donald F). The instrumental variables passed the overidentification test (Sargan), as reflected by the p-value of the Sargan test in columns (6) and (7) being greater than 0.1. Therefore, the null hypothesis of all instrumental variables being exogenous cannot be rejected. In all seven instrumental variable regression models, all the estimation coefficients of lnLIL were significantly positive at the 1% level. This confirms the reliability of the benchmark model’s regression results, and highlights the influential role of logistics intelligence development in increasing carbon emissions within the logistics industry.
Table 6.
Regression results based on instrumental variables.
5.3. Robustness Test
To further examine the relationship between intelligentization and decarbonization in the logistics industry, robustness checks were conducted in this part. Various methods were employed, such as re-measuring the intelligence level, replacing the main dependent variables, conducting heterogeneity analysis, and using quantile regression.
- Re-measure intelligentization level
To enhance the robustness of intelligentization level measurements in the logistics industry, this paper re-calculated them using a different indicators system. We used mobile phone switch capacity instead of mobile phone penetration rate. We replaced the intelligent equipment investment indicator with the ratio of high-tech industry imports to logistics industry added value. We employed the number of internet access ports instead of internet penetration rate. The regression results with a new intelligentization level are presented in Table 7. The results indicate that the estimation coefficients for L.lnLCO2 and L2.lnLCO2 were significantly positive at a 1% level, while the estimation coefficients for were significantly positive at a 5% level. This confirms the consistency of the estimation outcomes and corroborates the validity of the conclusion.
Table 7.
Regression results of the re-measurement of LIL.
- 2.
- Replacement of explanatory variables
In this study, we replaced the main explanatory variable with the number of patents per 10,000 people (T) and internet broadband access ports (IPN, ten thousand) to eliminate the possible measurement bias using the entropy weight method. Table 8 presents the specific regression outcomes. The conclusion confirms the robustness of both the basic model and the original conclusion.
Table 8.
Replacing the regression results of core explanatory variables.
- 3.
- Regional heterogeneity analysis
Due to regional disparities in economic, technical and industrial conditions, the relationship between logistics intelligentization and decarbonization might feature heterogeneity. We divided the sample into two sub-samples (north and south regions) in Table 9 and three sub-samples (east, center, and west regions) in Table 10 for further exploration. The regression results derived using fixed effects models and instrumental variable models (land_LIP) are presented, respectively. The coefficients of are significantly positive at the 1% level in all models, revealing that intelligence development in the logistics industry leads to a significant increase in carbon emissions regardless of the geographical region.
Table 9.
Regression results of north and south regions.
Table 10.
Regression results of east, center and west regions.
In our study, we calculated the Degree of Intelligence level in logistics (denoted as LIL) for the 29 provinces over the period of 2006 to 2019, with values ranging from 0.025 to 0.844. This indicates a significant disparity in the development of AI in logistics among different provinces, highlighting the necessity of conducting a grouped regression analysis to investigate the varying relationships within the intelligentization–carbon emission nexus. Therefore, we classified the provinces into two categories based on whether their LIL values in 2019 exceeded the annual average. The results of regression in the two groups (regions with low and high intelligence levels in logistics) are shown in Table 11. The regression results derived with both the fixed effects models and the instrumental variable models (land_LIP) are presented, respectively. The coefficients of were found to be insignificant in regions with a high intelligence level. However, the coefficients of were significantly positive at a 1% level in regions with a low intelligence level, suggesting that the developing use of AI in logistics in these provinces is not aligned with decarbonization.
Table 11.
Regression results of regions with low and high levels of artificial intelligence in logistics.
- 4.
- Quantile regression
We have used the quantile regression method to further explore the relationship between intelligentization and decarbonization in the logistics industry. The method first proposed by Koenker and Bassett [57] could be used to examine the relationship between variables at different points of the distribution by minimizing the sum of weighted residual absolute values [58,59]. The regression results are shown in Table 12. The level of logistics intelligence in all quantile samples has a significant positive impact on carbon emissions from the logistics industry, indicating that the basic conclusion will remain robust even if carbon emissions vary across different times or regions.
Table 12.
Results of quantile regression.
5.4. Mediating Pathways Analysis
To examine the compatibility of intelligentization and decarbonization in the logistics industry, this study delves into how logistics intelligence levels influence carbon emissions via three different mediating pathways: the scale effect, the structure effect, and the technology effect. In fact, these three mechanisms are frequently discussed in the relevant literature, as evidenced by the works of Wang et al. [3], Zhao et al. [13], and Ding and Liu [37]. Figure 3 shows how these effects work in the relationship between intelligentization and decarbonization.
As regards the scale effect, intelligent logistics plays a pivotal role in logistics industry development, stimulating a growth in demand in the logistics industry [10]. It also fuels investments in technology and infrastructure, ultimately expanding the supply capacity of the logistics industry [13,60]. Hence, intelligent logistics expands the industry from both the demand and supply sides, leading to an increase in carbon emissions, known as the scale effect.
As regards the structure effect, intelligent logistics can expedite industrial transformation and optimize the industrial structure [35], leading to carbon emissions reduction. However, upgrading the industrial structure would also promote the innovation and optimization of the organization mode, increase demand, and extend the scope of the logistics service, leading to an increase in carbon emissions in the logistics industry.
Regarding the technology effect, applying new technology can potentially decrease transaction costs and optimize resource allocation, reducing carbon emissions within the logistics industry [12]. However, new technologies and equipment will correlate with increased energy consumption during the research and development, construction, and operation stages, leading to increased carbon emissions in the logistics sector [5].
To verify the above paths, we have used the causally mediated effects model. Previous researchers have tended to use the stepwise test, Sobel test, and coefficient difference test [61,62] However, linear regression methods for examining the mediating effect suffer from low efficacy and possible bias [63,64]. To solve the problems, Dippel et al. [65] introduced a model that utilizes instrumental variables to analyze both causal and mediated effects simultaneously. Therefore, we have applied their estimation method to analyze the mediation effects of scale, structure and technology. The regression results are presented in Table 13.
Table 13.
Regression results of the mediating effects of instrumental variables.
The first column represents the scale effect, with freight volume (Freight) as the mediator variable. Columns (2)–(4) reflect structure effect, employing industrial structure (INDS), energy mix (ES), and transportation structure (TS) as the mediator variables, respectively. These outcomes confirm the validity of the pathways associated with the three structural impacts. Column (5) presents the results of the technology effect, utilizing transportation efficiency (TE) as the mediating variable. These results indicate that all three pathways—the scale effect, the structure effect, and the technology effect—are substantiated. Our findings support the analyses of the mechanism put forth by Wang et al. (2022) [3], Zhao et al. (2022) [13], and Ding & Liu (2024) [37], and they have been further validated using a more rigorous causally mediated effects model.
To further validate the mediating pathways, we have used the mediating variables as explanatory variables to estimate the significance of the mediating effect. The results in Table 14 show that all direct regression results are significantly positive at the 1% level, consistent with the direction of the regression results on mediation effect with different instrumental variables. This consistency indicates the robustness of the three pathways.
Table 14.
Mediating effect regression results yielded by the direct regression model.
These mediating effects can actually explain the different impacts of on carbon emissions in various regions, which were observed in our analysis of regional heterogeneity (Table 11). Regions with low LIL include less economically developed provinces, such as Yunnan, Guizhou, and Heilongjiang, as well as provinces with a high proportion of mineral extraction and heavy industry in their economic structures, such as Inner Mongolia, Shanxi, Hebei, and Liaoning. Conversely, regions with a higher level of AI in logistics predominantly include economically developed provinces with robust tertiary industries, such as Shanghai, Hainan, and Guangdong. In terms of scale effect, in regions with low LIL, the development of intelligent logistics drives the demand for more infrastructure and higher service levels, which in turn increases the scale of logistics activities, leading to a rise in carbon emissions. In contrast, the infrastructure and service levels in regions with high LIL are generally already well-developed; hence, a mere enhancement of LIL does not significantly affect the scale. In terms of the structural effect, regions with low LIL primarily rely on sectors such as mining and heavy industry. Therefore, the overall development of AI here is less pronounced compared to in other regions. When LIL begins to develop in these areas, the benefits are primarily felt in mining and heavy industrial sectors, which tend to generate higher carbon emissions. In terms of the technology effect, the application of AI in logistics can enhance technological efficiency and enable comprehensive emissions management, thereby reducing carbon emissions. However, when AI capabilities are at a low level, the effect of improving logistics efficiency may not be significant, since the efficiency and effectiveness of AI requires substantial data training and computational support. Therefore, only regions with high LIL are more likely to achieve comprehensive carbon emissions management in logistics through the technology effect path.
5.5. Moderating Mechanisms Analysis
Economic development, market openness, and transportation efficiency might moderate the relationship between intelligentization and decarbonization in the logistics industry. Therefore, we have used regional GDP (GDP), ratio of total imports and exports to GDP (Open) and ratio of freight volume to road transportation distance (Efficiency) as the moderators in order to conduct moderating effect regression in Table 15. In columns (1) and (2), we find that, as regional GDP increases, logistics intelligentization growth mitigates carbon emissions growth. In columns (3) and (4), we see that market openness reduces the incompatibility of intelligentization and decarbonization. Also, the results in columns (5) and (6) show that transportation efficiency also acts as a negative moderator in the regression.
Table 15.
Results of moderating effects.
6. Conclusions and Policy Recommendation
This study employs the panel data from 29 provinces in China, spanning from 2006 to 2019, and establishes dynamic panel GMM estimation models to investigate whether intelligentization is compatible with decarbonization in the logistics industry. The conclusions reveal that, while intelligent logistics can reduce carbon emissions through operational improvements, the resulting increase in supply and demand significantly raises carbon dioxide emissions, highlighting an incompatibility between intelligentization and decarbonization.
To address the endogeneity issue in the model, we constructed instrumental variables and applied the IV-GMM method to derive robust estimation results. Meanwhile, we tested the robustness of the model by replacing variables, regional heterogeneity analysis, and quantile regressions. Moreover, we identified three significant mediating pathways, namely, scale, structure and technology effects. The moderating effects of economic development, market openness, and transportation efficiency were found to mitigate the negative impacts of intelligence on decarbonization.
The findings of this paper provide new insights of interest for policymakers in the logistics sector. First, the government should be aware of the incompatibilities between promoting intelligent development and green development. For instance, policymakers should establish environmental standards for intelligent technology adoption and prioritize developments that effectively reduce carbon emissions, such as electric vehicles. Second, efforts should be made to regulate intermediary pathways by upgrading industrial structures, energy mixes, and transportation systems to minimize the negative impacts of intelligence on decarbonization. Third, the government is encouraged to consider enhancing intelligence–decarbonization compatibility by use of moderating mechanisms, such as promoting economic development and market openness.
In conclusion, while this study offers significant insights into the interplay between intelligentization and decarbonization in the logistics industry, it is important to acknowledge certain limitations. First, the analysis is based on panel data from 29 provinces, which may limit the generalizability of the findings; future studies could benefit from examining data at the city level so as to provide a more granular understanding of the dynamics involved. Second, the selection of instrumental variables poses challenges, as some of the chosen instruments may inevitably introduce bias; thus, it would be valuable for future researchers to explore alternative instruments or methodologies in order to address potential endogeneity concerns more effectively.
Author Contributions
Z.J., conception and supervision; N.Y., data collection and drafting; X.W., analysis and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Social Science Fund of China (Grant Number 23BJY127) and the Asian Research Center of Nankai University (Grant number AS2302).
Data Availability Statement
Dataset available on request from the authors.
Acknowledgments
The authors gratefully acknowledge the helpful reviews and comments from the editors and anonymous reviewers, which improved this manuscript considerably.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Goldfarb, A.; Tucker, C. Digital Economics. J. Econ. Lit. 2019, 57, 3–43. [Google Scholar] [CrossRef]
- Pu, S.; Lam Jasmine, S.L. Greenhouse gas impact of digitalizing shipping documents: Blockchain vs. centralized system. Transp. Res. Part E Logist. Transp. Rev. 2021, 97, 102942. [Google Scholar] [CrossRef]
- Wang, J.; Dong, K.; Dong, X.; Taghizadeh-Hesary, F. Assessing the Digital Economy and its Carbon-Mitigation Effects: The case of China. Energy Econ. 2022, 113, 106198. [Google Scholar] [CrossRef]
- Nikhil, J.; Hendrik, W.J.; Ernst, W.; Marko, H. How key-enabling technologies’ regimes influence sociotechnical transitions: The impact of artificial intelligence on decarbonization in the steel industry. J. Clean. Prod. 2022, 370, 133624. [Google Scholar]
- Magazzino, C.; Mele, M.; Morelli, G.; Schneider, N. The Nexus between Information Technology and Environmental Pollution: Application of a New Machine Learning Algorithm to OECD Countries. Util. Policy 2021, 72, 101256. [Google Scholar] [CrossRef]
- He, N.; Jian, M.; Liu, S.; Wu, J.; Chen, X. Do publicly developed logistics parks cause carbon emission transfer? Evidence from Chengdu. Transp. Res. Part D Transp. Environ. 2023, 125, 103988. [Google Scholar] [CrossRef]
- Lin, J.Y.; Nowak, A.Z. New Structural Economics for Less Advanced Countries; University of Warsaw Faculty of Management Press: Warsaw, Poland, 2017. [Google Scholar]
- Liu, W.; Wang, S.; Lin, Y.; Xie, D.; Zhang, J. Effect of Intelligent Logistics Policy on Shareholder Value: Evidence from Chinese Logistics Companies. Transp. Res. Part E Logist. Transp. Rev. 2020, 137, 101928. [Google Scholar] [CrossRef]
- Saidi, S.; Mani, V.; Mefteh, H.; Shahbaz, M.; Akhtar, P. Dynamic Linkages Between Transport, Logistics, Foreign Direct Investment, and Economic Growth: Empirical Evidence from Developing Countries. Transp. Res. Part A Policy Pract. 2020, 141, 277–293. [Google Scholar] [CrossRef]
- Kos-Labedowicz, J.; Urbanek, A. Do information and communications technologies influence transport demand? An exploratory study in the European Union. Transp. Res. Procedia 2017, 25, 2664–2680. [Google Scholar] [CrossRef]
- Ren, S.; Hao, Y.; Xu, L.; Wu, H.; Ba, N. Digitalization and Energy: How does Internet Development Affect China’s Energy Consumption? Energy Econ. 2021, 98, 105220. [Google Scholar] [CrossRef]
- Yang, Z.; Peng, J.; Wu, L.; Ma, C.; Zou, C.; Wei, N.; Mao, H. Speed-guided intelligent transportation system helps achieve low-carbon and green traffic: Evidence from real-world measurements. J. Clean. Prod. 2020, 268, 122230. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, K.; Dong, X.; Dong, K. Is smart transportation associated with reduced carbon emissions? The case of China. Energy Econ. 2022, 105, 105715. [Google Scholar] [CrossRef]
- Kirch, M.; Poenicke, O.; Richter, K. RFID in logistics and production-applications, research and visions for smart logistics zones. Procedia Eng. 2017, 178, 526–533. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, J.; Shi, Y.; Lee Paul, T.W.; Liang, Y. Intelligent logistics transformation problems in efficient commodity distribution. Transp. Res. Part E Logist. Transp. Rev. 2022, 163, 102735. [Google Scholar] [CrossRef]
- Yigitcanlar, T.; Fabian, L.; Coiacetto, E. Challenges to urban transport sustainability and smart transport in a tourist city: The Gold Coast. Open Transp. J. 2008, 2, 29–46. [Google Scholar] [CrossRef]
- Song, Y.; Yu, F.R.; Zhou, L.; Yang, X.; He, Z. Applications of the internet of things(IoT)in smart logistics:a comprehensive survey. IEEE Internet Things J. 2021, 6, 250–274. [Google Scholar]
- Dong, F. Key problems and countermeasures of smart logistics industry development under the New development pattern. Econ. Rev. J. 2021, 10, 77–84. [Google Scholar]
- Barbara, J.K. Intelligent Transportation Systems: An Economic and Environmental Policy Assessment. Transp. Res. Part A Policy Pract. 1996, 30, 1–10. [Google Scholar]
- Banister, D. Impact of information and communications technology on transport. Transp. Rev. 2004, 4, 611–632. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Li, W.; Ma, R. Carbon emission measurement of island cities and its influencing factors: A case study of Zhoushan city, Zhejiang province. Geogr. Res. 2018, 05, 1023–1033. [Google Scholar]
- Lau, C.K.; Gozgor, G.; Mahalik, M.K.; Patel, G.; Li, J. Introducing a new measure of energy transition: Green quality of energy mix and its impact on CO2 emissions. Energy Econ. 2023, 122, 106702. [Google Scholar] [CrossRef]
- Sun, X.; Xiao, S.; Ren, V.; Xu, B. Time-varying impact of information and communication technology on carbon emissions. Energy Econ. 2023, 118, 106492. [Google Scholar] [CrossRef]
- Chen, L.; Wang, K. The spatial spillover effect of low-carbon city pilot scheme on green efficiency in China’s cities: Evidence from a quasi-natural experiment. Energy Econ. 2022, 110, 106018. [Google Scholar] [CrossRef]
- Bai, D.; Dong, Q.; Khan, S.A.R.; Li, J.; Wang, D.; Chen, Y.; Wu, J. Spatio-temporal heterogeneity of logistics CO2 emissions and their influencing factors in China: An analysis based on spatial error model and geographically and temporally weighted regression model. Environ. Technol. Innov. 2022, 28, 102791. [Google Scholar] [CrossRef]
- Hu, S.; Yang, J.; Jiang, Z.; Ma, M.; Cai, W. CO2 emission and energy consumption from automobile industry in China: Decomposition and analyses of driving forces. Processes 2021, 9, 810. [Google Scholar] [CrossRef]
- Xu, W.; Zhou, J.; Liu, C. Spatial effects of digital economy development on urban carbon emissions. Geogr. Res. 2022, 41, 111–129. [Google Scholar]
- Chen, C.; Luo, Y.; Zou, H.; Huang, J. Understanding the driving factors and finding the pathway to mitigating carbon emissions in China’s Yangtze River Delta region. Energy 2023, 278, 127897. [Google Scholar] [CrossRef]
- Rogers, E.M. Diffusion of Innovations, 4th ed.; The Free Press: New York, NY, USA, 2010. [Google Scholar]
- Bunker, D.; Kautz, K.-H.; Nguyen, A.L.T. Role of value compatibility in it adoption. J. Inf. Technol. 2007, 22, 69–78. [Google Scholar] [CrossRef]
- Oliveira, T.; Thomas, M.; Baptista, G.; Campos, F. Mobile payment: Understanding the determinants of customer adoption and intention to recommend the technology. Comput. Hum. Behav. 2016, 61, 404–414. [Google Scholar] [CrossRef]
- Charfeddine, L.; Kahia, M. Do information and communication technology and renewable energy use matter for carbon dioxide emissions reduction? Evidence from the Middle East and North Africa region. J. Clean. Prod. 2021, 327, 129410. [Google Scholar] [CrossRef]
- Wang, L.; Chen, Y.; Ramsey, T.S.; Hewings, G.J. Will researching digital technology really empower green development? Technol. Soc. 2021, 66, 101638. [Google Scholar] [CrossRef]
- Charfeddine, L.; Hussain, B.; Montassar, K. Analysis of the Impact of Information and Communication Technology, Digitalization, Renewable Energy and Financial Development on Environmental Sustainability. Renew. Sustain. Energy Rev. 2024, 201, 114609. [Google Scholar] [CrossRef]
- Liang, H.; Lin, S.; Wang, J. Impact of technological innovation on carbon emissions in China’s logistics industry: Based on the rebound effect. J. Clean. Prod. 2022, 377, 134371. [Google Scholar] [CrossRef]
- Pan, X.; Li, M.; Wang, M.; Zong, T.; Song, M. The effects of a smart logistics policy on carbon emissions in China: A difference-in-differences analysis. Transp. Res. Part E 2020, 137, 101939. [Google Scholar] [CrossRef]
- Ding, H.; Liu, C. Carbon Emission Efficiency of China’s Logistics Industry: Measurement, Evolution Mechanism, and Promotion Countermeasures. Energy Econ. 2024, 129, 107221. [Google Scholar] [CrossRef]
- Kostrzewski, M.; Kosacka-Olejnik, M.; Werner-Lewandowska, K. Assessment of innovativeness level for chosen solutions related to Logistics 4.0. Procedia Manuf. 2019, 38, 621–628. [Google Scholar] [CrossRef]
- Xu, K. The influence factors and mechanism of intelligent logistics on rural industry integration development. J. Commer. Econ. 2022, 16, 110–112. [Google Scholar]
- Zheng, Y.M.; Lv, Q.; Wang, Y.D. Economic Development, Technological Progress, and Provincial Carbon Emissions Intensity: Empirical Research Based on the Threshold Panel Model. Appl. Econ. 2022, 54, 3495–3504. [Google Scholar] [CrossRef]
- Dietz, T.; Rose, E.A. Rethinking the environmental impact of population affluence and technology. Hum. Ecol. Rev. 1994, 1, 277–300. [Google Scholar]
- Xing, L.; Khan, Y.A.; Arshed, N.; Iqbal, M. Investigating the Impact of Economic Growth on Environment Degradation in Developing Economies Through STIRPAT Model Approach. Renew. Sustain. Energy Rev. 2023, 182, 113365. [Google Scholar] [CrossRef]
- Wang, S.; Hua, G.; Li, C. Urbanization, Air Quality, and the Panel Threshold Effect in China Based on Kernel Density Estimation. Emerg. Mark. Financ. Trade 2019, 55, 3575–3590. [Google Scholar] [CrossRef]
- Wang, Q.; Yang, T.; Li, R. Economic Complexity and Ecological Footprint: The Role of Energy Structure, Industrial Structure, and Labor Force. J. Clean. Prod. 2023, 412, 137389. [Google Scholar] [CrossRef]
- Yeh, J.C.; Liao, C.H. Impact of population and economic growth on carbon emissions in Taiwan using an analytic tool STIRPAT. Sustain. Environ. Res. 2016, 2, 41–48. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, S.; Ma, W.; Liu, X.; Cai, B.; Liu, J.; Jia, X.; Zhang, M.; Chen, Y.; Xu, L. Analysis of influencing factors of carbon dioxide emission in cities above prefecture level in China: Based on extended STIRPAT model. China Popul. Resour. Environ. 2018, 28, 45–54. [Google Scholar]
- IPCC (Intergovernmental Panel on Climate Change). 2006 IPCC Guidelines for National Greenhouse Gas Inventories; IGES: Tokyo, Japan, 2006. [Google Scholar]
- Lewbel, A. Using heteroscedasticity to identify and Estimate Mismeasured and Endogenous Regressor Models. J. Bus. Econ. Stat. 2012, 30, 67–80. [Google Scholar] [CrossRef]
- Joshua, A.; Jörn-Steffen, P. Mastering Mostly Harmless Econometrics, 1st ed.; Lang, J.; Li, J., Translators; Truth & Wisdom Press: Shanghai, China, 2012. [Google Scholar]
- Chen, Z.; Kahn, M.E.; Liu, Y.; Wang, Z. The Consequences of Spatially Differentiated Water Pollution Regulation in China. Natl. Bur. Econ. Res. 2016, 88, 22507. [Google Scholar]
- Jefferson, G.H.; Tanaka, S.; Yin, W. Environmental Regulation and Industrial Performance: Evidence from Unexpected Externalities in China. In SSRN Working Papers; SSRN: Rochester, NY, USA, 2013. [Google Scholar]
- Hering, L.; Poncet, S. Environmental Policy and Exports: Evidence from Chinese Cities. J. Environ. Econ. Manag. 2014, 68, 296–318. [Google Scholar] [CrossRef]
- Arellano, M.; Bond, S. Some tests of specification for panel data; Monte Carlo evidence and an application to employment equations. Rev. Econ. Stud. 1991, 58, 277–297. [Google Scholar] [CrossRef]
- Blundell, R.; Bond, S. Initial conditions and moment rest rictions in dynamic panel data models. J. Econom. 1998, 87, 115–143. [Google Scholar] [CrossRef]
- Girma, S. A Quasi-Differencing Approach to Dynamic Modelling from a Time Series of Independent Cross-Sections. J. Econom. 2000, 98, 365–383. [Google Scholar] [CrossRef][Green Version]
- Windmeijer, F. A Finite Sample Correction for The Variance of Linear Efficient Two-Step GMM Estimators. J. Econom. 2005, 126, 25–51. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Bera, A.K.; Galvao, A.F.; Montes-Rojas, G.V.; Park, S.Y. Asymmetric laplace regression: Maximum likelihood, maximum entropy and quantile regression. J. Econ. Methods 2016, 5, 79–101. [Google Scholar] [CrossRef]
- Sherwood, B.; Wang, L. Partially linear additive quantile regression in ultrahigh dimension. Annu. Stat. 2016, 44, 288–317. [Google Scholar] [CrossRef]
- Karami, Z.; Kashef, R. ST planning: Data, models, and algorithms. Transp. Eng. 2020, 2, 100013. [Google Scholar] [CrossRef]
- Sobel, M.E. Asymptotic confidence intervals for indirect effects in structural equation models. In Sociological Methodology; Leinhardt, S., Ed.; American Sociological Association: Washington, DC, USA, 1982; pp. 290–312. [Google Scholar]
- MacKinnon, D.P.; Lockwood, C.M.; Hoffman, J.M.; West, S.G.; Sheets, V. A comparison of methods to test mediation and other intervening variable effects. Psychol. Methods 2002, 7, 83–104. [Google Scholar] [CrossRef]
- Judd, C.M.; Kenny, D.A. Process Analysis: Estimating Mediation in Treatment Evaluations. Eval. Rev. 1981, 5, 602–619. [Google Scholar] [CrossRef]
- Judd, C.M.; Kenny, D.A. Estimating the Effects of Social Interventions; Cambridge University Press: New York, NY, USA, 1981. [Google Scholar]
- Dippel, C.; Ferrara, A.; Heblich, S. Causal mediation analysis in instrumental-variables regressions. Stata J. 2020, 20, 613–626. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).