1. Introduction
The growing demand for energy from renewable sources has led to the construction of many wind farms in Brazil and other countries. However, two main factors can hamper the development of the wind power industry: the probabilistic nature of wind speed and the uncertainty involving its production [
1,
2]. These factors require more robust and reliable models that better replicate the behavior of local wind generation to support the planning, monitoring and operational management of the power grid and increase the reliability of the electrical network [
3,
4,
5,
6].
For the correct dimensioning of power generation, it is necessary to understand the functioning of wind turbine generators [
1]. It is well established that the power from a wind turbine varies in function with the wind speed, air density and turbine blade parameters (size, design, tip speed and pitch angle ratio) [
7]. The manufacturers usually supply a power curve for their models, which is typically generic and related only to the wind speed for the power generated [
8]. Nevertheless, this information serves as a parameter for initial monitoring of the performance of a wind farm’s turbines [
9].
For managers of wind farms and power systems, it is not advisable to apply the manufacturer’s power curve directly since the real working conditions of a turbine can be very different. The power curve made available by the manufacturer is projected for the functioning of a single wind turbine operating under ideal conditions. It does not consider the various types of interference they generate with each other within a wind farm. Hence, a need exists to develop models to estimate wind power in specific generation locations [
9].
Researchers have described various deterministic or probabilistic strategies to create reliable estimation models. These power curve models are also subdivided into parametric and nonparametric techniques [
7,
10,
11]. The parametric methods are based on mathematical formulations, such as the linearized segmented model; polynomial power curves [
12,
13]; exponential [
14], cubic [
7] and maximum principle methods; the least squares method [
10]; cubic spline interpolation; dynamic power curves; and models based on probabilistic distributions [
6,
10,
15], among others. In general, they are methods that are easy to apply and calculate the parameters, need little historical data, and have precise adjustments. Their drawbacks are poor accuracy, the need for comprehensive data from the manufacturer and the local conditions, and failure to consider the variability of these data [
11].
The nonparametric models include copulas [
16,
17], kernel density estimation, artificial neural networks [
18], fuzzy logic systems, support vector machines, response surface methodology and data mining algorithms (such as random forest and clustering) [
18], among many others [
9,
19,
20,
21,
22]. These do not impose any model specified in advance, are more precise, contemplate the variance of the data and estimate the power curve as closely as possible with the available data subject to smoothing of the fit. However, these methods require long historical data series and are complex to implement [
11,
23].
In [
18], the authors used machine learning, artificial neural networks (ANNs), decision trees (DTs) and random forests (RFs) to infer the best alternative to represent the outputs of a wind turbine. The same evaluation is described in [
23] via three dynamic Bayesian models considering wind speed and power. In turn, refs. [
16,
17] propose the use of copula functions to model this relationship through the measured data, while [
16] also uses a probabilistic method to exclude outliers. The article by [
24] evaluates the performance of multivariate models based on the Gaussian mixture copula model (GMCM), artificial neural networks and Bayesian artificial neural networks (BANNs) to characterize the power curve and estimated power.
Many other studies have also used wind speed distribution as a basis to model the relationship between wind speed and power output. Most of these have recommended using a two-parameter Weibull distribution [
25]. More recent studies have suggested modifications of the Weibull distribution [
26] and the use of a four-parameter Kappa probability distribution or five-parameter Wakeby probability distribution to obtain better results [
27].
In [
7], the authors describe the fitting of polynomial, exponential and cubic equations to represent the power curves of turbines. The authors found the polynomial and cubic approaches to be most precise. Still, the polynomial approach required complex equations, making it hard to find a general expression, leading to the recommendation of the cubic, which only depends on the parameters provided by the manufacturer. Ref. [
11] warns that these mathematical models should only be used for initial evaluation of the power output, because they do not precisely consider the inflection point of the power curve and can result in large forecasting errors. They serve to evaluate new undertakings, dimensioning and the optimization of costs. Ref. [
28] suggests using sigmoid, logistic and Hill functions, while [
10] proposes the spline regression method to obtain better performance and overcome the problems of determining the curve’s inflection point. However, although these mathematical expressions are widely used, there is little evidence that these curves fit the data pertaining to real wind power turbines [
12,
13,
14].
For this reason, this study aims to describe a model that more accurately represents this relationship between wind speed and power, requiring only historical data for both variables. Although the method uses only these two data points, it can indirectly incorporate the complexity inherent in the variability of the different sources of meteorological data and those specific to the turbine designer, which can also influence the prospection of the resulting wind energy.
In this context, a method is presented to segment the wind speed ranges through clustering data by K-means, mapping possible wind power outputs associated with each range and constructing the probability density function of the power data using the kernel density estimation method. Finally, the Monte Carlo simulation is applied to make the model flexible regarding wind power generation.
To improve the modeling of the relationship between wind speed and wind energy generation, this paper combines these methods to create a more reliable and effective methodology. This will help us make more accurate projections that align with real-life conditions in wind turbines. Once implemented, this model will enable us to use wind speed projections to estimate wind power effectively.
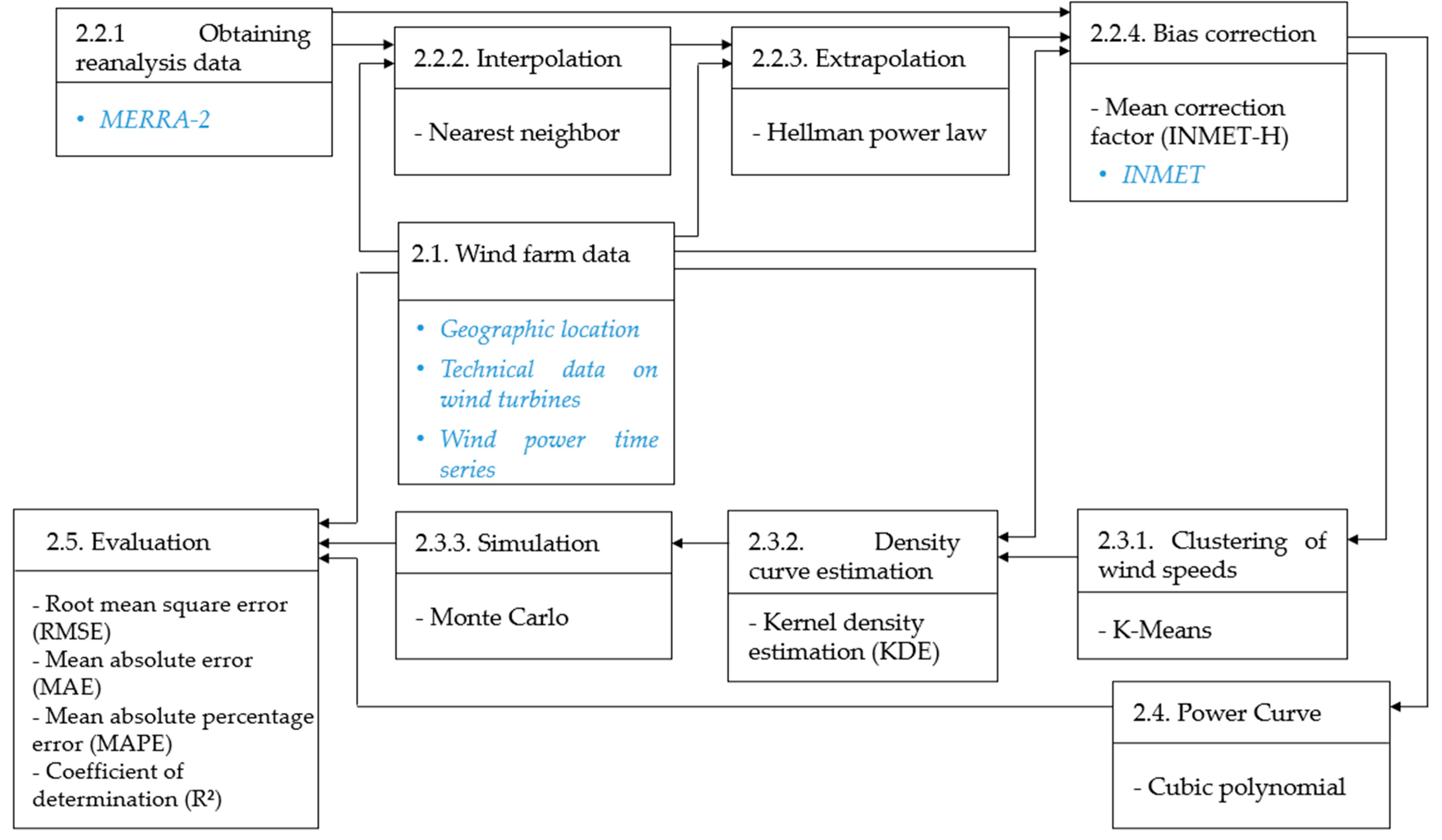
This article is divided into five sections, including this introduction. The second section presents the method used to model the relationship between wind speed and power; the third section presents the data used in the tests; the fourth section describes and discusses the results; and the fifth section presents the conclusions and some recommendations for future research.
4. Results and Discussion
This section will present the results of the wind power estimates achieved by the traditional approach and the different application strategies of the proposed method. The work presented here was developed using R software, version 4.3.0 [
45].
Table 3 presents some of the data used and calculated in adjusting the wind speed time series from MERRA-2 to each wind farm’s conditions. Gruber et al. [
32] recommend applying the bias correction step to MERRA-2 data only when the INMET station is 40 km from the wind farm. Otherwise, bias correction is not advisable due to the considerable distance between the station and wind farm, such that the INMET data may not adequately represent the real local conditions of the wind farm.
In this study, certain wind farms were situated over 40 km away from an INMET station. To assess the influence of utilizing these data in bias correction, tests were conducted on the wind speed time series both with and without bias correction.
Other information used to generate the results of this work, such as the geographic coordinates of the points on the MERRA-2 network closest to the wind farms and INMET stations, is not shown here due to the confidentiality agreement signed with the wind farm operators.
With the wind speed data, the wind power estimations were made using different techniques and approaches. The theoretical power curve method used the information from the manufacturer presented in
Table 2 to delineate the regions of zero, constant and variable generation in terms of the wind speed, as depicted in Equation (4).
The modeling of the nonlinear region was performed with the cubic power curve presented in Equation (5), with the parameter
set to 1.16 kg/m
3, as recommended by [
46]. The
values were adjusted empirically to enable the maximum power to be found at the nominal wind speed; the other parameters of the curve were assumed to be known and accurate to adjust [
46]. Comparing the power outputs generated by the curves based on the wind speed time series with the historical power time series through the evaluation metrics, the results will be listed.
The results achieved with the traditional cubic power curve approach were used to develop the steps of the proposed method, which was tested in four approaches: single-period, monthly, hourly, and monthly–hourly.
In the first step of the proposed method, K-means clustering was performed only once with all data in the single-period approach. In the monthly approach, the clustering was carried out 12 times, each with the wind speed data for the respective month, while this was 24 times in the hourly approach and 288 times in the monthly–hourly case. In all cases, defining the number of clusters with the elbow method was first necessary. In the single-period approach, the number of clusters varied from 20 to 22, in the monthly case it ranged from 17 to 22, in the hourly case it ranged from 12 to 20, and in the monthly–hourly case it ranged from 3 to 14.
Table 4 details the number of clusters used in each test. Irrespective of the wind farm and the steps adopted to construct the wind speed time series, the number of clusters defined with the elbow method for applying clustering was practically the same, only diminishing when the data segregation was increased to apply the new proposed method.
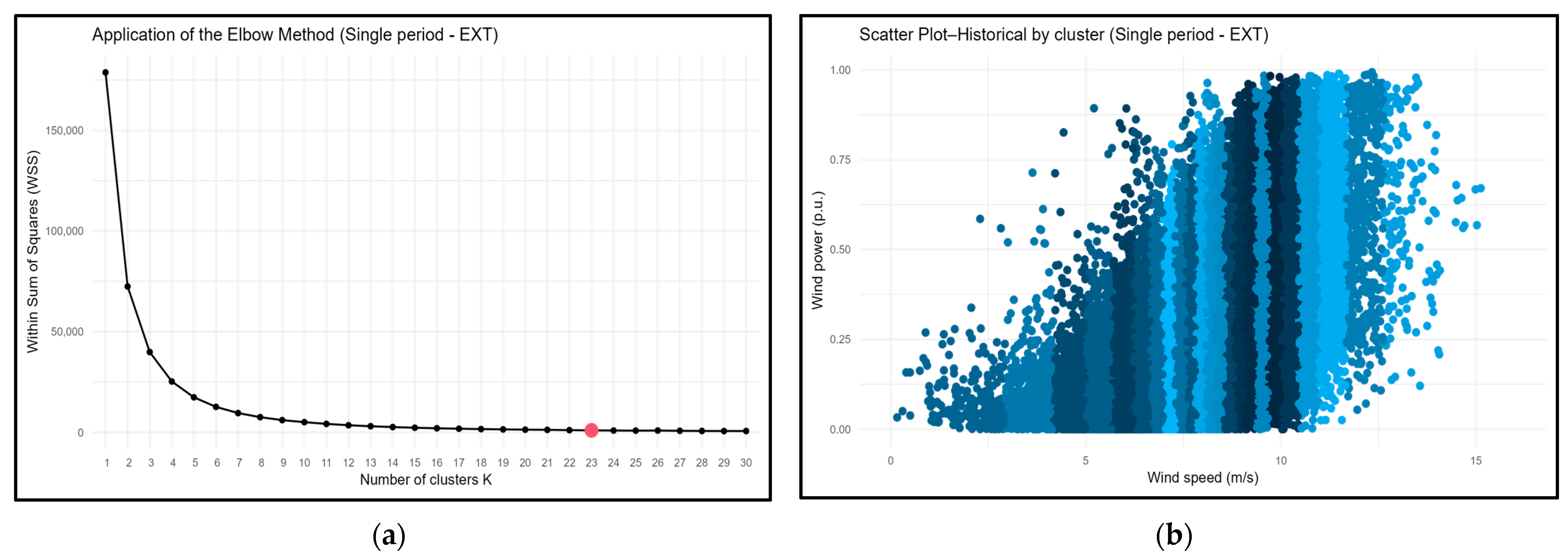
Figure 4 presents the result of applying the elbow method to Wind Farm 5 using a single period with extrapolated speed data (single-EXT) and a dispersion graph of the speed and power data. In the second graph, the different blue shades indicate the different wind speed clusters, permitting visualization of the variability in the power levels generated in each speed range. Corresponding graphs for the other farms and approaches are contained in the
Supplementary Materials.
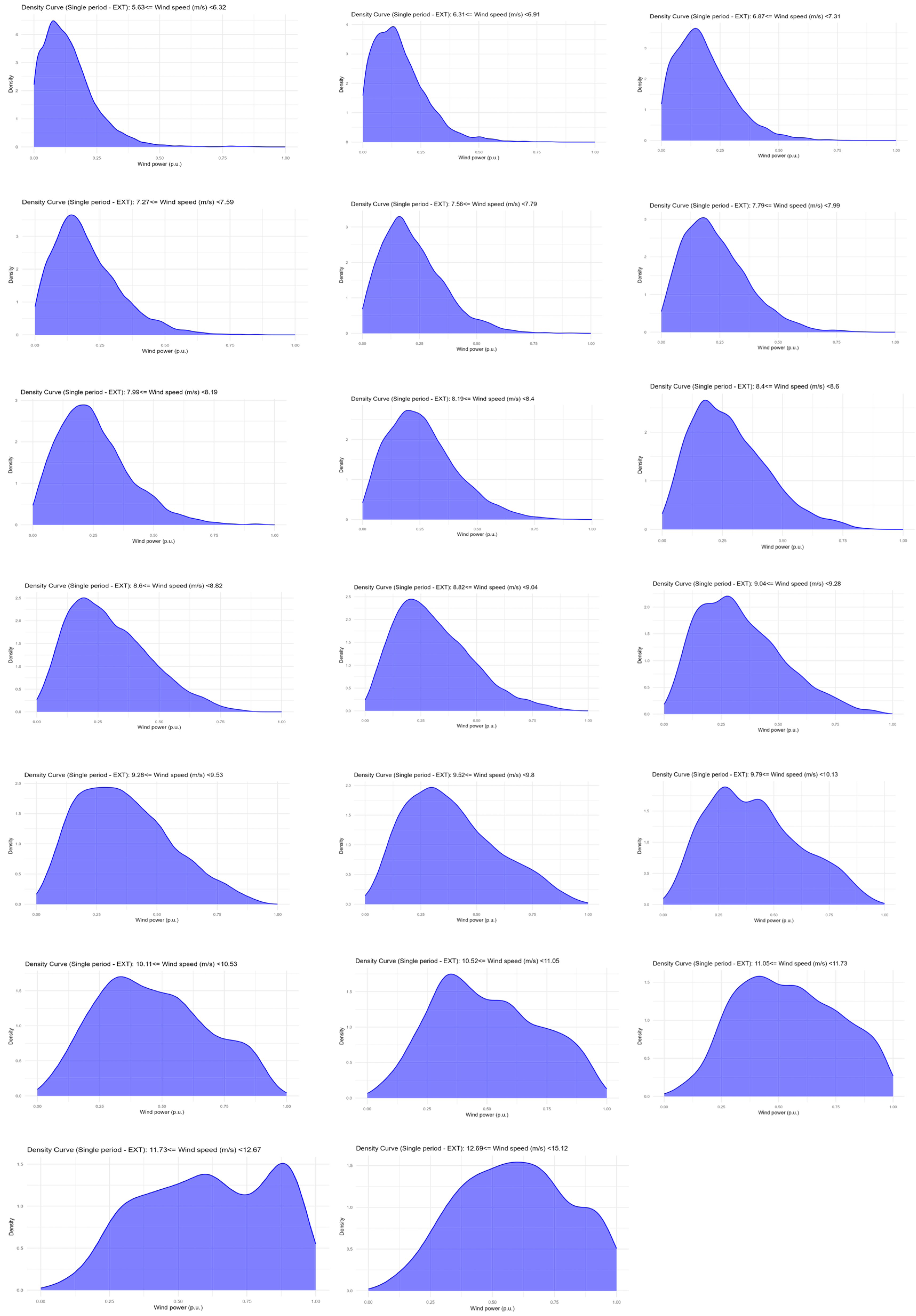
Then, KDE was applied to estimate the probability density function of the power values for each cluster resulting from the previous step.
Figure 5 contains the PDF resulting from this step for each wind speed interval on Wind Farm 5 by the single-EXT approach. Note that as the wind speed values of the intervals increase, the peak of the density curve shifts toward the end of the interval. This behavior was seen for all the wind farms and approaches and was expected since faster wind speeds tend to generate more energy. Figures with the probability distributions of all the speed ranges for all the wind farms and approaches are shown in the
Supplementary Materials.
It is important to mention that the KDE technique adopted in this work, based on [
37,
38], generates probability distributions that can infer negative power values. Other methods were tested, such as KDE Beta, but the results were worse, as observed by visualizing the graphs and the evaluation metrics. This highlights the great advantage of kernel density estimation, which adjusts according to the data and allows the proposal to be generalized regardless of the data used.
To emulate the variability in the behavior of a turbine in operation, Monte Carlo simulation was performed, which requires the wind speed time series and the density functions of the clusters. In applying the simulation for a single period, only the PDF utilized varied based on the generating wind speed cluster. At the same time, in the approaches with temporal segmentation, the choice of the PDF changed due to the wind speed and instant of time for estimating the wind power.
To measure the quality of the results, the metrics RMSE, MAE, MAPE and R
2 were used, compared to the active, historical and estimated power time series. To construct the estimates using the method proposed here, 100 power time series simulations were generated, and each time point’s average power was calculated. The number of scenarios adopted was found experimentally by ceasing to increase the number of scenarios when no further gains were obtained based on the evaluation metrics (only increases in computational cost).
Table 5 depicts the results obtained by the different estimation strategies, with the best result of each test highlighted in boldface. Note that irrespective of the evaluation metric, wind farm analysis or steps adopted to construct the wind speed time series employed in the test, the new proposed method always performed better than the cubic power curve, and the monthly–hourly strategy was the best in all cases.
Regarding the new proposed method, as the segmentation of the data for applying the three techniques increased, the simulations based on the metrics indicated in
Table 5 improved, with only one exception. In the test of Wind Farm 3 using speed EXT data, the monthly approach performed better than the hourly approach, as identified by the four evaluation metrics.
Table 6 and
Table 7 detail the results of
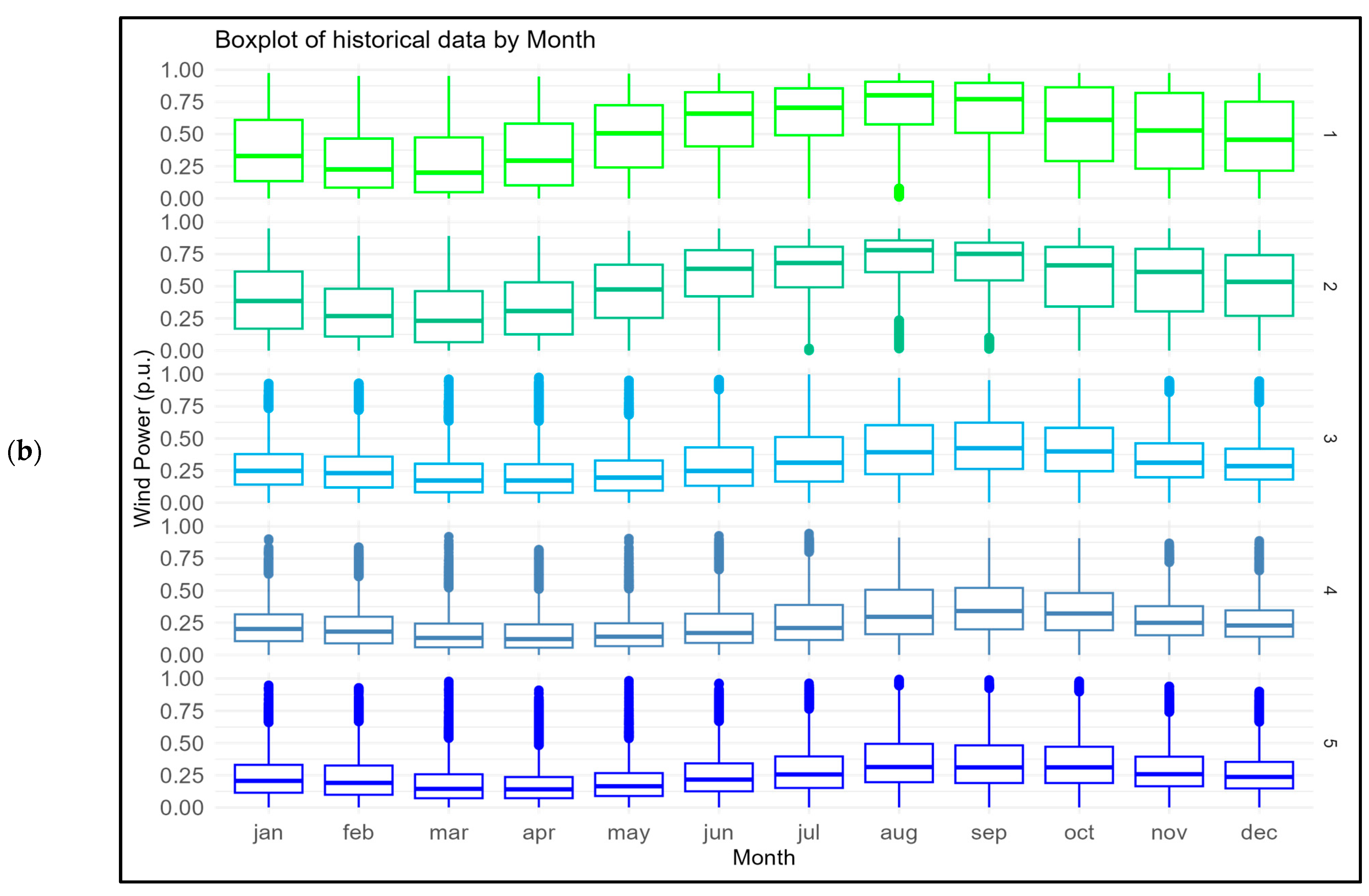
Table 5, where it is possible to see the behavior of the RMSE metric by month and hour in each test, respectively, and verify whether a trend exists other than that observed in
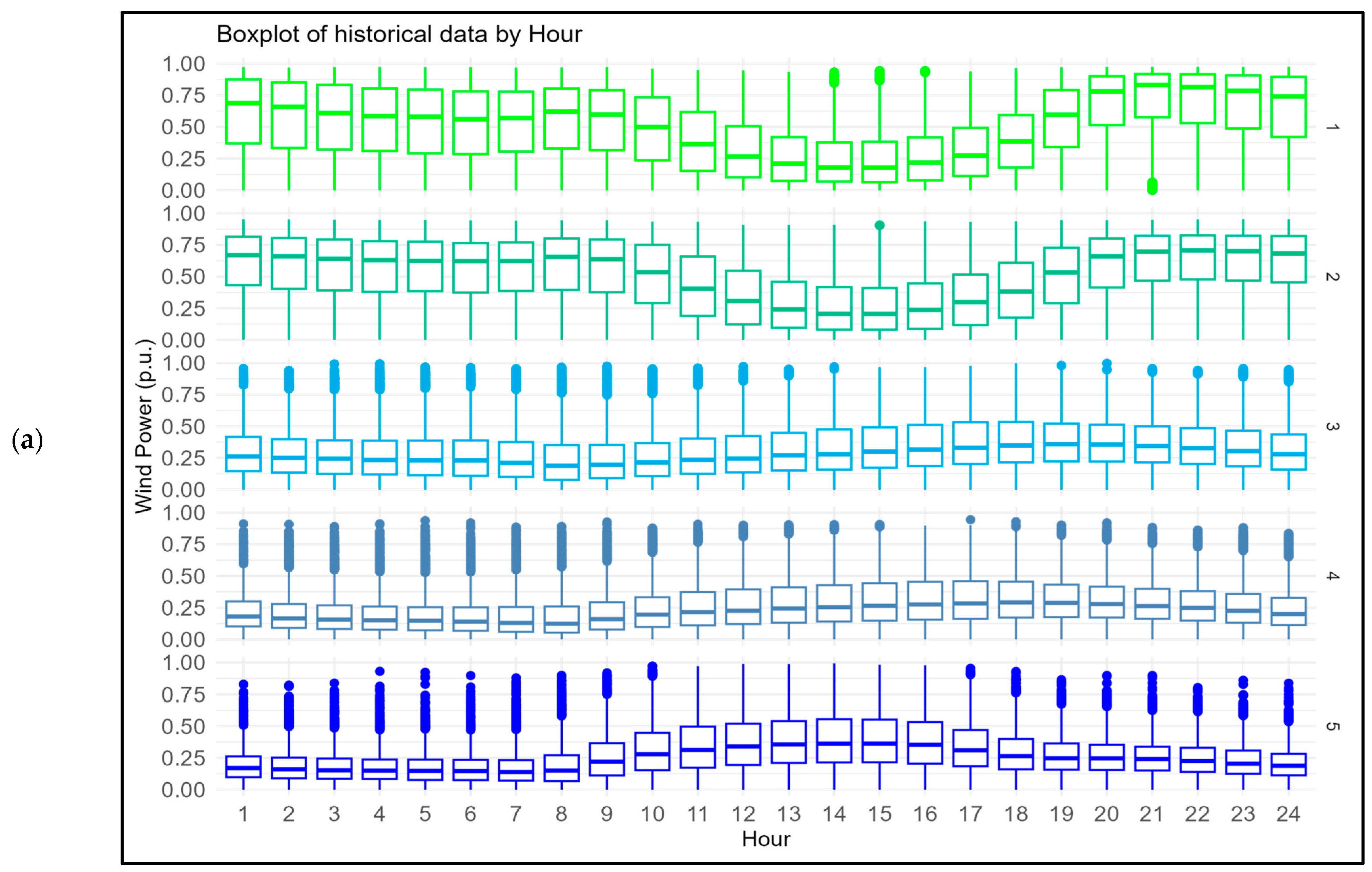
Table 5. Again, the best performance was achieved by the monthly–hourly approach in all the wind farms in all months and hours. Nevertheless, in a few isolated months and hours, the theoretical power curve method performed better than the proposed technique, with the single-period and monthly approaches being better than the hourly approach. All these analyses were carried out using the metrics MAE, MAPE and R
2; the respective tables are in the
Supplementary Materials. The conclusions were the same as those with the RMSE.
The type of treatment applied to wind speed did not influence the performance of the modeling strategies presented here for the evaluation metrics. Mainly, it did not impair the identification of the best approach to estimate the wind power. Thus, as pointed out in a previous study [
29], the wind speed time series data that only underwent interpolation and extrapolation (EXT) also achieved a good representation of the series measured on the farms; in some cases, this was better than the series that underwent the third step, bias correction (INMET-H). This might have happened because the quality of the correction is directly related to the quality and quantity of measurements supplied by the INMET station and its distance from the wind farm. It is not always possible to satisfy these factors. For example, the EXT series produced better performance at Wind Farms 1 and 2, where the maximum distance requirement between the farm and INMET station was not satisfied. At the other wind farms, the best performance between the two treatment options in the monthly case was alternated.
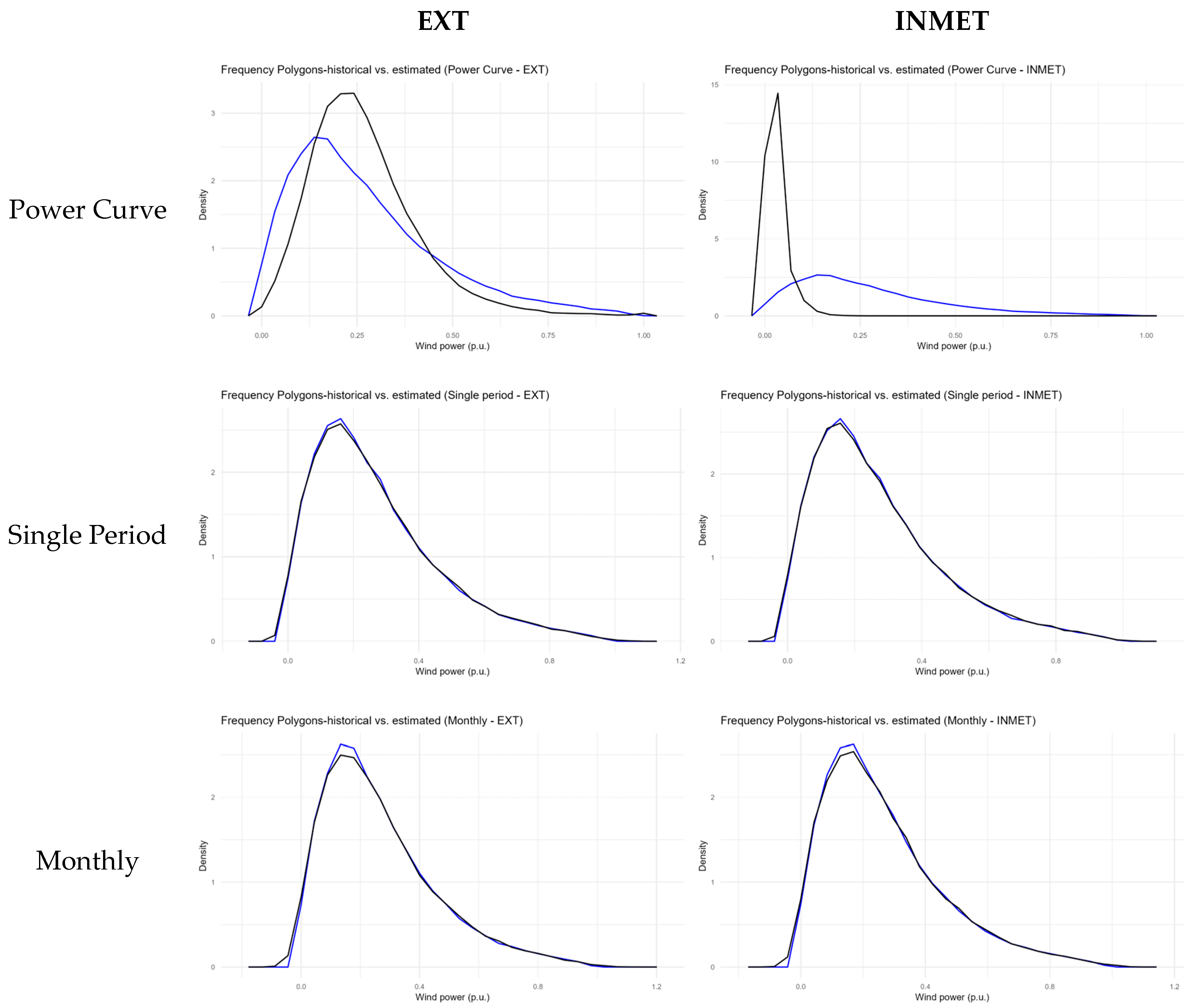
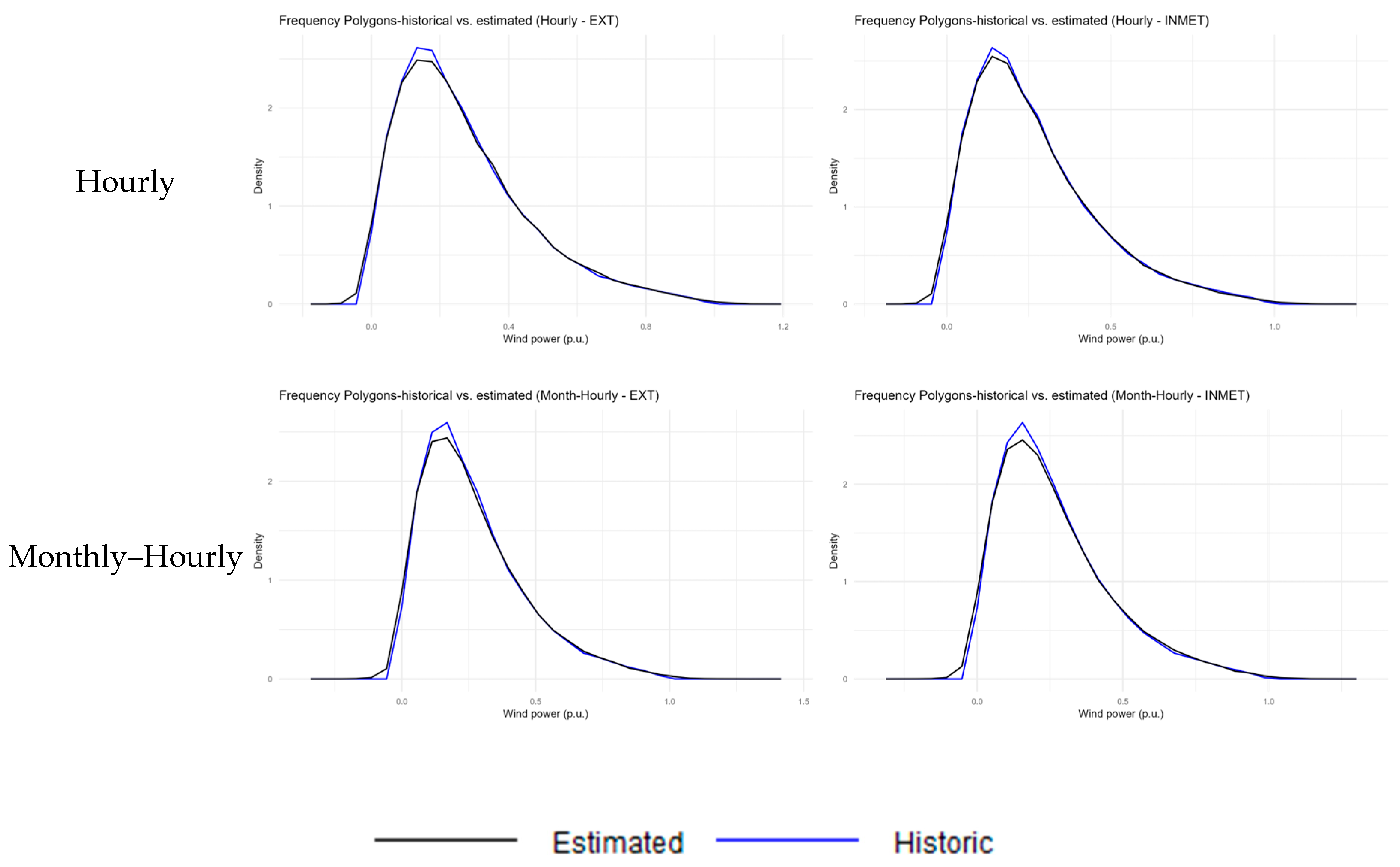
Figure 6 and
Figure 7 compare the behavior of the wind farms’ historical data with the estimates resulting from each approach of the proposed method. The blue dots and lines in the graphs refer to historical data, while the black ones denote the estimated values.
Figure 6 presents the dispersion graphs, evidencing the behavior of the power variable using the wind speed variable. From these graphs, it is possible to infer that the strategies described in this study managed to better replicate the inherent generation variability for the same speed values, with a highlight on the monthly–hourly proposal, which best captured the existing stochasticity.
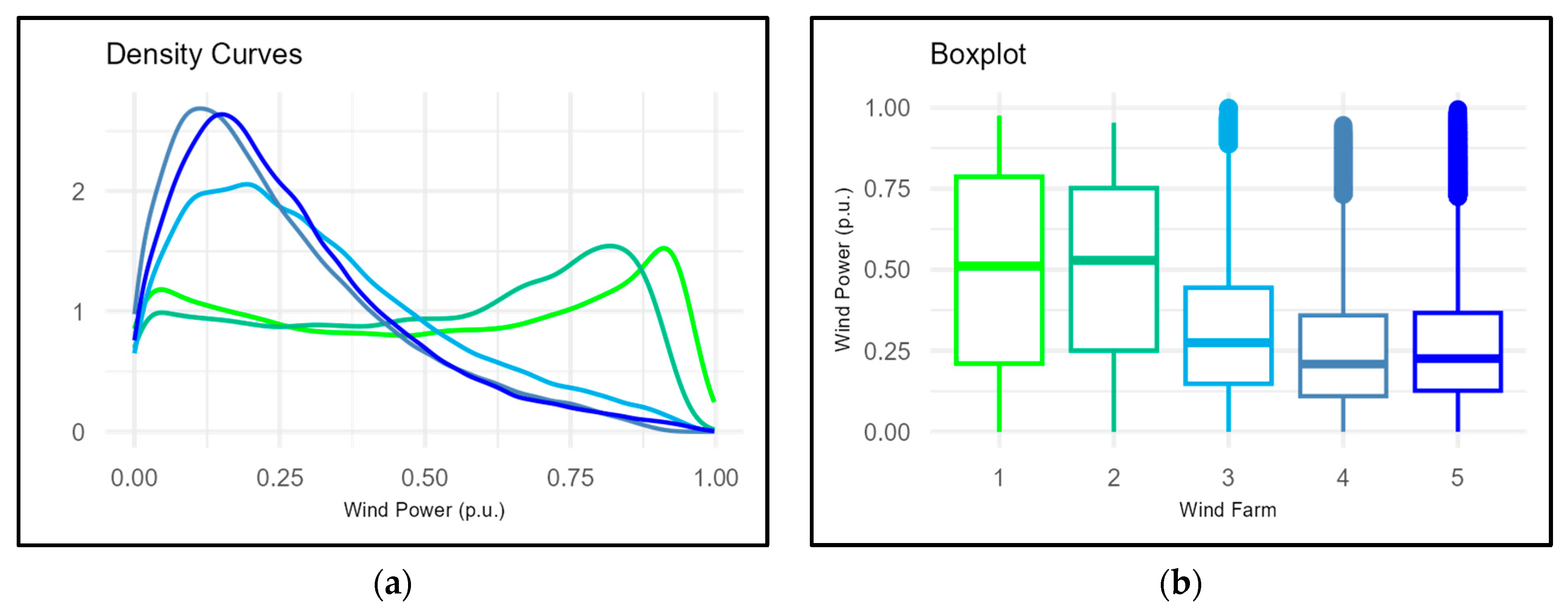
Figure 7 contains the frequency polygon graphs that estimate the density curve based on the frequencies of the power value intervals. Once again, it can be noted that the suggested strategies (single-period, monthly, hourly and monthly–hourly) replicate the power frequencies obtained from the historical data better than the cubic power curve.
5. Conclusions
Wind speed significantly influences wind power generation, although it is not the sole determining factor. The power curve traditionally represents the relationship between wind speed and power output, often employing the cubic approach. However, this method fails to fully capture the variability in this relationship and necessitates data, such as the air density, turbine height and efficiency factor, which may not always be readily available. Moreover, the theoretical power curve does not entirely reflect the dynamic regions of wind power generation.
To address this limitation, this paper developed a method that replicates wind generation variability based solely on wind speed, without the need for additional data. The approach leverages clustering, probability density function estimation and simulation, making it a probabilistic and nonparametric technique. A key advantage of this proposal is its reliance solely on historical wind power and speed data; however, one downside is its requirement for measured wind generation data, which may be unavailable or limited for new or recently completed wind farms.
This paper utilized historical active wind power data and MERRA-2 reanalysis wind speed data in a study involving five wind farms in Northeast Brazil. The monthly–hourly strategy outperformed the traditional cubic power curve approach.
This new power estimation technique accurately represents power generation variability concerning wind speed, facilitating enhanced project planning and understanding of wind power utilization. It improves data segregation and performance across evaluation criteria by effectively reflecting the probability distribution of historical power production and capturing wind power data characteristics and stochastic behavior.
When accurate wind speed data were challenging to acquire, the proposal turned to the MERRA-2 dataset as a dependable alternative. Two types of wind speed series from MERRA-2 were employed: one with interpolation and extrapolation (EXT) and the other with these steps and bias correction (INMET). Both types yielded favorable results in the four approaches considered. When the performances were compared, they alternated in producing the best results and sometimes even yielded the same results for each evaluation metric. This pattern persisted across all tests, irrespective of the evaluation metric, wind farms and analysis details.
Notably, wind speed data from the INMET station consistently indicated low values, potentially resulting in underestimation after the bias correction step. This impact was observed across all wind farms, including the recommended bias correction sites (Farms 3, 4, and 5). Conversely, the power curve method did not consistently demonstrate complete formation, often leaving the maximum turbine generation unspecified. However, the new method proposed in this article remains unaffected, as all power possibilities derive from occurring wind speeds, effectively addressing the underestimation.
Future endeavors include evaluating this method with other renewable energy sources to ascertain its efficacy, exploring additional clustering and PDF estimation approaches, and considering improved methods for segmenting the data to apply the new method. Furthermore, leveraging a multivariate modeling approach for evaluating other variables from MERRA-2 and wind speed to estimate wind generation warrants consideration.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}