1. Introduction
The global climate is changing, and this poses ever greater risks to ecosystems, human health, and the economy. Fossil fuel-based energy production is one of the main sources of CO
2 [
1]. According to [
2], we can see that the power sector accounts for the majority of CO
2 sources in Nordic countries. Moreover, non-optimal energy consumption in the heating systems entails an increased demand for energy generation and transportation systems and increased financial costs [
3]. To manage harmful CO
2 emissions as well as to improve energy- and cost-efficiency, accurate prediction models are needed for the operation and planning of energy production and usage in district heating networks. In the case of accurate prediction of the power consumption of district heating, the energy producer can schedule the energy generation and the load in the transmission and generation systems. Consequently, this will reduce the load in the system and optimize production energy costs. In the literature, a planning horizon of power consumption can be divided into three categories: short-term [
4], medium-term [
5], and long-term [
5] planning horizons. In the short-term prediction, the period is equal to a period ranging from hours to a week. Usually, it is used for power distribution and load dispatching. In medium-term prediction, the time period ranges from a few weeks to a few months. The main goal of this prediction is typically to maintain energy systems and purchase energy to balance demand and generation. The long-term prediction is especially for planning power consumption from a year to ten to twelve years into the future. This prediction is for expansion planning and purchasing of new units for energy generation. Today, there are some developed mathematical techniques for solving energy consumption prediction problems [
6]. Some of these methods are ARIMA (autoregressive integrated moving average) [
7], SARIMA (seasonal ARIMA) [
8], Bayesian vector autoregression [
9], multiple linear regression [
10], BVAR (Bayesian vector autoregressive) [
11], and Markov processes [
12]. In solving real-world problems, it is essential to consider numerous nuances in the development and application of models. For instance, in paper [
13], the authors address power consumption prediction and power-aware packing in consolidated computing environments. The authors propose methods for predicting power usage in systems where multiple virtual machines or tasks are hosted on a single physical server. They introduce algorithms for energy-efficient task placement to minimize overall power consumption, including strategies for server consolidation and load distribution. The study includes empirical evaluations demonstrating the effectiveness of these approaches in reducing power usage without compromising system performance and reliability. Another good example of how real problems are solved with a detailed description of the features is presented in [
14]. In the paper, the proposed approach employs sparse Gaussian process regression to handle large datasets efficiently, making it suitable for real-time applications. By integrating numerical weather predictions with on-site measurements, the proposed approach enhances the reliability and precision of wind gust forecasts, which is critical for various practical applications such as renewable energy management and weather-dependent operations. In recent years, along with the increasing availability of large amounts of measurement data, machine learning (ML) is increasingly applied in energy industry and applications, e.g., for predicting power consumption in various contexts, such as energy management, demand forecasting, and optimizing energy usage.
The accurate prediction of daily heating demand is the key operation needed in the short-term planning of district heating system operation. One challenge in the prediction is to find a model structure which has sufficient predictive power but is not too complicated in terms of model parameters and inputs. In this paper, we have developed a novel computational approach for the automated tuning of parameters and input features of ML models for the short-term prediction of hourly power demand in a district heating network based on the available measurement data. Various standard ML-based techniques were applied and evaluated using the power measurements from the district heating network.
The novelty of this work lies in the development of the hybrid evolutionary algorithm GA-SHADE, which for the first time combines the GA and SHADE. This approach does not require fine-tuning before execution and effectively self-optimizes during operation, significantly simplifying the process of building ML models. Moreover, the algorithm demonstrates high robustness to the number of features and hyperparameters, making it a versatile tool for solving a wide range of energy consumption prediction tasks in district heating systems. Our numerical experiments confirm that the proposed algorithm allows the identification of simplified models with excellent predictive performance, optimizing both feature selection and model hyperparameters. Through practical application during this study, we gained valuable insights into the type of ML models and features that yield the best performance. The models selected through this process effectively balanced complexity and predictive power with a well-defined set of features that contributed most significantly to the accuracy of the predictions. This highlights the practical utility of the GA-SHADE algorithm in generating robust and efficient predictive models for real-world applications.
The remainder of this paper is organized as below.
Section 2 describes popular and frequently used approaches for tuning the hyperparameters of ML models and selecting features.
Section 3 describes in detail the proposed GA-SHADE algorithm for automatically building ML models.
Section 4 consists of information about the dataset and the ML models used and conducting numerical experiments and providing information about a computation cluster and numerical results. The inclusion of
Section 4.7 on “Feature Importance based on classic approaches” in the study is consequential as it allows one to evaluate and compare how different traditional methods select input features. However, it is worth noting that comparing the effectiveness of selected features is complicated due to the fact that the choice of specific features can strongly depend on the model’s hyperparameters. This creates the problem of objectively assessing and observing results between other approaches. This subsection is intended to be a theoretical comparison using our case to understand what certain features have been identified as most significant by our proposed algorithm and how this compares with classical methods. Such analysis not only provides insight into the different methods of the feature selection process, but also provides a deeper understanding of the results reported in our studies. In
Section 5, we discuss the obtained numerical results in detail. In conclusion, the proposed GA-SHADE algorithm and the obtained results are summarized and some further ideas are suggested.
2. Related Work and Literature Review
A range of ML-based approaches have been developed for the operation of district heating networks [
15,
16], but these approaches have certain limitations when it comes to accurate prediction of power consumption. We can highlight the following main key limitations below.
ML models require large and high-quality datasets to make accurate predictions. In the case of power consumption, data may be missing or incomplete, and historical data might not always be representative of future conditions. Power consumption can exhibit significant seasonality and variability, which can be challenging for ML models to capture accurately. For example, extreme weather events, holidays, and special occasions can lead to sudden spikes or drops in power usage. Power consumption patterns can change over time due to factors like population growth, technological advancements, and policy changes. ML models may struggle to adapt to these non-stationary trends. ML models can overfit on the training data, capturing noise and idiosyncrasies instead of general patterns. This can lead to poor generalization on unseen data, especially if the training dataset is small. Different factors affecting power consumption can interact with each other in complex ways. For instance, weather conditions may influence both heating and cooling demand, and economic factors may affect industrial power usage. Capturing these interactions accurately is challenging. Many ML models, especially deep learning models, are considered “black boxes” that provide limited insights into why a particular prediction was made. Interpretability is crucial for trust and decision-making in critical applications. To address these limitations, domain expertise, careful data preprocessing, model selection, and ongoing model monitoring and maintenance are essential in the application of ML for power consumption prediction. Additionally, hybrid approaches that combine ML with physics-based models or expert knowledge can often yield better results in complex energy systems.
Smoothing predicted values of power consumption is vitally important when aiming for smooth changes in power consumption from hour to hour. This smoothing process has significant implications for various sectors, including energy management, power network stability, and cost efficiency. Because of the following factors, the correction can be crucial. Maintaining a stable power network is essential for providing reliable power to consumers. Abrupt fluctuations in power consumption can strain the power network, leading to voltage instability and potentially causing blackouts. Correcting prediction values helps to reduce sudden spikes or drops in demand, ensuring a smoother and more predictable load profile. This, in turn, contributes to a more stable network [
17].
Power plants, especially those relying on fossil fuels, have limitations on how quickly they can adjust their power consumption. Correcting power consumption predictions allows utilities to plan and optimize energy generation efficiently [
18]. Smoother changes in power consumption enable power plants to operate closer to their optimal points, reducing fuel consumption and emissions. This, in turn, supports environmental sustainability [
19].
Properly smoothed power consumption profiles facilitate load balancing. Utilities can distribute the load more evenly across different power generation sources, including renewables, ensuring efficient use of resources. Correcting power consumption predictions improves the accuracy of load forecasts. When utilities have a better understanding of future demand, they can plan maintenance, allocate resources, and schedule network operations more effectively. This enhanced predictability benefits not only utilities but also industries and businesses that rely on a stable power supply.
Physical
–statistical models that combine weather and statistical models are an innovative approach to address the limitations inherent in each type of model. Physical models, based on the laws of physics, provide detailed simulations of atmospheric processes but can be computationally expensive and sensitive to initial conditions. Statistical models, on the other hand, are data driven and can quickly process large datasets, but they might lack the detailed understanding of physical processes. By integrating these two approaches, physical
–statistical models leverage the strengths of both, providing more accurate and robust weather predictions. Accurate weather forecasts enable better predictions of these variations, allowing for more precise and reliable estimates of electricity consumption. This integration of weather and statistical models helps energy providers to optimize their operations, ensure efficient energy distribution, and reduce costs associated with over- or underestimating energy demand. Consequently, the improved weather predictions derived from physical
–statistical models contribute to more effective and sustainable energy management. This hybrid method can improve forecasting by combining the detailed, process-oriented insights of physical models with the flexibility and efficiency of statistical models. Additionally, these models can enhance the ability to predict extreme weather events by using the comprehensive data analysis capabilities of statistical methods alongside the detailed simulations from physical models. A good example is an approach that is representative of this class of hybrid models, such as CNN-BiLSTM [
20]. In the study, the authors propose a hybrid model that combines convolutional neural networks (CNNs) and bidirectional long short-term memory (BiLSTM) networks with a multi-head attention mechanism. This probabilistic model aims to improve the accuracy and reliability of day-ahead wind speed forecasts, which are crucial for optimizing the integration of wind energy into power systems and enhancing grid stability.
Hyperparameter optimization and feature selection represent pivotal stages in the construction of mathematical models [
21,
22,
23]. This section provides a succinct overview of prominent and widely adopted methodologies essential for the development of robust ML models. By meticulously fine-tuning hyperparameters and judiciously selecting relevant features, researchers can harness the full potential of their models, resulting in heightened predictive accuracy and enhanced model efficiency.
2.1. Approaches for Tuning Hyperparameters
The quality of a model can vary greatly depending on the hyperparameters, so there are a variety of methods and tools for tuning them. Here, we would like to mention the difference between hyperparameters and parameters of ML models, which are adjusted in the process of training an ML model on data. For example, the weights of a neural network and regression coefficients are parameters that are adjusted by the algorithm itself during the learning process. Parameters are values that the model uses to make predictions and are learned directly from the data during the training process. These include weights and biases in neural networks or regression coefficients in linear regression. The model adjusts these parameters automatically to minimize the error between the predictions and the actual outcomes. On the other hand, hyperparameters directly influence the training process. They are not learned from the data but are set prior to training and remain constant during the training process. Hyperparameters include the learning rate, the number of hidden layers and neurons in neural networks, the regularization strength, and the number of trees in a random forest. The choice of hyperparameters can significantly influence the learning algorithm’s behavior and the resulting model’s performance. In general, we can distinguish the following main groups of approaches for tuning hyperparameters:
Grid Search. The most natural way to quickly iterate over sets of hyperparameters is to do a grid iteration. The enumeration of some hyperparameter values can be carried out on a logarithmic scale, as this allows you to quickly determine the correct order of the parameter and at the same time significantly reduce the search time. So, for example, the learning rate for gradient descent, the regularization constant for linear regression, or the SVM method can be selected. A clear drawback associated with grid search is its potential for high computational costs, particularly when dealing with numerous hyperparameters or an extensive range of potential values for each hyperparameter. Grid search is used quite often in solving real-world applications using ML algorithms [
24,
25,
26]. The authors in [
27] have optimized parameters of machine learning models in the prediction of HIV/AIDS test results using grid search. They demonstrate how eight different ML models perform using optimized hyperparameters. The authors considered that the tuning of hyperparameters has a statistically significant positive effect on the prediction accuracy of the models. However, grid search has some limitations. The computational complexity increases exponentially at a rate of
, where
k is the number of parameters and
n is the number of separated values for tuning. Obviously, when
k and
n are large, the time required for numerical experiments will be substantial. However, when the model trains quickly and the number of parameters is small, grid search serves as an excellent starting point;
Random Search. Another well-known strategy is to determine the probability distributions for each parameter dimension and then randomly generate these values. This eliminates the minor grid search inefficiency that occurs when one of the parameters has a very small performance impact. Random search is also simple and parallelizable. However, if we are unlucky, we may either make many similar and/or identical observations that provide redundant information. Examples of using random search can be found in [
28,
29]. In practical scenarios, random search proves to be more efficient than grid search, accommodating a broad spectrum of hyperparameters. In real-world applications, employing random search for the assessment of arbitrarily chosen hyperparameter values helps in the comprehensive exploration of an extensive search space. One obvious downside to both grid and random search is that they do not use previous results during the optimization process into account. If measurements are taken sequentially, we could use previous results to make the best decision on where to sample next time. On the one hand, we could better study areas where few measurements were made, and thus we reduce the likelihood of missing a global maximum. On the other hand, we could use the refinement of those decisions that we received in relatively promising areas. To overcome obvious disadvantages, Random Search Plus (RSP) has been proposed in [
30] for tuning the hyperparameters of models. RSP is an enhanced hyperparameter optimization method that divides the hyperparameter space into smaller regions, focusing the search to improve efficiency and accuracy. This targeted approach allows it to achieve similar or better results than traditional random search in significantly less time;
Bayesian Optimization. Bayesian optimization is an iterative method that allows us to estimate the optimum of a function without differentiating it. In addition, at each iteration, the method indicates at which next point we are most likely to improve our current optimum estimate. This allows us to significantly reduce the number of function calculations, each of which can be quite time-consuming [
31]. The authors in [
32] developed a probabilistic framework using quantile random forests with Bayesian optimization to predict typhoon-induced dynamic responses of long-span bridges. Their approach demonstrated superior performance in accuracy and computational efficiency compared to traditional finite-element methods. In general, we can highlight several advantages and disadvantages of Bayesian optimization for hyperparameters. It efficiently uses data by building a probabilistic model to predict performance, making each trial valuable. It is effective at finding global optima in complex, high-dimensional spaces and handles uncertainty in predictions, which helps avoid local minima and provides reliable results. However, it has high computational costs for building and updating the model, requires many initial runs to build a reliable model, and its effectiveness depends on the choice of the prior model and acquisition function. Additionally, Bayesian optimization is more complex to implement compared to simpler methods like grid or random search;
Evolutionary Algorithms. Evolutionary algorithms (EAs) are used to optimize the hyperparameters of machine learning models. That is, they can automatically determine the best baseline settings. The effectiveness of training largely depends on the features of the model used. Hyperparameters define the general properties of the system, which are not visible during training in the system [
33]. In this study, we use an evolutionary-based algorithm because such approaches demonstrate good performance in practice when compared with classical methods [
34,
35]. EAs effectively explore large, complex search spaces by simulating natural selection processes, making them suitable for finding global optima. EAs handle diverse types of hyperparameters and maintain population diversity, which helps avoid local minima. However, they are computationally intensive, requiring significant resources and time, especially for large populations and many generations. Additionally, EAs can be sensitive to their own parameter settings, such as mutation rates and population sizes, and implementing them can be more complex compared to simpler search methods. To summarize, the following recommendations can be made. Use grid search when you have a small number of hyperparameters and computational resources that are not a concern, as it exhaustively searches all possible combinations. Random search is effective when dealing with a larger hyperparameter space and limited computational resources, as it samples randomly and can find good solutions faster. Bayesian optimization and evolutionary algorithm-based approaches are suitable for complex, high-dimensional search spaces when a global optimization approach is needed to effectively explore the hyperparameter space.
2.2. Approaches for Feature Selection
When building a machine learning model, it is not always clear which of the features are important for it (i.e., have a connection with the target variable) and which are redundant (or noise). Removing redundant features allows you to better understand the data, as well as reduce model tuning time, improve its accuracy, and facilitate interpretation [
36,
37]. Sometimes this task may even be the most significant; for example, finding the optimal set of features can help decipher the mechanisms underlying the problem under study. Feature selection approaches can be divided into two groups. Unsupervised methods [
38,
39] do not use information about target data values. They are focused on analyzing the structure of data without considering any dependence on the variable that the model will have to predict. These methods look for patterns based on input data. Supervised feature selection methods [
40], on the other hand, use target values when analyzing data. These methods select those features that are most significant for predicting the target variable. It is important to consider that the results of feature selection can greatly depend on the hyperparameters of the model, which must be carefully selected. Supervised methods most often reveal only linear relationships between features and target values.
2.3. Machine Learning Algorithms
It is a challenging task to determine the most suitable ML algorithm for new data before evaluating its performance in practice [
41]. In this study, six different ML algorithms are applied to predict the power consumption of the heating boiler in the district heating network. In this study, scikit-learn [
42] has been used for implementing all considered models. Different ML models were applied to energy consumption modeling. The brief description and cases for applying energy area in each considered regression algorithm are placed below.
The example of a linear regression (LR) model application in practice for forecasting power consumption in Italy [
43];
An instance of Elastic Net’s (EN’s) practical application can be observed in the prediction of ground-source heat pump performance in California, USA [
44];
Decision tree (DT) has been used for building energy demand modeling [
45];
The case of applying support vector regression (SVR) in power demand forecasting is in [
46];
The case of applying random forest (RF) for an hourly building energy prediction problem [
47];
An artificial neural network (NN) has been successively applied, including in the energy industry [
48].
3. The Proposed GA-SHADE Algorithm
We propose a population-based GA-SHADE hybrid algorithm for the simultaneous optimization of hyperparameters and a number of features. In our study, the GA (Genetic Algorithm) [
49] is used for the optimization of the set of features, since the algorithm performs well with optimization problems where a solution is represented as a vector of 0 and 1. In the solution, the features used and not used are defined as 1 and 0, respectively. The SHADE (success-history-based parameter adaptation for differential evolution) algorithm [
50] performs the optimization of hyperparameters of ML models. We chose the SHADE algorithm since approaches based on its principles are at the top of algorithms in various single-objective optimization competitions [
51]. As evidenced by the review in the previous section, the process of simultaneously tuning parameters and feature selection is difficult due to the specifics of the approaches. The unifying feature of these approaches is that it is necessary to adjust model hyperparameters and select certain features for which the prediction will be made. The proposed GA-SHADE algorithm tunes an ML model for an adequate number of experiments. The SHADE algorithm in practice has proven its effectiveness in parametric optimization of the black-box type [
52]; also, parameters of SHADE, such as scale factor,
F, and crossover rate,
CR, are self-adapted during an optimization process. In optimization features, we use a crossover operator from the GA [
53] to create new solution candidates. A detailed description of the SHADE, GA, and the proposed GA-SHADE algorithms is placed below in this section. Before describing the proposed approaches, we have to pay attention to the terminology in DE-based and GA-based evolutionary algorithms.
3.1. Success-History-Based Parameter Adaptation for Differential Evolution
We would like to note that Equations (1)–(10) have been used according to the study [
50]. The differential evolution algorithm starts with random initialization of a set of N D-dimensional vectors, so-called population,
. Each value is generated using uniform distribution in the following interval,
, where
and
are the left and right searching border for the
j-th dimension, respectively.
After initializing the population, the main cycle of alternately applying operators starts. Firstly, we have to apply a mutation operator to generate new individuals. SHADE uses the current-to-pbest/1 mutation strategy, Equation (1):
where
is the
i-th newly generated vector.
is a scale factor.
is randomly chosen from the best-predefined
p% of the individuals in the population.
and
are randomly taken individuals from the main population and the main population and an external archive, respectively,
Here,
is the size of the external archive. If the parent vector in the selection stage is worse than the trial vector, we place the parent vector in the external archive. If the external archive is full, we randomly replace the solution from the archive. After applying the mutation operator, we have to generate trial individuals
by the following formula, Equation (2):
where
CR is the crossover rate value.
is a uniformly generated value from [1,
D] to avoid the situation when
CR is too small and we have not selected any value from
v. After applying the crossover operator, all trial vectors need to be checked to ensure they are within the original search interval to avoid being out of bounds (Equation (3)). Equation (3) pushes the values of the variables back if they exceed the boundaries of the search interval.
The final operation in the main loop of differential evolution is a selection. It is needed to evaluate all
solutions using the predefined fitness function
. If a better solution than the parent individual is achieved, it should be replaced by the new solution. Equation (4) shows the case of solving the minimization problem. In the case of solving maximization problems, the sign “
” should be replaced with “
”. If we replace a parent, we have to save the solution in the external archive to maintain the diversity of generated solutions.
If the termination criterion is not met, then the optimization process starts from the mutation operator.
As mentioned before, SHADE self-adapts two control parameters,
F and
CR, during the optimization process. The self-adaptation process is based on the historical memory which contains
H pairs of
F and
CR values. Before the optimization process, the size of the historical memory is set to
H. All cell
and
filled values equal to 0.5. For each individual in the population, we have to randomly generate
k from the interval
, and then apply the following Equations (5) and (6):
where
is a normally distributed random value.
is a Cauchy distributed random value. The normal distribution features a bell-shaped curve with tails that drop off quickly, while the Cauchy distribution has significantly broader tails, signifying a greater likelihood of extreme values. Applying different distributions for
F and
CR comes from the idea that
CR should not be generated so far from the mean value. However, for increasing searching performance, bigger possible variance for
F allows us to generate more diverse solutions in the population. In each generation, when a trial solution replaces a parent solution, we have to record three values,
.
and
record
F and
CR values, Equations (9) and (10), when the algorithm could find a better solution, and
is the value by which the function was improved. If certain values of the parameters
CR and
F lead to a greater improvement in the fitness function, the mean value will shift towards them. Consequently, new values of
CR and
F will be generated around those new values that allow achieving better improvements in the fitness function. When all trial solutions are evaluated, pairs of values in historical memory are updated using the following equations, Equations (7) and (8):
here,
and
are defined as:
where
. The index of the memory cell is iterated from 1 to
H and the pair
and
is updated as shown in Equations (7) and (8). After evaluating all individuals in the population, it is necessary to check the termination condition. If the termination condition is not satisfied, the optimization process continues.
3.2. Background of Genetic Algorithm
In a traditional way, the GA was inspired by Charles Darwin’s theory of natural selection [
49]. The optimization process in the GA behaves according to selection-based mechanisms found in the natural biological world. The probability of each individual being chosen for reproduction strongly depends on its fitness. Usually, the solution is presented as a set of zeros and ones. We used this representation for a possible solution for the feature set.
Based on the classic approach, the optimization process in the GA starts with a randomly created population. After that, a set of operators is applied, including selection, crossover, and mutation. At the end of each generation, we obtain a new population of possible solutions. The main steps of the GA are presented below.
Initialization. Generating an initial population of individuals randomly.
Evaluation. The fitness function of each individual in the population is evaluated.
Selection. Individuals are selected based on their fitness scores for reproduction. The most common selection techniques are roulette wheel selection, tournament selection, rank-based selection, and various other methods.
Crossover (recombination). Pairs of individuals are crossed over at random points in their structure to produce offspring, which inherit traits from both parents.
Mutation. With a small probability, some parts of the individuals are mutated or changed to introduce variability.
Replacement. The offspring form the new generation, which replaces the old generation fully or partially.
The cycle of evaluation, selection, crossover, mutation, and replacement is repeated over several generations.
GAs have been successfully applied to various domains, including optimization problems, automatic programming, machine learning, economics, immune system modeling, ecology, population genetics, and evolving artificial life. In our proposed GA-SHADE algorithm, the uniform recombination [
53] for creating trial solutions in the part with features can be represented as follows, Equation (11):
where
is
i-th gene in the offspring.
is the
i-th gene from the
j-th parent, selected for the
i-th position in the offspring.
is selected based on a probability distribution
, such that
. In this study, the probability of each gene of offspring is the same and is equal to
, where
k is the total number of selected offspring.
3.3. The GA-SHADE Hybrid Algorithm
As observed in the previous section’s review, the process of simultaneously tuning parameters and feature selection is difficult due to the specifics of the approaches. The unifying feature of these approaches is that it is necessary to adjust model hyperparameters and select certain features for which the prediction will be made. In this paper, we propose utilizing a population-based GA-SHADE algorithm for the simultaneous optimization of hyperparameters and a number of features. In our study, the proposed hybridization of SHADE and GA tunes an ML model for an adequate number of experiments. One of the main aims of the study is to simplify the ML model. By model simplification, we mean a compromise between the number of variables and predictive accuracy. The proposed algorithm has one main control parameter, which is the preferred number of features in the used ML model. Without loss, an optimization problem can be defined as:
where
f denotes an objective function, and
and
are the left and right searching borders, respectively, of the
-th variable. GA- and DE-based algorithms are zeroth-order optimization algorithms that do not require any derivatives. They do not need to use the gradient of the problem being optimized. The problem of building an ML model can be reduced to an optimization problem; therefore, in this paper, the fitness function is defined as the MAE on the validation dataset:
where
and
denote a set of hyperparameters and the selected features for an ML model.
. If
means the model uses the
-th feature; if
the
-th feature is not used, and
.
PF is the preferred number of features.
where
is the MAE on a validation dataset of an ML model with
parameters and
features, and
AF is the actual number of used features.
Mutation operator Equation (1) of the SHADE algorithm has been modified using Equation (16). We use the first condition in Equation (16) to generate a real or integer part of the trial solution (hyperparameters of an ML model) and the second line to generate the set of features of an ML model. The second line is the uniform recombination from the GA, Equation (11), using four parents from the current population and the external archive,
.
In this paper, we multiply the MAE by the difference in the preferred and actual number of features, as shown in Equation (14), to further penalize solutions that have a different number of variables than the desired number, thereby influencing the behavior of the EA by penalizing excessive or insufficient feature selection. We do not use weights balancing the penalty and the error because of the following factors. The impact of the MAE and penalty is proportional to their values. If the MAE is higher, it will lead to a higher fitness cost. Similarly, if the penalty value is higher (i.e., the difference between actual and preferred features is larger), it will contribute to a higher fitness cost. This proportionality naturally accounts for their influence without needing explicit weighting coefficients. Adding weights can complicate the optimization problem and increase the risk of introducing local optima or convergence issues. Without weights, the optimization process is simpler and may lead to more effective and straightforward search dynamics. However, there may be cases where it is desirable to emphasize one component of the fitness function over the other. In such cases, you could consider using a different functional form for your fitness function or introducing weights if you have a clear understanding of how much importance each component should have in guiding the optimization process. As a starting point, it is often a good idea to keep the fitness function simple and let the evolutionary algorithm handle the balance naturally through its selection mechanisms and scaling techniques. We can define the following purposes of the calculation penalty coefficient in the proposed way:
Controlling overfitting. One of the primary objectives of feature selection is to prevent overfitting. Overfitting happens when a model becomes overly complex, capturing the noise in the training data and resulting in poor performance on new, unseen data. Selecting too many features can contribute to overfitting. Starting with small PF values, we can find sets of features with which the model performs well;
Encouraging parsimony. Parsimony is a principle in model selection that favors simpler models when they perform similarly to more complex models. In the context of feature selection, it means preferring a smaller number of informative features over a larger set of features;
Optimizing for model efficiency. Reducing the number of features can improve computational efficiency, reduce memory requirements, and speed up training and prediction times. This is especially important in large-scale applications.
The optimal value of the PF parameter depends on the specific problem (dataset), and the goals of feature selection. It is necessary to conduct numerical experiments to find the right balance between model performance and feature subset size.
When generating new solutions, it is necessary to check whether a feasible solution exists. In other words, there is at least one feature to make an ML model. If the part of the solution vector responsible for the features in the ML model contains all zeros, then this must be corrected. In the algorithm, we generate one in a random index equal to one, Equation (17).
where
is a randomly taken index from the
set.
In the GA, mutation is applied to individuals in a population and consists of a random change in the values of one or more genes on a chromosome. The purpose of mutation in the GA is to introduce diversity into the population so that the algorithm can explore new regions of the search space and avoid premature convergence to local optima. Mutation in the GA is usually carried out with low probability and can be implemented in different ways depending on the chromosome representation, for example, inverting a bit from 0 to 1 or from 1 to 0. In the GA-SHADE algorithm, we apply a GA mutation () for the part of the solution that consists of information about features. The probability of applying the operator for each gene is equal to .
A complete pseudo-code of the proposed GA-SHADE algorithm is presented below. To perform the GA-SHADE algorithm, it is necessary to set an ML model, the set of the searching range of the model hyperparameters, the lower and upper bounds of the domain of definition of the parameters, and the set of features from a dataset.
Without loss of generality, the main steps of the GA-SHADE algorithm can be described as follows.
Require: an ML model, the set of parameters and their searching borders, the set of features , the population size, the value of PF, set the maximum number of fitness evaluations.
Randomly initialize the population, initialize H pairs of CR and F parameters.
Check the population for the existence of a feasible solution. If any solution is not feasible, it must be fixed using Equation (17).
Evaluate the initial population.
If the termination criterion is not met, then go to Step 5; otherwise, go to Step 13
Generate trial solutions using Equation (16).
Apply the crossover operator using Equation (2).
Apply for the part of the vector with features.
Check trial solutions for their feasibility.
Apply the selection operator using Equation (4).
Update the external archive.
Update the historical memory.
Go to Step 4.
Return the best found solution.
5. Discussion
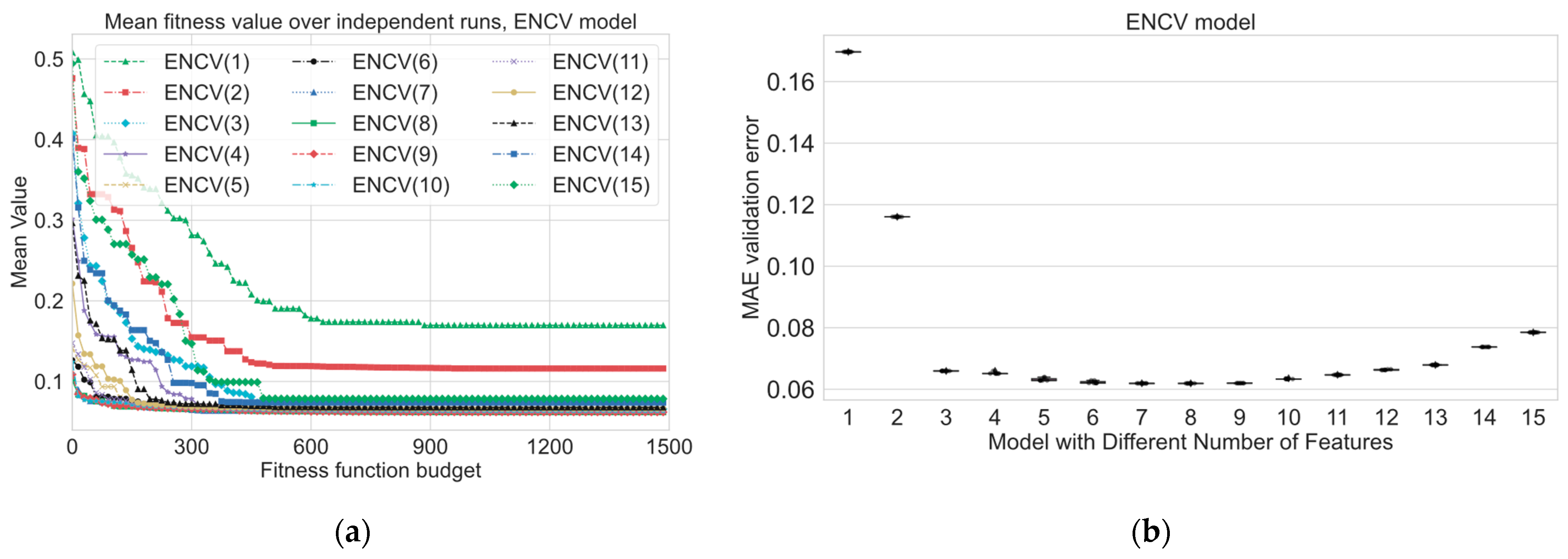
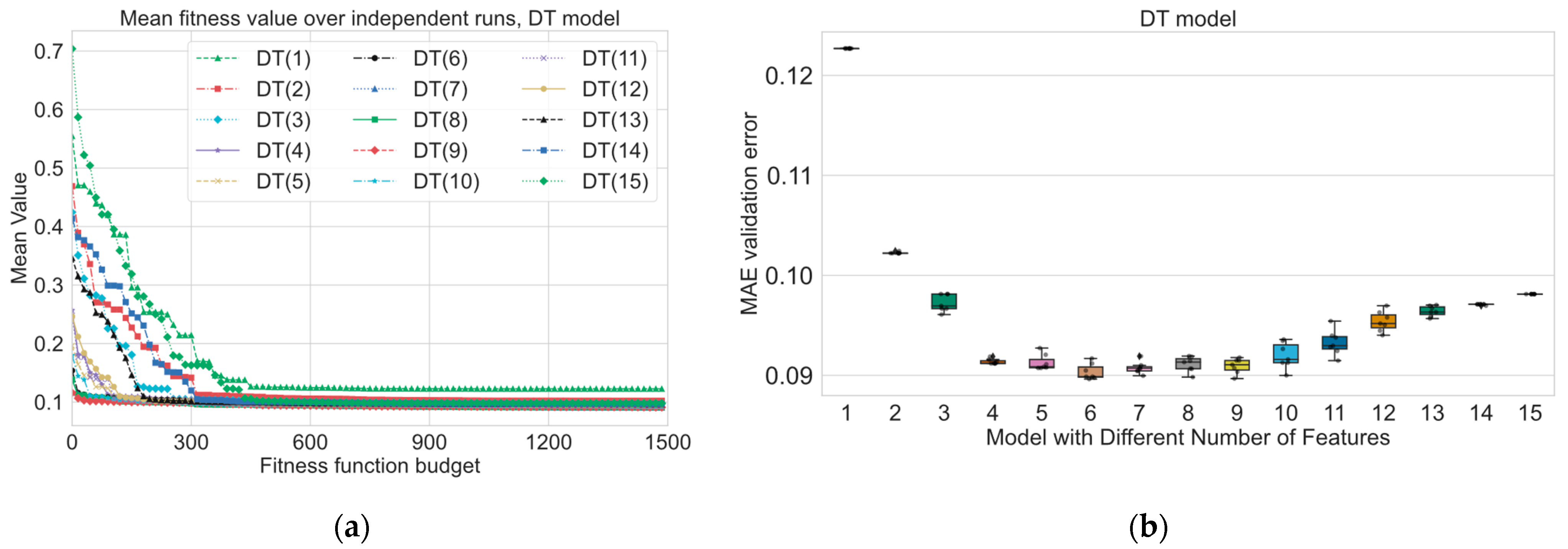
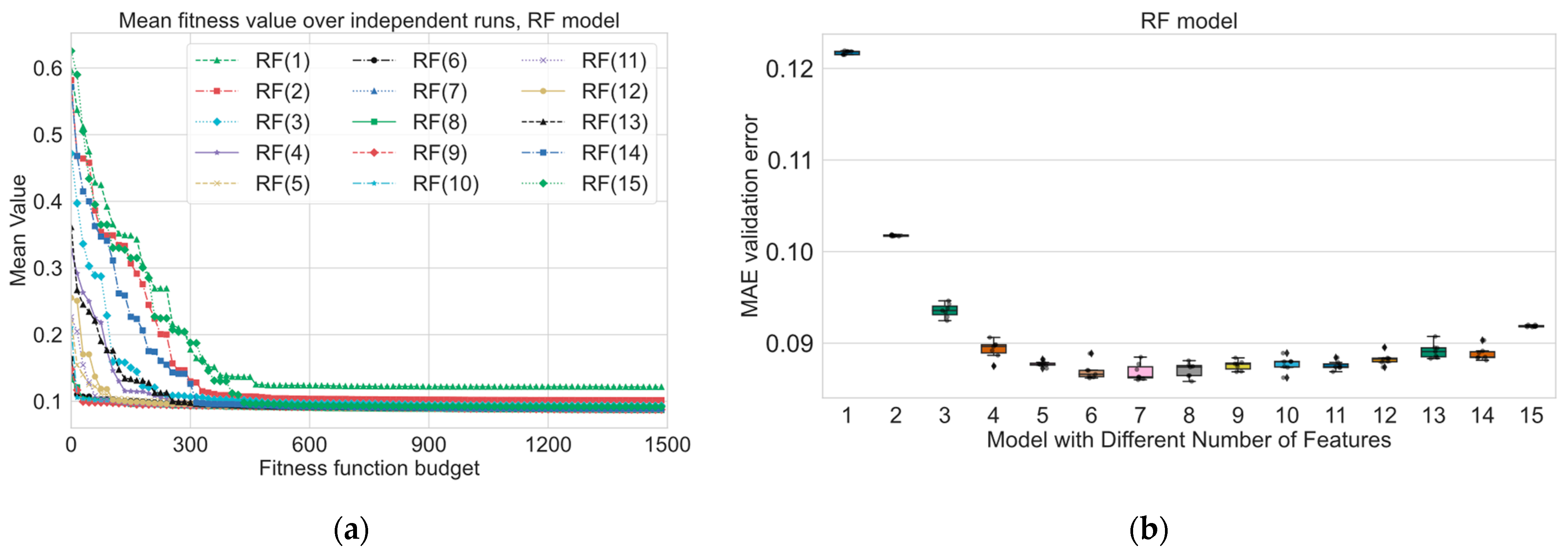
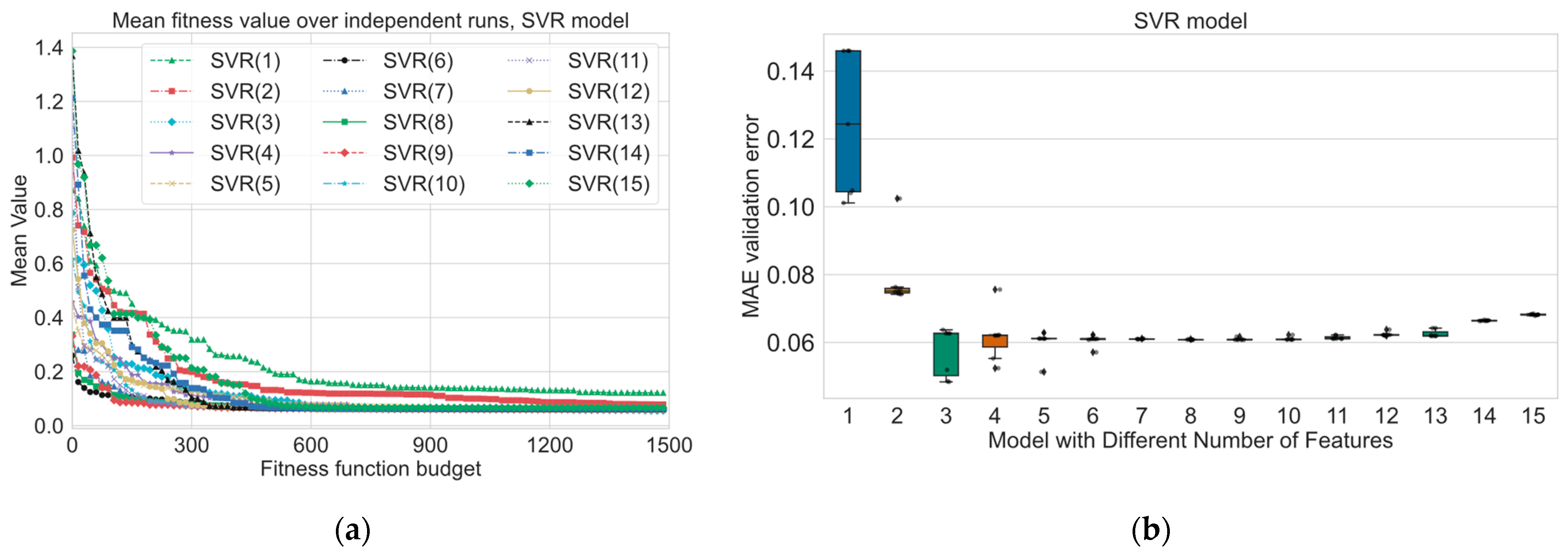
Experimental results for the short-term power prediction section highlight the effectiveness of the hybrid evolutionary-based algorithm GA-SHADE in optimizing machine learning (ML) models for short-term power prediction in district heating systems. The use of the GA-SHADE algorithm allowed for the automated tuning of ML models and feature selection, leading to the identification of optimized feature subsets and hyperparameters across several runs. As we can see from
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8a, the GA-SHADE algorithm shows fast convergence in the first 300–500 fitness evaluations; after that, the improvements to the function are minor, but the optimization process still continues. The predefined value of
PF strongly influences the convergence process and the final best found solution. As we can see from
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8b, the MAE validation error usually greatly decreases from changing the
PF from 1 to 2 and from 2 to 3. According to the numerical results, from
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, we can define the following sets of three features which show a good performance for the following discussion: LR, ENCV—{“Temp”, “P24lag”, “T24lag”}, DT—{”Temp”, ”P24lag”, ”P72lag”}, RF—{“Temp”, “P48lag”, “hcos”}, SVR—{“Temp”, “T24lag”, “P24lag”}, and NN—{“Temp”, “T24lag”, “P24lag”}. In comparison with results from
Figure 12 and
Figure 13, we can find some similarities. All these features, except “hcos”, have a strong linear correlation with the target feature. However, from
Figure 13, we can see that “hcos” is placed in the second place in terms of influence for RF. As we mentioned before, the result of permutation-based feature importance approaches strongly depends on hyperparameters of the considered model; for instance, the best found median SVR(8) model contains the “dsin” feature; however, the permutation-based approach places this feature to the pre-last place. The ”wcos” feature, in the same model, is placed fifth, but in
Table 6, ”wcos” begins to be used from a
PF equal to 12, 13, 14, and 15. This indicates that tuning the model hyperparameters is closely related to the selection of features on which the model will be built. In addition, it is necessary to consider whether the model can capture nonlinear relationships.
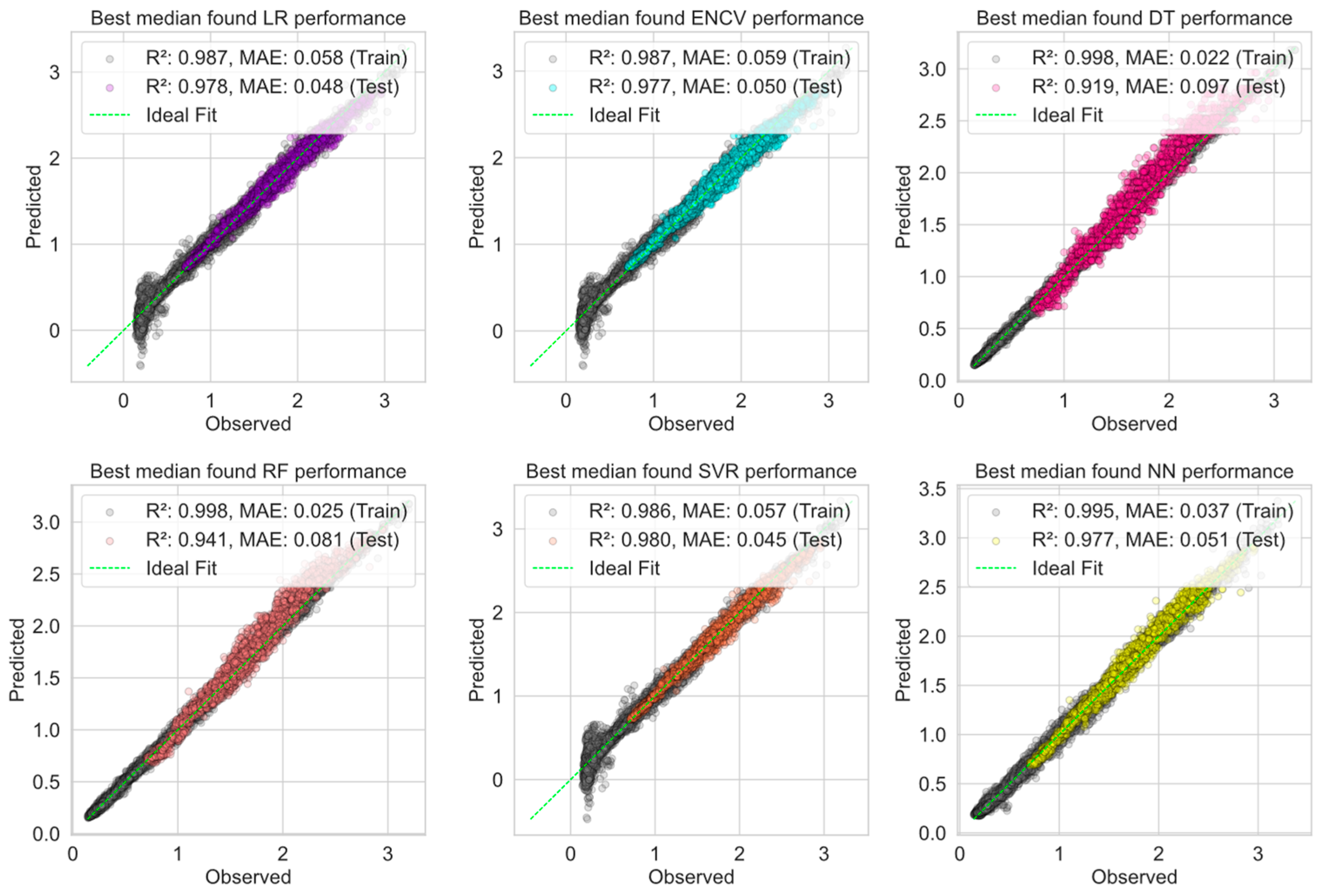
From
Figure 9 and
Table 10, we can see that NN shows the best results on validation data for all five metrics (MAE, MAPE, RMSE, IA, R
2), which indicates correct modeling and the most accurate predictions of the tuned NN model. On the test data, the LR, ENCV, and SVR models show very similar results in MAE, MAPE, and IA, indicating that they have similar prediction performance, but SVR has a slightly higher R
2. DT and RF perform worse in terms of MAE, MAPE, RMSE, and R
2 on the test data, but have relatively high IA, which may indicate that they are good at predicting trends but are not as accurate in absolute terms. In general, models show better performance on test data than on validation data, especially in terms of the R
2 metric. In more detail, the worse performance on the validation set by the LR, ENCV, and SVR models for R
2 can be explained by the summer period. As we can see in
Figure 10, even on the training dataset, linear-based models (the tuned SVR model has a “poly” kernel with degree 1), cannot correctly forecast low values of power consumption. On the other hand, models that do not belong to the class of linear models, such as DT, RF, and NN, can be trained enough to find a correct connection between features. However, in
Figure 10 and
Figure 11, when predicting large power consumption values, the DT and RF algorithms sometimes predict values larger than they actually are. This is observed when the predicted value is greater than about 2.0. Despite using fewer features, NN(5) performs exceptionally well, demonstrating that a well-selected subset of features can lead to high model performance. SVR uses the set of eight features but achieves comparable performance, suggesting that it efficiently utilizes the available information. Based on these scatter plots and the results of the numerical experiments, it can be concluded that NN and SVR may be better candidates for this forecasting task based on the accuracy of the predictions. It is also important to note that, regardless of the model, performance on validation and test data turned out to be comparable, which indicates a good generalization ability of the models under consideration.
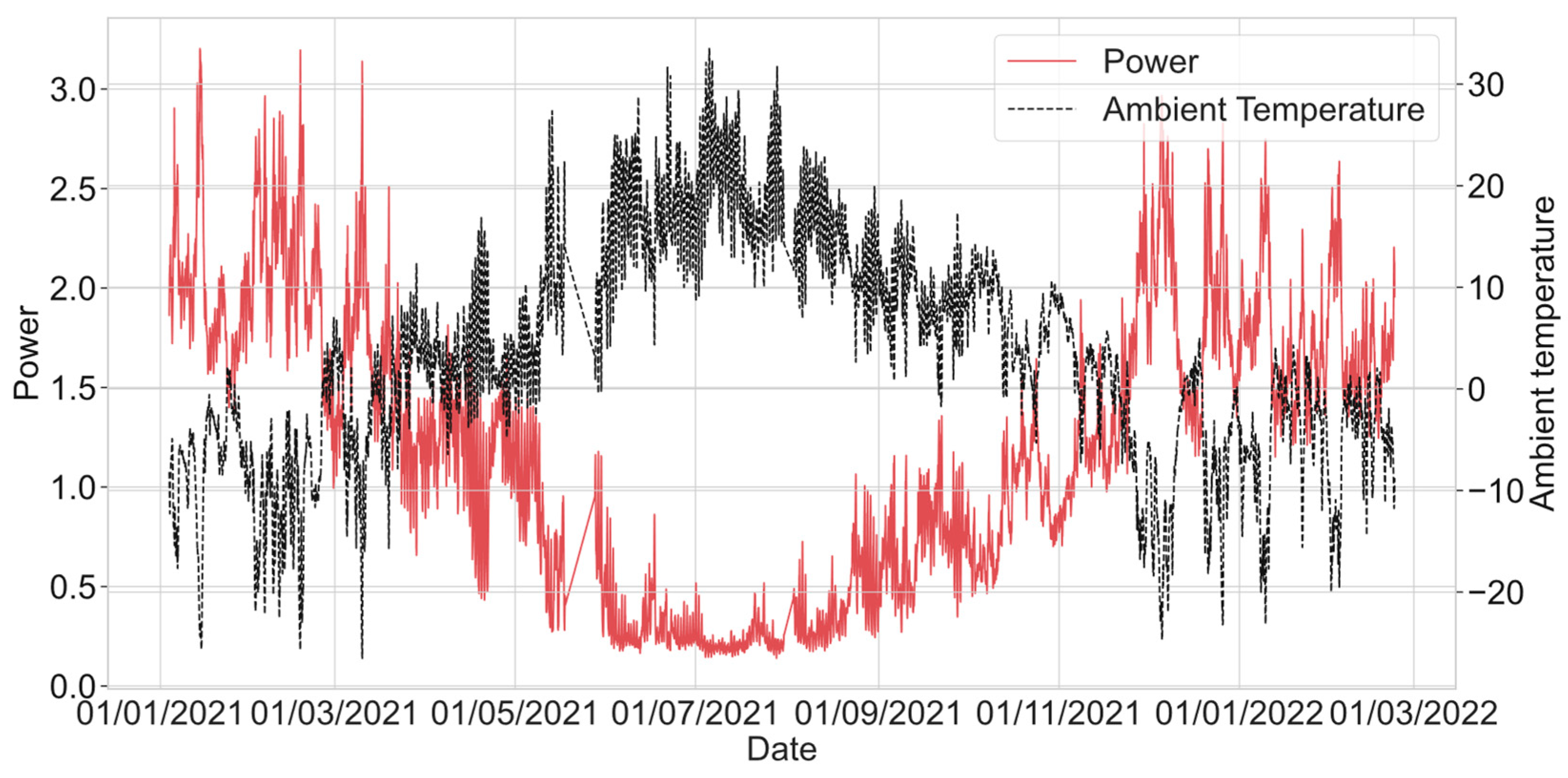
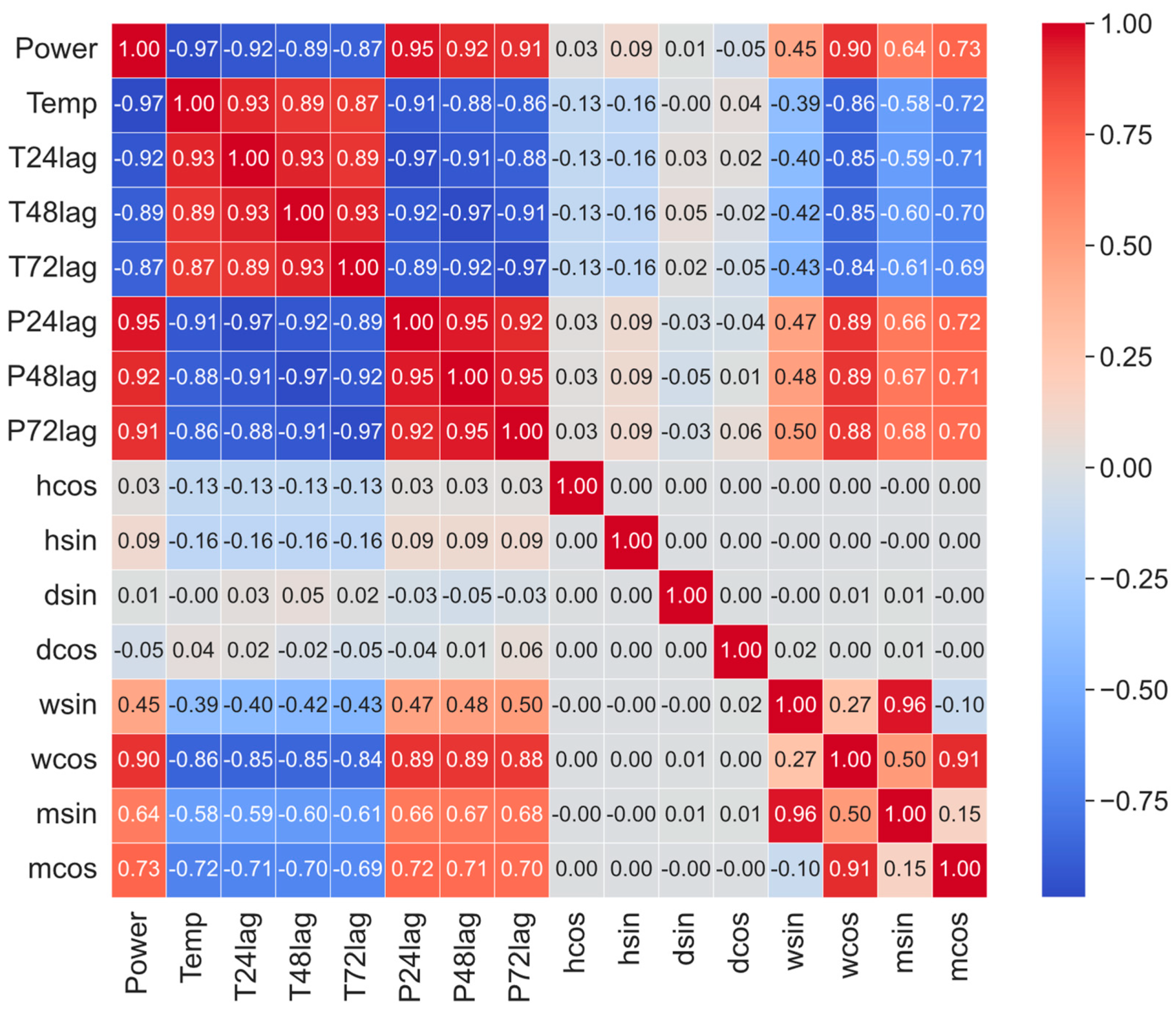
As we can see from
Figure 12, the feature “Power” has a strong negative correlation with the temperature features. This could indicate that as the temperature increases, the power decreases or vice versa. “P24lag”, “P48lag”, and “P72lag” have a strong positive correlation with the target “Power” feature. In comparison, for power and temperature lag, we can see that power lag features have a bit bigger absolute correlation. It can be explained by the following. Power consumption is usually characterized by a certain inertia. This means that changes in consumption do not occur instantly in response to changes in weather conditions. Instead, energy consumption is more dependent on past consumption as it reflects established consumer behavior patterns and the operational needs of the power system. Although weather conditions have a significant impact on energy consumption (for example, colder weather increases heating energy consumption), the effect may not be immediate. The features at the end of the matrix, “hcos”, “hsin”, “dsin”, and “dcos”, show a different pattern. Their correlations with the target feature “Power” are generally weak, which suggests that they might consist of different, less linearly related information compared to the temperature and power features. Given the high correlations among the temperature and power lag features, multicollinearity could be a concern for certain types of models, such as LR, if hourly or daily features will be used. We also can see that “wcos” and “mcos” show quite a high correlation with the “Power” feature. Correlation estimation is a popular method for selecting features when building models in various fields of science and engineering, including machine learning, statistics, and econometrics. However, despite its usefulness, this method has some disadvantages and limitations that are important to consider. Correlation works well for identifying linear relationships between features, but it may not capture nonlinear relationships. This means that features with a strong nonlinear relationship may be erroneously excluded from analysis based on low correlation scores. Correlation does not indicate the direction of the relationship between features and cannot be used to determine cause-and-effect relationships because two features may be related due to the presence of a latent third feature that influences both of them. In some cases, two features may show a high correlation without having a direct relationship with each other. Such cases can be misleading when choosing features to model. Correlation analysis is sensitive to outliers, which can significantly distort the results. A small number of extreme values may result in high or low correlations without reflecting the overall trend of the majority of the data. High correlations between independent features (multicollinearity) can create problems when building regression models, as it makes it difficult to determine the contribution of each feature to the predicted feature.
Based on the results from
Figure 13, we can see the following. Some features have a larger impact on certain models than on others. For instance, “Temp” seems to have a significant effect on the performance of the LR, DT, and RF models. This suggests that “Temp” could be a key feature in the processes modeled by these algorithms. On the other hand, its impact is less in the SVR model, which might suggest that this model is either less sensitive to this particular feature or that the feature’s relationship with the target feature is non-linear and complex. The length of the error bars shows the consistency of the feature importance measure across different permutations. Large error bars, as seen in some of the features in NN, indicate that the importance of these features varies more when the data are permuted, suggesting a less stable model with respect to those features. The SVR model’s feature importance values are on a much smaller scale, from
to
, which is significantly smaller than the scales for other models. This could be due to the specific configuration of the SVR model, its sensitivity to feature scaling, or the nature of the error metric used for this model. Each model shows a different pattern of feature importance. For example, the RF model shows a fairly sharp decline in importance after the top few features, whereas the importance values are more evenly spread in the DT and NN models. This could indicate that the RF model relies on a few strong features and may ignore other features, while the SVR and NN models may utilize a broader range of features when making predictions.
The permutation-based approach to feature selection is a method for assessing feature importance used in statistics and machine learning that involves reordering the values of a feature in a dataset and assessing changes in model performance. Despite its popularity and usefulness, this approach has several disadvantages. The permutation method requires many model recalculations, which makes it computationally expensive, especially for large datasets or complex models. The importance of a variable can vary significantly depending on the model chosen. A variable considered important in one model may not have the same impact in another model with different hyperparameters. Interpretation of changes in performance can be ambiguous, especially when differences are small or when there is interaction between variables. The method can be sensitive to noise in the data, especially when rearranging the values of a variable does not appreciably change the model’s performance. If there is multicollinearity in the data, then permuting the values of one variable may not adequately reflect its true effect due to its relationship with other variables.
In addition to our result, we have compared our obtained results with results from a previous research. The research in [
55] investigates a machine learning-based integrated feature selection method designed to enhance power demand forecasting within decentralized energy systems. The study introduces a novel approach that combines multiple feature selection techniques to improve the accuracy and reliability of demand predictions. By optimizing the selection of relevant features, the method aims to reduce forecasting errors and enhance the efficiency of energy distribution. The findings suggest that this integrated approach can significantly contribute to the stability and performance of decentralized energy networks. The authors obtained a single set of features for each building that provides the best performance for their regression models. They did not aim to create multiple models with varying numbers of features but rather focused on achieving maximum performance. Compared to the set of features from our study, theirs contains a greater number of weather-related variables, and some of them do not overlap with ours. For instance, their dataset includes relative humidity, dew point, wind speed, etc. Moreover, due to the nature of the problem, they did not use lagged ambient temperature values due to the nature of their problem. However, some similarities in selected features can be noticed. The GA-SHADE algorithm was able to select ambient temperature and power features with and without lag, as well as features related to days and hours, for NN(5) and SVR(8). The same features were also selected in [
55].
Another research work [
56] focuses on developing a feature selection strategy for ML methods used to predict building power consumption. The authors have investigated various feature selection algorithms and their impact on the accuracy of energy consumption predictions. Three buildings have been investigated for which time and methodological features were considered. The main emphasis was on identifying the most significant features that have the greatest influence on power consumption, with the goal of improving the performance of ML models while reducing their complexity. The paper [
56] also identified temperature and lagged ambient temperature values as significant predictors, indicating a similar pattern of importance of temperature-related features. This alignment shows that temperature and its variations over time are critical for accurate energy consumption forecasting. Also, the similarities in time features can be found. The authors found that the hour and day of the year are important features with high impact in general ML model performance. In [
56], the authors do not include power lag features as we have. This difference could be attributed to the specific context of our study, which focuses on a district heating network rather than individual buildings.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}