
Supervised Contrastive Learning for Fault Diagnosis Based on Phase-Resolved Partial Discharge in Gas-Insulated Switchgear

 ,
,
Abstract
:1. Introduction
2. Related Works
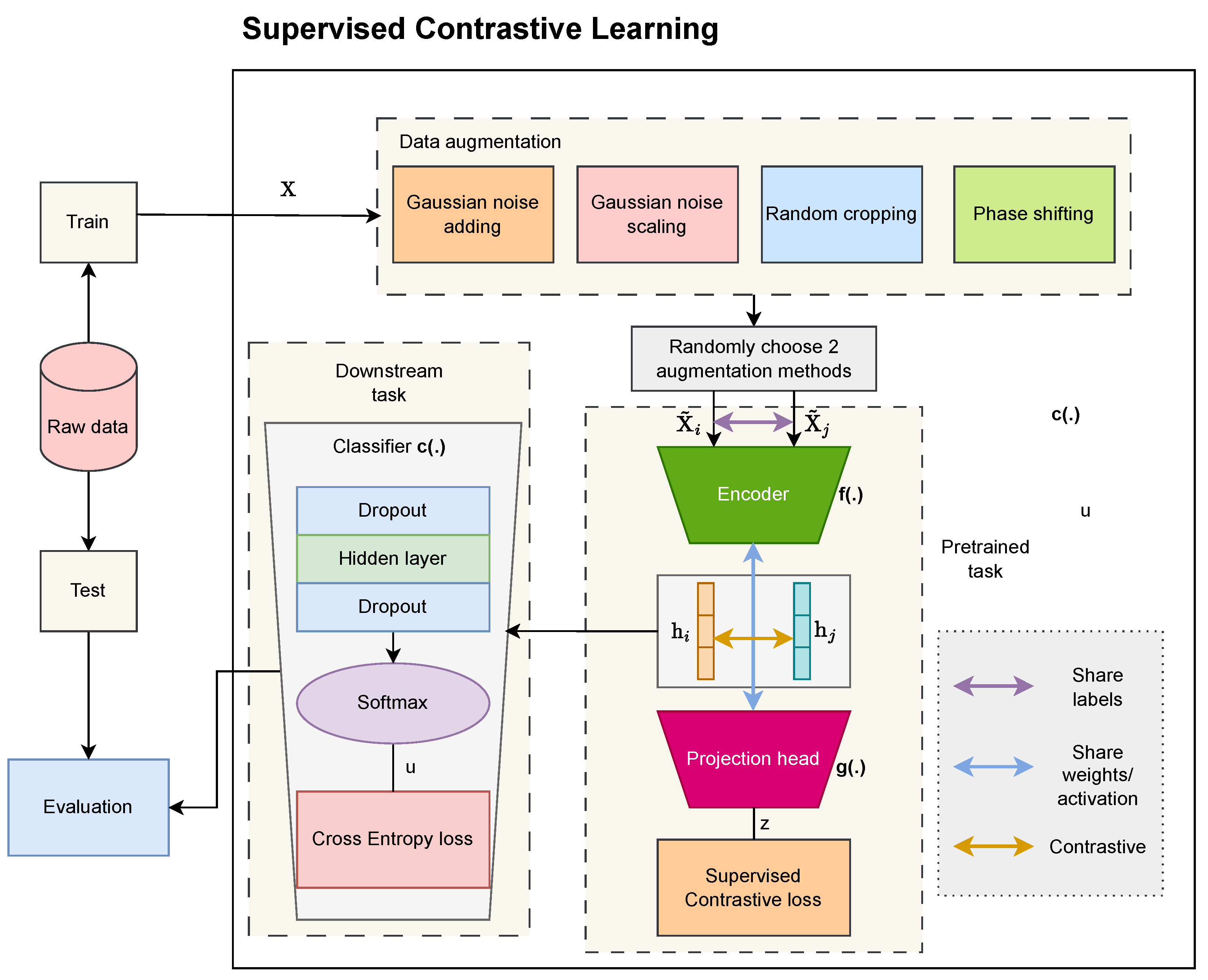
2.1. Supervised Contrastive Learning
2.1.1. Pretrained Task
2.1.2. Contrastive Loss
2.1.3. Downstream Task
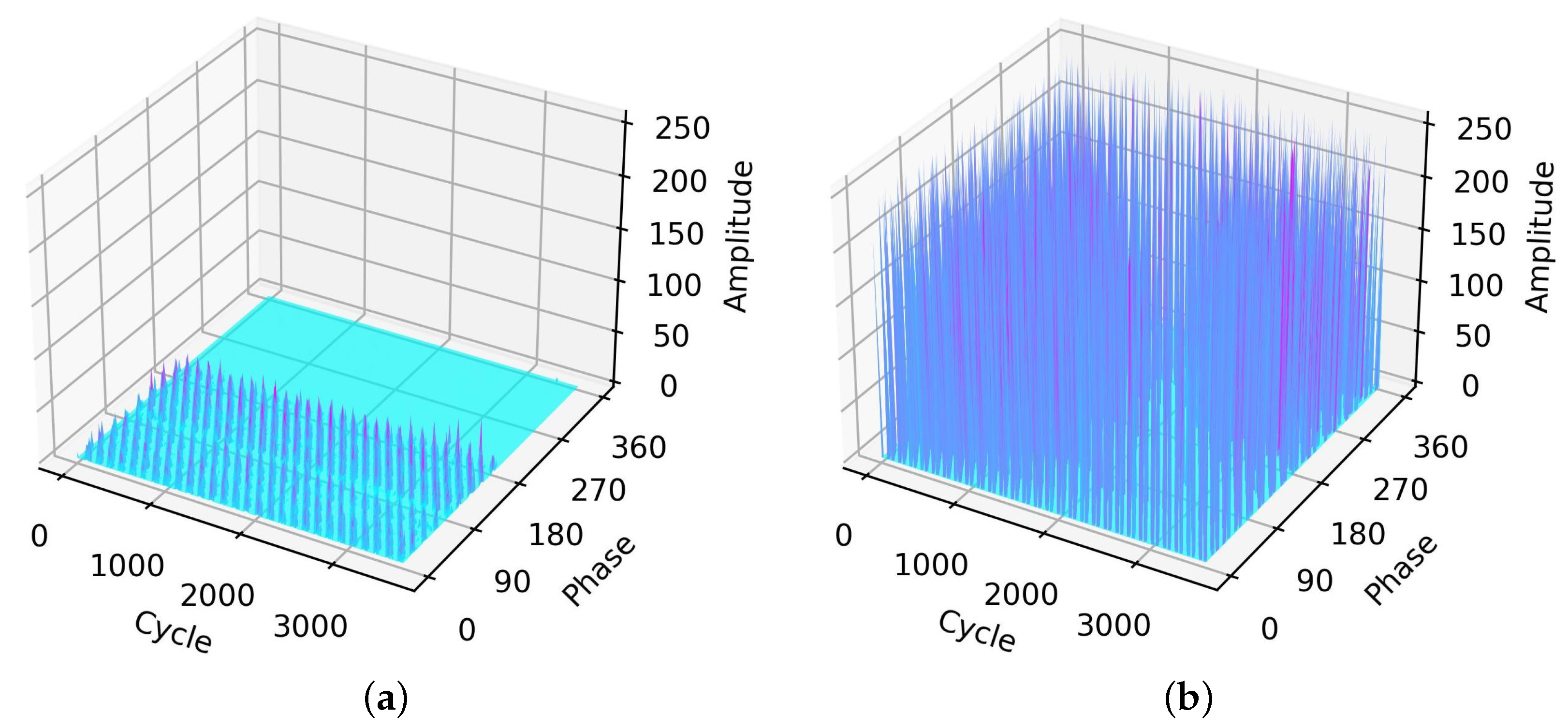
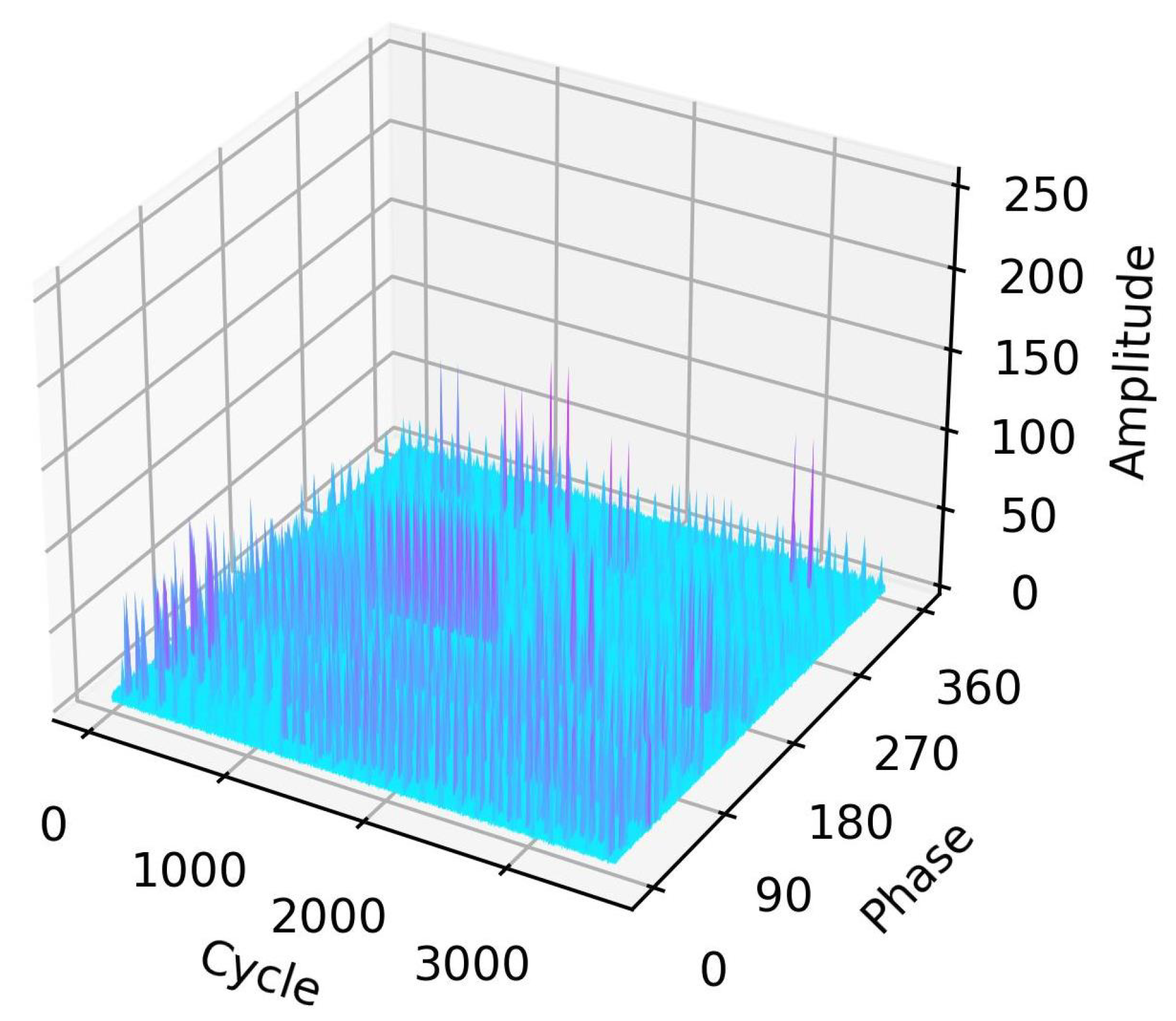
2.2. PRPD Measurements and On-Site Noise for GIS
2.2.1. PRPD Measurements
2.2.2. On-Site Noise
3. Proposed Scheme
3.1. Data Augmentation
3.1.1. Gaussian Noise Adding
3.1.2. Gaussian Noise Scaling
3.1.3. Random Cropping
3.1.4. Phase Shifting
3.2. Supervised Contrastive Learning
- 1.
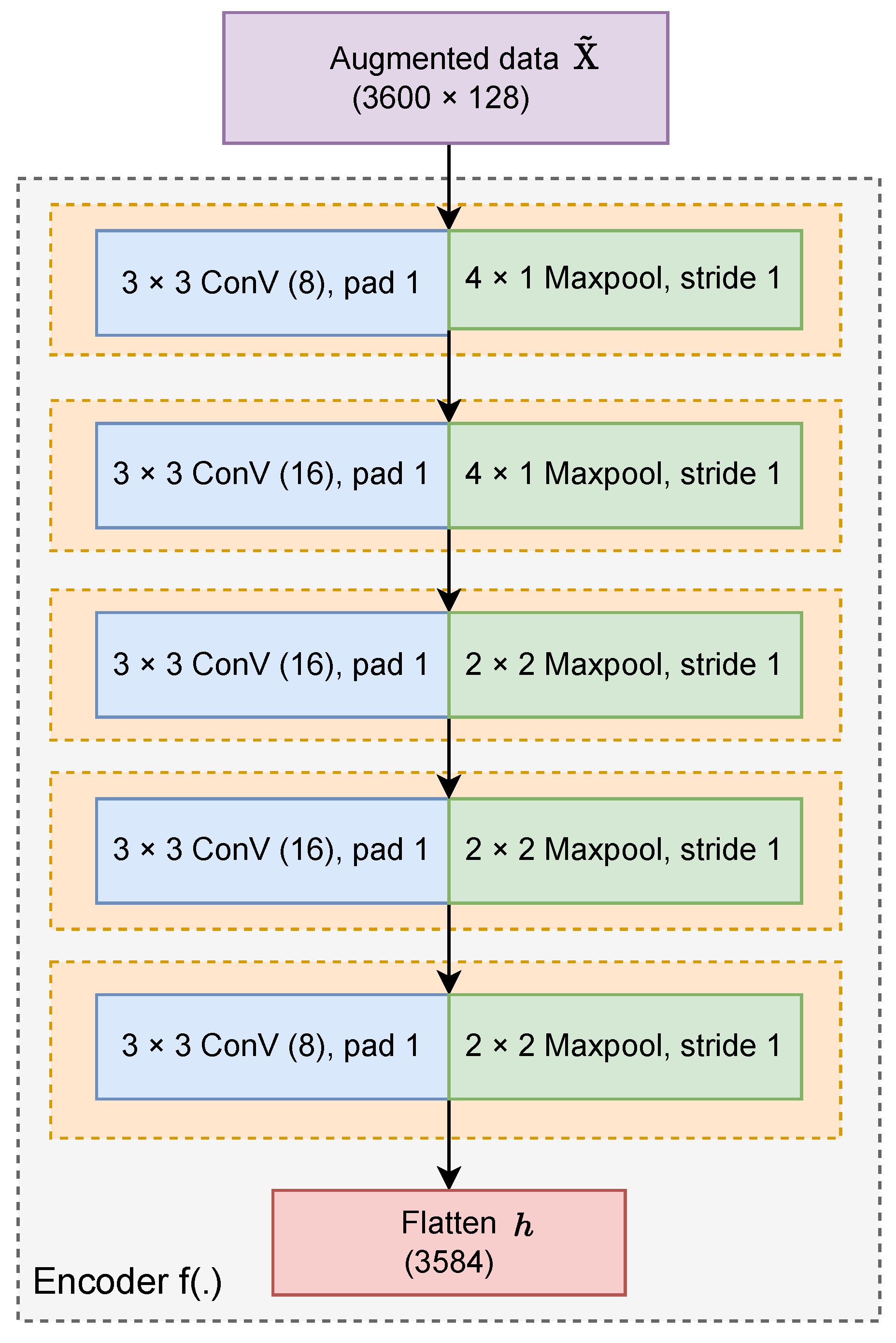
- The first part is encoder network with the operation to turn the two-dimensional matrix into a one-dimensional vector, which is denoted as , where is the output shape of the last layer in the network. From and , we obtain a pair of representation vectors and , respectively. The encoder network comprises convolution layers to extract high features and a flattened layer.
- 2.
- Projection head is expressed as , where comprises a single linear layer of units with a nonlinear activation ReLU function and is the index of an arbitrary augmented sample within a multiviewer batch.
- 3.
- The supervised contrastive loss is expressed as [24]withwhere is the set that eliminates element i from I and is the set of indices of the positive samples whose label is the same as the i-th label. Here, > 0 denotes the scalar temperature parameter and denotes the total number of elements of the set.
- 4.
- The target of the pretrained task is to minimize the contrastive loss function in (7). Consequently, the weights of the encoder are frozen for the downstream task.
| Algorithm 1: Training process for the proposed SCL method |
| Input: training set X, label y, batch size B, temperature , learning rate , and number of epochs E Data augmentation: randomly choose two augmented views from Pretrained task:
|
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2D | Two-dimensional |
| CNN | Convolution neural network |
| DAS | Data acquisition system |
| DNN | Deep neural network |
| MLP | Multilayer perceptron |
| GIS | Gas-insulated switchgear |
| PD | Partial discharge |
| PRPD | Phase-resolved partial discharge |
| ReLU | Rectified linear unit |
| SCL | Supervised contrastive learning |
| SSCL | Self-supervised contrastive learning |
| SVM | Support vector machine |
| t-SNE | t-distributed stochastic neighbor embedding |
| UHF | Ultra-high frequency |
References
- Bolin, P.; Koch, H. Gas Insulated Switchgear GIS - State of the Art. In Proceedings of the 2007 IEEE Power Engineering Society General Meeting, Tampa, FL, USA, 24–28 June 2007; pp. 1–3. [Google Scholar] [CrossRef]
- Zhang, G.; Tian, J.; Zhang, X.; Liu, J.; Lu, C. A Flexible Planarized Biconical Antenna for Partial Discharge Detection in Gas-Insulated Switchgear. IEEE Antennas Wirel. Propag. Lett. 2022, 21, 2432–2436. [Google Scholar] [CrossRef]
- He, N.; Liu, H.; Qian, M.; Miao, W.; Liu, K.; Wu, L. Gas-insulated Switchgear Discharge Pattern Recognition Based on KPCA and Multilayer Neural Network. In Proceedings of the 2021 6th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 19–21 November 2021; pp. 208–213. [Google Scholar] [CrossRef]
- Li, L.; Yin, H.; Zhao, W.; Jia, C. A new technology of GIS partial discharge location method based on DFB fiber laser. In Proceedings of the 2021 IEEE International Conference on the Properties and Applications of Dielectric Materials (ICPADM), Johor Bahru, Malaysia, 12–14 July 2021; pp. 191–193. [Google Scholar] [CrossRef]
- Rozi, F.; Khayam, U. Design, implementation and testing of triangle, circle, and square shaped loop antennas as partial discharge sensor. In Proceedings of the 2nd IEEE Conference on Power Engineering and Renewable Energy (ICPERE) 2014, Bali, Indonesia, 9–11 December 2014; pp. 273–276. [Google Scholar] [CrossRef]
- Su, C.C.; Tai, C.C.; Chen, C.Y.; Hsieh, J.C.; Chen, J.F. Partial discharge detection using acoustic emission method for a waveguide functional high-voltage cast-resin dry-type transformer. In Proceedings of the 2008 International Conference on Condition Monitoring and Diagnosis, Beijing, China, 21–24 April 2008; pp. 517–520. [Google Scholar] [CrossRef]
- Wang, B.; Dong, M.; Xie, J.; Ma, A. Ultrasonic Localization Research for Corona Discharge Based on Double Helix Array. In Proceedings of the 2018 IEEE International Power Modulator and High Voltage Conference (IPMHVC), Jackson, WY, USA, 3–7 June 2018; pp. 297–300. [Google Scholar] [CrossRef]
- Liu, D.; Guan, A.; Zheng, S.; Zhao, Y.; Zheng, Z.; Zhong, A. Design of External UHF Sensor for Partial Discharge of Power Transformer. In Proceedings of the 2021 IEEE 2nd China International Youth Conference on Electrical Engineering (CIYCEE), Chengdu, China, 15–17 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Luo, G.; Zhang, D. Study on performance of HFCT and UHF sensors in partial discharge detection. In Proceedings of the 2010 Conference Proceedings IPEC, Singapore, 27–29 October 2010; pp. 630–635. [Google Scholar] [CrossRef]
- Tuyet-Doan, V.-N.; Pho, H.-A.; Lee, B.; Kim, Y.-H. Deep Ensemble Model for Unknown Partial Discharge Diagnosis in Gas-Insulated Switchgears Using Convolutional Neural Networks. IEEE Access 2021, 9, 80524–80534. [Google Scholar] [CrossRef]
- Wang, X.; Li, X.; Rong, M.; Xie, D.; Ding, D.; Wang, Z. UHF Signal Processing and Pattern Recognition of Partial Discharge in Gas-Insulated Switchgear Using Chromatic Methodology. Sensors 2017, 17, 177. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Yang, F.; Zhang, Y.; Hou, S. Feature extraction and classification of partial discharge signal in GIS based on Hilbert transform. In Proceedings of the 2021 International Conference on Information Control, Electrical Engineering and Rail Transit (ICEERT), Lanzhou, China, 30 October–1 November 2021; pp. 208–213. [Google Scholar] [CrossRef]
- Zheng, K.; Si, G.; Diao, L.; Zhou, Z.; Chen, J.; Yue, W. Applications of support vector machine and improved k-Nearest neighbor algorithm in fault diagnosis and fault degree evaluation of gas insulated switchgear. In Proceedings of the 2017 1st International Conference on Electrical Materials and Power Equipment (ICEMPE), Xi’an, China, 14–17 May 2017; pp. 364–368. [Google Scholar] [CrossRef]
- Tang, J.; Jin, M.; Zeng, F.; Zhou, S.; Zhang, X.; Yang, Y.; Ma, Y. Feature Selection for Partial Discharge Severity Assessment in Gas-Insulated Switchgear Based on Minimum Redundancy and Maximum Relevance. Energies 2017, 10, 1516. [Google Scholar] [CrossRef]
- Janani, H.; Kordi, B.; Jozani, M.J. Classification of simultaneous multiple partial discharge sources based on probabilistic interpretation using a two-step logistic regression algorithm. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 54–65. [Google Scholar] [CrossRef]
- Li, L.; Tang, Z.; Liu, Y. Partial discharge recognition in gas insulated switchgear based on multi-information fusion. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 1080–1087. [Google Scholar] [CrossRef]
- Chauhan, N.K.; Singh, K. A Review on Conventional Machine Learning vs Deep Learning. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 347–352. [Google Scholar] [CrossRef]
- Song, H.; Dai, J.; Sheng, G.; Jiang, X. GIS partial discharge pattern recognition via deep convolutional neural network under complex data source. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 678–685. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, J.; Yang, Z.; Liu, T.; Zhao, Y.; Li, J. Partial Discharge Pattern Recognition of Gas-Insulated Switchgear via a Light-Scale Convolutional Neural Network. Energies 2019, 12, 4674. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, Z.; Qin, J.; Chen, Y.; Zhai, B. Exploration on Automatic Management of GIS Using TL-CNN and IoT. IEEE Access 2022, 10, 40932–40944. [Google Scholar] [CrossRef]
- Atliha, V.; Šešok, D. Comparison of VGG and ResNet used as Encoders for Image Captioning. In Proceedings of the 2020 IEEE Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 30 April 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Gutiérrez, Y.; Arevalo, J.; Martánez, F. Multimodal Contrastive Supervised Learning to Classify Clinical Significance MRI Regions on Prostate Cancer. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, Scotland, UK, 11–15 July 2022; pp. 1682–1685. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, Z.; Zhou, S.; Feng, K.; Yu, K.; Liu, Z. Supervised Contrastive Learning-Based Domain Adaptation Network for Intelligent Unsupervised Fault Diagnosis of Rolling Bearing. IEEE/ASME Trans. Mechatronics 2022, 27, 5371–5380. [Google Scholar] [CrossRef]
- Mohamad, H.T.-N. An evolutionary ensemble convolutional neural network for fault diagnosis problem. Expert Syst. Appl. 2023, 223, 120678. [Google Scholar] [CrossRef]
- Bijoy, M.B.; Pebbeti, B.P.; Manoj, A.S.; Fathaah, S.A.; Raut, A.; Pournami, P.N.; Jayaraj, P.B. Deep Cleaner—A Few Shot Image Dataset Cleaner Using Supervised Contrastive Learning. IEEE Access 2023, 11, 18727–18738. [Google Scholar] [CrossRef]
- Moukafih, Y.; Sbihi, N.; Ghogho, M.; Smaili, K. SuperConText: Supervised Contrastive Learning Framework for Textual Representations. IEEE Access 2023, 11, 16820–16830. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS 2020), Virtual, 6–12 December 2020; pp. 18661–18673. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Proceedings of the 16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; pp. 776–794. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedno, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Kim, S.-W.; Jung, J.-R.; Kim, Y.-M.; Kil, G.-S.; Wang, G. New diagnosis method of unknown phase-shifted PD signals for gas insulated switchgears. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 102–109. [Google Scholar] [CrossRef]
- Nguyen, M.-T.; Nguyen, V.-H.; Yun, S.-J.; Kim, Y.-H. Recurrent Neural Network for Partial Discharge Diagnosis in Gas-Insulated Switchgear. Energies 2018, 11, 1202. [Google Scholar] [CrossRef]
- Cai, T.T.; Ma, R. Theoretical Foundations of t-SNE for Visualizing High-Dimensional Clustered Data. J. Mach. Learn. Res. 2022, 23, 1–54. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hu, C.; Wu, C.; Sun, C.; Yan, R.; Chen, X. Robust Supervised Contrastive Learning for Fault Diagnosis Under Different Noises and Conditions. In Proceedings of the 2021 International Conference on Sensing, Measurement & Data Analytics in the era of Artificial Intelligence (ICSMD), Nanjing, China, 21–23 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning; Cambridge University Press: Cambridge, UK, 2021; pp. 125–131. [Google Scholar]
- Kumar, G.P.; Priya, G.S.; Dileep, M.; Raju, B.E.; Shaik, A.R.; Sarman, K.V.S.H.G. Image Deconvolution using Deep Learning-based Adam Optimizer. In Proceedings of the 2022 6th International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 1–3 December 2022; pp. 901–904. [Google Scholar] [CrossRef]
- Kulkarni, A.; Chong, D.; Bartarseh, F.A. Foundations of Data Imbalance and Solutions for a Data Democracy. In Data Democracy: At the Nexus of Artificial Intelligence, Software Development, and Knowledge Engineering; Bartarseh, F.A., Yang, R., Eds.; Elsevier Inc.: Amsterdam, The Netherlands, 2020; pp. 83–106. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | Corona | Floating | Void | Particle | Noise | Overall |
|---|---|---|---|---|---|---|
| Number of experiments | 94 | 35 | 242 | 66 | 298 | 735 |
| Hyperparameter | Minimum | Maximum | Type |
|---|---|---|---|
| Minibatch size | 8 | 128 | Integer |
| Number of layers | 1 | 8 | Integer |
| Kernel size | 3 × 3 | 7 × 7 | Integer |
| Epochs | 50 | 200 | Integer |
| Learning rate | 0.0001 | 0.01 | Real |
| Classifier network nodes | 600 | 1200 | Integer |
| Projection head nodes | 64 | 512 | Integer |
| Dropout rate | 0.2 | 0.5 | Real |
| Hyperparameter | Minimum | Maximum | Type |
|---|---|---|---|
| SVM parameter | 0.001 | 100 | Real |
| Number of MLP hidden layers | 1 | 5 | Integer |
| Fault Types | SVM (%) | MLP (%) | CNN (%) | Proposed SCL (%) |
|---|---|---|---|---|
| Corona | 94.74 | 94.74 | 100 | 94.74 |
| Floating | 85.71 | 85.71 | 85.71 | 85.71 |
| Particle | 53.85 | 92.31 | 84.62 | 100 |
| Void | 87.50 | 91.67 | 95.83 | 95.83 |
| Noise | 100 | 93.33 | 96.67 | 100 |
| Overall | 90.48 | 93.00 | 95.24 | 97.28 |
| Fault Types | Corona | Floating | Particle | Void | Noise | |
|---|---|---|---|---|---|---|
| SVM | 1 | 1 | 1 | 0.955 | 0.833 | |
| MLP | 1 | 0.750 | 0.857 | 0.957 | 0.918 | |
| CNN | 0.950 | 0.857 | 1 | 1 | 0.921 | |
| Proposed SCL | 1 | 1 | 0.929 | 0.979 | 0.968 | |
| SVM | 0.947 | 0.857 | 0.538 | 0.875 | 1 | |
| MLP | 0.947 | 0.857 | 0.923 | 0.917 | 0.933 | |
| CNN | 1 | 0.857 | 0.846 | 0.958 | 0.967 | |
| Proposed SCL | 0.947 | 0.857 | 1 | 0.958 | 1 | |
| SVM | 0.973 | 0.923 | 0.700 | 0.913 | 0.909 | |
| MLP | 0.973 | 0.800 | 0.889 | 0.936 | 0.926 | |
| CNN | 0.974 | 0.857 | 0.917 | 0.979 | 0.943 | |
| Proposed SCL | 0.973 | 0.923 | 0.963 | 0.968 | 0.984 |
| Methods | Raw Data | GA | GS | RC | PS |
|---|---|---|---|---|---|
| Test Accuracy (%) | 91.84 | 93.20 | 93.20 | 93.20 | 93.20 |
| Tasks | SVM | MLP | CNN | Proposed SCL |
|---|---|---|---|---|
| Training Time (s) | 3.193 | 4.654 | 318.146 | 1154.029 |
| Testing Time (s) | 0.010 | 0.004 | 0.763 | 0.978 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, N.-Q.; Ho, T.-T.; Vo-Nguyen, T.-D.; Youn, Y.-W.; Choi, H.-S.; Kim, Y.-H. Supervised Contrastive Learning for Fault Diagnosis Based on Phase-Resolved Partial Discharge in Gas-Insulated Switchgear. Energies 2024, 17, 4. https://doi.org/10.3390/en17010004
Dang N-Q, Ho T-T, Vo-Nguyen T-D, Youn Y-W, Choi H-S, Kim Y-H. Supervised Contrastive Learning for Fault Diagnosis Based on Phase-Resolved Partial Discharge in Gas-Insulated Switchgear. Energies. 2024; 17(1):4. https://doi.org/10.3390/en17010004
Chicago/Turabian StyleDang, Nhat-Quang, Trong-Tai Ho, Tuyet-Doan Vo-Nguyen, Young-Woo Youn, Hyeon-Soo Choi, and Yong-Hwa Kim. 2024. "Supervised Contrastive Learning for Fault Diagnosis Based on Phase-Resolved Partial Discharge in Gas-Insulated Switchgear" Energies 17, no. 1: 4. https://doi.org/10.3390/en17010004
APA StyleDang, N.-Q., Ho, T.-T., Vo-Nguyen, T.-D., Youn, Y.-W., Choi, H.-S., & Kim, Y.-H. (2024). Supervised Contrastive Learning for Fault Diagnosis Based on Phase-Resolved Partial Discharge in Gas-Insulated Switchgear. Energies, 17(1), 4. https://doi.org/10.3390/en17010004