
A Two-Terminal Fault Location Fusion Model of Transmission Line Based on CNN-Multi-Head-LSTM with an Attention Module





Abstract
:1. Introduction
2. CNN-Multi-Head-LSTM Model with an Attention Module Embedded (CMLA)
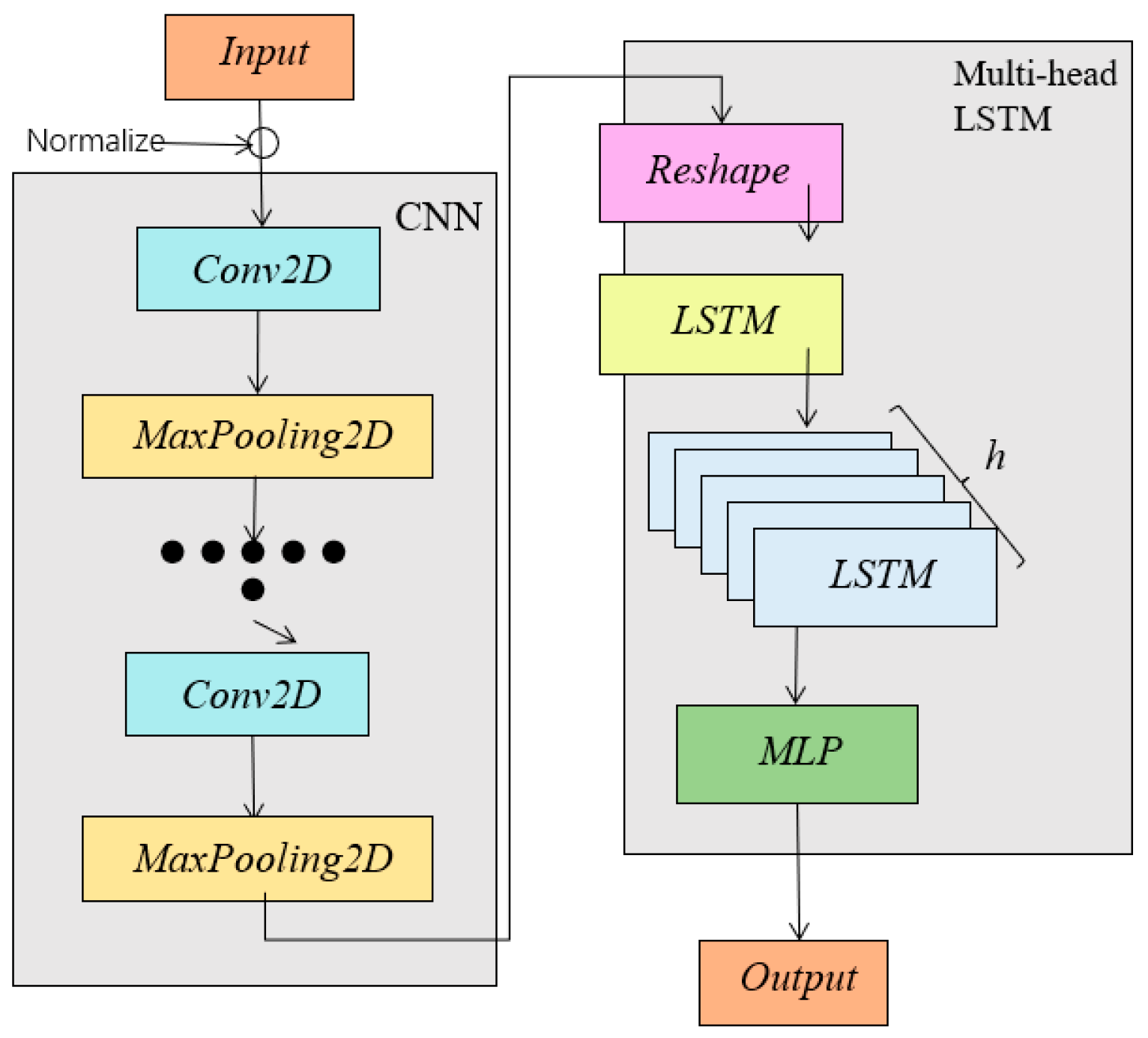
2.1. Overall Architecture of CMLA
2.2. Convolutional Neural Network
2.3. Attention Module
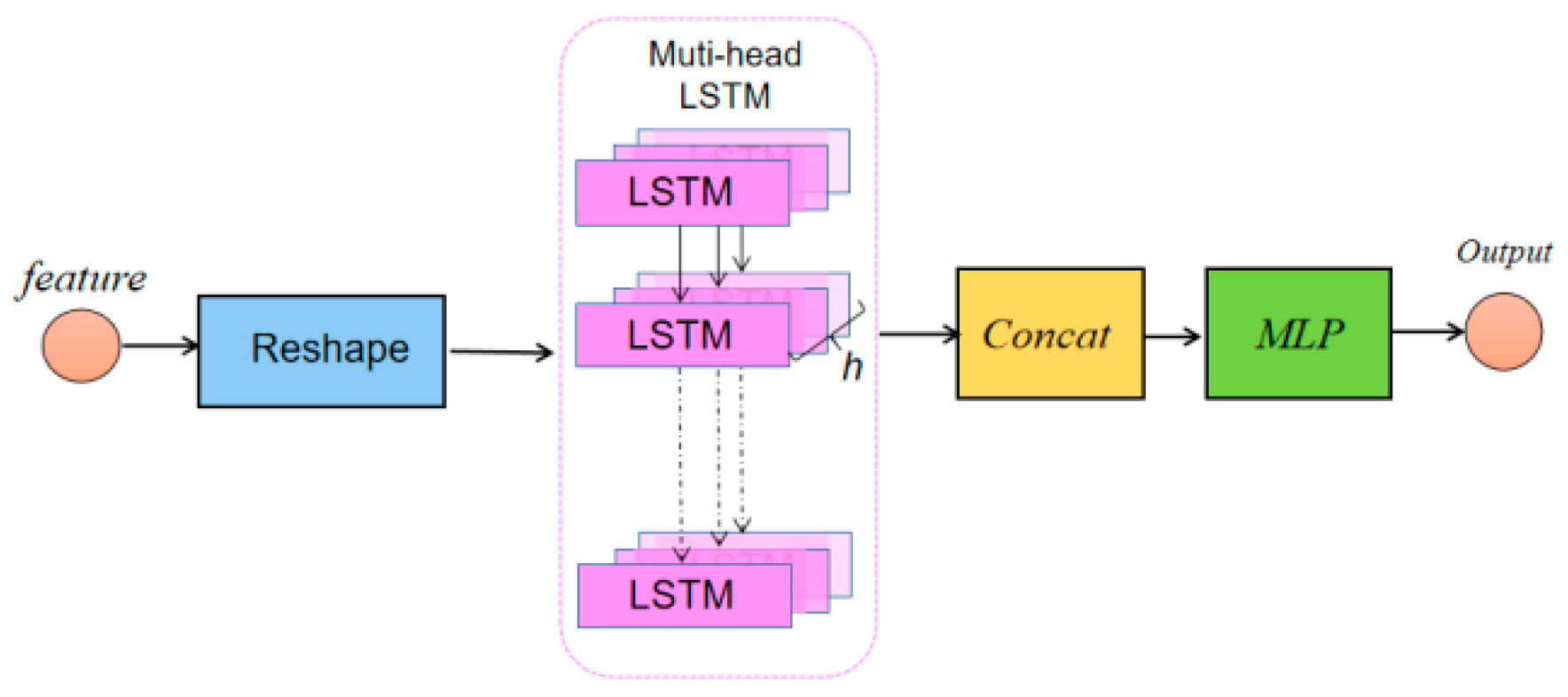
2.4. Multi-Head-LSTM Network
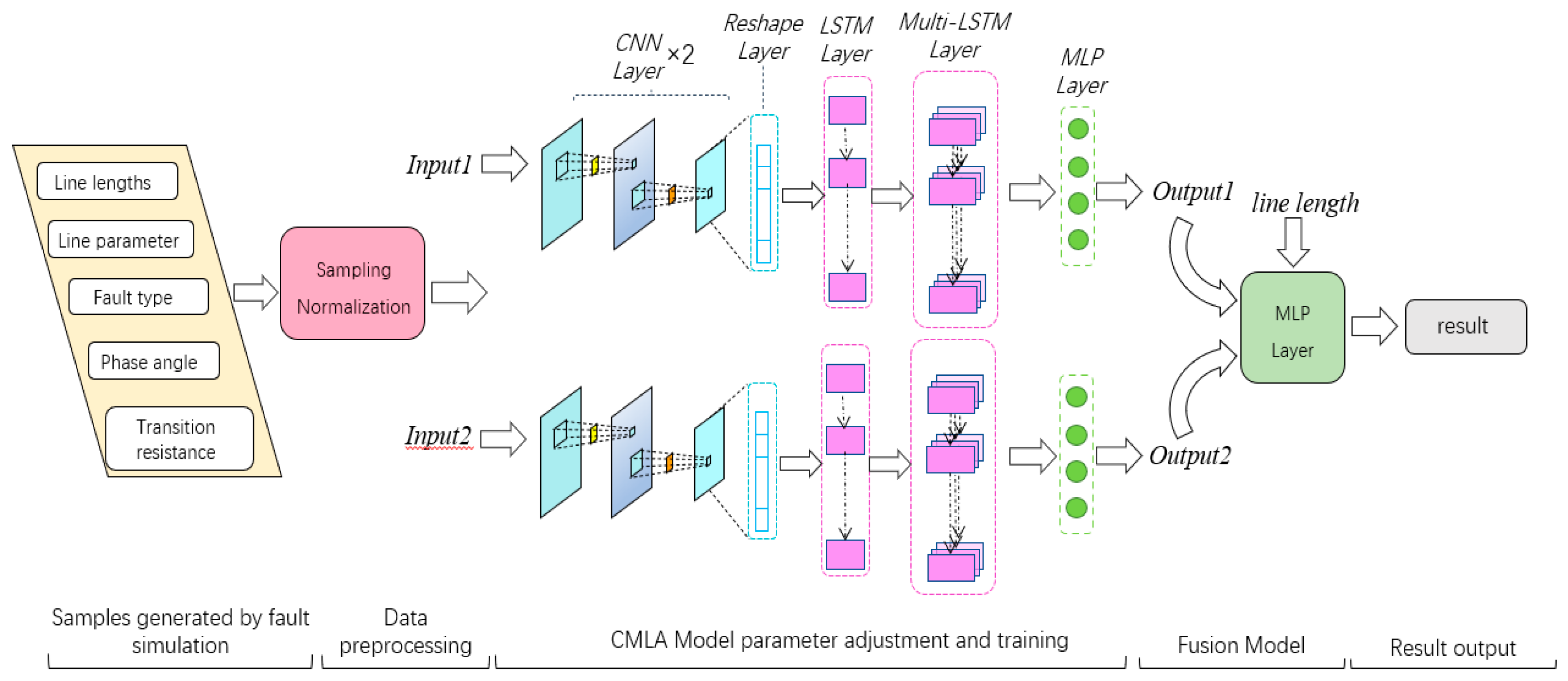
3. Fault Location Based on CMLA Model
3.1. Basic Process
3.2. Hyperband Optimization Algorithm
3.3. Fusion CMLA Model with the MLP Output Layer (FCMLA)
3.4. Experimental Evaluation Index and Optimization Algorithm
4. Simulation and Analysis
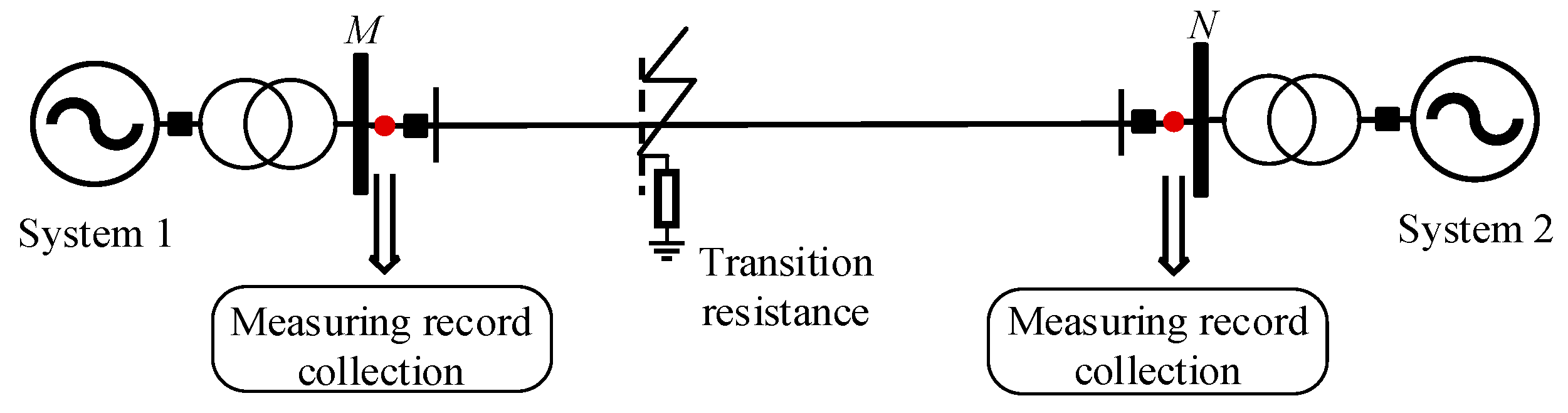
4.1. Transmission Line Simulation Model Building
4.2. Location Accuracy Analysis of the Model
4.3. Generalization Performance Analysis of the Model
4.4. Comparison of Training Speed of Different Depth Models
5. Conclusions
- (1)
- Compared with the artificially designed feature extraction method, the proposed FCMLA model (fusion CNN-multi-head-LSTM with an attention module) obtains more important feature distributions through selective feature self-learning, which is beneficial to the subsequent LSTM to capture the timing characteristics and achieve accurate fault location.
- (2)
- The multi-head LSTM model based on the “multi-head” idea not only obtains a higher fault location accuracy, but also improves the training speed of the multi-layer depth model. The reason is that the original multi-layer series LSTM layer is transformed into a parallel connection, so as to realize the synchronous training and comprehensive feature extraction of multiple LSTM networks.
- (3)
- Due to the difference in the fault location accuracy of the model when the fault point is close to different sides, the stability of the final fault location result is improved by adding a full connection layer to fuse the results of the models on both sides.
- (4)
- The final fault location results of the FCMLA model proposed in this paper can meet the needs of practical applications. The simulation results show that its generalization ability can adapt to the differences of line length and parameters.
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Attention Module | Location | Evaluation Indicators | ||
|---|---|---|---|---|
| RMSE | MAE | MAPE | ||
| CAM | Maxpooling1 | 0.776 | 0.544 | 6.4% |
| SAM | Maxpooling1 | 0.720 | 0.4764 | 4.6% |
| CBAM | Maxpooling1 | 0.7582 | 0.4745 | 5.34% |
| CBAM | Maxpooling2 | 0.5836 | 0.4047 | 3.99% |
| CBAM | Maxpooling1,2 | 0.5418 | 0.3714 | 4.60% |
| Parameter Type | Zero-Sequence Parameter | Positive-Sequence Parameter | Line |
|---|---|---|---|
| R/(Ω/km) | 0.22846 | 0.01979 | Line 1 |
| L/(mH/km) | 2.77238 | 0.87579 | |
| C/(uF/km) | 8.5809 × 10−3 | 13.310 × 10−3 | |
| R/(Ω/km) | 0.3 | 0.03648 | Line 2 |
| L/(mH/km) | 3.639 | 1.348 | |
| C/(uF/km) | 6.166 × 10−3 | 8.68 × 10−3 | |
| R/(Ω/km) | 0.1148 | 0.02083 | Line 3 |
| L/(mH/km) | 2.28858 | 0.8984 | |
| C/(uF/km) | 5.2809 × 10−3 | 12.910 × 10−3 | |
| R/(Ω/km) | 0.3089 | 0.023 | Line 4 |
| L/(mH/km) | 2.5874 | 0.9372 | |
| C/(uF/km) | 6.3502 × 10−3 | 13.71 × 10−3 | |
| R/(Ω/km) | 0.3674 | 0.054 | Line 5 |
| L/(mH/km) | 3.323 | 1.086 | |
| C/(uF/km) | 5.019 × 10−3 | 11.068 × 10−3 |
| Parameter Type | Parameter Setting | Number of Parameters | Line |
|---|---|---|---|
| Voltage level | 220 kV | 1 | Line 1 |
| Fault type | LG, LLG, LLL | 3 | |
| Line length (km) | 25, 20, 15 | 3 | |
| Phase angle difference (degree) | 5, 30, 60 | 3 | |
| Fault distance (km) | L0 = 2,3(initial) Step length = 2 | 26 | |
| Transition resistance (Ω) | 0.01, 10, 20, 50, 80, 100, 120, 150 | 8 | |
| Voltage level | 220 kV | 1 | Line 2 |
| Fault type | LG, LLG, LLL | 3 | |
| Line length (km) | 60, 55, 50 | 3 | |
| Phase angle difference (degree) | 5, 30, 60 | 3 | |
| Fault distance (km) | L0 = 5,6,8(initial) Step length = 3,4 | 36 | |
| Transition resistance (Ω) | 0.01, 10, 20, 50, 80, 100, 120, 150 | 8 | |
| Voltage level | 220 kV | 1 | Line 3 |
| Fault type | LG, LLG, LLL | 3 | |
| Line length (km) | 45, 35, 30 | 3 | |
| Phase angle difference (degree) | 5, 30, 60 | 3 | |
| Fault distance (km) | L0 = 3.5,4(initial) Step length = 3,4 | 27 | |
| Transition resistance (Ω) | 0.01, 10, 20, 50, 80, 100, 120, 150 | 8 | |
| Voltage level | 220 kV | 1 | Line 4 |
| Fault type | LG, LLG, LLL | 3 | |
| Line length (km) | 30 | 1 | |
| Phase angle difference (degree) | 5, 30, 60 | 3 | |
| Transition resistance (Ω) | 0.01, 10, 20, 50, 80, 100, 120, 150 | 8 | |
| Voltage level | 220 kV | 1 | Line 5 |
| Fault type | LG, LLG, LLL | 3 | |
| Line length (km) | 70 | 1 | |
| Phase angle difference (degree) | 5, 30, 60 | 3 | |
| Transition resistance (Ω) | 0.01, 10, 20, 50, 80, 100, 120, 150 | 8 |
Appendix B
| Input (12 × 40) M | Input (12 × 40) N |
|---|---|
| Time Distributed (Conv1D (64,3)) | Time Distributed (Conv1D (256,3)) |
| Time Distributed (Maxpooling (2)) | Time Distributed (Maxpooling (2)) |
| CBAM | CBAM |
| Time Distributed (Conv1D (32,3)) | Time Distributed (Conv1D (64,3)) |
| Time Distributed (Maxpooling (2)) | Time Distributed (Maxpooling (2)) |
| CBAM | CBAM |
| Time Distributed (Flatten ()) | Time Distributed (Flatten ()) |
| LSTM (64) | LSTM (100) |
| Dense (1) | Dense (1) |
| Output | |
References
- Saha, M.M.; Izykowski, J.J.; Rosolowski, E. Fault Location on Power Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Panahi, H.; Zamani, R.; Sanaye-Pasand, M.; Mehrjerdi, A.H. Advances in transmission network fault location in modern power systems: Review, outlook and future works. IEEE Access 2021, 9, 158599–158615. [Google Scholar] [CrossRef]
- Johns, A.T.; Lai, L.L.; El-Hami, M.; Daruvala, D.J. New approach to directional fault location for overhead power distribution feeders. IEE Proc.–Gener. Transm. Distrib. 1991, 138, 351–357. [Google Scholar] [CrossRef]
- El-Hami, M.; Lai, L.L.; Daruvala, D.J.; Johns, A.T. A new travelling-wave based scheme for fault detection on overhead power distribution feeders. IEEE Trans. Power Deliv. 1992, 7, 1825–1833. [Google Scholar] [CrossRef]
- Tong, N.; Tang, Z.; Lai, C.S.; Li, X.; Vaccaro, A.; Lai, L.L. A novel acceleration criterion for remote-end grounding-fault in MMC-MTDC under communication anomalies. Int. J. Electr. Power Energy Syst. 2022, 141, 108131. [Google Scholar] [CrossRef]
- Zhang, C.; Song, G.; Yang, L.M.; Sun, Z. Time-domain single-ended fault location method no need for remote-end system information. IET Gener. Transm. Distrib. 2019, 14, 284–293. [Google Scholar] [CrossRef]
- Tong, N.; Tang, Z.; Wang, Y.; Lai, C.S.; Lai, L.L. Semi AI-based protection element for MMC-MTDC using local-measurements. Int. J. Electr. Power Energy Syst. 2022, 142, 108310. [Google Scholar] [CrossRef]
- Yu, C.S.; Chang, L.R.; Cho, J.R. New fault impedance computations for unsynchronized two-terminal fault-location computations. IEEE Trans. Power Deliv. 2011, 26, 2879–2881. [Google Scholar] [CrossRef]
- Chen, R.; Yin, X.; Li, Y. Fault location method for transmission grids based on time difference of arrival of wide area travelling wave. J. Eng. 2018, 2019, 3202–3208. [Google Scholar] [CrossRef]
- Silva, A.; Lima, A.; Souza, S.M. Fault location on transmission lines using complex-domain neural networks. Int. J. Electr. Power Energy Syst. 2012, 43, 720–727. [Google Scholar] [CrossRef]
- Farshad, M.; Sadeh, J. Accurate Single-Phase Fault-Location Method for Transmission Lines Based on K-Nearest Neighbor Algorithm Using One-End Voltage. IEEE Trans. Power Deliv. 2012, 27, 2360–2367. [Google Scholar] [CrossRef]
- Joorabian, M.; Asl, S.; Aggarwal, R.K. Accurate fault locator for EHV transmission lines based on radial basis function neural networks. Electr. Power Syst. Res. 2004, 71, 195–202. [Google Scholar] [CrossRef]
- Silva, K.M.; Souza, B.A.; Brito, N. Fault detection and classification in transmission lines based on wavelet transform and ANN. IEEE Trans. Power Deliv. 2006, 21, 2058–2063. [Google Scholar] [CrossRef]
- Samantaray, S.R.; Dash, P.K.; Panda, G. Distance relaying for transmission line using support vector machine and radial basis function neural network. Int. J. Electr. Power Energy Syst. 2007, 29, 551–556. [Google Scholar] [CrossRef]
- Jamil, M.; Kalam, A.; Ansari, A.; Rizwan, M. Generalized neural network and wavelet transform based approach for fault location estimation of a transmission line. Appl. Soft Comput. 2014, 19, 322–332. [Google Scholar] [CrossRef]
- Hao, Y.Q.; Wang, Q.; Li, Y.N.; Song, W.F. An intelligent algorithm for fault location on VSC-HVDC system. Int. J. Electr. Power Energy Syst. 2018, 94, 116–123. [Google Scholar] [CrossRef]
- Tse, N.; Chan, J.; Liu, R.; Lai, L.L. Hybrid wavelet and Hilbert transform with frequency shifting decomposition for power quality analysis. IEEE Trans. Instrum. Meas. 2012, 61, 3225–3233. [Google Scholar] [CrossRef]
- Farshad, M.; Sadeh, J. Transmission line fault location using hybrid wavelet-Prony method and relief algorithm. Int. J. Electr. Power Energy Syst. 2014, 61, 127–136. [Google Scholar] [CrossRef]
- Ravesh, N.R.; Ramezani, N.; Ahmadi, I.; Nouri, H. A hybrid artificial neural network and wavelet packet transform approach for fault location in hybrid transmission lines. Electr. Power Syst. Res. 2022, 204, 107721. [Google Scholar] [CrossRef]
- Liu, C.C.; Stefanov, A.; Hong, J. Artificial Intelligence and Computational Intelligence: A Challenge for Power System Engineers; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Luo, G.M.; Hei, J.X.; Liu, Y.Y.; Li, M.; He, J.H. Fault location in VSC-HVDC using stacked denoising autoencoder. In Proceedings of the 2019 IEEE 3rd International Electrical and Energy Conference (CIEEC), Beijing, China, 7–9 September 2019; pp. 36–41. [Google Scholar]
- Li, X.T.; Qin, L.W.; Li, Y.Z.; Yang, X.; Yu, X.Y. Fault location of distribution network based on stacked autoencoder. In Proceedings of the 16th Annual Conference of China Electrotechnical Society, Singapore, 24–26 September 2022; pp. 564–572. [Google Scholar]
- Luo, G.; Yao, C.; Liu, Y.; Tan, Y.; He, J.; Wang, K. Stacked Auto-Encoder Based Fault Location in VSC-HVDC. IEEE Access 2018, 6, 33216–33224. [Google Scholar] [CrossRef]
- Zhu, B.E.; Wang, H.Z.; Shi, S.X.; Dong, X.Z. Fault location in AC transmission lines with back-to-back MMC-HVDC using ConvNets. J. Eng. 2019, 2019, 2430–2434. [Google Scholar] [CrossRef]
- Lan, S.; Chen, M.; Chen, D.Y. A novel HVDC double-terminal non-synchronous fault location method based on convolutional neural network. IEEE Trans. Power Deliv. 2019, 34, 848–857. [Google Scholar] [CrossRef]
- Shadi, M.R.; Mohammad-Taghi, A.; Sasan, A. A real-time hierarchical framework for fault detection, classification, and location in power systems using PMUs data and deep learning. Int. J. Electr. Power Energy Syst. 2022, 134, 107399. [Google Scholar] [CrossRef]
- Hei, J.; Luo, G.; Cheng, M.; Liu, Y.; Tan, Y.; Li, M. A research review on application of artificial intelligence in power system fault analysis and location. Proc. CSEE 2020, 40, 5506–5516. [Google Scholar]
- Duan, Y.; Yuan, H.L.; Lai, C.S.; Lai, L.L. Fusing local and global information for one-step multi-view subspace clustering. Appl. Sci. 2022, 12, 10. [Google Scholar] [CrossRef]
- Chen, R.; Lai, C.S.; Zhong, C.; Pan, K.; Ng, W.W.Y.; Li, Z.L.; Lai, L.L. MultiCycleNet: Multiple cycles self-boosted neural network for short-term household load forecasting. Sustain. Cities Soc. 2022, 76, 103484. [Google Scholar] [CrossRef]
- Lai, C.S.; Yang, Y.; Pan, K.; Zhang, J.; Yuan, H.; Ng, W.W.Y.; Gao, Y.; Zhao, Z.; Wang, T.; Shahidehpour, M.; et al. Multi-view neural network ensemble for short and mid-term load forecasting. IEEE Trans. Power Syst. 2021, 36, 2992–3003. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Scholkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Jia, R.; Song, Y.C.; Piao, D.M.; Kim, K.; Lee, C.Y.; Park, J. Exploration of deep learning models for real-time monitoring of state and performance of anaerobic digestion with online sensors. Bioresour. Technol. 2022, 363, 127908. [Google Scholar] [CrossRef]
- Liang, J.; Jing, T.; Niu, H.; Wang, J. Two-Terminal Fault Location Method of Distribution Network Based on Adaptive Convolution Neural Network. IEEE Access 2020, 8, 54035–54043. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomze, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017. [Google Scholar] [CrossRef]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. IEEE Int. Conf. Comput. Vis. 2021, 357–366. [Google Scholar] [CrossRef]


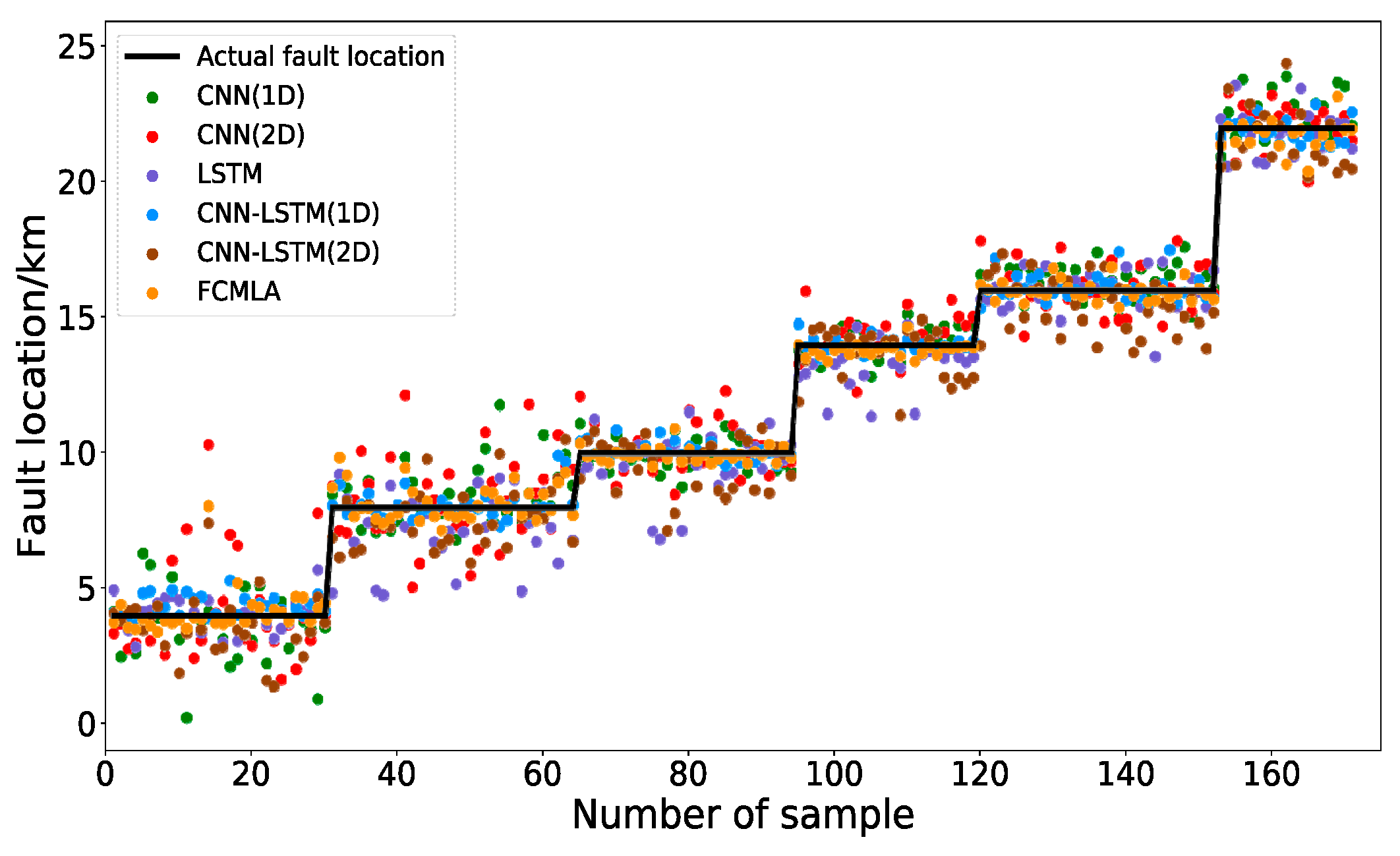


| Predictive Model | XRMSE | X MAE | X MAPE |
|---|---|---|---|
| CNN (1D) | 0.8460 | 0.6521 | 8.22% |
| CNN (2D) | 1.1760 | 0.8665 | 10.87% |
| LSTM | 1.0916 | 0.7840 | 8.53% |
| CNN-LSTM (1D) | 0.5773 | 0.5323 | 3.99% |
| CNN-LSTM (2D) | 1.0829 | 0.8461 | 9.62% |
| FCMLA | 0.5418 | 0.3714 | 4.60% |
| Predictive Model | XRMSE | X MAE | X MAPE |
|---|---|---|---|
| KNN | 2.729 | 1.768 | 16.43% |
| SVR | 1.414 | 0.957 | 7.20% |
| DT | 0.663 | 0.218 | 3.31% |
| WT-DT | 1.431 | 0.377 | 2.09% |
| FFT-DT | 1.470 | 0.461 | 2.62% |
| SAE | 0.886 | 0.421 | 3.4% |
| CLMA | 0.5418 | 0.3714 | 4.60% |
| Line | Length (km) | Fault Location (km) | Average Fault Location Result (km) | |
|---|---|---|---|---|
| Forecast Result | Error | |||
| 4 | 30 | 15 | 14.512 | 0.488 |
| 5 | 70 | 40 | 40.765 | −0.765 |
| Predictive Model | XRMSE | X MAE | X MAPE |
|---|---|---|---|
| CMLA (single)-M | 0.5418 | 0.3714 | 4.60% |
| CMLA (single)-N | 0.5513 | 0.4023 | 3.60% |
| FCMLA (fusion MCLA) | 0.4625 | 0.3042 | 0.84% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, C.; Yang, Q.; Wu, X.; Lai, C.S.; Lai, L.L. A Two-Terminal Fault Location Fusion Model of Transmission Line Based on CNN-Multi-Head-LSTM with an Attention Module. Energies 2023, 16, 1827. https://doi.org/10.3390/en16041827
Su C, Yang Q, Wu X, Lai CS, Lai LL. A Two-Terminal Fault Location Fusion Model of Transmission Line Based on CNN-Multi-Head-LSTM with an Attention Module. Energies. 2023; 16(4):1827. https://doi.org/10.3390/en16041827
Chicago/Turabian StyleSu, Chao, Qiang Yang, Xiaomei Wu, Chun Sing Lai, and Loi Lei Lai. 2023. "A Two-Terminal Fault Location Fusion Model of Transmission Line Based on CNN-Multi-Head-LSTM with an Attention Module" Energies 16, no. 4: 1827. https://doi.org/10.3390/en16041827
APA StyleSu, C., Yang, Q., Wu, X., Lai, C. S., & Lai, L. L. (2023). A Two-Terminal Fault Location Fusion Model of Transmission Line Based on CNN-Multi-Head-LSTM with an Attention Module. Energies, 16(4), 1827. https://doi.org/10.3390/en16041827