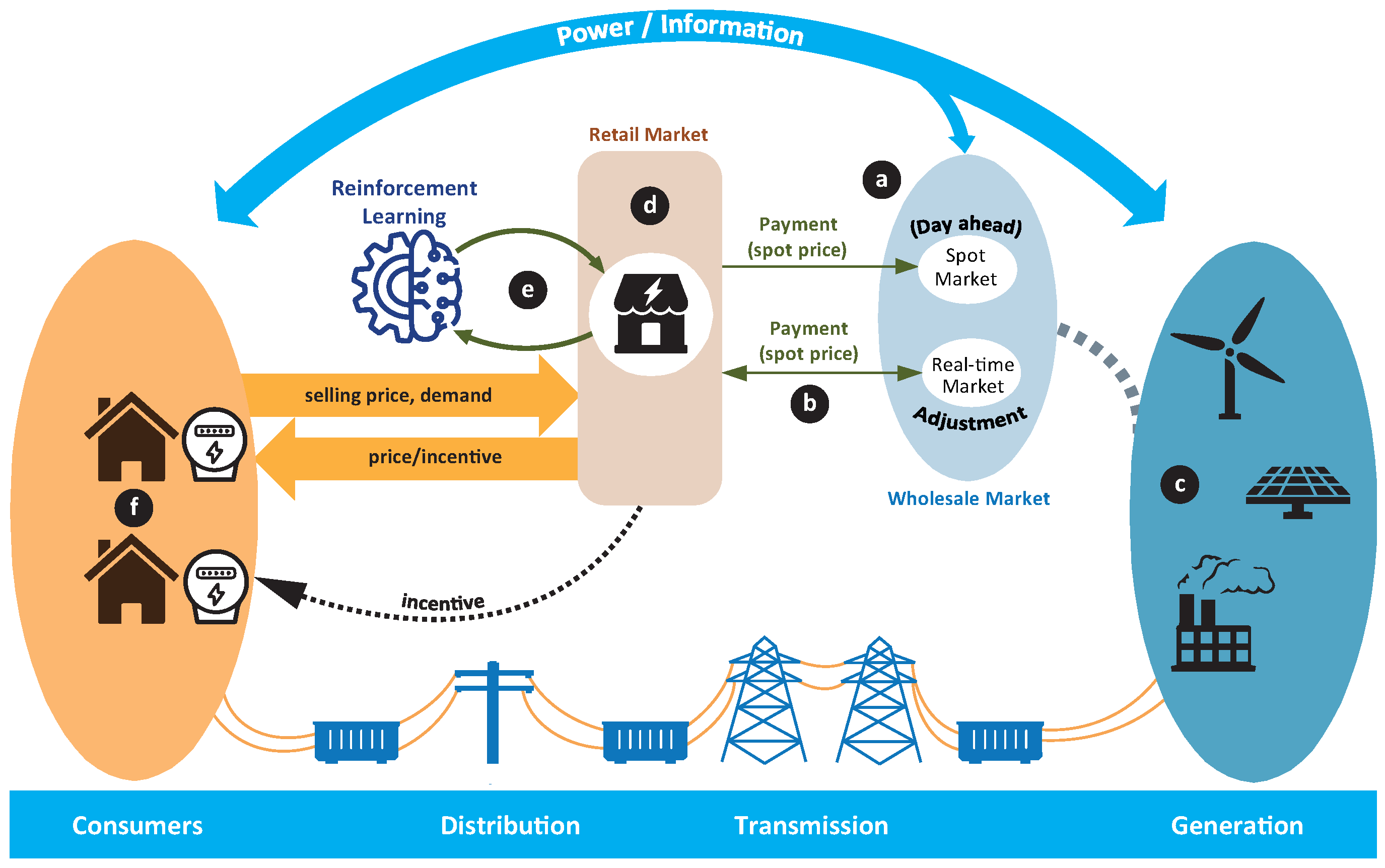
This section presents the state of the art of economic planning strategies and demand response schemes in smart distribution networks. In addition, the main contributions of this work are detailed.
2.5. Reinforcement Learning Background
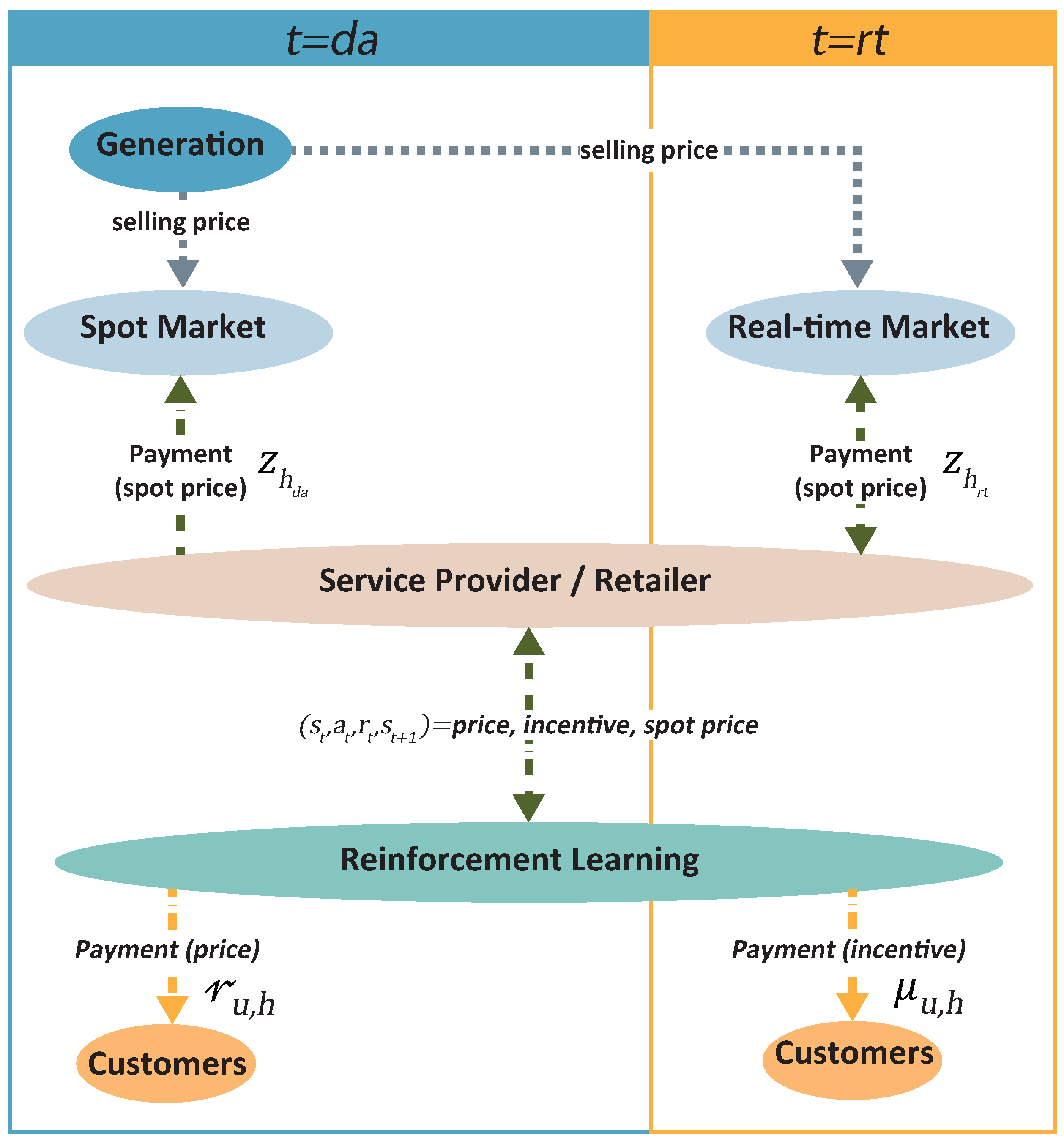
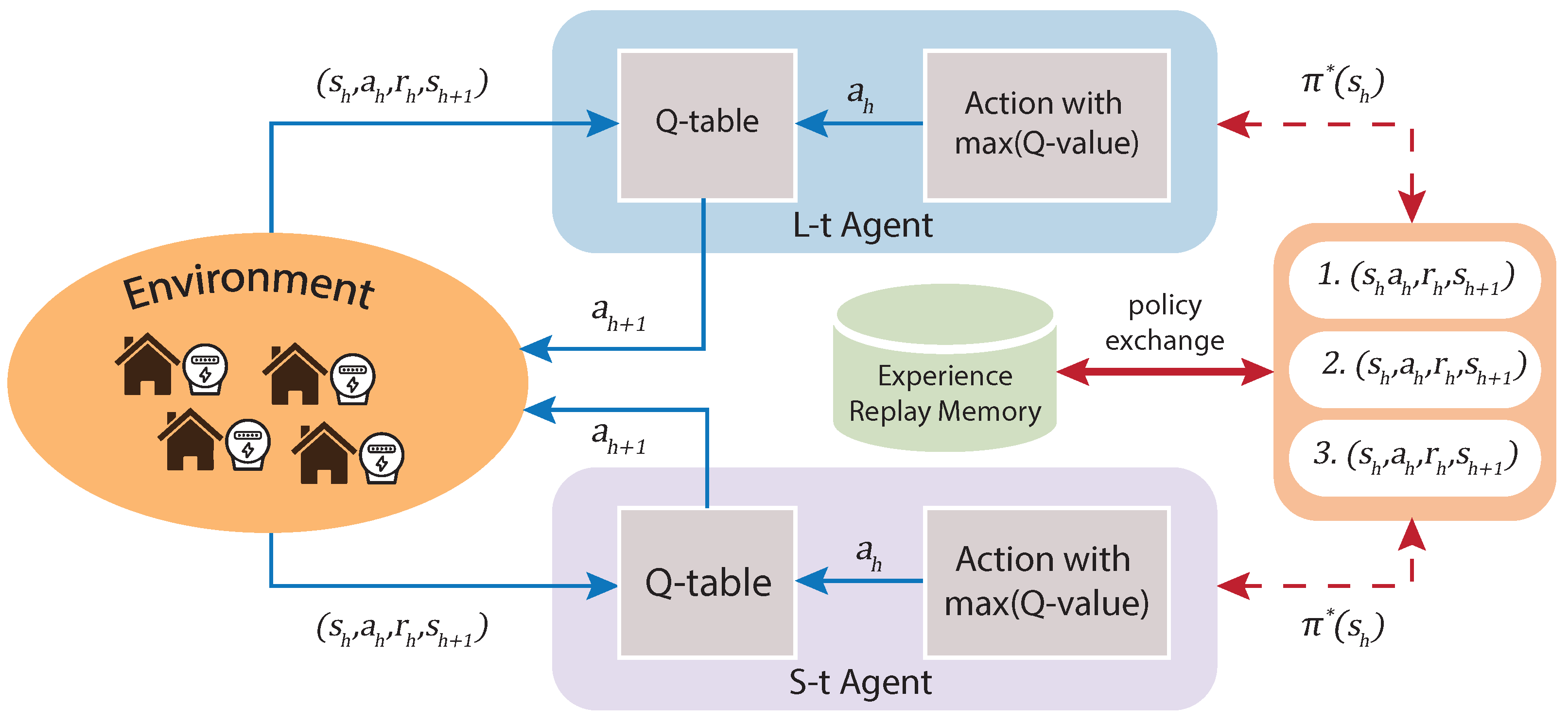
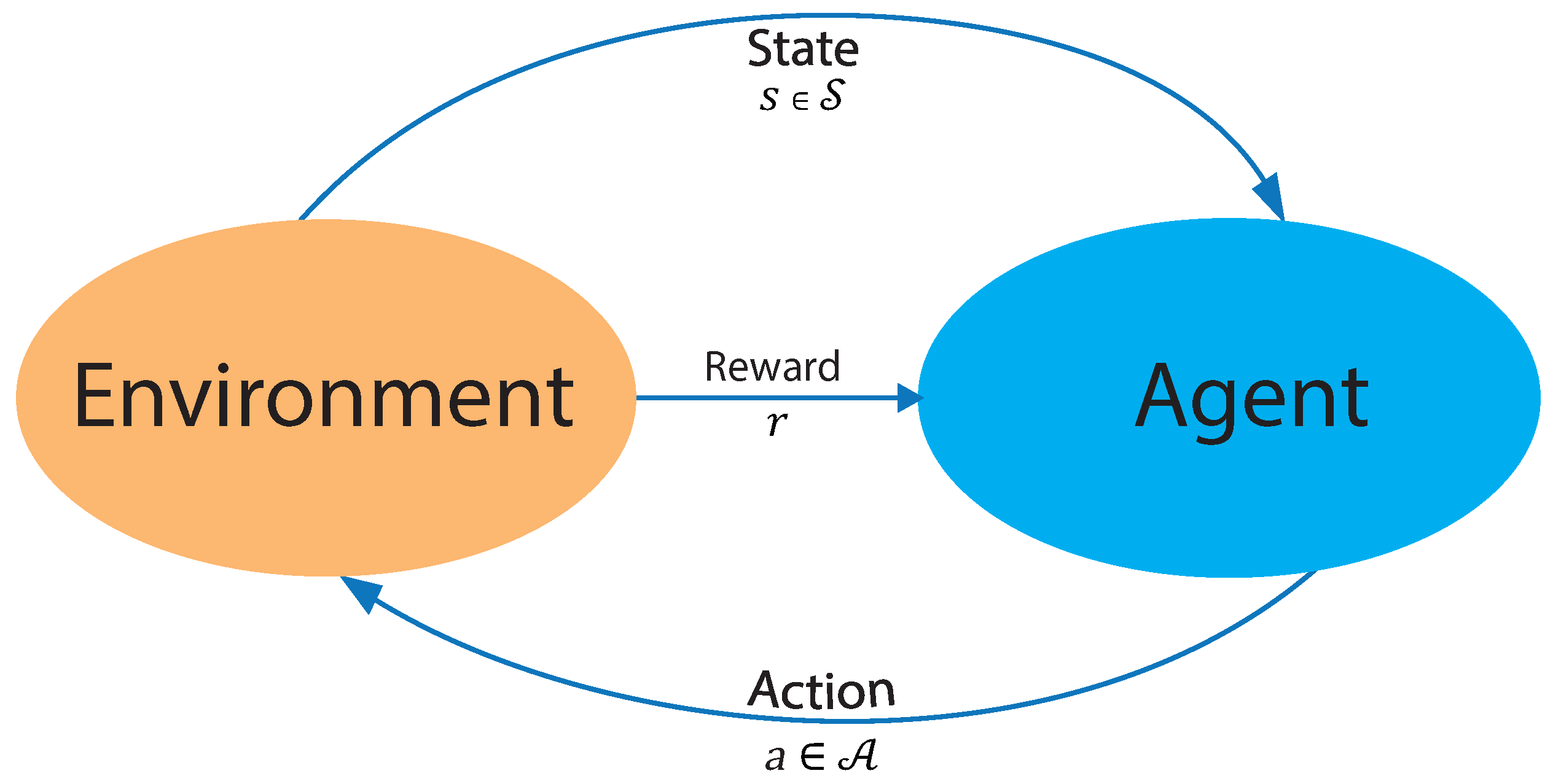
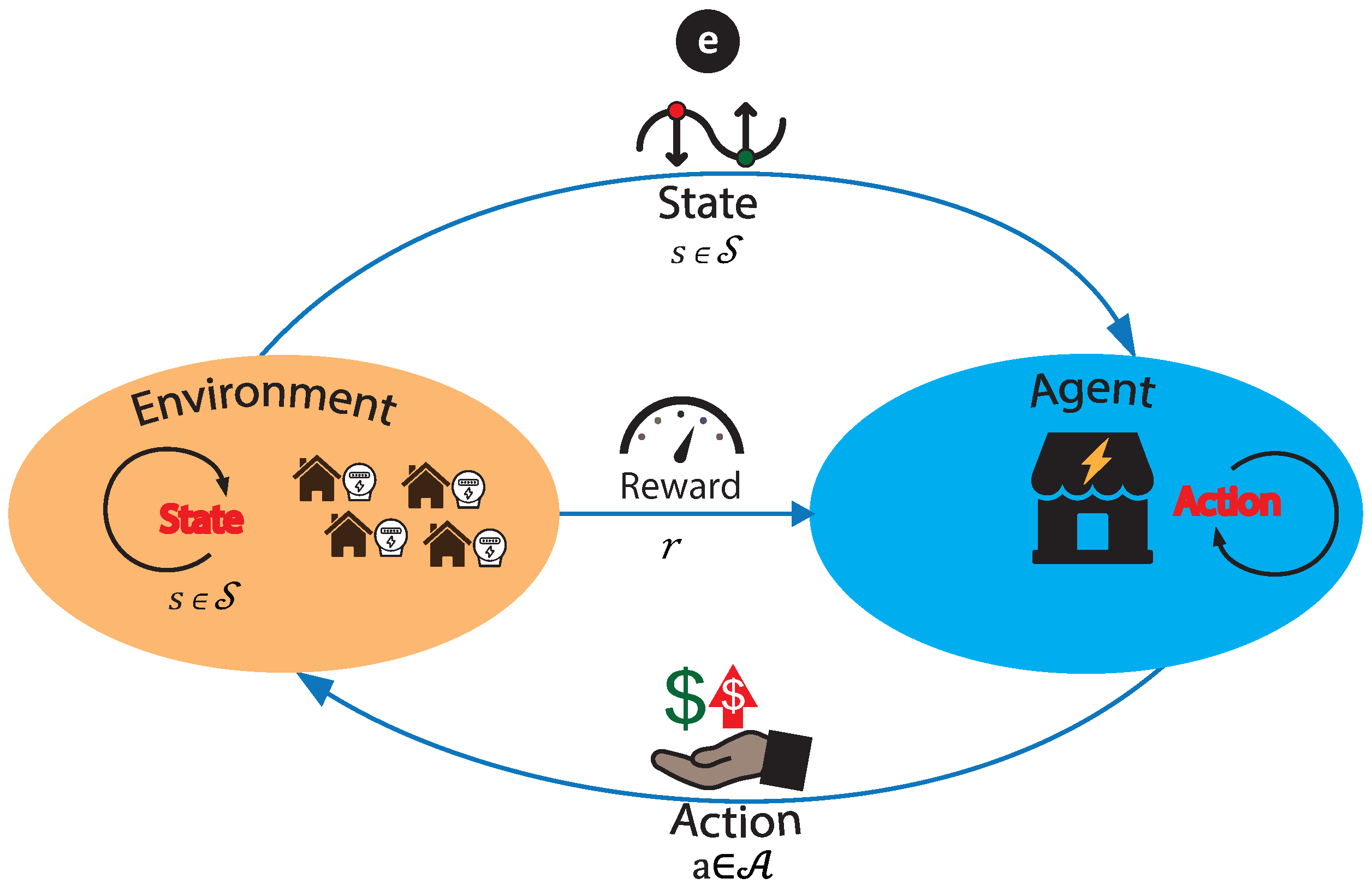
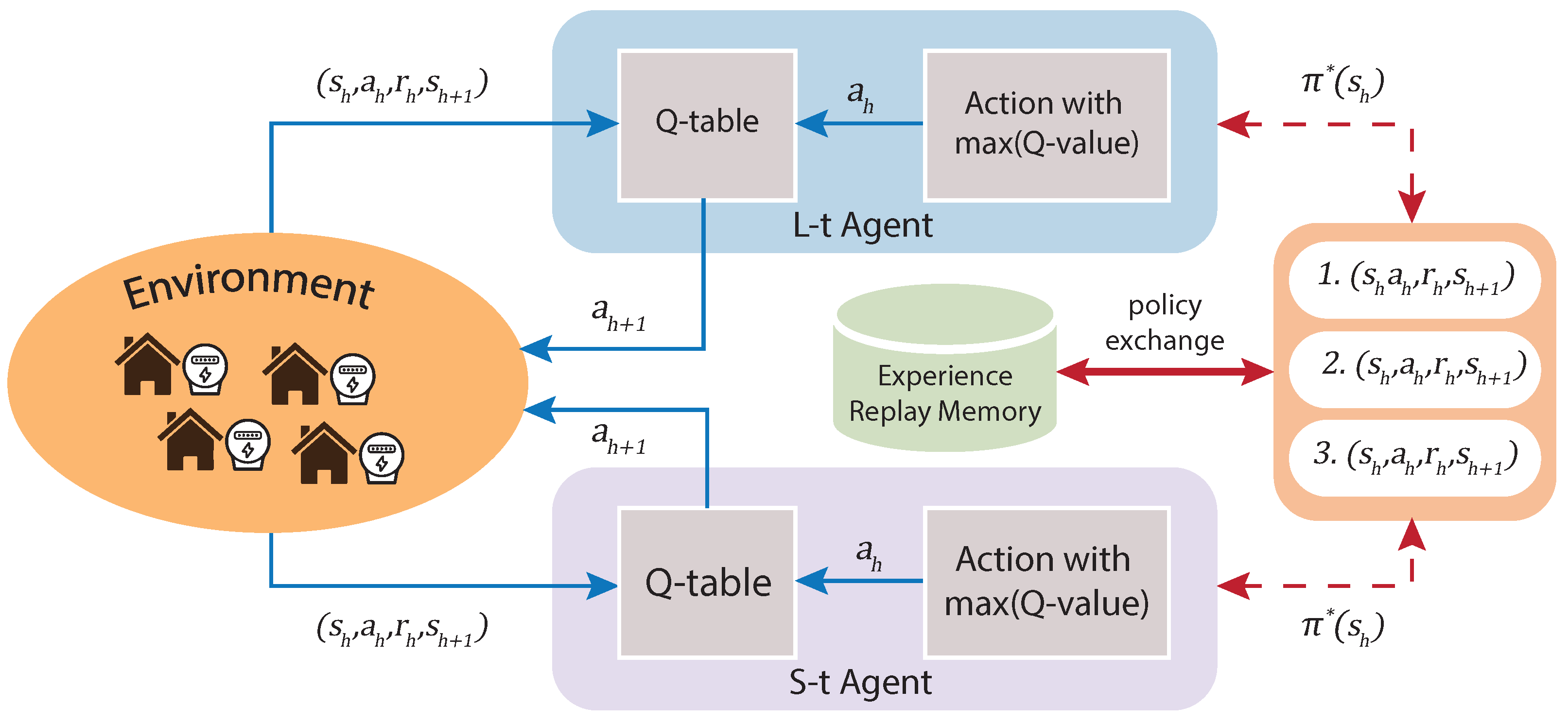
The reinforcement learning (RL) approach is based on object-directed learning from interaction (agent–environment) much more than other learning approaches within machine learning. Specifically, the learning algorithm has no specific actions to perform but must discover which actions will produce a more significant reward through trial and error. That is the goal of the algorithm: to maximize the reward. Furthermore, such actions may affect immediate and future rewards, as current actions will figure out future scenarios. Thus, in each state, the environment makes available a set of actions from which the agent will choose. The agent influences the environment through these actions, and the environment can change state in response to the action of the agent. Next, the process mentioned above is graphically summarized in
Figure 1.
Accordingly, it was found that one of the techniques that best understands consumer preferences in a dynamic environment is RL, which is in fact state-of-the-art approach focused on this method. Consequently, articles that consider DR programs based on prices and incentives, consumer satisfaction, RL, consumer classification, and application in practical cases were analyzed in depth.
In [
40], an RL architecture is proposed for the best control of HVAC air conditioning systems of an entire building to save energy considering thermal comfort while taking advantage of demand response capabilities. The work mentioned above achieves a maximum weekly energy reduction of up to 22% by applying RL compared to a reference controller. In contrast, the feasibility of applying deep reinforcement learning to control an entire building for demand response purposes is proven. Thus, average power reductions (or increases) of up to 50% were achieved, considering the limits of acceptable comfort. It has been found in these works that the use of applications is improved. For example, in [
8], a method is proposed for managing a multipurpose energy storage system (ESS) to participate in response programs for the demand with RL. The work above focuses primarily on industrial consumers to provide them the opportunity to obtain added profits through market participation in addition to offering an improvement for the management of electrical loads. This paper also explores the benefits of using ToU rates, explicitly showing that consumers can obtain more benefits due to changing their consumption from one-time slot to another with a lower price.
Similarly, a neural network is established in [
51] to build a series of strategies to obtain control actions in discrete time. For this, RL is used as support to determine a policy that establishes the optimal point for the thermostat configuration. One of the noteworthy features developed by the author is the development of a new objective function truncation method to limit the size of the update step and improve the robustness of the algorithm. In addition, a DR strategy was formulated based on electricity prices according to the time of use, which considers factors such as the environment, thermal comfort, and energy consumption; the proposed RL algorithm is used to learn the thermostat settings in DR time.
In [
52], the author proposed a centralized control strategy utilizing a single-agent reinforcement learning (RL) algorithm known as a soft actor critical for optimizing electrical demand across multiple levels, including individual buildings, clusters, and networks. This approach diverges from traditional rule-based control methods, which typically focus on optimizing the performance of individual buildings. Thus, the evaluation of the proposed controller revealed a cost reduction of approximately 4%, with a maximum decrease of 12%. Additionally, daily peaks in electrical demand were found to be lowered by an average of 8%, resulting in a decrease in the peak-to-average ratio of 6–22%. However, it is essential to note that the study also highlights a possible issue with price-based programs, stating that these approaches can sometimes lead to unintended increases in demand during periods of low electricity prices. Despite this, the study also notes that the adoption of multi-agent coordination in demand response applications has not been widely adopted in recent years, possibly due to the lack of understanding of its potential benefits in reducing peak demand or altering daily load profiles.
A DR algorithm based on dynamic prices for smart grids is presented in [
53]. Furthermore, the development and formulation of prices to deal with high and highly variable bid prices in the context of RL are shown in this paper. For this, an hourly real-time demand response approach is used. One of the advantages pointed out by the author is that with this algorithm, reliability support is provided to the system, and it achieves a general reduction in energy costs in the market. At the same time, the approach allows flexibility for the system to react quickly to supply demand and correct differences in the energy balance. In addition, a method presented supplies incentives to reduce energy consumption; this occurs when market prices are high, or if the system reliability is at risk.
One of the motivations presented by the author to choose RL is the solution to the problem of making decisions that occur stochastically and thus being able to maximize an immediate and cumulative reward. The scenario presented has a single centralized network operator that keeps, installs, and manages the electrical system. In addition, an electricity service provider is formed of residential, commercial, and industrial consumers. Therefore, the supplier plays a fundamental economic role in the energy supply since it buys the energy from the wholesale market and sells it to consumers at retail prices.
Likewise, [
54] presents a multi-agent reinforcement learning (MARL) algorithm for addressing the challenges of community energy management, specifically, peak rebound and uncertain renewable energy generation. The proposed method utilizes a leader-follower Stackelberg game framework, in which a community aggregator serves as the leader, forecasting future renewable energy generation and optimizing energy storage scheduling, updating a Q-table, and initializing a community load profile for all residential consumers. Residential consumers, acting as followers, predict their own renewable energy generation, and schedule home appliances through a sequential decision-making process, utilizing their own individual Q-tables. The proposed MARL algorithm was extensively evaluated against state-of-the-art methods and was shown to be more efficient, reducing peak load, average cost, and standard deviation of cost while effectively addressing the uncertainty of renewable energy generation.
A hybrid DR mechanism is developed in [
38], which combines prices and incentives in real-time. This hybrid DR mechanism is modeled under the approach of a Stackelberg game. Within this approach, the agents that participate in the mechanism are the network operator, a retailer that performs the functions of a demand aggregator, and finally, the end consumers. Similarly, in [
55], these theoretical RL practical feasibility of approaches is shown by implementing an experimental setup. This work, however, does not consider an incentive scheme that reinforces the participation of consumers.
In the same way, in [
56], an online pricing method is proposed considering the response of consumers as unknown, for which the RL approach is used as a tool for decision-making, offering the best incentives. In this work, it is considered that the response behavior of the consumers is unknown, which complicates the resolution of the problem with economic incentives. Seven deep reinforcement learning algorithms (with a transfer learning approach) are empirically compared in [
3]. Limitations in the RL and DR studies are highlighted here, including methods for comparing methodologies and categorizing algorithms and their benefits. In [
57], the method is framed under the scenario in which the long-term response of consumers is unknown, thus, the author proposes an online pricing method, where long short-term memory (LSTM) networks are combined with a reinforcement learning approach to perform the virtual exploration. In addition, LSTM networks are used to predict the response of the consumer, and through reinforcement learning, the response of the consumer is framed to find the best prices to maximize total benefit and avoid the adverse effects of myopic optimization on RL.
The author in [
58], focuses on solving the industrial consumer demand response problem; the need for these schemes is evident due to the size of consumption in the industrial sector compared to the residential or commercial one. In this article, the author proposes a demand response scheme based on multi-agent deep reinforcement learning for the energy management of the components of a discrete industrial process. Here, the simulation results showed that the presented demand response algorithm can minimize electricity costs and support production tasks compared to a non-demand response benchmark.
The articles that include the theme of reinforcement learning are extensively reviewed in [
59], emphasizing those algorithms used to solve each problem. In addition, the contribution made by the research mentioned above is that of proposing a basic framework to help standardize the classification of demand response methods. In this extensive investigation, the author briefly deduces that although many articles have considered human comfort and satisfaction as part of the control problem, most have investigated single-agent systems in which electricity prices do not depend on electricity demand energy. These characteristics do not represent the electricity real-world behavior of markets since electricity prices strongly depend on demand. The maximum demand can be shifted instead of reduced by modeling these characteristics.
Among the articles that concentrate their study on electric heating is [
60], in which a model that focuses on improving the reduction in carbon emissions and the use of RES is presented. Therefore, this study uses the Weber–Fechner law and a clustering algorithm to build quantitative models of demand response characteristics. In addition, a deep Q network is used to generate dynamic prices for demand aggregators. Specifically, this study considers the quantification of consumer behavior of demand response participants and the differences between consumers. Finally, intelligent electric heating management can provide a favorable environment for demand response.
As has been already mentioned, demand response improves grid security by supplying flexibility to the electricity system through the efficient management of consumer demand while supporting the real-time balance between supply and demand. Thus, with the large-scale deployment of communication and information technologies, distributed digitalization, and the improvement of advanced measurement infrastructures, approaches based on copious amounts of data, such as multi-agent reinforcement learning (MARL), are widely relevant in solving demand response problems.
Due to the massive interaction of data, it is expected that these management systems can lead to significant threats from an information security perspective. For this reason, in [
61], the author suggested a robust adversarial multi-agent reinforcement learning framework for demand response (RAMARL-DR) with increased resilience against adversarial attacks. Therefore, the process contemplates formulating a scenario in which the worst case of an adversary attack is simulated. In this case, in addition to the benefits of demand response, it is possible to improve the resilience of the electrical system.
The impact of demand response in a long-term scenario is evaluated in [
62], using a model from the Portuguese electricity system in the OSeMOSYS tool. Three scenarios were analyzed to obtain the potential long-term demand response, which differs by the carbon emissions restrictions. This work showed the potentiality of the demand response algorithm to face the problems of optimal management of resources in scenarios with a high penetration of RES derived from the energy transition.
Similarly, in [
50], an incentive-based DR program with modified deep learning and reinforcement learning is put forward. First, a modified deep learning model based on a recurrent neural network (MDL-RNN) was proposed, which identifies the future uncertainties of the environment by forecasting the wholesale price of electricity, the production of photovoltaic (PV) sources, and the consumer load. In addition, reinforcement learning (RL) was used to obtain the optimal hourly incentive rates that maximize the profits of the energy service of providers and consumers.
In the literature, there are also hybrid methods that combine the reinforcement learning approach with methods such as those based on rules, a sample of them is [
63]; this study investigates the economic benefits of implementing a reinforcement learning (RL) control strategy for the participation in an incentive-based demand response program for a cluster of commercial buildings. The performance of the RL approach is evaluated through comparison with optimized rule-based control (RBC) strategies, and a hybrid control strategy that combines both is also proposed. The study results indicate that while the RL algorithm is more effective in reducing total energy costs, it is less effective in fulfilling demand response requirements. On the other hand, the hybrid control strategy, which combines RBC and RL, demonstrates a reduction in energy consumption and energy costs by 7% and 4%, respectively, compared to a manually optimized RBC and effectively meets the constraints during incentive-based events. The proposed hybrid approach is discussed as a trade-off between random exploration and rule-based expert procedures that can effectively handle peak rebound and promote incentive-based demand response programs in clusters of small commercial buildings.
Within the bibliography, approaches that contemplate the electrical restrictions of networks, as in [
64], have also been found where a demand response approach based on batch reinforcement learning is formulated. This approach has the objective of avoiding violations of restrictions to the distribution network. Consequently, through the adjusted Q iteration, the author calculates a secure network policy through historical measurements of load aggregators. Thus, the wide use of the reinforcement learning approach to deal with frequency regulation problems is shown in this study. It is also interesting to mention the vital adaptability for unknown electrical networks achieved by using these artificial intelligence-based approaches.
The demand response methodology not only shows promising results for the electricity market but some studies have also demonstrated its significant relevance to achieving benefits for the actors involved in a supply process, as is the case of the natural gas market. For example, in [
65], the point mentioned earlier was demonstrated in this approach, like the electricity market. Furthermore, demand response is used for predictive management in the multilevel natural gas market. In this case, it is shown that it is possible to achieve a better trade-off between supplier profits, gas demand volatility, and consumer satisfaction. In addition, the author developed a model based on the Markov decision process to illustrate the dynamic optimization of energy prices. In that way, the results indicated that the proposed method can achieve the objectives of peak reduction and valley filling in different periods.
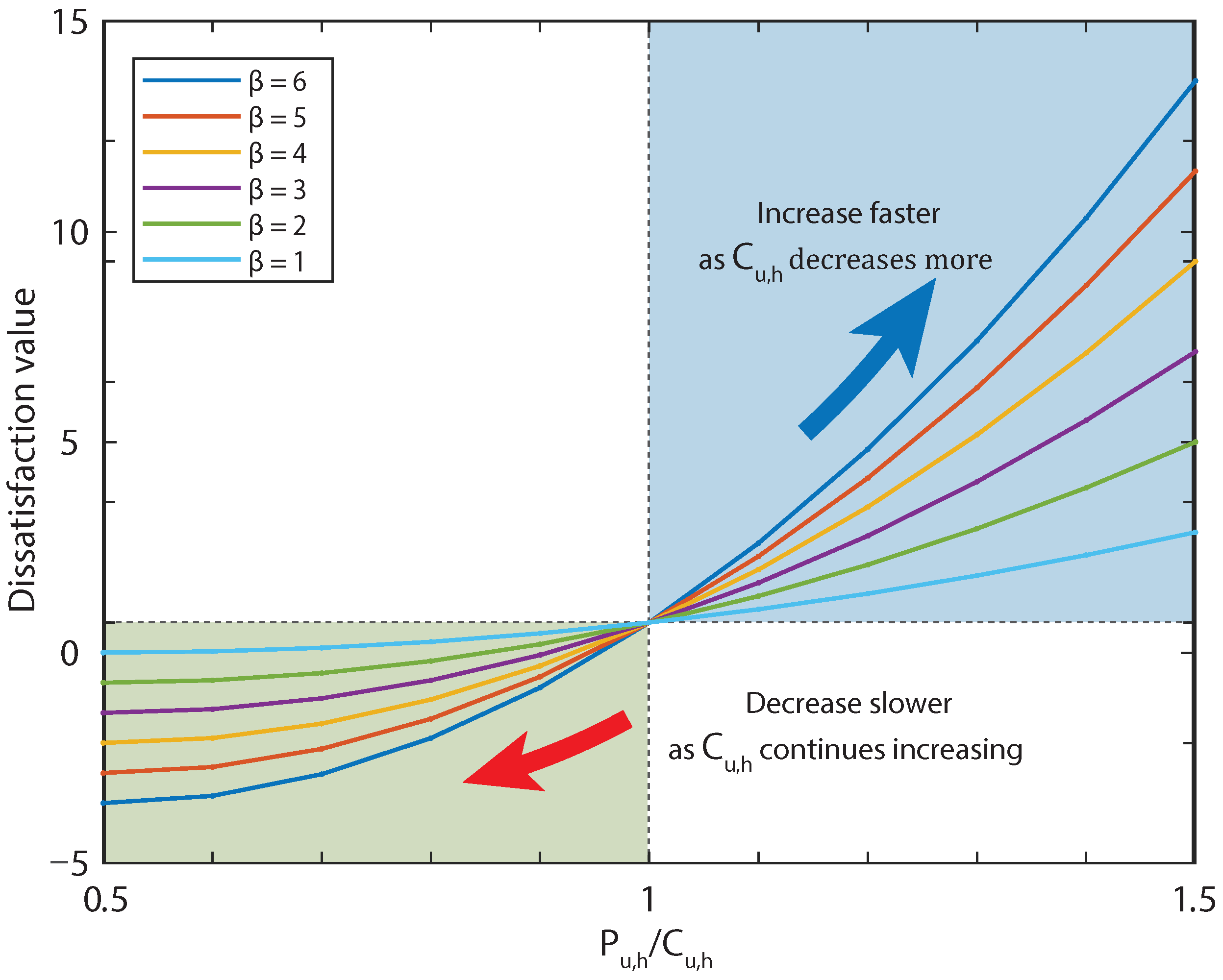
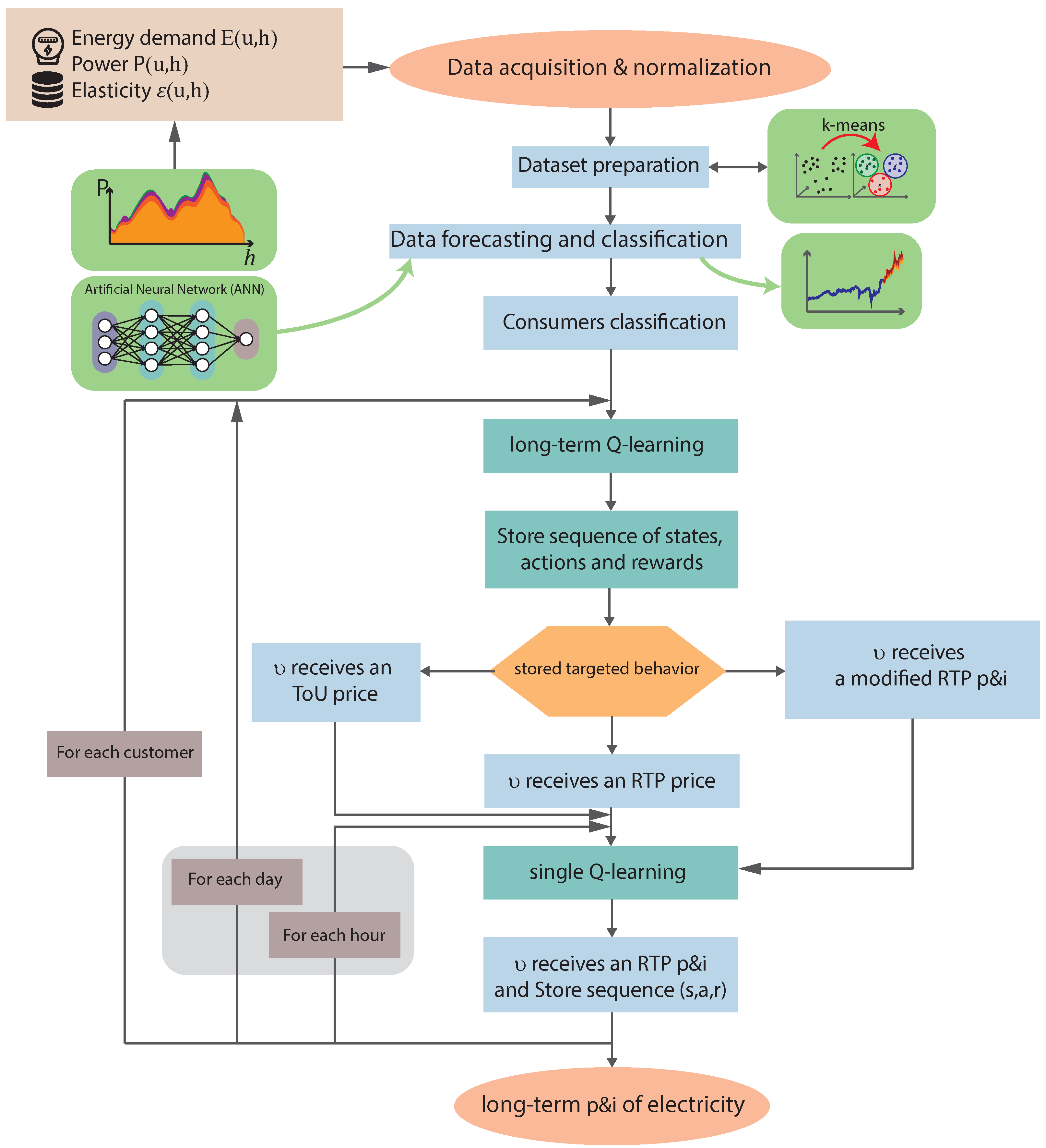
Accordingly, a model that helps consumer contribution to DR programs is developed in this paper by combining the price-based DR approach with an incentive proposal. Furthermore, this model is framed within modern AI techniques, specifically reinforcement learning (RL). Consequently, the contribution of this work to the state of the art is its proposal of a novel DR model that combines prices and incentives (PB-IB-DR) to efficiently manage the active response of the end-consumer demand with reinforcement learning.








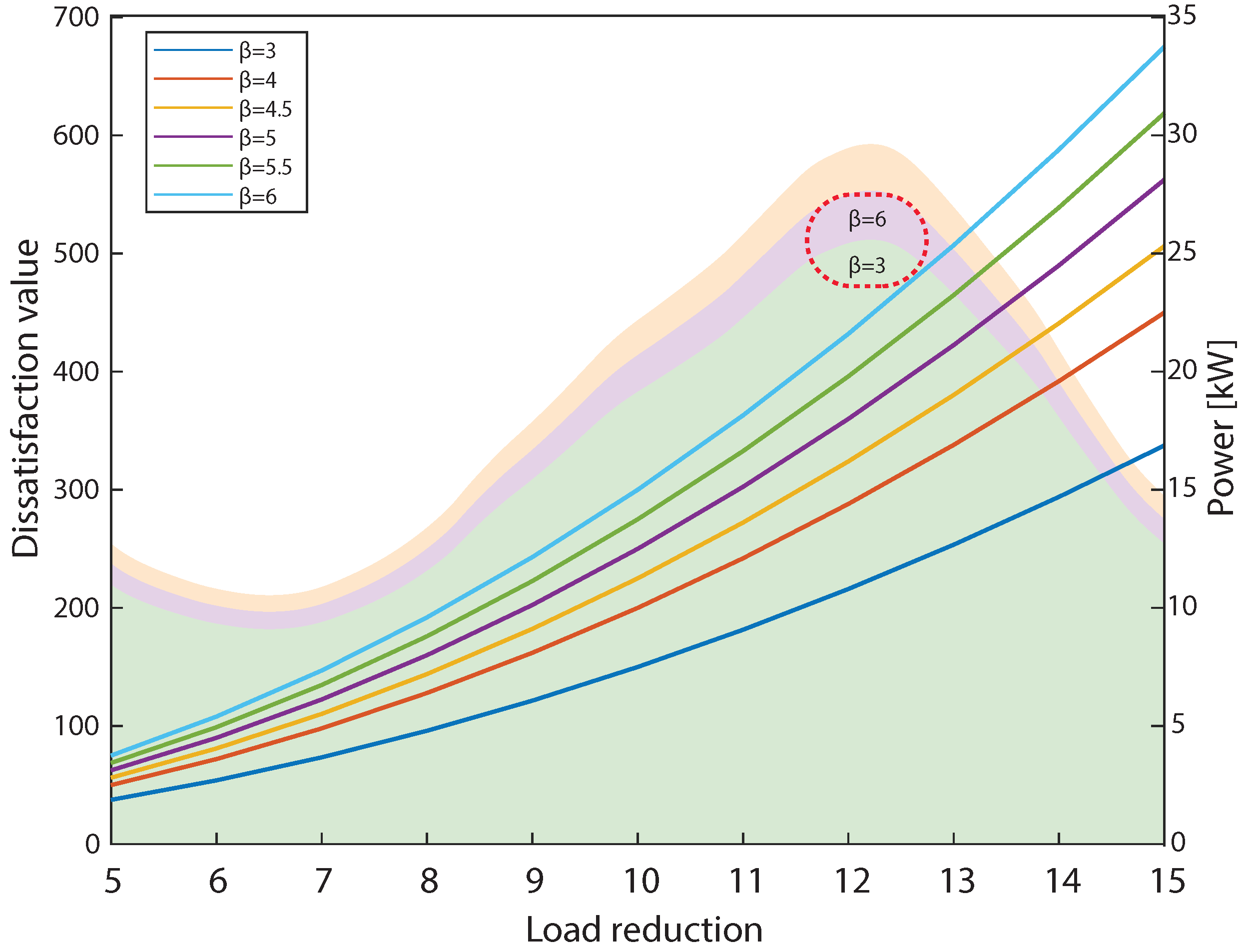
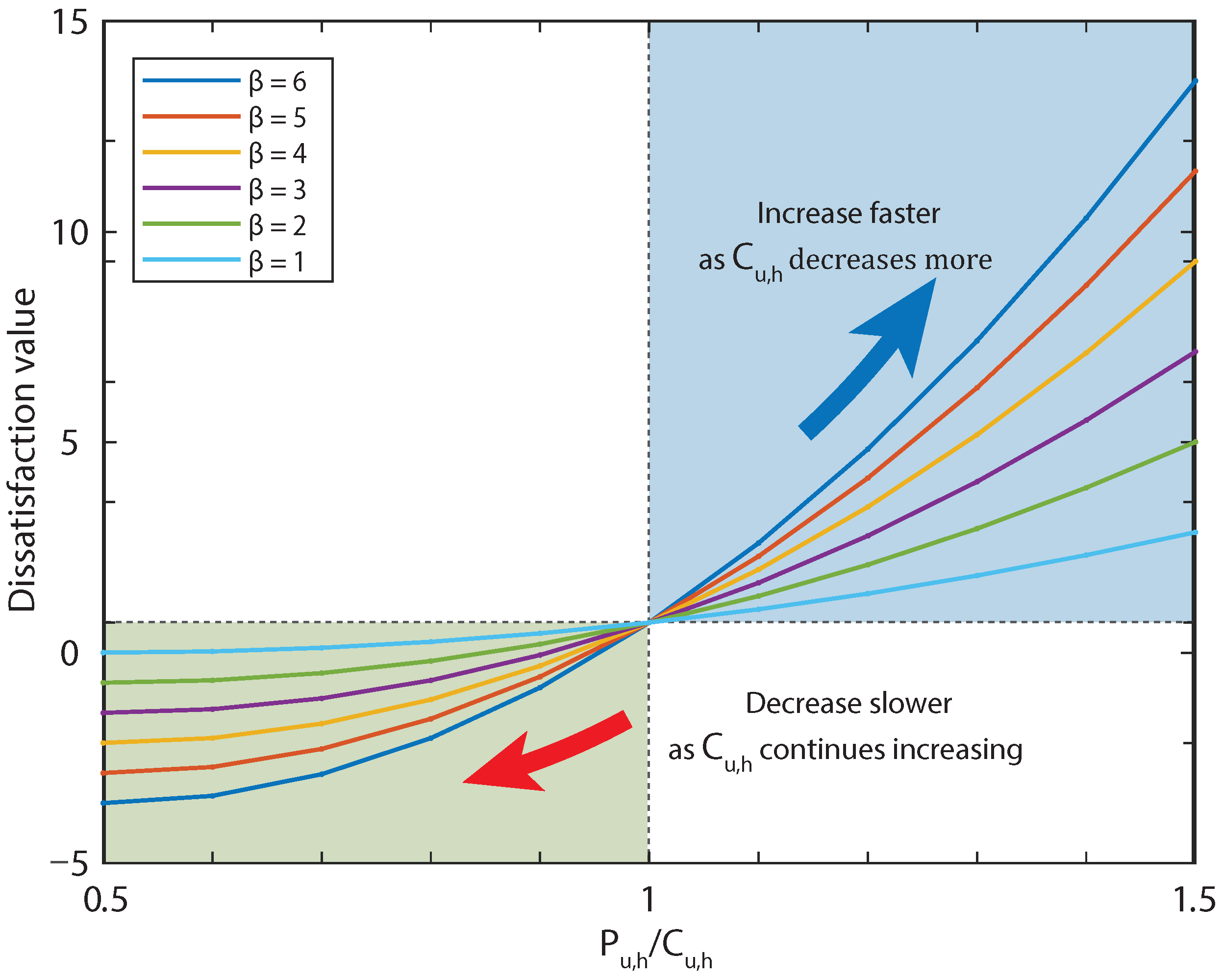
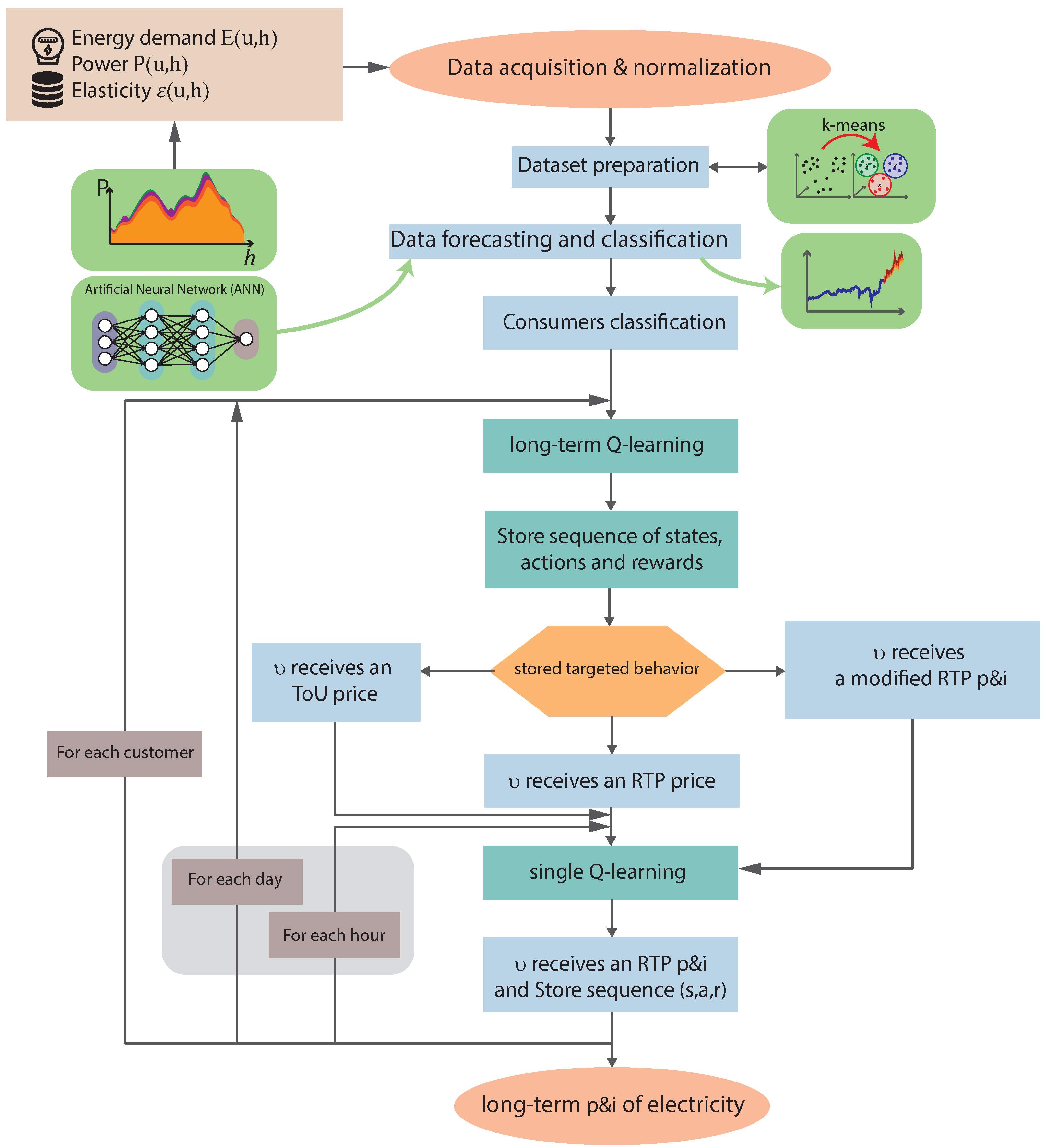
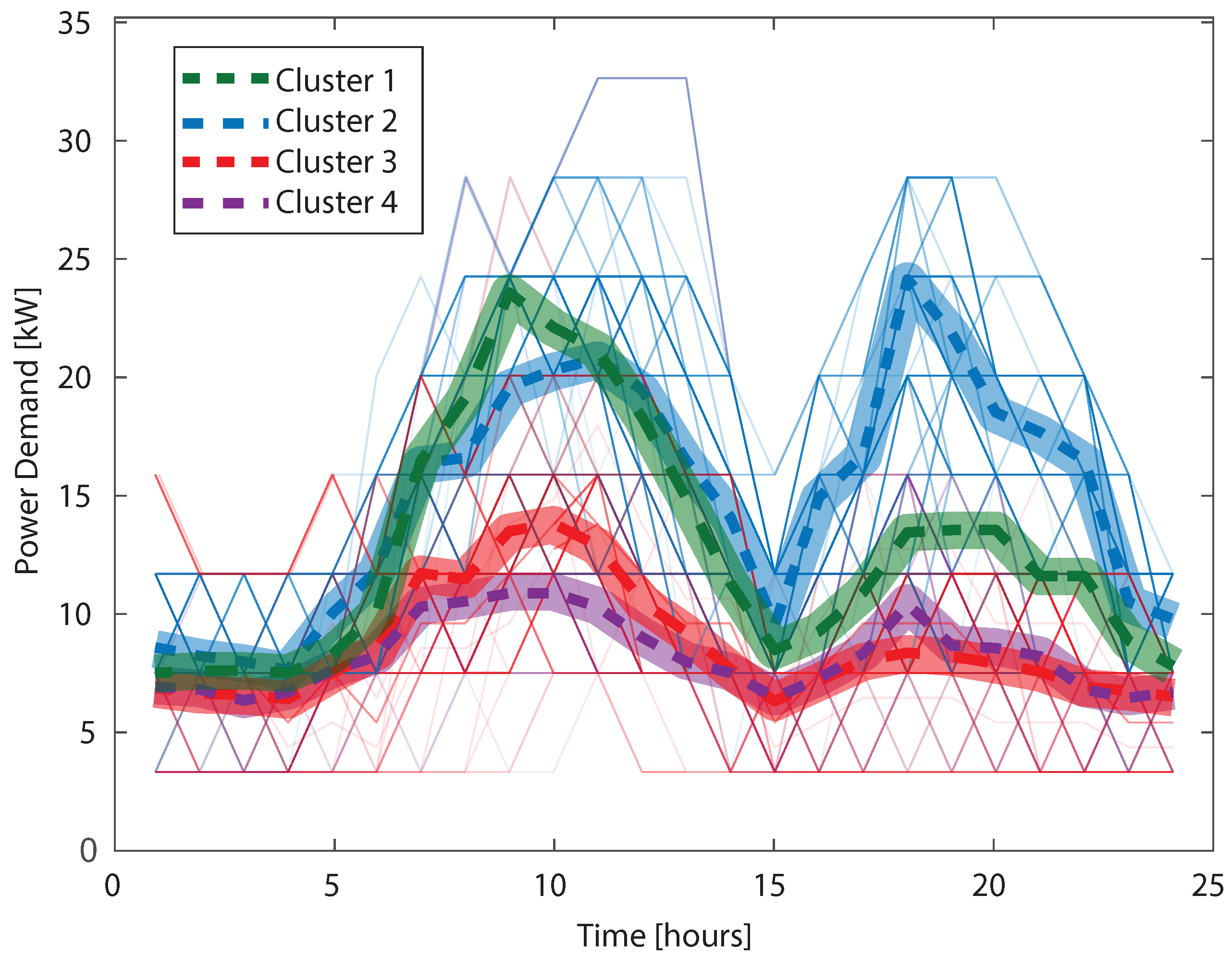
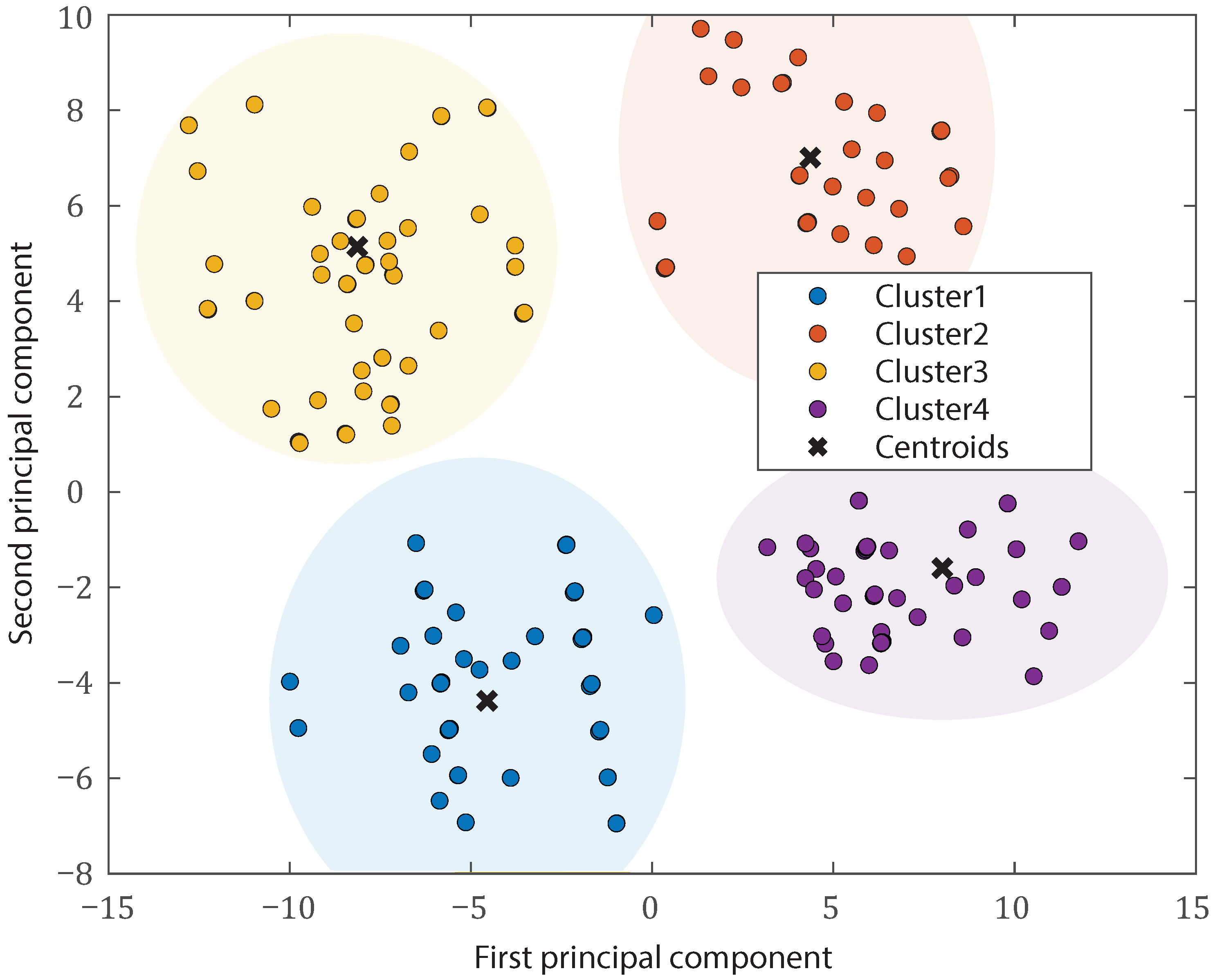
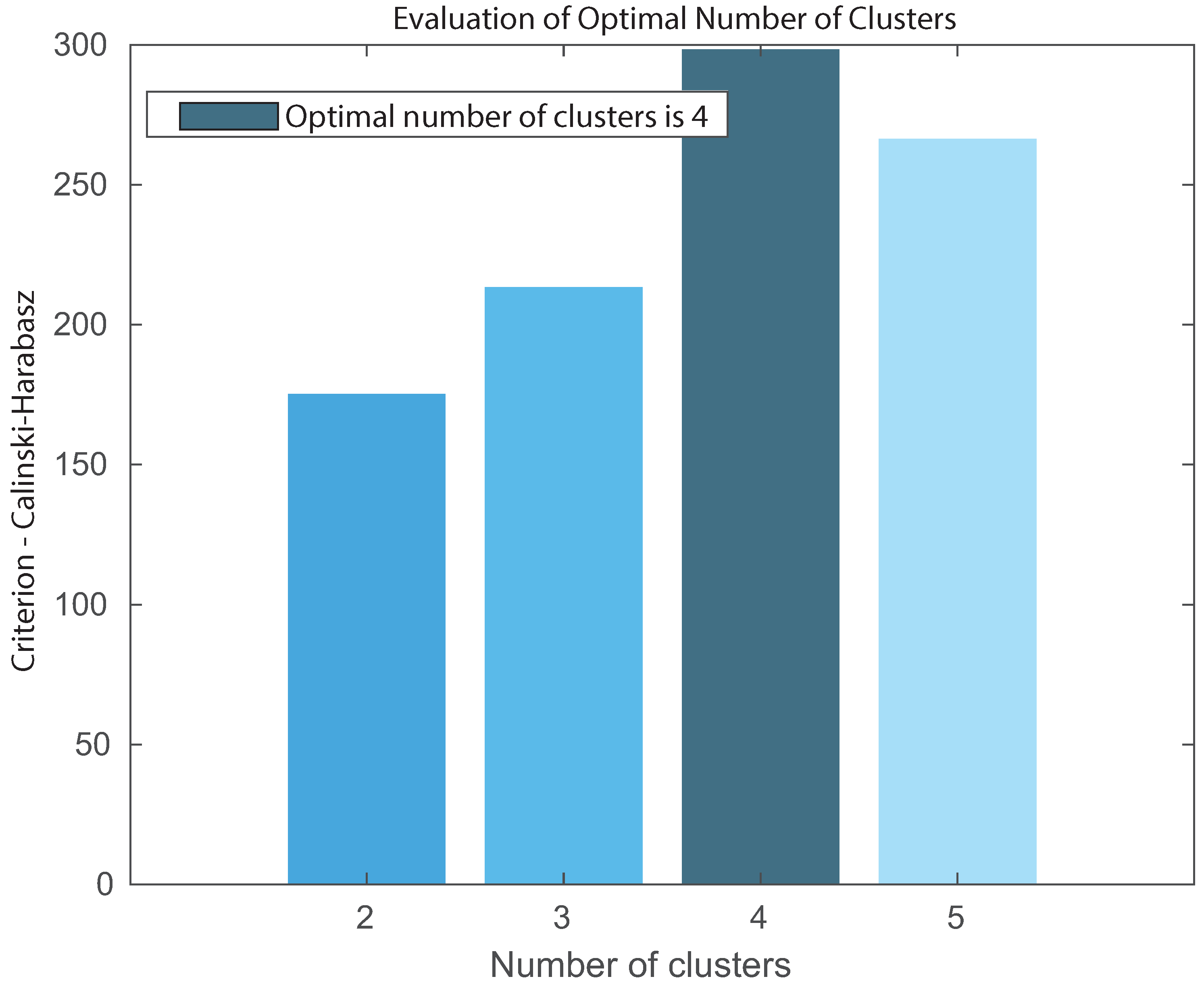
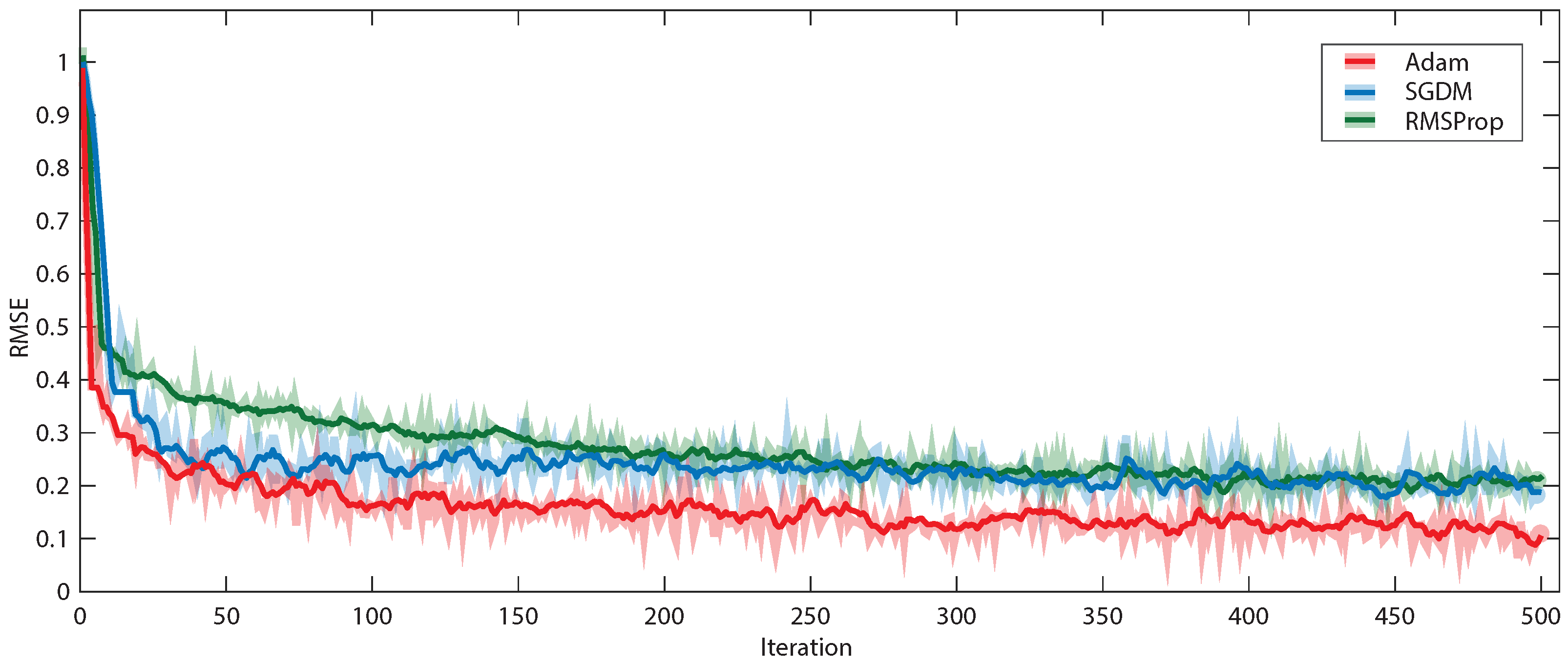
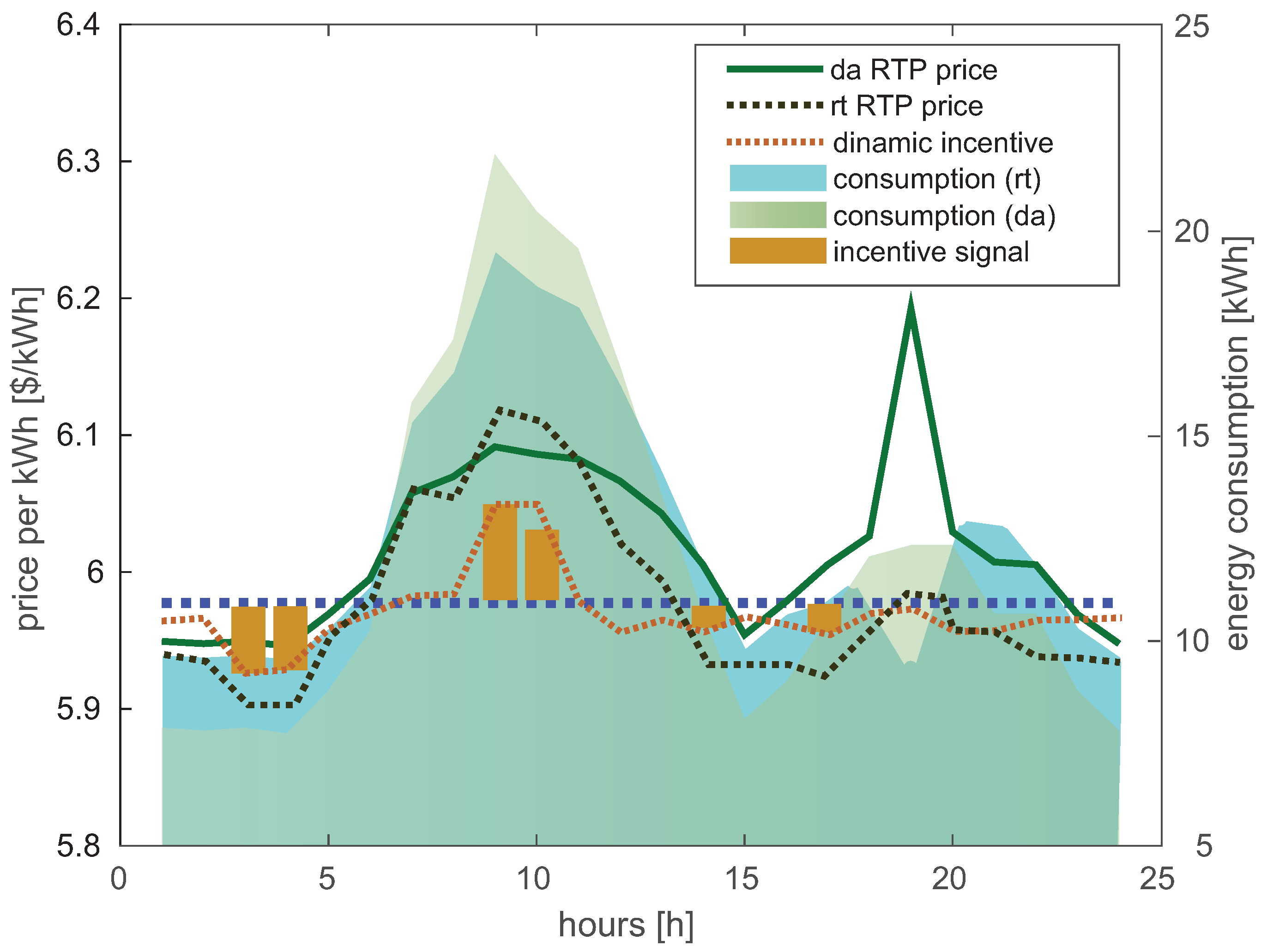
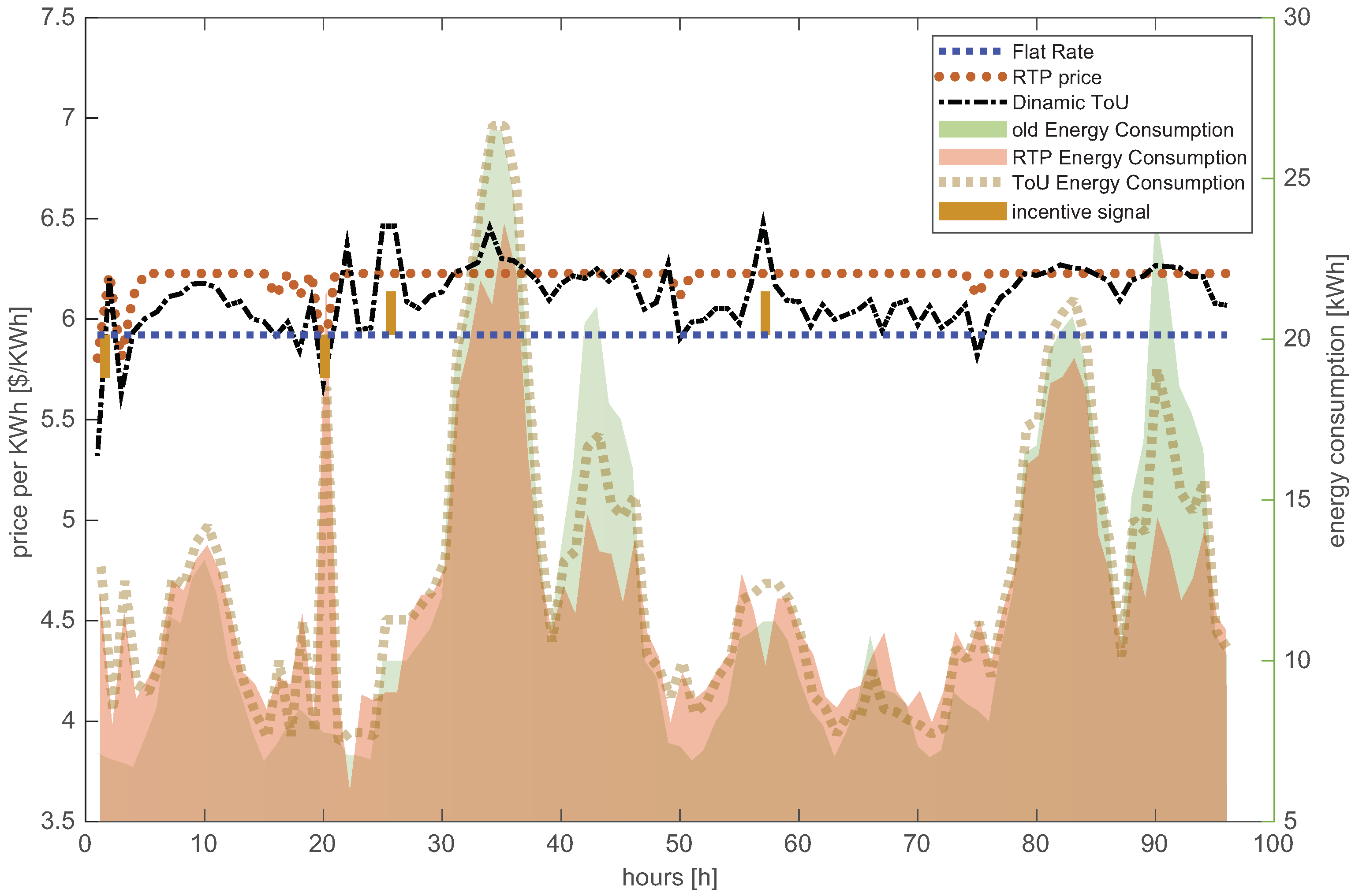
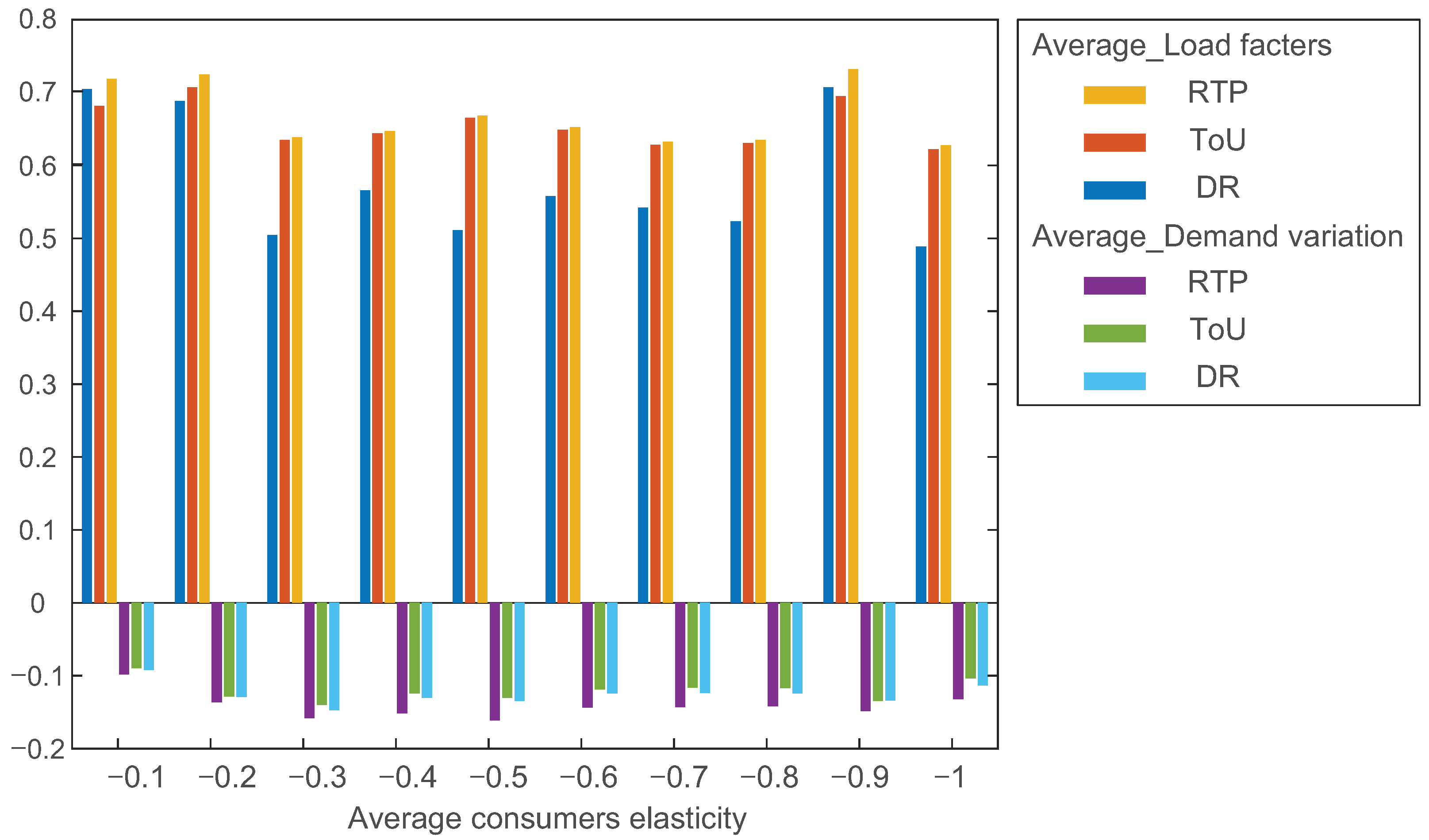

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
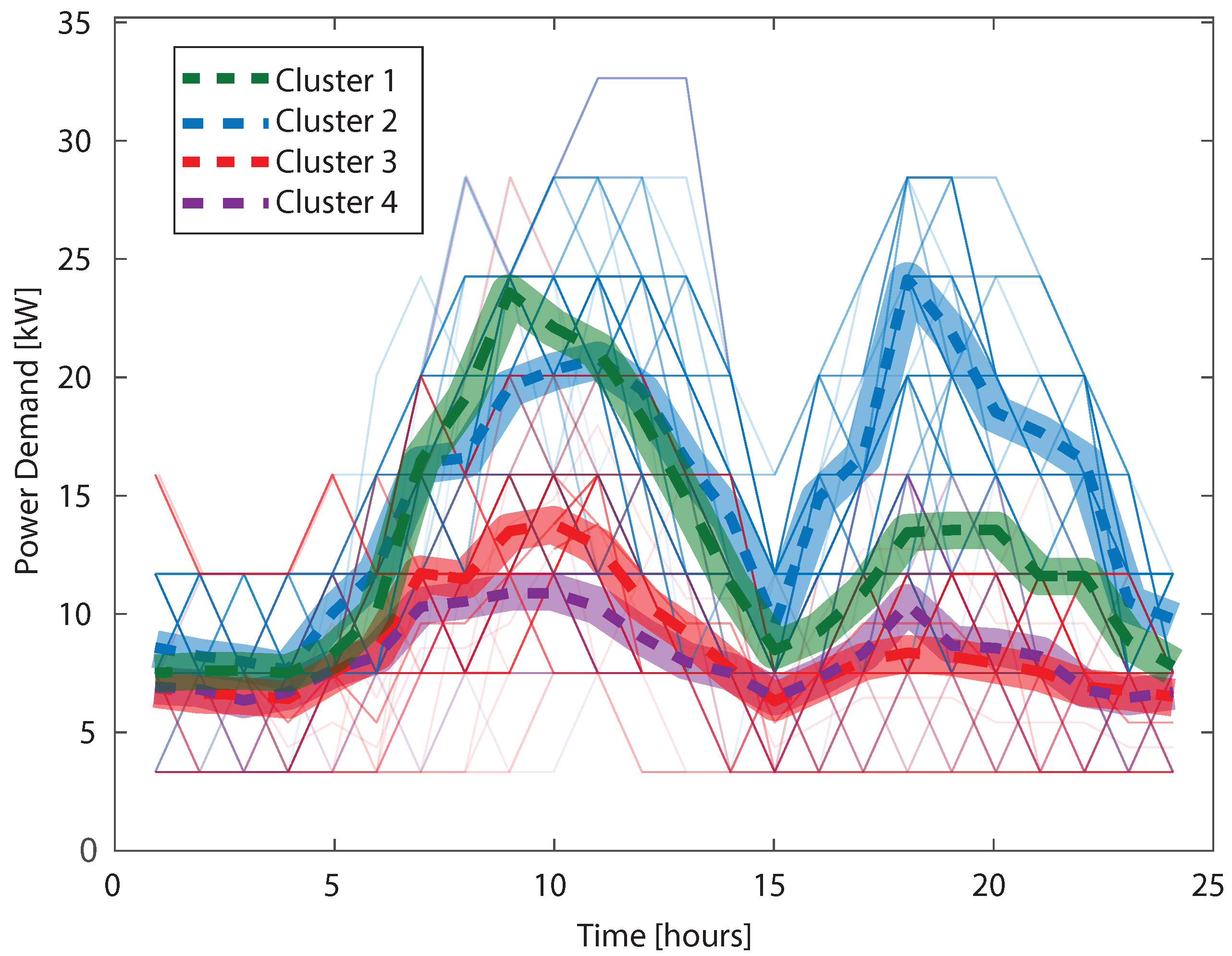{kind=link}
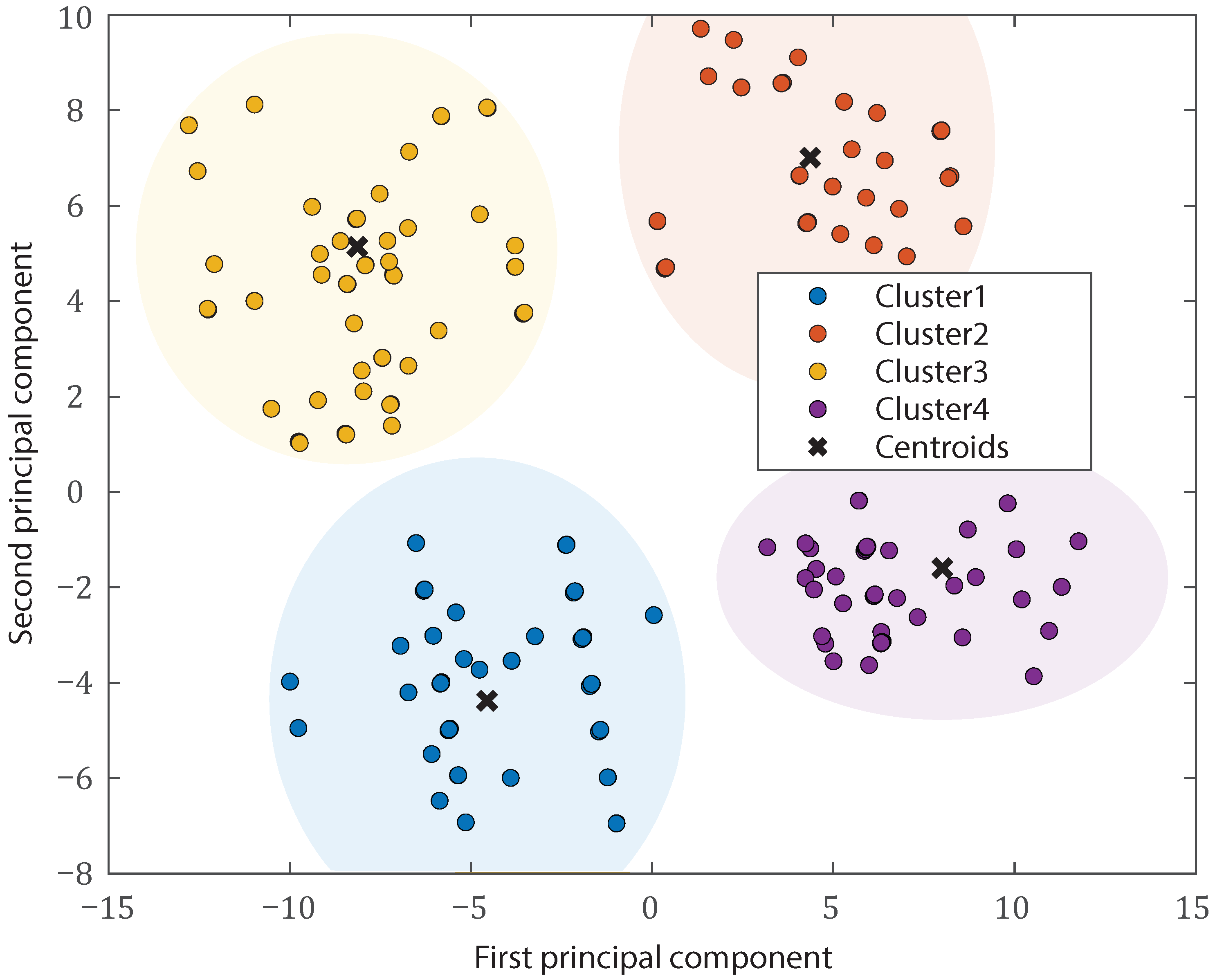{kind=link}
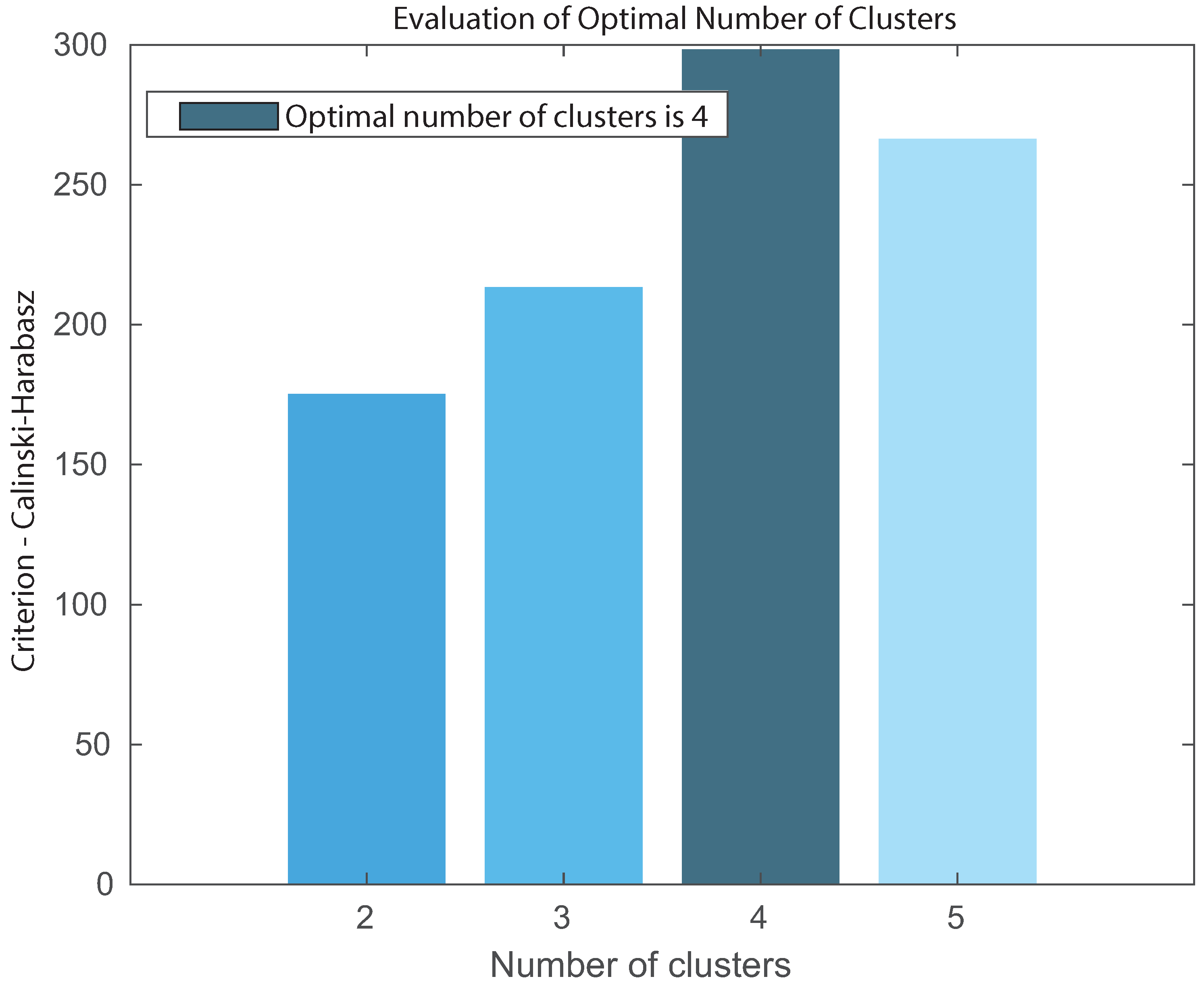{kind=link}
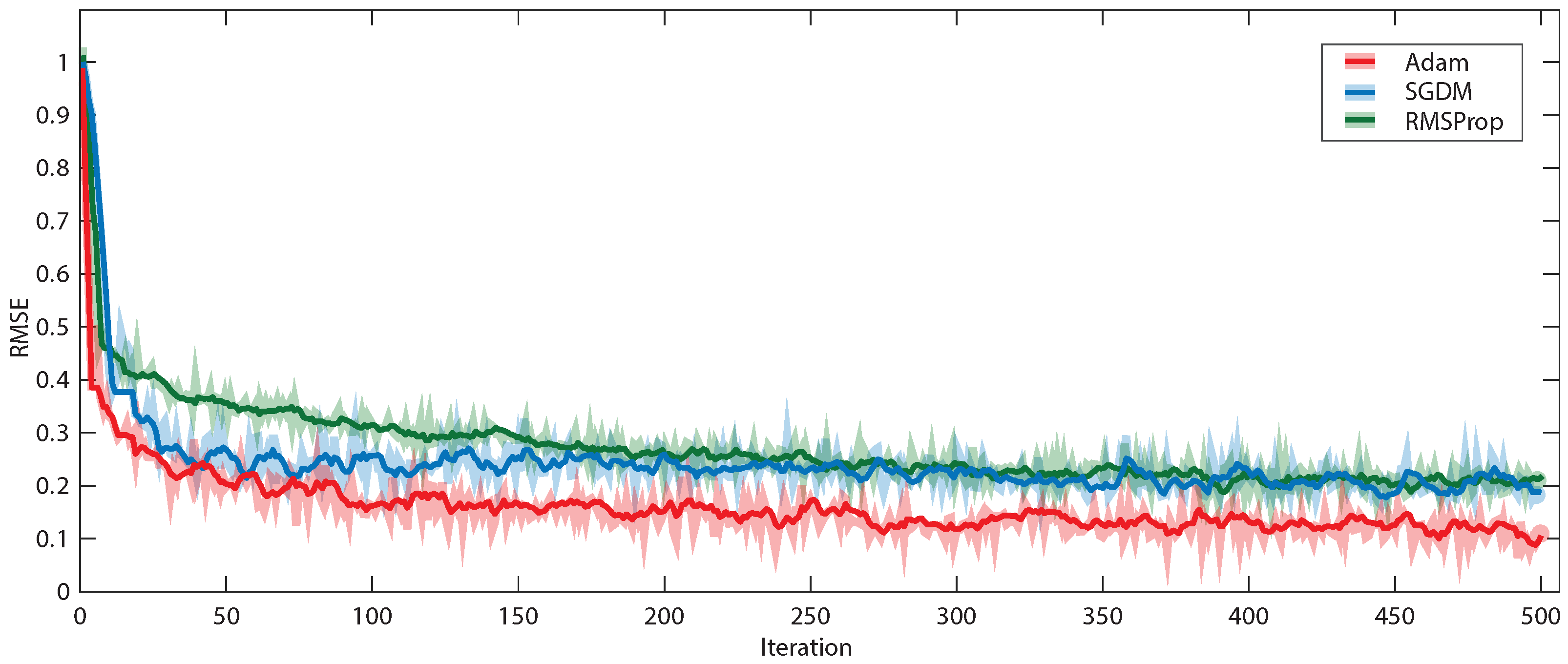{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}