
Renewable Energy Forecasting Based on Stacking Ensemble Model and Al-Biruni Earth Radius Optimization Algorithm

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Literature Review
2.1. Wind Speed Prediction Review
2.2. Solar Radiation Prediction Review
2.3. This Research
3. Data Sources and Methods
3.1. Wind Speed Data Source
3.2. Solar Radiation Data Source
3.3. Data Standardization
3.4. Feature Selection
3.5. Long Short-Term Memory (LSTM)
3.6. Bidirectional LSTM
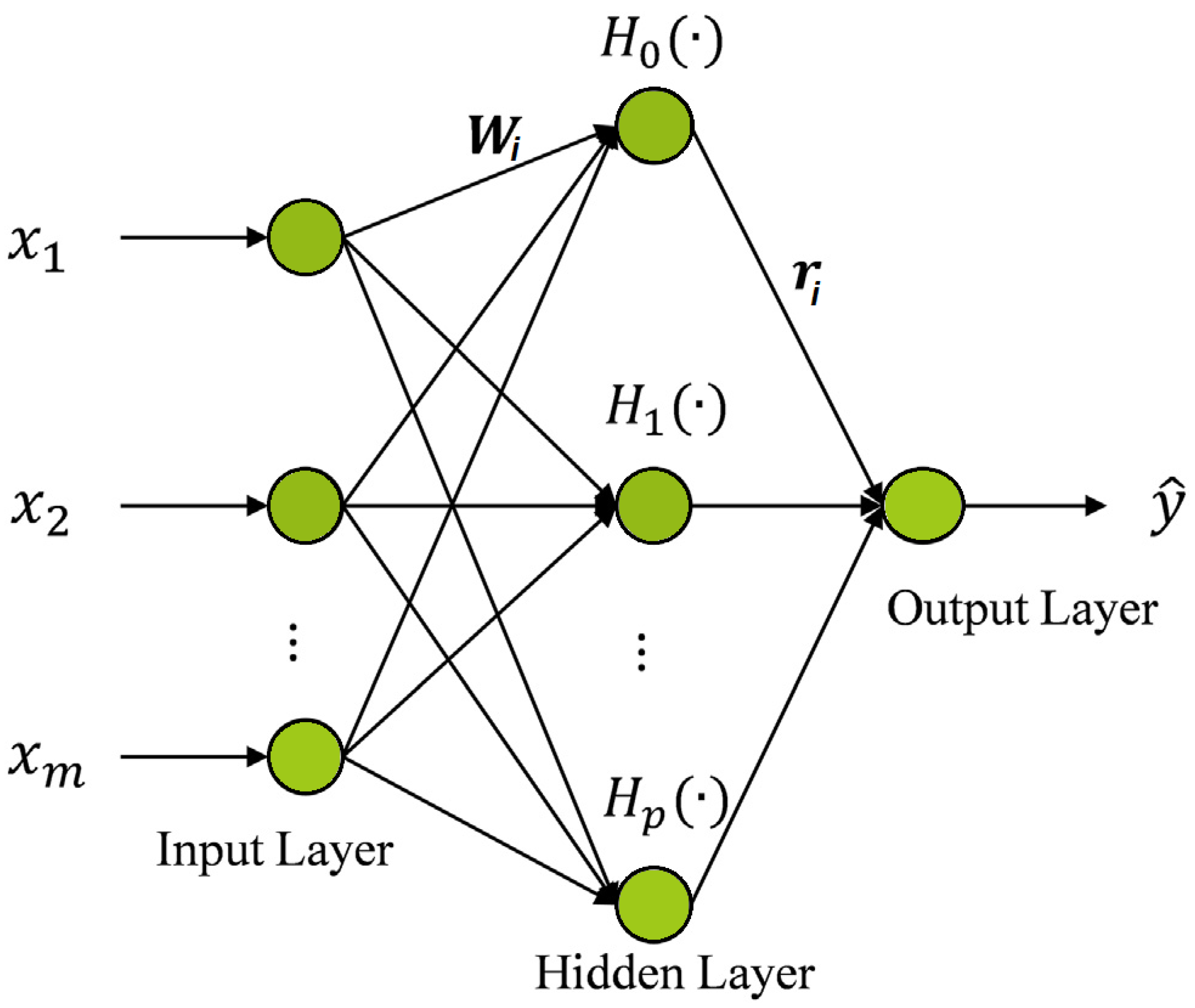
3.7. Hermite Neural Network
3.8. Al-Biruni Earth Radius (BER) Algorithm
3.8.1. Exploration Operation
3.8.2. Exploitation Operation
3.9. Genetic Algorithm (GA)
4. The Proposed Methodology
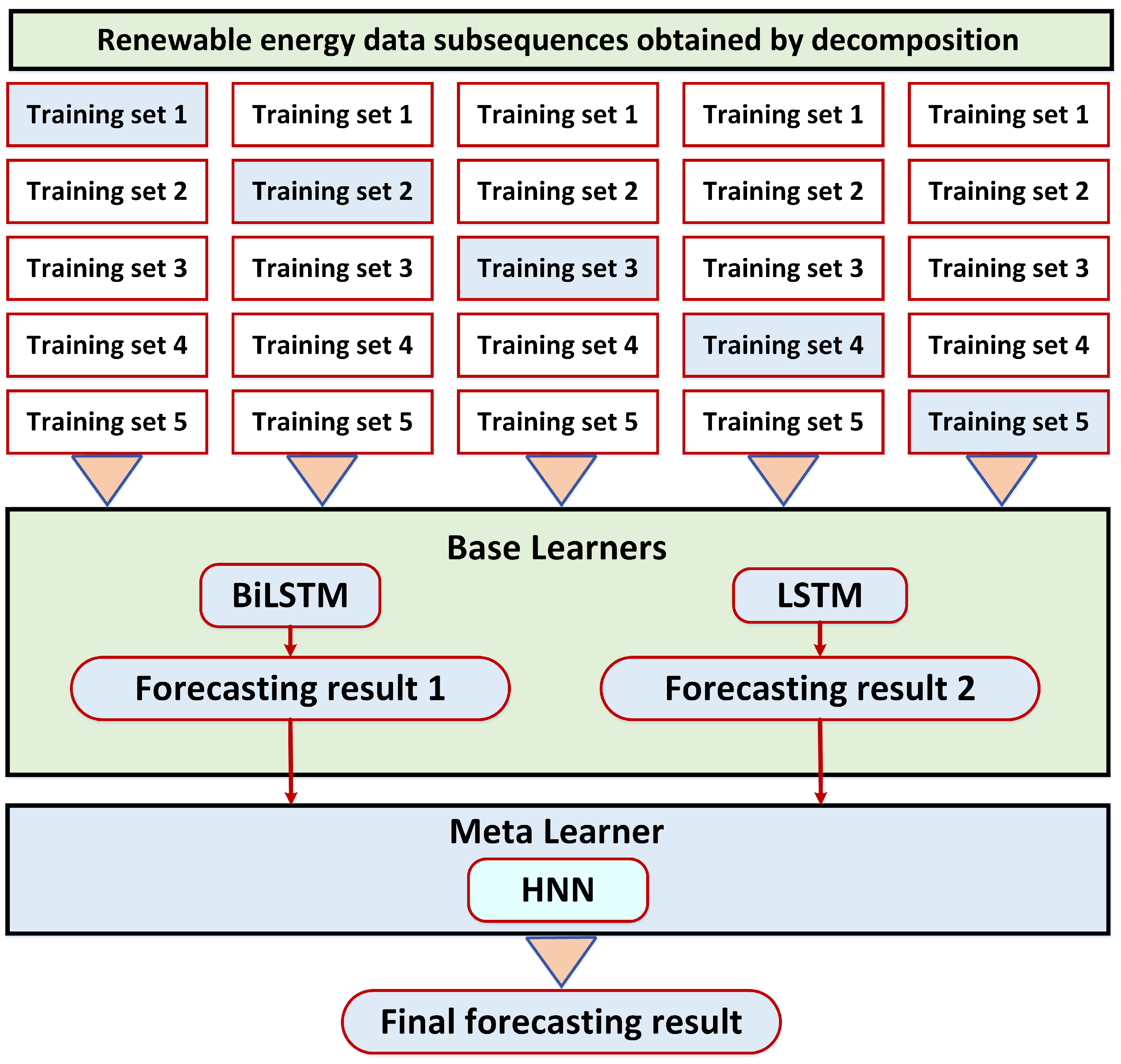
4.1. Stacking Ensemble Model
4.2. The Proposed Forecasting Model
- The dataset is preprocessed to avoid outliers and adjust the scale of the samples in all recordings.
- The dataset is divided into training and test sets with 5-fold cross-validation.
- The GABER-HNN model was used for training and forecasting based on the following steps:
- –
- The GABER and HNN parameters are initialized.
- –
- The fitness value is computed, and the results are shown. Within the iteration range, the parameters of the HNN are optimized, with the fitness value being the mean square error gained from training the HNN network and being updated.
- –
- The HNN is trained based on the optimal parameter combination.
- The optimized HNN is used to forecast the testing samples, and each sample’s result is saved for analysis.
- A statistical analysis is performed to measure the effectiveness and superiority of the proposed approach.
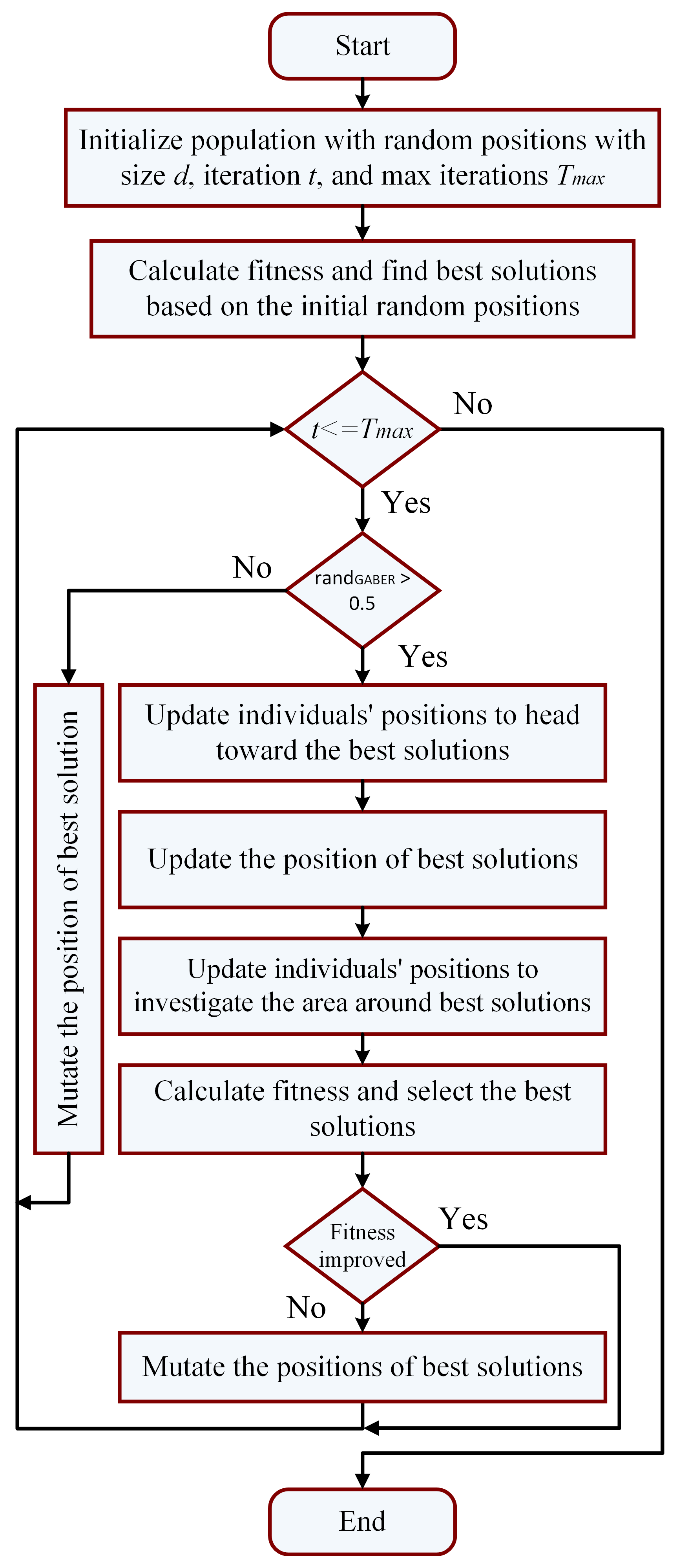
4.3. The Proposed Optimization Algorithm
| Algorithm 1: The proposed GABER algorithm |
|
4.4. GABER-Based Feature Selection
5. Experimental Results
5.1. Evaluation Metrics
5.2. Wind Speed Prediction Results
5.2.1. Feature Selection Results
5.2.2. Prediction Results
5.3. Solar Radiation Prediction Results
5.3.1. Feature Selection Results
5.3.2. Prediction Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Machine learning models | |
| ANN | Artificial neural network |
| ARMA | Auto-regressive moving average |
| AWNN | Adaptive wavelet neural network |
| BER | Al-Biruni earth radius algorithm |
| BiLSTM | Bidirectional long short-term memory |
| CNN | Convolutional neural network |
| DL | Deep learning |
| GA | Genetic algorithm |
| GABER | Genetic algorithm with Al-Biruni earth radius algorithm |
| GSA | Gravitational search algorithm |
| GWO | Grey wolf optimization algorithm |
| HNN | Hermite neural network |
| KNN | K-nearest neighbors |
| LSSVM | Least squares support vector machine |
| LSTM | Long short-term memory |
| MAE | Mean absolute error |
| MBE | Mean bias error |
| ML | Machine learning |
| NSE | Nash Sutcliffe Efficiency |
| PCA | Principle component analysis |
| PSO | Particle swarm optimization algorithm |
| RF | Random forest |
| RMSE | Root mean square error |
| RNN | Recurrent neural network |
| RRMSE | Relative root mean square error |
| SVM | Support vector machines |
| WOA | Whale optimization algorithm |
References
- Alkesaiberi, A.; Harrou, F.; Sun, Y. Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study. Energies 2022, 15, 2327. [Google Scholar] [CrossRef]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A Critical Review of Wind Power Forecasting Methods—Past, Present and Future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Treiber, N.A.; Heinermann, J.; Kramer, O. Wind Power Prediction with Machine Learning. In Computational Sustainability; Lässig, J., Kersting, K., Morik, K., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 13–29. [Google Scholar] [CrossRef]
- Mao, Y.; Shaoshuai, W. A review of wind power forecasting & prediction. In Proceedings of the 2016 International Conference on Probabilistic Methods Applied to Power Systems (PMAPS), Beijing, China, 16–20 October 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Ouyang, T.; Zha, X.; Qin, L.; He, Y.; Tang, Z. Prediction of wind power ramp events based on residual correction. Renew Energy 2019, 136, 781–792. [Google Scholar] [CrossRef]
- Ding, F.; Tian, Z.; Zhao, F.; Xu, H. An integrated approach for wind turbine gearbox fatigue life prediction considering instantaneously varying load conditions. Renew Energy 2018, 129, 260–270. [Google Scholar] [CrossRef]
- Han, S.; hui Qiao, Y.; Yan, J.; qian Liu, Y.; Li, L.; Wang, Z. Mid-to-long term wind and photovoltaic power generation prediction based on copula function and long short term memory network. Appl. Energy 2019, 239, 181–191. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Uzunoglu, M. A review of combined approaches for prediction of short-term wind speed and power. Renew. Sustain. Energy Rev. 2014, 34, 243–254. [Google Scholar] [CrossRef]
- Bouyeddou, B.; Harrou, F.; Saidi, A.; Sun, Y. An Effective Wind Power Prediction using Latent Regression Models. In Proceedings of the 2021 International Conference on ICT for Smart Society (ICISS), Bandung City, Indonesia, 2–4 August 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Yan, J.; Ouyang, T. Advanced wind power prediction based on data-driven error correction. Energy Convers. Manag. 2019, 180, 302–311. [Google Scholar] [CrossRef]
- Karakuş, O.; Kuruoğlu, E.E.; Altınkaya, M.A. One-day ahead wind speed/power prediction based on polynomial autoregressive model. IET Renew. Power Gener. 2017, 11, 1430–1439. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Rajagopalan, S.; Santoso, S. Wind power forecasting and error analysis using the autoregressive moving average modeling. In Proceedings of the 2009 IEEE Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–6, ISSN: 1932-5517. [Google Scholar] [CrossRef]
- Singh, P.K.; Singh, N.; Negi, R. Wind Power Forecasting Using Hybrid ARIMA-ANN Technique. In Advances in Intelligent Systems and Computing, Proceedings of the Ambient Communications and Computer Systems, Ajmer, India, 16–17 August 2019; Hu, Y.C., Tiwari, S., Mishra, K.K., Trivedi, M.C., Eds.; Springer: Singapore, 2019; pp. 209–220. [Google Scholar]
- Sayed, E.T.; Wilberforce, T.; Elsaid, K.; Rabaia, M.K.H.; Abdelkareem, M.A.; Chae, K.J.; Olabi, A.G. A critical review on environmental impacts of renewable energy systems and mitigation strategies: Wind, hydro, biomass and geothermal. Sci. Total. Environ. 2021, 766, 144505. [Google Scholar] [CrossRef]
- Araujo, J.M.S.d. Improvement of Coding for Solar Radiation Forecasting in Dili Timor Leste—A WRF Case Study. J. Power Energy Eng. 2021, 9, 7–20. [Google Scholar] [CrossRef]
- Ziane, A.; Necaibia, A.; Sahouane, N.; Dabou, R.; Mostefaoui, M.; Bouraiou, A.; Khelifi, S.; Rouabhia, A.; Blal, M. Photovoltaic output power performance assessment and forecasting: Impact of meteorological variables. Sol. Energy 2021, 220, 745–757. [Google Scholar] [CrossRef]
- Alawasa, K.M.; Al-Odienat, A.I. Power quality characteristics of residential grid-connected inverter ofphotovoltaic solar system. In Proceedings of the 2017 IEEE 6th International Conference on Renewable Energy Research and Applications (ICRERA), San Diego, CA, USA, 5–8 November 2017; pp. 1097–1101. [Google Scholar] [CrossRef]
- Gielen, D.; Boshell, F.; Saygin, D.; Bazilian, M.D.; Wagner, N.; Gorini, R. The role of renewable energy in the global energy transformation. Energy Strategy Rev. 2019, 24, 38–50. [Google Scholar] [CrossRef]
- Strielkowski, W.; Civín, L.; Tarkhanova, E.; Tvaronavičienė, M.; Petrenko, Y. Renewable Energy in the Sustainable Development of Electrical Power Sector: A Review. Energies 2021, 14, 8240. [Google Scholar] [CrossRef]
- Lay-Ekuakille, A.; Ciaccioli, A.; Griffo, G.; Visconti, P.; Andria, G. Effects of dust on photovoltaic measurements: A comparative study. Measurement 2018, 113, 181–188. [Google Scholar] [CrossRef]
- McGee, T.G.; Mori, K. The Management of Urbanization, Development, and Environmental Change in the Megacities of Asia in the Twenty-First Century. In Living in the Megacity: Towards Sustainable Urban Environments; Muramatsu, S., McGee, T.G., Mori, K., Eds.; Global Environmental Studies, Springer: Tokyo, Japan, 2021; pp. 17–33. [Google Scholar] [CrossRef]
- Wilson, G.A.; Bryant, R.L. Environmental Management: New Directions for the Twenty-First Century, 1st ed.; Routledge: London, UK, 2021. [Google Scholar] [CrossRef]
- Ismail, A.M.; Ramirez-Iniguez, R.; Asif, M.; Munir, A.B.; Muhammad-Sukki, F. Progress of solar photovoltaic in ASEAN countries: A review. Renew. Sustain. Energy Rev. 2015, 48, 399–412. [Google Scholar] [CrossRef]
- Al-Odienat, A.; Al-Maitah, K. A modified Active Frequency Drift Method for Islanding Detection. In Proceedings of the 2021 12th International Renewable Engineering Conference (IREC), Amman, Jordan, 14–15 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Srivastava, R.; Tiwari, A.N.; Giri, V.K. Prediction of Electricity Generation using Solar Radiation Forecasting Data. In Proceedings of the 2020 International Conference on Electrical and Electronics Engineering (ICE3), Gorakhpur, India, 14–15 February 2020; pp. 168–172. [Google Scholar] [CrossRef]
- Alawasa, K.M.; Al-Odienat, A.I. Power Quality Investigation of Single Phase Grid-connected Inverter of Photovoltaic System. J. Eng. Technol. Sci. 2019, 51, 597–614. [Google Scholar] [CrossRef]
- Bhaskar, K.; Singh, S.N. AWNN-Assisted Wind Power Forecasting Using Feed-Forward Neural Network. IEEE Trans. Sustain. Energy 2012, 3, 306–315. [Google Scholar] [CrossRef]
- Chen, N.; Qian, Z.; Nabney, I.T.; Meng, X. Wind Power Forecasts Using Gaussian Processes and Numerical Weather Prediction. IEEE Trans. Power Syst. 2014, 29, 656–665. [Google Scholar] [CrossRef]
- Azimi, R.; Ghofrani, M.; Ghayekhloo, M. A hybrid wind power forecasting model based on data mining and wavelets analysis. Energy Convers. Manag. 2016, 127, 208–225. [Google Scholar] [CrossRef]
- Yang, L.; He, M.; Zhang, J.; Vittal, V. Support-Vector-Machine-Enhanced Markov Model for Short-Term Wind Power Forecast. IEEE Trans. Sustain. Energy 2015, 6, 791–799. [Google Scholar] [CrossRef]
- Ti, Z.; Deng, X.W.; Zhang, M. Artificial Neural Networks based wake model for power prediction of wind farm. Renew. Energy 2021, 172, 618–631. [Google Scholar] [CrossRef]
- Saroha, S.; Aggarwal, S.K. Wind power forecasting using wavelet transforms and neural networks with tapped delay. CSEE J. Power Energy Syst. 2018, 4, 197–209. [Google Scholar] [CrossRef]
- Dowell, J.; Pinson, P. Very-Short-Term Probabilistic Wind Power Forecasts by Sparse Vector Autoregression. IEEE Trans. Smart Grid 2016, 7, 763–770. [Google Scholar] [CrossRef]
- Wu, J.L.; Ji, T.Y.; Li, M.S.; Wu, P.Z.; Wu, Q.H. Multistep Wind Power Forecast Using Mean Trend Detector and Mathematical Morphology-Based Local Predictor. IEEE Trans. Sustain. Energy 2015, 6, 1216–1223. [Google Scholar] [CrossRef]
- Demolli, H.; Dokuz, A.S.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Lekkas, D.; Price, G.D.; Jacobson, N.C. Using smartphone app use and lagged-ensemble machine learning for the prediction of work fatigue and boredom. Comput. Hum. Behav. 2022, 127, 107029. [Google Scholar] [CrossRef]
- Bi, J.W.; Han, T.Y.; Li, H. International tourism demand forecasting with machine learning models: The power of the number of lagged inputs. Tour. Econ. 2022, 28, 621–645. [Google Scholar] [CrossRef]
- Shang, H.L. Dynamic principal component regression for forecasting functional time series in a group structure. Scand. Actuar. J. 2020, 2020, 307–322. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, Y.; Infield, D.; Zhao, Y.; Han, S.; Yan, J. A Hybrid Forecasting Method for Wind Power Ramp Based on Orthogonal Test and Support Vector Machine (OT-SVM). IEEE Trans. Sustain. Energy 2017, 8, 451–457. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Yuan, Y.; Huang, Y.; Tan, Q. Short-term wind power prediction based on LSSVM–GSA model. Energy Convers. Manag. 2015, 101, 393–401. [Google Scholar] [CrossRef]
- Buturache, A.N.; Stancu, S. Wind Energy Prediction Using Machine Learning. Low Carbon Econ. 2021, 12, 1–21. [Google Scholar] [CrossRef]
- Liu, T.; Wei, H.; Zhang, K. Wind power prediction with missing data using Gaussian process regression and multiple imputation. Appl. Soft Comput. 2018, 71, 905–916. [Google Scholar] [CrossRef]
- Deng, Y.; Jia, H.; Li, P.; Tong, X.; Qiu, X.; Li, F. A Deep Learning Methodology Based on Bidirectional Gated Recurrent Unit for Wind Power Prediction. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 591–595. [Google Scholar] [CrossRef]
- Xiaoyun, Q.; Xiaoning, K.; Chao, Z.; Shuai, J.; Xiuda, M. Short-term prediction of wind power based on deep Long Short-Term Memory. In Proceedings of the 2016 IEEE PES Asia–Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 1148–1152. [Google Scholar] [CrossRef]
- Castangia, M.; Aliberti, A.; Bottaccioli, L.; Macii, E.; Patti, E. A compound of feature selection techniques to improve solar radiation forecasting. Expert Syst. Appl. 2021, 178, 114979. [Google Scholar] [CrossRef]
- Prado-Rujas, I.I.; García-Dopico, A.; Serrano, E.; Pérez, M.S. A Flexible and Robust Deep Learning-Based System for Solar Irradiance Forecasting. IEEE Access 2021, 9, 12348–12361. [Google Scholar] [CrossRef]
- Yan, K.; Shen, H.; Wang, L.; Zhou, H.; Xu, M.; Mo, Y. Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology. Information 2020, 11, 32. [Google Scholar] [CrossRef]
- Yen, C.F.; Hsieh, H.Y.; Su, K.W.; Yu, M.C.; Leu, J.S. Solar Power Prediction via Support Vector Machine and Random Forest. E3S Web Conf. 2018, 69, 01004. [Google Scholar] [CrossRef]
- Lee, W.; Kim, K.; Park, J.; Kim, J.; Kim, Y. Forecasting Solar Power Using Long-Short Term Memory and Convolutional Neural Networks. IEEE Access 2018, 6, 73068–73080. [Google Scholar] [CrossRef]
- Poolla, C.; Ishihara, A.K. Localized solar power prediction based on weather data from local history and global forecasts. In Proceedings of the 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC) (A Joint Conference of 45th IEEE PVSC, 28th PVSEC & 34th EU PVSEC), Waikoloa, HI, USA, 10–15 June 2018; pp. 2341–2345. [Google Scholar] [CrossRef]
- Han, J.; Park, W.K. A Solar Radiation Prediction Model Using Weather Forecast Data and Regional Atmospheric Data. In Proceedings of the 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC) (A Joint Conference of 45th IEEE PVSC, 28th PVSEC & 34th EU PVSEC), Waikoloa, Hi, USA, 10–15 June 2018; pp. 2313–2316. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Y.; Liu, H.; Ma, X.; Su, X.; Liu, Q. Day-Ahead Photovoltaic Power Forcasting Using Convolutional-LSTM Networks. In Proceedings of the 2021 3rd Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 26–29 March 2021; pp. 917–921. [Google Scholar] [CrossRef]
- Munir, M.A.; Khattak, A.; Imran, K.; Ulasyar, A.; Khan, A. Solar PV Generation Forecast Model Based on the Most– Effective Weather Parameters. In Proceedings of the 2019 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Swat, Pakistan, 24–25 July 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Obiora, C.N.; Ali, A.; Hasan, A.N. Estimation of Hourly Global Solar Radiation Using Deep Learning Algorithms. In Proceedings of the 2020 11th International Renewable Energy Congress (IREC), Hammamet, Tunisia, 29–31 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- de Guia, J.D.; Concepcion, R.S.; Calinao, H.A.; Alejandrino, J.; Dadios, E.P.; Sybingco, E. Using Stacked Long Short Term Memory with Principal Component Analysis for Short Term Prediction of Solar Irradiance based on Weather Patterns. In Proceedings of the 2020 IEEE region 10 conference (TENCON), Osaka, Japan, 16–19 November 2020; pp. 946–951. [Google Scholar] [CrossRef]
- Zou, M.; Fang, D.; Harrison, G.; Djokic, S. Weather Based Day-Ahead and Week-Ahead Load Forecasting using Deep Recurrent Neural Network. In Proceedings of the 2019 IEEE 5th International forum on Research and Technology for Society and Industry (RTSI), Florence, Italy, 9–12 September 2019; pp. 341–346, ISSN: 2687-6817. [Google Scholar] [CrossRef]
- Tiwari, S.; Sabzehgar, R.; Rasouli, M. Short Term Solar Irradiance Forecast based on Image Processing and Cloud Motion Detection. In Proceedings of the 2019 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 7–8 February 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Fedesoriano, F. Wind Speed Prediction Dataset. 2019. Available online: https://www.kaggle.com/datasets/fedesoriano/wind-speed-prediction-dataset (accessed on 1 November 2022).
- Dodur, A. Solar Radiation Prediction. 2019. Available online: https://www.kaggle.com/code/alexanderthestudent/solar-radiation-prediction (accessed on 1 November 2022).
- Huang, H.; Jia, R.; Shi, X.; Liang, J.; Dang, J. Feature selection and hyper parameters optimization for short-term wind power forecast. Appl. Intell. 2021, 51, 6752–6770. [Google Scholar] [CrossRef]
- Edelmann, D.; Móri, T.F.; Székely, G.J. On relationships between the Pearson and the distance correlation coefficients. Stat. Probab. Lett. 2021, 169, 108960. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl.-Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Khodayar, M.; Liu, G.; Wang, J.; Khodayar, M.E. Deep learning in power systems research: A review. CSEE J. Power Energy Syst. 2021, 7, 209–220. [Google Scholar] [CrossRef]
- Mishra, M.; Nayak, J.; Naik, B.; Abraham, A. Deep learning in electrical utility industry: A comprehensive review of a decade of research. Eng. Appl. Artif. Intell. 2020, 96, 104000. [Google Scholar] [CrossRef]
- Ozcanli, A.K.; Yaprakdal, F.; Baysal, M. Deep learning methods and applications for electrical power systems: A comprehensive review. Int. J. Energy Res. 2020, 44, 7136–7157. [Google Scholar] [CrossRef]
- Zhen, H.; Niu, D.; Yu, M.; Wang, K.; Liang, Y.; Xu, X. A Hybrid Deep Learning Model and Comparison for Wind Power Forecasting Considering Temporal-Spatial Feature Extraction. Sustainability 2020, 12, 9490. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Atef, S.; Eltawil, A.B. Assessment of stacked unidirectional and bidirectional long short-term memory networks for electricity load forecasting. Electr. Power Syst. Res. 2020, 187, 106489. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. Wind power forecasting based on stacking ensemble model, decomposition and intelligent optimization algorithm. Neurocomputing 2021, 462, 169–184. [Google Scholar] [CrossRef]
- El Sayed, M.; Abdelhamid, A.A.; Ibrahim, A.; Mirjalili, S.; Khodadad, N.; Alhussan, A.A.; Khafaga, D.S. Al-Biruni Earth Radius (BER) Metaheuristic Search Optimization Algorithm. Comput. Syst. Sci. Eng. 2023, 45, 1917–1934. [Google Scholar] [CrossRef]
- Kim, D.G.; Choi, J.Y. Optimization of Design Parameters in LSTM Model for Predictive Maintenance. Appl. Sci. 2021, 11, 6450. [Google Scholar] [CrossRef]
- Sivanandam, S.; Deepa, S. Genetic Algorithm Optimization Problems. In Introduction to Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008; pp. 165–209. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.D.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel Meta-Heuristic Algorithm for Feature Selection, Unconstrained Functions and Engineering Problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- Khafaga, D.S.; Alhussan, A.A.; El-Kenawy, E.S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Solving Optimization Problems of Metamaterial and Double T-Shape Antennas Using Advanced Meta-Heuristics Algorithms. IEEE Access 2022, 10, 74449–74471. [Google Scholar] [CrossRef]
- Alhussan, A.A.; Khafaga, D.S.; El-Kenawy, E.S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Pothole and Plain Road Classification Using Adaptive Mutation Dipper Throated Optimization and Transfer Learning for Self Driving Cars. IEEE Access 2022, 10, 84188–84211. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Mirjalili, S.; Abdelhamid, A.A.; Ibrahim, A.; Khodadadi, N.; Eid, M.M. Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users. Mathematics 2022, 10, 2912. [Google Scholar] [CrossRef]
- El-kenawy, E.S.M.; Albalawi, F.; Ward, S.A.; Ghoneim, S.S.M.; Eid, M.M.; Abdelhamid, A.A.; Bailek, N.; Ibrahim, A. Feature Selection and Classification of Transformer Faults Based on Novel Meta-Heuristic Algorithm. Mathematics 2022, 10, 3144. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
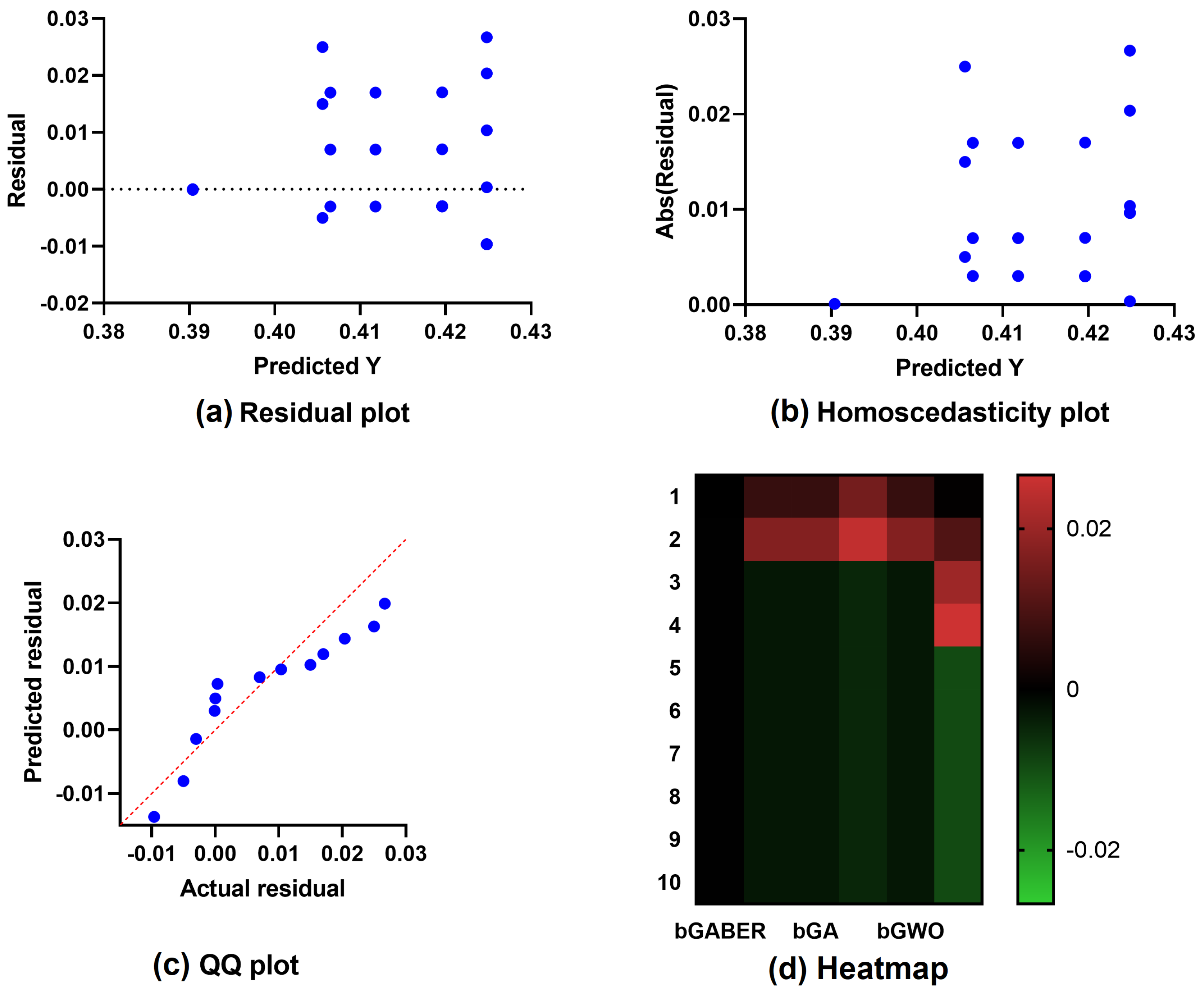{kind=link}
{kind=link}
{kind=link}
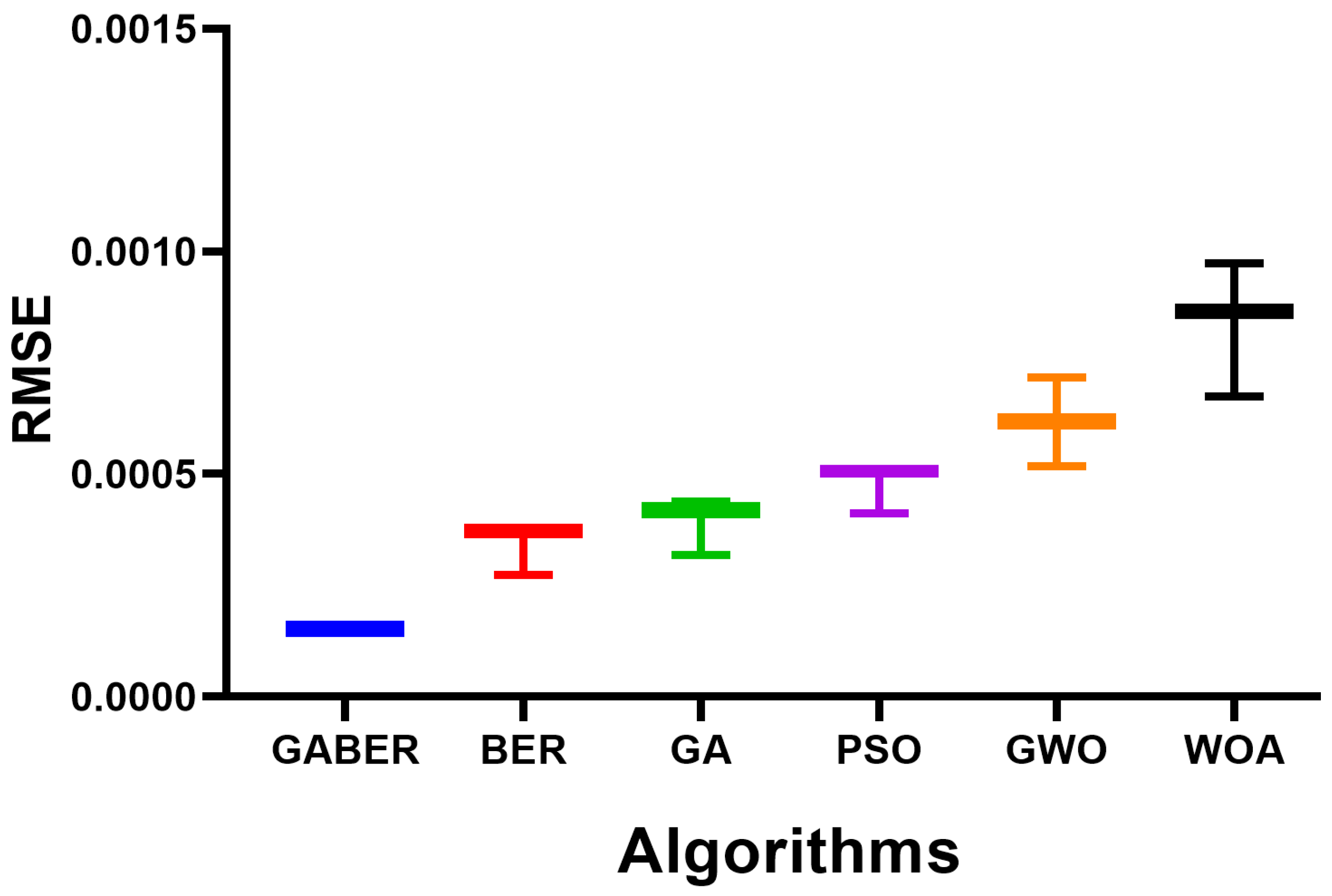{kind=link}
| Parameter | Values |
|---|---|
| # Agents | 10 |
| # Iterations | 80 |
| # Repetitions | 20 |
| Mutation probability | 0.5 |
| Exploration percentage | 70 |
| k (decreases from 2 to 0) | 1 |
| Algorithm | Parameter | Values |
|---|---|---|
| GA | Cross over | 0.9 |
| Mutation ratio | 0.1 | |
| Selection mechanism | Roulette wheel | |
| Iterations | 80 | |
| Agents | 10 | |
| PSO | Acceleration constants | [2, 2] |
| Inertia , | [0.6, 0.9] | |
| Particles | 10 | |
| Iterations | 80 | |
| GWO | a | 2 to 0 |
| Iterations | 80 | |
| Wolves | 10 | |
| WOA | r | [0, 1] |
| Iterations | 80 | |
| Whales | 10 | |
| a | 2 to 0 |
| Metric | Formula |
|---|---|
| Best Fitness | |
| Worst Fitness | |
| Average Error | |
| Average Fitness | |
| Average fitness size | |
| Standard deviation |
| Metric | Formula |
|---|---|
| RMSE | |
| RRMSE | |
| MAE | |
| MBE | |
| NSE | |
| WI | |
| r |
| bGABER | bBER | bGA | bPSO | bGWO | bWOA | |
|---|---|---|---|---|---|---|
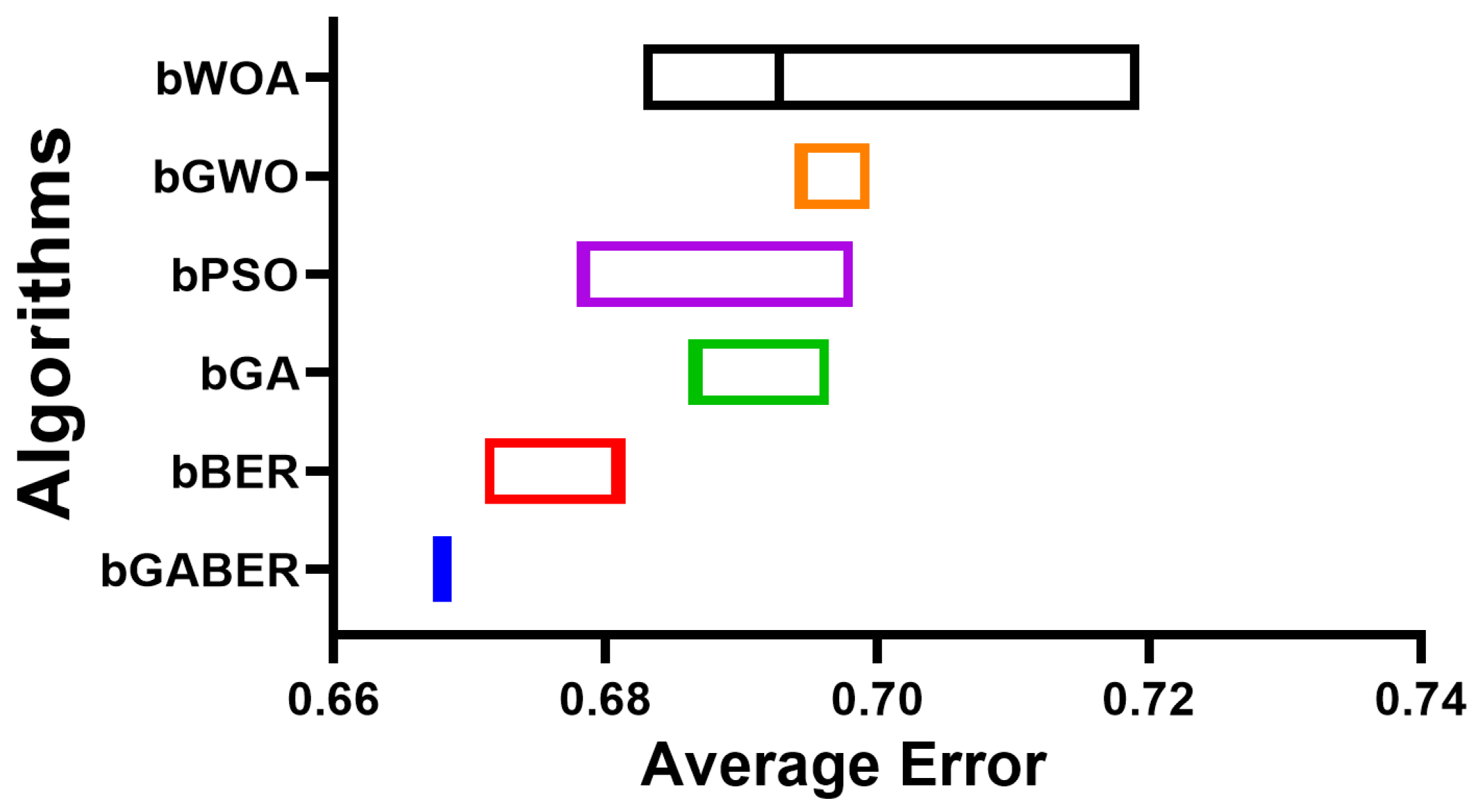
| Average Error | 0.6680 | 0.6811 | 0.6865 | 0.6782 | 0.6942 | 0.6928 |
| Average Select Size | 0.8683 | 0.9617 | 0.9700 | 0.9700 | 0.9784 | 0.97003 |
| Average Fitness | 0.8043 | 0.8523 | 0.8575 | 0.8494 | 0.8652 | 0.86379 |
| Best Fitness | 0.7696 | 0.7888 | 0.7792 | 0.7792 | 0.7984 | 0.7984 |
| Worst Fitness | 0.9114 | 0.8946 | 0.9234 | 0.9234 | 0.9618 | 1.06756 |
| Std Fitness | 0.3233 | 0.3261 | 0.3373 | 0.3350 | 0.3377 | 0.3613 |
| Processing Time (S) | 13.513 | 14.336 | 14.896 | 14.456 | 14.82 | 15.132 |
| SS | DF | MS | F (DFn, DFd) | p Value | |
|---|---|---|---|---|---|
| Treatment | 0.005468 | 5 | 0.001094 | F (5, 54) = 41.67 | p < 0.0001 |
| Residual | 0.001417 | 54 | 0.00002624 | ||
| Total | 0.006885 | 59 |
| bGABER | bBER | bGA | bPSO | bGWO | bWOA | |
|---|---|---|---|---|---|---|
| Theoretical median | 0 | 0 | 0 | 0 | 0 | 0 |
| Actual median | 0.668 | 0.681 | 0.686 | 0.678 | 0.694 | 0.692 |
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Wilcoxon Test | ||||||
| Sum of signed ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of +ve ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of −ve ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p value (two tailed) | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| Exact or estimate? | Exact | Exact | Exact | Exact | Exact | Exact |
| Significant? | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.668 | 0.6811 | 0.6865 | 0.6782 | 0.6942 | 0.6928 |
| RMSE | MAE | MBE | r | RRMSE | NSE | WI | ||
|---|---|---|---|---|---|---|---|---|
| LSTM | 0.0095 | 0.0069 | −0.0006 | 0.9605 | 0.9226 | 19.1545 | 0.9218 | 0.8868 |
| BILSTM | 0.0031 | 0.0020 | −0.0002 | 0.9952 | 0.9904 | 8.3202 | 0.9903 | 0.9630 |
| Non-Optimized HNN Ensemble | 0.0011 | 0.0007 | −0.0001 | 0.9994 | 0.9989 | 3.3862 | 0.9989 | 0.9885 |
| Proposed Optimized HNN Ensemble | 0.0003 | 0.0003 | 0.0000 | 0.9997 | 0.9995 | 2.2035 | 0.9995 | 0.9922 |
| GABER | BER | GA | PSO | GWO | WOA | |
|---|---|---|---|---|---|---|
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Range | 0.00002 | 0.00014 | 0.0001 | 0.0002 | 0.000124 | 0.0001 |
| Minimum | 0.000333 | 0.000457 | 0.00052 | 0.000599 | 0.000785 | 0.000871 |
| Mean | 0.000343 | 0.000551 | 0.0005924 | 0.000699 | 0.0008039 | 0.0009126 |
| Maximum | 0.000353 | 0.000597 | 0.00062 | 0.000799 | 0.000909 | 0.000971 |
| Median | 0.000343 | 0.000557 | 0.000598 | 0.000699 | 0.000785 | 0.000912 |
| 75% Percentile | 0.000343 | 0.000557 | 0.000598 | 0.000699 | 0.0008013 | 0.000922 |
| 25% Percentile | 0.000343 | 0.000557 | 0.000598 | 0.000699 | 0.000785 | 0.0008885 |
| Std. Deviation | 0.000004714 | 0.00003534 | 0.00002636 | 0.00004714 | 0.0000422 | 0.00003011 |
| Std. Error of Mean | 0.000001491 | 0.00001118 | 0.000008336 | 0.00001491 | 0.00001335 | 0.000009522 |
| Sum | 0.00343 | 0.00551 | 0.005924 | 0.00699 | 0.008039 | 0.009126 |
| SS | DF | MS | F (DFn, DFd) | p-Value | |
|---|---|---|---|---|---|
| Treatment | 0.000002024 | 5 | F (5, 54) = 353.3 | p < 0.0001 | |
| Residual | 54 | ||||
| Total | 0.000002086 | 59 |
| GABER | BER | GA | PSO | GWO | WOA | |
|---|---|---|---|---|---|---|
| Theoretical median | 0 | 0 | 0 | 0 | 0 | 0 |
| Actual median | 0.000343 | 0.000557 | 0.000598 | 0.000699 | 0.000785 | 0.000912 |
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Sum of signed ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of +ve ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of −ve ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p-value | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| Exact or estimate? | Exact | Exact | Exact | Exact | Exact | Exact |
| Significant? | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.000343 | 0.000557 | 0.000598 | 0.000699 | 0.000785 | 0.000912 |
| bGABER | bBER | bGA | bPSO | bGWO | bWOA | |
|---|---|---|---|---|---|---|
| Average Error | 0.3904 | 0.4035 | 0.4088 | 0.4006 | 0.4166 | 0.4152 |
| Average Select Size | 0.5907 | 0.6841 | 0.6924 | 0.6924 | 0.7008 | 0.6924 |
| Average Fitness | 0.5267 | 0.5746 | 0.5799 | 0.5718 | 0.5876 | 0.5862 |
| Best Fitness | 0.4920 | 0.5112 | 0.5016 | 0.5016 | 0.5208 | 0.5208 |
| Worst Fitness | 0.6338 | 0.6169 | 0.6458 | 0.6458 | 0.6842 | 0.7899 |
| Std Fitness | 0.0457 | 0.0485 | 0.0597 | 0.0574 | 0.0600 | 0.0837 |
| Processing Time (s) | 7.783 | 8.606 | 9.166 | 8.726 | 9.09 | 9.402 |
| SS | DF | MS | F (DFn, DFd) | p-Value | |
|---|---|---|---|---|---|
| Treatment | 0.007312 | 5 | 0.001462 | F (5, 54) = 19.40 | p < 0.0001 |
| Residual | 0.00407 | 54 | 0.00007538 | ||
| Total | 0.01138 | 59 |
| bGABER | bBER | bGA | bPSO | bGWO | bWOA | |
|---|---|---|---|---|---|---|
| Theoretical median | 0 | 0 | 0 | 0 | 0 | 0 |
| Actual median | 0.3904 | 0.4035 | 0.4088 | 0.4006 | 0.4166 | 0.4152 |
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Wilcoxon Signed Rank Test | ||||||
| Sum of signed ranks (W) | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of +ve ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of −ve ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p-value (two tailed) | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| Exact or estimate? | Exact | Exact | Exact | Exact | Exact | Exact |
| Significant? | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.3904 | 0.4035 | 0.4088 | 0.4006 | 0.4166 | 0.4152 |
| RMSE | MAE | MBE | r | RRMSE | NSE | WI | ||
|---|---|---|---|---|---|---|---|---|
| LSTM | 0.00423 | 0.00307 | −0.00026 | 0.96085 | 0.92293 | 15.46608 | 0.92217 | 0.88721 |
| BILSTM | 0.00138 | 0.00090 | −0.00008 | 0.99552 | 0.99073 | 4.95515 | 0.99068 | 0.96332 |
| Non-Optimized HNN Ensemble | 0.00049 | 0.00031 | −0.00003 | 0.99980 | 0.99926 | 3.23935 | 0.99925 | 0.98883 |
| Proposed Optimized HNN Ensemble | 0.00015 | 0.00011 | 0.00001 | 0.99990 | 0.99986 | 0.91144 | 0.99985 | 0.99260 |
| GABER | BER | GA | PSO | GWO | WOA | |
|---|---|---|---|---|---|---|
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Range | 0 | 0.0001 | 0.00012 | 0.0001 | 0.0002 | 0.0003 |
| Maximum | 0.000153 | 0.000373 | 0.000439 | 0.000512 | 0.000717 | 0.000974 |
| Mean | 0.000153 | 0.0003614 | 0.000411 | 0.0004941 | 0.000617 | 0.000854 |
| Minimum | 0.000153 | 0.000273 | 0.000319 | 0.000412 | 0.000517 | 0.000674 |
| Median | 0.000153 | 0.000373 | 0.000419 | 0.000512 | 0.000617 | 0.000874 |
| 75% Percentile | 0.000153 | 0.000373 | 0.000419 | 0.000512 | 0.000617 | 0.000874 |
| 25% Percentile | 0.000153 | 0.000369 | 0.000419 | 0.0004923 | 0.000617 | 0.000849 |
| Std. Deviation | 0 | 0.00003146 | 0.00003293 | 0.00003806 | 0.00004714 | 0.00007888 |
| Std. Error of Mean | 0 | 0.00000995 | 0.00001041 | 0.00001204 | 0.00001491 | 0.00002494 |
| Sum | 0.00153 | 0.003614 | 0.00411 | 0.004941 | 0.00617 | 0.00854 |
| SS | DF | MS | F (DFn, DFd) | p Value | |
|---|---|---|---|---|---|
| Treatment | 0.000002846 | 5 | F (5, 54) = 285.4 | p < 0.0001 | |
| Residual | 54 | ||||
| Total | 0.000002954 | 59 |
| GABER | BER | GA | PSO | GWO | WOA | |
|---|---|---|---|---|---|---|
| Theoretical median | 0 | 0 | 0 | 0 | 0 | 0 |
| Actual median | 0.000153 | 0.000373 | 0.000419 | 0.000512 | 0.000617 | 0.000874 |
| Number of values | 10 | 10 | 10 | 10 | 10 | 10 |
| Wilcoxon Signed Rank Test | ||||||
| Sum of signed ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of +ve ranks | 55 | 55 | 55 | 55 | 55 | 55 |
| Sum of −ve ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p-value (two tailed) | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 |
| Exact or estimate? | Exact | Exact | Exact | Exact | Exact | Exact |
| Significant? | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.000153 | 0.000373 | 0.000419 | 0.000512 | 0.000617 | 0.000874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alghamdi, A.A.; Ibrahim, A.; El-Kenawy, E.-S.M.; Abdelhamid, A.A. Renewable Energy Forecasting Based on Stacking Ensemble Model and Al-Biruni Earth Radius Optimization Algorithm. Energies 2023, 16, 1370. https://doi.org/10.3390/en16031370
Alghamdi AA, Ibrahim A, El-Kenawy E-SM, Abdelhamid AA. Renewable Energy Forecasting Based on Stacking Ensemble Model and Al-Biruni Earth Radius Optimization Algorithm. Energies. 2023; 16(3):1370. https://doi.org/10.3390/en16031370
Chicago/Turabian StyleAlghamdi, Abdulrahman A., Abdelhameed Ibrahim, El-Sayed M. El-Kenawy, and Abdelaziz A. Abdelhamid. 2023. "Renewable Energy Forecasting Based on Stacking Ensemble Model and Al-Biruni Earth Radius Optimization Algorithm" Energies 16, no. 3: 1370. https://doi.org/10.3390/en16031370
APA StyleAlghamdi, A. A., Ibrahim, A., El-Kenawy, E.-S. M., & Abdelhamid, A. A. (2023). Renewable Energy Forecasting Based on Stacking Ensemble Model and Al-Biruni Earth Radius Optimization Algorithm. Energies, 16(3), 1370. https://doi.org/10.3390/en16031370