1. Introduction
Power and distribution transformers are critical and costly components in any power system grid. They play a vital role in ensuring the reliability of the power grid by transferring electrical energy from one voltage level to another. The overall health condition of these transformers is mainly dependent on the state of their insulation system, and especially the paper insulation [
1]. Overloading or internal faults during operation can expedite the aging process of the transformer paper insulation. Hence, monitoring the transformer insulation paper’s health condition is critical to ensure its satisfactory performance, efficiency, and longevity. To ensure the stability and reliability of the power system, it is crucial to monitor, maintain, diagnose, and upgrade transformers regularly. This helps prevent costly accidents and damage, extend transformer life, increase grid reliability, and reduce maintenance costs [
2,
3,
4]. Accurately evaluating the condition of power transformers is essential for creating and sustaining a highly reliable power system [
5,
6].
One key parameter in assessing the health condition of the transformer paper insulation is the concentration of furan compounds. A correlation between the level of furan in transformer oil and the degree of polymerization (DP) has been reported [
7,
8,
9]. Moreover, many studies have correlated the remaining lifespan of transformers with the condition of the oil–paper insulation system [
10,
11,
12]. Therefore, measuring the amount of furan in transformer oil can effectively assess the transformer’s paper health condition. Thus, furan measurements offer a non-intrusive way to estimate the degradation of the paper insulation instead of measuring the DP and tensile strength (TS) of cellulose insulation paper, which requires taking a sample from the paper itself. This non-intrusive method is not only less invasive but also reduces the need for transformers to be taken out of service, which can be costly and disruptive to utilities.
Predicting furan concentrations can reduce the overall transformer maintenance cost. This is mainly due to the fact that the furan testing facilities may not be readily available for some countries, and hence testing one oil sample can be expensive [
13]. This highlights the importance of developing alternative methods, such as machine learning (ML) algorithms, to predict furan concentration.
ML algorithms have seen significant advancements in recent years, proving efficacy in numerous applications. Previous studies have applied intelligent techniques to monitoring and diagnosing transformers. Most of these studies use intelligent techniques to analyze and predict dissolved gas, oil tests, or transformer health [
5,
6]. Jahromi et al. presented a practical approach to implementing the computed HI, which can serve as a basis for developing a capital plan to replace assets nearing the end of their lifespan [
14]. This method has proven to be an effective tool for assessing the likelihood of transformer failure and determining the remaining lifespan of the equipment. Another study developed an AI-based health index approach to accurately assess power transformer conditions while handling data uncertainty [
15]. A hybrid AI system for the prognostic health management of power transformers that integrates various algorithms and models for diagnostics, health monitoring, and maintenance optimization has also been introduced.
In a different study, a general regression neural network (GRNN) was created to evaluate the health index (HI) of four different conditions (very poor, poor, fair, and good). The transformer’s health condition was predicted with 83% accuracy using six crucial inputs, namely the oil’s total dissolved combustible gas, furan levels, dielectric strength, acidity, water content, and dissipation factor [
16]. Alqudsi et al. focused on utilizing ML to predict the insulation health condition of medium voltage distribution transformers based on oil test results. The study demonstrated the effectiveness of ML algorithms by testing large databases of transformer oil samples. The research highlights the potential cost reduction in transformer asset management using ML prediction models [
17]. Different ML algorithms have been proven to be beneficial for the assessment of the transformer health index. A study compared seven different ML approaches and found that random forest has the highest predicting accuracy [
15]. Another work employed the k-Nearest Neighbors (kNN) algorithm to classify distribution transformers’ health index, and achieved good accuracy [
18].
Leveraging ML techniques to predict furan concentrations in transformers can provide a more economical and accessible approach to monitoring the health of transformer paper insulation. Thus, some studies have focused on predicting such expensive tests as furan concentrations. Ghunem et al. used an artificial neural network to predict furan content based on input parameters such as carbon monoxide, carbon dioxide, water content, acidity, and breakdown voltage [
19]. The results showed an average prediction accuracy of 90%. Another paper took a similar approach and utilized a neural network with stepwise regression to predict furan content in transformer oil using oil quality parameters and dissolved gases as inputs. The model achieved around 90% prediction accuracy [
20]. Mahdjoubi et al. used a different methodology and used least squares support vector machines (LS-SVM) to predict furan in power transformers [
21]. In this work, dissolved gases (carbon monoxide and carbon dioxide) were used as input variables. This approach was proven to reduce testing time and provides a good estimation of results validated by experimental tests. Another work investigated using dissolved gas analysis, breakdown voltage, oil properties, and furan compounds to estimate the degree of polymerization of transformer insulating paper, which indicates paper aging and remaining transformer life [
22]. Furan content in transformer oil can also be estimated via a fuzzy logic approach using UV-Vis spectroscopy, which was developed in [
23].
This paper investigates the prediction of furan using two distinct datasets, Utility A and Utility B, representing different geographical locations. To ensure the generalizability of the model, three scenarios are proposed based on common features between the two datasets. In the first scenario, round-robin cross-validation was employed by training on 75% of the data from Utility A and testing on the remaining 25%, with results averaged across all iterations. In the second scenario, the model was trained on the entirety of Utility A and tested on Utility B. In the third scenario, the Utility A and Utility B datasets were merged to create a new combined dataset, which was used for round-robin cross-validation similar to the first scenario. These three scenarios are explored to establish the robustness and generalizability of the furan prediction model across different geographical locations.
In the context of learning-based problems, the primary objective is to identify a model that can accurately predict the output. Relying solely on a single model may not yield the best results, as its accuracy is not guaranteed. To overcome this limitation, a stacked regression model is proposed to generate a final, more robust model. This stacked generalized model offers a more comprehensive and reliable approach to predicting outputs by incorporating a diverse range of models. This can enhance the accuracy and effectiveness of learning-based systems.
Given the shortcomings of the previous works, the difference between the scientific contributions of this paper and the other ones can be summarized as follows:
To validate the model, a method known as round-robin cross-validation is employed, which offers significant advantages over traditional training and testing approaches. Unlike the conventional method, where a limited number of new cases is used for testing, cross-validation allows us to utilize all available data for training and testing the regression model concurrently. This comprehensive approach enables us to assess the algorithm’s performance at multiple stages, such as before and after each data filtration step. By doing so, we gain valuable insights into the influence of each filtering process on the results produced by the classifier. This approach provides a better understanding of the model’s effectiveness and improves our ability to make informed decisions.
2. Materials and Methods
2.1. Datasets
This study used two distinct datasets: Utility A and Utility B. The Utility A dataset includes maintenance records for 730 power transformers from a local Gulf region utility. The dataset encompasses test results of dissolved gas analysis (DGA) and oil quality tests, such as breakdown voltage, water content, acidity, and furan content. The transformers in this dataset were produced between 1960 and 2011, with power ratings ranging from 12.5 to 40 MVA and voltage levels of 66/11 kV. Utility B comprises 327 transformer oil samples with a voltage level of 33/11 kV and a rating of 15 MVA. As some oil test results in Utility A are absent in Utility B, only the common features between these two datasets were considered in this study. For instance, CO, CO
2, color, and dissipation factor data do not exist in Utility B and were therefore excluded from Utility A to construct a comparable model. Notably, both datasets differ in geographical location and were obtained from two different countries.
Table 1 shows nine common features between Utility A and Utility B that were used in this study, along with their corresponding index.
2.2. Data Pre-Processing
The pre-processing of the data was divided into two main steps to ensure the quality of the data used for regression. In the first step, outliers were identified and removed, as they can significantly impact a regressor’s performance and lead to inaccurate results. Each feature’s mean and standard deviation were computed to identify and remove outliers, and any observation whose absolute difference from the mean exceeded three times the standard deviation was removed. In the second pre-processing step, the data were normalized to ensure that all features had the same significance. This was important because features with larger values can dominate the learning process, leading to biased results. A standard scaling method was employed, which involved subtracting the mean from each feature and dividing by the standard deviation. This resulted in a feature with a mean of zero and a standard deviation of one, which ensured that all features had equal weight in the learning process and reduced the impact of any outliers that were not removed in the first step.
2.3. The Machine Learning Methodology
This study used an ML approach to predict furan content. This approach involves three phases: training, testing, and deployment. During the training phase, data with known target values, which in this study were furan, were collected, and a subset of features was selected to construct a predictive model, specifically a regressor. In the testing phase, the performance of the models was evaluated on a separate set of data not used for training, which ensures that the model can generalize well to new unseen data. Finally, the model was applied to new data in the deployment phase to predict the furan content. A feature selection method called stepwise regression was employed to eliminate irrelevant and redundant features, reducing noise and dimensionality, which will be discussed later.
There are several algorithms available to build ML-based regression models, and in this study, ExtraTrees, k-Nearest Neighbors, and Extreme Gradient Boosting were used to predict furan content, followed by a stacked regression model that combines all of these algorithms together, which will be discussed later. Each algorithm has its strengths and weaknesses and may adapt differently to the given data. A brief description of the machine learning algorithms that were used in this study is presented below:
ExtraTrees is an ensemble learning method that builds on decision tree algorithms, similar to Random Forests (RF) [
25]. It utilizes an ensemble of decision trees trained on different subsets of the input data. By averaging the predictions from multiple decision trees, RF achieves better predictive performance and helps prevent overfitting compared to using a single decision tree model. While Random Forests uses bootstrap aggregating (bagging) to sample different variations of the training data for each decision tree, ExtraTrees differs in that it trains each decision tree using the full dataset. ExtraTrees randomly selects feature values to split on when creating child nodes in the trees [
26]. This reduces bias but increases variance and computation cost, though ExtraTrees still tend to be faster than Random Forests.
The k-Nearest Neighbor (kNN) algorithm is a popular supervised learning technique widely used in various ML applications. The core principle of kNN involves classifying objects based on their proximity to the training examples in the feature space. Specifically, the algorithm seeks to identify a predefined number of training samples that are closest in distance to a given query instance and then uses these samples to predict the label of the query instance [
27]. While kNN shares some similarities with decision tree algorithms, it is unique in that it seeks to find a path around the graph rather than constructing a tree.
XGBoost, or Extreme Gradient Boosting, is a powerful ML technique that combines decision trees and gradient boosting to achieve high accuracy in both regression and classification tasks. The algorithm works by repeatedly refining decision trees using the errors from previous trees [
28]. To improve the accuracy of the model, a loss function is minimized to measure the discrepancy between predicted and actual values. This is achieved through gradient descent, which involves adding new decision trees that better fit the training data. To avoid overfitting, XGBoost includes a regularization term in its objective function. What sets XGBoost apart is its speed, scalability, and ability to work with high-dimensional features. It is also adept at handling missing values, selecting important features, and performing parallel processing.
A stacked regression approach is proposed to enhance the generalizability and performance of the predictive model. Relying on a single model may not always yield optimal results; therefore, a stack of multiple ML algorithms is used. The key concept behind this approach is to overcome the limitations of individual algorithms, as a weakness of one algorithm might be a strength of another [
29].
For instance, kNN assumes that similar values close to each other are likely to belong to the same class [
27], which may not hold true in many physical systems where features are not correlated. However, this method requires loading all labeled data points into memory and computing distances between them and the test data points to assign a label. Combining these algorithms in a stacked regression model allows us to leverage their strengths while overcoming limitations, leading to a more robust and accurate prediction model.
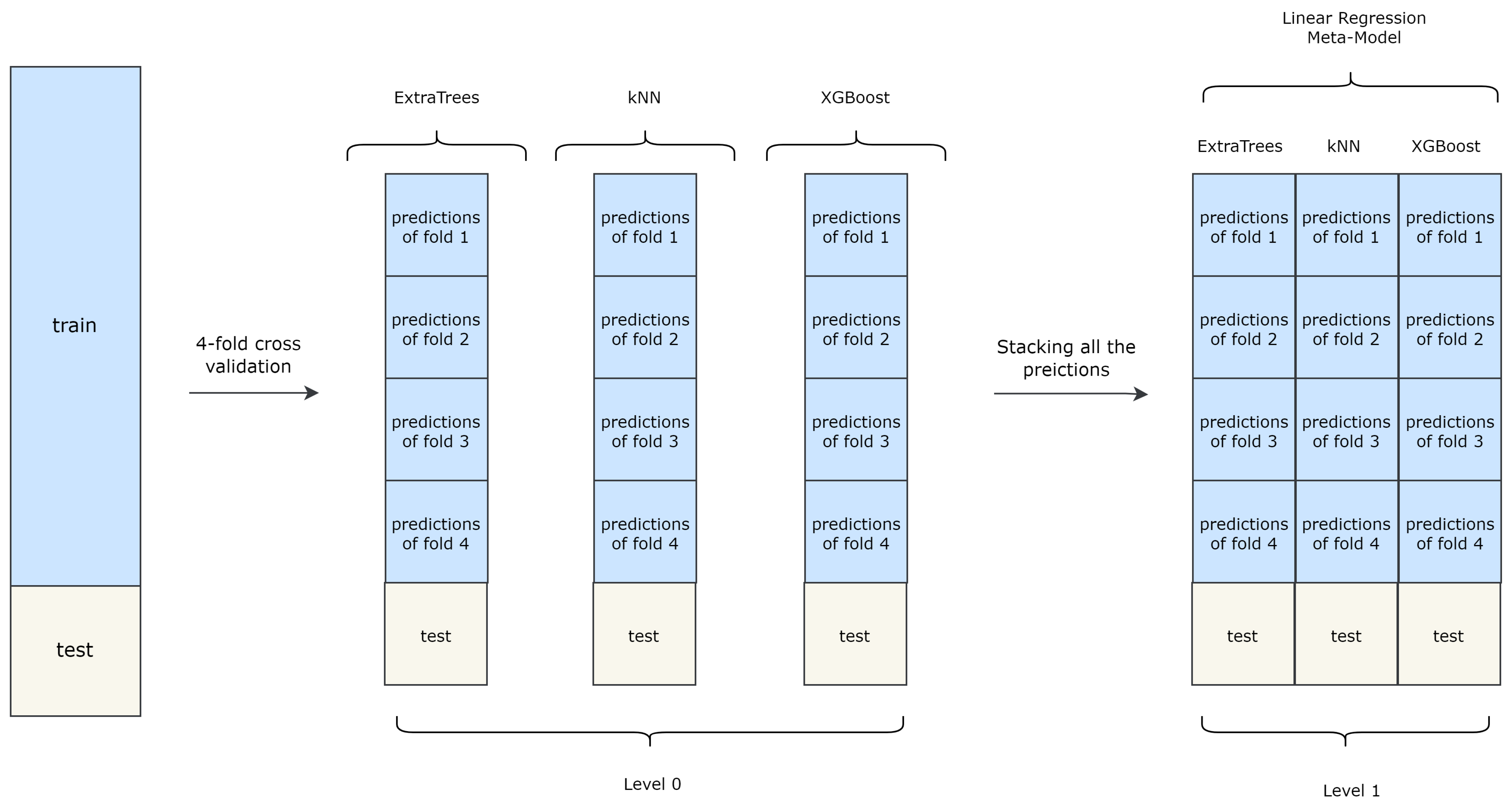
Stacked Generalization, an ensemble learning technique originally proposed by [
30], involves creating a meta-model by combining the predictions of multiple-base ML models, also known as weak learners, using k-fold cross-validation. The meta-model is then trained with an additional ML model called the “final estimator”, which in this study is a simple linear regression model. The Stacked Generalization method consists of two stages of training, referred to as “level 0” and “level 1”.
Figure 1 illustrates a Stacked Generalization architecture comprising three base models (weak learners) and a final estimator.
In the initial stage (level 0), k-fold cross-validation is implemented for each weak learner to generate training data for the meta-model. The predictions of the weak learners are then aggregated to create the new training set for the meta-model. In the second stage (level 1), the meta-model is trained using the predetermined final estimator.
The key idea behind stacked generalization is to use the outputs of the initial weak learners as the inputs to train a higher-level learner. By leveraging the predictions of the weak learners, the meta-model can achieve better performance than any individual base model. While stacked generalization is a powerful technique for improving ML models’ accuracy, it has drawbacks. One of the main drawbacks of stacked generalization methods is their computation cost and slow processing time. The technique involves training multiple base models, which can be computationally expensive, and then using them to generate predictions for a meta-model, which increases the computational burden. Additionally, the need for k-fold cross-validation and multiple training stages can further slow down the process.
2.4. Stepwise Regression as a Feature Selection Method
Decreasing the number of tests needed to forecast furan levels will additionally lower the cost of testing the transformer. As a feature selection method, Stepwise Regression is a widely used statistical technique for selecting the most relevant features in a dataset by iteratively adding and removing them from a predictive model based on their statistical significance. The primary goal of this approach is to eliminate irrelevant and redundant features and identify the most significant ones for building an accurate predictive model. By applying feature selection, the dimensionality of the data is reduced, and the computation cost is minimized without compromising the model’s performance.
As described in [
31] and detailed in [
32], the stepwise regression approach involves analyzing the statistical significance of a set of candidate features with respect to the target variable. In this study, the stepwise regression technique is used to determine which of the nine oil test features are sufficient for predicting the HI value accurately while eliminating insignificant ones. The stepwise regression process develops a final multilinear regression model for predicting the target variable by adding or removing candidate features in a stepwise manner.
The process begins by including a single feature in the regression model and then adding additional features to assess the incremental performance of the model in predicting the target variable. In each step, the F-statistic of the added feature in the model is computed. The F-statistic measures the significance of the relationship between the added feature and the target variable. If the F-statistic is significant, the feature is retained, and the process continues by adding another feature to the model. Otherwise, the feature is removed, and the process continues with the remaining features until the optimal model is obtained. The F-statistic is found using Equation (
1).
where the regression coefficient
determines the association between a given feature and the outcome variable, and the F-statistic value
is calculated for each feature when added to the regression model, accounting for the other existing features in the model. The regression sum of squares
represents the difference between the model’s predicted output and the actual values of the dataset. The mean squared error
measures the error of the model with all its current features.
During the stepwise feature selection process, a p-value is calculated for the F-statistic of each added feature and tested against the null hypothesis. If the p-value is below the pre-defined entrance threshold, the null hypothesis is rejected, indicating that the feature is statistically significant to the target variable and is added to the model.
Once the forward stepwise process is completed, the backward stepwise process begins. If a feature in the model has an F-statistic p-value above the exit threshold, the null hypothesis is accepted and removed from the final model.
2.5. Evaluation Metrics
After the training phase, the model’s performance is evaluated on the test set using commonly used metrics for evaluating regression models. The mean absolute error (MAE) measures the average absolute difference between the predicted and actual values. It is calculated by taking the sum of absolute differences between predicted and actual values and dividing it by the number of observations. The formula for the MAE is given in Equation (
2).
where
n is the number of observations,
is the actual value for observation
i, and
is the predicted value for observation
i.
The mean squared error (MSE) is a metric for evaluating the performance of regression models that measures the average squared difference between the predicted values and the actual values, as depicted in Equation (
3).
where
n is the number of observations,
is the actual value for observation
i, and
is the predicted value for observation
i.







{kind=link}
{kind=link}