2.1. Division of Different Working Conditions and Changes in Characteristic Parameters in the Drilling Process
In the current field operation, the artificial division of the drilling process through the recording parameters is subjective, and it is a prerequisite for the automatic identification of the working conditions to clarify the changes in the signs and response patterns of different parameters under different working conditions. Based on the drilling diary and previous summary, this paper analyzes the parameter changes under seven working conditions, such as standpipe connection, tripping out, tripping in, Reaming, back Reaming, circulation, drilling and other conditions. Other working conditions, such as drilling cement plugs and installing blowout preventers, are attributed to ‘other‘. Based on the parameters that change most directly and obviously under different working conditions, a total of eight parameters, weight on bit (WOB), rotary torque (TQ), rotary speed (RPM), standpipe pressure (SPP), hook load (HKL), mud flow out (MFO), depth bit (DBTM), and depth hole (DME), were selected to identify the working conditions.
In general, there are corresponding changes in the logging parameters under various drilling conditions, called sign changes under certain conditions. The drilling conditions are judged by the changes in parameters and logical relationships. According to the actual drilling conditions, this paper analyzes and summarizes the changes in parameters under various conditions.
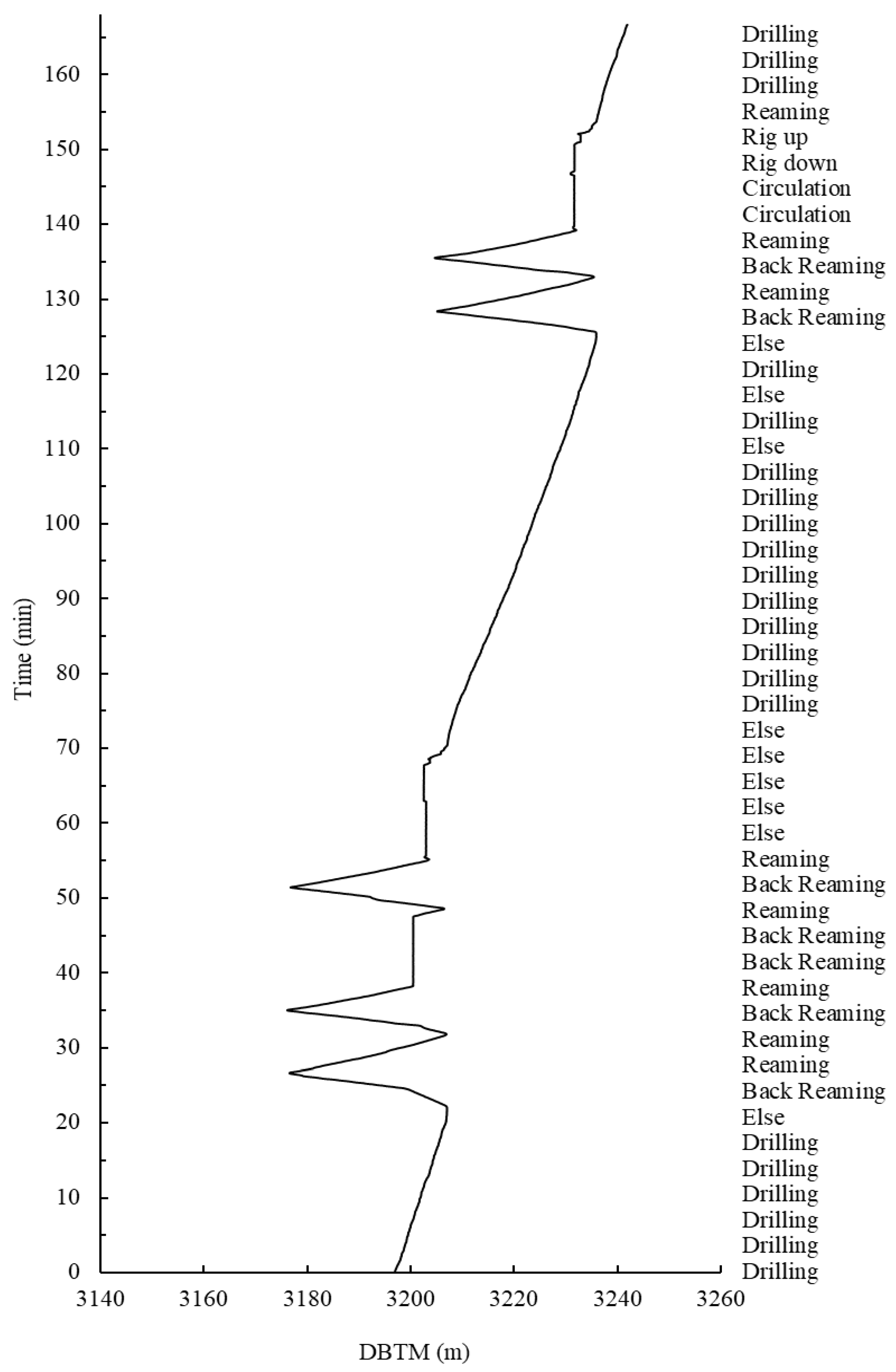
Standpipe Connection: In the process of standpipe connection, WOB, TQ, RPM, SPP, and MFO are all zero, HKL increases, and the increased weight is approximately the weight of the single root. The bit position remains the same, and the depth is less than the borehole depth.
Round Trip: When tripping out, WOB, TQ, RPM, SPP, and MFO are all zero. HKL gradually decreases, DBTM decreases, and its depth is less than DME. When tripping in, WOB, TQ, RPM, and SPP are all zero. MFO is certain, HKL gradually increases, and DBTM increases, but is less than DME.
Reaming and Back Reaming: When Reaming, WOB, TQ, RPM, SPP, MFO and HKL are all more significant than 0, and DBTM is increasing, but the depth is less than or equal to DME. When back Reaming, WOB is 0, and torque, RPM, SPP, MFO and HKL are all greater than 0. DBTM is decreasing, and the depth is less than DME.
Circulation: During circulation, WOB and TQ are 0, RPM, HKL, and MFO are more significant than 0, DBTM is constant, and the depth is less than or equal to DME.
Drilling: During drilling, WOB, TQ, RPM, and SPP are more significant than 0, MFO is not 0, HKL decreases, and DBTM increases. Since the well depth measurement sensor is installed above the drill bit position, DBTM is slightly greater than or equal to DME.
Define the position ratio Deta: Deta is used to describe the relative position relationship between DBTM and DME during drilling. Where the expression of the position ratio is Deta = DBTM/DME, then when DBTM is less than DME, Deta < 1, and when DBTM is greater than or equal to DME, Deta ≥ 1.
Based on the above principles, the established parameter variations for different drilling conditions are shown in
Table 1, which describes the parameter variations under each state. The statistical parameter variation characteristics include WOB, TQ, RPM, SPP, MFO, DBTM, HKL, and Deta.
2.3. Principle of Drilling Condition Identification Based on Stacking Learning with Multi-Model Fusion
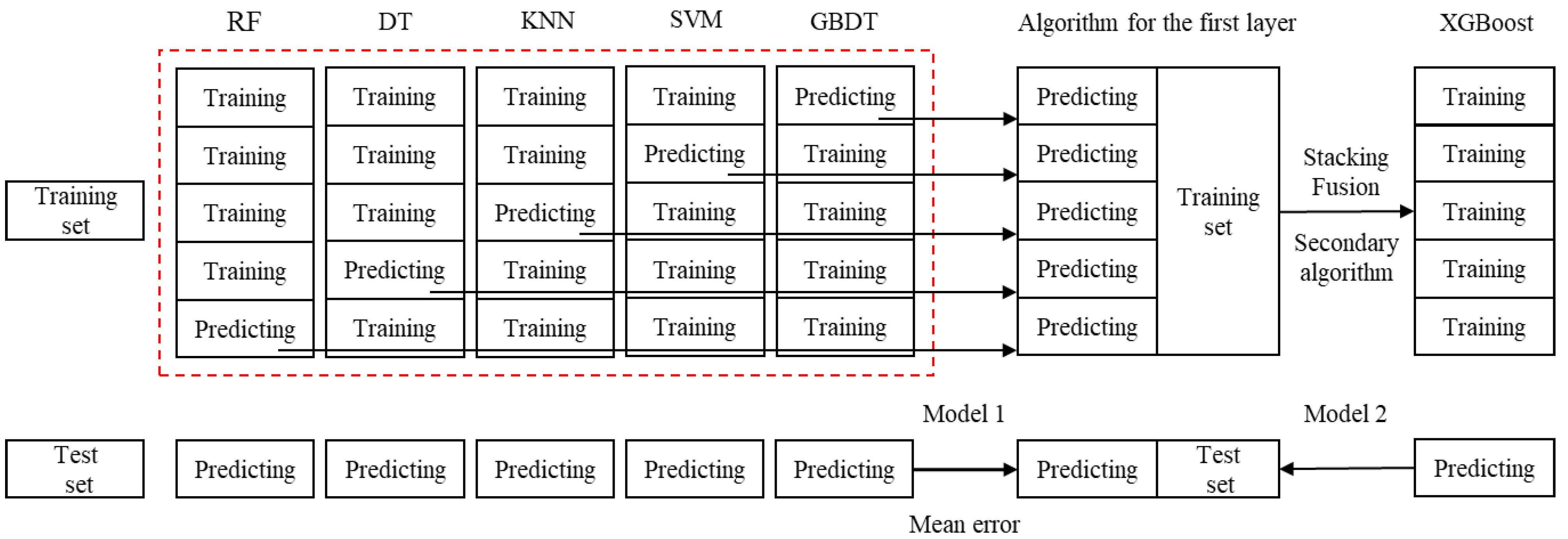
The model stacking algorithm in ensemble learning is a hierarchical multi-model fusion algorithm. The pseudo-code of the Stacking model fusion is shown in
Figure 1.
Figure 1 describes a two-layer Stacking model fusion algorithm. The first layer consists of 5 base learners. The input of the base learner is the original training set, and the output is the prediction result of the base learner using the original data. The model in the second layer takes the prediction results of the base learners in the first layer as input features and adds them to the training set. These training sets are again trained in the algorithm’s second layer, and the output results are weighted to find the average.
When each base learner completes the 5-fold cross-validation, the predicted value of the current training set denoted as T1 is obtained. After this part of the operation is completed, it is necessary to predict the test set of the original data. This process will generate the corresponding predictive value pred1, which will be used as part of the next layer of the model test set. The above process is performed on each base classifier, generating T1, T2, T3, T4, and T5 for the training set data and pred1, pred2, pred3, pred4, and pred5 for the test set. The training sets of T1, T2, T3, T4, and T5 are combined to form the training set of the second layer algorithm, denoted as T. We combine pred1, pred2, pred3, pred4, and pred5 as the test set Pred for the second layer algorithm. Finally, the second layer algorithm is used to train the data output from the first layer. In drilling condition recognition, the data set is first preprocessed. Then, eight working conditions in the drilling process are finally identified by the two-layer Stacking classification method.
2.4. Multi-Classification Recognition Method Based on Stacking Learning Multi-Model Fusion
- (1)
Processing of data sets
The sample data of the XX well on 23 October are used for training. The sample size in this data is O = 17266, and each sample has seven features, namely WOB, TQ, ROPA, HKL, MFOP, DBTM, and Deta. The sample matrix is X, and the shape of the sample matrix is (17266, 7). There are eight categories in total, which correspond to eight drilling conditions, namely Y = {0,1,2,3,4,5,6,7} T.
The pre-processed sample information is shown in
Table 4, which is the statistical information of the number of sample categories.
- (2)
The implementation process of the Stacking learning algorithm based on the two-layer structure
Figure 2 shows a schematic diagram of the two-layer Stacking model fusion method. During the training of the stacking algorithm, five base classifiers with two layers are used to identify the drilling conditions. The first layer uses random forest (RF), decision tree (DT), K-nearest neighbor (KNN), support vector machines (SVM), and gradient boosting decision tree (GBDT) as the five algorithms of the base learner and uses eXtreme gradient boosting (XGBoost) as the prediction algorithm in the second layer.
It can be seen from
Table 4 that the category distribution of the original sample data is unbalanced. Category 6, with the most significant number of samples, is the drilling condition, with 6656 samples. Category 2, with the least samples, is tripping in, with 93 samples, and the highest ratio between samples is up to 71. Therefore, it is necessary to pre-process the sample data to achieve sample balance and normalize the original data. The SMOTE method was used to resample the samples, and in the data set partitioning, the order of the original input data was first disrupted for random sampling. The sample data set is divided into a training set X_train with a size of (11,567, 6) and a test set X_test with a size of (5698, 6), and a label result training set Y_train with a size of (11,567, 1) and a label result test set Y_test with a size of (5698, 1). In the data set Y, each label takes an integer in the range of 0–7, representing the corresponding working condition for that sample at that moment.
As shown in
Figure 2, the top half represents the process of 5-fold cross-validation with different base learners, outputting the predicted values. In the 5-fold cross-validation process of the RF model, the model training process is as follows: Firstly, the 11,567 sample data of each training set X_train is divided into five parts. In each cross-validation process, 2313 × 4 data are taken for multi-classification training. After training, the remaining 2315 data are verified, the predicted value is recorded as rf_pred1, and the size of rf_pred1 is (2315, 1). The trained RF model is used to predict the test set Y_test from the original data, and the random forest classifier prediction result on the test set Y_test, denoted as rf_test1, can be obtained. The model correctness of the random forest-based learner for the first cross-validation, denoted as rf_acc1, is obtained by comparing the true label Y_test1 in the predicted dataset of rf_test1 and the original dataset. The above process was repeated four times, and the remaining 4 data were cross-validated separately. In the training process of each base learner, the training set prediction data rf_pred1, rf_pred2, rf_pred3, rf_pred4, and rf_pred5 under each cross-validation, and the test set prediction data rf_test1, rf_test2, rf_test3, rf_test4, and rf_test5 under each cross-validation can be obtained. The training set prediction data RF_pred with a size of (2315, 5) can be obtained by combining the training set prediction data by columns. For the test set prediction data rf_test1, rf_test2, rf_test3, rf_test4, and rf_test5, the test set prediction data RF_test with a size of (5698, 1) can be obtained by averaging the parts of the test set prediction data. The random forest model accuracy rate RF_acc can be obtained by averaging the accuracy of each output of the random forest model with five cross-validations. At this point, the first base learner training is completed.
Similarly, DT_pred, SVM_pred, KNN_pred, GDBT_pred, DT_test, SVM_test, KNN_test, and GDBT_test, and the accuracy of each base classifier DT_acc, SVM_acc, KNN_acc and GDBT_acc are obtained. The bottom half of
Figure 2 is the model fusion section, where RF_pred, DT_pred, SVM_pred, KNN_pred, and GDBT_pred are combined into a new training data set, denoted as Stacking_train, with a size of (11,567, 5) as the training set for the second layer of the stacked model. RF_test, DT_test, SVM_test, KNN_test, and GDBT_test are combined to obtain a test set with a size of (5698, 5), denoted as the Stacking_test. In the second layer, the XGBoost algorithm is used to predict the Stacking_train and Stacking_test to complete the model fusion of multiple base classifiers and output the model’s accuracy, precision, and recall.








{kind=link}
{kind=link}
{kind=link}
{kind=link}