
An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection


Abstract
:1. Introduction
1.1. Background
1.2. Literature Review
1.3. Research Motivation and Objectives
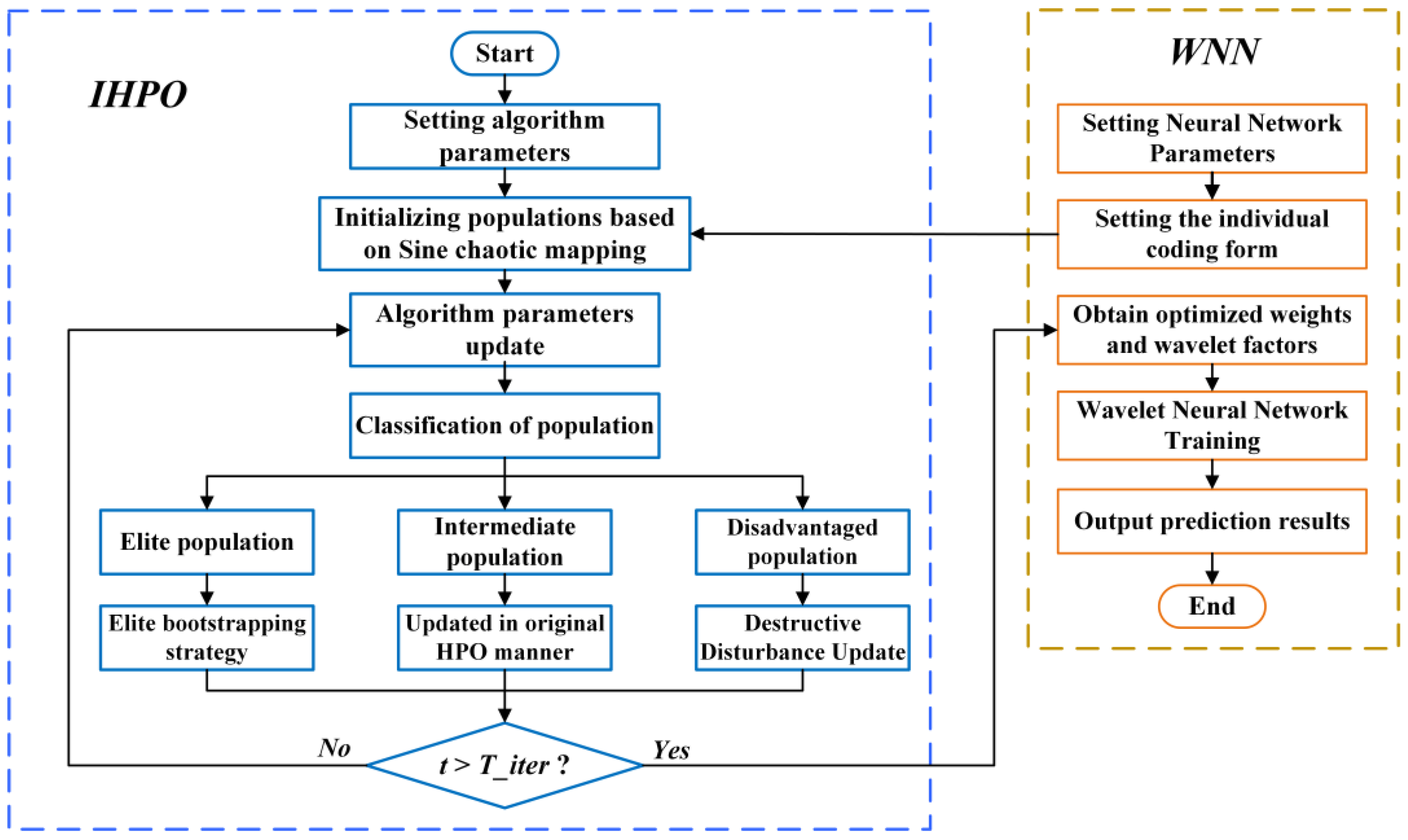
2. Power Load Forecasting Model Based on IHPO-WNN
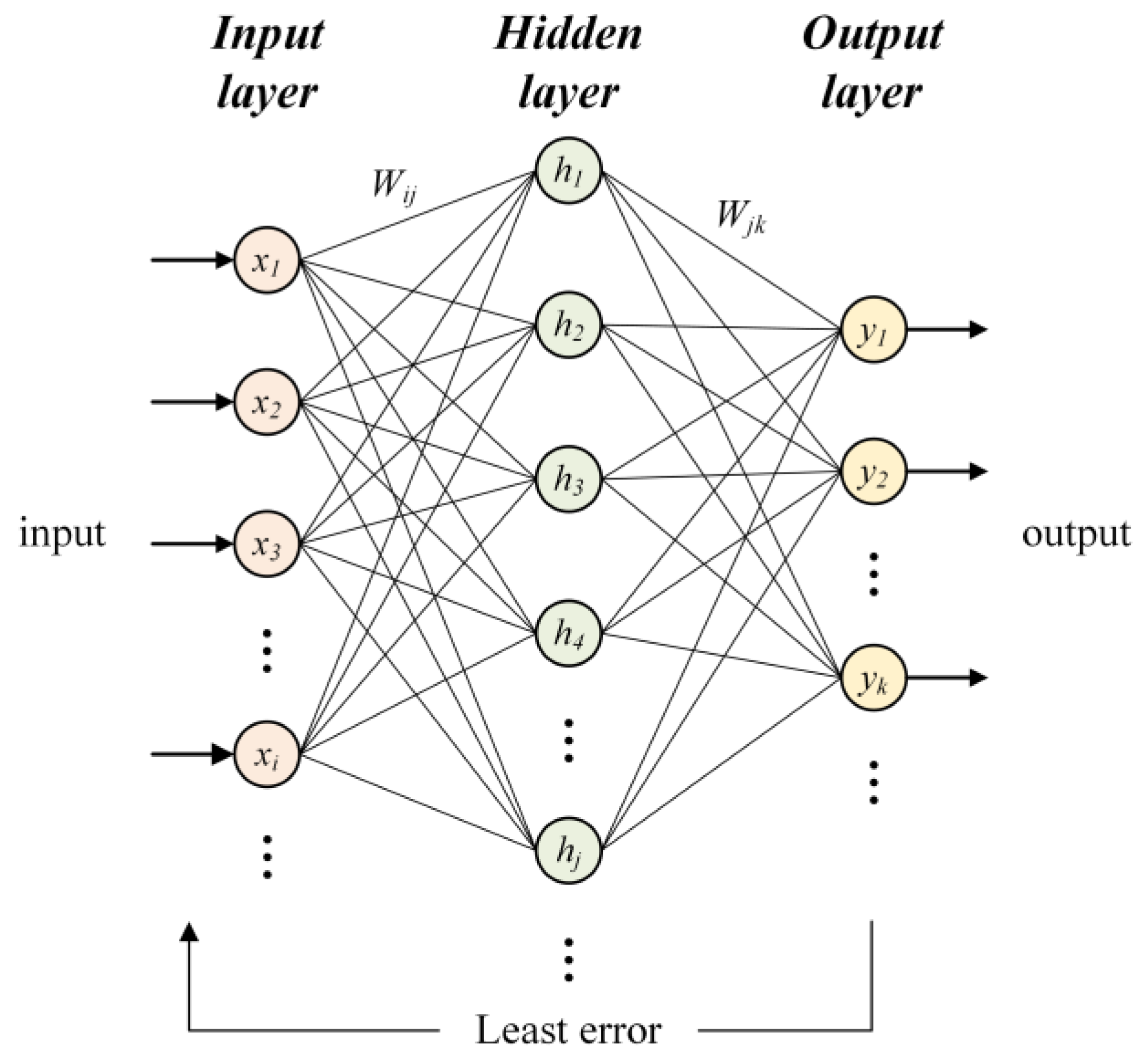
2.1. Wavelet Neural Network
2.2. Hunter-Prey Optimizer
2.3. Improved Hunter–Prey Optimizer
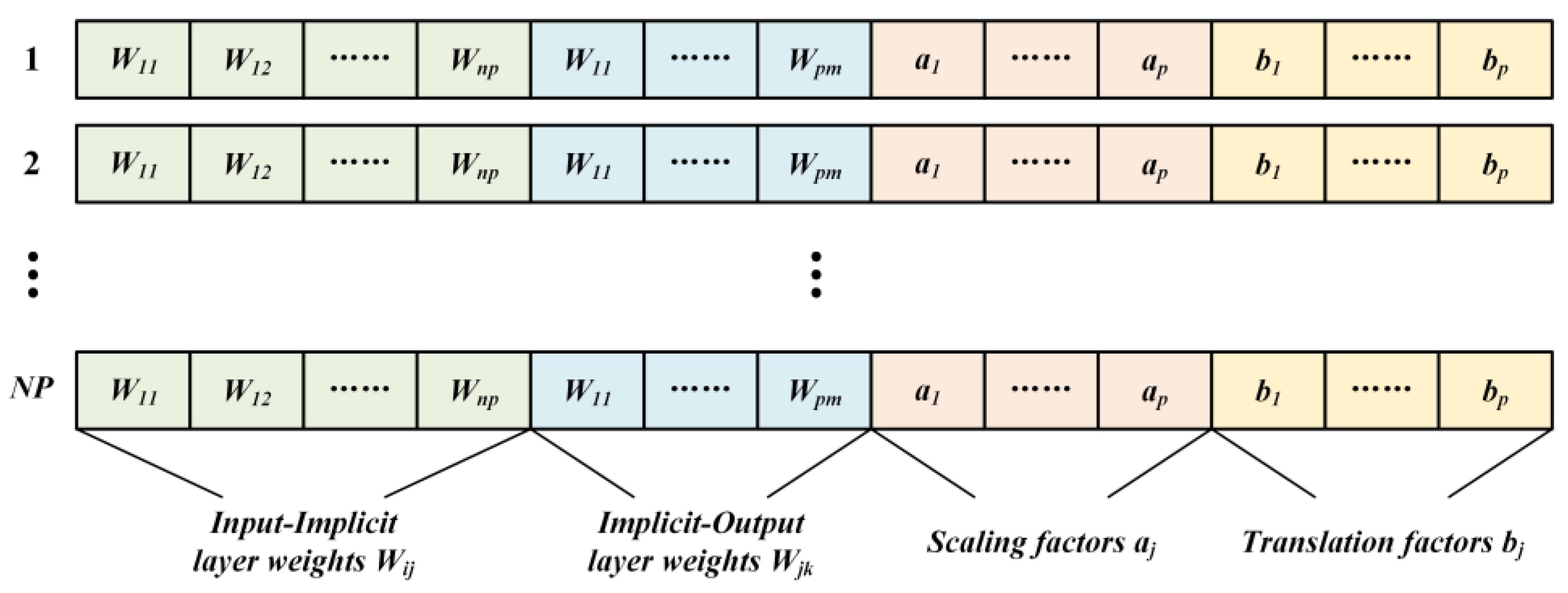
2.3.1. Coding and Decoding of Individuals
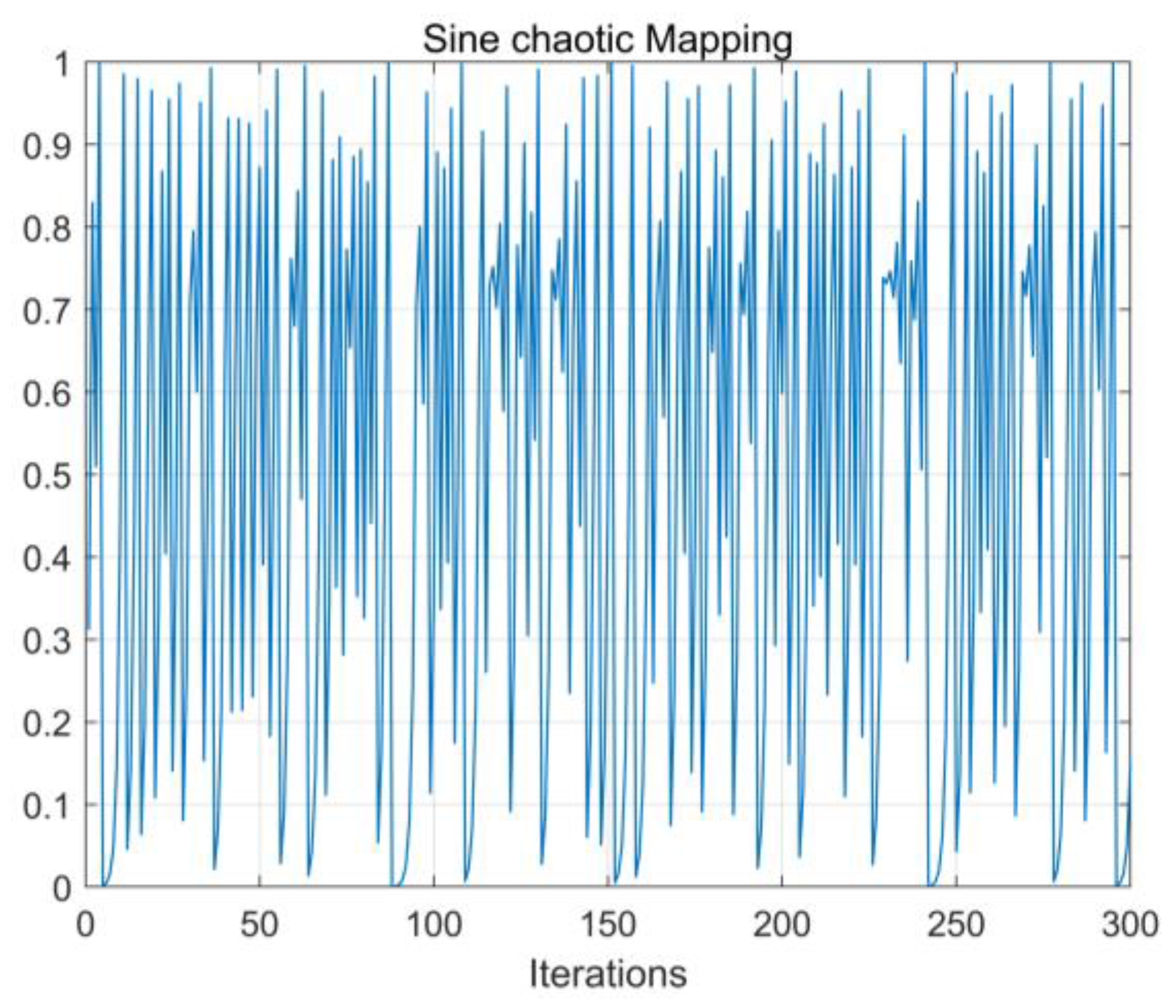
2.3.2. Population Initialization Based on Sine Chaotic Mapping
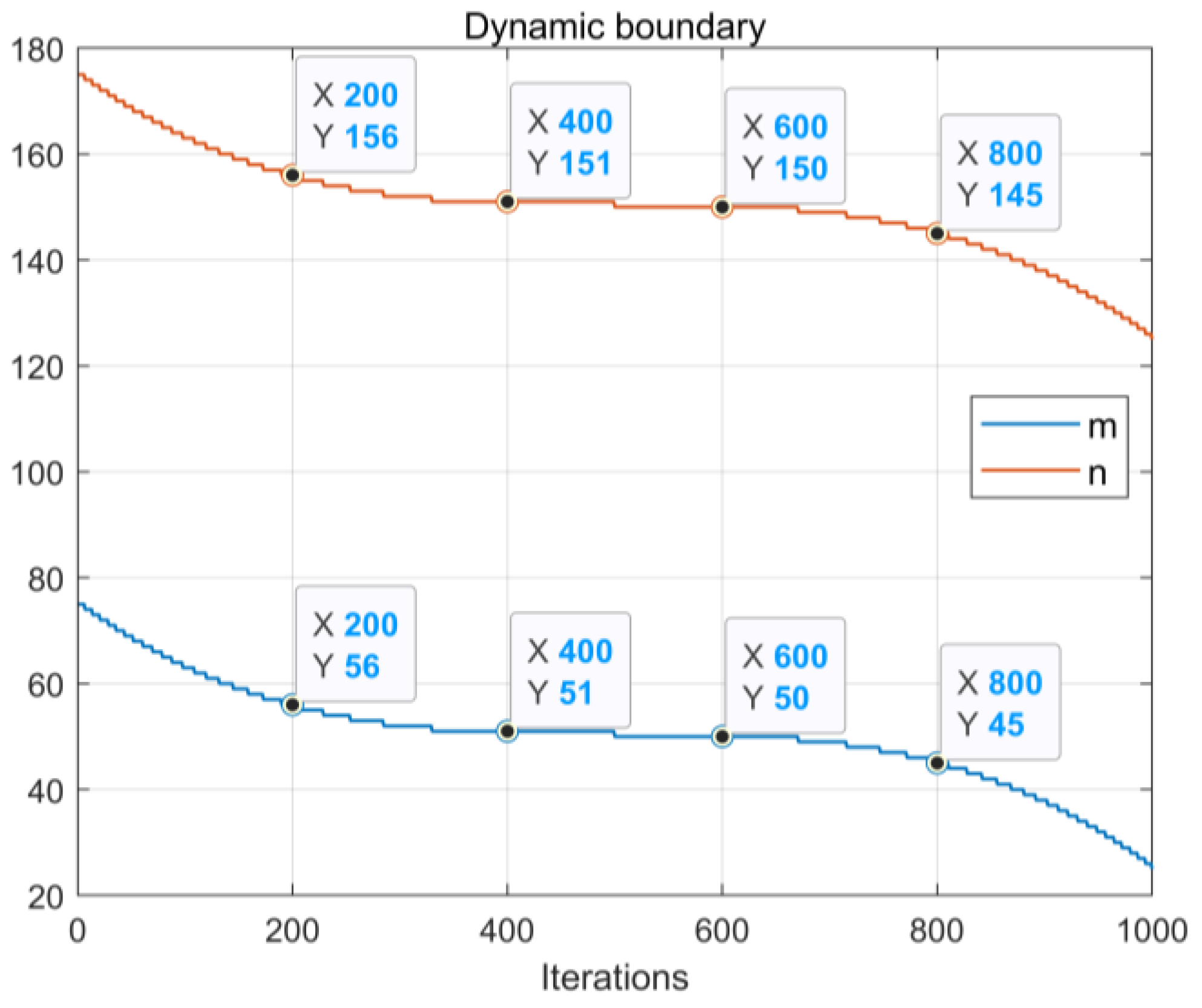
2.3.3. Parallel Search Mechanism Based on Dynamic Boundaries
- (1)
- Intermediate population: traditional HPO updating approach
- (2)
- Elite population: elite guidance strategy
- (3)
- Disadvantaged populations: destructive perturbation strategy
2.4. IHPO-WNN
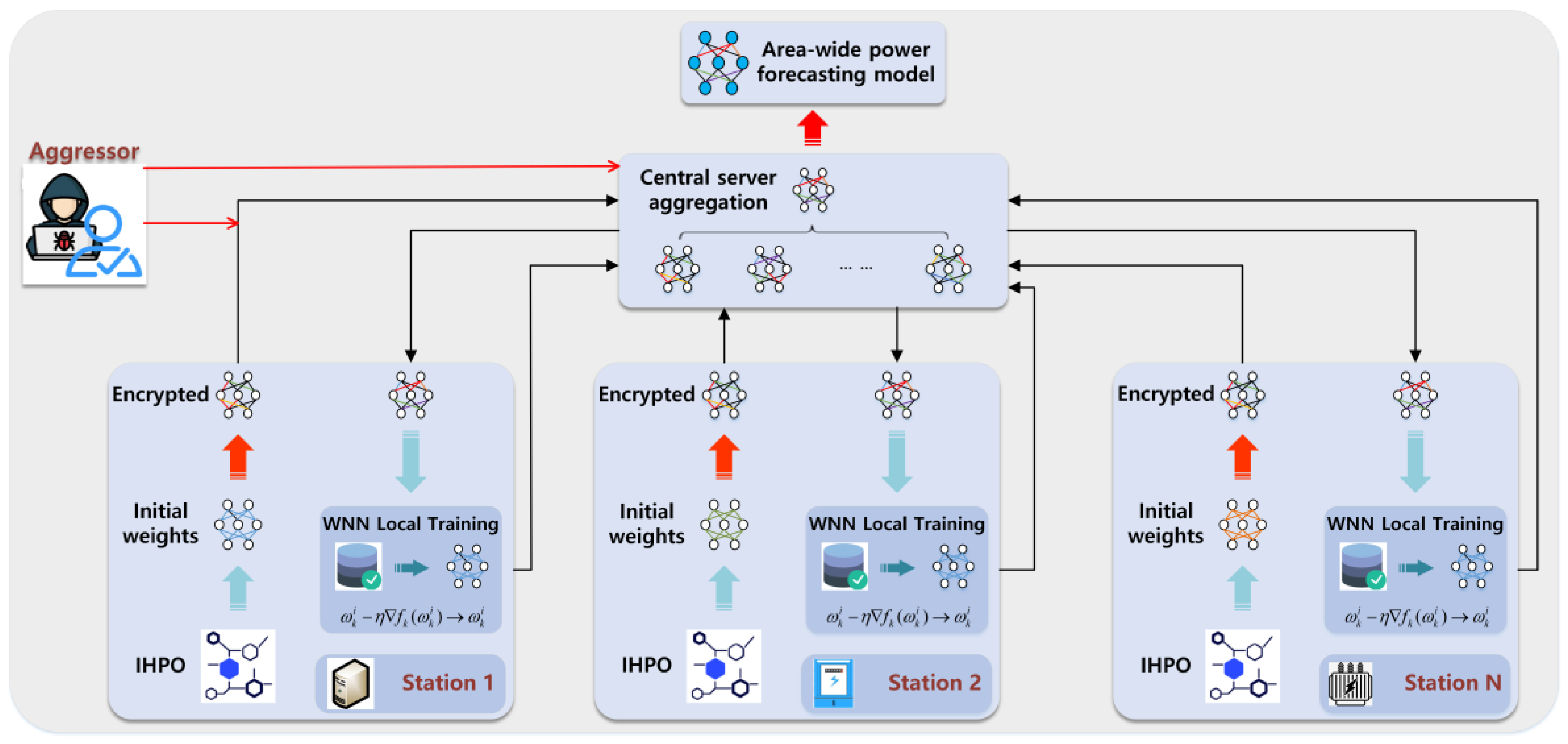
3. An IHPO-WNN-Based Federated Learning Architecture for Power Data Prediction
3.1. Federated Learning Based on IHPO-WNN
- (1)
- Local model initialization
- (2)
- Metering master center aggregation
- (3)
- Local training process
- (4)
- Aggregate again to get the final model
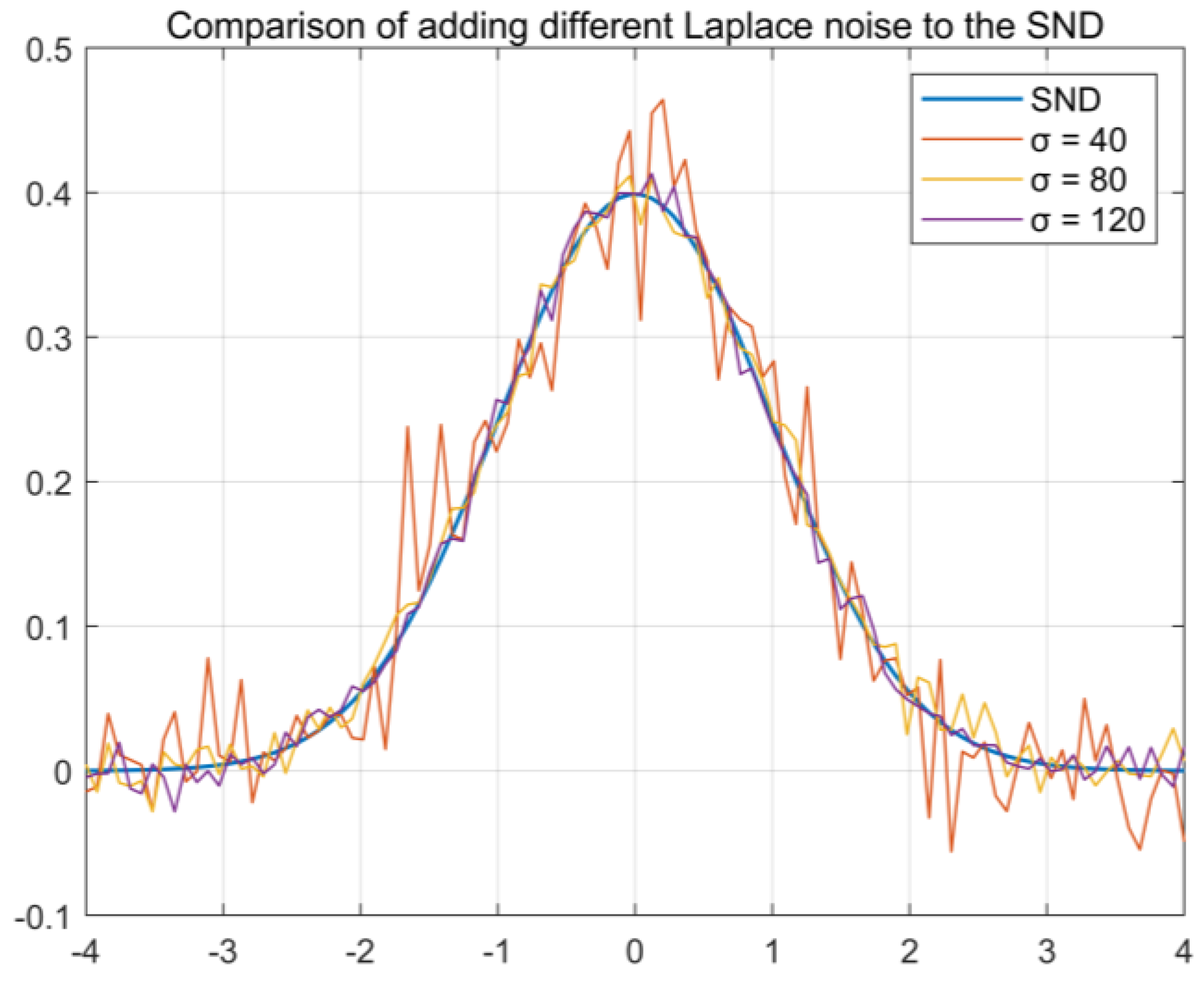
3.2. Channel Encryption Mechanism Based on Localized Differential Privacy
3.3. An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting
4. Experimental Results and Analysis
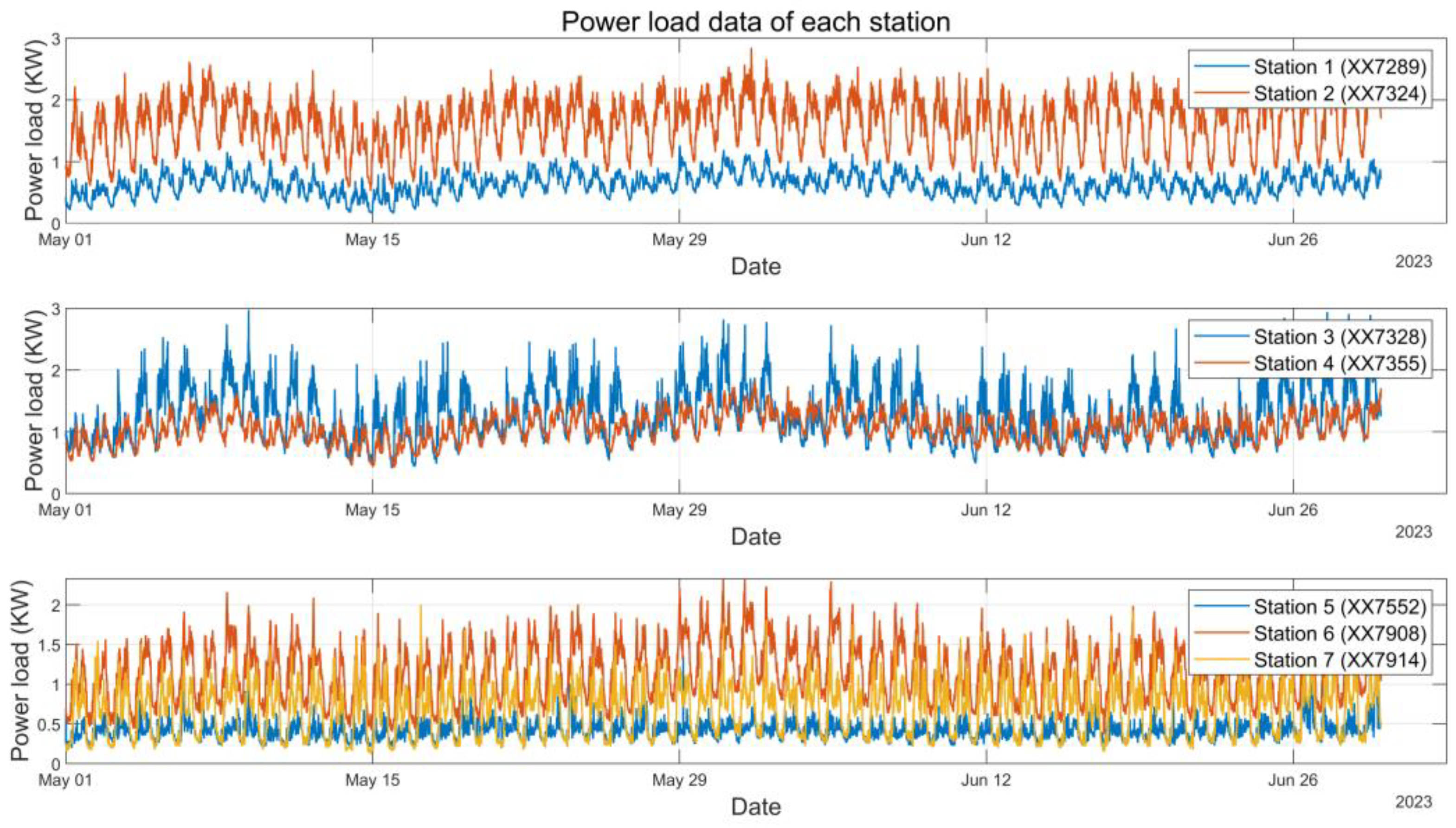
4.1. Description of the Dataset
4.2. Forecast Evaluation Indicators
4.3. IHPO-WNN Performance Testing
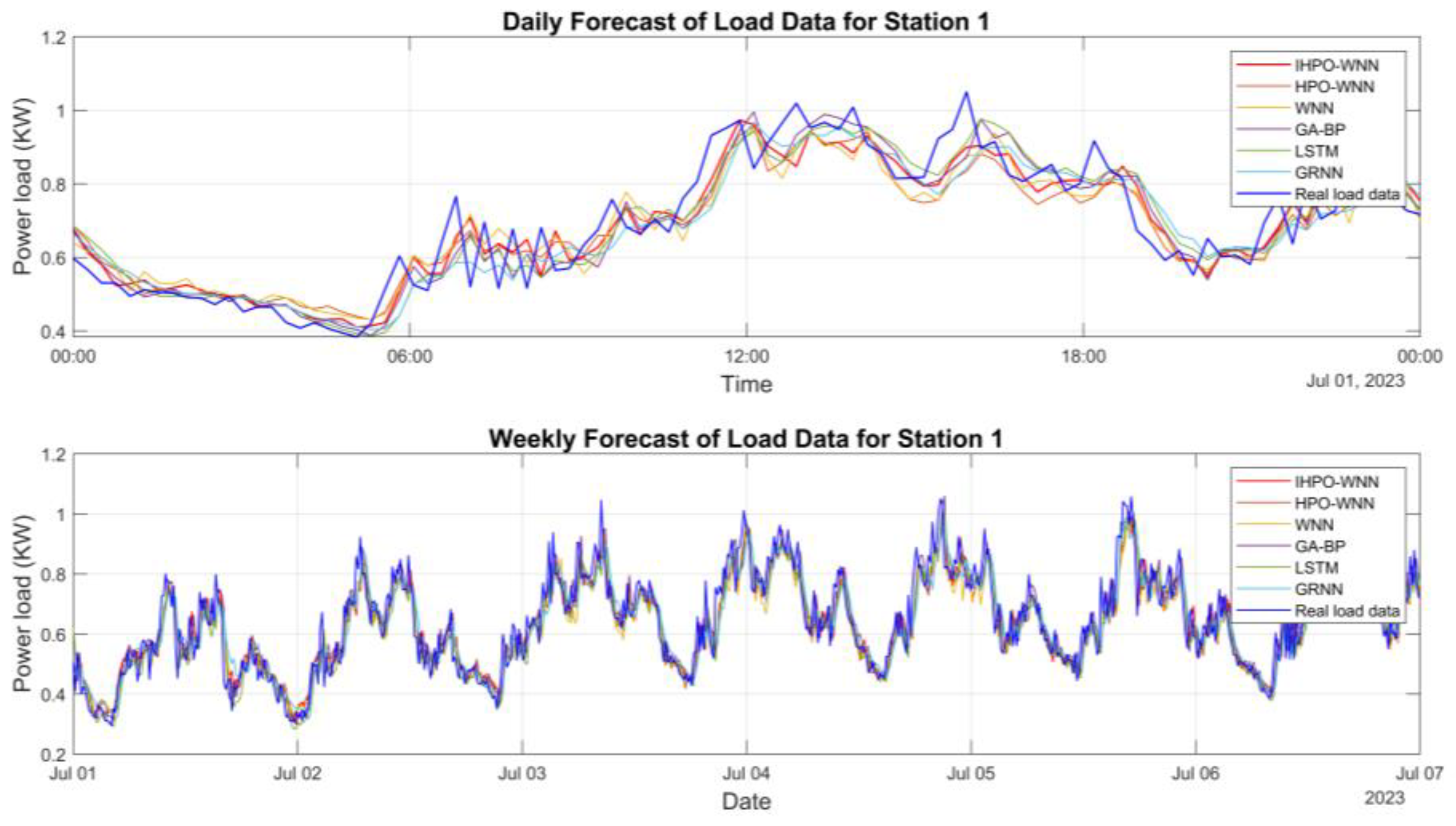
4.4. Simulation Testing of a Domain-Wide Load Factor Prediction Model
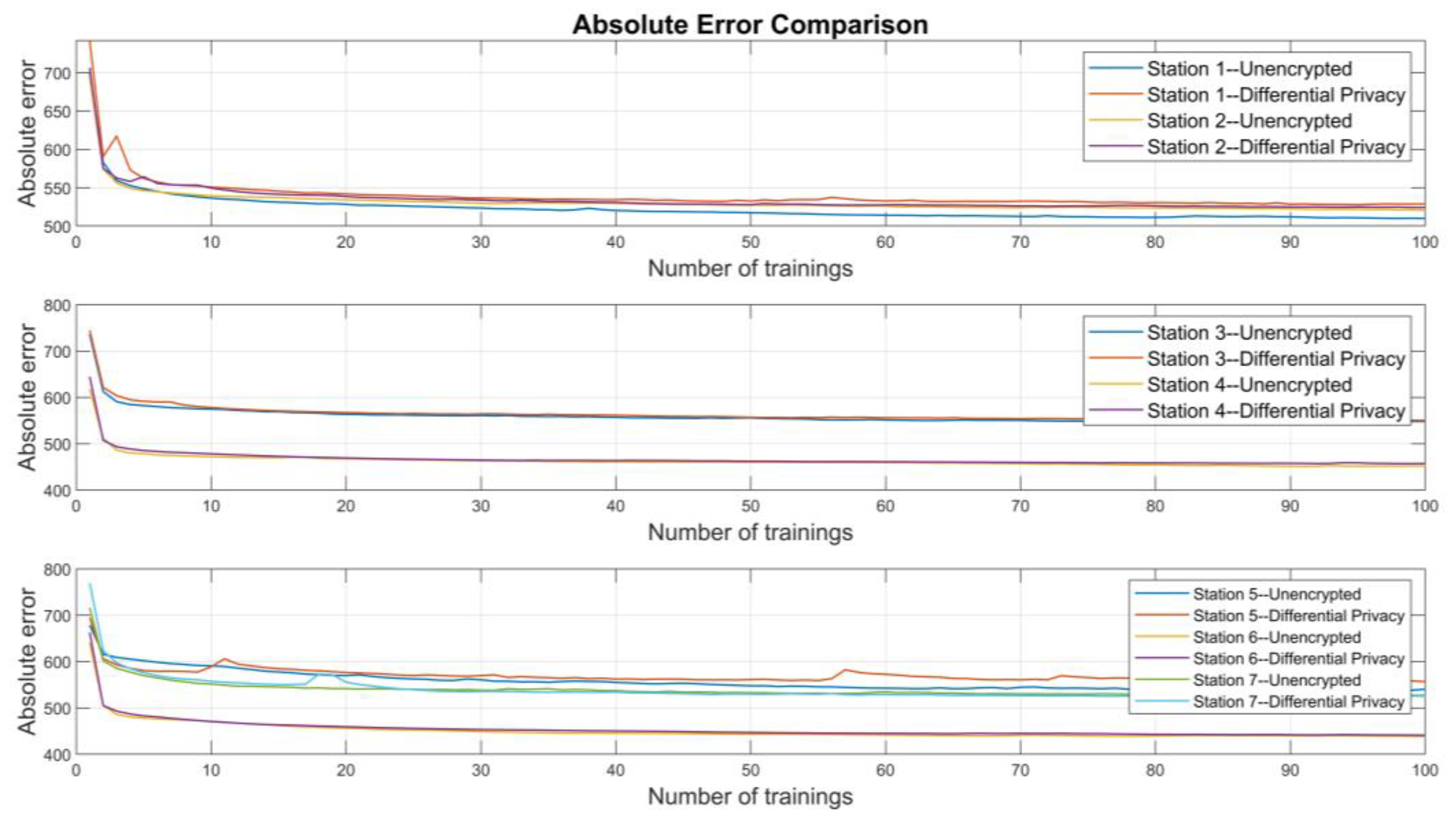
4.5. Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Code Availability Statement
Conflicts of Interest
References
- Jiang, Y.; Gao, T.; Dai, Y.; Si, R.; Hao, J.; Zhang, J.; Gao, D.W. Very short-term residential load forecasting based on deep-autoformer. Appl. Energy 2022, 328, 120120. [Google Scholar] [CrossRef]
- Cai, Z.; Dai, S.; Ding, Q.; Zhang, J.; Xu, D.; Li, Y. Gray wolf optimization-based wind power load mid-long term forecasting algorithm. Comput. Electr. Eng. 2023, 109, 108769. [Google Scholar] [CrossRef]
- Jahani, A.; Zare, K.; Khanli, L.M. Short-term load forecasting for microgrid energy management system using hybrid SPM-LSTM. Sustain. Cities Soc. 2023, 98, 104775. [Google Scholar] [CrossRef]
- Xia, Y.; Wang, J.; Zhang, Z.; Wei, D.; Yin, L. Short-term PV power forecasting based on time series expansion and high-order fuzzy cognitive maps. Appl. Soft Comput. 2023, 135, 110037. [Google Scholar] [CrossRef]
- Behmiri, N.B.; Fezzi, C.; Ravazzolo, F. Incorporating air temperature into mid-term electricity load forecasting models using time-series regressions and neural networks. Energy 2023, 278, 127831. [Google Scholar] [CrossRef]
- Atef, S.; Nakata, K.; Eltawil, A.B. A deep bi-directional long-short term memory neural network-based methodology to enhance short-term electricity load forecasting for residential applications. Comput. Ind. Eng. 2022, 170, 108364. [Google Scholar] [CrossRef]
- Bu, X.; Wu, Q.; Zhou, B.; Li, C. Hybrid short-term load forecasting using CGAN with CNN and semi-supervised regression. Appl. Energy 2023, 338, 120920. [Google Scholar] [CrossRef]
- Sitapure, N.; Kwon, J.S.-I. CrystalGPT: Enhancing system-to-system transferability in crystallization prediction and control using time-series-transformers. Comput. Chem. Eng. 2023, 177, 108339. [Google Scholar] [CrossRef]
- Sitapure, N.; Kwon, J.S.-I. Exploring the potential of time-series transformers for process modeling and control in chemical systems: An inevitable paradigm shift? Chem. Eng. Res. Des. 2023, 194, 461–477. [Google Scholar] [CrossRef]
- Zhang, Y.; Kong, L. Photovoltaic power prediction based on hybrid modeling of neural network and stochastic differential equation. ISA Trans. 2022, 128, 181–206. [Google Scholar] [CrossRef]
- Xian, H.; Che, J. Multi-space collaboration framework based optimal model selection for power load forecasting. Appl. Energy 2022, 314, 118937. [Google Scholar] [CrossRef]
- Lee, D.; Jayaraman, A.; Kwon, J.S. Development of a hybrid model for a partially known intracellular signaling pathway through correction term estimation and neural network modeling. PLoS Comput. Biol. 2020, 16, e1008472. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.; Zhong, Y.; Wu, J.; Wang, Y.; Wang, L. State of health estimation of the lithium-ion power battery based on the principal component analysis-particle swarm optimization-back propagation neural network. Energy 2023, 283, 129061. [Google Scholar] [CrossRef]
- Zhang, H.; Xue, J.; Wang, Q.; Li, Y. A security optimization scheme for data security transmission in UAV-assisted edge networks based on federal learning. Ad Hoc Netw. 2023, 150, 103277. [Google Scholar] [CrossRef]
- Chandiramani, K.; Garg, D.; Maheswari, N. Performance Analysis of Distributed and Federated Learning Models on Private Data. Procedia Comput. Sci. 2019, 165, 349–355. [Google Scholar] [CrossRef]
- Guendouzi, B.S.; Ouchani, S.; EL Assaad, H.; EL Zaher, M. A systematic review of federated learning: Challenges, aggregation methods, and development tools. J. Netw. Comput. Appl. 2023; in press. [Google Scholar] [CrossRef]
- Li, C.; Song, M.; Luo, Y. Federated learning based on Stackelberg game in unmanned-aerial-vehicle-enabled mobile edge computing. Expert Syst. Appl. 2024, 235, 121023. [Google Scholar] [CrossRef]
- Urooj, S.; Lata, S.; Ahmad, S.; Mehfuz, S.; Kalathil, S. Cryptographic Data Security for Reliable Wireless Sensor Network. Alex. Eng. J. 2023, 72, 37–50. [Google Scholar] [CrossRef]
- Errounda, F.Z.; Liu, Y. Adaptive differential privacy in vertical federated learning for mobility forecasting. Future Gener. Comput. Syst. 2023, 149, 531–546. [Google Scholar] [CrossRef]
- Naruei, I.; Keynia, F.; Molahosseini, A.S. Hunter–prey optimization: Algorithm and applications. Soft Comput. 2022, 26, 1279–1314. [Google Scholar] [CrossRef]
- Sun, L.; Li, M.; Xu, J. Binary Harris Hawk optimization and its feature selection algorithm. Comput. Sci. 2023, 50, 277–291. [Google Scholar] [CrossRef]
- Mohapatra, S.; Mohapatra, P. Fast random opposition-based learning Golden Jackal Optimization algorithm. Knowl.-Based Syst. 2023, 275, 110679. [Google Scholar] [CrossRef]
- Wei, C.; Wei, X.; Huang, H. Pigeon flocking algorithm based on chaotic initialization and Gaussian variation. Comput. Eng. Des. 2023, 44, 1112–1121. [Google Scholar] [CrossRef]
- Fu, S.; Zhao, X.; Yang, C. Data heterogeneous federated learning algorithm for industrial entity extraction. Displays 2023, 80, 102504. [Google Scholar] [CrossRef]
- Yang, M.; Cheng, H.; Chen, F.; Liu, X.; Wang, M.; Li, X. Model poisoning attack in differential privacy-based federated learning. Inf. Sci. 2023, 630, 158–172. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station 1 | Station 2 | ||||
| Unique Station Identification XXXX7289 | Unique Station Identification XXXX7324 | ||||
| Average Load | Max Load | Min Load | Average Load | Max Load | Min Load |
| 0.6240 kW | 1.2616 kW | 0.1587 kW | 1.6218 kW | 2.8466 kW | 0.5214 kW |
| Station 3 | Station 4 | ||||
| Unique station identification XXXX7328 | Unique station identification XXXX7355 | ||||
| Average Load | Max Load | Min Load | Average Load | Max Load | Min Load |
| 1.2828 kW | 2.9747 kW | 0.4067 kW | 1.0616 kW | 1.8219 kW | 0.4221 kW |
| Station 5 | Station 6 | ||||
| Unique station identification XXXX7552 | Unique station identification XXXX7908 | ||||
| Average Load | Max Load | Min Load | Average Load | Max Load | Min Load |
| 0.4152 kW | 1.3594 kW | 0.1809 kW | 1.1681 kW | 2.3307 kW | 0.3662 kW |
| Station 7 | |||||
| Unique station identification XXXX7914 | |||||
| Average Load | Max Load | Min Load | |||
| 0.6781 kW | 2.0028 kW | 0.1197 kW | |||
| IHPO-WNN | HPO-WNN | WNN | GA-BP | LSTM | GRNN | |
|---|---|---|---|---|---|---|
| RMSE | 0.071059 | 0.074338 | 0.07892 | 0.07488 | 0.074069 | 0.078006 |
| MAPE | 8.3034% | 8.7870% | 9.4693% | 8.5060% | 8.5247% | 8.5569% |
| R2 | 0.8355 | 0.81997 | 0.79709 | 0.81730 | 0.82127 | 0.80177 |
| IHPO-WNN | HPO-WNN | WNN | GA-BP | LSTM | GRNN | |
|---|---|---|---|---|---|---|
| RMSE | 0.068131 | 0.068972 | 0.07287 | 0.68969 | 0.069701 | 0.073649 |
| MAPE | 8.2140% | 8.2149% | 8.4293% | 8.3331% | 7.9723% | 8.8684% |
| R2 | 0.83038 | 0.82617 | 0.80597 | 0.82619 | 0.82248 | 0.80180 |
| IHPO-WNN | HPO-WNN | WNN | GA-BP | LSTM | GRNN | |
|---|---|---|---|---|---|---|
| RMSE | 0.12965 | 0.14656 | 0.15733 | 0.13444 | 0.14159 | 0.16062 |
| MAPE | 5.3901% | 5.8837% | 6.0895% | 5.4373% | 5.9587% | 5.9088% |
| R2 | 0.91393 | 0.89002 | 0.87326 | 0.90745 | 0.89734 | 0.86789 |
| IHPO-WNN | HPO-WNN | WNN | GA-BP | LSTM | GRNN | |
|---|---|---|---|---|---|---|
| RMSE | 0.13750 | 0.13996 | 0.14567 | 0.13941 | 0.13277 | 0.14335 |
| MAPE | 6.2056% | 6.3356% | 6.5528% | 6.3054% | 5.9875% | 6.5828% |
| R2 | 0.89669 | 0.89296 | 0.88404 | 0.89381 | 0.90368 | 0.88772 |
| Station Number | Differential Privacy | Unencrypted | ||||
|---|---|---|---|---|---|---|
| RMSE | MAPE | R2 | RMSE | MAPE | R2 | |
| Station 1 | 0.10440 | 15.0973% | 0.64492 | 0.11896 | 12.6128% | 0.53900 |
| Station 2 | 0.31743 | 13.7480% | 0.48405 | 0.37544 | 14.7143% | 0.27826 |
| Station 3 | 0.28284 | 15.9380% | 0.55777 | 0.26832 | 11.3850% | 0.60200 |
| Station 4 | 0.13668 | 8.6843% | 0.60064 | 0.20990 | 12.5242% | 0.05815 |
| Station 5 | 0.22885 | 47.0206% | 0.03619 | 0.14092 | 18.0187% | 0.63453 |
| Station 6 | 0.17789 | 13.3376% | 0.64627 | 0.17994 | 9.7863% | 0.63806 |
| Station 7 | 0.36251 | 71.3801% | 0.01856 | 0.15480 | 16.5710% | 0.82104 |
| Station Number | σ = 60 | σ = 80 | ||||
|---|---|---|---|---|---|---|
| RMSE | MAPE | R2 | RMSE | MAPE | R2 | |
| Station 1 | 0.11746 | 14.5860% | 0.55053 | 0.13082 | 17.0072% | 0.44249 |
| Station 2 | 0.29947 | 13.5867% | 0.54078 | 0.36354 | 15.9714% | 0.32329 |
| Station 3 | 0.31446 | 15.6211% | 0.45336 | 0.30796 | 16.5139% | 0.47572 |
| Station 4 | 0.16259 | 11.2651% | 0.43490 | 0.17466 | 10.8942% | 0.34787 |
| Station 5 | 0.18931 | 32.3783% | 0.34048 | 0.18644 | 34.9640% | 0.36027 |
| Station 6 | 0.20232 | 12.9618% | 0.54241 | 0.18584 | 13.5295% | 0.61394 |
| Station 7 | 0.39531 | 67.8287% | 0.16707 | 0.25223 | 45.7235% | 0.52485 |
| Station Number | σ = 120 | σ = 140 | ||||
| RMSE | MAPE | R2 | RMSE | MAPE | R2 | |
| Station 1 | 0.12746 | 18.3574% | 0.47070 | 0.10420 | 14.8352% | 0.64627 |
| Station 2 | 0.33395 | 15.8748% | 0.42895 | 0.21694 | 10.9808% | 0.75903 |
| Station 3 | 0.33014 | 19.7675% | 0.39747 | 0.27449 | 15.8748% | 0.58350 |
| Station 4 | 0.15127 | 10.3784% | 0.51085 | 0.11061 | 7.42880% | 0.73843 |
| Station 5 | 0.24279 | 29.4584% | 0.08484 | 0.23452 | 16.0809% | 0.52153 |
| Station 6 | 0.21546 | 16.0744% | 0.48104 | 0.36633 | 12.4916% | 0.68007 |
| Station 7 | 0.28079 | 47.7928% | 0.41117 | 0.15480 | 37.8438% | 0.52387 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, B.; Zhou, X.; Li, P.; Ma, W.; Pan, N. An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection. Energies 2023, 16, 6921. https://doi.org/10.3390/en16196921
Shi B, Zhou X, Li P, Ma W, Pan N. An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection. Energies. 2023; 16(19):6921. https://doi.org/10.3390/en16196921
Chicago/Turabian StyleShi, Bujin, Xinbo Zhou, Peilin Li, Wenyu Ma, and Nan Pan. 2023. "An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection" Energies 16, no. 19: 6921. https://doi.org/10.3390/en16196921
APA StyleShi, B., Zhou, X., Li, P., Ma, W., & Pan, N. (2023). An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection. Energies, 16(19), 6921. https://doi.org/10.3390/en16196921