1. Introduction
In today’s liberalized electricity market, price forecasting has become challenging for everyone involved. Accurate and efficient electricity price forecasts represent an advantage for market players (buyers and suppliers) and are crucial for risk management. In particular, the forecasting of electricity prices is vital for cash-flow analysis, investment budgeting, securities markets, regulatory formulation, and centralized resource planning. Therefore, electricity price modeling and forecasting could help in evaluating bilateral contracts. Moreover, an electricity price forecast is essential for manufacturing enterprises that must implement offers for the spot market at short notice: determine the guidelines of the medium-term contracts, and set out their long-term development plans. However, the behavior of the electricity price varies from that of other financial and commodity markets because it has unique characteristics connected to its physical attributes that can dramatically alter pricing. The primary difference is that electricity is a commodity that cannot be stored, so a slight change in output can result in large price swings in a matter of hours or minutes. For example, spot electricity prices exhibit long-term trends (linear or nonlinear), seasonality (daily, weekly, seasonal, and yearly), calendar effects, extreme volatility, and outliers (jumps or spikes). Because of these specific characteristics, the electricity price forecast is more challenging from the three forecast perspectives: the short-term, the medium-term, and the long-term [
1,
2,
3,
4,
5,
6,
7].
Long-term price forecasting (LTPF) in the electricity market generally refers to forecasting electricity prices from a few months to several years ahead, and these are used for planning and investment profitability analysis, which involves making decisions for future investments in energy plants, convincing spots, and fuel sources. Medium-term price forecasting (MTPF) commonly includes horizons from a few weeks to a few months ahead. It is essential for expanding power plants, developing investment, scheduling maintenance levels, bilateral contracting, fuel contracting, and establishing financing policies. Short-term price forecasting (STPF) typically considers forecasts of electricity prices from one day to a few days. Separately from energy planning, organization, and risk assessment, an STPF is vital for market contestants to enhance their bidding plans [
8,
9,
10]. In the literature on the deregulated electricity market, the STPF has received more scholarly attention since excessive electrical trading happens in these markets.
Due to the high unpredictability and uncertainty of electricity price series, extensive studies on the issue of electricity price forecasting have been carried out using various modeling methodologies over the last three decades. Many statistical, econometric, machine learning, knowledge-based expert systems, evolutionary calculation, and hybrid models have been considered in the electricity price literature to predict electricity prices [
11,
12,
13,
14,
15]. Generally, statistical forecasting models are classified into three types: parametric and nonparametric regression, linear and nonlinear time-series, and exponential smoothing models [
16,
17,
18]. Polynomial, sinusoidal, smoothing spline, kernel, and quantile regression are examples of parametric and nonparametric regression models. Linear and nonlinear time-series models with autoregressive, autoregressive integrated moving average, vector autoregressive moving average, and nonlinear time-series models with nonparametric autoregressive, autoregressive conditional heteroscedasticity, generalized autoregressive conditional heteroskedasticity, and threshold conditional autoregression heteroscedasticity are considered [
19,
20,
21,
22,
23,
24]. For instance, in a study referenced as [
25], different linear and nonlinear models were assessed to predict electricity prices for the next day using component estimation techniques. The study also included two simple benchmarks, the Naive 1 and Naive 2 models, which were compared to the proposed models using the price data. The findings revealed that the proposed models were remarkably more effective and precise than the benchmark models in terms of mean error accuracy. Similarly, the exponential smoothing models that accommodate varied periodicities, such as Holt-Winters single, double, and triple exponential smoothing [
26,
27,
28,
29] are frequently used for predicting purposes. In [
30] the authors, for example, utilized two distinct exponential smoothing models for node electricity prices. In addition, a comparison of the evaluated models with several alpha values and multiple trends was undertaken. The suggested models’ performance was effectively validated using average real-node electricity pricing data obtained from ISO New England. Machine learning algorithms (artificial neural networks, decision tree algorithms, random forest algorithms, support vector machines, etc.) were also used to forecast electricity prices one day ahead [
31,
32,
33,
34]. For example, in [
35], the researchers proposed an ensemble-based approach for predicting short-term electricity spot prices in the Italian electricity market. The outcomes (accuracy mean errors) show that the ensemble learning models outperform other single models.
In contrast to the above-discussed methods and models, there is a tendency towards employing combination (hybrid) predictive models, such as optimization (single-objective and multi-objective techniques), preprocessing (decomposition), and artificial intelligence decomposition models, to produce efficient and accurate prediction models. From this perspective, each method can add its ability to deal with different properties of the signals to the prediction model. For instance, in ref. [
36] proposed that the Long Short-Term Memory and Nonlinear Logistic Smooth Transition Autoregressive Model models be combined with GARCH volatility to improve the forecast accuracies of predictive models. Based on the empirical results, the proposed methodology offers a vital tool for investors and policymakers. Although the preprocessing methods, in particular the decomposition approaches, have the goal of cleaning up the noise and nonlinearity of the data by decomposing the observed series into different types of subseries, the long-term trend (linear or nonlinear), multiple seasonality (daily, weekly, monthly, seasonal, and yearly), and low and high volatility series [
37,
38]. In this sense, for forecasting purposes, a separate class of models (heterogeneous) or the same model (homogeneous) in terms of learning structure can be employed to estimate and forecast each decomposed subseries of the evaluated signal [
39,
40,
41]. During this process, diversity increased, and an efficient and accurate final prediction model was created by accumulation (direct accumulation). For example, in [
42], the decomposition methodologies of variational modal decomposition (VMD) and full-set empirical modal decomposition supplemented by adaptive noise were initially coupled. A partly iterative Elman neural network is then used to train and forecast each component, which is subsequently optimized using a multi-objective Gray-Wolf optimizer. Therefore, the results confirmed the efficiency and accuracy of the proposed decomposition methodology for electricity price forecasting. In reference [
43], the authors used VMD with exaggerated parameters specified by self-adaptive particle swarm optimization. The seasonal autoregressive moving average and the deep belief network were utilized to estimate the regular and irregular modes in a one-step-ahead system to anticipate the modes. In addition, ref. [
44], used the wavelet transform, which is made up of a stacked auto-encoder model and short-term memory, to anticipate commercial, industrial, and residential power costs. However, the authors of [
45] proposed a hybrid modeling and forecasting technique based on a search-based feature selection from Cuckoo integrated with singular spectrum analysis and support vector regression; for short-term electricity price forecasting by exploiting and evaluating important information hidden in the electricity price time-series. The stated hybrid modeling and forecasting methodology was verified in the New South Wales power market. This shows that the proposed forecasting approach outperforms the baseline models used in practice and is a trustworthy and promising instrument for short-term electricity price forecasting. On the other hand, ref. [
46], a flexible deterministic and probabilistic interval forecasting framework based on the VMD method, improved the multi-objective sine approach and regulated the extreme learning machine for multi-step electricity price forecasting, providing more valuable information to energy market policymakers.
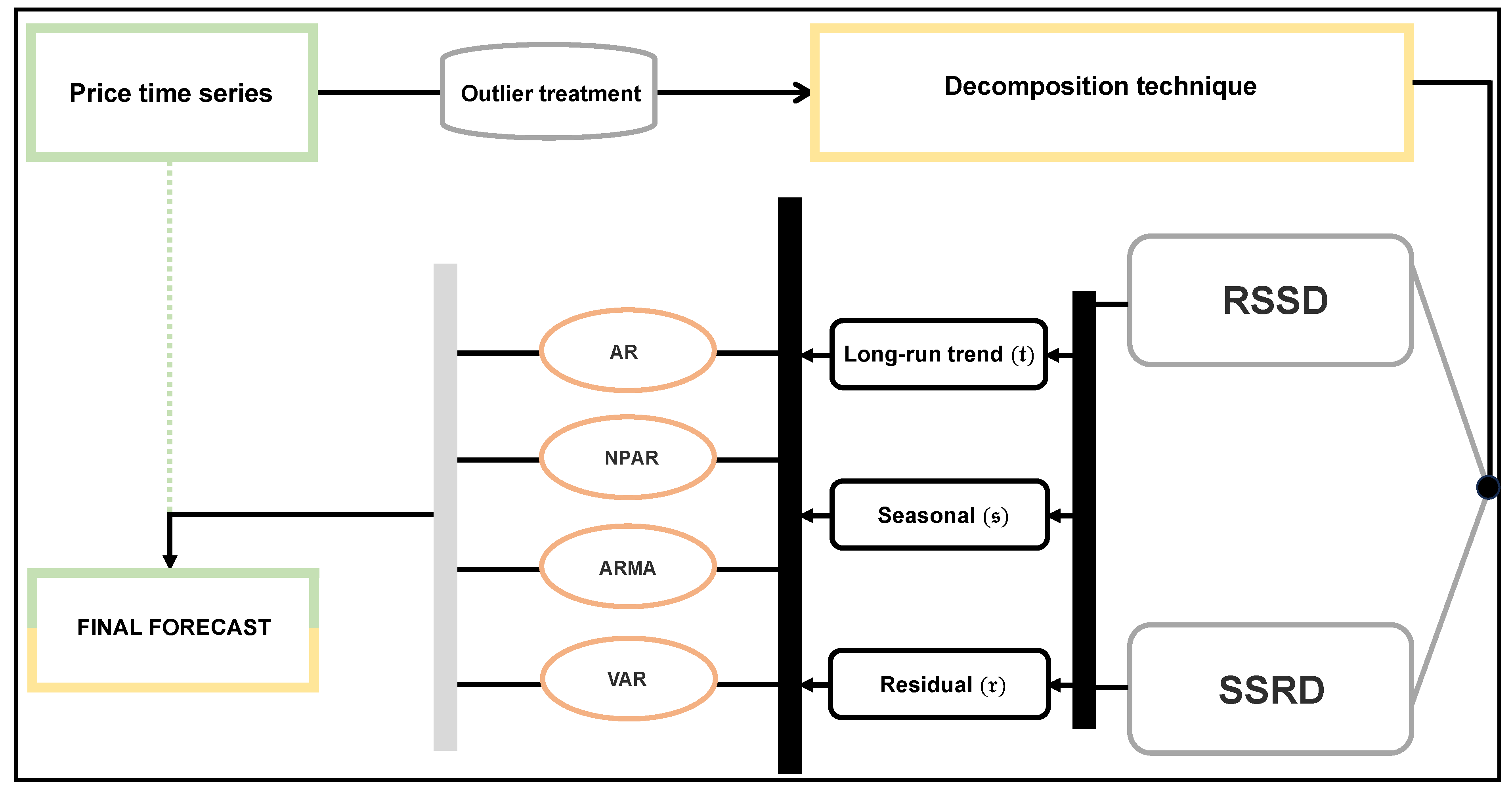
As previously discussed, the STPF has become a vital topic for market participants to improve their bid strategies. In this regard, new contributions should be encouraged by proposing different forecasting tools to provide an extensive range of forecasting models that can be applied to other customer needs to find the most effective one for each case. Thus, this work proposes a novel decomposition–combination modeling and forecasting technique. For this purpose, the original time-series of electricity prices is treated for outliers in the first step. In the second step, the filtered series of the electricity prices is decomposed into three new subseries, such as the long-term trend, a seasonal series, and a residual series, using two new proposed decomposition methods, namely regression splines decomposition and smoothing splines decomposition. Third, forecast each subseries using different univariate and multivariate time-series models, including parametric autoregressive, nonparametric autoregressive, autoregressive moving average, vector autoregressive, and all possible combinations. Finally, the individual forecasting models are combined directly to obtain the final one-day-ahead price forecast. The proposed decomposition–combination forecasting technique is applied to hourly spot electricity prices from the Italian electricity-market data from 1 January 2014 to 31 December 2019. Hence, four different accuracy mean errors, including mean absolute error, mean squared absolute percent error, root mean squared error, and mean absolute percent error; a statistical test, the Diebold–Marino test; and graphical analysis, are determined to check the performance of the proposed decomposition–combination forecasting method. Therefore, the main contributions of this work are the following:
To improve the efficiency and accuracy of day-ahead electricity price forecasting, a novel decomposition–combination technique is proposed based on different nonparametric regression methods and various time-series models.
Compare the performance of the proposed decomposition methods inside the proposed forecasting technique. In analogy, examine different combinations of univariate and multivariate time-series models within the proposed forecasting methodology.
To evaluate the performance of the proposed decomposition–combination forecasting method, four different accuracy mean errors are determined: mean absolute error, mean squared absolute percent error, root mean squared error, and mean absolute percent error; a statistical test, the Diebold–Marino test; and a visual evaluation.
In this study, the results of the best-combined model are compared with the best model proposed in the literature and the comparative results are recorded. Based on these results, the proposed best combination model from this work is highly accurate and efficient compared to the best models reported in the literature for day-ahead electricity price forecasting.
Finally, while this study is limited to the IPEX electricity market, it may be extended and generalized to other energy markets to assess the efficacy of the proposed decomposition–combination forecasting approach.
The remainder of the work is structured as follows: The general method of the proposed decomposition-combining forecasting technique is described in
Section 2. The proposed decomposition-combining forecasting technique is applied to hourly IPEX electricity price data in
Section 3.
Section 4 covers a comparative discussion of the best-proposed combination model with the best models proposed in the literature and some standard benchmark models. Finally,
Section 5 discusses conclusions, limitations, and directions for future research.
3. Case Study Results
This research article primarily focuses on electricity price fluctuations before COVID-19. For this purpose, this work uses the hourly spot electricity prices (euro/MWh) from the Italian electricity market collected from 1 January 2014 to 31 December 2019. Each day consists of 24 data points, with each data point corresponding to a load period. Therefore, it corresponds to 52,584 data points (2191 days). We divided the data into two groups for modeling and forecasting motives: a training group (model estimation) and the validation group(out-of-sample forecast). The training part configured the data from 1 January 2014 to 31 December 2018 (1826 days or 43,824 observations), which is approximately 80% of the total data, and the period from 1 January 2019 to 31 December 2019 (365 days or 8760 observations) was used as the out-of-ample forecast. The one-day-ahead out-of-sample forecast is determined by the moving or rolling window method [
60]. A rolling or moving window technique of analysis of a time-series model is often used to evaluate stability over time. When analyzing financial time-series data (energy prices) using statistical models, the main assumption is that the model parameters are unchanged over time. However, the economic environment often changes abruptly, and it may not be reasonable to assume that the parameters of a model are constant. A common technique to evaluate the constancy of model parameters is to compute parameter estimates over a fixed-size moving window over the sample. If the parameters are constant over the entire sample, the estimates on the sliding windows should not be too different. If the parameters change at some point during the sampling, then the alternate estimates will capture this instability.
However, this technique is one of the most popular methods for evaluating the accuracy and ability to forecast a statistical model using past data. This involves splitting the historical data into two sets: estimation and out-of-sample. The estimation set is used to develop the model and produce k-step-ahead (one-step-ahead in our case) projections for the out-of-sample set. However, the predictions may contain errors since the data used has already been observed. To address this, the estimation set is shifted by a set amount, and the process of estimation and out-of-sample is repeated until no further k-step predictions can be made. It is important to note that in this approach, the number of parameters used remains constant throughout the rolling window analysis.
To acquire the forecast of electricity prices one day ahead using the proposed modeling framework, the following steps must be followed: First, the recursive price filtering technique was used to identify and impute the outliers. However, the filtered electricity price is shown in
Figure 2 (right) and the original
Figure 2 (left). The visual representation indicates that the filtered price time-series has no more extremes than the original electricity price time-series. Also, the descriptive statistics, non-stationary statistics (augmented dickey-fuller (ADF) [
61] and Phillips-Perron unit root (PP) [
62] tests), and autoregressive conditional heteroskedasticity (ARCH) effect tests [
63] (the Ljung-Box (Box) and the Lagrange Multiplier (LM) tests) for the original electricity prices time-series, the filtered prices time-series, and the log-filtered prices time-series are provided in
Table 1. Hence, descriptive metrics are a collection of methods for summarizing and describing the key characteristics of a dataset, such as its central tendency, variability, and distribution. These statistics give an overview of the data and aid in determining the presence of patterns and linkages. It can be seen from
Table 1 that the minimum and maximum electricity prices, standard deviation, skewness, and kurtosis change before and after treating outliers, while the mean, mode, median, and first and third quartiles are the same. In the same way, the log-filtered series has the least descriptive statistic values.
In addition to the above, to check the unit root issue of the original electricity prices time-series, the filtered prices time-series, and the log-filtered prices time-series statistically by the ADF and PP tests. The results (statistic values) are listed in
Table 1, which suggests that the log-filtered electricity prices time-series have a higher negative statistic value, which indicates that the series is stationary. Furthermore, two ARCH tests, including Box and LM, are performed to verify the time-varying phenomena in conditional volatility. The test statistic results are listed in
Table 1. From this table, it can be observed that in both tests, the log-filtered series showed better results. Based on all these results, we will proceed with further modeling and forecasting purposes with the log-filtered series. In addition, it is confirmed in
Table 1 that the results of the ARCH test show that all three series (the original, the filtered, and the log-filtered electricity price time-series) have an ARCH effect. To achieve it, the proposed forecasting methodology is processed as follows: As we know, the log-filtered electricity series is an hourly time-series, and generally, it contains many periodicities (hourly, weekly, and yearly), with a linear or nonlinear trend component. To do this, in this work, the hourly dynamics were captured by each load period being modeled separately [
64].
In the second step, the proposed decomposition methods were used to obtain long-term (
), seasonal (
), and residuals (
) time subseries. Thus, a graphical representation of decomposed subseries is given in
Figure 3 (left panel) and
Figure 3 (right panel). In both panels, first, the filtered log price series; second, the long-trend (
); third, the seasonal (
) and fourth, the residual (
), respectively. For both figures, it can be seen that both methods, the RSD and the SSD, decomposed the real-time-series of electricity prices and adequately captured both the dynamics, i.e., the long-term trend component, and the seasonality (yearly and weekly), which adequately captured the series of electricity prices.
Finally, in the third step, previously outdated univariate and multivariate models were applied to each subseries. After modeling these decomposed series, we checked their residuals for ARCH effects, so there was no more evidence of an ARCH effect this time. Therefore, the estimation of models was made to obtain a one-day-ahead forecast for 365 days, which comprises 8760 data points, using the rolling window method. The Equation (
9) was used to obtain the final day-ahead price forecasts.
In this empirical study, the decomposition of the hourly filtered electricity spot prices time-series (
) into new subseries containing the long-term trend (
), a seasonal (
), and a residual series (
) was obtained by two proposed decomposition methods. On the other side, all three subseries are estimated using four different linear and nonlinear, univariate, and multivariate time-series models, and all possible combinations are considered. Hence, combining the models for the subseries estimations leads us to compare 64 (
= 64) different combinations for one decomposition method. Consequently, for both decomposition methods, the RSD and the SSD, there are 128 (2 × 64) models. For these all one hundred and 28 models, one day-ahead out-of-sample forecast results (MAE, MSPE, MAPE, and RMSE) are listed in
Table 2 and
Table 3. From
Table 2, it is confirmed that the
RSD
combination model led to a better forecast compared to the rest of all combination models using the RSD method. The best forecasting model is obtained by
RSD
, which produced 3.5880, 1.3480, 7.5116, and 4.7130 for MAE, MSPE, MAPE, and RMSE, respectively. Although the
RSD
,
RSD
and
RSD
models produced the second, third, and fourth-best results within all 64 combination models using the RSD method. In the same way, from
Table 3, one can see that the
SSD
combination model shows the best results compared to the rest of all 64 combination models using the SSD method. This best model obtained the following forecasting results: 3.5880, 1.3480, 7.5116, and 4.7130 for MAE, MSPE, MAPE, and RMSE, respectively. On the other hand, the
SSD
,
SSD
and
SSD
models showed the second, third, and fourth-best results within all 64 combination models using the SSD method. When comparing the overall one hundred and 28 models from both decomposition methods, the RSD and SSD, the best one-day-ahead forecasting results were shown by the
RSD
combination model, while the second, third, and fourth-best results were within all one hundred and 28 combination models shown by the
RSD
,
RSD
and
RSD
models. As a result of these results (accuracy mean errors), it is confirmed that, within the proposed decomposition methods, the RSD method shows high accuracy and efficiency in one-day-ahead electricity price forecasting. In contrast, the best combination model (
RSD
) shows high accuracy and efficiency in forecasting across all 128 models.
Similarly, from the proposed decomposition methods (RSD and SSD), the four best combination models from each decomposition method are selected and compared. For these 8 (4 × 2) best models, the mean accuracy errors are numerically tabulated in
Table 4. It is confirmed that from this table, the
RSD
produced the smallest mean error values: RMSPE = 1.3480, MAPE = 7.5116, MAE = 3.5880, and RMSE = 4.7126, respectively. The
RSD
,
RSD
, and
RSD
showed the second, third, and fourth-best results in terms of accuracy mean errors. Thus, it is concluded that once again, within the proposed decomposition methods, the RSD decomposition method produced the lowest mean errors, and the
RSD
final super best combination model was considered the best model among the 12 best combination models.
After computing the mean errors, the next step is to identify the supremacy of these outcomes. This study used the DM test to validate the superiority of the final eight best combination models findings (mean errors) shown in
Table 4. The outcomes (
p-values) DM test are presented in
Table 5. Compared to the alternate that each entry in
Table 5 and the column/row predictive algorithms accuracy are higher compared to the row or column predictive scores for the hypothesis procedure, the null hypothesis cannot occur predictor. This table indicates that at the level of significance of 5%, the
RSD
,
RSD
,
RSD
, and
RSD
models are statistically superior to the others among the best eight combination models in
Table 4.
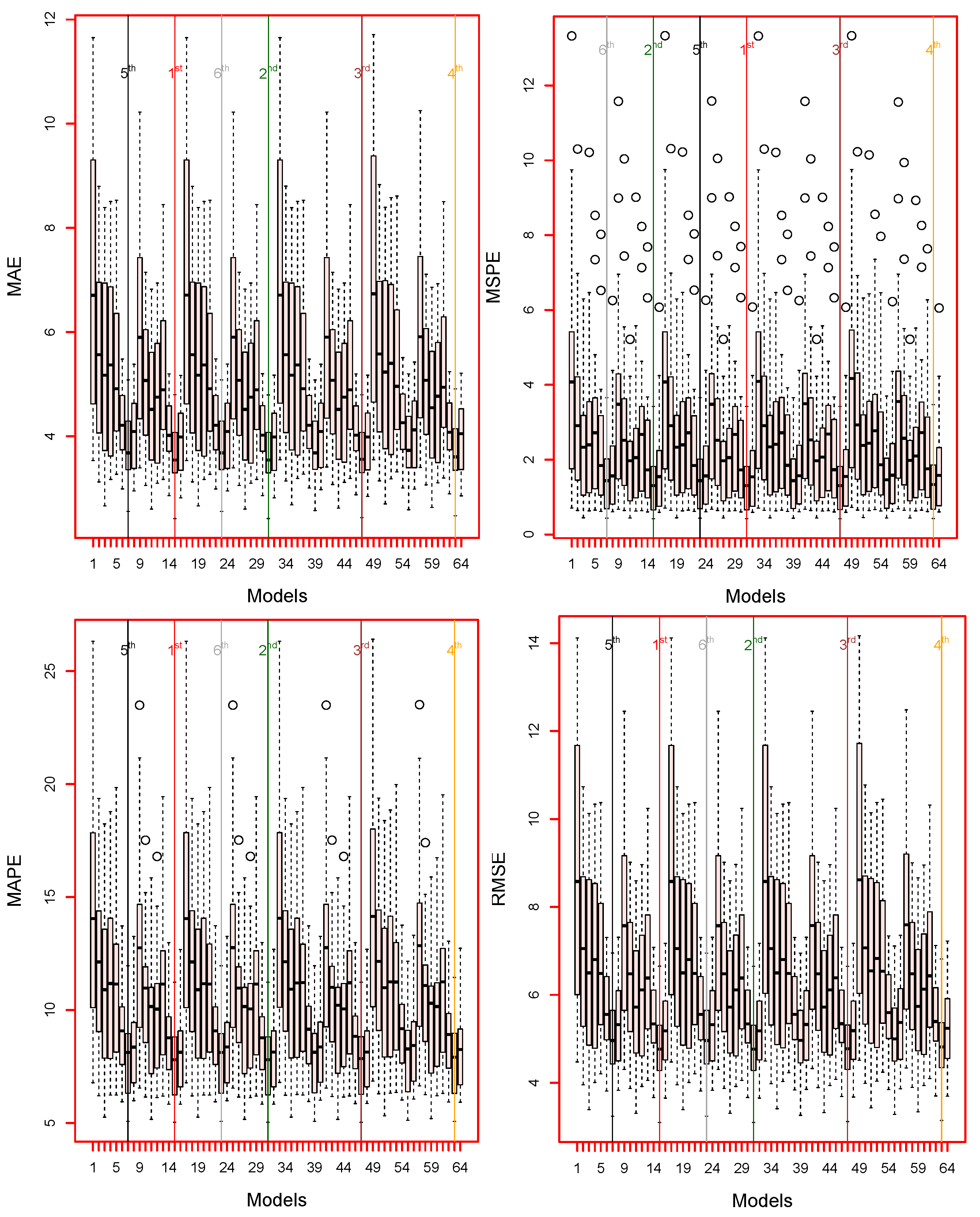
Finally, to verify the superiority of the proposed decomposition–combination approach using graphical analysis, including box plots, line plots, bar plots, and dot plots in this work. For example, the box plots of the MAE, MSPE, MAPE, and RMSE for all models (128) are given in
Figure 4 and
Figure 5. It can be seen from
Figure 4; the smallest accuracy mean errors are produced by
RSD
combination models, while the
RSD
,
RSD
and
RSD
combination models are second, third and fourth-best models, using the RSD method. In contrast, the results of the SSD method of the visual representation are shown in
Figure 5; it is confirmed from these box plots that the lowest mean errors (MAE, MAPE, MSPE, and RMSE) values are obtained by
SSD
combination model, while the
SSD
,
SSD
and
SSD
combination models, second, third, and fourth-best models. In the same way, from the proposed decomposition methods: RSD and SSD, the four best combination models from each decomposition method are selected and compared. For these 8 (4 × 2) best combination models, the mean accuracy errors are plotted in
Figure 6. This figure shows that the
RSD
combination model obtained the lowest mean errors, while
RSD
,
RSD
and
RSD
combination models are second, third and fourth-best results; in terms of accuracy mean errors comparing the eight best models form both proposed decomposition methods.
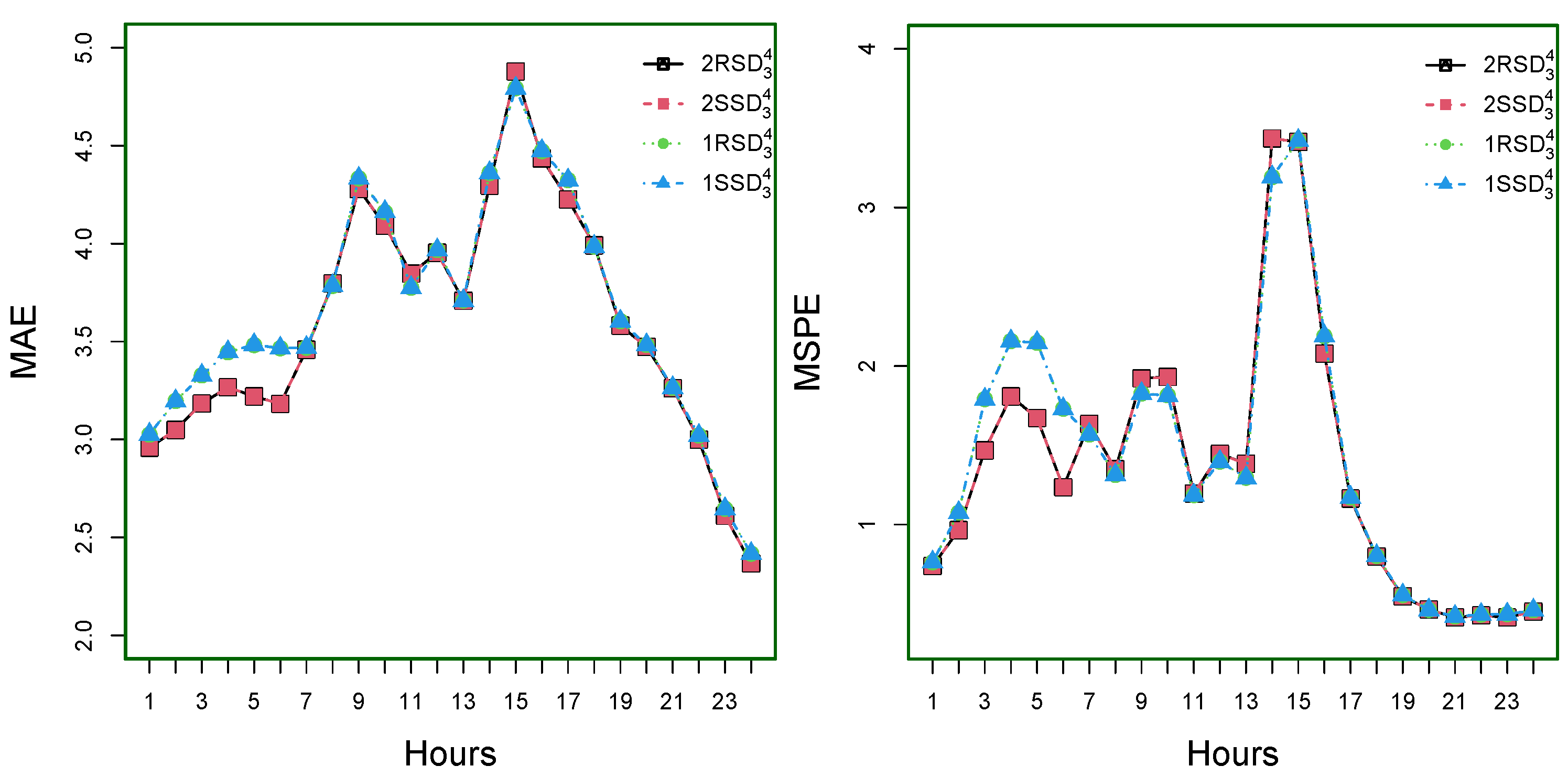
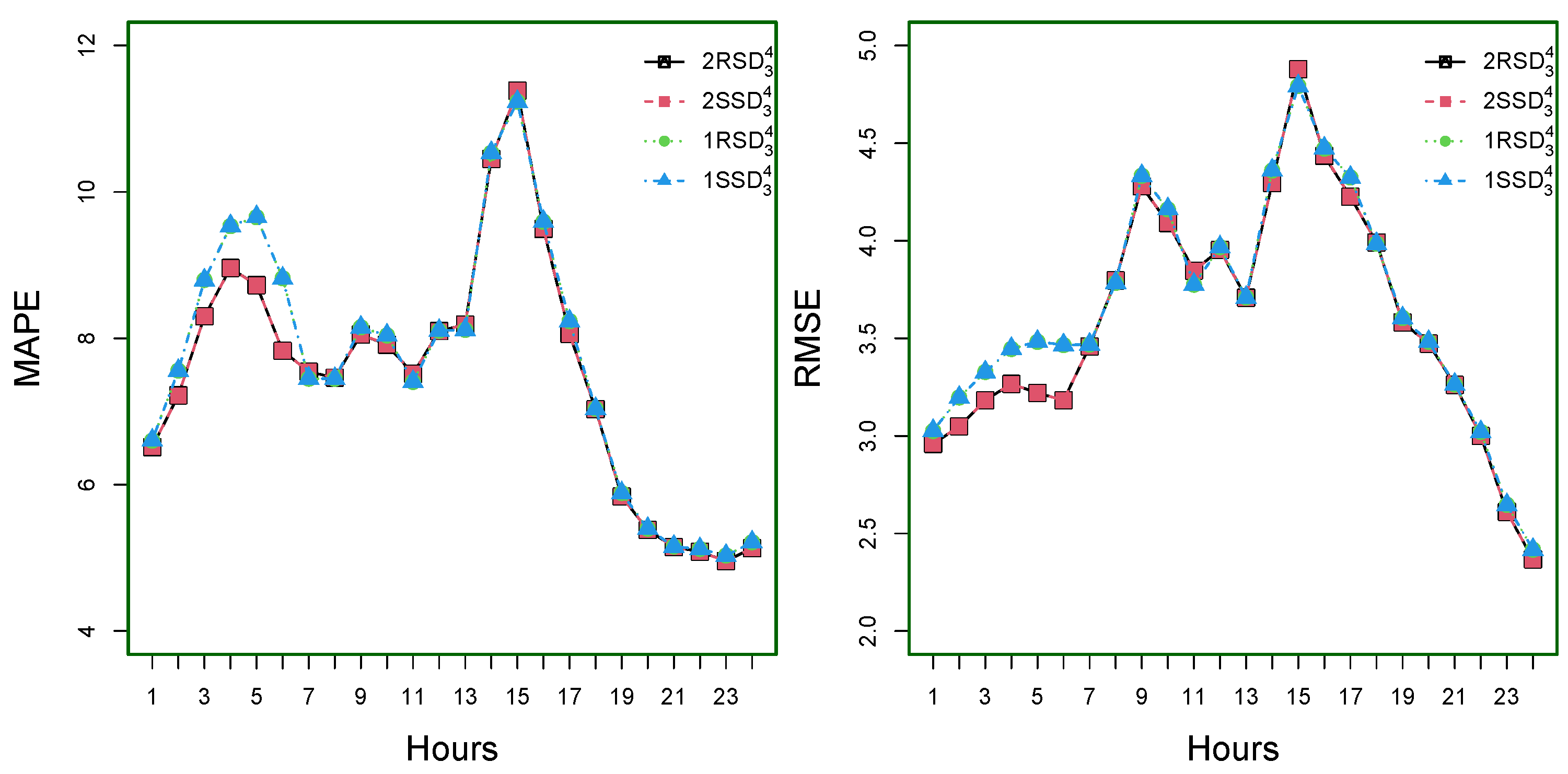
On the other hand, the hourly MAE, MSPE, MAPE, and RMSE for the super best four models among the eight best models, such as
RSD
,
RSD
,
SSD
, and
SSD
are shown in
Figure 7 for MAE (top-left), MSPE (top-right), MAPE (bottom-left), and RMSE (bottom-right). As of this figure, note that the hour means errors are lower at the start of the day and slowly increase with the first peak around 9:00 a.m.; after this, the values of mean errors are monotonically decreased and increase with the second peak around 3:00 p.m.
At the end of this section, the original and forecasted values for the best four combinations of models are
RSD
,
RSD
,
SSD
, and
SSD
, as shown in
Figure 8. As confirmed by the figure, our model`s forecast follows observed prices very well. Therefore, we can determine that the
RSD
,
RSD
,
SSD
, and
SSD
, models outperformed the rest of them. Therefore, to conclude this section, from the accuracy mean errors (MSPE, MAPE, MAE, and RMSE), a statistical test (DM test), and graphical results (box-plot, bar-plot, and line plots), we can conclude that the proposed decomposition–combination forecasting methodology is highly efficient and accurate for one-day-ahead IPEX electricity prices. In addition, within the proposed all combination models, the
RSD
combination model produces more precise forecasts when compared with the alternative combinations.
At the end of this section, it is worth mentioning that all implementations were done using ‘R’, a language and environment for statistical computing. In more detail: Decomposition methods, modeling, and forecasting were implemented using the GAM library. The forecast, tsDyn, and vars libraries were used to estimate and forecast univariate and multivariate time-series models. In addition, all calculations were performed using an Intel (R) Core (TM) i5-6200U CPU at 2.40 GHz (Santa Clara, CA, USA).
4. Discussion
This section provides an overview of the comparison of the final best combination model (
RSD
) of this work with the literature’s best models and uses standard univariate and multivariate time-series benchmark models. Hence, in
Table 6 numerically and graphically in
Figure 9, an empirical comparison of our best combination model (
RSD
) with other researchers’ proposed models is presented. For example, It can be seen from these presentations that the best-proposed model (Stoc-AR) of [
65] was applied to this work’s dataset, and their accuracy mean errors were obtained. The best-proposed model (Stoc-AR) of [
65] reported the accuracy mean error values as the following: MSPE = 4.1204, MAE = 5.9122, RMSE = 7.2821, and MAPE = 12.0175, respectively, which are remarkable greater than our accuracy mean error values: MSPE = 1.3480, MAE = 3.5880, RMSE = 4.7130, and MAPE = 7.5120. In another work, ref. [
66], the best-proposed model (NPAR) used the current study dataset and obtained performance measures that were comparatively higher than our best combination model. In the same way, for instance, the obtained forecasting mean errors by the best model [
66] are the following: 4.9121, 4.1061, 6.8534, and 10.9031, which are significantly higher than our best combination model forecasting mean errors. In addition, in ref. [
47], the best-proposed model (MPF-VAR) used the current study dataset and computed the accuracy measures that were also comparatively higher than our best model. To sum up, it can be seen that the best combination model of this work significantly obtained high accuracy as compared to the literature’s best models.
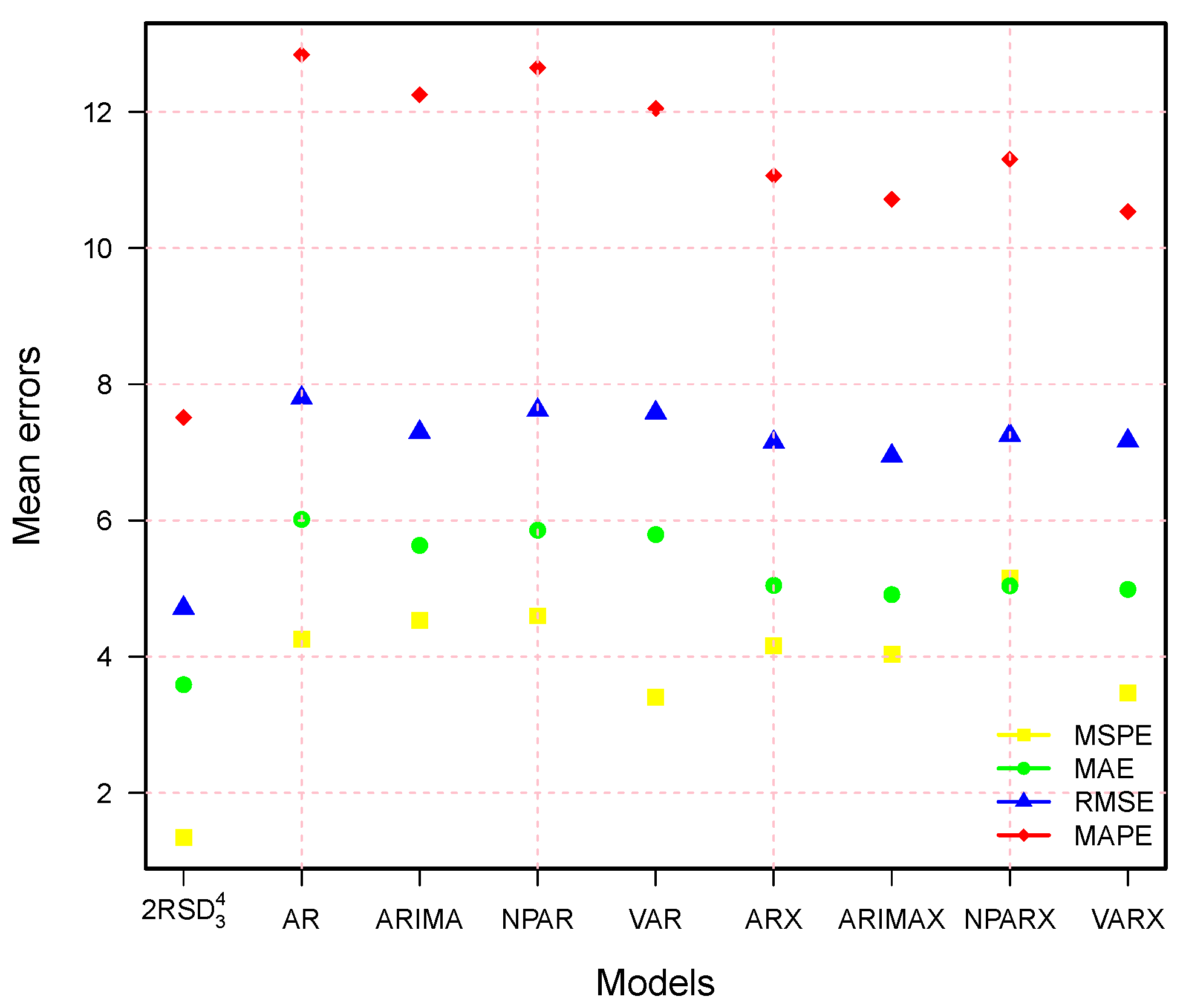
On the other hand, to assess the performance of our best combination model (
RSD
), it is compared to the standard benchmark univariate and multivariate time-series models: AR, ARIMA, NPAR, VAR, ARX, ARIMAX, NPARX, and VARX. In these models, X denotes the deterministic components, including a linear or nonlinear trend component, an annual cycle dummy, and a weekly period dummy. Therefore, the comparison results (numerically and graphically) are presented in
Table 7 and
Figure 10. In these presentations, one can easily see that all benchmark models (AR, ARIMA, NPAR, VAR, ARX, ARIMAX, NPARX, and VARX) are outperformed by this work’s best model (
RSD
). Although the ARX, ARIMAX, NPARX, and VARX models show the best results compared to the models without deterministic components (AR, ARIMA, NPAR, and VAR), they still show the worst results compared to our best model. Thus, we can say that the best combination model in this study achieved significantly higher accuracy compared to all other benchmark models.
In summary, from the comparison results of the proposed best model from the literature and the recommended standard time-series model, the proposed best combination model has high efficiency and high efficiency for predicting the one-day-ahead electricity price of IPEX in this work. However, short-term accurate and efficient forecasts will help sellers (buyers and suppliers) optimize their bidding strategies, maximize profits, and use the resources needed to generate electricity more effectively. This also benefits the end user in terms of a reliable and economical energy system. In addition, good forecasts and knowledge of electricity price trends in developed and developing economies can help traders make more profitable business and trading plans and make beneficial asset allocation decisions. In addition, based on the best-proposed model, the sellers (buyers and suppliers) can develop a more robust trading plan and choose the model with the best risk-reward combination.
On the other hand, this study only utilizes data on electricity prices in Italy; however, it has the potential to be expanded to include other countries (the United States, the United Kingdom, the Nordic countries, Australia, Brazil, Chile, Peru, etc.) and energy market variables (electricity demand, electricity curves, natural gas prices, crude oil prices, etc.). This will allow for a more comprehensive evaluation of the effectiveness of the proposed decomposition methods in combination with the proposed forecasting methodology. In addition, the nonparametric regression methods (regression splines and smoothing splines) used in the proposed decomposition methods are adaptable to different data patterns, such as long-term linear or nonlinear trends, various periodicities (yearly, seasonal, weekly, and daily), non-constant mean and variance, jumps or peaks (extreme values), high volatility, calendar effects, and a tendency to return to average levels. These are achieved through the tuning of knots and sparsity levels.




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}