
Research on Product Yield Prediction and Benefit of Tuning Diesel Hydrogenation Conversion Device Based on Data-Driven System


Abstract
:1. Introduction
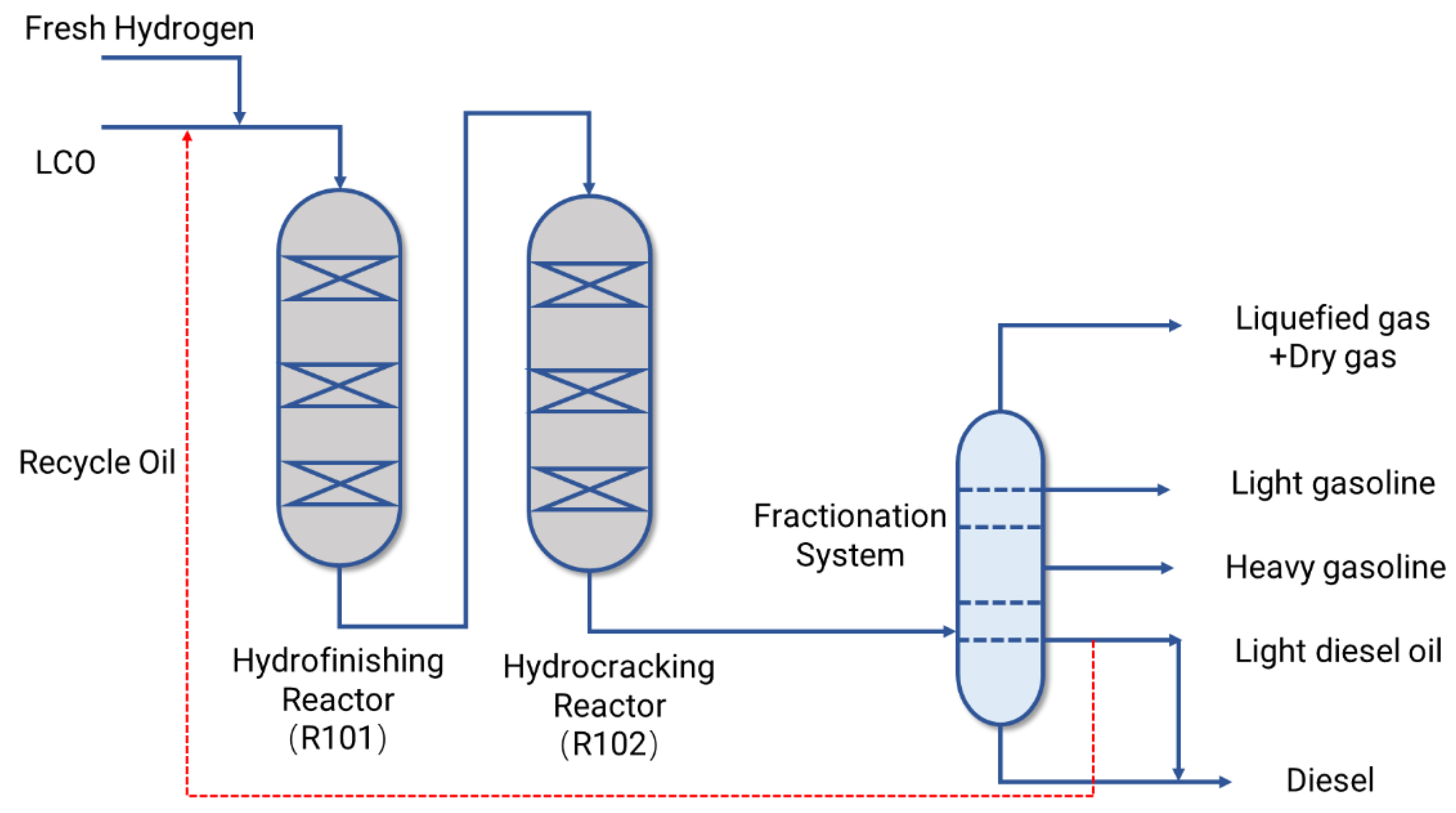
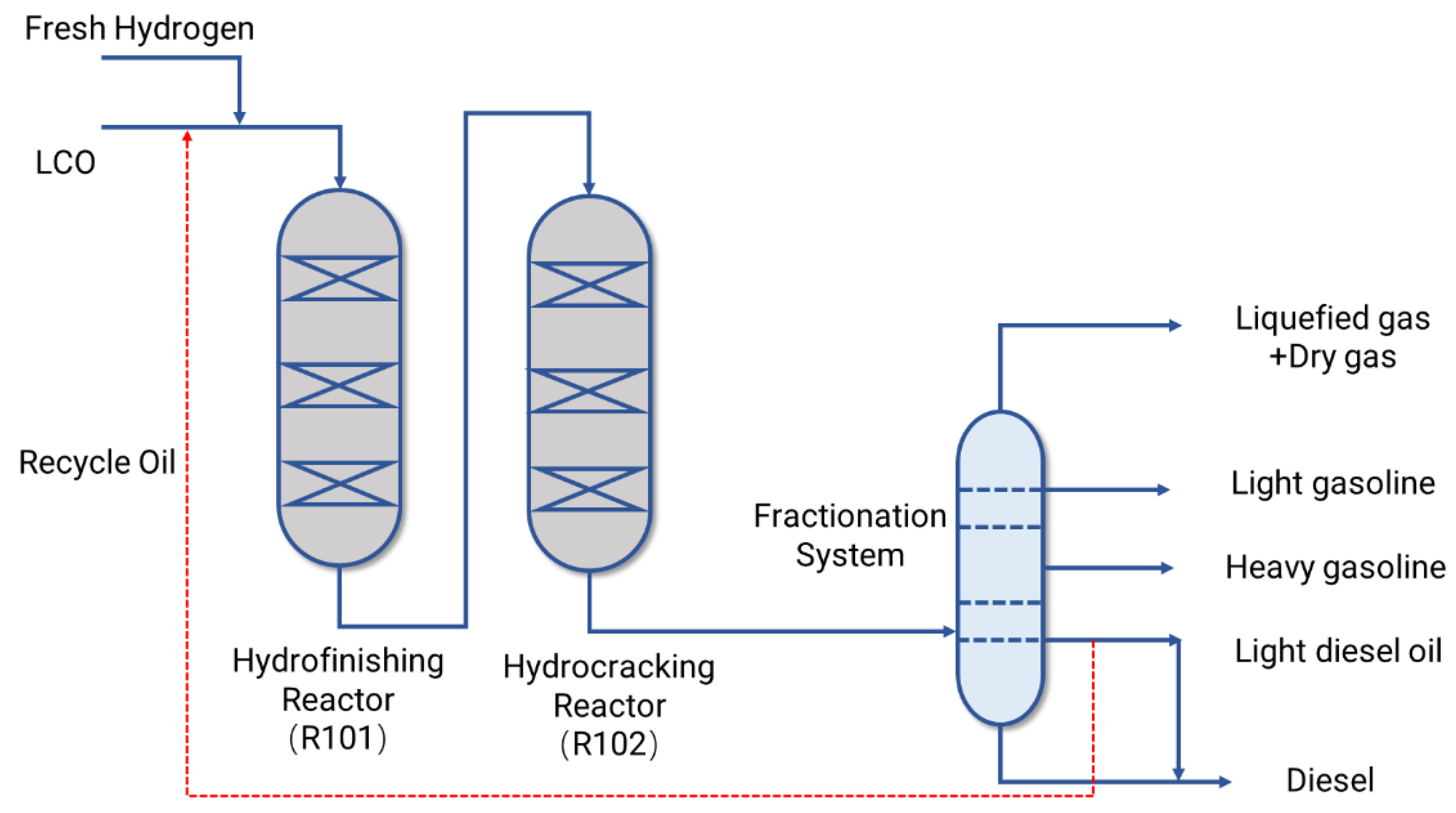
2. Industrial Hydrocracking Process
3. Experimental Methods
3.1. Overall Framework
3.2. Deep Nerual Network
3.3. Data Collection and Preprocessing
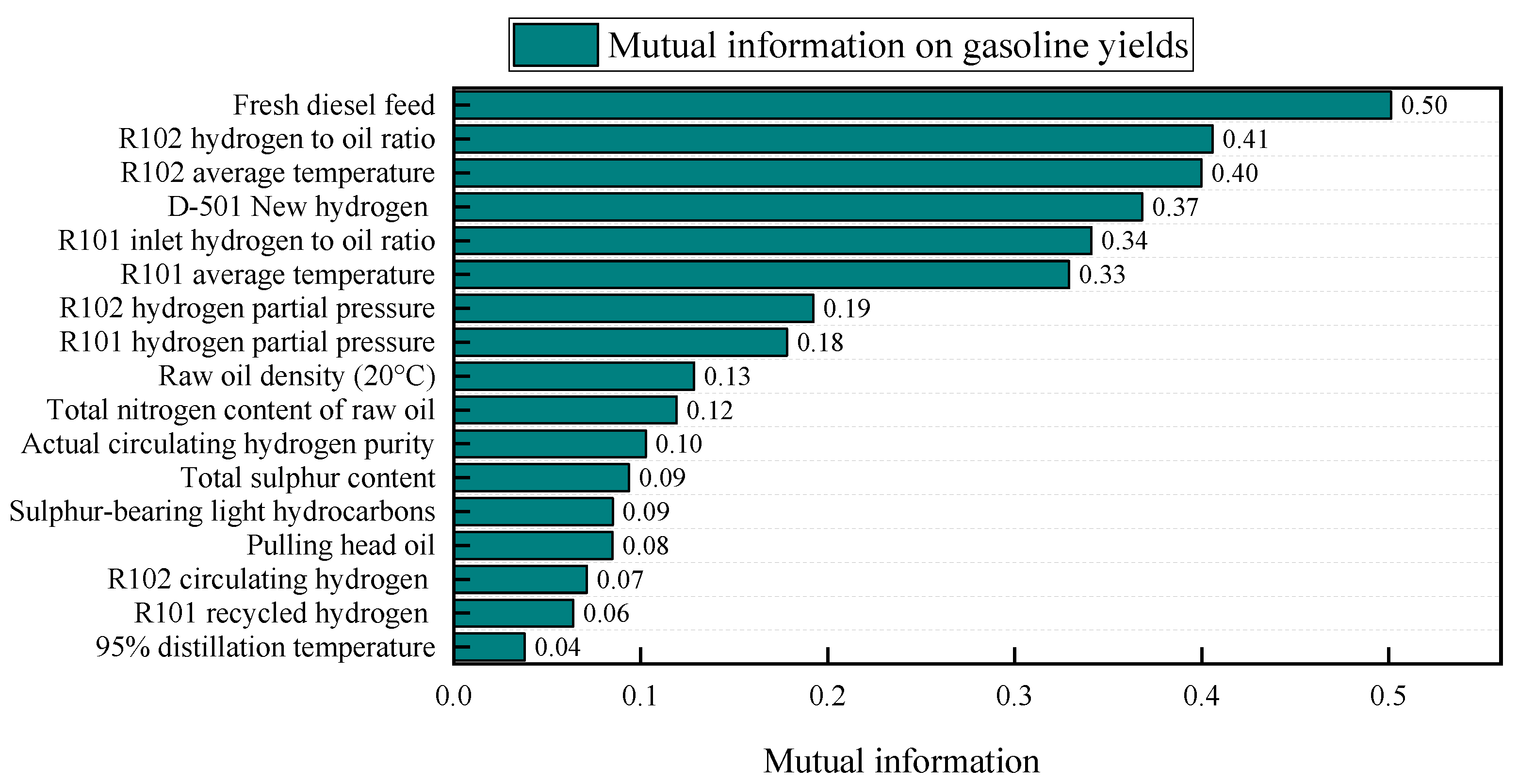
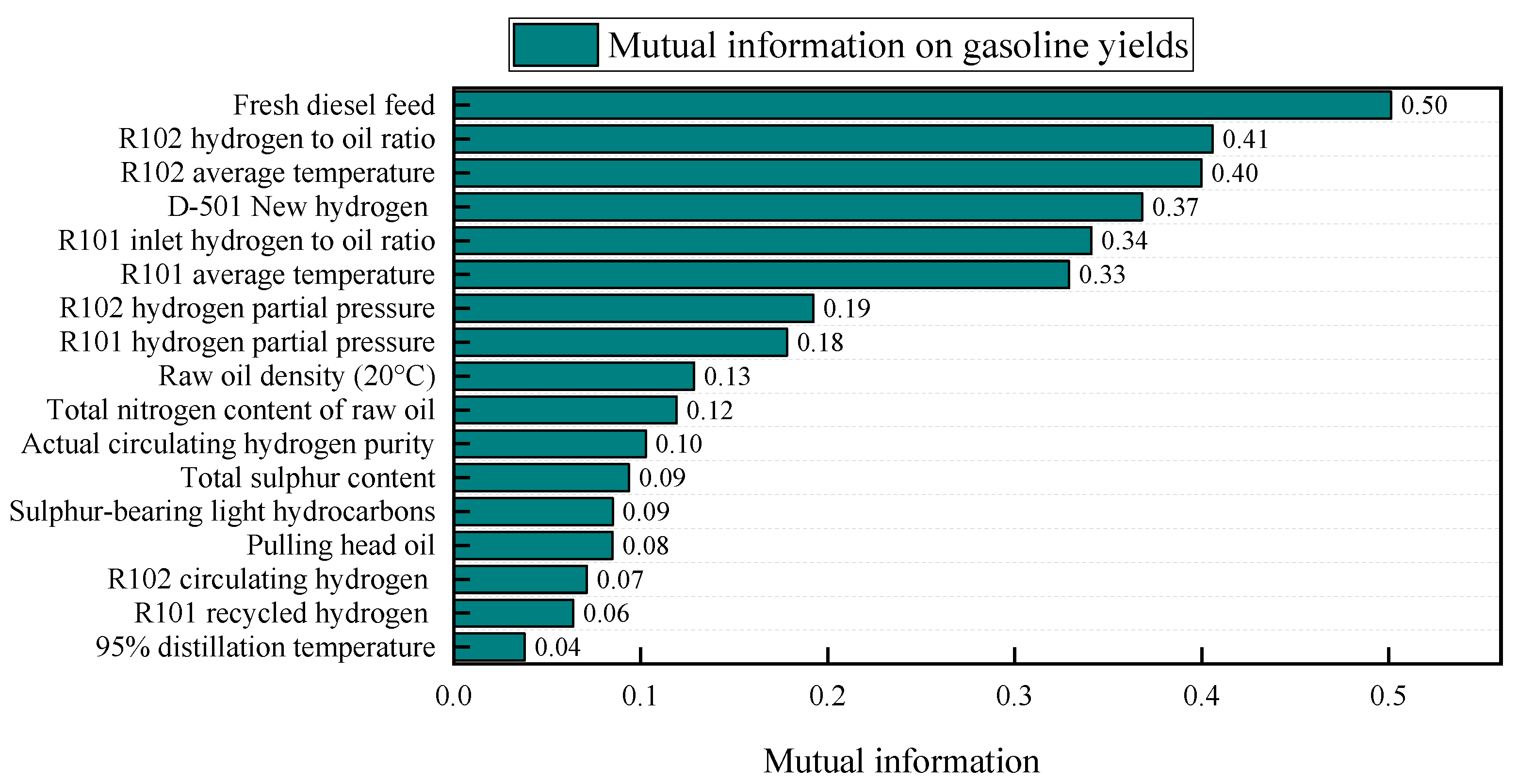
3.4. Analysis and Selection of Modeling Variables
3.5. Genetic Algorithm
4. Results and Discussion
4.1. RLG Device Yield Prediction Model
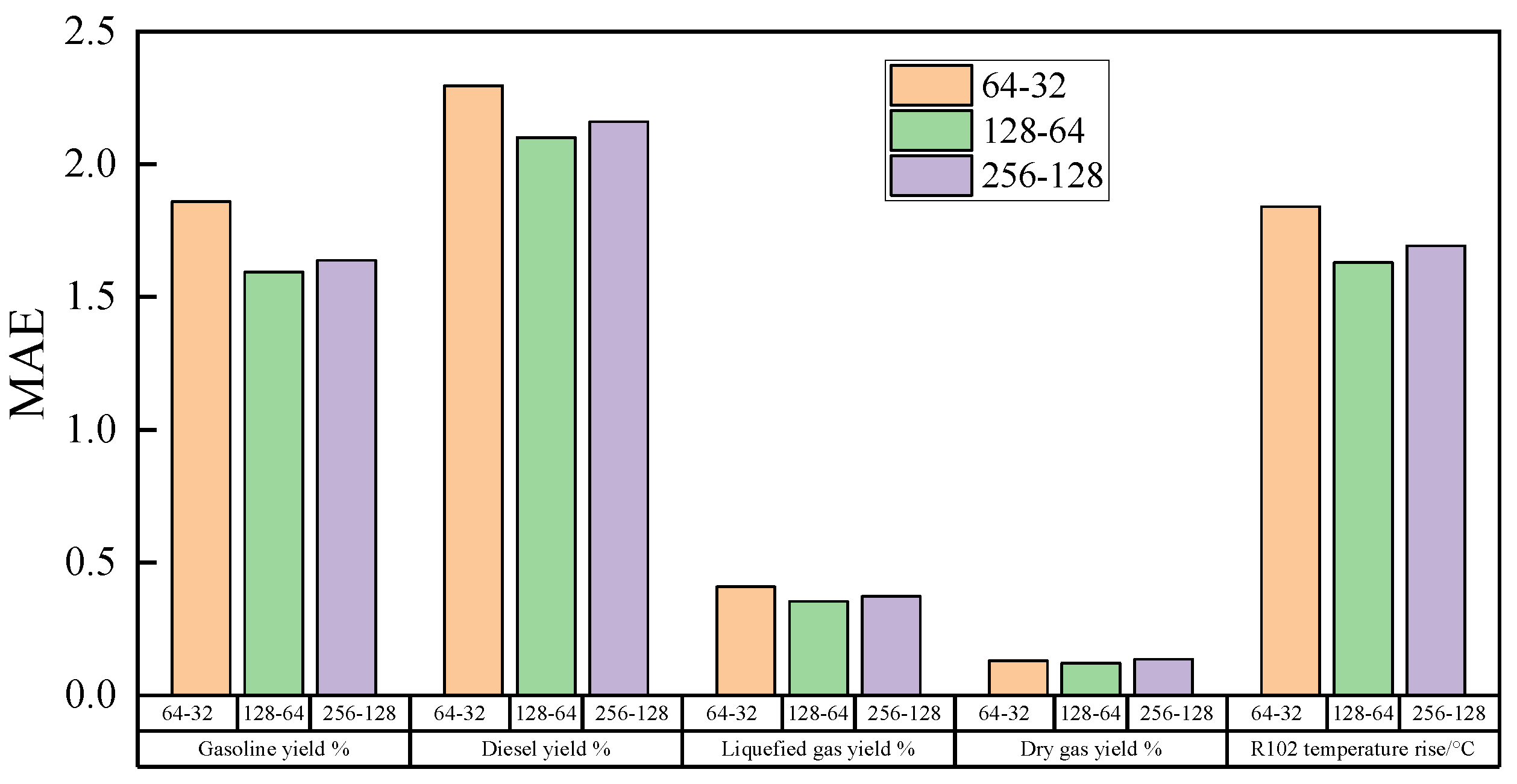
4.1.1. Selection of DNN Model Parameters
- (1)
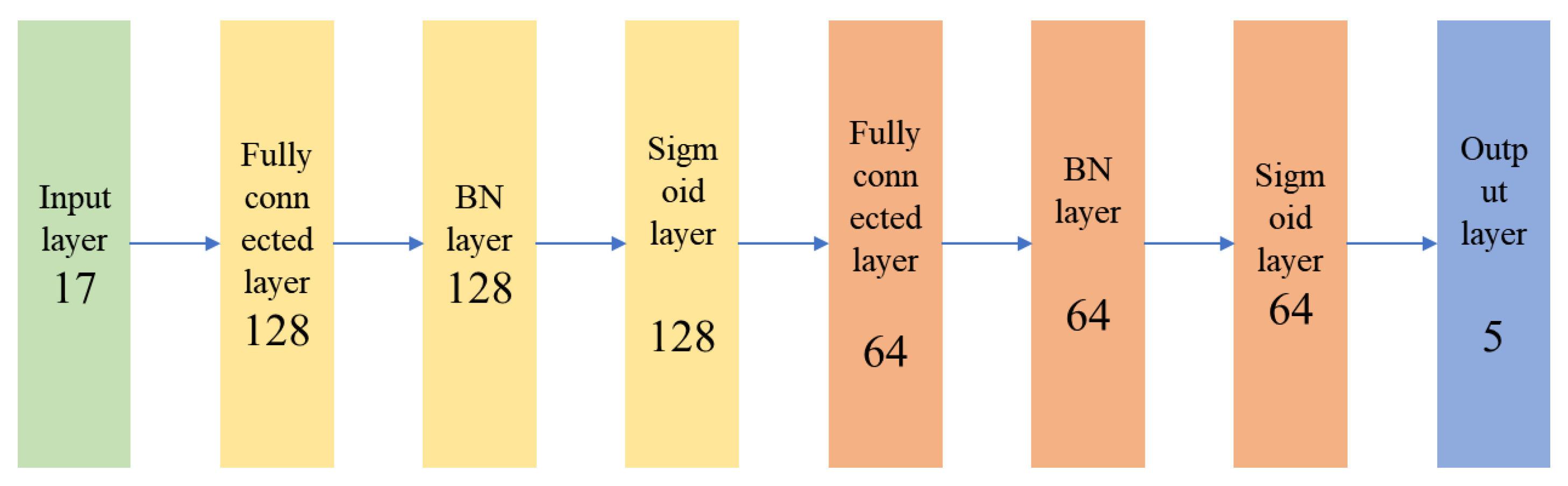
- Establishment of input and output neuron layers
- (2)
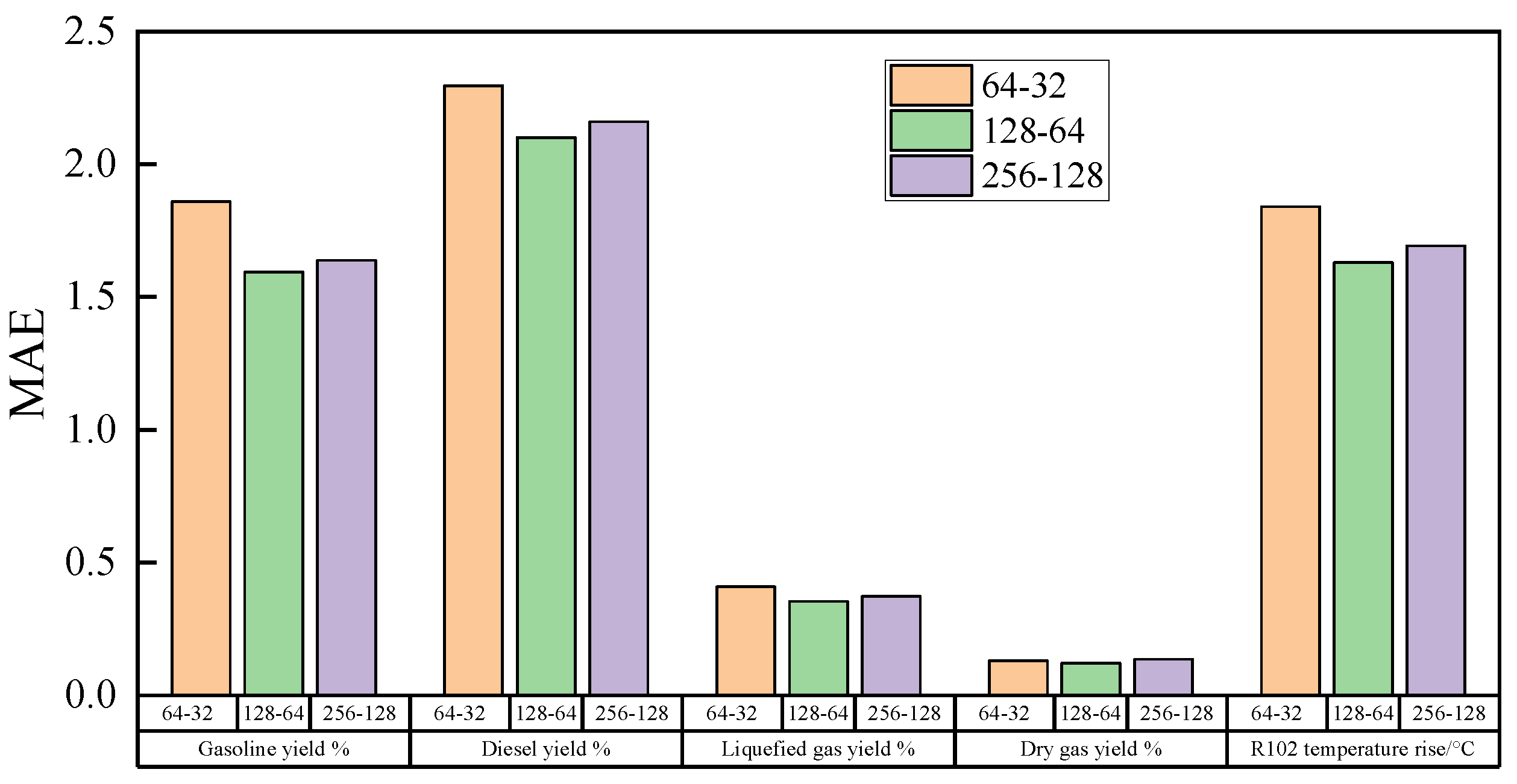
- Batch_Size
- (3)
- Batch Normalization
- (4)
- Determination of the number of neurons in the hidden layer
- (5)
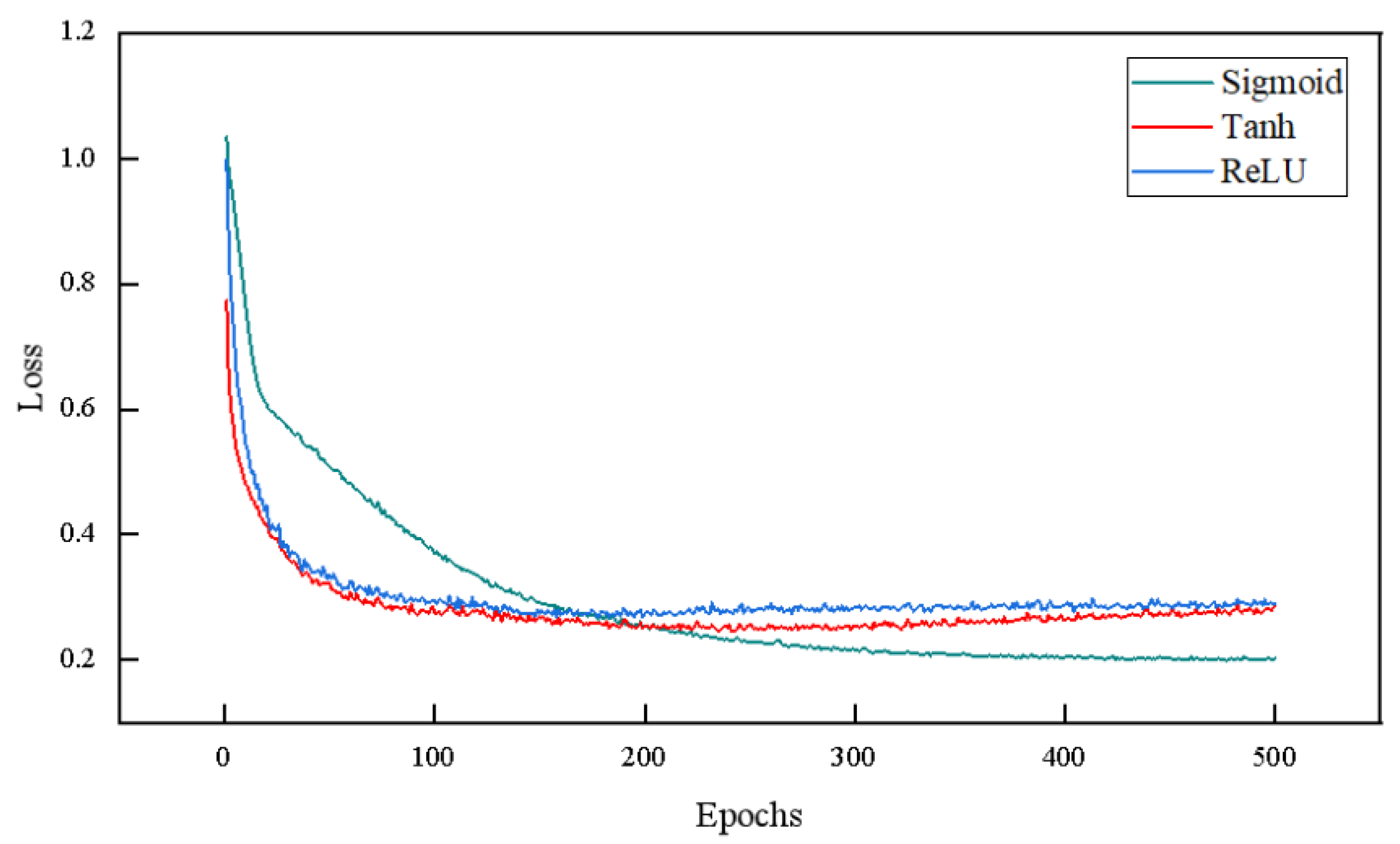
- Choice of activation function
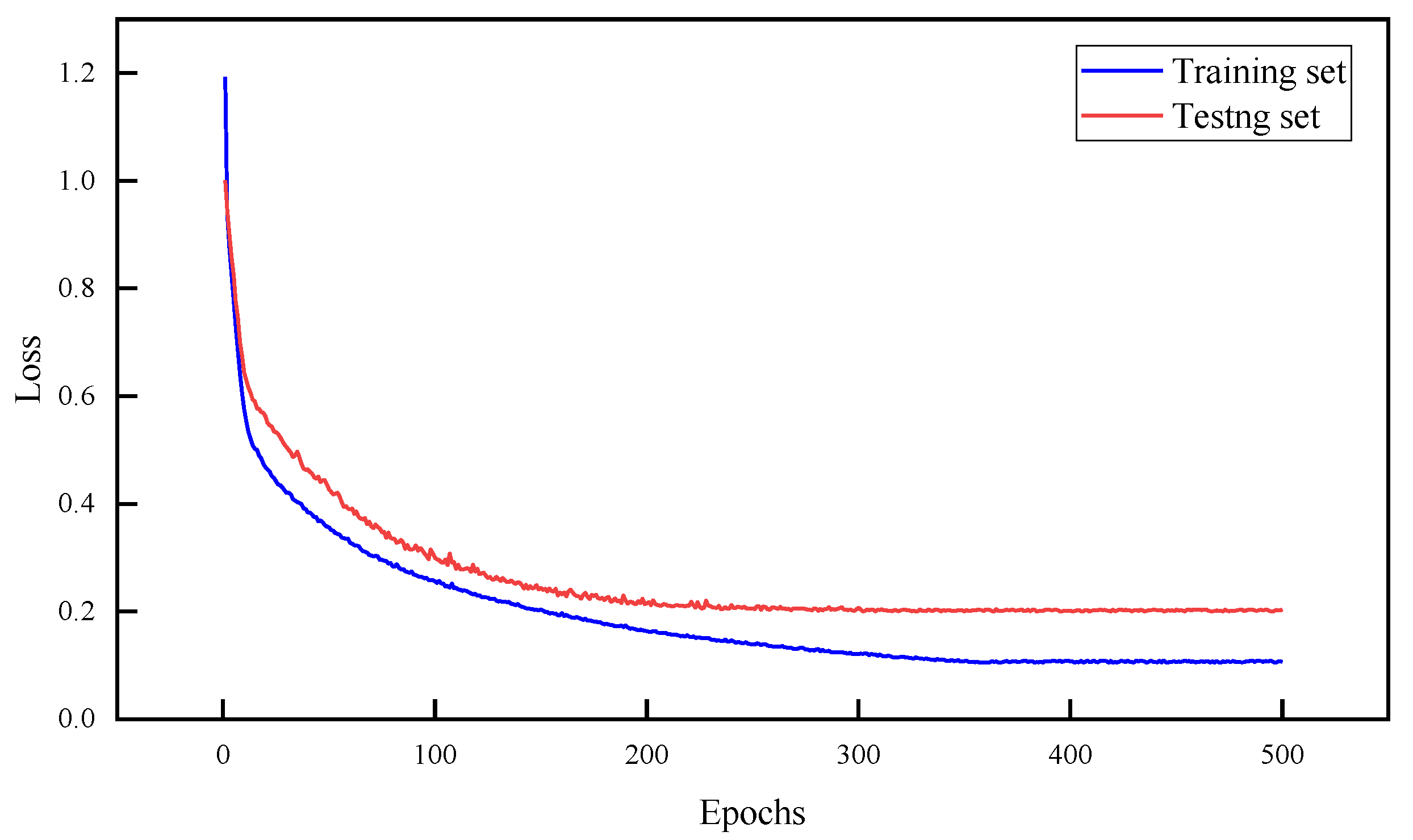
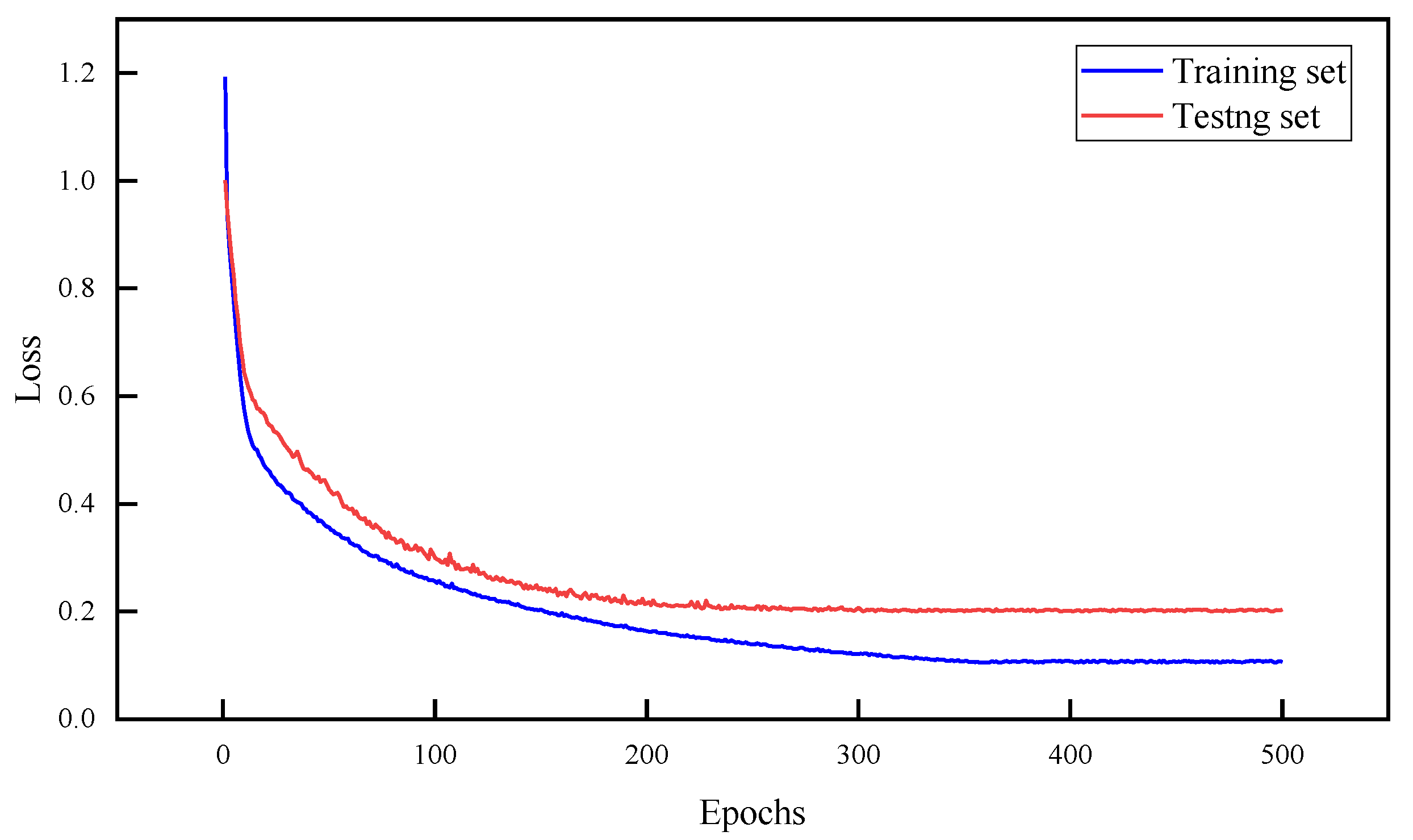
4.1.2. DNN Model Training
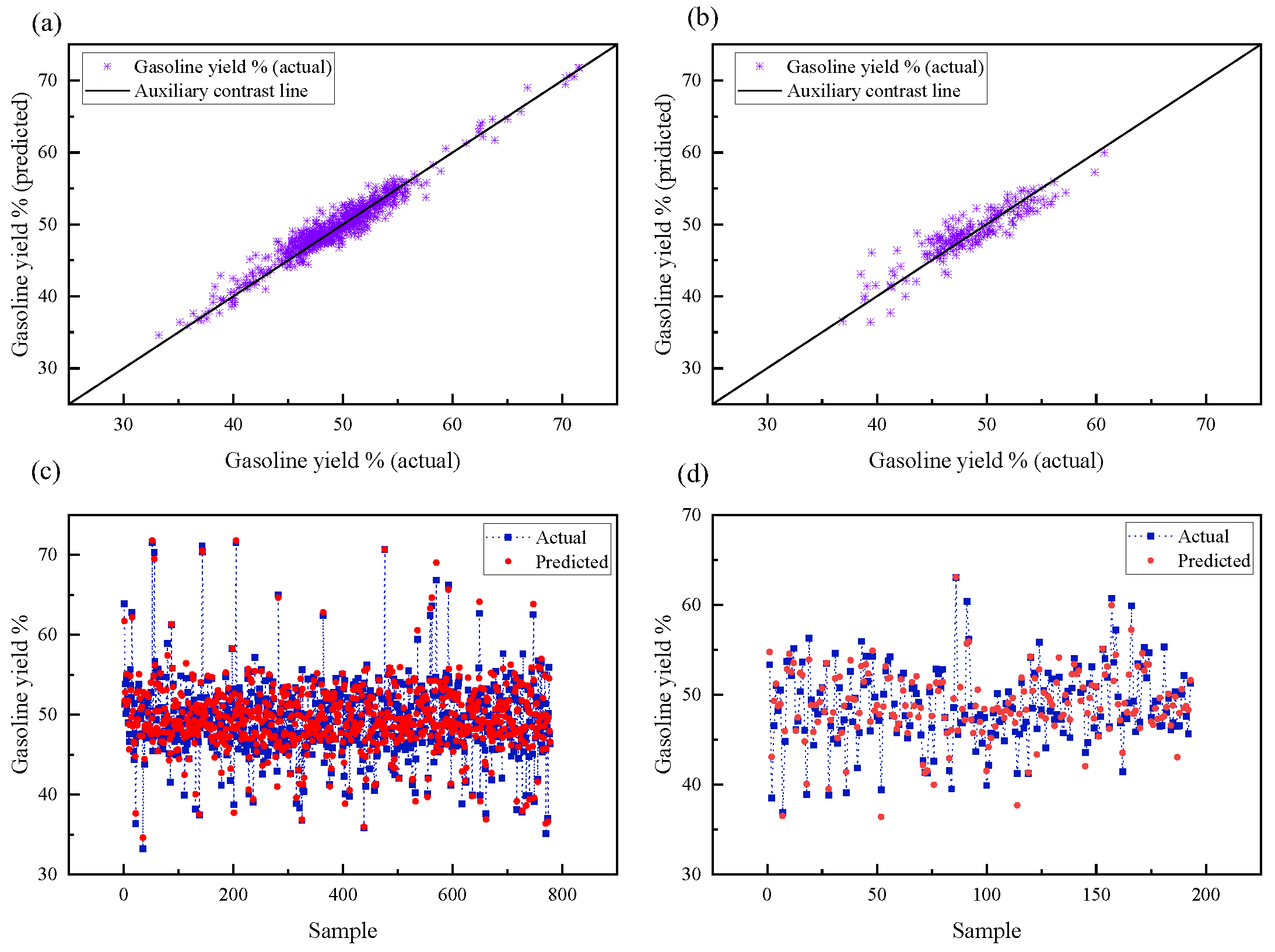
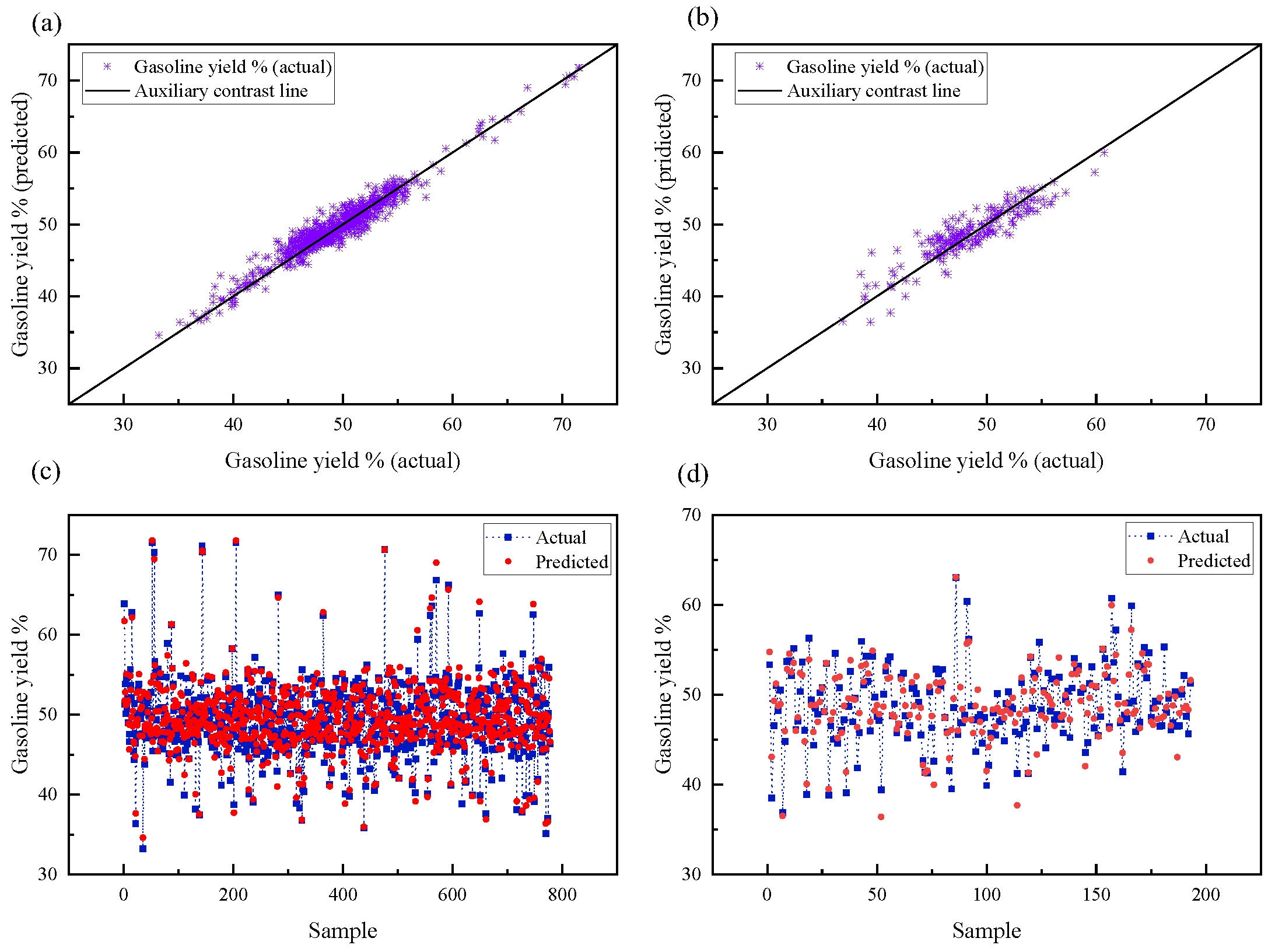
4.1.3. Model Prediction Results and Evaluation
4.2. Mathematical Model for Revenue Optimization of RLG Device
4.2.1. The Objective Function of the Optimization Problem
4.2.2. Binding Conditions
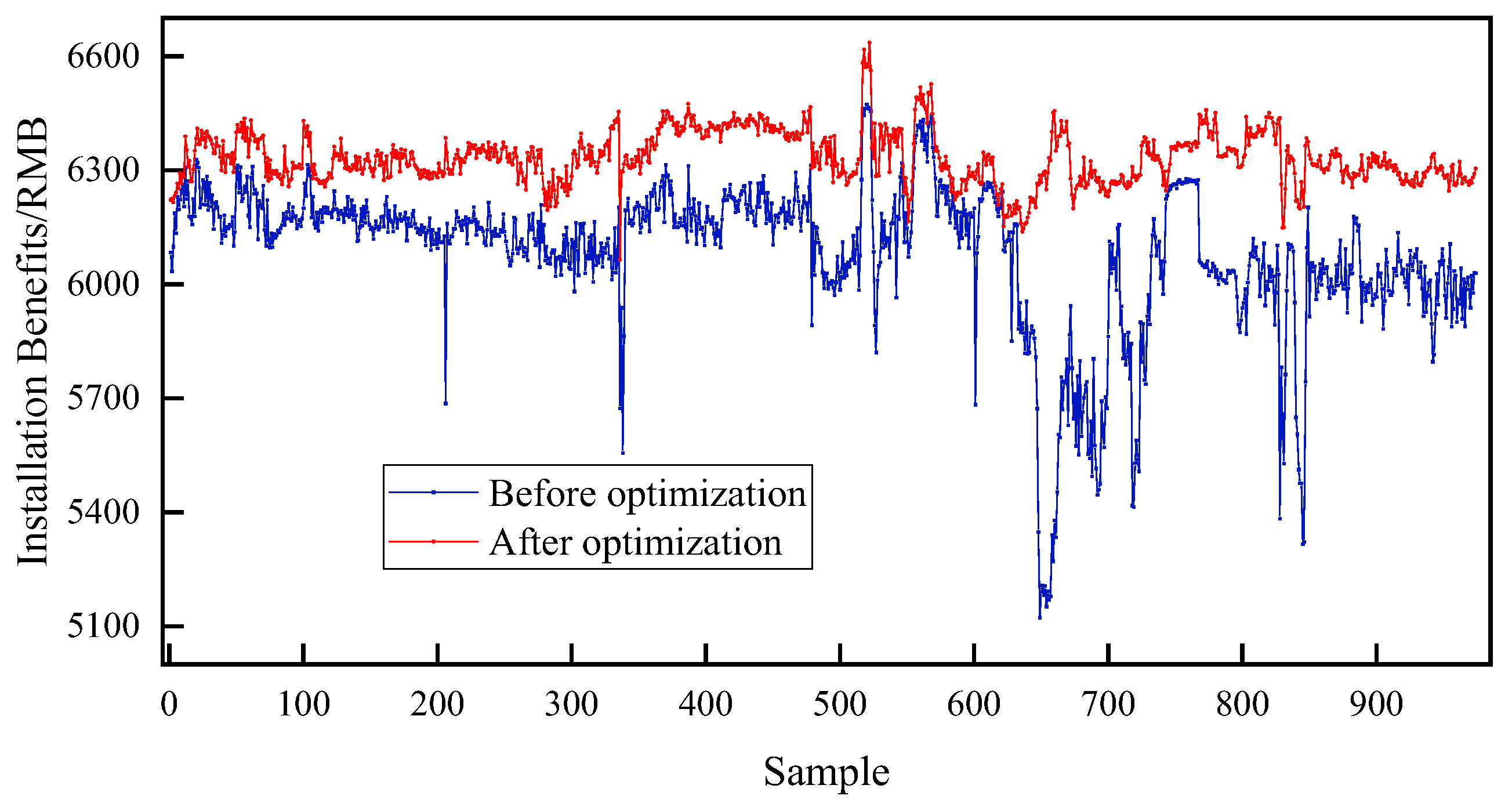
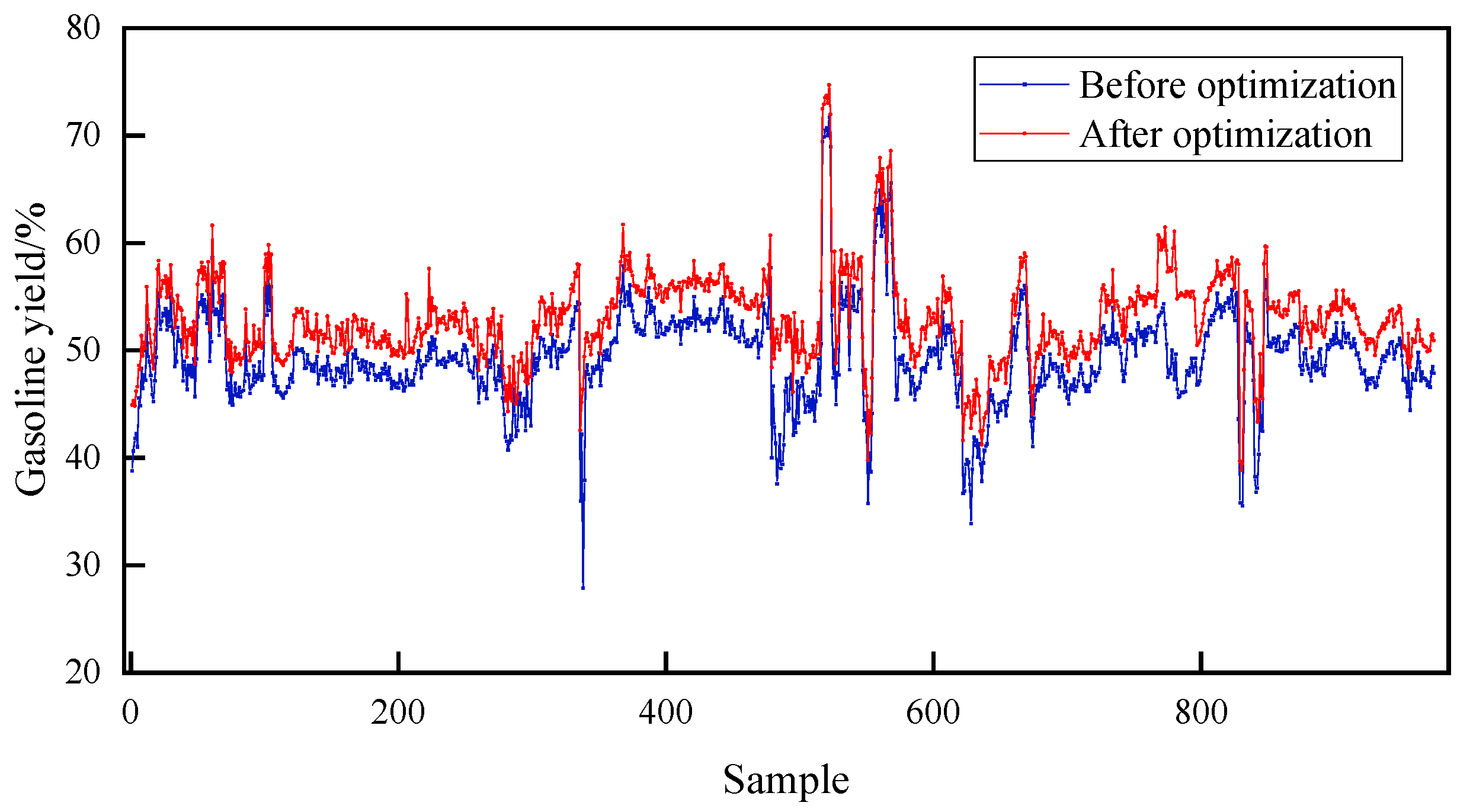
4.2.3. Genetic Algorithm to Optimize RLG Device Yield
- (1)
- Parameter setting of the genetic algorithm
- (2)
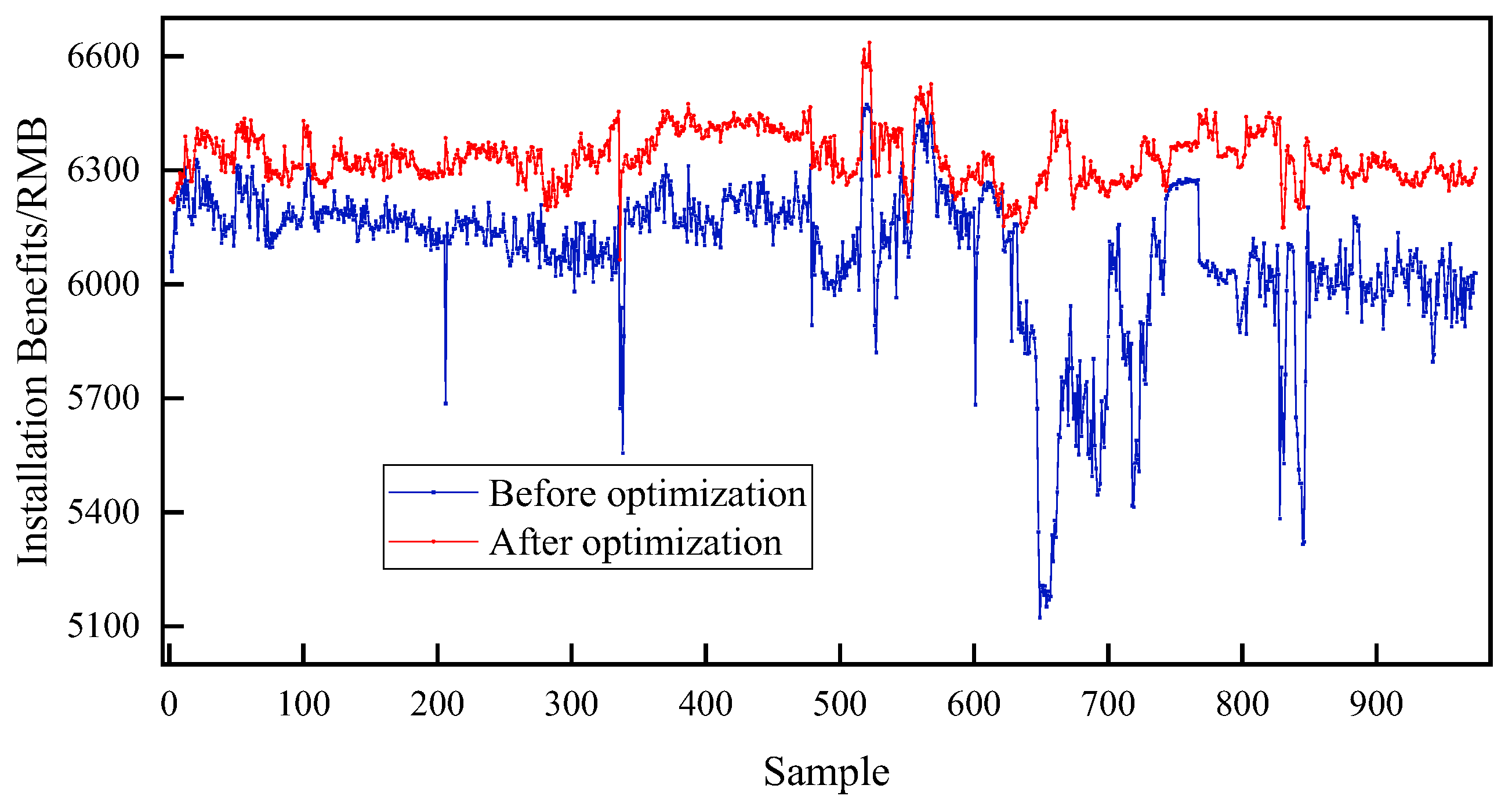
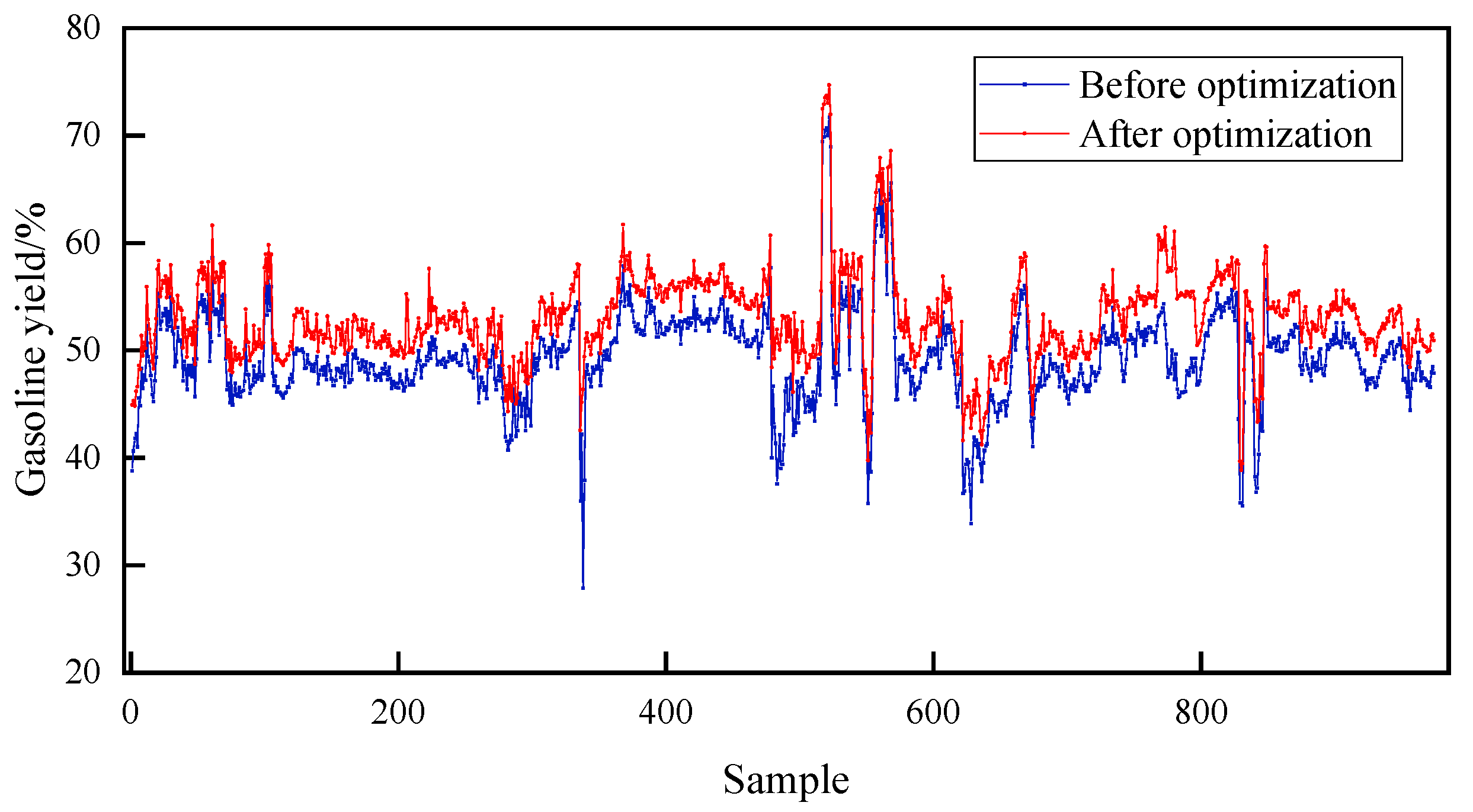
- RLG device yield optimization results
5. Conclusions
- First, by combining the reaction mechanism and characteristics of the RLG process, data such as the properties of the crude oil and process operation variables were separated and preprocessed. A three-layer DNN model with (17, 128, 64) nodes was then established. This model predicts the gasoline yield with an average absolute error of 1.58%, showing a better prediction performance.
- Then, on the basis of this predictive model, plant tuning operations were carried out with the goal of maximizing plant efficiency.
- Next, the results show that optimizing the operating conditions using the GA algorithm to meet the 3% increase in gasoline production can maximize the economic benefits of the plant.
- Finally, it was verified that the optimization value of the operating conditions is consistent with the actual situation of the RLG process, which proves that the established model has good applicability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LCO | Light Cycle Oil |
| RLG | React LCO into Gasoline |
| DNN | Deep Neural Network |
| GA | Genetic Algorithm |
| MDM | Mechanism-driven Model |
| DDM | Data-driven Model |
| FNN | Forward Neural Network |
| FCC | Fluid Catalytic Cracking |
| HPS | High-Pressure Separator |
| LPS | Low-Pressure Separator |
| MLP | Multi-Layer Perceptron |
| ANN | Artificial Neural Network |
| DCS | Distributed Control System |
| PSO | Particle Swarm Algorithm |
| SA | Simulated Annealing Algorithm |
| ACO | Ant Colony Algorithms |
| BN | Batch Normalization |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
| LPG | Liquefied Gas |
| R2 | R Square |
| MAPE | Mean Absolute Percentage Error |
| RON | Research Octane Number |
References
- Song, W.; Du, W.; Fan, C.; Yang, M.; Qian, F. Adaptive Weighted Hybrid Modeling of Hydrocracking Process and Its Operational Optimization. Ind. Eng. Chem. Res. 2021, 60, 3617–3632. [Google Scholar] [CrossRef]
- Stangeland, B.E. A kinetic model for the prediction of hydrocracker yields. Ind. Eng. Chem. Process Des. Dev. 1974, 13, 71–76. [Google Scholar] [CrossRef]
- Laxminarasimhan, C.S.; Verma, R.P.; Ramachandran, P.A. Continuous lumping model for simulation of hydrocracking. AIChE J. 1996, 42, 2645–2653. [Google Scholar] [CrossRef]
- Mohanty, S.; Saraf, D.N.; Kunzru, D. Modeling of a hydrocracking reactor. Fuel Process. Technol. 1991, 29, 1–17. [Google Scholar] [CrossRef]
- Pacheco, M.A.; Dassori, C.G. Hydrocracking: An improved kinetic model and reactor modeling. Chem. Eng. Commun. 2002, 189, 1684–1704. [Google Scholar] [CrossRef]
- Thybaut, J.W.; Marin, G.B. Multiscale aspects in hydrocracking: From reaction mechanism over catalysts to kinetics and industrial application. In Advances in Catalysis; Academic Press: Cambridge, MA, USA, 2016; Volume 59, pp. 109–238. [Google Scholar]
- Song, W.; Mahalec, V.; Long, J.; Yang, M.-L.; Qian, F. Modeling the Hydrocracking Process with Deep Neural Networks. Ind. Eng. Chem. Res. 2020, 59, 3077–3090. [Google Scholar] [CrossRef]
- Chen, Q.; Ding, J.; Yang, S.; Chai, T. Constrained Operational Optimization of a Distillation Unit in Refineries With Varying Feedstock Properties. IEEE Trans. Control. Syst. Technol. 2019, 28, 2752–2761. [Google Scholar] [CrossRef]
- Taud, H.; Mas, J.F. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Cham, Switzerland, 2018; pp. 451–455. [Google Scholar]
- Hussain, H.; Tamizharasan, P.S.; Rahul, C.S. Design possibilities and challenges of DNN models: A review on the perspective of end devices. Artif. Intell. Rev. 2022, 55, 5109–5167. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Hu, L.; Gao, L.; Li, Y.; Zhang, P.; Gao, W. Feature-specific mutual information variation for multi-label feature selection. Inf. Sci. 2022, 593, 449–471. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y.; Wang, Z. A machine learning based credit card fraud detection using the GA algorithm for feature selection. J. Big Data 2022, 9, 1–17. [Google Scholar] [CrossRef]
- Lira, J.O.; Riella, H.G.; Padoin, N.; Soares, C. Computational fluid dynamics (CFD), artificial neural network (ANN) and genetic algorithm (GA) as a hybrid method for the analysis and optimization of micro-photocatalytic reactors: NOx abatement as a case study. Chem. Eng. J. 2021, 431, 133771. [Google Scholar] [CrossRef]
- Huang, C.L.; Dun, J.F. A distributed PSO–SVM hybrid system with feature selection and parameter optimization. Appl. Soft Comput. 2008, 8, 1381–1391. [Google Scholar] [CrossRef]
- Ghannadi, P.; Kourehli, S.S.; Mirjalili, S. A review of the application of the simulated annealing algorithm in structural health monitoring (1995–2021). Frat. Ed Integrità Strutt. 2023, 17, 51–76. [Google Scholar] [CrossRef]
- Dubey, A.K.; Kumar, A.; Agrawal, R. An efficient ACO-PSO-based framework for data classification and preprocessing in big data. Evol. Intell. 2021, 14, 909–922. [Google Scholar] [CrossRef]
- Citovsky, G.; DeSalvo, G.; Gentile, C.; Karydas, L.; Rajagopalan, A.; Rostamizadeh, A.; Kumar, S. Batch active learning at scale. Adv. Neural Inf. Process. Syst. 2021, 34, 11933–11944. [Google Scholar]
- Lobacheva, E.; Kodryan, M.; Chirkova, N.; Malinin, A.; Vetrov, D.P. On the periodic behavior of neural network training with batch normalization and weight decay. Adv. Neural Inf. Process. Syst. 2021, 34, 21545–21556. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Zhao, Q.; Chen, X.; Zhang, Y.; Sha, M.; Yang, Z.; Lin, W.; Tang, E.; Chen, Q.; Li, X. Synthesizing ReLU neural networks with two hidden layers as barrier certificates for hybrid systems. In Proceedings of the 24th International Conference on Hybrid Systems: Computation and Control, Nashville, TN, USA, 19–21 May 2021; pp. 1–11. [Google Scholar]
- Sun, J.; Wang, J.; Zhu, Z.; He, R.; Peng, C.; Zhang, C.; Huang, J.; Wang, Y.; Wang, X. Mechanical Performance Prediction for Sustainable High-Strength Concrete Using Bio-Inspired Neural Network. Buildings 2022, 12, 65. [Google Scholar] [CrossRef]
- Hong, Q.; Tan, Q.; Siegel, J.W.; Xu, J. On the activation function dependence of the spectral bias of neural networks. arXiv 2022, arXiv:2208.04924. [Google Scholar]
- Tian, Y.; Lai, Y.; Yang, C. Research of consumption behavior prediction based on improved DNN. Sci. Program. 2022, 2022, 6819525. [Google Scholar] [CrossRef]
- Reyad, M.; Sarhan, A.M.; Arafa, M. A modified Adam algorithm for deep neural network optimization. Neural Comput. Appl. 2023, 1–18. [Google Scholar] [CrossRef]
- Saini, M.; Gupta, N.; Shankar, V.G.; Kumar, A. Stochastic modeling and availability optimization of condenser used in steam turbine power plants using GA and PSO. Qual. Reliab. Eng. Int. 2022, 38, 2670–2690. [Google Scholar] [CrossRef]
- Abdi, H. Profit-based unit commitment problem: A review of models, methods, challenges, and future directions. Renew. Sustain. Energy Rev. 2020, 138, 110504. [Google Scholar] [CrossRef]
- Martínez, J.; Zúñiga-Hinojosa, M.A.; Ruiz-Martínez, R.S. A Thermodynamic Analysis of Naphtha Catalytic Reforming Reactions to Produce High-Octane Gasoline. Processes 2022, 10, 313. [Google Scholar] [CrossRef]
- Lahijani, P.; Mohammadi, M.; Mohamed, A.R.; Ismail, F.; Lee, K.T.; Amini, G. Upgrading biomass-derived pyrolysis bio-oil to bio-jet fuel through catalytic cracking and hydrodeoxygenation: A review of recent progress. Energy Convers. Manag. 2022, 268, 115956. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number | Definition |
|---|---|---|
| inputs | 17 | (1) Fresh diesel feed, new hydrogen, the earliest distilled light oil fraction volume, amount of pre-hydrogenated sulfur-containing light hydrocarbons in the take-up reformer, feedstock density (20 °C), feedstock total sulfur content, feedstock total nitrogen content, and 95% distillation temperature of feedstock. (2) R101 average temperature, R101 inlet hydrogen partial pressure, R101 inlet circulating hydrogen volume, R101 inlet hydrogen–oil ratio, R102 average temperature, R102 inlet hydrogen partial pressure, R102 inlet circulating hydrogen volume, R102 inlet hydrogen–oil ratio, R102 inlet hydrogen–oil ratio, actual circulating hydrogen purity, |
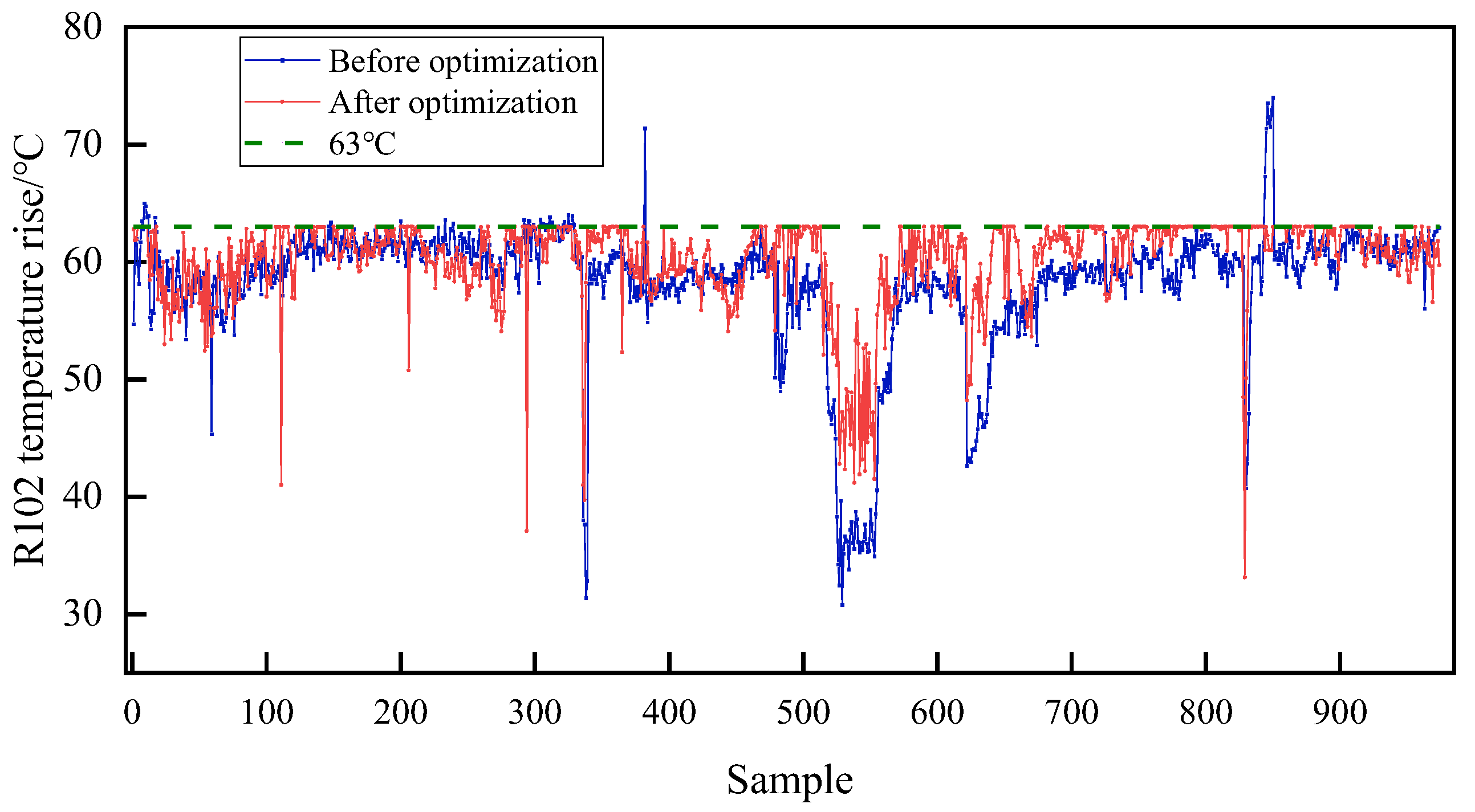
| outputs | 5 | gasoline yield, diesel yield, LPG yield, dry gas yield. R102 temperature rise |
| Program | Number of Variables | Variable Name |
|---|---|---|
| Input variables | 17 | (1) Fresh diesel feed volume, D-501 fresh hydrogen inlet flow rate, the earliest distilled light oil fraction volume, amount of sulfur-containing light hydrocarbons in the pre-hydrogenation of the collected reformer, feedstock density (20 °C), feedstock total sulfur content, feedstock total nitrogen content, and 95% distillation temperature of the feedstock; (2) R101 average temperature, R101 inlet hydrogen partial pressure, R101 inlet circulating hydrogen volume, R101 inlet hydrogen–oil ratio, R102 average temperature, R102 inlet hydrogen partial pressure, R102 inlet circulating hydrogen volume, R102 inlet hydrogen–oil ratio, R102 inlet hydrogen–oil ratio Actual circulating hydrogen purity |
| Output variables | 5 | Gasoline yield, diesel yield, LPG yield, dry gas yield; R102 temperature rise |
| Program | Gasoline Yield | Diesel Yield | LPG Yield | Dry Gas Yield | R102 Temperature Rise |
|---|---|---|---|---|---|
| MAE | 0.9122 | 1.0565 | 0.2382 | 0.0987 | 0.9671 |
| MSE | 1.4305 | 2.0185 | 0.1030 | 0.0171 | 1.7750 |
| R2 | 0.9370 | 0.9333 | 0.9469 | 0.9266 | 0.9603 |
| MAPE | 0.0188 | 0.0262 | 0.1040 | 0.0467 | 0.0202 |
| Program | Gasoline Yield | Diesel Yield | LPG Yield | Dry Gas Yield | R102 Temperature Rise |
|---|---|---|---|---|---|
| MAE | 1.5810 | 1.9810 | 0.3519 | 0.1290 | 1.5575 |
| MSE | 6.8294 | 10.6909 | 0.4005 | 0.0283 | 7.7243 |
| R2 | 0.7252 | 0.6929 | 0.7843 | 0.8811 | 0.7891 |
| MAPE | 0.0370 | 0.0469 | 31.2087 | 0.0615 | 0.0300 |
| Process Conditions | Space for Excellence |
|---|---|
| R101 average temperature (°C) | 360~395 |
| R101 Inlet hydrogen partial pressure (MPa) | 6.5~9.1 |
| R101 inlet circulating hydrogen flow rate (kN3/h) | 120~140 |
| R101 inlet hydrogen-to-oil ratio | 800~1200 |
| R102 average temperature (°C) | 370~415 |
| R102 inlet hydrogen partial pressure (MPa) | 6.5~9.1 |
| R102 inlet circulating hydrogen flow rate (kN3/h) | 130~150 |
| R102 inlet hydrogen-to-oil ratio | 900~1400 |
| Process Conditions | Group 1 | Group 2 | Group 3 | Group 4 | ||||
|---|---|---|---|---|---|---|---|---|
| Original Value | Optimization Value | Original Value | Optimization Value | Original Value | Optimization Value | Original Value | Optimization Value | |
| R101 average temperature (°C) | 370.3 | 377.2 | 381.3 | 390.5 | 367.2 | 376.7 | 371.2 | 378.5 |
| R101 inlet hydrogen partial pressure (MPa) | 6.9 | 6.8 | 8.5 | 9.10 | 6.7 | 6.7 | 7.9 | 7.1 |
| R101 inlet circulating hydrogen flow rate (kN3/h) | 148 | 132 | 132 | 140 | 153 | 124 | 153 | 140 |
| R101 inlet hydrogen-to-oil ratio | 1435 | 1200 | 1232 | 800 | 1518 | 1200 | 11,451 | 1200 |
| R102 average temperature (°C) | 375.8 | 377.7 | 381.9 | 391.0 | 381.8 | 383.4 | 388.6 | 398.5 |
| R102 inlet hydrogen partial pressure (MPa) | 6.85 | 6.80 | 8.48 | 9.01 | 6.63 | 6.58 | 7.78 | 6.94 |
| R102 inlet circulating hydrogen flow rate (kN3/h) | 155 | 146 | 145 | 145 | 160 | 145 | 160 | 142 |
| R102 inlet hydrogen-to-oil ratio | 1506 | 1400 | 1357 | 900 | 1591 | 1400 | 1516 | 1400 |
| R102 temperature rise (°C) | 58.8 | 60.4 | 59.96 | 60.5 | 57.9 | 60.0 | 61.0 | 63.0 |
| Gasoline yield% | 53.86 | 57.01 | 52.10 | 55.31 | 49.10 | 52.11 | 49.71 | 53.62 |
| Plant revenue (CNY/ton) | 6240 | 6382 | 6030 | 6381 | 6269 | 6331 | 6083 | 6302 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Q.; Fan, Y.; Zhou, Z.; Jiang, H.; Zhou, X. Research on Product Yield Prediction and Benefit of Tuning Diesel Hydrogenation Conversion Device Based on Data-Driven System. Energies 2023, 16, 5332. https://doi.org/10.3390/en16145332
Zheng Q, Fan Y, Zhou Z, Jiang H, Zhou X. Research on Product Yield Prediction and Benefit of Tuning Diesel Hydrogenation Conversion Device Based on Data-Driven System. Energies. 2023; 16(14):5332. https://doi.org/10.3390/en16145332
Chicago/Turabian StyleZheng, Qianqian, Yijun Fan, Zhi Zhou, Hongbo Jiang, and Xiaolong Zhou. 2023. "Research on Product Yield Prediction and Benefit of Tuning Diesel Hydrogenation Conversion Device Based on Data-Driven System" Energies 16, no. 14: 5332. https://doi.org/10.3390/en16145332
APA StyleZheng, Q., Fan, Y., Zhou, Z., Jiang, H., & Zhou, X. (2023). Research on Product Yield Prediction and Benefit of Tuning Diesel Hydrogenation Conversion Device Based on Data-Driven System. Energies, 16(14), 5332. https://doi.org/10.3390/en16145332