

Deterministic and Probabilistic Prediction of Wind Power Based on a Hybrid Intelligent Model
 , , ,
, , , 
 ,
,
Abstract
1. Introduction
- To obtain more meaningful training features, isolation forest is introduced to detect morbid data points of wind power, and WT is utilized to extract multi-level time-frequency features from wind power sequence data.
- To reduce errors in deterministic wind power forecasting, a new hybrid intelligent model is initially constructed by isolated forest, WT, and CatBoost to accurately predict wind power.
- To reasonably evaluate the uncertainty of wind power, a probabilistic predictor based on QR is developed to generate prediction intervals at different confidence levels.
2. The Proposed Hybrid Intelligent Model for Wind Power Prediction
2.1. Isolated Forest
2.2. Wavelet Transform
2.3. Categorical Boosting
3. Probabilistic Wind Power Prediction and Performance Criterion
3.1. Quantile-Regression-Based Probabilistic Forecasting
3.2. Implementation of the Proposed Hybrid Intelligence Model
3.3. Performance Criterion
3.3.1. Errors for Point Prediction Performance
3.3.2. Errors for Probabilistic Performance
4. Numerical Results and Analysis
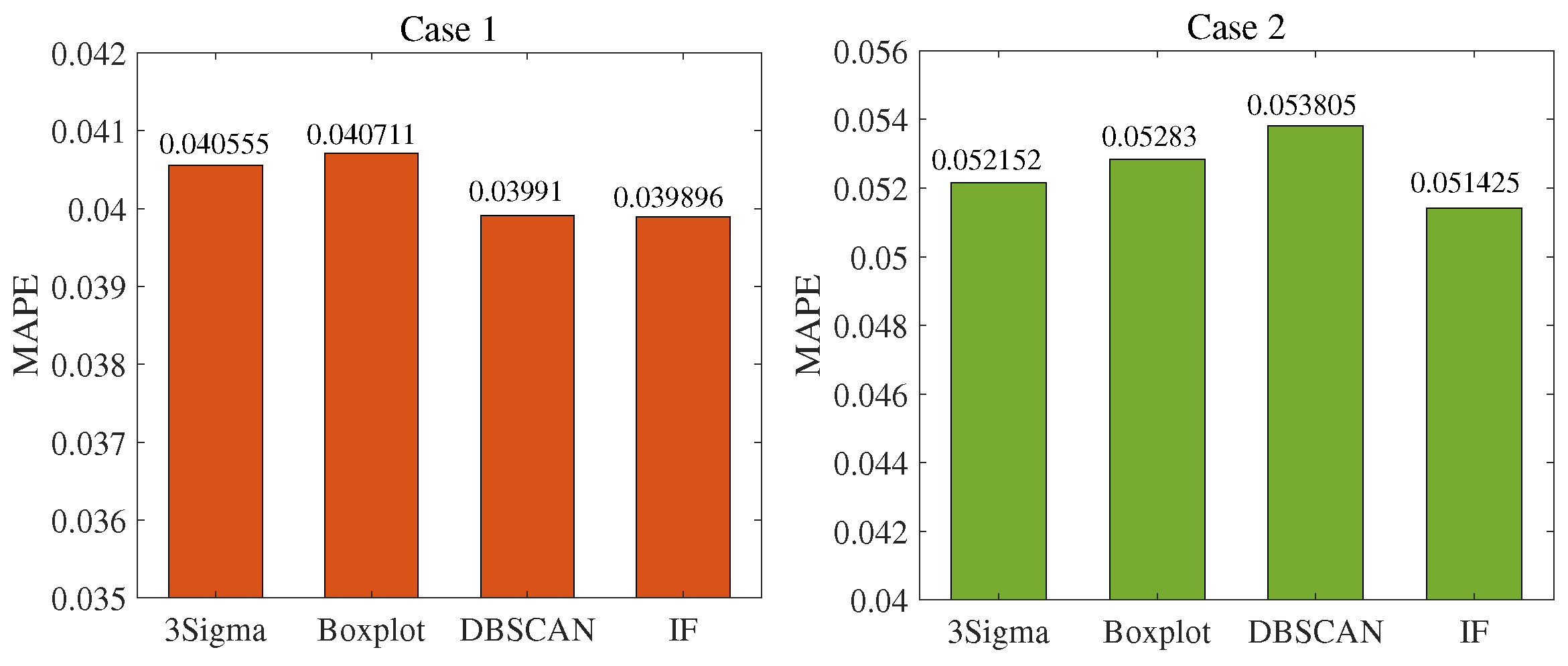
4.1. Outlier Detection Based on Isolated Forest
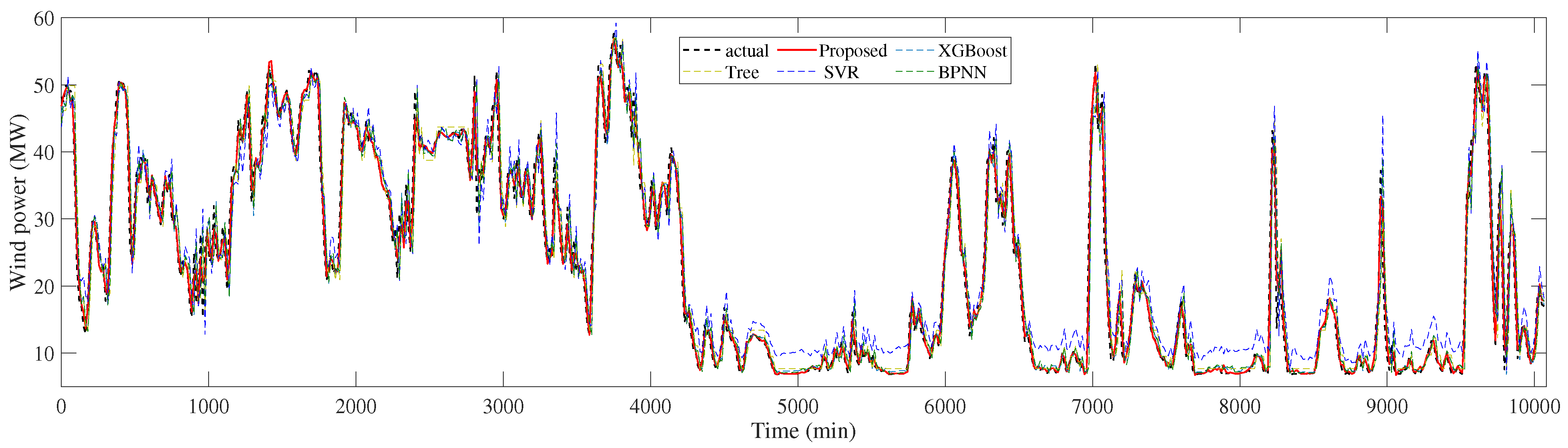
4.2. 15-Min-Ahead Prediction Results
4.3. Multi-Step-Ahead Prediction Results
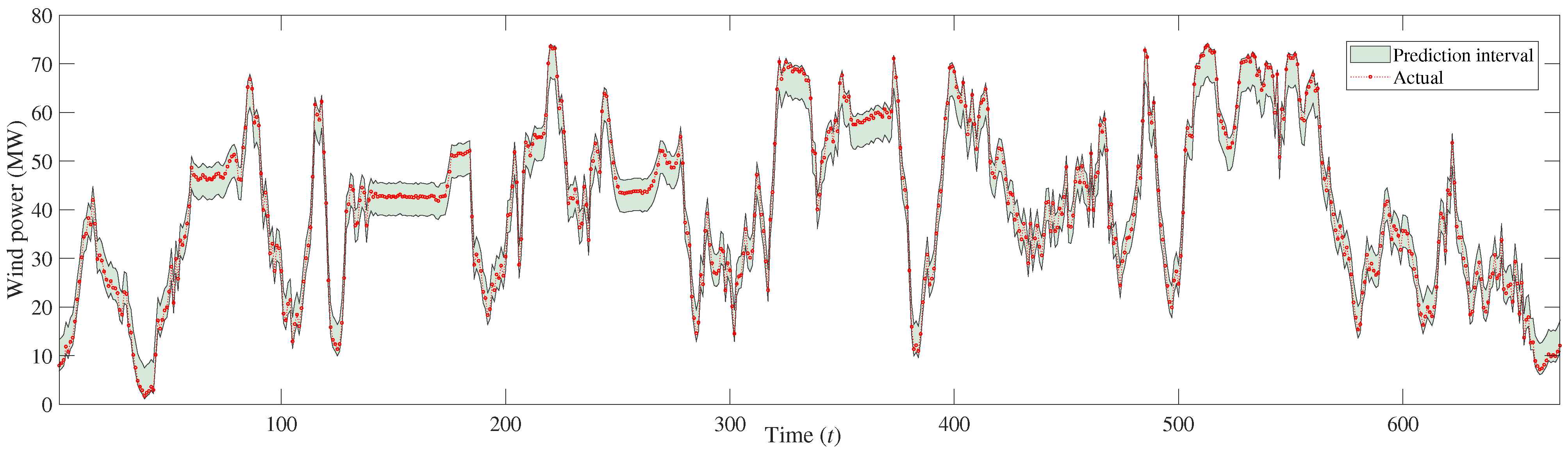
4.4. Probabilistic Prediction Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ARMA | Auto-regressive moving average |
| NWP | Numerical weather prediction |
| KNN | K-nearest neighbors algorithm |
| SVR | Support vector regression |
| DT | Decision tree |
| MLP | Multilayer perceptron |
| RNN | Recurrent neural network |
| CNN | Convolutional neural network |
| DBN | Deep belief network |
| DRL | Deep reinforcement learning |
| CatBoost | Categorical boosting |
| WT | Wavelet transform |
| QR | Quantile regression |
| TS | Target-based statistics |
| GBDT | Gradient-boosting decision tree |
| MAE | Mean absolute error |
| RMSE | Root mean square error |
| MAPE | Mean absolute percentage error |
| PICP | Prediction interval coverage probability |
| AIS | Average interval sharpness |
| XGBoost | eXtreme gradient boosting |
| BPNN | Back-propagation neural network |
References
- GWEC. Global Wind Report; Global Wind Energy Council: Bonn, Germany, 2022. [Google Scholar]
- Cui, W.; Wan, C.; Song, Y. Ensemble Deep Learning-Based Non-Crossing Quantile Regression for Nonparametric Probabilistic Forecasting of Wind Power Generation. IEEE Trans. Power Syst. 2022, 1–16. [Google Scholar] [CrossRef]
- Choi, J.; Eom, H.; Baek, S.M. A Wind Power Probabilistic Model Using the Reflection Method and Multi-Kernel Function Kernel Density Estimation. Energies 2022, 15, 9436. [Google Scholar] [CrossRef]
- Liu, G.; Wang, C.; Qin, H.; Fu, J.; Shen, Q. A Novel Hybrid Machine Learning Model for Wind Speed Probabilistic Forecasting. Energies 2022, 15, 6942. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, X.; Mei, S.; Zhen, Z.; Jia, M.; Li, Z.; Tang, H. Numerical weather prediction enhanced wind power forecasting: Rank ensemble and probabilistic fluctuation awareness. Appl. Energy 2022, 313, 118769. [Google Scholar] [CrossRef]
- Hoolohan, V.; Tomlin, A.S.; Cockerill, T. Improved near surface wind speed predictions using Gaussian process regression combined with numerical weather predictions and observed meteorological data. Renew. Energy 2018, 126, 1043–1054. [Google Scholar] [CrossRef]
- Hur, S.H. Short-term wind speed prediction using Extended Kalman filter and machine learning. Energy Rep. 2021, 7, 1046–1054. [Google Scholar] [CrossRef]
- Ezzat, A.A.; Jun, M.; Ding, Y. Spatio-temporal asymmetry of local wind fields and its impact on short-term wind forecasting. IEEE Trans. Sustain. Energy 2018, 9, 1437–1447. [Google Scholar] [CrossRef]
- Allen, D.; Tomlin, A.; Bale, C.; Skea, A.; Vosper, S.; Gallani, M. A boundary layer scaling technique for estimating near-surface wind energy using numerical weather prediction and wind map data. Appl. Energy 2017, 208, 1246–1257. [Google Scholar] [CrossRef]
- Li, Y.; He, Y.; Su, Y.; Shu, L. Forecasting the daily power output of a grid-connected photovoltaic system based on multivariate adaptive regression splines. Appl. Energy 2016, 180, 392–401. [Google Scholar] [CrossRef]
- Bae, K.Y.; Jang, H.S.; Jung, B.C.; Sung, D.K. Effect of prediction error of machine learning schemes on photovoltaic power trading based on energy storage systems. Energies 2019, 12, 1249. [Google Scholar] [CrossRef]
- Xu, D.; Liu, J.; Yan, X.G.; Yan, W. A novel adaptive neural network constrained control for a multi-area interconnected power system with hybrid energy storage. IEEE Trans. Ind. Electron. 2017, 65, 6625–6634. [Google Scholar] [CrossRef]
- Tripathy, D.S.; Prusty, B.R.; Bingi, K. A k-nearest neighbor-based averaging model for probabilistic PV generation forecasting. Int. J. Numer. Model. Electron. Netw. Devices Fields 2022, 35, e2983. [Google Scholar] [CrossRef]
- Maldonado, S.; Gonzalez, A.; Crone, S. Automatic time series analysis for electric load forecasting via support vector regression. Appl. Soft Comput. 2019, 83, 105616. [Google Scholar] [CrossRef]
- Torres-Barrán, A.; Alonso, Á.; Dorronsoro, J.R. Regression tree ensembles for wind energy and solar radiation prediction. Neurocomputing 2019, 326, 151–160. [Google Scholar] [CrossRef]
- Samadianfard, S.; Hashemi, S.; Kargar, K.; Izadyar, M.; Mostafaeipour, A.; Mosavi, A.; Nabipour, N.; Shamshirband, S. Wind speed prediction using a hybrid model of the multi-layer perceptron and whale optimization algorithm. Energy Rep. 2020, 6, 1147–1159. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G. A hybrid attention-based deep learning approach for wind power prediction. Appl. Energy 2022, 323, 119608. [Google Scholar] [CrossRef]
- Kisvari, A.; Lin, Z.; Liu, X. Wind power forecasting—A data-driven method along with gated recurrent neural network. Renew. Energy 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- Gu, C.; Li, H. Review on deep learning research and applications in wind and wave energy. Energies 2022, 15, 1510. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H.; Song, J. Deep belief network based k-means cluster approach for short-term wind power forecasting. Energy 2018, 165, 840–852. [Google Scholar] [CrossRef]
- Han, L.; Jing, H.; Zhang, R.; Gao, Z. Wind power forecast based on improved Long Short Term Memory network. Energy 2019, 189, 116300. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, Q.; Yan, J.; Zhang, S.; Xu, J. A novel asynchronous deep reinforcement learning model with adaptive early forecasting method and reward incentive mechanism for short-term load forecasting. Energy 2021, 236, 121492. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, L.; Zhang, Z.; Zhao, T.; Zou, L. Ultra Short Term Wind Power Prediction Model Based on WRF Wind Speed prediction and catboost. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Sanya, China, 8–10 July 2021; Volume 838, p. 012001. [Google Scholar]
- Prokhorenkova, L.O.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 6639–6649. [Google Scholar]
- Wu, L.; Huang, G.; Fan, J.; Zhang, F.; Wang, X.; Zeng, W. Potential of kernel-based nonlinear extension of Arps decline model and gradient boosting with categorical features support for predicting daily global solar radiation in humid regions. Energy Convers. Manag. 2019, 183, 280–295. [Google Scholar] [CrossRef]
- Niu, D.; Diao, L.; Zang, Z.; Che, H.; Zhang, T.; Chen, X. A machine-learning approach combining wavelet packet denoising with Catboost for weather forecasting. Atmosphere 2021, 12, 1618. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H.; Bales, C. A hybrid model based on bidirectional long short-term memory neural network and Catboost for short-term electricity spot price forecasting. J. Oper. Res. Soc. 2022, 73, 301–325. [Google Scholar] [CrossRef]
- Taylor, W.O.; Anagnostou, M.N.; Cerrai, D.; Anagnostou, E.N. Machine Learning Methods to Approximate Rainfall and Wind From Acoustic Underwater Measurements (February 2020). IEEE Trans. Geosci. Remote Sens. 2021, 59, 2810–2821. [Google Scholar] [CrossRef]
- Singh, R.; Gaonkar, G.; Bandre, V.; Sarang, N.; Deshpande, S. Gradient Boosting Approach for Traffic Flow Prediction Using CatBoost. In Proceedings of the 2021 International Conference on Advances in Computing, Communication, and Control (ICAC3), Mumbai, India, 3–4 December 2021; pp. 1–5. [Google Scholar]
- Massaoudi, M.; Refaat, S.S.; Abu-Rub, H.; Chihi, I.; Wesleti, F.S. A Hybrid Bayesian Ridge Regression-CWT-Catboost Model for PV Power Forecasting. In Proceedings of the 2020 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 13–14 July 2020; pp. 1–5. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 eighth ieee international conference on data mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting sparsity of interconnections in spatio-temporal wind speed forecasting using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Krishnapuram, B., Shah, M., Smola, A.J., Aggarwal, C.C., Shen, D., Rastogi, R., Eds.; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Bracale, A.; Caramia, P.; De Falco, P.; Hong, T. Multivariate quantile regression for short-term probabilistic load forecasting. IEEE Trans. Power Syst. 2019, 35, 628–638. [Google Scholar] [CrossRef]
- Lauret, P.; David, M.; Pedro, H.T. Probabilistic solar forecasting using quantile regression models. Energies 2017, 10, 1591. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Li, Z. Wind speed deterministic forecasting and probabilistic interval forecasting approach based on deep learning, modified tunicate swarm algorithm, and quantile regression. Renew. Energy 2021, 179, 1246–1261. [Google Scholar] [CrossRef]
- Gunawan, A.; Thamrin, S.; Kuntjoro, Y.D.; Idris, A.M. Backpropagation Neural Network (BPNN) Algorithm for Predicting Wind Speed Patterns in East Nusa Tenggara. Trends Renew. Energy 2022, 8, 107–118. [Google Scholar] [CrossRef]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Xu, X.; Lei, Y.; Li, Z. An incorrect data detection method for big data cleaning of machinery condition monitoring. IEEE Trans. Ind. Electron. 2019, 67, 2326–2336. [Google Scholar] [CrossRef]
- De Vito, S.; Di Francia, G.; Esposito, E.; Ferlito, S.; Formisano, F.; Massera, E. Adaptive machine learning strategies for network calibration of IoT smart air quality monitoring devices. Pattern Recognit. Lett. 2020, 136, 264–271. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, J. Probabilistic deep autoencoder for power system measurement outlier detection and reconstruction. IEEE Trans. Smart Grid 2019, 11, 1796–1798. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Case 1 | Case 2 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| Proposed | 1.2947 | 1.8313 | 0.0399 | 1.0684 | 1.7028 | 0.0514 | 1.1816 | 1.7671 | 0.0457 |
| XGBoost | 3.1223 | 4.2845 | 0.0957 | 2.6575 | 4.1248 | 0.1295 | 2.8899 | 4.2047 | 0.1126 |
| Tree | 3.4286 | 4.5733 | 0.1061 | 2.9484 | 4.4929 | 0.1468 | 3.1885 | 4.5331 | 0.1265 |
| SVR | 3.5099 | 4.6770 | 0.1213 | 3.5996 | 4.7609 | 0.1608 | 3.5548 | 4.7189 | 0.1410 |
| BPNN | 3.1764 | 4.3475 | 0.0978 | 2.6698 | 4.1583 | 0.1301 | 2.9231 | 4.2529 | 0.1139 |
| Week Indexes | 1–7 February 2020 | 1–7 July 2020 | Average | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Proposed | 1.9561 | 2.7355 | 1.7032 | 2.6381 | 1.8296 | 2.6868 |
| XGBoost | 4.8045 | 6.4742 | 4.1977 | 6.3391 | 4.5011 | 6.4066 |
| Tree | 5.2411 | 7.1790 | 4.4980 | 6.6882 | 4.8710 | 6.9336 |
| SVR | 5.1523 | 6.9257 | 4.9391 | 6.8726 | 5.0457 | 6.8991 |
| BPNN | 4.6884 | 6.3173 | 4.2677 | 6.4232 | 4.4780 | 6.3703 |
| Case | Metric | XGBoost+QR | SVR+QR | Deep AR | Proposed |
|---|---|---|---|---|---|
| Case 1 | PICP | 100% | 100% | 100% | 100% |
| AIS | −6.1008 | −6.4662 | −6.1687 | −2.5151 | |
| Case 2 | PICP | 100% | 68% | 100% | 100% |
| AIS | −5.1985 | −6.3533 | −5.0871 | −1.9611 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, R.; Zhao, Y.; Qiu, J.; Bu, S.; Zhu, Y.; Li, G. Deterministic and Probabilistic Prediction of Wind Power Based on a Hybrid Intelligent Model. Energies 2023, 16, 4237. https://doi.org/10.3390/en16104237
Zhang J, Zhang R, Zhao Y, Qiu J, Bu S, Zhu Y, Li G. Deterministic and Probabilistic Prediction of Wind Power Based on a Hybrid Intelligent Model. Energies. 2023; 16(10):4237. https://doi.org/10.3390/en16104237
Chicago/Turabian StyleZhang, Jiawei, Rongquan Zhang, Yanfeng Zhao, Jing Qiu, Siqi Bu, Yuxiang Zhu, and Gangqiang Li. 2023. "Deterministic and Probabilistic Prediction of Wind Power Based on a Hybrid Intelligent Model" Energies 16, no. 10: 4237. https://doi.org/10.3390/en16104237
APA StyleZhang, J., Zhang, R., Zhao, Y., Qiu, J., Bu, S., Zhu, Y., & Li, G. (2023). Deterministic and Probabilistic Prediction of Wind Power Based on a Hybrid Intelligent Model. Energies, 16(10), 4237. https://doi.org/10.3390/en16104237