Application of Deep Neural Network in Gearbox Compound Fault Diagnosis

Abstract
1. Introduction
2. Related Theory
2.1. One-Dimensional Convolution
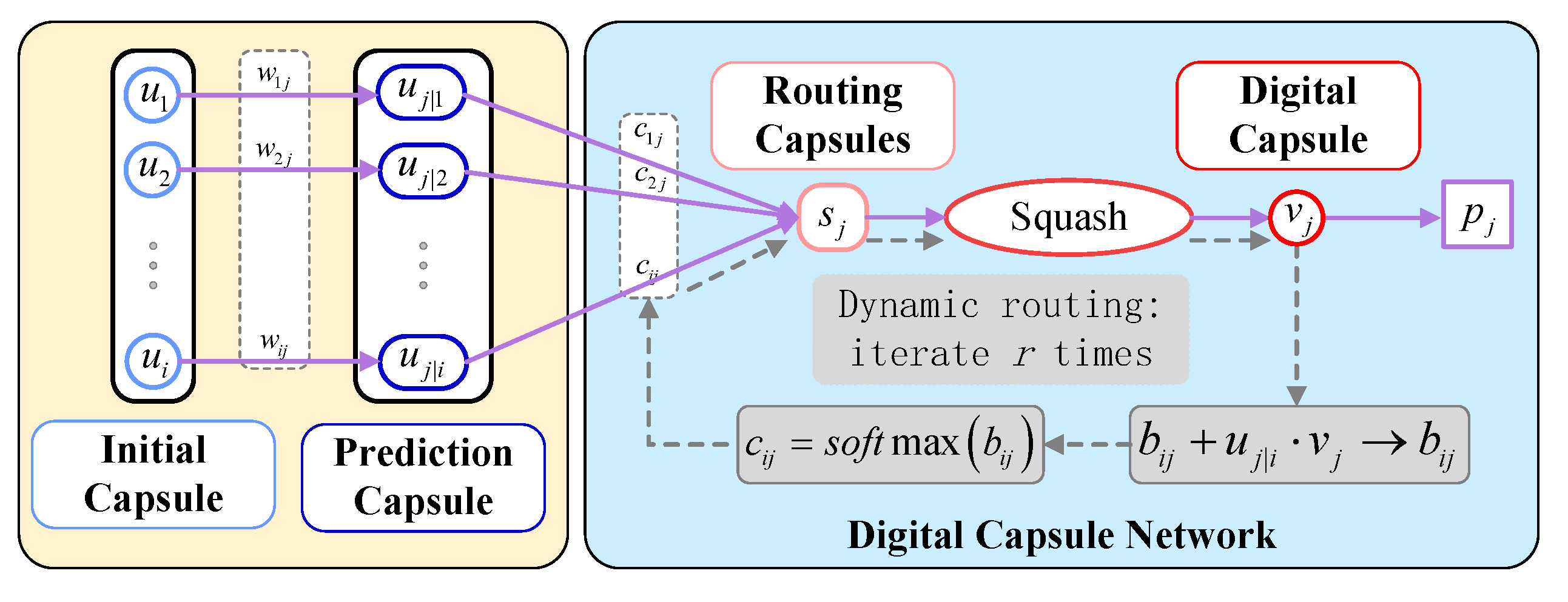
2.2. Capsule Network
2.3. Marginal Loss Function
3. Fault Diagnosis Method Based on Efficient Channel Attention Capsule Network
3.1. Efficient Channel Attention Module
3.2. Efficient Channel Attention Capsule Network
- (1)
- The vibration signal sample is input from the input layer, and the fault feature is finally obtained using one-dimensional convolutional step-by-step feature extraction. It is worth noting that the method uses wide convolutional kernels in convolutional layer 1, which can extract global features and reduce the effect of noise. In addition, the kernel sizes of the subsequent convolutional layers are chosen as narrow convolutional kernels, which become progressively smaller as the network level deepens, fully exploiting the local features.
- (2)
- The ECA module assigns weights to the features of different channels in and obtains the attention-corrected feature map . Channel attention can enhance critical fault information, suppress useless information, and solve the feature redundancy problem.
- (3)
- In the initial capsule layer, five groups of convolution are performed on , the features of which can be further extracted. After convolution, the scalar values in the feature matrix are spliced to construct 320 initial capsules with a capsule dimension of 5. For the initial capsules, the spatial relationship is represented by each corresponding capsule because of the large number of pills. Since the initial and digital tablets are weighted mapping relationships, the number of digital capsules decreases, but the fault information embedded in each capsule increases. In the digital capsule layer, the dynamic routing algorithm is used to calculate the correlation between the initial capsule and the digital capsule, update the weights, complete the conversion between the pills to realize the accurate categorization of fault information and, finally, generate six digital tablets with a capsule dimension of 10.
- (4)
- The two-parametric number of the digital capsules is calculated to obtain the probability of the different gearbox health states, as in Equation (11).
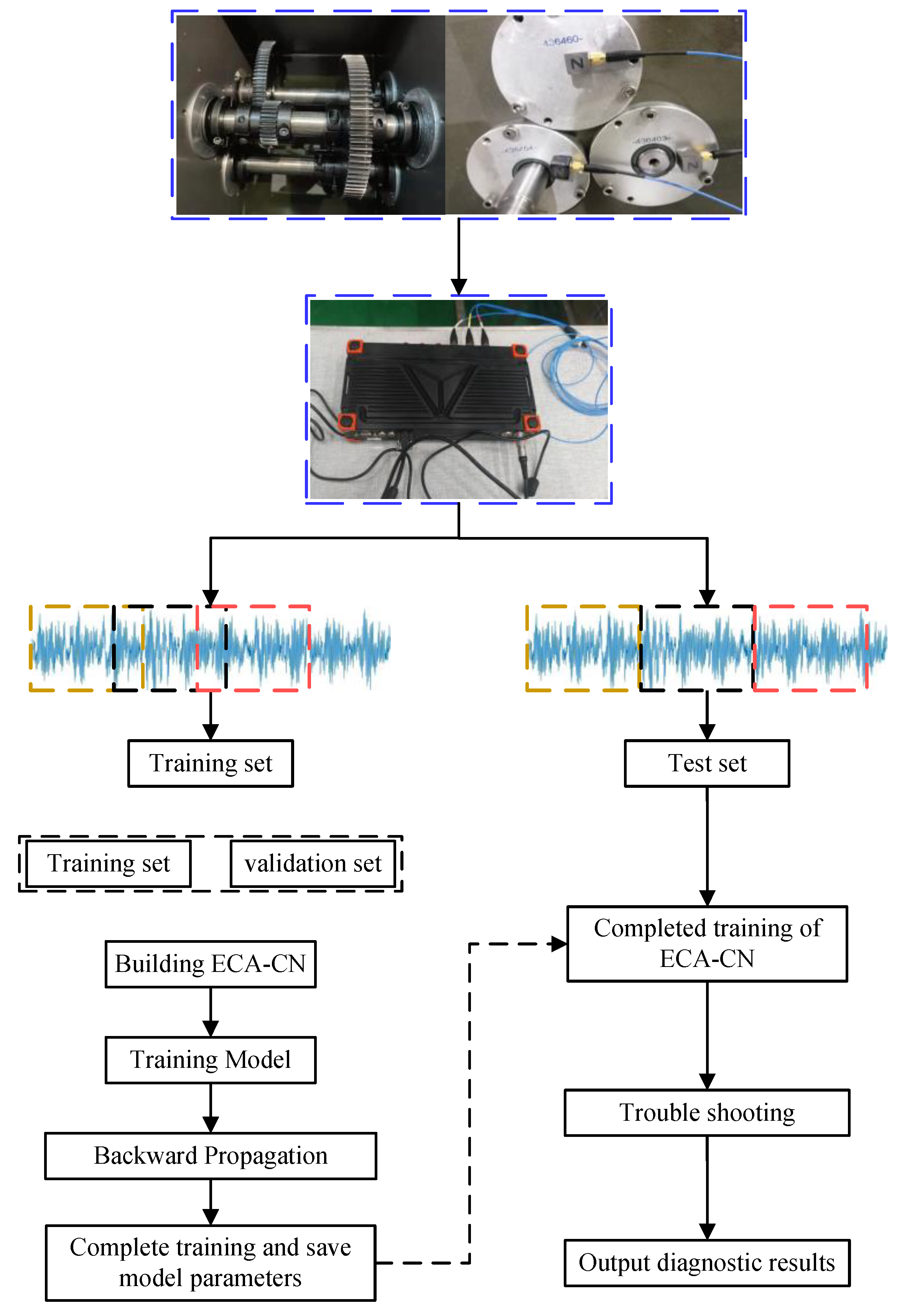
3.3. Fault Diagnosis Process
- (1)
- Collect the vibration data of the gearbox at different rotational speeds using acceleration sensors.
- (2)
- Overlap sampling of the vibration data is performed to obtain the training set. The leave-out method randomly divides the training set into a new training set and a validation set. To prevent information leakage of the test set, the vibration data are routinely window sampled to obtain the test set.
- (3)
- Construct the ECA-CN model and initialize the parameters.
- (4)
- Train the model using the training set, select the optimal model based on the validation set, and save the model parameters.
- (5)
- Evaluate the final model using the test set and derive the diagnosis results.
4. Experimental Verification
4.1. Experimental Data Introduction
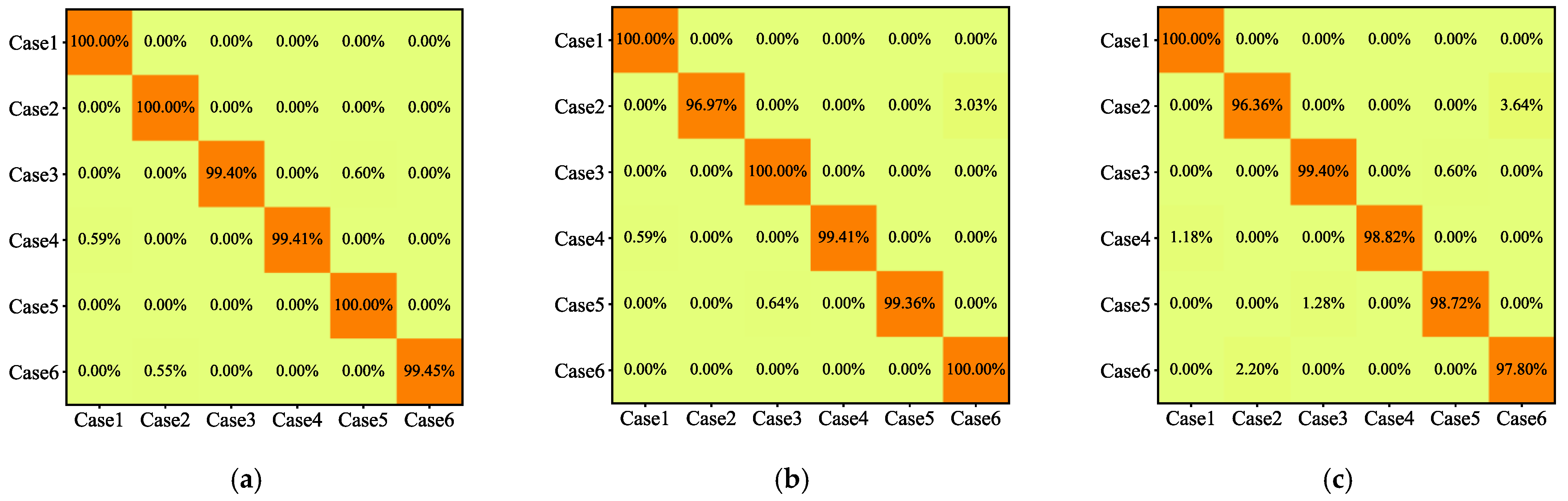
4.2. Ablation Experiments
4.3. Comparison Experiments
5. Conclusions
- (1)
- The ECA-CN model uses a GELU as the activation function, and the experimental results show that the ECA-CN (GELU) converges faster and is more robust than the ECA-CN (ReLU);
- (2)
- The ECA-CN model introduces the ECA module, and the experimental results show that the CN has an accuracy of 99.70%, while the accuracy of the CN without the attention module is 98.68%, indicating that the ECA module can effectively improve the fault diagnosis accuracy of the model;
- (3)
- Compared with the shallow machine learning model and the traditional CNN model, the average accuracy of the ECA-CN is improved by 4.62%, and the standard deviation is reduced by 0.58%, showing a more competitive fault diagnosis performance, which can achieve the compound fault diagnosis of gearboxes at different rotational speeds.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qian, Q.; Qin, Y.; Luo, J.; Wang, Y.; Wu, F. Deep discriminative transfer learning network for cross-machine fault diagnosis. Mech. Syst. Signal Process. 2023, 186, 109884. [Google Scholar] [CrossRef]
- Chen, X.; Guo, Y.; Xu, C.; Shang, H. A review of wind power equipment fault diagnosis and health monitoring research. China Mech. Eng. 2020, 31, 15. [Google Scholar]
- Zhang, D.; Yu, D.; Zhang, W. Energy operator demodulating of optimal resonance components for the compound faults diagnosis of gearboxes. Meas. Sci. Technol. 2015, 26, 115003. [Google Scholar] [CrossRef]
- Meng, L.; Su, Y.; Kong, X.; Xu, T.; Lan, X.; Li, Y. Intelligent fault diagnosis of gearbox based on differential continuous wavelet transform-parallel multi-block fusion residual network. Measurement 2023, 206, 112318. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, W.; Gu, J.X.; Song, D.; Cheng, Y.; Zhou, Z.; Gu, F.; Ball, A.D. Product envelope spectrum optimization-gram: An enhanced envelope analysis for rolling bearing fault diagnosis. Mech. Syst. Signal Process. 2023, 193, 110270. [Google Scholar] [CrossRef]
- Gu, J.; Peng, Y. An improved complementary ensemble empirical mode decomposition method and its application in rolling bearing fault diagnosis. Digit. Signal Process. 2021, 113, 103050. [Google Scholar] [CrossRef]
- Xu, B.; Li, H. A Novel Empirical Variational Mode Decomposition for Early Fault Feature Extraction. IEEE Access 2022, 10, 134826–134847. [Google Scholar] [CrossRef]
- Pi, J.; Liu, P.; Ma, S.; Liang, C.; Meng, L.; Wang, L. Fault diagnosis of aerospace bearings based on MGA-BP network. Vibration. Test Diagn. 2020, 40, 9. [Google Scholar]
- Cao, H.; Sun, P.; Zhao, L. PCA-SVM method with sliding window for online fault diagnosis of a small pressurized water reactor. Ann. Nucl. Energy 2022, 171, 109036. [Google Scholar] [CrossRef]
- Wang, H.; Li, S.; Song, L.; Cui, L. A novel convolutional neural network based fault recognition method via image fusion of multi-vibration-signals. Comput. Ind. 2019, 105, 182–190. [Google Scholar] [CrossRef]
- Qian, Q.; Qin, Y.; Wang, Y.; Liu, F. A new deep transfer learning network based on convolutional auto-encoder for mechanical fault diagnosis. Measurement 2021, 178, 109352. [Google Scholar] [CrossRef]
- Zhou, J.; Qin, Y.; Luo, J.; Wang, S.; Zhu, T. Dual-thread gated recurrent unit for gear remaining useful life prediction. IEEE Trans. Ind. Inform. 2022, 1–11. [Google Scholar] [CrossRef]
- Zhou, J.; Qin, Y.; Luo, J.; Zhu, T. Remaining useful life prediction by distribution contact ratio health indicator and consolidated memory GRU. IEEE Trans. Ind. Inform. 2022, 1–11. [Google Scholar] [CrossRef]
- Xu, Q.; Jiang, H.; Zhang, X.; Li, J.; Chen, L. Multiscale Convolutional Neural Network Based on Channel Space Attention for Gearbox Compound Fault Diagnosis. Sensors 2023, 23, 3827. [Google Scholar] [CrossRef] [PubMed]
- Yao, D.; Liu, H.; Yang, J.; Li, X.; Cui, X. Research on compound fault diagnosis of urban rail train bearings based on deep learning. J. Railw. 2021, 43, 37–44. [Google Scholar]
- Zhang, Y.; Zhang, Z.; Shao, F.; Wang, Y.; Zhao, X.; Lv, K. Composite Fault Diagnosis Based on Deep Convolutional Generative Adversarial Network. In Proceedings of the 2020 Asia-Pacific International Symposium on Advanced Reliability and Maintenance Modeling (APARM), Vancouver, BC, Canada, 20–23 August 2020. [Google Scholar]
- Sun, G.D.; Wang, Y.R.; Sun, C.F.; Jin, Q. Intelligent Detection of a Planetary Gearbox Composite Fault Based on Adaptive Separation and Deep Learning. Sensors 2019, 19, 5222. [Google Scholar] [CrossRef]
- Yang, Z.B.; Zhang, J.P.; Zhao, Z.B.; Zhai, Z.; Chen, X.F. Interpreting network knowledge with attention mechanism for bearing fault diagnosis. Appl. Soft Comput. 2020, 97, 106829. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wan, S.; Liu, S.; Zhang, Y.; Hong, J.; Wang, D. Bearing fault diagnosis method based on attention mechanism and multilayer fusion network. ISA Trans. 2021, 128, 550–564. [Google Scholar] [CrossRef]
- Xie, Y.; Niu, T.; Shao, S.; Zhao, Y.; Cheng, Y. Attention-based Convolutional Neural Networks for Diesel Fuel System Fault Diagnosis. In Proceedings of the 2020 International Conference on Sensing, Measurement & Data Analytics in the Era of Artificial Intelligence (ICSMD), Xi’an, China, 15–17 October 2020. [Google Scholar]
- Chen, T.; Wang, Z.; Yang, X.; Jiang, K. A deep capsule neural network with stochastic delta rule for bearing fault diagnosis on raw vibration signals. Measurement 2019, 148, 106857. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, Y.; Jiang, Y.; Yang, Y.; Gou, Y.; Zhang, W.; Chen, J. Unknown Compound Faults Diagnosis of High-Speed Train Based on Capsule Network. In Proceedings of the 2019 IEEE 14th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Dalian, China, 14–16 November 2019. [Google Scholar]
- Ke, L.; Liu, Y.; Yang, Y. Compound Fault Diagnosis Method of Modular Multilevel Converter Based on Improved Capsule Network. IEEE Access 2022, 10, 41201–41214. [Google Scholar] [CrossRef]
- Hendricks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Cao, X.; Xu, X.; Duan, Y.; Yang, X. Health Status Recognition of Rotating Machinery Based on Deep Residual Shrinkage Network under Time-varying Conditions. IEEE Sens. J. 2022, 22, 18332–18348. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Phm Data Challenge 2009. Available online: https://www.phmsociety.org/competition/PHM/09 (accessed on 10 April 2009).
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Liang, P.; Deng, C.; Wu, J.; Yang, Z.; Zhu, J.; Zhang, Z. Compound Fault Diagnosis of Gearboxes via Multi-label Convolutional Neural Network and Wavelet Transform. Comput. Ind. 2019, 113, 103132. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Health Status | Sample Length | Overlap Sampling | Conventional Sampling | One-Hot Label Vector |
|---|---|---|---|---|
| 1 | 2048 | 1500 | 600 | [1,0,0,0,0,0] |
| 2 | 2048 | 1500 | 600 | [0,1,0,0,0,0] |
| 3 | 2048 | 1500 | 600 | [0,0,1,0,0,0] |
| 4 | 2048 | 1500 | 600 | [0,0,0,1,0,0] |
| 5 | 2048 | 1500 | 600 | [0,0,0,0,1,0] |
| 6 | 2048 | 1500 | 600 | [0,0,0,0,0,1] |
| Total | - | 9000 | 3600 | - |
| Serial Number | Health Status | Gear | Bearings | Shaft | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 T | 48 T | 24 T | 40 T | 1 | 2 | 3 | 4 | 5 | 6 | Input | Output | ||
| Case 1 | 1 | N | N | N | N | N | N | N | N | N | N | N | N |
| Case 2 | 2 | N | N | M | N | N | N | N | N | N | N | N | N |
| Case 3 | 3 | N | N | B | N | N | C | N | I | N | N | A | N |
| Case 4 | 4 | N | N | N | N | N | C | N | R | N | N | S | N |
| Case 5 | 5 | N | N | B | N | N | N | N | I | N | N | N | N |
| Case 6 | 6 | N | N | N | N | N | N | N | N | N | N | A | N |
| Parameter Item | Parameter Setting |
|---|---|
| Loss function | Margin loss |
| Sample lot Size | 64 |
| Training rounds | 30 |
| Optimization algorithm | Adam |
| Learning rate | 0.001 |
| Learning rate decay factor | 0.0001 |
| Dropout | 0.5 |
| Health Status | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Average Accuracy Rate | Standard Deviation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 100 | 100 | 100 | 100 | 100 | 99.37 | 100 | 100 | 100 | 100 | 99.93 | 0.19 |
| 2 | 99.39 | 99.39 | 100 | 98.18 | 100 | 98.79 | 99.39 | 100 | 99.39 | 100 | 99.45 | 0.57 |
| 3 | 99.40 | 100 | 100 | 98.21 | 100 | 100 | 100 | 100 | 97.62 | 100 | 99.52 | 0.83 |
| 4 | 100 | 100 | 99.41 | 99.41 | 99.41 | 99.41 | 99.41 | 100 | 99.41 | 99.41 | 99.58 | 0.27 |
| 5 | 100 | 100 | 99.36 | 99.36 | 100 | 99.36 | 99.36 | 100 | 100 | 99.36 | 99.68 | 0.32 |
| 6 | 100 | 99.45 | 98.90 | 100 | 99.45 | 100 | 100 | 99.45 | 99.45 | 100 | 99.67 | 0.36 |
| Test set | 99.79 | 99.80 | 99.61 | 99.19 | 99.81 | 99.48 | 99.69 | 99.90 | 99.31 | 99.79 | 99.63 | 0.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Xu, Q.; Jiang, H.; Li, J. Application of Deep Neural Network in Gearbox Compound Fault Diagnosis. Energies 2023, 16, 4164. https://doi.org/10.3390/en16104164
Zhang X, Xu Q, Jiang H, Li J. Application of Deep Neural Network in Gearbox Compound Fault Diagnosis. Energies. 2023; 16(10):4164. https://doi.org/10.3390/en16104164
Chicago/Turabian StyleZhang, Xiangfeng, Qinghong Xu, Hong Jiang, and Jun Li. 2023. "Application of Deep Neural Network in Gearbox Compound Fault Diagnosis" Energies 16, no. 10: 4164. https://doi.org/10.3390/en16104164
APA StyleZhang, X., Xu, Q., Jiang, H., & Li, J. (2023). Application of Deep Neural Network in Gearbox Compound Fault Diagnosis. Energies, 16(10), 4164. https://doi.org/10.3390/en16104164