
Prediction Model for the Viscosity of Heavy Oil Diluted with Light Oil Using Machine Learning Techniques


Abstract
1. Introduction
2. Data and Methods
2.1. Data Collection
2.2. Artificial Neural Network Theory
2.3. Artificial Neural Network Construction and Optimization
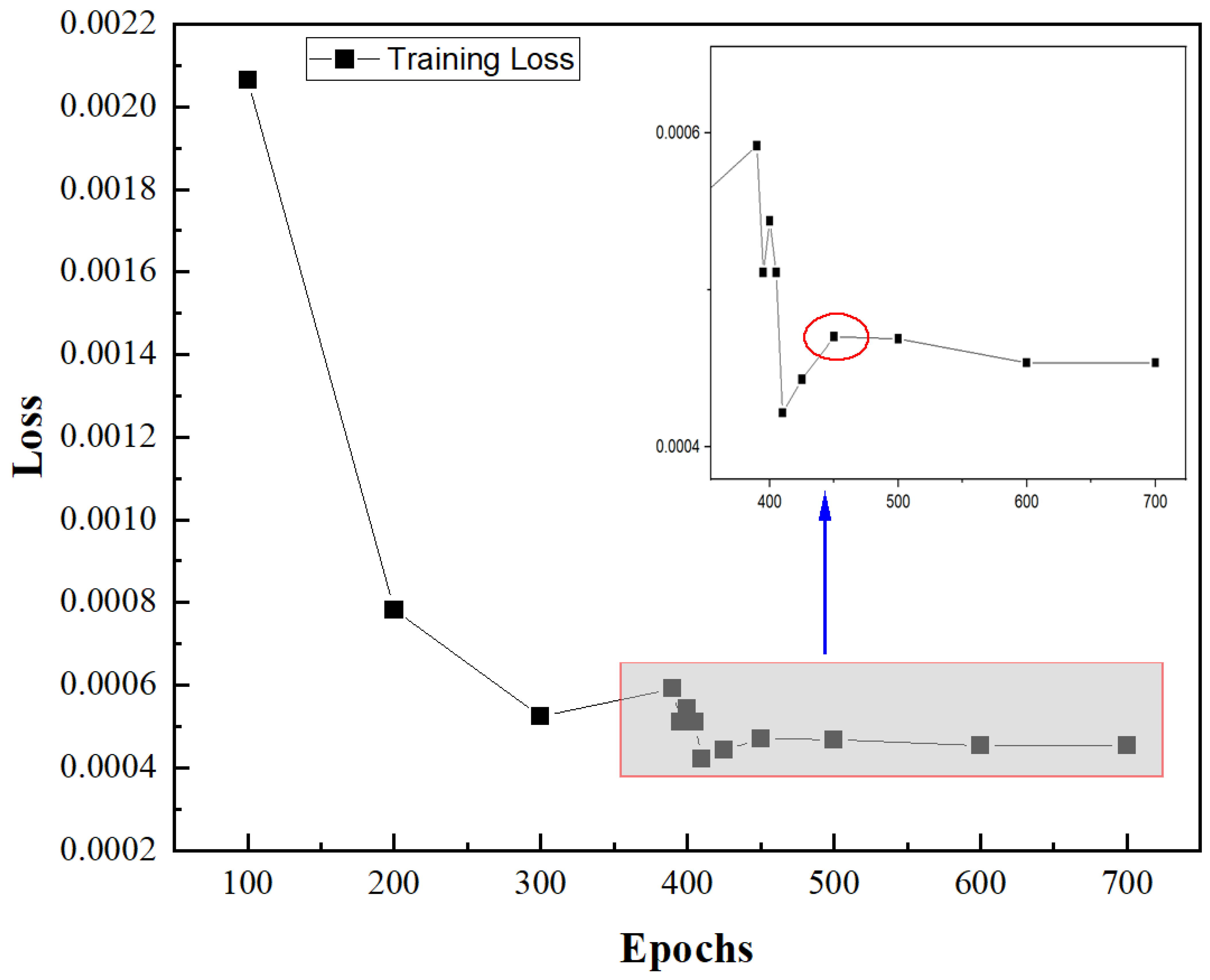
2.3.1. Neural Network Training Times
2.3.2. Optimization Model
2.3.3. Execution Procedure
2.4. Statistical Error Analysis
3. Results and Discussion
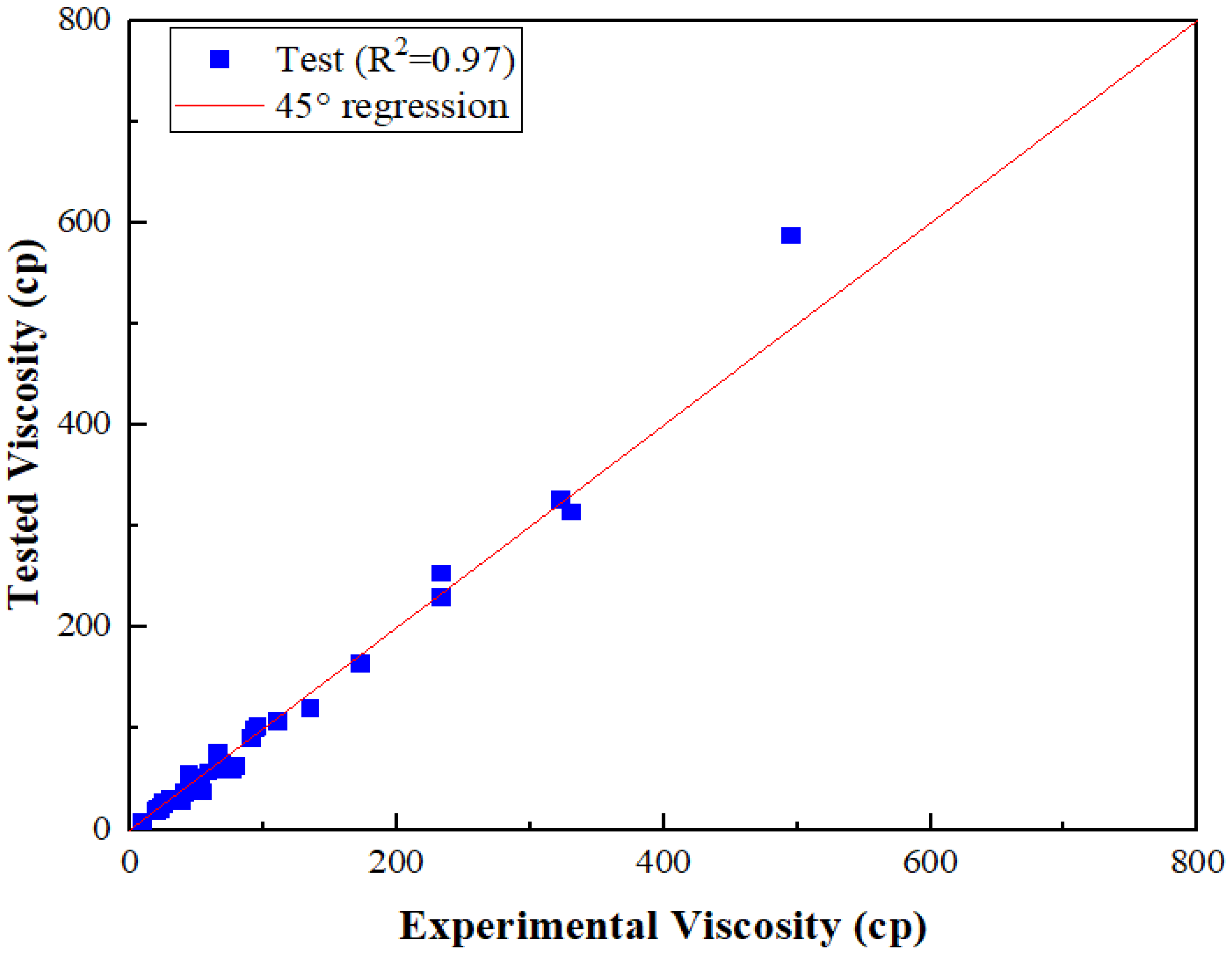
3.1. Prediction of Crude Oil Viscosity
3.2. Determination of the New Viscosity Model
3.3. Comparison of the ANN with Existing Empirical Correlations
- (1)
- Compared with the Arrhenius, Double log, Cragoe, and Kendal-Monroe models, the new model considered the effect of temperature on viscosity, which increased the accuracy of the new model;
- (2)
- As for the Xing model, this model was developed on the basis of the Arrhenius model by introducing a correction coefficient. It can be seen from Figure 9 that the viscosity predicted by the Arrhenius model was larger than the measured viscosity, while the viscosity predicted by the new model was smaller than the experimental viscosity, which may be caused by an inappropriate correlation coefficient of the Xing model.
4. Conclusions
- (1)
- From the analysis of the results, the new viscosity model had the lowest absolute average relative error values of 10.45%, standard deviation values of 8.45%, and coefficient of determination (R2 = 0.95).
- (2)
- The new viscosity showed a good accuracy as well when compared to the conventional viscosity correlations in the published literature. In other words, the new viscosity model outperformed empirical correlations.
- (3)
- The presence of asphaltene in heavy crude oil is also an important parameter affecting the viscosity of the heavy crude oil, and it can be studied in future research.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| X1, X2……,Xn | Input values |
| Wi1, Wi2,……,Win | Weighting coefficient for the corresponding input |
| b | Activation thresholds added to the production of inputs |
| n | Number of nodes. |
| ytar | Correct output |
| ei | Error of the output node i |
| xi | Arbitrary value |
| xmin | Minimum value |
| xmax | Maximum value |
| μExperimental | Experimental viscosity, cp |
| μPredicted | Calculated viscosity, cp |
| μm | Viscosity of the diluted heavy crude oil, cp |
| X1 | Mass fraction of heavy oil |
| X2 | Mass fraction of light oil |
| μ1 | Viscosity of heavy oil, cp |
| μ2 | Viscosity of light oil, cp |
| T | Temperature, °C |
| SD | Standard deviation |
| AARE | Average absolute relative error |
| ARE | Average relative error |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Weight | Bias |
|---|---|---|
| Input-Layer 1 (4 × 11) | [−0.26 −0.24 0.16 −0.2 −0.54 0.39 0.45 −0.15 0.09 −0.09 −0.32] [0.36 0.2 0.084 0.17 0.5 −0.73 0.15 −0.45 −0.43 0.14 −0.59] [0.45 −0.5 −0.13 −0.025 −0.26 −0.16 −0.51 −0.024 0.29 −0.39 0.15] [0.16 −0.38 0.4 −0.062 −0.24 −0.19 −0.35 −0.3 −0.41 0.4 −0.41] | [0.22 0.04 0.08 −0.01 0.14 0.26 −0.08 0.24 −0.17 0.08 0.17]T |
| Layer 1–2 (11 × 11) | [0.1 −0.045 −0.95 0.088 0.57 0.46 −0.12 −0.37 0.38 0.023 0.76] [0.003 −0.06 −0.059 0.29 0.29 0.32 0.46 0.31 −0.37 −0.12 −0.22] [0.81 0.29 −0.04 0.38 −0.61 −0.54 −0.095 0.32 −0.71 −0.77 0.23] [−0.18 −0.37 0.37 −0.15 0.43 0.35 0.097 0.21 0.041 −0.15 −0.57] [0.047 0.079 0.31 0.3 0.19 0.54 −0.038 −0.1 0.35 −0.39 −0.02] [0.26 −0.44 0.54 0.45 −0.11 0.29 0.17 −0.36 0.09 0.55 0.07] [0.28 0.4 −0.10 −0.13 −0.24 0.55 −0.15 −0.19 −0.21 0.37 −0.46] [0.06 −0.80 0.38 −0.06 0.27 0.15 0.28 −0.09 0.48 0.37 −0.53] [−0.25 0.28 −0.32 −0.29 −0.06 −0.39 −0.43 −0.25 −0.08 0.48 0.29] [0.21 0.32 −0.18 −0.26 −0.018 0.16 −0.25 −0.2 0.33 0.14 0.57] [−0.12 −0.49 −0.11 0.33 −0.05 −0.23 0.31 −0.14 −0.09 0.16 −0.46] | [−0.06 0.04 0.05 0.13 −0.02 0.17 0.15 −0.04 0.15 0.14 0.07]T |
| Layer 2–3 (11 × 11) | [−0.23 0.31 −0.41 0.16 −0.46 −0.24 −0.25 −0.41 0.14 0.65 −0.33] [−0.60 0.44 0.21 0.11 −0.42 0.21 −0.13 −0.38 −0.13 0.36 −0.38] [0.20 −0.32 0.26 0.51 0.41 0.50 0.42 −0.21 −0.18 −0.96 −0.01] [0.43 −0.49 −0.2 −0.38 −0.01 0.51 −0.31 0.13 −0.07 0.32 0.21] [0.49 0.22 0.36 −0.28 0.02 0.35 0.25 0.16 0.05 −1 0.21] [0.10 −0.48 −0.45 0.51 −0.12 0.5 −0.52 −0.23 −0.58 −0.27 0.17] [0.44 −0.12 0.07 −0.082 −0.5 0.33 −0.14 0.38 −0.10 −1 0.42] [0.17 0.42 −0.05 −0.46 −0.3 0.36 0.36 −0.10 0.12 −0.29 −0.2] [−0.45 0.25 0.05 0.46 −0.12 0.12 0.08 0.54 −0.13 −0.38 0.43] [0.09 0 −0.17 0.26 −0.22 0.04 0.03 −0.41 −0.41 −0.67 0.47] [0.19 −0.54 0.37 −0.43 −0.44 −0.58 −0.13 −0.2 0.16 0.75 0.15] | [−0.12 −0.05 −0.01 0.09 0 0.15 −0.03 0.16 −0.07 0.26 0.12]T |
| Layer 3-Output(11 × 1) | [0.73 0.14 −0.19 −0.08 −0.08 −0.41 0.28 −0.2 −0.46 0.83 −0.47]T | −0.07 |
References
- Ramasamy, M. Processing of Heavy Crude Oils Challenges and Opportunities; IntechOpen: London, UK, 2019. [Google Scholar]
- Taborda, E.A.; Alvarado, V.; Franco, C.A.; Cortes. Rheological demonstration of alteration in the heavy crude oil fluid structure upon addition of nanoparticles. Fuel 2017, 189, 322–333. [Google Scholar] [CrossRef]
- Taborda, E.A.; Franco, C.A.; Ruiz, M.A.; Alvarado, V.; Cortes, F.B. Experimental and theoretical study of viscosity reduction in heavy crude oils by addition of nanoparticles. Energy Fuel 2017, 31, 1329–1338. [Google Scholar] [CrossRef]
- Montes, D.; Taborda, E.A.; Minale, M.; Cortes, F.B.; Franco, C.A. Effect of the NiO/SiO2 nanoparticles-assisted ultrasound cavitation process on the rheological properties of heavy crude oil: Steady-state rheometry and oscillatory tests. Energy Fuel 2019, 33, 9671–9680. [Google Scholar] [CrossRef]
- Anto, R.; Deshmukh, S.; Sanyal, S.; Bhui, U.K. Nanoparticles as flow improver of petroleum crudes: A study on temperature-dependent steady-state and dynamic rheological behavior of crude oils. Fuel 2020, 275, 117873. [Google Scholar] [CrossRef]
- Nunez, G.; Briceno, M.; Mata, C.; Rivas, H.; Joseph, D. Flow characteristics of concentrated emulsions of very viscous oil in water systems. J. Rheol. 1996, 40, 405–423. [Google Scholar] [CrossRef]
- Fruman, D.H.; Briant, J. Investigation of the rheological characteristics of heavy crude oil-in-water emulsions. In Proceedings of the International conference on the Physical Modeling of Multi-Phase Flow, Coventry, UK, 19–21 April 1983. [Google Scholar]
- Schumacher, M.M. Enhanced Recovery of Residual and Heavy Oils; Noyes Press: Park Ridge, NJ, USA, 1980. [Google Scholar]
- Todd, C.M. Downstream Planning and Innovation for Heavy Oil Development—A Producer’s Perspective. J. Can. Pet. Technol. 1988, 27, 79–86. [Google Scholar] [CrossRef]
- Guevara, E.; Gonzalez, J.; Nuñez, G. Highly Viscous Oil Transportation Methods in the Venezuela Industry. In Proceedings of the 15th World Pet. Congress, Beijing, China, 12–17 October 1997; pp. 495–502. [Google Scholar]
- Hart, A. A review of technologies for transporting heavy crude oil and bitumen via pipelines. J. Pet. Explor. Prod. Technol. 2014, 4, 327–336. [Google Scholar] [CrossRef]
- Zhu, M.; Zhong, H.; Li, Y.; Zeng, C.; Gao, Y. Research on viscosity-reduction technology by electric heating and blending light oil, in ultra-deep heavy oil wells. J. Pet. Explor. Prod. Technol. 2015, 5, 233–239. [Google Scholar] [CrossRef][Green Version]
- Wróblewski, P.; Lewicki, W. A Method of Analyzing the Residual Values of Low-Emission Vehicles Based on a Selected Expert Method Taking into Account Stochastic Operational Parameters. Energies 2021, 14, 6859. [Google Scholar] [CrossRef]
- Wróblewski, P. The second paper is Analysis of Torque Waveforms in Two-Cylinder Engines for Ultralight Aircraft Propulsion Operating on 0W-8 and 0W-16 Oils at High Thermal Loads Using the DiamondLike Carbon Composite Coating. SAE Int. J. Energ. 2022, 15, 2022. [Google Scholar]
- Yaghi, B.M.; Al-Bemani, A. Heavy crude oil viscosity reduction for pipeline transportation. Energy Sources 2002, 24, 93–102. [Google Scholar] [CrossRef]
- Hasan, S.W.; Ghannam, M.T.; Esmail. Heavy crude oil viscosity reduction and rheology for pipeline transportation. Fuel 2010, 89, 1095–1100. [Google Scholar] [CrossRef]
- Arrhenius, S.A. Uber die Dissociation der in Wasser gelosten Stoffe. Z. Phys. Chem. 1887, 1, 631–648. [Google Scholar] [CrossRef]
- Kendall, J.; Monroe, K. The viscosity of liquids II. The viscosity-composition curve for ideal liquid mixtures. Am. Chem. J. 1917, 9, 1787–1802. [Google Scholar] [CrossRef]
- Centeno, G.; Sánchez-Reyna, G.; Ancheyta, J.; Muñoz, J.A.; Cardona, N. Testing Various Mixing Rules for Calculation of Viscosity of Petroleum Blends. Fuel 2011, 90, 3561–3570. [Google Scholar] [CrossRef]
- Cragoe, C.S. Changes in the viscosity of liquids with temperature, pressure and composition. In Proceedings of the 1st World Petroleum Congress, London, UK, 19–25 July 1933; pp. 529–541. [Google Scholar]
- Al-Besharah, J.M.; Akashah, S.A.; Mumford, C.J. The Effect of Temperature and Pressure on the Viscosities of Crude Oils and Their Mixtures. Ind. Eng. Chem. Res. 1989, 28, 213–221. [Google Scholar] [CrossRef]
- ASTM Designation: ASTM D341-09. Viscosity–Temperature Charts for Liquid Petroleum Products; The American Society for Testing and Materials: West Conshohocken, PA, USA, 1983. [Google Scholar]
- Baird, C.T. IV Guide to Petroleum Product Blending; HPI Consultants, Inc.: Austin, TX, USA, 1989. [Google Scholar]
- Ratcliff, G.A.; Khan, M.A. Prediction of the viscosities of liquid mixtures by a group solution model. Can. J. Chem. Eng. 1971, 49, 125–129. [Google Scholar] [CrossRef]
- Mohammadi, S.; Sobati, M.A.; Sadeghi, M.T. Viscosity Reduction of Heavy Crude Oil by Dilution Methods: New Correlations for the Prediction of the Kinematic Viscosity of Blends. Iran J. Sci. Technol. A. 2019, 8, 60–77. [Google Scholar]
- Jing, J.; Yin, R.; Yuan, Y.; Shi, Y.; Sun, J.; Zhang, M. Determination of the Transportation Limits of Heavy Crude Oil Using Three Combined Methods of Heating, Water Blending, and Dilution. ACS. Omega 2020, 5, 9870–9884. [Google Scholar] [CrossRef] [PubMed]
- Xu, G. Study on Simulation of Mixing Process of Heavy and Thin Crude Oil and Viscosity Prediction Model of Mixed Oil; China University of petroleum: Beijing, China, 2021. [Google Scholar]
- Elsheikh, A.H.; Sharshir, S.W.; Abd Elaziz, M.; Kabeel, A.E.; Guilan, W.; Haiou, Z. Modeling of solar energy systems using artificial neural network: A comprehensive review. Sol. Energy 2019, 180, 622–639. [Google Scholar] [CrossRef]
- Ghandourah, E.I.; Sangeetha, A.; Shanmugan, S.; Zayed, M.E.; Moustafa, E.B.; Tounsi, A.; Elsheikh, A.H. A new optimized artificial neural network model to predict thermal efficiency and water yield of tubular solar still. Case Stud. Therm. Eng. 2022, 30, 101750. [Google Scholar]
- Elsheikh, A.H.; Panchal, H.; Ahmadein, M.; Mosleh, A.O.; Sadasivuni, K.K.; Alsaleh, N.A. Productivity forecasting of solar distiller integrated with evacuated tubes and external condenser using artificial intelligence model and moth-flame optimizer. Case Stud. Therm. Eng. 2021, 28, 101671. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Katekar, V.P.; Muskens, O.L.; Deshmukh, S.S.; Abd Elaziz, M.; Dabour, S.M. Utilization of LSTM neural network for water production forecasting of a stepped solar still with a corrugated absorber plate. Process. Saf. Environ. Prot. 2021, 148, 273–282. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, C.; Zhao, H.; Wang, Y.; Han, X. A Robust Method to Predict Fluid Properties Based on Big Data and Machine Learning Algorithms. In Proceedings of the International Petroleum Technology Conference, Virtual, 23 April–1 March 2021. [Google Scholar]
- Koffi, I. A Deep Learning Approach for the Prediction of Oil Formation Volume Factor. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dubai, United Arab Emirates, 21–23 September 2021. [Google Scholar]
- Alade, O.; Al Shehri, D.; Mahmoud, M.; Sasaki, K. Viscosity–Temperature–Pressure Relationship of Extra-Heavy Oil (Bitumen): Empirical Modelling versus Artificial Neural Network (ANN). Energies 2019, 12, 2390. [Google Scholar] [CrossRef]
- Yiqing, M.; Rooney Quan, G. Artificial Neural Network for Compositional Ionic Liquid Viscosity Prediction. Int. J. Comput. Intell. Syst. 2012, 5, 460–471. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 2008. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Zhongyun, X.J.; Guoxin, S. Prediction of House Price Based on The Back Propagation Neural Network in The Keras Deep Learning Framework. In Proceedings of the 2019 6th International Conference on Systems and Informatics, Bandung, Indonesia, 18–20 September 2019. [Google Scholar]










| Title 1 | Title 2 | Minimum Value | Maximum Value |
|---|---|---|---|
| 1 | Heavy crude viscosity, cp | 121 | 4020.6 |
| 2 | Light crude viscosity, cp | 2.9 | 35.7 |
| 3 | Dilution rate | 0.2 | 0.9 |
| 4 | Temperature, °C | 20 | 60 |
| 5 | Diluted heavy viscosity, cp | 9.3 | 882 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Dong, P.; Cui, J.; Gao, Q. Prediction Model for the Viscosity of Heavy Oil Diluted with Light Oil Using Machine Learning Techniques. Energies 2022, 15, 2297. https://doi.org/10.3390/en15062297
Gao X, Dong P, Cui J, Gao Q. Prediction Model for the Viscosity of Heavy Oil Diluted with Light Oil Using Machine Learning Techniques. Energies. 2022; 15(6):2297. https://doi.org/10.3390/en15062297
Chicago/Turabian StyleGao, Xiaodong, Pingchuan Dong, Jiawei Cui, and Qichao Gao. 2022. "Prediction Model for the Viscosity of Heavy Oil Diluted with Light Oil Using Machine Learning Techniques" Energies 15, no. 6: 2297. https://doi.org/10.3390/en15062297
APA StyleGao, X., Dong, P., Cui, J., & Gao, Q. (2022). Prediction Model for the Viscosity of Heavy Oil Diluted with Light Oil Using Machine Learning Techniques. Energies, 15(6), 2297. https://doi.org/10.3390/en15062297