
Machine Learning Algorithms for Flow Pattern Classification in Pulsating Heat Pipes



Abstract
:1. Introduction
1.1. Flow Patterns in PHPs
1.2. Machine Learning Algorithms for Two-Phase Flow Heat Transfer
2. Methodology
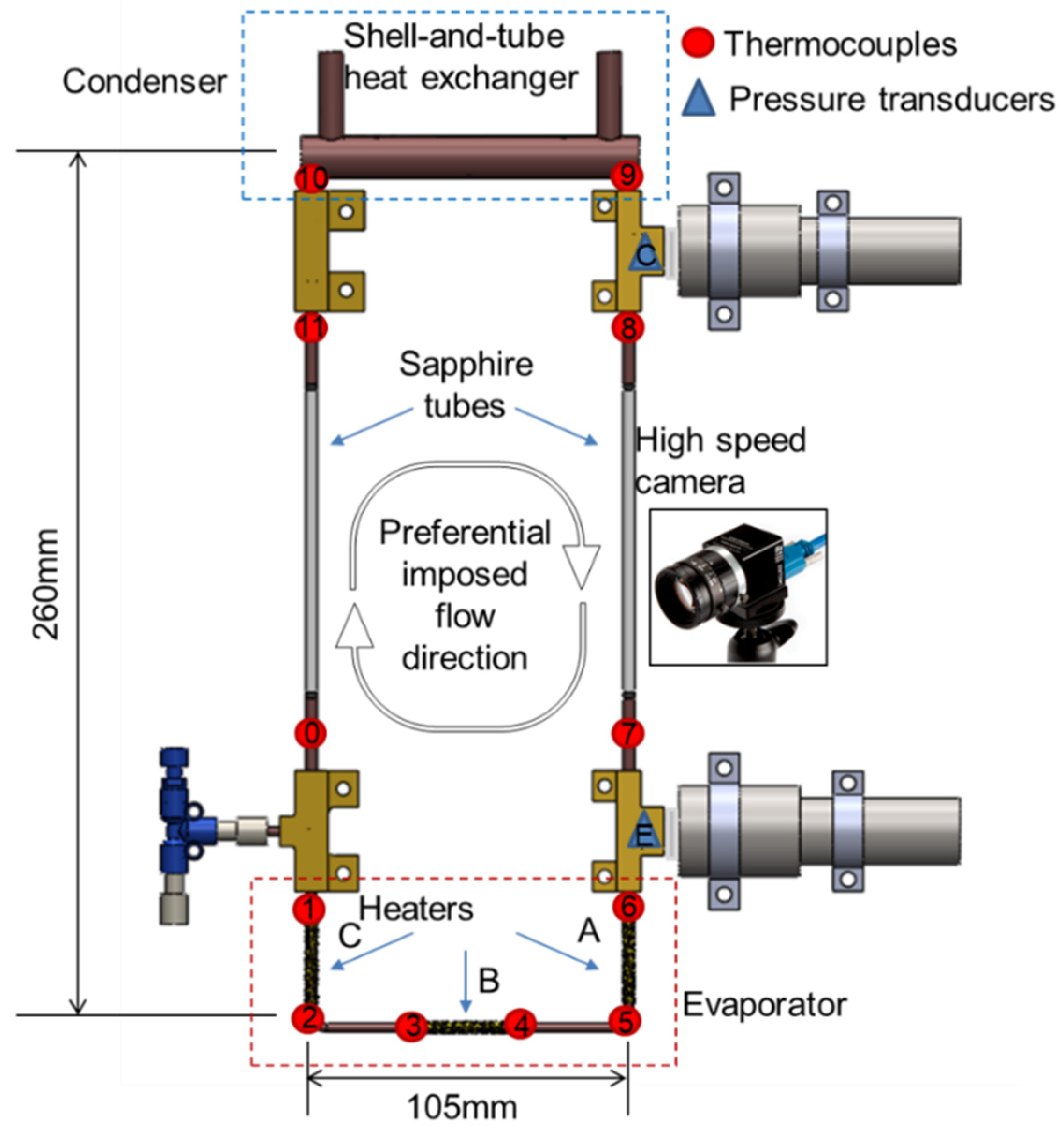
2.1. Experimental Setup
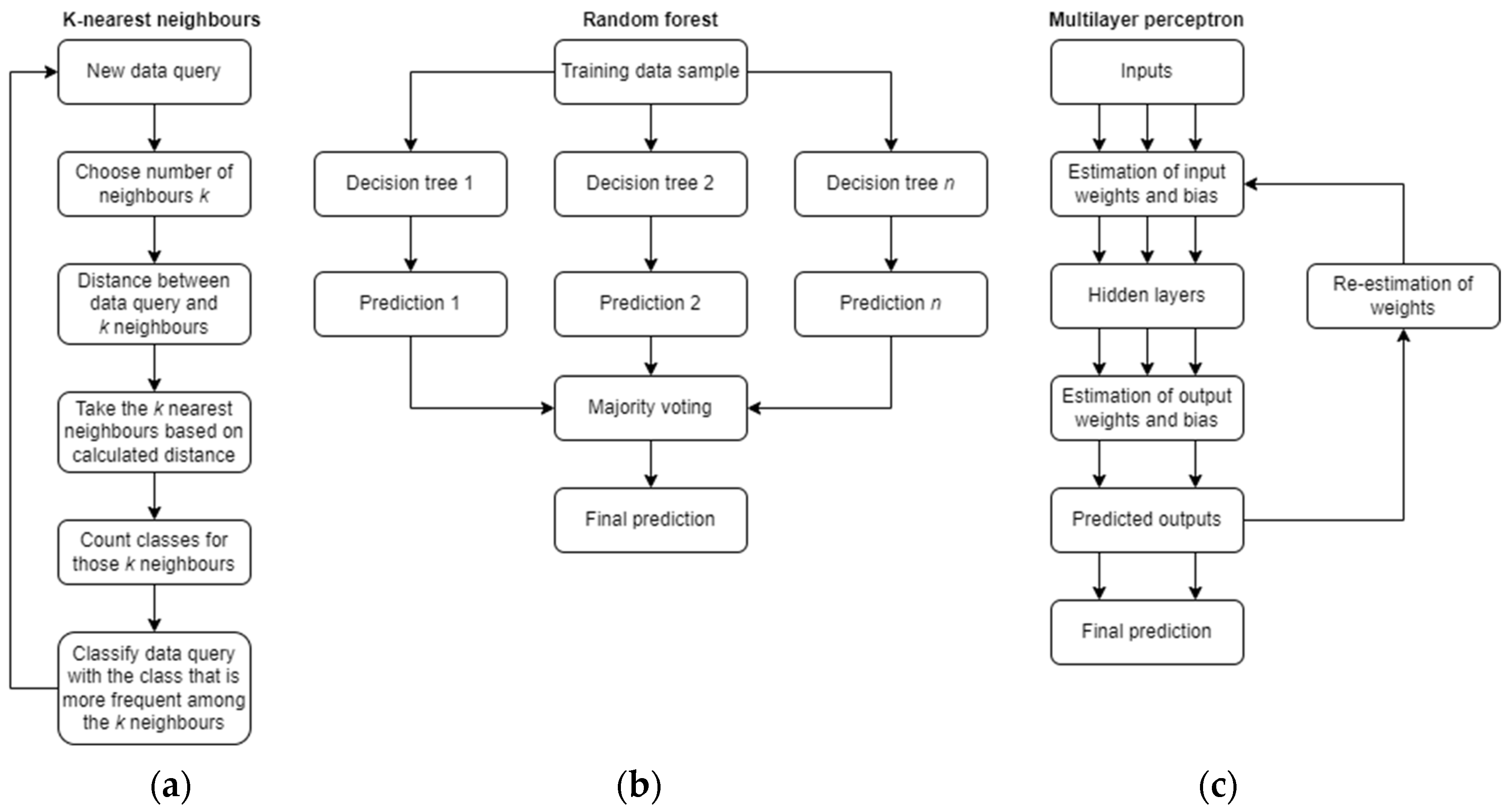
2.2. Classification Algorithms
2.2.1. K-Nearest Neighbors
2.2.2. Random Forest
2.2.3. Multilayer Perceptron
3. Results and Discussion
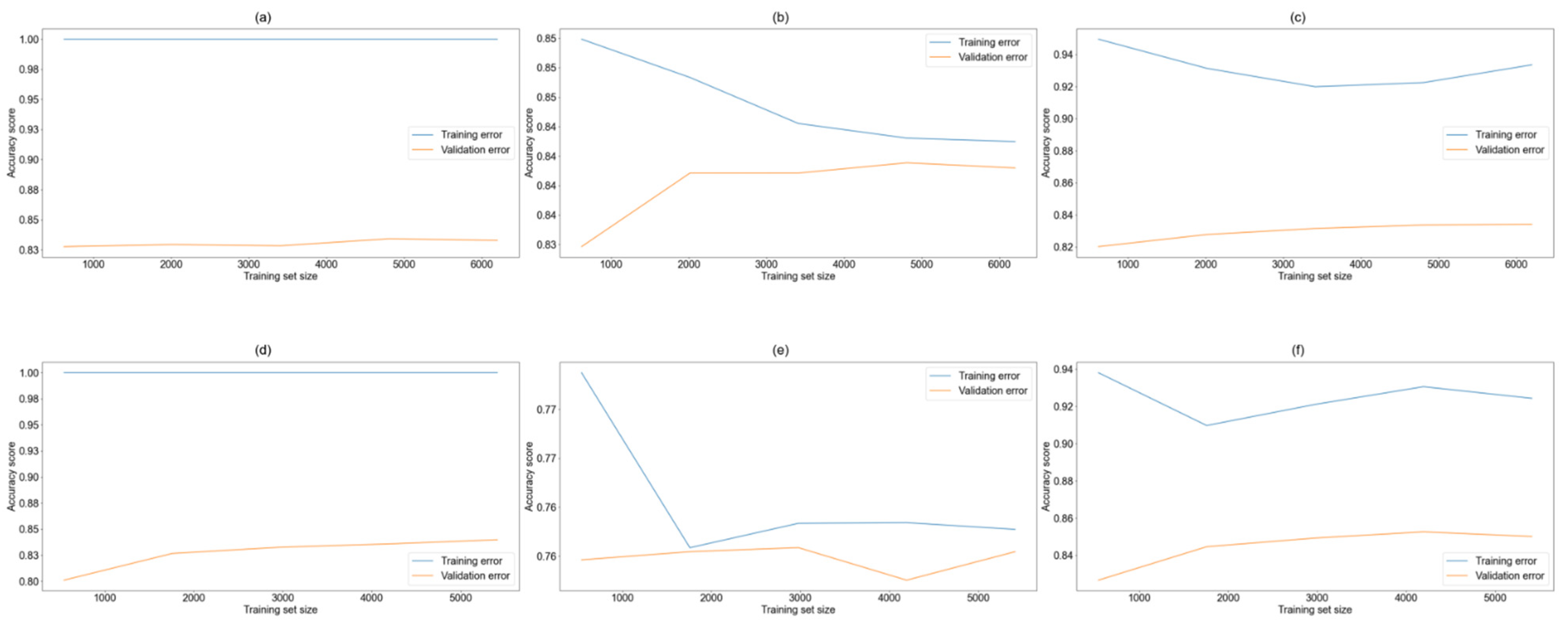
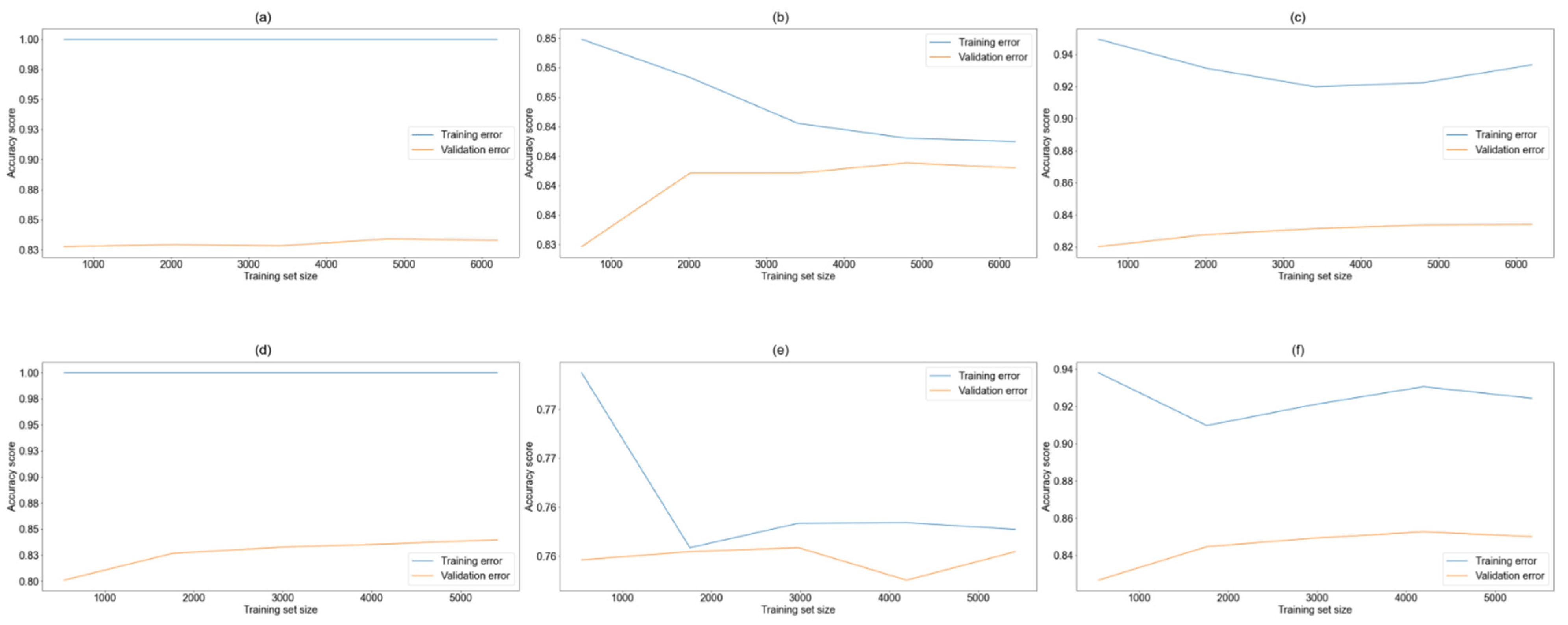
3.1. Data Splitting
3.2. Data Scaling
3.3. Classifier Creation
3.4. Cross-Validation
3.5. Accuracy Assessment
3.6. Selection of Hyperparameters
3.7. Classification Results
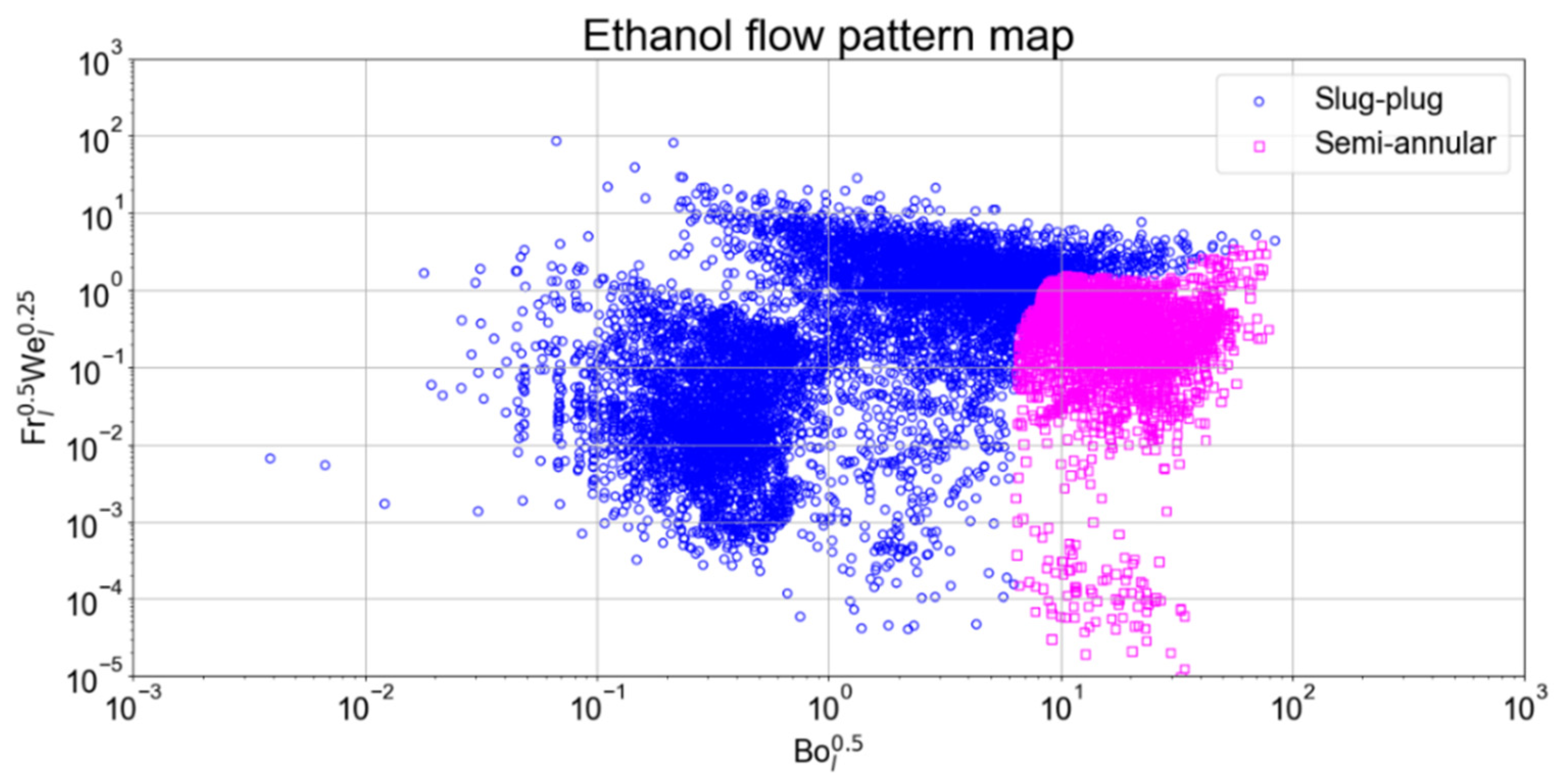
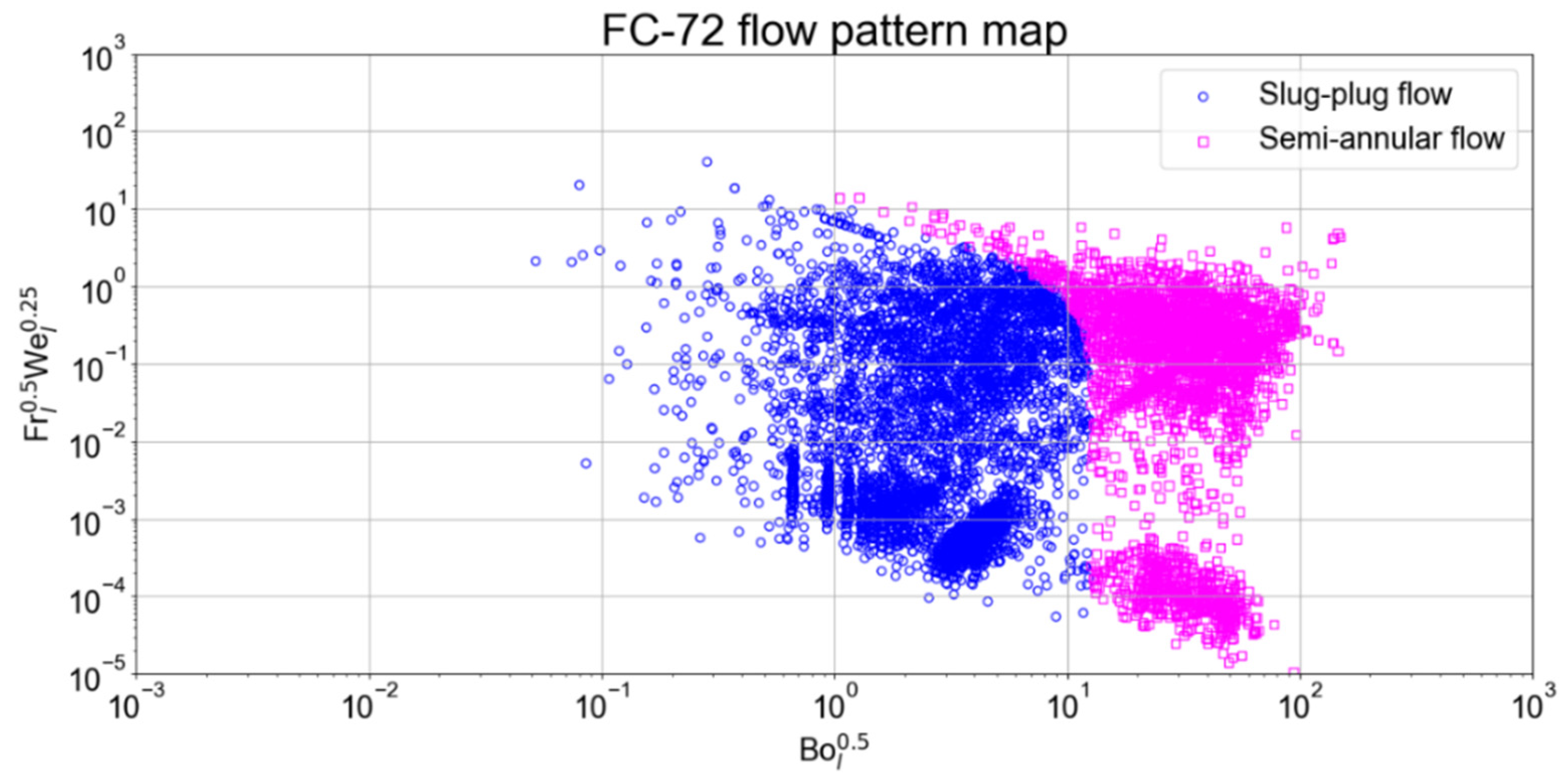
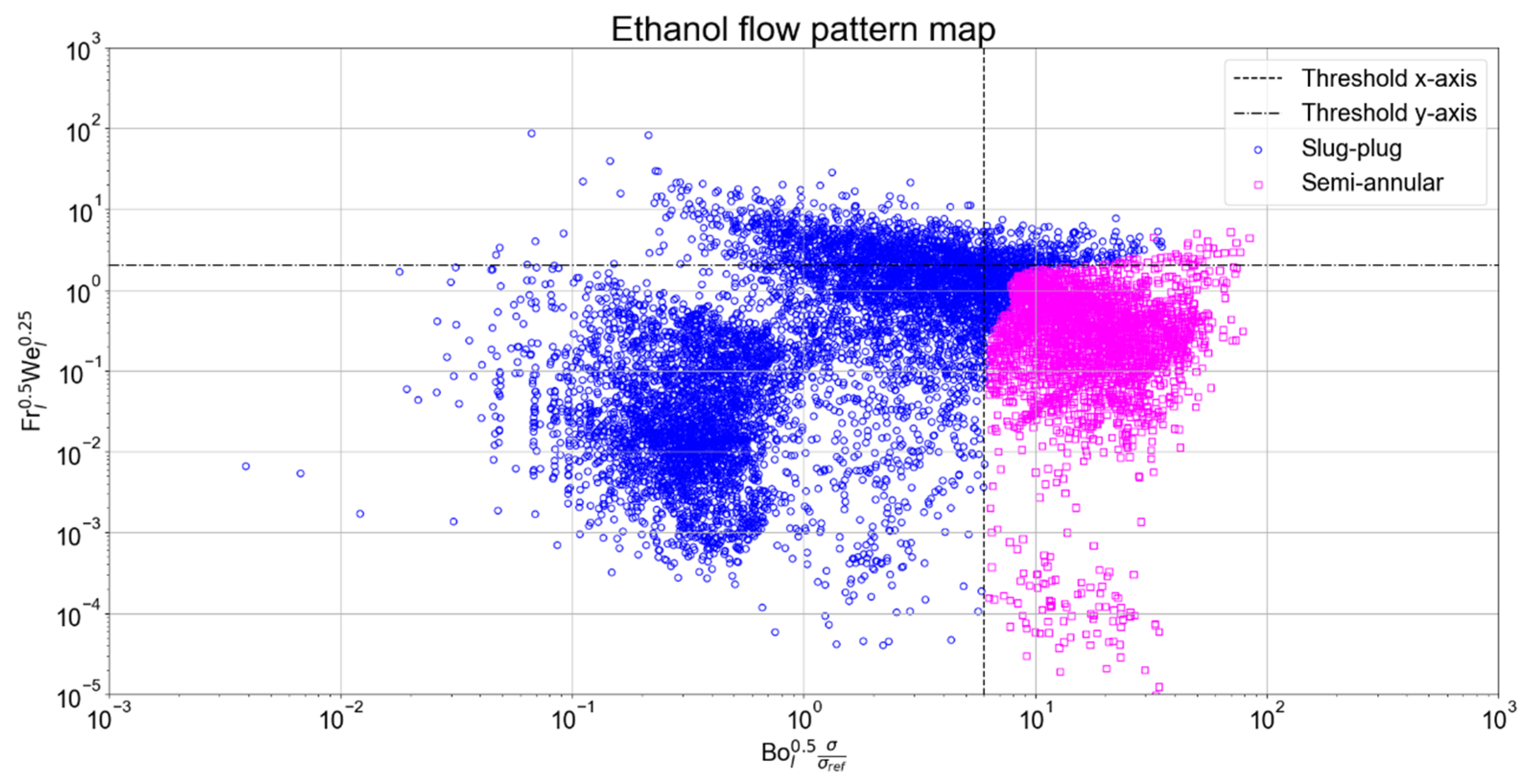
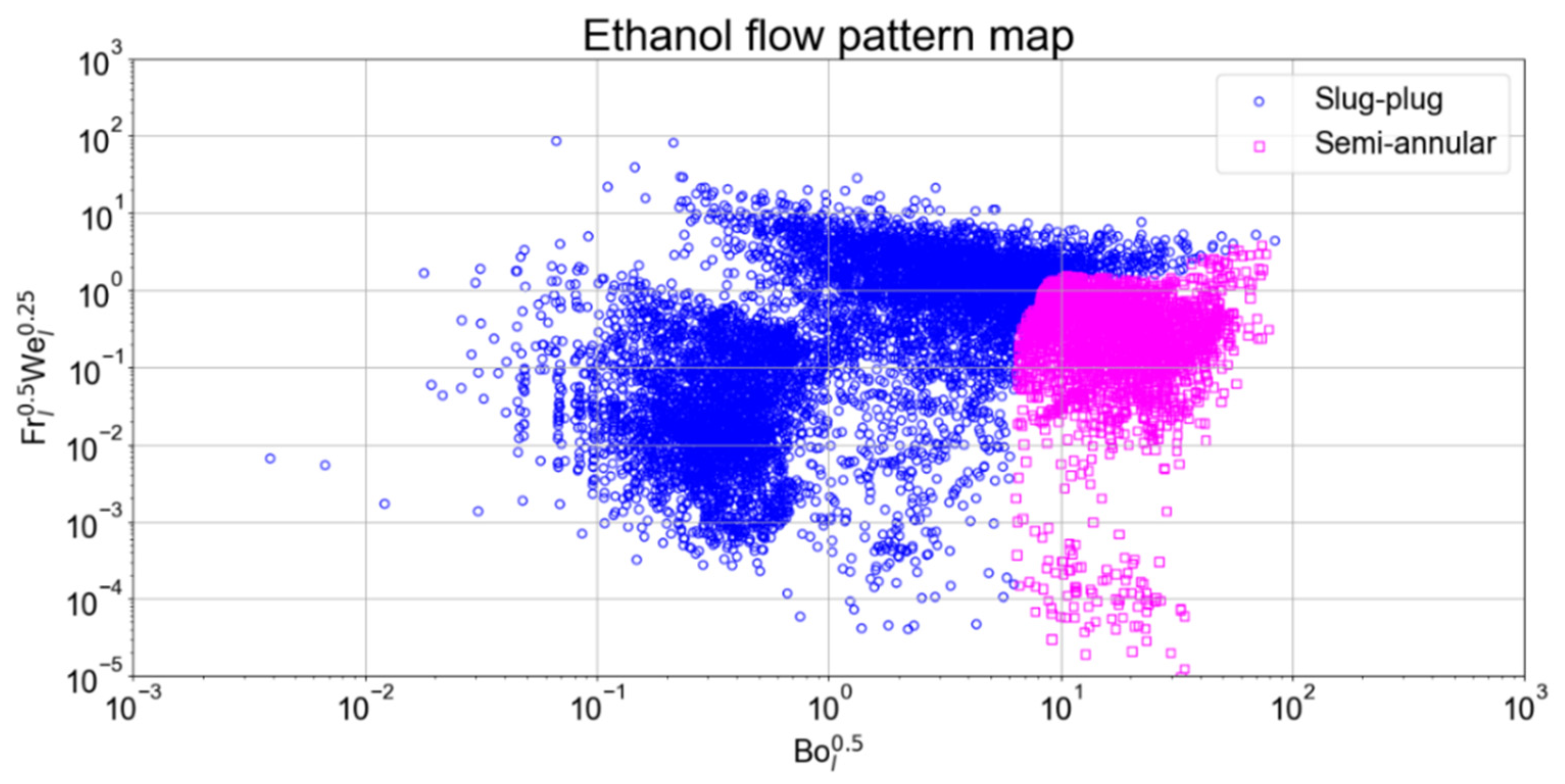
3.8. Flow Pattern Maps
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Nomenclature | |||
| a | Fluid acceleration (m/s2) | Heat load input (W) | |
| Bo | Bond number | ρ | Density (kg/m3) |
| Co | Confinement number | score | Accuracy score |
| d | Diameter (mm) | sd | Standard deviation |
| f | Frequency (Hz) | σ | Surface tension (N/m) |
| Fr | Froude number | T | Temperature (°C) |
| g | Gravitational acceleration (m/s2) | θ | Angle (°) |
| h | Enthalpy (J/kg) | u | Velocity (m/ms) |
| l | length (m) | We | Weber number |
| μ | Dynamic viscosity (Pa·s) | Data point | |
| Expected or average value | True categorical value | ||
| N | Number of turns | Predicted categorical value | |
| n | Total number of data points | Normalized data point | |
| P | Pressure (Pa) | ||
| Subscripts | |||
| b | Bubble | l | Liquid |
| c | Condenser | l,v | Liquid to vapor |
| cr | Critical | ref | Reference value |
| e | Evaporator | v | Vapor |
| f | Fluid | w | Wall |
| Abbreviations | |||
| ANN | Artificial neural network | PCB | Printed circuit board |
| ESA | European Space Agency | PHP | Pulsating heat pipe |
| FR | Filling ratio | RF | Random forest |
| KNN | K-nearest neighbors | TC | Thermocouples |
| ML | Machine learning | TCS | Thermal control system |
| MLP | Multilayer Perceptron | TS | Thermosyphon |
| p | Parabola | ||
References
- Karthik, C.A.; Kalita, P.; Cui, X.; Peng, X. Thermal Management for Prevention of Failures of Lithium Ion Battery Packs in Electric Vehicles: A Review and Critical Future Aspects. Energy Storage 2020, 2, e137. [Google Scholar] [CrossRef]
- Feng, X.; Ren, D.; He, X.; Ouyang, M. Mitigating Thermal Runaway of Lithium-Ion Batteries. Joule 2020, 4, 743–770. [Google Scholar] [CrossRef]
- Jones, N. How to Stop Data Centres from Gobbling up the world’s Electricity. Nature 2018, 561, 163–166. [Google Scholar] [CrossRef] [PubMed]
- Kandlikar, S.G. Heat Transfer Mechanisms during Flow Boiling in Microchannels. J. Heat Transf. 2004, 126, 8–16. [Google Scholar] [CrossRef]
- Thome, J.R. Boiling in Microchannels: A Review of Experiment and Theory. Int. J. Heat Fluid Flow 2004, 25, 128–139. [Google Scholar] [CrossRef]
- Liu, D.; Garimella, S.V. Flow Boiling Heat Transfer in Microchannels. J. Heat Transf. 2007, 129, 1321–1332. [Google Scholar] [CrossRef]
- Bar-Cohen, A.; Sheehan, J.R.; Rahim, E. Two-Phase Thermal Transport in Microgap Channels—Theory, Experimental Results, and Predictive Relations. Microgravity Sci. Technol. 2011, 24, 1–15. [Google Scholar] [CrossRef]
- Baldassari, C.; Marengo, M. Flow Boiling in Microchannels and Microgravity. Prog. Energy Combust. Sci. 2013, 39, 1–36. [Google Scholar] [CrossRef]
- Mahmoud, M.M.; Karayiannis, T.G. Flow Pattern Transition Models and Correlations for Flow Boiling in Mini-Tubes. Exp. Therm. Fluid Sci. 2016, 70, 270–282. [Google Scholar] [CrossRef] [Green Version]
- Karayiannis, T.; Mahmoud, M. Flow Boiling in Microchannels: Fundamentals and Applications. Appl. Therm. Eng. 2017, 115, 1372–1397. [Google Scholar] [CrossRef]
- Ahmad, S.W.; Lewis, J.S.; McGlen, R.J.; Karayiannis, T.G. Pool Boiling on Modified Surfaces Using R-123. Heat Transf. Eng. 2014, 35, 1491–1503. [Google Scholar] [CrossRef] [Green Version]
- Berenson, P. Experiments on Pool-Boiling Heat Transfer. Int. J. Heat Mass Transf. 1962, 5, 985–999. [Google Scholar] [CrossRef]
- Marto, P.J.; Lepere, V.J. Pool Boiling Heat Transfer from Enhanced Surfaces to Dielectric Fluids. J. Heat Transf. 1982, 104, 292–299. [Google Scholar] [CrossRef]
- Mudawar, I.; Anderson, T.M. Optimization of Enhanced Surfaces for High Flux Chip Cooling by Pool Boiling. J. Electron. Packag. 1993, 115, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Estes, K.A.; Mudawar, I. Comparison of Two-Phase Electronic Cooling Using Free Jets and Sprays. J. Electron. Packag. 1995, 117, 323–332. [Google Scholar] [CrossRef]
- Bintoro, J.S.; Akbarzadeh, A.; Mochizuki, M. A Closed-Loop Electronics Cooling by Implementing Single Phase Impinging Jet and Mini Channels Heat Exchanger. Appl. Therm. Eng. 2005, 25, 2740–2753. [Google Scholar] [CrossRef]
- Rau, M.J.; Dede, E.M.; Garimella, S.V. Local Single- and Two-Phase Heat Transfer from an Impinging Cross-Shaped Jet. Int. J. Heat Mass Transf. 2014, 79, 432–436. [Google Scholar] [CrossRef] [Green Version]
- De Oliveira, P.A.; Barbosa, J.R. Novel Two-Phase Jet Impingement Heat Sink for Active Cooling of Electronic Devices. Appl. Therm. Eng. 2017, 112, 952–964. [Google Scholar] [CrossRef]
- Thome, J.R. Encyclopedia of Two-Phase Heat Transfer and Flow IV; World Scientific Pub Co. Pte. Lt.: Singapore, 2018; Volume 1. [Google Scholar] [CrossRef]
- Akachi, H. Structure of a Heat Pipe. U.S. Patent 4921041, 1990. Available online: https://patentimages.storage.googleapis.com/pdfs/US4921041.pdf (accessed on 23 October 2020).
- Akachi, H. Structure of a Micro-Heat Pipe. U.S. Patent US005219020A, 1993. Available online: https://patentimages.storage.googleapis.com/8d/87/57/18fa8dfa9abc67/US5219020.pdf (accessed on 23 October 2020).
- Das, S.; Nikolayev, V.; Lefevre, F.; Pottier, B.; Khandekar, S.; Bonjour, J. Thermally Induced Two-Phase Oscillating Flow Inside a Capillary Tube. Int. J. Heat Mass Transf. 2010, 53, 3905–3913. [Google Scholar] [CrossRef] [Green Version]
- Nine, J.; Tanshen, R.; Munkhbayar, B.; Chung, H.; Jeong, H. Analysis of Pressure Fluctuations to Evaluate Thermal Performance of Oscillating Heat Pipe. Energy 2014, 70, 135–142. [Google Scholar] [CrossRef]
- Nikolayev, V.S. A Dynamic Film Model of the Pulsating Heat Pipe. J. Heat Transf. 2011, 133, 081504. [Google Scholar] [CrossRef]
- Nekrashevych, I.; Nikolayev, V.S. Effect of Tube Heat Conduction on the Pulsating Heat Pipe Start-up. Appl. Therm. Eng. 2017, 117, 24–29. [Google Scholar] [CrossRef] [Green Version]
- Nekrashevych, I.; Nikolayev, V.S. Pulsating Heat Pipe Simulations: Impact of PHP Orientation. Microgravity Sci. Technol. 2019, 31, 241–248. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Li, J.; Dong, X.; Chen, H. Experimental Study of Flow Patterns and Improved Configurations for Pulsating Heat Pipes. J. Therm. Sci. 2007, 16, 56–62. [Google Scholar] [CrossRef]
- Nazari, M.A.; Ahmadi, M.H.; Ghasempour, R.; Shafii, M.B. How to Improve the Thermal Performance of Pulsating Heat Pipes: A Review on Working Fluid. Renew. Sustain. Energy Rev. 2018, 91, 630–638. [Google Scholar] [CrossRef]
- Pietrasanta, L.; Mameli, M.; Mangini, D.; Georgoulas, A.; Miché, N.; Filippeschi, S.; Marengo, M. Developing Flow Pattern Maps for Accelerated Two-Phase Capillary Flows. Exp. Therm. Fluid Sci. 2020, 112, 109981. [Google Scholar] [CrossRef]
- Cheng, L.; Ribatski, G.; Thome, J.R. Two-Phase Flow Patterns and Flow-Pattern Maps: Fundamentals and Applications. Appl. Mech. Rev. 2008, 61, 050802. [Google Scholar] [CrossRef]
- Özdemir, M.R.; Mahmoud, M.M.; Karayiannis, T.G. Flow Boiling of Water in a Rectangular Metallic Microchannel. Heat Transf. Eng. 2021, 42, 492–516. [Google Scholar] [CrossRef] [Green Version]
- Kandlikar, S.G.; Garimella, S.; Li, D.; Colin, S.; King, M.R. Heat Transfer and Fluid Flow in Minichannels and Microchannels; Elsevier: Amsterdam, The Netherlands, 2006; pp. 175–226. [Google Scholar] [CrossRef]
- Mameli, M.; Catarsi, A.; Mangini, D.; Pietrasanta, L.; Miché, N.; Marengo, M.; Di Marco, P.; Filippeschi, S. Start-up in Microgravity and Local Thermodynamic States of a Hybrid Loop thermosyphon/Pulsating Heat Pipe. Appl. Therm. Eng. 2019, 158, 113771. [Google Scholar] [CrossRef]
- Andredaki, M.; Georgoulas, A.; Miché, N.; Marengo, M. Accelerating Taylor Bubbles within Circular Capillary Channels: Break-up Mechanisms and Regimes. Int. J. Multiph. Flow 2020, 134, 103488. [Google Scholar] [CrossRef]
- Guillen-Rondon, P.; Robinson, M.D.; Torres, C.; Pereya, E. Support Vector Machine Application for Multiphase Flow Pattern Prediction. arXiv 2018, arXiv:1806.05054. [Google Scholar]
- Zhu, G.; Wen, T.; Zhang, D. Machine Learning Based Approach for the Prediction of Flow boiling/Condensation Heat Transfer Performance in Mini Channels with Serrated Fins. Int. J. Heat Mass Transf. 2021, 166, 120783. [Google Scholar] [CrossRef]
- Suh, Y.; Bostanabad, R.; Won, Y. Deep Learning Predicts Boiling Heat Transfer. Sci. Rep. 2021, 11, 5622. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, J.S.; Valencia, C.; Ratkovich, N.; Torres, C.F.; Muñoz, F. Data Driven Methodology for Model Selection in Flow Pattern Prediction. Heliyon 2019, 5, e02718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Azman, A.N.; Xu, K.-W.; Kang, C.; Kim, H.-B. Two-Phase Flow Regime Identification Based on the Liquid-Phase Velocity Information and Machine Learning. Exp. Fluids 2020, 61, 212. [Google Scholar] [CrossRef]
- Jokar, A.; Godarzi, A.A.; Saber, M.; Shafii, M.B. Simulation and Optimization of a Pulsating Heat Pipe Using Artificial Neural Network and Genetic Algorithm. Heat Mass Transf. 2016, 52, 2437–2445. [Google Scholar] [CrossRef]
- Jalilian, M.; Kargarsharifabad, H.; Godarzi, A.A.; Ghofrani, A.; Shafii, M.B. Simulation and Optimization of Pulsating Heat Pipe Flat-Plate Solar Collectors Using Neural Networks and Genetic Algorithm: A Semi-Experimental Investigation. Clean Technol. Environ. Policy 2016, 18, 2251–2264. [Google Scholar] [CrossRef]
- Patel, V.M.; Mehta, H.B. Thermal Performance Prediction Models for a Pulsating Heat Pipe Using Artificial Neural Network (ANN) and Regression/Correlation Analysis (RCA). Sādhanā 2018, 43, 184. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yan, Y.; Meng, X.; Chen, G. A General Method to Predict the Performance of Closed Pulsating Heat Pipe by Artificial Neural Network. Appl. Therm. Eng. 2019, 157, 113761. [Google Scholar] [CrossRef]
- Pietrasanta, L.; Mangini, D.; Fioriti, D.; Miché, N.; Andredaki, M.; Georgoulas, A.; Araneo, L.; Marengo, M. A Single Loop Pulsating Heat Pipe in Varying Gravity Conditions: Experimental Results and Numerical Simulations. In Proceedings of the International Heat Transfer Conference 16, Beijing, China, 10–15 August 2018; Volume 16, pp. 4877–4884. [Google Scholar] [CrossRef]
- Pletser, V. European Aircraft Parabolic Flights for Microgravity Research, Applications and Exploration: A Review. Reach 2016, 1, 11–19. [Google Scholar] [CrossRef]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Heart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2000; ISBN 9780471056690. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Pal, S.; Mitra, S. Multilayer Perceptron, Fuzzy Sets, and Classification. IEEE Trans. Neural Networks 1992, 3, 683–697. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Model Description | Input Parameters | Output | Prediction Accuracy |
|---|---|---|---|---|---|
| Jokar et al. [40] | 2016 | Combination of ANN and GA 2 hidden layers (50 and 40 neurons) Batch learning method 70% of data used for training | Heat flux Inclination angle Filling ratio | Equivalent thermal resistance | Relative errors of 5–12% |
| Jalilian et al. [41] | 2016 | ANN to describe behaviour of PHP in solar collectors GA for optimizing design parameters of solar collector | Solar radiation PHP evaporator length Filling ratio Water tank temperature Inclination angle | Heat gained by collector | Root-mean-square error between 7% and 13% |
| Patel and Mehta [42] | 2018 | ANN as a prediction model RCA to find correlation among input and outputs Data collected from 2003 to 2017 | Geometrical parameters Working fluids Operational parameters | Thermal resistance | Correlation coefficient of 0.89 for ANN and 0.95 for RCA with dimensionless numbers |
| Wang et al. [43] | 2019 | General model for varied working fluids and conditions Use of ANN for prediction Evaporation and condensation temperature estimated from model | Dimensionless numbers related to heat transfer and system geometry Ratio of evaporation length and diameter | Thermal resistance | Mean square error of 0.014 and correlation coefficient of 0.98 |
| Fluid | σ (N/m) | ρ (kg/m3) | hl,v (kJ/kg) | μ (Pa·s) | dcr (mm) |
|---|---|---|---|---|---|
| Ethanol | 0.0224 | 789.59 | 927.57 | 1.22 × 10−3 | 3.40 |
| FC-72 | 0.0118 | 1701.6 | 94.024 | 0.72 × 10−3 | 1.69 |
| Controlled Parameters | Value |
|---|---|
| Working fluid | Ethanol, FC-72 |
| Diameter | 2 mm |
| Gravity level | ~10−2 g, ~1 g, ~2 g |
| Total power input (W) | 9, 15, 18, 24 |
| Observed parameters | Range |
| Wall temperature (°C) | from 20 to 43 |
| Heat flux (W/cm2) | from 6.5 to 13.6 |
| Absolute fluid velocity (m/s) | from 0 to 0.6 |
| Absolute fluid acceleration | from 0 to 20 g |
| Data Sample | Total Data Points | Training Set Data Points | Testing Set Data Points |
|---|---|---|---|
| Ethanol | 9841 | 6888 | 2953 |
| FC-72 | 8590 | 6013 | 2577 |
| KNN | Random Forest | MLP |
|---|---|---|
| Leaf size | Number of trees in the forest | Maximum number of iterations |
| Number of neighbors | Criterion for split quality | Number of hidden layers |
| Distance metric | Criterion for maximum features per split | Activation function |
| - | Minimum samples to split an internal node | Optimization solver |
| - | Minimum samples to be at a leaf node | Regularization parameter |
| - | Bootstrap Boolean (resampling) | Learning rate |
| Parameter | Value—Ethanol | Value—FC-72 |
|---|---|---|
| Leaf size | 1 | 1 |
| Number of neighbors | 25 | 26 |
| Distance metric | Manhattan distance | Manhattan distance |
| Parameter | Value—Ethanol | Value—FC-72 |
|---|---|---|
| Number of trees in the forest | 100 | 100 |
| Criterion for split quality | Entropy | Entropy |
| Criterion for maximum features per split | Squared root of features | Squared root of features |
| Minimum samples to split an internal node | 10 | 2 |
| Minimum samples to be at a leaf node | 2 | 2 |
| Bootstrap Boolean (resampling) | True | True |
| Parameter | Value—Ethanol | Value—FC-72 |
|---|---|---|
| Maximum number of iterations | 1000 | 100 |
| Number of hidden layers | 2 | 2 |
| Activation function | ReLU | ReLU |
| Optimization solver | Adam | Adam |
| Regularization parameter | 0.0001 | 0.0001 |
| Learning rate | adaptive | adaptive |
| Actual Slug/Plug | Actual Semi-Annular | ||
|---|---|---|---|
| KNN | Predicted slug/plug | 0.89 | 0.32 |
| Predicted semi-annular | 0.11 | 0.68 | |
| Random Forest | Predicted slug/plug | 0.88 | 0.32 |
| Predicted semi-annular | 0.12 | 0.68 | |
| MLP | Predicted slug/plug | 0.90 | 0.30 |
| Predicted semi-annular | 0.10 | 0.70 |
| Actual Slug/Plug | Actual Semi-Annular | ||
|---|---|---|---|
| KNN | Predicted slug/plug | 0.90 | 0.33 |
| Predicted semi-annular | 0.10 | 0.67 | |
| Random Forest | Predicted slug/plug | 0.89 | 0.34 |
| Predicted semi-annular | 0.11 | 0.66 | |
| MLP | Predicted slug/plug | 0.91 | 0.33 |
| Predicted semi-annular | 0.09 | 0.67 |
| Classifier | Accuracy (%) |
|---|---|
| K-nearest neighbors | 82.8 |
| ANN | 83.9 |
| Random forest | 82.2 |
| Classifier | Accuracy (%) |
|---|---|
| K-nearest neighbors | 75.8 |
| ANN | 77.1 |
| Random forest | 75.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loyola-Fuentes, J.; Pietrasanta, L.; Marengo, M.; Coletti, F. Machine Learning Algorithms for Flow Pattern Classification in Pulsating Heat Pipes. Energies 2022, 15, 1970. https://doi.org/10.3390/en15061970
Loyola-Fuentes J, Pietrasanta L, Marengo M, Coletti F. Machine Learning Algorithms for Flow Pattern Classification in Pulsating Heat Pipes. Energies. 2022; 15(6):1970. https://doi.org/10.3390/en15061970
Chicago/Turabian StyleLoyola-Fuentes, Jose, Luca Pietrasanta, Marco Marengo, and Francesco Coletti. 2022. "Machine Learning Algorithms for Flow Pattern Classification in Pulsating Heat Pipes" Energies 15, no. 6: 1970. https://doi.org/10.3390/en15061970
APA StyleLoyola-Fuentes, J., Pietrasanta, L., Marengo, M., & Coletti, F. (2022). Machine Learning Algorithms for Flow Pattern Classification in Pulsating Heat Pipes. Energies, 15(6), 1970. https://doi.org/10.3390/en15061970