
Coal Mine Belt Conveyor Foreign Objects Recognition Method of Improved YOLOv5 Algorithm with Defogging and Deblurring


Abstract
1. Introduction
2. Algorithm Improvement
2.1. Video Image Preprocessing
2.1.1. Image Defogging Method Based on Dark Channel Prior
2.1.2. Image Enhancement Method of User-Defined Convolution Kernel
2.2. Foreign Objects Recognition Method of Improved YOLOv5 Algorithm
2.2.1. Improved YOLOv5 Algorithm
- (1)
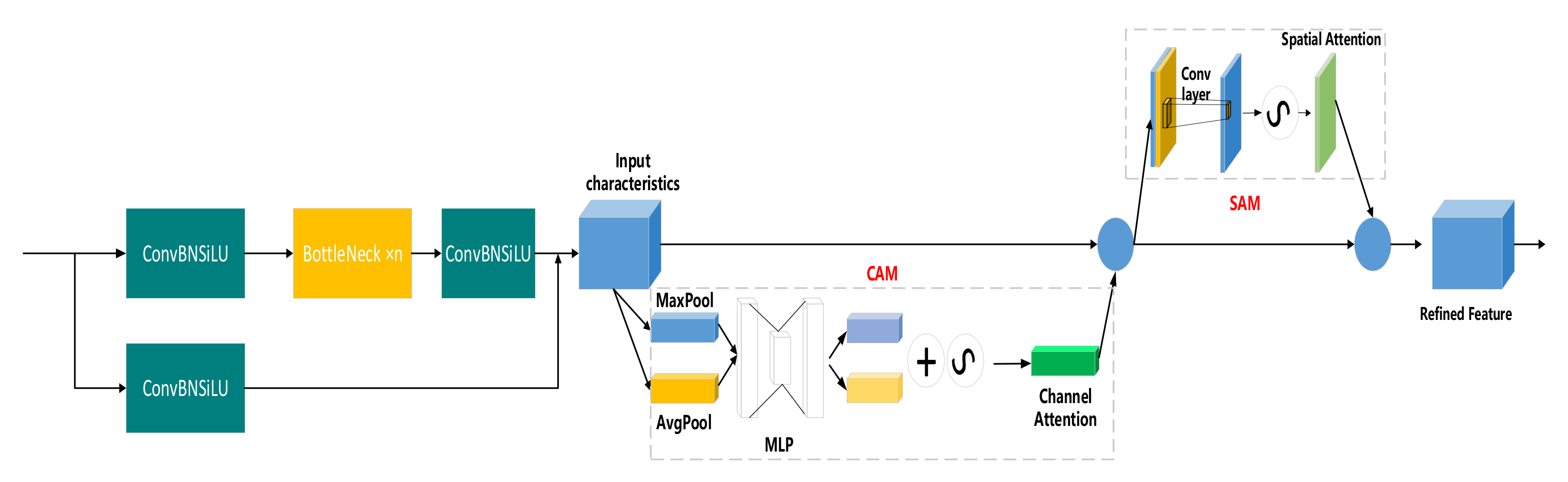
- CBAM is integrated into the C3 module of the backbone network to form CBAM-C3.
- (2)
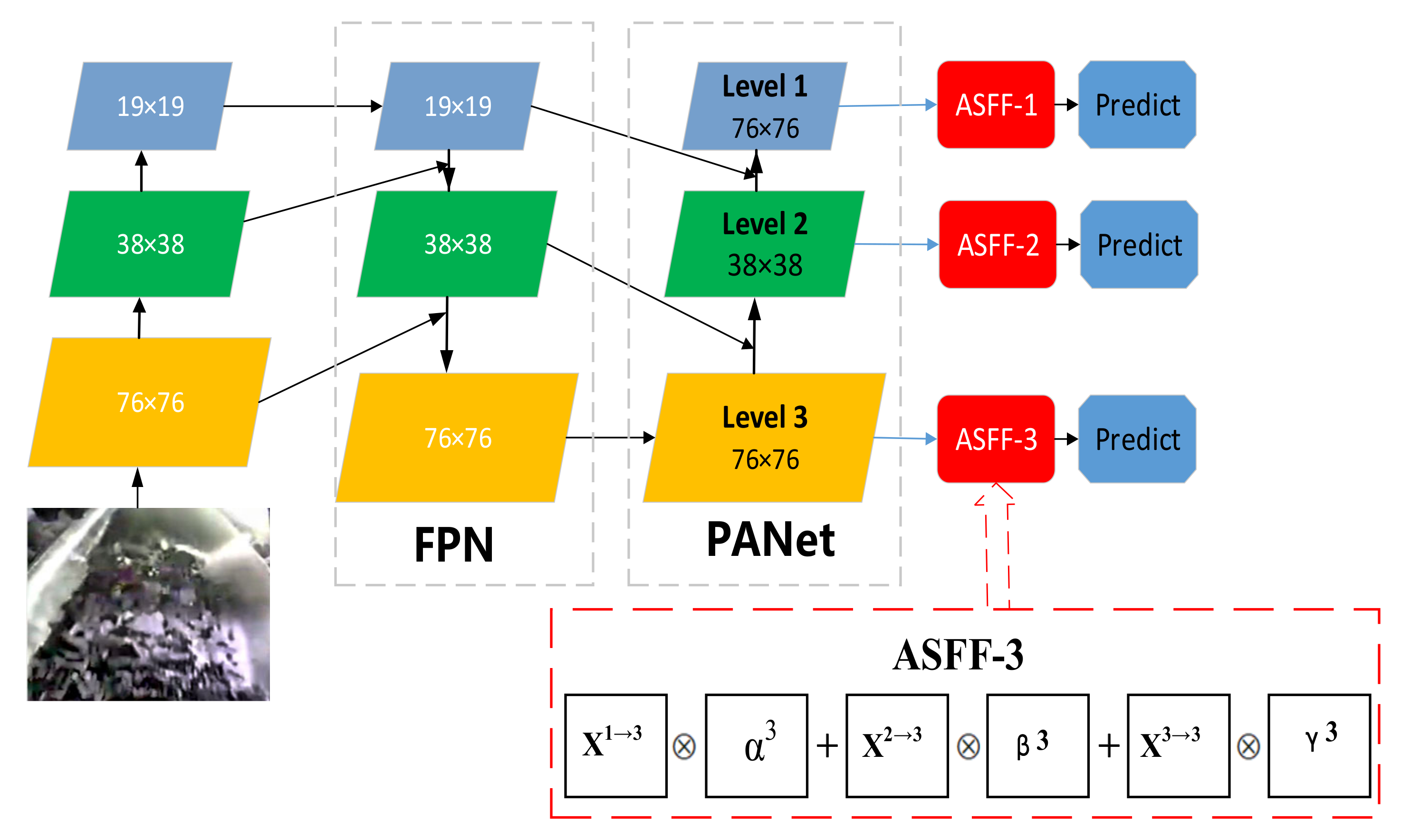
- The adaptive spatial feature fusion is added to the neck.

2.2.2. Method of Improving Precision of Foreign Object Identification
2.2.3. Method of Improving the Ability of Feature Fusion
3. Foreign Objects Identification Process of Belt Conveyor
4. Experimental Results and Analysis
4.1. Experimental Equipment
4.2. Dataset Production
4.3. Analysis of Experimental Results
4.3.1. Analysis of Image Preprocessing Results
4.3.2. Analysis of Recognition Results for Improved YOLOv5 Algorithm
4.4. Analysis of Laboratory and Coal Mine Field Test Results
4.4.1. Analysis of Laboratory Test Results
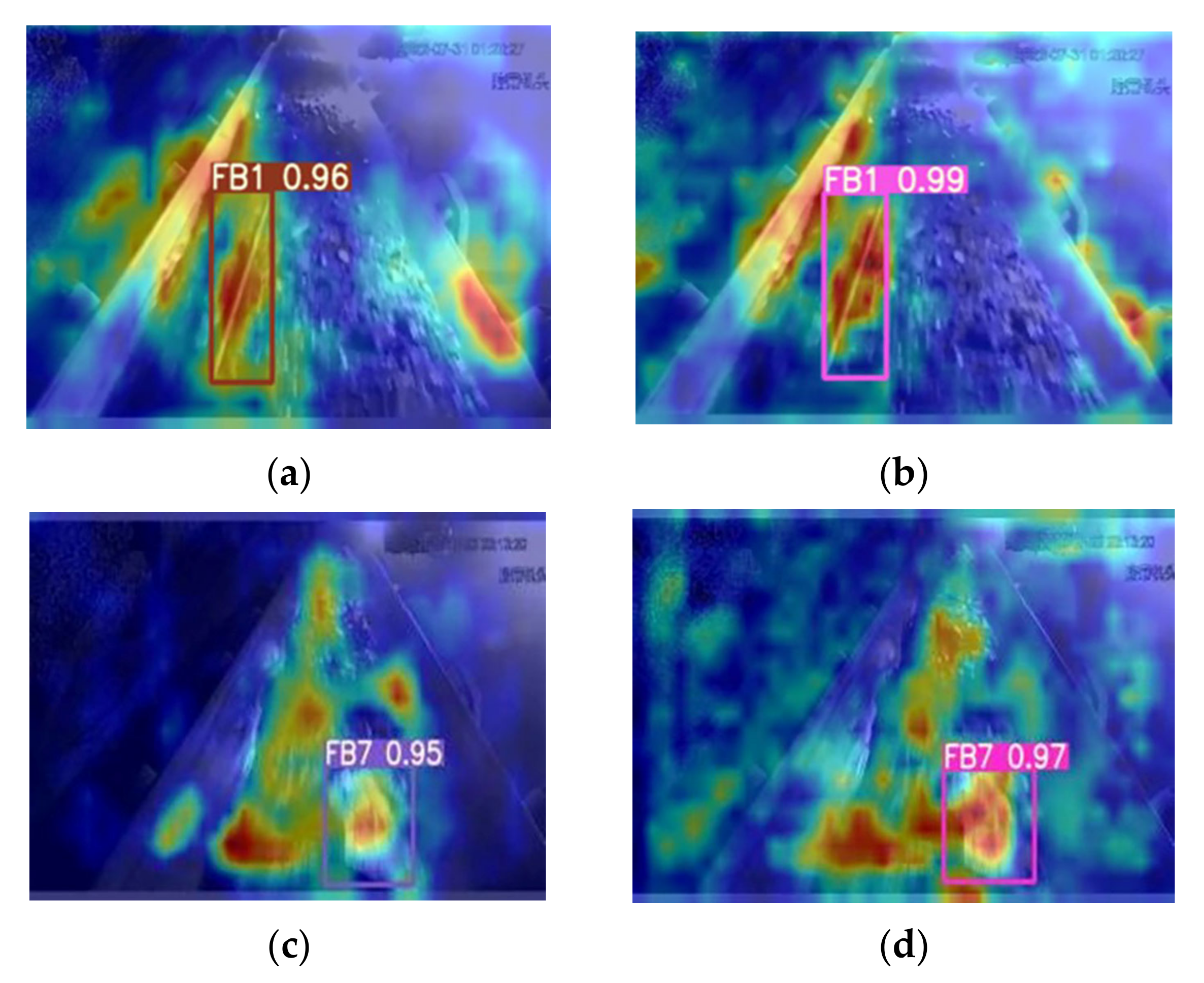
4.4.2. Analysis of Test Results in Coal Mine
4.4.3. Comparison of Recognition Results of the Improved YOLOv5 Algorithm
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, J.; Huang, Z.; Wang, M.; Fu, L.; Liu, A.; Li, Y.; Yv, Z.; Wang, Z.; Huang, L. Unwanted object recognition based on the pyramid convolution model of the machine vision grayscale for the coal flow monitoring. Coal Sci. Technol. 2021, 1–9. [Google Scholar] [CrossRef]
- Hao, S.; Zhang, X.; Ma, X.; Sun, S.; Wen, H.; Wang, J.; Bai, Q. Foreign objects detection in coal mine conveyor belt based on CBAM-YOLOv5. J. China Coal Soc. 2022, 1–11. [Google Scholar] [CrossRef]
- Gao, R.; Miao, C.; Miao, D.; Li, X. Multi-view image adaptive enhancement method for conveyor belt fault detection. J. China Coal Soc. 2017, 42, 594–602. [Google Scholar] [CrossRef]
- Wang, G.; Zhao, G.; Ren, H. Analysis on key technologies of intelligent coal mine and intelligent mining. J. China Coal Soc. 2019, 44, 34–41. [Google Scholar] [CrossRef]
- Wang, G.; Ren, H.; Zhao, G.; Du, Y.; Pang, Y.; Xv, Y.; Zhang, D. Analysis and countermeasures of ten’pain points’ of intelligent coal mine. Ind. Mine Autom. 2021, 47, 1–11. [Google Scholar] [CrossRef]
- Wu, S. Rescarch on Detcction Mcthod of Forcign Object on Coal Conveyor Belt Based on Computer Vision. Ph.D. Thesis, China University of Mining and Technology, Xuzhou, China, 2019. [Google Scholar]
- Wu, S.; Ding, E.; Yu, X. Foreign Body ldentification of Belt Based on Improved FPN. Saf. Coal Mines 2019, 50, 127–130. [Google Scholar] [CrossRef]
- Lv, Z. Research on Imagc Recognition of Foreign Bodies in the Process of Coal Minc Belt Transportation in Complex Environmcnt. Ph.D. Thesis, China University of Mining and Technology, Xuzhou, China, 2020. [Google Scholar]
- Ren, Z.; Zhu, Y. Research on foreign objects Recognition of Coal Mine Belt Transportation with Improved CenterNet Algorithm. Control. Eng. China 2021, 1–8. [Google Scholar] [CrossRef]
- Ma, G.; Wang, X.; Liu, J.; Chen, W.; Niu, Q.; Liu, Y.; Gao, X. Intelligent Detection of Foreign Matter in Coal Mine Transportation Belt Based on Convolution Neural Network. Sci. Program. 2022, 2022, 9740622. [Google Scholar] [CrossRef]
- Hu, J.; Gao, Y.; Zhang, H.; Jin, B. Research on the identification method of non-coal foreign object of belt conveyor based on deep learning. Ind. Mine Autom. 2021, 47, 57–62+90. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Dang, L. Video detection of foreign objects on the surface of belt conveyor underground coal mine based on improved SSD. J. Ambient. Intell. Humaniz. Comput. 2020, 1–10. [Google Scholar] [CrossRef]
- Du, J.; Chen, R.; Hao, L.; Shi, Z. Coal mine belt conveyor foreign objects detection. Ind. Mine Autom. 2021, 47, 77–83. [Google Scholar] [CrossRef]
- Cheng, D.; Xu, J.; Kou, Q.; Zhang, H.; Han, C.; Yv, B.; Qian, J. Lightweight network based on residual information for foreign body classification on coal conveyor belt. J. China Coal Soc. 2022, 47, 1361–1369. [Google Scholar] [CrossRef]
- Xiao, D.; Kang, Z.; Yu, H.; Wan, L. Research on belt foreign body detection method based on deep learning. Trans. Inst. Meas. Control. 2022, 44, 2919–2927. [Google Scholar] [CrossRef]
- Wang, R. The Research of Real-Time Image Dehazing Based on Dark Channel Prior. Ph.D. Thesis, Xi’an University of Electronic Science and Technology, Xi’an, China, 2018; pp. 1–54. [Google Scholar]
- Wang, Y.; Wei, S.; Duan, Y.; Wu, H. Defogging algorithm of underground coal mine image based on adaptive dual-channel prior. J. Mine Autom. 2022, 48, 46–51+84. [Google Scholar] [CrossRef]
- Wei, L.; Wang, J. Simulation research on edge sharpening enhancement of motion blurred digital image. Comput. Simul. 2020, 37, 459–462. [Google Scholar]
- Hu, D.; Tan, J.; Zhang, L.; Ge, X. Image deblurring based on enhanced salient edge selection. Vis. Comput. 2021, 1–16. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Yan, P.; Sun, Q.; Yin, N.; Hua, L.; Shang, S.; Zhang, C. Detection of coal and gangue based on improved YOLOv5. 1 which embedded scSE module. Measurement 2022, 188, 110530. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In European Conference on Computer Vision (ECCV), Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018, Proceedings, Part VII; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Mao, Q.; Wang, Y.; Zhang, X.; Zhao, X.; Zhang, G.; Mushayi, K. Clarity method of fog and dust image in fully mechanized mining face. Mach. Vis. Appl. 2022, 33, 30. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Name | Parameter |
|---|---|
| Operating system | Windows10 |
| GPU | NVIDIA GeForce RTX 3080 |
| CPU | 12thGen Intel(R) Core(TM)i7-12700K 3.61 GHZ |
| Deep learning framework | Pytorch |
| Monitor camera frame rate | 25 FPS |
| Belt conveyor running speed | 3.5 m/s |
| Vollath Value | Information Entropy | |
|---|---|---|
| Original image | 82.19 | 7.6755 |
| Image after preprocessing | 90.35 | 7.8305 |
| Category | Recognition Precision before Improvement/% | Recognition Precision after Improvement/% |
|---|---|---|
| Anchor rod | 93.1 | 97.5 |
| Angle iron | 92.7 | 96.9 |
| wood | 92.0 | 96.6 |
| Gangue | 91.0 | 96.8 |
| Large coal | 90.2 | 95.4 |
| Category | Recall Rate before Improvement/% | Recall Rate after Improvement/% |
|---|---|---|
| Anchor rod | 94.7 | 98.3 |
| Angle iron | 90.4 | 97.6 |
| wood | 93.4 | 97.2 |
| Gangue | 90.1 | 96.2 |
| Large coal | 88.2 | 96.6 |
| Preprocessing | CBAM | ASFF | Precision/% | t/s |
|---|---|---|---|---|
| 91.8 | 0.0090 | |||
| √ | 92.6 | 0.0134 | ||
| √ | 96.2 | 0.0120 | ||
| √ | 92.8 | 0.0110 | ||
| √ | √ | √ | 96.6 | 0.0157 |
| Algorithm | Average Precision/% | t/s |
|---|---|---|
| YOLOv5 | 91.8 | 0.0100 |
| YOLOv5-SE-BIFPN | 93.4 | 0.0110 |
| YOLOV5-CA-ASFF | 96.1 | 0.0150 |
| Our improved YOLOv5 algorithm | 96.6 | 0.0157 |
| Algorithm | Average Precision/% | Average Recall/% |
|---|---|---|
| YOLOv5 | 74.2 | 57.3 |
| The improved YOLOv5 algorithm | 76.4 | 61.0 |
| Algorithm | Average Precision/% | Average Recall/% |
|---|---|---|
| YOLOv5 | 93.6 | 92.5 |
| The improved YOLOv5 algorithm | 95.6 | 93.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, Q.; Li, S.; Hu, X.; Xue, X. Coal Mine Belt Conveyor Foreign Objects Recognition Method of Improved YOLOv5 Algorithm with Defogging and Deblurring. Energies 2022, 15, 9504. https://doi.org/10.3390/en15249504
Mao Q, Li S, Hu X, Xue X. Coal Mine Belt Conveyor Foreign Objects Recognition Method of Improved YOLOv5 Algorithm with Defogging and Deblurring. Energies. 2022; 15(24):9504. https://doi.org/10.3390/en15249504
Chicago/Turabian StyleMao, Qinghua, Shikun Li, Xin Hu, and Xusheng Xue. 2022. "Coal Mine Belt Conveyor Foreign Objects Recognition Method of Improved YOLOv5 Algorithm with Defogging and Deblurring" Energies 15, no. 24: 9504. https://doi.org/10.3390/en15249504
APA StyleMao, Q., Li, S., Hu, X., & Xue, X. (2022). Coal Mine Belt Conveyor Foreign Objects Recognition Method of Improved YOLOv5 Algorithm with Defogging and Deblurring. Energies, 15(24), 9504. https://doi.org/10.3390/en15249504