

Non-Linear Clustering of Distribution Feeders


Abstract
1. Introduction
2. Clustering Analysis
2.1. Algorithms
2.2. Optimal Number of Clusters
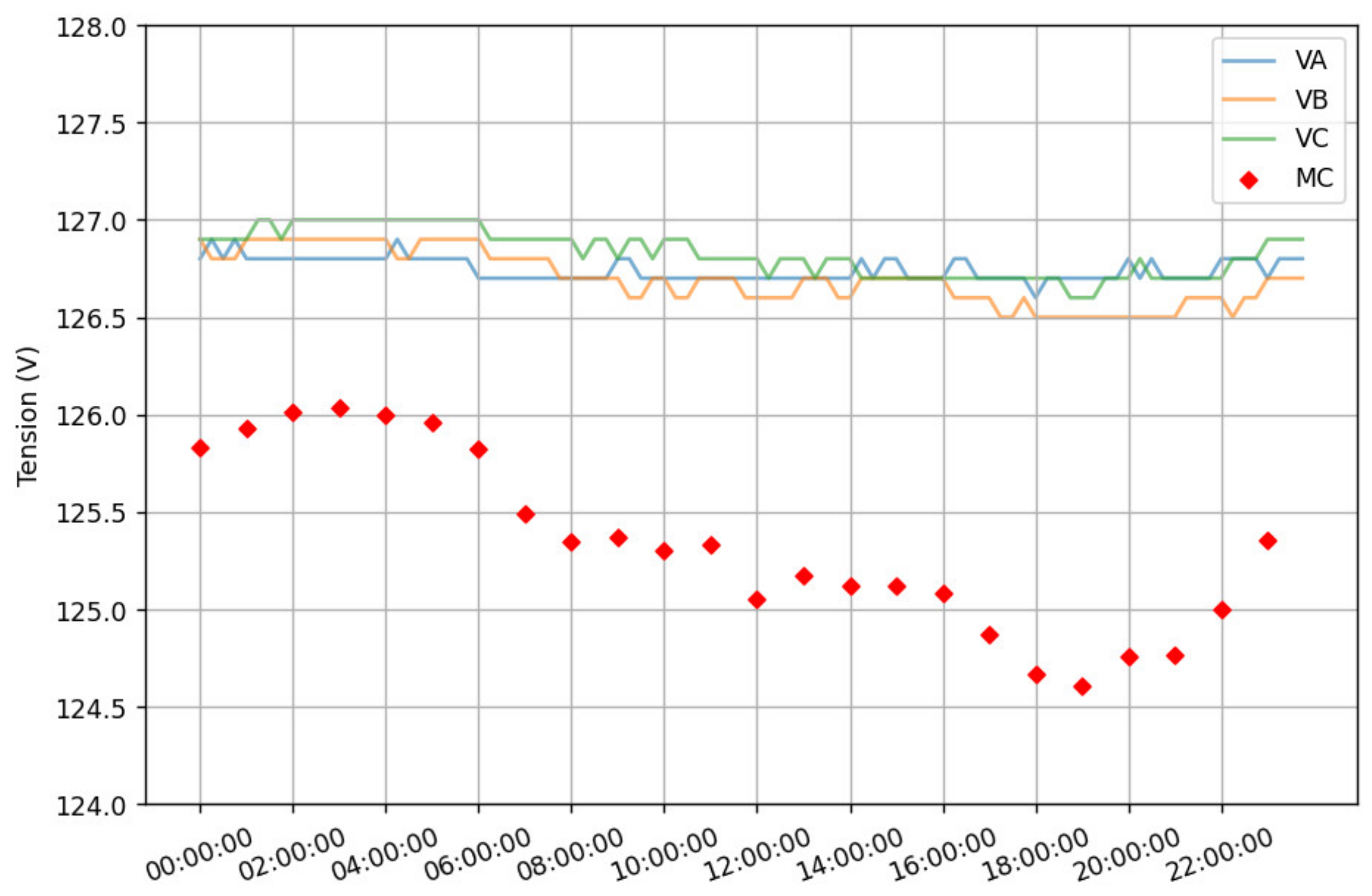
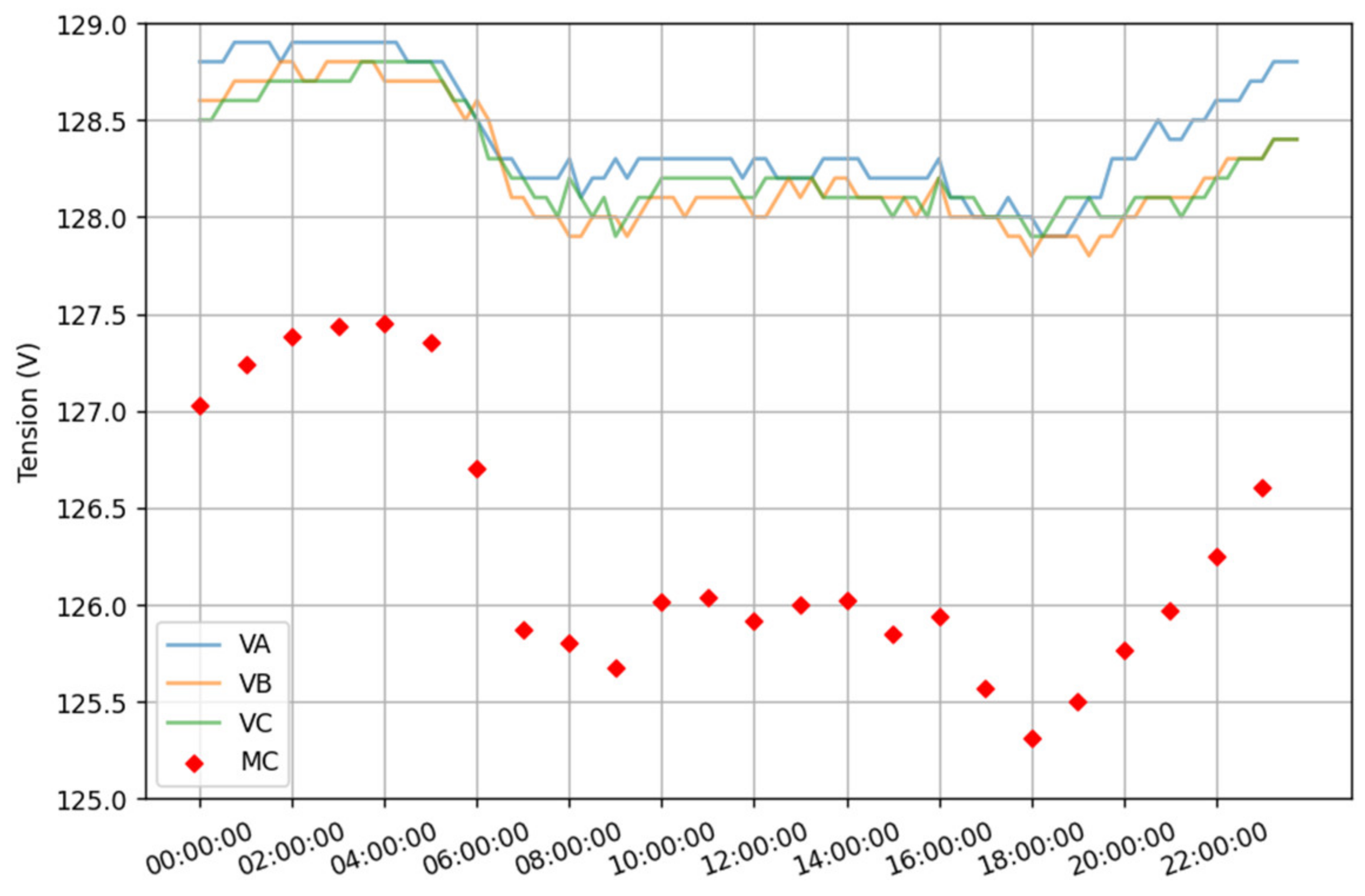
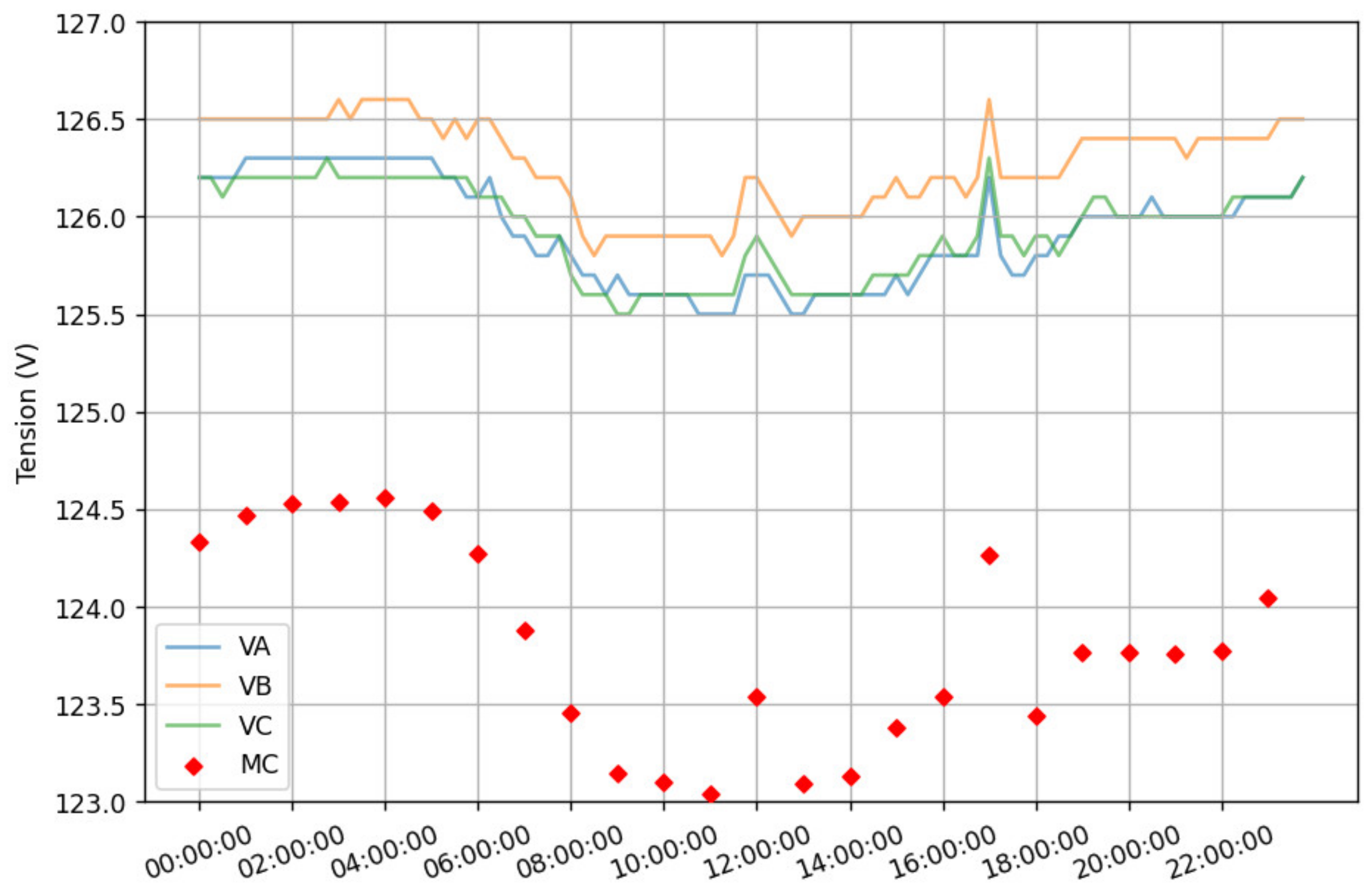
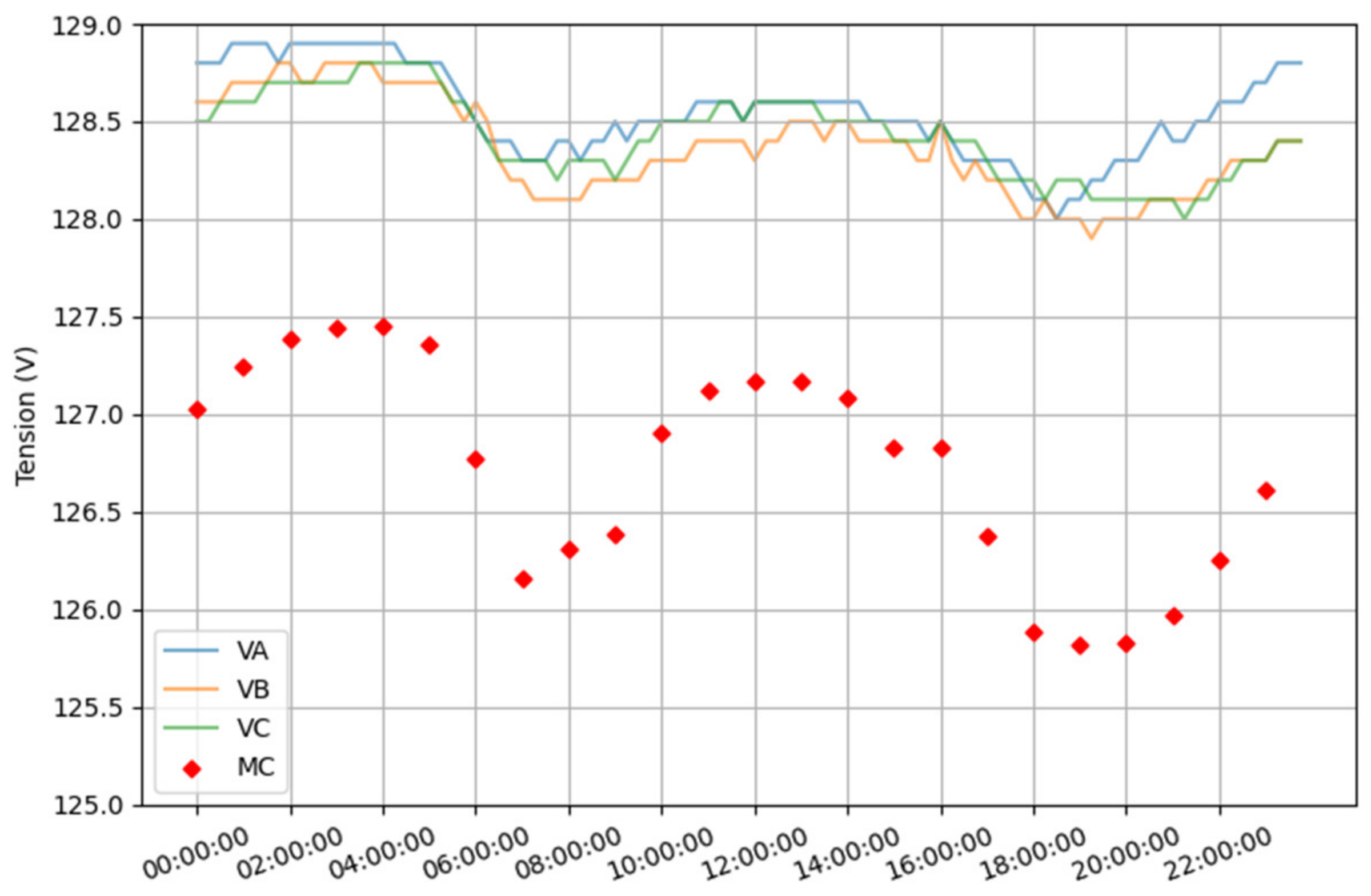
3. Dataset
4. Data Preprocessing
4.1. Data Imputation
4.2. Feature Selection
4.2.1. Feature Scaling
4.2.2. Feature Correlation
4.2.3. PCA
5. Linear Clustering
Number of Clusters
6. Nonlinear Clustering
6.1. t-SNE
6.2. DBSCAN
6.2.1. Optimal Parameters
6.2.2. Clustering Evaluation
7. Obtained Clusters
Comparison
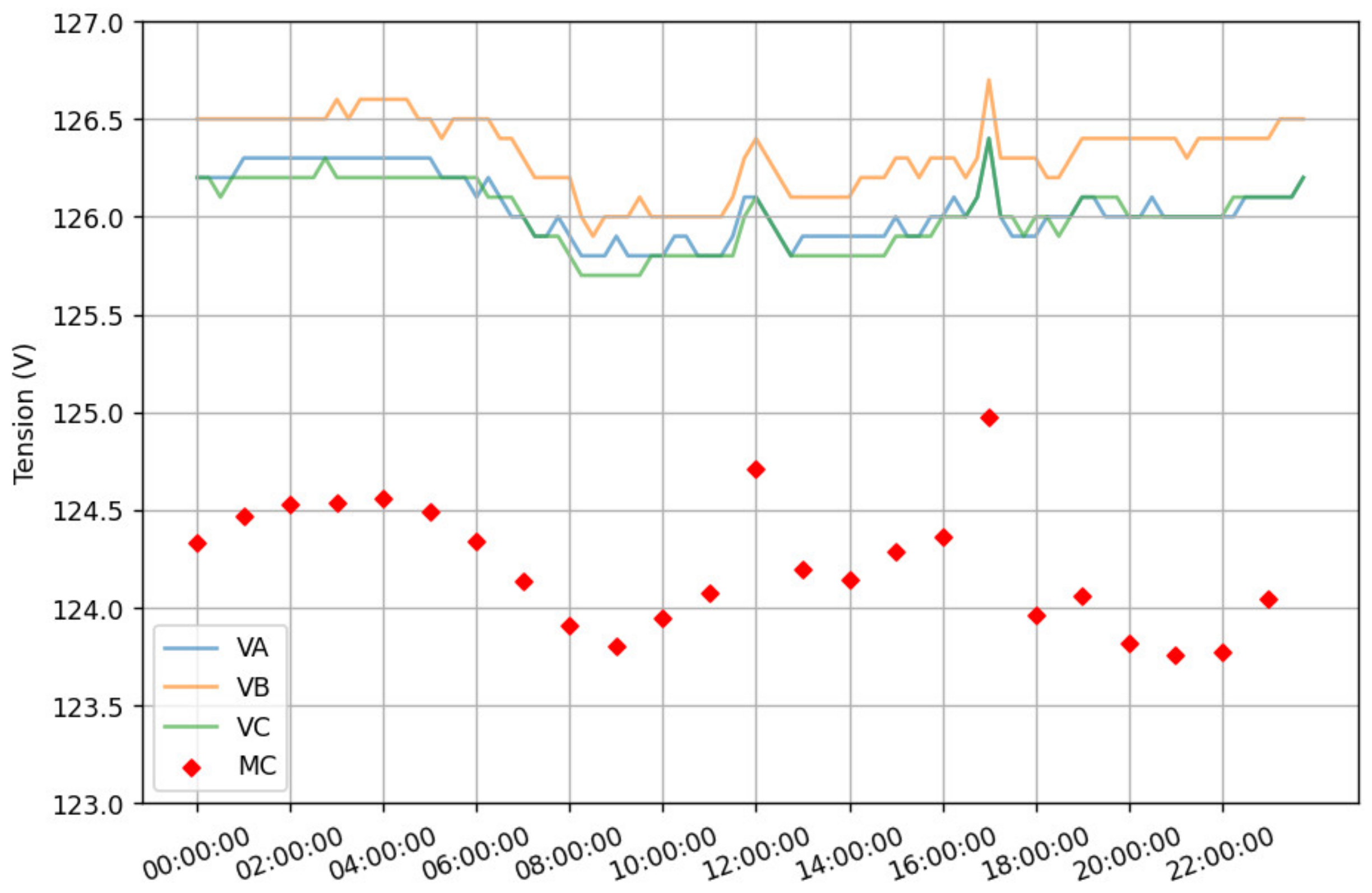
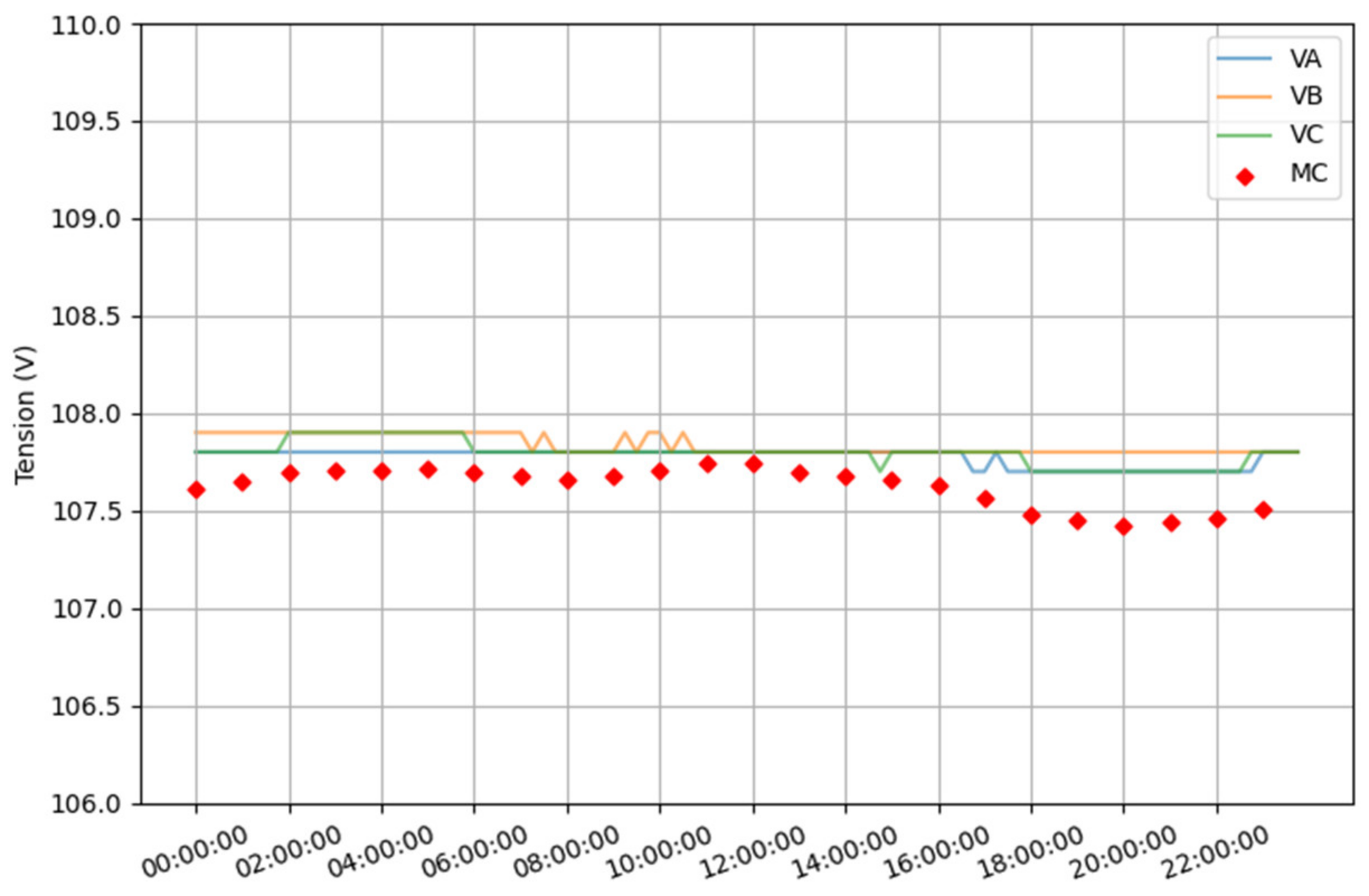
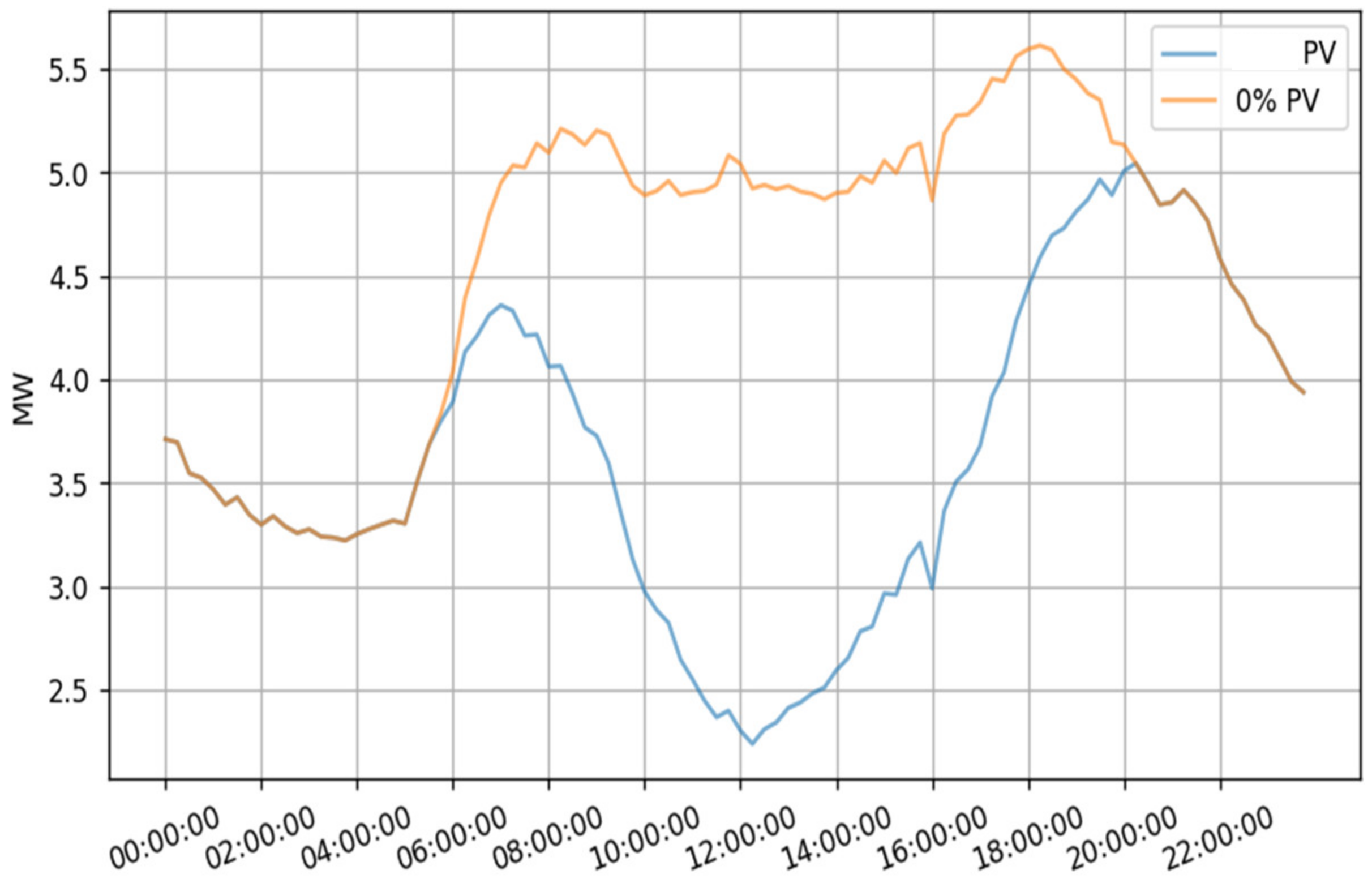
8. DER Penetration Studies
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kroposki, B. Summarizing the Technical Challenges of High Levels of Inverter Based Resources in Power Grids. In Proceedings of the Grid-Forming Inverters for Low-Inertia Power Systems Workshop, Washington, DC, USA, 20–22 April 2019. [Google Scholar]
- Oladeji, I.; Makolo, P.; Zamora, R.; Lie, T.T. Density-based clustering and probabilistic classification for integrated transmission-distribution network security state prediction. Electr. Power Syst. Res. 2022, 211, 108164. [Google Scholar] [CrossRef]
- Willis, H.L.; Tram, H.N.; Powell, R.W. A Computerized, Cluster Based Method of Building Representative Models of Distribution Systems. IEEE Trans. Power Appar. Syst. 1985, 104, 3469–3474. [Google Scholar] [CrossRef]
- Schneider, L.P.; Chen, Y.; Engle, D.; Chassin, D. A Taxonomy of North American Radial Distribution Feeders. In Proceedings of the IEEE Power and Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009. [Google Scholar]
- Broderick, R.J.; Williams, J.R. Clustering Methodology for Classifying Distribution Feeders. In Proceedings of the IEEE 39th Photovoltaic Specialists Conference (PVSC), Tampa, FL, USA, 16–21 June 2013. [Google Scholar]
- Cale, J.; Palmintier, B.; Narang, D.; Carroll, K. Clustering Distribution Feeders in the Arizona Public Service Territory. In Proceedings of the 2014 IEEE 40th Photovoltaic Specialist Conference (PVSC), Denver, CO, USA, 8–13 June 2014. [Google Scholar]
- Broderick, R.; Munoz-Ramos, K.; Reno, M. Accuracy of Clustering as a Method to Group Distribution Feeders by PV Hosting Capacity. In Proceedings of the 2016 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Dallas, TX, USA, 3–5 May 2016. [Google Scholar]
- Zhang, Y.; Zhong, X.; Wang, L.; Liu, W.; Zhu, K.; Yan, L. Multi-objective Cluster Partition Method for Distribution Network Considering Uncertainties of Distributed Generations and Loads. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; pp. 926–932. [Google Scholar] [CrossRef]
- Zhang, L.; Li, G.; Huang, Y.; Jiang, J.; Bie, Z.; Li, X.; Ling, Y.; Tian, H. Distributed Baseline Load Estimation for Load Aggregators Based on Joint FCM Clustering. IEEE Trans. Ind. Appl. 2022. [Google Scholar] [CrossRef]
- Malatesta, T.; Breadsell, J.K. Identifying Home System of Practices for Energy Use with K-Means Clustering Techniques. Sustainability 2022, 14, 9017. [Google Scholar] [CrossRef]
- Berry, A.M.; Moore, T.; Ward, J.K.; Lindsay, S.A.; Proctor, K. National Feeder Taxonomy Describing a Representative Feeder Set for Australian Networks; The Commonwealth Scientific and Industrial Research Organisation (CSIRO): Canberra, Australia, 2013. [Google Scholar]
- Jain, A.K.; Mather, B. Clustering Methods and Validation of Representative Distribution Feeders. In Proceedings of the 2018 IEEE/PES Transmission and Distribution Conference and Exposition, Denver, CO, USA, 16–19 April 2018. [Google Scholar]
- Li, Y.; Wolfs, P. Statistical Discriminant Analysis of High Voltage Feeders in Western Australia Distribution Networks. In Proceedings of the Power and Engineering Society General Meeting, Detroit, MI, USA, 24–28 July 2011. [Google Scholar]
- Rigoni, V.; Ochoa, L.F.; Chicco, G.; Navarro-Espinosa, A.; Gozel, T. Representative Residential LV feeders: A case study for the North West of England. IEEE Trans. Power Syst. 2016, 31, 348–360. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principle Component Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Milligan, G.W.; Cooper, M.C. An examination of procedures for determining the number of clusters in a data set. Psychometrika 1985, 50, 159179. [Google Scholar] [CrossRef]
- Rousseuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall: Englewood Cliffs, NJ, USA, 1988. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. TODS 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Madhu, G.; Bharadwaj, B.L.; Nagachandrika, G.; Vardhan, K.S. A Novel Algorithm for Missing Data Imputation on Machine Learning. In Proceedings of the 2019 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 27–29 November 2019; pp. 173–177. [Google Scholar] [CrossRef]
- Ding, C. K-Means Clustering via Principal Component Analysis; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2004.
- Pal, K.; Sharma, M. Performance Evaluation of Non-Linear Techniques UMAP and t-SNE For Data in Higher Dimensional Topological Space. In Proceedings of the 2020 Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 7–9 October 2020; pp. 1106–1110. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature |
|---|---|
| 1 | Max KVA consumed |
| 2 | % of KVA residential |
| 3 | % of KVA commercial |
| 4 | % of KVA industrial |
| 5 | Avg KVA consumed |
| 6 | KVA coefficient of var |
| 7 | Impedance |
| 8 | 3 phase branches |
| 9 | Total length of 1 ph overhead lines |
| 10 | Total length of 1 ph underground lines |
| 11 | Total length of 3 ph overhead lines |
| 12 | Total length of 3 ph underground lines |
| 13 | Avg. distance load-source |
| 14 | Load-source coefficient of var |
| Iteration | No. Clusters | SC | eps | Minimum Points | Noise |
|---|---|---|---|---|---|
| 30 | 5 | −0.421624 | 3.1 | 3 | 11 |
| 31 | 3 | −0.282537 | 3.1 | 4 | 17 |
| 32 | 5 | −0.126718 | 3.1 | 5 | 22 |
| 33 | 6 | −0.260816 | 3.1 | 6 | 26 |
| 34 | 9 | −0.242705 | 3.1 | 7 | 32 |
| 35 | 11 | −0.280420 | 3.1 | 8 | 55 |
| 36 | 5 | −0.416717 | 3.2 | 3 | 10 |
| 37 | 3 | −0.275497 | 3.2 | 4 | 16 |
| 38 | 4 | −0.111859 | 3.2 | 5 | 21 |
| 39 | 5 | −0.258129 | 3.2 | 6 | 23 |
| 40 | 7 | −0.201680 | 3.2 | 7 | 25 |
| 41 | 10 | −0.270471 | 3.2 | 8 | 41 |
| 42 | 5 | −0.416717 | 3.3 | 3 | 10 |
| 43 | 3 | −0.275497 | 3.3 | 4 | 16 |
| 44 | 3 | −0.282584 | 3.3 | 5 | 17 |
| 45 | 4 | −0.111090 | 3.3 | 6 | 21 |
| 46 | 5 | −0.126071 | 3.3 | 7 | 22 |
| 47 | 4 | −0.058377 | 3.3 | 8 | 32 |
| 48 | 4 | −0.349103 | 3.4 | 3 | 8 |
| 49 | 3 | −0.271663 | 3.4 | 4 | 12 |
| 50 | 3 | −0.271377 | 3.4 | 5 | 14 |
| 51 | 4 | −0.108871 | 3.4 | 6 | 19 |
| 52 | 5 | −0.117087 | 3.4 | 7 | 19 |
| 53 | 4 | −0.041692 | 3.4 | 8 | 27 |
| 54 | 4 | −0.362375 | 3.5 | 3 | 7 |
| 55 | 3 | −0.273334 | 3.5 | 4 | 10 |
| 56 | 3 | −0.268879 | 3.5 | 5 | 11 |
| 57 | 4 | −0.077055 | 3.5 | 6 | 15 |
| 58 | 5 | −0.087780 | 3.5 | 7 | 15 |
| 59 | 4 | −0.026381 | 3.5 | 8 | 24 |
| Cluster No. | Type | No. Elem. DBSCAN | No. Elem. HC | No. Elem. KM+ |
|---|---|---|---|---|
| 1 | Urban commercial/residential | 1605 | 1314 | 1013 |
| 2 | Rural residential | 603 | 387 | 420 |
| 3 | Urban industrial | 235 | 213 | 176 |
| 4 | Urban residential | 32 | 152 | 78 |
| 5 | Rural commercial | 24 | 214 | 110 |
| 6 | Urban residential/undg | 6 | 211 | 189 |
| 7 | Rural industrial | 7 | 21 | 28 |
| 8 | Other | 425 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos-Leaños, O.; Jneid, J.; Fazio, B. Non-Linear Clustering of Distribution Feeders. Energies 2022, 15, 7883. https://doi.org/10.3390/en15217883
Ramos-Leaños O, Jneid J, Fazio B. Non-Linear Clustering of Distribution Feeders. Energies. 2022; 15(21):7883. https://doi.org/10.3390/en15217883
Chicago/Turabian StyleRamos-Leaños, Octavio, Jneid Jneid, and Bruno Fazio. 2022. "Non-Linear Clustering of Distribution Feeders" Energies 15, no. 21: 7883. https://doi.org/10.3390/en15217883
APA StyleRamos-Leaños, O., Jneid, J., & Fazio, B. (2022). Non-Linear Clustering of Distribution Feeders. Energies, 15(21), 7883. https://doi.org/10.3390/en15217883