
Synthesizing Nuclear Magnetic Resonance (NMR) Outputs for Clastic Rocks Using Machine Learning Methods, Examples from North West Shelf and Perth Basin, Western Australia

Abstract
:1. Introduction
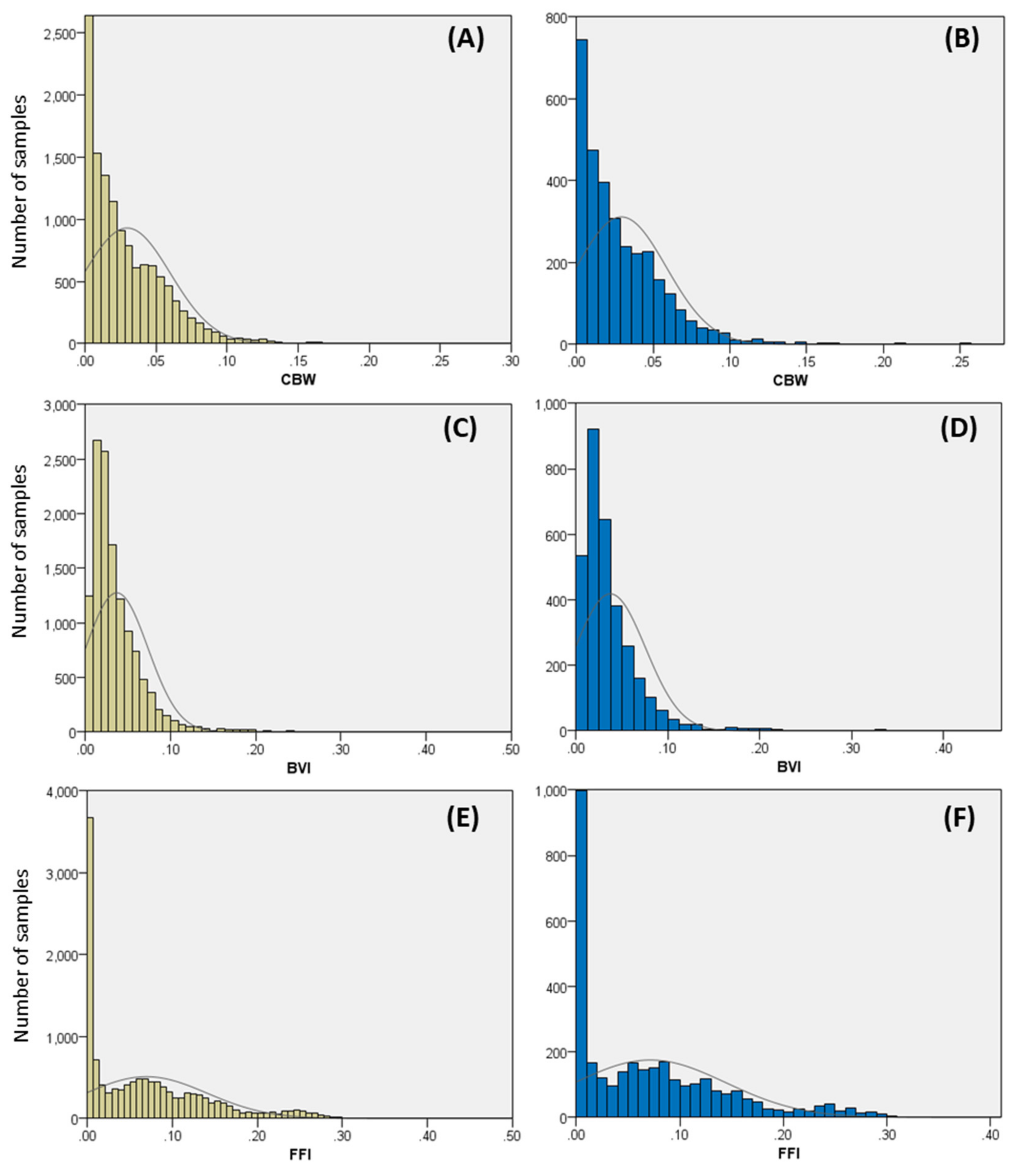
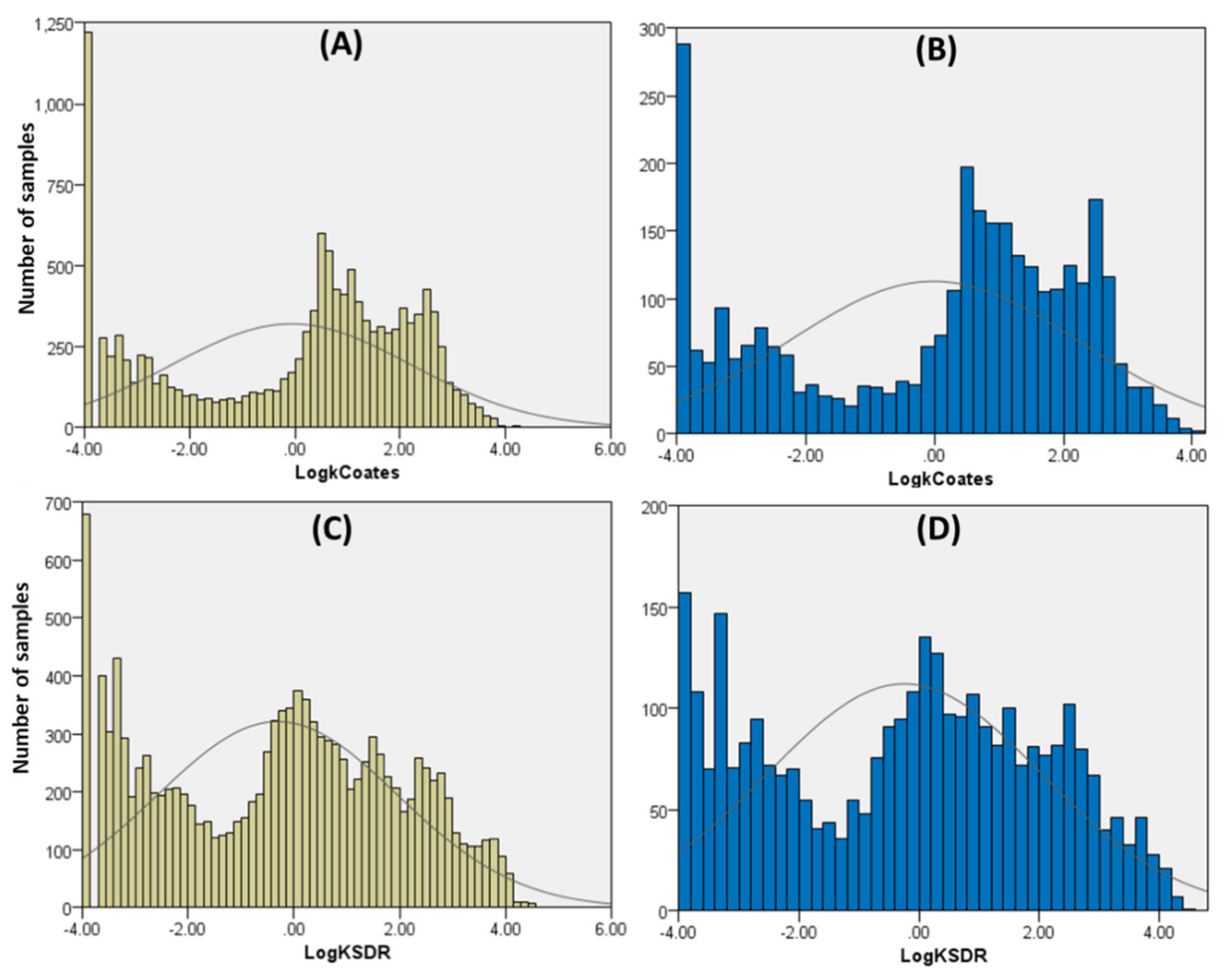
2. Data Acquisition and Preparation
3. Machine Learning (ML) Models
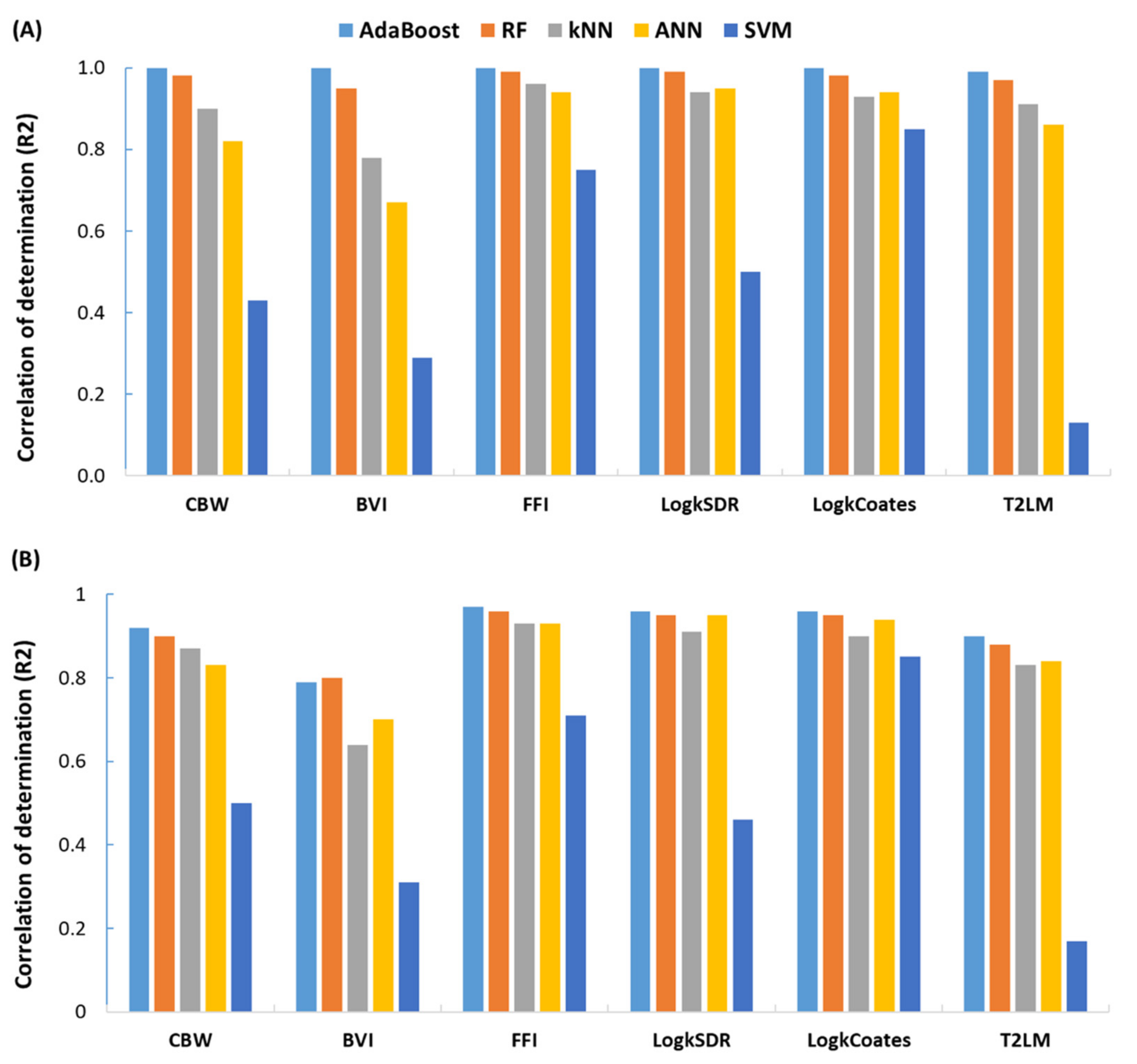
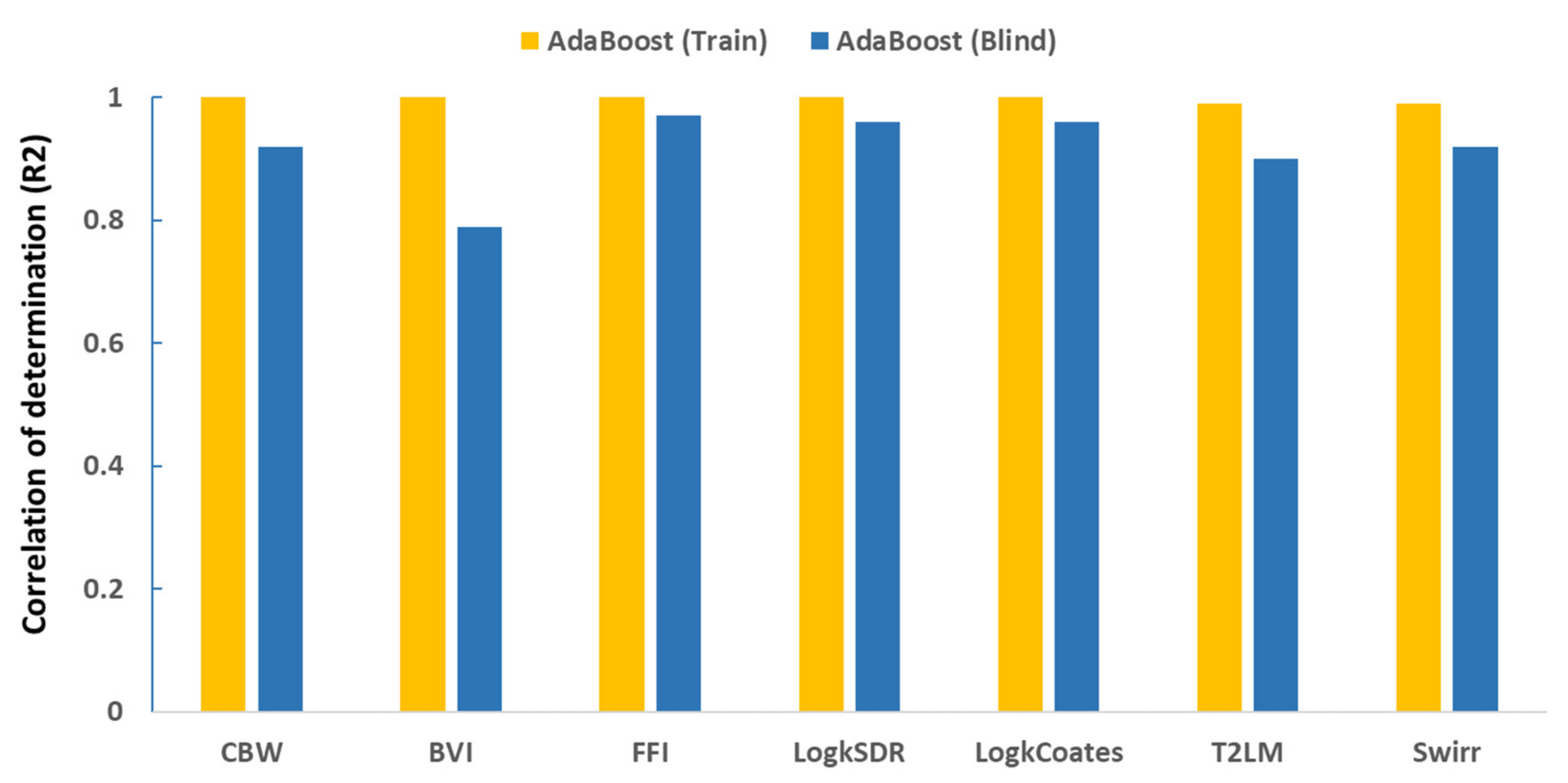
4. Results
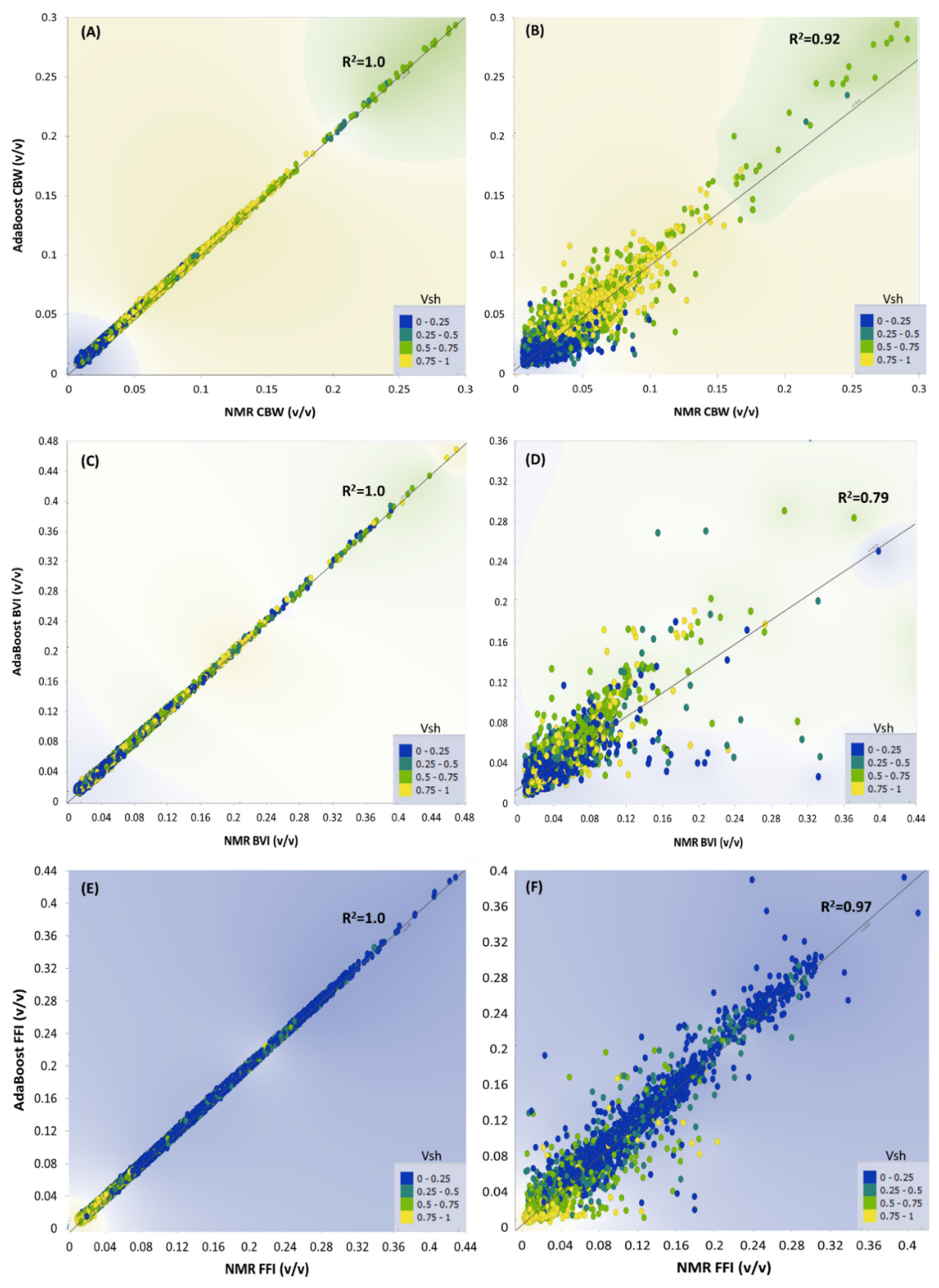
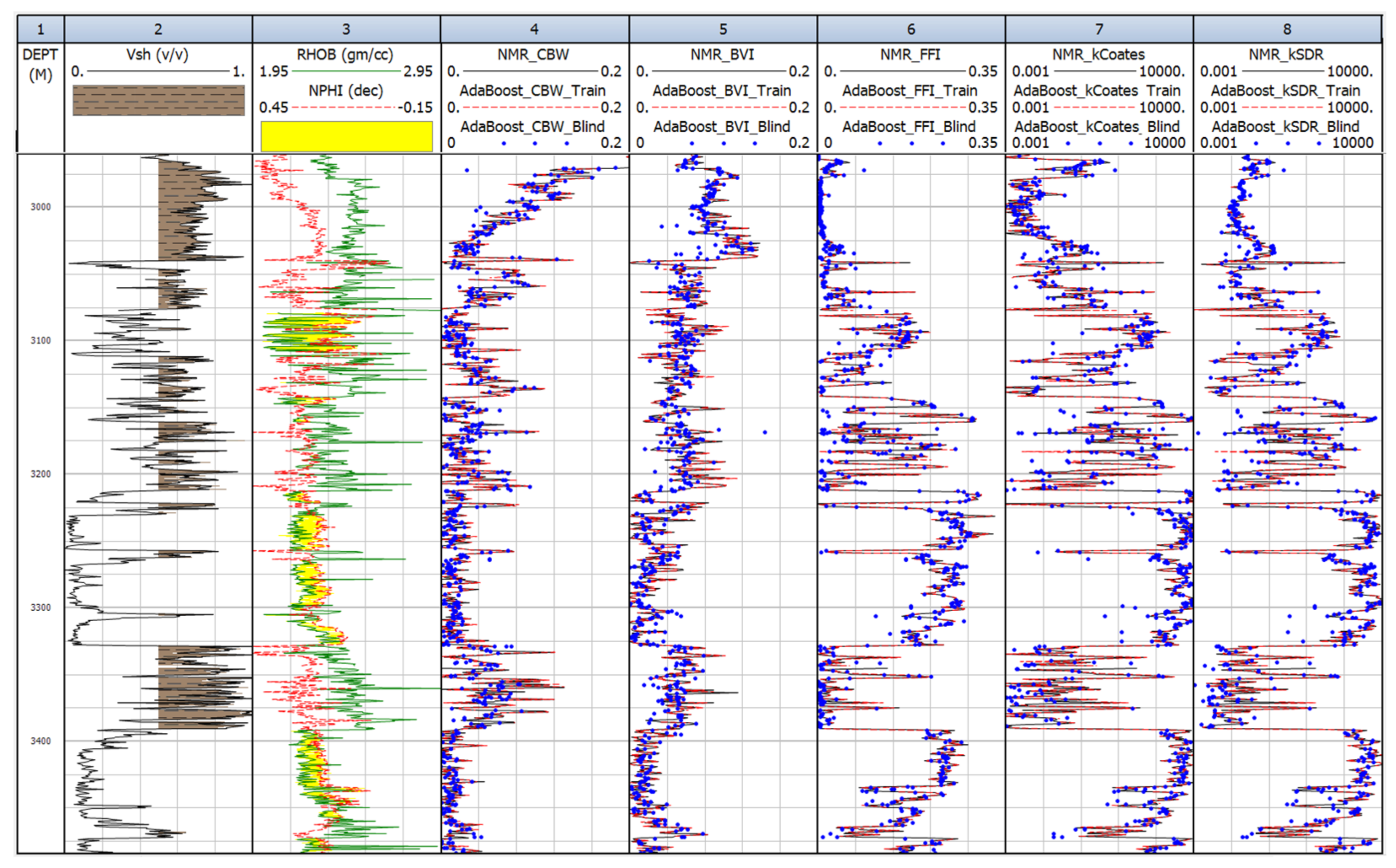
4.1. Porosity Prediction
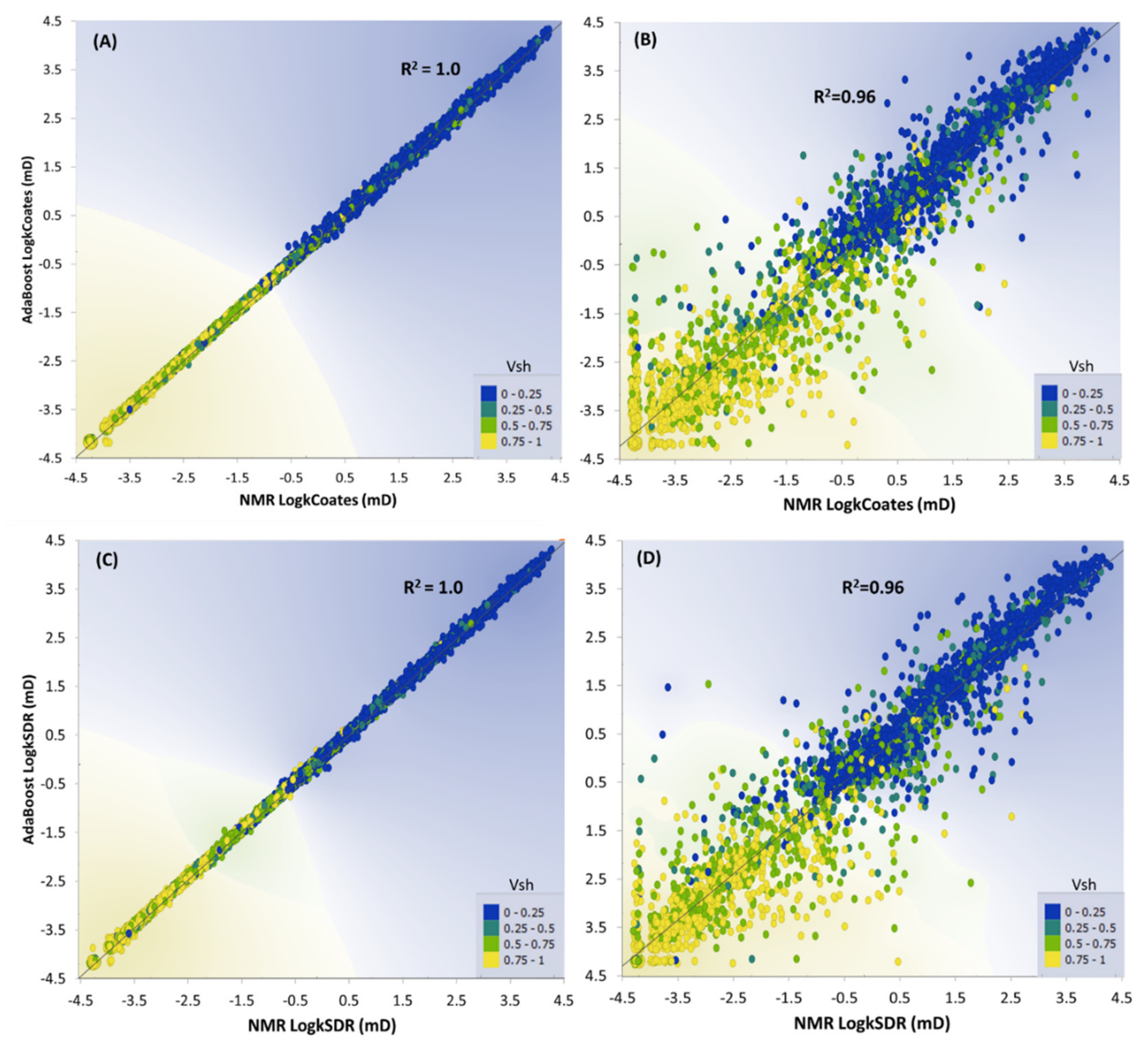
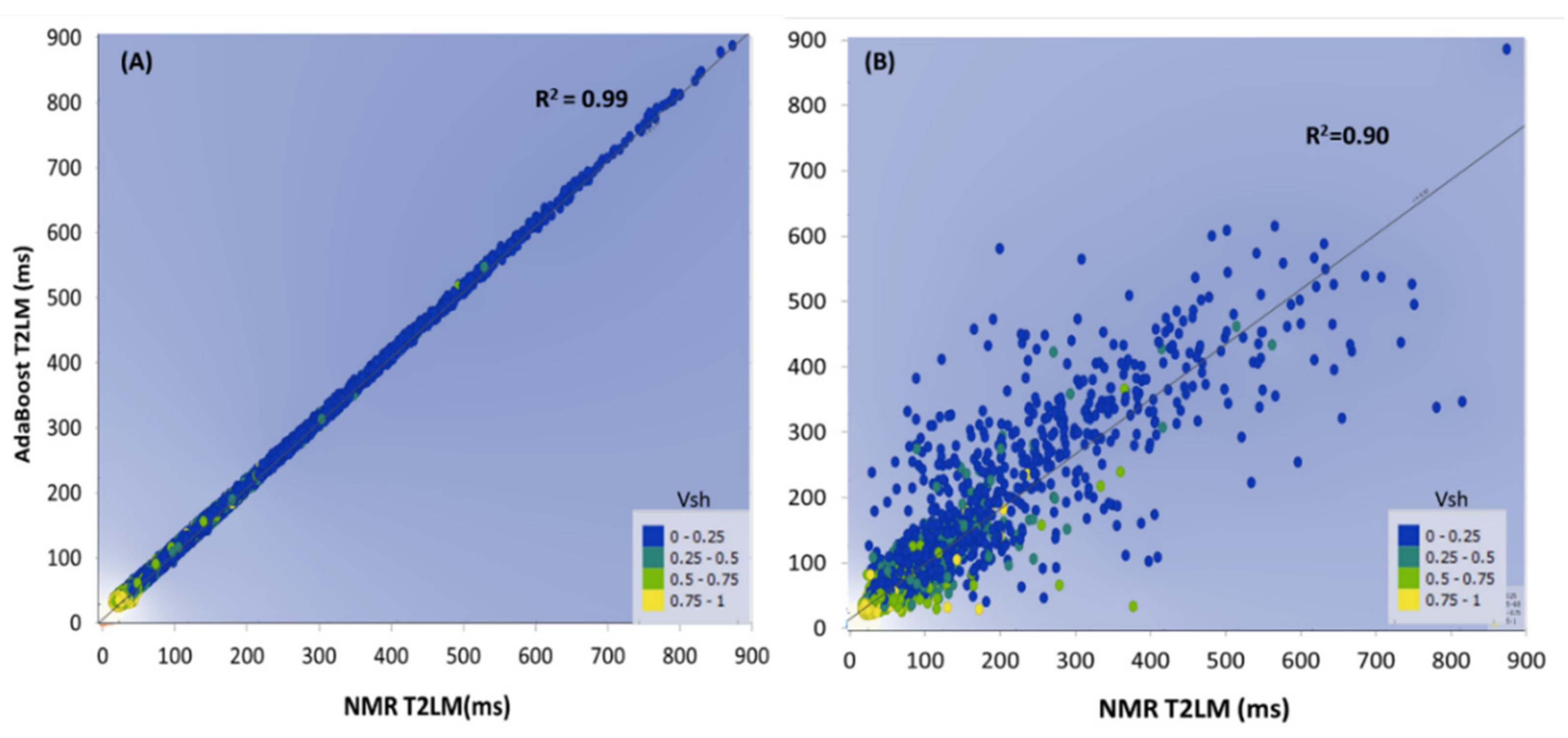
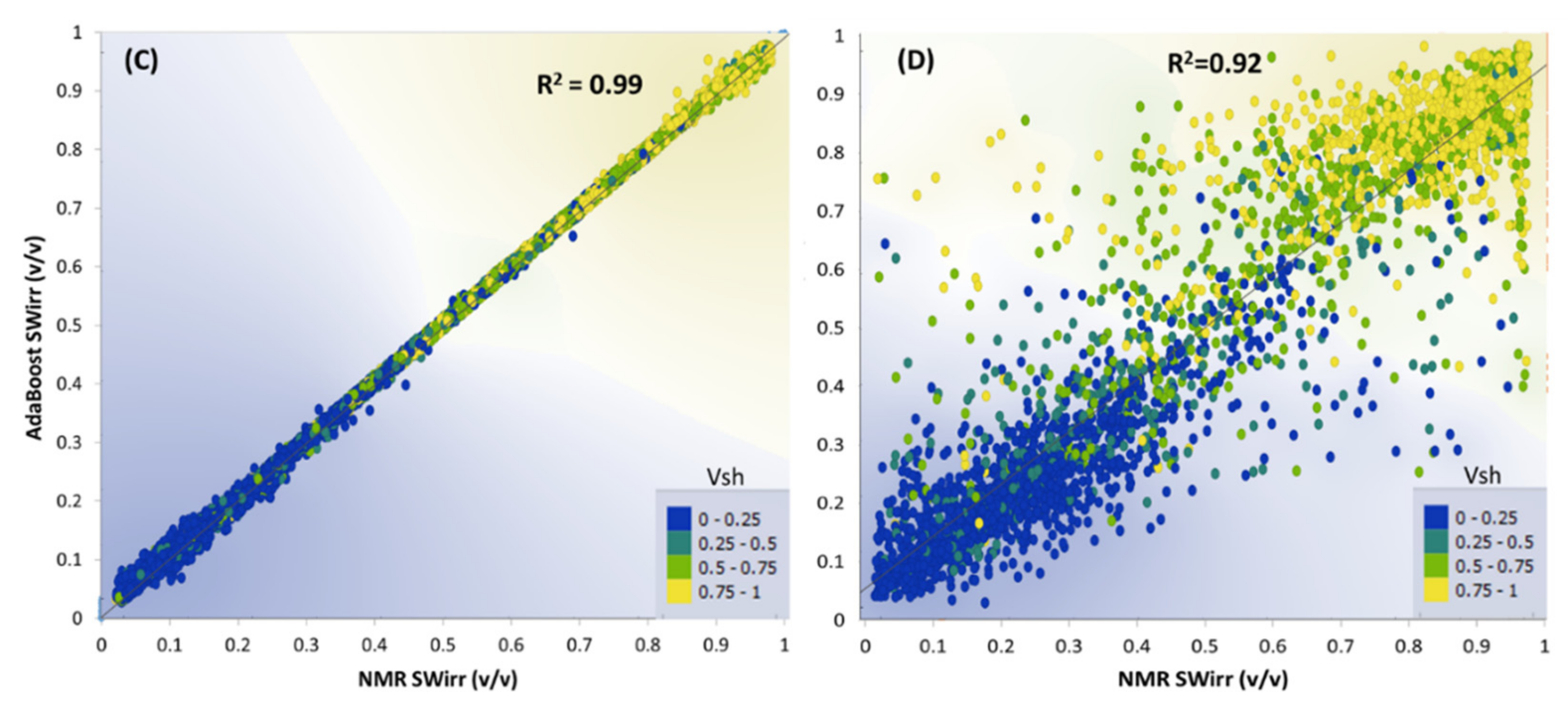
4.2. Permeability Prediction
5. Discussion and Conclusions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Coates, G.R.; Xiao, L.; Prammer, M.G. NMR Logging: Principles and Applications; Haliburton Energy Services: Houston, TX, USA, 1999; Volume 234. [Google Scholar]
- Freedman, R. Advances in NMR logging. J. Pet. Technol. 2006, 58, 60–66. [Google Scholar] [CrossRef]
- Dunn, K.-J.; Bergman, D.J.; LaTorraca, G.A. Nuclear Magnetic Resonance: Petrophysical and Logging Applications; Elsevier: New York, NY, USA, 2002. [Google Scholar]
- Kenyon, W. Petrophysical principles of applications of NMR logging. Log Anal. 1997, 38. [Google Scholar]
- Prammer, M.; Drack, E.; Bouton, J.; Gardner, J.; Coates, G.; Chandler, R.; Miller, M. Measurements of clay-bound water and total porosity by magnetic resonance logging: SPE-36522. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 6–9 October 1996. [Google Scholar]
- Kleinberg, R.L. Utility of NMR T2 distributions, connection with capillary pressure, clay effect, and determination of the surface relaxivity parameter ρ2. Magn. Reson. Imaging 1996, 14, 761–767. [Google Scholar] [CrossRef]
- Timur, A. Producible porosity and permeability of sandstones investigated through nuclear magnetic resonance principles. Log Anal. 1969, 10. SPWLA-1968-K. [Google Scholar]
- Kenyon, W.; Day, P.; Straley, C.; Willemsen, J. A three-part study of NMR longitudinal relaxation properties of water-saturated sandstones. SPE Form. Eval. 1988, 3, 622–636. [Google Scholar] [CrossRef]
- Prammer, M. NMR pore size distributions and permeability at the well site. In Proceedings of the SPE Annual Technical Conference and Exhibition, New Orleans, LA, USA, 25–28 September 1994. [Google Scholar]
- Dunn, K.-J.; LaTorraca, G.; Warner, J.; Bergman, D. On the calculation and interpretation of NMR relaxation time distributions. In Proceedings of the SPE Annual Technical Conference and Exhibition, New Orleans, LA, USA, 25–28 September 1994. [Google Scholar]
- Bloembergen, N.; Purcell, E.M.; Pound, R.V. Relaxation effects in nuclear magnetic resonance absorption. Phys. Rev. 1948, 73, 679. [Google Scholar] [CrossRef]
- Chen, S.; Arro, R.; Minetto, C.; Georgi, D.; Liu, C. Methods for computing SWI and BVI from NMR logs. In Proceedings of the Spwla 39th Annual Logging Symposium, Keystone, CO, USA, 26–29 May 1998. [Google Scholar]
- Howard, J.J.; Kenyon, W.E.; Morriss, C.E.; Straley, C. NMR in partially saturated rocks: Laboratory insights on free fluid index and comparison with borehole logs. Log Anal. 1995, 36. [Google Scholar]
- Coates, G.R.; Galford, J.; Mardon, D.; Marschall, D. A new characterization of bulk-volume irreducible using magnetic resonance. Log Anal. 1998, 39. SPWLA-1998-v39n1a4. [Google Scholar]
- Kleinberg, R.L. Nuclear Magnetic Resonance. In Experimental Methods in the Physical Sciences; Elsevier: New York, NY, USA, 1999; Volume 35, pp. 337–385. [Google Scholar]
- Wills, E. AI vs. Machine Learning: The Devil Is in the Details. Mach. Des. 2019, 91, 56–60. [Google Scholar]
- Jakhar, D.; Kaur, I. Artificial intelligence, machine learning and deep learning: Definitions and differences. Clin. Exp. Dermatol. 2020, 45, 131–132. [Google Scholar] [CrossRef]
- Anifowose, F.; Abdulraheem, A.; Al-Shuhail, A. A parametric study of machine learning techniques in petroleum reservoir permeability prediction by integrating seismic attributes and wireline data. J. Pet. Sci. Eng. 2019, 176, 762–774. [Google Scholar] [CrossRef]
- Keynejad, S.; Sbar, M.L.; Johnson, R.A. Assessment of machine-learning techniques in predicting lithofluid facies logs in hydrocarbon wells. Interpretation 2019, 7, SF1–SF13. [Google Scholar] [CrossRef]
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; López García, Á.; Heredia, I.; Malík, P.; Hluchý, L. Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef] [Green Version]
- Azad, T.D.; Ehresman, J.; Ahmed, A.K.; Staartjes, V.E.; Lubelski, D.; Stienen, M.N.; Veeravagu, A.; Ratliff, J.K. Fostering reproducibility and generalizability in machine learning for clinical prediction modeling in spine surgery. Spine J. 2021, 21, 1610–1616. [Google Scholar] [CrossRef] [PubMed]
- Rolon, L.; Mohaghegh, S.; Ameri, S.; Gaskari, R.; McDaniel, B. Using artificial neural networks to generate synthetic well logs. J. Nat. Gas Sci. Eng. 2009, 1, 118–133. [Google Scholar] [CrossRef]
- Rezaee, R.; Kadkhodaie-Ilkhchi, A.; Alizadeh, P.M. Intelligent approaches for the synthesis of petrophysical logs. J. Geophys. Eng. 2008, 5, 12–26. [Google Scholar] [CrossRef]
- Labani, M.M.; Kadkhodaie-Ilkhchi, A.; Salahshoor, K. Estimation of NMR log parameters from conventional well log data using a committee machine with intelligent systems: A case study from the Iranian part of the South Pars gas field, Persian Gulf Basin. J. Pet. Sci. Eng. 2010, 72, 175–185. [Google Scholar] [CrossRef]
- Golsanami, N.; Kadkhodaie-Ilkhchi, A.; Sharghi, Y.; Zeinali, M. Estimating NMR T2 distribution data from well log data with the use of a committee machine approach: A case study from the Asmari formation in the Zagros Basin, Iran. J. Pet. Sci. Eng. 2014, 114, 38–51. [Google Scholar] [CrossRef]
- Male, F.; Duncan, I.J. Lessons for machine learning from the analysis of porosity-permeability transforms for carbonate reservoirs. J. Pet. Sci. Eng. 2020, 187, 106825. [Google Scholar] [CrossRef]
- Aliouane, L.; Ouadfeul, S.-A.; Djarfour, N.; Boudella, A. Petrophysical Parameters Estimation from Well-Logs Data Using Multilayer Perceptron and Radial Basis Function Neural Networks. In Neural Information Processing; Huang, T., Zeng, Z., Li, C., Leung, C.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Ahmadi, M.A.; Chen, Z. Comparison of machine learning methods for estimating permeability and porosity of oil reservoirs via petro-physical logs. Petroleum 2019, 5, 271–284. [Google Scholar] [CrossRef]
- Rezaee, R.; Nikjoo, M.; Movahed, B.; Sabeti, N. Prediction of effective porosity and water saturation from wireline logs using artificial neural network technique. J. Geol. Soc. IRAN 2006, 1, 21–27. [Google Scholar]
- Rezaee, R.; Kadkhodaie, I.A.; Barabadi, A. Prediction of shear wave velocity from petrophysical data utilizing intelligent systems: An example from a sandstone reservoir of Carnarvon Basin, Australia. J. Pet. Sci. Eng. 2007, 55, 201–212. [Google Scholar] [CrossRef] [Green Version]
- Rezaee, R.; Slatt, R.M.; Sigal, R.F. Shale Gas Rock Properties Prediction using Artificial Neural Network Technique and Multi Regression Analysis, an example from a North American Shale Gas Reservoir. ASEG Ext. Abstr. 2007, 2007, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Elkatatny, S.; Tariq, Z.; Mahmoud, M.; Abdulraheem, A. New insights into porosity determination using artificial intelligence techniques for carbonate reservoirs. Petroleum 2018, 4, 408–418. [Google Scholar] [CrossRef]
- Kadkhodaie-Ilkhchi, A.; Rezaee, M.R.; Rahimpour-Bonab, H.; Chehrazi, A. Petrophysical data prediction from seismic attributes using committee fuzzy inference system. Comput. Geosci. 2009, 35, 2314–2330. [Google Scholar] [CrossRef] [Green Version]
- Wong, P.M.; Jian, F.X.; Taggart, I.J. A critical comparison of neural networks and discriminant analysis in lithofacies, porosity and permeability predictions. J. Pet. Geol. 1995, 18, 191–206. [Google Scholar] [CrossRef]
- Wong, P.M.; Jang, M.; Cho, S.; Gedeon, T.D. Multiple permeability predictions using an observational learning algorithm. Comput. Geosci. 2000, 26, 907–913. [Google Scholar] [CrossRef]
- Wong, P.M. Permeability prediction from well logs using an improved windowing technique. J. Pet. Geol. 1999, 22, 215–226. [Google Scholar] [CrossRef]
- Waszkiewicz, S.; Krakowska-Madejska, P.; Puskarczyk, E. Estimation of absolute permeability using artificial neural networks (multilayer perceptrons) based on well logs and laboratory data from Silurian and Ordovician deposits in SE Poland. Acta Geophys. 2019, 67, 1885–1894. [Google Scholar] [CrossRef] [Green Version]
- Shibili, S.A.R.; Wong, P.M. Use of Interpolation Neural Networks for Permeability Estimation from Well Logs. Log Anal. 1998, 39, 18–26. [Google Scholar]
- Bruce, A.G.; Wong, P.M. Permeability prediction from well logs using an evolutionary neural network. Pet. Sci. Technol. 2002, 20, 317–331. [Google Scholar] [CrossRef]
- Aminian, K.; Ameri, S. Application of artificial neural networks for reservoir characterization with limited data. J. Pet. Sci. Eng. 2005, 49, 212–222. [Google Scholar] [CrossRef]
- Ahmadi, M.A.; Zendehboudi, S.; Lohi, A.; Elkamel, A.; Chatzis, I. Reservoir permeability prediction by neural networks combined with hybrid genetic algorithm and particle swarm optimization. Geophys. Prospect. 2013, 61, 582–598. [Google Scholar] [CrossRef]
- Wong, P.M.; Henderson, D.J.; Brooks, L.J. Permeability Determination Using Neural Networks in the Ravva Field, Offshore India. SPE Reserv. Eval. Eng. 1998, 1, 99–104. [Google Scholar] [CrossRef]
- Wang, X.; Yang, S.; Wang, Y.; Zhao, Y.; Ma, B. Improved permeability prediction based on the feature engineering of petrophysics and fuzzy logic analysis in low porosity–permeability reservoir. J. Pet. Explor. Prod. Technol. 2019, 9, 869–887. [Google Scholar] [CrossRef] [Green Version]
- Eshkalak, M.O.; Mohaghegh, S.D.; Esmaili, S. Synthetic, Geomechanical Logs for Marcellus Shale. In Proceedings of the SPE Digital Energy Conference, The Woodlands, TX, USA, 5–7 March 2013. [Google Scholar] [CrossRef]
- Eshkalak, M.O.; Mohaghegh, S.D.; Esmaili, S. Geomechanical Properties of Unconventional Shale Reservoirs. J. Pet. Eng. 2014, 2014, 961641. [Google Scholar] [CrossRef] [Green Version]
- Jamshidian, M.; Hadian, M.; Zadeh, M.M.; Kazempoor, Z.; Bazargan, P.; Salehi, H. Prediction of free flowing porosity and permeability based on conventional well logging data using artificial neural networks optimized by imperialist competitive algorithm—A case study in the South Pars Gas field. J. Nat. Gas Sci. Eng. 2015, 24, 89–98. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble machine learning paradigms in hydrology: A review. J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- Simske, S. Chapter 1—Introduction, overview, and applications. In Meta-Analytics; Simske, S., Ed.; Morgan Kaufmann: Burlington, MA, USA, 2019; pp. 1–98. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Akkurt, R.; Conroy, T.T.; Psaila, D.; Paxton, A.; Low, J.; Spaans, P. Accelerating and Enhancing Petrophysical Analysis With Machine Learning: A Case Study of an Automated System for Well Log Outlier Detection and Reconstruction. In Proceedings of the SPWLA 59th Annual Logging Symposium, London, UK, 2–6 June 2018. [Google Scholar]
- Ertekin, T.; Sun, Q. Artificial intelligence applications in reservoir engineering: A status check. Energies 2019, 12, 2897. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. Citeseer 1996, 96, 148–156. [Google Scholar]
- Testamanti, N.; Rezaee, R. Determination of NMR T2 cut-off for clay bound water in shales: A case study of Carynginia Formation, Perth Basin, Western Australia. J. Pet. Sci. Eng. 2017, 149, 497–503. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Rezaee, R.; Verrall, M.; Hu, S.-Y.; Zou, J.; Testmanti, N. Pore characterization and clay bound water assessment in shale with a combination of NMR and low-pressure nitrogen gas adsorption. Int. J. Coal Geol. 2018, 194, 11–21. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Basin | Formation | Age | Depth (m) | Fluid Type | Main Lithology |
|---|---|---|---|---|---|
| Browse | Bassett | Tertiary | 1390–1408 | Gas-Cond. | Sandstone |
| Browse | Grebe | Tertiary | 1312–1385 | Gas-Cond. | Sandstone |
| Browse | Nome | Triassic | 3823–3848 | Gas | Sandstone |
| Browse | Plover | Jurassic | 3776–3823 | Gas | Sandstone |
| Browse | Vulcan | Juras. to Cre. | 3942–4138 | Oil | Sandstone |
| N. Carnarvon | Angel | Jurassic | 3400–3700 | Oil | Sandstone |
| N. Carnarvon | Barrow Group | Cretacous | 1890–1936 | Oil | Sandstone |
| N. Carnarvon | Brigadier | Triassic | 3037–3162 | Oil | Sandstone |
| N. Carnarvon | Forestier | Cretacous | 2983–3147 | Brine | Claystone |
| N. Carnarvon | Muderong | Cretacous | 2960–2982 | Brine | Shale |
| N. Carnarvon | Mungaroo | Triassic | 3045–3710 | Oil and Gas | Sandstone |
| Perth | Cattamarra | Jurassic | 2940–3052 | Oil | Sandstone |
| Perth | Dongara | Triassic | 1276–1281 | Oil | Sandstone |
| Perth | High Cliff | Permian | 1310–1476 | Oil | Sandstone |
| Perth | IRCM | Permian | 1278–1475 | Oil | Sandstone |
| Perth | Kockatea | Triassic | 1188–1427 | Brine | Shale |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rezaee, R. Synthesizing Nuclear Magnetic Resonance (NMR) Outputs for Clastic Rocks Using Machine Learning Methods, Examples from North West Shelf and Perth Basin, Western Australia. Energies 2022, 15, 518. https://doi.org/10.3390/en15020518
Rezaee R. Synthesizing Nuclear Magnetic Resonance (NMR) Outputs for Clastic Rocks Using Machine Learning Methods, Examples from North West Shelf and Perth Basin, Western Australia. Energies. 2022; 15(2):518. https://doi.org/10.3390/en15020518
Chicago/Turabian StyleRezaee, Reza. 2022. "Synthesizing Nuclear Magnetic Resonance (NMR) Outputs for Clastic Rocks Using Machine Learning Methods, Examples from North West Shelf and Perth Basin, Western Australia" Energies 15, no. 2: 518. https://doi.org/10.3390/en15020518
APA StyleRezaee, R. (2022). Synthesizing Nuclear Magnetic Resonance (NMR) Outputs for Clastic Rocks Using Machine Learning Methods, Examples from North West Shelf and Perth Basin, Western Australia. Energies, 15(2), 518. https://doi.org/10.3390/en15020518