
How Can Sustainable Public Transport Be Improved? A Traffic Sign Recognition Approach Using Convolutional Neural Network


 ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Methods
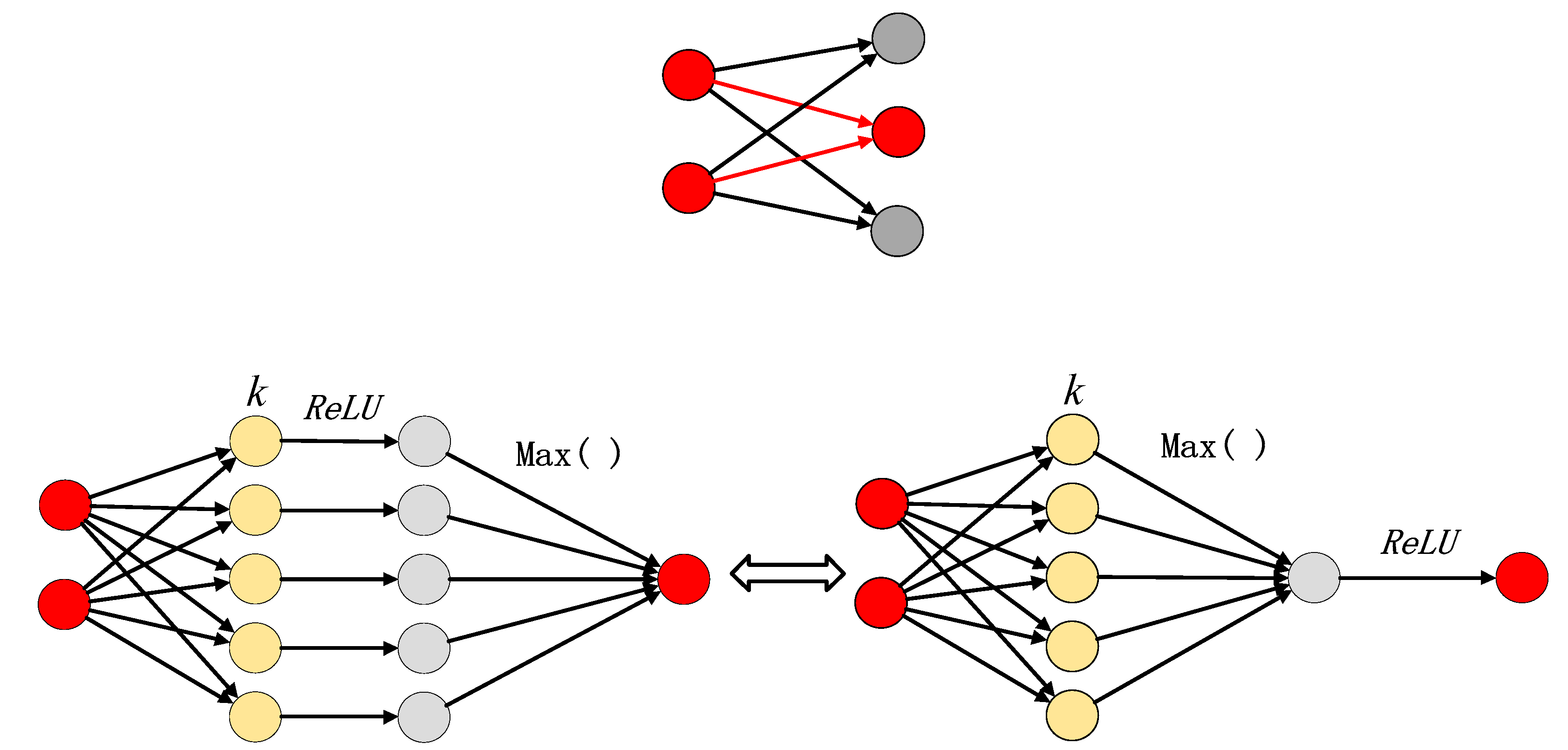
2.1.1. CNN Based on Sparse Maxout
- (1)
- Maxout neural network
- (2)
- Sparse maxout CNN
2.1.2. K-Means CNN
- (1)
- Assignment. Using the Euclidean distance, data points can be allocated to the nearest observation point, that is to say, they are allocated according to the following formula.It should be noted that although may be assigned to two or more categories in theory, in the specific operation, is only assigned to a certain cluster.
- (2)
- Update. The new clustering center in each cluster obtained in step 1st is calculated as the new mean point, and the formula is as follows:
- (1)
- By convoluting the above clustering results with the input data (images), the features of the input data can be obtained.
- (2)
- Generally, in order to decrease the feature dimension, speed up the computations, reduce the network size and obtain certain translation invariance, the image feature graph obtained above is pooled (using pooling).
2.2. Data
2.2.1. Data Source
2.2.2. Data Preprocessing
3. Results
3.1. K-Means Feature Extraction
3.2. Crude Classification Results
3.3. Fine Classification Results
3.4. Final Classification Results and Analysis
4. Discussion
4.1. Assumption of Carbon Reduction
4.2. Policy Recommendations
- (1)
- First, the government should greatly develop road traffic information recognition technology to improve the recognition accuracy. Road traffic signal identification is very important for the development of sustainable public transport. High-accuracy identification can promote the development of driverless technology and then promote the development of sustainable public transport. To improve the recognition accuracy, the government should increase the number of related projects and increase the amount of funding for each project. In the future, the government should establish a number of R&D centers for road traffic information identification and invest more funds in its research. The government should encourage enterprises to undertake more relevant projects independently or in cooperation with scientific research institutions to promote the development of the technology. The government should encourage private capital and enterprises to establish road traffic information identification research and development center, systematically participate in the research of this technology, and promote the development of this technology.
- (2)
- Moreover, the government should establish the relevant system of driverless public transport. First, it should formulate relevant policies and promote the cooperation of the relevant departments to develop driverless public transport. The development of driverless public transport is not isolated, since it involves cross-field, cross-industry and cross-sector cooperation. It is necessary for the government to formulate relevant policies to promote the cooperation of all departments and stipulate the division of the labor, power, responsibility and obligation of all departments. Second, the construction of a driverless public transport standardization system should be promoted in an all-round way. The development of driverless public transport involves many fields and levels; thus, it is necessary to formulate relevant standards in different fields and levels. A standardization system plays the role of guiding the top-level design and the leading norms, which will greatly promote the development of driverless public transport. Third, relevant financial support policies should be formulated. Cities that use driverless public transportation can be given financial subsidies, and the intensity of the subsidies can be determined according to their contribution to carbon emissions reductions. For driverless bus companies, preferential tax policies and loan policies should be given.
- (3)
- Finally, driverless transportation infrastructure should be investigated and constructed. The development of driverless driving requires infrastructure construction. First, a closed road test area should be established. The establishment of a test area that can meet the test conditions of driverless public transport is conducive to the testing of driverless public transport. Second, roads for open tests should be established. Although a closed test site can simulate the natural environment such as rain and fog, pedestrians and interfering vehicles, there is still a certain gap between a closed test site and actual road test data. Third, the operation of driverless public transport requires other investments, such as the traffic internet things, related road networks and road traffic signals. For finance support, the government needs to increase investment, and it can use new financial tools such as public–private partnership and build–operate–transfer policies.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Zhao, X.; Ke, Y.; Zuo, J.; Xiong, W.; Wu, P. Evaluation of sustainable transport research in 2000–2019. J. Clean. Prod. 2020, 256, 120404. [Google Scholar] [CrossRef]
- Song, X.; Geng, Y.; Dong, H.; Chen, W. Social network analysis on industrial symbiosis: A case of Gujiao eco-industrial park. J. Clean. Prod. 2018, 193, 414–423. [Google Scholar] [CrossRef]
- Song, X.; Ali, M.; Zhang, X.; Sun, H.; Wei, F. Stakeholder coordination analysis in hazardous waste management: A case study in China. J. Mater. Cycles Waste Manag. 2021, 23, 1873–1892. [Google Scholar] [CrossRef]
- Buyukozkan, G.; Feyzioglu, O.; Gocer, F. Selection of sustainable urban transportation alternatives using an integrated intuitionistic fuzzy Choquet integral approach. Transp. Res. Part D Transp. Environ. 2018, 58, 186–207. [Google Scholar] [CrossRef]
- Hatefi, S.M. Strategic planning of urban transportation system based on sustainable development dimensions using an integrated SWOT and fuzzy COPRAS approach. Glob. J. Environ. Sci. Manag. 2018, 4, 99–112. [Google Scholar]
- Eliasson, J.; Proost, S. Is sustainable transport policy sustainable? Transp. Policy 2015, 37, 92–100. [Google Scholar] [CrossRef]
- Barfod, M.B. Supporting sustainable transport appraisals using stakeholder involvement and mcda. Transport 2018, 33, 1052–1066. [Google Scholar] [CrossRef]
- Salehi, M.; Jalalian, M.; Siar, M.M. Green transportation scheduling with speed control: Trade-off between total transportation cost and carbon emission. Comput. Ind. Eng. 2017, 113, 392–404. [Google Scholar] [CrossRef]
- Hong, Y.; Chen, C.; Wu, Y. Biobutanol production from sulfuric acid-pretreated red algal biomass by a newly isolated Clostridium sp. strain WK. Biotechnol. Appl. Biochem. 2020, 67, 738–743. [Google Scholar] [CrossRef]
- Xue, Y.; Guan, H.; Corey, J.; Wei, H.; Yan, H. Quantifying a financially sustainable strategy of public transport: Private capital investment considering passenger value. Sustainability 2017, 9, 269. [Google Scholar] [CrossRef]
- Dubey, R.; Gunasekaran, A.; Papadopoulos, T.; Childe, S.J.; Shibin, K.T.; Wamba, S. Sustainable supply chain management: Framework and further research directions. J. Clean. Prod. 2017, 142, 1119–1130. [Google Scholar] [CrossRef]
- Buehler, R.; Pucher, J. Making public transport financially sustainable. Transp. Policy 2011, 18, 126–138. [Google Scholar] [CrossRef]
- Hensher, D.A. Sustainable public transport systems: Moving towards a value for money and network-based approach and away from blind commitment. Transp. Policy 2007, 14, 98–102. [Google Scholar] [CrossRef]
- Smieszek, M.; Dobrzanska, M.; Dobrzanski, P. Rzeszow as a city taking steps towards developing sustainable public transport. Sustainability 2019, 11, 402. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, J.; Li, Z.; Yuan, L.; Yang, Y.; Li, F. Re-estimating CO2 emission factors for gasoline passenger cars adding driving behaviour characteristics—A case study of Beijing. Energy Policy 2017, 102, 353–361. [Google Scholar] [CrossRef]
- Song, X.; Geng, Y.; Li, K.; Zhang, X.; Wu, F.; Pan, H.; Zhang, Y. Does environmental infrastructure investment contribute to emissions reduction? A case of China. Front. Energy 2020, 14, 57–70. [Google Scholar] [CrossRef]
- Luo, H.L.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1100–1111. [Google Scholar] [CrossRef]
- Tan, T.; Lu, J.; Wen, J.; Li, C.; Ling, W. Traffic sign recognition applying with convolution neural network and RPN. Comput. Eng. Appl. 2018, 54, 251–256. [Google Scholar]
- Xu, Z.; Feng, C. Modified scale dependent pooling model for traffic image recognition. J. Comput. Appl. 2018, 38, 671–676. [Google Scholar]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the IEEE international Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 8609–8613. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.C.; Bengio, Y. Maxout Networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1319–1327. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2013, arXiv:1207.0580. [Google Scholar]
- Cai, M.; Shi, Y.; Liu, J. Deep maxout neural networks for speech recognition. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–12 December 2013; pp. 291–296. [Google Scholar]
- Rueda, F.M.; Grzeszick, R.; Fink, G. Neuron pruning for compressing deep networks using maxout architectures. In Proceedings of the German Conference on Pattern Recognition, Basel, Switzerland, 13–15 September 2017; pp. 177–188. [Google Scholar]
- Jin, Z.; Han, Y.; Zhu, Q. A sentiment analysis model with the combination of deep learning and ensemble learning. J. Harbin Inst. Technol. 2018, 50, 32–39. [Google Scholar]
- Zhu, Q.; Du, B.; Turkbey, B.; Choyke, P.L.; Yan, P. Deeply-Supervised CNN for Prostate Segmentation. In Proceedings of the International Joint Conference on Neural Network (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 178–184. [Google Scholar]
- Chen, T.; Lu, S.; Fan, J. SS-HCNN: Semi-supervised hierarchical convolutional neural network for image classification. IEEE Trans. Image Process. 2019, 28, 2389–2398. [Google Scholar] [CrossRef]
- Jog, A.; Hoopes, A.; Greve, D.N.; Leemput, K.V.; Fisch, B. PSACNN: Pulse sequence adaptive fast whole brain segmentation. Neurolmage 2019, 99, 553–569. [Google Scholar] [CrossRef]
- Laskar, Z.; Kannala, J. Semi-supervised semantic matching. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 444–445. [Google Scholar]
- Garg, R.; Vijay, K.B.G.; Carneiro, G.; Reid, I. Unsupervised CNN for single view depth estimation: Geometry to the rescue. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 740–756. [Google Scholar]
- Darugar, M.J.; Kiong, L.C. Gender estimation based on supervised HOG, Action Units and unsupervised CNN feature extraction. In Proceedings of the Joint Conference on Artificial Intelligence & Robotics & Robocupiranopen International Symposium, Qazvin, Iran, 10 April 2017; pp. 23–27. [Google Scholar]
- Piekniewski, F.; Rybicki, L. Visual comparison of performance for different activation functions in MLP networks. In Proceedings of the International Joint Conference on Neural Networks: IJCNN, Budapest, Hungary, 25–29 July 2004; pp. 2947–2952. [Google Scholar]
- Sivaram, G.S.V.S.; Nemala, S.K.; Elhilali, M.; Tran, T.D.; Hermansky, H. Sparse coding for speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 14–19 March 2010; p. 9. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML Workshop on Deep Learning for Audio Speech and Language Processing, Atlanta, GA, USA, 16 June 2013; pp. 1–6. [Google Scholar]
- Cireşan, D.; Meier, U.; Masci, J.; Schmidhuber, J. Multi-column deep neural network for traffic sign classification. Neural Netw. 2012, 32, 333–338. [Google Scholar] [CrossRef]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef]
- Zaklouta, F.; Stanciulescu, B.; Hamdoun, O. Traffic sign classification using K-d trees and random forests. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2021; pp. 2151–2155. [Google Scholar]
- Ying, Z.; Wu, X.; Yang, W. Carbon emission accounting for the transition of public buses from gasoline to electricity in Hangzhou City, China. Acta Ecol. Sin. 2018, 38, 6452–6464. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number of Errors | Accuracy (%) |
|---|---|---|
| Speed limit (Total sum 4200) | 40 | 99.04 |
| Other ban (Total sum 1470) | 17 | 98.86 |
| Lifting ban (Total sum 360) | 16 | 95.56 |
| Indication (Total sum 1770) | 20 | 98.87 |
| Warning (Total sum 2790) | 25 | 99.10 |
| Others (Total sum 2040) | 32 | 98.43 |
| Methods | Limitation | Other Ban | Lifting Ban | Indication | Warning | Other Signs | Total |
|---|---|---|---|---|---|---|---|
| Multicolumn DNN | 99.47 | 99.93 | 99.72 | 99.89 | 99.07 | 99.22 | 99.46 |
| Human Performance | 97.63 | 99.93 | 98.89 | 99.72 | 98.67 | 100.00 | 98.84 |
| Proposed algorithm | 99.04 | 98.86 | 95.56 | 98.87 | 99.10 | 98.43 | 98.81 |
| Multiscale CNN | 98.61 | 99.87 | 94.44 | 97.18 | 98.03 | 98.63 | 98.31 |
| Random forests | 95.95 | 99.13 | 87.50 | 99.27 | 92.08 | 98.73 | 96.14 |
| LDA on HOG 2 | 95.37 | 96.80 | 85.83 | 97.18 | 93.73 | 98.63 | 95.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Ge, H.; Li, J.; He, P.; Hao, Z.; Hitch, M. How Can Sustainable Public Transport Be Improved? A Traffic Sign Recognition Approach Using Convolutional Neural Network. Energies 2022, 15, 7386. https://doi.org/10.3390/en15197386
Liu J, Ge H, Li J, He P, Hao Z, Hitch M. How Can Sustainable Public Transport Be Improved? A Traffic Sign Recognition Approach Using Convolutional Neural Network. Energies. 2022; 15(19):7386. https://doi.org/10.3390/en15197386
Chicago/Turabian StyleLiu, Jingjing, Hongwei Ge, Jiajie Li, Pengcheng He, Zhangang Hao, and Michael Hitch. 2022. "How Can Sustainable Public Transport Be Improved? A Traffic Sign Recognition Approach Using Convolutional Neural Network" Energies 15, no. 19: 7386. https://doi.org/10.3390/en15197386
APA StyleLiu, J., Ge, H., Li, J., He, P., Hao, Z., & Hitch, M. (2022). How Can Sustainable Public Transport Be Improved? A Traffic Sign Recognition Approach Using Convolutional Neural Network. Energies, 15(19), 7386. https://doi.org/10.3390/en15197386