


How to Train an Artificial Neural Network to Predict Higher Heating Values of Biofuel



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
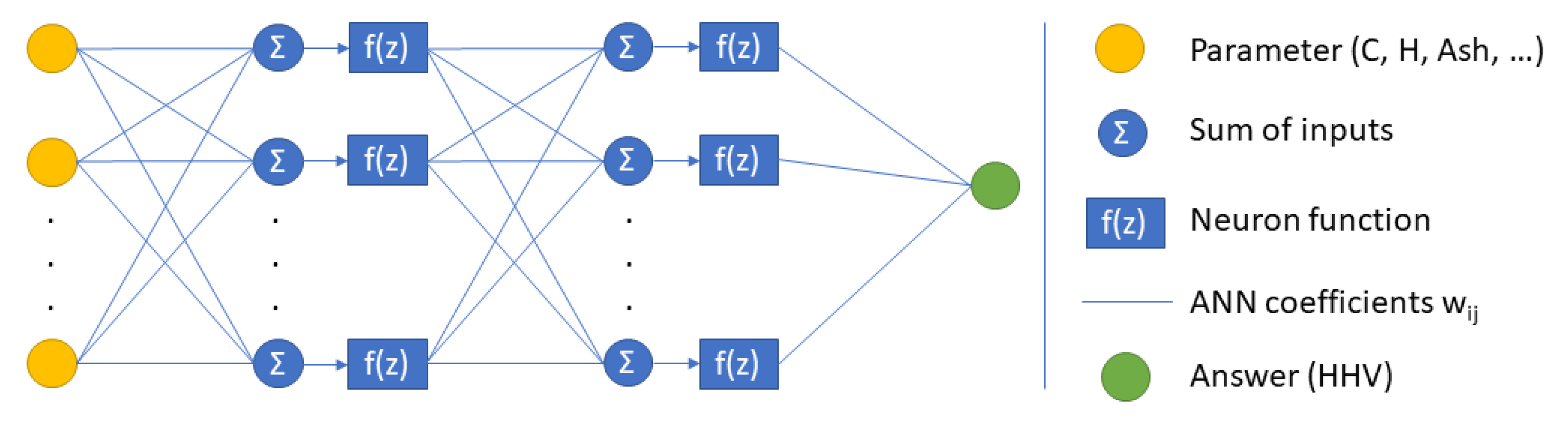
2.2. Artificial Neural Network Architecture and Evaluation
3. Results and Discussion
3.1. Scoring and Rules
- 1.
- Training set;
- 2.
- The ANN architecture (the number of neurons and the number of layers);
- 3.
- Neural response function;
- 4.
- The solver algorithm.
3.2. Preprocessing of the Inputs for Predicting the HHVs
- -
- The individual data from ultimate analysis (Set 1);
- -
- The individual data from proximate analysis (Set 2);
- -
- A combination of the data from ultimate and proximate analyses (Set 3);
- -
- A combination of the data from ultimate and proximate analyses, except for nitrogen content and volatile matter (Set 4).
3.3. ANN Architecture Tuning
3.4. Choosing the Activation Function
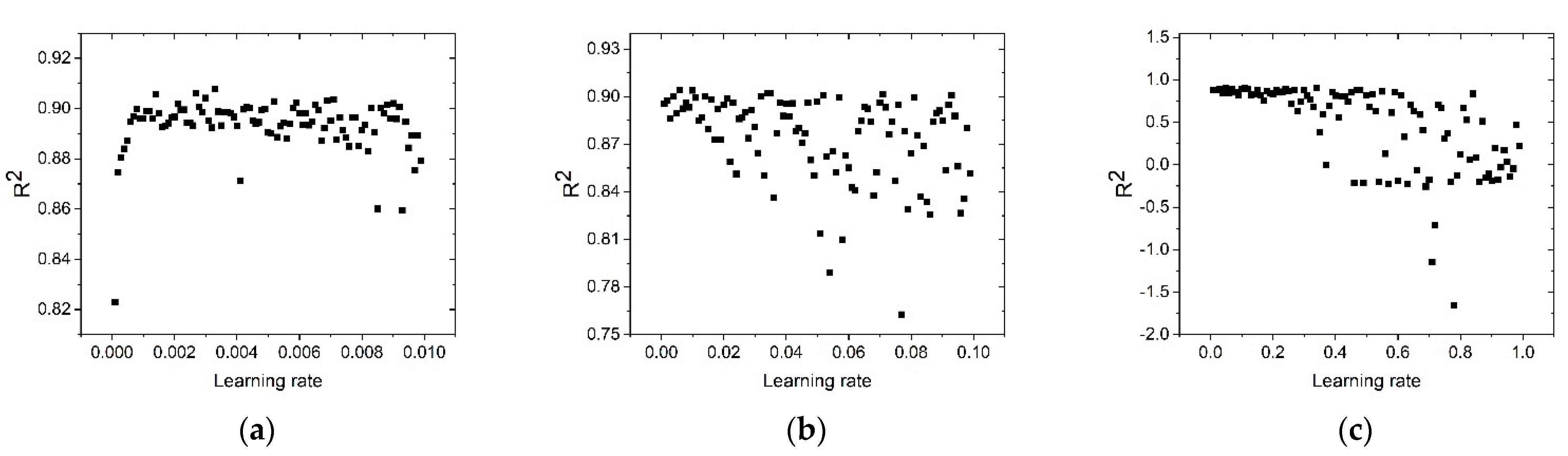
3.5. Optimizing the Operation of the Solver Algorithm
3.6. Comparing the Prediction Accuracies Ensured Using ANN and the Empirical Formulas
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dafnomilis, I.; Hoefnagels, R.; Pratama, Y.W.; Schott, D.L.; Lodewijks, G.; Junginger, M. Review of solid and liquid biofuel demand and supply in Northwest Europe towards 2030—A comparison of national and regional projections. Renew. Sustain. Energy Rev. 2017, 78, 31–45. [Google Scholar] [CrossRef]
- Mandley, S.; Daioglou, V.; Junginger, H.; van Vuuren, D.; Wicke, B. EU bioenergy development to 2050. Renew. Sustain. Energy Rev. 2020, 127, 109858. [Google Scholar] [CrossRef]
- Titova, E.S. Biofuel Application as a Factor of Sustainable Development Ensuring: The Case of Russia. Energies 2019, 12, 3948. [Google Scholar] [CrossRef]
- Proskurina, S.; Junginger, M.; Heinimö, J.; Tekinel, B.; Vakkilainen, E. Global biomass trade for energy—Part 2: Production and trade streams of wood pellets, liquid biofuels, charcoal, industrial roundwood and emerging energy biomass. Biofuels Bioprod. Biorefining 2019, 13, 371–387. [Google Scholar] [CrossRef]
- Pradhan, P.; Mahajani, S.M.; Arora, A. Production and utilization of fuel pellets from biomass: A review. Fuel Process. Technol. 2018, 181, 215–232. [Google Scholar] [CrossRef]
- Kim, J.-H.; Jung, S.; Lin, K.-Y.A.; Rinklebe, J.; Kwon, E.E. Comparative study on carbon dioxide-cofed catalytic pyrolysis of grass and woody biomass. Bioresour. Technol. 2021, 323, 124633. [Google Scholar] [CrossRef]
- Yin, C.Y. Prediction of higher heating values of biomass from proximate and ultimate analyses. Fuel 2011, 90, 1128–1132. [Google Scholar] [CrossRef]
- Vargas-Moreno, J.; Callejón-Ferre, A.; Pérez-Alonso, J.; Velázquez-Martí, B. A review of the mathematical models for predicting the heating value of biomass. Renew. Sustain. Energy Rev. 2012, 16, 3065–3083. [Google Scholar] [CrossRef]
- Qian, C.; Li, Q.; Zhang, Z.; Wang, X.; Hu, J.; Cao, W. Prediction of higher heating values of biochar from proximate and ultimate analysis. Fuel 2020, 265, 116925. [Google Scholar] [CrossRef]
- Górnicki, K.; Kaleta, A.; Winiczenko, R. Prediction of higher heating value of oat grain and straw biomass. E3S Web Conf. 2020, 154, 01003. [Google Scholar] [CrossRef]
- Maksimuk, Y.; Antonava, Z.; Krouk, V.; Korsakova, A.; Kursevich, V. Prediction of higher heating value based on elemental composition for lignin and other fuels. Fuel 2019, 263, 116727. [Google Scholar] [CrossRef]
- Bychkov, A.L.; Denkin, A.I.; Tikhova, V.; Lomovsky, O. Prediction of higher heating values of plant biomass from ultimate analysis data. J. Therm. Anal. Calorim. 2017, 130, 1399–1405. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Xing, J.; Luo, K.; Wang, H.; Gao, Z.; Fan, J. A comprehensive study on estimating higher heating value of biomass from proximate and ultimate analysis with machine learning approaches. Energy 2019, 188, 116077. [Google Scholar] [CrossRef]
- Obafemi, O.; Stephen, A.; Ajayi, O.; Nkosinathi, M. A survey of artificial neural network-based prediction models for thermal properties of biomass. Procedia Manuf. 2019, 33, 184–191. [Google Scholar] [CrossRef]
- Estiati, I.; Freire, F.B.; Freire, J.T.; Aguado, R.; Olazar, M. Fitting performance of artificial neural networks and empirical correlations to estimate higher heating values of biomass. Fuel 2016, 180, 377–383. [Google Scholar] [CrossRef]
- Uzun, H.; Yıldız, Z.; Goldfarb, J.L.; Ceylan, S. Improved prediction of higher heating value of biomass using an artificial neural network model based on proximate analysis. Bioresour. Technol. 2017, 234, 122–130. [Google Scholar] [CrossRef]
- Cao, H.; Xin, Y.; Yuan, Q. Prediction of biochar yield from cattle manure pyrolysis via least squares support vector machine intelligent approach. Bioresour. Technol. 2016, 202, 158–164. [Google Scholar] [CrossRef]
- Ozonoh, M.; Oboirien, B.O.; Daramola, M.O. Optimization of process variables during torrefaction of coal/biomass/waste tyre blends: Application of artificial neural network & response surface methodology. Biomass Bioenergy 2020, 143, 105808. [Google Scholar] [CrossRef]
- Goettsch, D.; Castillo-Villar, K.K.; Aranguren, M. Machine-learning methods to select potential depot locations for the supply chain of biomass co-firing. Energies 2020, 13, 6554. [Google Scholar] [CrossRef]
- Li, H.; Xu, Q.; Xiao, K. Predicting the higher heating value of syngas pyrolyzed from sewage sludge using an artificial neural network. Environ. Sci. Pollut. Res. 2020, 27, 785–797. [Google Scholar] [CrossRef] [PubMed]
- Olatunji, O.O.; Akinlabi, S.; Madushele, N.; Adedeji, P.A.; Felix, I. Multilayer perceptron artificial neural network for the prediction of heating value of municipal solid waste. AIMS Energy 2019, 7, 944–956. [Google Scholar] [CrossRef]
- Dashti, A.; Noushabadi, A.S.; Raji, M.; Razmi, A.; Ceylan, S.; Mohammadi, A.H. Estimation of biomass higher heating value (HHV) based on the proximate analysis: Smart modeling and correlation. Fuel 2019, 257, 115931. [Google Scholar] [CrossRef]
- Elmaz, F.; Büyükçakır, B.; Yücel, Ö.; Mutlu, A.Y. Classification of solid fuels with machine learning. Fuel 2020, 266, 117066. [Google Scholar] [CrossRef]
- Akkaya, E.; Demir, A. Predicting the heating value of municipal solid waste-based materials: An artificial neural network model. Energy Sources Part A Recover. Util. Environ. Eff. 2010, 32, 1777–1783. [Google Scholar] [CrossRef]
- Abidoye, L.K.; Mahdi, F.M. Novel linear and nonlinear equations for the higher heating values of municipal solid wastes and the implications of carbon to energy ratios. J. Energy Technol. Policy 2014, 4, 14–27. [Google Scholar]
- Phyllis2, Database for (Treated) Biomass, Algae, Feedstocks for Biogas Production and Biochar. TNO Biobased and Circular Technologies. Available online: https://phyllis.nl (accessed on 20 July 2022).
- Parikh, J.; Channiwala, S.A.; Ghosal, G.K. A correlation for calculating HHV from proximate analysis of solid fuels. Fuel 2005, 84, 487–494. [Google Scholar] [CrossRef]
- Krishnan, R.; Hauchhum, L.; Gupta, R.; Pattanayak, S. Prediction of equations for higher heating values of biomass using proximate and ultimate analysis. In Proceedings of the 2nd International Conference on Power, Energy and Environment: Towards Smart Technology (ICEPE), Shillong, India, 1–2 June 2018. [Google Scholar] [CrossRef]
- Myung, I.J. Tutorial on Maximum Likelihood Estimation. J. Math. Psychol. 2003, 47, 90–100. [Google Scholar] [CrossRef]
- Holzmüller, D.; Steinwart, I. Training two-layer ReLU networks with gradient descent is inconsistent. arXiv 2020, arXiv:2002.04861. [Google Scholar] [CrossRef]
- Cho, J.; Lee, K.; Shin, E.; Choy, G.; Do, S. How much data is needed to train a medical image deep learning system to achieve necessary high accuracy? arXiv 2015, arXiv:1511.06348. Available online: https://arxiv.org/pdf/1511.06348.pdf (accessed on 20 July 2022).
- Cireşan, D.C.; Meier, U.; Schmidhuber, J. Transfer learning for Latin and Chinese characters with deep neural networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012. [Google Scholar] [CrossRef]
- Jain, A.K.; Chandrasekaran, B. 39 Dimensionality and sample size considerations in pattern recognition practice. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2001; Volume 2, pp. 835–855. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Mather, P.M. The use of backpropagating artificial neural networks in land cover classification. Int. J. Remote Sens. 2003, 24, 4907–4938. [Google Scholar] [CrossRef]
- Raudys, S.J.; Jain, A.K. Small sample size effects in statistical pattern recognition: Recommendations for practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Bengio, Y.; Grandvalet, Y. No unbiased estimator of the variance of k-fold cross-validation. J. Mach. Learn. 2004, 5, 1089–1105. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Biomass | Number of Samples | HHV, MJ/kg | Ultimate Analysis | Proximate Analysis | ||||
|---|---|---|---|---|---|---|---|---|
| Carbon, % | Hydrogen, % | Nitrogen, % | Ash, % | VM, % | FC, % | |||
| Fossil fuel/peat | 11 | 19.57–21.97–24.60 | 49.90–53.50–55.20 | 5.30–5.60–5.90 | 0.80–1.43–2.00 | 2.70–4.20–7.50 | 67.5–71.10–77.40 | 18.40–25.40–28.50 |
| Grass plant | 101 | 8.89–18.51–21.58 | 19.12–46.66–51.76 | 2.00–5.80–8.66 | 0.18–0.73–4.22 | 0.90–5.30–48.70 | 47.70–76.69–92.55 | 3.60–17.20–26.56 |
| Husk/shell/peat | 89 | 13.31–19.79–25.73 | 31.44–48.93–58.93 | 4.30–5.90–9.18 | 0.02–0.76–3.03 | 0.40–3.30–23.37 | 38.80–73.86–84.90 | 8.69–20.62–37.90 |
| Manure | 18 | 4.22–14.69–19.35 | 12.96–35.75–49.01 | 1.45–4.70–6.14 | 0.69–2.63–6.32 | 9.80–23.48–73.52 | 21.33–62.12–70.27 | 5.15–13.58–23.22 |
| Marine biomass (algae) | 11 | 17.57–23.84–26.36 | 41.20–51.40–54.75 | 5.60–6.83–7.52 | 6.66–10.76–12.72 | 2.52–5.94–27.66 | 59.86–79.51–82.97 | 12.35–14.09–17.22 |
| Organic residue | 108 | 6.34–18.30–26.87 | 19.70–45.10–65.54 | 2.44–5.87–8.52 | 0.01–0.91–12.42 | 0.10–6.38–64.00 | 29.30–74.09–94.47 | 2.00–15.49–38.41 |
| RDF and MSW | 23 | 15.54–20.48–29.69 | 38.69–46.42–62.60 | 5.33–6.50–13.81 | 0.20–0.70–2.01 | 7.77–13.01–34.45 | 58.56–74.08–87.07 | 0.47–10.19–22.53 |
| Sludge | 34 | 7.19–12.09–17.80 | 22.90–28.75–39.30 | 2.21–4.24–5.80 | 0.09–3.61–5.95 | 24.39–44.08–63.57 | 26.42–51.75–62.70 | 1.21–6.80–14.11 |
| Straw | 82 | 14.49–17.94–20.30 | 34.60–45.49–48.70 | 3.93–5.60–6.61 | 0.01–0.64–2.47 | 1.36–6.57–24.36 | 61.10–75.29–87.20 | 5.20–17.78–26.65 |
| Untreated wood | 243 | 12.67–19.57–22.78 | 32.69–49.38–57.75 | 3.32–5.95–8.65 | 0.02–0.29–2.81 | 0.10–1.53–39.37 | 46.50–81.37–94.73 | 5.07–16.67–34.71 |
| Total | 720 | 4.22–18.99–29.69 | 12.96–47.59–65.54 | 1.45–5.85–13.81 | 0.01–0.60–12.72 | 0.10–4.19–73.52 | 21.33–76.88–94.73 | 0.47–16.94–38.41 |
| C | H | N | Ash | VM | FC | HHV | |
|---|---|---|---|---|---|---|---|
| C | 1 | 0.61395 | −0.09708 | −0.86872 | 0.72001 | 0.48792 | 0.90531 |
| H | 0.61395 | 1 | −0.00773 | −0.58941 | 0.59749 | 0.12217 | 0.66756 |
| N | −0.09708 | −0.00773 | 1 | 0.14893 | −0.13275 | −0.06766 | −0.00673 |
| Ash | −0.86872 | −0.58941 | 0.14893 | 1 | −0.87962 | −0.46699 | −0.78388 |
| VM | 0.72001 | 0.59749 | −0.13275 | −0.87962 | 1 | −0.00681 | 0.65963 |
| FC | 0.48792 | 0.12217 | −0.06766 | −0.46699 | −0.00681 | 1 | 0.42134 |
| HHV | 0.90531 | 0.66756 | −0.00673 | −0.78388 | 0.65963 | 0.42134 | 1 |
| # | Used Parameters | Without Processing | After Normalization | After Centralization | |||
|---|---|---|---|---|---|---|---|
| R2 | Number of Iterations | R2 | Number of Iterations | R2 | Number of Iterations | ||
| Set 1 | ultimate analysis | 0.8604 | 300 | 0.8192 | 40 | 0.8738 | 100 |
| Set 2 | proximate analysis | 0.2922 | 200 | 0.3347 | 40 | 0.3151 | 100 |
| Set 3 | Set 1 + Set 2 | 0.8192 | 280 | 0.7997 | 40 | 0.8946 | 220 |
| Set 4 | Set 3—N—VM | 0.8591 | 460 | 0.8200 | 40 | 0.9012 | 240 |
| No-Op Activation | Logistic Sigmoid | Hyperbolic | Rectified Linear Unit |
|---|---|---|---|
| 0.86225 | 0.8479 | 0.8357 | 0.9012 |
| Algorithm | Features of the Algorithm | Outputs of the Algorithm for Different Types of ANN Architecture | |
|---|---|---|---|
| 1D ANN (100 Neurons) | 2D ANN (25 and 25 Neurons) | ||
| “sgd” | Basic stochastic gradient descent | 0.85176 | 0.81938 |
| “lbfgs” | Quasi-Newton limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm; for small datasets | 0.60501 | 0.48802 |
| “adam” | Adaptive Moment Estimation; for large datasets | 0.90123 | 0.89721 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matveeva, A.; Bychkov, A. How to Train an Artificial Neural Network to Predict Higher Heating Values of Biofuel. Energies 2022, 15, 7083. https://doi.org/10.3390/en15197083
Matveeva A, Bychkov A. How to Train an Artificial Neural Network to Predict Higher Heating Values of Biofuel. Energies. 2022; 15(19):7083. https://doi.org/10.3390/en15197083
Chicago/Turabian StyleMatveeva, Anna, and Aleksey Bychkov. 2022. "How to Train an Artificial Neural Network to Predict Higher Heating Values of Biofuel" Energies 15, no. 19: 7083. https://doi.org/10.3390/en15197083
APA StyleMatveeva, A., & Bychkov, A. (2022). How to Train an Artificial Neural Network to Predict Higher Heating Values of Biofuel. Energies, 15(19), 7083. https://doi.org/10.3390/en15197083