
An Auto-Extraction Framework for CEP Rules Based on the Two-Layer LSTM Attention Mechanism: A Case Study on City Air Pollution Forecasting


Abstract
:1. Introduction
- We propose a novel framework LAD for the automatic extraction of CEP rules by combining a two-layer LSTM attention mechanism with a decision tree data mining approach.
- We present a method for predicting air quality data and extracting meaningful CEP rules based on the LAD. The extracted CEP rules can be used to monitor the incoming air quality data stream in real time through the CEP engine.
2. Related Work
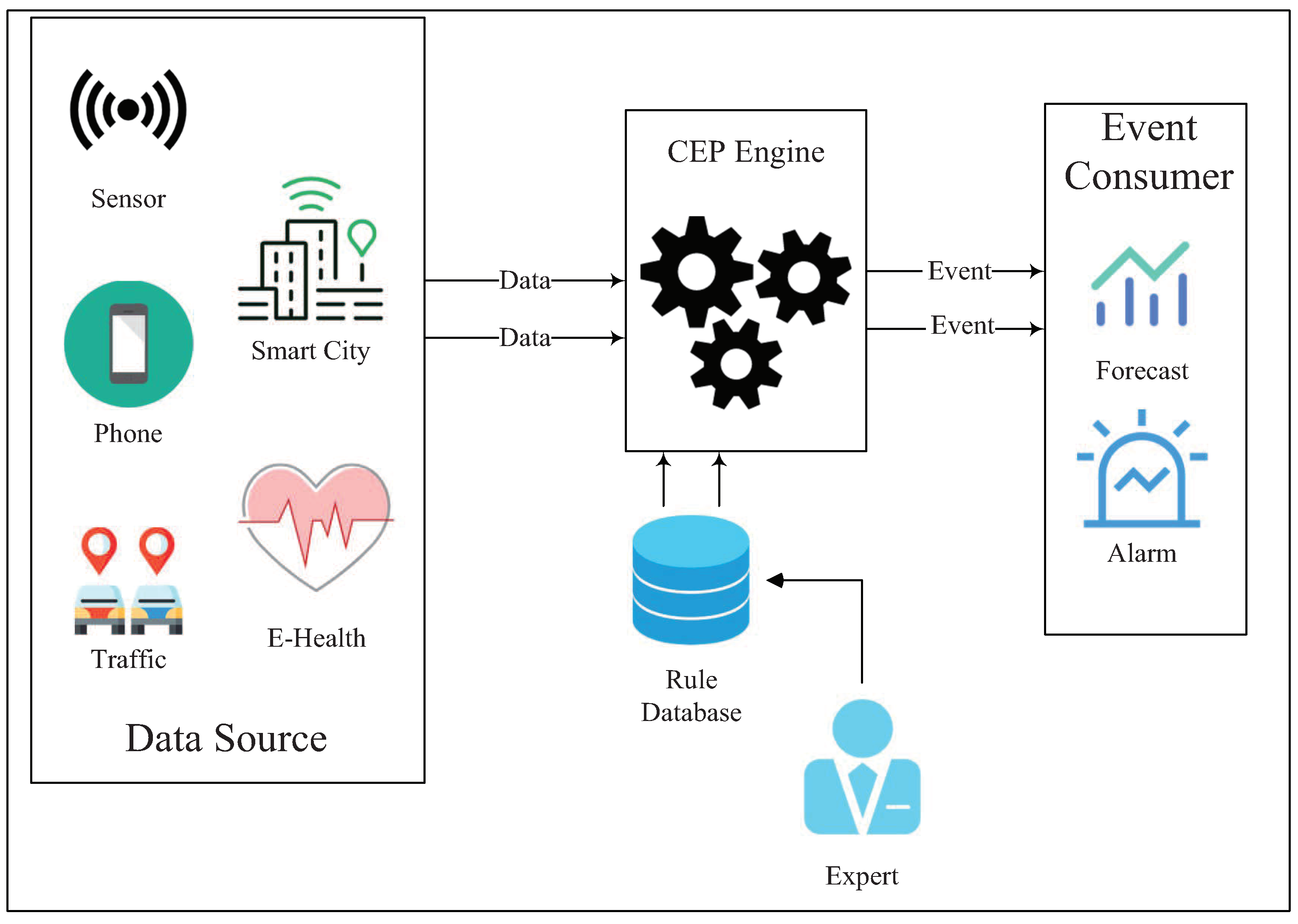
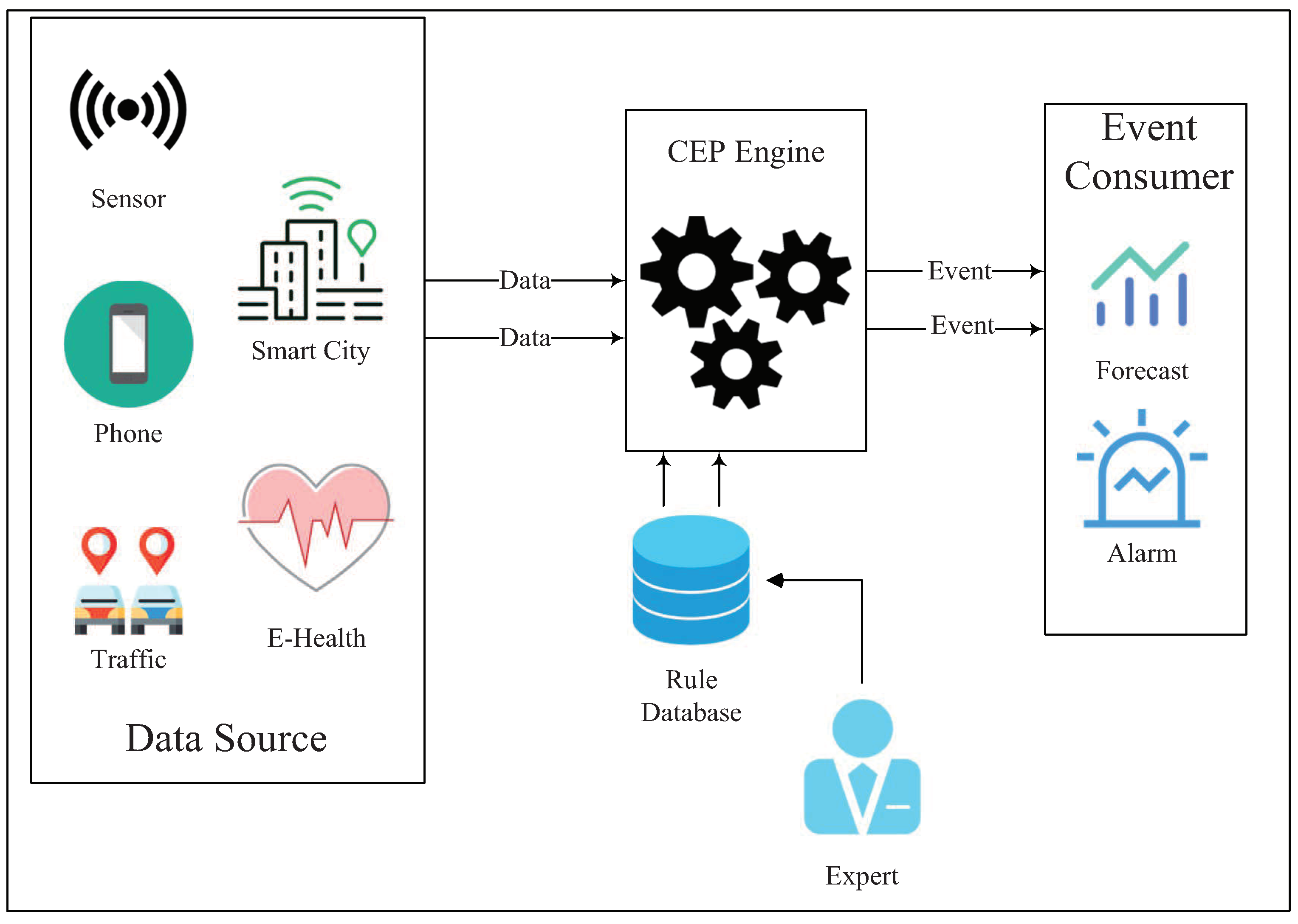
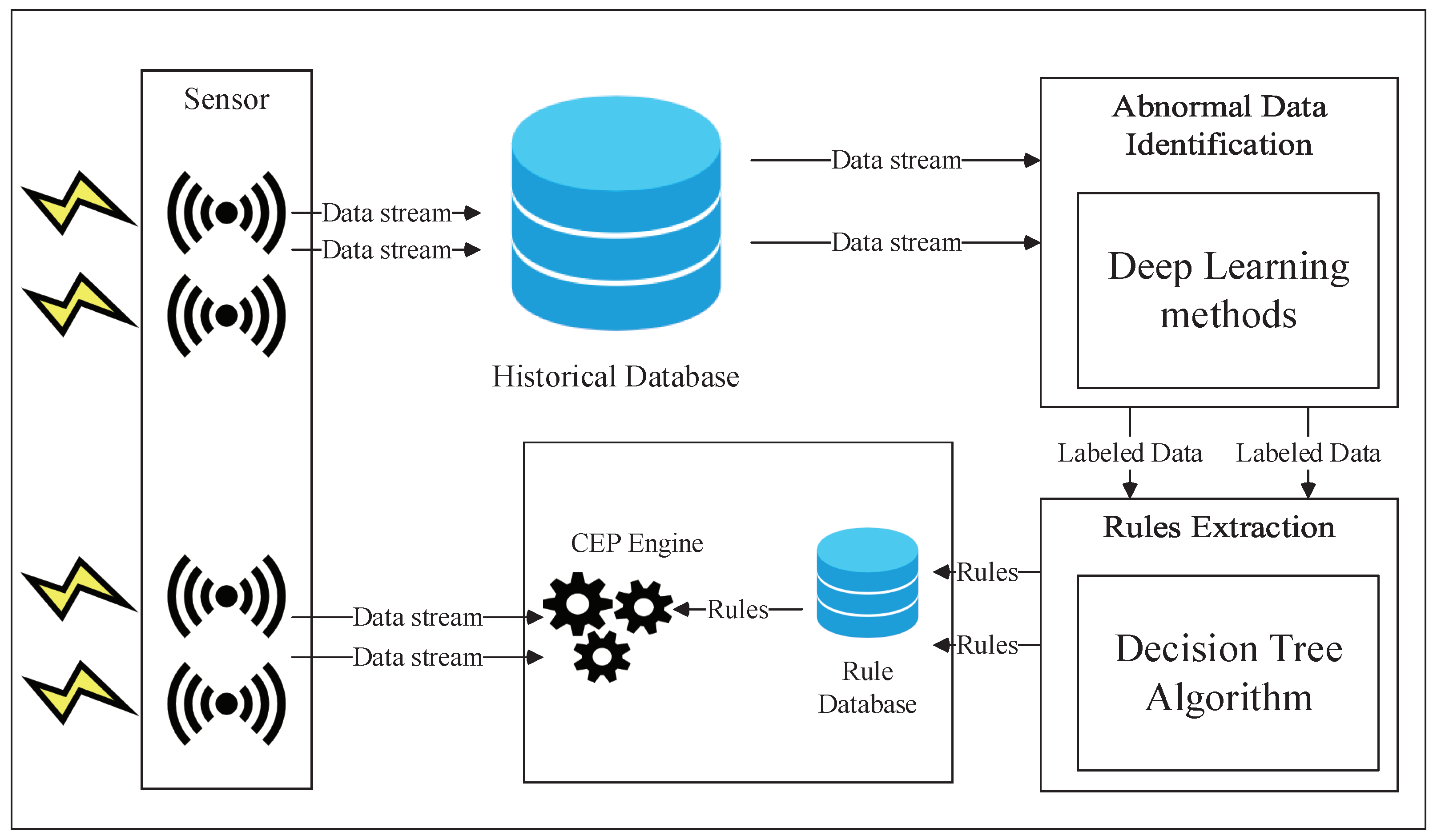
3. The Introduction of LAD
3.1. The Structure of Framework
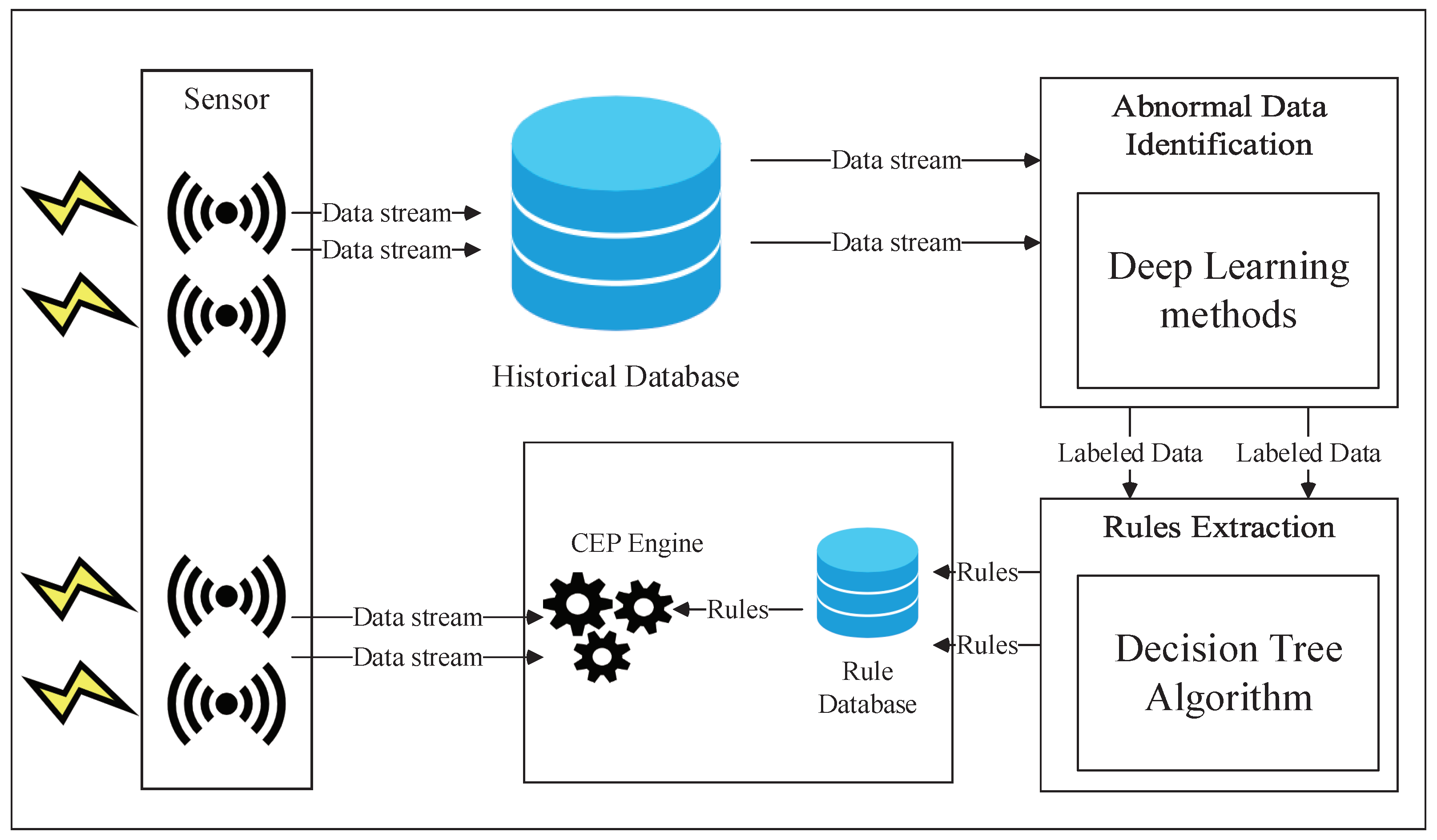
3.2. The First Phase: Abnormal Data Identification
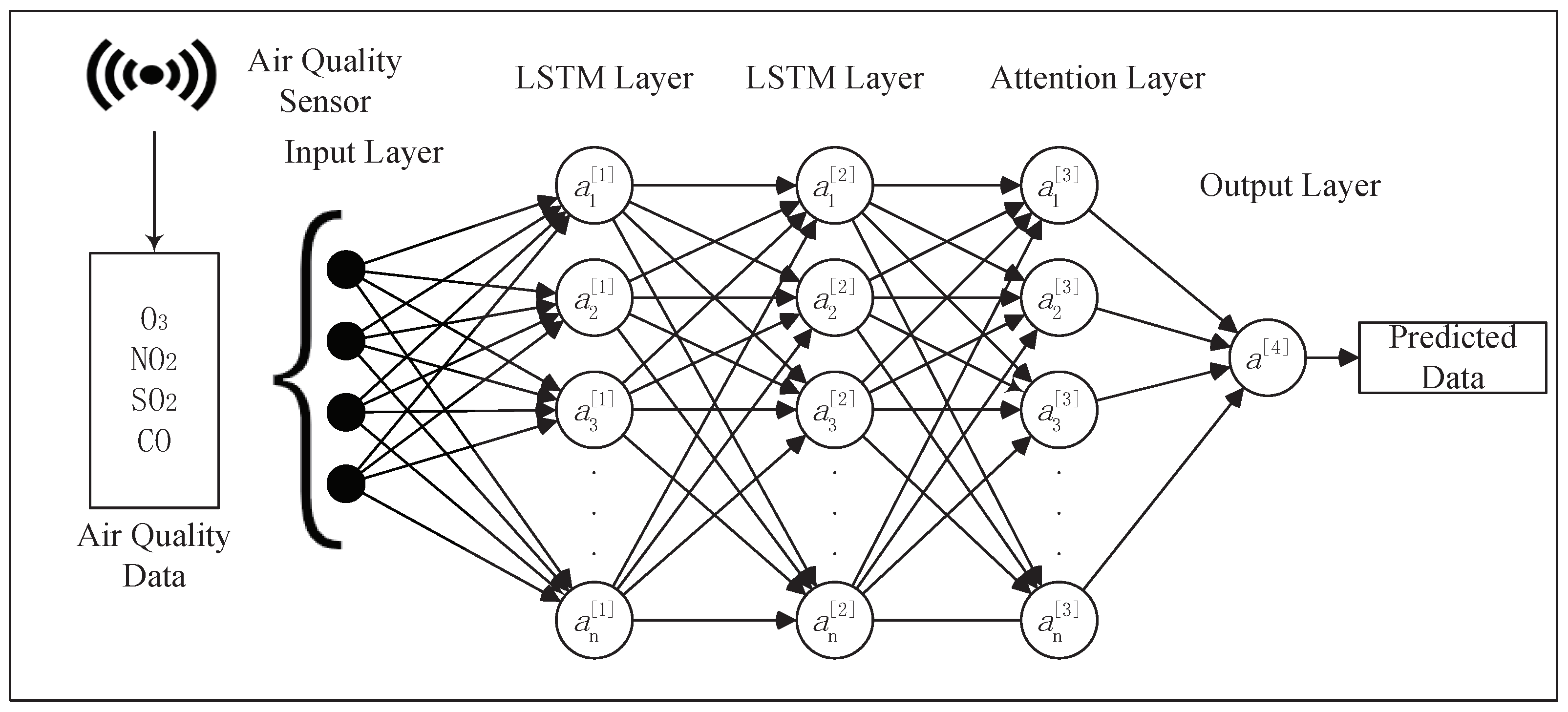
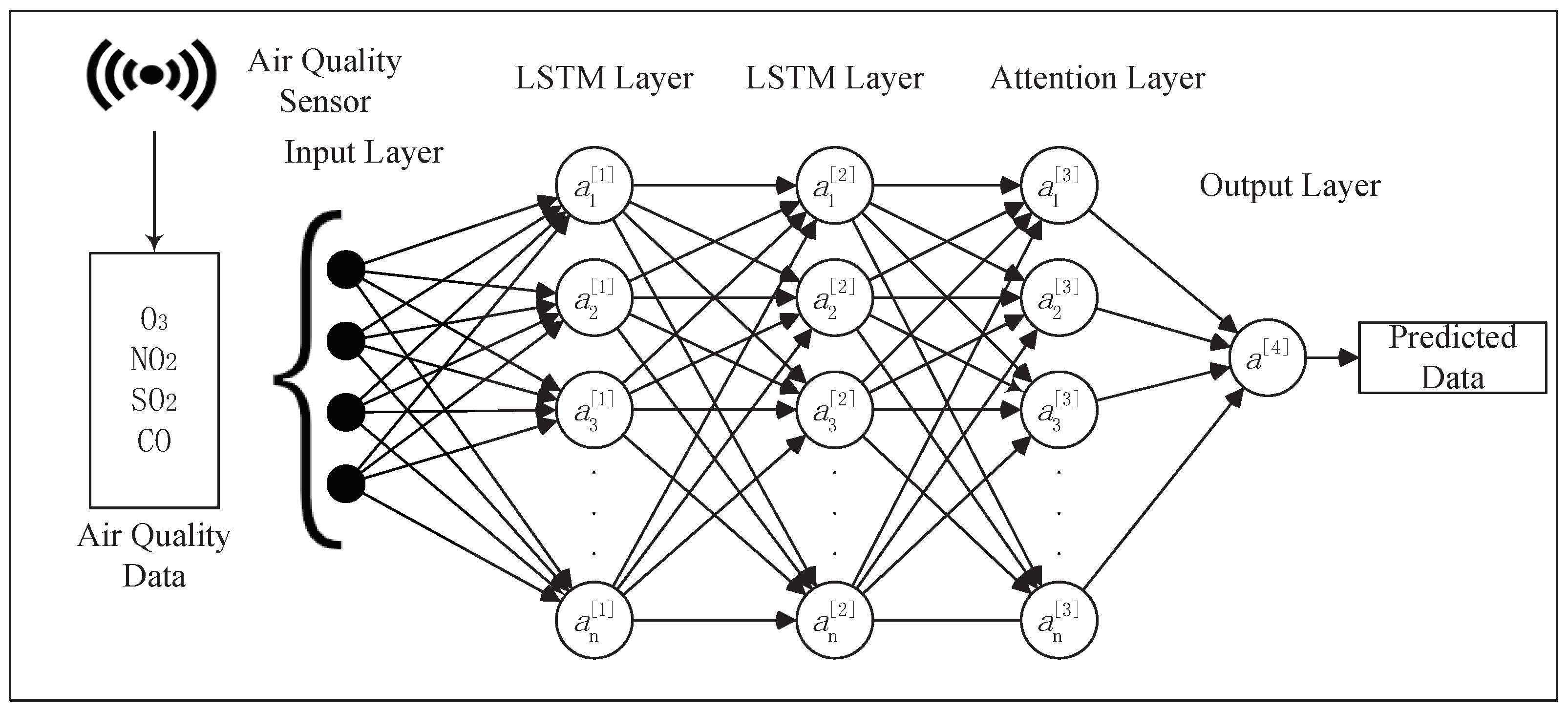
3.2.1. Two-Layer LSTM Attention Mechanism Model
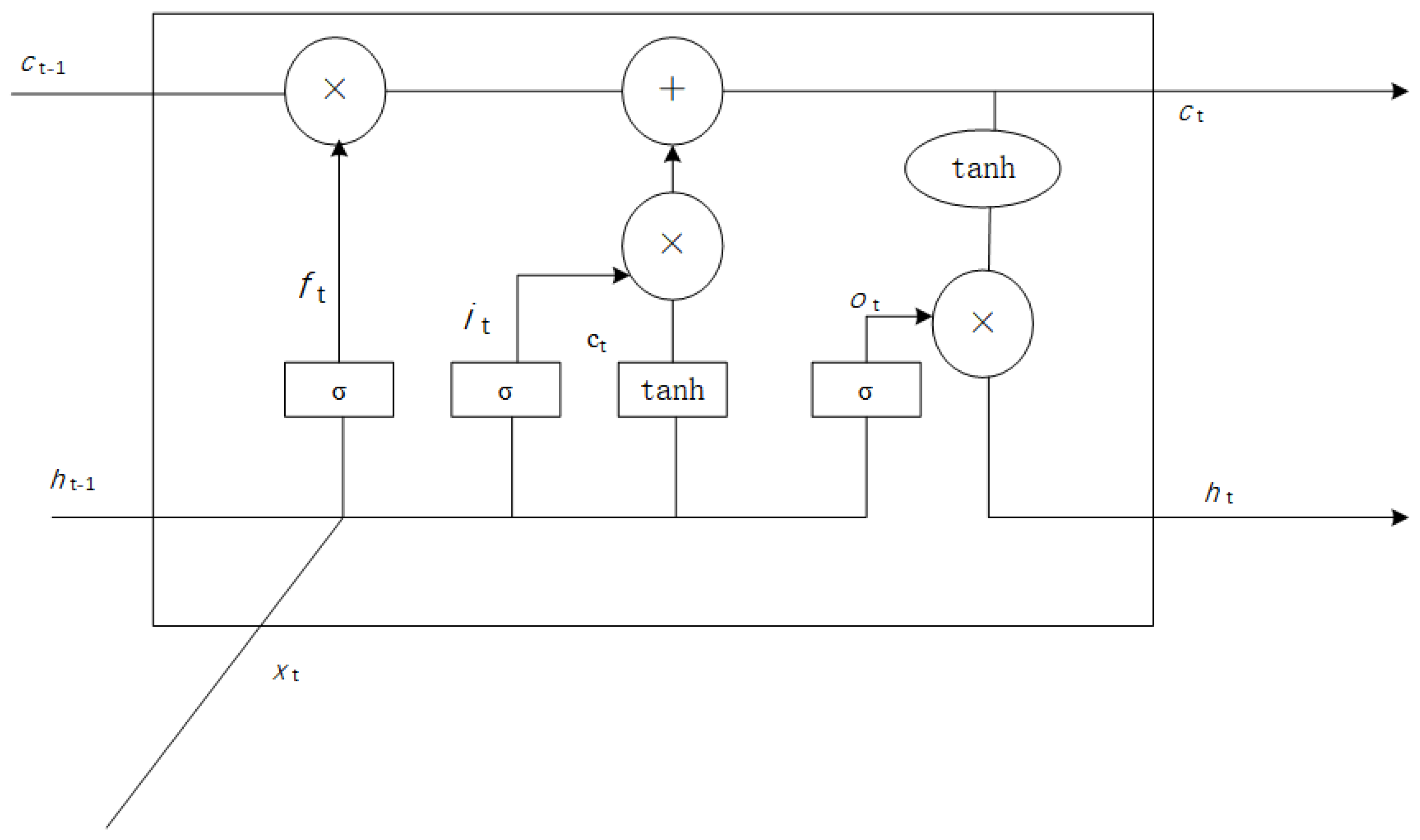
3.2.2. LSTM Layer
3.2.3. Attention Mechanism
3.2.4. Example
3.2.5. Abnormal Data Filtering
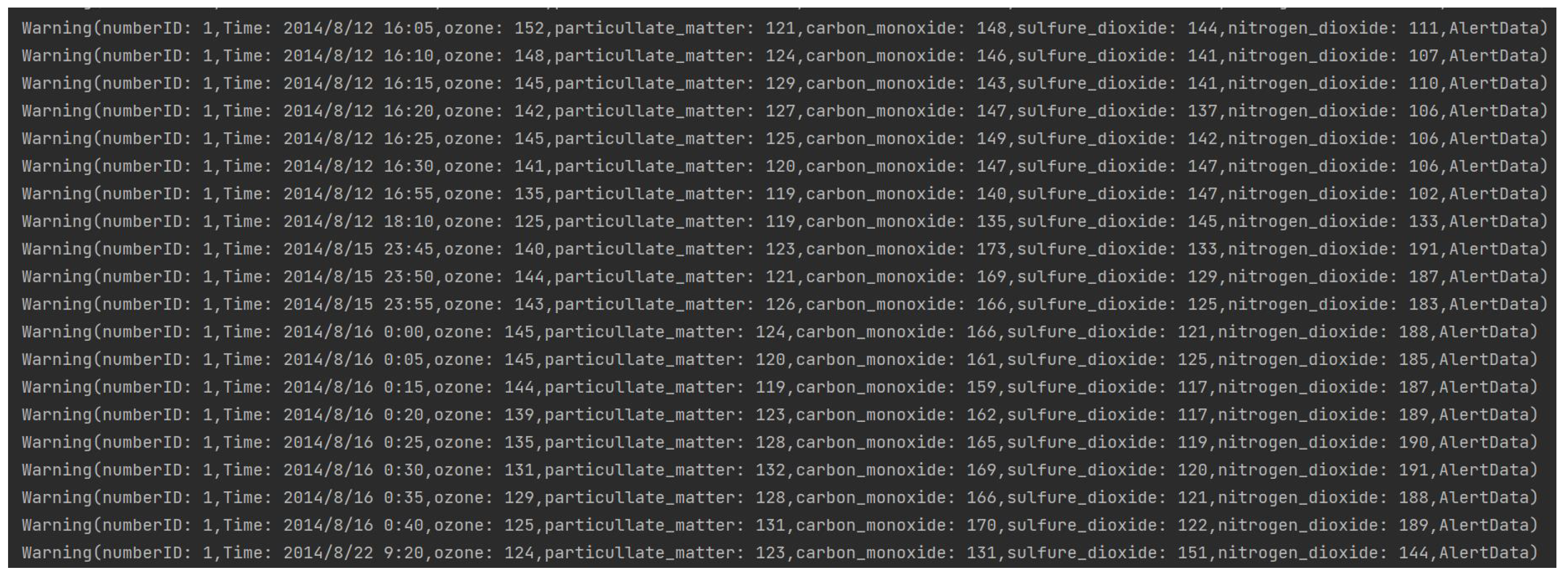
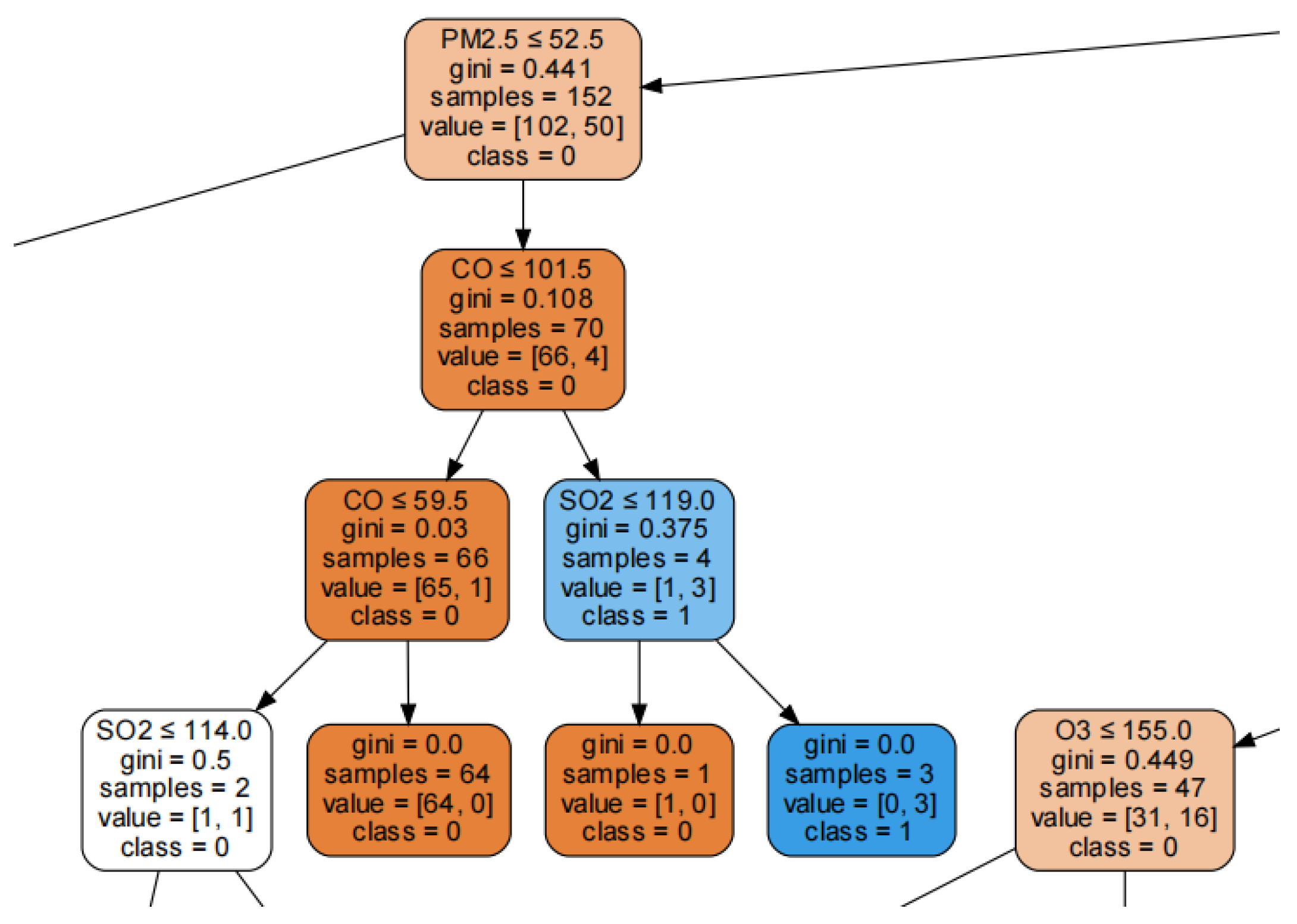
3.3. The Second Phase: CEP Rules Extraction
4. Experiment Evaluations and Results
4.1. Data Set
4.2. Evaluation Metrics
4.2.1. Mean Absolute Error (MAE)
4.2.2. Root Mean Squared Error (RMSE)
4.2.3. Mean Absolute Percentage Error (MAPE)
4.3. Experiment Environment
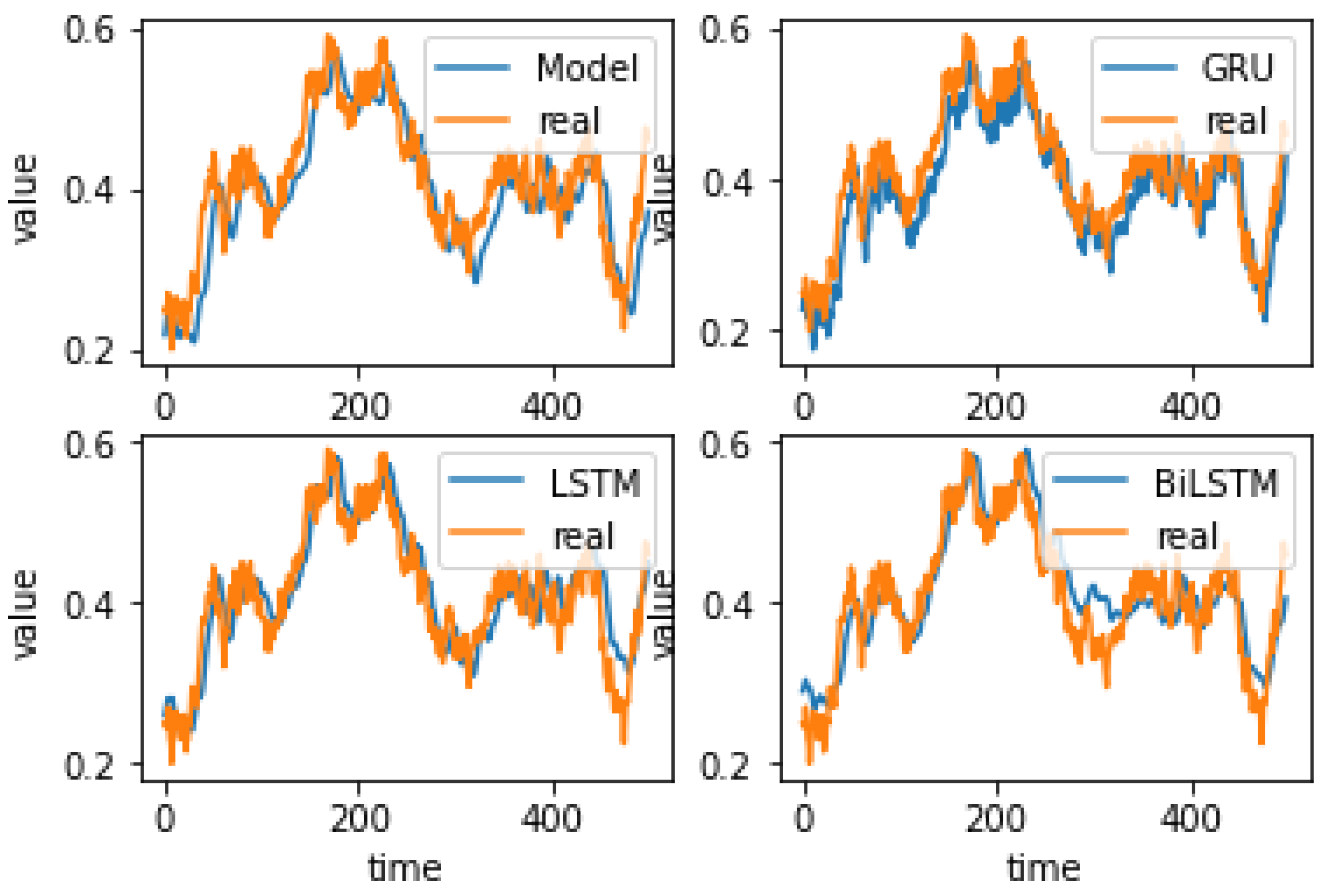
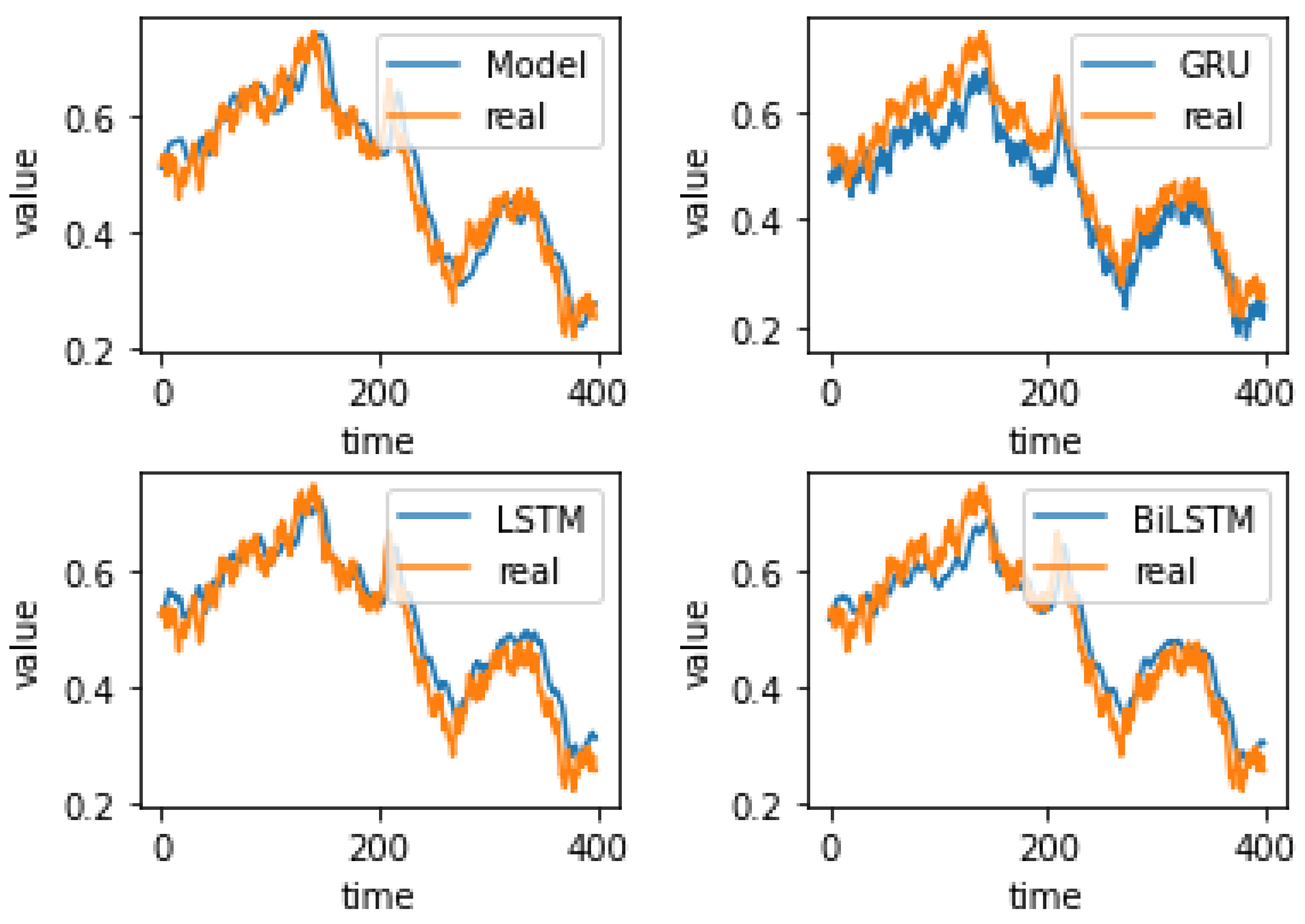
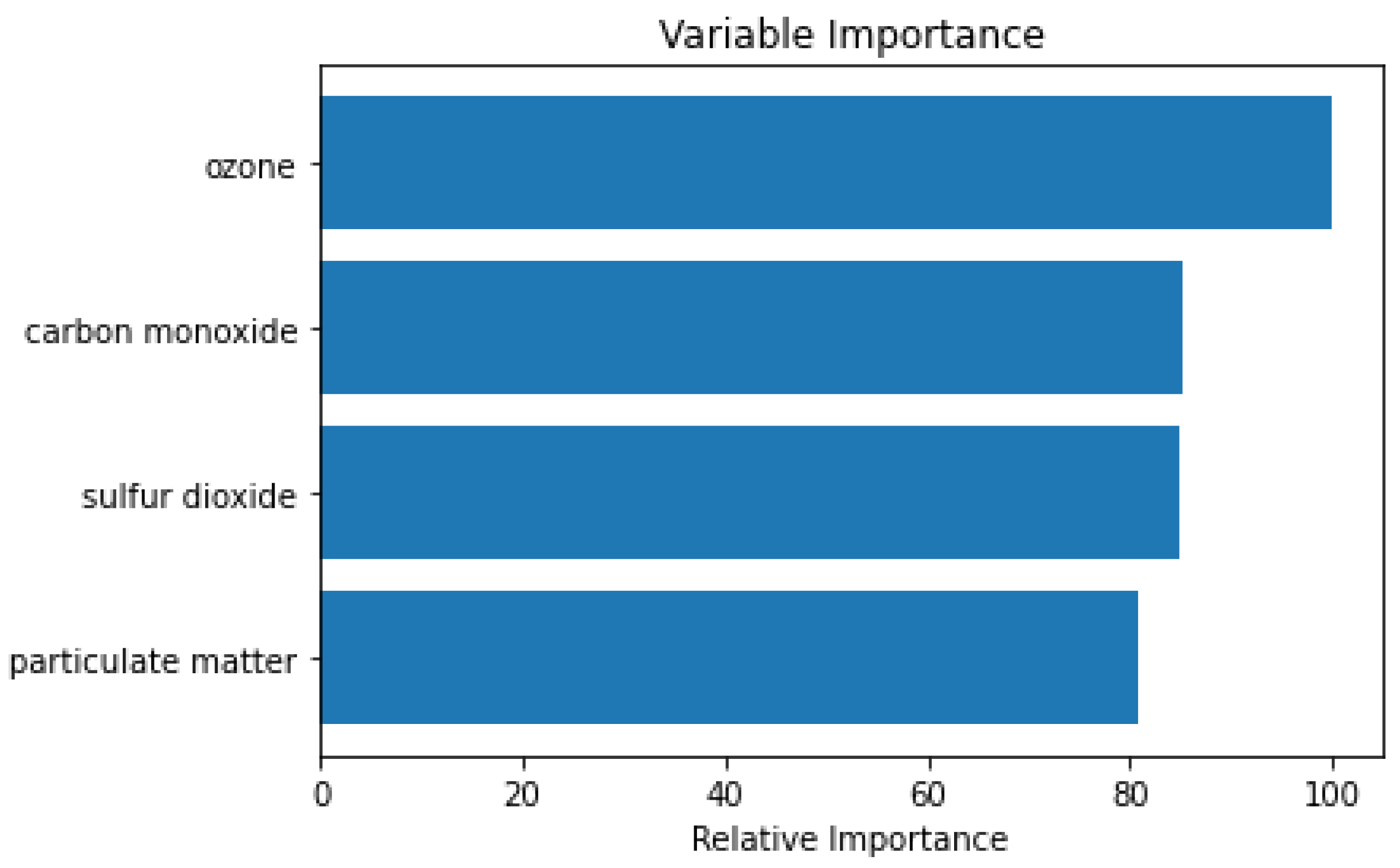
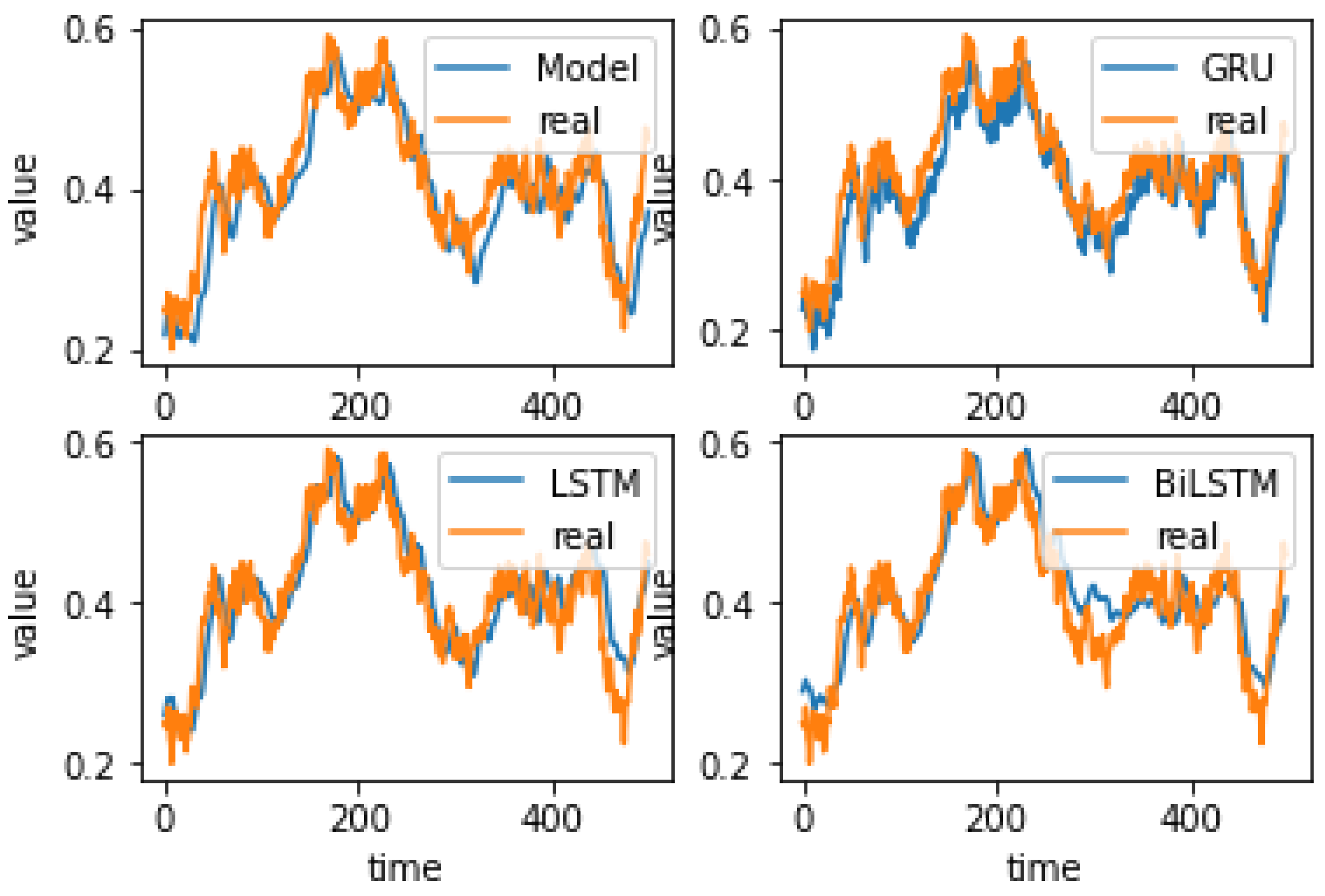
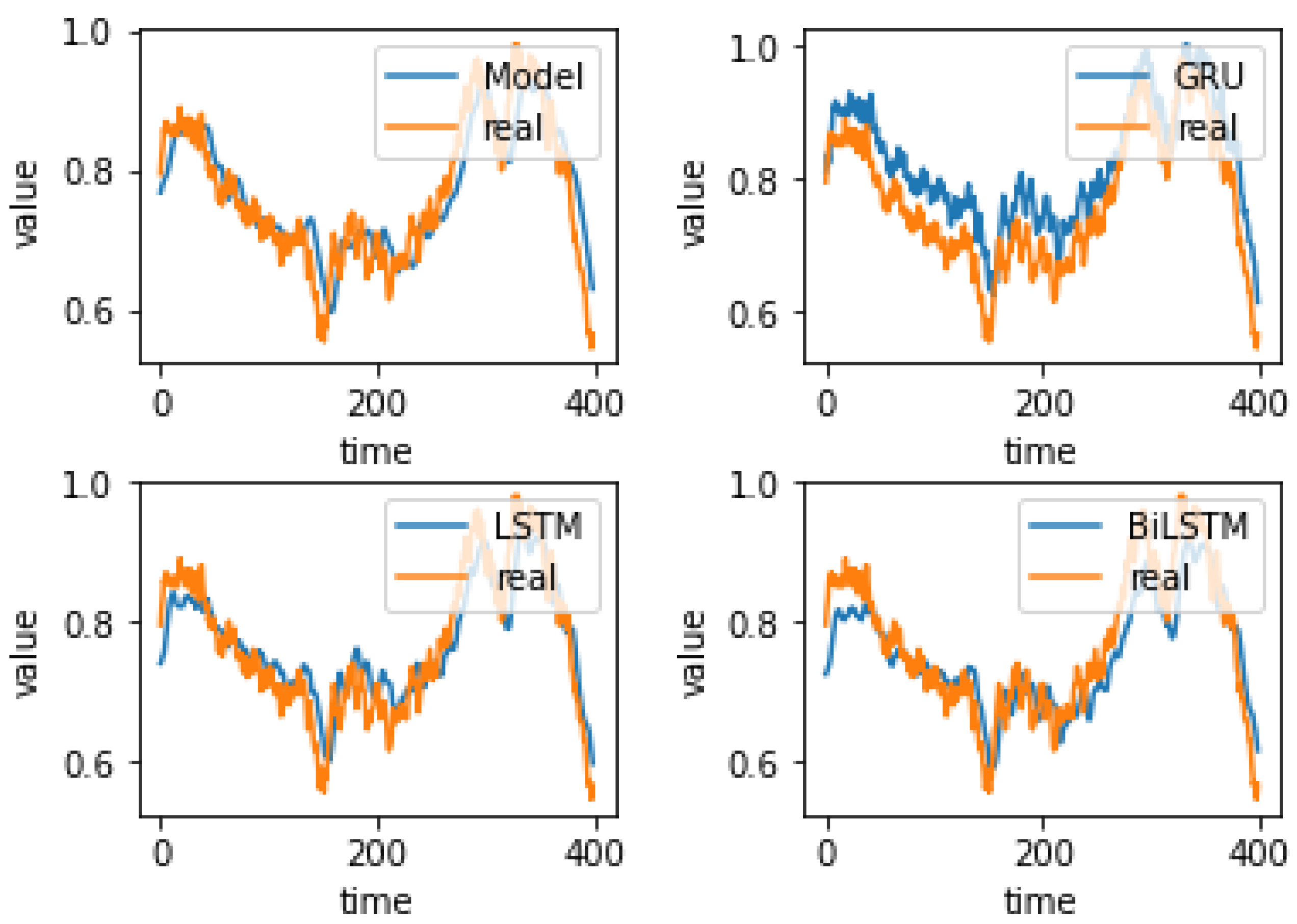
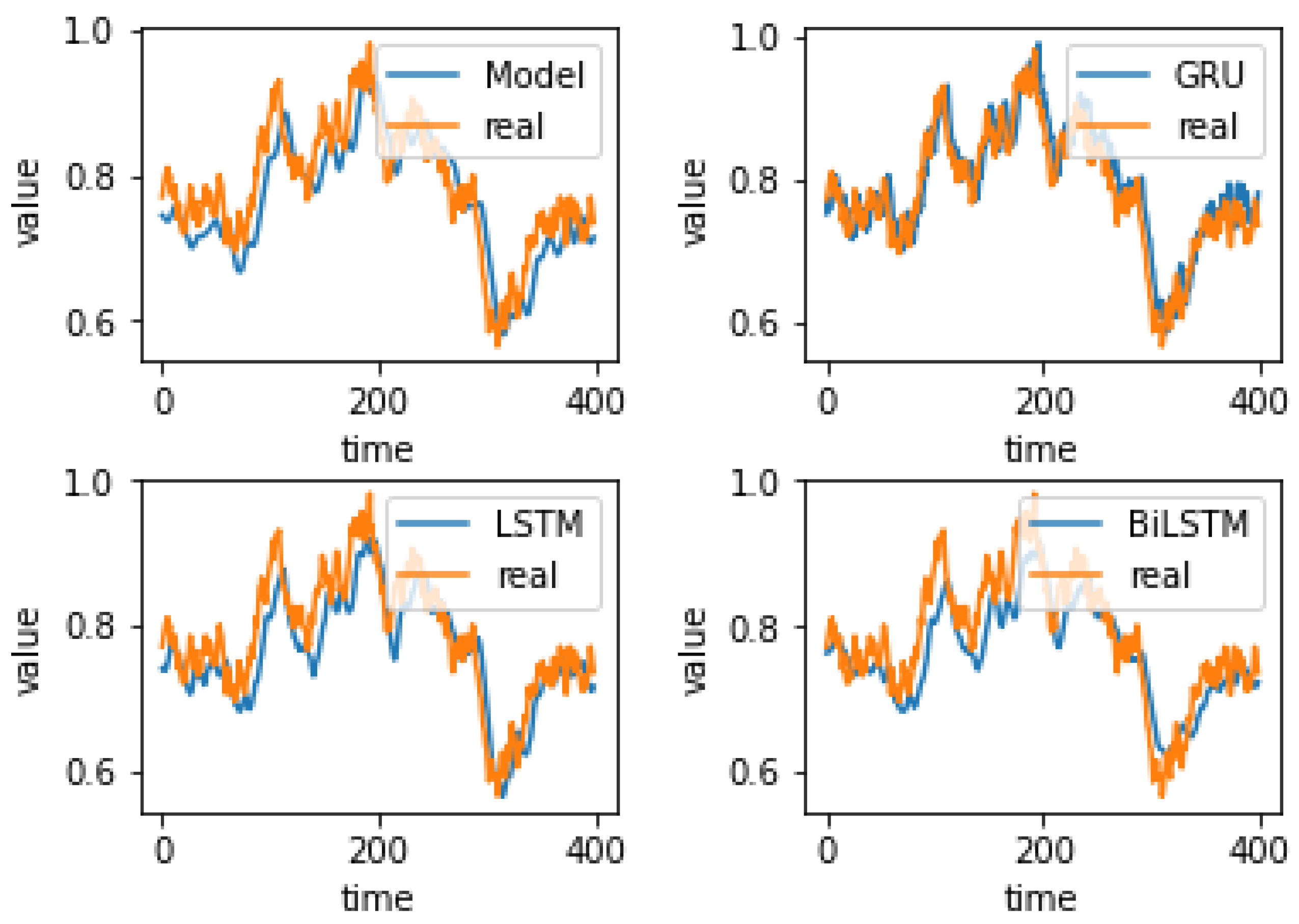
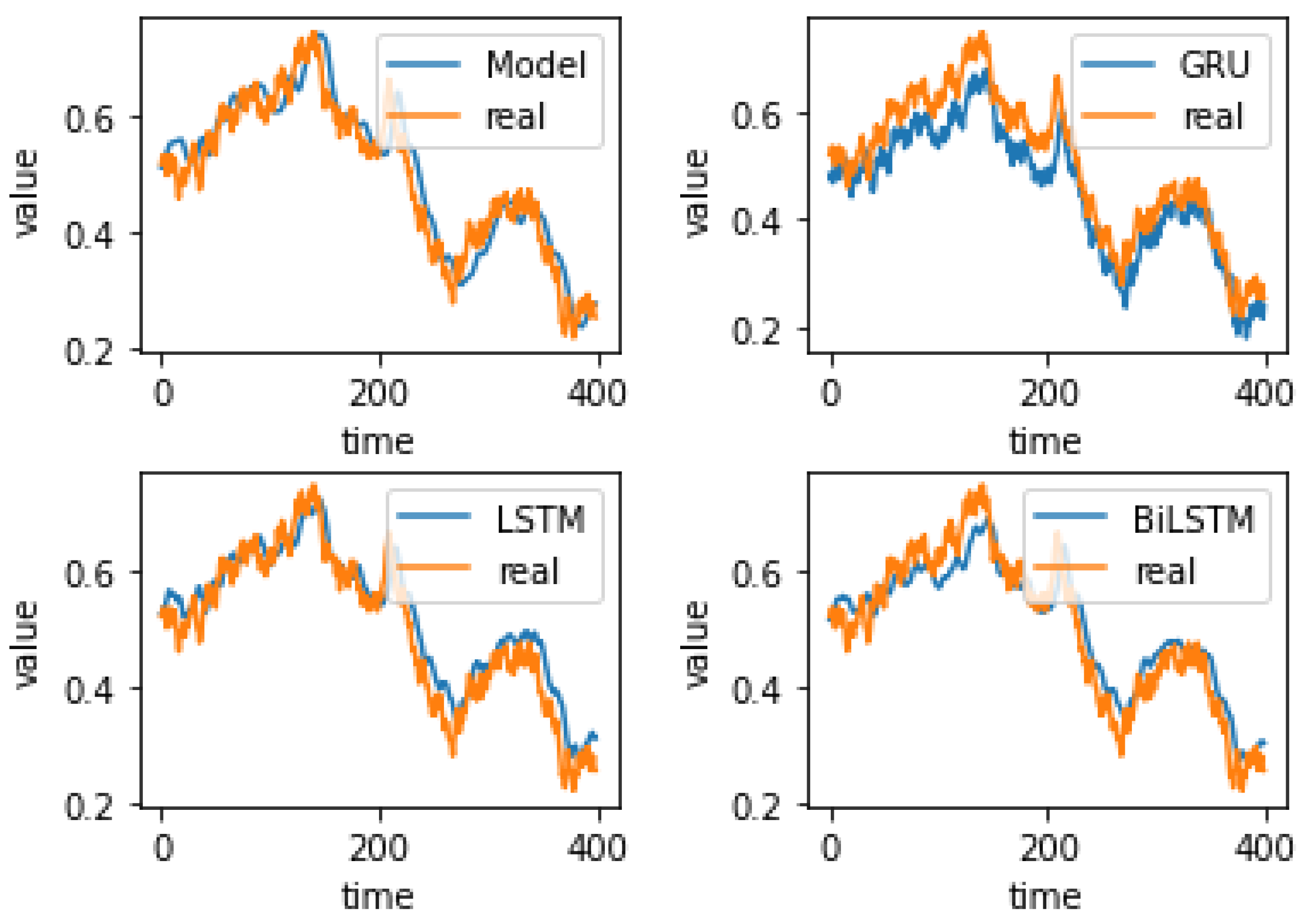
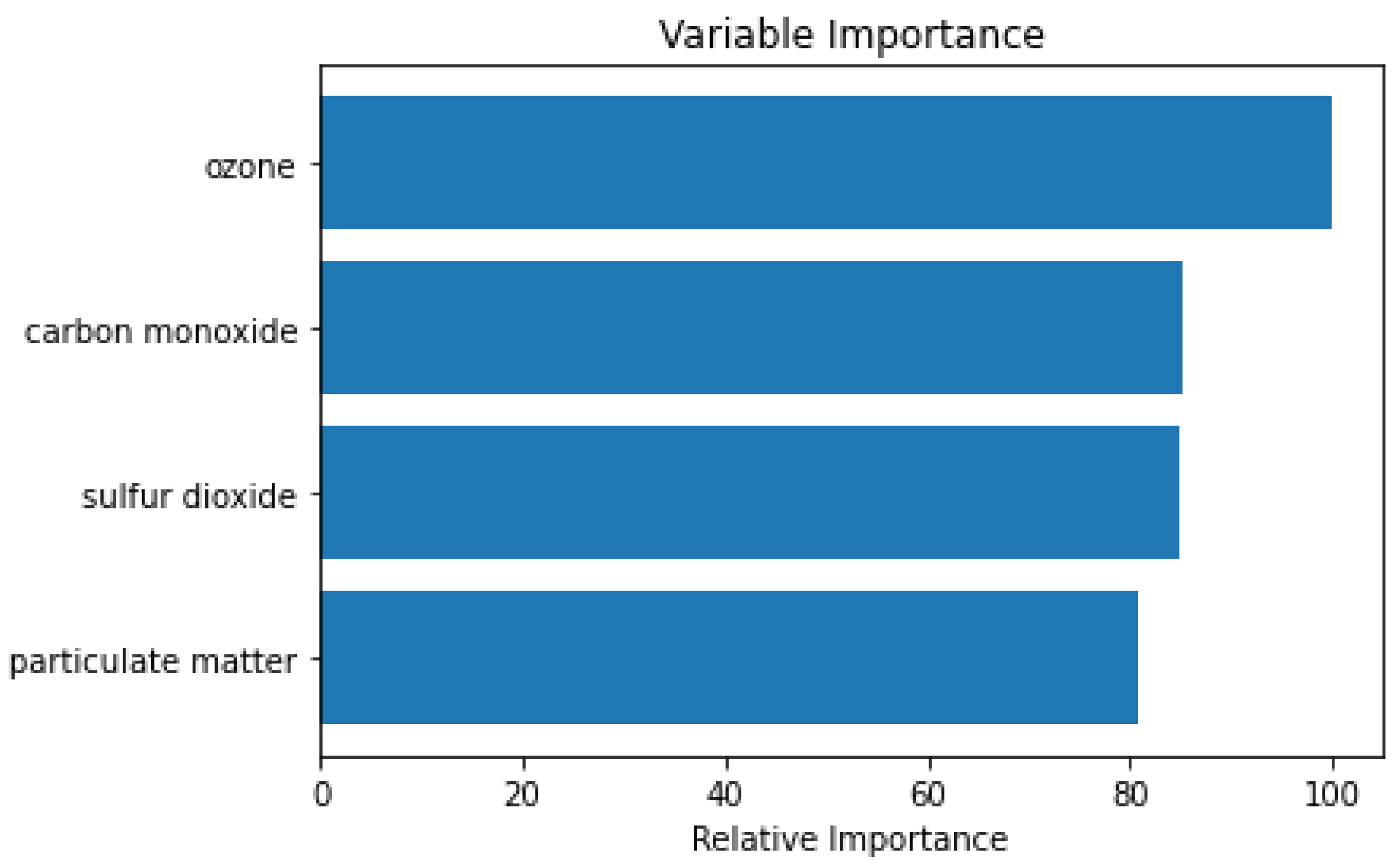
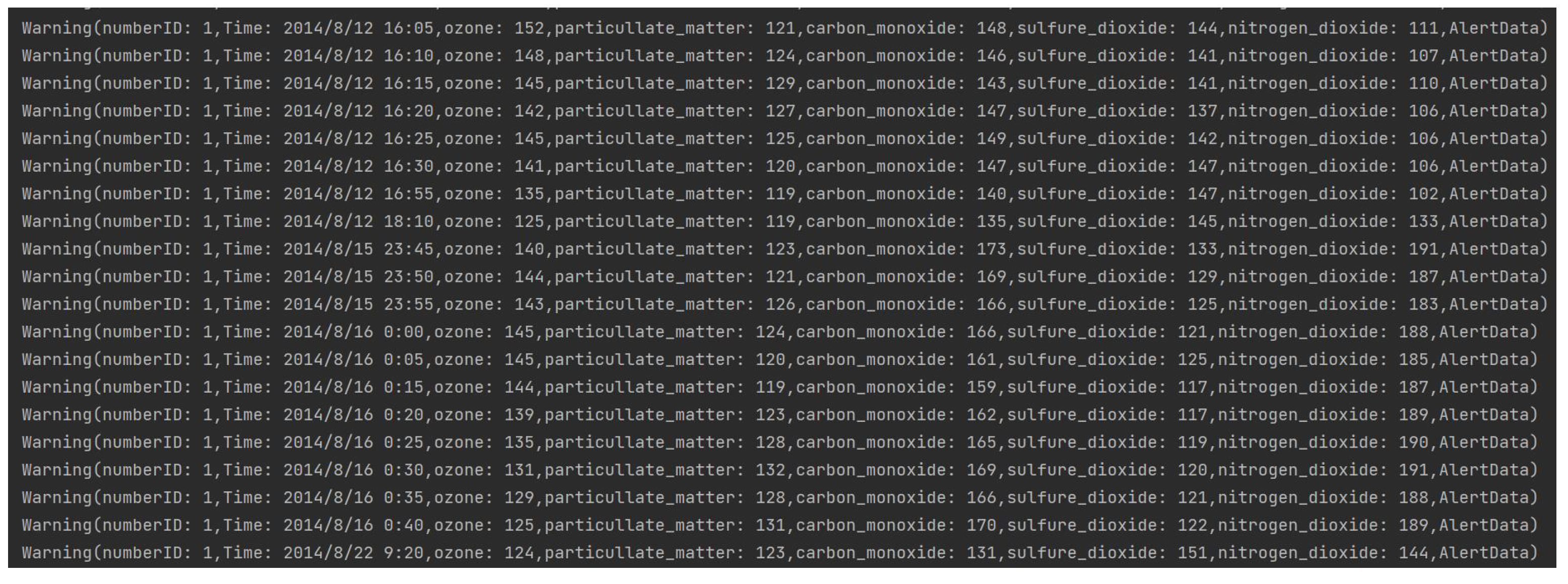
4.4. Experiment Results
- “ozone > 124 and ozone < 193 and particulate matter > 117.5 and carbon monoxide > 126.5 and carbon monoxide < 173.5 and sulfur dioxide > 106.5 and sulfur dioxide < 192.5”.
- “ozone > 79.5 and ozone < 193 and particulate matter > 125.5 and carbon monoxide > 126.5 and sulfur dioxide > 106.5 and sulfur dioxide < 191”.
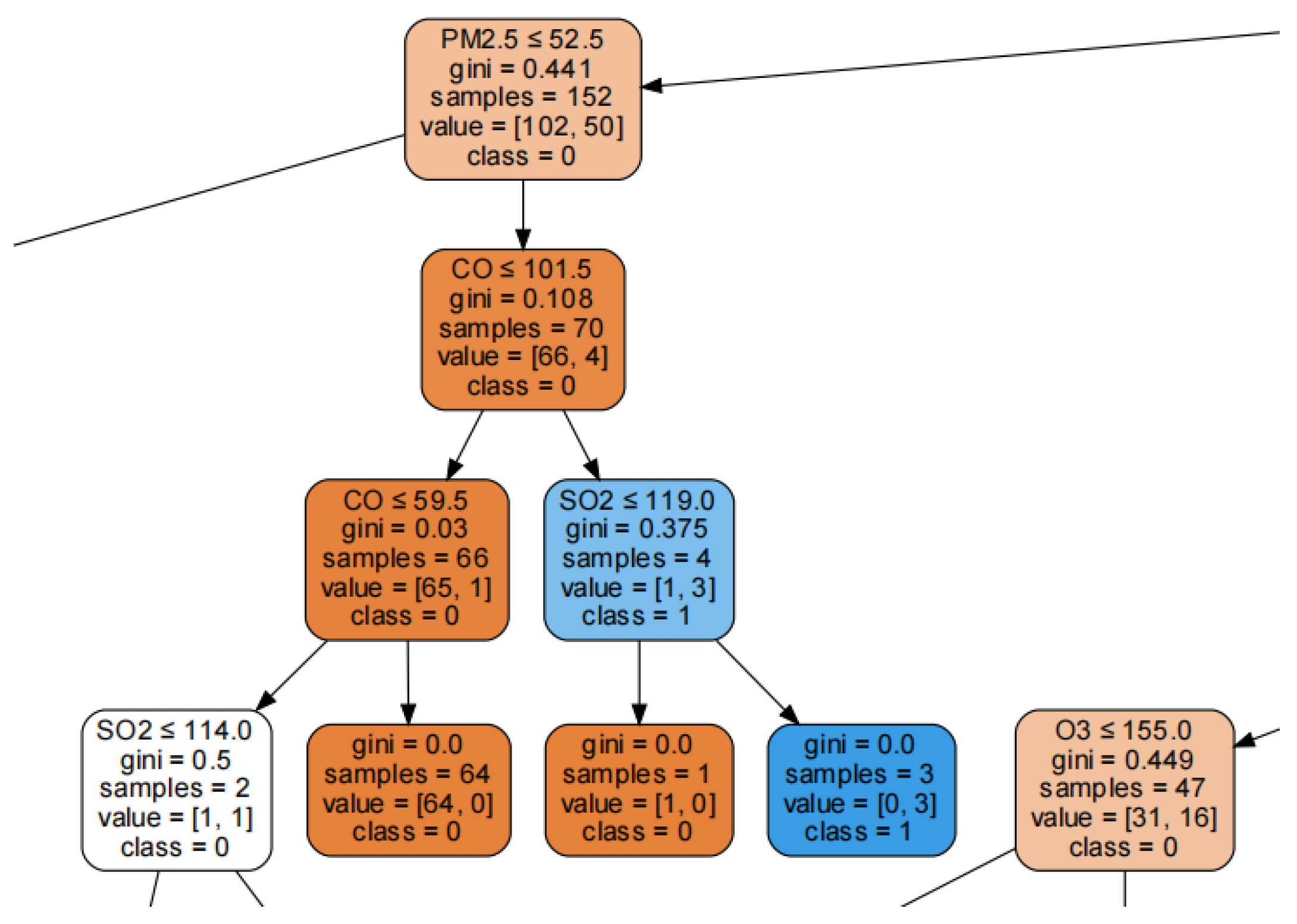
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, T.; Zhang, D.; Huang, C.; Zhang, H.; Dai, N.; Song, Y.; Chen, H. Artificial intelligence in sustainable energy industry: Status Quo, challenges and opportunities. J. Clean. Prod. 2021, 289, 125834. [Google Scholar] [CrossRef]
- Kaplan, A.; Haenlein, M. Rulers of the world, unite! The challenges and opportunities of artificial intelligence. Bus. Horiz. 2020, 63, 37–50. [Google Scholar] [CrossRef]
- Sarker, I.H.; Khan, A.I.; Abushark, Y.B.; Alsolami, F. Internet of things (iot) security intelligence: A comprehensive overview, machine learning solutions and research directions. Mob. Netw. Appl. 2022, preview. [Google Scholar] [CrossRef]
- Hossein Motlagh, N.; Mohammadrezaei, M.; Hunt, J.; Zakeri, B. Internet of Things (IoT) and the energy sector. Energies 2020, 13, 494. [Google Scholar] [CrossRef]
- Zhou, K.; Song, S.; Xue, A.; You, K.; Wu, H. Smart train operation algorithms based on expert knowledge and reinforcement learning. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 716–727. [Google Scholar] [CrossRef]
- Chen, L.W.; Liu, J.X. Time-efficient indoor navigation and evacuation with fastest path planning based on Internet of Things technologies. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 3125–3135. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q. New IT driven service-oriented smart manufacturing: Framework and characteristics. IEEE Trans. Syst. Man Cybern. Syst. 2017, 49, 81–91. [Google Scholar] [CrossRef]
- Saxena, D.; Raychoudhury, V. Design and verification of an NDN-based safety-critical application: A case study with smart healthcare. IEEE Trans. Syst. Man Cybern. Syst. 2017, 49, 991–1005. [Google Scholar] [CrossRef]
- de Assuncao, M.D.; da Silva Veith, A.; Buyya, R. Distributed data stream processing and edge computing: A survey on resource elasticity and future directions. J. Netw. Comput. Appl. 2018, 103, 1–17. [Google Scholar] [CrossRef]
- Şimşek, M.U.; Özdemir, S. CEP Rule Extraction From Unlabeled Data in IoT. In Proceedings of the 2018 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 429–433. [Google Scholar]
- Gökalp, M.O.; Koçyiğit, A.; Eren, P.E. A visual programming framework for distributed Internet of Things centric complex event processing. Comput. Electr. Eng. 2019, 74, 581–604. [Google Scholar] [CrossRef]
- Starks, F.; Goebel, V.; Kristiansen, S.; Plagemann, T. Mobile distributed complex event processing—Ubi Sumus? Quo vadimus? In Mobile Big Data; Springer: Berlin/Heidelberg, Germany, 2018; pp. 147–180. [Google Scholar]
- Monnier, O. A Smarter Grid with the Internet of Things. Texas Instruments. 2013. Available online: https://files.iccmedia.com/pdf/ti-iot-tf140513.pdf (accessed on 2 May 2022).
- Eckert, M.; Bry, F. Aktuelles Schlagwort “Complex Event Processing (cep)”. Informatik-Spektrum. 2009, pp. 163–167. Available online: https://epub.ub.uni-muenchen.de/14902/1/bry_14902.pdf (accessed on 3 May 2022).
- Wanner, J.; Wissuchek, C.; Janiesch, C. Machine Learning and Complex Event Processing. EMISAJ 2020, 15, 1. [Google Scholar] [CrossRef]
- Ma, Z.; Yu, W.; Zhai, X.; Jia, M. A complex event processing-based online shopping user risk identification system. IEEE Access 2019, 7, 172088–172096. [Google Scholar] [CrossRef]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. 2012, 44, 1–62. [Google Scholar] [CrossRef]
- Akbar, A.; Carrez, F.; Moessner, K.; Sancho, J.; Rico, J. Context-aware stream processing for distributed IoT applications. In Proceedings of the 2015 IEEE 2nd World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; pp. 663–668. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; 2012; pp. 37–45. Available online: https://linkspringer.53yu.com/chapter/10.1007/978-3-642-24797-2_4 (accessed on 3 May 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Thirty-First Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Chang, Y.S.; Chiao, H.T.; Abimannan, S.; Huang, Y.P.; Tsai, Y.T.; Lin, K.M. An LSTM-based aggregated model for air pollution forecasting. Atmos. Pollut. Res. 2020, 11, 1451–1463. [Google Scholar] [CrossRef]
- Cichowicz, R.; Dobrzański, M. Analysis of Air Pollution around a CHP Plant: Real Measurements vs. Computer Simulations. Energies 2022, 15, 553. [Google Scholar] [CrossRef]
- Delavar, M.R.; Gholami, A.; Shiran, G.R.; Rashidi, Y.; Nakhaeizadeh, G.R.; Fedra, K.; Hatefi Afshar, S. A novel method for improving air pollution prediction based on machine learning approaches: A case study applied to the capital city of Tehran. ISPRS Int. J. Geo-Inf. 2019, 8, 99. [Google Scholar] [CrossRef]
- Todorov, V.; Dimov, I. Innovative Digital Stochastic Methods for Multidimensional Sensitivity Analysis in Air Pollution Modelling. Mathematics 2022, 10, 2146. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Zaidan, M.A.; Fung, P.L.; Li, X.; Matsumi, Y.; Petäjä, T.; Kulmala, M.; Tarkoma, S.; Hussein, T. Low-cost air quality sensing process: Validation by indoor-outdoor measurements. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 223–228. [Google Scholar]
- Mehdiyev, N.; Krumeich, J.; Enke, D.; Werth, D.; Loos, P. Determination of rule patterns in complex event processing using machine learning techniques. Procedia Comput. Sci. 2015, 61, 395–401. [Google Scholar] [CrossRef]
- Boubeta-Puig, J.; Ortiz, G.; Medina-Bulo, I. MEdit4CEP: A model-driven solution for real-time decision making in SOA 2.0. Knowl.-Based Syst. 2015, 89, 97–112. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Ning, B. Automatic Rule Updating based on Machine Learning in Complex Event Processing. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1338–1343. [Google Scholar]
- Naseri, M.M.; Tabibian, S.; Homayounvala, E. Intelligent Rule Extraction in Complex Event Processing Platform for Health Monitoring Systems. In Proceedings of the 2021 11th International Conference on Computer Engineering and Knowledge (ICCKE), Mashhad, Iran, 28–29 October 2021; pp. 163–168. [Google Scholar]
- Petersen, E.; To, M.A.; Maag, S.; Yamga, T. An unsupervised rule generation approach for online complex event processing. In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018; pp. 1–8. [Google Scholar]
- Margara, A.; Cugola, G.; Tamburrelli, G. Learning from the past: Automated rule generation for complex event processing. In Proceedings of the 8th ACM International Conference on Distributed Event-Based Systems, Mumbai, India, 26–29 May 2014; pp. 47–58. [Google Scholar]
- Simsek, M.U.; Yildirim Okay, F.; Ozdemir, S. A deep learning-based CEP rule extraction framework for IoT data. J. Supercomput. 2021, 77, 8563–8592. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, B.; Yan, S.; Li, J.; Qu, G.; Li, Y.; Lang, J.; Gu, R. An attention-based air quality forecasting method. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 728–733. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Xiong, Q.; Wu, C.; Zou, Q.; Yu, Y.; Yi, H.; Gao, M. A study on water quality prediction by a hybrid CNN-LSTM model with attention mechanism. Environ. Sci. Pollut. Res. 2021, 28, 55129–55139. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Braei, M.; Wagner, S. Anomaly detection in univariate time-series: A survey on the state-of-the-art. arXiv 2020, arXiv:2004.00433. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- The CityPulse Consortium. CityPulse Annual Report. 2016. Available online: http://iot.ee.surrey.ac.uk:8080/datasets/pollution (accessed on 30 May 2022).
- Ali, M.I.; Gao, F.; Mileo, A. CityBench: A Configurable Benchmark to Evaluate RSP Engines Using Smart City Datasets. In Proceedings of the ISWC 2015, 14th International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 374–389. [Google Scholar]
- Kolozali, S.; Bermudez-Edo, M.; Puschmann, D.; Ganz, F.; Barnaghi, P. A Knowledge-based Approach for Real-Time IoT Data Stream Annotation and Processing. In Proceedings of the IEEE International Conference on Internet of Things (iThings), Taipei, Taiwan, 1–3 September 2014. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Zhang, J.; Florita, A.; Hodge, B.M.; Lu, S.; Hamann, H.F.; Banunarayanan, V.; Brockway, A.M. A suite of metrics for assessing the performance of solar power forecasting. Solar Energy 2015, 111, 157–175. [Google Scholar] [CrossRef]
- Jain, A.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
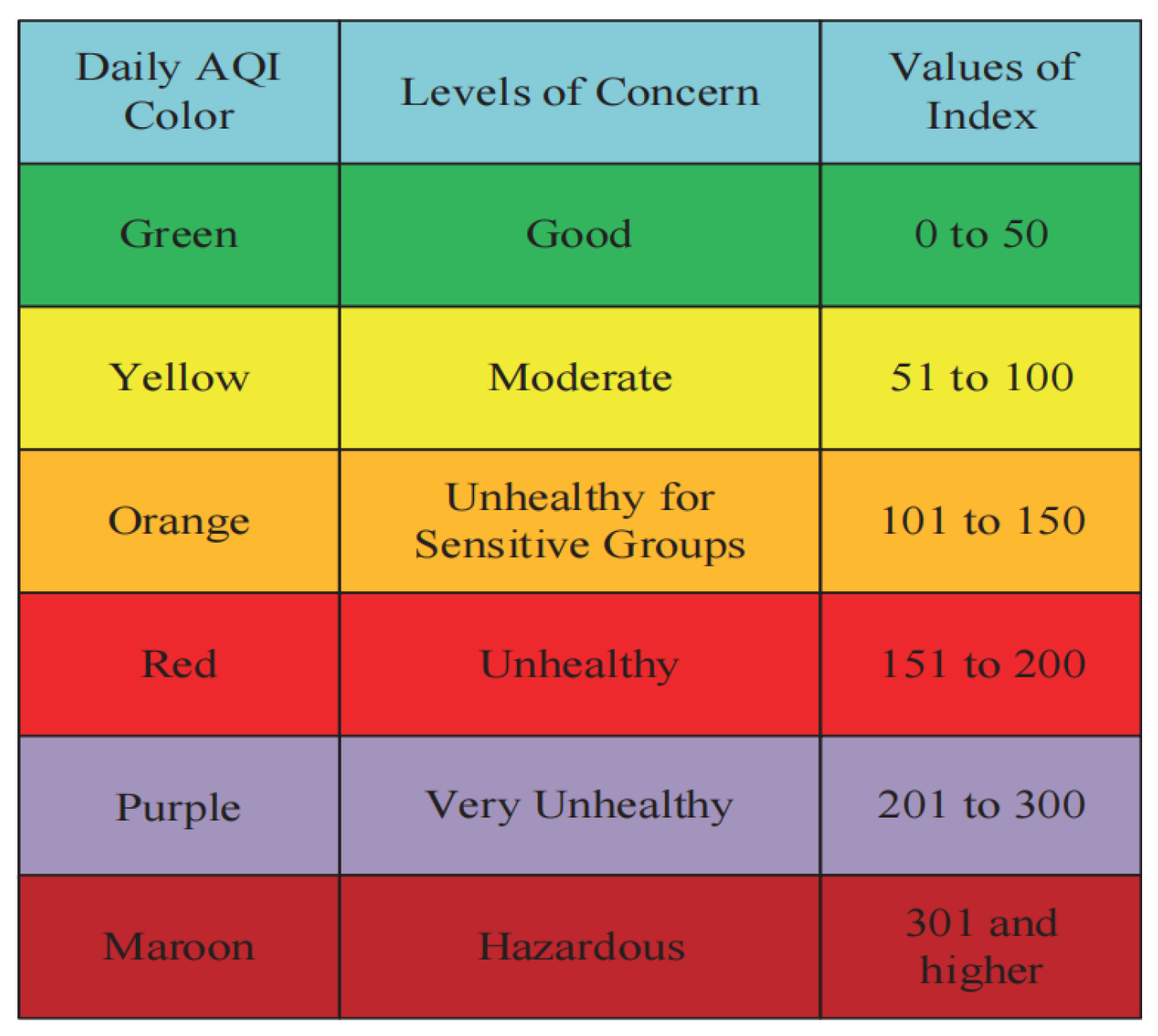
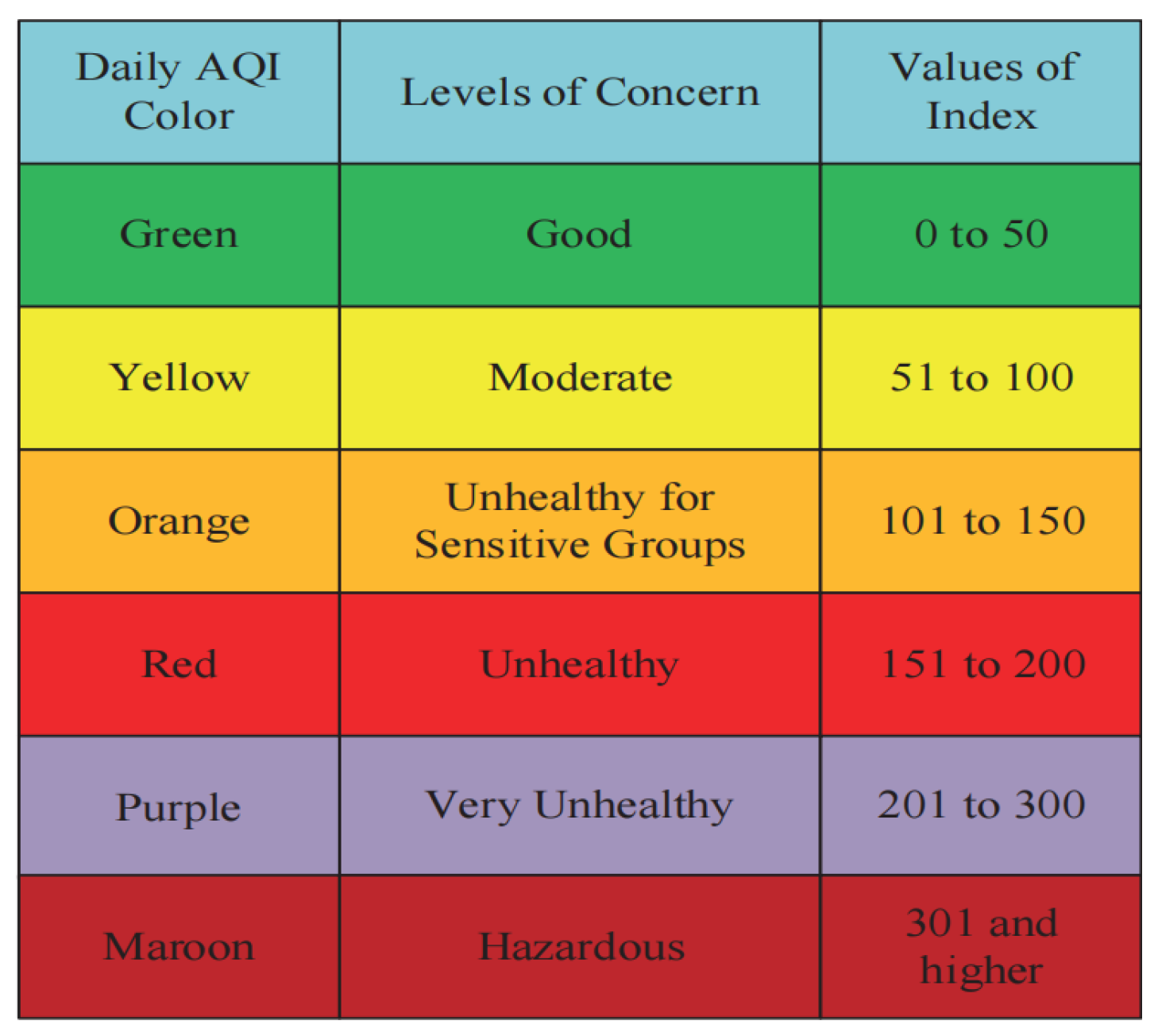
- Gadekar, M.C.S. Air Quality Index (AQI) Basics. Int. J. Res. Publ. Rev. 2022, 3, 805–807. [Google Scholar]
- McMahan, H.B.; Holt, G.; Sculley, D.; Young, M.; Ebner, D.; Grady, J.; Nie, L.; Phillips, T.; Davydov, E.; Golovin, D.; et al. Ad click prediction: A view from the trenches. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1222–1230. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Max | Min | Mean | Std | |
|---|---|---|---|---|
| particulate matter | 215 | 15 | 124.90 | 54.04 |
| nitrogen dioxide | 215 | 15 | 107.10 | 54.09 |
| sulfur dioxide | 215 | 15 | 116.59 | 54.61 |
| carbon monoxide | 215 | 15 | 98.13 | 49.70 |
| ozone | 215 | 15 | 111.04 | 55.04 |
| Model Name | Parameter Setting | Learning Rate |
|---|---|---|
| LSTM | Epoch: 50, Batch Size: 128, Units: 128 | 0.001 |
| Bidirectional LSTM | Epoch: 40, Batch Size: 128, Units: 128 | 0.001 |
| GRU | Epoch: 40, Batch Size: 128, Units: 128 | 0.001 |
| NewModel | Epoch: 40, Batch Size: 128, | 0.001 |
| First-Layer LSTM Units: 64, | ||
| Second-Layer LSTM Units: 32 |
| LSTM | BiLSTM | GRU | New Model | |
|---|---|---|---|---|
| MAE | 0.0458 | 0.0524 | 0.0446 | 0.0407 |
| RMSE | 0.059 | 0.066 | 0.057 | 0.051 |
| MAPE | 27.15 | 25.60 | 19.71 | 16.49 |
| Class | 0 | 1 | Accuracy |
|---|---|---|---|
| Precision | 0.79 | 0.93 | |
| Recall | 0.80 | 0.92 | |
| F1-Score | 0.79 | 0.93 | 0.89 |
| Support | 180 | 519 | 699 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Yu, W.; Gao, C.; Chen, M. An Auto-Extraction Framework for CEP Rules Based on the Two-Layer LSTM Attention Mechanism: A Case Study on City Air Pollution Forecasting. Energies 2022, 15, 5892. https://doi.org/10.3390/en15165892
Liu Y, Yu W, Gao C, Chen M. An Auto-Extraction Framework for CEP Rules Based on the Two-Layer LSTM Attention Mechanism: A Case Study on City Air Pollution Forecasting. Energies. 2022; 15(16):5892. https://doi.org/10.3390/en15165892
Chicago/Turabian StyleLiu, Yuan, Wangyang Yu, Cong Gao, and Minsi Chen. 2022. "An Auto-Extraction Framework for CEP Rules Based on the Two-Layer LSTM Attention Mechanism: A Case Study on City Air Pollution Forecasting" Energies 15, no. 16: 5892. https://doi.org/10.3390/en15165892
APA StyleLiu, Y., Yu, W., Gao, C., & Chen, M. (2022). An Auto-Extraction Framework for CEP Rules Based on the Two-Layer LSTM Attention Mechanism: A Case Study on City Air Pollution Forecasting. Energies, 15(16), 5892. https://doi.org/10.3390/en15165892