
Enabling Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study

 , , , ,
, , , ,  , ,
, ,
Abstract
:1. Introduction
1.1. Creating FAIR Data Frameworks
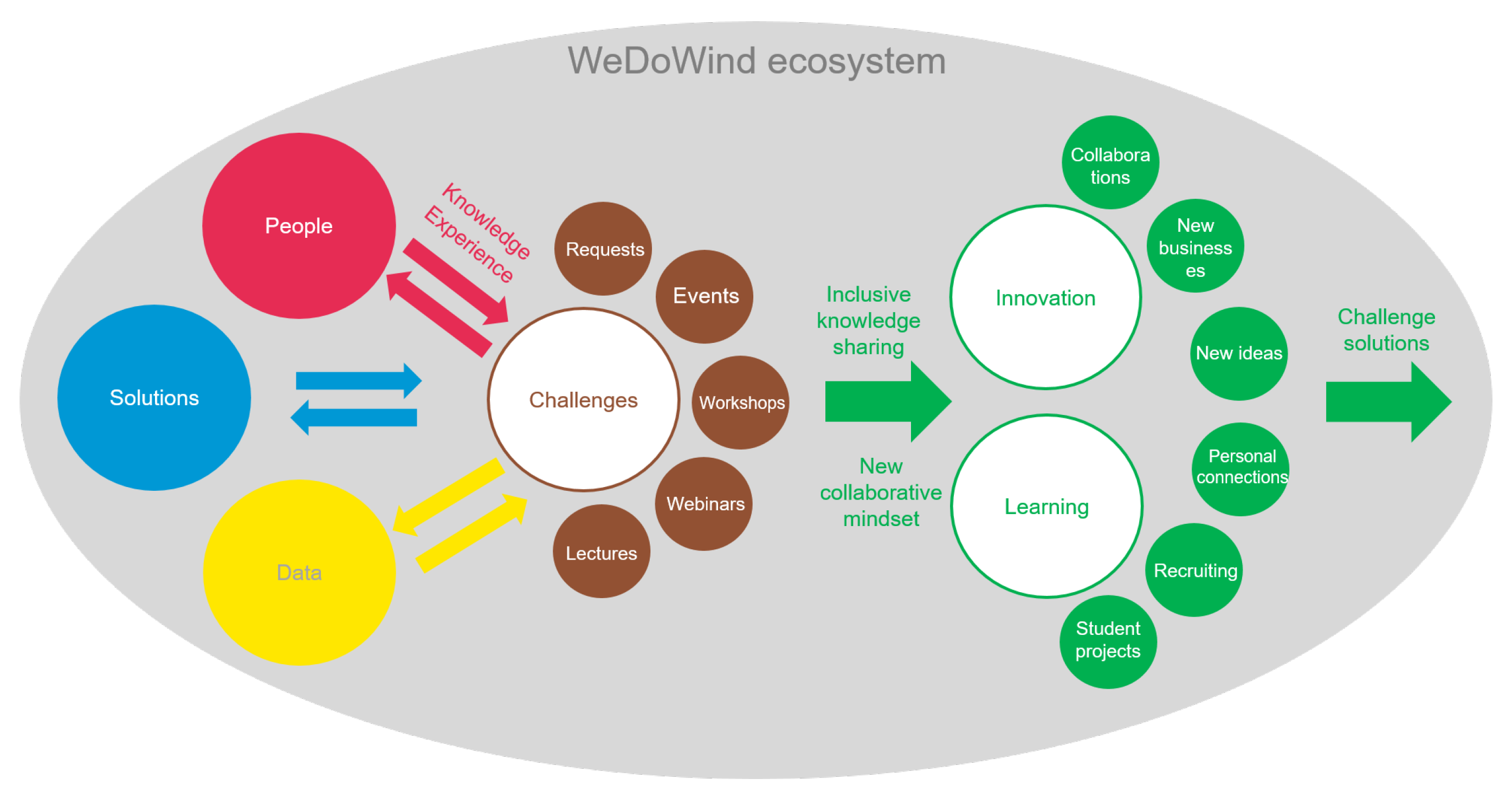
1.2. Connecting People and Data to Foster Innovation
1.3. Enabling Collaboration and Competition between Organisations
1.4. Goals of the Present Work
2. The Collaboration Method
2.1. Requirements
- Owner/operators: Getting all the data in one spot; IT issues; Cleaning/filtering raw data (different time scales and resolutions, different formats); Refining and processing data ready for machine learning model (80% of time); Interfaces to collect data reliably;
- Academia: Lack of public data; No standard format for analysing and processing data; Poor data quality; Lack of willingness to share data, especially higher resolution; Lack of change logs;
- Technology providers: Data quality; Different format and structure of data; Data filtering for analyses; Data collection: different devices need to be programmed differently; Time for downloading, cleaning, and training data.
- Enable co-innovation within and between organisations;
- Incentivise data sharing and allow a fair evaluation of solutions, with a particular focus on contextual and higher-frequency data;
- Make wind energy data FAIR (Findable, Accessible, Interoperable and Reusable);
- Provide a central location for data and knowledge related to a certain topic within the sector;
- Include solutions and code for data filtering and standard analysis tasks;
- Allow data standards and data structure translation solutions to be published and shared.
2.2. Method Description
- Gearbox challenge: Participants should make use of the provided Supervisory and Data Acquisition (SCADA) data in order to train, test and validate methods that will provide clear indicators of an upcoming gearbox related fault, as well as/or a horizon-based probability of the event occurring;
- Metadata challenge: Propose standard metadata schemes and related semantics for sharing data in the wind energy sector in three separate steps: (1) Summarise and evaluate all existing initiatives; (2) Identify the gaps; (3) Suggest solutions for filling the gaps;
- Brazil challenge: Define the main problems needing solutions for implementing offshore wind energy in Brazil;
- Diversity challenge: Document existing resources for Diversity, Equity and Inclusion that might be useful for the wind energy community, such as guidelines, toolboxes, techniques, workshops, etc.
3. The Case Study
3.1. The Challenge
3.2. The Co-Innovation Process
- A dedicated space called “EDP Challenges” was created on the digital platform together with EDP. The challenge description, including direct links to download the data, was developed together with EDP and posted inside this space;
- A public “call for participants” website was created with a direct link to the registration form. This was shared within the wind energy community using social media;
- A process for allowing EDP to decide who may participate or not was set up. This process was not meant to reduce accessibility to the challenge, but instead to ensure that applicants were real people interested in the challenge and not robots, bots or imposters;
- A “Getting Started Guide” to using the digital platform was created and explainer videos were recorded in order to help users interact on the platform;
- A series of online workshops were organised for the participants—a launch workshop, interim workshops every month and then a final workshop. These involved brainstorming sessions in small groups as well as question and answer sessions with EDP. The sessions were documented on a digital whiteboard and recordings were posted in the digital space;
- Regular email updates were sent with specific questions and actions to encourage interaction. This included requests to summarise and comment on different possible methods, as well as discussions of evaluation methods;
- The space was regularly checked, cleaned and coordinated by the ecosystem operators to ensure that the information was up-to-date and understandable;
- Regular updates were communicated on social media during the challenge.
- A downloadable docker was made available to allow beginners easy access to the data and code. This was integrated into a smaller “sub-challenge” run at the Eastern Switzerland University of Applied Sciences.
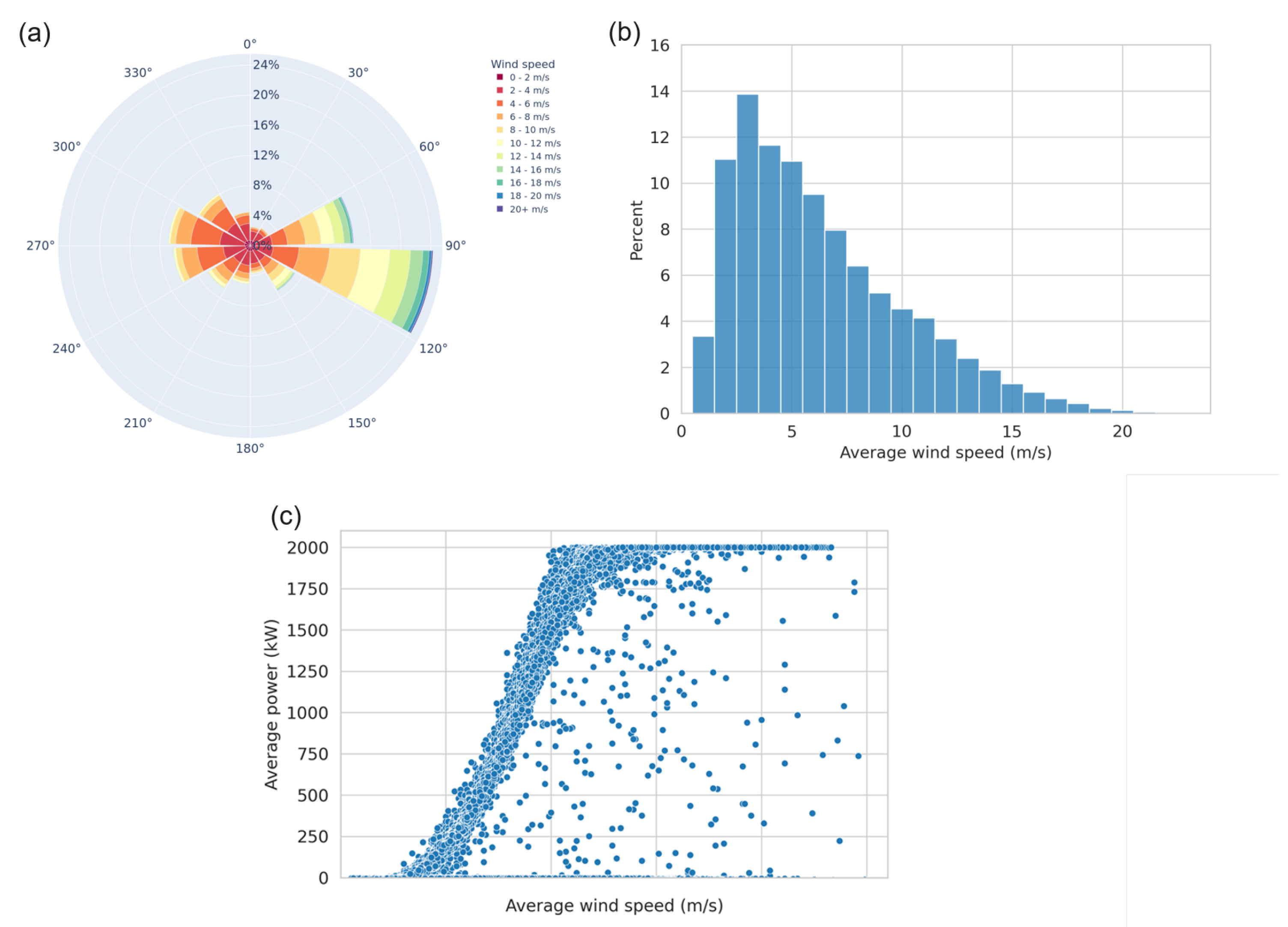
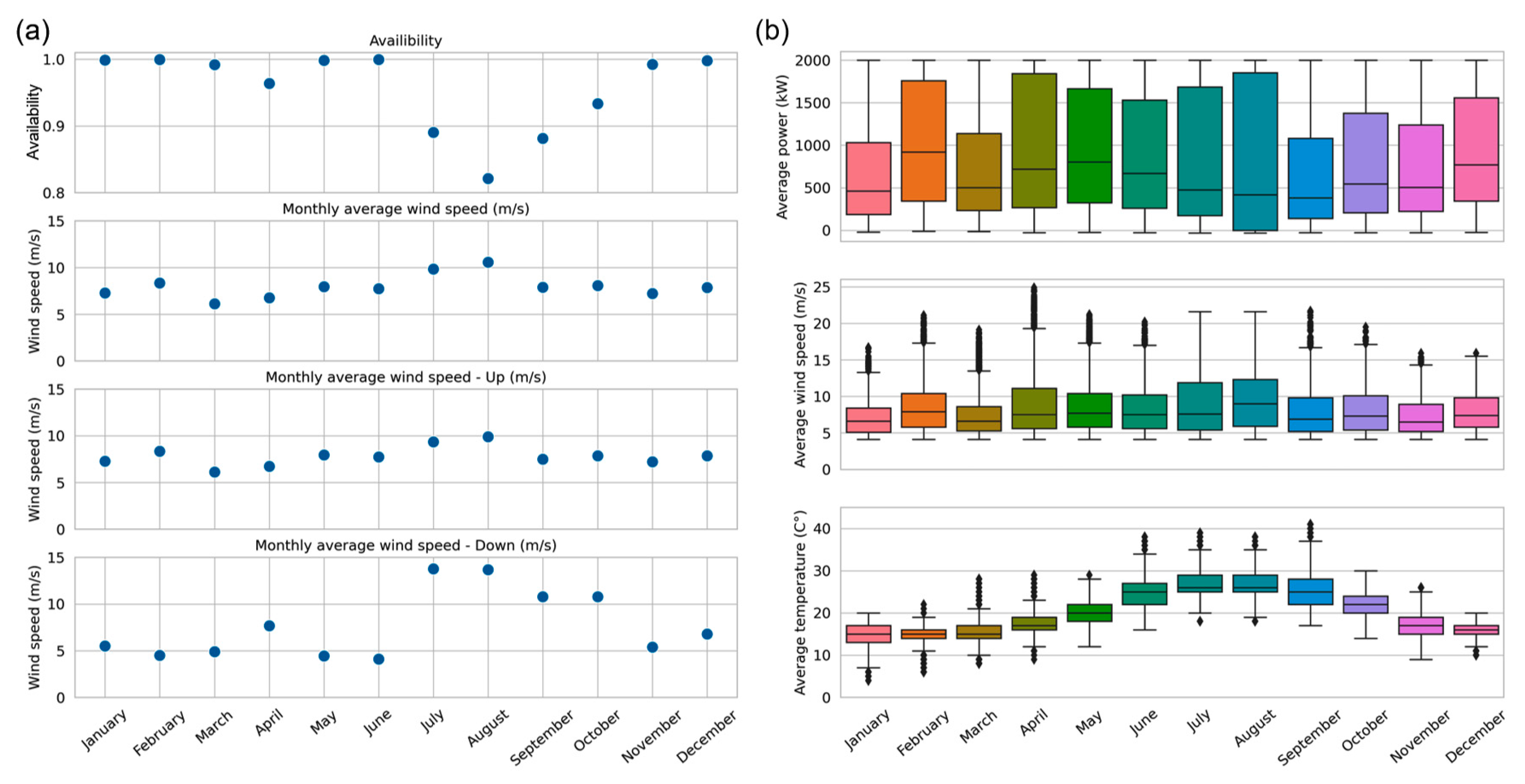
3.3. Existing Wind Turbine Fault Detection Methods
3.3.1. Wind Turbine Fault Detection Methods
3.3.2. Model Evaluation Methods
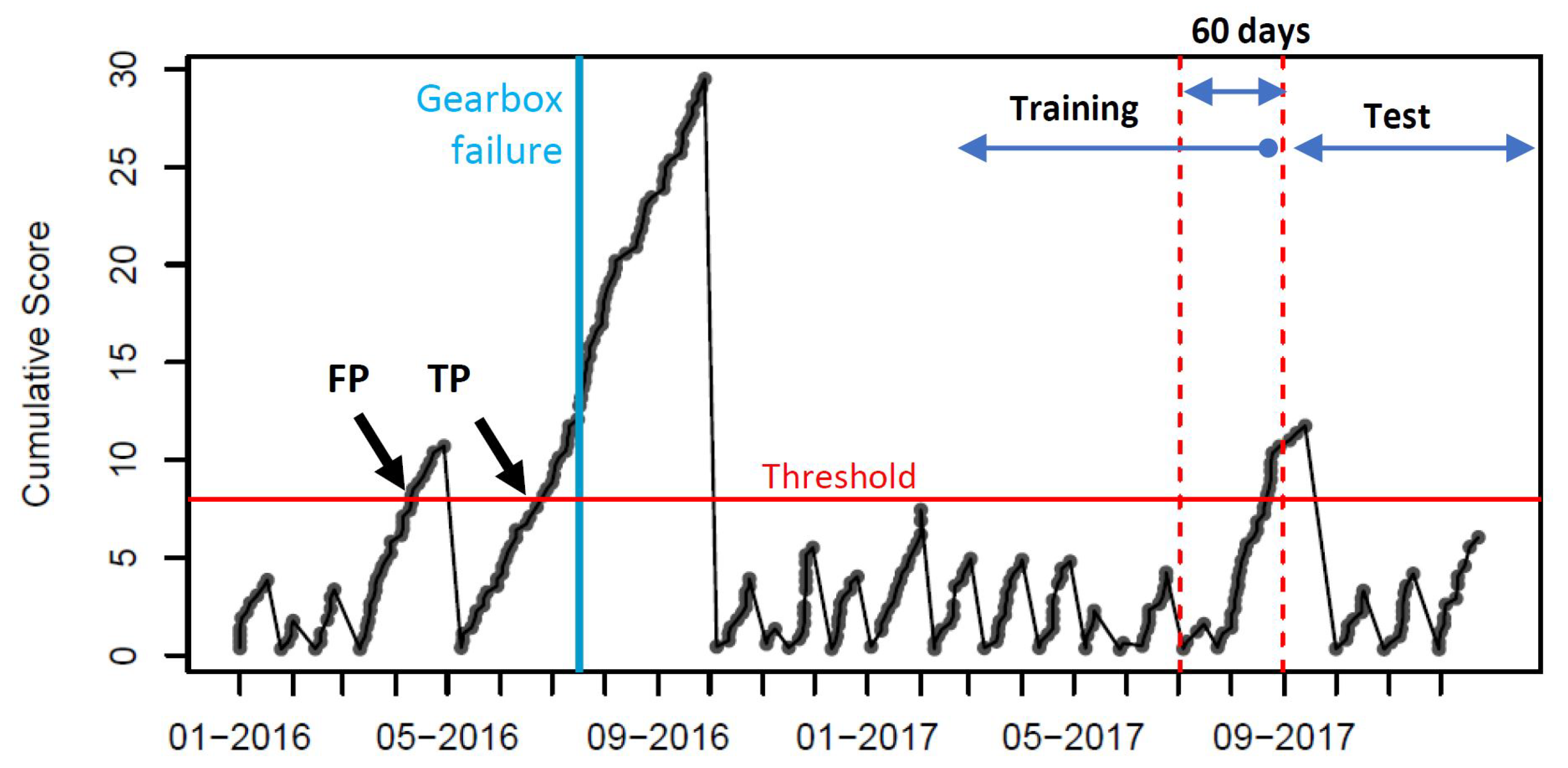
- True positives (TP): a failure of the correct wind turbine and subsystem is correctly predicted between two and 60 days before the actual failure;
- False negatives (FN): an actual failure is not detected between two and 60 days in advance;
- False positives (FP): a failure is predicted that does not actually occur in the next two to 60 days.
- True positives (TP): translated into savings, , which are the difference between replacement costs, , and repair costs, ;
- False negatives (FN): translated into costs, , due to replacements, ;
- False positives (FP): translated into costs, , due to inspections, .
3.4. Description of the Submitted Solutions
3.4.1. Normal Behaviour Models (NBM)
3.4.2. Combined Local Minimum Spanning Tree and Cumulative Sum of Multivariate Time Series Data (LoMST-CUSUM)
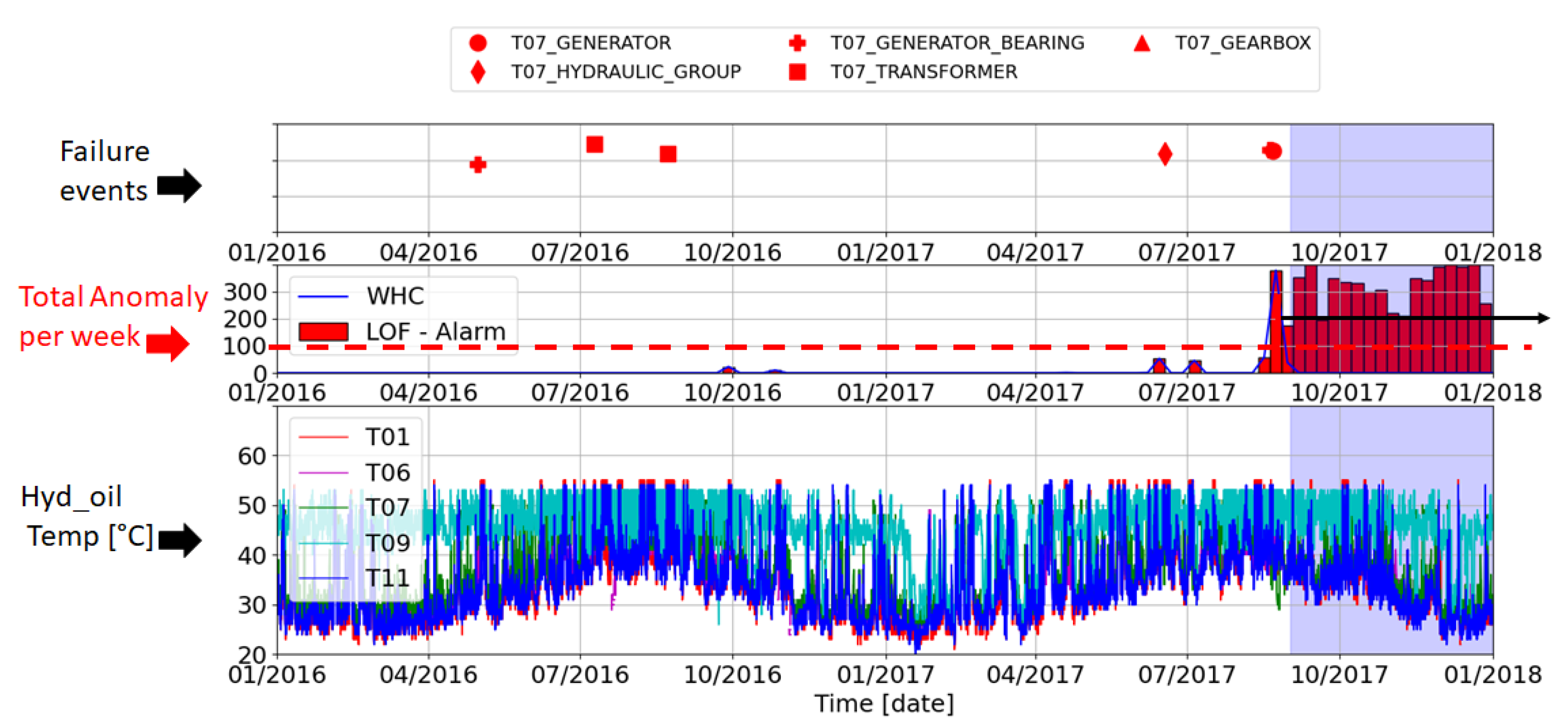
3.4.3. Combined Ward Hierarchical Clustering and Novelty Detection with Local Outlier Factor (WHC-LOF)
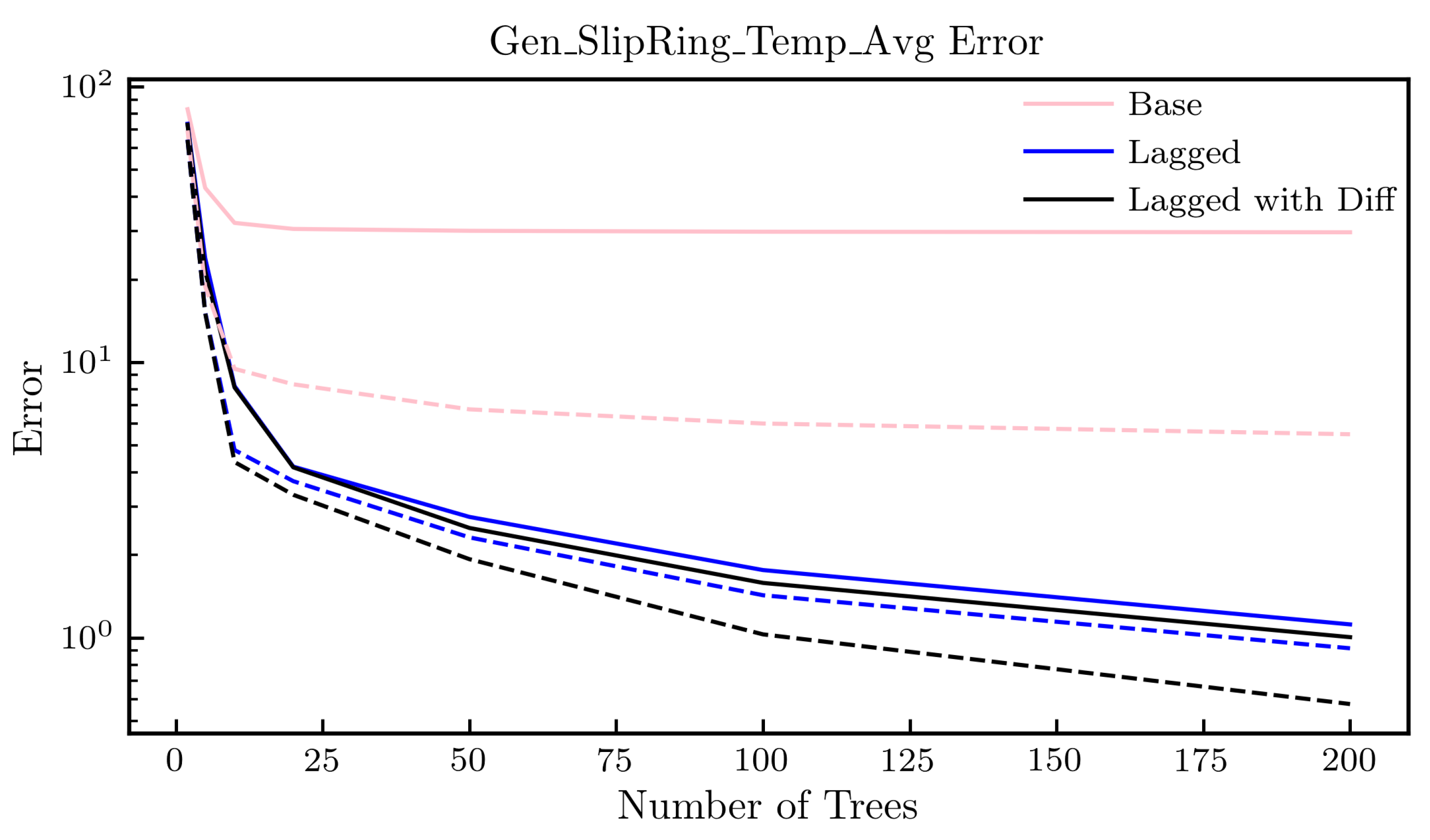
3.4.4. Normal Behaviour Model with Lagged Inputs (NBM-LI)
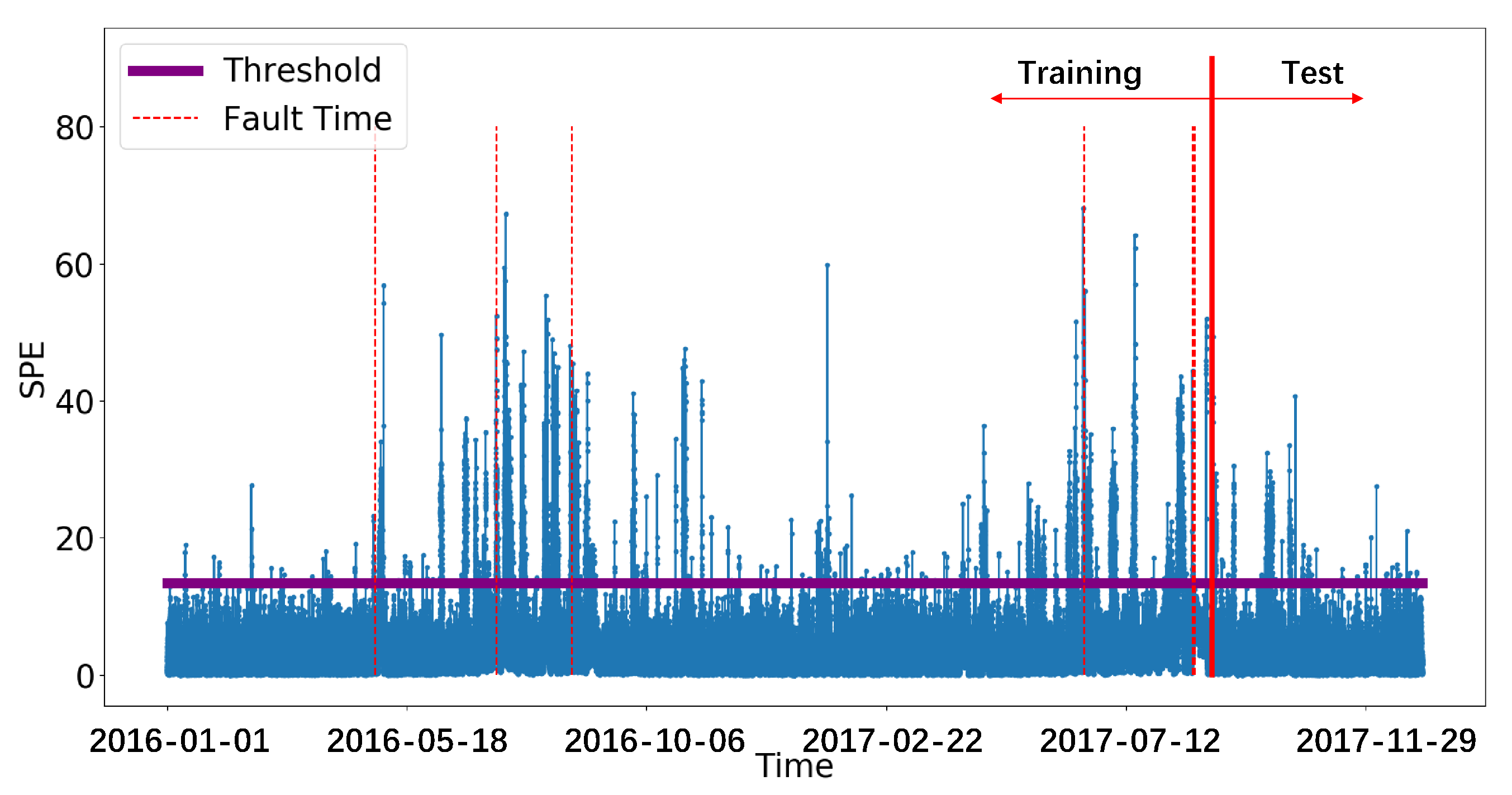
3.4.5. Canonical Correlation Analysis (CCA)
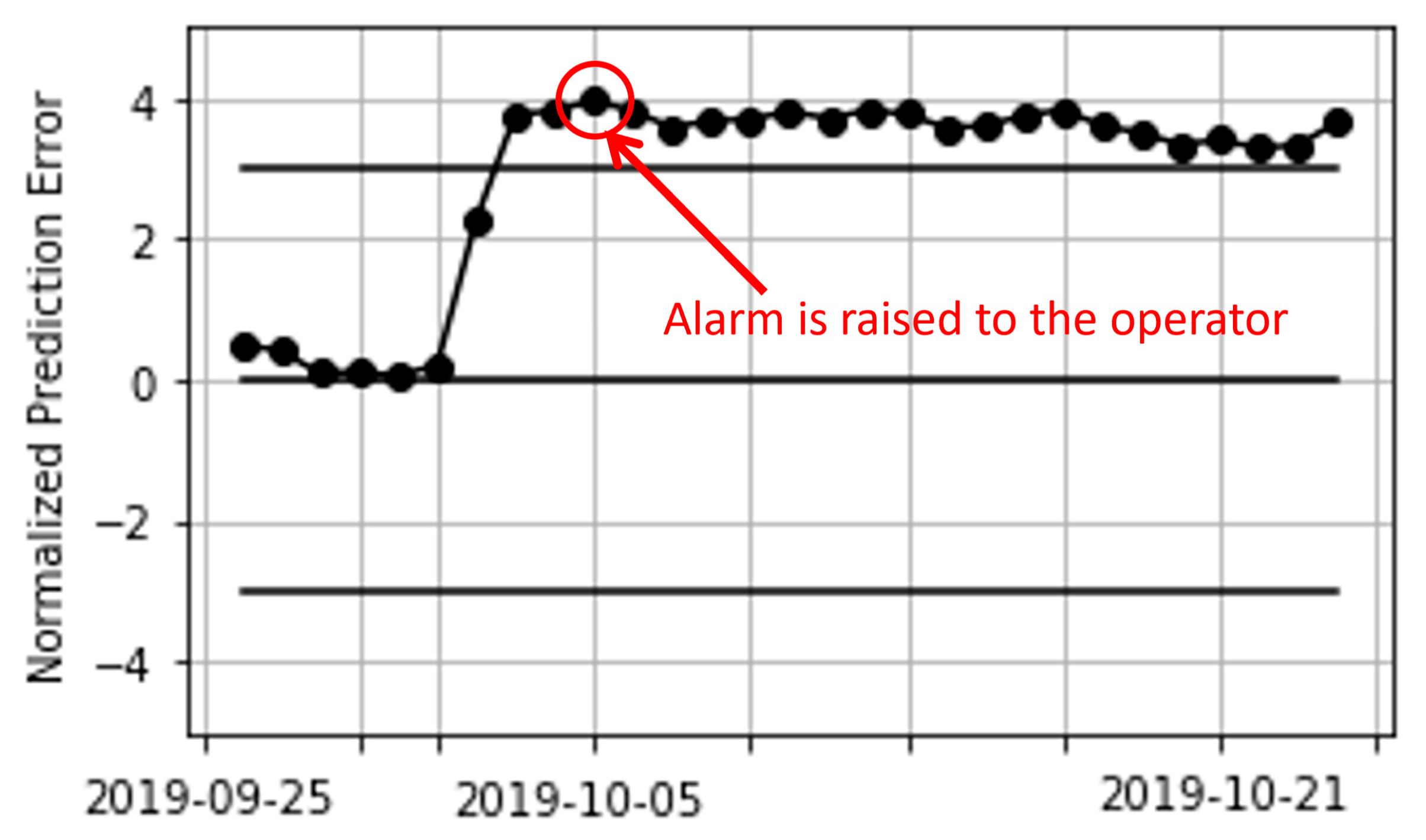
3.4.6. Kernel Change-Point Detection (KCPD)
3.4.7. Summary of Solutions
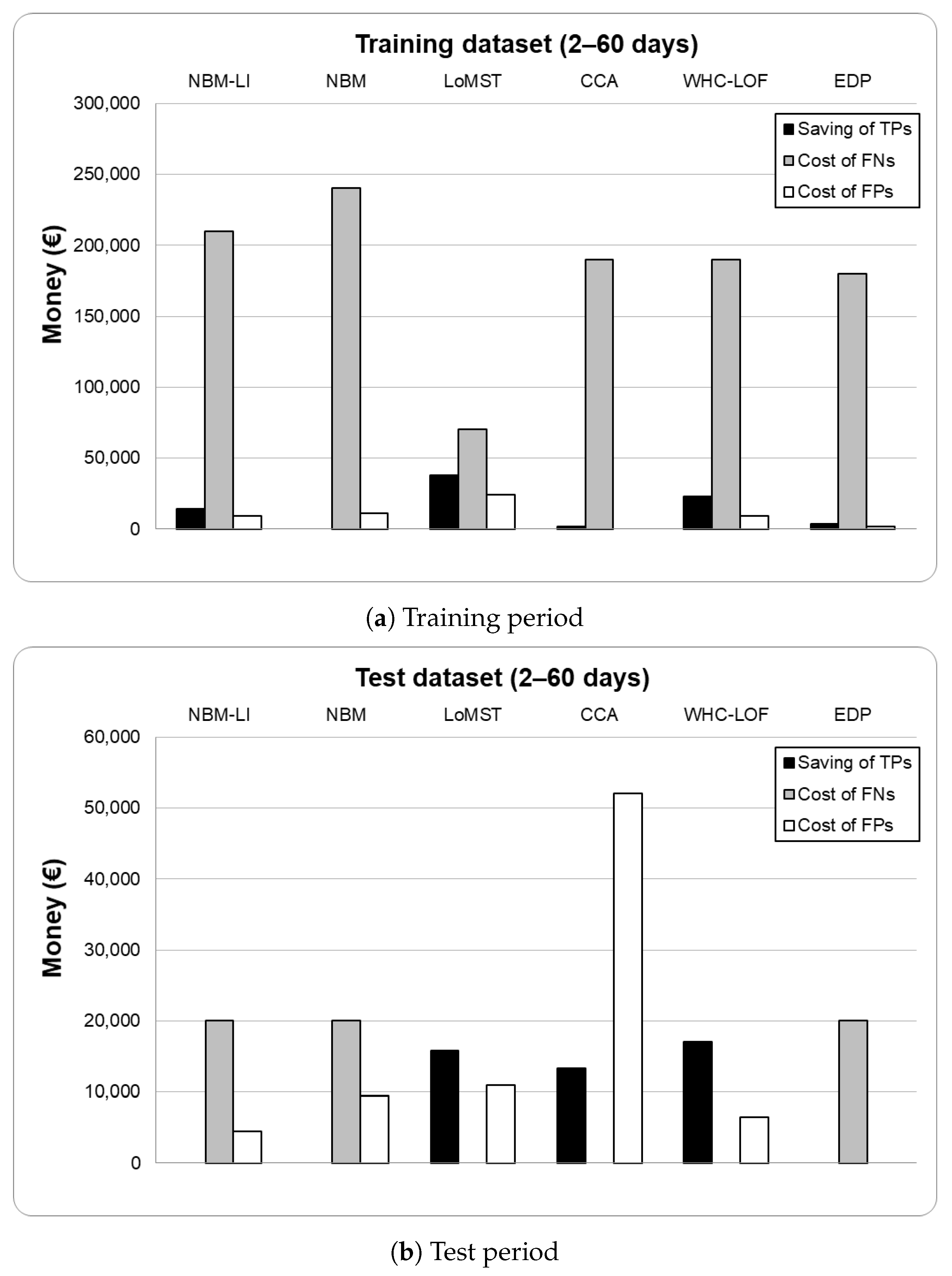
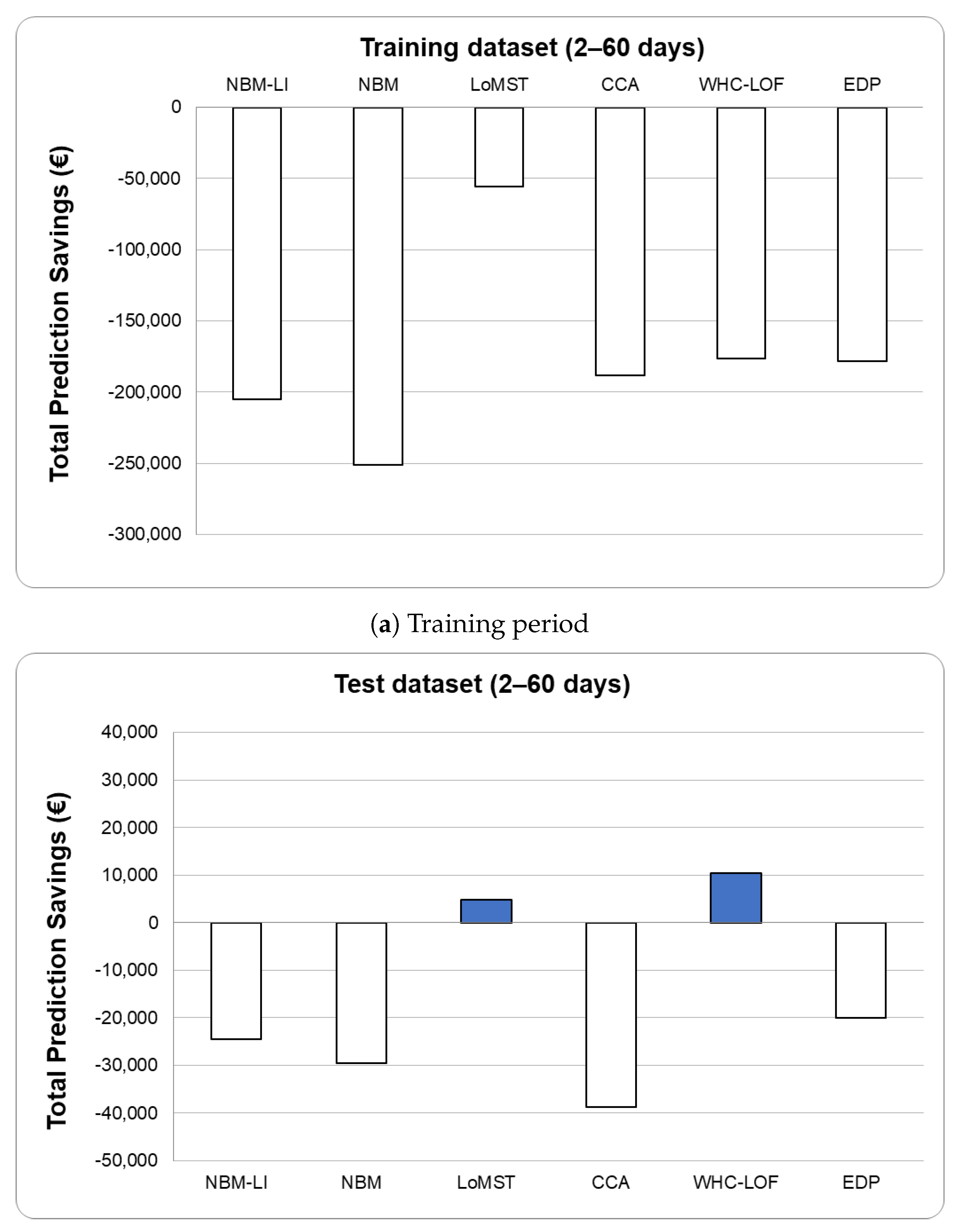
3.5. Evaluation of Solutions
4. Discussion of Results
4.1. Assumptions of the EDP Evaluation Method
- A predicted alarm may lead to savings if detected even later than two days before the fault. Figure 14 shows the effect of altering the definition of TP from 2–60 days to 1–90 days;
- It may very well be the case that not every annotated failure leads to a failure that requires complete replacement or a component. This would reduce the costs of an FN. Figure 14 shows the effect of halving the replacement costs for each component on the TPS for each model (using 2–60 days);
- An asset owner may decide not to inspect repeating alarms for the same components. This would reduce the number of FPs. Figure 14 shows the effect of removing inspection costs for repeat alarms for each component on the TPS for each model (using 2–60 days).
4.2. Qualitative Evaluation of Each Method
4.2.1. NBM
4.2.2. LoMST-CUSUM
4.2.3. WHC-LOF
4.2.4. NBM-LI
4.2.5. CCA
4.2.6. KCPD
4.3. Challenges of the Evaluation Method
4.4. Evaluation of the Collaboration Method
- EDP received six new solutions to their challenge, two of which performed significantly better than their own method for the provided datasets. The average performance of all solutions was slightly better than the EDP method;
- EDP obtained access to the knowledge and code exchanged during the workshops and on the digital platform, as well as to the people participating. They were able to further their understanding on the topics of fault detection, data pre-processing and model evaluation;
- The monthly meetings combined with the digital platform provided an excellent opportunity for participants to exchange ideas and knowledge, as well as to ensure continued motivation and guidance;
- A range of people with different backgrounds got access to the challenge, leading to a large diversity of solutions and to some interesting exchanges, which would not have otherwise happened;
- The participants got to apply their methods to measurement data from a real wind farm under real conditions in collaboration with a real customer;
- The participants learned the difference between theoretical studies and real studies together with customers, when the required data are not always available in exactly the required format or volume.
- All the participants received access to the documentation of the workshops and the all of the knowledge related to the topic shared within the project;
- All the participants made new contacts and connections;
- Both EDP and the participants had the opportunity to discuss and test various evaluation methods.
- The digital platform requires further functionalities, such as automatic notifications and regular summaries, in order to improve activity;
- It is important for the ecosystem operators to ensure that the challenge provider remains fully engaged throughout the project;
- Further datasets over longer time periods and including more faults would improve the evaluation process;
- More information about the actual maintenance activities that took place in the turbine, with information such as what was done (component fixed or replaced?) and the associated cost would be useful in the future;
- A pre-defined evaluation method would help direct the efforts more clearly from the start;
- A co-innovation process allowing different solutions to be combined may improve the results even more;
- A more formally-defined set of workshops including pre-defined goals and steps for each workshop would help the co-innovation effort;
- Definition of standard data formats or even the provision of a standardised docker for uploading code would reduce the evaluation effort and make the results more accessible to the challenge providers;
- Some broader challenges related to data sharing and co-innovation that have been highlighted during this work need to be solved (see Section).
5. Impact of the Results on the Wider Community
5.1. Application of the Algorithms
5.2. Application of the Collaboration Method
- A general fear of losing competitive advantage or communicating a negative message related to data sharing and open innovation that still exists in some organisations or entire industries [69];
- A lack of organisational structures that accommodate co-innovation or data sharing in some industries (e.g., [70]);
- The issue of data privacy and security related to sharing commercially sensitive data;
- A general “black and white” thinking of many people and organisations when it comes to data and knowledge sharing, where “black” refers to “sharing everything with the public” and “white” refers to “sharing nothing”. There is a large grey area that can be exploited to the benefit of everyone.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clifton, A.; Barber, S.; Bray, A.; Enevoldsen, P.; Fields, J.; Sempreviva, A.M.; Williams, L.; Quick, J.; Purdue, M.; Totaro, P.; et al. Grand Challenges in the Digitalisation of Wind Energy. Wind Energy Sci. 2022; in review. [Google Scholar] [CrossRef]
- Barber, S.; Clark, T.; Day, J.; Totaro, P. The IEA Wind Task 43 Metadata Challenge: A Roadmap to Enable Commonality in Wind Energy Data. 2022. [Google Scholar]
- Wilkinson, M.; Dumontier, M.; Aalbersberg, I. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maria, S.A.; Allan, V.; Christian, B.; Robert, V.D.; Gregor, G.; Kjartansson, D.H.; Pilgaard, M.L.; Mattias, A.; Nikola, V.; Stephan, B.; et al. Taxonomy and Metadata for Wind Energy Research & Development. IRPWind Rep. 2017. [Google Scholar] [CrossRef]
- van Kuik, G.A.M.; Peinke, J.; Nijssen, R.; Lekou, D.; Mann, J.; Sørensen, J.N.; Ferreira, C.; van Wingerden, J.W.; Schlipf, D.; Gebraad, P.; et al. Long-term research challenges in wind energy—A research agenda by the European Academy of Wind Energy. Wind Energy Sci. 2016, 1, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Chesbrough, H. Business Model Innovation: Opportunities and Barriers. Long Range Plan. 2010, 43, 354–363. [Google Scholar] [CrossRef]
- Pisano, G. You need an innovation strategy. Harv. Bus. Rev. 2015, 93, 44–54. [Google Scholar]
- Bresciani, S.; Ciampi, F.; Meli, F.; Ferraris, A. Using big data for co-innovation processes: Mapping the field of data-driven innovation, proposing theoretical developments and providing a research agenda. Int. J. Inf. Manag. 2021, 60, 102347. [Google Scholar] [CrossRef]
- Saragih, H.S.; Tan, J.D. Co-innovation: A review and conceptual framework. Int. J. Bus. Innov. Res. 2018, 17, 361–377. [Google Scholar] [CrossRef]
- Chae, B.K. A General framework for studying the evolution of the digital innovation ecosystem: The case of big data. Int. J. Inf. Manag. 2019, 45, 83–94. [Google Scholar] [CrossRef]
- Janardhanan, N. Leveraging Co-innovation Model for Energy Transition: Examining India’s Engagement with Japan and China. In Renewable Energy Transition in Asia: Policies, Markets and Emerging Issues; Janardhanan, N., Chaturvedi, V., Eds.; Springer: Singapore, 2021; pp. 21–40. [Google Scholar] [CrossRef]
- Mortensen, N.; Nielsen, M.; Ejsing Jørgensen, H. Comparison of Resource and Energy Yield Assessment Procedures 2011–2015: What have we learned and what needs to be done? In Proceedings of the EWEA Annual Event and Exhibition 2015. European Wind Energy Association (EWEA), Paris, France, 17–20 November 2015. [Google Scholar]
- Janusz, A.; Dominik Slezak, S.S.M.R. Knowledge Pit—A Data Challenge Platform. 2013. Available online: http://ceur-ws.org/Vol-1492/Paper_18.pdf (accessed on 28 June 2022).
- Woods, H.B.; Pinfield, S. Incentivising research data sharing: A scoping review. Wellcome Open Res. 2021, 6, 355. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.M.; Olson, D.L.; Trimi, S. Co-innovation: Convergenomics, collaboration, and co-creation for organizational values. Manag. Decis. 2012, 50, 817–831. [Google Scholar] [CrossRef]
- Chen, S.; Kang, J.; Liu, S.; Sun, Y. Cognitive computing on unstructured data for customer co-innovation. Eur. J. Mark. 2019, 54, 570–593. [Google Scholar] [CrossRef]
- Bugshan, H. Co-innovation: The role of online communities. J. Strateg. Mark. 2015, 23, 175–186. [Google Scholar] [CrossRef]
- Gjørtler Elkjær, L.; Horst, M.; Nyborg, S. Identities, innovation, and governance: A systematic review of co-creation in wind energy transitions. Energy Res. Soc. Sci. 2021, 71, 101834. [Google Scholar] [CrossRef]
- Solman, H.; Smits, M.; van Vliet, B.; Bush, S. Co-production in the wind energy sector: A systematic literature review of public engagement beyond invited stakeholder participation. Energy Res. Soc. Sci. 2021, 72, 101876. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Ferreira Santos, I. Comparative analysis of neural network and regression based condition monitoring approaches for wind turbine fault detection. Mech. Syst. Signal Process. 2011, 25, 1849–1875. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, B.; Nasraoui, O. Transparency in Fair Machine Learning: The Case of Explainable Recommender Systems. In Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent; Zhou, J., Chen, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 21–35. [Google Scholar] [CrossRef]
- de Greeff, J.; de Boer, M.H.; Hillerström, F.H.J.; Bomhof, F.; Jorritsma, W.; Neerincx, M. The FATE System: FAir, Transparent and Explainable Decision Making. In Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE 2021), Stanford University. Palo Alto, CA, USA, 22–24 March 2021. [Google Scholar]
- Das Sarma, A.; Sreenivas Gollapudi, R.P. Ranking Mechanisms in Twitter-like Forums. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 4–6 February 2010. [Google Scholar]
- Carroll, J.; McDonald, A.; McMillan, D. Failure rate, repair time and unscheduled O&M cost analysis of offshore wind turbines. Wind Energy 2016, 19, 1107–1119. [Google Scholar]
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind Turbine Condition Monitoring: State-of-the-Art Review, New Trends, and Future Challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef] [Green Version]
- Maldonado-Correa, J.; Martín-Martínez, S.; Artigao, E.; Gómez-Lázaro, E. Using SCADA Data for Wind Turbine Condition Monitoring: A Systematic Literature Review. Energies 2020, 13, 3132. [Google Scholar] [CrossRef]
- Madsen, B.N. Condition Monitoring of Wind Turbines by Electric Signature Analysis. Master’s Thesis, Technical University of Denemark, Copenhagen, Denmark, 2011. [Google Scholar]
- Barber, S.; Deparday, J.; Marykovskiy, Y.; Chatzi, E.; Abdallah, I.; Duthé, G.; Magno, M.; Polonelli, T.; Fischer, R.; Müller, H. Development of a wireless, non-intrusive, MEMS-based pressure and acoustic measurement system for large-scale operating wind turbine blades. Wind Energy Sci. Discuss. 2022, 7, 1383–1398. [Google Scholar] [CrossRef]
- Yampikulsakul, N.; Byon, E.; Huang, S.; Sheng, S.; You, M. Condition Monitoring of Wind Power System With Nonparametric Regression Analysis. IEEE Trans. Energy Convers. 2014, 29, 288–299. [Google Scholar] [CrossRef]
- Dao, P.B. A CUSUM-Based Approach for Condition Monitoring and Fault Diagnosis of Wind Turbines. Energies 2021, 14, 3236. [Google Scholar] [CrossRef]
- Xu, Q.; Lu, S.X.; Zhai, Z.; Jiang, C. Adaptive fault detection in wind turbine via RF and CUSUM. Iet Renew. Power Gener. 2020, 14, 1789–1796. [Google Scholar] [CrossRef]
- Liu, Y.; Fontanella, A.; Wu, P.; Ferrari, R.M.; van Wingerden, J.W. Fault Detection of the Mooring system in Floating Offshore Wind Turbines based on the Wave-excited Linear Model. J. Phys: Conf. Ser. 2020, 1618, 022049. [Google Scholar] [CrossRef]
- Zaher, A.; McArthur, S.; Infield, D.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind Energy Int. J. Prog. Appl. Wind Power Convers. Technol. 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Bangalore, P.; Letzgus, S.; Karlsson, D.; Patriksson, M. An artificial neural network-based condition monitoring method for wind turbines, with application to the monitoring of the gearbox. Wind Energy 2017, 20, 1421–1438. [Google Scholar] [CrossRef]
- Bach-Andersen, M.; Rømer-Odgaard, B.; Winther, O. Flexible nonlinear predictive models for large-scale wind turbine diagnostics. Wind Energy 2017, 20, 753–764. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Using SCADA data for wind turbine condition monitoring—A review. IET Renew. Power Gener. 2016, 11, 382–394. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Dao, C.; Kazemtabrizi, B.; Crabtree, C. Wind turbine reliability data review and impacts on levelised cost of energy. Wind Energy 2019, 22, 1848–1871. [Google Scholar] [CrossRef] [Green Version]
- Butler, S.; Ringwood, J.; O’Connor, F. Exploiting SCADA system data for wind turbine performance monitoring. In Proceedings of the 2013 Conference on Control and Fault-Tolerant Systems (SysTol), Nice, France, 9–11 October 2013; pp. 389–394. [Google Scholar]
- Kusiak, A.; Verma, A. Analyzing bearing faults in wind turbines: A data-mining approach. Renew. Energy 2012, 48, 110–116. [Google Scholar] [CrossRef]
- Sun, P.; Li, J.; Wang, C.; Lei, X. A generalized model for wind turbine anomaly identification based on SCADA data. Appl. Energy 2016, 168, 550–567. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ferrari, R.; Wu, P.; Jiang, X.; Li, S.; van Wingerden, J.W. Fault diagnosis of the 10MW Floating Offshore Wind Turbine Benchmark: A mixed model and signal-based approach. Renew. Energy 2021, 164, 391–406. [Google Scholar] [CrossRef]
- Tatbul, N.; Lee, T.J.; Zdonik, S.; Alam, M.; Gottschlich, J. Precision and recall for time series. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.R. A Unifying Review of Deep and Shallow Anomaly Detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Long, H.; Xu, J.; Liu, R. Wind Turbine Gearbox Failure Identification With Deep Neural Networks. IEEE Trans. Ind. Inform. 2017, 13, 1360–1368. [Google Scholar] [CrossRef]
- Orozco, R.; Sheng, S.; Phillips, C. Diagnostic Models for Wind Turbine Gearbox Components Using SCADA Time Series Data. In Proceedings of the 2018 IEEE International Conference on Prognostics and Health Management (ICPHM), Seattle, WA, USA, 11–13 June 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Arcos Jiménez, A.; Gómez Muñoz, C.Q.; García Márquez, F.P. Machine Learning for Wind Turbine Blades Maintenance Management. Energies 2018, 11, 13. [Google Scholar] [CrossRef] [Green Version]
- Tang, B.; Song, T.; Li, F.; Deng, L. Fault diagnosis for a wind turbine transmission system based on manifold learning and Shannon wavelet support vector machine. Renew. Energy 2014, 62, 1–9. [Google Scholar] [CrossRef]
- EDP. Hack the Wind 2018—Algorithm Evaluation; EDP: Lisbon, Portugal, 2018. [Google Scholar]
- Lima, L.A.M.; Blatt, A.; Fujise, J. Wind Turbine Failure Prediction Using SCADA Data. J. Phys. Conf. Ser. 2020, 1618, 022017. [Google Scholar] [CrossRef]
- Ahmed, I.; Dagnino, A.; Ding, Y. Unsupervised Anomaly Detection Based on Minimum Spanning Tree Approximated Distance Measures and its Application to Hydropower Turbines. IEEE Trans. Autom. Sci. Eng. 2019, 16, 654–667. [Google Scholar] [CrossRef]
- Latiffianti, E.; Sheng, S.; Ding, Y. Wind Turbine Gearbox Failure Detection Through Cumulative Sum of Multivariate Time Series Data. Front. Energy Res. 2022, 10. [Google Scholar] [CrossRef]
- Ward, J.H. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Breunig, M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 Acm Sigmod International Conference On Management Of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Zhu, Q.; Liu, Q.; Qin, S.J. Quality-relevant fault detection of nonlinear processes based on kernel concurrent canonical correlation analysis. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 5404–5409. [Google Scholar]
- Chen, Q.; Goulding, P.; Sandoz, D.; Wynne, R. The application of kernel density estimates to condition monitoring for process industries. In Proceedings of the 1998 American Control Conference. ACC (IEEE Cat. No. 98CH36207), Philadelphia, PA, USA, 26 June 1998; Volume 6, pp. 3312–3316. [Google Scholar]
- Jiang, G.; Xie, P.; He, H.; Yan, J. Wind turbine fault detection using a denoising autoencoder with temporal information. IEEE/ASME Trans. Mechatron. 2017, 23, 89–100. [Google Scholar] [CrossRef]
- Letzgus, S. Change-point detection in wind turbine SCADA data for robust condition monitoring with normal behaviour models. Wind Energy Sci. 2020, 5, 1375–1397. [Google Scholar] [CrossRef]
- Wu, P.; Liu, Y.; Ferrari, R.M.; van Wingerden, J.W. Floating offshore wind turbine fault diagnosis via regularized dynamic canonical correlation and fisher discriminant analysis. IET Renew. Power Gener. 2021, 15, 4006–4018. [Google Scholar] [CrossRef]
- Leahy, K.; Gallagher, C.; O’Donovan, P.; O’Sullivan, D.T. Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses. Energies 2019, 12, 201. [Google Scholar] [CrossRef] [Green Version]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.R. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Chatterjee, J.; Dethlefs, N. A Dual Transformer Model for Intelligent Decision Support for Maintenance of Wind Turbines. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Majeed, A.; Lee, S. Anonymization techniques for privacy preserving data publishing: A comprehensive survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Saebi, T.; Foss, N.J. Business models for open innovation: Matching heterogeneous open innovation strategies with business model dimensions. Eur. Manag. J. 2015, 33, 201–213. [Google Scholar] [CrossRef] [Green Version]
- Dahlander, L.; Gann, D.M. How open is innovation? Res. Policy 2010, 39, 699–709. [Google Scholar] [CrossRef]
- Lundin, M.; Annika Bergviken Rensfeldt, T.H.A.L.A.; Peterson, L. Higher education dominance and siloed knowledge: A systematic review of flipped classroom research. Int. J. Educ. Technol. High Educ. 2018, 15, 20. [Google Scholar] [CrossRef] [Green Version]
- de Waal, A.; Weaver, M.; Day, T.; van der Heijden, B. Silo-Busting: Overcoming the Greatest Threat to Organizational Performance. Sustainability 2019, 11, 6860. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Alarm Dates |
|---|---|
| Gearbox | None |
| Generator | 21 August 2017 |
| Generator Bearings | 30 April 2016 and 20 August 2017 |
| Transformer | 10 July 2016 and 23 August 2016 |
| Hydraulic Group | 17 June 2017 |
| Component | (€) (Replacement Costs) | (€) (Repair Costs) | (€) (Inspection Costs) |
|---|---|---|---|
| Gearbox | 100,000 | 20,000 | 5000 |
| Generator | 60,000 | 15,000 | 5000 |
| Generator Bearings | 30,000 | 12,500 | 4500 |
| Transformer | 50,000 | 3500 | 1500 |
| Hydraulic Group | 20,000 | 3000 | 2000 |
| Solution | NBM | LoMST-CUSUM | WHC-LOF | NBM-LI | CCA | KCPD |
|---|---|---|---|---|---|---|
| Contributer | Voltalia, France | TAMU, USA | Fed. Inst. Santa Catarina, Brazil | Univ. Colorado, USA | TU Delft, Netherlands | TU Berlin, Germany |
| Type (“S” = Supervised, “U” = Unsupervised, “SS” = Semi-supervised) | S | SS | S | S | U | U |
| Real time? | Yes | No | Yes | Yes | Yes | No |
| Type of detection (“PW” = Point-wise, “CB” = Chart-based) | PW | CB | PW | CB | CB | CB |
| Previous application to wind turbines? | Yes [51] | No | No | No | Yes [60] | Yes [59] |
| Used in comparison? | Yes | Yes | Yes | Yes | Yes | No |
| Solution | NBM | LoMST-CUSUM | WHC-LOF | NBM-LI | CCA | KCPD |
|---|---|---|---|---|---|---|
| Filtering | Iterative during training | Manual/Domain expert | Ward Cluster Algorithm | Manual/Domain expert | Manual/Domain expert | Non-operational based on power |
| Time resolution | 10 min | 1 h | 10 min | 10 min | 10 min | 24 h |
| NBM | LoMST-CUSUM | WHC-LOF | NBM-LI | CCA | EDP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| TP | 0 | 0 | 4 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| FN | 6 | 1 | 2 | 0 | 5 | 0 | 5 | 1 | 5 | 0 | 5 | 1 |
| FP | 3 | 2 | 7 | 3 | 2 | 2 | 2 | 1 | 0 | 4 | 1 | 0 |
| Average | NBM | LoMST-CUSUM | WHC-LOF | NBM-LI | CCA | EDP | |
|---|---|---|---|---|---|---|---|
| TPS | −€175,826 | −€251,000 | −€56,008 | −€176,250 | −€205,000 | −€188,450 | −€178,250 |
| - | −€72,750 | €122,242 | €2000 | −€26,750 | −€10,200 | - |
| Average | NBM | LoMST-CUSUM | WHC-LOF | NBM-LI | CCA | EDP | |
|---|---|---|---|---|---|---|---|
| TPS | −€16,219 | −€29,500 | €4867 | €10,500 | −€24,500 | −€38,683 | −€20,000 |
| - | −€9500 | €24,867 | €30,500 | −€4500 | −€18,683 | - |
| Solution | Alarm KPI | Temporal Resolution | Threshold | Remark |
|---|---|---|---|---|
| NBM | Model error | 24 h | +/− 3std (training) | Alarm if on >3 out of last 7 days |
| LoMST-CUSUM | Cost function | 1 h | Different by component | Empirical from training data |
| WHC-LOF | Cumulative | 1 week | >100 | total anomaly per week |
| NBM-LI | Model error | 10 min | +/− 15std (training) | All anomalies raised alarms |
| CCA | SPE | 10 min | 13.42 | – |
| KCPD | Cost function | 24 h | 80 | Empirical from different external SCADA data sets |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barber, S.; Lima, L.A.M.; Sakagami, Y.; Quick, J.; Latiffianti, E.; Liu, Y.; Ferrari, R.; Letzgus, S.; Zhang, X.; Hammer, F. Enabling Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study. Energies 2022, 15, 5638. https://doi.org/10.3390/en15155638
Barber S, Lima LAM, Sakagami Y, Quick J, Latiffianti E, Liu Y, Ferrari R, Letzgus S, Zhang X, Hammer F. Enabling Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study. Energies. 2022; 15(15):5638. https://doi.org/10.3390/en15155638
Chicago/Turabian StyleBarber, Sarah, Luiz Andre Moyses Lima, Yoshiaki Sakagami, Julian Quick, Effi Latiffianti, Yichao Liu, Riccardo Ferrari, Simon Letzgus, Xujie Zhang, and Florian Hammer. 2022. "Enabling Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study" Energies 15, no. 15: 5638. https://doi.org/10.3390/en15155638
APA StyleBarber, S., Lima, L. A. M., Sakagami, Y., Quick, J., Latiffianti, E., Liu, Y., Ferrari, R., Letzgus, S., Zhang, X., & Hammer, F. (2022). Enabling Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study. Energies, 15(15), 5638. https://doi.org/10.3390/en15155638